Abstract
Apache Hadoop 是使用通常由商品硬件组成的计算机集群对大型数据集进行分布式处理的框架。在过去的几年中,Apache Hadoop 已经成为使用商品硬件进行分布式数据处理的事实平台。 Apache Hive 是使用 Apache Hadoop 进行数据处理的流行 SQL 接口。
Hive 将用户提交的 SQL 查询转换为物理运算符树,该树经过优化并转换为 Tez Jobs,然后在 Hadoop 集群上执行。在处理中间结果集方面,Hadoop 中的分布式 SQL 查询处理与传统的关系查询引擎不同。配置单元查询处理通常需要对中间结果集进行排序和重新组合。在 Hadoop 术语中,这称为改组。
Hive 中大多数现有的查询优化都是关于最小化改组成本。当前,用户将必须以正确的连接 Sequences 向 Hive 提交优化的查询,以便有效执行查询。 Hive 中的逻辑优化仅限于过滤器下推,投影修剪和分区修剪。基于成本的逻辑优化可以显着改善 Apache Hive 的查询延迟和易用性。
可以从基于成本的优化器中受益的联接优化很少是联接重新排序和联接算法选择。基于成本的优化器将使用户不必以正确的 Sequences 重新排列联接,也不必通过使用查询提示和配置选项来指定联接算法。这样可以潜在地使用户腾出钱来建模他们的报告和 ETL 需求,使其接近业务流程,而不必担心查询优化。
Calcite 是一个基于开源成本的查询优化器和查询执行框架。 Calcite 当前具有五十多个可以重写查询树的查询优化规则,以及可以以最佳方式选择最便宜的查询计划的高效计划修剪器。在本文中,我们讨论了如何使用方解石将基于成本的逻辑优化器(CBO)引入 Apache Hive。
CBO 将分阶段引入 Hive。在第一阶段,方解石将用于重新排序连接并选择正确的连接算法,以减少查询延迟。表基数和边界统计信息将用于此基于成本的优化。
1. INTRODUCTION
Hive 是基于 Apache Hadoop 的数据仓库基础架构。 Hive 利用 Hadoop 的大规模横向扩展和容错功能来在商品硬件上进行数据存储和处理。 Hive 旨在简化数据汇总,临时查询和分析大量数据的过程。 Hive SQL 是声明性查询语言,它使熟悉 SQL 的用户可以轻松地进行即席查询,摘要和数据分析。
过去,Hadoop 作业往往具有较高的延迟,并在作业提交和调度中产生大量开销。结果-即使涉及的数据集很小,Hive 查询的延迟通常也很高。因此,Hive 通常用于 ETL,而很少用于交互式查询。使用 Hadoop2 和 Tez,作业提交和作业计划的开销已大大降低。在 Hadoop 版本 1 中,可以执行的作业只能是 Map-Reduce 作业。对于 Hadoop2 和 Tez,该限制不再适用。
在 Hadoop 中,对 Map 器的输出进行排序,有时会保留在 Map 器的本地磁盘上。然后,将经过排序的 Map 器输出发送到适当的 reducer,然后由其合并来自不同 Map 器的排序结果。当执行多个 map-reduce 作业时,连续的 map-reduce 作业需要消耗一个作业的输出,而先前的 map-reduce 作业的输出则需要保存到 HDFS 中。这种持久性成本很高,因为需要根据 HDFS 的复制因子将数据复制到其他节点。
基于 Hadoop 版本 1 的 Hive 通常必须提交多个 map-reduce 作业才能完成查询处理。这种 Map-Reduce 作业管道降低了性能,因为现在需要将中间结果集保留到容错 HDFS 中。另外,提交作业和安排作业是相对昂贵的操作。借助 Hadoop2 和 Tez,作业提交和调度的成本得以最小化。此外,Tez 并不将作业限制为仅 Map 之后是 Reduce;这意味着所有查询执行都可以在单个作业中完成,而不必跨越作业边界。由于不需要将中间结果集持久存储到 HDFS 甚至本地磁盘上,因此可以节省大量成本。
关系查询引擎中的查询优化可以大致分为逻辑查询优化和物理查询优化。逻辑查询优化通常是指可以基于与执行查询的物理层无关的关系代数派生的查询优化。物理查询优化是可识别物理层基元的查询优化。对于 Hive,物理层隐含 Map-Reduce 和 TezPrimitives。
