AccessServer Proposal
作者:卡尔斯坦伯格
Overview
本文档中描述的技术方法满足以下高级要求:
使 Apache Pig 数据流编程语言以及其他 Hadoop 语言运行时的用户可以访问 Apache Hive 的数据模型和元数据服务。
Hive 用户和其他 Hadoop 语言运行时用户可以共享存储在 Hive HDFS 数据仓库中的数据。
满足要求(1)和(2),同时还强制执行 Hive 的细粒度授权模型。
完成(1)和(2),同时还要确保辅助元数据工件(例如索引和统计数据)的准确性和一致性。
为了满足这些要求,我们建议扩展 HiveServer2,以使其能够在 Hive 运行时执行引擎之外还托管 Pig 运行时执行引擎。请注意,要求(3)和(4)假定parallel project已完成以实现一致的 Hive 授权。
HCatalog 是否满足这些要求?
“ HCatalog”是 Hadoop 的表和存储 Management 层,它使使用不同数据处理工具(Pig,MapReduce 和 Hive)的用户可以更轻松地在网格上读取和写入数据……HCatalog 构建在 Hive 元存储和包含 Hive 的 DDL。” “ HCatalog 在 Hive 的 SerDes 的基础上提供了 Pig 和 MapReduce 的读写接口,并使用 Hive 的命令行界面发布数据定义和元数据导出命令。”这也可以概括为 HCatalog 是一组包装器 API,旨在使 Pig 和 MapReduce 可以访问 Hive 的 MetaStore 服务和 SerDe 格式处理程序。 MetaStore API 包装器和 SerDe 包装器对于使 Hive 元数据可用于 Pig 和 MapReduce 程序很有用。
HCatalog 在目前的化身中在哪里不足?
HCatalog 中的授权
HCatalog 具有可插入的授权系统,当前唯一实现的插件采用基于存储的授权模型,该模型使用基础文件系统(HDFS)的权限作为确定每个数据库,表或分区的读写权限的基础。例如,为了确定用户是否具有从表中读取数据的权限,HCatalog 会检查用户是否具有读取 Hive 仓库目录的相应子目录的权限。使用此授权模型,用户或组对特定数据库,表或分区的读/写权限由 Hive 仓库中相应子目录上的文件系统权限确定。
列级访问控制
文件系统方法不能支持列级访问控制。这是由于 Hive 的数据模型使得可以将表数据存储在平面文件中的事实,其中每个文件可能包含多个列。为了使 HCatalog 支持列级 ACL,需要将其交给 Hive 进行授权决策,即需要 Hive 授权。
AccessServer 将支持使用 Hive 授权或使用文件系统授权的部署选择(因为某些站点更喜欢)。文件系统授权将通过 DoA 代理进行。
索引和统计信息的完整性
文件系统授权的另一个问题是,它难以确保 Hive 索引和统计信息的一致性和完整性。 HCatalog 的文件系统授权模型允许用户直接访问和操作仓库目录的内容,而无需通过 Hive 或 HCatalog。在这些目录中的任何一个目录中添加,删除或更改文件,意味着以前基于该目录的内容计算出的所有索引或统计信息现在都必须无效并重新生成。没有通知 Hive 进行了更改的机制,并且由于基石设计原则(它不跟踪仓库子目录中的单个文件),因此无法单独确定 Hive。
数据模型阻抗不匹配
Hive 具有强大的数据模型,允许用户将逻辑表和分区 Map 到 HDFS 文件系统上的物理目录。如前所述,此数据模型的基础设计原则之一是 Hive 不会跟踪位于这些目录中的单个文件,而是将该任务委托给 HDFS NameNode。进行此限制的主要动机是它允许 Metastore 通过减少 FS 元数据负载来扩展。但是,当我们尝试使用授权模型来调和此数据模型时,就会出现问题,该授权模型取决于基础文件系统权限,因此不能忽略应用于这些目录中各个文件的权限。
HCatalog documentation详细解释了 HCatalog 的基于存储的授权模型,但是以下引号提供了一个很好的高级概述:
Note
...当使用文件系统进行存储时,存在与数据库或表相对应的目录。使用此授权模型, 用户或组对此目录的读取/写入权限确定用户对数据库或表的权限 。
...
例如,alter table 操作将在允许操作之前检查用户是否对表目录具有权限,即使它可能不会更改文件系统上的任何内容。
...
