Hibernate ORM 5.4.18. 最终用户指南
Preface
同时使用面向对象的软件和关系数据库既麻烦又费时。由于对象和关系数据库中数据表示方式之间的范例不匹配,因此开发成本明显更高。 Hibernate 是用于 Java 环境的对象/关系 Map 解决方案。术语Object/Relational Mapping是指将数据从对象模型表示形式 Map 到关系数据模型表示形式(反之亦然)的技术。
Hibernate 不仅负责从 Java 类到数据库表(从 Java 数据类型到 SQL 数据类型)的 Map,而且还提供数据查询和检索功能。它可以大大减少开发时间,而这些开发时间要花费在 SQL 和 JDBC 中的手动数据处理上。 Hibernate 的设计目标是通过消除使用 SQL 和 JDBC 进行手工数据手工处理的需求,使开发人员摆脱 95%的常见数据持久性相关编程任务。但是,与许多其他持久性解决方案不同,Hibernate 不会向您隐藏 SQL 的强大功能,并保证您对关系技术和知识的投资一如既往地有效。
对于仅使用存储过程在数据库中实现业务逻辑的以数据为中心的应用程序,Hibernate 可能不是最佳解决方案,它对于基于 Java 的中间层中的面向对象域模型和业务逻辑最有用。但是,Hibernate 当然可以帮助您删除或封装特定于供应商的 SQL 代码,并将帮助完成将结果集从表格表示形式转换为对象图的常见任务。
Get Involved
使用 Hibernate 并报告发现的任何错误或问题。有关详情,请参见Issue Tracker。
尝试解决一些错误或实施增强功能。同样,请参见Issue Tracker。
使用邮件列表,论坛,IRC 或Community section中列出的其他方式与社区互动。
帮助改进或翻译本文档。如果您有兴趣,请在开发人员邮件列表上与我们联系。
传播这个词。让您的组织其他人了解 Hibernate 的好处。
System Requirements
Hibernate 5.2 和更高版本至少需要 Java 1.8 和 JDBC 4.2.
Hibernate 5.1 和更早版本至少需要 Java 1.6 和 JDBC 4.0.
Tip
从源代码构建 Hibernate 5.1 或更早版本时,由于 JDK 1.6 编译器中的错误,您需要 Java 1.7.
入门指南
新用户可能需要首先浏览Hibernate 入门指南以获得基本信息和教程。还有一系列topical guides提供对各种主题的深入研究。
Note
虽然不需要使用 Hibernate 具有扎实的 SQL 背景,但肯定有很大帮助,因为所有这些都归结为 SQL 语句。也许更重要的是对数据建模原理的理解。您可能希望将这些资源视为一个良好的起点:
了解事务和诸如工作单元(PoEAA)或应用程序事务之类的设计模式的基础也很重要。这些主题将在文档中进行讨论,但是事先理解当然会有所帮助。
1. Architecture
1.1. Overview

如上图所示,作为 ORM 解决方案,Hibernate 有效地“位于” Java 应用程序数据访问层和关系数据库之间。 Java 应用程序利用 Hibernate API 加载,存储,查询等其域数据。在这里,我们将介绍基本的 Hibernate API。这将是一个简短的介绍;我们将在后面详细讨论这些 Contract。
作为 JPA 提供者,Hibernate 实现 Java Persistence API 规范,并且 JPA 接口与 Hibernate 特定实现之间的关联可以在下图中显示:

SessionFactory(
org.hibernate.SessionFactory)- 应用程序域模型到数据库的 Map 的线程安全(且不可变)表示形式。充当
org.hibernate.Session个实例的工厂。EntityManagerFactory是SessionFactory的 JPA 等效项,并且基本上,这两个会融合为相同的SessionFactory实现。
- 应用程序域模型到数据库的 Map 的线程安全(且不可变)表示形式。充当
创建SessionFactory非常昂贵,因此,对于任何给定的数据库,该应用程序应仅具有一个关联的SessionFactory。 SessionFactory维护 Hibernate 在所有Session(s)上使用的服务,例如二级缓存,连接池,事务系统集成等。
会话(
org.hibernate.Session)- 从概念上讲,单线程,短期对象建模“工作单元”(PoEAA)。在 JPA 命名法中,
Session由EntityManager表示。
- 从概念上讲,单线程,短期对象建模“工作单元”(PoEAA)。在 JPA 命名法中,
在后台,Hibernate Session包装了 JDBC java.sql.Connection并充当org.hibernate.Transaction实例的工厂。它维护应用程序域模型的一般“可重复读取”持久性上下文(一级缓存)。
Transaction(
org.hibernate.Transaction)- 应用程序用来划分各个物理事务边界的单线程,短期对象。
EntityTransaction与 JPA 等价,并且两者都充当抽象 API,以将应用程序与使用中的基础事务系统(JDBC 或 JTA)隔离开。
- 应用程序用来划分各个物理事务边界的单线程,短期对象。
2.域模型
术语domain model来自数据建模领域。它是最终描述您正在使用的problem domain的模型。有时您还会听到术语* persistent classes *。
最终,应用程序领域模型是 ORM 中的核心角色。它们构成了您希望 Map 的类。如果这些类遵循普通旧 Java 对象(POJO)/ JavaBean 编程模型,则 Hibernate 的效果最佳。但是,这些规则都不是硬性要求。实际上,Hibernate 对持久性对象的性质几乎不做任何假设。您可以用其他方式(例如,使用java.util.Map实例树)来表示域模型。
从历史上看,使用 Hibernate 的应用程序会为此目的使用其专有的 XMLMap 文件格式。随着 JPA 的到来,现在大多数信息都是通过 Comments(和/或标准化 XML 格式)在 ORM/JPA 提供程序之间可移植的方式定义的。本章将重点介绍 JPAMap。对于 JPA 不支持的 HibernateMap 功能,我们将更喜欢 Hibernate 扩展 Comments。
2.1. Map 类型
Hibernate 可以理解应用程序数据的 Java 和 JDBC 表示形式。 Hibernate * type *的功能是从数据库读取数据或向数据库写入数据。在这种用法中,类型是org.hibernate.type.Type接口的实现。这种 Hibernate 类型还描述了 Java 类型的各种行为方面,例如如何检查是否相等,如何克隆值等。
Usage of the word type
休眠类型既不是 Java 类型也不是 SQL 数据类型。它提供了有关将 Java 类型 Map 到 SQL 类型以及如何在关系数据库中持久化和获取给定 Java 类型的信息。
当您在 Hibernate 的讨论中遇到术语类型时,根据上下文,它可能是指 Java 类型,JDBC 类型或 Hibernate 类型。
为了帮助理解类型分类,让我们看一下我们希望 Map 的简单表和域模型。
例子 1.一个简单的表和域模型
create table Contact (
id integer not null,
first varchar(255),
last varchar(255),
middle varchar(255),
notes varchar(255),
starred boolean not null,
website varchar(255),
primary key (id)
)
@Entity(name = "Contact")
public static class Contact {
@Id
private Integer id;
private Name name;
private String notes;
private URL website;
private boolean starred;
//Getters and setters are omitted for brevity
}
@Embeddable
public class Name {
private String first;
private String middle;
private String last;
// getters and setters omitted
}
从广义上讲,Hibernate 将类型分为两类:
2.1.1. 值类型
值类型是一条未定义其自身生命周期的数据。实际上,它由定义其生命周期的实体所有。
从另一种角度来看,实体的所有状态完全由值类型组成。这些状态字段或 JavaBean 属性称为持久属性。 Contact类的持久属性是值类型。
值类型进一步分为三个子类别:
Basic types
- 在 Map
Contact表时,除名称以外的所有属性都是基本类型。基本类型将在Basic types中详细讨论。
- 在 Map
Embeddable types
name属性是可嵌入类型的示例,在Embeddable types中将详细讨论
集合 类型
- 尽管集合类型在值类型中是一个明显的类别,但在上述示例中未作介绍。集合类型将在Collections中进一步讨论
2.1.2. 实体类型
实体根据其唯一标识符的性质独立于其他对象而存在,而值则不存在。实体是域模型类,使用唯一标识符与数据库表中的行相关。由于需要唯一标识符,因此实体独立存在并定义自己的生命周期。 Contact类本身就是一个实体的示例。
Entity types中详细讨论了 Map 实体。
2.2. 命名策略
对象模型到关系数据库的 Map 的一部分是将对象模型的名称 Map 到相应的数据库名称。 Hibernate 将其视为两个阶段的过程:
第一步是从域模型 Map 中确定适当的逻辑名。逻辑名称可以由用户明确指定(例如,使用
@Column或@Table),也可以由 Hibernate 通过ImplicitNamingStrategyContracts 隐式确定。第二个是将此逻辑名称解析为由PhysicalNamingStrategyContract 定义的物理名称。
Historical NamingStrategy contract
Hibernate 历史上只定义了一个org.hibernate.cfg.NamingStrategy。那个单一的 NamingStrategyContract 实际上结合了单独的关注点,这些关注点现在分别建模为 ImplicitNamingStrategy 和 PhysicalNamingStrategy。
而且,NamingStrategyContract 通常不够灵活,无法正确地应用给定的命名“规则”,这是因为 API 缺乏决定信息,或者因为 API 的 Developing 一直没有很好地定义。
由于这些限制,不推荐使用org.hibernate.cfg.NamingStrategy,而建议使用 ImplicitNamingStrategy 和 PhysicalNamingStrategy。
从根本上讲,每种命名策略背后的思想是使开发人员为 Map 域模型而必须提供的重复信息量最小化。
JPA Compatibility
JPA 定义了有关隐式逻辑名称确定的固有规则。如果主要关注 JPA 提供程序的可移植性,或者您真的很喜欢 JPA 定义的隐式命名规则,请确保坚持使用 ImplicitNamingStrategyJpaCompliantImpl(默认设置)。
而且,JPA 定义逻辑名称和物理名称之间没有分隔。按照 JPA 规范,逻辑名称**是物理名称。如果 JPA 提供程序的可移植性很重要,则应用程序不应选择不指定 PhysicalNamingStrategy。
2.2.1. ImplicitNamingStrategy
当实体未明确命名其 Map 到的数据库表时,我们需要隐式确定该表名。或者,当特定属性没有显式命名其 Map 到的数据库列时,我们需要隐式确定该列名称。当 Map 未提供显式名称时,可以使用org.hibernate.boot.model.naming.ImplicitNamingStrategyContract 来确定逻辑名称的示例。

Hibernate 开箱即用地定义了多个 ImplicitNamingStrategy 实现。应用程序也可以自由插入自定义实现。
有多种方法可以指定要使用的 ImplicitNamingStrategy。首先,应用程序可以使用hibernate.implicit_naming_strategy配置设置指定实现,该设置接受:
现成实现的 sched 义“短名称”
defaultorg.hibernate.boot.model.naming.ImplicitNamingStrategyJpaCompliantImpl的别名-jpa的别名
jpaorg.hibernate.boot.model.naming.ImplicitNamingStrategyJpaCompliantImpl-符合 JPA 2.0 的命名策略
legacy-hbmorg.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyHbmImpl-符合原始的 Hibernate NamingStrategy
legacy-jpaorg.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl-符合为 JPA 1.0 开发的旧版 NamingStrategy,遗憾的是,在很多方面都不清楚隐式命名规则
component-path- 对于
org.hibernate.boot.model.naming.ImplicitNamingStrategyComponentPathImpl-除遵循结尾属性部分外,大多数情况都遵循ImplicitNamingStrategyJpaCompliantImpl规则,但它使用完整的复合路径
- 对于
引用实现
org.hibernate.boot.model.naming.ImplicitNamingStrategyContract 的类实现
org.hibernate.boot.model.naming.ImplicitNamingStrategyContract 的类的 FQN
其次,应用程序和集成可以利用org.hibernate.boot.MetadataBuilder#applyImplicitNamingStrategy来指定要使用的 ImplicitNamingStrategy。有关引导的更多详细信息,请参见Bootstrap。
2.2.2. PhysicalNamingStrategy
许多组织围绕数据库对象(表,列,外键等)的命名定义规则。 PhysicalNamingStrategy 的思想是帮助实现此类命名规则,而不必通过显式名称将其硬编码到 Map 中。
虽然 ImplicitNamingStrategy 的目的是确定名为accountNumber的属性在未明确指定时 Map 到逻辑列名称accountNumber,但是 PhysicalNamingStrategy 的目的例如是说应将物理列名称缩写为acct_num。 。
Note
的确,在这种情况下,可以使用ImplicitNamingStrategy处理acct_num的分辨率。
但是这里的重点是关注点分离。不管属性是显式指定列名还是隐式确定列名,都将应用PhysicalNamingStrategy。 ImplicitNamingStrategy仅在未提供明确名称的情况下才会应用。因此,这完全取决于需求和意图。
默认实现是简单地使用逻辑名作为物理名。但是,应用程序和集成可以定义此 PhysicalNamingStrategyContract 的自定义实现。这是一个名为 Acme Corp 的虚拟公司的物理命名策略示例,其命名标准为:
喜欢用下划线定界的单词而不是驼峰式的单词
用标准缩写替换某些单词
例子 2.例子 PhysicalNamingStrategy 实现
/*
* Hibernate, Relational Persistence for Idiomatic Java
*
* License: GNU Lesser General Public License (LGPL), version 2.1 or later.
* See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
*/
package org.hibernate.userguide.naming;
import java.util.LinkedList;
import java.util.List;
import java.util.Locale;
import java.util.Map;
import java.util.TreeMap;
import org.hibernate.boot.model.naming.Identifier;
import org.hibernate.boot.model.naming.PhysicalNamingStrategy;
import org.hibernate.engine.jdbc.env.spi.JdbcEnvironment;
import org.apache.commons.lang3.StringUtils;
/**
* An example PhysicalNamingStrategy that implements database object naming standards
* for our fictitious company Acme Corp.
* <p/>
* In general Acme Corp prefers underscore-delimited words rather than camel casing.
* <p/>
* Additionally standards call for the replacement of certain words with abbreviations.
*
* @author Steve Ebersole
*/
public class AcmeCorpPhysicalNamingStrategy implements PhysicalNamingStrategy {
private static final Map<String,String> ABBREVIATIONS = buildAbbreviationMap();
@Override
public Identifier toPhysicalCatalogName(Identifier name, JdbcEnvironment jdbcEnvironment) {
// Acme naming standards do not apply to catalog names
return name;
}
@Override
public Identifier toPhysicalSchemaName(Identifier name, JdbcEnvironment jdbcEnvironment) {
// Acme naming standards do not apply to schema names
return name;
}
@Override
public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment jdbcEnvironment) {
final List<String> parts = splitAndReplace( name.getText() );
return jdbcEnvironment.getIdentifierHelper().toIdentifier(
join( parts ),
name.isQuoted()
);
}
@Override
public Identifier toPhysicalSequenceName(Identifier name, JdbcEnvironment jdbcEnvironment) {
final LinkedList<String> parts = splitAndReplace( name.getText() );
// Acme Corp says all sequences should end with _seq
if ( !"seq".equalsIgnoreCase( parts.getLast() ) ) {
parts.add( "seq" );
}
return jdbcEnvironment.getIdentifierHelper().toIdentifier(
join( parts ),
name.isQuoted()
);
}
@Override
public Identifier toPhysicalColumnName(Identifier name, JdbcEnvironment jdbcEnvironment) {
final List<String> parts = splitAndReplace( name.getText() );
return jdbcEnvironment.getIdentifierHelper().toIdentifier(
join( parts ),
name.isQuoted()
);
}
private static Map<String, String> buildAbbreviationMap() {
TreeMap<String,String> abbreviationMap = new TreeMap<> ( String.CASE_INSENSITIVE_ORDER );
abbreviationMap.put( "account", "acct" );
abbreviationMap.put( "number", "num" );
return abbreviationMap;
}
private LinkedList<String> splitAndReplace(String name) {
LinkedList<String> result = new LinkedList<>();
for ( String part : StringUtils.splitByCharacterTypeCamelCase( name ) ) {
if ( part == null || part.trim().isEmpty() ) {
// skip null and space
continue;
}
part = applyAbbreviationReplacement( part );
result.add( part.toLowerCase( Locale.ROOT ) );
}
return result;
}
private String applyAbbreviationReplacement(String word) {
if ( ABBREVIATIONS.containsKey( word ) ) {
return ABBREVIATIONS.get( word );
}
return word;
}
private String join(List<String> parts) {
boolean firstPass = true;
String separator = "";
StringBuilder joined = new StringBuilder();
for ( String part : parts ) {
joined.append( separator ).append( part );
if ( firstPass ) {
firstPass = false;
separator = "_";
}
}
return joined.toString();
}
}
有多种方法可以指定要使用的 PhysicalNamingStrategy。首先,应用程序可以使用hibernate.physical_naming_strategy配置设置指定实现,该设置接受:
引用实现
org.hibernate.boot.model.naming.PhysicalNamingStrategyContract 的类实现
org.hibernate.boot.model.naming.PhysicalNamingStrategyContract 的类的 FQN
其次,应用程序和集成可以利用org.hibernate.boot.MetadataBuilder#applyPhysicalNamingStrategy。有关引导的更多详细信息,请参见Bootstrap。
2.3. 基本类型
基本值类型通常将单个数据库列 Map 到单个非聚合 Java 类型。 Hibernate 提供了许多内置的基本类型,它们遵循 JDBC 规范建议的自然 Map。
在内部,Hibernate 需要解析特定的org.hibernate.type.Type时使用基本类型的注册表。
2.3.1. 休眠提供的 BasicTypes
*表 1.标准 BasicTypes *
| Hibernate 类型(org.hibernate.type 包) | JDBC type | Java type | BasicTypeRegistry key(s) |
|---|---|---|---|
| StringType | VARCHAR | java.lang.String | string, java.lang.String |
| MaterializedClob | CLOB | java.lang.String | materialized_clob |
| TextType | LONGVARCHAR | java.lang.String | text |
| CharacterType | CHAR | char, java.lang.Character | 字符,char,java.lang.Character |
| BooleanType | BOOLEAN | boolean, java.lang.Boolean | boolean, java.lang.Boolean |
| NumericBooleanType | 整数,0 为假,1 为真 | boolean, java.lang.Boolean | numeric_boolean |
| YesNoType | CHAR,'N'/'n'为假,'Y'/'y'为真。大写的值将写入数据库。 | boolean, java.lang.Boolean | yes_no |
| TrueFalseType | CHAR,'F'/'f'为假,'T'/'t'为真。大写的值将写入数据库。 | boolean, java.lang.Boolean | true_false |
| ByteType | TINYINT | byte, java.lang.Byte | byte, java.lang.Byte |
| ShortType | SMALLINT | short, java.lang.Short | short, java.lang.Short |
| IntegerType | INTEGER | int, java.lang.Integer | 整数,整数,java.lang.Integer |
| LongType | BIGINT | long, java.lang.Long | long, java.lang.Long |
| FloatType | FLOAT | float, java.lang.Float | float, java.lang.Float |
| DoubleType | DOUBLE | double, java.lang.Double | double, java.lang.Double |
| BigIntegerType | NUMERIC | java.math.BigInteger | big_integer, java.math.BigInteger |
| BigDecimalType | NUMERIC | java.math.BigDecimal | big_decimal, java.math.bigDecimal |
| TimestampType | TIMESTAMP | java.util.Date | 时间戳记,java.sql.Timestamp,java.util.Date |
| DbTimestampType | TIMESTAMP | java.util.Date | dbtimestamp |
| TimeType | TIME | java.util.Date | time, java.sql.Time |
| DateType | DATE | java.util.Date | date, java.sql.Date |
| CalendarType | TIMESTAMP | java.util.Calendar | calendar,java.util.Calendar,java.util.GregorianCalendar |
| CalendarDateType | DATE | java.util.Calendar | calendar_date |
| CalendarTimeType | TIME | java.util.Calendar | calendar_time |
| CurrencyType | VARCHAR | java.util.Currency | currency, java.util.Currency |
| LocaleType | VARCHAR | java.util.Locale | locale, java.util.Locale |
| TimeZoneType | VARCHAR,使用 TimeZone ID | java.util.TimeZone | timezone, java.util.TimeZone |
| UrlType | VARCHAR | java.net.URL | url, java.net.URL |
| ClassType | VARCHAR(FQN 类) | java.lang.Class | class, java.lang.Class |
| BlobType | BLOB | java.sql.Blob | blob, java.sql.Blob |
| ClobType | CLOB | java.sql.Clob | clob, java.sql.Clob |
| BinaryType | VARBINARY | byte[] | binary, byte[] |
| MaterializedBlobType | BLOB | byte[] | materialized_blob |
| ImageType | LONGVARBINARY | byte[] | image |
| WrapperBinaryType | VARBINARY | java.lang.Byte[] | wrapper-binary,Byte [],java.lang.Byte [] |
| CharArrayType | VARCHAR | char[] | characters, char[] |
| CharacterArrayType | VARCHAR | java.lang.Character[] | 包装字符,Character [],java.lang.Character [] |
| UUIDBinaryType | BINARY | java.util.UUID | uuid-binary, java.util.UUID |
| UUIDCharType | CHAR,也可以读取 VARCHAR | java.util.UUID | uuid-char |
| PostgresUUIDType | 通过 Types#OTHER 的 PostgreSQL UUID,它符合 PostgreSQL JDBC 驱动程序定义 | java.util.UUID | pg-uuid |
| SerializableType | VARBINARY | java.lang.Serializable 的实现者 | 与其他值类型不同,该类型的多个实例被注册。它在 java.io.Serializable 下注册一次,并在特定的 java.io.Serializable 实现类名称下注册。 |
| StringNVarcharType | NVARCHAR | java.lang.String | nstring |
| NTextType | LONGNVARCHAR | java.lang.String | ntext |
| NClobType | NCLOB | java.sql.NClob | nclob, java.sql.NClob |
| MaterializedNClobType | NCLOB | java.lang.String | materialized_nclob |
| PrimitiveCharacterArrayNClobType | NCHAR | char[] | N/A |
| CharacterNCharType | NCHAR | java.lang.Character | ncharacter |
| CharacterArrayNClobType | NCLOB | java.lang.Character[] | N/A |
| RowVersionType | VARBINARY | byte[] | row_version |
| ObjectType | VARCHAR | java.lang.Serializable 的实现者 | object, java.lang.Object |
*表 2. Java 8 BasicTypes *
| Hibernate 类型(org.hibernate.type 包) | JDBC type | Java type | BasicTypeRegistry key(s) |
|---|---|---|---|
| DurationType | BIGINT | java.time.Duration | Duration, java.time.Duration |
| InstantType | TIMESTAMP | java.time.Instant | Instant, java.time.Instant |
| LocalDateTimeType | TIMESTAMP | java.time.LocalDateTime | LocalDateTime, java.time.LocalDateTime |
| LocalDateType | DATE | java.time.LocalDate | LocalDate, java.time.LocalDate |
| LocalTimeType | TIME | java.time.LocalTime | LocalTime, java.time.LocalTime |
| OffsetDateTimeType | TIMESTAMP | java.time.OffsetDateTime | OffsetDateTime, java.time.OffsetDateTime |
| OffsetTimeType | TIME | java.time.OffsetTime | OffsetTime, java.time.OffsetTime |
| ZonedDateTimeType | TIMESTAMP | java.time.ZonedDateTime | ZonedDateTime, java.time.ZonedDateTime |
*表 3. Hibernate Spatial BasicTypes *
| Hibernate 类型(org.hibernate.spatial 包) | JDBC type | Java type | BasicTypeRegistry key(s) |
|---|---|---|---|
| JTSGeometryType | 取决于方言 | com.vividsolutions.jts.geom.Geometry | jts_geometry,以及 Geometry 及其子类的类名 |
| GeolatteGeometryType | 取决于方言 | org.geolatte.geom.Geometry | geolatte_geometry,以及 Geometry 及其子类的类名 |
Note
要使用 Hibernate Spatial 类型,必须将hibernate-spatial依赖项添加到您的 Classpath 中并使用org.hibernate.spatial.SpatialDialect实现。
有关更多详细信息,请参见Spatial章。
这些 Map 由 Hibernate 内部称为org.hibernate.type.BasicTypeRegistry的服务 Management,该服务本质上维护着以名称为关键字的org.hibernate.type.BasicType(一个org.hibernate.type.Type专业化)实例的 Map。这就是先前表中“ BasicTypeRegistry 键”列的目的。
2.3.2. @Basic 注解
严格来说,基本类型由javax.persistence.BasicComments 表示。一般来说,默认情况下可以忽略@BasicComments。以下两个示例最终都是相同的。
例子 3. @Basic明确声明
@Entity(name = "Product")
public class Product {
@Id
@Basic
private Integer id;
@Basic
private String sku;
@Basic
private String name;
@Basic
private String description;
}
例子 4. @Basic被隐式暗示
@Entity(name = "Product")
public class Product {
@Id
private Integer id;
private String sku;
private String name;
private String description;
}
Tip
JPA 规范严格将可以标记为基本的 Java 类型限制在以下列表中:
Java 基本类型(
boolean,int等)基本类型(
java.lang.Boolean,java.lang.Integer等)的包装java.lang.Stringjava.math.BigIntegerjava.math.BigDecimaljava.util.Datejava.util.Calendarjava.sql.Datejava.sql.Timejava.sql.Timestampbyte[]或Byte[]char[]或Character[]enums实现
Serializable的任何其他类型(JPA 对Serializable类型的“支持”是直接将其状态序列化到数据库)。
如果需要提供程序的可移植性,则应仅遵循这些基本类型。
请注意,JPA 2.1 引入了javax.persistence.AttributeConverterContract 以帮助减轻其中的一些担忧。有关此主题的更多信息,请参见JPA 2.1 AttributeConverters。
@BasicComments 定义 2 个属性。
optional-布尔值(默认为 true)- 定义此属性是否允许空值。 JPA 将其定义为“提示”,这实际上意味着特别需要其效果。只要类型不是原始类型,Hibernate 就会将此表示基础列应为
NULLABLE。
- 定义此属性是否允许空值。 JPA 将其定义为“提示”,这实际上意味着特别需要其效果。只要类型不是原始类型,Hibernate 就会将此表示基础列应为
fetch-FetchType(默认为 EAGER)- 定义此属性是应立即获取还是应延迟获取。 JPA 说,EAGER 是提供程序(休眠)的一项要求,要求在获取所有者时应获取值,而 LAZY 只是提示访问属性时要获取值。除非您使用字节码增强功能,否则 Hibernate 对于基本类型将忽略此设置。有关获取和字节码增强的更多信息,请参见Bytecode Enhancement。
2.3.3. @Column 注解
JPA 定义了用于隐式确定表和列名称的规则。有关隐式命名的详细讨论,请参见Naming strategies。
对于基本类型属性,隐式命名规则是列名称与属性名称相同。如果该隐式命名规则不符合您的要求,则可以显式告诉 Hibernate(和其他提供程序)要使用的列名。
例子 5.显式列命名
@Entity(name = "Product")
public class Product {
@Id
private Integer id;
private String sku;
private String name;
@Column( name = "NOTES" )
private String description;
}
在这里,我们使用@Column将description属性显式 Map 到NOTES列,而不是隐式列名description。
@ColumnComments 还定义了其他 Map 信息。有关详细信息,请参见其 Javadocs。
2.3.4. BasicTypeRegistry
前面我们说过,Hibernate 类型既不是 Java 类型,也不是 SQL 类型,但是它既可以理解两者,又可以在它们之间进行编组。但是,从前面的示例中看到基本的类型 Map,Hibernate 如何知道使用其org.hibernate.type.StringTypeMapjava.lang.String属性,还是使用org.hibernate.type.IntegerTypeMapjava.lang.Integer属性?
答案在于 Hibernate 内部的一个名为org.hibernate.type.BasicTypeRegistry的服务,该服务实际上维护着以名称为关键字的org.hibernate.type.BasicType(一个org.hibernate.type.Type专业化)实例的 Map。
稍后我们将在Explicit BasicTypes部分中看到,我们可以明确告诉 Hibernate 对特定属性使用哪个 BasicType。但是首先,让我们探讨隐式分辨率的工作原理以及应用程序如何调整隐式分辨率。
Note
对BasicTypeRegistry和所有其他类型的贡献方式的详尽讨论超出了本文档的范围。
有关完整的详细信息,请参见Integration Guide。
例如,采用我们之前在 Product#sku 中看到的 String 属性。由于没有显式的类型 Map,因此 Hibernate 依靠BasicTypeRegistry查找java.lang.String的注册 Map。这可以 traceback 到我们在本章开头的表中看到的“ BasicTypeRegistry 键”列。
作为BasicTypeRegistry的基线,Hibernate 遵循针对 Java 类型的 JDBC 推荐 Map。 JDBC 建议将字符串 Map 到 VARCHAR,VARCHAR 是StringType处理的确切 Map。这就是BasicTypeRegistry中字符串的基线 Map。
应用程序还可以在引导过程中使用MetadataBuilder#applyBasicType方法或MetadataBuilder#applyTypes方法之一扩展(添加新的BasicType注册)或覆盖(替换现有的BasicType注册)。有关更多详细信息,请参见Custom BasicTypes部分。
2.3.5. 显式 BasicType
有时您希望对特定属性进行不同的处理。有时,Hibernate 会隐式选择一个您不需要的BasicType(并且由于某些原因,您不想调整BasicTypeRegistry)。
在这些情况下,您必须通过org.hibernate.annotations.Type注解明确告知 Hibernate 使用BasicType。
例子 6.使用@org.hibernate.annotations.Type
@Entity(name = "Product")
public class Product {
@Id
private Integer id;
private String sku;
@org.hibernate.annotations.Type( type = "nstring" )
private String name;
@org.hibernate.annotations.Type( type = "materialized_nclob" )
private String description;
}
这告诉 Hibernate 将字符串存储为国有化数据。这只是出于说明目的;有关指示民族化字符数据的更好方法,请参见Map 民族化字符数据部分。
另外,该描述将作为 LOB 处理。同样,有关指示 LOB 的更好方法,请参见Mapping LOBs部分。
org.hibernate.annotations.Type#type属性可以命名以下任意一项:
org.hibernate.type.Type实现的全限定名称在
BasicTypeRegistry注册的任何密钥任何已知的“类型定义”的名称
2.3.6. 自定义 BasicType
Hibernate 使开发人员相对容易地创建自己的基本类型 Map 类型。例如,您可能要保留java.util.BigInteger到VARCHAR列的属性,或支持全新的类型。
开发自定义类型有两种方法:
实施并注册
BasicType实现不需要类型注册的
UserType
作为说明不同方法的一种方式,让我们考虑一个用例,在该用例中,我们需要支持存储为 VARCHAR 的java.util.BitSetMap。
实现 BasicType
第一种方法是直接实现BasicType接口。
Note
因为BasicType接口有很多实现的方法,所以如果将值存储在单个数据库列中,则扩展AbstractStandardBasicType或AbstractSingleColumnStandardBasicType Hibernate 类更加方便。
首先,我们需要像这样扩展AbstractSingleColumnStandardBasicType:
例子 7.定制BasicType实现
public class BitSetType
extends AbstractSingleColumnStandardBasicType<BitSet>
implements DiscriminatorType<BitSet> {
public static final BitSetType INSTANCE = new BitSetType();
public BitSetType() {
super( VarcharTypeDescriptor.INSTANCE, BitSetTypeDescriptor.INSTANCE );
}
@Override
public BitSet stringToObject(String xml) throws Exception {
return fromString( xml );
}
@Override
public String objectToSQLString(BitSet value, Dialect dialect) throws Exception {
return toString( value );
}
@Override
public String getName() {
return "bitset";
}
}
AbstractSingleColumnStandardBasicType需要sqlTypeDescriptor和javaTypeDescriptor。 sqlTypeDescriptor是VarcharTypeDescriptor.INSTANCE,因为数据库列是 VARCHAR。在 Java 方面,我们需要使用BitSetTypeDescriptor实例,该实例可以这样实现:
例子 8.定制AbstractTypeDescriptor实现
public class BitSetTypeDescriptor extends AbstractTypeDescriptor<BitSet> {
private static final String DELIMITER = ",";
public static final BitSetTypeDescriptor INSTANCE = new BitSetTypeDescriptor();
public BitSetTypeDescriptor() {
super( BitSet.class );
}
@Override
public String toString(BitSet value) {
StringBuilder builder = new StringBuilder();
for ( long token : value.toLongArray() ) {
if ( builder.length() > 0 ) {
builder.append( DELIMITER );
}
builder.append( Long.toString( token, 2 ) );
}
return builder.toString();
}
@Override
public BitSet fromString(String string) {
if ( string == null || string.isEmpty() ) {
return null;
}
String[] tokens = string.split( DELIMITER );
long[] values = new long[tokens.length];
for ( int i = 0; i < tokens.length; i++ ) {
values[i] = Long.valueOf( tokens[i], 2 );
}
return BitSet.valueOf( values );
}
@SuppressWarnings({"unchecked"})
public <X> X unwrap(BitSet value, Class<X> type, WrapperOptions options) {
if ( value == null ) {
return null;
}
if ( BitSet.class.isAssignableFrom( type ) ) {
return (X) value;
}
if ( String.class.isAssignableFrom( type ) ) {
return (X) toString( value);
}
throw unknownUnwrap( type );
}
public <X> BitSet wrap(X value, WrapperOptions options) {
if ( value == null ) {
return null;
}
if ( String.class.isInstance( value ) ) {
return fromString( (String) value );
}
if ( BitSet.class.isInstance( value ) ) {
return (BitSet) value;
}
throw unknownWrap( value.getClass() );
}
}
将BitSet作为PreparedStatement绑定参数传递时使用unwrap方法,而wrap方法用于将 JDBC 列值对象(例如本例中的String)转换为实际的 Map 对象类型(例如本例中的BitSet)。
BasicType必须注册,这可以在引导时完成:
例子 9.注册一个 Custom BasicType实现
configuration.registerTypeContributor( (typeContributions, serviceRegistry) -> {
typeContributions.contributeType( BitSetType.INSTANCE );
} );
或使用MetadataBuilder
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
MetadataBuilder metadataBuilder = sources.getMetadataBuilder();
metadataBuilder.applyBasicType( BitSetType.INSTANCE );
将新的BitSetType注册为bitset,实体 Map 如下所示:
例子 10.自定义BasicTypeMap
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
@Type( type = "bitset" )
private BitSet bitSet;
public Integer getId() {
return id;
}
//Getters and setters are omitted for brevity
}
或者,您可以使用@TypeDef并跳过注册阶段:
例子 11.使用@TypeDef注册一个自定义类型
@Entity(name = "Product")
@TypeDef(
name = "bitset",
defaultForType = BitSet.class,
typeClass = BitSetType.class
)
public static class Product {
@Id
private Integer id;
private BitSet bitSet;
//Getters and setters are omitted for brevity
}
要验证此新的BasicType实施,我们可以对其进行如下测试:
例子 12.坚持定制BasicType
BitSet bitSet = BitSet.valueOf( new long[] {1, 2, 3} );
doInHibernate( this::sessionFactory, session -> {
Product product = new Product( );
product.setId( 1 );
product.setBitSet( bitSet );
session.persist( product );
} );
doInHibernate( this::sessionFactory, session -> {
Product product = session.get( Product.class, 1 );
assertEquals(bitSet, product.getBitSet());
} );
执行此单元测试时,Hibernate 生成以下 SQL 语句:
例子 13.坚持定制BasicType
DEBUG SQL:92 -
insert
into
Product
(bitSet, id)
values
(?, ?)
TRACE BasicBinder:65 - binding parameter [1] as [VARCHAR] - [{0, 65, 128, 129}]
TRACE BasicBinder:65 - binding parameter [2] as [INTEGER] - [1]
DEBUG SQL:92 -
select
bitsettype0_.id as id1_0_0_,
bitsettype0_.bitSet as bitSet2_0_0_
from
Product bitsettype0_
where
bitsettype0_.id=?
TRACE BasicBinder:65 - binding parameter [1] as [INTEGER] - [1]
TRACE BasicExtractor:61 - extracted value ([bitSet2_0_0_] : [VARCHAR]) - [{0, 65, 128, 129}]
如您所见,BitSetType负责* Java-to-SQL 和 SQL-to-Java *类型转换。
实现用户类型
第二种方法是实现UserType接口。
例子 14.定制UserType实现
public class BitSetUserType implements UserType {
public static final BitSetUserType INSTANCE = new BitSetUserType();
private static final Logger log = Logger.getLogger( BitSetUserType.class );
@Override
public int[] sqlTypes() {
return new int[] {StringType.INSTANCE.sqlType()};
}
@Override
public Class returnedClass() {
return BitSet.class;
}
@Override
public boolean equals(Object x, Object y)
throws HibernateException {
return Objects.equals( x, y );
}
@Override
public int hashCode(Object x)
throws HibernateException {
return Objects.hashCode( x );
}
@Override
public Object nullSafeGet(
ResultSet rs, String[] names, SharedSessionContractImplementor session, Object owner)
throws HibernateException, SQLException {
String columnName = names[0];
String columnValue = (String) rs.getObject( columnName );
log.debugv("Result set column {0} value is {1}", columnName, columnValue);
return columnValue == null ? null :
BitSetTypeDescriptor.INSTANCE.fromString( columnValue );
}
@Override
public void nullSafeSet(
PreparedStatement st, Object value, int index, SharedSessionContractImplementor session)
throws HibernateException, SQLException {
if ( value == null ) {
log.debugv("Binding null to parameter {0} ",index);
st.setNull( index, Types.VARCHAR );
}
else {
String stringValue = BitSetTypeDescriptor.INSTANCE.toString( (BitSet) value );
log.debugv("Binding {0} to parameter {1} ", stringValue, index);
st.setString( index, stringValue );
}
}
@Override
public Object deepCopy(Object value)
throws HibernateException {
return value == null ? null :
BitSet.valueOf( BitSet.class.cast( value ).toLongArray() );
}
@Override
public boolean isMutable() {
return true;
}
@Override
public Serializable disassemble(Object value)
throws HibernateException {
return (BitSet) deepCopy( value );
}
@Override
public Object assemble(Serializable cached, Object owner)
throws HibernateException {
return deepCopy( cached );
}
@Override
public Object replace(Object original, Object target, Object owner)
throws HibernateException {
return deepCopy( original );
}
}
实体 Map 如下所示:
例子 15.自定义UserTypeMap
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
@Type( type = "bitset" )
private BitSet bitSet;
//Constructors, getters, and setters are omitted for brevity
}
在此示例中,UserType以bitset名称注册,并且这样做是这样的:
例子 16.注册一个 Custom UserType实现
configuration.registerTypeContributor( (typeContributions, serviceRegistry) -> {
typeContributions.contributeType( BitSetUserType.INSTANCE, "bitset");
} );
或使用MetadataBuilder
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
MetadataBuilder metadataBuilder = sources.getMetadataBuilder();
metadataBuilder.applyBasicType( BitSetUserType.INSTANCE, "bitset" );
Note
像BasicType一样,您也可以使用简单的名称注册UserType。
无需注册名称,UserTypeMap 就需要完全限定的类名称:
@Type( type = "org.hibernate.userguide.mapping.basic.BitSetUserType" )
当针对BitSetUserType实体 Map 运行先前的测试用例时,Hibernate 执行以下 SQL 语句:
例子 17.坚持定制BasicType
DEBUG SQL:92 -
insert
into
Product
(bitSet, id)
values
(?, ?)
DEBUG BitSetUserType:71 - Binding 1,10,11 to parameter 1
TRACE BasicBinder:65 - binding parameter [2] as [INTEGER] - [1]
DEBUG SQL:92 -
select
bitsetuser0_.id as id1_0_0_,
bitsetuser0_.bitSet as bitSet2_0_0_
from
Product bitsetuser0_
where
bitsetuser0_.id=?
TRACE BasicBinder:65 - binding parameter [1] as [INTEGER] - [1]
DEBUG BitSetUserType:56 - Result set column bitSet2_0_0_ value is 1,10,11
2.3.7. Map 枚举
Hibernate 支持通过多种不同方式将 Java 枚举 Map 为基本值类型。
@Enumerated
最初的 JPA 兼容 Map 枚举方法是通过@Enumerated或@MapKeyEnumerated进行 Map 键 Comments,其工作原理是,枚举值根据javax.persistence.EnumType指示的两种策略之一进行存储:
ORDINAL- 根据枚举类中枚举值的序号位置存储,如
java.lang.Enum#ordinal
- 根据枚举类中枚举值的序号位置存储,如
STRING- 根据枚举值的名称存储,如
java.lang.Enum#name
- 根据枚举值的名称存储,如
假设以下列举:
例子 18. PhoneType枚举
public enum PhoneType {
LAND_LINE,
MOBILE;
}
在 ORDINAL 示例中,phone_type列被定义为(可为空)INTEGER 类型,并且将保留:
NULL- 对于空值
0- 对于
LAND_LINE枚举
- 对于
1- 对于
MOBILE枚举
- 对于
例子 19. @Enumerated(ORDINAL)例子
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "phone_number")
private String number;
@Enumerated(EnumType.ORDINAL)
@Column(name = "phone_type")
private PhoneType type;
//Getters and setters are omitted for brevity
}
持久化该实体时,Hibernate 生成以下 SQL 语句:
例子 20.用@Enumerated(ORDINAL)Map 持久化一个实体
Phone phone = new Phone( );
phone.setId( 1L );
phone.setNumber( "123-456-78990" );
phone.setType( PhoneType.MOBILE );
entityManager.persist( phone );
INSERT INTO Phone (phone_number, phone_type, id)
VALUES ('123-456-78990', 2, 1)
在 STRING 示例中,phone_type列被定义为(空)VARCHAR 类型,并将保留:
NULL- 对于空值
LAND_LINE- 对于
LAND_LINE枚举
- 对于
MOBILE- 对于
MOBILE枚举
- 对于
例子 21. @Enumerated(STRING)例子
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "phone_number")
private String number;
@Enumerated(EnumType.STRING)
@Column(name = "phone_type")
private PhoneType type;
//Getters and setters are omitted for brevity
}
与@Enumerated(ORDINAL)示例中的实体相同,Hibernate 生成以下 SQL 语句:
例子 22.用@Enumerated(STRING)Map 持久化一个实体
INSERT INTO Phone (phone_number, phone_type, id)
VALUES ('123-456-78990', 'MOBILE', 1)
AttributeConverter
让我们考虑以下Gender枚举,该枚举使用'M'和'F'代码存储其值。
例子 23.带有自定义构造函数的枚举
public enum Gender {
MALE( 'M' ),
FEMALE( 'F' );
private final char code;
Gender(char code) {
this.code = code;
}
public static Gender fromCode(char code) {
if ( code == 'M' || code == 'm' ) {
return MALE;
}
if ( code == 'F' || code == 'f' ) {
return FEMALE;
}
throw new UnsupportedOperationException(
"The code " + code + " is not supported!"
);
}
public char getCode() {
return code;
}
}
您可以使用 JPA 2.1 AttributeConverter 以符合 JPA 的方式 Map 枚举。
例子 24.带有AttributeConverter例子的枚举 Map
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@Convert( converter = GenderConverter.class )
public Gender gender;
//Getters and setters are omitted for brevity
}
@Converter
public static class GenderConverter
implements AttributeConverter<Gender, Character> {
public Character convertToDatabaseColumn( Gender value ) {
if ( value == null ) {
return null;
}
return value.getCode();
}
public Gender convertToEntityAttribute( Character value ) {
if ( value == null ) {
return null;
}
return Gender.fromCode( value );
}
}
在这里,gender 列定义为 CHAR 类型,并将保留:
NULL- 对于空值
'M'- 对于
MALE枚举
- 对于
'F'- 对于
FEMALE枚举
- 对于
有关使用 AttributeConverters 的其他详细信息,请参见JPA 2.1 AttributeConverters部分。
Note
JPA 明确禁止使用带有标记为@Enumerated的属性的AttributeConverter。
因此,在使用AttributeConverter方法时,请确保不要将属性标记为@Enumerated。
使用 AttributeConverter 实体属性作为查询参数
假设您具有以下实体:
例子 25. Photo实体和AttributeConverter
@Entity(name = "Photo")
public static class Photo {
@Id
private Integer id;
private String name;
@Convert(converter = CaptionConverter.class)
private Caption caption;
//Getters and setters are omitted for brevity
}
Caption类如下所示:
例子 26. Caption Java 对象
public static class Caption {
private String text;
public Caption(String text) {
this.text = text;
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Caption caption = (Caption) o;
return text != null ? text.equals( caption.text ) : caption.text == null;
}
@Override
public int hashCode() {
return text != null ? text.hashCode() : 0;
}
}
我们有一个AttributeConverter处理Caption Java 对象:
例子 27. Caption Java 对象 AttributeConverter
public static class CaptionConverter
implements AttributeConverter<Caption, String> {
@Override
public String convertToDatabaseColumn(Caption attribute) {
return attribute.getText();
}
@Override
public Caption convertToEntityAttribute(String dbData) {
return new Caption( dbData );
}
}
传统上,在引用caption实体属性时,只能使用 DB 数据Caption表示形式(在我们的情况下为String)。
例子 28.使用数据库数据表示按Caption属性过滤
Photo photo = entityManager.createQuery(
"select p " +
"from Photo p " +
"where upper(caption) = upper(:caption) ", Photo.class )
.setParameter( "caption", "Nicolae Grigorescu" )
.getSingleResult();
为了使用 Java 对象Caption表示,您必须获取关联的 Hibernate Type。
例子 29.使用 Java Object 表示按Caption属性过滤
SessionFactory sessionFactory = entityManager.getEntityManagerFactory()
.unwrap( SessionFactory.class );
MetamodelImplementor metamodelImplementor = (MetamodelImplementor) sessionFactory.getMetamodel();
Type captionType = metamodelImplementor
.entityPersister( Photo.class.getName() )
.getPropertyType( "caption" );
Photo photo = (Photo) entityManager.createQuery(
"select p " +
"from Photo p " +
"where upper(caption) = upper(:caption) ", Photo.class )
.unwrap( Query.class )
.setParameter( "caption", new Caption("Nicolae Grigorescu"), captionType)
.getSingleResult();
通过传递关联的 Hibernate Type,可以在绑定查询参数值时使用Caption对象。
使用 HBMMapMapAttributeConverter
使用 HBMMap 时,您仍然可以使用 JPA AttributeConverter,因为 Hibernate 通过type属性支持这种 Map,如以下示例所示。
让我们考虑一下我们有一个特定于应用程序的Money类型:
例子 30.特定于应用的Money类型
public class Money {
private long cents;
public Money(long cents) {
this.cents = cents;
}
public long getCents() {
return cents;
}
public void setCents(long cents) {
this.cents = cents;
}
}
现在,我们想在 MapAccount实体时使用Money类型:
例子 31. Account使用Money类型的实体
public class Account {
private Long id;
private String owner;
private Money balance;
//Getters and setters are omitted for brevity
}
由于 Hibernate 不知道如何持久化Money类型,因此我们可以使用 JPA AttributeConverter将Money类型转换为Long。为此,我们将使用以下MoneyConverterUtil:
例子 32. MoneyConverter实现 JPA AttributeConverter接口
public class MoneyConverter
implements AttributeConverter<Money, Long> {
@Override
public Long convertToDatabaseColumn(Money attribute) {
return attribute == null ? null : attribute.getCents();
}
@Override
public Money convertToEntityAttribute(Long dbData) {
return dbData == null ? null : new Money( dbData );
}
}
要使用 HBM 配置文件 MapMoneyConverter,您需要在property元素的type属性中使用converted::前缀。
例子 33. AttributeConverter的 HBMMap
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.userguide.mapping.converter.hbm">
<class name="Account" table="account" >
<id name="id"/>
<property name="owner"/>
<property name="balance"
type="converted::org.hibernate.userguide.mapping.converter.hbm.MoneyConverter"/>
</class>
</hibernate-mapping>
Custom type
您还可以使用 Hibernate 自定义类型 Map 来 Map 枚举。让我们再次回顾 Gender 枚举示例,这次使用自定义类型存储更标准化的'M'和'F'代码。
例子 34.带有自定义类型的枚举 Map 例子
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@Type( type = "org.hibernate.userguide.mapping.basic.GenderType" )
public Gender gender;
//Getters and setters are omitted for brevity
}
public class GenderType extends AbstractSingleColumnStandardBasicType<Gender> {
public static final GenderType INSTANCE = new GenderType();
public GenderType() {
super(
CharTypeDescriptor.INSTANCE,
GenderJavaTypeDescriptor.INSTANCE
);
}
public String getName() {
return "gender";
}
@Override
protected boolean registerUnderJavaType() {
return true;
}
}
public class GenderJavaTypeDescriptor extends AbstractTypeDescriptor<Gender> {
public static final GenderJavaTypeDescriptor INSTANCE =
new GenderJavaTypeDescriptor();
protected GenderJavaTypeDescriptor() {
super( Gender.class );
}
public String toString(Gender value) {
return value == null ? null : value.name();
}
public Gender fromString(String string) {
return string == null ? null : Gender.valueOf( string );
}
public <X> X unwrap(Gender value, Class<X> type, WrapperOptions options) {
return CharacterTypeDescriptor.INSTANCE.unwrap(
value == null ? null : value.getCode(),
type,
options
);
}
public <X> Gender wrap(X value, WrapperOptions options) {
return Gender.fromCode(
CharacterTypeDescriptor.INSTANCE.wrap( value, options )
);
}
}
同样,gender 列被定义为 CHAR 类型,并将保留:
NULL- 对于空值
'M'- 对于
MALE枚举
- 对于
'F'- 对于
FEMALE枚举
- 对于
有关使用自定义类型的其他详细信息,请参见Custom BasicTypes部分。
2.3.8. MapLOB
MapLOB(数据库大对象)有两种形式,一种使用 JDBC 定位器类型,另一种用于实现 LOB 数据。
存在 JDBC LOB 定位器以允许有效访问 LOB 数据。它们允许 JDBC 驱动程序根据需要流式传输 LOB 数据的一部分,从而潜在地释放内存空间。但是,它们可能不自然地处理并且具有一定的局限性。例如,LOB 定位器仅在获得它的 Transaction 期间有效。
物化 LOB 的想法是,使用熟悉的 Java 类型(例如String或byte[]等)为这些 LOB 权衡潜在的效率(并非所有驱动程序都有效地处理 LOB 数据),以实现更自然的编程范例。
物化处理内存中的整个 LOB 内容,而 LOB 定位器(理论上)允许根据需要将部分 LOB 内容流式传输到内存中。
JDBC LOB 定位器类型包括:
java.sql.Blobjava.sql.Clobjava.sql.NClob
Map 这些 LOB 值的实体化形式将使用更熟悉的 Java 类型,例如String,char[],byte[]等。“更熟悉”的权衡通常是性能。
Mapping CLOB
乍一看,假设我们有一个要 Map 的CLOB列(Map 民族化字符数据部分将介绍NCLOB字符LOB数据)。
考虑到我们有以下数据库表:
例子 35. CLOB-SQL
CREATE TABLE Product (
id INTEGER NOT NULL,
name VARCHAR(255),
warranty CLOB,
PRIMARY KEY (id)
)
首先使用@Lob JPA 注解和java.sql.Clob类型对此进行 Map:
例子 36. CLOBMap 到java.sql.Clob
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private Clob warranty;
//Getters and setters are omitted for brevity
}
要保留这样的实体,您必须使用ClobProxy HibernateUtil 创建Clob:
例子 37.坚持一个java.sql.Clob实体
String warranty = "My product warranty";
final Product product = new Product();
product.setId( 1 );
product.setName( "Mobile phone" );
product.setWarranty( ClobProxy.generateProxy( warranty ) );
entityManager.persist( product );
要检索Clob的内容,您需要转换基础的java.io.Reader:
例子 38.返回一个java.sql.Clob实体
Product product = entityManager.find( Product.class, productId );
try (Reader reader = product.getWarranty().getCharacterStream()) {
assertEquals( "My product warranty", toString( reader ) );
}
我们还可以将物化形式 Map 到 CLOB。这样,我们可以使用String或char[]。
例子 39. CLOBMap 到String
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private String warranty;
//Getters and setters are omitted for brevity
}
Note
JDBC 处理LOB数据的方式因驱动程序而异,并且 Hibernate 尝试代表您处理所有这些差异。
但是,某些驱动程序比较棘手(例如 PostgreSQL),在这种情况下,您可能需要执行一些额外的步骤才能使 LOB 正常工作。此类讨论超出了本指南的范围。
我们甚至可能希望将物化数据作为 char 数组(尽管这可能不是一个好主意)。
例子 40. CLOB-实现char[]Map
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private char[] warranty;
//Getters and setters are omitted for brevity
}
Mapping BLOB
BLOB数据以类似的方式 Map。
考虑到我们有以下数据库表:
例子 41. BLOB-SQL
CREATE TABLE Product (
id INTEGER NOT NULL ,
image blob ,
name VARCHAR(255) ,
PRIMARY KEY ( id )
)
让我们首先使用 JDBC java.sql.Blob类型对此进行 Map。
例子 42. BLOBMap 到java.sql.Blob
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private Blob image;
//Getters and setters are omitted for brevity
}
要保留这样的实体,您必须使用BlobProxy HibernateUtil 创建Blob:
例子 43.坚持一个java.sql.Blob实体
byte[] image = new byte[] {1, 2, 3};
final Product product = new Product();
product.setId( 1 );
product.setName( "Mobile phone" );
product.setImage( BlobProxy.generateProxy( image ) );
entityManager.persist( product );
要检索Blob的内容,您需要转换基础的java.io.InputStream:
例子 44.返回一个java.sql.Blob实体
Product product = entityManager.find( Product.class, productId );
try (InputStream inputStream = product.getImage().getBinaryStream()) {
assertArrayEquals(new byte[] {1, 2, 3}, toBytes( inputStream ) );
}
我们还可以将物化形式的 BLOBMap(例如byte[])。
例子 45. BLOBMap 到byte[]
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private byte[] image;
//Getters and setters are omitted for brevity
}
2.3.9. Map 民族化字符数据
JDBC 4 添加了显式处理国有化字符数据的功能。为此,它添加了特定的国有化字符数据类型:
NCHARNVARCHARLONGNVARCHARNCLOB
考虑到我们有以下数据库表:
例子 46. NVARCHAR-SQL
CREATE TABLE Product (
id INTEGER NOT NULL ,
name VARCHAR(255) ,
warranty NVARCHAR(255) ,
PRIMARY KEY ( id )
)
为了将特定的属性 Map 到国家化的变量数据类型,Hibernate 定义了@NationalizedComments。
例子 47. NVARCHARMap
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Nationalized
private String warranty;
//Getters and setters are omitted for brevity
}
就像CLOB一样,Hibernate 也可以处理NCLOB SQL 数据类型:
例子 48. NCLOB-SQL
CREATE TABLE Product (
id INTEGER NOT NULL ,
name VARCHAR(255) ,
warranty nclob ,
PRIMARY KEY ( id )
)
Hibernate 可以将NCLOBMap 到java.sql.NClob
例子 49. NCLOBMap 到java.sql.NClob
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
@Nationalized
// Clob also works, because NClob extends Clob.
// The database type is still NCLOB either way and handled as such.
private NClob warranty;
//Getters and setters are omitted for brevity
}
要保留这样的实体,您必须使用NClobProxy HibernateUtil 创建NClob:
例子 50.坚持一个java.sql.NClob实体
String warranty = "My product warranty";
final Product product = new Product();
product.setId( 1 );
product.setName( "Mobile phone" );
product.setWarranty( NClobProxy.generateProxy( warranty ) );
entityManager.persist( product );
要检索NClob的内容,您需要转换基础的java.io.Reader:
例子 51.返回一个java.sql.NClob实体
Product product = entityManager.find( Product.class, productId );
try (Reader reader = product.getWarranty().getCharacterStream()) {
assertEquals( "My product warranty", toString( reader ) );
}
我们也可以以实体化形式 MapNCLOB。这样,我们可以使用String或char[]。
例子 52. NCLOBMap 到String
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
@Nationalized
private String warranty;
//Getters and setters are omitted for brevity
}
我们甚至可能希望将物化数据作为 char 数组。
例子 53. NCLOB-物化的char[]Map
@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
@Nationalized
private char[] warranty;
//Getters and setters are omitted for brevity
}
Note
如果您的应用程序和数据库使用国有化,则您可能希望启用国有化字符数据作为默认设置。
您可以通过hibernate.use_nationalized_character_data设置或在引导过程中调用MetadataBuilder#enableGlobalNationalizedCharacterDataSupport来执行此操作。
2.3.10. MapUUID 值
Hibernate 还允许您以多种方式 MapUUID 值。
Note
默认的 UUIDMap 是二进制 Map,因为它使用了更有效的列存储。
但是,许多应用程序更喜欢基于字符的列存储的可读性。要切换默认 Map,只需调用MetadataBuilder.applyBasicType( UUIDCharType.INSTANCE, UUID.class.getName() )。
2.3.11. UUID 为二进制
如前所述,UUID 属性的默认 Map。使用java.util.UUID#getMostSignificantBits和java.util.UUID#getLeastSignificantBits将 UUIDMap 到byte[]并将其存储为BINARY数据。
之所以选择默认值,是因为从存储角度来看,它通常更有效。
2.3.12. UUID 为(var)char
使用java.util.UUID#toString和java.util.UUID#fromString将 UUIDMap 到字符串,并将其存储为CHAR或VARCHAR数据。
2.3.13. PostgreSQL 特定的 UUID
Tip
使用 PostgreSQL 方言之一时,特定于 PostgreSQL 的 UUID 休眠类型将成为默认的 UUIDMap。
使用 PostgreSQL 特定的 UUID 数据类型 MapUUID。 PostgreSQL JDBC 驱动程序选择将其 UUID 类型 Map 到OTHER代码。请注意,这可能会导致困难,因为驱动程序选择将许多不同的数据类型 Map 到OTHER。
2.3.14. UUID 作为标识符
Hibernate 支持使用 UUID 值作为标识符,甚至可以代表用户生成它们。有关详细信息,请参见Identifiers中有关生成器的讨论。
2.3.15. Map 日期/时间值
Hibernate 允许将各种 Java Date/Time 类 Map 为持久域模型实体属性。 SQL 标准定义了三种日期/时间类型:
DATE
- 通过存储年,月和日来表示 calendar 日期。 JDBC 等效为
java.sql.Date
- 通过存储年,月和日来表示 calendar 日期。 JDBC 等效为
TIME
- 表示一天中的时间,并存储小时,分钟和秒。 JDBC 等效为
java.sql.Time
- 表示一天中的时间,并存储小时,分钟和秒。 JDBC 等效为
TIMESTAMP
- 它存储 DATE 和 TIME 加上纳秒。 JDBC 等效为
java.sql.Timestamp
- 它存储 DATE 和 TIME 加上纳秒。 JDBC 等效为
Note
为了避免依赖java.sql包,通常使用java.util或java.time日期/时间类而不是java.sql.Timestamp和java.sql.Time类。
虽然java.sql类定义了与 SQL 日期/时间数据类型的直接关联,但是java.util或java.time属性需要使用@TemporalComments 显式标记 SQL 类型相关性。这样,可以将java.util.Date或java.util.CalendarMap 到 SQL DATE,TIME或TIMESTAMP类型。
考虑以下实体:
例子 54. java.util.DateMap 为DATE
@Entity(name = "DateEvent")
public static class DateEvent {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@Temporal(TemporalType.DATE)
private Date timestamp;
//Getters and setters are omitted for brevity
}
保留此类实体时:
例子 55.保持java.util.DateMap
DateEvent dateEvent = new DateEvent( new Date() );
entityManager.persist( dateEvent );
Hibernate 生成以下 INSERT 语句:
INSERT INTO DateEvent ( timestamp, id )
VALUES ( '2015-12-29', 1 )
仅年,月和日字段被保存到数据库中。
如果我们将@Temporal类型更改为TIME:
例子 56. java.util.DateMap 为TIME
@Column(name = "`timestamp`")
@Temporal(TemporalType.TIME)
private Date timestamp;
Hibernate 将发出一个包含小时,分钟和秒的 INSERT 语句。
INSERT INTO DateEvent ( timestamp, id )
VALUES ( '16:51:58', 1 )
当@Temporal类型设置为TIMESTAMP时:
例子 57. java.util.DateMap 为TIMESTAMP
@Column(name = "`timestamp`")
@Temporal(TemporalType.TIMESTAMP)
private Date timestamp;
Hibernate 将在 INSERT 语句中同时包含DATE,TIME和纳秒:
INSERT INTO DateEvent ( timestamp, id )
VALUES ( '2015-12-29 16:54:04.544', 1 )
Note
就像java.util.Date一样,java.util.Calendar需要@Temporal注解,以便知道要选择哪种 JDBC 数据类型:DATE,TIME或TIMESTAMP。
如果java.util.Date标记为某个时间点,则java.util.Calendar将考虑默认时区。
MapJava 8 日期/时间值
Java 8 附带了一个新的 Date/Time API,它对即时日期,时间间隔,本地和分区的 Date/Time 不可变实例提供支持,这些实例 Binding 在java.time软件包中。
标准 SQL 日期/时间类型和受支持的 Java 8 日期/时间类类型之间的 Map 如下所示;
DATE
java.time.LocalDate
TIME
java.time.LocalTime,java.time.OffsetTime
TIMESTAMP
java.time.Instant,java.time.LocalDateTime,java.time.OffsetDateTime和java.time.ZonedDateTime
Tip
因为 Java 8 Date/Time 类和 SQL 类型之间的 Map 是隐式的,所以不需要指定@TemporalComments。
将其设置在java.time类上会引发以下异常:
org.hibernate.AnnotationException: @Temporal should only be set on a java.util.Date or java.util.Calendar property
使用特定时区
默认情况下,Hibernate 在保存java.sql.Timestamp或java.sql.Time属性时将使用PreparedStatement.setTimestamp(int parameterIndex,java.sql.Timestamp)或PreparedStatement.setTime(int parameterIndex,java.sql.Time x)。
如果未指定时区,则 JDBC 驱动程序将使用底层的 JVM 默认时区,如果在 Global 范围内使用该应用程序,则可能不适合。因此,每当从数据库中保存/加载数据时,通常都使用单个参考时区(例如 UTC)。
一种替代方法是将所有 JVM 配置为使用参考时区:
Declaratively
java -Duser.timezone = UTC ...
