Background
Java API 专注于使用 Hive 的ACID功能将记录突变(插入/更新/删除)到事务表中。它是在 Hive 2.0.0(HIVE-10165)中引入的。
在某些数据处理用例中,有必要在新事实到达时修改现有数据。这方面的一个示例是经典的 ETL 合并,其中数据集的副本通过频繁应用增量而与主数据库保持同步。增量描述了自上次同步以来主机发生的突变(插入,更新,删除)。为了使用 Hadoop 实现这种情况,传统上要求重写包含突变目标记录的分区。这是一个粗略的方法。由于单个记录更改,可能会重建包含数百万条记录的分区。另外,这些分区不能原子还原。在某些时候,旧分区数据必须与新分区数据交换。发生这种交换时,通常通过先发出 HDFS rm后再发出mv的方式,有可能出现数据不可用的情况,因此使用该数据的所有下游作业都可能会意外失败。因此,如果没有某种外部机制来协调对更改数据的并发访问,则在 HDFS 上重述原始数据的数据处理模式将无法稳定运行。
Hive 中 ACID 表的可用性提供了一种机制,该机制既可以并发访问 HDFS 中存储的数据(只要是 ORC ACID 格式),还可以在表中的记录上进行行级更改,而无需重写现有表数据。但是,尽管 Hive 本身支持INSERT,UPDATE和DELETE命令,并且 ORC 格式可以支持事务中的大量突变,但是 Hive 的执行引擎当前在单独的事务中提交每个单独的突变操作,并向其中发出表扫描(M/R 作业)执行它们。当前,它不能满足以原子方式处理大增量的需求。此外,通过使原子批处理突变功能可用于其他数据处理框架,将其扩展到 Hive 之外是有利的。 Streaming Mutation API 就是这样做的。
尽管与Streaming API相似,Streaming Mutation API 也有许多区别,并且可以支持非常不同的用例。从表面上看,Streaming API 只能写入新数据,而变异 API 也可以修改现有数据。但是,这两个 API 也基于非常不同的 Transaction 模型。 Streaming API 的重点是将新数据的连续流显示在 Hive 表中,并通过将少量写入批处理成多个短期事务来实现。相反,突变 API 旨在不频繁地以原子方式将大量突变应用于数据集:将不应用所有突变,也可以不应用任何突变。相反,这要求使用单个长期 Transaction。下表总结了每个 API 的属性:
| Attribute | Streaming API | Mutation API |
|---|---|---|
| Ingest type | 数据连续到达。 | 定期进行摄取,并在单个批次中应用突变。 |
| Transaction scope | 为小批量写入创建事务。 | 整个突变集应在单个事务中应用。 |
| Data availability | 频繁且快速地向用户显示新数据。 | 更改集应原子应用,无论增量的影响是可见的还是不可见的。 |
| 记录订单敏感 | 否,记录没有预先存在的 lastTxnIds 或 bucketIds。记录可能被写入单个分区(例如,今天的日期)。 | 是的,所有突变记录都具有RecordIdentifiers,并且必须按[partitionValues,bucketId]分组,并按 lastTxnId 排序。这些记录坐标最初以有效随机的 Sequences 到达。 |
| 写入失败的影响 | Transaction 可以中止,生产者可以选择重新提交失败的记录,因为排序并不重要。 | 必须暂停各个组的摄取(partitionValues bucketId),并重新提交失败的记录以保留序列。 |
| 用户对丢失数据的感知 | 数据尚未到达→“await 时间?” | “此数据不一致,某些记录已更新,但其他相关记录尚未更新” –在此考虑银行帐户之间的经典转移方案。 |
| API 端点范围 | 给定的HiveEndPoint实例将许多事务提交到特定表的特定分区中的特定存储桶。 |
一组MutationCoordinators可在单个事务中将更 Rewrite 入未知的存储桶集,分区的未知集,特定表(可以多个)。 |