当前,Hive 中的逻辑查询优化可以大致分为以下几类:
Projection Pruning
推导及物动词
谓词下推
将 Select-Select,Filter-Filter 合并为单个运算符
Multi-way Join
查询重写以适应某些列值的连接偏斜
Hive 中的物理优化可大致分为以下几类:
Partition Pruning
根据分区和存储桶扫描修剪
如果查询基于采样,则扫描修剪
在某些情况下,在 Map 端应用分组依据
在 Map 器上执行加入
优化联合,以便仅可以在 Map 侧执行联合
根据用户提示,以多方联接的方式决定最后一个流表
删除不必要的减少接收器运算符
对于带有 limit 子句的查询,减少需要为该表扫描的文件数。
对于带有 Limit 子句的查询,通过限制 Reduce Sink 运算符生成的内容来限制来自 Map 器的输出。
减少回答用户提交的 SQL 查询所需的 Tez 作业数量
如果是简单的提取查询,请避免使用 Map-Reduce 作业
对于带有聚合的简单获取查询,请执行不带 Map-Reduce 任务的聚合
重写按查询分组以使用索引表代替原始表
当表扫描之上的谓词是相等谓词且谓词中的列具有索引时,请使用索引扫描。
在 Hive 中,大多数优化都不基于查询执行的成本。除了过滤器下推和操作员合并之外,大多数优化都不会重新排列操作员树。大多数运算符树突变是用于删除 reducesink 和 reducer 运算符的。下面列出了一些可以从 CBO 中受益的优化决策:
如何 Order
给定 Join 使用什么算法
应该保留中间结果,还是应该在操作员失败时重新计算中间结果。
任何运算符的并行度(具体来说是要使用的减速器数量)。
半联接选择
Calcite 是一个开放源代码,Apache 许可的查询计划和执行框架。方解石很多是从 Eigenbase Project 衍生而来的。 Calcite 具有可选的 JDBC 服务器,查询解析器和验证器,查询优化器和可插入数据源适配器。可用的方解石优化器之一是基于火山纸的基于成本的优化器。当前在以下项目/产品中使用了不同的方解石块:
Apache Drill
Cascading (Lingual)
Lucid DB
Mondrian/Pentaho
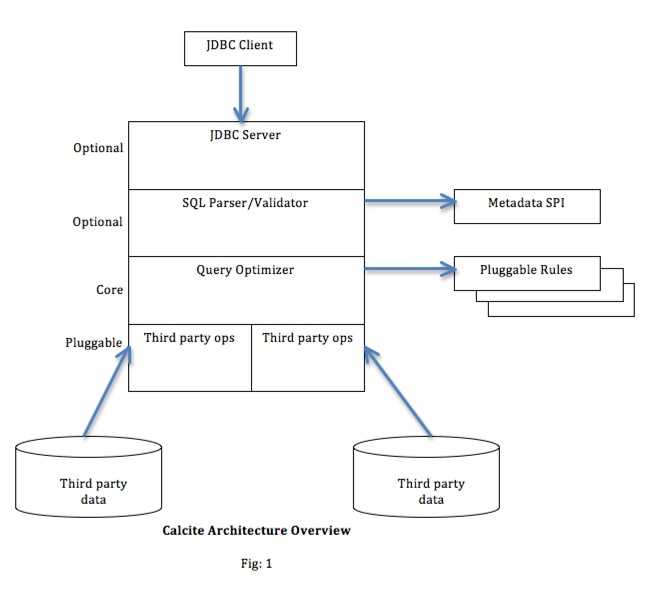
方解石目前有超过五十种基于成本的优化规则。下面列出了一些主要的基于成本的优化规则:
通过 union 推动加入
推送过滤器通过表格功能
Join Reordering
半联接选择
通过联合推动聚合
通过联合拉动骨料
通过常量拉常量
Merge Unions
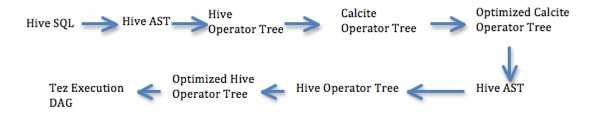
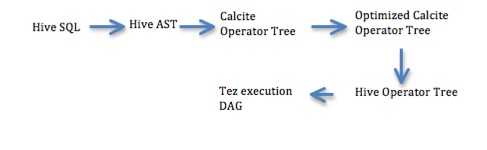
在本文档中,我们建议使用方解石的基于成本的优化器 Volcano 在 Hive 中执行基于成本的优化。我们建议分阶段实施基于方解石的 CBO。请注意,此处的建议是仅使用方解石的优化器,而不能使用其他任何东西。下面列出了使用方解石将 CBO 引入 Hive 的预期阶段:
阶段 1 –联接重新排序和联接算法选择
表基数和边界统计信息将用于计算操作员基数。
Hive 运算符树将转换为方解石运算符树。
方解石中的 Volcano Optimizer 将用于重新排列连接并选择连接算法。
优化的方解石运算符树将转换回 Hive AST,并将像以前一样执行。因此,Hive 的所有现有优化都将在 Calcite 优化的 SQL 之上运行。
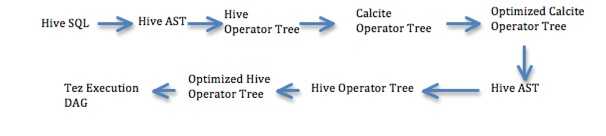
阶段 2 –添加对直方图的支持,在方解石中使用其他优化
介绍空间有效的直方图
更改运算符基数计算以使用直方图
像上面列出的那样,注册 Calcite 中可用的其他优化规则。
阶段 3 –代码重组,以便 Calcite 生成优化的 Hive Operator 树
与 phase1 不同,Hive AST 将直接转换为 Calcite 运算符树。