- Programmatically
- ```java
TimeZone.setDefault( TimeZone.getTimeZone( "UTC" ) );
但是,如this article中所述,这并不总是可行的,尤其是对于前端节点。因此,Hibernate 提供了hibernate.jdbc.time_zone配置属性,该属性可以配置:
声明性地,在
SessionFactory级别
settings.put(
AvailableSettings.JDBC_TIME_ZONE,
TimeZone.getTimeZone(“ UTC”)
);
- Programmatically, on a per `Session` basis
- ```java
Session session = sessionFactory()
.withOptions()
.jdbcTimeZone( TimeZone.getTimeZone( "UTC" ) )
.openSession();
使用此配置属性后,Hibernate 将调用PreparedStatement.setTimestamp(int parameterIndex,java.sql.Timestamp,Calendar cal)或PreparedStatement.setTime(int parameterIndex,java.sql.Time x,Calendar cal),其中java.util.Calendar引用通过hibernate.jdbc.time_zone属性提供的时区。
2.3.16. JPA 2.1 AttributeConverters
尽管 Hibernate 长期以来一直提供custom types作为 JPA 2.1 提供程序,但它也支持AttributeConverter。
使用自定义AttributeConverter,应用程序开发人员可以将给定的 JDBC 类型 Map 到实体基本类型。
在下面的示例中,java.time.Period将 Map 到VARCHAR数据库列。
例子 58. java.time.Period自定义AttributeConverter
@Converter
public class PeriodStringConverter
implements AttributeConverter<Period, String> {
@Override
public String convertToDatabaseColumn(Period attribute) {
return attribute.toString();
}
@Override
public Period convertToEntityAttribute(String dbData) {
return Period.parse( dbData );
}
}
要使用此自定义转换器,@ConvertComments 必须修饰实体属性。
例子 59.使用自定义java.time.Period AttributeConverterMap 的实体
@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Convert(converter = PeriodStringConverter.class)
@Column(columnDefinition = "")
private Period span;
//Getters and setters are omitted for brevity
}
当持久化此类实体时,Hibernate 将基于AttributeConverter逻辑进行类型转换:
例子 60.使用自定义AttributeConverter持久化实体
INSERT INTO Event ( span, id )
VALUES ( 'P1Y2M3D', 1 )
AttributeConverter Java 和 JDBC 类型
如果为转换的“数据库端”指定的 Java 类型(第二个AttributeConverter绑定参数)未知,则 Hibernate 将回退为java.io.Serializable类型。
如果 Hibernate 不知道 Java 类型,您将遇到以下消息:
Note
HHH000481:遇到 Java 类型,我们无法为其找到 JavaTypeDescriptor,并且该 Java 类型似乎未实现 equals 和/或 hashCode。执行涉及此 Java 类型的相等/脏检查时,这可能导致严重的性能问题。考虑注册一个自定义 JavaTypeDescriptor 或至少实现 equals/hashCode。
Java 类型是否为“已知”意味着它在JavaTypeDescriptorRegistry中具有一个条目。虽然默认情况下,Hibernate 将许多 JDK 类型加载到JavaTypeDescriptorRegistry,但是应用程序还可以通过添加新的JavaTypeDescriptor条目来扩展JavaTypeDescriptorRegistry。
这样,Hibernate 也将知道如何在 JDBC 级别处理特定的 Java 对象类型。
JPA 2.1 AttributeConverter 可变性计划
如果基础 Java 类型是不可变的,则由 JPA AttributeConverter转换的基本类型是不可变的;如果关联的属性类型也是可变的,则该类型是可变的。
因此,可变性由关联实体属性类型的JavaTypeDescriptor#getMutabilityPlan给出。
Immutable types
如果实体属性是String,原始包装器(例如Integer,Long),枚举类型或任何其他不可变的Object类型,则只能通过将其重新分配为新值来更改它。
考虑到我们具有与JPA 2.1 AttributeConverters部分中所示的相同的Period实体属性:
@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Convert(converter = PeriodStringConverter.class)
@Column(columnDefinition = "")
private Period span;
//Getters and setters are omitted for brevity
}
更改span属性的唯一方法是将其重新分配为其他值:
Event event = entityManager.createQuery( "from Event", Event.class ).getSingleResult();
event.setSpan(Period
.ofYears( 3 )
.plusMonths( 2 )
.plusDays( 1 )
);
Mutable types
另一方面,请考虑以下示例,其中Money类型是可变的。
public static class Money {
private long cents;
//Getters and setters are omitted for brevity
}
@Entity(name = "Account")
public static class Account {
@Id
private Long id;
private String owner;
@Convert(converter = MoneyConverter.class)
private Money balance;
//Getters and setters are omitted for brevity
}
public static class MoneyConverter
implements AttributeConverter<Money, Long> {
@Override
public Long convertToDatabaseColumn(Money attribute) {
return attribute == null ? null : attribute.getCents();
}
@Override
public Money convertToEntityAttribute(Long dbData) {
return dbData == null ? null : new Money( dbData );
}
}
可变的Object允许您修改其内部结构,而 Hibernate 脏检查机制将把更改传播到数据库:
Account account = entityManager.find( Account.class, 1L );
account.getBalance().setCents( 150 * 100L );
entityManager.persist( account );
Tip
尽管AttributeConverter类型是可变的,以便脏检查,深度复制和二级缓存正常工作,但将它们视为不可变的(实际上是不可变的)更为有效。
因此,在可能的情况下,最好使用不可变类型而不是可变类型。
2.3.17. SQL 带引号的标识符
您可以通过将表名或列名放在 Map 文档的反引号中来强制 Hibernate 在生成的 SQL 中用标识符引起来。传统上,Hibernate 使用反引号转义 SQL 保留关键字,而 JPA 则使用双引号。
一旦保留的关键字被转义,Hibernate 将对 SQL Dialect使用正确的引号样式。这通常是双引号,但是 SQL Server 使用方括号,而 MySQL 使用反引号。
例子 61.休眠传统的报价
@Entity(name = "Product")
public static class Product {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
例子 62. JPA 引用
@Entity(name = "Product")
public static class Product {
@Id
private Long id;
@Column(name = "\"name\"")
private String name;
@Column(name = "\"number\"")
private String number;
//Getters and setters are omitted for brevity
}
因为name和number是保留字,所以Product实体 Map 使用反引号来引用这些列名。
保存以下Product entity时,Hibernate 会生成以下 SQL 插入语句:
例子 63.保留一个带引号的列名
Product product = new Product();
product.setId( 1L );
product.setName( "Mobile phone" );
product.setNumber( "123-456-7890" );
entityManager.persist( product );
INSERT INTO Product ("name", "number", id)
VALUES ('Mobile phone', '123-456-7890', 1)
Global quoting
Hibernate 还可以使用以下配置属性引用所有标识符(例如表,列):
<property
name="hibernate.globally_quoted_identifiers"
value="true"
/>
这样,我们不需要手动引用任何标识符:
例子 64. JPA 引用
@Entity(name = "Product")
public static class Product {
@Id
private Long id;
private String name;
private String number;
//Getters and setters are omitted for brevity
}
持久化Product实体时,Hibernate 将引用所有标识符,如以下示例所示:
INSERT INTO "Product" ("name", "number", "id")
VALUES ('Mobile phone', '123-456-7890', 1)
如您所见,表名和所有列均已被引用。
有关与报价相关的配置属性的更多信息,请同时查看Mapping configurations部分。
2.3.18. 生成的属性
生成的属性是其值由数据库生成的属性。通常,Hibernate 应用程序需要refresh个对象,这些对象包含数据库为其生成值的任何属性。但是,将属性标记为已生成可让应用程序将此职责委派给 Hibernate。当 Hibernate 对已定义生成属性的实体发出 SQL INSERT 或 UPDATE 时,它将立即发出选择以检索生成的值。
标记为已生成的属性还必须是不可插入和不可更新。只能将@Version和@Basic类型标记为已生成。
NEVER(默认值)- 给定的属性值不在数据库内生成。
INSERT- 给定的属性值在插入时生成,但在后续更新中不会重新生成。 * creationTimestamp *之类的属性属于此类别。
ALWAYS- 属性值是在插入和更新时生成的。
要将属性标记为已生成,请使用特定于 Hibernate 的@GeneratedComments。
@Generated annotation
使用@Generated注解,以便 Hibernate 在持久保存或更新实体后可以获取当前注解的属性。因此,@Generated注解接受GenerationTime枚举值。
考虑以下实体:
例子 65. @GeneratedMap 例子
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String firstName;
private String lastName;
private String middleName1;
private String middleName2;
private String middleName3;
private String middleName4;
private String middleName5;
@Generated( value = GenerationTime.ALWAYS )
@Column(columnDefinition =
"AS CONCAT(" +
" COALESCE(firstName, ''), " +
" COALESCE(' ' + middleName1, ''), " +
" COALESCE(' ' + middleName2, ''), " +
" COALESCE(' ' + middleName3, ''), " +
" COALESCE(' ' + middleName4, ''), " +
" COALESCE(' ' + middleName5, ''), " +
" COALESCE(' ' + lastName, '') " +
")")
private String fullName;
}
当Person实体保留后,Hibernate 将从数据库中获取计算出的fullName列,该列将名字,中间名和姓氏连接在一起。
例子 66. @Generated坚持的例子
Person person = new Person();
person.setId( 1L );
person.setFirstName( "John" );
person.setMiddleName1( "Flávio" );
person.setMiddleName2( "André" );
person.setMiddleName3( "Frederico" );
person.setMiddleName4( "Rúben" );
person.setMiddleName5( "Artur" );
person.setLastName( "Doe" );
entityManager.persist( person );
entityManager.flush();
assertEquals("John Flávio André Frederico Rúben Artur Doe", person.getFullName());
INSERT INTO Person
(
firstName,
lastName,
middleName1,
middleName2,
middleName3,
middleName4,
middleName5,
id
)
values
(?, ?, ?, ?, ?, ?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [John]
-- binding parameter [2] as [VARCHAR] - [Doe]
-- binding parameter [3] as [VARCHAR] - [Flávio]
-- binding parameter [4] as [VARCHAR] - [André]
-- binding parameter [5] as [VARCHAR] - [Frederico]
-- binding parameter [6] as [VARCHAR] - [Rúben]
-- binding parameter [7] as [VARCHAR] - [Artur]
-- binding parameter [8] as [BIGINT] - [1]
SELECT
p.fullName as fullName3_0_
FROM
Person p
WHERE
p.id=?
-- binding parameter [1] as [BIGINT] - [1]
-- extracted value ([fullName3_0_] : [VARCHAR]) - [John Flávio André Frederico Rúben Artur Doe]
Person实体更新时也是如此。修改实体后,Hibernate 将从数据库中获取计算出的fullName列。
例子 67. @Generated更新例子
Person person = entityManager.find( Person.class, 1L );
person.setLastName( "Doe Jr" );
entityManager.flush();
assertEquals("John Flávio André Frederico Rúben Artur Doe Jr", person.getFullName());
UPDATE
Person
SET
firstName=?,
lastName=?,
middleName1=?,
middleName2=?,
middleName3=?,
middleName4=?,
middleName5=?
WHERE
id=?
-- binding parameter [1] as [VARCHAR] - [John]
-- binding parameter [2] as [VARCHAR] - [Doe Jr]
-- binding parameter [3] as [VARCHAR] - [Flávio]
-- binding parameter [4] as [VARCHAR] - [André]
-- binding parameter [5] as [VARCHAR] - [Frederico]
-- binding parameter [6] as [VARCHAR] - [Rúben]
-- binding parameter [7] as [VARCHAR] - [Artur]
-- binding parameter [8] as [BIGINT] - [1]
SELECT
p.fullName as fullName3_0_
FROM
Person p
WHERE
p.id=?
-- binding parameter [1] as [BIGINT] - [1]
-- extracted value ([fullName3_0_] : [VARCHAR]) - [John Flávio André Frederico Rúben Artur Doe Jr]
@GeneratorType annotation
使用@GeneratorType注解,以便您可以提供一个自定义生成器来设置当前已注解的属性的值。
因此,@GeneratorType注解接受GenerationTime枚举值和自定义ValueGenerator类类型。
考虑以下实体:
例子 68. @GeneratorTypeMap 例子
public static class CurrentUser {
public static final CurrentUser INSTANCE = new CurrentUser();
private static final ThreadLocal<String> storage = new ThreadLocal<>();
public void logIn(String user) {
storage.set( user );
}
public void logOut() {
storage.remove();
}
public String get() {
return storage.get();
}
}
public static class LoggedUserGenerator implements ValueGenerator<String> {
@Override
public String generateValue(
Session session, Object owner) {
return CurrentUser.INSTANCE.get();
}
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String firstName;
private String lastName;
@GeneratorType( type = LoggedUserGenerator.class, when = GenerationTime.INSERT)
private String createdBy;
@GeneratorType( type = LoggedUserGenerator.class, when = GenerationTime.ALWAYS)
private String updatedBy;
}
保留Person实体后,Hibernate 将使用当前登录的用户填充createdBy列。
例子 69. @Generated坚持的例子
CurrentUser.INSTANCE.logIn( "Alice" );
doInJPA( this::entityManagerFactory, entityManager -> {
Person person = new Person();
person.setId( 1L );
person.setFirstName( "John" );
person.setLastName( "Doe" );
entityManager.persist( person );
} );
CurrentUser.INSTANCE.logOut();
INSERT INTO Person
(
createdBy,
firstName,
lastName,
updatedBy,
id
)
VALUES
(?, ?, ?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Alice]
-- binding parameter [2] as [VARCHAR] - [John]
-- binding parameter [3] as [VARCHAR] - [Doe]
-- binding parameter [4] as [VARCHAR] - [Alice]
-- binding parameter [5] as [BIGINT] - [1]
Person实体更新时也是如此。 Hibernate 将使用当前登录的用户填充updatedBy列。
例子 70. @Generated更新例子
CurrentUser.INSTANCE.logIn( "Bob" );
doInJPA( this::entityManagerFactory, entityManager -> {
Person person = entityManager.find( Person.class, 1L );
person.setFirstName( "Mr. John" );
} );
CurrentUser.INSTANCE.logOut();
UPDATE Person
SET
createdBy = ?,
firstName = ?,
lastName = ?,
updatedBy = ?
WHERE
id = ?
-- binding parameter [1] as [VARCHAR] - [Alice]
-- binding parameter [2] as [VARCHAR] - [Mr. John]
-- binding parameter [3] as [VARCHAR] - [Doe]
-- binding parameter [4] as [VARCHAR] - [Bob]
-- binding parameter [5] as [BIGINT] - [1]
@CreationTimestamp annotation
持久化实体时,@CreationTimestampComments 指示 Hibernate 使用 JVM 的当前时间戳值设置带 Comments 的实体属性。
支持的属性类型为:
java.util.Datejava.util.Calendarjava.sql.Datejava.sql.Timejava.sql.Timestamp
例子 71. @CreationTimestampMap 例子
@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@CreationTimestamp
private Date timestamp;
//Constructors, getters, and setters are omitted for brevity
}
保留Event实体后,Hibernate 将使用当前的 JVM 时间戳值填充基础timestamp列:
例子 72. @CreationTimestamp坚持的例子
Event dateEvent = new Event( );
entityManager.persist( dateEvent );
INSERT INTO Event ("timestamp", id)
VALUES (?, ?)
-- binding parameter [1] as [TIMESTAMP] - [Tue Nov 15 16:24:20 EET 2016]
-- binding parameter [2] as [BIGINT] - [1]
@UpdateTimestamp annotation
持久化实体时,@UpdateTimestampComments 指示 Hibernate 使用 JVM 的当前时间戳值设置带 Comments 的实体属性。
支持的属性类型为:
java.util.Datejava.util.Calendarjava.sql.Datejava.sql.Timejava.sql.Timestamp
例子 73. @UpdateTimestampMap 例子
@Entity(name = "Bid")
public static class Bid {
@Id
@GeneratedValue
private Long id;
@Column(name = "updated_on")
@UpdateTimestamp
private Date updatedOn;
@Column(name = "updated_by")
private String updatedBy;
private Long cents;
//Getters and setters are omitted for brevity
}
保留Bid实体后,Hibernate 将使用当前的 JVM 时间戳值填充基础updated_on列:
例子 74. @UpdateTimestamp坚持的例子
Bid bid = new Bid();
bid.setUpdatedBy( "John Doe" );
bid.setCents( 150 * 100L );
entityManager.persist( bid );
INSERT INTO Bid (cents, updated_by, updated_on, id)
VALUES (?, ?, ?, ?)
-- binding parameter [1] as [BIGINT] - [15000]
-- binding parameter [2] as [VARCHAR] - [John Doe]
-- binding parameter [3] as [TIMESTAMP] - [Tue Apr 18 17:21:46 EEST 2017]
-- binding parameter [4] as [BIGINT] - [1]
更新Bid实体时,Hibernate 将使用当前 JVM 时间戳值修改updated_on列:
例子 75. @UpdateTimestamp更新例子
Bid bid = entityManager.find( Bid.class, 1L );
bid.setUpdatedBy( "John Doe Jr." );
bid.setCents( 160 * 100L );
entityManager.persist( bid );
UPDATE Bid SET
cents = ?,
updated_by = ?,
updated_on = ?
where
id = ?
-- binding parameter [1] as [BIGINT] - [16000]
-- binding parameter [2] as [VARCHAR] - [John Doe Jr.]
-- binding parameter [3] as [TIMESTAMP] - [Tue Apr 18 17:49:24 EEST 2017]
-- binding parameter [4] as [BIGINT] - [1]
@ValueGenerationType meta-annotation
Hibernate 4.3 引入了@ValueGenerationType元 Comments,这是一种声明生成的属性或定制生成器的新方法。
@Generated已被改装为使用@ValueGenerationType元 Comments。但是@ValueGenerationType所提供的功能比@Generated当前所支持的功能更多,并且要利用其中的某些功能,您只需连接一个新的生成器 Comments。
正如您将在以下示例中看到的那样,在声明用于标记需要特定生成策略的实体属性的自定义 Comments 时,将使用@ValueGenerationType元 Comments。必须将实际的生成逻辑添加到实现AnnotationValueGeneration接口的类中。
Database-generated values
例如,假设我们希望通过对标准 ANSI SQL 函数current_timestamp(而不是触发器或 DEFAULT 值)的调用来生成时间戳:
例子 76.一个用于数据库生成的ValueGenerationTypeMap
@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@FunctionCreationTimestamp
private Date timestamp;
//Constructors, getters, and setters are omitted for brevity
}
@ValueGenerationType(generatedBy = FunctionCreationValueGeneration.class)
@Retention(RetentionPolicy.RUNTIME)
public @interface FunctionCreationTimestamp {}
public static class FunctionCreationValueGeneration
implements AnnotationValueGeneration<FunctionCreationTimestamp> {
@Override
public void initialize(FunctionCreationTimestamp annotation, Class<?> propertyType) {
}
/**
* Generate value on INSERT
* @return when to generate the value
*/
public GenerationTiming getGenerationTiming() {
return GenerationTiming.INSERT;
}
/**
* Returns null because the value is generated by the database.
* @return null
*/
public ValueGenerator<?> getValueGenerator() {
return null;
}
/**
* Returns true because the value is generated by the database.
* @return true
*/
public boolean referenceColumnInSql() {
return true;
}
/**
* Returns the database-generated value
* @return database-generated value
*/
public String getDatabaseGeneratedReferencedColumnValue() {
return "current_timestamp";
}
}
持久化Event实体时,Hibernate 生成以下 SQL 语句:
INSERT INTO Event ("timestamp", id)
VALUES (current_timestamp, 1)
如您所见,current_timestamp值用于分配timestamp列值。
In-memory-generated values
如果需要在内存中生成时间戳记值,则必须使用以下 Map:
例子 77.用于内存中值生成的ValueGenerationTypeMap
@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@FunctionCreationTimestamp
private Date timestamp;
//Constructors, getters, and setters are omitted for brevity
}
@ValueGenerationType(generatedBy = FunctionCreationValueGeneration.class)
@Retention(RetentionPolicy.RUNTIME)
public @interface FunctionCreationTimestamp {}
public static class FunctionCreationValueGeneration
implements AnnotationValueGeneration<FunctionCreationTimestamp> {
@Override
public void initialize(FunctionCreationTimestamp annotation, Class<?> propertyType) {
}
/**
* Generate value on INSERT
* @return when to generate the value
*/
public GenerationTiming getGenerationTiming() {
return GenerationTiming.INSERT;
}
/**
* Returns the in-memory generated value
* @return {@code true}
*/
public ValueGenerator<?> getValueGenerator() {
return (session, owner) -> new Date( );
}
/**
* Returns false because the value is generated by the database.
* @return false
*/
public boolean referenceColumnInSql() {
return false;
}
/**
* Returns null because the value is generated in-memory.
* @return null
*/
public String getDatabaseGeneratedReferencedColumnValue() {
return null;
}
}
持久化Event实体时,Hibernate 生成以下 SQL 语句:
INSERT INTO Event ("timestamp", id)
VALUES ('Tue Mar 01 10:58:18 EET 2016', 1)
如您所见,new Date()对象值用于分配timestamp列值。
2.3.19. 列转换器:读取和写入表达式
Hibernate 允许您自定义用于读取和写入 Map 到@Basic类型的列的值的 SQL。例如,如果您的数据库提供了一组数据加密功能,则可以像下面的示例一样为各个列调用它们。
例子 78. @ColumnTransformer例子
@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String username;
@Column(name = "pswd")
@ColumnTransformer(
read = "decrypt( 'AES', '00', pswd )",
write = "encrypt('AES', '00', ?)"
)
private String password;
private int accessLevel;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
@ManyToMany(mappedBy = "employees")
private List<Project> projects = new ArrayList<>();
//Getters and setters omitted for brevity
}
如果一个属性使用多个列,则必须使用forColumn属性来指定@ColumnTransformer读写表达式所针对的列。
例子 79. @ColumnTransformer forColumn属性的用法
@Entity(name = "Savings")
public static class Savings {
@Id
private Long id;
@Type(type = "org.hibernate.userguide.mapping.basic.MonetaryAmountUserType")
@Columns(columns = {
@Column(name = "money"),
@Column(name = "currency")
})
@ColumnTransformer(
forColumn = "money",
read = "money / 100",
write = "? * 100"
)
private MonetaryAmount wallet;
//Getters and setters omitted for brevity
}
只要在查询中引用了属性,Hibernate 就会自动应用自定义表达式。此功能类似于派生属性@Formula,但有两个区别:
该属性由作为自动模式生成的一部分导出的一列或多列支持。
该属性是可读写的,而不是只读的。
write表达式(如果指定)必须恰好包含一个“?”价值的占位符。
例子 80.持久化具有@ColumnTransformer和复合类型的实体
doInJPA( this::entityManagerFactory, entityManager -> {
Savings savings = new Savings( );
savings.setId( 1L );
savings.setWallet( new MonetaryAmount( BigDecimal.TEN, Currency.getInstance( Locale.US ) ) );
entityManager.persist( savings );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
Savings savings = entityManager.find( Savings.class, 1L );
assertEquals( 10, savings.getWallet().getAmount().intValue());
} );
INSERT INTO Savings (money, currency, id)
VALUES (10 * 100, 'USD', 1)
SELECT
s.id as id1_0_0_,
s.money / 100 as money2_0_0_,
s.currency as currency3_0_0_
FROM
Savings s
WHERE
s.id = 1
2.3.20. @Formula
有时,您希望数据库为您而不是在 JVM 中执行一些计算,因此您可能还会创建某种虚拟列。您可以使用 SQL 片段(也称为公式)来代替将属性 Map 到列中。这种属性是只读的(其值由您的公式片段计算)
Note
您应该知道@FormulaComments 带有本机 SQL 子句,这可能会影响数据库的可移植性。
例子 81. @FormulaMap 用法
@Entity(name = "Account")
public static class Account {
@Id
private Long id;
private Double credit;
private Double rate;
@Formula(value = "credit * rate")
private Double interest;
//Getters and setters omitted for brevity
}
加载Account实体时,Hibernate 将使用配置的@Formula来计算interest属性:
例子 82.用@FormulaMap 持久化一个实体
doInJPA( this::entityManagerFactory, entityManager -> {
Account account = new Account( );
account.setId( 1L );
account.setCredit( 5000d );
account.setRate( 1.25 / 100 );
entityManager.persist( account );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
Account account = entityManager.find( Account.class, 1L );
assertEquals( Double.valueOf( 62.5d ), account.getInterest());
} );
INSERT INTO Account (credit, rate, id)
VALUES (5000.0, 0.0125, 1)
SELECT
a.id as id1_0_0_,
a.credit as credit2_0_0_,
a.rate as rate3_0_0_,
a.credit * a.rate as formula0_0_
FROM
Account a
WHERE
a.id = 1
Note
@Formula注解定义的 SQL 片段可以任意复杂,甚至可以包含子选择。
2.4. 可嵌入类型
Hibernate 历史上称这些组件。 JPA 称它们为可嵌入对象。无论哪种方式,概念都是相同的:价值构成。
例如,我们可能有一个Publisher类,由name和country组成,或者有一个Location类,由country和city组成。
Usage of the word embeddable
为了避免与标记给定可嵌入类型的 Comments 产生任何混淆,该 Comments 将进一步称为@Embeddable。
在本章及其后的整个章节中,为了简洁起见,可嵌入类型也可以称为* embeddable *。
例子 83.可嵌入类型的例子
@Embeddable
public static class Publisher {
private String name;
private Location location;
public Publisher(String name, Location location) {
this.name = name;
this.location = location;
}
private Publisher() {}
//Getters and setters are omitted for brevity
}
@Embeddable
public static class Location {
private String country;
private String city;
public Location(String country, String city) {
this.country = country;
this.city = city;
}
private Location() {}
//Getters and setters are omitted for brevity
}
可嵌入类型是值类型的另一种形式,其生命周期绑定到父实体类型,因此从其父类继承属性访问(有关属性访问的详细信息,请参见Access strategies)。
可嵌入类型可以由基本值以及关联组成,但需要注意的是,当用作集合元素时,它们不能自己定义集合。
2.4.1. 组件/嵌入式
通常,可嵌入类型用于对多个基本类型 Map 进行分组,并在多个实体之间重用它们。
例子 84.简单的可嵌入
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
private Publisher publisher;
//Getters and setters are omitted for brevity
}
@Embeddable
public static class Publisher {
@Column(name = "publisher_name")
private String name;
@Column(name = "publisher_country")
private String country;
//Getters and setters, equals and hashCode methods omitted for brevity
}
create table Book (
id bigint not null,
author varchar(255),
publisher_country varchar(255),
publisher_name varchar(255),
title varchar(255),
primary key (id)
)
Note
JPA 定义了两个用于可嵌入类型的术语:@Embeddable和@Embedded。
@Embeddable用于描述 Map 类型本身(例如Publisher)。
@Embedded用于引用给定的可嵌入类型(例如book.publisher)。
因此,可嵌入类型由Publisher类表示,并且父实体通过book#publisher对象组成来使用它。
组合值 Map 到与父表相同的表。组合是良好的面向对象数据建模(惯用 Java)的一部分。实际上,该表也可以由以下实体类型 Map。
例子 85.可嵌入类型组成的替代
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
@Column(name = "publisher_name")
private String publisherName;
@Column(name = "publisher_country")
private String publisherCountry;
//Getters and setters are omitted for brevity
}
组合形式当然更面向对象,并且随着我们使用多个可嵌入类型而变得更加明显。
2.4.2. 多种可嵌入类型
尽管从面向对象的角度来看,使用可嵌入类型要方便得多,但是此示例不能按原样工作。当同一父实体类型中多次包含同一可嵌入类型时,JPA 规范要求显式设置关联的列名称。
此要求是由于如何将对象属性 Map 到数据库列。默认情况下,JPA 期望数据库列与其关联的对象属性具有相同的名称。当包含多个可嵌入对象时,基于隐式基于名称的 Map 规则不再起作用,因为多个对象属性最终可能会 Map 到同一数据库列。
我们有一些解决方案。
2.4.3. 覆盖可嵌入类型
JPA 定义了@AttributeOverrideComments 来处理这种情况。这样,可以通过设置显式的基于名称的属性-列类型 Map 来解决 Map 冲突。
如果某个实体中多次使用 Embeddable 类型,则需要使用@AttributeOverride和@AssociationOverride注解来覆盖 Embeddable 定义的默认列名称。
考虑到您具有以下Publisher可嵌入类型,该类型定义了与Country实体的@ManyToOne关联:
例子 86.具有@ManyToOne关联的可嵌入类型
@Embeddable
public static class Publisher {
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private Country country;
//Getters and setters, equals and hashCode methods omitted for brevity
}
@Entity(name = "Country")
public static class Country {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String name;
//Getters and setters are omitted for brevity
}
create table Country (
id bigint not null,
name varchar(255),
primary key (id)
)
alter table Country
add constraint UK_p1n05aafu73sbm3ggsxqeditd
unique (name)
现在,如果您有一个Book实体为电子书和平装本声明了两种Publisher可嵌入类型,则不能使用默认的Publisher可嵌入 Map,因为这两个可嵌入列 Map 之间会发生冲突。
因此,Book实体需要覆盖每个Publisher属性的可嵌入类型 Map:
例子 87.重写可嵌入类型属性
@Entity(name = "Book")
@AttributeOverrides({
@AttributeOverride(
name = "ebookPublisher.name",
column = @Column(name = "ebook_publisher_name")
),
@AttributeOverride(
name = "paperBackPublisher.name",
column = @Column(name = "paper_back_publisher_name")
)
})
@AssociationOverrides({
@AssociationOverride(
name = "ebookPublisher.country",
joinColumns = @JoinColumn(name = "ebook_publisher_country_id")
),
@AssociationOverride(
name = "paperBackPublisher.country",
joinColumns = @JoinColumn(name = "paper_back_publisher_country_id")
)
})
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
private Publisher ebookPublisher;
private Publisher paperBackPublisher;
//Getters and setters are omitted for brevity
}
create table Book (
id bigint not null,
author varchar(255),
ebook_publisher_name varchar(255),
paper_back_publisher_name varchar(255),
title varchar(255),
ebook_publisher_country_id bigint,
paper_back_publisher_country_id bigint,
primary key (id)
)
alter table Book
add constraint FKm39ibh5jstybnslaoojkbac2g
foreign key (ebook_publisher_country_id)
references Country
alter table Book
add constraint FK7kqy9da323p7jw7wvqgs6aek7
foreign key (paper_back_publisher_country_id)
references Country
2.4.4. 嵌入式和隐式命名策略
Tip
ImplicitNamingStrategyComponentPathImpl是特定于 Hibernate 的功能。关心 JPA 提供程序可移植性的用户应改为使用@AttributeOverride进行显式列命名。
Naming详细介绍了休眠命名策略。但是,出于本讨论的目的,Hibernate 具有以安全的方式解释隐式列名的能力,可与多种可嵌入类型一起使用。
例子 88.隐式多个可嵌入类型 Map
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
private Publisher ebookPublisher;
private Publisher paperBackPublisher;
//Getters and setters are omitted for brevity
}
@Embeddable
public static class Publisher {
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private Country country;
//Getters and setters, equals and hashCode methods omitted for brevity
}
@Entity(name = "Country")
public static class Country {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String name;
//Getters and setters are omitted for brevity
}
要使其正常工作,您需要使用ImplicitNamingStrategyComponentPathImpl命名策略。
例子 89.使用组件路径命名策略启用隐式可嵌入类型 Map
metadataBuilder.applyImplicitNamingStrategy(
ImplicitNamingStrategyComponentPathImpl.INSTANCE
);
现在,隐式列命名中使用了属性的“路径”:
create table Book (
id bigint not null,
author varchar(255),
ebookPublisher_name varchar(255),
paperBackPublisher_name varchar(255),
title varchar(255),
ebookPublisher_country_id bigint,
paperBackPublisher_country_id bigint,
primary key (id)
)
您甚至可以开发自己的命名策略来执行其他类型的隐式命名策略。
2.4.5. 可嵌入类型的集合
可嵌入类型的集合是特定值的集合(因为可嵌入类型是值类型)。 值类型的集合中详细介绍了值集合。
2.4.6. 可嵌入类型作为 Map 键
可嵌入类型也可以用作Map键。该主题在Map-键中进行了详细转换。
2.4.7. 可嵌入类型作为标识符
可嵌入类型也可以用作实体类型标识符。 Composite identifiers中详细介绍了此用法。
Tip
用作集合条目,Map 键或实体类型标识符的可嵌入类型不能包含其自己的集合 Map。
2.4.8. @TargetMap
@Target注解用于指定通过接口 Map 的给定关联的实现类。 @ManyToOne,@OneToOne,@OneToMany和@ManyToMany具有targetEntity属性,用于在将接口用于 Map 时指定实体关联的实际类。
出于相同目的,@ElementCollection关联具有targetClass属性。
但是,对于简单的可嵌入类型,没有这样的构造,因此您需要使用特定于 Hibernate 的@TargetComments。
例子 90. @TargetMap 用法
public interface Coordinates {
double x();
double y();
}
@Embeddable
public static class GPS implements Coordinates {
private double latitude;
private double longitude;
private GPS() {
}
public GPS(double latitude, double longitude) {
this.latitude = latitude;
this.longitude = longitude;
}
@Override
public double x() {
return latitude;
}
@Override
public double y() {
return longitude;
}
}
@Entity(name = "City")
public static class City {
@Id
@GeneratedValue
private Long id;
private String name;
@Embedded
@Target( GPS.class )
private Coordinates coordinates;
//Getters and setters omitted for brevity
}
coordinates可嵌入类型被 Map 为Coordinates接口。但是,Hibernate 需要知道实际的实现方式,在这种情况下为GPS,因此@TargetComments 用于提供此信息。
假设我们保留了以下City实体:
例子 91. @Target坚持的例子
doInJPA( this::entityManagerFactory, entityManager -> {
City cluj = new City();
cluj.setName( "Cluj" );
cluj.setCoordinates( new GPS( 46.77120, 23.62360 ) );
entityManager.persist( cluj );
} );
提取City实体时,@Target表达式 Mapcoordinates属性:
例子 92. @Target取得例子
doInJPA( this::entityManagerFactory, entityManager -> {
City cluj = entityManager.find( City.class, 1L );
assertEquals( 46.77120, cluj.getCoordinates().x(), 0.00001 );
assertEquals( 23.62360, cluj.getCoordinates().y(), 0.00001 );
} );
SELECT
c.id as id1_0_0_,
c.latitude as latitude2_0_0_,
c.longitude as longitud3_0_0_,
c.name as name4_0_0_
FROM
City c
WHERE
c.id = ?
-- binding parameter [1] as [BIGINT] - [1]
-- extracted value ([latitude2_0_0_] : [DOUBLE]) - [46.7712]
-- extracted value ([longitud3_0_0_] : [DOUBLE]) - [23.6236]
-- extracted value ([name4_0_0_] : [VARCHAR]) - [Cluj]
因此,@Target注解用于定义父子关联之间的自定义联接关联。
2.4.9. @父 Map
特定于 Hibernate 的@Parent注解允许您从可嵌入对象内部引用所有者实体。
例子 93. @ParentMap 用法
@Embeddable
public static class GPS {
private double latitude;
private double longitude;
@Parent
private City city;
//Getters and setters omitted for brevity
}
@Entity(name = "City")
public static class City {
@Id
@GeneratedValue
private Long id;
private String name;
@Embedded
@Target( GPS.class )
private GPS coordinates;
//Getters and setters omitted for brevity
}
假设我们保留了以下City实体:
例子 94. @Parent坚持的例子
doInJPA( this::entityManagerFactory, entityManager -> {
City cluj = new City();
cluj.setName( "Cluj" );
cluj.setCoordinates( new GPS( 46.77120, 23.62360 ) );
entityManager.persist( cluj );
} );
提取City实体时,可嵌入类型的city属性充当对拥有父实体的反向引用:
例子 95. @Parent取得例子
doInJPA( this::entityManagerFactory, entityManager -> {
City cluj = entityManager.find( City.class, 1L );
assertSame( cluj, cluj.getCoordinates().getCity() );
} );
因此,@Parent注解用于定义可嵌入类型与拥有实体之间的关联。
2.5. 实体类型
Usage of the word entity
实体类型描述了实际的持久域模型对象和数据库表行之间的 Map。为了避免与标记给定实体类型的 Comments 产生任何混淆,该 Comments 将进一步称为@Entity。
在本章及其后的整个章节中,实体类型将简称为* entity *。
2.5.1. POJO 模型
- JPA 2.1 规范的 2.1 节中的实体类*定义了其对实体类的要求。希望在 JPA 提供程序之间可移植的应用程序应遵守以下要求:
实体类必须使用
javax.persistence.EntityComments 进行 Comments(或在 XMLMap 中这样表示)。实体类必须具有公共或受保护的无参数构造函数。它还可以定义其他构造函数。
实体类必须是顶级类。
枚举或接口不能指定为实体。
实体类不能是最终的。实体类的任何方法或持久实例变量都不得为最终的。
如果实体实例要作为分离对象远程使用,则实体类必须实现
Serializable接口。抽象类和具体类都可以是实体。实体可以扩展非实体类以及实体类,并且非实体类可以扩展实体类。
实体的持久状态由实例变量表示,实例变量可以对应于 JavaBean 样式的属性。实例变量只能由实体实例本身直接从实体的方法内部访问。Client 端只能通过实体的访问器方法(getter/setter 方法)或其他业务方法来使用实体的状态。
但是,Hibernate 的要求并不严格。与上面列表的区别包括:
实体类必须具有无参数构造函数,该构造函数可以是公共的,受保护的或程序包可见性。它还可以定义其他构造函数。
实体类不必是顶级类。
从技术上讲,Hibernate 可以持久化最终类或具有最终持久性状态访问器(getter/setter)方法的类。但是,通常不是一个好主意,因为这样做将使 Hibernate 不能生成用于延迟加载实体的代理。
Hibernate 并不限制应用程序开发人员公开实例变量并从实体类本身之外引用它们。然而,这种范例的有效性至多是有争议的。
让我们详细了解每个需求。
2.5.2. 偏好非决赛类
Hibernate 的主要功能是可以通过运行时代理延迟加载某些实体实例变量(属性)。此功能取决于实体类是否为非最终类,或者取决于实现声明所有属性获取器/设置器的接口。您仍然可以使用 Hibernate 持久化未实现此类接口的最终类,但是您将无法使用代理来获取懒惰的关联,因此限制了性能调整的选项。出于同样的原因,您还应该避免将持久属性 getter 和 setter 声明为 final。
Note
从 5.0 开始,Hibernate 提供了更健壮的字节码增强版本,作为处理延迟加载的另一种方法。 Hibernate 在 5.0 之前具有一些字节码重写功能,但是它们非常初级。有关获取和字节码增强的更多信息,请参见Bytecode Enhancement。
2.5.3. 实现无参数构造函数
实体类应具有无参数的构造函数。 Hibernate 和 JPA 都需要这样做。
JPA 要求将此构造函数定义为 public 或 protected。大多数情况下,只要系统 SecurityManager 允许覆盖可见性设置,Hibernate 都不在乎构造函数的可见性。就是说,如果您希望利用运行时代理生成,则应至少使用包可见性来定义构造函数。
2.5.4. 声明持久性属性的获取器和设置器
JPA 规范要求这样做,否则,该模型将阻止直接从实体本身外部访问实体持久状态字段。
尽管 Hibernate 不需要它,但建议遵循 JavaBean 约定并为实体持久属性定义 getter 和 setter。尽管如此,您仍然可以告诉 Hibernate 直接访问实体字段。
无需将属性(无论是字段还是 getter/setter)声明为公共属性。 Hibernate 可以处理以公共,受保护,程序包或私有可见性声明的属性。同样,如果要使用运行时代理生成进行延迟加载,则 getter/setter 方法应至少授予对程序包可见性的访问权限。
2.5.5. 提供标识符属性
Tip
从历史上看,提供标识符属性被认为是可选的。
但是,未在实体上定义标识符属性应被视为已弃用的功能,该功能将在以后的版本中删除。
标识符属性不一定需要 Map 到物理上定义主键的列。但是,它应该 Map 到可以唯一标识每一行的列。
Note
我们建议您在持久性类上声明以统一名称命名的标识符属性,并使用包装器(即非原始)类型(例如Long或Integer)。
@IdComments 的位置标记为持久状态访问策略。
例子 96.标识符 Map
@Id
private Long id;
Hibernate 提供了多种标识符生成策略,有关此主题的更多信息,请参见Identifier Generators章。
2.5.6. Map 实体
Map 实体的主要步骤是javax.persistence.EntityComments。
@EntityComments 仅定义name属性,该属性用于提供用于 JPQL 查询的特定实体名称。
默认情况下,如果缺少@Entity注解的 name 属性,则实体类本身的非限定名称将用作实体名称。
Tip
因为实体名称是由类的非限定名称给出的,所以即使实体类驻留在不同的包中,Hibernate 也不允许注册具有相同名称的多个实体。
如果不加此限制,则如果不合格的实体名称与一个以上的实体类相关联,则 Hibernate 将不知道在 JPQL 查询中引用了哪个实体类。
在以下示例中,实体名称(例如Book)由实体类名称的非限定名称给出。
例子 97. @Entity隐式名字的 Map
@Entity
public class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
但是,也可以如以下示例所示显式设置实体名称。
例子 98. @Entity用一个明确的名字 Map
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
实体为数据库表建模。该标识符唯一地标识该表中的每一行。默认情况下,假定表的名称与实体的名称相同。要显式给出表的名称或指定有关表的其他信息,我们将使用javax.persistence.Table注解。
例子 99.简单@Entity和@Table
@Entity(name = "Book")
@Table(
catalog = "public",
schema = "store",
name = "book"
)
public static class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
Map 关联表的目录
没有指定给定实体 Map 到的关联数据库表的目录,Hibernate 将使用与当前数据库连接关联的默认目录。
但是,如果您的数据库托管多个目录,则可以使用 JPA @Table注解的catalog属性指定给定表所在的目录。
假设我们正在使用 MySQL,并且想将Book实体 Map 到public目录中的book表,该表如下所示。
例子 100. public目录中的book表
create table public.book (
id bigint not null,
author varchar(255),
title varchar(255),
primary key (id)
) engine=InnoDB
现在,要将Book实体 Map 到public目录中的book表,我们可以使用@Table JPA 注解的catalog属性。
例子 101.使用@Table注解指定数据库目录
@Entity(name = "Book")
@Table(
catalog = "public",
name = "book"
)
public static class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
Map 关联表的架构
在不指定给定实体 Map 到关联数据库表的架构的情况下,Hibernate 将使用与当前数据库连接关联的默认架构。
但是,如果数据库支持架构,则可以使用 JPA @Table注解的schema属性指定给定表所在的架构。
假设我们使用的是 PostgreSQL,并且想将Book实体 Map 到library模式中的book表,该表如下所示。
例子 102. library模式中的book表
create table library.book (
id int8 not null,
author varchar(255),
title varchar(255),
primary key (id)
)
现在,要将Book实体 Map 到library模式中的book表,我们可以使用@Table JPA 注解的schema属性。
例子 103.使用@Table注解指定数据库模式
@Entity(name = "Book")
@Table(
schema = "library",
name = "book"
)
public static class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
Tip
@Table注解的schema属性仅在基础数据库支持架构(例如 PostgreSQL)时有效。
因此,如果使用的 MySQL 或 MariaDB 本身不支持架构(方案只是目录的别名),则需要使用catalog属性,而不是schema属性。
2.5.7. 实现 equals()和 hashCode()
Note
本节中的许多讨论都针对实体与 Hibernate Session 的关系,无论该实体是托管的,临时的还是分离的。如果您不熟悉这些主题,请在Persistence Context章中对它们进行说明。
对于 ORM,是否在您的域模型中实现equals()和hashCode()方法,更不用说如何实现它们了,是一个非常棘手的讨论。
确实只有一种绝对情况:充当标识符的类必须基于 id 值实现 equals/hashCode。通常,这与用作复合标识符的用户定义类有关。除了这个非常具体的用例之外,我们将在下面讨论其他几个用例,您可能要考虑完全不实施 equals/hashCode。
那有什么大惊小怪的?通常,大多数 Java 对象根据对象的身份提供内置的equals()和hashCode(),因此每个新对象都将与其他所有对象不同。这通常是普通 Java 编程中想要的。但是,从概念上讲,当您开始考虑某个类的多个实例代表同一数据的可能性时,这种情况就开始崩溃。
实际上,在处理来自数据库的数据时确实如此。每次我们从数据库中加载特定的Person时,我们自然都会获得一个唯一的实例。但是,Hibernate 会努力确保在给定的Session内不会发生这种情况。实际上,Hibernate 保证了特定会话范围内的持久身份(数据库行)和 Java 身份相等。因此,如果我们要求休眠Session多次加载该特定 Person,我们实际上将返回相同的* instance *:
例子 104.身份范围
Book book1 = entityManager.find( Book.class, 1L );
Book book2 = entityManager.find( Book.class, 1L );
assertTrue( book1 == book2 );
考虑我们有一个Library父实体,其中包含java.util.Set的Book实体:
例子 105.库实体 Map
@Entity(name = "Library")
public static class Library {
@Id
private Long id;
private String name;
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "book_id")
private Set<Book> books = new HashSet<>();
//Getters and setters are omitted for brevity
}
例子 106.使用会话范围的身份设置用法
Library library = entityManager.find( Library.class, 1L );
Book book1 = entityManager.find( Book.class, 1L );
Book book2 = entityManager.find( Book.class, 1L );
library.getBooks().add( book1 );
library.getBooks().add( book2 );
assertEquals( 1, library.getBooks().size() );
但是,当我们混合从不同 Session 加载的实例时,语义会发生变化:
例子 107.混合会话
Book book1 = doInJPA( this::entityManagerFactory, entityManager -> {
return entityManager.find( Book.class, 1L );
} );
Book book2 = doInJPA( this::entityManagerFactory, entityManager -> {
return entityManager.find( Book.class, 1L );
} );
assertFalse( book1 == book2 );
doInJPA( this::entityManagerFactory, entityManager -> {
Set<Book> books = new HashSet<>();
books.add( book1 );
books.add( book2 );
assertEquals( 2, books.size() );
} );
具体来说,最后一个示例中的结果将取决于实现的Book类是否等于 equals/hashCode,如果取决于,则取决于方式。
如果Book类没有覆盖默认的 equals/hashCode,则这两个Book对象引用将不相等,因为它们的引用不同。
考虑另一种情况:
例子 108.具有瞬态实体的集合
Library library = entityManager.find( Library.class, 1L );
Book book1 = new Book();
book1.setId( 100L );
book1.setTitle( "High-Performance Java Persistence" );
Book book2 = new Book();
book2.setId( 101L );
book2.setTitle( "Java Persistence with Hibernate" );
library.getBooks().add( book1 );
library.getBooks().add( book2 );
assertEquals( 2, library.getBooks().size() );
如果您要处理会话外部的实体(无论它们是临时实体还是分离实体),尤其是在 Java 集合中使用它们的情况下,则应考虑实现 equals/hashCode。
一种常见的初始方法是使用实体的标识符属性作为 equals/hashCode 计算的基础:
例子 109.天真的 equals/hashCode 实现
@Entity(name = "Library")
public static class Library {
@Id
private Long id;
private String name;
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "book_id")
private Set<Book> books = new HashSet<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Book book = (Book) o;
return Objects.equals( id, book.id );
}
@Override
public int hashCode() {
return Objects.hash( id );
}
}
事实证明,如上一个示例所示,当将Book的瞬时实例添加到集合中时,这仍然无法解决:
例子 110.自动生成的带有 Sets 和朴素的 equals/hashCode 的标识符
Book book1 = new Book();
book1.setTitle( "High-Performance Java Persistence" );
Book book2 = new Book();
book2.setTitle( "Java Persistence with Hibernate" );
Library library = doInJPA( this::entityManagerFactory, entityManager -> {
Library _library = entityManager.find( Library.class, 1L );
_library.getBooks().add( book1 );
_library.getBooks().add( book2 );
return _library;
} );
assertFalse( library.getBooks().contains( book1 ) );
assertFalse( library.getBooks().contains( book2 ) );
这里的问题是生成的标识符的使用,Set的约定和 equals/hashCode 实现之间的冲突。 Set表示,当对象是Set的一部分时,对象的 equals/hashCode 值不应更改。但这正是此处发生的情况,因为 equals/hasCode 基于(生成的)id,在提交 JPA 事务之前,该 id 才设置。
注意,使用生成的标识符时,这只是一个问题。如果您正在使用分配的标识符,这将是没有问题的,假设标识符值是在添加到Set之前分配的。
另一种选择是强制在添加到Set之前生成并设置标识符:
例子 111.在添加到集合之前强制刷新
Book book1 = new Book();
book1.setTitle( "High-Performance Java Persistence" );
Book book2 = new Book();
book2.setTitle( "Java Persistence with Hibernate" );
Library library = doInJPA( this::entityManagerFactory, entityManager -> {
Library _library = entityManager.find( Library.class, 1L );
entityManager.persist( book1 );
entityManager.persist( book2 );
entityManager.flush();
_library.getBooks().add( book1 );
_library.getBooks().add( book2 );
return _library;
} );
assertTrue( library.getBooks().contains( book1 ) );
assertTrue( library.getBooks().contains( book2 ) );
但这通常是不可行的。
最终的方法是使用“更好”的 equals/hashCode 实现,并使用自然 ID 或业务密钥。
例子 112.自然 Id 等于/ hashCode
@Entity(name = "Library")
public static class Library {
@Id
private Long id;
private String name;
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "book_id")
private Set<Book> books = new HashSet<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
@NaturalId
private String isbn;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Book book = (Book) o;
return Objects.equals( isbn, book.isbn );
}
@Override
public int hashCode() {
return Objects.hash( isbn );
}
}
这次,将Book添加到Library Set时,即使已将Book保留下来,也可以检索它:
例子 113.自然 Id equals/hashCode 保持例子
Book book1 = new Book();
book1.setTitle( "High-Performance Java Persistence" );
book1.setIsbn( "978-9730228236" );
Library library = doInJPA( this::entityManagerFactory, entityManager -> {
Library _library = entityManager.find( Library.class, 1L );
_library.getBooks().add( book1 );
return _library;
} );
assertTrue( library.getBooks().contains( book1 ) );
如您所见,equals/hashCode 问题并不简单,也没有一种“一刀切”的解决方案。
Tip
尽管最适合equals和hashCode的用户使用自然 ID,但有时您只有提供唯一约束的实体标识符。
可以使用实体标识符进行相等性检查,但是需要一种变通方法:
您需要为
hashCode提供一个恒定值,以便在刷新实体前后哈希码值不会改变。您只需要比较非瞬态实体的实体标识符相等性。
有关 Map 标识符的详细信息,请参见Identifiers章。
2.5.8. 将实体 Map 到 SQL 查询
您可以使用@Subselect注解将实体 Map 到 SQL 查询。
例子 114. @Subselect实体 Map
@Entity(name = "Client")
@Table(name = "client")
public static class Client {
@Id
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
//Getters and setters omitted for brevity
}
@Entity(name = "Account")
@Table(name = "account")
public static class Account {
@Id
private Long id;
@ManyToOne
private Client client;
private String description;
//Getters and setters omitted for brevity
}
@Entity(name = "AccountTransaction")
@Table(name = "account_transaction")
public static class AccountTransaction {
@Id
@GeneratedValue
private Long id;
@ManyToOne
private Account account;
private Integer cents;
private String description;
//Getters and setters omitted for brevity
}
@Entity(name = "AccountSummary")
@Subselect(
"select " +
" a.id as id, " +
" concat(concat(c.first_name, ' '), c.last_name) as clientName, " +
" sum(atr.cents) as balance " +
"from account a " +
"join client c on c.id = a.client_id " +
"join account_transaction atr on a.id = atr.account_id " +
"group by a.id, concat(concat(c.first_name, ' '), c.last_name)"
)
@Synchronize( {"client", "account", "account_transaction"} )
public static class AccountSummary {
@Id
private Long id;
private String clientName;
private int balance;
//Getters and setters omitted for brevity
}
在上面的示例中,Account实体不保留任何余额,因为每个帐户操作都被注册为AccountTransaction。要找到Account余额,我们需要查询与Account实体共享相同标识符的AccountSummary。
但是,AccountSummary并不 Map 到物理表,而是 Map 到 SQL 查询。
因此,如果我们有以下AccountTransaction记录,则AccountSummary余额将与此Account中的适当金额匹配。
例子 115.找到一个@Subselect实体
doInJPA( this::entityManagerFactory, entityManager -> {
Client client = new Client();
client.setId( 1L );
client.setFirstName( "John" );
client.setLastName( "Doe" );
entityManager.persist( client );
Account account = new Account();
account.setId( 1L );
account.setClient( client );
account.setDescription( "Checking account" );
entityManager.persist( account );
AccountTransaction transaction = new AccountTransaction();
transaction.setAccount( account );
transaction.setDescription( "Salary" );
transaction.setCents( 100 * 7000 );
entityManager.persist( transaction );
AccountSummary summary = entityManager.createQuery(
"select s " +
"from AccountSummary s " +
"where s.id = :id", AccountSummary.class)
.setParameter( "id", account.getId() )
.getSingleResult();
assertEquals( "John Doe", summary.getClientName() );
assertEquals( 100 * 7000, summary.getBalance() );
} );
如果我们添加新的AccountTransaction实体并刷新AccountSummary实体,则余额将相应更新:
例子 116.刷新一个@Subselect实体
doInJPA( this::entityManagerFactory, entityManager -> {
AccountSummary summary = entityManager.find( AccountSummary.class, 1L );
assertEquals( "John Doe", summary.getClientName() );
assertEquals( 100 * 7000, summary.getBalance() );
AccountTransaction transaction = new AccountTransaction();
transaction.setAccount( entityManager.getReference( Account.class, 1L ) );
transaction.setDescription( "Shopping" );
transaction.setCents( -100 * 2200 );
entityManager.persist( transaction );
entityManager.flush();
entityManager.refresh( summary );
assertEquals( 100 * 4800, summary.getBalance() );
} );
Tip
AccountSummary实体 Map 中的@SynchronizeComments 的目的是指示 Hibernate 基础@Subselect SQL 查询需要哪些数据库表。这是因为与 JPQL 和 HQL 查询不同,Hibernate 无法解析基础本机 SQL 查询。
有了@Synchronize注解,当执行从AccountSummary实体中选择的 HQL 或 JPQL 时,如果有未决的Account,Client或AccountTransaction实体状态转换,则 Hibernate 将触发持久性上下文刷新。
2.5.9. 定义自定义实体代理
默认情况下,当需要使用代理而不是实际的 POJO 时,Hibernate 将使用Javassist或Byte Buddy之类的字节码操作库。
但是,如果实体类是最终的,则 Javassist 将不会创建代理,即使您仅需要代理引用,也将获得 POJO。在这种情况下,您可以代理此特定实体实现的接口,如以下示例所示。
例子 117.实现Identifiable接口的最终实体类
public interface Identifiable {
Long getId();
void setId(Long id);
}
@Entity( name = "Book" )
@Proxy(proxyClass = Identifiable.class)
public static final class Book implements Identifiable {
@Id
private Long id;
private String title;
private String author;
@Override
public Long getId() {
return id;
}
@Override
public void setId(Long id) {
this.id = id;
}
//Other getters and setters omitted for brevity
}
@ProxyComments 用于为当前带 Comments 的实体指定自定义代理实现。
加载Book实体代理时,Hibernate 将代为Identifiable接口代理,如以下示例所示:
例子 118.代理实现Identifiable接口的最终实体类
doInHibernate( this::sessionFactory, session -> {
Book book = new Book();
book.setId( 1L );
book.setTitle( "High-Performance Java Persistence" );
book.setAuthor( "Vlad Mihalcea" );
session.persist( book );
} );
doInHibernate( this::sessionFactory, session -> {
Identifiable book = session.getReference( Book.class, 1L );
assertTrue(
"Loaded entity is not an instance of the proxy interface",
book instanceof Identifiable
);
assertFalse(
"Proxy class was not created",
book instanceof Book
);
} );
insert
into
Book
(author, title, id)
values
(?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Vlad Mihalcea]
-- binding parameter [2] as [VARCHAR] - [High-Performance Java Persistence]
-- binding parameter [3] as [BIGINT] - [1]
正如您在关联的 SQL 代码段中所看到的那样,Hibernate 不会发出任何 SQL SELECT 查询,因为可以构造代理而不需要获取实际的实体 POJO。
2.5.10. 使用@Tuplizer 注解的动态实体代理
可以使用@TuplizerComments 将您的实体 Map 为动态代理。
在以下实体 Map 中,可嵌入对象和实体都被 Map 为接口,而不是 POJO。
例子 119.动态实体代理 Map
@Entity
@Tuplizer(impl = DynamicEntityTuplizer.class)
public interface Cuisine {
@Id
@GeneratedValue
Long getId();
void setId(Long id);
String getName();
void setName(String name);
@Tuplizer(impl = DynamicEmbeddableTuplizer.class)
Country getCountry();
void setCountry(Country country);
}
@Embeddable
public interface Country {
@Column(name = "CountryName")
String getName();
void setName(String name);
}
@Tuplizer指示 Hibernate 使用DynamicEntityTuplizer和DynamicEmbeddableTuplizer处理关联的实体和可嵌入对象类型。
Cuisine实体和Country可嵌入类型都将被实例化为 Java 动态代理,如下面的DynamicInstantiator示例所示:
例子 120.实例化实体和可嵌入对象作为动态代理
public class DynamicEntityTuplizer extends PojoEntityTuplizer {
public DynamicEntityTuplizer(
EntityMetamodel entityMetamodel,
PersistentClass mappedEntity) {
super( entityMetamodel, mappedEntity );
}
@Override
protected Instantiator buildInstantiator(
EntityMetamodel entityMetamodel,
PersistentClass persistentClass) {
return new DynamicInstantiator(
persistentClass.getClassName()
);
}
@Override
protected ProxyFactory buildProxyFactory(
PersistentClass persistentClass,
Getter idGetter,
Setter idSetter) {
return super.buildProxyFactory(
persistentClass, idGetter,
idSetter
);
}
}
public class DynamicEmbeddableTuplizer
extends PojoComponentTuplizer {
public DynamicEmbeddableTuplizer(Component embeddable) {
super( embeddable );
}
protected Instantiator buildInstantiator(Component embeddable) {
return new DynamicInstantiator(
embeddable.getComponentClassName()
);
}
}
public class DynamicInstantiator
implements Instantiator {
private final Class targetClass;
public DynamicInstantiator(String targetClassName) {
try {
this.targetClass = Class.forName( targetClassName );
}
catch (ClassNotFoundException e) {
throw new HibernateException( e );
}
}
public Object instantiate(Serializable id) {
return ProxyHelper.newProxy( targetClass, id );
}
public Object instantiate() {
return instantiate( null );
}
public boolean isInstance(Object object) {
try {
return targetClass.isInstance( object );
}
catch( Throwable t ) {
throw new HibernateException(
"could not get handle to entity as interface : " + t
);
}
}
}
public class ProxyHelper {
public static <T> T newProxy(Class<T> targetClass, Serializable id) {
return ( T ) Proxy.newProxyInstance(
targetClass.getClassLoader(),
new Class[] {
targetClass
},
new DataProxyHandler(
targetClass.getName(),
id
)
);
}
public static String extractEntityName(Object object) {
if ( Proxy.isProxyClass( object.getClass() ) ) {
InvocationHandler handler = Proxy.getInvocationHandler(
object
);
if ( DataProxyHandler.class.isAssignableFrom( handler.getClass() ) ) {
DataProxyHandler myHandler = (DataProxyHandler) handler;
return myHandler.getEntityName();
}
}
return null;
}
}
public final class DataProxyHandler implements InvocationHandler {
private String entityName;
private Map<String, Object> data = new HashMap<>();
public DataProxyHandler(String entityName, Serializable id) {
this.entityName = entityName;
data.put( "Id", id );
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if ( methodName.startsWith( "set" ) ) {
String propertyName = methodName.substring( 3 );
data.put( propertyName, args[0] );
}
else if ( methodName.startsWith( "get" ) ) {
String propertyName = methodName.substring( 3 );
return data.get( propertyName );
}
else if ( "toString".equals( methodName ) ) {
return entityName + "#" + data.get( "Id" );
}
else if ( "hashCode".equals( methodName ) ) {
return this.hashCode();
}
return null;
}
public String getEntityName() {
return entityName;
}
}
使用DynamicInstantiator后,我们可以像使用 POJO 实体一样使用动态代理实体。
例子 121.持久化实体和可嵌入对象作为动态代理
Cuisine _cuisine = doInHibernateSessionBuilder(
() -> sessionFactory()
.withOptions()
.interceptor( new EntityNameInterceptor() ),
session -> {
Cuisine cuisine = ProxyHelper.newProxy( Cuisine.class, null );
cuisine.setName( "Française" );
Country country = ProxyHelper.newProxy( Country.class, null );
country.setName( "France" );
cuisine.setCountry( country );
session.persist( cuisine );
return cuisine;
} );
doInHibernateSessionBuilder(
() -> sessionFactory()
.withOptions()
.interceptor( new EntityNameInterceptor() ),
session -> {
Cuisine cuisine = session.get( Cuisine.class, _cuisine.getId() );
assertEquals( "Française", cuisine.getName() );
assertEquals( "France", cuisine.getCountry().getName() );
} );
2.5.11. 定义自定义实体持久性
@Persister注解用于指定自定义实体或集合持久性。
对于实体,自定义持久程序必须实现EntityPersister接口。
对于集合,自定义持久程序必须实现CollectionPersister接口。
例子 122.实体持久性 Map
@Entity
@Persister( impl = EntityPersister.class )
public class Author {
@Id
public Integer id;
@OneToMany( mappedBy = "author" )
@Persister( impl = CollectionPersister.class )
public Set<Book> books = new HashSet<>();
//Getters and setters omitted for brevity
public void addBook(Book book) {
this.books.add( book );
book.setAuthor( this );
}
}
@Entity
@Persister( impl = EntityPersister.class )
public class Book {
@Id
public Integer id;
private String title;
@ManyToOne(fetch = FetchType.LAZY)
public Author author;
//Getters and setters omitted for brevity
}
通过提供自己的EntityPersister和CollectionPersister实现,您可以控制实体和集合如何持久存储到数据库中。
2.5.12. 访问策略
作为 JPA 提供程序,Hibernate 可以同时检查实体属性(实例字段)或访问器(实例属性)。默认情况下,@IdComments 的位置提供默认的访问策略。当放在一个字段上时,Hibernate 将假定基于字段的访问。当放置在标识符 getter 上时,Hibernate 将使用基于属性的访问。
Tip
为避免出现诸如HCANN-63-以至少两个大写字符开头的属性名称在 HQL 中具有奇数功能之类的问题,在命名属性方面应注意Java Bean 规范。
可嵌入类型从其父实体继承访问策略。
Field-based access
例子 123.基于字段的访问
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
当使用基于字段的访问时,添加其他实体级别的方法更加灵活,因为 Hibernate 不会考虑持久性状态的那些部分。要将字段排除在实体持久状态的一部分之外,必须使用@Transient注解标记该字段。
Note
使用基于字段的访问的另一个优点是,某些实体属性可以从实体外部隐藏。
这种属性的一个例子是实体@Version字段,通常不需要数据访问层对其进行操作。
使用基于字段的访问,我们可以简单地忽略此版本字段的 getter 和 setter,并且 Hibernate 仍然可以利用开放式并发控制机制。
Property-based access
例子 124.基于属性的访问
@Entity(name = "Book")
public static class Book {
private Long id;
private String title;
private String author;
@Id
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
当使用基于属性的访问时,Hibernate 使用访问器来读取和写入实体状态。将会添加到该实体的所有其他方法(例如,用于同步双向一对多关联的两端的辅助方法)都必须使用@TransientComments 进行标记。
覆盖默认访问策略
可以使用 JPA @AccessComments 覆盖默认的访问策略机制。在下面的示例中,@Version属性是通过其字段而不是其 getter 来访问的,就像其余实体属性一样。
例子 125.覆盖访问策略
@Entity(name = "Book")
public static class Book {
private Long id;
private String title;
private String author;
@Access( AccessType.FIELD )
@Version
private int version;
@Id
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
可嵌入的类型和访问策略
由于可嵌入对象由它们自己的实体 Management,因此访问策略也从该实体继承。这既适用于简单的可嵌入类型,也适用于可嵌入对象的集合。
可嵌入类型可以推翻默认的隐式访问策略(从拥有的实体继承)。在以下示例中,无论拥有实体选择哪种访问策略,可嵌入对象都使用基于属性的访问:
例子 126.可嵌入的独占访问策略
@Embeddable
@Access( AccessType.PROPERTY )
public static class Author {
private String firstName;
private String lastName;
public Author() {
}
public Author(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
}
拥有实体可以使用基于字段的访问,而可嵌入实体可以使用基于属性的访问,因为它已明确选择:
例子 127.包括一个单一可嵌入类型的实体
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@Embedded
private Author author;
//Getters and setters are omitted for brevity
}
这也适用于可嵌入类型的收集:
例子 128.实体包括可嵌入类型的集合
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@ElementCollection
@CollectionTable(
name = "book_author",
joinColumns = @JoinColumn(name = "book_id")
)
private List<Author> authors = new ArrayList<>();
//Getters and setters are omitted for brevity
}
2.6. Identifiers
标识符为实体的主键建模。它们用于唯一地标识每个特定实体。
Hibernate 和 JPA 都对相应的数据库列进行以下假设:
UNIQUE- 这些值必须唯一地标识每一行。
NOT NULL- 该值不能为空。对于复合 ID,任何部分都不能为 null。
IMMUTABLE- 这些值一旦插入,就无法更改。这是更一般的指南,而不是因意见而异的硬性规定。 JPA 定义了将标识符属性的值更改为未定义的行为;休眠根本不支持。如果您选择的 PK 的值将被更新,Hibernate 建议将可变值 Map 为自然 ID,并为 PK 使用替代 ID。参见Natural Ids。
Note
从技术上讲,标识符不必 Map 到物理上定义为表主键的列。他们只需要 Map 到唯一标识每一行的列即可。但是,本文档将 continue 互换使用术语标识符和主键。
每个实体都必须定义一个标识符。对于实体继承层次结构,必须仅在作为层次结构根的实体上定义标识符。
标识符可以是简单的(单个值)或复合的(多个值)。
2.6.1. 简单标识符
简单标识符 Map 到单个基本属性,并使用javax.persistence.IdComments 表示。
根据 JPA,只能将以下类型用作标识符属性类型:
任何 Java 基本类型
任何原始包装器类型
java.lang.Stringjava.util.Date(TemporalType#DATE)java.sql.Datejava.math.BigDecimaljava.math.BigInteger
此列表之外的用于标识符属性的任何类型都将不可移植。
Assigned identifiers
如上面的示例所示,可以分配简单标识符的值。对分配的标识符值的期望是应用程序在调用保存/持久化之前分配(在实体属性上设置它们)。
例子 129.简单的分配实体标识符
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
Generated identifiers
可以生成简单标识符的值。为了表示已生成标识符属性,将使用javax.persistence.GeneratedValue对其进行 Comments。
例子 130.简单生成的标识符
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
此外,对于上面的类型限制列表,JPA 表示,如果使用生成的标识符值(请参见下文),则仅可移植地支持整数类型(short,int,long)。
对于生成的标识符值的期望是,当保存/持久化发生时,Hibernate 将生成该值。
标识符值生成策略将在生成的标识符值部分中详细讨论。
2.6.2. 复合标识符
复合标识符对应于一个或多个持久属性。这是 JPA 规范定义的 Management 组合标识符的规则:
复合标识符必须由“主键类”表示。主键类可以使用
javax.persistence.EmbeddedId注解定义(请参见具有@EmbeddedId 的复合标识符),也可以使用javax.persistence.IdClass注解定义(请参见具有@IdClass 的复合标识符)。主键类必须是公共的,并且必须具有公共的无参数构造函数。
主键类必须可序列化。
主键类必须定义 equals 和 hashCode 方法,该方法与主键 Map 到的基础数据库类型的相等性一致。
Note
组合标识符必须由“主键类”(例如@EmbeddedId或@IdClass)表示的限制仅针对 JPA。
Hibernate 确实允许通过多个@Id属性定义组合标识符,而无需使用“主键类”。
组成合成的属性可以是 basic,复合@ManyToOne。特别要注意的是,收集和一对一是绝对不合适的。
2.6.3. 具有@EmbeddedId 的复合标识符
使用 EmbeddedId 对复合标识符进行建模仅意味着将可嵌入对象定义为组成该标识符的一个或多个属性的组合,然后在实体上公开该可嵌入类型的属性。
例子 131.基本的@EmbeddedId
@Entity(name = "SystemUser")
public static class SystemUser {
@EmbeddedId
private PK pk;
private String name;
//Getters and setters are omitted for brevity
}
@Embeddable
public static class PK implements Serializable {
private String subsystem;
private String username;
public PK(String subsystem, String username) {
this.subsystem = subsystem;
this.username = username;
}
private PK() {
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
PK pk = (PK) o;
return Objects.equals( subsystem, pk.subsystem ) &&
Objects.equals( username, pk.username );
}
@Override
public int hashCode() {
return Objects.hash( subsystem, username );
}
}
如前所述,EmbeddedIds 甚至可以包含@ManyToOne属性:
例子 132. @EmbeddedId和@ManyToOne
@Entity(name = "SystemUser")
public static class SystemUser {
@EmbeddedId
private PK pk;
private String name;
//Getters and setters are omitted for brevity
}
@Entity(name = "Subsystem")
public static class Subsystem {
@Id
private String id;
private String description;
//Getters and setters are omitted for brevity
}
@Embeddable
public static class PK implements Serializable {
@ManyToOne(fetch = FetchType.LAZY)
private Subsystem subsystem;
private String username;
public PK(Subsystem subsystem, String username) {
this.subsystem = subsystem;
this.username = username;
}
private PK() {
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
PK pk = (PK) o;
return Objects.equals( subsystem, pk.subsystem ) &&
Objects.equals( username, pk.username );
}
@Override
public int hashCode() {
return Objects.hash( subsystem, username );
}
}
Note
Hibernate 支持直接在@EmbeddedId或@IdClass主键类中对@ManyToOne关联进行建模。
但是,JPA 规范并不可移植地支持该功能。用 JPA 术语,将使用“派生的标识符”。有关更多详细信息,请参见Derived Identifiers。
2.6.4. 具有@IdClass 的复合标识符
使用 IdClass 对复合标识符进行建模与使用 EmbeddedId 进行建模的区别在于,实体定义了组成合成的每个单独属性。 IdClass 只是充当“影子”。
例子 133.基本的@IdClass
@Entity(name = "SystemUser")
@IdClass( PK.class )
public static class SystemUser {
@Id
private String subsystem;
@Id
private String username;
private String name;
public PK getId() {
return new PK(
subsystem,
username
);
}
public void setId(PK id) {
this.subsystem = id.getSubsystem();
this.username = id.getUsername();
}
//Getters and setters are omitted for brevity
}
public static class PK implements Serializable {
private String subsystem;
private String username;
public PK(String subsystem, String username) {
this.subsystem = subsystem;
this.username = username;
}
private PK() {
}
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
PK pk = (PK) o;
return Objects.equals( subsystem, pk.subsystem ) &&
Objects.equals( username, pk.username );
}
@Override
public int hashCode() {
return Objects.hash( subsystem, username );
}
}
非聚合的复合标识符也可以包含 ManyToOne 属性,正如我们在聚合的标识符中看到的那样(仍然是非便携式的)。
例子 134.具有@ManyToOne的 IdClass
@Entity(name = "SystemUser")
@IdClass( PK.class )
public static class SystemUser {
@Id
@ManyToOne(fetch = FetchType.LAZY)
private Subsystem subsystem;
@Id
private String username;
private String name;
//Getters and setters are omitted for brevity
}
@Entity(name = "Subsystem")
public static class Subsystem {
@Id
private String id;
private String description;
//Getters and setters are omitted for brevity
}
public static class PK implements Serializable {
private Subsystem subsystem;
private String username;
public PK(Subsystem subsystem, String username) {
this.subsystem = subsystem;
this.username = username;
}
private PK() {
}
//Getters and setters are omitted for brevity
}
使用非聚合的复合标识符,Hibernate 还支持复合值的“部分”生成。
例子 135. @IdClass使用@GeneratedValue生成部分标识符
@Entity(name = "SystemUser")
@IdClass( PK.class )
public static class SystemUser {
@Id
private String subsystem;
@Id
private String username;
@Id
@GeneratedValue
private Integer registrationId;
private String name;
public PK getId() {
return new PK(
subsystem,
username,
registrationId
);
}
public void setId(PK id) {
this.subsystem = id.getSubsystem();
this.username = id.getUsername();
this.registrationId = id.getRegistrationId();
}
//Getters and setters are omitted for brevity
}
public static class PK implements Serializable {
private String subsystem;
private String username;
private Integer registrationId;
public PK(String subsystem, String username) {
this.subsystem = subsystem;
this.username = username;
}
public PK(String subsystem, String username, Integer registrationId) {
this.subsystem = subsystem;
this.username = username;
this.registrationId = registrationId;
}
private PK() {
}
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
PK pk = (PK) o;
return Objects.equals( subsystem, pk.subsystem ) &&
Objects.equals( username, pk.username ) &&
Objects.equals( registrationId, pk.registrationId );
}
@Override
public int hashCode() {
return Objects.hash( subsystem, username, registrationId );
}
}
Note
由于 SpecJ 委员会对 JPA 规范进行了高度质疑的解释,因此存在允许在组合标识符中自动生成值的功能。
Hibernate 并不认为 JPA 定义了对此的支持,而是添加了该功能只是为了在 SpecJ 基准测试中可用。从 JPA 角度来看,此功能的使用可能是可移植的,也可能不是。
2.6.5. 具有关联的复合标识符
Hibernate 允许从实体关联中定义复合标识符。在以下示例中,PersonAddress实体标识符由两个@ManyToOne关联组成。
例子 136.具有关联的复合标识符
@Entity(name = "Book")
public static class Book implements Serializable {
@Id
@ManyToOne(fetch = FetchType.LAZY)
private Author author;
@Id
@ManyToOne(fetch = FetchType.LAZY)
private Publisher publisher;
@Id
private String title;
public Book(Author author, Publisher publisher, String title) {
this.author = author;
this.publisher = publisher;
this.title = title;
}
private Book() {
}
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Book book = (Book) o;
return Objects.equals( author, book.author ) &&
Objects.equals( publisher, book.publisher ) &&
Objects.equals( title, book.title );
}
@Override
public int hashCode() {
return Objects.hash( author, publisher, title );
}
}
@Entity(name = "Author")
public static class Author implements Serializable {
@Id
private String name;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Author author = (Author) o;
return Objects.equals( name, author.name );
}
@Override
public int hashCode() {
return Objects.hash( name );
}
}
@Entity(name = "Publisher")
public static class Publisher implements Serializable {
@Id
private String name;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Publisher publisher = (Publisher) o;
return Objects.equals( name, publisher.name );
}
@Override
public int hashCode() {
return Objects.hash( name );
}
}
尽管 Map 比使用@EmbeddedId或@IdClass简单得多,但实体实例和实际标识符之间没有分隔。要查询该实体,必须将实体本身的实例提供给持久性上下文。
例子 137.用复合标识符获取
Book book = entityManager.find( Book.class, new Book(
author,
publisher,
"High-Performance Java Persistence"
) );
assertEquals( "Vlad Mihalcea", book.getAuthor().getName() );
2.6.6. 具有生成属性的复合标识符
使用组合标识符时,底层标识符属性必须由用户手动分配。
不支持将自动生成的属性用于生成构成复合标识符的基础属性的值。
因此,您不能使用生成的属性部分描述的任何自动属性生成器,例如@Generated,@CreationTimestamp或@ValueGenerationType或数据库生成的值。
但是,仍然可以在构造复合标识符之前生成标识符属性,如以下示例所示。
假设我们有以下EventId复合标识符和使用上述复合标识符的Event实体。
例子 138.事件实体和 EventId 复合标识符
@Entity
class Event {
@Id
private EventId id;
@Column(name = "event_key")
private String key;
@Column(name = "event_value")
private String value;
//Getters and setters are omitted for brevity
}
@Embeddable
class EventId implements Serializable {
private Integer category;
private Timestamp createdOn;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
EventId that = (EventId) o;
return Objects.equals( category, that.category ) &&
Objects.equals( createdOn, that.createdOn );
}
@Override
public int hashCode() {
return Objects.hash( category, createdOn );
}
}
内存中生成的组合标识符属性
如果要在内存中生成复合标识符属性,则需要执行以下操作:
例子 139.内存中生成的复合标识符属性的例子
EventId id = new EventId();
id.setCategory( 1 );
id.setCreatedOn( new Timestamp( System.currentTimeMillis() ) );
Event event = new Event();
event.setId( id );
event.setKey( "Temperature" );
event.setValue( "9" );
entityManager.persist( event );
请注意,EventId复合标识符的createdOn属性是由数据访问代码生成的,并在持久保存Event实体之前分配给该标识符。
数据库生成的复合标识符属性
如果要使用数据库函数或存储过程生成复合标识符属性,则可以按照以下示例所示进行操作。
例子 140.数据库生成的复合标识符属性例子
Timestamp currentTimestamp = (Timestamp) entityManager
.createNativeQuery(
"SELECT CURRENT_TIMESTAMP" )
.getSingleResult();
EventId id = new EventId();
id.setCategory( 1 );
id.setCreatedOn( currentTimestamp );
Event event = new Event();
event.setId( id );
event.setKey( "Temperature" );
event.setValue( "9" );
entityManager.persist( event );
请注意,EventId复合标识符的createdOn属性是通过调用CURRENT_TIMESTAMP数据库函数生成的,在持久化Event实体之前,我们将其分配给了复合标识符。
2.6.7. 生成的标识符值
Note
您还可以自动生成非标识符属性的值。有关更多详细信息,请参见Generated properties部分。
Hibernate 支持跨多种不同类型的标识符值生成。请记住,JPA 仅针对整数类型可移植地定义标识符值的生成。
标识符值的生成使用javax.persistence.GeneratedValueComments 指示。这里最重要的信息是指定的javax.persistence.GenerationType,它指示如何生成值。
Note
下面的讨论假定应用程序在引导过程中使用hibernate.id.new_generator_mappings设置或MetadataBuilder.enableNewIdentifierGeneratorSupport方法指示的 Hibernate 的“新生成器 Map”。
从 Hibernate 5 开始,默认情况下将其设置为true。在将hibernate.id.new_generator_mappings配置设置为false的应用中,此处讨论的分辨率将有很大不同。此处的其余讨论假定启用了此设置(true)。
Tip
在 Hibernate 5.3 中,如果刷新模式不等于AUTO,则 Hibernate 尝试延迟实体的插入。对于使用IDENTITY或SEQUENCE生成的标识符的实体来说,这有点问题,这些标识符也以某种形式与同一笔 Transaction 中的另一个实体相关联。
在 Hibernate 5.4 中,Hibernate 尝试使用算法来决定插入是否应该延迟或是否需要立即插入的算法来解决该问题。我们只想在合理的非常特殊的用例中恢复 5.3 之前的行为。
实体 Map 有时可能很复杂,并且可能忽略了一个极端情况。如果DelayedPostInsertIdentifier出现问题,Hibernate 提供了一种完全禁用 5.3 行为的方法。要启用旧版行为,请设置hibernate.id.disable_delayed_identity_inserts=true。
此配置选项旨在充当临时修复程序,并弥合 Hibernate 5.x 发行版中此行为的更改之间的差距。如果 Map 需要此配置设置,请打开 JIRA 并报告 Map,以便可以检查算法。
AUTO(默认值)- 指示持久性提供程序(休眠)应选择适当的生成策略。参见Interpreting AUTO。
IDENTITY- 指示数据库 IDENTITY 列将用于生成主键值。参见使用 IDENTITY 列。
SEQUENCE- 指示应使用数据库序列来获取主键值。参见Using sequences。
TABLE- 指示应使用数据库表获取主键值。参见使用表标识符生成器。
2.6.8. 解释自动
持久性提供程序如何解释 AUTO 生成类型取决于该提供程序。
默认行为是查看标识符属性的 Java 类型。
如果标识符类型为 UUID,则 Hibernate 将使用UUID identifier。
如果标识符类型为数字(例如Long,Integer),则 Hibernate 将使用IdGeneratorStrategyInterpreter来解析标识符生成器策略。 IdGeneratorStrategyInterpreter有两个实现:
FallbackInterpreter- 这是 Hibernate 5.0 以来的默认策略。对于较旧的版本,可通过hibernate.id.new_generator_mappings配置属性启用此策略。使用此策略时,
AUTO始终解析为SequenceStyleGenerator。如果基础数据库支持序列,则使用 SEQUENCE 生成器。否则,将改为使用 TABLE 生成器。
- 这是 Hibernate 5.0 以来的默认策略。对于较旧的版本,可通过hibernate.id.new_generator_mappings配置属性启用此策略。使用此策略时,
LegacyFallbackInterpreter- 这是 Hibernate 5.0 之前的版本或hibernate.id.new_generator_mappings配置属性为 false 时使用的旧机制。传统策略将
AUTOMap 到native生成器策略,该策略使用Dialect#getNativeIdentifierGeneratorStrategy解析实际的标识符生成器(例如identity或sequence)。
- 这是 Hibernate 5.0 之前的版本或hibernate.id.new_generator_mappings配置属性为 false 时使用的旧机制。传统策略将
2.6.9. 使用序列
为了实现基于数据库序列的标识符值生成,Hibernate 利用了它的org.hibernate.id.enhanced.SequenceStyleGenerator id 生成器。重要的是要注意,SequenceStyleGenerator 能够通过切换到表作为基础支持来处理不支持序列的数据库。这使 Hibernate 在数据库之间具有很大程度的可移植性,同时仍保持一致的 id 生成行为(相对于说在 SEQUENCE 和 IDENTITY 之间进行选择)。此后备存储对用户完全透明。
配置此生成器的首选(便携式)方法是使用 JPA 定义的javax.persistence.SequenceGeneratorComments。
最简单的形式是简单地请求序列生成。对于所有此类未命名的定义,Hibernate 将使用单个隐式命名的序列(hibernate_sequence)。
例子 141.未命名的序列
@Entity(name = "Product")
public static class Product {
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE
)
private Long id;
@Column(name = "product_name")
private String name;
//Getters and setters are omitted for brevity
}
使用javax.persistence.SequenceGenerator,可以指定特定的数据库序列名称。
例子 142.命名序列
@Entity(name = "Product")
public static class Product {
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "sequence-generator"
)
@SequenceGenerator(
name = "sequence-generator",
sequenceName = "product_sequence"
)
private Long id;
@Column(name = "product_name")
private String name;
//Getters and setters are omitted for brevity
}
javax.persistence.SequenceGeneratorComments 还允许您指定其他配置。
例子 143.配置的序列
@Entity(name = "Product")
public static class Product {
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "sequence-generator"
)
@SequenceGenerator(
name = "sequence-generator",
sequenceName = "product_sequence",
allocationSize = 5
)
private Long id;
@Column(name = "product_name")
private String name;
//Getters and setters are omitted for brevity
}
2.6.10. 使用 IDENTITY 列
为了实现基于 IDENTITY 列的标识符值生成,Hibernate 利用其org.hibernate.id.IdentityGenerator id 生成器,该生成器期望通过 INSERT 将标识符生成到表中。 IdentityGenerator 了解可以检索 INSERT 生成的值的 3 种不同方式:
如果 Hibernate 认为 JDBC 环境支持
java.sql.Statement#getGeneratedKeys,那么该方法将用于提取 IDENTITY 生成的键。否则,如果
Dialect#supportsInsertSelectIdentity报告为 true,则 Hibernate 将使用方言特定的 INSERT SELECT 语句语法。否则,Hibernate 将期望数据库支持某种形式的查询,这些请求通过
Dialect#getIdentitySelectString指示的单独 SQL 命令来请求最近插入的 IDENTITY 值。
Tip
重要的是要认识到,使用 IDENTITY 列会强加一种运行时行为,其中必须在知道标识符值之前物理上**插入实体行。
这会弄乱扩展的持久性上下文(长时间的对话)。由于运行时强加/不一致,Hibernate 建议使用其他形式的标识符值生成(例如 SEQUENCE)。
Note
选择 IDENTITY 生成还有另一个重要的运行时影响:Hibernate 将无法使用 IDENTITY 生成为实体批处理 INSERT 语句。
这的重要性取决于特定于应用程序的用例。如果应用程序通常不使用 IDENTITY 生成器创建给定实体类型的许多新实例,则此限制将变得不那么重要,因为无论如何批处理都不会很有帮助。
2.6.11. 使用表标识符生成器
Hibernate 基于其org.hibernate.id.enhanced.TableGenerator实现了基于表的标识符生成,该org.hibernate.id.enhanced.TableGenerator定义了一个表,该表能够为任意数量的实体保存多个命名值段。
基本思想是给定的表生成器表(例如hibernate_sequences)可以保存标识符生成值的多个段。
例子 144.未命名表生成器
@Entity(name = "Product")
public static class Product {
@Id
@GeneratedValue(
strategy = GenerationType.TABLE
)
private Long id;
@Column(name = "product_name")
private String name;
//Getters and setters are omitted for brevity
}
create table hibernate_sequences (
sequence_name varchar2(255 char) not null,
next_val number(19,0),
primary key (sequence_name)
)
如果未给出表名,则 Hibernate 假定隐式名称为hibernate_sequences。
另外,由于未指定javax.persistence.TableGenerator#pkColumnValue,因此 Hibernate 将使用 hibernate_sequences 表中的默认段(sequence_name='default')。
但是,您可以使用@TableGeneratorComments 配置表标识符生成器。
例子 145.配置的表生成器
@Entity(name = "Product")
public static class Product {
@Id
@GeneratedValue(
strategy = GenerationType.TABLE,
generator = "table-generator"
)
@TableGenerator(
name = "table-generator",
table = "table_identifier",
pkColumnName = "table_name",
valueColumnName = "product_id",
allocationSize = 5
)
private Long id;
@Column(name = "product_name")
private String name;
//Getters and setters are omitted for brevity
}
create table table_identifier (
table_name varchar2(255 char) not null,
product_id number(19,0),
primary key (table_name)
)
现在,当插入 3 个Product实体时,Hibernate 生成以下语句:
例子 146.配置的表生成器持久化例子
for ( long i = 1; i <= 3; i++ ) {
Product product = new Product();
product.setName( String.format( "Product %d", i ) );
entityManager.persist( product );
}
select
tbl.product_id
from
table_identifier tbl
where
tbl.table_name = ?