Structure
API 包含两个主要方面:事务 Management,以及向数据集写入变异操作。这两个问题之间的耦合程度最小,因为可以预期,事务将从单个作业启动程序类型的过程启动,而突变的写入将扩展到任意数量的工作程序节点上。在 Hadoop M/R 的上下文中,可以将它们更具体地定义为工具和 Map/Reduce 任务组件。但是,这种结构的使用不是强制性的,实际上,这两种情况都可以在一个简单的过程中根据要求进行处理。
请注意,即使您不打算从 Hive 内部访问数据,也需要适当配置的 Hive 实例来 os。在内部,事务由 Hive MetaStoreManagement。通过绕过 MetaStore 的 ORC API 对 HDFS 执行突变。另外,您可能希望配置 MetaStore 实例以执行定期数据压缩。
关于包装的注意事项: 这些 API 在org.apache.hive.hcatalog.streaming.mutate Java 软件包中定义,并在hive-hcatalog-streaming jar 中包含。
Data Requirements
一般来说,要将变异应用于记录,必须具有一些唯一的密钥来标识该记录。但是,主键不是 Hive 提供的构造。在内部,Hive 使用存储在虚拟ROW__ID列中的RecordIdentifiers唯一标识 ACID 表中的记录。因此,任何希望通过此 API 向表发出变异的过程都必须具有对应于目标记录的行 ID。实际上,这意味着发出突变的过程必须首先读取数据的当前快照,然后将这些突变加入某个特定于域的主键上以获得相应的 Hive ROW__ID。这实际上是在执行UPDATE或DELETE语句时在 Hive 的表扫描过程中发生的情况。 AcidInputFormat通过AcidRecordReader.getRecordIdentifier()提供对此数据的访问。
ACID 格式的实现对记录的写入 Sequences 施加了一些限制,因此必须强制执行此排序。此外,必须对数据进行适当的分组以遵守OrcRecordUpdater施加的约束。分组还可以为了缩放而并行化突变的写入。最后,要正确存储新记录(插入),必须使用一个有点不直观的技巧。
所有这些数据排序问题均由调用 API 的 Client 端进程负责,该 API 假定具有一流的分组和排序功能(Hadoop Map/Reduce 等)。流式 API 仅提供了验证器,当它们遇到不规则的组和记录时,验证器会快速失败。
简而言之,APIClient 端进程应为 mutate API 准备数据,如下所示:
必须: 依次按
ROW__ID.originalTxn和ROW__ID.rowId排序记录。必须: 为要插入的每条记录分配一个
ROW__ID,其中包含计算的bucketId。应该: 按表分区值分组,然后按
ROW__ID.bucketId。
在分组和排序之前添加存储桶 ID 来插入记录似乎并不直观。但是,需要确保新数据的适当分区和存储桶分配均与 Hive 提供的一致。在典型的 ETL 中,大多数突变事件是插入片段,通常针对单个分区(前一天,小时等的新数据)。如果有更多的 Worker 在写这些事件,那么如果我们将存储桶 ID 留空,那么所有插入操作都将交给一个 Worker(例如:reducer),并且工作量可能会严重扭曲。计算铲斗的分配使插入件可以更有用地分布在各个 Worker 之间。此外,当 Hive 处理数据时,它可能期望记录以与其内部方案一致的方式进行存储。提供了一种便利类型和方法来更轻松地计算和附加存储桶 ID:BucketIdResolver和BucketIdResolverImpl。
更新操作不应尝试修改分区或存储分区列的值。 API 不会阻止这种情况,并且这种尝试可能会导致数据损坏。
Streaming Requirements
当前,使用流媒体需要做一些事情。
当前仅支持ORC 存储格式。因此,必须在表创建期间指定“
stored as orc”。Hive 表必须存储在桶中,但不能排序。因此,在创建表时必须指定类似“