使用 Volcano 优化器优化方解石运算符树。
将优化的方解石运算符树转换回 Hive 运算符树。这与阶段 1 不同,阶段 1 中将优化的方解石运算符树转换为 Hive AST。
2.相关工作
STATS
histogram_numeric():估算频率分布:https://cwiki.apache.org/confluence/x/CoOhAQ
数值列https://issues.apache.org/jira/browse/HIVE-1397的 histogram()UDAF
内置的汇总函数(UDAF):https://cwiki.apache.org/confluence/x/-oKhAQ
使用 metastore 中的统计信息 Comments 配置单元运算符树:https://issues.apache.org/jira/browse/HIVE-5369
PAPERS
- 大规模并行数据处理的查询优化
Sai Wu,Feng Li,Sharad Mehrotra,Beng Chin Ooi
*新加坡国立大学计算机学院,新加坡,117590 *
加 State 大学尔湾分校信息与计算机科学学院
- MapReduce 程序的性能分析,假设分析和基于成本的优化
希罗多德希罗多杜克大学,希夫纳特·巴布·杜克大学
- 在 Map-Reduce 环境中优化联接
Foto N. Afrati,希腊雅典国立技术大学
美国斯坦福大学 Jeffrey D.Ullman
- 针对 Oracle 11g 中大型数据库的高效且可伸缩的统计信息收集
Sunil Chakkappen,Thierry Cruanes,Benoit Dageville,Linan Jiang,Uri Shaft,Hong Su,Mohamed Zait 和 Oracle Redwood Shores CA
http://dl.acm.org/citation.cfm?doid=1376616.1376721
- 估计差异(Postgress SQL)
http://wiki.postgresql.org/wiki/Estimating_Distinct
- 直方图的历史
雅典大学信息与电信系 Yannis Ioannidis
http://www.vldb.org/conf/2003/papers/S02P01.pdf
3. BACKGROUND
Hive 查询优化问题
Hive 将用户指定的 SQL 语句转换为 AST,然后用于生成物理运算符树。所有查询优化都在物理运算符树上执行。 Hive 将语义信息与查询运算符树分开。语义信息是在计划生成期间提取的,然后在下游查询优化中经常查找。由于缺乏适当的逻辑查询计划,并且由于语义信息和查询树分离,通常难以在 Hive 中添加新的查询优化。
TEZ
Apache Tez 概括了 MapReduce 范例以执行复杂的任务 DAG(有向无环图)。请参阅以下链接以获取更多信息。
http://hortonworks.com/blog/apache-tez-a-new-chapter-in-hadoop-data-processing/
Hive 中的加入算法
Hive 当前仅支持 equi-Join。配置单元联接算法可以是以下任意一种:
多方加入
如果多个联接共享同一驾驶侧联接键,则所有这些联接都可以在单个任务中完成。
例如:(R1 PR1.x = R2.a-R2)PR1.x = R3.b-R3)PR1.x = R4.c-R4
所有的连接都可以在同一化简器中完成,因为 R1 已经基于连接键 x 进行了排序。
Common Join
使用 Map 器对联接键上的表进行并行排序,然后将这些表传递给化简器。具有相同键的所有 Tuples 都分配给相同的 reducer。减速器可能会为多个键获取 Tuples。Tuples 的键还将包含表 ID,因此可以识别具有相同键的两个不同表的排序输出。 Reducers 将合并排序后的流以获取联接输出。
Map Join
对于星型模式联接很有用,此联接算法将所有小表(维表)保留在所有 Map 器的内存中,大表(事实表)在 Map 器中流式传输。这避免了普通联接固有的改组成本。对于每个小表(维表),将使用联接键作为哈希表键来创建哈希表。