for update
-- binding parameter [1] - [Product]
insert
into
table_identifier
(table_name, product_id)
values
(?, ?)
-- binding parameter [1] - [Product]
-- binding parameter [2] - [1]
update
table_identifier
set
product_id= ?
where
product_id= ?
and table_name= ?
-- binding parameter [1] - [6]
-- binding parameter [2] - [1]
select
tbl.product_id
from
table_identifier tbl
where
tbl.table_name= ? for update
update
table_identifier
set
product_id= ?
where
product_id= ?
and table_name= ?
-- binding parameter [1] - [11]
-- binding parameter [2] - [6]
insert
into
Product
(product_name, id)
values
(?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 1]
-- binding parameter [2] as [BIGINT] - [1]
insert
into
Product
(product_name, id)
values
(?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 2]
-- binding parameter [2] as [BIGINT] - [2]
insert
into
Product
(product_name, id)
values
(?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 3]
-- binding parameter [2] as [BIGINT] - [3]
2.6.12. 使用 UUID 生成
如上所述,Hibernate 支持 UUID 标识符值生成。它的org.hibernate.id.UUIDGenerator id 生成器对此提供支持。
UUIDGenerator支持可插拔策略,以准确生成 UUID。这些策略由org.hibernate.id.UUIDGenerationStrategyContract 定义。默认策略是根据 IETF RFC 4122 的版本 4(随机)策略。Hibernate 确实随附了另一种策略,即 RFC 4122 版本 1(基于时间)策略(使用 IP 地址而不是 mac 地址)。
例子 147.隐式地使用随机 UUID 策略
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue
private UUID id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
要指定替代的生成策略,我们必须通过@GenericGenerator定义一些配置。在这里,我们选择名为org.hibernate.id.uuid.CustomVersionOneStrategy的符合 RFC 4122 版本 1 的策略。
例子 148.隐式地使用随机 UUID 策略
@Entity(name = "Book")
public static class Book {
@Id
@GeneratedValue( generator = "custom-uuid" )
@GenericGenerator(
name = "custom-uuid",
strategy = "org.hibernate.id.UUIDGenerator",
parameters = {
@Parameter(
name = "uuid_gen_strategy_class",
value = "org.hibernate.id.uuid.CustomVersionOneStrategy"
)
}
)
private UUID id;
private String title;
private String author;
//Getters and setters are omitted for brevity
}
2.6.13. Optimizers
大多数从数据库结构中分别获取标识符值的 Hibernate 生成器都支持可插入优化器的使用。优化器可帮助 ManagementHibernate 与数据库对话以生成标识符值的次数。例如,在没有将优化器应用于序列生成器的情况下,每次应用程序要求 Hibernate 生成标识符时,它都需要从数据库中获取下一个序列值。但是,如果我们可以最大程度地减少与数据库通信的次数,则应用程序将能够更好地运行,这实际上就是这些优化器的作用。
none
- 没有执行优化。每当生成器需要标识符值时,我们都会与数据库进行通信。
pooled-lo
- pool-lo 优化器的工作原理是将增量值编码到数据库表/序列结构中。在序列项中,这意味着序列以大于 1 的增量大小定义。
例如,考虑定义为create sequence m_sequence start with 1 increment by 20的全新序列。每次我们要求它的下一个值时,此序列实质上定义了一个由 20 个可用 id 值组成的“池”。 pool-lo 优化器将下一个值解释为该池的低端。
因此,当我们第一次要求它的下一个值时,我们将得到 1.然后,我们假定有效池将是 1 到 20 之间的值。
对该序列的下一个调用将得到 21,它将 21-40 定义为有效范围。等等。名称的“ lo”部分表示来自数据库表/序列的值被解释为池 lo(w)的末尾。
pooled
- 就像 pooled-lo 一样,除了这里的表/序列中的值被解释为值池的高端。
hilo; legacy-hilo
- 定义一个自定义算法,用于基于表或序列中的单个值生成值池。
不建议使用这些优化器。它们在这里维护(并提到)仅供以前使用这些策略的旧应用程序使用。
Note
应用程序还可以根据org.hibernate.id.enhanced.OptimizerContract 定义并实施自己的优化器策略。
2.6.14. 使用@GenericGenerator
@GenericGenerator允许集成任何 Hibernate org.hibernate.id.IdentifierGenerator实现,包括此处讨论的任何特定实现和任何自定义实现。
要使用池式或池式优化器,实体 Map 必须使用@GenericGenerator注解:
例子 149.使用@GenericGeneratorMap 的 Pool-lo 优化器 Map
@Entity(name = "Product")
public static class Product {
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "product_generator"
)
@GenericGenerator(
name = "product_generator",
strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",
parameters = {
@Parameter(name = "sequence_name", value = "product_sequence"),
@Parameter(name = "initial_value", value = "1"),
@Parameter(name = "increment_size", value = "3"),
@Parameter(name = "optimizer", value = "pooled-lo")
}
)
private Long id;
@Column(name = "p_name")
private String name;
@Column(name = "p_number")
private String number;
//Getters and setters are omitted for brevity
}
现在,当保存 5 个Person实体并在每 3 个实体后刷新持久化上下文时:
例子 150.使用@GenericGeneratorMap 的 pool-lo 优化器 Map
for ( long i = 1; i <= 5; i++ ) {
if(i % 3 == 0) {
entityManager.flush();
}
Product product = new Product();
product.setName( String.format( "Product %d", i ) );
product.setNumber( String.format( "P_100_%d", i ) );
entityManager.persist( product );
}
CALL NEXT VALUE FOR product_sequence
INSERT INTO Product (p_name, p_number, id)
VALUES (?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 1]
-- binding parameter [2] as [VARCHAR] - [P_100_1]
-- binding parameter [3] as [BIGINT] - [1]
INSERT INTO Product (p_name, p_number, id)
VALUES (?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 2]
-- binding parameter [2] as [VARCHAR] - [P_100_2]
-- binding parameter [3] as [BIGINT] - [2]
CALL NEXT VALUE FOR product_sequence
INSERT INTO Product (p_name, p_number, id)
VALUES (?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 3]
-- binding parameter [2] as [VARCHAR] - [P_100_3]
-- binding parameter [3] as [BIGINT] - [3]
INSERT INTO Product (p_name, p_number, id)
VALUES (?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 4]
-- binding parameter [2] as [VARCHAR] - [P_100_4]
-- binding parameter [3] as [BIGINT] - [4]
INSERT INTO Product (p_name, p_number, id)
VALUES (?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Product 5]
-- binding parameter [2] as [VARCHAR] - [P_100_5]
-- binding parameter [3] as [BIGINT] - [5]
从生成的 SQL 语句列表中可以看到,只需一个数据库序列调用就可以插入 3 个实体。这样,池优化器和池优化器可以减少数据库往返的次数,从而减少总体事务响应时间。
2.6.15. 派生标识符
JPA 2.0 增加了对派生标识符的支持,允许实体从多对一或一对一关联中借用该标识符。
例子 151.派生的标识符为@MapsId
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@NaturalId
private String registrationNumber;
public Person() {}
public Person(String registrationNumber) {
this.registrationNumber = registrationNumber;
}
//Getters and setters are omitted for brevity
}
@Entity(name = "PersonDetails")
public static class PersonDetails {
@Id
private Long id;
private String nickName;
@OneToOne
@MapsId
private Person person;
//Getters and setters are omitted for brevity
}
在上面的示例中,PersonDetails实体将id列用于实体标识符和与Person实体的一对一关联。 PersonDetails实体标识符的值是从其父Person实体的标识符“派生”的。
例子 152.带有@MapsId持久性例子的派生标识符
doInJPA( this::entityManagerFactory, entityManager -> {
Person person = new Person( "ABC-123" );
person.setId( 1L );
entityManager.persist( person );
PersonDetails personDetails = new PersonDetails();
personDetails.setNickName( "John Doe" );
personDetails.setPerson( person );
entityManager.persist( personDetails );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
PersonDetails personDetails = entityManager.find( PersonDetails.class, 1L );
assertEquals("John Doe", personDetails.getNickName());
} );
@MapsIdComments 也可以引用@EmbeddedId标识符中的列。
上一个示例也可以使用@PrimaryKeyJoinColumn进行 Map。
例子 153.派生标识符@PrimaryKeyJoinColumn
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@NaturalId
private String registrationNumber;
public Person() {}
public Person(String registrationNumber) {
this.registrationNumber = registrationNumber;
}
//Getters and setters are omitted for brevity
}
@Entity(name = "PersonDetails")
public static class PersonDetails {
@Id
private Long id;
private String nickName;
@OneToOne
@PrimaryKeyJoinColumn
private Person person;
public void setPerson(Person person) {
this.person = person;
this.id = person.getId();
}
//Other getters and setters are omitted for brevity
}
Note
与@MapsId不同,应用程序开发人员负责确保实体标识符和多对一(或一对一)关联是同步的,正如您在PersonDetails#setPerson方法中看到的那样。
2.6.16. @RowId
如果您使用@RowIdComments 对给定的实体进行 Comments,并且基础数据库支持通过 ROWID(例如 Oracle)提取记录,则 Hibernate 可以将ROWID伪列用于 CRUD 操作。
例子 154. @RowId实体 Map
@Entity(name = "Product")
@RowId("ROWID")
public static class Product {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
现在,当获取一个实体并对其进行修改时,Hibernate 将ROWID伪列用于 UPDATE SQL 语句。
例子 155. @RowId例子
Product product = entityManager.find( Product.class, 1L );
product.setName( "Smart phone" );
SELECT
p.id as id1_0_0_,
p."name" as name2_0_0_,
p."number" as number3_0_0_,
p.ROWID as rowid_0_
FROM
Product p
WHERE
p.id = ?
-- binding parameter [1] as [BIGINT] - [1]
-- extracted value ([name2_0_0_] : [VARCHAR]) - [Mobile phone]
-- extracted value ([number3_0_0_] : [VARCHAR]) - [123-456-7890]
-- extracted ROWID value: AAAwkBAAEAAACP3AAA
UPDATE
Product
SET
"name" = ?,
"number" = ?
WHERE
ROWID = ?
-- binding parameter [1] as [VARCHAR] - [Smart phone]
-- binding parameter [2] as [VARCHAR] - [123-456-7890]
-- binding parameter [3] as ROWID - [AAAwkBAAEAAACP3AAA]
2.7. Associations
关联描述基于数据库连接语义的两个或多个实体如何形成关系。
2.7.1. @ManyToOne
@ManyToOne是最常见的关联,在关系数据库中也具有直接等效项(例如外键),因此它在子实体和父实体之间构建关系。
例子 156. @ManyToOne关联
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@ManyToOne
@JoinColumn(name = "person_id",
foreignKey = @ForeignKey(name = "PERSON_ID_FK")
)
private Person person;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
person_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT PERSON_ID_FK
FOREIGN KEY (person_id) REFERENCES Person
每个实体都有其自己的生命周期。设置@ManyToOne关联后,Hibernate 将设置关联的数据库外键列。
例子 157. @ManyToOne关联生命周期
Person person = new Person();
entityManager.persist( person );
Phone phone = new Phone( "123-456-7890" );
phone.setPerson( person );
entityManager.persist( phone );
entityManager.flush();
phone.setPerson( null );
INSERT INTO Person ( id )
VALUES ( 1 )
INSERT INTO Phone ( number, person_id, id )
VALUES ( '123-456-7890', 1, 2 )
UPDATE Phone
SET number = '123-456-7890',
person_id = NULL
WHERE id = 2
2.7.2. @OneToMany
@OneToMany关联将一个父实体与一个或多个子实体链接。如果@OneToMany在子端没有镜像@ManyToOne关联,则@OneToMany关联是单向的。如果子级上有@ManyToOne关联,则@OneToMany关联是双向的,应用程序开发人员可以从两端导航此关系。
Unidirectional @OneToMany
当使用单向@OneToMany关联时,Hibernate 会使用两个连接实体之间的链接表。
例子 158.单向@OneToMany关联
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Phone (
Person_id BIGINT NOT NULL ,
phones_id BIGINT NOT NULL
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
PRIMARY KEY ( id )
)
ALTER TABLE Person_Phone
ADD CONSTRAINT UK_9uhc5itwc9h5gcng944pcaslf
UNIQUE (phones_id)
ALTER TABLE Person_Phone
ADD CONSTRAINT FKr38us2n8g5p9rj0b494sd3391
FOREIGN KEY (phones_id) REFERENCES Phone
ALTER TABLE Person_Phone
ADD CONSTRAINT FK2ex4e4p7w1cj310kg2woisjl2
FOREIGN KEY (Person_id) REFERENCES Person
Note
顾名思义,@OneToMany关联是父关联,无论它是单向还是双向。只有关联的父方才有意义将其实体状态转换级联到子级。
例子 159.级联@OneToMany关联
Person person = new Person();
Phone phone1 = new Phone( "123-456-7890" );
Phone phone2 = new Phone( "321-654-0987" );
person.getPhones().add( phone1 );
person.getPhones().add( phone2 );
entityManager.persist( person );
entityManager.flush();
person.getPhones().remove( phone1 );
INSERT INTO Person
( id )
VALUES ( 1 )
INSERT INTO Phone
( number, id )
VALUES ( '123-456-7890', 2 )
INSERT INTO Phone
( number, id )
VALUES ( '321-654-0987', 3 )
INSERT INTO Person_Phone
( Person_id, phones_id )
VALUES ( 1, 2 )
INSERT INTO Person_Phone
( Person_id, phones_id )
VALUES ( 1, 3 )
DELETE FROM Person_Phone
WHERE Person_id = 1
INSERT INTO Person_Phone
( Person_id, phones_id )
VALUES ( 1, 3 )
DELETE FROM Phone
WHERE id = 2
当持久化Person实体时,级联还将持久化操作传播到基础的Phone子级。从 phone 集合中删除Phone后,关联行将从链接表中删除,并且orphanRemoval属性也将触发Phone删除。
Note
在删除子实体时,单向关联不是非常有效。在上面的示例中,刷新持久性上下文后,Hibernate 从链接表(例如Person_Phone)中删除与父Person实体关联的所有数据库行,然后重新插入仍在@OneToMany集合中找到的行。
另一方面,双向@OneToMany关联效率更高,因为子实体控制该关联。
Bidirectional @OneToMany
双向@OneToMany关联在子端也需要@ManyToOne关联。尽管域模型公开了两个方面来导航此关联,但在后台,关系数据库只有一个用于此关系的外键。
每个双向关联都必须仅具有一个拥有侧(子侧),另一侧称为反向(或mappedBy)侧。
例子 160. @OneToMany关联被 Map 到@ManyToOne端
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
public void addPhone(Phone phone) {
phones.add( phone );
phone.setPerson( this );
}
public void removePhone(Phone phone) {
phones.remove( phone );
phone.setPerson( null );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@NaturalId
@Column(name = "`number`", unique = true)
private String number;
@ManyToOne
private Person person;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
person_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT UK_l329ab0g4c1t78onljnxmbnp6
UNIQUE (number)
ALTER TABLE Phone
ADD CONSTRAINT FKmw13yfsjypiiq0i1osdkaeqpg
FOREIGN KEY (person_id) REFERENCES Person
Tip
每当形成双向关联时,应用程序开发人员都必须确保双方始终保持同步。
addPhone()和removePhone()是 Util 方法,可在添加或删除子元素时同步两端。
因为Phone类具有@NaturalId列(电话 Numbers 是唯一的),所以equals()和hashCode()可以利用此属性,因此removePhone()逻辑简化为remove() Java Collection方法。
例子 161.具有所有者@ManyToOne生命周期的双向@OneToMany
Person person = new Person();
Phone phone1 = new Phone( "123-456-7890" );
Phone phone2 = new Phone( "321-654-0987" );
person.addPhone( phone1 );
person.addPhone( phone2 );
entityManager.persist( person );
entityManager.flush();
person.removePhone( phone1 );
INSERT INTO Person
( id )
VALUES ( 1 )
INSERT INTO Phone
( "number", person_id, id )
VALUES ( '123-456-7890', 1, 2 )
INSERT INTO Phone
( "number", person_id, id )
VALUES ( '321-654-0987', 1, 3 )
DELETE FROM Phone
WHERE id = 2
与单向@OneToMany不同,双向关联在 Management 收集持久性状态时效率更高。每次删除元素都只需要进行一次更新(外键列设置为NULL),并且,如果子实体生命周期绑定到其拥有的父代,这样子代在没有父代的情况下就无法存在,那么我们可以 Comments 关联具有orphanRemoval属性并取消关联子级也会在实际的子表行上触发一条 delete 语句。
2.7.3. @OneToOne
@OneToOne关联可以是单向或双向的。单向关联遵循关系数据库外键语义,Client 端拥有该关系。双向关联也具有mappedBy @OneToOne父侧。
Unidirectional @OneToOne
例子 162.单向的@OneToOne
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@OneToOne
@JoinColumn(name = "details_id")
private PhoneDetails details;
//Getters and setters are omitted for brevity
}
@Entity(name = "PhoneDetails")
public static class PhoneDetails {
@Id
@GeneratedValue
private Long id;
private String provider;
private String technology;
//Getters and setters are omitted for brevity
}
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
details_id BIGINT ,
PRIMARY KEY ( id )
)
CREATE TABLE PhoneDetails (
id BIGINT NOT NULL ,
provider VARCHAR(255) ,
technology VARCHAR(255) ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT FKnoj7cj83ppfqbnvqqa5kolub7
FOREIGN KEY (details_id) REFERENCES PhoneDetails
从关系数据库的角度来看,底层架构与单向@ManyToOne关联相同,因为 Client 端基于外键列控制关系。
但是,然后将Phone视为 Client 端,将PhoneDetails视为父端是不寻常的,因为没有实际的电话,详细信息就无法存在。更为自然的 Map 是Phone是父方,因此将外键推入PhoneDetails表。如下面的示例所示,此 Map 需要双向@OneToOne关联:
Bidirectional @OneToOne
例子 163.双向@OneToOne
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@OneToOne(
mappedBy = "phone",
cascade = CascadeType.ALL,
orphanRemoval = true,
fetch = FetchType.LAZY
)
private PhoneDetails details;
//Getters and setters are omitted for brevity
public void addDetails(PhoneDetails details) {
details.setPhone( this );
this.details = details;
}
public void removeDetails() {
if ( details != null ) {
details.setPhone( null );
this.details = null;
}
}
}
@Entity(name = "PhoneDetails")
public static class PhoneDetails {
@Id
@GeneratedValue
private Long id;
private String provider;
private String technology;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "phone_id")
private Phone phone;
//Getters and setters are omitted for brevity
}
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE PhoneDetails (
id BIGINT NOT NULL ,
provider VARCHAR(255) ,
technology VARCHAR(255) ,
phone_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE PhoneDetails
ADD CONSTRAINT FKeotuev8ja8v0sdh29dynqj05p
FOREIGN KEY (phone_id) REFERENCES Phone
这次,PhoneDetails拥有该关联,并且像任何双向关联一样,父端可以通过级联将其生命周期传播到子端。
例子 164.双向@OneToOne生命周期
Phone phone = new Phone( "123-456-7890" );
PhoneDetails details = new PhoneDetails( "T-Mobile", "GSM" );
phone.addDetails( details );
entityManager.persist( phone );
INSERT INTO Phone ( number, id )
VALUES ( '123-456-7890', 1 )
INSERT INTO PhoneDetails ( phone_id, provider, technology, id )
VALUES ( 1, 'T-Mobile', 'GSM', 2 )
当使用双向@OneToOne关联时,Hibernate 在获取子端时会强制执行唯一约束。如果同一个 parent 有多个子女,则 Hibernate 将抛出org.hibernate.exception.ConstraintViolationException。continue 前面的示例,当添加另一个PhoneDetails时,Hibernate 在重新加载Phone对象时验证唯一性约束。
例子 165.双向@OneToOne唯一约束
PhoneDetails otherDetails = new PhoneDetails( "T-Mobile", "CDMA" );
otherDetails.setPhone( phone );
entityManager.persist( otherDetails );
entityManager.flush();
entityManager.clear();
//throws javax.persistence.PersistenceException: org.hibernate.HibernateException: More than one row with the given identifier was found: 1
phone = entityManager.find( Phone.class, phone.getId() );
双向@OneToOne 惰性关联
尽管您可能会 Comments 要延迟获取的父端关联,但是 Hibernate 无法接受此请求,因为它无法知道关联是否为null。
找出子方是否有关联记录的唯一方法是使用辅助查询来获取子关联。因为这可能会导致 N 1 个查询问题,所以使用具有@MapsId注解的单向@OneToOne关联会更加有效。
但是,如果您确实需要使用双向关联,并且要确保始终懒惰地获取它,那么您需要启用惰性状态初始化字节码增强功能,并同时使用@LazyToOneComments。
例子 166.双向@OneToOne懒惰的 parent 一方关联
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@OneToOne(
mappedBy = "phone",
cascade = CascadeType.ALL,
orphanRemoval = true,
fetch = FetchType.LAZY
)
@LazyToOne( LazyToOneOption.NO_PROXY )
private PhoneDetails details;
//Getters and setters are omitted for brevity
public void addDetails(PhoneDetails details) {
details.setPhone( this );
this.details = details;
}
public void removeDetails() {
if ( details != null ) {
details.setPhone( null );
this.details = null;
}
}
}
@Entity(name = "PhoneDetails")
public static class PhoneDetails {
@Id
@GeneratedValue
private Long id;
private String provider;
private String technology;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "phone_id")
private Phone phone;
//Getters and setters are omitted for brevity
}
有关如何启用字节码增强的更多信息,请参见字节码增强一章。
2.7.4. @ManyToMany
@ManyToMany关联需要连接两个实体的链接表。像@OneToMany关联一样,@ManyToMany可以是单向或双向的。
Unidirectional @ManyToMany
例子 167.单向的@ManyToMany
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
private List<Address> addresses = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Address")
public static class Address {
@Id
@GeneratedValue
private Long id;
private String street;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
CREATE TABLE Address (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
street VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Address (
Person_id BIGINT NOT NULL ,
addresses_id BIGINT NOT NULL
)
ALTER TABLE Person_Address
ADD CONSTRAINT FKm7j0bnabh2yr0pe99il1d066u
FOREIGN KEY (addresses_id) REFERENCES Address
ALTER TABLE Person_Address
ADD CONSTRAINT FKba7rc9qe2vh44u93u0p2auwti
FOREIGN KEY (Person_id) REFERENCES Person
就像单向@OneToMany关联一样,链接表由拥有方控制。
从@ManyToMany集合中删除实体时,Hibernate 只需删除链接表中的加入记录。不幸的是,此操作需要删除与给定父级关联的所有条目,并重新创建当前正在运行的持久性上下文中列出的条目。
例子 168.单向的@ManyToMany生命周期
Person person1 = new Person();
Person person2 = new Person();
Address address1 = new Address( "12th Avenue", "12A" );
Address address2 = new Address( "18th Avenue", "18B" );
person1.getAddresses().add( address1 );
person1.getAddresses().add( address2 );
person2.getAddresses().add( address1 );
entityManager.persist( person1 );
entityManager.persist( person2 );
entityManager.flush();
person1.getAddresses().remove( address1 );
INSERT INTO Person ( id )
VALUES ( 1 )
INSERT INTO Address ( number, street, id )
VALUES ( '12A', '12th Avenue', 2 )
INSERT INTO Address ( number, street, id )
VALUES ( '18B', '18th Avenue', 3 )
INSERT INTO Person ( id )
VALUES ( 4 )
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 1, 2 )
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 1, 3 )
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 4, 2 )
DELETE FROM Person_Address
WHERE Person_id = 1
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 1, 3 )
Note
对于@ManyToMany关联,将REMOVE实体状态转换进行级联是没有意义的,因为它会传播到链接表之外。由于另一端可能被父端上的其他实体引用,因此自动删除可能以ConstraintViolationException结尾。
例如,如果定义了@ManyToMany(cascade = CascadeType.ALL)并且将删除第一个人,则 Hibernate 将引发异常,因为另一个人仍与要删除的地址相关联。
Person person1 = entityManager.find(Person.class, personId);
entityManager.remove(person1);
Caused by: javax.persistence.PersistenceException: org.hibernate.exception.ConstraintViolationException: could not execute statement
Caused by: org.hibernate.exception.ConstraintViolationException: could not execute statement
Caused by: java.sql.SQLIntegrityConstraintViolationException: integrity constraint violation: foreign key no action; FKM7J0BNABH2YR0PE99IL1D066U table: PERSON_ADDRESS
通过简单地删除父端,Hibernate 可以安全地删除关联的链接记录,如以下示例所示:
例子 169.单向@ManyToMany实体移除
Person person1 = entityManager.find( Person.class, personId );
entityManager.remove( person1 );
DELETE FROM Person_Address
WHERE Person_id = 1
DELETE FROM Person
WHERE id = 1
Bidirectional @ManyToMany
双向@ManyToMany关联具有所有者和mappedBy端。为了保持双方之间的同步,优良作法是提供用于添加或删除子实体的辅助方法。
例子 170.双向@ManyToMany
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String registrationNumber;
@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
private List<Address> addresses = new ArrayList<>();
//Getters and setters are omitted for brevity
public void addAddress(Address address) {
addresses.add( address );
address.getOwners().add( this );
}
public void removeAddress(Address address) {
addresses.remove( address );
address.getOwners().remove( this );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Person person = (Person) o;
return Objects.equals( registrationNumber, person.registrationNumber );
}
@Override
public int hashCode() {
return Objects.hash( registrationNumber );
}
}
@Entity(name = "Address")
public static class Address {
@Id
@GeneratedValue
private Long id;
private String street;
@Column(name = "`number`")
private String number;
private String postalCode;
@ManyToMany(mappedBy = "addresses")
private List<Person> owners = new ArrayList<>();
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Address address = (Address) o;
return Objects.equals( street, address.street ) &&
Objects.equals( number, address.number ) &&
Objects.equals( postalCode, address.postalCode );
}
@Override
public int hashCode() {
return Objects.hash( street, number, postalCode );
}
}
CREATE TABLE Address (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
postalCode VARCHAR(255) ,
street VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person (
id BIGINT NOT NULL ,
registrationNumber VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Address (
owners_id BIGINT NOT NULL ,
addresses_id BIGINT NOT NULL
)
ALTER TABLE Person
ADD CONSTRAINT UK_23enodonj49jm8uwec4i7y37f
UNIQUE (registrationNumber)
ALTER TABLE Person_Address
ADD CONSTRAINT FKm7j0bnabh2yr0pe99il1d066u
FOREIGN KEY (addresses_id) REFERENCES Address
ALTER TABLE Person_Address
ADD CONSTRAINT FKbn86l24gmxdv2vmekayqcsgup
FOREIGN KEY (owners_id) REFERENCES Person
有了辅助方法,就可以简化同步 Management,如下面的示例所示:
例子 171.双向@ManyToMany生命周期
Person person1 = new Person( "ABC-123" );
Person person2 = new Person( "DEF-456" );
Address address1 = new Address( "12th Avenue", "12A", "4005A" );
Address address2 = new Address( "18th Avenue", "18B", "4007B" );
person1.addAddress( address1 );
person1.addAddress( address2 );
person2.addAddress( address1 );
entityManager.persist( person1 );
entityManager.persist( person2 );
entityManager.flush();
person1.removeAddress( address1 );
INSERT INTO Person ( registrationNumber, id )
VALUES ( 'ABC-123', 1 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '12A', '4005A', '12th Avenue', 2 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '18B', '4007B', '18th Avenue', 3 )
INSERT INTO Person ( registrationNumber, id )
VALUES ( 'DEF-456', 4 )
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 1, 2 )
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 1, 3 )
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 4, 2 )
DELETE FROM Person_Address
WHERE owners_id = 1
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 1, 3 )
如果双向@OneToMany关联在删除或更改子元素的 Sequences 时表现更好,则@ManyToMany关系不能从这种优化中受益,因为外键侧不受控制。为了克服此限制,必须直接公开链接表,并将@ManyToMany关联拆分为两个双向@OneToMany关系。
具有链接实体的双向多对多
最自然的@ManyToMany关联遵循数据库模式所采用的相同逻辑,并且链接表具有关联的实体,该实体控制需要连接的双方的关系。
例子 172.具有链接实体的双向多对多
@Entity(name = "Person")
public static class Person implements Serializable {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String registrationNumber;
@OneToMany(
mappedBy = "person",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PersonAddress> addresses = new ArrayList<>();
//Getters and setters are omitted for brevity
public void addAddress(Address address) {
PersonAddress personAddress = new PersonAddress( this, address );
addresses.add( personAddress );
address.getOwners().add( personAddress );
}
public void removeAddress(Address address) {
PersonAddress personAddress = new PersonAddress( this, address );
address.getOwners().remove( personAddress );
addresses.remove( personAddress );
personAddress.setPerson( null );
personAddress.setAddress( null );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Person person = (Person) o;
return Objects.equals( registrationNumber, person.registrationNumber );
}
@Override
public int hashCode() {
return Objects.hash( registrationNumber );
}
}
@Entity(name = "PersonAddress")
public static class PersonAddress implements Serializable {
@Id
@ManyToOne
private Person person;
@Id
@ManyToOne
private Address address;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
PersonAddress that = (PersonAddress) o;
return Objects.equals( person, that.person ) &&
Objects.equals( address, that.address );
}
@Override
public int hashCode() {
return Objects.hash( person, address );
}
}
@Entity(name = "Address")
public static class Address implements Serializable {
@Id
@GeneratedValue
private Long id;
private String street;
@Column(name = "`number`")
private String number;
private String postalCode;
@OneToMany(
mappedBy = "address",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PersonAddress> owners = new ArrayList<>();
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Address address = (Address) o;
return Objects.equals( street, address.street ) &&
Objects.equals( number, address.number ) &&
Objects.equals( postalCode, address.postalCode );
}
@Override
public int hashCode() {
return Objects.hash( street, number, postalCode );
}
}
CREATE TABLE Address (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
postalCode VARCHAR(255) ,
street VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person (
id BIGINT NOT NULL ,
registrationNumber VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE PersonAddress (
person_id BIGINT NOT NULL ,
address_id BIGINT NOT NULL ,
PRIMARY KEY ( person_id, address_id )
)
ALTER TABLE Person
ADD CONSTRAINT UK_23enodonj49jm8uwec4i7y37f
UNIQUE (registrationNumber)
ALTER TABLE PersonAddress
ADD CONSTRAINT FK8b3lru5fyej1aarjflamwghqq
FOREIGN KEY (person_id) REFERENCES Person
ALTER TABLE PersonAddress
ADD CONSTRAINT FK7p69mgialumhegyl4byrh65jk
FOREIGN KEY (address_id) REFERENCES Address
Person和Address都具有mappedBy @OneToMany侧,而PersonAddress拥有person和address @ManyToOne关联。因为此 Map 是由两个双向关联构成的,所以辅助方法更加相关。
Note
前述示例对链接实体使用了特定于 Hibernate 的 Map,因为 JPA 不允许从多个@ManyToOne关联中构建复合标识符。
有关更多详细信息,请参见具有关联的复合标识符部分。
与先前的双向@ManyToMany情况相比,可以更好地 Management 实体状态转换。
例子 173.具有链接实体生命周期的双向多对多
Person person1 = new Person( "ABC-123" );
Person person2 = new Person( "DEF-456" );
Address address1 = new Address( "12th Avenue", "12A", "4005A" );
Address address2 = new Address( "18th Avenue", "18B", "4007B" );
entityManager.persist( person1 );
entityManager.persist( person2 );
entityManager.persist( address1 );
entityManager.persist( address2 );
person1.addAddress( address1 );
person1.addAddress( address2 );
person2.addAddress( address1 );
entityManager.flush();
log.info( "Removing address" );
person1.removeAddress( address1 );
INSERT INTO Person ( registrationNumber, id )
VALUES ( 'ABC-123', 1 )
INSERT INTO Person ( registrationNumber, id )
VALUES ( 'DEF-456', 2 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '12A', '4005A', '12th Avenue', 3 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '18B', '4007B', '18th Avenue', 4 )
INSERT INTO PersonAddress ( person_id, address_id )
VALUES ( 1, 3 )
INSERT INTO PersonAddress ( person_id, address_id )
VALUES ( 1, 4 )
INSERT INTO PersonAddress ( person_id, address_id )
VALUES ( 2, 3 )
DELETE FROM PersonAddress
WHERE person_id = 1 AND address_id = 3
仅执行一条 delete 语句,因为这次关联是由@ManyToOne端控制的,该端仅需监视基础外键关系的状态即可触发正确的 DML 语句。
2.7.5. @NotFound 关联 Map
当处理不是由外键强制执行的关联时,如果子记录无法引用父实体,则可能会出现不一致的情况。
默认情况下,每当子关联引用不存在的父记录时,Hibernate 都会进行投诉。但是,您可以配置此行为,以便 Hibernate 可以忽略此类异常,只需将null分配为所引用的父对象。
要忽略不存在的父实体引用,即使不建议这样做,也可以使用值为org.hibernate.annotations.NotFoundAction.IGNORE的 Commentsorg.hibernate.annotation.NotFoundComments。
Note
即使将fetch策略设置为FetchType.LAZY,也会始终热切地获取用@NotFound(action = NotFoundAction.IGNORE)Comments 的@ManyToOne和@OneToOne关联。
考虑以下City和Person实体 Map:
例子 174. @NotFoundMap 例子
@Entity
@Table( name = "Person" )
public static class Person {
@Id
private Long id;
private String name;
private String cityName;
@ManyToOne
@NotFound ( action = NotFoundAction.IGNORE )
@JoinColumn(
name = "cityName",
referencedColumnName = "name",
insertable = false,
updatable = false
)
private City city;
//Getters and setters are omitted for brevity
}
@Entity
@Table( name = "City" )
public static class City implements Serializable {
@Id
@GeneratedValue
private Long id;
private String name;
//Getters and setters are omitted for brevity
}
如果我们的数据库中包含以下实体:
例子 175. @NotFound坚持的例子
City _NewYork = new City();
_NewYork.setName( "New York" );
entityManager.persist( _NewYork );
Person person = new Person();
person.setId( 1L );
person.setName( "John Doe" );
person.setCityName( "New York" );
entityManager.persist( person );
加载Person实体时,Hibernate 能够找到关联的City父实体:
例子 176. @NotFound查找现有实体的例子
Person person = entityManager.find( Person.class, 1L );
assertEquals( "New York", person.getCity().getName() );
但是,如果我们将cityName属性更改为不存在的城市名称:
例子 177. @NotFound更改为不存在的城市例子
person.setCityName( "Atlantis" );
Hibernate 不会抛出任何异常,它将为不存在的City实体引用分配一个值null:
例子 178. @NotFound查找不存在的城市例子
Person person = entityManager.find( Person.class, 1L );
assertEquals( "Atlantis", person.getCityName() );
assertNull( null, person.getCity() );
2.7.6. @任何 Map
当可以有多个目标实体时,@AnyMap 对于模拟单向@ManyToOne关联很有用。
因为@AnyMap 定义了到多个表中的类的多态关联,所以此关联类型需要 FK 列,该列提供关联的父标识符和关联的实体类型的元数据信息。
Note
这不是 Map 多态关联的通常方法,您应该仅在特殊情况下使用此方法(例如,审核日志,用户会话数据等)。
@AnyComments 描述了保存元数据信息的列。为了链接元数据信息的值和实际的实体类型,使用@AnyDef和@AnyDefs注解。 metaType属性允许应用程序指定一个自定义类型,该类型将数据库列值 Map 到具有idType指定的类型的标识符属性的持久性类。您必须指定从metaType的值到类名的 Map。
对于下一个示例,请考虑以下Property类层次结构:
例子 179. Property类层次结构
public interface Property<T> {
String getName();
T getValue();
}
@Entity
@Table(name="integer_property")
public class IntegerProperty implements Property<Integer> {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`value`")
private Integer value;
@Override
public String getName() {
return name;
}
@Override
public Integer getValue() {
return value;
}
//Getters and setters omitted for brevity
}
@Entity
@Table(name="string_property")
public class StringProperty implements Property<String> {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`value`")
private String value;
@Override
public String getName() {
return name;
}
@Override
public String getValue() {
return value;
}
//Getters and setters omitted for brevity
}
PropertyHolder可以引用任何此类属性,并且由于每个Property都属于一个单独的表,因此需要@Any注解。
例子 180. @AnyMap 用法
@Entity
@Table( name = "property_holder" )
public class PropertyHolder {
@Id
private Long id;
@Any(
metaDef = "PropertyMetaDef",
metaColumn = @Column( name = "property_type" )
)
@JoinColumn( name = "property_id" )
private Property property;
//Getters and setters are omitted for brevity
}
CREATE TABLE property_holder (
id BIGINT NOT NULL,
property_type VARCHAR(255),
property_id BIGINT,
PRIMARY KEY ( id )
)
如您所见,有两列用于引用Property实例:property_id和property_type。 property_id用于匹配string_property或integer_property表的id列,而property_type用于匹配string_property或integer_property表。
表解析 Map 是由metaDef属性定义的,该属性引用了@AnyMetaDefMap。
package-info.java包含@AnyMetaDefMap:
例子 181. @AnyMetaDefMap 用法
@AnyMetaDef( name= "PropertyMetaDef", metaType = "string", idType = "long",
metaValues = {
@MetaValue(value = "S", targetEntity = StringProperty.class),
@MetaValue(value = "I", targetEntity = IntegerProperty.class)
}
)
package org.hibernate.userguide.associations.any;
import org.hibernate.annotations.AnyMetaDef;
import org.hibernate.annotations.MetaValue;
Note
尽管可以在@Any注解旁边设置@AnyMetaDefMap,但是在类或包级别配置它是一个好习惯,特别是如果您需要将其重用于多个@AnyMap 时。
要查看实际使用的@AnyComments,请考虑以下示例。
如果我们同时保留一个IntegerProperty和StringProperty实体,并将StringProperty实体与PropertyHolder关联,则 Hibernate 将生成以下 SQL 查询:
例子 182. @AnyMap 保持例子
IntegerProperty ageProperty = new IntegerProperty();
ageProperty.setId( 1L );
ageProperty.setName( "age" );
ageProperty.setValue( 23 );
session.persist( ageProperty );
StringProperty nameProperty = new StringProperty();
nameProperty.setId( 1L );
nameProperty.setName( "name" );
nameProperty.setValue( "John Doe" );
session.persist( nameProperty );
PropertyHolder namePropertyHolder = new PropertyHolder();
namePropertyHolder.setId( 1L );
namePropertyHolder.setProperty( nameProperty );
session.persist( namePropertyHolder );
INSERT INTO integer_property
( "name", "value", id )
VALUES ( 'age', 23, 1 )
INSERT INTO string_property
( "name", "value", id )
VALUES ( 'name', 'John Doe', 1 )
INSERT INTO property_holder
( property_type, property_id, id )
VALUES ( 'S', 1, 1 )
当获取PropertyHolder实体并导航其property关联时,Hibernate 将按如下方式获取关联的StringProperty实体:
例子 183. @AnyMap 查询例子
PropertyHolder propertyHolder = session.get( PropertyHolder.class, 1L );
assertEquals("name", propertyHolder.getProperty().getName());
assertEquals("John Doe", propertyHolder.getProperty().getValue());
SELECT ph.id AS id1_1_0_,
ph.property_type AS property2_1_0_,
ph.property_id AS property3_1_0_
FROM property_holder ph
WHERE ph.id = 1
SELECT sp.id AS id1_2_0_,
sp."name" AS name2_2_0_,
sp."value" AS value3_2_0_
FROM string_property sp
WHERE sp.id = 1
@ManyToAny mapping
当可能有多个目标实体时,@AnyMap 对于模拟@ManyToOne关联非常有用,而在模拟@OneToMany关联时,必须使用@ManyToAnyComments。
在以下示例中,PropertyRepository实体具有Property实体的集合。
repository_properties链接表保存PropertyRepository和Property实体之间的关联。
例子 184. @ManyToAnyMap 用法
@Entity
@Table( name = "property_repository" )
public class PropertyRepository {
@Id
private Long id;
@ManyToAny(
metaDef = "PropertyMetaDef",
metaColumn = @Column( name = "property_type" )
)
@Cascade( { org.hibernate.annotations.CascadeType.ALL })
@JoinTable(name = "repository_properties",
joinColumns = @JoinColumn(name = "repository_id"),
inverseJoinColumns = @JoinColumn(name = "property_id")
)
private List<Property<?>> properties = new ArrayList<>( );
//Getters and setters are omitted for brevity
}
CREATE TABLE property_repository (
id BIGINT NOT NULL,
PRIMARY KEY ( id )
)
CREATE TABLE repository_properties (
repository_id BIGINT NOT NULL,
property_type VARCHAR(255),
property_id BIGINT NOT NULL
)
要查看实际使用的@ManyToAnyComments,请考虑以下示例。
如果我们保留一个IntegerProperty和StringProperty实体,并将它们与PropertyRepository父实体相关联,则 Hibernate 将生成以下 SQL 查询:
例子 185. @ManyToAnyMap 持久化例子
IntegerProperty ageProperty = new IntegerProperty();
ageProperty.setId( 1L );
ageProperty.setName( "age" );
ageProperty.setValue( 23 );
session.persist( ageProperty );
StringProperty nameProperty = new StringProperty();
nameProperty.setId( 1L );
nameProperty.setName( "name" );
nameProperty.setValue( "John Doe" );
session.persist( nameProperty );
PropertyRepository propertyRepository = new PropertyRepository();
propertyRepository.setId( 1L );
propertyRepository.getProperties().add( ageProperty );
propertyRepository.getProperties().add( nameProperty );
session.persist( propertyRepository );
INSERT INTO integer_property
( "name", "value", id )
VALUES ( 'age', 23, 1 )
INSERT INTO string_property
( "name", "value", id )
VALUES ( 'name', 'John Doe', 1 )
INSERT INTO property_repository ( id )
VALUES ( 1 )
INSERT INTO repository_properties
( repository_id , property_type , property_id )
VALUES
( 1 , 'I' , 1 )
当获取PropertyRepository实体并导航其properties关联时,Hibernate 将按以下方式获取关联的IntegerProperty和StringProperty实体:
例子 186. @ManyToAnyMap 查询例子
PropertyRepository propertyRepository = session.get( PropertyRepository.class, 1L );
assertEquals(2, propertyRepository.getProperties().size());
for(Property property : propertyRepository.getProperties()) {
assertNotNull( property.getValue() );
}
SELECT pr.id AS id1_1_0_
FROM property_repository pr
WHERE pr.id = 1
SELECT ip.id AS id1_0_0_ ,
ip."name" AS name2_0_0_ ,
ip."value" AS value3_0_0_
FROM integer_property ip
WHERE ip.id = 1
SELECT sp.id AS id1_3_0_ ,
sp."name" AS name2_3_0_ ,
sp."value" AS value3_3_0_
FROM string_property sp
WHERE sp.id = 1
2.7.7. @JoinFormulaMap
@JoinFormula注解用于自定义子外键和父行主键之间的联接。
例子 187. @JoinFormulaMap 用法
@Entity(name = "User")
@Table(name = "users")
public static class User {
@Id
private Long id;
private String firstName;
private String lastName;
private String phoneNumber;
@ManyToOne
@JoinFormula( "REGEXP_REPLACE(phoneNumber, '\\+(\\d+)-.*', '\\1')::int" )
private Country country;
//Getters and setters omitted for brevity
}
@Entity(name = "Country")
@Table(name = "countries")
public static class Country {
@Id
private Integer id;
private String name;
//Getters and setters, equals and hashCode methods omitted for brevity
}
CREATE TABLE countries (
id int4 NOT NULL,
name VARCHAR(255),
PRIMARY KEY ( id )
)
CREATE TABLE users (
id int8 NOT NULL,
firstName VARCHAR(255),
lastName VARCHAR(255),
phoneNumber VARCHAR(255),
PRIMARY KEY ( id )
)
User实体中的country关联由phoneNumber属性提供的国家/地区标识符 Map。
考虑到我们具有以下实体:
例子 188. @JoinFormulaMap 用法
Country US = new Country();
US.setId( 1 );
US.setName( "United States" );
Country Romania = new Country();
Romania.setId( 40 );
Romania.setName( "Romania" );
doInJPA( this::entityManagerFactory, entityManager -> {
entityManager.persist( US );
entityManager.persist( Romania );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
User user1 = new User( );
user1.setId( 1L );
user1.setFirstName( "John" );
user1.setLastName( "Doe" );
user1.setPhoneNumber( "+1-234-5678" );
entityManager.persist( user1 );
User user2 = new User( );
user2.setId( 2L );
user2.setFirstName( "Vlad" );
user2.setLastName( "Mihalcea" );
user2.setPhoneNumber( "+40-123-4567" );
entityManager.persist( user2 );
} );
提取User实体时,@JoinFormula表达式 Mapcountry属性:
例子 189. @JoinFormulaMap 用法
doInJPA( this::entityManagerFactory, entityManager -> {
log.info( "Fetch User entities" );
User john = entityManager.find( User.class, 1L );
assertEquals( US, john.getCountry());
User vlad = entityManager.find( User.class, 2L );
assertEquals( Romania, vlad.getCountry());
} );
-- Fetch User entities
SELECT
u.id as id1_1_0_,
u.firstName as firstNam2_1_0_,
u.lastName as lastName3_1_0_,
u.phoneNumber as phoneNum4_1_0_,
REGEXP_REPLACE(u.phoneNumber, '\+(\d+)-.*', '\1')::int as formula1_0_,
c.id as id1_0_1_,
c.name as name2_0_1_
FROM
users u
LEFT OUTER JOIN
countries c
ON REGEXP_REPLACE(u.phoneNumber, '\+(\d+)-.*', '\1')::int = c.id
WHERE
u.id=?
-- binding parameter [1] as [BIGINT] - [1]
SELECT
u.id as id1_1_0_,
u.firstName as firstNam2_1_0_,
u.lastName as lastName3_1_0_,
u.phoneNumber as phoneNum4_1_0_,
REGEXP_REPLACE(u.phoneNumber, '\+(\d+)-.*', '\1')::int as formula1_0_,
c.id as id1_0_1_,
c.name as name2_0_1_
FROM
users u
LEFT OUTER JOIN
countries c
ON REGEXP_REPLACE(u.phoneNumber, '\+(\d+)-.*', '\1')::int = c.id
WHERE
u.id=?