clustered by (colName) into 10 buckets”的内容。有关详细示例,请参见Bucketed Tables。Client 端流处理过程的用户必须具有必要的权限才能写入表或分区并在表中创建分区。
必须为每个表(请参见蜂房 Transaction–表属性)和
hive-site.xml(请参见HiveTransaction–配置)配置 Hive 事务。
注意: Hive 还支持将流式突变添加到 未分区 表中。
Record Layout
记录的结构,布局和编码是 Client 端 ETL 突变过程的唯一考虑因素,并且可能与目标 Hive ACID 表完全不同。变异 API 需要MutatorFactory和Mutator类的具体实现,才能从 Logging 提取相关数据并将数据序列化为 ACID 文件。幸运的是,提供了 Base Class(AbstractMutator,RecordInspectorImpl)来简化此工作,通常所需要做的只是指定合适的ObjectInspector以及在记录结构内提供ROW__ID和存储区列的索引。请注意,这些类中的所有列索引都是相对于您的记录结构而不是 Hive 表结构而言的。
您可能还希望使用BucketIdResolver将存储区 ID 附加到新 Logging 以进行插入。幸运的是,核心实现是在BucketIdResolverImpl中提供的,但请注意,存储区列索引的显示 Sequences 必须与 Hive 表定义中的显示 Sequences 相同,以确保存储区一致。请注意,您无法在存储桶之间移动记录,并且如果尝试这样做,则会引发异常。实际上,这意味着您不应尝试使用UPDATE修改存储桶列中的值。
连接和事务 Management
MutatorClient类用于创建和 Management 可以执行变异的 Transaction。事务的范围可以扩展到多个 ACID 表。Client 端连接后,它将与元存储进行通信,以验证和获取目标表的元数据。调用newTransaction然后打开与 metastore 的事务,最终确定AcidTables的集合并返回新的Transaction实例。 ACID 表是轻量级的可序列化对象,API 的变异编写组件使用它们来定位特定的 ACID 文件位置。通常,您的MutatorClient将在某些主节点上运行,而协调器将在工作节点上运行。在这种情况下,AcidTableSerializer可用于以更可移植的形式对表进行编码,例如,用作Configuration属性。
如您所料,必须先调用begin才能启动Transaction,然后才能应用任何突变。此调用使用元存储获取对目标表的锁定,并启动心跳以防止事务超时。强烈建议您向 Client 端注册LockFailureListener,以便您的进程可以处理任何锁定或事务失败。通常,如果发生此类错误,您可能希望中止作业。有了事务,您现在可以开始使用一个或多个MutatorCoordinator实例流式传输变异(稍后将对此进行更多说明),然后在应用更改集后就可以commit或abort事务,这将释放与 MetastoreClient 端的锁定。最后,您应该close变异 Client 端释放所有持有的资源。
提供MutatorClientBuilder是为了简化 Client 端的构造。
警告: Hive 当前没有死锁检测器(正在作为HIVE-9675的一部分进行处理)。此 API 可能会与其他流编写器或 SQL 用户陷入僵局。
Writing Data
MutatorCoordinator类用于向 ACID 表发出突变。每个表中至少需要有一个实例参与事务。给定实例的目标由用于构造协调器的相应AcidTable定义。建议使用MutatorClientBuilder来简化构造过程。
可以通过调用协调器上的insert,update和delete方法来应用突变。这些方法均以记录的目标分区和突变的记录为参数。对于未分区的表,您只需传递一个空列表作为分区值。具体来说,对于插入,只会从RecordIdentifier中提取存储区 ID,事务 ID 和行 ID 将被忽略,并由RecordUpdater中的适当值替换。
