Using HCatalog
Version information
HCatalog 毕业于 Apache 孵化器,并于 2013 年 3 月 26 日与 Hive 项目合并。
Hive 版本 0.11.0 是包含 HCatalog 的第一个版本。
Overview
HCatalog 是 Hadoop 的表和存储 Management 层,它使使用不同数据处理工具(Pig,MapReduce)的用户能够更轻松地在网格上读写数据。 HCatalog 的表抽象为用户提供了 Hadoop 分布式文件系统(HDFS)中数据的关系视图,并确保用户不必担心其数据的存储位置或格式(RCFile 格式,文本文件,SequenceFiles 或 ORC 文件)。
HCatalog 支持以可以写入 SerDe(串行化器-反序列化器)的任何格式读取和写入文件。默认情况下,HCatalog 支持 RCFile,CSV,JSON,SequenceFile 和 ORC 文件格式。要使用自定义格式,必须提供 InputFormat,OutputFormat 和 SerDe。
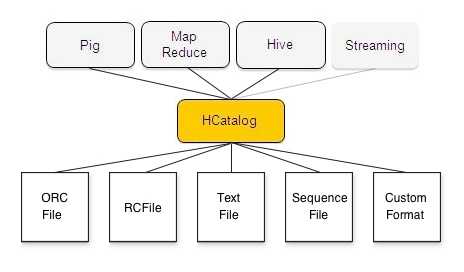
HCatalog Architecture
HCatalog 构建在 Hive Metastore 之上,并包含 Hive 的 DDL。 HCatalog 为 Pig 和 MapReduce 提供读写接口,并使用 Hive 的命令行界面发布数据定义和元数据探索命令。
Interfaces
Pig 的 HCatalog 接口由 HCatLoader 和 HCatStorer 组成,它们分别实现了 Pig 的加载和存储接口。 HCatLoader 接受一个表来读取数据;您可以通过紧跟在 load 语句之后并使用分区过滤器语句来指示要扫描的分区。 HCatStorer 接受要写入的表,还可以选择指定分区键的规范来创建新分区。您可以通过在 STORE 子句中指定分区键和值来写入单个分区。如果分区键是要存储的数据中的列,则可以写入多个分区。 HCatLoader 在 HCatInputFormat 之上实现,HCatStorer 在 HCatOutputFormat 之上实现。 (请参阅加载和存储接口。)
MapReduce 的 HCatalog 接口 HCatInputFormat 和 HCatOutputFormat 是 Hadoop InputFormat 和 OutputFormat 的实现。 HCatInputFormat 接受一个表以从中读取数据,还可以选择一个选择谓词来指示要扫描的分区。 HCatOutputFormat 接受要写入的表,还可以选择指定分区键的规范来创建新分区。您可以通过在 setOutput 方法中指定分区键和值来写入单个分区。如果分区键是要存储的数据中的列,则可以写入多个分区。 (请参阅Importing 和输出接口。)
注意: 没有特定于 Hive 的界面。由于 HCatalog 使用 Hive 的 metastore,因此 Hive 可以直接在 HCatalog 中读取数据。
数据是使用 HCatalog 的命令行界面(CLI)定义的。 HCatalog CLI 支持所有不需要 MapReduce 执行的 Hive DDL,允许用户创建,更改,删除表等。CLI 还支持 Hive 命令行的数据浏览部分,例如 SHOW TABLES,DESCRIBE TABLE 和以此类推。不支持的 Hive DDL 包括导入/导出,ALTER TABLE 的 REBUILD 和 CONCATENATE 选项,CREATE TABLE AS SELECT 以及 ANALYZE TABLE ... COMPUTE STATISTICS。 (请参阅命令行界面。)
Data Model
HCatalog 提供了数据的关系视图。数据存储在表中,这些表可以放置在数据库中。也可以将表散列在一个或多个键上。也就是说,对于一个键(或一组键)的给定值,将存在一个分区,其中包含具有该值(或一组值)的所有行。例如,如果一个表按日期分区,并且该表中有三天的数据,则该表中将有三个分区。可以将新分区添加到表中,并且可以从表中删除分区。分区表在创建时没有分区。未分区表实际上具有一个默认分区,该默认分区必须在表创建时创建。删除分区时,无法保证读取的一致性。
分区包含记录。创建分区后,无法将记录添加到分区,从分区中删除或在其中更新。分区是多维的,不是分层的。记录分为几列。列具有名称和数据类型。 HCatalog 支持与 Hive 相同的数据类型。有关数据类型的更多信息,请参见加载和存储接口。
数据流示例
这个简单的数据流示例显示了 HCatalog 如何帮助网格用户共享和访问数据。
首先:将数据复制到网格
Joe 在数据获取中使用distcp将数据获取到网格中。
hadoop distcp file:///file.dat hdfs://data/rawevents/20100819/data
hcat "alter table rawevents add partition (ds='20100819') location 'hdfs://data/rawevents/20100819/data'"
第二:准备数据
Sally 在数据处理中使用 Pig 清理并准备数据。
如果没有 HCatalog,则必须在数据可用时由 Joe 手动通知 Sally 或在 HDFS 上进行轮询。
A = load '/data/rawevents/20100819/data' as (alpha:int, beta:chararray, ...);
B = filter A by bot_finder(zeta) = 0;
...
store Z into 'data/processedevents/20100819/data';
使用 HCatalog,HCatalog 将发送一条 JMS 消息,表明数据可用。然后可以开始 Pig 工作。
A = load 'rawevents' using org.apache.hive.hcatalog.pig.HCatLoader();
B = filter A by date = '20100819' and by bot_finder(zeta) = 0;
...
store Z into 'processedevents' using org.apache.hive.hcatalog.pig.HCatStorer("date=20100819");
第三:分析数据
ClientManagement 中的 Robert 使用 Hive 分析其 Client 的业绩。
如果没有 HCatalog,Robert 必须更改表以添加所需的分区。
alter table processedevents add partition 20100819 hdfs://data/processedevents/20100819/data
select advertiser_id, count(clicks)
from processedevents
where date = '20100819'
group by advertiser_id;
使用 HCatalog,Robert 无需修改表结构。
select advertiser_id, count(clicks)
from processedevents
where date = '20100819'
group by advertiser_id;
HCatalog Web API
- WebHCat 是用于 HCatalog 的 REST API。 (REST 代表“ 代表性状态转移”,这是一种基于 HTTP 动词的 API 样式)。 WebHCat 的原始名称是 Templeton *。有关更多信息,请参见WebHCat manual。
Navigation Links
Next: HCatalog Installation
一般:HCatalog Manual – WebHCat Manual – Hive Wiki 主页 – Hive 项目 site