-- binding parameter [1] as [BIGINT] - [2]
因此,@JoinFormula注解用于定义父子关联之间的自定义联接关联。
2.7.8. @JoinColumnOrFormulaMap
当我们需要考虑列值和@JoinFormula时,@JoinColumnOrFormulaComments 用于自定义子外键和父行主键之间的联接。
例子 190. @JoinColumnOrFormulaMap 用法
@Entity(name = "User")
@Table(name = "users")
public static class User {
@Id
private Long id;
private String firstName;
private String lastName;
private String language;
@ManyToOne
@JoinColumnOrFormula( column =
@JoinColumn(
name = "language",
referencedColumnName = "primaryLanguage",
insertable = false,
updatable = false
)
)
@JoinColumnOrFormula( formula =
@JoinFormula(
value = "true",
referencedColumnName = "is_default"
)
)
private Country country;
//Getters and setters omitted for brevity
}
@Entity(name = "Country")
@Table(name = "countries")
public static class Country implements Serializable {
@Id
private Integer id;
private String name;
private String primaryLanguage;
@Column(name = "is_default")
private boolean _default;
//Getters and setters, equals and hashCode methods omitted for brevity
}
CREATE TABLE countries (
id INTEGER NOT NULL,
is_default boolean,
name VARCHAR(255),
primaryLanguage VARCHAR(255),
PRIMARY KEY ( id )
)
CREATE TABLE users (
id BIGINT NOT NULL,
firstName VARCHAR(255),
language VARCHAR(255),
lastName VARCHAR(255),
PRIMARY KEY ( id )
)
User实体中的country关联由language属性值和关联的Country is_default列值 Map。
考虑到我们具有以下实体:
例子 191.@JoinColumnOrFormula坚持的例子
Country US = new Country();
US.setId( 1 );
US.setDefault( true );
US.setPrimaryLanguage( "English" );
US.setName( "United States" );
Country Romania = new Country();
Romania.setId( 40 );
Romania.setDefault( true );
Romania.setName( "Romania" );
Romania.setPrimaryLanguage( "Romanian" );
doInJPA( this::entityManagerFactory, entityManager -> {
entityManager.persist( US );
entityManager.persist( Romania );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
User user1 = new User( );
user1.setId( 1L );
user1.setFirstName( "John" );
user1.setLastName( "Doe" );
user1.setLanguage( "English" );
entityManager.persist( user1 );
User user2 = new User( );
user2.setId( 2L );
user2.setFirstName( "Vlad" );
user2.setLastName( "Mihalcea" );
user2.setLanguage( "Romanian" );
entityManager.persist( user2 );
} );
提取User实体时,@JoinColumnOrFormula表达式 Mapcountry属性:
例子 192. @JoinColumnOrFormula取得例子
doInJPA( this::entityManagerFactory, entityManager -> {
log.info( "Fetch User entities" );
User john = entityManager.find( User.class, 1L );
assertEquals( US, john.getCountry());
User vlad = entityManager.find( User.class, 2L );
assertEquals( Romania, vlad.getCountry());
} );
SELECT
u.id as id1_1_0_,
u.language as language3_1_0_,
u.firstName as firstNam2_1_0_,
u.lastName as lastName4_1_0_,
1 as formula1_0_,
c.id as id1_0_1_,
c.is_default as is_defau2_0_1_,
c.name as name3_0_1_,
c.primaryLanguage as primaryL4_0_1_
FROM
users u
LEFT OUTER JOIN
countries c
ON u.language = c.primaryLanguage
AND 1 = c.is_default
WHERE
u.id = ?
-- binding parameter [1] as [BIGINT] - [1]
SELECT
u.id as id1_1_0_,
u.language as language3_1_0_,
u.firstName as firstNam2_1_0_,
u.lastName as lastName4_1_0_,
1 as formula1_0_,
c.id as id1_0_1_,
c.is_default as is_defau2_0_1_,
c.name as name3_0_1_,
c.primaryLanguage as primaryL4_0_1_
FROM
users u
LEFT OUTER JOIN
countries c
ON u.language = c.primaryLanguage
AND 1 = c.is_default
WHERE
u.id = ?
-- binding parameter [1] as [BIGINT] - [2]
因此,@JoinColumnOrFormula注解用于定义父子关联之间的自定义联接关联。
2.8. Collections
当然,Hibernate 也允许持久化集合。这些持久性集合几乎可以包含任何其他 Hibernate 类型,包括基本类型,自定义类型,可嵌入对象以及对其他实体的引用。在这种情况下,值语义和引用语义之间的区别非常重要。集合中的对象可能使用* value 语义处理(其生命周期完全取决于集合所有者),或者它可能是对具有其自身生命周期的另一个实体的引用。在后一种情况下,只有两个对象之间的 link *被视为集合所拥有的状态。
即使集合是由可嵌入类型定义的,集合的所有者也始终是实体。集合在类型之间形成一对多的关联,因此可以有:
值类型集合
可嵌入类型集合
entity collections
Hibernate 使用自己的集合实现,这些实现丰富了延迟加载,缓存或状态更改检测语义。因此,必须将持久性集合声明为接口类型。实际的接口可能是java.util.Collection,java.util.List,java.util.Set,java.util.Map,java.util.SortedSet,java.util.SortedMap甚至其他对象类型(这意味着您必须编写org.hibernate.usertype.UserCollectionType的实现)。
如下例所示,使用接口类型而不是实体 Map 中声明的集合实现很重要。
例子 193. Hibernate 使用它自己的 collection 实现
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@ElementCollection
private List<String> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
Person person = entityManager.find( Person.class, 1L );
//Throws java.lang.ClassCastException: org.hibernate.collection.internal.PersistentBag cannot be cast to java.util.ArrayList
ArrayList<String> phones = (ArrayList<String>) person.getPhones();
Note
使用适当的 Java Collections Framework 接口而不是特定的实现定义集合非常重要。
从理论上讲,这只是遵循良好的设计原则。从实际的角度来看,Hibernate(像其他持久性提供程序一样)将使用他们自己的符合 Java Collections Framework 接口的 collection 实现。
Hibernate 注入的持久性集合的行为类似于ArrayList,HashSet,TreeSet,HashMap或TreeMap,具体取决于接口类型。
2.8.1. 集合作为值类型
值和可嵌入类型集合的行为与基本类型相似,因为它们在由持久性对象引用时会自动保留,而在未引用时会自动删除。如果将集合从一个持久对象传递到另一个持久对象,则其元素可能会从一个表移动到另一个表。
Tip
两个实体不能共享对同一集合实例的引用。集合值的属性不支持空值语义,因为 Hibernate 不会区分空集合引用和空集合。
2.8.2. 值类型的集合
值类型的集合包括基本类型和可嵌入类型。集合不能嵌套,并且在集合中使用时,不允许可嵌入类型定义其他集合。
对于值类型的集合,JPA 2.0 定义了@ElementCollection注解。值类型集合的生命周期完全由其拥有的实体控制。
考虑到前面的示例 Map,在清除电话集合时,Hibernate 会删除所有关联的电话。将新元素添加到值类型集合时,Hibernate 发出新的 insert 语句。
例子 194.值类型收集生命周期
person.getPhones().clear();
person.getPhones().add( "123-456-7890" );
person.getPhones().add( "456-000-1234" );
DELETE FROM Person_phones WHERE Person_id = 1
INSERT INTO Person_phones ( Person_id, phones )
VALUES ( 1, '123-456-7890' )
INSERT INTO Person_phones (Person_id, phones)
VALUES ( 1, '456-000-1234' )
如果删除所有元素或添加新元素非常简单,则删除某个条目实际上需要从头开始重建整个集合。
例子 195.删除集合元素
person.getPhones().remove( 0 );
DELETE FROM Person_phones WHERE Person_id = 1
INSERT INTO Person_phones ( Person_id, phones )
VALUES ( 1, '456-000-1234' )
如果需要删除许多元素并将其重新插入数据库表中,则取决于元素的数量,此行为可能无效。一种解决方法是使用@OrderColumn,尽管效率不如使用实际链接表主键时有效,但可以提高删除操作的效率。
例子 196.使用@OrderColumn 移除集合元素
@ElementCollection
@OrderColumn(name = "order_id")
private List<String> phones = new ArrayList<>();
person.getPhones().remove( 0 );
DELETE FROM Person_phones
WHERE Person_id = 1
AND order_id = 1
UPDATE Person_phones
SET phones = '456-000-1234'
WHERE Person_id = 1
AND order_id = 0
Note
从集合的尾部删除时,@OrderColumn列最有效,因为它只需要一个 delete 语句。从集合的头部或中间删除需要删除多余的元素并更新其余元素以保留元素 Sequences。
可嵌入类型集合的行为与值类型集合相同。将可嵌入对象添加到集合中会触发关联的插入语句,并且从集合中删除元素将生成删除语句。
例子 197.可嵌入类型集合
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@ElementCollection
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Embeddable
public static class Phone {
private String type;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
person.getPhones().add( new Phone( "landline", "028-234-9876" ) );
person.getPhones().add( new Phone( "mobile", "072-122-9876" ) );
INSERT INTO Person_phones ( Person_id, number, type )
VALUES ( 1, '028-234-9876', 'landline' )
INSERT INTO Person_phones ( Person_id, number, type )
VALUES ( 1, '072-122-9876', 'mobile' )
2.8.3. 实体集合
如果值类型集合只能在所有者实体和多个基本或可嵌入类型之间形成一对多关联,则实体集合可以表示@OneToMany和@ManyToMany关联。
从关系数据库的角度来看,关联是由外键侧(子侧)定义的。对于值类型集合,只有实体可以控制关联(父级),但是对于实体集合,关联的两侧都由持久性上下文 Management。
因此,实体集合可以设计为两个主要类别:单向和双向关联。单向关联与值类型集合非常相似,因为只有父级控制此关系。双向关联更加棘手,因为即使双方始终需要保持同步,也只有一方负责 Management 关联。双向关联具有拥有一侧和*反向(mappedBy)*一侧。
对实体集合进行分类的另一种方法是通过基础集合类型,因此我们可以:
bags
indexed lists
sets
sorted sets
maps
sorted maps
arrays
在以下各节中,我们将介绍所有这些集合类型,并讨论单向和双向关联。
2.8.4. Bags
袋是无序的列表,我们可以有单向袋或双向袋。
Unidirectional bags
单向袋使用关联父级上的单个@OneToManyComments 进行 Map。在后台,Hibernate 需要一个关联表来 Management 父子关系,如下面的示例所示:
例子 198.单向袋
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Phone (
Person_id BIGINT NOT NULL ,
phones_id BIGINT NOT NULL
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
type VARCHAR(255) ,
PRIMARY KEY ( id )
)
ALTER TABLE Person_Phone
ADD CONSTRAINT UK_9uhc5itwc9h5gcng944pcaslf
UNIQUE (phones_id)
ALTER TABLE Person_Phone
ADD CONSTRAINT FKr38us2n8g5p9rj0b494sd3391
FOREIGN KEY (phones_id) REFERENCES Phone
ALTER TABLE Person_Phone
ADD CONSTRAINT FK2ex4e4p7w1cj310kg2woisjl2
FOREIGN KEY (Person_id) REFERENCES Person
Note
由于父级和子级都是实体,因此持久性上下文分别 Management 每个实体。
级联机制允许您传播从父实体到子实体的实体状态转换。
通过使用CascadeType.ALL属性标记父端,单向关联生命周期变得与值类型集合的生命周期非常相似。
例子 199.单向袋的生命周期
Person person = new Person( 1L );
person.getPhones().add( new Phone( 1L, "landline", "028-234-9876" ) );
person.getPhones().add( new Phone( 2L, "mobile", "072-122-9876" ) );
entityManager.persist( person );
INSERT INTO Person ( id )
VALUES ( 1 )
INSERT INTO Phone ( number, type, id )
VALUES ( '028-234-9876', 'landline', 1 )
INSERT INTO Phone ( number, type, id )
VALUES ( '072-122-9876', 'mobile', 2 )
INSERT INTO Person_Phone ( Person_id, phones_id )
VALUES ( 1, 1 )
INSERT INTO Person_Phone ( Person_id, phones_id )
VALUES ( 1, 2 )
在上面的示例中,父实体持久化后,子实体也将持久化。
Note
就像值类型集合一样,单向袋在修改集合结构(删除或重新组合元素)时效率不高。
由于父方不能唯一地标识每个子项,因此 Hibernate 删除与父实体关联的所有链接表行,并重新添加在当前集合状态下找到的其余行。
Bidirectional bags
双向袋是最常见的实体集合类型。 @ManyToOne面是双向包装袋关联的拥有面,而@OneToMany是* inverse *面,用mappedBy属性标记。
例子 200.双向袋
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
public void addPhone(Phone phone) {
phones.add( phone );
phone.setPerson( this );
}
public void removePhone(Phone phone) {
phones.remove( phone );
phone.setPerson( null );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`", unique = true)
@NaturalId
private String number;
@ManyToOne
private Person person;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
CREATE TABLE Person (
id BIGINT NOT NULL, PRIMARY KEY (id)
)
CREATE TABLE Phone (
id BIGINT NOT NULL,
number VARCHAR(255),
type VARCHAR(255),
person_id BIGINT,
PRIMARY KEY (id)
)
ALTER TABLE Phone
ADD CONSTRAINT UK_l329ab0g4c1t78onljnxmbnp6
UNIQUE (number)
ALTER TABLE Phone
ADD CONSTRAINT FKmw13yfsjypiiq0i1osdkaeqpg
FOREIGN KEy (person_id) REFERENCES Person
例子 201.双向袋子的生命周期
person.addPhone( new Phone( 1L, "landline", "028-234-9876" ) );
person.addPhone( new Phone( 2L, "mobile", "072-122-9876" ) );
entityManager.flush();
person.removePhone( person.getPhones().get( 0 ) );
INSERT INTO Phone (number, person_id, type, id)
VALUES ( '028-234-9876', 1, 'landline', 1 )
INSERT INTO Phone (number, person_id, type, id)
VALUES ( '072-122-9876', 1, 'mobile', 2 )
UPDATE Phone
SET person_id = NULL, type = 'landline' where id = 1
例子 202.除去了孤儿的双向袋子
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Phone> phones = new ArrayList<>();
DELETE FROM Phone WHERE id = 1
当重新运行上一个示例时,子级将被删除,因为父级在取消关联子级实体引用时会传播该删除。
2.8.5. 有序列表
尽管它们在 Java 端使用List接口,但 bag 并不会保留元素 Sequences。要保留收集元素的 Sequences,有两种可能性:
@OrderBy- 使用子实体属性在检索时对集合进行排序
@OrderColumn- collections 使用 collections 链接表中的专用订单列
单向有序列表
使用@OrderByComments 时,Map 如下所示:
例子 203.单向的@OrderBy列表
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@OrderBy("number")
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
数据库 Map 与Unidirectional bags示例相同,因此不再重复。在获取集合时,Hibernate 生成以下选择语句:
例子 204.单向的@OrderBy列表选择语句
SELECT
phones0_.Person_id AS Person_i1_1_0_,
phones0_.phones_id AS phones_i2_1_0_,
unidirecti1_.id AS id1_2_1_,
unidirecti1_."number" AS number2_2_1_,
unidirecti1_.type AS type3_2_1_
FROM
Person_Phone phones0_
INNER JOIN
Phone unidirecti1_ ON phones0_.phones_id=unidirecti1_.id
WHERE
phones0_.Person_id = 1
ORDER BY
unidirecti1_."number"
子表列用于对列表元素进行排序。
Note
@OrderByComments 可以采用多个实体属性,并且每个属性也可以采用排序方向(例如@OrderBy("name ASC, type DESC"))。
如果未指定任何属性(例如@OrderBy),则子实体表的主键用于排序。
另一个 Order 选项是使用@OrderColumn注解:
例子 205.单向的@OrderColumn列表
@OneToMany(cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
private List<Phone> phones = new ArrayList<>();
CREATE TABLE Person_Phone (
Person_id BIGINT NOT NULL ,
phones_id BIGINT NOT NULL ,
order_id INTEGER NOT NULL ,
PRIMARY KEY ( Person_id, order_id )
)
这次,链接表使用order_id列,并使用它来实现收集元素的 Sequences。提取列表时,将执行以下选择查询:
例子 206.单向@OrderColumn列表选择语句
select
phones0_.Person_id as Person_i1_1_0_,
phones0_.phones_id as phones_i2_1_0_,
phones0_.order_id as order_id3_0_,
unidirecti1_.id as id1_2_1_,
unidirecti1_.number as number2_2_1_,
unidirecti1_.type as type3_2_1_
from
Person_Phone phones0_
inner join
Phone unidirecti1_
on phones0_.phones_id=unidirecti1_.id
where
phones0_.Person_id = 1
有了order_id列后,Hibernate 可以在从数据库中获取列表后在内存中对其进行排序。
双向有序列表
Map 与Bidirectional bags示例相似,只是父端将使用@OrderBy或@OrderColumn进行 Comments。
例子 207.双向@OrderBy列表
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderBy("number")
private List<Phone> phones = new ArrayList<>();
就像单向@OrderBy列表一样,number列用于在 SQL 级别对语句进行排序。
使用@OrderColumn注解时,order_id列将嵌入子表中:
例子 208.双向@OrderColumn列表
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
private List<Phone> phones = new ArrayList<>();
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
type VARCHAR(255) ,
person_id BIGINT ,
order_id INTEGER ,
PRIMARY KEY ( id )
)
当获取集合时,Hibernate 将使用获取的有序列根据@OrderColumnMap 对元素进行排序。
自定义有序列表 Sequences
您可以使用@ListIndexBase注解来自定义基础有序列表的 Sequences。
例子 209. @ListIndexBaseMap 例子
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
@ListIndexBase(100)
private List<Phone> phones = new ArrayList<>();
当插入两个Phone记录时,Hibernate 这次将从 100 开始启动 List 索引。
范例 210.@ListIndexBase持续范例
Person person = new Person( 1L );
entityManager.persist( person );
person.addPhone( new Phone( 1L, "landline", "028-234-9876" ) );
person.addPhone( new Phone( 2L, "mobile", "072-122-9876" ) );
INSERT INTO Phone("number", person_id, type, id)
VALUES ('028-234-9876', 1, 'landline', 1)
INSERT INTO Phone("number", person_id, type, id)
VALUES ('072-122-9876', 1, 'mobile', 2)
UPDATE Phone
SET order_id = 100
WHERE id = 1
UPDATE Phone
SET order_id = 101
WHERE id = 2
自定义 ORDER BY SQL 子句
虽然 JPA @OrderBy注解允许您指定在获取当前带 Comments 的集合时用于排序的实体属性,但是特定于 Hibernate 的@OrderBy注解用于指定 SQL 子句。
在下面的示例中,@OrderBy注解使用CHAR_LENGTH SQL 函数通过name属性的字符数对Article实体进行排序。
例子 211. @OrderByMap 例子
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@OneToMany(
mappedBy = "person",
cascade = CascadeType.ALL
)
@org.hibernate.annotations.OrderBy(
clause = "CHAR_LENGTH(name) DESC"
)
private List<Article> articles = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Article")
public static class Article {
@Id
@GeneratedValue
private Long id;
private String name;
private String content;
@ManyToOne(fetch = FetchType.LAZY)
private Person person;
//Getters and setters are omitted for brevity
}
当获取articles集合时,Hibernate 使用 Map 提供的 ORDER BY SQL 子句:
例子 212. @OrderBy取得例子
Person person = entityManager.find( Person.class, 1L );
assertEquals(
"High-Performance Hibernate",
person.getArticles().get( 0 ).getName()
);
select
a.person_id as person_i4_0_0_,
a.id as id1_0_0_,
a.content as content2_0_1_,
a.name as name3_0_1_,
a.person_id as person_i4_0_1_
from
Article a
where
a.person_id = ?
order by
CHAR_LENGTH(a.name) desc
2.8.6. Sets
集合是不允许重复条目的集合,并且 Hibernate 支持无序的Set和自然排序的SortedSet。
Unidirectional sets
单向集使用链接表来保存父子关联,并且实体 Map 如下所示:
例子 213.单向集
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
private Set<Phone> phones = new HashSet<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
单向设置的生命周期与Unidirectional bags相似,因此可以省略。唯一的区别是Set不允许重复,但是此约束是由 Java 对象协定而不是数据库 Map 强制执行的。
Note
使用 Set 时,为子实体提供适当的 equals/hashCode 实现非常重要。
在没有自定义的 equals/hashCode 实现逻辑的情况下,Hibernate 将使用默认的基于 Java 参考的对象相等性,当混合分离对象实例和托管对象实例时,这可能会导致意外结果。
Bidirectional sets
就像双向包一样,双向集不使用链接表,并且子表具有引用父表主键的外键。生命周期就像双向包装袋一样,只是重复袋被过滤掉了。
例子 214.双向集合
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
private Set<Phone> phones = new HashSet<>();
//Getters and setters are omitted for brevity
public void addPhone(Phone phone) {
phones.add( phone );
phone.setPerson( this );
}
public void removePhone(Phone phone) {
phones.remove( phone );
phone.setPerson( null );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`", unique = true)
@NaturalId
private String number;
@ManyToOne
private Person person;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
2.8.7. 排序集
对于排序集,实体 Map 必须改为使用SortedSet接口。根据SortedSetContract,所有元素都必须实现Comparable接口,因此必须提供排序逻辑。
单向排序集
依赖于子元素Comparable实现逻辑给出的自然排序 Sequences 的SortedSet必须使用@SortNatural HibernateComments 进行 Comments。
例子 215.单向自然排序集
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@SortNatural
private SortedSet<Phone> phones = new TreeSet<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone implements Comparable<Phone> {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
@Override
public int compareTo(Phone o) {
return number.compareTo( o.getNumber() );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
生命周期和数据库 Map 与Unidirectional bags相同,因此有意省略了它们。
为了提供自定义的排序逻辑,Hibernate 还提供了@SortComparatorComments:
例子 216.单向定制比较器排序集
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@SortComparator(ReverseComparator.class)
private SortedSet<Phone> phones = new TreeSet<>();
//Getters and setters are omitted for brevity
}
public static class ReverseComparator implements Comparator<Phone> {
@Override
public int compare(Phone o1, Phone o2) {
return o2.compareTo( o1 );
}
}
@Entity(name = "Phone")
public static class Phone implements Comparable<Phone> {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
@Override
public int compareTo(Phone o) {
return number.compareTo( o.getNumber() );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
双向排序集
@SortNatural和@SortComparator对于双向排序集也相同:
例子 217.双向自然排序集
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@SortNatural
private SortedSet<Phone> phones = new TreeSet<>();
@SortComparator(ReverseComparator.class)
private SortedSet<Phone> phones = new TreeSet<>();
2.8.8. Maps
java.util.Map是三元关联,因为它需要一个父实体,一个 Map 键和一个值。取决于 Map,实体可以是 Map 键或 Map 值。 Hibernate 允许使用以下 Map 键:
MapKeyColumn- 对于值类型 Map,Map 键是链接表中的一列,用于定义分组逻辑
MapKey- Map 键是存储为 Map 条目值的实体的主键或其他属性
MapKeyEnumerated- Map 键是目标子实体的
Enum
- Map 键是目标子实体的
MapKeyTemporal- Map 键是目标子实体的
Date或Calendar
- Map 键是目标子实体的
MapKeyJoinColumn- Map 键是一个 Map 为关联关系的实体,该子实体存储为 Map 条目键
值类型 Map
值类型的 Map 必须使用@ElementCollection注解,就像值类型列表,包装袋或集合一样。
例子 218.以实体作为 Map 键的值类型 Map
public enum PhoneType {
LAND_LINE,
MOBILE
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@Temporal(TemporalType.TIMESTAMP)
@ElementCollection
@CollectionTable(name = "phone_register")
@Column(name = "since")
private Map<Phone, Date> phoneRegister = new HashMap<>();
//Getters and setters are omitted for brevity
}
@Embeddable
public static class Phone {
private PhoneType type;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE phone_register (
Person_id BIGINT NOT NULL ,
since TIMESTAMP ,
number VARCHAR(255) NOT NULL ,
type INTEGER NOT NULL ,
PRIMARY KEY ( Person_id, number, type )
)
ALTER TABLE phone_register
ADD CONSTRAINT FKrmcsa34hr68of2rq8qf526mlk
FOREIGN KEY (Person_id) REFERENCES Person
将条目添加到 Map 将生成以下 SQL 语句:
例子 219.添加值类型 Map 项
person.getPhoneRegister().put(
new Phone( PhoneType.LAND_LINE, "028-234-9876" ), new Date()
);
person.getPhoneRegister().put(
new Phone( PhoneType.MOBILE, "072-122-9876" ), new Date()
);
INSERT INTO phone_register (Person_id, number, type, since)
VALUES (1, '072-122-9876', 1, '2015-12-15 17:16:45.311')
INSERT INTO phone_register (Person_id, number, type, since)
VALUES (1, '028-234-9876', 0, '2015-12-15 17:16:45.311')
具有自定义键类型的 Map
Hibernate 定义了@MapKeyType注解,可用于自定义Map键类型。
考虑到数据库中有以下表:
create table person (
id int8 not null,
primary key (id)
)
create table call_register (
person_id int8 not null,
phone_number int4,
call_timestamp_epoch int8 not null,
primary key (person_id, call_timestamp_epoch)
)
alter table if exists call_register
add constraint FKsn58spsregnjyn8xt61qkxsub
foreign key (person_id)
references person
call_register记录每person的通话记录。 call_timestamp_epoch列将电话时间戳记存储为自 Unix 时代以来的 Unix 时间戳记。
Note
@MapKeyColumn注解用于定义保存键的表列,而@ColumnMap 给出所讨论的java.util.Map的值。
由于我们要通过关联的java.util.DateMap 所有调用,而不是从 epoch(即一个数字)开始按其时间戳 Map,因此实体 Map 如下所示:
例子 220. @MapKeyTypeMap 例子
@Entity
@Table(name = "person")
public static class Person {
@Id
private Long id;
@ElementCollection
@CollectionTable(
name = "call_register",
joinColumns = @JoinColumn(name = "person_id")
)
@MapKeyType(
@Type(
type = "org.hibernate.userguide.collections.type.TimestampEpochType"
)
)
@MapKeyColumn( name = "call_timestamp_epoch" )
@Column(name = "phone_number")
private Map<Date, Integer> callRegister = new HashMap<>();
//Getters and setters are omitted for brevity
}
关联的TimestampEpochType如下所示:
public class TimestampEpochType
extends AbstractSingleColumnStandardBasicType<Date>
implements VersionType<Date>, LiteralType<Date> {
public static final TimestampEpochType INSTANCE = new TimestampEpochType();
public TimestampEpochType() {
super(
BigIntTypeDescriptor.INSTANCE,
JdbcTimestampTypeDescriptor.INSTANCE
);
}
@Override
public String getName() {
return "epoch";
}
@Override
public Date next(
Date current,
SharedSessionContractImplementor session) {
return seed( session );
}
@Override
public Date seed(
SharedSessionContractImplementor session) {
return new Timestamp( System.currentTimeMillis() );
}
@Override
public Comparator<Date> getComparator() {
return getJavaTypeDescriptor().getComparator();
}
@Override
public String objectToSQLString(
Date value,
Dialect dialect) throws Exception {
final Timestamp ts = Timestamp.class.isInstance( value )
? ( Timestamp ) value
: new Timestamp( value.getTime() );
return StringType.INSTANCE.objectToSQLString(
ts.toString(), dialect
);
}
@Override
public Date fromStringValue(
String xml) throws HibernateException {
return fromString( xml );
}
}
TimestampEpochType允许我们将自 epoch 以来的 Unix 时间戳 Map 到java.util.Date。但是,如果没有@MapKeyType休眠 Comments,则无法自定义Map密钥类型。
以界面类型为键的 Map
考虑到您具有以下PhoneNumber接口以及MobilePhone类类型给出的实现:
例子 221. PhoneNumber接口和MobilePhone类类型
public interface PhoneNumber {
String get();
}
@Embeddable
public static class MobilePhone
implements PhoneNumber {
static PhoneNumber fromString(String phoneNumber) {
String[] tokens = phoneNumber.split( "-" );
if ( tokens.length != 3 ) {
throw new IllegalArgumentException( "invalid phone number: " + phoneNumber );
}
int i = 0;
return new MobilePhone(
tokens[i++],
tokens[i++],
tokens[i]
);
}
private MobilePhone() {
}
public MobilePhone(
String countryCode,
String operatorCode,
String subscriberCode) {
this.countryCode = countryCode;
this.operatorCode = operatorCode;
this.subscriberCode = subscriberCode;
}
@Column(name = "country_code")
private String countryCode;
@Column(name = "operator_code")
private String operatorCode;
@Column(name = "subscriber_code")
private String subscriberCode;
@Override
public String get() {
return String.format(
"%s-%s-%s",
countryCode,
operatorCode,
subscriberCode
);
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
MobilePhone that = (MobilePhone) o;
return Objects.equals( countryCode, that.countryCode ) &&
Objects.equals( operatorCode, that.operatorCode ) &&
Objects.equals( subscriberCode, that.subscriberCode );
}
@Override
public int hashCode() {
return Objects.hash( countryCode, operatorCode, subscriberCode );
}
}
如果要将PhoneNumber界面用作java.util.Map键,则还需要提供@MapKeyClassComments。
例子 222. @MapKeyClassMap 例子
@Entity
@Table(name = "person")
public static class Person {
@Id
private Long id;
@ElementCollection
@CollectionTable(
name = "call_register",
joinColumns = @JoinColumn(name = "person_id")
)
@MapKeyColumn( name = "call_timestamp_epoch" )
@MapKeyClass( MobilePhone.class )
@Column(name = "call_register")
private Map<PhoneNumber, Integer> callRegister = new HashMap<>();
//Getters and setters are omitted for brevity
}
create table person (
id bigint not null,
primary key (id)
)
create table call_register (
person_id bigint not null,
call_register integer,
country_code varchar(255) not null,
operator_code varchar(255) not null,
subscriber_code varchar(255) not null,
primary key (person_id, country_code, operator_code, subscriber_code)
)
alter table call_register
add constraint FKqyj2at6ik010jqckeaw23jtv2
foreign key (person_id)
references person
当插入包含 2 个MobilePhone引用的callRegister时,Hibernate 生成以下 SQL 语句:
例子 223. @MapKeyClass坚持的例子
Person person = new Person();
person.setId( 1L );
person.getCallRegister().put( new MobilePhone( "01", "234", "567" ), 101 );
person.getCallRegister().put( new MobilePhone( "01", "234", "789" ), 102 );
entityManager.persist( person );
insert into person (id) values (?)
-- binding parameter [1] as [BIGINT] - [1]
insert into call_register(
person_id,
country_code,
operator_code,
subscriber_code,
call_register
)
values
(?, ?, ?, ?, ?)
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [VARCHAR] - [01]
-- binding parameter [3] as [VARCHAR] - [234]
-- binding parameter [4] as [VARCHAR] - [789]
-- binding parameter [5] as [INTEGER] - [102]
insert into call_register(
person_id,
country_code,
operator_code,
subscriber_code,
call_register
)
values
(?, ?, ?, ?, ?)
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [VARCHAR] - [01]
-- binding parameter [3] as [VARCHAR] - [234]
-- binding parameter [4] as [VARCHAR] - [567]
-- binding parameter [5] as [INTEGER] - [101]
当获取Person并访问callRegister Map时,Hibernate 生成以下 SQL 语句:
例子 224. @MapKeyClass获取例子
Person person = entityManager.find( Person.class, 1L );
assertEquals( 2, person.getCallRegister().size() );
assertEquals(
Integer.valueOf( 101 ),
person.getCallRegister().get( MobilePhone.fromString( "01-234-567" ) )
);
assertEquals(
Integer.valueOf( 102 ),
person.getCallRegister().get( MobilePhone.fromString( "01-234-789" ) )
);
select
cr.person_id as person_i1_0_0_,
cr.call_register as call_reg2_0_0_,
cr.country_code as country_3_0_,
cr.operator_code as operator4_0_,
cr.subscriber_code as subscrib5_0_
from
call_register cr
where
cr.person_id = ?
-- binding parameter [1] as [BIGINT] - [1]
-- extracted value ([person_i1_0_0_] : [BIGINT]) - [1]
-- extracted value ([call_reg2_0_0_] : [INTEGER]) - [101]
-- extracted value ([country_3_0_] : [VARCHAR]) - [01]
-- extracted value ([operator4_0_] : [VARCHAR]) - [234]
-- extracted value ([subscrib5_0_] : [VARCHAR]) - [567]
-- extracted value ([person_i1_0_0_] : [BIGINT]) - [1]
-- extracted value ([call_reg2_0_0_] : [INTEGER]) - [102]
-- extracted value ([country_3_0_] : [VARCHAR]) - [01]
-- extracted value ([operator4_0_] : [VARCHAR]) - [234]
-- extracted value ([subscrib5_0_] : [VARCHAR]) - [789]
Unidirectional maps
单向 Map 仅从父侧公开父子关联。
以下示例显示了也使用@MapKeyTemporalComments 的单向 Map。Map 键是一个时间戳,它是从子实体表中获取的。
Note
@MapKey注解用于定义用作所讨论的java.util.Map的键的实体属性。
例子 225.单向 Map
public enum PhoneType {
LAND_LINE,
MOBILE
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinTable(
name = "phone_register",
joinColumns = @JoinColumn(name = "phone_id"),
inverseJoinColumns = @JoinColumn(name = "person_id"))
@MapKey(name = "since")
@MapKeyTemporal(TemporalType.TIMESTAMP)
private Map<Date, Phone> phoneRegister = new HashMap<>();
//Getters and setters are omitted for brevity
public void addPhone(Phone phone) {
phoneRegister.put( phone.getSince(), phone );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
private PhoneType type;
@Column(name = "`number`")
private String number;
private Date since;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
since TIMESTAMP ,
type INTEGER ,
PRIMARY KEY ( id )
)
CREATE TABLE phone_register (
phone_id BIGINT NOT NULL ,
person_id BIGINT NOT NULL ,
PRIMARY KEY ( phone_id, person_id )
)
ALTER TABLE phone_register
ADD CONSTRAINT FKc3jajlx41lw6clbygbw8wm65w
FOREIGN KEY (person_id) REFERENCES Phone
ALTER TABLE phone_register
ADD CONSTRAINT FK6npoomh1rp660o1b55py9ndw4
FOREIGN KEY (phone_id) REFERENCES Person
Bidirectional maps
像大多数双向关联一样,该关系由子方拥有,而父方是反向方,并且可以将其自身的状态转换传播到子实体。
在下面的示例中,您可以看到使用了@MapKeyEnumerated,以便Phone枚举成为 Map 键。
例子 226.双向 Map
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
@MapKey(name = "type")
@MapKeyEnumerated
private Map<PhoneType, Phone> phoneRegister = new HashMap<>();
//Getters and setters are omitted for brevity
public void addPhone(Phone phone) {
phone.setPerson( this );
phoneRegister.put( phone.getType(), phone );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
private PhoneType type;
@Column(name = "`number`")
private String number;
private Date since;
@ManyToOne
private Person person;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
since TIMESTAMP ,
type INTEGER ,
person_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT FKmw13yfsjypiiq0i1osdkaeqpg
FOREIGN KEY (person_id) REFERENCES Person
2.8.9. Arrays
在讨论数组时,重要的是要了解 SQL 数组类型与作为应用程序域模型的一部分 Map 的 Java 数组之间的区别。
并非所有数据库都实现 SQL-99 ARRAY 类型,因此,Hibernate 不支持本机数据库数组类型。
Hibernate 确实支持 Java 域模型中的数组 Map-在概念上与 MapList 相同。但是,重要的是要意识到,Hibernate 无法为实体数组提供延迟加载,因此,强烈建议使用 List 而不是数组来 Map 实体的“集合”。
2.8.10. 数组为二进制
默认情况下,Hibernate 将选择当前Dialect支持的 BINARY 类型。
例子 227.数组存储为二进制
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String[] phones;
//Getters and setters are omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL ,
phones VARBINARY(255) ,
PRIMARY KEY ( id )
)
Note
如果要将诸如String[]或int[]之类的数组 Map 到特定于数据库的数组类型(如 PostgreSQL integer[]或text[]),则需要编写一个自定义的 Hibernate Type。
请查看this article,以获取有关如何编写此类自定义休眠类型的示例。
2.8.11. 集合作为基本值类型
注意前面的所有示例如何将 collection 属性显式标记为ElementCollection,OneToMany或ManyToMany。未标记为此类的集合需要自定义的 Hibernate Type,并且集合元素必须存储在单个数据库列中。
有时这是有益的。考虑一个用例,例如VARCHAR列,它表示分隔的字符串列表/字符串集。
例子 228.以逗号分隔的集合
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@Type(type = "comma_delimited_strings")
private List<String> phones = new ArrayList<>();
public List<String> getPhones() {
return phones;
}
}
public class CommaDelimitedStringsJavaTypeDescriptor extends AbstractTypeDescriptor<List> {
public static final String DELIMITER = ",";
public CommaDelimitedStringsJavaTypeDescriptor() {
super(
List.class,
new MutableMutabilityPlan<List>() {
@Override
protected List deepCopyNotNull(List value) {
return new ArrayList( value );
}
}
);
}
@Override
public String toString(List value) {
return ( (List<String>) value ).stream().collect( Collectors.joining( DELIMITER ) );
}
@Override
public List fromString(String string) {
List<String> values = new ArrayList<>();
Collections.addAll( values, string.split( DELIMITER ) );
return values;
}
@Override
public <X> X unwrap(List value, Class<X> type, WrapperOptions options) {
return (X) toString( value );
}
@Override
public <X> List wrap(X value, WrapperOptions options) {
return fromString( (String) value );
}
}
public class CommaDelimitedStringsType extends AbstractSingleColumnStandardBasicType<List> {
public CommaDelimitedStringsType() {
super(
VarcharTypeDescriptor.INSTANCE,
new CommaDelimitedStringsJavaTypeDescriptor()
);
}
@Override
public String getName() {
return "comma_delimited_strings";
}
}
开发人员可以像今天到目前为止讨论的任何其他集合一样使用逗号分隔的集合,并且 Hibernate 将负责类型转换部分。集合本身的行为类似于任何其他基本值类型,因为其生命周期绑定到其所有者实体。
例子 229.用逗号分隔的集合生命周期
person.phones.add( "027-123-4567" );
person.phones.add( "028-234-9876" );
session.flush();
person.getPhones().remove( 0 );
INSERT INTO Person ( phones, id )
VALUES ( '027-123-4567,028-234-9876', 1 )
UPDATE Person
SET phones = '028-234-9876'
WHERE id = 1
有关开发自定义值类型 Map 的更多详细信息,请参见《 Hibernate 集成指南》。
2.8.12. 自定义集合类型
如果您希望使用List,Set或Map以外的其他集合类型(例如Queue),则必须使用自定义集合类型,如以下示例所示:
例子 230.定制集合 Map 例子
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@CollectionType( type = "org.hibernate.userguide.collections.type.QueueType")
private Collection<Phone> phones = new LinkedList<>();
//Constructors are omitted for brevity
public Queue<Phone> getPhones() {
return (Queue<Phone>) phones;
}
}
@Entity(name = "Phone")
public static class Phone implements Comparable<Phone> {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
@Override
public int compareTo(Phone o) {
return number.compareTo( o.getNumber() );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}
public class QueueType implements UserCollectionType {
@Override
public PersistentCollection instantiate(
SharedSessionContractImplementor session,
CollectionPersister persister) throws HibernateException {
return new PersistentQueue( session );
}
@Override
public PersistentCollection wrap(
SharedSessionContractImplementor session,
Object collection) {
return new PersistentQueue( session, (List) collection );
}
@Override
public Iterator getElementsIterator(Object collection) {
return ( (Queue) collection ).iterator();
}
@Override
public boolean contains(Object collection, Object entity) {
return ( (Queue) collection ).contains( entity );
}
@Override
public Object indexOf(Object collection, Object entity) {
int i = ( (List) collection ).indexOf( entity );
return ( i < 0 ) ? null : i;
}
@Override
public Object replaceElements(
Object original,
Object target,
CollectionPersister persister,
Object owner,
Map copyCache,
SharedSessionContractImplementor session)
throws HibernateException {
Queue result = (Queue) target;
result.clear();
result.addAll( (Queue) original );
return result;
}
@Override
public Object instantiate(int anticipatedSize) {
return new LinkedList<>();
}
}
public class PersistentQueue extends PersistentBag implements Queue {
public PersistentQueue(SharedSessionContractImplementor session) {
super( session );
}
public PersistentQueue(SharedSessionContractImplementor session, List list) {
super( session, list );
}
@Override
public boolean offer(Object o) {
return add(o);
}
@Override
public Object remove() {
return poll();
}
@Override
public Object poll() {
int size = size();
if(size > 0) {
Object first = get(0);
remove( 0 );
return first;
}
throw new NoSuchElementException();
}
@Override
public Object element() {
return peek();
}
@Override
public Object peek() {
return size() > 0 ? get( 0 ) : null;
}
}
Note
Queue接口未用于实体属性的原因是因为 Hibernate 仅允许以下类型:
java.util.Listjava.util.Setjava.util.Mapjava.util.SortedSetjava.util.SortedMap
但是,自定义收集类型仍然可以自定义,只要基本类型是上述持久性类型之一即可。
这样,Phone集合可用作java.util.Queue:
例子 231.定制集合的例子
Person person = entityManager.find( Person.class, 1L );
Queue<Phone> phones = person.getPhones();
Phone head = phones.peek();
assertSame(head, phones.poll());
assertEquals( 1, phones.size() );
2.9. 自然身份证
自然 ID 代表领域模型唯一标识符,在现实世界中也具有意义。即使自然 ID 不能成为好的主键(通常首选代理键),将其告知 Hibernate 仍然很有用。稍后我们将看到,Hibernate 提供了一个专用,高效的 API,用于通过其自然 ID 加载实体,就像它通过其标识符(PK)来加载实体一样。
2.9.1. 自然 IDMap
自然 ID 是根据一个或多个持久属性定义的。
例子 232.使用单个基本属性的自然 ID
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
@NaturalId
private String isbn;
//Getters and setters are omitted for brevity
}
例子 233.使用单个嵌入式属性的自然 ID
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
@NaturalId
@Embedded
private Isbn isbn;
//Getters and setters are omitted for brevity
}
@Embeddable
public static class Isbn implements Serializable {
private String isbn10;
private String isbn13;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Isbn isbn = (Isbn) o;
return Objects.equals( isbn10, isbn.isbn10 ) &&
Objects.equals( isbn13, isbn.isbn13 );
}
@Override
public int hashCode() {
return Objects.hash( isbn10, isbn13 );
}
}
例子 234.使用多个持久属性的自然 ID
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
@NaturalId
private String productNumber;
@NaturalId
@ManyToOne(fetch = FetchType.LAZY)
private Publisher publisher;
//Getters and setters are omitted for brevity
}
@Entity(name = "Publisher")
public static class Publisher implements Serializable {
@Id
private Long id;
private String name;
//Getters and setters are omitted for brevity
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Publisher publisher = (Publisher) o;
return Objects.equals( id, publisher.id ) &&
Objects.equals( name, publisher.name );
}
@Override
public int hashCode() {
return Objects.hash( id, name );
}
}
2.9.2. 自然 ID API
如前所述,Hibernate 提供了一个 API,用于通过关联的自然 ID 加载实体。这由通过 Session#byNaturalId 获得的org.hibernate.NaturalIdLoadAccessContract 表示。
Note
如果实体未定义自然 ID,则尝试通过其自然 ID 加载实体将引发异常。
例子 235.使用 NaturalIdLoadAccess
Book book = entityManager
.unwrap(Session.class)
.byNaturalId( Book.class )
.using( "isbn", "978-9730228236" )
.load();
Book book = entityManager
.unwrap(Session.class)
.byNaturalId( Book.class )
.using(
"isbn",
new Isbn(
"973022823X",
"978-9730228236"
) )
.load();
Book book = entityManager
.unwrap(Session.class)
.byNaturalId( Book.class )
.using("productNumber", "973022823X")
.using("publisher", publisher)
.load();
NaturalIdLoadAccess 提供了两种不同的方法来获取实体:
load()- 获取对实体的引用,确保实体状态已初始化。
getReference()- 获取对该实体的引用。状态可以初始化也可以不初始化。如果该实体已经与当前正在运行的 Session 相关联,则返回该引用(已加载或未加载)。如果该实体未在当前会话中加载并且该实体支持代理生成,则会生成并返回未初始化的代理,否则从数据库加载该实体并返回。
NaturalIdLoadAccess允许通过自然 ID 加载实体,同时应用悲观锁。有关锁定的其他详细信息,请参见Locking章。
我们将讨论自然 ID-可变性和缓存中 NaturalIdLoadAccess(setSynchronizationEnabled())上可用的最后一种方法。
由于前两个示例中的Book实体定义了“简单”自然 ID,因此我们可以按以下方式加载它们:
例子 236.通过简单的自然 ID 加载
Book book = entityManager
.unwrap(Session.class)
.bySimpleNaturalId( Book.class )
.load( "978-9730228236" );
Book book = entityManager
.unwrap(Session.class)
.bySimpleNaturalId( Book.class )
.load(
new Isbn(
"973022823X",
"978-9730228236"
)
);
在这里,我们看到了通过Session#bySimpleNaturalId()获得的org.hibernate.SimpleNaturalIdLoadAccessContract 的使用。
SimpleNaturalIdLoadAccess与NaturalIdLoadAccess类似,除了它没有定义 using 方法。相反,因为这些简单自然 ID 是仅基于一个属性定义的,所以我们可以直接将相应的自然 ID 属性值直接传递给load()和getReference()方法。
Note
如果实体未定义自然 ID,或者自然 ID 并非“简单”类型,则将在此处引发异常。
2.9.3. 自然 ID-可变性和缓存
自然 ID 可能是可变的或不可变的。默认情况下,@NaturalId注解标记不可变的自然 id 属性。不变的自然 ID 永远不会改变其值。
如果自然 ID 属性的值更改,则应改用@NaturalId(mutable = true)。
例子 237.可变自然 idMap
@Entity(name = "Author")
public static class Author {
@Id
private Long id;
private String name;
@NaturalId(mutable = true)
private String email;
//Getters and setters are omitted for brevity
}
在会话内,Hibernate 维护从自然 ID 值到实体标识符(PK)值的 Map。如果自然 id 值更改,则此 Map 可能会过时,直到发生刷新。
要解决此情况,Hibernate 将尝试发现任何此类未决更改,并在执行load()或getReference()方法时对其进行调整。需要明确的是:这仅与可变的自然 ID 有关。
Tip
发现和调整会对性能产生影响。如果确定没有任何与当前Session关联的可变自然 ID 发生变化,则可以通过调用setSynchronizationEnabled(false)(默认值为true)来禁用此检查。这将迫使 Hibernate 绕过对可变自然 ID 的检查。
例子 238.可变自然标识同步用例
Author author = entityManager
.unwrap(Session.class)
.bySimpleNaturalId( Author.class )
.load( "john@acme.com" );
author.setEmail( "john.doe@acme.com" );
assertNull(
entityManager
.unwrap(Session.class)
.bySimpleNaturalId( Author.class )
.setSynchronizationEnabled( false )
.load( "john.doe@acme.com" )
);
assertSame( author,
entityManager
.unwrap(Session.class)
.bySimpleNaturalId( Author.class )
.setSynchronizationEnabled( true )
.load( "john.doe@acme.com" )
);
如果启用了第二级缓存,不仅可以在 Session 中缓存此 NaturalId-to-PK 分辨率,还可以将其缓存在第二级缓存中。
例子 239.自然 id 缓存
@Entity(name = "Book")
@NaturalIdCache
public static class Book {
@Id
private Long id;
private String title;
private String author;
@NaturalId
private String isbn;
//Getters and setters are omitted for brevity
}
2.10. 动态模型
Tip
JPA 只承认实体模型 Map,因此,如果您担心 JPA 提供程序的可移植性,最好坚持使用严格的 POJO 模型。另一方面,Hibernate 可以同时使用 POJO 实体和动态实体模型。
2.10.1. 动态 Map 模型
持久性实体不一定必须表示为 POJO/JavaBean 类。 Hibernate 还支持动态模型(在运行时使用Map的Map)。使用这种方法,您不必编写持久性类,而只需编写 Map 文件。
给定实体在给定 SessionFactory 中只有一个实体模式。这是对先前版本的更改,以前的版本允许为实体定义多个实体模式并选择要加载的模式。实体模式现在可以在域模型中混合;动态实体可以引用 POJO 实体,反之亦然。
例子 240.动态域模型休眠 Map
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class entity-name="Book">
<id name="isbn" column="isbn" length="32" type="string"/>
<property name="title" not-null="true" length="50" type="string"/>
<property name="author" not-null="true" length="50" type="string"/>
</class>
</hibernate-mapping>
定义实体 Map 后,需要指示 Hibernate 使用动态 Map 模式:
例子 241.动态域模型休眠 Map
settings.put( "hibernate.default_entity_mode", "dynamic-map" );
当您要保存以下Book动态实体时,Hibernate 将生成以下 SQL 语句:
例子 242.持久化动态实体
Map<String, String> book = new HashMap<>();
book.put( "isbn", "978-9730228236" );
book.put( "title", "High-Performance Java Persistence" );
book.put( "author", "Vlad Mihalcea" );
entityManager
.unwrap(Session.class)
.save( "Book", book );
insert
into
Book
(title, author, isbn)
values
(?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [High-Performance Java Persistence]
-- binding parameter [2] as [VARCHAR] - [Vlad Mihalcea]
-- binding parameter [3] as [VARCHAR] - [978-9730228236]
Note
动态模型的主要优点是无需实体类实现即可快速进行原型开发。主要的缺点是您会丢失编译时类型检查,并且可能会在运行时处理许多异常。但是,由于使用了 HibernateMap,因此可以轻松地对数据库模式进行规范化和完善,从而允许稍后在顶部添加适当的域模型实现。
有趣的是,动态模型也适用于某些集成用例。例如,Envers 广泛使用动态模型来表示历史数据。
2.11. Inheritance
尽管关系数据库系统不提供对继承的支持,但是 Hibernate 提供了几种策略来将这种面向对象的 Feature 利用到域模型实体上:
MappedSuperclass
- 继承仅在域模型中实现,而没有在数据库模式中反映出来。参见MappedSuperclass。
Single table
- 域模型类层次结构被具体化为一个表,其中包含属于不同类类型的实体。参见Single table。
Joined table
- Base Class 和所有子类都有自己的数据库表,而获取子类实体也需要与父表进行联接。参见Joined table。
每班桌
- 每个子类都有自己的表,其中包含子类和 Base Class 属性。参见每班桌。
2.11.1. MappedSuperclass
在以下域模型类层次结构中,DebitAccount和CreditAccount共享相同的AccountBase Class。

使用MappedSuperclass时,继承仅在域模型中可见,并且每个数据库表都包含 Base Class 和子类属性。
例子 243. @MappedSuperclass继承
@MappedSuperclass
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
CREATE TABLE DebitAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
CREATE TABLE CreditAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
Note
由于@MappedSuperclass继承模型未在数据库级别进行镜像,因此在通过 Base Class 获取持久对象时,无法使用引用@MappedSuperclass的多态查询。
2.11.2. 单桌
单表继承策略将所有子类仅 Map 到一个数据库表。每个子类声明其自己的持久属性。假定版本和 id 属性是从根类继承的。
Note
当省略显式继承策略(例如@Inheritance)时,JPA 默认会选择SINGLE_TABLE策略。
例子 244.单表继承
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
CREATE TABLE Account (
DTYPE VARCHAR(31) NOT NULL ,
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
层次结构中的每个子类必须定义一个唯一的鉴别符值,该值用于区分属于单独子类类型的行。如果未指定,则DTYPE列用作区分符,并存储关联的子类名称。
例子 245.单表继承鉴别符列
DebitAccount debitAccount = new DebitAccount();
debitAccount.setId( 1L );
debitAccount.setOwner( "John Doe" );
debitAccount.setBalance( BigDecimal.valueOf( 100 ) );
debitAccount.setInterestRate( BigDecimal.valueOf( 1.5d ) );
debitAccount.setOverdraftFee( BigDecimal.valueOf( 25 ) );
CreditAccount creditAccount = new CreditAccount();
creditAccount.setId( 2L );
creditAccount.setOwner( "John Doe" );
creditAccount.setBalance( BigDecimal.valueOf( 1000 ) );
creditAccount.setInterestRate( BigDecimal.valueOf( 1.9d ) );
creditAccount.setCreditLimit( BigDecimal.valueOf( 5000 ) );
entityManager.persist( debitAccount );
entityManager.persist( creditAccount );
INSERT INTO Account (balance, interestRate, owner, overdraftFee, DTYPE, id)
VALUES (100, 1.5, 'John Doe', 25, 'DebitAccount', 1)
INSERT INTO Account (balance, interestRate, owner, creditLimit, DTYPE, id)
VALUES (1000, 1.9, 'John Doe', 5000, 'CreditAccount', 2)
使用多态查询时,只需要扫描一个表即可获取所有关联的子类实例。
例子 246.单表多态查询
List<Account> accounts = entityManager
.createQuery( "select a from Account a" )
.getResultList();
SELECT singletabl0_.id AS id2_0_ ,
singletabl0_.balance AS balance3_0_ ,
singletabl0_.interestRate AS interest4_0_ ,
singletabl0_.owner AS owner5_0_ ,
singletabl0_.overdraftFee AS overdraf6_0_ ,
singletabl0_.creditLimit AS creditLi7_0_ ,
singletabl0_.DTYPE AS DTYPE1_0_
FROM Account singletabl0_
Tip
在所有其他继承选择中,单表策略执行效果最好,因为它仅需要访问一个表。由于所有子类列都存储在单个表中,因此无法再使用 NOT NULL 约束,因此必须将完整性检查移入数据访问层或通过CHECK或TRIGGER约束进行强制。
Discriminator
discriminator 列包含标记值,这些值告诉持久性层要为特定行实例化的子类。 Hibernate Core 支持以下类型的受限集合作为区分符列:String,char,int,byte,short,boolean(包括yes_no,true_false)。
使用@DiscriminatorColumn定义“标识符”列以及标识符类型。
Note
javax.persistence.DiscriminatorColumn中使用的枚举DiscriminatorType仅包含值STRING,CHAR和INTEGER,这意味着并非所有 Hibernate 支持的类型都可以通过@DiscriminatorColumnComments 获得。您也可以使用@DiscriminatorFormula在 SQL 中表示虚拟区分符列。当可以从表的一列或多列中提取鉴别值时,这特别有用。 @DiscriminatorColumn和@DiscriminatorFormula都将在根实体上设置(每个持久化层次一次)。
@org.hibernate.annotations.DiscriminatorOptions允许有选择地指定特定于 Hibernate 的鉴别器选项,这些选项在 JPA 中未标准化。可用的选项是force和insert。
如果表包含带有* extra *区分符值且未 Map 到持久类的行,则force属性很有用。例如,在使用旧数据库时可能会发生这种情况。如果force设置为true,则即使在检索根类的所有实例时,Hibernate 也会在 SELECT 查询中指定允许的标识符值。
第二个选项insert告诉 Hibernate 在 SQL INSERT 中是否包括区分符列。通常,该列应该是 INSERT 语句的一部分,但是如果您的区分符列也是 Map 的复合标识符的一部分,则必须将此选项设置为false。
Tip
曾经有一个@org.hibernate.annotations.ForceDiscriminatorComments,该 Comments 在 3.6 版中已弃用,后来被删除。请改用@DiscriminatorOptions。
Discriminator formula
假设其中鉴别符基于检查特定列的传统数据库架构,我们可以利用 Hibernate 特定的@DiscriminatorFormulaComments 并按如下方式 Map 继承模型:
例子 247.单表鉴别符公式
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorFormula(
"case when debitKey is not null " +
"then 'Debit' " +
"else ( " +
" case when creditKey is not null " +
" then 'Credit' " +
" else 'Unknown' " +
" end ) " +
"end "
)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
@DiscriminatorValue(value = "Debit")
public static class DebitAccount extends Account {
private String debitKey;
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
@DiscriminatorValue(value = "Credit")
public static class CreditAccount extends Account {
private String creditKey;
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
CREATE TABLE Account (
id int8 NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
debitKey VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
creditKey VARCHAR(255) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
@DiscriminatorFormula定义了一个可用于标识特定子类类型的自定义 SQL 子句。 @DiscriminatorValue定义@DiscriminatorFormula的结果与继承子类类型之间的 Map。
隐式鉴别值
除了分配给每个单独的子类类型的常规区分符值之外,@DiscriminatorValue还可以采用两个附加值:
null- 如果基础鉴别符列为空,则将使用
null鉴别符 Map。
- 如果基础鉴别符列为空,则将使用
not null- 如果基础标识符列具有未为空的值,该值未明确 Map 到任何实体,则使用
not-null标识符 Map。
- 如果基础标识符列具有未为空的值,该值未明确 Map 到任何实体,则使用
要了解这两个值如何工作,请考虑以下实体 Map:
例子 248. @DiscriminatorValue null和not-null实体 Map
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorValue( "null" )
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
@DiscriminatorValue( "Debit" )
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
@DiscriminatorValue( "Credit" )
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
@Entity(name = "OtherAccount")
@DiscriminatorValue( "not null" )
public static class OtherAccount extends Account {
private boolean active;
//Getters and setters are omitted for brevity
}
Account类具有@DiscriminatorValue( "null" )Map,这意味着不包含任何鉴别符值的任何account行将被 Map 到AccountBase Class 实体。 DebitAccount和CreditAccount实体使用显式标识符值。 OtherAccount实体用作通用帐户类型,因为它会 Map 未将标识符列明确分配给当前继承树中任何其他实体的任何数据库行。
要可视化其工作方式,请考虑以下示例:
例子 249. @DiscriminatorValue null和not-null实体持久性
DebitAccount debitAccount = new DebitAccount();
debitAccount.setId( 1L );
debitAccount.setOwner( "John Doe" );
debitAccount.setBalance( BigDecimal.valueOf( 100 ) );
debitAccount.setInterestRate( BigDecimal.valueOf( 1.5d ) );
debitAccount.setOverdraftFee( BigDecimal.valueOf( 25 ) );
CreditAccount creditAccount = new CreditAccount();
creditAccount.setId( 2L );
creditAccount.setOwner( "John Doe" );
creditAccount.setBalance( BigDecimal.valueOf( 1000 ) );
creditAccount.setInterestRate( BigDecimal.valueOf( 1.9d ) );
creditAccount.setCreditLimit( BigDecimal.valueOf( 5000 ) );
Account account = new Account();
account.setId( 3L );
account.setOwner( "John Doe" );
account.setBalance( BigDecimal.valueOf( 1000 ) );
account.setInterestRate( BigDecimal.valueOf( 1.9d ) );
entityManager.persist( debitAccount );
entityManager.persist( creditAccount );
entityManager.persist( account );
entityManager.unwrap( Session.class ).doWork( connection -> {
try(Statement statement = connection.createStatement()) {
statement.executeUpdate(
"insert into Account (DTYPE, active, balance, interestRate, owner, id) " +
"values ('Other', true, 25, 0.5, 'Vlad', 4)"
);
}
} );
Map<Long, Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class )
.getResultList()
.stream()
.collect( Collectors.toMap( Account::getId, Function.identity()));
assertEquals(4, accounts.size());
assertEquals( DebitAccount.class, accounts.get( 1L ).getClass() );
assertEquals( CreditAccount.class, accounts.get( 2L ).getClass() );
assertEquals( Account.class, accounts.get( 3L ).getClass() );
assertEquals( OtherAccount.class, accounts.get( 4L ).getClass() );
INSERT INTO Account (balance, interestRate, owner, overdraftFee, DTYPE, id)
VALUES (100, 1.5, 'John Doe', 25, 'Debit', 1)
INSERT INTO Account (balance, interestRate, owner, overdraftFee, DTYPE, id)
VALUES (1000, 1.9, 'John Doe', 5000, 'Credit', 2)
INSERT INTO Account (balance, interestRate, owner, id)
VALUES (1000, 1.9, 'John Doe', 3)
INSERT INTO Account (DTYPE, active, balance, interestRate, owner, id)
VALUES ('Other', true, 25, 0.5, 'Vlad', 4)
SELECT a.id as id2_0_,
a.balance as balance3_0_,
a.interestRate as interest4_0_,
a.owner as owner5_0_,
a.overdraftFee as overdraf6_0_,
a.creditLimit as creditLi7_0_,
a.active as active8_0_,
a.DTYPE as DTYPE1_0_
FROM Account a
如您所见,Account实体行在DTYPE鉴别符列中的值为NULL,而OtherAccount实体以DTYPE列值other进行保存,该值没有显式 Map。
2.11.3. 联接表
每个子类也可以 Map 到其自己的表。这也称为“每个子表”Map 策略。通过与超类的表联接来检索继承的状态。
此 Map 策略不需要区分符列。但是,每个子类都必须声明一个包含对象标识符的表列。
例子 250.联接表
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.JOINED)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
CREATE TABLE Account (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE CreditAccount (
creditLimit NUMERIC(19, 2) ,
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE DebitAccount (
overdraftFee NUMERIC(19, 2) ,
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
ALTER TABLE CreditAccount
ADD CONSTRAINT FKihw8h3j1k0w31cnyu7jcl7n7n
FOREIGN KEY (id) REFERENCES Account
ALTER TABLE DebitAccount
ADD CONSTRAINT FKia914478noepymc468kiaivqm
FOREIGN KEY (id) REFERENCES Account
Note
CreditAccount和DebitAccount表的主键也是超类表主键的外键,由@PrimaryKeyJoinColumns描述。
表名仍默认为非限定的类名。另外,如果未设置@PrimaryKeyJoinColumn,则假定主键/外键列与超类的主表的主键列具有相同的名称。
例子 251.用@PrimaryKeyJoinColumn加入表
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.JOINED)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
@PrimaryKeyJoinColumn(name = "account_id")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
@PrimaryKeyJoinColumn(name = "account_id")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
CREATE TABLE CreditAccount (
creditLimit NUMERIC(19, 2) ,
account_id BIGINT NOT NULL ,
PRIMARY KEY ( account_id )
)
CREATE TABLE DebitAccount (
overdraftFee NUMERIC(19, 2) ,
account_id BIGINT NOT NULL ,
PRIMARY KEY ( account_id )
)
ALTER TABLE CreditAccount
ADD CONSTRAINT FK8ulmk1wgs5x7igo370jt0q005
FOREIGN KEY (account_id) REFERENCES Account
ALTER TABLE DebitAccount
ADD CONSTRAINT FK7wjufa570onoidv4omkkru06j
FOREIGN KEY (account_id) REFERENCES Account
使用多态查询时,必须将 Base Class 表与所有子类表连接在一起,以获取每个关联的子类实例。
例子 252.联接表多态查询
List<Account> accounts = entityManager
.createQuery( "select a from Account a" )
.getResultList();
SELECT jointablet0_.id AS id1_0_ ,
jointablet0_.balance AS balance2_0_ ,
jointablet0_.interestRate AS interest3_0_ ,
jointablet0_.owner AS owner4_0_ ,
jointablet0_1_.overdraftFee AS overdraf1_2_ ,
jointablet0_2_.creditLimit AS creditLi1_1_ ,
CASE WHEN jointablet0_1_.id IS NOT NULL THEN 1
WHEN jointablet0_2_.id IS NOT NULL THEN 2
WHEN jointablet0_.id IS NOT NULL THEN 0
END AS clazz_
FROM Account jointablet0_
LEFT OUTER JOIN DebitAccount jointablet0_1_ ON jointablet0_.id = jointablet0_1_.id
LEFT OUTER JOIN CreditAccount jointablet0_2_ ON jointablet0_.id = jointablet0_2_.id
Tip
联接的表继承多态查询可以使用多个 JOINS,这可能会在获取大量实体时影响性能。
2.11.4. 每班桌
第三种选择是仅将继承层次结构的具体类 Map 到表。这称为每个具体表的策略。每个表定义该类的所有持久状态,包括继承状态。
在 Hibernate 中,不必显式 Map 此类继承层次结构。您可以将每个类 Map 为单独的实体根。但是,如果您希望使用多态关联(例如,与层次结构超类的关联),则需要使用并集子类 Map。
例子 253.每个类的表
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
//Getters and setters are omitted for brevity
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
//Getters and setters are omitted for brevity
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
//Getters and setters are omitted for brevity
}
CREATE TABLE Account (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE CreditAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
CREATE TABLE DebitAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
使用多态查询时,还需要 UNION 来获取 Base Class 表以及所有子类表。
例子 254.每个类的表多态查询
List<Account> accounts = entityManager
.createQuery( "select a from Account a" )
.getResultList();
SELECT tablepercl0_.id AS id1_0_ ,
tablepercl0_.balance AS balance2_0_ ,
tablepercl0_.interestRate AS interest3_0_ ,
tablepercl0_.owner AS owner4_0_ ,
tablepercl0_.overdraftFee AS overdraf1_2_ ,
tablepercl0_.creditLimit AS creditLi1_1_ ,
tablepercl0_.clazz_ AS clazz_
FROM (
SELECT id ,
balance ,
interestRate ,
owner ,
CAST(NULL AS INT) AS overdraftFee ,
CAST(NULL AS INT) AS creditLimit ,
0 AS clazz_
FROM Account
UNION ALL
SELECT id ,
balance ,
interestRate ,
owner ,
overdraftFee ,
CAST(NULL AS INT) AS creditLimit ,
1 AS clazz_
FROM DebitAccount
UNION ALL
SELECT id ,
balance ,
interestRate ,
owner ,
CAST(NULL AS INT) AS overdraftFee ,
creditLimit ,
2 AS clazz_
FROM CreditAccount
) tablepercl0_
Tip
多态查询需要多个 UNION 查询,因此请注意大型类层次结构对性能的影响。
不幸的是,并非所有数据库系统都支持 UNION ALL,在这种情况下,将使用 UNION 代替 UNION ALL。
以下 Hibernate 方言支持 UNION ALL:
AbstractHANADialectAbstractTransactSQLDialectCUBRIDDialectDB2DialectH2DialectHSQLDialectIngres9DialectMySQL5DialectOracle8iDialectOracle9DialectPostgreSQL81DialectRDMSOS2200Dialect
2.11.5. 隐式和显式多态
默认情况下,当您查询 Base Class 实体时,多态查询将获取属于该 Base Class 型的所有子类。
但是,您甚至可以查询**不属于 JPA 实体继承模型的接口或 Base Class。
例如,考虑以下DomainModelEntity接口:
例子 255. DomainModelEntity 接口
public interface DomainModelEntity<ID> {
ID getId();
Integer getVersion();
}
如果我们有两个实体 MapBook和Blog,并且Blog实体使用@Polymorphism注解并采用PolymorphismType.EXPLICIT设置进行 Map:
例子 256. @Polymorphism实体 Map
@Entity(name = "Event")
public static class Book implements DomainModelEntity<Long> {
@Id
private Long id;
@Version
private Integer version;
private String title;
private String author;
//Getter and setters omitted for brevity
}
@Entity(name = "Blog")
@Polymorphism(type = PolymorphismType.EXPLICIT)
public static class Blog implements DomainModelEntity<Long> {
@Id
private Long id;
@Version
private Integer version;
private String site;
//Getter and setters omitted for brevity
}
如果我们的系统中有以下实体对象:
例子 257.域模型实体对象
Book book = new Book();
book.setId( 1L );
book.setAuthor( "Vlad Mihalcea" );
book.setTitle( "High-Performance Java Persistence" );
entityManager.persist( book );
Blog blog = new Blog();
blog.setId( 1L );
blog.setSite( "vladmihalcea.com" );
entityManager.persist( blog );
现在,我们可以针对DomainModelEntity接口进行查询,并且 Hibernate 将仅获取用@Polymorphism(type = PolymorphismType.IMPLICIT)Map 的实体,或者根本不使用@PolymorphismComments 对其进行 Comments 的实体(暗示 IMPLICIT 行为):
例子 258.使用非 MapBase Class 多态性获取域模型实体
List<DomainModelEntity> accounts = entityManager
.createQuery(
"select e " +
"from org.hibernate.userguide.inheritance.polymorphism.DomainModelEntity e" )
.getResultList();
assertEquals(1, accounts.size());
assertTrue( accounts.get( 0 ) instanceof Book );
因此,由于Blog实体被标记了@Polymorphism(type = PolymorphismType.EXPLICIT)Comments,因此仅获取了Book,这指示 Hibernate 在对未 Map 的 Base Class 执行多态查询时跳过它。
2.12. Immutability
可以为实体和集合指定不变性。
2.12.1. 实体不变性
如果特定实体是不可变的,则最好使用@Immutable注解对其进行标记。
例子 259.不变的实体
@Entity(name = "Event")
@Immutable
public static class Event {
@Id
private Long id;
private Date createdOn;
private String message;
//Getters and setters are omitted for brevity
}
在内部,Hibernate 将执行一些优化,例如:
减少内存占用,因为脏检查机制无需保持脱水状态
由于不可变实体可以跳过脏检查过程,因此可以加快持久性上下文刷新阶段的速度
考虑以下实体保留在数据库中:
例子 260.持久化一个不变的实体
doInJPA( this::entityManagerFactory, entityManager -> {
Event event = new Event();
event.setId( 1L );
event.setCreatedOn( new Date( ) );
event.setMessage( "Hibernate User Guide rocks!" );
entityManager.persist( event );
} );
加载实体并尝试更改其状态时,Hibernate 将跳过任何修改,因此不会执行任何 SQL UPDATE语句。
例子 261.不可变实体忽略任何更新
doInJPA( this::entityManagerFactory, entityManager -> {
Event event = entityManager.find( Event.class, 1L );
log.info( "Change event message" );
event.setMessage( "Hibernate User Guide" );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
Event event = entityManager.find( Event.class, 1L );
assertEquals("Hibernate User Guide rocks!", event.getMessage());
} );
SELECT e.id AS id1_0_0_,
e.createdOn AS createdO2_0_0_,
e.message AS message3_0_0_
FROM event e
WHERE e.id = 1
-- Change event message
SELECT e.id AS id1_0_0_,
e.createdOn AS createdO2_0_0_,
e.message AS message3_0_0_
FROM event e
WHERE e.id = 1
2.12.2. 集合不变性
就像实体一样,集合也可以用@ImmutableComments 标记。
考虑以下实体 Map:
例子 262.不可变的集合
@Entity(name = "Batch")
public static class Batch {
@Id
private Long id;
private String name;
@OneToMany(cascade = CascadeType.ALL)
@Immutable
private List<Event> events = new ArrayList<>( );
//Getters and setters are omitted for brevity
}
@Entity(name = "Event")
@Immutable
public static class Event {
@Id
private Long id;
private Date createdOn;
private String message;
//Getters and setters are omitted for brevity
}
这次,不仅Event实体是不可变的,而且Batch父实体存储的Event集合也是不可变的。一旦创建了不可变集合,就永远不能对其进行修改。
例子 263.持久化一个不可变的集合
doInJPA( this::entityManagerFactory, entityManager -> {
Batch batch = new Batch();
batch.setId( 1L );
batch.setName( "Change request" );
Event event1 = new Event();
event1.setId( 1L );
event1.setCreatedOn( new Date( ) );
event1.setMessage( "Update Hibernate User Guide" );
Event event2 = new Event();
event2.setId( 2L );
event2.setCreatedOn( new Date( ) );
event2.setMessage( "Update Hibernate Getting Started Guide" );
batch.getEvents().add( event1 );
batch.getEvents().add( event2 );
entityManager.persist( batch );
} );
Batch实体是可变的。只有events集合是不可变的。
例如,我们仍然可以修改实体名称:
例子 264.改变可变实体
doInJPA( this::entityManagerFactory, entityManager -> {
Batch batch = entityManager.find( Batch.class, 1L );
log.info( "Change batch name" );
batch.setName( "Proposed change request" );
} );
SELECT b.id AS id1_0_0_,
b.name AS name2_0_0_
FROM Batch b
WHERE b.id = 1
-- Change batch name
UPDATE batch
SET name = 'Proposed change request'
WHERE id = 1
但是,在尝试修改events集合时:
例子 265.不可变集合不能被修改
try {
doInJPA( this::entityManagerFactory, entityManager -> {
Batch batch = entityManager.find( Batch.class, 1L );
batch.getEvents().clear();
} );
}
catch ( Exception e ) {
log.error( "Immutable collections cannot be modified" );
}
javax.persistence.RollbackException: Error while committing the transaction
Caused by: javax.persistence.PersistenceException: org.hibernate.HibernateException:
Caused by: org.hibernate.HibernateException: changed an immutable collection instance: [
org.hibernate.userguide.immutability.CollectionImmutabilityTest$Batch.events#1
]
Tip
尽管不可变的实体更改被简单地丢弃,但修改不可变的集合将导致抛出HibernateException。
3. Bootstrap
引导是指初始化和启动软件组件。在 Hibernate 中,我们专门讨论为 JPA 构建功能齐全的SessionFactory实例或EntityManagerFactory实例的过程。每个过程都非常不同。
Tip
在引导过程中,您可能需要自定义 Hibernate 行为,因此请确保同时选中Configurations部分。
3.1. 本机引导
本节讨论引导 Hibernate SessionFactory的过程。具体来说,它解决了 5.0 中重新设计的自举 API。有关旧版自举 API 的讨论,请参见Legacy Bootstrapping。
3.1.1. 构建服务注册表
本机引导的第一步是构建一个ServiceRegistry,以保存 Hibernate 在引导期间和运行时所需的服务。
实际上,我们关心构建两个不同的 ServiceRegistries。首先是org.hibernate.boot.registry.BootstrapServiceRegistry。 BootstrapServiceRegistry用于保存 Hibernate 在引导和运行时所需的服务。这归结为 3 种服务:
org.hibernate.boot.registry.classloading.spi.ClassLoaderService- 该控件控制 Hibernate 与
ClassLoaders 交互的方式。
- 该控件控制 Hibernate 与
org.hibernate.integrator.spi.IntegratorService- 控制
org.hibernate.integrator.spi.Integrator实例的 Management 和发现。
- 控制
org.hibernate.boot.registry.selector.spi.StrategySelector- 它控制了 Hibernate 如何解决各种战略 Contract 的实现。这是一项非常强大的服务,但是对其的完整讨论不在本指南的范围之内。
Note
如果您对这些BootstrapServiceRegistry服务的默认行为是 Hibernate 满意(这是常见的情况,尤其是在独立环境中),则无需显式构建BootstrapServiceRegistry。
如果您想更改BootstrapServiceRegistry的构建方式,则可以通过org.hibernate.boot.registry.BootstrapServiceRegistryBuilder进行控制:
例子 266.控制BootstrapServiceRegistry构建
BootstrapServiceRegistryBuilder bootstrapRegistryBuilder =
new BootstrapServiceRegistryBuilder();
// add a custom ClassLoader
bootstrapRegistryBuilder.applyClassLoader( customClassLoader );
// manually add an Integrator
bootstrapRegistryBuilder.applyIntegrator( customIntegrator );
BootstrapServiceRegistry bootstrapRegistry = bootstrapRegistryBuilder.build();
Note
BootstrapServiceRegistry的服务不能扩展(添加到)或覆盖(替换)。
第二个 ServiceRegistry 是org.hibernate.boot.registry.StandardServiceRegistry。您几乎总是需要配置StandardServiceRegistry,这是通过org.hibernate.boot.registry.StandardServiceRegistryBuilder完成的:
例子 267.构建一个BootstrapServiceRegistryBuilder
// An example using an implicitly built BootstrapServiceRegistry
StandardServiceRegistryBuilder standardRegistryBuilder =
new StandardServiceRegistryBuilder();
// An example using an explicitly built BootstrapServiceRegistry
BootstrapServiceRegistry bootstrapRegistry =
new BootstrapServiceRegistryBuilder().build();
StandardServiceRegistryBuilder standardRegistryBuilder =
new StandardServiceRegistryBuilder( bootstrapRegistry );
StandardServiceRegistry也可以通过 StandardServiceRegistryBuilder API 进行高度配置。有关更多详细信息,请参见StandardServiceRegistryBuilder Javadocs。
一些感兴趣的特定方法:
例子 268.配置一个MetadataSources
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
// alternatively, we can build the MetadataSources without passing
// a service registry, in which case it will build a default
// BootstrapServiceRegistry to use. But the approach shown
// above is preferred
// MetadataSources sources = new MetadataSources();
// add a class using JPA/Hibernate annotations for mapping
sources.addAnnotatedClass( MyEntity.class );
// add the name of a class using JPA/Hibernate annotations for mapping.