桶图加入
如果对 map-join 的连接键进行了存储桶化,则不会保留每个 Map 器中的整个小表(维度表),而只会保留匹配的存储桶。这减少了 Map 联接的内存占用。
SMB Join
这是对“ Bucket Map Join”的优化;如果要连接的数据已经在连接键上排序,则避免创建哈希表,而是使用排序合并连接算法。
Skew Join
如果数据的分布偏向某些特定值,则联接性能可能会受到影响,因为联接运算符的某些实例(map-reduce 世界中的归约器)可能超载,而另一些实例可能未得到充分利用。根据用户提示,配置单元将围绕偏斜值重写为一个联合的联接查询。
示例 R1 PR1.x = R2.a-大部分数据分布在 x = 1 附近的 R2,则此联接可以重写为(R1 PR1.x = R2.a 和 PR1.x = 1-R2)所有(R1 PR1)并集。 x = R2.a 和 PR1.x<> 1-R2)
4.实施细节
CBO 将在三个不同的阶段引入 Hive。以下概述了这些阶段:
Phase 1
Statistics:
Table Cardinality
列边界状态:最小值,最大值,平均值,不同值的数量
基于成本的优化:
Join ordering
Join Algorithm
Restrictions:
方解石 CBO 仅用于选择表达式
如果 select 表达式包含以下任何一个运算符,将不使用方解石 CBO:
Sort By
Hive 支持全部排序(排序依据)和部分排序(排序依据)。关系代数和 SQL 不能表示部分排序。将来我们可能将 Sort By 表示为表函数。
- Map/Reduce/Transform
Hive 允许用户在 sql 中指定 map/reduce/transform 运算符;数据将使用提供的 mapper/reducer 脚本进行转换。这些 operator 没有直接转换为关系代数。我们将来可能将它们表示为表函数。
- 群集依据/分布依据
- Cluster By 和 Distribute By *主要与Transform/Map-Reduce Scripts一起使用。但是,如果需要对查询的输出进行分区和排序以用于后续查询,有时在 SELECT 语句中很有用。 * Cluster By 是 Distribute By 和 Sort By 的快捷方式。 Hive 使用 Distribute By 中的列在减速器之间分配行。具有相同 Distribute By 列的所有行将进入相同的 reducer。但是, Distribute By *不保证分布式键上的聚类或排序属性。
- Table Sample
TABLESAMPLE 子句允许用户为数据 samples 而不是整个表编写查询。 TABLESAMPLE 子句可以添加到 FROM 子句中的任何表中。将来我们可以将 Table Sample 表示为表函数。
- Lateral Views
横向视图与用户定义的表生成功能(例如 explode())结合使用。 UDTF 为每个 Importing 行生成一个或多个输出行。侧视图首先将 UDTF 应用于基础表的每一行,然后将结果输出行与 Importing 行连接起来以形成具有所提供表别名的虚拟表。
UDTF(表函数)
PTF(分区表函数)
方解石相关的增强功能:
介绍运算符以代表配置单元关系运算符。表扫描,联接,联合,选择,过滤,分组依据,不同,排序依据。这些运算符将为每个运算符实施具有实际成本的呼叫约定。
介绍规则以将 Joins 从 CommonJoin 转换为 MapJoin,将 MapJoin 转换为 BucketJoin,将 BucketJoin 转换为 SMBJoin,将 CommonJoin 转换为 SkewJoin。
介绍合并联接的规则,以便单个联接运算符表示多路联接(类似于 Hive 中的 MergedJoin)。
Hive 中的合并联接将转换为方解石中的 MultiJoinRel。
Phase 2
Statistics:
- Histograms
基于成本的优化:
基于直方图的联接排序
连接算法–直方图用于估计连接选择性
利用方解石中的其他优化。实际使用的规则是待定。