此外,在删除的情况下,Logging 除RecordIdentifier之外的所有内容都将被忽略,因此通常更容易提交原始记录。
警告: 如前所述,突变必须以特定 Sequences 到达,以使生成的表数据保持一致。协调者将验证[lastTransactionId,rowId]的自然排序序列,如果此序列被破坏,则将引发异常。几乎可以肯定应将此异常升级,以使事务中止。这以及数据的正确排序是使用 API 的 Client 端的责任。
动态分区创建
自动创建新分区(按小时创建)是非常可取的。在这种情况下,要求 HiveManagement 员预先创建必要的分区可能是不合理的。该 API 允许协调器根据需要创建分区(请参阅:MutatorClientBuilder.addSinkTable(String, String, boolean))。分区创建是一个原子动作,多个协调器可以争用创建分区,但是只有一个成功,因此协调器的 Client 端在创建分区时无需同步。需要为协调程序进程的用户授予对 Hive 表的写权限,以便创建分区。
使用此选项时必须小心,因为它要求协调器保持与 Metastore 数据库的连接。当协调器在分布式环境中运行时(很可能是这样),他们可能会淹没元存储。在这种情况下,最好在 ETL 合并过程中禁用分区创建并收集一组受影响的分区。集群端合并过程完成后,即可使用 Client 端代码中的单个 metastore 连接创建这些文件。
最后,请注意,当禁用分区创建时,协调器必须合成分区 URI,因为他们无法从元存储中检索它。如果 HDFS 中分区的布局不符合 Hive 标准(在org.apache.hadoop.hive.metastore.Warehouse.getPartitionPath(Path, LinkedHashMap <String, String>)中实现),则可能会导致问题。
Reading Data
尽管此 API 与写入数据更改有关,但是如前所述,我们几乎肯定要先读取现有数据才能获得相关的ROW__ID。因此,值得注意的是,以健壮和一致的方式读取 ACID 数据需要满足以下条件:
从元存储(
ValidTxnList)获取有效的 Transaction 列表。使用元存储获取锁并发出心跳(
LockImpl可以帮助您解决此问题)。配置
OrcInputFormat,然后读取数据。确保您还 ImportingROW__ID值。参见:AcidRecordReader.getRecordIdentifier。释放锁。
Example
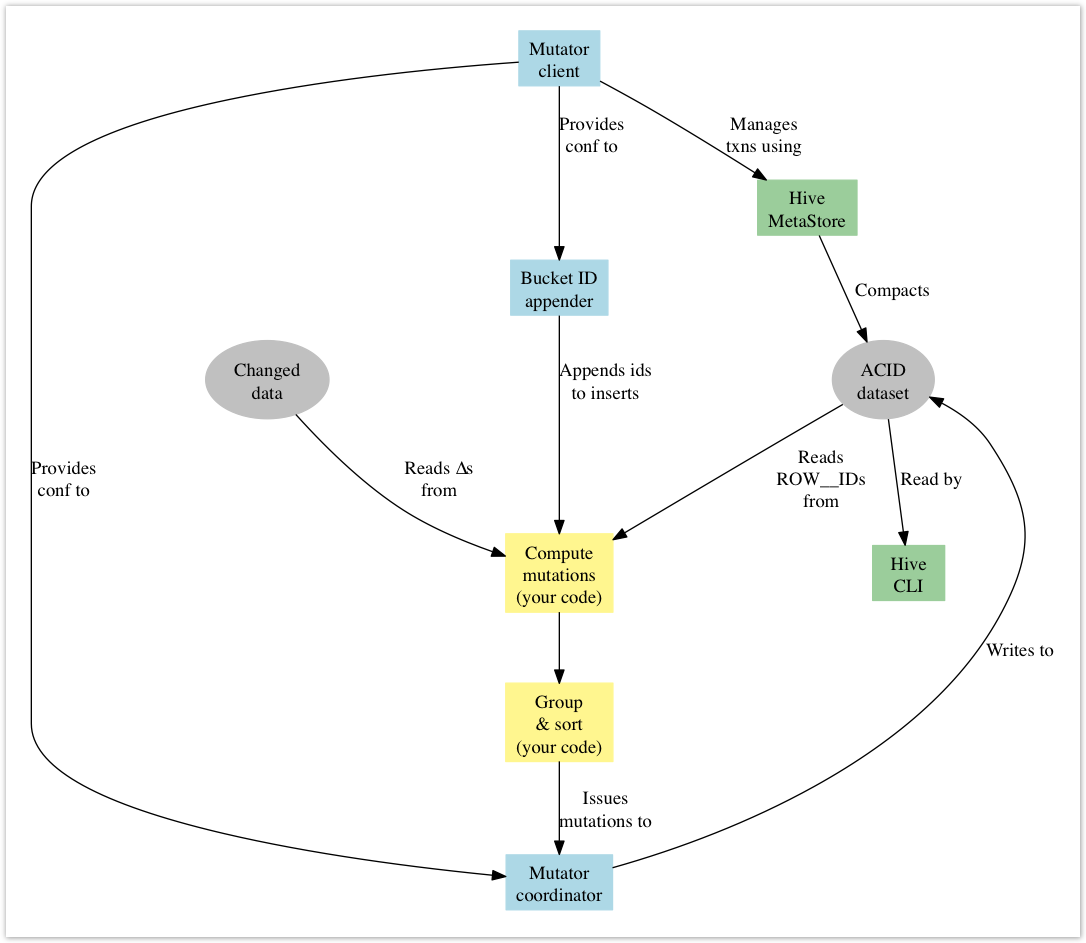
综上所述,使用 API 将突变应用于数据集所需的事件 Sequences 为:
创建一个
MutatorClient来 Management 目标 ACID 表的事务。这组表应包括任何 Transaction 目的地或来源。不要忘记注册LockFailureListener,以便您处理事务失败。与 Client 端打开一个新的
Transaction。从 Client 端获取
AcidTables。开始 Transaction。
为每个表至少创建一个
MutatorCoordinator。当您的员工处于分布式环境中时,AcidTableSerializer可帮助您运输AcidTables。计算您的突变集(这是您的 ETL 合并过程)。
(可选):收集受影响的分区集。
将存储区 ID 附加到插入 Logging。
BucketIdResolver可以在这里提供帮助。适当地对数据进行分组和排序。
向您的协调员发布突变事件。
关闭您的协调员。
中止或提交事务。
关闭您的突变 Client 端。
(可选):创建元存储中不存在的所有受影响的分区。
有关一些非常简单的用法,请参见ExampleUseCase和TestMutations.testUpdatesAndDeletes()。