// differs from above in that accessing the Class is deferred which is
// important if using runtime bytecode-enhancement
sources.addAnnotatedClassName( "org.hibernate.example.Customer" );
// Read package-level metadata.
sources.addPackage( "hibernate.example" );
// Read package-level metadata.
sources.addPackage( MyEntity.class.getPackage() );
// Adds the named hbm.xml resource as a source: which performs the
// classpath lookup and parses the XML
sources.addResource( "org/hibernate/example/Order.hbm.xml" );
// Adds the named JPA orm.xml resource as a source: which performs the
// classpath lookup and parses the XML
sources.addResource( "org/hibernate/example/Product.orm.xml" );
// Read all mapping documents from a directory tree.
// Assumes that any file named *.hbm.xml is a mapping document.
sources.addDirectory( new File( ".") );
// Read mappings from a particular XML file
sources.addFile( new File( "./mapping.xml") );
// Read all mappings from a jar file.
// Assumes that any file named *.hbm.xml is a mapping document.
sources.addJar( new File( "./entities.jar") );
// Read a mapping as an application resource using the convention that a class named foo.bar.MyEntity is
// mapped by a file named foo/bar/MyEntity.hbm.xml which can be resolved as a classpath resource.
sources.addClass( MyEntity.class );
3.1.2. 事件监听器注册
org.hibernate.integrator.spi.Integrator现在的主要用例是注册事件侦听器并提供服务(请参阅org.hibernate.integrator.spi.ServiceContributingIntegrator)。在 5.0 版本中,我们计划进行扩展,以允许更改描述对象模型和关系模型之间 Map 的元模型。
例子 269.配置一个事件监听器
public class MyIntegrator implements org.hibernate.integrator.spi.Integrator {
@Override
public void integrate(
Metadata metadata,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// As you might expect, an EventListenerRegistry is the thing with which event
// listeners are registered
// It is a service so we look it up using the service registry
final EventListenerRegistry eventListenerRegistry =
serviceRegistry.getService( EventListenerRegistry.class );
// If you wish to have custom determination and handling of "duplicate" listeners,
// you would have to add an implementation of the
// org.hibernate.event.service.spi.DuplicationStrategy contract like this
eventListenerRegistry.addDuplicationStrategy( new CustomDuplicationStrategy() );
// EventListenerRegistry defines 3 ways to register listeners:
// 1) This form overrides any existing registrations with
eventListenerRegistry.setListeners( EventType.AUTO_FLUSH,
DefaultAutoFlushEventListener.class );
// 2) This form adds the specified listener(s) to the beginning of the listener chain
eventListenerRegistry.prependListeners( EventType.PERSIST,
DefaultPersistEventListener.class );
// 3) This form adds the specified listener(s) to the end of the listener chain
eventListenerRegistry.appendListeners( EventType.MERGE,
DefaultMergeEventListener.class );
}
@Override
public void disintegrate(
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
}
}
3.1.3. 构建元数据
本机引导的第二步是构建org.hibernate.boot.Metadata对象,该对象包含应用程序域模型的已解析表示形式及其到数据库的 Map。我们显然需要构建解析表示形式的第一件事是要解析的源信息(带 Comments 的类,hbm.xml文件,orm.xml文件)。这是org.hibernate.boot.MetadataSources的目的。
MetadataSources还有许多其他方法。探索其 API 和Javadocs以获取更多信息。同样,MetadataSources上的所有方法都提供 Fluent 的样式的调用链:
例子 270.用方法链接配置MetadataSources
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry )
.addAnnotatedClass( MyEntity.class )
.addAnnotatedClassName( "org.hibernate.example.Customer" )
.addResource( "org/hibernate/example/Order.hbm.xml" )
.addResource( "org/hibernate/example/Product.orm.xml" );
一旦定义了 Map 信息的来源,就需要构建Metadata对象。如果您对构建元数据的默认行为没意见,那么您只需调用MetadataSources的buildMetadata方法即可。
Note
请注意,在此引导过程中,可以在多个点传递ServiceRegistry。建议的方法是自己构建一个StandardServiceRegistry并将其传递给MetadataSources构造函数。从那里,MetadataBuilder,Metadata,SessionFactoryBuilder和SessionFactory都将拾取相同的StandardServiceRegistry。
但是,如果要调整从MetadataSources构建Metadata的过程,则需要使用通过MetadataSources#getMetadataBuilder获得的MetadataBuilder。 MetadataBuilder可以对Metadata构建过程进行很多控制。有关完整的详细信息,请参见其Javadocs。
例子 271.通过MetadataBuilder构建元数据
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
MetadataBuilder metadataBuilder = sources.getMetadataBuilder();
// Use the JPA-compliant implicit naming strategy
metadataBuilder.applyImplicitNamingStrategy(
ImplicitNamingStrategyJpaCompliantImpl.INSTANCE );
// specify the schema name to use for tables, etc when none is explicitly specified
metadataBuilder.applyImplicitSchemaName( "my_default_schema" );
// specify a custom Attribute Converter
metadataBuilder.applyAttributeConverter( myAttributeConverter );
Metadata metadata = metadataBuilder.build();
3.1.4. 构建 SessionFactory
本机引导的最后一步是构建SessionFactory本身。与上面讨论的非常相似,如果您可以从Metadata引用构建SessionFactory的默认行为可以,则只需在Metadata对象上调用buildSessionFactory方法即可。
但是,如果您要调整该构建过程,则需要使用__,它是通过Metadata#getSessionFactoryBuilder获得的。同样,请参见其Javadocs以获取更多详细信息。
例子 272.本机引导-将它们放在一起
StandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder()
.configure( "org/hibernate/example/hibernate.cfg.xml" )
.build();
Metadata metadata = new MetadataSources( standardRegistry )
.addAnnotatedClass( MyEntity.class )
.addAnnotatedClassName( "org.hibernate.example.Customer" )
.addResource( "org/hibernate/example/Order.hbm.xml" )
.addResource( "org/hibernate/example/Product.orm.xml" )
.getMetadataBuilder()
.applyImplicitNamingStrategy( ImplicitNamingStrategyJpaCompliantImpl.INSTANCE )
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.applyBeanManager( getBeanManager() )
.build();
自举 API 非常灵活,但是在大多数情况下,将其视为一个三步过程是最有意义的:
构建
StandardServiceRegistry构建
Metadata使用那 2 个来构建
SessionFactory
例子 273.通过SessionFactoryBuilder构建SessionFactory
StandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder()
.configure( "org/hibernate/example/hibernate.cfg.xml" )
.build();
Metadata metadata = new MetadataSources( standardRegistry )
.addAnnotatedClass( MyEntity.class )
.addAnnotatedClassName( "org.hibernate.example.Customer" )
.addResource( "org/hibernate/example/Order.hbm.xml" )
.addResource( "org/hibernate/example/Product.orm.xml" )
.getMetadataBuilder()
.applyImplicitNamingStrategy( ImplicitNamingStrategyJpaCompliantImpl.INSTANCE )
.build();
SessionFactoryBuilder sessionFactoryBuilder = metadata.getSessionFactoryBuilder();
// Supply a SessionFactory-level Interceptor
sessionFactoryBuilder.applyInterceptor( new CustomSessionFactoryInterceptor() );
// Add a custom observer
sessionFactoryBuilder.addSessionFactoryObservers( new CustomSessionFactoryObserver() );
// Apply a CDI BeanManager ( for JPA event listeners )
sessionFactoryBuilder.applyBeanManager( getBeanManager() );
SessionFactory sessionFactory = sessionFactoryBuilder.build();
3.2. JPA 引导
将 Hibernate 作为 JPA 提供程序进行引导可以通过符合 JPA 规范的方式或使用专有的引导方法来完成。标准化方法在某些环境中有一些限制,但除此以外,强烈建议您使用 JPA 标准化的引导程序。
3.2.1. 符合 JPA 的自举
在 JPA 中,我们最终对引导javax.persistence.EntityManagerFactory实例感兴趣。 JPA 规范定义了两种主要的标准化引导程序方法,具体取决于应用程序打算如何从EntityManagerFactory访问javax.persistence.EntityManager实例。
对于这两种方法,它使用* EE 和 SE *术语,但是这些术语在这种情况下极具误导性。 JPA 规范所谓的 EE 引导意味着存在容器(EE,OSGi 等),该容器将代表应用程序 Management 和注入持久性上下文。它所谓的 SE 自举是其他所有内容。在本指南中,我们将使用术语容器引导和应用程序引导。
对于兼容的容器引导,容器将为META-INF/persistence.xml配置文件中定义的每个持久单元构建一个EntityManagerFactory,并通过javax.persistence.PersistenceUnitComments 或通过 JNDI 查找将其提供给应用程序以进行注入。
例子 274.注入默认的EntityManagerFactory
@PersistenceUnit
private EntityManagerFactory emf;
或者,如果您有多个持久性单元(例如,多个persistence.xml配置文件),则可以按单元名称注入特定的EntityManagerFactory:
例子 275.注入一个特定的EntityManagerFactory
@PersistenceUnit(
unitName = "CRM"
)
private EntityManagerFactory entityManagerFactory;
META-INF/persistence.xml文件如下所示:
例子 276. META-INF/persistence.xml 配置文件
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd"
version="2.1">
<persistence-unit name="CRM">
<description>
Persistence unit for Hibernate User Guide
</description>
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>org.hibernate.documentation.userguide.Document</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE" />
<property name="javax.persistence.jdbc.user"
value="sa" />
<property name="javax.persistence.jdbc.password"
value="" />
<property name="hibernate.show_sql"
value="true" />
<property name="hibernate.hbm2ddl.auto"
value="update" />
</properties>
</persistence-unit>
</persistence>
对于合规的应用程序引导,而不是使用为应用程序构建EntityManagerFactory的容器,应用程序使用javax.persistence.Persistence bootstrap 类构建EntityManagerFactory本身。应用程序通过调用createEntityManagerFactory方法来创建EntityManagerFactory:
例子 277.应用程序引导了EntityManagerFactory
// Create an EMF for our CRM persistence-unit.
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "CRM" );
Note
如果您不想提供persistence.xml配置文件,则 JPA 允许您在PersistenceUnitInfo实现中提供所有配置选项并调用HibernatePersistenceProvider.html#createContainerEntityManagerFactory。
要注入默认的持久性上下文,可以使用@PersistenceContext注解。
例子 278.注入默认的EntityManager
@PersistenceContext
private EntityManager em;
要注入特定的持久性上下文,可以使用@PersistenceContextComments,甚至可以使用@PersistencePropertyComments 传递EntityManager的特定属性。
例子 279.注入一个可配置的EntityManager
@PersistenceContext(
unitName = "CRM",
properties = {
@PersistenceProperty(
name="org.hibernate.flushMode",
value= "MANUAL"
)
}
)
private EntityManager entityManager;
Note
如果您想获得有关访问和使用EntityManager实例的更多详细信息,JPA 2.1 规范的 7.6 和 7.7 节分别介绍了容器 Management 的和应用程序 Management 的EntityManagers。
3.2.2. 外部化 XMLMap 文件
JPA 提供了两个 Map 选项:
annotations
XML mappings
尽管 Comments 更为常见,但在某些项目中首选 XMLMap。您甚至可以混合使用 Comments 和 XMLMap,以便可以使用可以轻松更改而无需重新编译项目源代码的 XML 配置覆盖 CommentsMap。这是可能的,因为如果存在两个冲突的 Map,则 XMLMap 将优先于其对应的 Comments。
JPA 规范要求 XMLMap 位于 Classpath 上:
Note
可以在持久性单元根目录的META-INF目录中或persistence.xml引用的任何 jar 文件的META-INF目录中指定名为orm.xml的对象/关系 MapXML 文件。
替代地或另外,持久性单元元素的 Map 文件元素可以引用一个或多个 Map 文件。这些 Map 文件可能存在于 Classpath 上的任何位置。
— JPA 2.1 规范的第 8.2.1.6.2 节
因此,Map 文件可以驻留在应用程序 jar 工件中,或者可以将它们存储在外部文件夹位置中,因为该位置已包含在 Classpath 中。
Hibernate 在这方面更为宽大,因此您甚至可以在应用程序配置的 Classpath 之外使用任何外部位置。
例子 280.用于外部 XMLMap 的 META-INF/persistence.xml 配置文件
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd"
version="2.1">
<persistence-unit name="CRM">
<description>
Persistence unit for Hibernate User Guide
</description>
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<mapping-file>file:///etc/opt/app/mappings/orm.xml</mapping-file>
<properties>
<property name="javax.persistence.jdbc.driver"
value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE" />
<property name="javax.persistence.jdbc.user"
value="sa" />
<property name="javax.persistence.jdbc.password"
value="" />
<property name="hibernate.show_sql"
value="true" />
<property name="hibernate.hbm2ddl.auto"
value="update" />
</properties>
</persistence-unit>
</persistence>
在上面的persistence.xml配置文件中,包含所有 JPA 实体 Map 的orm.xml XML 文件位于/etc/opt/app/mappings/文件夹中。
3.2.3. 通过 JPA 引导程序配置 SessionFactory 元数据
如前所述,Hibernate 本机引导机制允许您自定义通过Metadata对象传递的各种配置。
将 Hibernate 用作 JPA 提供程序时,EntityManagerFactory由SessionFactory支持。因此,您可能仍想使用Metadata对象传递各种设置,而这些设置不能通过标准的 Hibernate configuration settings提供。
因此,可以使用MetadataBuilderContributor类,如以下示例所示。
例子 281.实现一个MetadataBuilderContributor
public class SqlFunctionMetadataBuilderContributor
implements MetadataBuilderContributor {
@Override
public void contribute(MetadataBuilder metadataBuilder) {
metadataBuilder.applySqlFunction(
"instr", new StandardSQLFunction( "instr", StandardBasicTypes.STRING )
);
}
}
上面的MetadataBuilderContributor用于注册SqlFuction,它不是由当前运行的 Hibernate Dialect定义的,但是我们需要在 JPQL 查询中引用它。
通过访问底层SessionFactory使用的MetadataBuilder类,JPA 引导程序变得与 Hibernate 本机引导程序机制一样灵活。
然后,您可以按照Configuration chapter中的说明通过hibernate.metadata_builder_contributor配置属性传递自定义MetadataBuilderContributor。
4.模式生成
Hibernate 允许您从实体 Map 生成数据库。
Tip
尽管自动模式生成对于测试和原型设计非常有用,但是在生产环境中,使用增量迁移脚本来 Management 模式更加灵活。
传统上,从实体 Map 生成架构的过程称为HBM2DDL。要获取 Hibernate 本地和 JPA 特定配置属性的列表,请考虑阅读Configurations部分。
考虑以下域模型:
例子 282.模式生成域模型
@Entity(name = "Customer")
public class Customer {
@Id
private Integer id;
private String name;
@Basic( fetch = FetchType.LAZY )
private UUID accountsPayableXrefId;
@Lob
@Basic( fetch = FetchType.LAZY )
@LazyGroup( "lobs" )
private Blob image;
//Getters and setters are omitted for brevity
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "author")
private List<Book> books = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
@ManyToOne
private Person author;
//Getters and setters are omitted for brevity
}
如果hibernate.hbm2ddl.auto配置设置为create,则 Hibernate 将生成以下数据库架构:
例子 283.自动生成的数据库模式
create table Customer (
id integer not null,
accountsPayableXrefId binary,
image blob,
name varchar(255),
primary key (id)
)
create table Book (
id bigint not null,
isbn varchar(255),
title varchar(255),
author_id bigint,
primary key (id)
)
create table Person (
id bigint not null,
name varchar(255),
primary key (id)
)
alter table Book
add constraint UK_u31e1frmjp9mxf8k8tmp990i unique (isbn)
alter table Book
add constraint FKrxrgiajod1le3gii8whx2doie
foreign key (author_id)
references Person
4.1. 导入脚本文件
要自定义模式生成过程,必须使用hibernate.hbm2ddl.import_files配置属性来提供启动SessionFactory时 Hibernate 可以使用的其他脚本文件。
例如,考虑以下schema-generation.sql导入文件:
例子 284.模式生成导入文件
create sequence book_sequence start with 1 increment by 1
如果我们将 Hibernate 配置为导入上面的脚本:
例子 285.启用模式生成导入文件
<property
name="hibernate.hbm2ddl.import_files"
value="schema-generation.sql" />
模式自动生成后,Hibernate 将执行脚本文件。
4.2. 数据库对象
Hibernate 允许您通过 HBM database-object元素来自定义模式生成过程。
考虑以下 HBMMap:
例子 286.模式生成 HBM 数据库对象
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd" >
<hibernate-mapping>
<database-object>
<create>
CREATE OR REPLACE FUNCTION sp_count_books(
IN authorId bigint,
OUT bookCount bigint)
RETURNS bigint AS
$BODY$
BEGIN
SELECT COUNT(*) INTO bookCount
FROM book
WHERE author_id = authorId;
END;
$BODY$
LANGUAGE plpgsql;
</create>
<drop></drop>
<dialect-scope name="org.hibernate.dialect.PostgreSQL95Dialect" />
</database-object>
</hibernate-mapping>
引导SessionFactory时,Hibernate 将执行database-object,因此将创建sp_count_books函数。
4.3. 数据库级检查
Hibernate 提供了@Check注解,以便您可以指定一个任意的 SQL CHECK 约束,该约束可以定义如下:
例子 287.数据库检查实体 Map 例子
@Entity(name = "Book")
@Check( constraints = "CASE WHEN isbn IS NOT NULL THEN LENGTH(isbn) = 13 ELSE true END")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
private Double price;
//Getters and setters omitted for brevity
}
现在,如果您尝试添加一个具有isbn属性且长度不为 13 个字符的Book实体,则将抛出ConstraintViolationException。
例子 288.数据库检查失败的例子
Book book = new Book();
book.setId( 1L );
book.setPrice( 49.99d );
book.setTitle( "High-Performance Java Persistence" );
book.setIsbn( "11-11-2016" );
entityManager.persist( book );
INSERT INTO Book (isbn, price, title, id)
VALUES ('11-11-2016', 49.99, 'High-Performance Java Persistence', 1)
-- WARN SqlExceptionHelper:129 - SQL Error: 0, SQLState: 23514
-- ERROR SqlExceptionHelper:131 - ERROR: new row for relation "book" violates check constraint "book_isbn_check"
4.4. 数据库列的默认值
使用 Hibernate,您可以使用@ColumnDefaultComments 为给定的数据库列指定默认值。
例子 289. @ColumnDefaultMap 例子
@Entity(name = "Person")
@DynamicInsert
public static class Person {
@Id
private Long id;
@ColumnDefault("'N/A'")
private String name;
@ColumnDefault("-1")
private Long clientId;
//Getter and setters omitted for brevity
}
CREATE TABLE Person (
id BIGINT NOT NULL,
clientId BIGINT DEFAULT -1,
name VARCHAR(255) DEFAULT 'N/A',
PRIMARY KEY (id)
)
在上面的 Map 中,name和clientId表列都将使用DEFAULT值。
Note
上面的Person实体带有@DynamicInsertComments,因此INSERT语句不包含任何不包含值的实体属性。
这样,当省略name和clientId属性时,数据库将根据其默认值进行设置。
例子 290. @ColumnDefaultMap 例子
doInJPA( this::entityManagerFactory, entityManager -> {
Person person = new Person();
person.setId( 1L );
entityManager.persist( person );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
Person person = entityManager.find( Person.class, 1L );
assertEquals( "N/A", person.getName() );
assertEquals( Long.valueOf( -1L ), person.getClientId() );
} );
INSERT INTO Person (id) VALUES (?)
4.5. 列唯一约束
@UniqueConstraintComments 用于为与当前带 Comments 的实体相关联的主表或辅助表指定唯一的约束,该约束将由自动模式生成器包括在内。
考虑以下实体 Map,Hibernate 在创建数据库模式时会生成唯一约束 DDL:
例子 291. @UniqueConstraintMap 例子
@Entity
@Table(
name = "book",
uniqueConstraints = @UniqueConstraint(
name = "uk_book_title_author",
columnNames = {
"title",
"author_id"
}
)
)
public static class Book {
@Id
@GeneratedValue
private Long id;
private String title;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(
name = "author_id",
foreignKey = @ForeignKey(name = "fk_book_author_id")
)
private Author author;
//Getter and setters omitted for brevity
}
@Entity
@Table(name = "author")
public static class Author {
@Id
@GeneratedValue
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
//Getter and setters omitted for brevity
}
create table author (
id bigint not null,
first_name varchar(255),
last_name varchar(255),
primary key (id)
)
create table book (
id bigint not null,
title varchar(255),
author_id bigint,
primary key (id)
)
alter table book
add constraint uk_book_title_author
unique (title, author_id)
alter table book
add constraint fk_book_author_id
foreign key (author_id)
references author
有了uk_book_title_author唯一性约束,就不再可能添加具有相同标题和同一作者的两本书。
例子 292.@UniqueConstraintTest持续的例子
Author _author = doInJPA( this::entityManagerFactory, entityManager -> {
Author author = new Author();
author.setFirstName( "Vlad" );
author.setLastName( "Mihalcea" );
entityManager.persist( author );
Book book = new Book();
book.setTitle( "High-Performance Java Persistence" );
book.setAuthor( author );
entityManager.persist( book );
return author;
} );
try {
doInJPA( this::entityManagerFactory, entityManager -> {
Book book = new Book();
book.setTitle( "High-Performance Java Persistence" );
book.setAuthor( _author );
entityManager.persist( book );
} );
}
catch (Exception expected) {
assertNotNull( ExceptionUtil.findCause( expected, ConstraintViolationException.class ) );
}
insert
into
author
(first_name, last_name, id)
values
(?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [Vlad]
-- binding parameter [2] as [VARCHAR] - [Mihalcea]
-- binding parameter [3] as [BIGINT] - [1]
insert
into
book
(author_id, title, id)
values
(?, ?, ?)
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [VARCHAR] - [High-Performance Java Persistence]
-- binding parameter [3] as [BIGINT] - [2]
insert
into
book
(author_id, title, id)
values
(?, ?, ?)
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [VARCHAR] - [High-Performance Java Persistence]
-- binding parameter [3] as [BIGINT] - [3]
-- SQL Error: 23505, SQLState: 23505
-- Unique index or primary key violation: "UK_BOOK_TITLE_AUTHOR_INDEX_1 ON PUBLIC.BOOK(TITLE, AUTHOR_ID) VALUES ( /* key:1 */ 3, 'High-Performance Java Persistence', 1)";
由于唯一约束冲突,第二条 INSERT 语句失败。
4.6. 列索引
自动化模式生成工具使用@IndexComments 来创建数据库索引。
考虑以下实体 Map。 Hibernate 在创建数据库模式时会生成索引:
例子 293. @IndexMap 例子
@Entity
@Table(
name = "author",
indexes = @Index(
name = "idx_author_first_last_name",
columnList = "first_name, last_name",
unique = false
)
)
public static class Author {
@Id
@GeneratedValue
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
//Getter and setters omitted for brevity
}
create table author (
id bigint not null,
first_name varchar(255),
last_name varchar(255),
primary key (id)
)
create index idx_author_first_last_name
on author (first_name, last_name)
5.持久性上下文
org.hibernate.Session API 和javax.persistence.EntityManager API 均表示用于处理持久性数据的上下文。这个概念称为persistence context。持久性数据具有与持久性上下文和基础数据库有关的状态。
transient- 该实体刚刚被实例化,并且未与持久性上下文关联。它在数据库中没有持久性表示形式,并且通常没有分配标识符值(除非使用* assigned *生成器)。
managed或persistent- 该实体具有关联的标识符,并且与持久性上下文关联。它可能已经存在,也可能尚未物理存在于数据库中。
detached- 实体具有关联的标识符,但不再与持久性上下文关联(通常是因为持久性上下文已关闭或实例已从上下文中退出)
removed- 该实体具有关联的标识符,并且与持久性上下文关联,但是已安排将其从数据库中删除。
org.hibernate.Session和javax.persistence.EntityManager方法中的大多数都处理这些状态之间的移动实体。
5.1. 从 JPA 访问 Hibernate API
JPA 定义了一种非常有用的方法,以允许应用程序访问基础提供程序的 API。
例子 294.从 JPA 访问 Hibernate API
Session session = entityManager.unwrap( Session.class );
SessionImplementor sessionImplementor = entityManager.unwrap( SessionImplementor.class );
SessionFactory sessionFactory = entityManager.getEntityManagerFactory().unwrap( SessionFactory.class );
5.2. 字节码增强
休眠“长大了”根本不支持字节码增强。当时,Hibernate 仅支持基于代理的延迟加载替代方案,并且始终使用基于差异的脏计算。 Hibernate 3.x 首次尝试在 Hibernate 中支持字节码增强。我们将这些最初的尝试(直至 5.0)完全视为一次孵化。从 5.0 开始对字节码增强的支持就是我们在这里讨论的内容。
5.2.1. Capabilities
Hibernate 支持增强应用程序 Java 域模型,以将各种与持久性相关的功能直接添加到类中。
延迟加载属性
将此视为部分加载支持。从本质上讲,您可以告诉 Hibernate 在从数据库中获取时仅应加载实体的一部分,以及何时应加载其他部分。请注意,这与基于代理的延迟加载思想非常不同,后者以实体为中心,在这种情况下,根据需要立即加载实体的状态。通过字节码增强,可以根据需要加载单个属性或属性组。
可以将惰性属性指定为一起加载,这称为“惰性组”。默认情况下,所有奇异属性都是单个组的一部分,这意味着当访问一个惰性奇异属性时,将加载所有惰性奇异属性。默认情况下,惰性复数属性本身都是惰性组。此行为可通过@org.hibernate.annotations.LazyGroupComments 显式控制。
例子 295.@LazyGroup例子
@Entity
public class Customer {
@Id
private Integer id;
private String name;
@Basic( fetch = FetchType.LAZY )
private UUID accountsPayableXrefId;
@Lob
@Basic( fetch = FetchType.LAZY )
@LazyGroup( "lobs" )
private Blob image;
//Getters and setters are omitted for brevity
}
在上面的示例中,我们有 2 个惰性属性:accountsPayableXrefId和image。每一个都是不同的访存组的一部分(accountsPayableXrefId 是默认访存组的一部分),这意味着访问accountsPayableXrefId不会强制加载image属性,反之亦然。
Note
作为希望的临时遗留保留,当前要求所有惰性单数关联(多对一和一对一)也包括@LazyToOne(LazyToOneOption.NO_PROXY)。计划是稍后放宽该要求。
在线脏跟踪
从历史上看,Hibernate 仅支持基于差异的脏计算来确定持久性上下文中的哪些实体已更改。从本质上讲,这意味着 Hibernate 将跟踪有关数据库的实体的最后一个已知状态(通常是最后一次读取或写入)。然后,作为刷新持久性上下文的一部分,Hibernate 将遍历与持久性上下文关联的每个实体,并针对该“最新已知数据库状态”检查其当前状态。到目前为止,这是进行脏检查的最彻底的方法,因为它考虑了可以更改其内部状态的数据类型(java.util.Date是这种情况的主要示例)。但是,在具有大量关联实体的持久性上下文中,它也可能是抑制性能的方法。
如果您的应用程序不需要关心“内部状态更改数据类型”用例,则字节码增强的脏跟踪可能是值得考虑的替代方法,尤其是在性能方面。在这种方法中,Hibernate 将操纵您的类的字节码以直接向实体添加“脏污跟踪”,从而使实体本身可以跟踪其属性中的哪些已更改。在刷新期间,Hibernate 会询问您的实体发生了什么变化,而不必执行状态差异计算。
双向关联 Management
Hibernate 努力使您的应用程序尽可能接近“正常 Java 使用率”(惯用 Java)。考虑具有正常的Person/Book双向关联的域模型:
例子 296.双向关联
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "author")
private List<Book> books = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
@ManyToOne
private Person author;
//Getters and setters are omitted for brevity
}
例子 297.不正确的普通 Java 用法
Person person = new Person();
person.setName( "John Doe" );
Book book = new Book();
person.getBooks().add( book );
try {
book.getAuthor().getName();
}
catch (NullPointerException expected) {
// This blows up ( NPE ) in normal Java usage
}
这在正常的 Java 使用中会爆炸。正确的常规 Java 用法是:
例子 298.正确的使用 Java
Person person = new Person();
person.setName( "John Doe" );
Book book = new Book();
person.getBooks().add( book );
book.setAuthor( person );
book.getAuthor().getName();
字节码增强的双向关联 Management 通过操纵双向关联的“另一侧”来使第一个示例起作用。
内部绩效优化
此外,我们使用增强过程添加了一些其他代码,这些代码使我们能够优化持久性上下文的某些性能 Feature。不深入讨论 Hibernate 内部原理,就很难讨论这些内容。
5.2.2. 执行增强
Runtime enhancement
当前,仅在遵循 JPA 定义的 SPI 来执行类转换的托管 JPA 环境中支持域模型的运行时增强。
即使这样,默认情况下也会禁用此支持。要启用运行时增强,请指定以下配置属性之一:
hibernate.enhancer.enableDirtyTracking(例如true或false(默认值))- 在运行时字节码增强中启用脏跟踪功能。
hibernate.enhancer.enableLazyInitialization(例如true或false(默认值))- 在运行时字节码增强中启用延迟加载功能。这样,即使是基本类型(例如
@Basic(fetch = FetchType.LAZY)也可以延迟获取。
- 在运行时字节码增强中启用延迟加载功能。这样,即使是基本类型(例如
hibernate.enhancer.enableAssociationManagement(例如true或false(默认值))- 在运行时字节码增强中启用关联 Management 功能,当仅更改一侧时,该功能会自动同步双向关联。
Note
另外,目前,只有带 Comments 的类支持运行时增强。
Gradle plugin
Hibernate 提供了一个 Gradle 插件,当它们作为 Gradle 构建的一部分进行编译时,它能够提供域模型的构建时增强。要使用该插件,项目首先需要应用它:
例子 299.应用 Gradle 插件
apply plugin: 'org.hibernate.orm'
ext {
hibernateVersion = 'hibernate-version-you-want'
}
buildscript {
dependencies {
classpath "org.hibernate:hibernate-gradle-plugin:$hibernateVersion"
}
}
hibernate {
enhance {
enableLazyInitialization = true
enableDirtyTracking = true
enableAssociationManagement = true
}
}
可用的配置通过已注册的 Gradle DSL 扩展公开:
enableLazyInitialization
- 是否应该对延迟属性加载进行增强。
enableDirtyTracking
- 是否应该对自脏跟踪进行增强。
enableAssociationManagement
- 是否应进行双向关联 Management 的增强。
所有 3 个配置设置的默认值为false。
需要enhance { }块才能进行增强。默认情况下,禁用增强功能以准备插件中的附加功能(hbm2ddl 等)。
Maven plugin
Hibernate 提供了一个 Maven 插件,能够在将域模型作为 Maven 构建的一部分进行编译时提供构建时增强。有关配置设置的详细信息,请参见Gradle plugin上的部分。同样,这 3 个默认值是false。
Maven 插件支持一种附加的配置设置:failOnError,它控制发生错误时的情况。默认行为是使构建失败,但是可以将其设置为仅发出警告。
例子 300.应用 Maven 插件
<build>
<plugins>
[...]
<plugin>
<groupId>org.hibernate.orm.tooling</groupId>
<artifactId>hibernate-enhance-maven-plugin</artifactId>
<version>$currentHibernateVersion</version>
<executions>
<execution>
<configuration>
<failOnError>true</failOnError>
<enableLazyInitialization>true</enableLazyInitialization>
<enableDirtyTracking>true</enableDirtyTracking>
<enableAssociationManagement>true</enableAssociationManagement>
</configuration>
<goals>
<goal>enhance</goal>
</goals>
</execution>
</executions>
</plugin>
[...]
</plugins>
</build>
5.3. 使实体持久化
一旦创建了新的实体实例(使用标准的new运算符),它就处于new状态。您可以通过将其与org.hibernate.Session或javax.persistence.EntityManager关联来使其持久化。
例子 301.使用 JPA 使实体持久化
Person person = new Person();
person.setId( 1L );
person.setName("John Doe");
entityManager.persist( person );
例子 302.使用 Hibernate API 使实体持久化
Person person = new Person();
person.setId( 1L );
person.setName("John Doe");
session.save( person );
org.hibernate.Session还有一个名为 persist 的方法,该方法遵循 JPA 规范中为 persist 方法定义的确切语义。 Hibernate javax.persistence.EntityManager实现委托的是此org.hibernate.Session方法。
如果DomesticCat实体类型具有生成的标识符,则在调用 save 或 persist 时,该值与实例相关联。如果没有自动生成标识符,则在调用 save 或 persist 方法之前,必须在实例上设置手动分配的(通常是自然的)键值。
5.4. 删除(删除)实体
实体也可以删除。
例子 303.用 JPA 删除一个实体
entityManager.remove( person );
例子 304.用 Hibernate API 删除一个实体
session.delete( person );
Note
Hibernate 本身可以处理处于分离状态的删除实体。但是,JPA 不允许这种行为。
这里的含义是,传递给org.hibernate.Session delete 方法的实体实例可以处于托管或分离状态,而传递给javax.persistence.EntityManager上的 remove 的实体实例必须处于托管状态。
5.5. 获取实体引用而不初始化其数据
有时称为延迟加载,在无需加载其数据的情况下获取对实体的引用的能力非常重要。最常见的情况是需要在一个实体和另一个现有实体之间创建关联。
例子 305.获得一个实体引用而不用 JPA 初始化它的数据
Book book = new Book();
book.setAuthor( entityManager.getReference( Person.class, personId ) );
例子 306.在不使用 Hibernate API 初始化其数据的情况下获得实体引用
Book book = new Book();
book.setId( 1L );
book.setIsbn( "123-456-7890" );
entityManager.persist( book );
book.setAuthor( session.load( Person.class, personId ) );
上面的假设是,通常通过使用运行时代理将实体定义为允许延迟加载。在这两种情况下,如果在应用程序尝试以任何需要访问其数据的方式来使用返回的代理时,如果给定实体未引用实际的数据库状态,则会在以后引发异常。
Tip
除非实体类声明为final,否则代理将扩展实体类。如果实体类为final,则代理将改为实现接口。有关更多信息,请参见@Proxy mapping部分。
5.6. 获取其数据已初始化的实体
想要与数据一起获得实体也是很常见的(例如,当我们需要在 UI 中显示实体时)。
例子 307.获得一个实体引用,其实体数据用 JPA 初始化
Person person = entityManager.find( Person.class, personId );
例子 308.获得一个实体引用,其数据用 Hibernate API 初始化
Person person = session.get( Person.class, personId );
例子 309.获得一个实体引用,其实体数据使用byId() Hibernate API 初始化
Person person = session.byId( Person.class ).load( personId );
在这两种情况下,如果都找不到匹配的数据库行,则返回 null。
也可以返回 Java 8 Optional:
例子 310.获得一个可选实体引用,其数据使用byId() Hibernate API 初始化
Optional<Person> optionalPerson = session.byId( Person.class ).loadOptional( personId );
5.7. 通过标识符获取多个实体
如果要通过提供其标识符来加载多个实体,则多次调用EntityManager#find方法不仅不方便,而且效率低下。
尽管 JPA 标准不支持一次检索多个实体(除了运行 JPQL 或 Criteria API 查询),但 Hibernate 通过 Hibernate Session的byMultipleIds method提供了此功能。
byMultipleIds方法返回一个MultiIdentifierLoadAccess,您可以使用MultiIdentifierLoadAccess来定制多加载请求。
MultiIdentifierLoadAccess界面提供了几种方法,可用于更改多负载调用的行为:
enableOrderedReturn(boolean enabled)- 此设置控制返回的
List是否相对于传入 ID 进行排序和位置。如果启用(默认设置),则返回List的 Sequences 和位置相对于传入 ID。换句话说,对multiLoad([2,1,3])的请求将返回[Entity#2, Entity#1, Entity#3]。
- 此设置控制返回的
在此方面,根据此“有序return”设置,在处理未知实体方面存在重要区别。如果启用,则将 NULL 插入List的适当位置。如果禁用,则不将空值放入返回列表中。
换句话说,返回的有序列表的使用者将需要能够处理空元素。
enableSessionCheck(boolean enabled)- 此设置默认情况下处于禁用状态,它告诉 Hibernate 首先检查一级缓存(又名
Session或 Persistence Context),如果该实体已找到并已由 HibernateSessionManagement,则该缓存的实体将添加到返回的实体中。List,因此跳过了通过多负载查询获取它的操作。
- 此设置默认情况下处于禁用状态,它告诉 Hibernate 首先检查一级缓存(又名
enableReturnOfDeletedEntities(boolean enabled)- 如果允许多次加载操作,则此设置指示 Hibernate 返回被当前持久性上下文删除的实体。删除的实体是已传递给此
Session.delete或Session.remove方法的实体,但尚未刷新Session,这意味着未在数据库表中删除关联的行。
- 如果允许多次加载操作,则此设置指示 Hibernate 返回被当前持久性上下文删除的实体。删除的实体是已传递给此
默认行为是在返回中将它们作为 null 处理(请参见enableOrderedReturn)。启用后,结果集将包含已删除的实体。禁用时(这是默认行为),删除的实体不包含在返回的List中。
with(LockOptions lockOptions)- 此设置允许您将给定的LockOptions模式传递给多负载查询。
with(CacheMode cacheMode)- 此设置允许您传递给定的CacheMode策略,以便我们可以从二级缓存中加载实体,因此跳过了通过多加载查询获取的缓存实体。
withBatchSize(int batchSize)- 此设置可让您指定用于加载实体的批量大小(例如,一次加载多少个)。
默认设置是使用Dialect.getDefaultBatchLoadSizingStrategy()方法定义的批量大小调整策略。
此处的任何大于 1 的值都将覆盖该默认行为。
with(RootGraph<T> graph)RootGraph是 JPAEntityGraphContract 的 Hibernate 扩展,该方法允许您将特定的RootGraph传递给多加载查询,以便它可以获取当前加载实体的其他关系。
现在,假设我们在数据库中有 3 个Person实体,我们可以通过一次调用将它们全部加载,如以下示例所示:
例子 311.使用byMultipleIds() Hibernate API 加载多个实体
Session session = entityManager.unwrap( Session.class );
List<Person> persons = session
.byMultipleIds( Person.class )
.multiLoad( 1L, 2L, 3L );
assertEquals( 3, persons.size() );
List<Person> samePersons = session
.byMultipleIds( Person.class )
.enableSessionCheck( true )
.multiLoad( 1L, 2L, 3L );
assertEquals( persons, samePersons );
SELECT p.id AS id1_0_0_,
p.name AS name2_0_0_
FROM Person p
WHERE p.id IN ( 1, 2, 3 )
注意,由于第二次调用使用MultiIdentifierLoadAccess的enableSessionCheck方法来指示 Hibernate 跳过当前持久性上下文中已经加载的实体,因此仅执行了一条 SQL SELECT 语句。
如果这些实体在当前的持久性上下文中不可用,但可以从第二级缓存中加载,则可以使用MultiIdentifierLoadAccess对象的with(CacheMode)方法。
例子 312.从第二级缓存加载多个实体
SessionFactory sessionFactory = entityManagerFactory().unwrap( SessionFactory.class );
Statistics statistics = sessionFactory.getStatistics();
sessionFactory.getCache().evictAll();
statistics.clear();
sqlStatementInterceptor.clear();
assertEquals( 0, statistics.getQueryExecutionCount() );
doInJPA( this::entityManagerFactory, entityManager -> {
Session session = entityManager.unwrap( Session.class );
List<Person> persons = session
.byMultipleIds( Person.class )
.multiLoad( 1L, 2L, 3L );
assertEquals( 3, persons.size() );
} );
assertEquals( 0, statistics.getSecondLevelCacheHitCount() );
assertEquals( 3, statistics.getSecondLevelCachePutCount() );
assertEquals( 1, sqlStatementInterceptor.getSqlQueries().size() );
doInJPA( this::entityManagerFactory, entityManager -> {
Session session = entityManager.unwrap( Session.class );
sqlStatementInterceptor.clear();
List<Person> persons = session.byMultipleIds( Person.class )
.with( CacheMode.NORMAL )
.multiLoad( 1L, 2L, 3L );
assertEquals( 3, persons.size() );
} );
assertEquals( 3, statistics.getSecondLevelCacheHitCount() );
assertEquals( 0, sqlStatementInterceptor.getSqlQueries().size() );
在上面的示例中,我们首先确保清除二级缓存,以证明多负载查询会将返回的实体放入二级缓存中。
在执行第一个byMultipleIds调用之后,Hibernate 将获取请求的实体,并且如getSecondLevelCachePutCount方法调用所示,确实将 3 个实体添加到共享缓存中。
然后,当在新的 Hibernate Session中对相同实体执行第二个byMultipleIds调用时,我们设置CacheMode.NORMAL二级缓存模式,以便实体将从二级缓存中返回。
getSecondLevelCacheHitCount统计信息方法这次返回 3,因为这 3 个实体是从二级缓存中加载的,并且如sqlStatementInterceptor.getSqlQueries()所示,这次没有执行多负载 SELECT 语句。
5.8. 通过 natural-id 获取实体
除了允许通过其标识符加载实体之外,Hibernate 还允许应用程序pass 语句的自然标识符加载实体。
例子 313.自然-idMap
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
@ManyToOne
private Person author;
//Getters and setters are omitted for brevity
}
当使用自然标识符加载方法时,我们还可以选择获取实体或仅检索对其的引用。
例子 314.通过简单的自然 id 获得实体引用
Book book = session.bySimpleNaturalId( Book.class ).getReference( isbn );
例子 315.通过自然标识加载实体
Book book = session
.byNaturalId( Book.class )
.using( "isbn", isbn )
.load( );
我们还可以使用 Java 8 Optional通过其自然 ID 加载实体:
例子 316.通过自然标识加载一个可选的实体
Optional<Book> optionalBook = session
.byNaturalId( Book.class )
.using( "isbn", isbn )
.loadOptional( );
Hibernate 提供了一个一致的 API,用于按标识符或按自然 ID 访问持久数据。这些中的每一个都定义了相同的两种数据访问方法:
getReference
- 应该在假定标识符存在的情况下使用,不存在将是实际错误。永远不要用来测试存在。这是因为,如果数据尚未与 Session 关联,而不是访问数据库,则此方法将更喜欢创建并返回代理。使用此方法的典型用例是创建基于外键的关联。
load
- 将返回与给定标识符值关联的持久性数据;如果该标识符不存在,则返回 null。
这两个方法中的每一个都定义一个接受org.hibernate.LockOptions参数的重载变量。锁定在单独的chapter中讨论。
5.9. 过滤实体和关联
如果要过滤实体或实体关联,Hibernate 提供了两个选项:
静态(例如
@Where和@WhereJoinTable)- 它们在 Map 时定义,并且无法在运行时更改。
动态(例如
@Filter和@FilterJoinTable)- 在运行时应用和配置。
5.9.1. @Where
有时,您想使用自定义 SQL 条件过滤掉实体或集合。这可以使用@Where注解来实现,该注解可以应用于实体和集合。
例子 317. @WhereMap 用法
public enum AccountType {
DEBIT,
CREDIT
}
@Entity(name = "Client")
public static class Client {
@Id
private Long id;
private String name;
@Where( clause = "account_type = 'DEBIT'")
@OneToMany(mappedBy = "client")
private List<Account> debitAccounts = new ArrayList<>( );
@Where( clause = "account_type = 'CREDIT'")
@OneToMany(mappedBy = "client")
private List<Account> creditAccounts = new ArrayList<>( );
//Getters and setters omitted for brevity
}
@Entity(name = "Account")
@Where( clause = "active = true" )
public static class Account {
@Id
private Long id;
@ManyToOne
private Client client;
@Column(name = "account_type")
@Enumerated(EnumType.STRING)
private AccountType type;
private Double amount;
private Double rate;
private boolean active;
//Getters and setters omitted for brevity
}
如果数据库包含以下实体:
例子 318.用@WhereMap 持久化和获取实体
doInJPA( this::entityManagerFactory, entityManager -> {
Client client = new Client();
client.setId( 1L );
client.setName( "John Doe" );
entityManager.persist( client );
Account account1 = new Account( );
account1.setId( 1L );
account1.setType( AccountType.CREDIT );
account1.setAmount( 5000d );
account1.setRate( 1.25 / 100 );
account1.setActive( true );
account1.setClient( client );
client.getCreditAccounts().add( account1 );
entityManager.persist( account1 );
Account account2 = new Account( );
account2.setId( 2L );
account2.setType( AccountType.DEBIT );
account2.setAmount( 0d );
account2.setRate( 1.05 / 100 );
account2.setActive( false );
account2.setClient( client );
client.getDebitAccounts().add( account2 );
entityManager.persist( account2 );
Account account3 = new Account( );
account3.setType( AccountType.DEBIT );
account3.setId( 3L );
account3.setAmount( 250d );
account3.setRate( 1.05 / 100 );
account3.setActive( true );
account3.setClient( client );
client.getDebitAccounts().add( account3 );
entityManager.persist( account3 );
} );
INSERT INTO Client (name, id)
VALUES ('John Doe', 1)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (true, 5000.0, 1, 0.0125, 'CREDIT', 1)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (false, 0.0, 1, 0.0105, 'DEBIT', 2)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (true, 250.0, 1, 0.0105, 'DEBIT', 3)
当执行Account实体查询时,Hibernate 将过滤掉所有不活动的记录。
例子 319.查询 Map 为@Where的实体
doInJPA( this::entityManagerFactory, entityManager -> {
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
assertEquals( 2, accounts.size());
} );
SELECT
a.id as id1_0_,
a.active as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE ( a.active = true )
当获取debitAccounts或creditAccounts集合时,Hibernate 将@Where子句过滤条件应用于关联的子实体。
例子 320.遍历用@WhereMap 的集合
doInJPA( this::entityManagerFactory, entityManager -> {
Client client = entityManager.find( Client.class, 1L );
assertEquals( 1, client.getCreditAccounts().size() );
assertEquals( 1, client.getDebitAccounts().size() );
} );
SELECT
c.client_id as client_i6_0_0_,
c.id as id1_0_0_,
c.id as id1_0_1_,
c.active as active2_0_1_,
c.amount as amount3_0_1_,
c.client_id as client_i6_0_1_,
c.rate as rate4_0_1_,
c.account_type as account_5_0_1_
FROM
Account c
WHERE ( c.active = true and c.account_type = 'CREDIT' ) AND c.client_id = 1
SELECT
d.client_id as client_i6_0_0_,
d.id as id1_0_0_,
d.id as id1_0_1_,
d.active as active2_0_1_,
d.amount as amount3_0_1_,
d.client_id as client_i6_0_1_,
d.rate as rate4_0_1_,
d.account_type as account_5_0_1_
FROM
Account d
WHERE ( d.active = true and d.account_type = 'DEBIT' ) AND d.client_id = 1
5.9.2. @WhereJoinTable
就像@WhereComments 一样,@WhereJoinTable用于通过联接表(例如@ManyToMany 关联)过滤出集合。
例子 321. @WhereJoinTableMap 例子
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
private String author;
@ManyToMany
@JoinTable(
name = "Book_Reader",
joinColumns = @JoinColumn(name = "book_id"),
inverseJoinColumns = @JoinColumn(name = "reader_id")
)
@WhereJoinTable( clause = "created_on > DATEADD( 'DAY', -7, CURRENT_TIMESTAMP() )")
private List<Reader> currentWeekReaders = new ArrayList<>( );
//Getters and setters omitted for brevity
}
@Entity(name = "Reader")
public static class Reader {
@Id
private Long id;
private String name;
//Getters and setters omitted for brevity
}
create table Book (
id bigint not null,
author varchar(255),
title varchar(255),
primary key (id)
)
create table Book_Reader (
book_id bigint not null,
reader_id bigint not null
)
create table Reader (
id bigint not null,
name varchar(255),
primary key (id)
)
alter table Book_Reader
add constraint FKsscixgaa5f8lphs9bjdtpf9g
foreign key (reader_id)
references Reader
alter table Book_Reader
add constraint FKoyrwu9tnwlukd1616qhck21ra
foreign key (book_id)
references Book
alter table Book_Reader
add created_on timestamp
default current_timestamp
在上面的示例中,当前星期Reader实体包含在currentWeekReaders集合中,该集合使用@WhereJoinTable注解根据提供的 SQL 子句过滤联接的表行。
考虑到以下两个Book_Reader条目已添加到我们的系统中:
例子 322. @WhereJoinTable测试数据
Book book = new Book();
book.setId( 1L );
book.setTitle( "High-Performance Java Persistence" );
book.setAuthor( "Vad Mihalcea" );
entityManager.persist( book );
Reader reader1 = new Reader();
reader1.setId( 1L );
reader1.setName( "John Doe" );
entityManager.persist( reader1 );
Reader reader2 = new Reader();
reader2.setId( 2L );
reader2.setName( "John Doe Jr." );
entityManager.persist( reader2 );
statement.executeUpdate(
"INSERT INTO Book_Reader " +
" (book_id, reader_id) " +
"VALUES " +
" (1, 1) "
);
statement.executeUpdate(
"INSERT INTO Book_Reader " +
" (book_id, reader_id, created_on) " +
"VALUES " +
" (1, 2, DATEADD( 'DAY', -10, CURRENT_TIMESTAMP() )) "
);
在获取currentWeekReaders集合时,Hibernate 将仅找到一个条目:
例子 323. @WhereJoinTable获取例子
Book book = entityManager.find( Book.class, 1L );
assertEquals( 1, book.getCurrentWeekReaders().size() );
5.9.3. @Filter
@FilterComments 是使用自定义 SQL 条件过滤掉实体或集合的另一种方法。与@Where注解不同,@Filter允许您在运行时参数化 filter 子句。
现在,考虑到我们拥有以下Account实体:
例子 324. @FilterMap 实体级用法
@Entity(name = "Account")
@FilterDef(
name="activeAccount",
parameters = @ParamDef(
name="active",
type="boolean"
)
)
@Filter(
name="activeAccount",
condition="active_status = :active"
)
public static class Account {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Client client;
@Column(name = "account_type")
@Enumerated(EnumType.STRING)
private AccountType type;
private Double amount;
private Double rate;
@Column(name = "active_status")
private boolean active;
//Getters and setters omitted for brevity
}
Note
请注意,active属性已 Map 到active_status列。
完成此 Map 是为了向您显示@Filter条件使用 SQL 条件而不是 JPQL 过滤谓词。
如前所述,我们也可以为集合应用@FilterComments,如Client实体所示:
例子 325. @FilterMap 集合级别的用法
@Entity(name = "Client")
public static class Client {
@Id
private Long id;
private String name;
@OneToMany(
mappedBy = "client",
cascade = CascadeType.ALL
)
@Filter(
name="activeAccount",
condition="active_status = :active"
)
private List<Account> accounts = new ArrayList<>( );
//Getters and setters omitted for brevity
public void addAccount(Account account) {
account.setClient( this );
this.accounts.add( account );
}
}
如果我们用三个关联的Account实体持久化Client,则 Hibernate 将执行以下 SQL 语句:
例子 326.使用@FilterMap 持久化和获取实体
Client client = new Client()
.setId( 1L )
.setName( "John Doe" );
client.addAccount(
new Account()
.setId( 1L )
.setType( AccountType.CREDIT )
.setAmount( 5000d )
.setRate( 1.25 / 100 )
.setActive( true )
);
client.addAccount(
new Account()
.setId( 2L )
.setType( AccountType.DEBIT )
.setAmount( 0d )
.setRate( 1.05 / 100 )
.setActive( false )
);
client.addAccount(
new Account()
.setType( AccountType.DEBIT )
.setId( 3L )
.setAmount( 250d )
.setRate( 1.05 / 100 )
.setActive( true )
);
entityManager.persist( client );
INSERT INTO Client (name, id)
VALUES ('John Doe', 1)
INSERT INTO Account (active_status, amount, client_id, rate, account_type, id)
VALUES (true, 5000.0, 1, 0.0125, 'CREDIT', 1)
INSERT INTO Account (active_status, amount, client_id, rate, account_type, id)
VALUES (false, 0.0, 1, 0.0105, 'DEBIT', 2)
INSERT INTO Account (active_status, amount, client_id, rate, account_type, id)
VALUES (true, 250.0, 1, 0.0105, 'DEBIT', 3)
默认情况下,在没有显式启用过滤器的情况下,Hibernate 将获取所有Account实体。
例子 327.查询实体而没有激活@Filter
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
assertEquals( 3, accounts.size());
SELECT
a.id as id1_0_,
a.active_status as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
如果启用了过滤器并提供了过滤器参数值,则 Hibernate 将把过滤条件应用于关联的Account实体。
例子 328.查询用@FilterMap 的实体
entityManager
.unwrap( Session.class )
.enableFilter( "activeAccount" )
.setParameter( "active", true);
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
assertEquals( 2, accounts.size());
SELECT
a.id as id1_0_,
a.active_status as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE
a.active_status = true
Fetching entities mapped with @Filter
过滤器适用于实体查询,但不适用于直接提取。
因此,在下面的示例中,从持久性上下文中获取实体时不考虑过滤器。
entityManager
.unwrap( Session.class )
.enableFilter( "activeAccount" )
.setParameter( "active", true);
Account account = entityManager.find( Account.class, 2L );
assertFalse( account.isActive() );
SELECT
a.id as id1_0_0_,
a.active_status as active2_0_0_,
a.amount as amount3_0_0_,
a.client_id as client_i6_0_0_,
a.rate as rate4_0_0_,
a.account_type as account_5_0_0_,
c.id as id1_1_1_,
c.name as name2_1_1_
FROM
Account a
WHERE
a.id = 2
从上面的示例中可以看到,与实体查询相反,过滤器不会阻止实体的加载。
与实体查询一样,也可以过滤集合,但前提是必须在当前运行的 Hibernate Session上显式启用过滤器。
例子 329.在不激活@Filter的情况下遍历集合
Client client = entityManager.find( Client.class, 1L );
assertEquals( 3, client.getAccounts().size() );
SELECT
c.id as id1_1_0_,
c.name as name2_1_0_
FROM
Client c
WHERE
c.id = 1
SELECT
a.id as id1_0_,
a.active_status as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE
a.client_id = 1
当激活@Filter并获取accounts集合时,Hibernate 会将过滤条件应用于关联的集合条目。
例子 330.遍历用@FilterMap 的集合
entityManager
.unwrap( Session.class )
.enableFilter( "activeAccount" )
.setParameter( "active", true);
Client client = entityManager.find( Client.class, 1L );
assertEquals( 2, client.getAccounts().size() );
SELECT
c.id as id1_1_0_,
c.name as name2_1_0_
FROM
Client c
WHERE
c.id = 1
SELECT
a.id as id1_0_,
a.active_status as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE
accounts0_.active_status = true
and a.client_id = 1
Note
@Filter优于@Where子句的主要优点是可以在运行时自定义过滤条件。
Warning
无法合并@Filter和@Cache集合 Comments。此限制是由于确保一致性,并且由于过滤信息未存储在二级缓存中。
如果当前过滤的集合允许使用缓存,则二级缓存将仅存储整个集合的一部分。此后,即使未显式激活会话级过滤器,其他所有会话也将从缓存中获取过滤的集合。
因此,第二级集合缓存仅限于存储整个集合,而不是子集。
5.9.4. @Filter 与@SqlFragmentAlias
使用@Filter注解并处理 Map 到多个数据库表的实体时,如果@Filter定义了在多个表中使用谓词的条件,则需要使用@SqlFragmentAlias注解。
例子 331. @SqlFragmentAliasMap 用法
@Entity(name = "Account")
@Table(name = "account")
@SecondaryTable(
name = "account_details"
)
@SQLDelete(
sql = "UPDATE account_details SET deleted = true WHERE id = ? "
)
@FilterDef(
name="activeAccount",
parameters = @ParamDef(
name="active",
type="boolean"
)
)
@Filter(
name="activeAccount",
condition="{a}.active = :active and {ad}.deleted = false",
aliases = {
@SqlFragmentAlias( alias = "a", table= "account"),
@SqlFragmentAlias( alias = "ad", table= "account_details"),
}
)
public static class Account {
@Id
private Long id;
private Double amount;
private Double rate;
private boolean active;
@Column(table = "account_details")
private boolean deleted;
//Getters and setters omitted for brevity
}
现在,当获取Account实体并激活过滤器时,Hibernate 将对过滤器谓词应用正确的表别名:
例子 332.获取一个用@SqlFragmentAlias过滤的集合
entityManager
.unwrap( Session.class )
.enableFilter( "activeAccount" )
.setParameter( "active", true);
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
select
filtersqlf0_.id as id1_0_,
filtersqlf0_.active as active2_0_,
filtersqlf0_.amount as amount3_0_,
filtersqlf0_.rate as rate4_0_,
filtersqlf0_1_.deleted as deleted1_1_
from
account filtersqlf0_
left outer join
account_details filtersqlf0_1_
on filtersqlf0_.id=filtersqlf0_1_.id
where
filtersqlf0_.active = ?
and filtersqlf0_1_.deleted = false
-- binding parameter [1] as [BOOLEAN] - [true]
5.9.5. @FilterJoinTable
当对集合使用@Filter注解时,将对子条目(实体或可嵌入对象)进行过滤。但是,如果在父实体和子表之间有一个链接表,则需要使用@FilterJoinTable根据联接表中包含的某些列来过滤子项。
因此,可以将@FilterJoinTableComments 应用于单向@OneToMany集合,如以下 Map 所示:
例子 333. @FilterJoinTableMap 用法
@Entity(name = "Client")
@FilterDef(
name="firstAccounts",
parameters=@ParamDef(
name="maxOrderId",
type="int"
)
)
@Filter(
name="firstAccounts",
condition="order_id <= :maxOrderId"
)
public static class Client {
@Id
private Long id;
private String name;
@OneToMany(cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
@FilterJoinTable(
name="firstAccounts",
condition="order_id <= :maxOrderId"
)
private List<Account> accounts = new ArrayList<>( );
//Getters and setters omitted for brevity
public void addAccount(Account account) {
this.accounts.add( account );
}
}
@Entity(name = "Account")
public static class Account {
@Id
private Long id;
@Column(name = "account_type")
@Enumerated(EnumType.STRING)
private AccountType type;
private Double amount;
private Double rate;
//Getters and setters omitted for brevity
}
firstAccounts过滤器将使我们仅获得order_id(表示accounts集合中每个条目的位置)小于给定数字(例如maxOrderId)的Account实体。
假设我们的数据库包含以下实体:
例子 334.使用@FilterJoinTableMap 持久化和获取实体
Client client = new Client()
.setId( 1L )
.setName( "John Doe" );
client.addAccount(
new Account()
.setId( 1L )
.setType( AccountType.CREDIT )
.setAmount( 5000d )
.setRate( 1.25 / 100 )
);
client.addAccount(
new Account()
.setId( 2L )
.setType( AccountType.DEBIT )
.setAmount( 0d )
.setRate( 1.05 / 100 )
);
client.addAccount(
new Account()
.setType( AccountType.DEBIT )
.setId( 3L )
.setAmount( 250d )
.setRate( 1.05 / 100 )
);
entityManager.persist( client );
INSERT INTO Client (name, id)
VALUES ('John Doe', 1)
INSERT INTO Account (amount, client_id, rate, account_type, id)
VALUES (5000.0, 1, 0.0125, 'CREDIT', 1)
INSERT INTO Account (amount, client_id, rate, account_type, id)
VALUES (0.0, 1, 0.0105, 'DEBIT', 2)
INSERT INTO Account (amount, client_id, rate, account_type, id)
VALUES (250.0, 1, 0.0105, 'DEBIT', 3)
INSERT INTO Client_Account (Client_id, order_id, accounts_id)
VALUES (1, 0, 1)
INSERT INTO Client_Account (Client_id, order_id, accounts_id)
VALUES (1, 0, 1)
INSERT INTO Client_Account (Client_id, order_id, accounts_id)
VALUES (1, 1, 2)
INSERT INTO Client_Account (Client_id, order_id, accounts_id)
VALUES (1, 2, 3)
仅当在当前运行的 Hibernate Session上启用了关联的过滤器时,才可以过滤集合。
例子 335.遍历用@FilterJoinTableMap 的集合而不启用过滤器
Client client = entityManager.find( Client.class, 1L );
assertEquals( 3, client.getAccounts().size());
SELECT
ca.Client_id as Client_i1_2_0_,
ca.accounts_id as accounts2_2_0_,
ca.order_id as order_id3_0_,
a.id as id1_0_1_,
a.amount as amount3_0_1_,
a.rate as rate4_0_1_,
a.account_type as account_5_0_1_
FROM
Client_Account ca
INNER JOIN
Account a
ON ca.accounts_id=a.id
WHERE
ca.Client_id = ?