当数据库或表由具有 Unix/POSIX 样式权限模型(例如 HDFS)的文件系统支持时,可以为所有者用户,组和“其他”设置读(r)和写(w)权限。 '。 Hive 将使用文件系统的逻辑来确定用户是否对目录或文件具有**权限。
这种方法存在几个问题,第一个问题实际上是由前面引号中突出显示的不一致提示的。为了确定特定用户是否具有对表foo的读取权限,HCatalog 的HdfsAuthorizationProvider class检查以查看该用户是否对包含表数据的相应 HDFS 目录/hive/warehouse/foo具有读取权限。但是,在具有目录的读取权限的 HDFS 中,仅表示您具有列出目录内容的能力–它对读取目录中包含的文件的能力没有任何影响。
Execution container
HCatalog 包含一个子项目 Templeton,该子项目公开了两组 REST API:一组用于访问 Hive 元数据的组以及一组用于启动和 ManagementMapReduce 作业的组。元数据 REST API 是 AccessServer 所需要的。 HCatalog 不是工作 Management 的正确位置。 Templeton 复制了 Oozie 代码以进行工作提交和 Management。我们认为用户应使用 Oozie 的 REST API 将作业提交给 Oozie。 HCatalog 计划是在 Templeton 作业控制 REST API 的基础上实现 JDBC 和 ODBC。这将是一项巨大的工作(尽管我们已经有 HiveServer2 的 JDBC 和 ODBC 也可以用于 Pig 了),并且由于 Templeton 将每条指令作为 Oozie 作业执行,因此不允许交互式 JDBC 或 ODBC 使用。
Technical Approach
我们将修改 HiveServer2,以使其能够支持除 HQL 之外的语言运行时,实际上是将 HiveServer2 转换为可插拔模块的应用程序服务器,其近期目标是支持 Pig。这些努力的最终结果将称为 AccessServer。
在讨论这些修改之前,重要的是首先了解 HiveServer2 的基本设计。
HiveServer2 设计概述
下图是 HiveServer2 中主要子模块的块级表示,其中水平边界表示依赖关系。在 HiveServer2 项目开始之前,Hive 中存在绿色模块,而蓝色模块已作为 HiveServer2 项目的一部分实施。
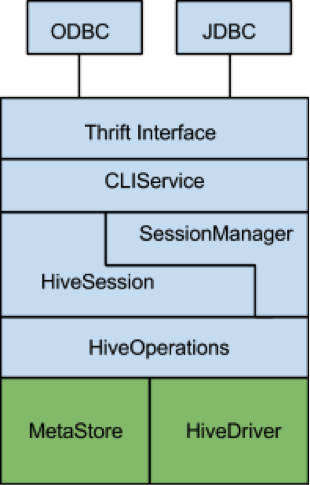
HiveServer2 的核心是 HiveSession 类。此类提供了用于用户会话状态的容器,并且还 Management 由用户触发的操作的生命周期。在这种情况下,操作是通过 CLIService API 公开的任何可以生成结果集的命令。这包括 ExecuteStatement()操作和元数据操作,例如 GetTables()和 GetSchemas()。这些操作中的每一个都由特定的 Operation 子类实现。为了执行 Hive 查询,ExecuteStatementOperation 使用了预先存在的 HiveDriver 类。 HiveDriver 封装了 Hive 的编译器和计划执行引擎,并且在大多数方面与 Pig 的 PigServer 类非常相似。
AccessServer Design
下图简要概述了在 AccessServer 中支持 Pig 运行时引擎所需的更改。为简单起见,我们从图中删除了特定于 Hive 的组件,例如 HiveOperation 和 HiveSession 类。
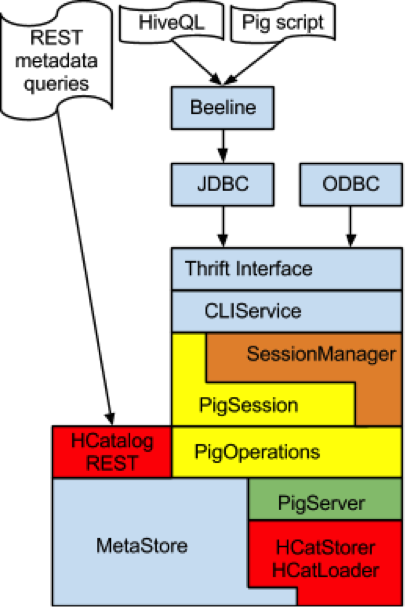
在该图中,蓝色表示 HiveServer2 中不需要修改的现有组件。这包括 Thrift 接口,JDBC/ODBC 驱动程序,CLIService 和 Metastore。
橙色表示必须修改的现有 HiveServer2 组件。我们需要修改 SessionManager 以便支持可插入会话工厂。请注意,CLIService API 已经允许 Client 端通过 OpenSession 调用中的一组配置参数来请求特定的 Session 类型。
黄色表示必须从头开始制作的新组件:PigSession 类和 Pig Operation 类集。值得注意的是以下与这些类有关的实现细节:
我们将需要提供 CLIService API 中定义的特定于 Pig 的元数据操作的实现,例如 GetTables,GetSchemas,GetTypeInfo 等。在某些情况下,我们将能够重用这些操作的 Hive 版本,而无需进行修改(例如,GetSchemas)。其他元数据操作(例如 GetTables)可以基于相应的 Hive 版本,但是必须进行修改才能滤除 Pig 不支持的目录对象(例如索引和视图)。
Pig 版本的 ExecuteStatementOperation 可能需要花费最大的精力来实现。此类将用作 AccessServer Session API 和 PigServer 类的实例之间的适配器。
最后,在上图中使用红色突出显示了我们计划使用的 HCatalog 组件:HCatStorer 和 HCatLoader 模块,以及 REST API。这些类充当适配器层,使 Pig 可以访问 Hive 的元数据和 SerDes。