Phase 3
Configuration
配置参数hive.cbo.enable确定是否启用基于成本的优化。
建议的费用模型
Hive 使用 Hadoop 集群采用并行分布式查询执行。这意味着对于给定的查询运算符树,不同的运算符可以在不同的节点上运行。同样,同一操作员可能会在集群中的不同节点上并行运行,从而处理原始关系的不同分区。这种并行执行模型导致较高的 I/O 和 CPU 成本。由于以下原因,配置单元查询执行成本倾向于以 I/O 为中心。
- Shuffling cost
运算符在查询树中需要其子运算符所需的数据,需要将所有子运算符实例的数据进行组合。然后,需要对这些数据进行分类和切分,以便将关系的分区呈现给运算符的实例。
改组成本涉及将中间结果集写入本地文件系统的成本,从本地文件系统读取数据的成本以及将中间结果集传输到运行子处理器的节点的成本。除 I/O 成本外,混洗还要求对数据进行排序,这些数据应计入 CPU 成本。
- HDFS 读/写成本高昂
与本地 FS 相比,将数据读取和写入 HDFS 的成本更高。在 Map-Reduce 框架中,当在两个 Map-Reduce 作业之间切换时,表扫描通常会从 HDFS 读取数据并将数据写入 HDFS。在 Tez 中,所有操作员都应在一个 Tez Job 中一起工作,因此我们不必支付将中间结果集写入 HDFS 的费用。
Hive 中基于成本的优化将按照以下方面跟踪成本
CPU usage
IO Usage
Cardinality
关系中 Tuples 的平均大小。
关系中 Tuples 的平均大小和该关系的基数将用于估计将一个关系保存在内存中所需的资源。保持关系所需的内存用于确定是否可以使用某些联接算法,例如 Map/Bucket Join。
Calcite 中的 Volcano Optimizer 通过获取树中每个运算符的成本并对它们进行求和以求出累积成本,从而比较了两个等效查询计划的成本。选择具有最低累积成本的计划作为执行查询的最佳计划。 “ VolcanoCost”是表示 Calcite 的 Volcano 优化器的成本的 Java 类。 “ VolcanoCost”比较运算符似乎仅考虑行数来确定一种成本是否低于另一种。
对于 Hive,我们希望在比较基数之前先考虑 CPU 和 IO 的使用情况。
我们建议引入一个新的“ RelOptCost”实现“ HiveVolcanoCost”,该实现源自“ VolcanoCost”。 “ HiveVolcanoCost”将保留 CPU,I/O,基数和 Tuples 的平均大小。成本比较算法在关注基数之前会先考虑 CPU 和 IO 成本。 CPU 和 IO 成本将以纳秒级粒度存储。以下是“ RelOptCost.isLe”函数的伪代码:
HiveVolcanoCost 类扩展了 VolcanoCost {
Double m_sizeOfTuple;
@Override
public boolean isLe(RelOptCost other){
VolcanoCost =(VolcanoCost)其他;
如果((((this.dCpu this.dIo)<(that.dCpu that.dIo))
|| ((this.dCpu this.dIo)==(that.dCpu that.dIo)
&& this.dRows <= that.dRows)){
return true;
}其他{
return false;
}
}
}
设计选择 :
在没有直方图的情况下,可以假设基数遵循不同值的均匀分布。使用这种方法,基数/差异计算可以始终遵循相同的代码路径(直方图)。另一种方法是在没有直方图时使用启发式方法(例如 Hector Garcia Molina,Jeffrey D. Ullman 和 Jennifer Widom 在“数据库系统”中描述的方法)。当前,Hive 统计信息无法跟踪属性的不同值(仅保留不同值的数量);但是,可以根据最小值,最大值,不同值的数量以及表基数均匀分布的直方图来构建。下面描述统一直方图构造的公式。
桶数=(最大-最小)/不同值的数量。
铲斗宽度=(最大-最小)/铲斗数。
铲斗高度=表基数/铲斗数。