-- binding parameter [1] as [BIGINT] - [1]
如果我们在获取accounts集合时启用过滤器并将maxOrderId设置为1,则 Hibernate 将应用@FilterJoinTable子句过滤条件,我们将仅获得2 Account实体,其中order_id值为0和1。
例子 336.遍历用@FilterJoinTableMap 的集合
Client client = entityManager.find( Client.class, 1L );
entityManager
.unwrap( Session.class )
.enableFilter( "firstAccounts" )
.setParameter( "maxOrderId", 1);
assertEquals( 2, client.getAccounts().size());
SELECT
ca.Client_id as Client_i1_2_0_,
ca.accounts_id as accounts2_2_0_,
ca.order_id as order_id3_0_,
a.id as id1_0_1_,
a.amount as amount3_0_1_,
a.rate as rate4_0_1_,
a.account_type as account_5_0_1_
FROM
Client_Account ca
INNER JOIN
Account a
ON ca.accounts_id=a.id
WHERE
ca.order_id <= ?
AND ca.Client_id = ?
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [BIGINT] - [1]
5.10. 修改 Management/永久状态
处于托管/持久状态的实体可以由应用程序操纵,并且刷新持久化上下文时,将自动检测并持久保存任何更改。无需调用特定方法即可使您的修改持久化。
例子 337.用 JPA 修改托管状态
Person person = entityManager.find( Person.class, personId );
person.setName("John Doe");
entityManager.flush();
例子 338.用 Hibernate API 修改托管状态
Person person = session.byId( Person.class ).load( personId );
person.setName("John Doe");
session.flush();
默认情况下,修改实体时,将在更新期间设置除标识符以外的所有列。
因此,考虑到您具有以下Product实体 Map:
例子 339. Product实体 Map
@Entity(name = "Product")
public static class Product {
@Id
private Long id;
@Column
private String name;
@Column
private String description;
@Column(name = "price_cents")
private Integer priceCents;
@Column
private Integer quantity;
//Getters and setters are omitted for brevity
}
如果您坚持以下Product实体:
例子 340.坚持一个Product实体
Product book = new Product();
book.setId( 1L );
book.setName( "High-Performance Java Persistence" );
book.setDescription( "Get the most out of your persistence layer" );
book.setPriceCents( 29_99 );
book.setQuantity( 10_000 );
entityManager.persist( book );
修改Product实体时,Hibernate 会生成以下 SQL UPDATE 语句:
例子 341.修改Product实体
doInJPA( this::entityManagerFactory, entityManager -> {
Product book = entityManager.find( Product.class, 1L );
book.setPriceCents( 24_99 );
} );
UPDATE
Product
SET
description = ?,
name = ?,
price_cents = ?,
quantity = ?
WHERE
id = ?
-- binding parameter [1] as [VARCHAR] - [Get the most out of your persistence layer]
-- binding parameter [2] as [VARCHAR] - [High-Performance Java Persistence]
-- binding parameter [3] as [INTEGER] - [2499]
-- binding parameter [4] as [INTEGER] - [10000]
-- binding parameter [5] as [BIGINT] - [1]
包含所有列的默认 UPDATE 语句有两个优点:
它使您可以更好地从 JDBC 语句缓存中受益。
即使多个实体修改了不同的属性,它也允许您启用批量更新。
但是,在 SQL UPDATE 语句中包括所有列也有一个缺点。如果您有多个索引,即使您实际上并未修改所有列值,数据库也可能会冗余地更新这些索引。
要解决此问题,可以使用动态更新。
5.10.1. 动态更新
要启用动态更新,您需要使用@DynamicUpdateComments 对实体进行 Comments:
例子 342. Product实体 Map
@Entity(name = "Product")
@DynamicUpdate
public static class Product {
@Id
private Long id;
@Column
private String name;
@Column
private String description;
@Column(name = "price_cents")
private Integer priceCents;
@Column
private Integer quantity;
//Getters and setters are omitted for brevity
}
这次,当重新运行先前的测试用例时,Hibernate 生成以下 SQL UPDATE 语句:
例子 343.用动态更新修改Product实体
UPDATE
Product
SET
price_cents = ?
WHERE
id = ?
-- binding parameter [1] as [INTEGER] - [2499]
-- binding parameter [2] as [BIGINT] - [1]
动态更新允许您仅设置在关联实体中修改的列。
5.11. 刷新实体状态
您可以随时重新加载实体实例及其集合。
例子 344.用 JPA 刷新实体状态
Person person = entityManager.find( Person.class, personId );
entityManager.createQuery( "update Person set name = UPPER(name)" ).executeUpdate();
entityManager.refresh( person );
assertEquals("JOHN DOE", person.getName() );
例子 345.使用 Hibernate API 刷新实体状态
Person person = session.byId( Person.class ).load( personId );
session.doWork( connection -> {
try(Statement statement = connection.createStatement()) {
statement.executeUpdate( "UPDATE Person SET name = UPPER(name)" );
}
} );
session.refresh( person );
assertEquals("JOHN DOE", person.getName() );
一种有用的情况是,已知自读取数据以来数据库状态已更改。刷新允许将当前数据库状态提取到实体实例和持久性上下文中。
可能有用的另一种情况是,使用数据库触发器来初始化实体的某些属性。
Note
除非您指定REFRESH作为任何关联的级联样式,否则仅刷新实体实例及其值类型集合。但是,请注意,Hibernate 可以通过其生成的属性概念自动处理此问题。请参阅非标识符generated attributes的讨论。
Tip
传统上,Hibernate 允许刷新分离的实体。不幸的是,JPA 禁止这种做法,并指定应抛出IllegalArgumentException。
因此,当使用本机 API 引导 Hibernate SessionFactory时,将保留旧式的分离实体刷新行为。另一方面,在通过 JPA EntityManagerFactory构建过程引导 Hibernate 时,默认情况下不允许刷新分离的实体。
但是,可以通过hibernate.allow_refresh_detached_entity配置属性覆盖此默认行为。如果将此属性显式设置为true,那么即使使用 JPA 引导程序机制,也可以刷新分离的实体,因此绕过了 JPA 规范限制。
有关hibernate.allow_refresh_detached_entity配置属性的更多信息,请同时查看Configurations部分。
5.11.1. 刷新陷阱
refresh实体状态转换旨在根据关联数据库 Logging 当前包含的信息来覆盖实体属性。
但是,将刷新操作级联到任何临时实体时必须非常小心。
例如,考虑以下示例:
例子 346.刷新实体状态陷阱
try {
Person person = entityManager.find( Person.class, personId );
Book book = new Book();
book.setId( 100L );
book.setTitle( "Hibernate User Guide" );
book.setAuthor( person );
person.getBooks().add( book );
entityManager.refresh( person );
}
catch ( EntityNotFoundException expected ) {
log.info( "Beware when cascading the refresh associations to transient entities!" );
}
在上述示例中,由于Book实体仍处于过渡状态,因此引发了EntityNotFoundException。当刷新动作从Person实体级联时,Hibernate 将无法在数据库中找到Book实体。
因此,在将刷新操作与瞬态子实体对象混合使用时,应格外小心。
5.12. 处理分离的数据
分离是在任何持久性上下文范围之外使用数据的过程。数据以多种方式分离。关闭持久性上下文后,与其关联的所有数据都将被分离。清除持久性上下文具有相同的效果。从持久性上下文中逐出特定实体会使它脱离。最后,序列化将使反序列化的表单分离(原始实例仍在 Management 中)。
分离的数据仍然可以操作,但是,持久性上下文将不再自动了解这些修改,并且应用程序将需要进行干预以使更改再次持久化。
5.12.1. 重新附加分离的数据
重新连接是获取处于分离状态的传入实体实例,并将其与当前持久性上下文重新关联的过程。
Tip
JPA 不支持重新附加分离的数据。这只能通过 Hibernate org.hibernate.Session使用。
例子 347.使用lock重新附加一个分离的实体
Person person = session.byId( Person.class ).load( personId );
//Clear the Session so the person entity becomes detached
session.clear();
person.setName( "Mr. John Doe" );
session.lock( person, LockMode.NONE );
例子 348.使用saveOrUpdate重新附加一个分离的实体
Person person = session.byId( Person.class ).load( personId );
//Clear the Session so the person entity becomes detached
session.clear();
person.setName( "Mr. John Doe" );
session.saveOrUpdate( person );
Note
方法名称update在这里有点误导。这并不意味着立即执行SQL UPDATE。但是,这确实意味着刷新持久性上下文时将执行SQL UPDATE,因为 Hibernate 不知道要与之进行比较的先前状态。如果该实体使用select-before-updateMap,则 Hibernate 将从数据库中获取当前状态,并查看是否需要更新。
如果实体已分离,则update和saveOrUpdate的操作完全相同。
5.12.2. 合并分离的数据
合并是获取处于分离状态的传入实体实例并将其数据复制到新的托管实例上的过程。
尽管本身并不完全正确,但以下示例是merge操作内部的良好可视化。
例子 349.可视化合并
public Person merge(Person detached) {
Person newReference = session.byId( Person.class ).load( detached.getId() );
newReference.setName( detached.getName() );
return newReference;
}
例子 350.将一个分离的实体与 JPA 合并
Person person = entityManager.find( Person.class, personId );
//Clear the EntityManager so the person entity becomes detached
entityManager.clear();
person.setName( "Mr. John Doe" );
person = entityManager.merge( person );
例子 351.用 Hibernate API 合并一个分离的实体
Person person = session.byId( Person.class ).load( personId );
//Clear the Session so the person entity becomes detached
session.clear();
person.setName( "Mr. John Doe" );
person = (Person) session.merge( person );
Merging gotchas
例如,Hibernate 在合并引用了 2 个分离的子实体child1和child2(从不同的会话获得)的父实体时会抛出IllegalStateException,而child1和child2表示相同的持久实体Child。
新的配置属性hibernate.event.merge.entity_copy_observer控制合并时检测到同一持久性实体(“实体副本”)的多种表示形式时,Hibernate 如何响应。
可能的值为:
禁止(默认)
- 如果检测到实体副本,则抛出
IllegalStateException
- 如果检测到实体副本,则抛出
allow
- 对检测到的每个实体副本执行合并操作
log
- (仅用于测试)对检测到的每个实体副本执行合并操作,并记录有关实体副本的信息。此设置要求为
org.hibernate.event.internal.EntityCopyAllowedLoggedObserver启用调试日志记录
- (仅用于测试)对检测到的每个实体副本执行合并操作,并记录有关实体副本的信息。此设置要求为
此外,应用程序可以通过提供org.hibernate.event.spi.EntityCopyObserver的实现并将hibernate.event.merge.entity_copy_observer设置为类名来自定义行为。当此属性设置为allow或log时,Hibernate 将在级联合并操作时合并检测到的每个实体副本。在合并每个实体副本的过程中,Hibernate 将从每个实体副本到与cascade=CascadeType.MERGE或CascadeType.ALL关联的合并操作进行级联。当合并另一个实体副本时,由于合并一个实体副本而导致的实体状态将被覆盖。
Warning
因为级联 Sequences 是不确定的,所以实体副本的合并 Sequences 是不确定的。结果,如果实体副本中的属性值不一致,则最终的实体状态将不确定,并且除最后一个合并的实体外,所有实体副本中的数据都将丢失。因此,“最后一位 Writer 获胜”。
如果一个实体副本将合并操作级联为一个(或包含)新实体的关联,则该新实体将被合并(即持久存在,并且合并操作将根据其 Map 级联到其关联),即使那样当 Hibernate 合并对其关联具有不同值的不同表示形式时,相同的关联最终将被覆盖。
如果关联是用orphanRemoval = trueMap 的,则新的实体将不会被删除,因为如果孤立的实体是新实体,则 orphanRemoval 的语义将不适用。
当同一持久性实体的表示对于一个集合具有不同的值时,存在一些已知的问题。有关更多详细信息,请参见HHH-9239和HHH-9240。这些问题可能会导致数据丢失或损坏。
通过将hibernate.event.merge.entity_copy_observer配置属性设置为allow或log,Hibernate 将允许合并任何类型的实体的实体副本。
排除包含关键数据的特定实体类或关联的唯一方法是提供具有所需行为的org.hibernate.event.spi.EntityCopyObserver的自定义实现,并将hibernate.event.merge.entity_copy_observer设置为类名。
Tip
Hibernate 提供有限的 DEBUG 日志记录功能,可以帮助确定发现了实体副本的实体类。通过将hibernate.event.merge.entity_copy_observer设置为log并为org.hibernate.event.internal.EntityCopyAllowedLoggedObserver启用调试日志记录,每次应用程序调用EntityManager.merge( entity )或Session.merge( entity ) :
检测到的相同持久性实体的多种表示形式的次数(按实体名称汇总);
实体名称和 ID 的详细信息,包括在每个要合并的表示形式上调用 toString()的输出以及合并结果。
应该检查日志以确定是否检测到包含关键数据的实体的多种表示形式。如果是这样,应修改该应用程序,以便只有一种表示形式,并且应提供org.hibernate.event.spi.EntityCopyObserver的自定义实现,以禁止具有关键数据的实体的实体副本。
建议使用乐观锁定来检测不同表示形式是否来自同一持久性实体的不同版本。如果它们不是同一版本,则 Hibernate 会根据您的引导策略抛出 JPA OptimisticLockException或本机StaleObjectStateException。
5.13. 检查持久状态
应用程序可以验证与持久性上下文有关的实体和集合的状态。
例子 352.用 JPA 验证 Management 状态
boolean contained = entityManager.contains( person );
例 353.使用 Hibernate API 验证托管状态
boolean contained = session.contains( person );
例子 354.用 JPA 验证懒惰
PersistenceUnitUtil persistenceUnitUtil = entityManager.getEntityManagerFactory().getPersistenceUnitUtil();
boolean personInitialized = persistenceUnitUtil.isLoaded( person );
boolean personBooksInitialized = persistenceUnitUtil.isLoaded( person.getBooks() );
boolean personNameInitialized = persistenceUnitUtil.isLoaded( person, "name" );
例子 355.用 Hibernate API 验证惰性
boolean personInitialized = Hibernate.isInitialized( person );
boolean personBooksInitialized = Hibernate.isInitialized( person.getBooks() );
boolean personNameInitialized = Hibernate.isPropertyInitialized( person, "name" );
在 JPA 中,有另一种方法可以使用以下javax.persistence.PersistenceUtil模式(最好在可能的情况下建议使用此模式)检查懒惰。
例子 356.另一种 JPA 手段是验证懒惰
PersistenceUtil persistenceUnitUtil = Persistence.getPersistenceUtil();
boolean personInitialized = persistenceUnitUtil.isLoaded( person );
boolean personBooksInitialized = persistenceUnitUtil.isLoaded( person.getBooks() );
boolean personNameInitialized = persistenceUnitUtil.isLoaded( person, "name" );
5.14. 驱逐实体
调用flush()方法时,实体的状态与数据库同步。如果您不希望发生这种同步,或者正在处理大量对象并且需要有效地 Management 内存,则可以使用evict()方法从一级缓存中删除对象及其集合。
例子 357.从EntityManager分离一个实体
for(Person person : entityManager.createQuery("select p from Person p", Person.class)
.getResultList()) {
dtos.add(toDTO(person));
entityManager.detach( person );
}
例子 358.从休眠Session中驱逐一个实体
Session session = entityManager.unwrap( Session.class );
for(Person person : (List<Person>) session.createQuery("select p from Person p").list()) {
dtos.add(toDTO(person));
session.evict( person );
}
为了从当前持久性上下文中分离所有实体,EntityManager和 Hibernate Session都定义了clear()方法。
例子 359.清除持久性上下文
entityManager.clear();
session.clear();
为了验证当前是否将实体实例附加到正在运行的持久性上下文,EntityManager和 Hibernate Session都定义了contains(Object entity)方法。
例子 360.验证一个实体是否包含在持久性上下文中
entityManager.contains( person );
session.contains( person );
5.15. 级联实体状态转换
JPA 允许您传播从父实体到子实体的状态转换。为此,JPA javax.persistence.CascadeType定义了各种层叠类型:
ALL- 级联所有实体状态转换。
PERSIST- 级联实体持久操作。
MERGE- 级联实体合并操作。
REMOVE- 级联实体删除操作。
REFRESH- 级联实体刷新操作。
DETACH- 级联实体分离操作。
此外,CascadeType.ALL将传播由org.hibernate.annotations.CascadeType枚举定义的任何特定于 Hibernate 的操作:
SAVE_UPDATE- 级联实体 saveOrUpdate 操作。
REPLICATE- 级联实体复制操作。
LOCK- 级联实体锁定操作。
以下示例将使用以下实体说明上述某些层叠操作:
@Entity
public class Person {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL)
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
public void addPhone(Phone phone) {
this.phones.add( phone );
phone.setOwner( this );
}
}
@Entity
public class Phone {
@Id
private Long id;
@Column(name = "`number`")
private String number;
@ManyToOne(fetch = FetchType.LAZY)
private Person owner;
//Getters and setters are omitted for brevity
}
5.15.1. CascadeType.PERSIST
CascadeType.PERSIST允许我们与父实体一起保留子实体。
范例 361.CascadeType.PERSIST范例
Person person = new Person();
person.setId( 1L );
person.setName( "John Doe" );
Phone phone = new Phone();
phone.setId( 1L );
phone.setNumber( "123-456-7890" );
person.addPhone( phone );
entityManager.persist( person );
INSERT INTO Person ( name, id )
VALUES ( 'John Doe', 1 )
INSERT INTO Phone ( `number`, person_id, id )
VALUE ( '123-456-7890', 1, 1 )
即使只有Person父实体被持久化,Hibernate 也设法将持久化操作也级联到关联的Phone子实体。
5.15.2. CascadeType.MERGE
CascadeType.MERGE允许我们将子实体与父实体合并。
例子 362.CascadeType.MERGE例子
Phone phone = entityManager.find( Phone.class, 1L );
Person person = phone.getOwner();
person.setName( "John Doe Jr." );
phone.setNumber( "987-654-3210" );
entityManager.clear();
entityManager.merge( person );
SELECT
p.id as id1_0_1_,
p.name as name2_0_1_,
ph.owner_id as owner_id3_1_3_,
ph.id as id1_1_3_,
ph.id as id1_1_0_,
ph."number" as number2_1_0_,
ph.owner_id as owner_id3_1_0_
FROM
Person p
LEFT OUTER JOIN
Phone ph
on p.id=ph.owner_id
WHERE
p.id = 1
在合并期间,实体的当前状态被复制到刚从数据库中获取的实体版本上。这就是 Hibernate 执行 SELECT 语句的原因,该语句同时获取Person实体及其子代。
5.15.3. CascadeType.REMOVE
CascadeType.REMOVE允许我们与父实体一起删除子实体。传统上,Hibernate 将此操作称为删除,这就是org.hibernate.annotations.CascadeType提供DELETE级联选项的原因。但是,CascadeType.REMOVE和org.hibernate.annotations.CascadeType.DELETE相同。
例子 363. CascadeType.REMOVE例子
Person person = entityManager.find( Person.class, 1L );
entityManager.remove( person );
DELETE FROM Phone WHERE id = 1
DELETE FROM Person WHERE id = 1
5.15.4. CascadeType.DETACH
CascadeType.DETACH用于将分离操作从父实体传播到子实体。
例子 364.CascadeType.DETACH例子
Person person = entityManager.find( Person.class, 1L );
assertEquals( 1, person.getPhones().size() );
Phone phone = person.getPhones().get( 0 );
assertTrue( entityManager.contains( person ));
assertTrue( entityManager.contains( phone ));
entityManager.detach( person );
assertFalse( entityManager.contains( person ));
assertFalse( entityManager.contains( phone ));
5.15.5. CascadeType.LOCK
尽管不直观,但CascadeType.LOCK不会将锁定请求从父实体传播到其子实体。这种用例需要使用javax.persistence.lock.scope属性的PessimisticLockScope.EXTENDED值。
但是,CascadeType.LOCK允许我们将父实体及其子代重新附加到当前正在运行的持久性上下文。
例子 365. CascadeType.LOCK例子
Person person = entityManager.find( Person.class, 1L );
assertEquals( 1, person.getPhones().size() );
Phone phone = person.getPhones().get( 0 );
assertTrue( entityManager.contains( person ) );
assertTrue( entityManager.contains( phone ) );
entityManager.detach( person );
assertFalse( entityManager.contains( person ) );
assertFalse( entityManager.contains( phone ) );
entityManager.unwrap( Session.class )
.buildLockRequest( new LockOptions( LockMode.NONE ) )
.lock( person );
assertTrue( entityManager.contains( person ) );
assertTrue( entityManager.contains( phone ) );
5.15.6. CascadeType.REFRESH
CascadeType.REFRESH用于将刷新操作从父实体传播到子实体。刷新操作将丢弃当前实体状态,并将使用从数据库加载的状态来覆盖它。
例子 366.CascadeType.REFRESH例子
Person person = entityManager.find( Person.class, 1L );
Phone phone = person.getPhones().get( 0 );
person.setName( "John Doe Jr." );
phone.setNumber( "987-654-3210" );
entityManager.refresh( person );
assertEquals( "John Doe", person.getName() );
assertEquals( "123-456-7890", phone.getNumber() );
SELECT
p.id as id1_0_1_,
p.name as name2_0_1_,
ph.owner_id as owner_id3_1_3_,
ph.id as id1_1_3_,
ph.id as id1_1_0_,
ph."number" as number2_1_0_,
ph.owner_id as owner_id3_1_0_
FROM
Person p
LEFT OUTER JOIN
Phone ph
ON p.id=ph.owner_id
WHERE
p.id = 1
在上述示例中,您可以看到Person和Phone实体都被刷新,即使我们仅在父实体上调用了此操作。
5.15.7. CascadeType.REPLICATE
CascadeType.REPLICATE用于复制父实体和子实体。复制操作使您可以同步来自不同数据源的实体。
例子 367. CascadeType.REPLICATE例子
Person person = new Person();
person.setId( 1L );
person.setName( "John Doe Sr." );
Phone phone = new Phone();
phone.setId( 1L );
phone.setNumber( "(01) 123-456-7890" );
person.addPhone( phone );
entityManager.unwrap( Session.class ).replicate( person, ReplicationMode.OVERWRITE );
SELECT
id
FROM
Person
WHERE
id = 1
SELECT
id
FROM
Phone
WHERE
id = 1
UPDATE
Person
SET
name = 'John Doe Sr.'
WHERE
id = 1
UPDATE
Phone
SET
"number" = '(01) 123-456-7890',
owner_id = 1
WHERE
id = 1
如生成的 SQL 语句所示,Person和Phone实体均被复制到基础数据库行。
5.15.8. @OnDelete 级联
虽然以前的级联类型传播实体状态转换,但是@OnDelete级联是 DDL 级的 FK 功能,无论何时删除父行,都可以删除子记录。
因此,当用@OnDelete( action = OnDeleteAction.CASCADE )Comments@ManyToOne关联时,自动模式生成器会将 ON DELETE CASCADE SQL 指令应用于外键声明,如以下示例所示。
例子 368. @OnDelete @ManyToOneMap
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "`number`")
private String number;
@ManyToOne(fetch = FetchType.LAZY)
@OnDelete( action = OnDeleteAction.CASCADE )
private Person owner;
//Getters and setters are omitted for brevity
}
create table Person (
id bigint not null,
name varchar(255),
primary key (id)
)
create table Phone (
id bigint not null,
"number" varchar(255),
owner_id bigint,
primary key (id)
)
alter table Phone
add constraint FK82m836qc1ss2niru7eogfndhl
foreign key (owner_id)
references Person
on delete cascade
现在,您只需删除Person实体,关联的Phone实体将通过外键级联自动删除。
例子 369. @OnDelete @ManyToOne删除例子
Person person = entityManager.find( Person.class, 1L );
entityManager.remove( person );
delete from Person where id = ?
-- binding parameter [1] as [BIGINT] - [1]
@OnDelete注解也可以放置在集合上,如以下示例所示。
例子 370. @OnDelete @OneToManyMap
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "owner", cascade = CascadeType.ALL)
@OnDelete(action = OnDeleteAction.CASCADE)
private List<Phone> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "`number`")
private String number;
@ManyToOne(fetch = FetchType.LAZY)
private Person owner;
//Getters and setters are omitted for brevity
}
现在,当删除Person实体时,即使@OneToMany集合正在使用CascadeType.ALL属性,也会通过外键级联删除所有关联的Phone子实体。
范例 371.``删除范例
Person person = entityManager.find( Person.class, 1L );
entityManager.remove( person );
delete from Person where id = ?
-- binding parameter [1] as [BIGINT] - [1]
Note
如果没有@OnDelete注解,则@OneToMany关联将依靠cascade属性将remove实体状态转换从父实体传播到其子实体。但是,当使用@OnDelete注解时,Hibernate 会在刷新持久化上下文时阻止执行子实体DELETE语句。
这样,仅父实体将被删除,而所有关联的子记录将由数据库引擎删除,而不是通过DELETE语句显式删除。
5.16. 异常处理
如果 JPA EntityManager或特定于 Hibernate 的Session引发异常(包括任何 JDBC SQLException),则必须立即回滚数据库事务并关闭当前的EntityManager或Session。
JPA EntityManager或 Hibernate Session的某些方法不会使持久性上下文保持一致状态。根据经验,Hibernate 抛出的异常不能被视为可恢复的。通过在 finally 块中调用close()方法来确保关闭会话。
回滚数据库事务不会使您的业务对象回到事务开始时的状态。这意味着数据库状态和业务对象将不同步。通常,这不是问题,因为异常是不可恢复的,并且无论如何您都必须在回滚后重新开始。
JPA PersistenceException或HibernateException包装了大多数在 Hibernate 持久层中可能发生的错误。
PersistenceException和HibernateException都是运行时异常,因为我们认为不应强迫应用程序开发人员在底层捕获不可恢复的异常。在大多数系统中,未检查和致命的异常是在方法调用堆栈的前几个帧之一(即在更高层中)中处理的,或者向应用程序用户显示错误消息,或者采取其他适当的措施。注意,Hibernate 可能还会引发其他非HibernateException的未经检查的异常。这些也不可恢复,应采取适当的措施。
Hibernate 将与数据库交互时抛出的 JDBC SQLException包装在JDBCException中。实际上,Hibernate 将尝试将异常转换为JDBCException的更有意义的子类。底层SQLException始终可通过JDBCException.getSQLException()获得。 Hibernate 使用附加到当前SessionFactory的SQLExceptionConverter将SQLException转换为适当的 JDBCException 子类。
默认情况下,SQLExceptionConverter由配置的 Hibernate Dialect通过buildSQLExceptionConversionDelegate方法定义,该方法被多个特定于数据库的Dialect覆盖。
但是,也可以插入自定义实现。有关更多详细信息,请参见hibernate.jdbc.sql_exception_converter配置属性。
标准的JDBCException子类型为:
ConstraintViolationException
- 表示某种形式的完整性约束违规。
DataException
- 表示针对给定数据评估有效 SQL 语句会导致某些非法操作,类型不匹配,截断或基数不正确。
GenericJDBCException
- 不属于任何其他类别的一般性 exception。
JDBCConnectionException
- 表示基础 JDBC 通信错误。
LockAcquisitionException
- 表示获取执行请求的操作所需的锁定级别的错误。
LockTimeoutException
- 表示锁获取请求已超时。
PessimisticLockException
- 表示锁获取请求失败。
QueryTimeoutException
- 指示当前正在执行的查询已超时。
SQLGrammarException
- 表示发出的 SQL 的语法或语法问题。
Note
从 Hibernate 5.2 开始,Hibernate Session扩展了 JPA EntityManager。因此,当通过 Hibernate 的本机引导构建SessionFactory时,HibernateException或SQLException可以在被实现EntityManager方法的Session方法(例如Session.merge(Object object),Session.flush())抛出时,包装在 JPA PersistenceException中。
如果您的SessionFactory是通过 Hibernate 的本机引导构建的,并且您不希望将 Hibernate 异常包装在 JPA PersistenceException中,则需要将hibernate.native_exception_handling_51_compliance配置属性设置为true。有关更多详细信息,请参见hibernate.native_exception_handling_51_compliance配置属性。
6. Flushing
刷新是将持久性上下文的状态与基础数据库同步的过程。 EntityManager和 Hibernate Session公开了一组方法,应用程序开发人员可以通过这些方法来更改实体的持久状态。
持久性上下文充当事务后写式高速缓存,对任何实体状态更改进行排队。像任何后写式高速缓存一样,更改首先会在内存中应用,并在刷新期间与数据库同步。刷新操作接受每个实体状态更改,并将其转换为INSERT,UPDATE或DELETE语句。
Note
由于 DML 语句组合在一起,因此 Hibernate 可以透明地应用批处理。有关更多信息,请参见Batching chapter。
刷新策略由当前运行的 Hibernate Session的flushMode给出。尽管 JPA 仅定义了两种刷新策略(AUTO和COMMIT),但是 Hibernate 具有更广泛的刷新类型范围:
ALWAYS
- 每次查询前都要刷新
Session。
- 每次查询前都要刷新
AUTO
- 这是默认模式,仅在必要时才刷新
Session。
- 这是默认模式,仅在必要时才刷新
COMMIT
Session尝试将刷新延迟到提交当前Transaction时,尽管它也可能过早刷新。
MANUAL
Session刷新被委派给应用程序,该应用程序必须显式调用Session.flush()才能应用持久性上下文更改。
6.1. 自动冲洗
默认情况下,Hibernate 使用AUTO刷新模式,该模式在以下情况下触发刷新:
提交
Transaction之前在执行与排队的实体操作重叠的 JPQL/HQL 查询之前
在执行任何没有注册同步的本机 SQL 查询之前
6.1.1. 提交时自动刷新
在以下示例中,实体被持久保存,然后事务被提交。
例子 372.提交时自动刷新
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
Person person = new Person( "John Doe" );
entityManager.persist( person );
log.info( "Entity is in persisted state" );
txn.commit();
--INFO: Entity is in persisted state
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
Hibernate 在插入实体之前记录消息,因为刷新仅在事务提交期间发生。
Note
这对于SEQUENCE和TABLE标识符生成器有效。 IDENTITY生成器必须在调用persist()之后立即执行插入。有关更多详细信息,请参见Identifier generators中有关生成器的讨论。
6.1.2. 自动刷新 JPQL/HQL 查询
执行实体查询时,也可能触发刷新。
例子 373.在 JPQL/HQL 上自动刷新
Person person = new Person( "John Doe" );
entityManager.persist( person );
entityManager.createQuery( "select p from Advertisement p" ).getResultList();
entityManager.createQuery( "select p from Person p" ).getResultList();
SELECT a.id AS id1_0_ ,
a.title AS title2_0_
FROM Advertisement a
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT p.id AS id1_1_ ,
p.name AS name2_1_
FROM Person p
Advertisement实体查询未触发刷新的原因是Advertisement和Person表之间没有重叠:
例子 374. JPQL/HQL 实体上的自动刷新
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
private String name;
//Getters and setters are omitted for brevity
}
@Entity(name = "Advertisement")
public static class Advertisement {
@Id
@GeneratedValue
private Long id;
private String title;
//Getters and setters are omitted for brevity
}
当查询Person实体时,将在执行实体查询之前触发刷新。
例子 375.在 JPQL/HQL 上自动冲洗
Person person = new Person( "John Doe" );
entityManager.persist( person );
entityManager.createQuery( "select p from Person p" ).getResultList();
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT p.id AS id1_1_ ,
p.name AS name2_1_
FROM Person p
这次,刷新是由 JPQL 查询触发的,因为未决实体持久操作与正在执行的查询重叠。
6.1.3. 在本机 SQL 查询上自动刷新
执行本机 SQL 查询时,使用EntityManager API 时始终会触发刷新。
例子 376.使用EntityManager在本机 SQL 上自动刷新
assertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 0 );
Person person = new Person( "John Doe" );
entityManager.persist( person );
assertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 1 );
如果默认情况下以本地方式(而不是通过 JPA)引导 Hibernate,则Session API 将在执行本地查询时自动触发刷新。
例子 377.使用Session在本机 SQL 上自动刷新
assertTrue(((Number) session
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 0 );
Person person = new Person( "John Doe" );
session.persist( person );
assertTrue(((Number) session
.createNativeQuery( "select count(*) from Person")
.uniqueResult()).intValue() == 0 );
要刷新Session,查询必须使用同步:
例子 378.用Session同步在本机 SQL 上自动刷新
assertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 0 );
Person person = new Person( "John Doe" );
entityManager.persist( person );
Session session = entityManager.unwrap( Session.class );
assertTrue(((Number) session
.createNativeQuery( "select count(*) from Person")
.addSynchronizedEntityClass( Person.class )
.uniqueResult()).intValue() == 1 );
6.2. 提交刷新
JPA 还定义了 COMMIT 刷新模式,其描述如下:
Note
如果设置了FlushModeType.COMMIT,则不确定在持久性上下文中对实体进行的更新对查询的影响。
— JPA 2.1 规范的第 3.10.8 节
执行 JPQL 查询时,仅在提交当前正在运行的事务时才刷新持久性上下文。
例子 379. COMMIT在 JPQL 上刷新
Person person = new Person("John Doe");
entityManager.persist(person);
entityManager.createQuery("select p from Advertisement p")
.setFlushMode( FlushModeType.COMMIT)
.getResultList();
entityManager.createQuery("select p from Person p")
.setFlushMode( FlushModeType.COMMIT)
.getResultList();
SELECT a.id AS id1_0_ ,
a.title AS title2_0_
FROM Advertisement a
SELECT p.id AS id1_1_ ,
p.name AS name2_1_
FROM Person p
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
由于 JPA 并未对延迟刷新施加严格的规则,因此在执行本机 SQL 查询时,将刷新持久性上下文。
例子 380. COMMIT在本机 SQL 上刷新
Person person = new Person("John Doe");
entityManager.persist(person);
assertTrue(((Number) entityManager
.createNativeQuery("select count(*) from Person")
.getSingleResult()).intValue() == 1);
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT COUNT(*) FROM Person
6.3. 总是冲洗
Note
ALWAYS仅适用于本机Session API。
即使针对Session API 执行本机 SQL 查询,ALWAYS刷新模式也会触发持久性上下文刷新。
例子 381. COMMIT在本机 SQL 上刷新
Person person = new Person("John Doe");
entityManager.persist(person);
Session session = entityManager.unwrap( Session.class);
assertTrue(((Number) session
.createNativeQuery("select count(*) from Person")
.setFlushMode( FlushMode.ALWAYS)
.uniqueResult()).intValue() == 1);
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT COUNT(*) FROM Person
6.4. 手动冲洗
EntityManager和 Hibernate Session都定义了flush()方法,该方法在被调用时会触发手动刷新。 Hibernate 还提供了MANUAL刷新模式,因此持久性上下文只能手动刷新。
例子 382. MANUAL冲洗
Person person = new Person("John Doe");
entityManager.persist(person);
Session session = entityManager.unwrap( Session.class);
session.setHibernateFlushMode( FlushMode.MANUAL );
assertTrue(((Number) entityManager
.createQuery("select count(id) from Person")
.getSingleResult()).intValue() == 0);
assertTrue(((Number) session
.createNativeQuery("select count(*) from Person")
.uniqueResult()).intValue() == 0);
SELECT COUNT(p.id) AS col_0_0_
FROM Person p
SELECT COUNT(*)
FROM Person
由于没有手动flush()调用,因此未执行INSERT语句。
Note
MANUAL刷新模式在使用多请求逻辑事务时很有用,并且只有最后一个请求才应刷新持久性上下文。
6.5. 冲洗操作 Sequences
从数据库的角度来看,可以使用INSERT,UPDATE或DELETE语句更改行状态。由于实体状态更改会自动转换为 SQL 语句,因此重要的是要知道哪些实体操作与给定的 SQL 语句相关联。
INSERTINSERT语句由EntityInsertAction或EntityIdentityInsertAction生成。这些动作是通过persist操作明确或通过将PersistEvent从父级到子级联进行调度的。
DELETEDELETE语句由EntityDeleteAction或OrphanRemovalAction生成。
UPDATE- 如果被 Management 实体已标记为已修改,则在刷新过程中
EntityUpdateAction会生成UPDATE语句。脏检查机制负责确定自从首次加载 Management 实体以来是否对其进行了修改。
- 如果被 Management 实体已标记为已修改,则在刷新过程中
Hibernate 不会按照关联的实体状态操作的 Sequences 执行 SQL 语句。
为了直观地了解其工作原理,请考虑以下示例:
例子 383.刷新操作 Sequences
Person person = entityManager.find( Person.class, 1L);
entityManager.remove(person);
Person newPerson = new Person( );
newPerson.setId( 2L );
newPerson.setName( "John Doe" );
entityManager.persist( newPerson );
INSERT INTO Person (name, id)
VALUES ('John Doe', 2L)
DELETE FROM Person WHERE id = 1
即使我们删除了第一个实体然后保留一个新实体,Hibernate 也会在INSERT之后执行DELETE语句。
Tip
ActionQueue给出执行 SQL 语句的 Sequences,而不是预先定义实体状态操作的 Sequences。
ActionQueue按以下 Sequences 执行所有操作:
OrphanRemovalActionEntityInsertAction或EntityIdentityInsertActionEntityUpdateActionQueuedOperationCollectionActionCollectionRemoveActionCollectionUpdateActionCollectionRecreateActionEntityDeleteAction
7.数据库访问
7.1. ConnectionProvider
作为 ORM 工具,您可能需要告诉 Hibernate 的最重要的事情就是如何连接到数据库,以便它可以代表您的应用程序进行连接。最终,这是org.hibernate.engine.jdbc.connections.spi.ConnectionProvider界面的功能。 Hibernate 提供了该接口的一些现成的实现。 ConnectionProvider也是扩展点,因此您也可以使用第三方的自定义实现或自己编写。通过hibernate.connection.provider_class设置定义要使用的ConnectionProvider。见org.hibernate.cfg.AvailableSettings#CONNECTION_PROVIDER
一般来说,如果使用 Hibernate 提供的一种实现,则应用程序不必显式配置ConnectionProvider。 Hibernate 将根据以下算法在内部确定要使用的ConnectionProvider:
如果设置了
hibernate.connection.provider_class,则优先否则,如果设置了
hibernate.connection.datasource→Using DataSources否则,如果设置了以
hibernate.c3p0.为前缀的任何设置→Using c3p0否则,如果设置了以
hibernate.proxool.为前缀的任何设置→Using Proxool否则,如果设置了以
hibernate.hikari.为前缀的任何设置→Using HikariCP否则,如果设置了以
hibernate.vibur.为前缀的任何设置→使用 Vibur DBCP否则,如果设置了以
hibernate.agroal.为前缀的任何设置→Using Agroal否则,如果设置了
hibernate.connection.url→使用 Hibernate 的内置(且不受支持)池
7.2. 使用数据源
Hibernate 可以与javax.sql.DataSource集成以获得 JDBC 连接。应用程序将通过(必需的)hibernate.connection.datasource设置告知 Hibernate 有关DataSource的信息,该设置可以指定 JNDI 名称,也可以引用实际的DataSource实例。对于给出 JNDI 名称的情况,请务必阅读JNDI。
Note
对于 JPA 应用程序,请注意hibernate.connection.datasource对应于javax.persistence.jtaDataSource或javax.persistence.nonJtaDataSource。
DataSource ConnectionProvider也(可选)接受hibernate.connection.username和hibernate.connection.password。如果指定,将使用DataSource#getConnection(字符串用户名,字符串密码)。否则,将使用 no-arg 形式。
7.3. 驱动程式设定
hibernate.connection.driver_class- 要使用的 JDBC Driver 类的名称
hibernate.connection.url- JDBC 连接网址
hibernate.connection.*- 所有此类设置名称(predefined ones除外)都将删除
hibernate.connection.前缀。其余名称和原始值将作为 JDBC 连接属性传递给驱动程序
- 所有此类设置名称(predefined ones除外)都将删除
Note
并非所有属性都适用于所有情况。例如,如果要提供数据源,将不使用hibernate.connection.driver_class设置。
7.4. 使用 c3p0
Tip
要使用 c3p0 集成,应用程序必须在 Classpath 上包括hibernate-c3p0模块 jar(及其依赖项)。
Hibernate 还为应用程序使用c3p0连接池提供支持。启用 c3p0 支持后,除了Driver Configuration中描述的常规设置外,还识别了许多 c3p0 特定的配置设置。
连接的事务隔离由ConnectionProvider本身 Management。参见ConnectionProvider 支持事务隔离设置。
hibernate.c3p0.min_size或c3p0.minPoolSize- c3p0 池的最小大小。见c3p0 minPoolSize
hibernate.c3p0.max_size或c3p0.maxPoolSize- c3p0 池的最大大小。见c3p0 maxPoolSize
hibernate.c3p0.timeout或c3p0.maxIdleTime- 连接空闲时间。见c3p0 maxIdleTime
hibernate.c3p0.max_statements或c3p0.maxStatements- 控制 c3p0 PreparedStatement 缓存大小(如果使用)。见c3p0 maxStatements
hibernate.c3p0.acquire_increment或c3p0.acquireIncrement- 池耗尽时应获取的连接数 c3p0.见c3p0 acquireIncrement
hibernate.c3p0.idle_test_period或c3p0.idleConnectionTestPeriod- 验证 c3p0 池连接之前的空闲时间。见c3p0 idleConnectionTestPeriod
hibernate.c3p0.initialPoolSize- 初始 c3p0 池大小。如果未指定,则默认为使用最小池大小。见c3p0 initialPoolSize
其他带有
hibernate.c3p0.前缀的设置- 将剥去
hibernate.部分并将其传递给 c3p0.
- 将剥去
其他带有
c3p0.前缀的设置- 照原样传递给 c3p0.见c3p0 configuration
7.5. 使用 Proxool
Tip
要使用 Proxool 集成,应用程序必须在 Classpath 中包含hibernate-proxool模块 jar(及其依赖项)。
Hibernate 还为应用程序使用Proxool连接池提供支持。
连接的事务隔离由ConnectionProvider本身 Management。参见ConnectionProvider 支持事务隔离设置。
7.5.1. 使用现有的 Proxool 池
由hibernate.proxool.existing_pool设置控制。如果设置为 true,则此 Provider 将通过hibernate.proxool.pool_alias设置指示的别名使用已经存在的 Proxool 池。
7.5.2. 通过 XML 配置 Proxool
hibernate.proxool.xml设置命名 Proxool 配置 XML 文件,该文件将作为 Classpath 资源加载并由 Proxool 的 JAXPConfigurator 加载。参见proxool configuration。必须设置hibernate.proxool.pool_alias来指示要使用哪个池。
7.5.3. 通过属性配置 Proxool
hibernate.proxool.properties设置为 Proxool 配置属性文件命名,该文件将作为 Classpath 资源加载并由 Proxool 的PropertyConfigurator加载。参见proxool configuration。必须设置hibernate.proxool.pool_alias来指示要使用哪个池。
7.6. 使用 HikariCP
Tip
要使用 HikariCP 进行此集成,应用程序必须在 Classpath 中包含hibernate-hikari模块 jar(及其依赖项)。
Hibernate 还为应用程序使用Hikari连接池提供支持。
在 Hibernate 中将所有的 Hikari 设置设置为hibernate.hikari.,然后此ConnectionProvider会将它们拾取并将其传递给 Hikari。此外,此ConnectionProvider将选择以下特定于 Hibernate 的属性,并将它们 Map 到对应的 Hikari 属性(任何带有hibernate.hikari.前缀的属性优先):
hibernate.connection.driver_class- Map 到 Hikari 的
driverClassName设置
- Map 到 Hikari 的
hibernate.connection.url- Map 到 Hikari 的
jdbcUrl设置
- Map 到 Hikari 的
hibernate.connection.username- Map 到 Hikari 的
username设置
- Map 到 Hikari 的
hibernate.connection.password- Map 到 Hikari 的
password设置
- Map 到 Hikari 的
hibernate.connection.isolation- Map 到 Hikari 的
transactionIsolation设置。参见ConnectionProvider 支持事务隔离设置。请注意,Hikari 仅支持 JDBC 标准隔离级别(显然)。
- Map 到 Hikari 的
hibernate.connection.autocommit- Map 到 Hikari 的
autoCommit设置
- Map 到 Hikari 的
7.7. 使用 Vibur DBCP
Tip
要使用 Vibur DBCP 集成,应用程序必须在 Classpath 中包含hibernate-vibur模块 jar(及其依赖项)。
Hibernate 还为应用程序使用Vibur DBCP连接池提供支持。
在 Hibernate 中以hibernate.vibur.为前缀设置所有 Vibur 设置,而此ConnectionProvider会选择它们并将其传递给 Vibur DBCP。此外,此ConnectionProvider将选择以下特定于 Hibernate 的属性,并将它们 Map 到相应的 Vibur 属性(任何带有hibernate.vibur.前缀的属性优先):
hibernate.connection.driver_class- Map 到 Vibur 的
driverClassName设置
- Map 到 Vibur 的
hibernate.connection.url- Map 到 Vibur 的
jdbcUrl设置
- Map 到 Vibur 的
hibernate.connection.username- Map 到 Vibur 的
username设置
- Map 到 Vibur 的
hibernate.connection.password- Map 到 Vibur 的
password设置
- Map 到 Vibur 的
hibernate.connection.isolation- Map 到 Vibur 的
defaultTransactionIsolationValue设置。参见ConnectionProvider 支持事务隔离设置。
- Map 到 Vibur 的
hibernate.connection.autocommit- Map 到 Vibur 的
defaultAutoCommit设置
- Map 到 Vibur 的
7.8. 使用农业
Tip
要使用 Agroal 集成,应用程序必须在 Classpath 中包含hibernate-agroal模块 jar(及其依赖项)。
Hibernate 还为应用程序使用Agroal连接池提供支持。
在 Hibernate 中以hibernate.agroal.前缀设置您的所有 Agroal 设置,而此ConnectionProvider会选择它们并将其传递给 Agroal 连接池。此外,此ConnectionProvider将选择以下特定于 Hibernate 的属性,并将它们 Map 到相应的 Agroal 属性(任何带有hibernate.agroal.前缀的属性优先):
hibernate.connection.driver_class- Map 到 Agroal 的
driverClassName设置
- Map 到 Agroal 的
hibernate.connection.url- Map 到 Agroal 的
jdbcUrl设置
- Map 到 Agroal 的
hibernate.connection.username- Map 到 Agroal 的
principal设置
- Map 到 Agroal 的
hibernate.connection.password- Map 到 Agroal 的
credential设置
- Map 到 Agroal 的
hibernate.connection.isolation- Map 到 Agroal 的
jdbcTransactionIsolation设置。参见ConnectionProvider 支持事务隔离设置。
- Map 到 Agroal 的
hibernate.connection.autocommit- Map 到 Agroal 的
autoCommit设置
- Map 到 Agroal 的
7.9. 使用 Hibernate 的内置(且不受支持)池
Tip
内置连接池不支持在生产系统中使用。
本部分仅出于完整性考虑。
7.10. 用户提供的连接
打开会话时,只需将要使用的连接传递给会话,就可以使用 Hibernate。不鼓励使用此方法,此处不再讨论。
7.11. ConnectionProvider 支持事务隔离设置
除DataSourceConnectionProvider之外,所有提供的 ConnectionProvider 实现都支持对从基础池中获取的所有Connections的事务隔离进行一致设置。可以使用以下三种格式之一指定hibernate.connection.isolation的值:
在 JDBC 级别接受的整数值。
java.sql.Connection常量字段的名称,表示您要使用的隔离。例如,TRANSACTION_REPEATABLE_READ表示java.sql.Connection#TRANSACTION_REPEATABLE_READ。并非仅 JDBC 标准隔离级别支持此功能,特定于特定 JDBC 驱动程序的隔离级别不支持此功能。java.sql.Connection 常量字段的短名称版本,不带
TRANSACTION_前缀。例如,REPEATABLE_READ表示java.sql.Connection#TRANSACTION_REPEATABLE_READ。同样,仅 JDBC 标准隔离级别支持此功能,特定于特定 JDBC 驱动程序的隔离级别不支持此功能。
7.12. 连接处理
连接处理方式由PhysicalConnectionHandlingMode枚举定义,该枚举提供以下策略:
IMMEDIATE_ACQUISITION_AND_HOLDSession打开并保持直到Session关闭,就将获取Connection。
DELAYED_ACQUISITION_AND_HOLDConnection将在需要时立即获取,然后保留直到Session关闭。
DELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENTConnection将在需要时立即获取,并将在每个语句执行后释放。
DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTIONConnection将在需要时立即获取,并将在每次 Transaction 完成后释放。
如果不想使用默认的连接处理模式,则可以通过hibernate.connection.handling_mode配置属性指定连接处理模式。有关更多详细信息,请查看数据库连接属性部分。
7.12.1. 事务类型和连接处理
默认情况下,连接处理模式由基础事务协调器指定。事务有两种类型:RESOURCE_LOCAL(涉及单个数据库Connection,并且事务通过commit和``方法控制)和JTA(可能涉及多个资源,包括数据库连接,JMS 队列等)。
RESOURCE_LOCAL 事务连接处理
对于RESOURCE_LOCAL事务,连接处理方式为DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION,这意味着在需要时可获取数据库连接,并在提交或回滚当前正在运行的事务后释放数据库连接。
但是,由于 Hibernate 需要确保在启动新事务时在 JDBC Connection上禁用默认的自动提交模式,因此将获取Connection并将自动提交模式设置为false。
Note
如果您使用的连接池DataSource已经为每个池Connection禁用了自动提交模式,则应将hibernate.connection.provider_disables_autocommit设置为true,并且数据库连接的获取实际上会延迟到 Hibernate 需要执行第一个 SQL 语句之前。
JTA 事务连接处理
对于JTA事务,连接处理方式为DELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENT,表示需要时获取数据库连接,并在每次执行语句后释放数据库连接。
语句执行后释放数据库连接的原因是,当方法调用从一个 EJB 转移到另一个 EJB 时,某些 Java EE 应用程序服务器报告连接泄漏。但是,即使将 JDBC Connection释放到池中,也仍会将Connection分配给当前正在执行的Thread,因此在当前运行的事务中执行后续语句时,将从池中获得相同的Connection对象引用。
Note
如果当事务从外部 EJB 传播到内部 EJB 时,Java EE 应用程序服务器或 JTA 事务 Management 器支持从一个 EJB 切换到另一 EJB,并且没有报告连接泄漏错误肯定,那么您应该考虑通过以下方式切换到DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION hibernate.connection.handling_mode配置属性。
7.12.2. 用户提供的连接
如果当前的Session是使用SessionBuilder创建的,并且 JDBC Connection是通过SessionBuilder#connection方法提供的,则将使用用户提供的Connection,连接处理方式将为IMMEDIATE_ACQUISITION_AND_HOLD。
因此,对于用户提供的连接,该连接将立即获得并保持,直到关闭当前Session为止,而不受 JPA 或 Hibernate 事务上下文的影响。
7.13. 数据库方言
尽管 SQL 是相对标准化的,但是每个数据库供应商都使用 ANSI SQL 定义的语法的子集和超集。这称为数据库的方言。 Hibernate 通过其org.hibernate.dialect.Dialect类和每个数据库供应商的各种子类来处理这些方言中的变体。
在大多数情况下,Hibernate 将能够通过在引导过程中询问 JDBC 连接的一些问题来确定要使用的正确方言。有关 Hibernate 确定要使用的适当方言的能力(以及影响该分辨率的能力)的信息,请参见Dialect resolution。
如果由于某种原因无法确定正确的方言,或者您想使用自定义方言,则需要设置hibernate.dialect设置。
表 4.提供的方言
| 方言(简称) | Remarks |
|---|---|
| Cache71 | 支持 Caché数据库 2007.1 版 |
| CUBRID | 支持 CUBRID 数据库,版本 8.3. 可能适用于更高版本。 |
| DB2 | 支持 DB2 数据库 8.2 版。 |
| DB297 | 支持 9.7 版的 DB2 数据库。 |
| DB2390 | 支持 OS/390 的 DB2 通用数据库,也称为 DB2/390. |
| DB2400 | 支持 iSeries 的 DB2 通用数据库,也称为 DB2/400. |
| DB2400V7R3 | 支持 i2 的 DB2 通用数据库,也称为 DB2/400,版本 7.3 |
| DerbyTenFive | 支持 10.5 版的 Derby 数据库 |
| DerbyTenSix | 支持 Derby 数据库 10.6 版 |
| DerbyTenSeven | 支持 Derby 数据库 10.7 版 |
| Firebird | 支持 Firebird 数据库 |
| FrontBase | 支持 Frontbase 数据库 |
| H2 | 支持 H2 数据库 |
| HANACloudColumnStore | 支持 SAP HANA Cloud 数据库列存储。 |
| HANAColumnStore | 支持 SAP HANA 数据库列存储 2.x 版。这是 SAP HANA 数据库的推荐方言。可以与 SAP HANA 1.x 版一起使用 |
| HANARowStore | 支持 SAP HANA 数据库行存储版本 2.x。可以与 SAP HANA 1.x 版一起使用 |
| HSQL | 支持 HSQL(HyperSQL)数据库 |
| Informix | 支持 Informix 数据库 |
| Ingres | 支持 Ingres 数据库 9.2 版 |
| Ingres9 | 支持 Ingres 数据库 9.3 版。可能适用于较新的版本 |
| Ingres10 | 支持 Ingres 数据库版本 10. |
| Interbase | 支持 Interbase 数据库。 |
| JDataStore | 对 JDataStore 数据库的支持 |
| McKoi | 支持 McKoi 数据库 |
| Mimer | 支持 Mimer 数据库 9.2.1 版。可能适用于较新的版本 |
| MySQL5 | 支持 MySQL 数据库 5.x 版 |
| MySQL5InnoDB | 导出表时,支持 MySQL 数据库 5.x 版,最好使用 InnoDB 存储引擎。 |
| MySQL57InnoDB | 导出表时,支持 MySQL 数据库 5.7 版,最好使用 InnoDB 存储引擎。可能适用于较新的版本 |
| MariaDB | 支持 MariaDB 数据库。可能适用于较新的版本 |
| MariaDB53 | 支持 5.3 及更高版本的 MariaDB 数据库。 |
| Oracle8i | 支持 Oracle 数据库版本 8i |
| Oracle9i | 支持 Oracle 数据库 9i 版 |
| Oracle10g | 支持 Oracle 数据库 10g 版 |
| Pointbase | 支持 Pointbase 数据库 |
| PostgresPlus | 支持 Postgres Plus 数据库 |
| PostgreSQL81 | 支持 PostgrSQL 数据库版本 8.1 |
| PostgreSQL82 | 支持 PostgreSQL 数据库 8.2 版 |
| PostgreSQL9 | 支持 PostgreSQL 数据库版本 9.可能与更高版本一起使用。 |
| Progress | 支持进度数据库,版本 9.1C。可能适用于较新的版本。 |
| SAPDB | 支持 SAPDB/MAXDB 数据库。 |
| SQLServer | 对 SQL Server 2000 数据库的支持 |
| SQLServer2005 | 支持 SQL Server 2005 数据库 |
| SQLServer2008 | 支持 SQL Server 2008 数据库 |
| Sybase11 | 支持 Sybase 数据库,最高版本为 11.9.2 |
| SybaseAnywhere | 支持 Sybase Anywhere 数据库 |
| SybaseASE15 | 支持 Sybase Adaptive Server Enterprise 数据库版本 15 |
| SybaseASE157 | 支持 Sybase Adaptive Server Enterprise 数据库 15.7 版。可能适用于较新的版本。 |
| Teradata | 支持 Teradata 数据库 |
| TimesTen | 支持 TimesTen 数据库 5.1 版。可能适用于较新的版本 |
8.Transaction 和并发控制
重要的是要理解,术语“事务”在持久性和对象/关系 Map 方面具有许多不同但相关的含义。在大多数用例中,这些定义是一致的,但并非总是如此。
它可能是指与数据库的物理事务。
它可能是指与持久性上下文相关的事务的逻辑概念。
它可能是指原型模式所定义的工作单元的应用程序概念。
Note
该文档在很大程度上将事务的物理和逻辑概念视为同一对象。
8.1. 实物 Transaction
Hibernate 使用 JDBC API 进行持久化。在 Java 领域中,有两种定义良好的机制来处理 JDBC 中的事务:JDBC 本身和 JTA。 Hibernate 支持与事务集成和允许应用程序 Management 物理事务的两种机制。
每个Session的 Transaction 处理由org.hibernate.resource.transaction.spi.TransactionCoordinatorContract 处理,该 Contract 由org.hibernate.resource.transaction.spi.TransactionCoordinatorBuilder服务构建。 TransactionCoordinatorBuilder表示一种用于处理事务的策略,而 TransactionCoordinator 表示该策略与会话相关的一个实例。 hibernate.transaction.coordinator_class设置定义要使用的TransactionCoordinatorBuilder实现。
jdbc(非 JPA 应用程序的默认设置)- 通过致电
java.sql.ConnectionManagementTransaction
- 通过致电
jta- 通过 JTAManagementTransaction。见Java EE 引导
如果 JPA 应用程序未提供hibernate.transaction.coordinator_class的设置,则 Hibernate 将基于持久性单元的事务类型自动构建适当的事务协调器。
如果非 JPA 应用程序未提供hibernate.transaction.coordinator_class的设置,则 Hibernate 将使用jdbc作为默认设置。如果应用程序实际使用基于 JTA 的事务,则此默认值将导致问题。使用基于 JTA 的事务的非 JPA 应用程序应显式设置hibernate.transaction.coordinator_class=jta或提供自定义org.hibernate.resource.transaction.TransactionCoordinatorBuilder来构建org.hibernate.resource.transaction.TransactionCoordinator以正确地与基于 JTA 的事务进行协调。
Note
有关实现自定义TransactionCoordinatorBuilder的详细信息,或者只是更好地了解其工作方式,请参见Integration Guide。
Hibernate 直接使用 JDBC 连接和 JTA 资源,而无需添加任何其他锁定行为。休眠不会将对象锁定在内存中。使用 Hibernate 时,数据库事务的隔离级别定义的行为不会更改。 Hibernate Session充当事务范围的缓存,可重复读取以通过标识符和查询进行查找,从而导致加载实体。
Tip
为了减少数据库中的锁争用,物理数据库事务需要尽可能短。
长时间运行的数据库事务会阻止您的应用程序扩展到高度并行的负载。不要在最终用户级别的工作期间使数据库事务保持打开状态,而应在最终用户级别的工作完成后将其打开。
这个概念称为transactional write-behind。
8.2. JTA 配置
与 JTA 系统的交互被合并在名为org.hibernate.engine.transaction.jta.platform.spi.JtaPlatform的单个 Contract 之后,该 Contract 公开了对该系统对javax.transaction.TransactionManager和javax.transaction.UserTransaction的访问权限,并公开了注册javax.transaction.Synchronization实例,检查事务状态等的能力。
Note
通常,JtaPlatform将需要访问 JNDI 才能解析 JTA TransactionManager,UserTransaction等。有关配置对 JNDI 的访问的详细信息,请参见JNDI chapter。
Hibernate 尝试通过使用另一个名为org.hibernate.engine.transaction.jta.platform.spi.JtaPlatformResolver的服务来发现它应使用的JtaPlatform。如果该分辨率不起作用,或者您希望提供自定义实现,则需要指定hibernate.transaction.jta.platform设置。 Hibernate 提供了JtaPlatformContract 的许多实现,所有实现都使用短名称:
AtomikosJtaPlatform代表 Atomikos。
BorlandJtaPlatform用于 Borland Enterprise Server。
BitronixJtaPlatform代表 Bitronix。
JBossAS- 在 JBoss/WildFly Application Server 中使用时,表示 Arjuna/JBossTransactions/Narayana 的
JtaPlatform。
- 在 JBoss/WildFly Application Server 中使用时,表示 Arjuna/JBossTransactions/Narayana 的
JBossTS- 单独使用时,表示 Arjuna/JBossTransactions/Narayana 的
JtaPlatform。
- 单独使用时,表示 Arjuna/JBossTransactions/Narayana 的
JOnAS- 在 JOnAS 中使用时,表示 JOTM 为
JtaPlatform。
- 在 JOnAS 中使用时,表示 JOTM 为
JOTM- 单独使用时,适用于 JOTM 的
JtaPlatform。
- 单独使用时,适用于 JOTM 的
JRun4JtaPlatform用于 JRun 4 应用程序服务器。
OC4JJtaPlatform用于 Oracle 的 OC4J 容器。
OrionJtaPlatform用于 Orion 应用服务器。
ResinJtaPlatform用于树脂应用服务器。
SapNetWeaverJtaPlatform用于 SAP NetWeaver 应用程序服务器。
SunOneJtaPlatform用于 SunOne 应用程序服务器。
WeblogicJtaPlatform用于 Weblogic 应用程序服务器。
WebSphereJtaPlatform用于旧版本的 WebSphere Application Server。
WebSphereExtendedJtaPlatform用于更新版本的 WebSphere Application Server。
8.3. 休眠事务 API
Hibernate 提供了一个 API,可帮助将应用程序与所使用的基础物理事务系统中的差异区分开。基于已配置的TransactionCoordinatorBuilder,当应用程序使用此事务处理 API 时,Hibernate 只会做正确的事情。这使您的应用程序和组件可以更方便地移植到不同的环境中。
要使用此 API,您需要从会话中获取org.hibernate.Transaction。 Transaction允许您期望的所有常规操作:begin,commit和rollback,甚至还公开了一些很酷的方法,例如:
markRollbackOnly- 在 JTA 和 JDBC 中均可使用。
getTimeout和setTimeout- 再次在 JTA 和 JDBC 中都起作用。
registerSynchronization- 这样,即使在非 JTA 环境中,也可以注册 JTA 同步。实际上,在 JTA 和 JDBC 环境中,这些
Synchronizations都由 Hibernate 保留在本地。在 JTA 环境中,Hibernate 只会向TransactionManager注册一个单独的Synchronization以避免 Sequences 问题。
- 这样,即使在非 JTA 环境中,也可以注册 JTA 同步。实际上,在 JTA 和 JDBC 环境中,这些
此外,它还公开了一个 getStatus 方法,该方法返回org.hibernate.resource.transaction.spi.TransactionStatus枚举。如果需要,此方法将与基础事务系统进行检查,因此应注意使其使用最少。在某些 JTA 设置中,它可能会对性能产生重大影响。
让我们看一下在各种环境中使用 Transaction API 的情况。
例子 384.在 JDBC 中使用事务 API
StandardServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
// "jdbc" is the default, but for explicitness
.applySetting( AvailableSettings.TRANSACTION_COORDINATOR_STRATEGY, "jdbc" )
.build();
Metadata metadata = new MetadataSources( serviceRegistry )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.build();
Session session = sessionFactory.openSession();
try {
// calls Connection#setAutoCommit( false ) to
// signal start of transaction
session.getTransaction().begin();
session.createQuery( "UPDATE customer set NAME = 'Sir. '||NAME" )
.executeUpdate();
// calls Connection#commit(), if an error
// happens we attempt a rollback
session.getTransaction().commit();
}
catch ( Exception e ) {
// we may need to rollback depending on
// where the exception happened
if ( session.getTransaction().getStatus() == TransactionStatus.ACTIVE
|| session.getTransaction().getStatus() == TransactionStatus.MARKED_ROLLBACK ) {
session.getTransaction().rollback();
}
// handle the underlying error
}
finally {
session.close();
sessionFactory.close();
}
例子 385.在 JTA(CMT)中使用 Transaction API
StandardServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
// "jdbc" is the default, but for explicitness
.applySetting( AvailableSettings.TRANSACTION_COORDINATOR_STRATEGY, "jta" )
.build();
Metadata metadata = new MetadataSources( serviceRegistry )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.build();
// Note: depending on the JtaPlatform used and some optional settings,
// the underlying transactions here will be controlled through either
// the JTA TransactionManager or UserTransaction
Session session = sessionFactory.openSession();
try {
// Since we are in CMT, a JTA transaction would
// already have been started. This call essentially
// no-ops
session.getTransaction().begin();
Number customerCount = (Number) session.createQuery( "select count(c) from Customer c" ).uniqueResult();
// Since we did not start the transaction ( CMT ),
// we also will not end it. This call essentially
// no-ops in terms of transaction handling.
session.getTransaction().commit();
}
catch ( Exception e ) {
// again, the rollback call here would no-op (aside from
// marking the underlying CMT transaction for rollback only).
if ( session.getTransaction().getStatus() == TransactionStatus.ACTIVE
|| session.getTransaction().getStatus() == TransactionStatus.MARKED_ROLLBACK ) {
session.getTransaction().rollback();
}
// handle the underlying error
}
finally {
session.close();
sessionFactory.close();
}
例子 386.在 JTA(BMT)中使用事务 API
StandardServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
// "jdbc" is the default, but for explicitness
.applySetting( AvailableSettings.TRANSACTION_COORDINATOR_STRATEGY, "jta" )
.build();
Metadata metadata = new MetadataSources( serviceRegistry )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.build();
// Note: depending on the JtaPlatform used and some optional settings,
// the underlying transactions here will be controlled through either
// the JTA TransactionManager or UserTransaction
Session session = sessionFactory.openSession();
try {
// Assuming a JTA transaction is not already active,
// this call the TM/UT begin method. If a JTA
// transaction is already active, we remember that
// the Transaction associated with the Session did
// not "initiate" the JTA transaction and will later
// nop-op the commit and rollback calls...
session.getTransaction().begin();
session.persist( new Customer( ) );
Customer customer = (Customer) session.createQuery( "select c from Customer c" ).uniqueResult();
// calls TM/UT commit method, assuming we are initiator.
session.getTransaction().commit();
}
catch ( Exception e ) {
// we may need to rollback depending on
// where the exception happened
if ( session.getTransaction().getStatus() == TransactionStatus.ACTIVE
|| session.getTransaction().getStatus() == TransactionStatus.MARKED_ROLLBACK ) {
// calls TM/UT commit method, assuming we are initiator;
// otherwise marks the JTA transaction for rollback only
session.getTransaction().rollback();
}
// handle the underlying error
}
finally {
session.close();
sessionFactory.close();
}
在 CMT 情况下,我们确实可以省略所有的 Transaction 调用。但是这些示例的目的是表明 Transaction API 确实确实将您的代码与基础事务机制隔离了。实际上,如果删除 Comments 和引导程序提供的单个配置设置,则所有 3 个示例中的代码都完全相同。换句话说,我们可以开发该代码并将其按原样放置在这三个事务环境中的任何一个中。
事务 API 努力使体验在所有环境中保持一致。为此,通常存在差异时会遵循 JTA 规范(例如,在提交失败时自动尝试回滚)。
8.4. 上下文会话
大多数使用 Hibernate 的应用程序都需要某种形式的* contextual *会话,其中给定会话在给定上下文范围内有效。但是,在不同的应用程序中,构成上下文的定义通常是不同的。不同的上下文为当前的概念定义了不同的范围。在 3.0 版之前使用 Hibernate 的应用程序倾向于利用基于本地的ThreadLocal的上下文会话,诸如HibernateUtil的帮助程序类,或者利用第三方框架(如 Spring 或 Pico)来提供基于代理/拦截的上下文会话。
从版本 3.0.1 开始,Hibernate 添加了SessionFactory.getCurrentSession()方法。最初,此假定使用JTA事务,其中JTA事务定义了当前会话的范围和上下文。鉴于众多独立的JTA TransactionManager实现的成熟度,大多数(如果不是全部)应用程序都应使用JTA事务 Management,无论它们是否已部署到J2EE容器中。基于此,您只需要使用基于JTA的上下文会话。
但是,从 3.1 版开始,SessionFactory.getCurrentSession()后面的处理现在是可插入的。为此,添加了新的扩展接口org.hibernate.context.spi.CurrentSessionContext和新的配置参数hibernate.current_session_context_class,以允许定义当前会话的范围和上下文具有可插入性。
有关 Contract 的详细讨论,请参见Javadocs的org.hibernate.context.spi.CurrentSessionContext界面。它定义了一个方法currentSession(),实现通过该方法负责跟踪当前上下文会话。 Hibernate 开箱即用,带有此接口的三种实现:
org.hibernate.context.internal.JTASessionContextJTATransaction 会跟踪当前会话并确定范围。这里的处理与旧的仅 JTA 的方法完全相同。
org.hibernate.context.internal.ThreadLocalSessionContext- 当前会话由执行线程跟踪。有关更多详细信息,请参见Javadocs。
org.hibernate.context.internal.ManagedSessionContext- 当前会话由执行线程跟踪。但是,您有责任在此类上使用静态方法绑定和取消绑定
Session实例;它不会打开,冲洗或关闭Session。
- 当前会话由执行线程跟踪。但是,您有责任在此类上使用静态方法绑定和取消绑定
通常,此参数的值只是命名要使用的实现类。但是,对于三个现成的实现,有三个对应的简称:* jta , thread 和 managed *。
前两个实现提供了一个会话-一个数据库事务编程模型。这也被称为* session-per-request *。 Hibernate 会话的开始和结束由数据库事务的持续时间定义。如果在没有 JTA 的纯 Java SE 中使用程序化事务划分,则建议使用 Hibernate Transaction API 从代码中隐藏基础事务系统。如果使用 JTA,则可以利用 JTA 接口来划分事务。如果在支持 CMT 的 EJB 容器中执行,则声明式定义事务边界,并且您的代码中不需要任何事务或会话划分操作。
hibernate.current_session_context_class配置参数定义应使用哪个org.hibernate.context.spi.CurrentSessionContext实现。为了向后兼容,如果未设置此配置参数,但配置了org.hibernate.engine.transaction.jta.platform.spi.JtaPlatform,则 Hibernate 将使用org.hibernate.context.internal.JTASessionContext。
8.5. Transaction 模式(和反模式)
8.5.1. 每次操作会话反模式
这是在单个线程中为每个数据库调用打开和关闭Session的反模式。就数据库事务而言,它也是一种反模式。将数据库调用分组为计划的 Sequences。以同样的方式,不要在应用程序中的每个 SQL 语句之后自动提交。 Hibernate 禁用或希望应用程序服务器立即禁用自动提交模式。数据库事务绝不是可选的。与数据库的所有通信都必须由事务封装。避免自动提交行为来读取数据,因为许多小事务的执行效果不佳于一个明确定义的工作单元,并且更难以维护和扩展。
Note
使用自动提交不会规避数据库事务。
相反,在自动提交模式下,JDBC 驱动程序仅在隐式事务调用中执行每个调用。就像您的应用程序在每个 JDBC 调用之后都调用了 commit 一样。
8.5.2. 每次请求会话模式
这是最常见的 Transaction 模式。这里的术语“请求”涉及对来自 Client 端/用户的一系列请求作出反应的系统的概念。 Web 应用程序是此类系统的主要示例,尽管当然不是唯一的。在开始处理此类请求时,应用程序打开一个 Hibernate Session,启动一个事务,执行所有与数据相关的工作,结束该事务并关闭 Session。模式的症结在于 Transaction 与会话之间的一对一关系。
在此模式内,存在一种定义当前会话的通用技术,以简化将Session传递给可能需要对其进行访问的所有应用程序组件的需求。 Hibernate 通过SessionFactory的getCurrentSession方法提供了对该技术的支持。 “当前”会话的概念必须具有定义“当前”概念有效的范围的范围。这是org.hibernate.context.spi.CurrentSessionContextContract 的目的。
有 2 个可靠的定义范围:
首先是 JTA 事务,因为它允许回调钩子知道结束时间,这使 Hibernate 有机会关闭
Session并进行清理。这由org.hibernate.context.spi.CurrentSessionContextContract 的org.hibernate.context.internal.JTASessionContext实现表示。使用此实现,在该事务中第一次调用getCurrentSession时将打开Session。其次是这个应用程序请求周期本身。最好用
org.hibernate.context.spi.CurrentSessionContextContract 的org.hibernate.context.internal.ManagedSessionContext实现来表示。在这里,一个外部组件负责 Management* current *会话的生命周期和范围。在这种作用域的开头,调用Session称为ManagedSessionContext#bind()方法。最后,调用它的unbind()方法。此类“外部组件”的一些常见示例包括:javax.servlet.Filter实施带有切入点的 AOP 拦截器的服务方法
代理/拦截容器
Tip
getCurrentSession()方法在 JTA 环境中有一个缺点。如果使用它,则默认情况下也使用after_statement连接释放模式。由于 JTA 规范的限制,Hibernate 无法自动清除scroll()或iterate()返回的任何未关闭的ScrollableResults或Iterator实例。通过从 finally 块显式调用ScrollableResults#close()或Hibernate.close(Iterator)释放基础数据库游标。
8.5.3. 对话(应用程序级 Transaction)
每次请求会话模式不是设计工作单元的唯一有效方法。许多业务流程需要与用户进行一系列与数据库访问交错的交互。在 Web 和企业应用程序中,数据库事务跨越用户交互是不可接受的。考虑以下示例:
对话框的第一个屏幕打开。用户看到的数据将加载到特定的Session和数据库事务中。用户可以自由修改对象。
用户在编辑五分钟后使用 UI 元素保存其工作。修改被持久化。用户还希望在编辑会话期间对数据具有独占访问权限。
即使我们在这里有多个数据库访问权限,从用户的角度来看,这一系列步骤也代表了一个工作单元。有许多方法可以在您的应用程序中实现此目的。
第一个简单的实现可能是在用户编辑时使用数据库级锁来保持Session和数据库事务处于打开状态,以防止其他用户修改相同的数据并保证隔离性和原子性。这是一种反模式,因为锁争用是一个瓶颈,它将阻止将来的可伸缩性。
几个数据库事务用于实现对话。在这种情况下,保持业务流程的隔离成为应用程序层的部分责任。单个对话通常跨越几个数据库事务。如果这些数据库事务中只有一个(通常是最后一个)存储更新的数据,则这些多个数据库访问只能是整体的原子访问。所有其他人仅读取数据。接收此数据的一种常用方法是通过一个跨越多个请求/响应周期的向导式对话框。 Hibernate 包含一些使其易于实现的功能。
| Automatic Versioning | Hibernate 可以为您执行自动乐观并发控制。它可以自动检测(在对话结束时)用户思考期间是否发生了并发修改。 |
| Detached Objects | 如果您决定使用按请求的会话模式,则在用户思考期间,所有加载的实例都将处于分离状态。 Hibernate 允许您重新附加对象并保留修改。该模式称为每个请求与分离对象的会话。自动版本控制用于隔离并发修改。 |
扩展Session |
提交数据库事务后,可以将 Hibernate Session与基础 JDBC 连接断开连接,并在发生新的 Client 端请求时重新连接。这种模式称为“每次会话会话”,不需要重新连接。自动版本控制用于隔离并发修改,并且不允许Session自动刷新,而只能显式刷新。 |
每个带有分离对象的请求会话和每个会话会话各有利弊。
8.5.4. 每次应用会话反模式
*“每个应用会话数” *也被视为反模式。像 JPA EntityManager一样,Hibernate Session也不是线程安全的对象,它旨在一次被限制在单个线程中。如果Session在多个线程之间共享,则将存在争用条件以及可见性问题,因此请当心。
Hibernate 引发的异常意味着您必须回滚数据库事务并立即关闭Session。如果您的Session绑定到该应用程序,则必须停止该应用程序。回滚数据库事务不会使您的业务对象回到事务开始时的状态。这意味着数据库状态和业务对象将不同步。通常,这不是问题,因为异常是不可恢复的,并且无论如何您都必须在回滚后重新开始。
有关更多详细信息,请查看持久性上下文一章中的exception handling部分。
Session缓存处于持久状态(由 Hibernate 监视并检查是否为脏状态)的每个对象。如果您长时间将其保持打开状态或只是加载太多数据,它将不断增长,直到获得OutOfMemoryException为止。一种解决方案是调用clear()和evict()来 ManagementSession缓存,但是如果需要海量数据操作,则应考虑使用存储过程。 Batching chapter中显示了一些解决方案。在用户会话期间保持Session开放状态也意味着过时数据的可能性更高。
9. JNDI
Hibernate 确实可以代表应用程序与 JNDI 进行交互。通常,它在应用程序执行以下操作时:
已要求 SessionFactory 绑定到 JNDI
已指定要通过 JNDI 名称使用的数据源
正在使用 JTA 事务,并且
JtaPlatform需要对TransactionManager,UserTransaction等进行 JNDI 查找
所有这些 JNDI 调用都通过角色为org.hibernate.engine.jndi.spi.JndiService的单个服务进行路由。标准JndiService接受许多配置设置:
hibernate.jndi.class- 命名要使用的
javax.naming.InitialContext实现类。见javax.naming.Context#INITIAL_CONTEXT_FACTORY
- 命名要使用的
hibernate.jndi.url- 命名 JNDI InitialContext 连接 URL。见javax.naming.Context.PROVIDER_URL
所有其他带有hibernate.jndi.前缀的设置都将被收集并传递给 JNDI 提供程序。
Note
标准JndiService假定所有 JNDI 调用都相对于同一InitialContext。如果您的应用程序出于任何原因使用多个命名服务器,则需要一个自定义JndiService实现来处理这些详细信息。
10. Locking
在关系数据库中,锁定是指为防止数据在读取时间和使用时间之间发生更改而采取的操作。
您的锁定策略可以是乐观的也可以是悲观的。
Optimistic
- Optimistic locking假设多个事务可以完成而不会互相影响,因此事务可以 continue 进行而不会锁定它们影响的数据资源。在提交之前,每个事务都将验证没有其他事务已修改其数据。如果检查显示有冲突的修改,则提交的事务将回滚。
Pessimistic
- 悲观锁定假定并发事务会相互冲突,并要求在读取资源后将其锁定,并且仅在应用程序使用完数据后将其解锁。
Hibernate 提供了在应用程序中实现两种锁定类型的机制。
10.1. Optimistic
当您的应用程序使用长事务或跨越多个数据库事务的对话时,您可以存储版本控制数据,以便如果两个对话更新了同一实体,则最后一次提交更改的通知会发生冲突,并且不会覆盖其他对话的工作。这种方法可以保证一定程度的隔离,但是可以很好地扩展,并且在“经常读有时写”情况下特别有效。
Hibernate 提供了两种用于存储版本控制信息的机制:专用版本号或时间戳。
Note
对于分离的实例,version 或 timestamp 属性永远不能为 null。无论您指定的其他未保存值策略如何,Hibernate 都会将具有空版本或时间戳的任何实例检测为瞬态。声明可为空的版本或时间戳属性是避免在 Hibernate 中进行传递重新连接问题的一种简便方法,特别是在使用分配的标识符或组合键的情况下尤其有用。
10.1.1. Map 乐观锁定
JPA 基于版本(Sequences 数字)或时间戳策略定义了对乐观锁定的支持。要启用这种乐观锁定样式,只需将javax.persistence.Version添加到定义乐观锁定值的持久属性中。根据 JPA,这些属性的有效类型限于:
int或Integershort或Shortlong或Longjava.sql.Timestamp
但是,Hibernate 甚至允许您使用 Java 8 日期/时间类型,例如Instant。
例子 387. @VersionCommentsMap
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@Column(name = "`name`")
private String name;
@Version
private long version;
//Getters and setters are omitted for brevity
}
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@Column(name = "`name`")
private String name;
@Version
private Timestamp version;
//Getters and setters are omitted for brevity
}
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@Column(name = "`name`")
private String name;
@Version
private Instant version;
//Getters and setters are omitted for brevity
}
专用版本号
通过@VersionComments 提供了用于乐观锁定的版本号机制。
例子 388. @Version 注解
@Version
private long version;
在这里,版本属性被 Map 到version列,并且实体 Management 器使用它来检测冲突的更新,并防止丢失更新,否则这些更新会被最后一次提交-获胜策略覆盖。
版本列可以是任何类型的类型,只要您定义并实现适当的UserVersionType即可。
禁止您的应用程序更改 Hibernate 设置的版本号。要人为增加版本号,请参阅 Hibernate Entity Manager 参考文档中有关属性LockModeType.OPTIMISTIC_FORCE_INCREMENT或LockModeType.PESSIMISTIC_FORCE_INCREMENT的文档。
Note
如果版本号是由数据库生成的(例如触发器),请在 version 属性上使用 Comments@org.hibernate.annotations.Generated(GenerationTime.ALWAYS)。
Timestamp
与版本号相比,时间戳是最不可靠的乐观锁定方式,但应用程序也可以将其用于其他目的。如果您在Date或Calendar属性类型上使用@VersionComments,则会自动使用时间戳记。
例子 389.使用时间戳进行乐观锁定
@Version
private Date version;
Hibernate 可以通过读取您为@org.hibernate.annotations.SourceComments 指定的值来从数据库或 JVM 中检索时间戳值。该值可以是org.hibernate.annotations.SourceType.DB或org.hibernate.annotations.SourceType.VM。默认行为是使用数据库,如果根本不指定 Comments,则也使用数据库。
如果使用@org.hibernate.annotations.Generated(GenerationTime.ALWAYS)或@Source注解,则时间戳记也可以由数据库而不是 Hibernate 生成。
例子 390.数据库生成的版本时间戳 Map
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String firstName;
private String lastName;
@Version
@Source(value = SourceType.DB)
private Date version;
}
现在,当持久化Person实体时,Hibernate 调用特定于数据库的当前时间戳检索函数:
例子 391.数据库生成的版本时间戳例子
Person person = new Person();
person.setId( 1L );
person.setFirstName( "John" );
person.setLastName( "Doe" );
assertNull( person.getVersion() );
entityManager.persist( person );
assertNotNull( person.getVersion() );
CALL current_timestamp()
INSERT INTO
Person
(firstName, lastName, version, id)
VALUES
(?, ?, ?, ?)
-- binding parameter [1] as [VARCHAR] - [John]
-- binding parameter [2] as [VARCHAR] - [Doe]
-- binding parameter [3] as [TIMESTAMP] - [2017-05-18 12:03:03.808]
-- binding parameter [4] as [BIGINT] - [1]
Excluding attributes
默认情况下,每次实体属性修改都会触发版本增加。如果存在一个不应增加实体版本的实体属性,则需要使用 Hibernate @OptimisticLockComments 对其进行 Comments,如以下示例所示。
例子 392. @OptimisticLockMap 例子
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "`number`")
private String number;
@OptimisticLock( excluded = true )
private long callCount;
@Version
private Long version;
//Getters and setters are omitted for brevity
public void incrementCallCount() {
this.callCount++;
}
}
这样,如果一个线程修改Phone号,而第二个线程修改callCount属性,则两个并发事务不会冲突,如以下示例所示。
例子 393. @OptimisticLock 排除属性例子
doInJPA( this::entityManagerFactory, entityManager -> {
Phone phone = entityManager.find( Phone.class, 1L );
phone.setNumber( "+123-456-7890" );
doInJPA( this::entityManagerFactory, _entityManager -> {
Phone _phone = _entityManager.find( Phone.class, 1L );
_phone.incrementCallCount();
log.info( "Bob changes the Phone call count" );
} );
log.info( "Alice changes the Phone number" );
} );
-- Bob changes the Phone call count
update
Phone
set
callCount = 1,
"number" = '123-456-7890',
version = 0
where
id = 1
and version = 0
-- Alice changes the Phone number
update
Phone
set
callCount = 0,
"number" = '+123-456-7890',
version = 1
where
id = 1
and version = 0
当 Bob 更改Phone实体callCount时,实体版本不会增加。这就是为什么自从实体版本仍然为 0 以来,爱丽丝的 UPDATE 成功的原因,即使鲍勃自从爱丽丝加载记录以来就更改了该记录。
Warning
尽管 Bob 和 Alice 之间没有冲突,但是 Alice 的 UPDATE 会覆盖 Bob 对callCount属性的更改。
因此,仅当您可以容纳排除的实体属性上丢失的更新时,才应使用此功能。
无版本乐观锁定
尽管默认的@Version属性乐观锁定机制在许多情况下已足够,但是有时您仍需要依靠数据库的实际行列值来防止 丢失更新 。
Hibernate 支持一种乐观锁定的形式,该形式不需要专用的“版本属性”。这对于与建模旧模式一起使用也很有用。
这个想法是,您可以让 Hibernate 使用实体的所有属性或仅使用已更改的属性来执行“版本检查”。这是通过使用@OptimisticLocking注解实现的,该注解定义了org.hibernate.annotations.OptimisticLockType类型的单个属性。
有 4 种可用的 OptimisticLockType:
NONE- 即使存在
@VersionComments,开放式锁定也会被禁用
- 即使存在
VERSION(默认值)- 如上所述,基于
@Version执行乐观锁定
- 如上所述,基于
ALL- 基于* all *字段执行乐观锁定,这是 UPDATE/DELETE SQL 语句的扩展 WHERE 子句限制的一部分
DIRTY- 根据* dirty *字段执行乐观锁定,这是 UPDATE/DELETE SQL 语句的扩展 WHERE 子句限制的一部分
使用 OptimisticLockType.ALL 的无版本乐观锁定
例子 394. OptimisticLockType.ALLMap 例子
@Entity(name = "Person")
@OptimisticLocking(type = OptimisticLockType.ALL)
@DynamicUpdate
public static class Person {
@Id
private Long id;
@Column(name = "`name`")
private String name;
private String country;
private String city;
@Column(name = "created_on")
private Timestamp createdOn;
//Getters and setters are omitted for brevity
}
当您需要修改上面的Person实体时:
例子 395.OptimisticLockType.ALL更新例子
Person person = entityManager.find( Person.class, 1L );
person.setCity( "Washington D.C." );
UPDATE
Person
SET
city=?
WHERE
id=?
AND city=?
AND country=?
AND created_on=?
AND "name"=?
-- binding parameter [1] as [VARCHAR] - [Washington D.C.]
-- binding parameter [2] as [BIGINT] - [1]
-- binding parameter [3] as [VARCHAR] - [New York]
-- binding parameter [4] as [VARCHAR] - [US]
-- binding parameter [5] as [TIMESTAMP] - [2016-11-16 16:05:12.876]
-- binding parameter [6] as [VARCHAR] - [John Doe]
如您所见,相关数据库行的所有列都在WHERE子句中使用。如果在加载行后更改了任何列,则不会有任何匹配,并且将抛出StaleStateException或OptimisticLockException。
Note
使用OptimisticLockType.ALL时,还应使用@DynamicUpdate,因为UPDATE语句必须考虑所有实体属性值。
使用 OptimisticLockType.DIRTY 的无版本乐观锁定
OptimisticLockType.DIRTY与OptimisticLockType.ALL的不同之处在于,它仅考虑自从实体在当前运行的持久性上下文中加载以来已更改的实体属性。
例子 396. OptimisticLockType.DIRTYMap 例子
@Entity(name = "Person")
@OptimisticLocking(type = OptimisticLockType.DIRTY)
@DynamicUpdate
@SelectBeforeUpdate
public static class Person {
@Id
private Long id;
@Column(name = "`name`")
private String name;
private String country;
private String city;
@Column(name = "created_on")
private Timestamp createdOn;
//Getters and setters are omitted for brevity
}
当您需要修改上面的Person实体时:
例子 397.OptimisticLockType.DIRTY更新例子
Person person = entityManager.find( Person.class, 1L );
person.setCity( "Washington D.C." );
UPDATE
Person
SET
city=?
WHERE
id=?
and city=?
-- binding parameter [1] as [VARCHAR] - [Washington D.C.]
-- binding parameter [2] as [BIGINT] - [1]
-- binding parameter [3] as [VARCHAR] - [New York]
这次,在WHERE子句中仅使用了已更改的数据库列。
Note
OptimisticLockType.DIRTY优于OptimisticLockType.ALL以及与@VersionMap 一起隐式使用的默认OptimisticLockType.VERSION的主要优点是,它使您可以将跨非重叠实体属性更改的OptimisticLockException的风险降至最低。
使用OptimisticLockType.DIRTY时,还应该使用@DynamicUpdate,因为UPDATE语句必须考虑所有脏实体属性值以及@SelectBeforeUpdate注解,以便通过Session#update(entity)操作正确处理分离的实体。
10.2. Pessimistic
通常,您只需要为 JDBC 连接指定隔离级别,然后让数据库处理锁定问题。如果确实需要在新事务开始时获得排他的悲观锁或重新获得锁,则 Hibernate 将为您提供所需的工具。
Note
Hibernate 始终使用数据库的锁定机制,从不锁定内存中的对象。
10.3. LockMode 和 LockModeType
早在 JPA 1.0 之前,Hibernate 已经通过其LockMode枚举定义了各种显式锁定策略。 JPA 带有自己的LockModeType枚举,该枚举定义了与 Hibernate-native LockMode类似的策略。
LockModeType |
LockMode |
Description |
|---|---|---|
NONE |
NONE |
没有锁。在事务结束时,所有对象都切换到此锁定模式。通过调用update()或saveOrUpdate()与会话相关联的对象也以此锁定模式启动。 |
READ和OPTIMISTIC |
READ |
在当前运行的事务即将结束时检查实体版本。 |
WRITE和OPTIMISTIC_FORCE_INCREMENT |
WRITE |
即使未更改实体,实体版本也会自动增加。 |
PESSIMISTIC_FORCE_INCREMENT |
PESSIMISTIC_FORCE_INCREMENT |
实体被悲观地锁定,即使实体未更改,其版本也会自动增加。 |
PESSIMISTIC_READ |
PESSIMISTIC_READ |
如果数据库支持这样的功能,则使用共享锁悲观地锁定实体。否则,将使用显式锁。 |
PESSIMISTIC_WRITE |
PESSIMISTIC_WRITE , UPGRADE |
使用显式锁来锁定实体。 |
PESSIMISTIC_WRITE的javax.persistence.lock.timeout设置为 0 |
UPGRADE_NOWAIT |
如果行已被锁定,则锁定获取请求将快速失败。 |
PESSIMISTIC_WRITE的javax.persistence.lock.timeout设置为-2 |
UPGRADE_SKIPLOCKED |
锁定获取请求将跳过已经锁定的行。它在 Oracle 和 PostgreSQL 9.5 中使用SELECT … FOR UPDATE SKIP LOCKED或SELECT … with (rowlock, updlock, readpast) in SQL Server。 |
上面提到的明确的用户请求是以下任何操作的结果:
调用
Session.load(),并指定LockMode。致电
Session.lock()。致电
Query.setLockMode()。
如果使用选项UPGRADE,UPGRADE_NOWAIT或UPGRADE_SKIPLOCKED调用Session.load(),并且会话尚未加载请求的对象,则使用SELECT … FOR UPDATE加载该对象。
如果您为一个已加载了比您所请求的限制较少的锁定的对象调用load(),则 Hibernate 对该对象调用lock()。
Session.lock()执行版本号检查,是否指定的锁定模式是READ,UPGRADE,UPGRADE_NOWAIT或UPGRADE_SKIPLOCKED。在UPGRADE,UPGRADE_NOWAIT或UPGRADE_SKIPLOCKED的情况下,使用SELECT … FOR UPDATE语法。
如果数据库不支持请求的锁定模式,则 Hibernate 将使用适当的替代模式,而不是引发异常。这样可以确保应用程序是可移植的。
10.4. JPA 锁定查询提示
JPA 2.0 引入了两个查询提示:
javax.persistence.lock.timeout
- 它给出锁定获取请求在引发异常之前将 await 的毫秒数
javax.persistence.lock.scope
- 定义锁获取请求的scope。范围可以是
NORMAL(默认值)或EXTENDED。EXTENDED范围将导致锁获取请求被传递到结构化的其他拥有的表(例如@Inheritance(strategy=InheritanceType.JOINED),@ElementCollection)
- 定义锁获取请求的scope。范围可以是
例子 398.javax.persistence.lock.timeout例子
entityManager.find(
Person.class, id, LockModeType.PESSIMISTIC_WRITE,
Collections.singletonMap( "javax.persistence.lock.timeout", 200 )
);
SELECT explicitlo0_.id AS id1_0_0_,
explicitlo0_."name" AS name2_0_0_
FROM person explicitlo0_
WHERE explicitlo0_.id = 1
FOR UPDATE wait 2
Note
并非所有的 JDBC 数据库驱动程序都支持为锁定请求设置超时值。如果不支持,则 Hibernate 方言将忽略此查询提示。
Note
JPA 标准指定javax.persistence.lock.scope为尚不支持。
10.5. buildLockRequest API
传统上,Hibernate 提供了Session#lock()方法来获取给定实体的乐观或悲观锁。由于使用单个LockMode参数很难改变锁定选项,因此 Hibernate 添加了Session#buildLockRequest()方法 API。
以下示例显示如何在不 await 锁获取请求的情况下获取共享数据库锁。
例子 399.buildLockRequest例子
Person person = entityManager.find( Person.class, id );
Session session = entityManager.unwrap( Session.class );
session
.buildLockRequest( LockOptions.NONE )
.setLockMode( LockMode.PESSIMISTIC_READ )
.setTimeOut( LockOptions.NO_WAIT )
.lock( person );
SELECT p.id AS id1_0_0_ ,
p.name AS name2_0_0_
FROM Person p
WHERE p.id = 1
SELECT id
FROM Person
WHERE id = 1
FOR SHARE NOWAIT
10.6. Follow-on-locking
使用 Oracle 时,FOR UPDATE 排他锁定子句不能与以下项一起使用:
DISTINCTGROUP BYUNION内联视图(派生表),因此也影响了旧版 Oracle 分页机制。
因此,Hibernate 使用辅助选择来锁定以前获取的实体。
例子 400.跟随锁定例子
List<Person> persons = entityManager.createQuery(
"select DISTINCT p from Person p", Person.class)
.setLockMode( LockModeType.PESSIMISTIC_WRITE )
.getResultList();
SELECT DISTINCT p.id as id1_0_, p."name" as name2_0_
FROM Person p
SELECT id
FROM Person
WHERE id = 1 FOR UPDATE
SELECT id
FROM Person
WHERE id = 1 FOR UPDATE
Note
为了避免 N 1 查询问题,可以使用单独的查询使用关联的实体标识符来应用锁。
例子 401.辅助查询实体锁定
List<Person> persons = entityManager.createQuery(
"select DISTINCT p from Person p", Person.class)
.getResultList();
entityManager.createQuery(
"select p.id from Person p where p in :persons")
.setLockMode( LockModeType.PESSIMISTIC_WRITE )
.setParameter( "persons", persons )
.getResultList();
SELECT DISTINCT p.id as id1_0_, p."name" as name2_0_
FROM Person p
SELECT p.id as col_0_0_
FROM Person p
WHERE p.id IN ( 1 , 2 )
FOR UPDATE
锁定请求从原始查询移到了第二个请求,该请求使用先前获取的实体来锁定其关联的数据库记录。
在 Hibernate 5.2.1 之前,后续锁定机制被统一应用于在 Oracle 上执行的任何锁定查询。从 5.2.1 开始,Oracle 方言尝试找出当前查询是否需要跟随锁定机制。
更为重要的是,您可以否决默认的锁定后检测逻辑,并根据每个查询显式启用或禁用它。
例子 402.明确地禁用跟随锁定机制
List<Person> persons = entityManager.createQuery(
"select p from Person p", Person.class)
.setMaxResults( 10 )
.unwrap( Query.class )
.setLockOptions(
new LockOptions( LockMode.PESSIMISTIC_WRITE )
.setFollowOnLocking( false ) )
.getResultList();
SELECT *
FROM (
SELECT p.id as id1_0_, p."name" as name2_0_
FROM Person p
)
WHERE rownum <= 10
FOR UPDATE
Note
仅当当前正在执行的查询由于无法应用FOR UPDATE子句而失败时,才应显式启用跟随锁定机制,这意味着需要进一步改进方言解析机制。
11. Fetching
本质上,获取是从数据库中获取数据并将其提供给应用程序的过程。调整应用程序的获取方式是确定应用程序将如何执行的最大因素之一。就宽度(值/列)和/或深度(结果/行)而言,获取太多数据会增加 JDBC 通信和 ResultSet 处理方面的不必要开销。提取的数据太少可能会导致需要进行其他的提取。调整应用程序获取数据的方式提供了一个很大的机会来影响整体应用程序性能。
11.1. 基础
访存的概念分为两个不同的问题。
何时应提取数据?现在?后来?
应该如何获取数据?
Note
“现在”通常被称为渴望或立即,而“稍后”通常被称为懒惰或延迟。
定义访存有很多范围:
static
- 提取策略的静态定义在 Map 中完成。在没有任何动态定义策略的情况下使用静态定义的访存策略。
SELECT
执行单独的 SQL 选择以加载数据。可以是 EAGER(立即发出第二个选择)或 LAZY(延迟第二个选择直到需要数据)。这通常称为 N 1.
JOIN
- 固有的获取风格。通过使用 SQL 外部联接获取要获取的数据。
BATCH
- 根据批次大小,使用 IN 限制作为 SQL WHERE 子句的一部分,执行单独的 SQL 选择以加载许多相关数据项。同样,它可以是 EAGER(立即发出第二个选择)或 LAZY(延迟第二个选择直到需要数据)。
SUBSELECT
- 根据用于加载所有者的 SQL 限制执行单独的 SQL 选择以加载关联的数据。同样,它可以是 EAGER(立即发出第二个选择)或 LAZY(延迟第二个选择直到需要数据)。
动态(有时称为运行时)
- 动态定义实际上是以用例为中心的。有多种定义动态获取的方法:
fetch profiles
在 Map 中定义,但可以在
Session上启用/禁用。HQL/JPQL
- Hibernate 和 JPA Criteria 查询都可以指定特定于所述查询的访存。
entity graphs
- 从 Hibernate 4.2(JPA 2.1)开始,这也是一个选择。
11.2. 直接获取与实体查询
要查看在直接获取的关联方面直接获取和实体查询之间的区别,请考虑以下实体:
例子 403.域模型
@Entity(name = "Department")
public static class Department {
@Id
private Long id;
//Getters and setters omitted for brevity
}
@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String username;
@ManyToOne(fetch = FetchType.EAGER)
private Department department;
//Getters and setters omitted for brevity
}
Employee实体与Department有着@ManyToOne关联,而Department则急切获取。
发出直接实体获取时,Hibernate 执行以下 SQL 查询:
例子 404.直接获取例子
Employee employee = entityManager.find( Employee.class, 1L );
select
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.username as username2_1_0_,
d.id as id1_0_1_
from
Employee e
left outer join
Department d
on e.department_id=d.id
where
e.id = 1
LEFT JOIN子句被添加到生成的 SQL 查询中,因为需要热切地获取此关联。
另一方面,如果您使用的实体查询不包含指向Department关联的JOIN FETCH指令:
例子 405.实体查询获取例子
Employee employee = entityManager.createQuery(
"select e " +
"from Employee e " +
"where e.id = :id", Employee.class)
.setParameter( "id", 1L )
.getSingleResult();
select
e.id as id1_1_,
e.department_id as departme3_1_,
e.username as username2_1_
from
Employee e
where
e.id = 1
select
d.id as id1_0_0_
from
Department d
where
d.id = 1
Hibernate 改为使用辅助选择。这是因为实体查询的提取策略无法被覆盖,因此 Hibernate 要求进行二次选择,以确保在将结果返回给用户之前已提取 EAGER 关联。
Tip
如果您忘记了加入所有 EAGER 关联,Hibernate 将为每个关联发出第二选择,这反过来会导致 N 1 个查询问题。
因此,您应该首选 LAZY 关联。
11.3. 应用提取策略
让我们考虑这些主题,因为它们涉及一个简单的域模型和一些用例。
例子 406.samples 域模型
@Entity(name = "Department")
public static class Department {
@Id
private Long id;
@OneToMany(mappedBy = "department")
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String username;
@Column(name = "pswd")
@ColumnTransformer(
read = "decrypt( 'AES', '00', pswd )",
write = "encrypt('AES', '00', ?)"
)
private String password;
private int accessLevel;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
@ManyToMany(mappedBy = "employees")
private List<Project> projects = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Project")
public class Project {
@Id
private Long id;
@ManyToMany
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
Tip
Hibernate 的建议是静态地标记所有懒惰的关联,并使用动态获取策略来提高渴望。
不幸的是,这与 JPA 规范不一致,该规范定义默认应急切获取所有一对一和多对一关联。
作为 JPA 提供程序,Hibernate 遵守该默认设置。
11.4. 不取
对于第一个用例,请考虑Employee的应用程序登录过程。假设登录仅需要访问Employee信息,而不需要Project或Department信息。
例子 407.没有获取例子
Employee employee = entityManager.createQuery(
"select e " +
"from Employee e " +
"where " +
" e.username = :username and " +
" e.password = :password",
Employee.class)
.setParameter( "username", username)
.setParameter( "password", password)
.getSingleResult();
在此示例中,应用程序获取Employee数据。但是,由于来自Employee的所有关联都声明为 LAZY(JPA 将集合的默认值定义为 LAZY),因此不会获取其他数据。
如果登录过程不需要专门访问Employee信息,则此处的另一种获取优化将是限制查询结果的宽度。
例子 408.没有获取(标量)的例子
Integer accessLevel = entityManager.createQuery(
"select e.accessLevel " +
"from Employee e " +
"where " +
" e.username = :username and " +
" e.password = :password",
Integer.class)
.setParameter( "username", username)
.setParameter( "password", password)
.getSingleResult();
11.5. 通过查询动态获取
对于第二个用例,请考虑一个屏幕,其中显示Projects表示Employee。当然,需要Employee的访问权限,也需要对该员工的Projects的集合。不需要有关Departments,其他Employees或其他Projects的信息。
例子 409.动态 JPQL 提取例子
Employee employee = entityManager.createQuery(
"select e " +
"from Employee e " +
"left join fetch e.projects " +
"where " +
" e.username = :username and " +
" e.password = :password",
Employee.class)
.setParameter( "username", username)
.setParameter( "password", password)
.getSingleResult();
例子 410.动态查询获取例子
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Employee> query = builder.createQuery( Employee.class );
Root<Employee> root = query.from( Employee.class );
root.fetch( "projects", JoinType.LEFT);
query.select(root).where(
builder.and(
builder.equal(root.get("username"), username),
builder.equal(root.get("password"), password)
)
);
Employee employee = entityManager.createQuery( query ).getSingleResult();
在此示例中,我们在单个查询中加载了一个Employee和它们的Projects,同时显示为 HQL 查询和 JPA Criteria 查询。在这两种情况下,这都只解析为一个数据库查询即可获取所有信息。
11.6. 通过 JPA 实体图动态获取
JPA 2.1 引入了实体图,因此应用程序开发人员可以更好地控制获取计划。
例子 411.获取图例子
@Entity(name = "Employee")
@NamedEntityGraph(name = "employee.projects",
attributeNodes = @NamedAttributeNode("projects")
)
Employee employee = entityManager.find(
Employee.class,
userId,
Collections.singletonMap(
"javax.persistence.fetchgraph",
entityManager.getEntityGraph( "employee.projects" )
)
);
Note
在执行 JPQL 查询时,如果省略 EAGER 关联,则 Hibernate 将为需要急切获取的每个关联发出辅助选择,这可能导致 N 1 个查询问题。
出于这个原因,最好使用 LAZY 关联,并且仅在每个查询的基础上热切地获取它们。
EntityGraph 是“加载计划”的根,并且必须与 EntityType 相对应。
11.6.1. JPA(关键)子图
子图用于控制对其应用的 AttributeNode 的子属性的获取。通常是通过@NamedSubgraphComments 定义的。
如果我们有一个具有employees个子关联的Project父实体,并且我们想为Employee子关联获取department。
例子 412.用子图 Map 获取图
@Entity(name = "Project")
@NamedEntityGraph(name = "project.employees",
attributeNodes = @NamedAttributeNode(
value = "employees",
subgraph = "project.employees.department"
),
subgraphs = @NamedSubgraph(
name = "project.employees.department",
attributeNodes = @NamedAttributeNode( "department" )
)
)
public static class Project {
@Id
private Long id;
@ManyToMany
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
当获取该实体图时,Hibernate 生成以下 SQL 查询:
例子 413.使用子图 Map 获取图
Project project = doInJPA( this::entityManagerFactory, entityManager -> {
return entityManager.find(
Project.class,
1L,
Collections.singletonMap(
"javax.persistence.fetchgraph",
entityManager.getEntityGraph( "project.employees" )
)
);
} );
select
p.id as id1_2_0_, e.id as id1_1_1_, d.id as id1_0_2_,
e.accessLevel as accessLe2_1_1_,
e.department_id as departme5_1_1_,
decrypt( 'AES', '00', e.pswd ) as pswd3_1_1_,
e.username as username4_1_1_,
p_e.projects_id as projects1_3_0__,
p_e.employees_id as employee2_3_0__
from
Project p
inner join
Project_Employee p_e
on p.id=p_e.projects_id
inner join
Employee e
on p_e.employees_id=e.id
inner join
Department d
on e.department_id=d.id
where
p.id = ?
-- binding parameter [1] as [BIGINT] - [1]
指定子图仅对类型为 ManagedType 的属性(或其“键”)有效。因此,尽管 EntityGraph 必须对应于 EntityType,但是 Subgraph 对于任何 ManagedType 都是合法的。属性的键定义为:
对于单个属性,该属性的类型必须为 IdentifiableType,并且该 IdentifiableType 必须具有复合标识符。 “关键子图”应用于标识符类型。非关键子图适用于属性的值,该值必须是 ManagedType。
对于复数属性,该属性必须是 Map,并且 Map 的键值必须是 ManagedType。 “键子图”将应用于 Map 的键类型。在这种情况下,非关键子图适用于复数属性的值/元素。
11.6.2. JPA SubGraph 子类型
子图也可以是特定于子类型的。给定一个属性值是继承层次结构的属性,我们可以使用接受子类型 Class 的子图定义形式来引用特定子类型的属性。
11.6.3. 通过文本表示创建和应用 JPA 图
Hibernate 允许通过解析图的文本表示来创建 JPA 提取/加载图。一般而言,图形的文本表示形式是属性名称的逗号分隔列表,可选地包括任何子图形规范。 org.hibernate.graph.EntityGraphParser是此类解析操作的起点。
Note
解析图的文本表示形式(尚未)是 JPA 规范的一部分。因此,此处描述的语法特定于 Hibernate。我们确实希望最终使该语法成为 JPA 规范的一部分。
例子 414.解析一个简单的图
final EntityGraph<Project> graph = GraphParser.parse(
Project.class,
"employees( department )",
entityManager
);
本示例实际上仅使用解析图而不是命名图,其功能完全与使用子图 Map 获取图相同。
该语法还支持定义“关键子图”。要指定关键子图,请将.key添加到属性名称的末尾。
例子 415.解析实体键图
final EntityGraph<Movie> graph = GraphParser.parse(
Movie.class,
"cast.key( name )",
entityManager
);
例子 416.解析一个 Map 键图
final EntityGraph<Ticket> graph = GraphParser.parse(
Ticket.class,
"showing.key( movie( cast ) )",
entityManager
);
解析还可以处理特定于子类型的子图。例如,给定一个实体层次结构LegalEntity←(Corporation | Person | NonProfit)和一个名为responsibleParty且其类型为LegalEntity基本类型的属性,我们可能具有:
responsibleParty(Corporation: ceo)
我们甚至可以复制属性名称以应用不同的子类型子图:
responsibleParty(taxIdNumber), responsibleParty(Corporation: ceo), responsibleParty(NonProfit: sector)
重复的属性名称是根据 JPA 规范进行处理的,JPA 规范指出,属性节点的重复规范会导致原始注册的 AttributeNode 被重新使用,从而有效地将 2 个 AttributeNode 规范合并在一起。换句话说,以上规范创建了具有 3 个不同的 SubGraphs 的单个 AttributeNode。它在功能上与调用相同:
Class<Invoice> invoiceClass = ...;
javax.persistence.EntityGraph<Invoice> invoiceGraph = entityManager.createEntityGraph( invoiceClass );
invoiceGraph.addAttributeNode( "responsibleParty" );
invoiceGraph.addSubgraph( "responsibleParty" ).addAttributeNode( "taxIdNumber" );
invoiceGraph.addSubgraph( "responsibleParty", Corporation.class ).addAttributeNode( "ceo" );
invoiceGraph.addSubgraph( "responsibleParty", NonProfit.class ).addAttributeNode( "sector" );
11.6.4. 将多个 JPA 实体图组合成一个
可以将多个实体图组合成一个充当联合的单个“超级图”。也可以通过将单独的方面图组合为一个来构建上一个示例中的图,例如:
例子 417.将多个图组合成一个
final EntityGraph<Project> a = GraphParser.parse(
Project.class, "employees( username )", entityManager
);
final EntityGraph<Project> b = GraphParser.parse(
Project.class, "employees( password, accessLevel )", entityManager
);
final EntityGraph<Project> c = GraphParser.parse(
Project.class, "employees( department( employees( username ) ) )", entityManager
);
final EntityGraph<Project> all = EntityGraphs.merge( entityManager, Project.class, a, b, c );
11.7. 通过 Hibernate 配置文件动态获取
假设我们想利用 Natural-id 加载,以获取“针对员工的项目”用例中的Employee信息。通过 natural-id 加载使用静态定义的获取策略,但未提供定义负载特定的获取的方法。因此,我们将利用提取配置文件。
例子 418.获取配置文件例子
@Entity(name = "Employee")
@FetchProfile(
name = "employee.projects",
fetchOverrides = {
@FetchProfile.FetchOverride(
entity = Employee.class,
association = "projects",
mode = FetchMode.JOIN
)
}
)
session.enableFetchProfile( "employee.projects" );
Employee employee = session.bySimpleNaturalId( Employee.class ).load( username );
这里的Employee是通过自然 ID 查找获得的,而员工的Project数据则被急切地获取。如果Employee数据是从缓存中解析的,则Project数据将自己解析。但是,如果未在缓存中解析Employee数据,则如上所述,通过联接在一个 SQL 查询中解析了Employee和Project数据。
11.8. 批量提取
Hibernate 提供了@BatchSize注解,可在获取未初始化的实体代理时使用。
考虑以下实体 Map:
例子 419. @BatchSizeMap 例子
@Entity(name = "Department")
public static class Department {
@Id
private Long id;
@OneToMany(mappedBy = "department")
//@BatchSize(size = 5)
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
//Getters and setters omitted for brevity
}
考虑到我们以前已经获取了多个Department实体,现在我们需要为每个特定的Department初始化employees实体集合,@BatchSize注解允许我们在单个数据库往返中加载多个Employee实体。
例子 420. @BatchSize获取例子
List<Department> departments = entityManager.createQuery(
"select d " +
"from Department d " +
"inner join d.employees e " +
"where e.name like 'John%'", Department.class)
.getResultList();
for ( Department department : departments ) {
log.infof(
"Department %d has {} employees",
department.getId(),
department.getEmployees().size()
);
}
SELECT
d.id as id1_0_
FROM
Department d
INNER JOIN
Employee employees1_
ON d.id=employees1_.department_id
SELECT
e.department_id as departme3_1_1_,
e.id as id1_1_1_,
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.name as name2_1_0_
FROM
Employee e
WHERE
e.department_id IN (
0, 2, 3, 4, 5
)
SELECT
e.department_id as departme3_1_1_,
e.id as id1_1_1_,
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.name as name2_1_0_
FROM
Employee e
WHERE
e.department_id IN (
6, 7, 8, 9, 1
)
如上例所示,只有两个 SQL 语句用于获取与多个Department实体关联的Employee实体。
Tip
如果没有@BatchSize,则会遇到 N 1 个查询问题,因此,代替 2 条 SQL 语句,将需要 10 个查询来提取Employee个子实体。
但是,尽管@BatchSize比遇到 N 1 查询问题更好,但是在大多数情况下,DTO 投影或JOIN FETCH是更好的选择,因为它允许您通过单个查询获取所有必需的数据。
11.9. @FetchCommentsMap
除了FetchType.LAZY或FetchType.EAGER JPA 注解,您还可以使用特定于 Hibernate 的@Fetch注解,该注解接受以下FetchMode之一:
SELECT
- 对于每个单独的实体,集合或联接负载,将使用辅助选择来延迟获取关联。这等效于 JPA
FetchType.LAZY提取策略。
- 对于每个单独的实体,集合或联接负载,将使用辅助选择来延迟获取关联。这等效于 JPA
JOIN
- 使用直接获取时,请使用外部联接加载相关的实体,集合或联接。这等效于 JPA
FetchType.EAGER提取策略。
- 使用直接获取时,请使用外部联接加载相关的实体,集合或联接。这等效于 JPA
SUBSELECT
- 仅适用于收藏集。当访问未初始化的集合时,此获取模式将触发使用单个辅助选择为与持久性上下文关联的所有所有者加载具有相同角色的所有集合的所有元素。
11.10. FetchMode.SELECT
为了演示FetchMode.SELECT的工作原理,请考虑以下实体 Map:
例子 421. FetchMode.SELECTMap 例子
@Entity(name = "Department")
public static class Department {
@Id
private Long id;
@OneToMany(mappedBy = "department", fetch = FetchType.LAZY)
@Fetch(FetchMode.SELECT)
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Employee")
public static class Employee {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String username;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
//Getters and setters omitted for brevity
}
考虑到存在多个Department实体,每个实体具有多个Employee实体,在执行以下测试用例时,Hibernate 在首次访问子集合时使用辅助SELECT语句获取每个未初始化的Employee集合:
例子 422. FetchMode.SELECTMap 例子
List<Department> departments = entityManager.createQuery(
"select d from Department d", Department.class )
.getResultList();
log.infof( "Fetched %d Departments", departments.size());
for (Department department : departments ) {
assertEquals( 3, department.getEmployees().size() );
}
SELECT
d.id as id1_0_
FROM
Department d
-- Fetched 2 Departments
SELECT
e.department_id as departme3_1_0_,
e.id as id1_1_0_,
e.id as id1_1_1_,
e.department_id as departme3_1_1_,
e.username as username2_1_1_
FROM
Employee e
WHERE
e.department_id = 1
SELECT
e.department_id as departme3_1_0_,
e.id as id1_1_0_,
e.id as id1_1_1_,
e.department_id as departme3_1_1_,
e.username as username2_1_1_
FROM
Employee e
WHERE
e.department_id = 2
第一个查询获取的Department个实体越多,执行第二个SELECT多个语句来初始化employees集合。因此,FetchMode.SELECT可能导致 N 1 个查询问题。
11.11. FetchMode.SUBSELECT
为了演示FetchMode.SUBSELECT的工作原理,我们将修改FetchMode.SELECTMap 示例以使用FetchMode.SUBSELECT:
例子 423. FetchMode.SUBSELECTMap 例子
@OneToMany(mappedBy = "department", fetch = FetchType.LAZY)
@Fetch(FetchMode.SUBSELECT)
private List<Employee> employees = new ArrayList<>();
现在,我们将获取与给定过滤谓词匹配的所有Department实体,然后浏览其employees集合。
Hibernate 将通过生成单个 SQL 语句来初始化先前获取的所有Department实体的所有employees集合,从而避免 N 1 查询问题。 Hibernate 无需使用传递所有实体标识符的方式,而只是重新运行先前获取Department实体的查询。
例子 424. FetchMode.SUBSELECTMap 例子
List<Department> departments = entityManager.createQuery(
"select d " +
"from Department d " +
"where d.name like :token", Department.class )
.setParameter( "token", "Department%" )
.getResultList();
log.infof( "Fetched %d Departments", departments.size());
for (Department department : departments ) {
assertEquals( 3, department.getEmployees().size() );
}
SELECT
d.id as id1_0_
FROM
Department d
where
d.name like 'Department%'
-- Fetched 2 Departments
SELECT
e.department_id as departme3_1_1_,
e.id as id1_1_1_,
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.username as username2_1_0_
FROM
Employee e
WHERE
e.department_id in (
SELECT
fetchmodes0_.id
FROM
Department fetchmodes0_
WHERE
d.name like 'Department%'
)
11.12. FetchMode.JOIN
为了演示FetchMode.JOIN的工作原理,我们将FetchMode.SELECTMap 示例修改为使用FetchMode.JOIN:
例子 425. FetchMode.JOINMap 例子
@OneToMany(mappedBy = "department")
@Fetch(FetchMode.JOIN)
private List<Employee> employees = new ArrayList<>();
现在,我们将获取一个Department并浏览其employees集合。
Note
我们之所以不使用 JPQL 查询来获取多个Department实体,是因为FetchMode.JOIN策略将被查询获取指令所覆盖。
要通过 JPQL 查询获取多个关系,必须改用JOIN FETCH指令。
因此,FetchMode.JOIN对于通过实体的标识符或自然 ID 直接获取实体非常有用。
同样,FetchMode.JOIN充当FetchType.EAGER策略。即使我们将关联标记为FetchType.LAZY,FetchMode.JOIN也会热切加载该关联。
Hibernate 将通过为employees集合发出 OUTER JOIN 来避免二次查询。
例子 426. FetchMode.JOINMap 例子
Department department = entityManager.find( Department.class, 1L );
log.infof( "Fetched department: %s", department.getId());
assertEquals( 3, department.getEmployees().size() );
SELECT
d.id as id1_0_0_,
e.department_id as departme3_1_1_,
e.id as id1_1_1_,
e.id as id1_1_2_,
e.department_id as departme3_1_2_,
e.username as username2_1_2_
FROM
Department d
LEFT OUTER JOIN
Employee e
on d.id = e.department_id
WHERE
d.id = 1
-- Fetched department: 1
这次没有辅助查询,因为子集合与父实体一起加载。
11.13. @LazyCollection
@LazyCollection注解用于指定给定集合的延迟获取行为。可能的值由LazyCollectionOption枚举给出:
TRUE- 在请求状态时加载它。
FALSE- 认真加载它。
EXTRA- 优先选择额外的查询而不是完整的集合加载。
TRUE和FALSE值已弃用,因为您应该使用@ElementCollection,@OneToMany或@ManyToMany集合的 JPA FetchType属性。
EXTRA值在 JPA 规范中没有等效项,即使在首次访问该集合时,也可以避免加载整个集合。使用辅助查询分别获取每个元素。
例子 427. LazyCollectionOption.EXTRAMap 例子
@Entity(name = "Department")
public static class Department {
@Id
private Long id;
@OneToMany(mappedBy = "department", cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
@LazyCollection( LazyCollectionOption.EXTRA )
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String username;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
//Getters and setters omitted for brevity
}
Note
LazyCollectionOption.EXTRA仅适用于有序集合,即用@OrderColumnComments 的 List 或 Map。
对于包(例如不保留任何特定 Sequences 的常规实体列表),@LazyCollection(LazyCollectionOption.EXTRA)的行为与其他FetchType.LAZY集合类似(该集合在首次访问时便会完全提取)。
现在,考虑到我们具有以下实体:
例子 428.LazyCollectionOption.EXTRA域模型例子
Department department = new Department();
department.setId( 1L );
entityManager.persist( department );
for (long i = 1; i <= 3; i++ ) {
Employee employee = new Employee();
employee.setId( i );
employee.setUsername( String.format( "user_%d", i ) );
department.addEmployee(employee);
}
当按它们在List中的位置获取employee集合条目时,Hibernate 生成以下 SQL 语句:
例子 429. LazyCollectionOption.EXTRA取得例子
Department department = entityManager.find(Department.class, 1L);
int employeeCount = department.getEmployees().size();
for(int i = 0; i < employeeCount; i++ ) {
log.infof( "Fetched employee: %s", department.getEmployees().get( i ).getUsername());
}
SELECT
max(order_id) + 1
FROM
Employee
WHERE
department_id = ?
-- binding parameter [1] as [BIGINT] - [1]
SELECT
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.username as username2_1_0_
FROM
Employee e
WHERE
e.department_id=?
AND e.order_id=?
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [INTEGER] - [0]
SELECT
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.username as username2_1_0_
FROM
Employee e
WHERE
e.department_id=?
AND e.order_id=?
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [INTEGER] - [1]
SELECT
e.id as id1_1_0_,
e.department_id as departme3_1_0_,
e.username as username2_1_0_
FROM
Employee e
WHERE
e.department_id=?
AND e.order_id=?
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [INTEGER] - [2]
Warning
因此,子实体是在不触发完整集合初始化的情况下一个接一个地获取的。
因此,建议谨慎,因为使用LazyCollectionOption.EXTRA访问所有元素可能会导致 N 1 个查询问题。
12. Batching
12.1. JDBC 批处理
JDBC 提供了对批处理在一起的 SQL 语句的支持,这些语句可以表示为单个 PreparedStatement。在实现方面,这通常意味着驱动程序将在一个调用中将批处理操作发送到服务器,这可以节省对数据库的网络调用。 Hibernate 可以利用 JDBC 批处理。以下设置控制此行为。
hibernate.jdbc.batch_size- 控制 Hibernate 将在要求驱动程序执行批处理之前将批处理在一起的最大语句数。零或负数将禁用此功能。
hibernate.jdbc.batch_versioned_data- 执行批处理时,某些 JDBC 驱动程序返回不正确的行数。如果 JDBC 驱动程序属于此类别,则此设置应设置为
false。否则,可以安全地启用此功能,这将允许 Hibernate 仍然为版本化的实体批处理 DML,并且仍将返回的行数用于乐观锁检查。从 5.0 开始,它默认为 true。以前(版本 3.x 和 4.x),它曾经是 false。
- 执行批处理时,某些 JDBC 驱动程序返回不正确的行数。如果 JDBC 驱动程序属于此类别,则此设置应设置为
hibernate.jdbc.batch.builder- 命名用于 Management 批处理功能的实现类。从 Hibernate 的默认实现切换几乎从来不是一个好主意。但是,如果您愿意,此设置将命名要使用的
org.hibernate.engine.jdbc.batch.spi.BatchBuilder实现。
- 命名用于 Management 批处理功能的实现类。从 Hibernate 的默认实现切换几乎从来不是一个好主意。但是,如果您愿意,此设置将命名要使用的
hibernate.order_updates- 强制 Hibernate 按实体类型和要更新项目的主键值对 SQL 更新进行排序。这允许使用更多的批处理。在高度并发的系统中,这还将导致较少的事务死锁。它会带来性能上的损失,因此请在进行基准测试之前和之后进行测试,看看这是否对您的应用程序有帮助或损害。
hibernate.order_inserts- 强制休眠命令插入,以允许使用更多的批处理。它会带来性能上的损失,因此请在进行基准测试之前和之后进行测试,看看这是否对您的应用程序有帮助或损害。
Note
从 5.2 版开始,Hibernate 允许在Session的基础上覆盖hibernate.jdbc.batch_size配置属性给出的全局 JDBC 批处理大小。
例子 430.基于Session休眠特定的 JDBC 批处理大小配置
entityManager
.unwrap( Session.class )
.setJdbcBatchSize( 10 );
12.2. 会话批处理
以下示例显示了批处理插入的反模式。
例子 431.天真的方式用 Hibernate 插入 100 000 个实体
EntityManager entityManager = null;
EntityTransaction txn = null;
try {
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
for ( int i = 0; i < 100_000; i++ ) {
Person Person = new Person( String.format( "Person %d", i ) );
entityManager.persist( Person );
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.isActive()) txn.rollback();
throw e;
} finally {
if (entityManager != null) {
entityManager.close();
}
}
此示例存在几个问题:
Hibernate 将所有新插入的
Customer实例都缓存在会话级缓存中,因此,当事务结束时,持久性上下文将 Management100000 个实体。如果分配给 JVM 的最大内存很小,则此示例可能会失败,并带有OutOfMemoryException。 Java 1.8 JVM 分配了 1/4 的可用 RAM 或 1Gb,可以轻松容纳堆上的 100 000 个对象。长时间运行的事务可能会耗尽连接池,因此其他事务没有机会 continue 进行。
默认情况下,不启用 JDBC 批处理,因此每个 insert 语句都需要数据库往返。要启用 JDBC 批处理,请将
hibernate.jdbc.batch_size属性设置为 10 到 50 之间的整数。
Tip
如果使用身份标识符生成器,则 Hibernate 透明地在 JDBC 级别禁用插入批处理。
12.2.1. 批量插入
当使新对象成为持久对象时,请定期对会话使用方法flush()和clear(),以控制第一级缓存的大小。
例子 432.冲洗和清除Session
EntityManager entityManager = null;
EntityTransaction txn = null;
try {
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
int batchSize = 25;
for ( int i = 0; i < entityCount; i++ ) {
if ( i > 0 && i % batchSize == 0 ) {
//flush a batch of inserts and release memory
entityManager.flush();
entityManager.clear();
}
Person Person = new Person( String.format( "Person %d", i ) );
entityManager.persist( Person );
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.isActive()) txn.rollback();
throw e;
} finally {
if (entityManager != null) {
entityManager.close();
}
}
12.2.2. 会话滚动
检索和更新数据时,请定期flush()和clear()会话。此外,使用方法scroll()可以利用服务器端游标进行返回许多数据行的查询。
例子 433.使用scroll()
EntityManager entityManager = null;
EntityTransaction txn = null;
ScrollableResults scrollableResults = null;
try {
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
int batchSize = 25;
Session session = entityManager.unwrap( Session.class );
scrollableResults = session
.createQuery( "select p from Person p" )
.setCacheMode( CacheMode.IGNORE )
.scroll( ScrollMode.FORWARD_ONLY );
int count = 0;
while ( scrollableResults.next() ) {
Person Person = (Person) scrollableResults.get( 0 );
processPerson(Person);
if ( ++count % batchSize == 0 ) {
//flush a batch of updates and release memory:
entityManager.flush();
entityManager.clear();
}
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.isActive()) txn.rollback();
throw e;
} finally {
if (scrollableResults != null) {
scrollableResults.close();
}
if (entityManager != null) {
entityManager.close();
}
}
Tip
如果应用程序未关闭它,则 Hibernate 将在当前事务结束(提交或回滚)时自动关闭ScrollableResults内部使用的基础资源(例如ResultSet和PreparedStatement)。
但是,优良作法是显式关闭ScrollableResults。
12.2.3. StatelessSession
StatelessSession是 Hibernate 提供的面向命令的 API。使用它以分离对象的形式在数据库之间传输数据。 StatelessSession没有与其关联的持久性上下文,并且不提供许多更高级别的生命周期语义。
StatelessSession未提供的某些功能包括:
一级缓存
与任何第二级或查询缓存的交互
事务后写或自动脏检查
StatelessSession的局限性:
使用 Stateless 会话执行的操作永远不会级联到关联的实例。
Stateless 会话将忽略集合。
不支持延迟加载关联。
通过 Stateless 会话执行的操作会绕过 Hibernate 的事件模型和拦截器。
由于缺少一级缓存,Stateless 会话很容易受到数据别名效应的影响。
Stateless 会话是更底层的 JDBC,它更接近底层 JDBC。
例子 434.使用StatelessSession
StatelessSession statelessSession = null;
Transaction txn = null;
ScrollableResults scrollableResults = null;
try {
SessionFactory sessionFactory = entityManagerFactory().unwrap( SessionFactory.class );
statelessSession = sessionFactory.openStatelessSession();
txn = statelessSession.getTransaction();
txn.begin();
scrollableResults = statelessSession
.createQuery( "select p from Person p" )
.scroll(ScrollMode.FORWARD_ONLY);
while ( scrollableResults.next() ) {
Person Person = (Person) scrollableResults.get( 0 );
processPerson(Person);
statelessSession.update( Person );
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.getStatus() == TransactionStatus.ACTIVE) txn.rollback();
throw e;
} finally {
if (scrollableResults != null) {
scrollableResults.close();
}
if (statelessSession != null) {
statelessSession.close();
}
}
查询返回的Customer个实例将立即分离。它们从不与任何持久性上下文相关联。
StatelessSession接口定义的insert(),update()和delete()操作直接对数据库行进行操作。它们导致相应的 SQL 操作立即执行。它们具有与Session接口定义的save(),saveOrUpdate()和delete()操作不同的语义。
12.3. DML 的休眠查询语言
DML 或数据处理语言,指的是诸如INSERT,UPDATE和DELETE之类的 SQL 语句。 Hibernate 以 Hibernate 查询语言(HQL)的形式提供了用于执行 SQL 风格 DML 语句的方法。
12.3.1. HQL/JPQL 用于更新和删除
Hibernate 本机查询语言和 JPQL(Java 持久性查询语言)都支持批量 UPDATE 和 DELETE。
例子 435.使用 HQL 的 UPDATE 和 DELETE 语句的伪语法
UPDATE FROM EntityName e WHERE e.name = ?