在本文中,对于成本公式,在没有直方图的情况下,我们将遵循 Hector Garcia Molina,Jeffrey D. Ullman 和 Jennifer Widom 在“数据库系统”一书中描述的启发式方法。
以下是将在成本计算中使用的成本变量 :
Hr-这是在纳秒内从 HDFS 读取 1 个字节的成本。
硬件-这是在 1 纳秒内向 HDFS 写入 1 个字节的成本。
Lr-这是在纳秒内从本地 FS 读取 1 个字节的成本。
Lw-这是在纳秒内将 1 个字节写入本地 FS 的成本。
NEt –这是通过 Hadoop 群集中的网络从任何节点到任何节点传输 1 个字节的平均成本;以纳秒表示。
T(R)-这是关系中的 Tuples 数。
Tsz –关系中 Tuples 的平均大小
V(R,a)–关系 R 中属性 a 的不同值的数量
CPUc – CPU 成本,以纳秒为单位进行比较
Assumptions :
磁盘,HDFS 和网络相互读写的相对成本比实际成本更为重要。
无论硬件类型,本地性和 I/O 涉及的数据大小,I/O 分散/收集的类型还是 Sequences 读/写,我们都假定成本是统一的。这显然过于简化,但我们对相对运营成本更感兴趣。
该成本模型忽略了需要从中读取/写入的磁盘块数,而是查看了需要读取/写入的字节数。这显然是 I/O 成本的过度简化。
该成本模型还忽略了存储布局,列存储与其他。
我们假定所有 Tuples 的大小均一。
假设没有主机托管任务,因此我们考虑了网络传输成本。
对于 CPU 成本,仅考虑比较成本。假设每个比较将花费 1 纳秒。
Tez 中的每个顶点都是一个不同的过程
HDFS 读取被假定为本地磁盘读取的 1.5 倍,HDFS 写入被假定为本地磁盘写入的 10 倍。
以下是成本变量的假定值 :
CPUc = 1 纳秒
NEt = 150 * CPUc 纳秒
Lw = 4 * NEt
Lr = 4 * NEt
重量= 10 *重量
Hr = 1.5 * Lr
Table Scan
T(R)=查阅元数据以获得基数;
Tsz =咨询元数据以获得平均 Tuples 大小;
V(R,a)=咨询元数据
CPU 使用率= 0;
IO 使用率= Hr * T(R)* Tsz
Common Join
T(R)=连接基数估计
Tsz =咨询元数据以基于连接架构获取平均 Tuples 大小;
CPU 使用率=每个关系的排序成本合并流的合并成本
=(T(R1)日志 T(R1) CPUc T(R2)日志 T(R2) CPUc…T(Rm)日志 T(Rm) CPUc)(T(R1)T(R2)… T(Rm))* CPUc 纳秒;
IO 使用率=将中间结果集写入本地 FS 以改组的成本从本地 FS 读取以传输到 Join 运算符节点的成本将 Map 的输出传输到 Join 运算符节点的成本
= Lw (T(R1) Tsz1 T(R2)* Tsz2…T(Rm)* Tszm)Lr (T(R1) Tsz1 T(R2)* Tsz2…T(Rm)* Tszm)NEt ( T(R1) Tsz1 T(R2)* Tsz2…T(Rm)* Tszm)
R1,R2…Rm 是 Connecting 涉及的关系。
Tsz1,Tsz2…Tszm 是关系 R1,R2…Rm 中 Tuples 的平均大小。
Map Join
行数=连接基数估计
Tuples 的大小=参考元数据以基于连接架构获取平均 Tuples 大小
CPU 使用率=哈希表构建成本联接成本
=(T(R2)…T(Rm))(T(R1)T(R2)…T(Rm))* CPUc 纳秒
IO 使用率=将小表转移到 Join 运算符节点的成本* Join 的并行化
= NEt (T(R2) Tsz2…T(Rm)* Tszm)*Map 数
R1,R2…Rm 是联接中涉及的关系,R1 是将要流传输的大表。
Tsz2…Tszm 是关系 R1,R2…Rm 中 Tuples 的平均大小。
桶图加入
行数=连接基数估计
Tuples 的大小=参考元数据以基于连接模式获取平均 Tuples 的大小;
CPU 使用率=哈希表构建成本联接成本
=(T(R2)…T(Rm))* CPUc(T(R1)T(R2)…T(Rm))* CPUc 纳秒
IO 使用率=将小表转移到联接的成本*联接的并行化
= NEt (T(R2) Tsz2…T(Rm)* Tszm)*Map 数
R1,R2…Rm 是 Connecting 涉及的关系。
Tsz2…Tszm 是关系 R2…Rm 中 Tuples 的平均大小。
SMB Join
行数=连接基数估计
Tuples 的大小=参考元数据以基于连接模式获取平均 Tuples 的大小;
CPU 使用率=加入成本
=(T(R1)T(R2)…T(Rm))* CPUc 纳秒
IO 使用率=将小表转移到联接的成本*联接的并行化
= NEt (T(R2) Tsz2…T(Rm)* Tszm)*Map 数
R1,R2…Rm 是 Connecting 涉及的关系。
Tsz2…Tszm 是关系 R2…Rm 中 Tuples 的平均大小。
Skew Join
查询将被重写为两个联接的并集。我们将有一条规则来重写偏斜联接的查询树。重写的查询将对联接和联合运算符使用成本模型。
Distinct/Group By
行数=基于组别选择性= V(R,a,b,c ..)其中 a,b,c 是按键分组
Tuples 的大小=根据架构查询元数据以获取平均 Tuples 大小
CPU 使用率=分类成本分类成本
=(T(R)* log T(R)T(R))* CPUc 纳秒;
IO 使用率=将中间结果集写入本地 FS 以进行改组的成本从本地 FS 读取以传输至 GB Reducer 操作员节点的成本将数据集传输至 GB 节点的成本
= Lw * T(R)* Tsz Lr * T(R)* Tsz NEt * T(R)* Tsz
Union All
行数=左边的行数右边的行数
Tuples 的大小=的平均值(左侧的平均大小,右侧的平均大小)
CPU 使用率= 0
IO 使用率=将中间结果集写入 HDFS 的成本从 HDFS 读取以传输到 UNIONMap 器节点的成本将数据集传输到 Mapper 节点的成本
=(T(R1)* Tsz1 T(R2)* Tsz2)* Hw(T(R1)* Tsz1 T(R2)* Tsz2)* Hr(T(R1)* Tsz1 T(R2)* Tsz2)* NEt
R1,R2 是参与连接的关系。
Tsz1,Tsz2 是关系 R1,R2 中 Tuples 的平均大小。
Filter/Having
行数=过滤器选择性*子行数
Tuples 的大小=来自子运算符的 Tuples 的大小
CPU 使用率= T(R)* CPUc 纳秒
IO 使用= 0
Select
行数=子行数
Tuples 的大小=来自子运算符的 Tuples 的大小
CPU 使用率= 0
IO 使用= 0
Filter Selectivity
Without Histogram
等式谓词,其中一侧是 Literals= 1/V(R,A)
当双方都不是 Literals 时的等式谓词= 1/max(V(R,A),V(R,B))
相等谓词中(小于/大于)= 1/3
不等于=(V(R,A)-1)/ V(R,A)
OR 条件= n *(1-(1-m1/n)(1-m2/n))其中,n 是子元素的 Tuples 总数,m1 和 m2 是析取谓词各部分的期望 Tuples 数量。
AND 条件=合并谓词中各个叶谓词的选择性乘积
加入基数(无直方图)
内部加入=子关系基数的乘积*加入选择性
一侧外连接=最大值(过滤器拒绝未连接的内部 Tuples 的选择性*(子关系基数的乘积),外基数)
例如:C(R1 a = b R2)=最大值(C(R2.b = R1.a C(R1 X R2)),C(R1))
- 完全外部联接=最大值(过滤器拒绝未联接的内部 Tuples 的选择性*(子关系基数的乘积),左右关系基数的总和)
= C(R1 a = b R2)=最大值(C(R1.a = R1.b C(R1 X R2)),C(R1)C(R2))
- 对于多路联接算法,将联接分解为不同联接的数量以进行基数和成本估算。
连接选择性(无直方图)
单个属性= 1/max(V(R1,a),V(R2,a))其中连接谓词为 R1.a = R2.a
多个属性= 1 /(max(V(R1,a),V(R2,a))* max(V(R1,b),V(R2,b)))其中连接谓词为 R1.a = R2. a 和 R1.b = R2.b
Distinct Estimation
内部加入-不同的估算
如果属性 a 仅来自连接的一侧,则 V(J,a)= V(R1,a); J 是表示 Join 输出的关系,而 R1 是涉及的关系之一。
如果在连接的两侧都存在属性 a,则 V(J,a)= max(V(R1,a),V(R2,a)); J 是代表 Join 输出的关系,R1,R2 是联接所涉及的关系。
如果属性 a 仅来自连接的一侧,则 V(J,a)= V(R1,a); J 是表示 Join 输出输出的关系,R1 是属性“ a”的来源关系。
V(J,a)= V(Ro,a)其中,Ro 是外侧的关系; J 是表示 Join 输出的关系,而 Ro 是 Join 的外部关系。
如果属性“ a”仅来自连接的一侧,则 V(J,a)= V(R1,a); J 是表示 Join 输出的关系,R1 是 a 来自属性的关系。
V(J,a)= max(V(R1,a),V(R2,a))其中,J 是表示 Join 输出的关系,R1,R2 是 join 中涉及的关系。
V(U,a)= max(V(R1,a),V(R2,a))其中,U 是表示联合所有输出的关系,而 R1,R2 是参与联合的关系。
单面外连接-不同的估计
完全外部联接-不同的估计
全部合并-不同的估算
GB-不同的估算
V(G,a)= V(R,a)其中,G 是代表 Group-By 输出的关系,R 是 Group-By 的子关系。假定属性“ a”是分组键的一部分。
V(G,a,b,c)= max(V(R,a),V(R,b),V(R,c))其中,G 是表示 Group-By 输出的关系,R 是子关系组的。假定属性“ a”,“ b”,“ c”是分组键的一部分。
过滤器-不同的估算
- V(F,a)= V(R,a)其中,F 是代表滤波器输出的关系,R 是滤波器的子关系。
5.第一阶段–工作项目
遍历 Hive OP 树,并确保 OP 树不包含任何无法转换为方解石的操作(横向视图,PTF,多维数据集和汇总,多表插入)。
遍历 Hive OP 树并引入强制转换函数,以确保所有比较(隐式和显式)都是严格类型安全的(类型必须在两侧相同)。
实现特定于 Hive 的方解石运算符,该运算符将进行成本计算和克隆。
将 Hive OP 树转换为方解石 OP 树。
将蜂房类型转换为方解石类型
将 Hive 表达式转换为方解石表达式
将 Hive 运算符转换为方解石运算符
处理隐藏的列
处理 ReduceSink 引入的列(用于改组)
存放在 Reducesink op 中的 Handle Join 条件表达式
在加入条件中处理过滤器
将 Hive Semi Join 转换为方解石
附加费用给运算符
别名顶级查询投影以查询用户期望的查询投影。
使用 Volcano Optimizer 优化 Calcite OP 树。
实施规则以将 Joins 转换为 Hive Join 算法。
普通联接->Map 联接
Map 联接->桶式 Map 联接
普通联接->桶图联接
斗图联接-> SMB 联接
普通联接->倾斜联接
遍历 Optimized Calcite OP 树,并引入派生表以将 OP 树转换为 SQL。
生成唯一表(包括派生表)别名
遍历 OP 树并转换为 AST。
AST 中的隐藏连接算法作为查询提示
修改计划生成器以注意方解石查询提示
重新运行 Hive 优化器并生成执行计划(此第二遍将不会调用 Calcite 优化器)。
Open Issues
- CBO 需要区分 IPC 的类型(耐用本地 FS 与耐用 HDFS,内存与流)
Reference
数据库系统完整书,第二版,赫克托·加西亚·莫利纳(Hector Garcia-Molina),杰弗里·乌尔曼(Jeffrey D.Ullman),珍妮弗·威多姆(Jennifer Widom)
大规模并行数据处理的查询优化
Sai Wu,Feng Li,Sharad Mehrotra,Beng Chin Ooi
*新加坡国立大学计算机学院,新加坡,117590 *
加 State 大学尔湾分校信息与计算机科学学院