DELETE FROM EntityName e WHERE e.name = ?
Note
尽管FROM和WHERE子句是可选的,但最好是显式声明它们。
FROM子句只能引用一个可以别名的实体。如果实体名称是别名,则任何属性引用都必须使用该别名进行限定。如果实体名称没有别名,则对任何属性引用进行限定都是非法的。
Note
批量 HQL 查询中禁止隐式或显式联接。您可以在WHERE子句中使用子查询,并且子查询本身可以包含联接。
例子 436.使用Query.executeUpdate()执行 JPQL UPDATE
int updatedEntities = entityManager.createQuery(
"update Person p " +
"set p.name = :newName " +
"where p.name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
例子 437.使用Query.executeUpdate()执行 HQL UPDATE
int updatedEntities = session.createQuery(
"update Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
与 EJB3 规范保持一致,默认情况下,HQL UPDATE语句不影响受影响实体的版本或时间戳属性值。通过在UPDATE关键字后添加VERSIONED关键字,可以使用版本更新来强制 Hibernate 重设版本或时间戳属性值。
例子 438.更新时间戳的版本
int updatedEntities = session.createQuery(
"update versioned Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
Note
如果使用VERSIONED语句,则不能使用实现org.hibernate.usertype.UserVersionType的自定义版本类型。
此功能仅在 HQL 中可用,因为 JPA 尚未对其进行标准化。
例子 439. JPQL DELETE语句
int deletedEntities = entityManager.createQuery(
"delete Person p " +
"where p.name = :name" )
.setParameter( "name", name )
.executeUpdate();
例子 440. HQL DELETE语句
int deletedEntities = session.createQuery(
"delete Person " +
"where name = :name" )
.setParameter( "name", name )
.executeUpdate();
方法Query.executeUpdate()返回int值,该值指示受该操作影响的实体数。这可能与数据库中受影响的行数相关或不相关。 JPQL/HQL 批量操作可能导致执行多个 SQL 语句,例如 joined-subclass。在 joined-subclass 的示例中,子级之一的DELETE实际上可能导致 join 所在的表中的删除,或者进一步导致继承层次结构的下降。
12.3.2. INSERT 的 HQL 语法
例子 441. INSERT 语句的伪语法
INSERT INTO EntityName
properties_list
SELECT properties_list
FROM ...
仅支持INSERT INTO … SELECT …表单。您不能指定要插入的显式值。
properties_list类似于SQL INSERT语句中的列规范。对于涉及 Map 继承的实体,您只能使用在properties_list中的给定类级别上直接定义的属性。不允许超类属性,而子类属性则无关。换句话说,INSERT语句本质上是非多态的。
SELECT 语句可以是任何有效的 HQL 选择查询,但是返回类型必须与 INSERT 期望的类型匹配。 Hibernate 在查询编译期间验证返回类型,而不是期望数据库对其进行检查。问题可能是由等同而不是相等的 Hibernate 类型导致的。一个这样的示例是定义为org.hibernate.type.DateType的属性和定义为org.hibernate.type.TimestampType的属性之间的不匹配,即使数据库可能没有区别,也可能能够处理转换。
如果未在properties_list中指定 id 属性,则 Hibernate 会自动生成一个值。仅当使用在数据库上运行的 ID 生成器时,自动生成才可用。否则,Hibernate 在解析过程中将引发异常。可用的数据库内生成器是org.hibernate.id.SequenceGenerator及其子类,以及实现org.hibernate.id.PostInsertIdentifierGenerator的对象。
对于 Map 为版本或时间戳的属性,insert 语句为您提供两个选项。您可以在 properties_list 中指定属性,在这种情况下,其值是从相应的 select 表达式中获取的,或者在 properties_list 中将其忽略,在这种情况下,将使用 org.hibernate.type.VersionType 定义的种子值。
例子 442. HQL INSERT 语句
int insertedEntities = session.createQuery(
"insert into Partner (id, name) " +
"select p.id, p.name " +
"from Person p ")
.executeUpdate();
本节仅是 HQL 的简要概述。有关更多信息,请参见HQL。
12.3.3. 大量 ID 策略
本文介绍的是HHH-11262 JIRA 问题,即使您无法创建临时表,该问题现在也允许批量 ID 策略起作用。
Class diagram
考虑到我们具有以下实体:
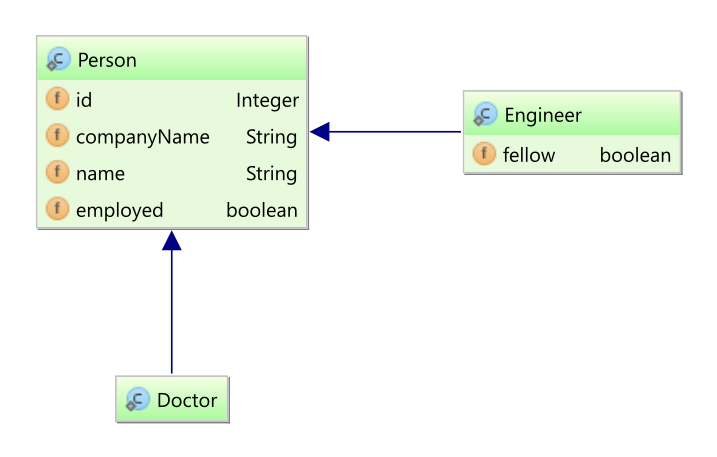
Person实体是该实体继承模型的 Base Class,并且 Map 如下:
例子 443.批量 IDBase Class 实体
@Entity(name = "Person")
@Inheritance(strategy = InheritanceType.JOINED)
public static class Person implements Serializable {
@Id
private Integer id;
@Id
private String companyName;
private String name;
private boolean employed;
//Getters and setters are omitted for brevity
}
Doctor和Engineer实体类都扩展了PersonBase Class:
例子 444. Bulk-id 子类实体
@Entity(name = "Doctor")
public static class Doctor extends Person {
}
@Entity(name = "Engineer")
public static class Engineer extends Person {
private boolean fellow;
//Getters and setters are omitted for brevity
}
继承树批量处理
现在,当您尝试执行批量实体删除查询时:
例子 445.批量 ID 删除查询例子
int updateCount = session.createQuery(
"delete from Person where employed = :employed" )
.setParameter( "employed", false )
.executeUpdate();
create temporary table
HT_Person
(
id int4 not null,
companyName varchar(255) not null
)
insert
into
HT_Person
select
p.id as id,
p.companyName as companyName
from
Person p
where
p.employed = ?
delete
from
Engineer
where
(
id, companyName
) IN (
select
id,
companyName
from
HT_Person
)
delete
from
Doctor
where
(
id, companyName
) IN (
select
id,
companyName
from
HT_Person
)
delete
from
Person
where
(
id, companyName
) IN (
select
id,
companyName
from
HT_Person
)
HT_Person是 Hibernate 创建的临时表,用于保存将由批量 ID 操作更新或删除的所有实体标识符。临时表可以是全局的也可以是局部的,具体取决于基础数据库的功能。
非临时表批量 ID 策略
正如HHH-11262问题所描述的,在某些情况下,由于数据库用户缺乏此特权,因此应用程序开发人员无法使用临时表。
在这种情况下,我们定义了几个选项,您可以根据数据库功能进行选择:
InlineIdsInClauseBulkIdStrategyInlineIdsSubSelectValueListBulkIdStrategyInlineIdsOrClauseBulkIdStrategyCteValuesListBulkIdStrategy
InlineIdsInClauseBulkIdStrategy
要使用此策略,您需要配置以下配置属性:
<property name="hibernate.hql.bulk_id_strategy"
value="org.hibernate.hql.spi.id.inline.InlineIdsInClauseBulkIdStrategy"
/>
现在,在运行前面的测试用例时,Hibernate 生成以下 SQL 语句:
例子 446. InlineIdsInClauseBulkIdStrategy删除实体查询的例子
select
p.id as id,
p.companyName as companyName
from
Person p
where
p.employed = ?
delete
from
Engineer
where
( id, companyName )
in (
( 1,'Red Hat USA' ),
( 3,'Red Hat USA' ),
( 1,'Red Hat Europe' ),
( 3,'Red Hat Europe' )
)
delete
from
Doctor
where
( id, companyName )
in (
( 1,'Red Hat USA' ),
( 3,'Red Hat USA' ),
( 1,'Red Hat Europe' ),
( 3,'Red Hat Europe' )
)
delete
from
Person
where
( id, companyName )
in (
( 1,'Red Hat USA' ),
( 3,'Red Hat USA' ),
( 1,'Red Hat Europe' ),
( 3,'Red Hat Europe' )
)
因此,首先选择实体标识符,并将其用于每个特定的更新或删除语句。
Tip
长期以来,Oracle,PostgreSQL 一直支持 IN 子句行值表达式,而如今,MySQL 5.7 支持 IN 子句行值表达式。但是,SQL Server 2014 不支持它,因此您必须使用其他策略。
InlineIdsSubSelectValueListBulkIdStrategy
要使用此策略,您需要配置以下配置属性:
<property name="hibernate.hql.bulk_id_strategy"
value="org.hibernate.hql.spi.id.inline.InlineIdsSubSelectValueListBulkIdStrategy"
/>
现在,在运行前面的测试用例时,Hibernate 生成以下 SQL 语句:
例子 447. InlineIdsSubSelectValueListBulkIdStrategy删除实体查询的例子
select
p.id as id,
p.companyName as companyName
from
Person p
where
p.employed = ?
delete
from
Engineer
where
( id, companyName ) in (
select
id,
companyName
from (
values
( 1,'Red Hat USA' ),
( 3,'Red Hat USA' ),
( 1,'Red Hat Europe' ),
( 3,'Red Hat Europe' )
) as HT
(id, companyName)
)
delete
from
Doctor
where
( id, companyName ) in (
select
id,
companyName
from (
values
( 1,'Red Hat USA' ),
( 3,'Red Hat USA' ),
( 1,'Red Hat Europe' ),
( 3,'Red Hat Europe' )
) as HT
(id, companyName)
)
delete
from
Person
where
( id, companyName ) in (
select
id,
companyName
from (
values
( 1,'Red Hat USA' ),
( 3,'Red Hat USA' ),
( 1,'Red Hat Europe' ),
( 3,'Red Hat Europe' )
) as HT
(id, companyName)
)
Tip
基础数据库必须支持VALUES list 子句,例如 PostgreSQL 或 SQL Server2008.但是,此策略要求复合标识符使用 IN 子句行值表达式,因此,只能在 PostgreSQL 中使用InlineIdsSubSelectValueListBulkIdStrategy策略。
InlineIdsOrClauseBulkIdStrategy
要使用此策略,您需要配置以下配置属性:
<property name="hibernate.hql.bulk_id_strategy"
value="org.hibernate.hql.spi.id.inline.InlineIdsOrClauseBulkIdStrategy"
/>
现在,在运行前面的测试用例时,Hibernate 生成以下 SQL 语句:
例子 448. InlineIdsOrClauseBulkIdStrategy删除实体查询的例子
select
p.id as id,
p.companyName as companyName
from
Person p
where
p.employed = ?
delete
from
Engineer
where
( id = 1 and companyName = 'Red Hat USA' )
or ( id = 3 and companyName = 'Red Hat USA' )
or ( id = 1 and companyName = 'Red Hat Europe' )
or ( id = 3 and companyName = 'Red Hat Europe' )
delete
from
Doctor
where
( id = 1 and companyName = 'Red Hat USA' )
or ( id = 3 and companyName = 'Red Hat USA' )
or ( id = 1 and companyName = 'Red Hat Europe' )
or ( id = 3 and companyName = 'Red Hat Europe' )
delete
from
Person
where
( id = 1 and companyName = 'Red Hat USA' )
or ( id = 3 and companyName = 'Red Hat USA' )
or ( id = 1 and companyName = 'Red Hat Europe' )
or ( id = 3 and companyName = 'Red Hat Europe' )
Tip
InlineIdsOrClauseBulkIdStrategy策略的优点是受到所有主要的关系数据库系统(例如 Oracle,SQL Server,MySQL 和 PostgreSQL)的支持。
CteValuesListBulkIdStrategy
要使用此策略,您需要配置以下配置属性:
<property name="hibernate.hql.bulk_id_strategy"
value="org.hibernate.hql.spi.id.inline.CteValuesListBulkIdStrategy"
/>
现在,在运行前面的测试用例时,Hibernate 生成以下 SQL 语句:
例子 449. CteValuesListBulkIdStrategy删除实体查询的例子
select
p.id as id,
p.companyName as companyName
from
Person p
where
p.employed = ?
with HT_Person (id,companyName ) as (
select id, companyName
from (
values
(?, ?),
(?, ?),
(?, ?),
(?, ?)
) as HT (id, companyName) )
delete
from
Engineer
where
( id, companyName ) in (
select
id, companyName
from
HT_Person
)
with HT_Person (id,companyName ) as (
select id, companyName
from (
values
(?, ?),
(?, ?),
(?, ?),
(?, ?)
) as HT (id, companyName) )
delete
from
Doctor
where
( id, companyName ) in (
select
id, companyName
from
HT_Person
)
with HT_Person (id,companyName ) as (
select id, companyName
from (
values
(?, ?),
(?, ?),
(?, ?),
(?, ?)
) as HT (id, companyName) )
delete
from
Person
where
( id, companyName ) in (
select
id, companyName
from
HT_Person
)
Tip
基础数据库必须支持 CTE(公用表表达式),也可以从非查询语句中引用它。例如,自 9.1 版以来 PostgreSQL 支持此功能,而自 2005 版起 SQL Server 提供了对此功能的支持。
基础数据库还必须支持 VALUES list 子句,例如 PostgreSQL 或 SQL Server 2008.
但是,此策略要求复合标识符使用 IN 子句行值表达式,因此您只能将此策略用于 PostgreSQL。
如果可以使用临时表,那可能是最好的选择。但是,如果不允许创建临时表,则必须选择与基础数据库一起使用的这四种策略之一。在下定决心之前,您应该确定哪种方法最适合当前的工作负载。例如CTE 是 PostgreSQL 中的优化围栏,因此请确保在做出决定之前先进行测量。
如果您使用的是 Oracle 或 MySQL 5.7,则可以选择InlineIdsOrClauseBulkIdStrategy或InlineIdsInClauseBulkIdStrategy。对于旧版本的 MySQL,则只能使用InlineIdsOrClauseBulkIdStrategy。
如果您使用的是 SQL Server,则InlineIdsOrClauseBulkIdStrategy是唯一的选择。
如果您使用的是 PostgreSQL,则可以选择这四种策略中的任何一种。
13. Caching
在运行时,Hibernate 响应Session所执行的操作来处理将数据移入和移出第二级缓存的操作,该操作充当持久性数据的事务级缓存。一旦实体被 Management,该对象将被添加到当前持久性上下文(EntityManager或Session)的内部缓存中。持久性上下文也称为第一级缓存,默认情况下启用。
可以在逐个类和逐个收集的基础上配置 JVM 级别(SessionFactory级别)甚至集群缓存。
Note
请注意,Hibernate 缓存不知道其他应用程序对持久性存储所做的更改。
要解决此限制,您可以在第二级缓存区域级别配置 TTL(生存时间)保留策略,以便基础缓存条目定期过期。
13.1. 配置二级缓存
Hibernate 可以与各种缓存提供程序集成,以在特定Session上下文之外缓存数据。本节定义了控制此行为的设置。
13.1.1. RegionFactory
org.hibernate.cache.spi.RegionFactory定义了 Hibernate 和可插拔缓存提供程序之间的集成。 hibernate.cache.region.factory_class用于声明要使用的提供程序。 Hibernate 内置了对 Java 缓存标准JCache的内置支持,以及两个流行的缓存库:Ehcache和Infinispan。本章稍后将提供详细信息。
13.1.2. 缓存配置属性
除了提供程序特定的配置之外,集成的 Hibernate 端还有许多配置选项可控制各种缓存行为:
hibernate.cache.use_second_level_cache- 整体启用或禁用二级缓存。默认情况下,如果当前配置的RegionFactory不是
NoCachingRegionFactory,那么将启用二级缓存。否则,将禁用二级缓存。
- 整体启用或禁用二级缓存。默认情况下,如果当前配置的RegionFactory不是
hibernate.cache.use_query_cache- 启用或禁用查询结果的二级缓存。默认为 false。
hibernate.cache.query_cache_factory- 查询结果缓存由特殊 Contract 处理,该 Contract 处理基于陈旧性的结果无效。默认实现根本不允许过时的结果。将此应用程序用于想要放松的地方。命名
org.hibernate.cache.spi.QueryCacheFactory的实现。
- 查询结果缓存由特殊 Contract 处理,该 Contract 处理基于陈旧性的结果无效。默认实现根本不允许过时的结果。将此应用程序用于想要放松的地方。命名
hibernate.cache.use_minimal_puts- 优化第二级缓存操作以最大程度地减少写入,但需要更频繁地读取。提供者通常对此进行适当设置。
hibernate.cache.region_prefix- 定义一个名称,用作所有第二级缓存区域名称的前缀。
hibernate.cache.default_cache_concurrency_strategy- 在 Hibernate 二级缓存中,可以对所有区域进行不同的配置,包括在访问特定区域时要使用的并发策略。此设置允许定义要使用的默认策略。由于可插拔提供程序确实指定了要使用的默认策略,因此很少需要此设置。有效值包括:
read-only,
read-write,
nonstrict-read-write,
transactional
hibernate.cache.use_structured_entries- 如果
true,则强制 Hibernate 以更人性化的格式将数据存储在二级缓存中。如果您希望能够直接在缓存中“浏览”数据,但确实会对性能产生影响,则可能很有用。
- 如果
hibernate.cache.auto_evict_collection_cache- 当仅从拥有方更改关联时,启用或禁用双向关联的集合缓存条目的自动驱逐。默认情况下禁用此功能,因为它会对跟踪此状态产生性能影响。但是,如果您的应用程序不 Management 双向高速缓存收集方的双向关联,则替代方法是在该高速缓存中保存陈旧的数据。
hibernate.cache.use_reference_entries- 为只读或不可变实体,将实体引用直接存储到二级缓存中。
hibernate.cache.keys_factory- 当将条目作为键值对存储到第二级缓存中时,可以将标识符包装到 Tuples\ <entity type, tenant, identifier>中,以确保唯一性,以防第二级缓存将所有实体存储在单个空间中。这些 Tuples 然后用作高速缓存中的键。当二级缓存实现(包括其配置)保证不同的实体类型分开存储并且不使用多租户时,您可以省略此包装以获得更好的性能。当前,仅在将 Infinispan 配置为第二级缓存实现时才支持此属性。有效值为:
default(在 Tuples 中包装标识符)simple(使用标识符作为键,不进行任何包装)实现
org.hibernate.cache.spi.CacheKeysFactory的全限定类名
13.2. 配置二级缓存 Map
可以通过 JPA 注解或 XMLDescriptors 或使用特定于 Hibernate 的 Map 文件来配置缓存 Map。
默认情况下,实体不属于二级缓存,我们建议您坚持使用此设置。但是,可以通过在persistence.xml文件中设置shared-cache-mode元素或在配置文件中使用javax.persistence.sharedCache.mode属性来覆盖此设置。可能有以下值:
ENABLE_SELECTIVE(默认和推荐值)- 除非明确标记为可缓存(带有@CacheableComments),否则不会缓存实体。
DISABLE_SELECTIVE- 除非明确标记为不可缓存,否则实体将被缓存。
ALL- 即使标记为不可缓存,实体也始终被缓存。
NONE- 即使标记为可缓存,也不会缓存任何实体。完全禁用第二级缓存很有意义。
可以通过hibernate.cache.default_cache_concurrency_strategy配置属性全局设置默认使用的缓存并发策略。此属性的值为:
read-only
- 如果您的应用程序需要读取而不是修改持久类的实例,则只读缓存是最佳选择。应用程序仍然可以删除实体,并且这些更改应反映在二级缓存中,以便缓存不提供陈旧的实体。实现可以基于实体的不变性使用性能优化。
read-write
- 如果应用程序需要更新数据,则可能需要读写缓存。该策略提供对单个实体的一致访问,但不能提供可序列化的事务隔离级别。例如当 TX1 读取查找一个实体但找不到它时,TX2 将该实体插入高速缓存,而 TX1 再次查找它,则可以在 TX1 中读取新实体。
nonstrict-read-write
- 与读写策略相似,但在并发访问实体时可能偶尔会有陈旧的读取。如果应用程序很少同时更新相同的数据并且不需要严格的事务隔离,则选择此策略可能是适当的。实现可以使用利用宽松的一致性保证的性能优化。
transactional
- 提供可序列化的事务隔离级别。
Note
建议不要在每个实体的基础上定义高速缓存并发策略,而不要使用全局设置。
为此,请使用@org.hibernate.annotations.CacheComments。
@CacheComments 定义了三个属性:
usage
- 定义
CacheConcurrencyStrategy
- 定义
region
- 定义将存储条目的缓存区域
include
- 如果惰性属性应包括在第二级缓存中。默认值为
all,因此可以缓存惰性属性。另一个可能的值是non-lazy,因此惰性属性不可缓存。
- 如果惰性属性应包括在第二级缓存中。默认值为
13.3. 实体继承和二级缓存 Map
传统上,在使用实体继承时,Hibernate 要求实体层次结构要完全缓存或根本不缓存。因此,如果要缓存属于给定实体层次结构的子类,则仅在根实体级别声明 JPA @Cacheable和特定于 Hibernate 的@Cache注解。
尽管我们仍然认为属于给定实体层次结构的所有实体都应该共享相同的缓存语义,但是 JPA 规范指出@CacheableComments 可以被子类覆盖:
Note
Cacheable注解的值由子类继承;可以通过在子类上指定Cacheable来覆盖它。
— JPA 2.1 规范的 11.1.7 节
Note
从 Hibernate ORM 5.3 开始,您现在可以在子类级别覆盖 Base Class@Cacheable或@Cache的定义。
但是,Hibernate 缓存并发策略(例如,只读,非严格读写,读写,事务性)仍在根实体级别定义,并且不能被覆盖。
但是,我们建议您让属于继承树的所有实体共享相同的缓存定义的原因可以总结如下:
从性能角度来看,在每个实体类型级别上添加其他检查会减慢引导过程。
为子类提供不同的缓存语义会违反里斯科夫替代原则。
13.4. 实体缓存
例子 450.实体缓存 Map
@Entity(name = "Phone")
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public static class Phone {
@Id
@GeneratedValue
private Long id;
private String mobile;
@ManyToOne
private Person person;
@Version
private int version;
//Getters and setters are omitted for brevity
}
Hibernate 以脱水形式存储缓存的实体,这与数据库表示类似。除了@ManyToOne或@OneToOne子方关联的外键列值外,实体关系未存储在缓存中,
将实体存储在二级缓存中后,您可以避免数据库命中,并仅从缓存中加载该实体:
例子 451.使用 JPA 加载实体
Person person = entityManager.find( Person.class, 1L );
例子 452.使用 Hibernate 本地 API 加载实体
Person person = session.get( Person.class, 1L );
Hibernate 二级缓存还可以通过natural id加载实体:
例子 453.休眠自然 id 实体 Map
@Entity(name = "Person")
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public static class Person {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
@NaturalId
@Column(name = "code", unique = true)
private String code;
//Getters and setters are omitted for brevity
}
例子 454.使用 Hibernate 本地自然 id API 加载实体
Person person = session
.byNaturalId( Person.class )
.using( "code", "unique-code")
.load();
13.5. 集合缓存
Hibernate 也可以缓存集合,并且必须将@CacheComments 添加到集合属性中。
如果集合是由值类型(Map 为@ElementCollection的基本或可嵌入对象)组成的,则集合将按原样存储。如果集合包含其他实体(@OneToMany或@ManyToMany),则集合缓存条目将仅存储实体标识符。
例子 455.集合缓存 Map
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
private List<Phone> phones = new ArrayList<>( );
集合是通读的,这意味着它们将在首次访问时被缓存:
例子 456.集合缓存的使用
Person person = entityManager.find( Person.class, 1L );
person.getPhones().size();
随后的集合检索将使用缓存,而不是访问数据库。
Note
集合缓存不是直写的,因此任何修改都会触发集合缓存条目无效。在后续访问中,将从数据库中加载集合并重新缓存。
13.6. 查询缓存
除了缓存实体和集合,Hibernate 还提供了查询缓存。这对于具有固定参数值的频繁执行的查询很有用。
Note
缓存查询结果会在应用程序正常事务处理方面带来一些开销。例如,如果您缓存针对Person的查询结果,则 Hibernate 将需要跟踪这些结果何时应无效,因为针对任何Person实体都已提交了更改。
这样,再加上大多数应用程序仅从缓存查询结果中得不到任何好处,导致 Hibernate 默认情况下禁用查询结果的缓存。
要使用查询缓存,您首先需要使用以下配置属性启用它:
例子 457.启用查询缓存
<property
name="hibernate.cache.use_query_cache"
value="true" />
如上所述,大多数查询都无法从缓存或其结果中受益。因此,默认情况下,即使启用查询缓存后,也不会缓存单个查询。必须将每个需要缓存的特定查询手动设置为可缓存。这样,查询将在执行时查找现有的缓存结果或将查询结果添加到缓存中。
例子 458.使用 JPA 缓存查询
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name = :name", Person.class)
.setParameter( "name", "John Doe")
.setHint( "org.hibernate.cacheable", "true")
.getResultList();
例子 459.使用 Hibernate 本地 API 缓存查询
List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.name = :name")
.setParameter( "name", "John Doe")
.setCacheable(true)
.list();
Note
对于实体查询,查询缓存不缓存实际实体的状态。相反,它存储实体标识符,并且当从缓存中获取查询结果时,将从第二级缓存实体区域中加载实体状态。
与集合缓存一样,对于那些期望作为查询结果缓存一部分进行缓存的实体,查询缓存应始终与二级缓存结合使用。
对于投影查询,查询缓存存储与基础 JDBC ResultSet关联的脱水实体状态(例如Object[])。
13.6.1. 查询缓存区域
此设置将创建两个新的缓存区域:
default-query-results-region- 保留缓存的查询结果。
default-update-timestamps-region- 保留可查询表的最新更新的时间戳。这些用于验证结果,因为它们是从查询缓存中提供的。
Tip
如果将基础缓存实现配置为使用到期,那么将default-update-timestamps-region的基础缓存区域的超时设置为比任何查询缓存的超时设置都高的值,这一点非常重要。
实际上,我们建议不要将default-update-timestamps-region区域配置为完全过期(基于时间)或逐出(基于大小/内存)。请注意,LRU(最近最少使用)缓存逐出策略永远不适用于此特定缓存区域。
如果您需要对查询缓存过期策略进行细粒度控制,则可以为特定查询指定命名缓存区域。
例子 460.使用 JPA 在自定义区域中缓存查询
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id > :id", Person.class)
.setParameter( "id", 0L)
.setHint( QueryHints.HINT_CACHEABLE, "true")
.setHint( QueryHints.HINT_CACHE_REGION, "query.cache.person" )
.getResultList();
例子 461.使用 Hibernate 本地 API 在自定义区域中缓存查询
List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.id > :id")
.setParameter( "id", 0L)
.setCacheable(true)
.setCacheRegion( "query.cache.person" )
.list();
如果要强制查询缓存刷新其区域之一(忽略在该区域找到的任何缓存结果),则可以使用自定义缓存模式。
例子 462.通过 JPA 使用自定义查询缓存模式
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id > :id", Person.class)
.setParameter( "id", 0L)
.setHint( QueryHints.HINT_CACHEABLE, "true")
.setHint( QueryHints.HINT_CACHE_REGION, "query.cache.person" )
.setHint( "javax.persistence.cache.storeMode", CacheStoreMode.REFRESH )
.getResultList();
例子 463.通过 Hibernate Native API 使用自定义查询缓存模式
List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.id > :id")
.setParameter( "id", 0L)
.setCacheable(true)
.setCacheRegion( "query.cache.person" )
.setCacheMode( CacheMode.REFRESH )
.list();
Note
当将CacheStoreMode.REFRESH或CacheMode.REFRESH与您为给定查询定义的区域结合使用时,Hibernate 将有选择地强制刷新在该特定区域中缓存的结果。
在基础数据可能已经通过单独的过程进行了更新的情况下,此行为特别有用,它是通过SessionFactory逐出对该区域进行大规模逐出的一种更有效的替代方法,其看起来如下:
session.getSessionFactory().getCache().evictQueryRegion( "query.cache.person" );
13.7. Management 缓存的数据
传统上,Hibernate 定义CacheMode枚举来描述与缓存数据进行交互的方式。 JPA 按存储(CacheStoreMode)和检索(CacheRetrieveMode)划分缓存模式。
下表显示了 Hibernate 和 JPA 缓存模式之间的关系:
表 5.缓存模式关系
| Hibernate | JPA | Description |
|---|---|---|
CacheMode.NORMAL |
CacheStoreMode.USE和CacheRetrieveMode.USE |
默认。从缓存中读取/写入数据 |
CacheMode.REFRESH |
CacheStoreMode.REFRESH和CacheRetrieveMode.BYPASS |
不从缓存中读取,而是在从数据库加载后写入缓存 |
CacheMode.PUT |
CacheStoreMode.USE和CacheRetrieveMode.BYPASS |
不从缓存中读取,而是在从数据库中读取时写入缓存 |
CacheMode.GET |
CacheStoreMode.BYPASS和CacheRetrieveMode.USE |
从缓存中读取,但不写入缓存 |
CacheMode.IGNORE |
CacheStoreMode.BYPASS和CacheRetrieveMode.BYPASS |
不从缓存读/写数据 |
设置缓存模式既可以在直接加载实体时也可以在执行查询时完成。
例子 464.在 JPA 中使用自定义缓存模式
Map<String, Object> hints = new HashMap<>( );
hints.put( "javax.persistence.cache.retrieveMode " , CacheRetrieveMode.USE );
hints.put( "javax.persistence.cache.storeMode" , CacheStoreMode.REFRESH );
Person person = entityManager.find( Person.class, 1L , hints);
例子 465.在 Hibernate 本机 API 中使用自定义缓存模式
session.setCacheMode( CacheMode.REFRESH );
Person person = session.get( Person.class, 1L );
还可以为查询设置自定义缓存模式:
例子 466.对 JPA 使用自定义缓存模式进行查询
List<Person> persons = entityManager.createQuery(
"select p from Person p", Person.class)
.setHint( QueryHints.HINT_CACHEABLE, "true")
.setHint( "javax.persistence.cache.retrieveMode " , CacheRetrieveMode.USE )
.setHint( "javax.persistence.cache.storeMode" , CacheStoreMode.REFRESH )
.getResultList();
例子 467.对 Hibernate 本机 API 使用自定义缓存模式进行查询
List<Person> persons = session.createQuery(
"select p from Person p" )
.setCacheable( true )
.setCacheMode( CacheMode.REFRESH )
.list();
13.7.1. 逐出缓存项
因为第二级缓存绑定到EntityManagerFactory或SessionFactory,所以必须通过这两个接口完成缓存逐出。
JPA 仅支持通过javax.persistence.Cache接口驱逐实体:
例子 468.用 JPA 驱逐实体
entityManager.getEntityManagerFactory().getCache().evict( Person.class );
Hibernate 在这方面更加灵活,因为它可以对需要驱逐的内容进行细粒度的控制。 org.hibernate.Cache界面定义了各种驱逐策略:
实体(按其类别或地区)
使用自然 ID 存储的实体(按其类别或地区)
集合(按区域划分,也可能带有集合所有者标识符)
查询(按地区)
例子 469.用 Hibernate 本地 API 驱逐实体
session.getSessionFactory().getCache().evictQueryRegion( "query.cache.person" );
13.8. 缓存统计
如果启用hibernate.generate_statistics配置属性,则 Hibernate 将通过SessionFactory.getStatistics()公开许多 Metrics。甚至可以将 Hibernate 配置为通过 JMX 公开这些统计信息。
这样,您就可以访问Statistics类,该类包含各种第二级缓存 Metrics。
例子 470.缓存统计
Statistics statistics = session.getSessionFactory().getStatistics();
CacheRegionStatistics secondLevelCacheStatistics =
statistics.getDomainDataRegionStatistics( "query.cache.person" );
long hitCount = secondLevelCacheStatistics.getHitCount();
long missCount = secondLevelCacheStatistics.getMissCount();
double hitRatio = (double) hitCount / ( hitCount + missCount );
13.9. JCache
Note
要将内置集成用于JCache,您需要hibernate-jcache模块 jar(及其所有依赖项)位于 Classpath 上。
另外,还需要添加 JCache 实现。 在 JCP 网站上找到兼容的实现的列表。兼容实现的替代来源可以通过JSR-107 测试动物园找到。
13.9.1. RegionFactory
hibernate-jcache模块定义以下区域工厂:JCacheRegionFactory。
要使用JCacheRegionFactory,您需要指定以下配置属性:
例子 471. JCacheRegionFactory配置
<property
name="hibernate.cache.region.factory_class"
value="jcache"/>
JCacheRegionFactory配置javax.cache.CacheManager。
13.9.2. JCache CacheManager
JCache 要求共享相同 URI 的CacheManager和类加载器在 JVM 中必须是唯一的。
如果未指定其他属性,则JCacheRegionFactory将加载默认的 JCache 提供程序并创建默认的CacheManager。同样,将使用默认的javax.cache.configuration.MutableConfiguration创建Cache。
为了控制使用哪个提供程序并为CacheManager和Cache指定配置,您可以使用以下两个属性:
例子 472. JCache 配置
<property
name="hibernate.javax.cache.provider"
value="org.ehcache.jsr107.EhcacheCachingProvider"/>
<property
name="hibernate.javax.cache.uri"
value="file:/path/to/ehcache.xml"/>
只有指定第二个属性hibernate.javax.cache.uri,您才能每个SessionFactory拥有CacheManager。
使用非默认的 JCache CacheManager
如果您不想使用默认的CacheManager,则需要将hibernate.javax.cache.cache_manager配置属性设置为以下值之一:
Object reference
- 如果该值为实现
CacheManager接口的Object实例,则将使用提供的CacheManager实例。
- 如果该值为实现
Class- 如果该值是实现
CacheManager接口的 JavaClass对象,则 Hibernate 将为此Class创建一个新实例,并使用它代替默认实例。
- 如果该值是实现
Note
传递实现CacheManager接口的 Java Class时,必须确保CacheManager实现类提供默认的 no-arg 构造函数,因为它将用于实例化CacheManager实现Object。
String- 如果该值为 Java
String,则 Hibernate 希望它是CacheManager实现的完全合格的Class名称,该名称将用于实例化非默认值CacheManager。
- 如果该值为 Java
Note
传递完全限定的类名时,必须确保关联的Class类型提供默认的 no-arg 构造函数,因为它将用于实例化CacheManager实现Object。
13.9.3. JCache 缺少缓存策略
默认情况下,当要求创建未在基础缓存 Management 器中明确配置并预先启动的缓存时,JCache 区域工厂将记录警告。因此,如果将实体类型或集合配置为已缓存,但未明确配置相应的缓存,则将为每个未明确配置的缓存记录一条警告。
您可以通过将hibernate.javax.cache.missing_cache_strategy属性设置为以下值之一来更改此行为:
表 6.缺少缓存策略
| Value | Description |
|---|---|
fail |
由于缺少缓存而失败。 |
create-warn |
默认值 。当找不到缓存时创建新的缓存(请参见下面的create),并记录有关缺少缓存的警告。 |
create |
当找不到缓存时创建新的缓存,而不记录有关丢失的缓存的任何警告。 |
Warning
请注意,除非高速缓存提供程序显式提供默认高速缓存的特定配置,否则以这种方式创建的高速缓存可能不适用于生产用途(大小不受限制,尤其是没有逐出)。
特别是,Ehcache 允许使用缓存模板设置这种默认配置。有关更多详细信息,请参见Ehcache documentation。
13.10. Ehcache
此集成涵盖了 Ehcache 2.x,为了将 Ehcache 3.x 用作第二级缓存,请参考JCache integration。
Note
对Ehcache使用内置集成要求hibernate-ehcache模块 jar(及其所有依赖项)在 Classpath 上。
13.10.1. RegionFactory
hibernate-ehcache 模块定义了两个特定的区域工厂:EhCacheRegionFactory和SingletonEhCacheRegionFactory。
EhCacheRegionFactory
要使用EhCacheRegionFactory,您需要指定以下配置属性:
例子 473. EhCacheRegionFactory配置
<property
name="hibernate.cache.region.factory_class"
value="ehcache"/>
EhCacheRegionFactory为每个SessionFactory配置一个net.sf.ehcache.CacheManager,因此CacheManager不在同一 JVM 中的多个SessionFactory实例之间共享。
SingletonEhCacheRegionFactory
要使用SingletonEhCacheRegionFactory,您需要指定以下配置属性:
例子 474. SingletonEhCacheRegionFactory配置
<property
name="hibernate.cache.region.factory_class"
value="ehcache-singleton"/>
SingletonEhCacheRegionFactory配置一个单例net.sf.ehcache.CacheManager(请参见CacheManager#create()),在同一 JVM 中的多个SessionFactory实例之间共享。
Note
当同一 JVM 中有多个 Hibernate SessionFactory实例运行时,Ehcache documentation建议使用多个非单个CacheManager。
13.10.2. Ehcache 缺少缓存策略
默认情况下,当要求创建未在基础缓存 Management 器中明确配置和预先启动的缓存时,Ehcache 区域工厂将记录警告。因此,如果将实体类型或集合配置为已缓存,但未明确配置相应的缓存,则将为每个未明确配置的缓存记录一条警告。
您可以通过将hibernate.cache.ehcache.missing_cache_strategy属性设置为以下值之一来更改此行为:
表 7.缺少缓存策略
| Value | Description |
|---|---|
fail |
由于缺少缓存而失败。 |
create-warn |
默认值 。当找不到缓存时创建新的缓存(请参见下面的create),并记录有关缺少缓存的警告。 |
create |
当找不到缓存时创建新的缓存,而不记录有关丢失的缓存的任何警告。 |
Warning
请注意,除非将适当的<defaultCache>条目添加到 Ehcache 配置中,否则用这种方式创建的缓存可能配置非常错误(特别是大容量)。
13.11. Infinispan
Infinispan 是一个分布式的内存中键/值数据存储,可以用作缓存或数据网格,也可以用作 Hibernate 二级缓存提供程序。
它支持高级功能,例如事务,事件,查询,分布式处理,堆外和地理故障转移。
有关更多详细信息,请查看Infinispan 用户指南。
14.拦截器和事件
对于应用程序响应 Hibernate 内部发生的某些事件很有用。这允许实现通用功能和扩展 Hibernate 功能。
14.1. Interceptors
org.hibernate.Interceptor接口提供从会话到应用程序的回调,从而允许应用程序在保存,更新,删除或加载持久对象之前检查和/或操纵该对象的属性。
一种可能的用途是跟踪审核信息。以下示例显示了Interceptor实现,该实现会在实体更新时自动记录日志。
public static class LoggingInterceptor extends EmptyInterceptor {
@Override
public boolean onFlushDirty(
Object entity,
Serializable id,
Object[] currentState,
Object[] previousState,
String[] propertyNames,
Type[] types) {
LOGGER.debugv( "Entity {0}#{1} changed from {2} to {3}",
entity.getClass().getSimpleName(),
id,
Arrays.toString( previousState ),
Arrays.toString( currentState )
);
return super.onFlushDirty( entity, id, currentState,
previousState, propertyNames, types
);
}
}
Note
您可以直接实现Interceptor或扩展org.hibernate.EmptyInterceptorBase Class。
拦截器可以是Session范围或SessionFactory范围。
打开会话时,将指定一个会话范围的拦截器。
SessionFactory sessionFactory = entityManagerFactory.unwrap( SessionFactory.class );
Session session = sessionFactory
.withOptions()
.interceptor(new LoggingInterceptor() )
.openSession();
session.getTransaction().begin();
Customer customer = session.get( Customer.class, customerId );
customer.setName( "Mr. John Doe" );
//Entity Customer#1 changed from [John Doe, 0] to [Mr. John Doe, 0]
session.getTransaction().commit();
在构建SessionFactory之前,将SessionFactory范围的拦截器注册到Configuration对象。除非明确指定要使用的拦截器打开了会话,否则SessionFactory范围的拦截器将应用于从该SessionFactory打开的所有会话。 SessionFactory范围的拦截器必须是线程安全的。确保您不存储特定于会话的状态,因为多个会话可能会同时使用此拦截器。
SessionFactory sessionFactory = new MetadataSources( new StandardServiceRegistryBuilder().build() )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build()
.getSessionFactoryBuilder()
.applyInterceptor( new LoggingInterceptor() )
.build();
14.2. 本机事件系统
如果您必须对持久层中的特定事件做出反应,则还可以使用 Hibernate * event *体系结构。该事件系统可以代替拦截器或除拦截器之外使用。
Session界面的许多方法都与事件类型相关。定义的事件类型的全部范围都声明为org.hibernate.event.spi.EventType上的枚举值。当从这些方法之一发出请求时,会话将生成适当的事件,并将其传递给该类型的已配置事件侦听器。
应用程序可以自定义侦听器接口(即LoadEvent由LoadEventListener接口的已注册实现处理),在这种情况下,它们的实现将负责处理Session提出的load()请求。
Note
侦听器应被视为 Stateless。它们在请求之间共享,并且不应将任何状态另存为实例变量。
自定义侦听器为想要处理和/或扩展便捷 Base Class 之一的事件实现适当的接口(甚至是 Hibernate 开箱即用的默认事件侦听器,因为它们为此被声明为非最终的)目的)。
这是一个自定义加载事件侦听器的示例:
范例 475.自定义LoadListener范例
EntityManagerFactory entityManagerFactory = entityManagerFactory();
SessionFactoryImplementor sessionFactory = entityManagerFactory.unwrap( SessionFactoryImplementor.class );
sessionFactory
.getServiceRegistry()
.getService( EventListenerRegistry.class )
.prependListeners( EventType.LOAD, new SecuredLoadEntityListener() );
Customer customer = entityManager.find( Customer.class, customerId );
14.3. 混合事件和拦截器
当您要自定义实体状态转换行为时,有两个选择:
您提供了一个自定义
Interceptor,默认的 Hibernate 事件侦听器会考虑到它。例如,Interceptor#onSave()方法由 HibernateAbstractSaveEventListener调用。或者,Interceptor#onLoad()由DefaultPreLoadEventListener调用。您可以使用自己的实现替换任何给定的默认事件监听器。这样做时,您可能应该扩展默认的侦听器,因为否则,您将必须照顾所有低层的实体状态转换逻辑。例如,如果用自己的实现替换
DefaultPreLoadEventListener,则只有显式调用Interceptor#onLoad()方法时,才可以将自定义加载事件侦听器与自定义 Hibernate 拦截器混合使用。
14.4. 休眠声明式安全
通常,在会话外观层中 ManagementHibernate 应用程序中的声明式安全。 Hibernate 允许通过 JACC 和 JAAS 授权某些操作。这是基于事件体系结构构建的可选功能。
首先,必须配置适当的事件侦听器,以启用 JACC 授权。同样,有关详细信息,请参见事件监听器注册。
下面是为此目的适当的org.hibernate.integrator.spi.Integrator实现的示例。
例子 476. JACC 侦听器注册例子
public static class JaccIntegrator implements ServiceContributingIntegrator {
private static final Logger log = Logger.getLogger( JaccIntegrator.class );
private static final DuplicationStrategy DUPLICATION_STRATEGY =
new DuplicationStrategy() {
@Override
public boolean areMatch(Object listener, Object original) {
return listener.getClass().equals( original.getClass() ) &&
JaccSecurityListener.class.isInstance( original );
}
@Override
public Action getAction() {
return Action.KEEP_ORIGINAL;
}
};
@Override
public void prepareServices(
StandardServiceRegistryBuilder serviceRegistryBuilder) {
boolean isSecurityEnabled = serviceRegistryBuilder
.getSettings().containsKey( AvailableSettings.JACC_ENABLED );
final JaccService jaccService = isSecurityEnabled ?
new StandardJaccServiceImpl() : new DisabledJaccServiceImpl();
serviceRegistryBuilder.addService( JaccService.class, jaccService );
}
@Override
public void integrate(
Metadata metadata,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
doIntegration(
serviceRegistry
.getService( ConfigurationService.class ).getSettings(),
// pass no permissions here, because atm actually injecting the
// permissions into the JaccService is handled on SessionFactoryImpl via
// the org.hibernate.boot.cfgxml.spi.CfgXmlAccessService
null,
serviceRegistry
);
}
private void doIntegration(
Map properties,
JaccPermissionDeclarations permissionDeclarations,
SessionFactoryServiceRegistry serviceRegistry) {
boolean isSecurityEnabled = properties
.containsKey( AvailableSettings.JACC_ENABLED );
if ( ! isSecurityEnabled ) {
log.debug( "Skipping JACC integration as it was not enabled" );
return;
}
final String contextId = (String) properties
.get( AvailableSettings.JACC_CONTEXT_ID );
if ( contextId == null ) {
throw new IntegrationException( "JACC context id must be specified" );
}
final JaccService jaccService = serviceRegistry
.getService( JaccService.class );
if ( jaccService == null ) {
throw new IntegrationException( "JaccService was not set up" );
}
if ( permissionDeclarations != null ) {
for ( GrantedPermission declaration : permissionDeclarations
.getPermissionDeclarations() ) {
jaccService.addPermission( declaration );
}
}
final EventListenerRegistry eventListenerRegistry =
serviceRegistry.getService( EventListenerRegistry.class );
eventListenerRegistry.addDuplicationStrategy( DUPLICATION_STRATEGY );
eventListenerRegistry.prependListeners(
EventType.PRE_DELETE, new JaccPreDeleteEventListener() );
eventListenerRegistry.prependListeners(
EventType.PRE_INSERT, new JaccPreInsertEventListener() );
eventListenerRegistry.prependListeners(
EventType.PRE_UPDATE, new JaccPreUpdateEventListener() );
eventListenerRegistry.prependListeners(
EventType.PRE_LOAD, new JaccPreLoadEventListener() );
}
@Override
public void disintegrate(SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// nothing to do
}
}
您还必须决定如何配置 JACC 提供程序。请查阅您的 JACC 提供程序文档。
14.5. JPA 回调
JPA 还通过 Comments 定义了一组更有限的回调。
表 8.回调 Comments
| Type | Description |
|---|---|
| @PrePersist | 在实体 Management 器持久操作实际执行或级联之前执行。此调用与持久操作同步。 |
| @PreRemove | 在实体 Management 器删除操作实际执行或级联之前执行。该调用与删除操作同步。 |
| @PostPersist | 在实体 Management 器持久操作实际执行或级联之后执行。在执行数据库 INSERT 之后,将调用此调用。 |
| @PostRemove | 在实体 Management 器删除操作实际执行或级联之后执行。该调用与删除操作同步。 |
| @PreUpdate | 在数据库执行 UPDATE 操作之前执行。 |
| @PostUpdate | 在数据库执行 UPDATE 操作后执行。 |
| @PostLoad | 在将实体加载到当前持久性上下文中或刷新实体之后执行。 |
定义了两种用于指定回调处理的方法:
第一种方法是对实体本身的方法进行 Comments,以接收有关特定实体生命周期事件的通知。
第二种是使用单独的实体侦听器类。实体侦听器是具有无参数构造函数的 Stateless 类。回调注解放置在此类的方法上,而不是实体类上。然后,使用
javax.persistence.EntityListeners注解将实体侦听器类与实体相关联
例子 477.指定 JPA 回调的例子
@Entity
@EntityListeners( LastUpdateListener.class )
public static class Person {
@Id
private Long id;
private String name;
private Date dateOfBirth;
@Transient
private long age;
private Date lastUpdate;
public void setLastUpdate(Date lastUpdate) {
this.lastUpdate = lastUpdate;
}
/**
* Set the transient property at load time based on a calculation.
* Note that a native Hibernate formula mapping is better for this purpose.
*/
@PostLoad
public void calculateAge() {
age = ChronoUnit.YEARS.between( LocalDateTime.ofInstant(
Instant.ofEpochMilli( dateOfBirth.getTime()), ZoneOffset.UTC),
LocalDateTime.now()
);
}
}
public static class LastUpdateListener {
@PreUpdate
@PrePersist
public void setLastUpdate( Person p ) {
p.setLastUpdate( new Date() );
}
}
这些方法可以混合使用,这意味着您可以同时使用这两种方法。
无论回调方法是在实体上定义还是在实体侦听器上定义,它都必须具有 void 返回签名。该方法的名称无关紧要,因为使方法成为回调的是回调 Comments 的位置。对于在实体类上定义的回调方法,该方法必须另外具有无参数签名。对于在实体侦听器类上定义的回调方法,该方法必须具有单个参数签名。该参数的类型可以是java.lang.Object(以便于附加到多个实体)或特定的实体类型。
回调方法可以抛出RuntimeException。如果回调方法确实抛出RuntimeException,则必须回滚当前事务(如果有)。
回调方法不得调用EntityManager或Query方法!
可能为特定的生命周期事件定义了多个回调方法。在这种情况下,JPA 规范(特别是第 3.5.4 节)很好地定义了定义的执行 Sequences:
与实体关联的任何默认侦听器都将首先按照在 XML 中指定的 Sequences 被调用。请参阅
javax.persistence.ExcludeDefaultListenersComments。接下来,将按照在
EntityListeners中定义的 Sequences 调用与实体层次结构关联的实体侦听器类回调。如果实体层次结构中的多个类定义了实体侦听器,则为超类定义的侦听器将在为其子类定义的侦听器之前调用。请参见javax.persistence.ExcludeSuperclassListener的 Comments。最后,调用在实体层次结构上定义的回调方法。如果在实体及其一个或多个超类上都标注了回调类型而没有方法覆盖,则将两者都称为最普通的超类。还允许实体类重写在超类中定义的回调方法,在这种情况下,不会调用超级回调。如果有 Comments,则覆盖方法将被调用。
14.6. 默认实体监听器
JPA 规范允许您定义默认的实体侦听器,该侦听器将应用于该特定系统中的每个实体。默认实体侦听器只能在 XMLMap 文件中定义。
例子 478.默认事件监听器 Map
public class DefaultEntityListener {
public void onPersist(Object entity) {
if ( entity instanceof BaseEntity ) {
BaseEntity baseEntity = (BaseEntity) entity;
baseEntity.setCreatedOn( now() );
}
}
public void onUpdate(Object entity) {
if ( entity instanceof BaseEntity ) {
BaseEntity baseEntity = (BaseEntity) entity;
baseEntity.setUpdatedOn( now() );
}
}
private Timestamp now() {
return Timestamp.from(
LocalDateTime.now().toInstant( ZoneOffset.UTC )
);
}
}
<entity-mappings xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence/orm
http://xmlns.jcp.org/xml/ns/persistence/orm_2_1.xsd"
version="2.1">
<persistence-unit-metadata>
<persistence-unit-defaults>
<entity-listeners>
<entity-listener
class="org.hibernate.userguide.events.DefaultEntityListener">
<pre-persist method-name="onPersist"/>
<pre-update method-name="onUpdate"/>
</entity-listener>
</entity-listeners>
</persistence-unit-defaults>
</persistence-unit-metadata>
</entity-mappings>
考虑到所有实体都扩展了BaseEntity类:
@MappedSuperclass
public abstract class BaseEntity {
private Timestamp createdOn;
private Timestamp updatedOn;
//Getters and setters are omitted for brevity
}
@Entity(name = "Person")
public static class Person extends BaseEntity {
@Id
private Long id;
private String name;
//Getters and setters omitted for brevity
}
@Entity(name = "Book")
public static class Book extends BaseEntity {
@Id
private Long id;
private String title;
@ManyToOne
private Person author;
//Getters and setters omitted for brevity
}
当持久化Person或Book实体时,createdOn将由DefaultEntityListener的onPersist方法设置。
例子 479.默认事件监听器持久事件
Person author = new Person();
author.setId( 1L );
author.setName( "Vlad Mihalcea" );
entityManager.persist( author );
Book book = new Book();
book.setId( 1L );
book.setTitle( "High-Performance Java Persistence" );
book.setAuthor( author );
entityManager.persist( book );
insert
into
Person
(createdOn, updatedOn, name, id)
values
(?, ?, ?, ?)
-- binding parameter [1] as [TIMESTAMP] - [2017-06-08 19:23:48.224]
-- binding parameter [2] as [TIMESTAMP] - [null]
-- binding parameter [3] as [VARCHAR] - [Vlad Mihalcea]
-- binding parameter [4] as [BIGINT] - [1]
insert
into
Book
(createdOn, updatedOn, author_id, title, id)
values
(?, ?, ?, ?, ?)
-- binding parameter [1] as [TIMESTAMP] - [2017-06-08 19:23:48.246]
-- binding parameter [2] as [TIMESTAMP] - [null]
-- binding parameter [3] as [BIGINT] - [1]
-- binding parameter [4] as [VARCHAR] - [High-Performance Java Persistence]
-- binding parameter [5] as [BIGINT] - [1]
更新Person或Book实体时,将通过DefaultEntityListener的onUpdate方法设置updatedOn。
例子 480.默认事件监听器更新事件
Person author = entityManager.find( Person.class, 1L );
author.setName( "Vlad-Alexandru Mihalcea" );
Book book = entityManager.find( Book.class, 1L );
book.setTitle( "High-Performance Java Persistence 2nd Edition" );
update
Person
set
createdOn=?,
updatedOn=?,
name=?
where
id=?
-- binding parameter [1] as [TIMESTAMP] - [2017-06-08 19:23:48.224]
-- binding parameter [2] as [TIMESTAMP] - [2017-06-08 19:23:48.316]
-- binding parameter [3] as [VARCHAR] - [Vlad-Alexandru Mihalcea]
-- binding parameter [4] as [BIGINT] - [1]
update
Book
set
createdOn=?,
updatedOn=?,
author_id=?,
title=?
where
id=?
-- binding parameter [1] as [TIMESTAMP] - [2017-06-08 19:23:48.246]
-- binding parameter [2] as [TIMESTAMP] - [2017-06-08 19:23:48.317]
-- binding parameter [3] as [BIGINT] - [1]
-- binding parameter [4] as [VARCHAR] - [High-Performance Java Persistence 2nd Edition]
-- binding parameter [5] as [BIGINT] - [1]
14.6.1. 排除默认实体侦听器
如果您已经注册了默认的实体侦听器,但是不想将其应用于特定的实体,则可以使用@ExcludeDefaultListeners和@ExcludeSuperclassListeners JPA 注解。
@ExcludeDefaultListeners指示当前类忽略当前实体的默认实体侦听器,而@ExcludeSuperclassListeners用于忽略传播到BaseEntity超类的默认实体侦听器。
例子 481.排除默认事件监听器 Map
@Entity(name = "Publisher")
@ExcludeDefaultListeners
@ExcludeSuperclassListeners
public static class Publisher extends BaseEntity {
@Id
private Long id;
private String name;
//Getters and setters omitted for brevity
}
持久化Publisher实体时,DefaultEntityListener的onPersist方法将不会设置createdOn,因为Publisher实体标记有@ExcludeDefaultListeners和@ExcludeSuperclassListeners注解。
例子 482.不包括默认事件监听器事件
Publisher publisher = new Publisher();
publisher.setId( 1L );
publisher.setName( "Amazon" );
entityManager.persist( publisher );
insert
into
Publisher
(createdOn, updatedOn, name, id)
values
(?, ?, ?, ?)
-- binding parameter [1] as [TIMESTAMP] - [null]
-- binding parameter [2] as [TIMESTAMP] - [null]
-- binding parameter [3] as [VARCHAR] - [Amazon]
-- binding parameter [4] as [BIGINT] - [1]
15. HQL 和 JPQL
休眠查询语言(HQL)和 Java 持久性查询语言(JPQL)都是面向对象模型的查询语言,其本质类似于 SQL。 JPQL 是 HQL 的一个受很大启发的子集。 JPQL 查询始终是有效的 HQL 查询,但是反之则不成立。
HQL 和 JPQL 都是执行查询操作的非类型安全方式。条件查询提供了一种类型安全的查询方法。有关更多信息,请参见Criteria。
15.1. 域模型示例
为了更好地理解其他 HQL 和 JPQL 示例,是时候熟悉本章所有示例功能中使用的域模型实体了。
例子 483.例子域模型
@NamedQueries({
@NamedQuery(
name = "get_person_by_name",
query = "select p from Person p where name = :name"
)
,
@NamedQuery(
name = "get_read_only_person_by_name",
query = "select p from Person p where name = :name",
hints = {
@QueryHint(
name = "org.hibernate.readOnly",
value = "true"
)
}
)
})
@NamedStoredProcedureQueries(
@NamedStoredProcedureQuery(
name = "sp_person_phones",
procedureName = "sp_person_phones",
parameters = {
@StoredProcedureParameter(
name = "personId",
type = Long.class,
mode = ParameterMode.IN
),
@StoredProcedureParameter(
name = "personPhones",
type = Class.class,
mode = ParameterMode.REF_CURSOR
)
}
)
)
@Entity
public class Person {
@Id
@GeneratedValue
private Long id;
private String name;
private String nickName;
private String address;
@Temporal(TemporalType.TIMESTAMP )
private Date createdOn;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
private List<Phone> phones = new ArrayList<>();
@ElementCollection
@MapKeyEnumerated(EnumType.STRING)
private Map<AddressType, String> addresses = new HashMap<>();
@Version
private int version;
//Getters and setters are omitted for brevity
}
public enum AddressType {
HOME,
OFFICE
}
@Entity
public class Partner {
@Id
@GeneratedValue
private Long id;
private String name;
@Version
private int version;
//Getters and setters are omitted for brevity
}
@Entity
public class Phone {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Person person;
@Column(name = "phone_number")
private String number;
@Enumerated(EnumType.STRING)
@Column(name = "phone_type")
private PhoneType type;
@OneToMany(mappedBy = "phone", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Call> calls = new ArrayList<>( );
@OneToMany(mappedBy = "phone")
@MapKey(name = "timestamp")
@MapKeyTemporal(TemporalType.TIMESTAMP )
private Map<Date, Call> callHistory = new HashMap<>();
@ElementCollection
private List<Date> repairTimestamps = new ArrayList<>( );
//Getters and setters are omitted for brevity
}
public enum PhoneType {
LAND_LINE,
MOBILE;
}
@Entity
@Table(name = "phone_call")
public class Call {
@Id
@GeneratedValue
private Long id;
@ManyToOne
private Phone phone;
@Column(name = "call_timestamp")
private Date timestamp;
private int duration;
//Getters and setters are omitted for brevity
}
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class Payment {
@Id
@GeneratedValue
private Long id;
private BigDecimal amount;
private boolean completed;
@ManyToOne
private Person person;
//Getters and setters are omitted for brevity
}
@Entity
public class CreditCardPayment extends Payment {
}
@Entity
public class WireTransferPayment extends Payment {
}
15.2. 查询 API
使用 Hibernate 时,可以通过 JPA 或特定于 Hibernate 的 API 执行实体查询。从 5.2 开始,Hibernate Session接口扩展了 JPA EntityManager接口。因此,查询 API 也已合并,现在 Hibernate org.hibernate.query.Query接口扩展了 JPA javax.persistence.Query。
接下来,我们将了解标准 JPA 接口和特定于 Hibernate 的 API 之间的查询 API 有何不同。
15.2.1. JPA 查询 API
在 JPA 中,查询由EntityManager表示的javax.persistence.Query或javax.persistence.TypedQuery表示。创建内联Query或TypedQuery,您需要使用EntityManager#createQuery方法。对于命名查询,需要EntityManager#createNamedQuery方法。
例子 484.获得一个 JPA Query或TypedQuery参考
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name"
);
TypedQuery<Person> typedQuery = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name", Person.class
);
例 485.为命名查询获取 JPA Query或TypedQuery参考
@NamedQuery(
name = "get_person_by_name",
query = "select p from Person p where name = :name"
)
Query query = entityManager.createNamedQuery( "get_person_by_name" );
TypedQuery<Person> typedQuery = entityManager.createNamedQuery(
"get_person_by_name", Person.class
);
Hibernate 提供了一个特定的@NamedQueryComments,该 Comments 提供了配置各种查询功能的方法,例如刷新模式,可缓存性,超时间隔。
例子 486.获取一个命名查询的 Hibernate Query或TypedQuery引用
@NamedQueries({
@NamedQuery(
name = "get_phone_by_number",
query = "select p " +
"from Phone p " +
"where p.number = :number",
timeout = 1,
readOnly = true
)
})
Phone phone = entityManager
.createNamedQuery( "get_phone_by_number", Phone.class )
.setParameter( "number", "123-456-7890" )
.getSingleResult();
然后,可以使用Query接口来控制查询的执行。例如,我们可能要指定执行超时或控件缓存。
例子 487.基本的 JPA Query用法
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
// timeout - in milliseconds
.setHint( "javax.persistence.query.timeout", 2000 )
// flush only at commit time
.setFlushMode( FlushModeType.COMMIT );
有关完整的详细信息,请参见Query Javadocs。控制查询执行的许多设置都定义为提示。 JPA 定义了一些标准提示(例如示例中的超时),但是大多数都是特定于提供程序的。依赖于提供程序的特定提示在某种程度上限制了应用程序的可移植性。
javax.persistence.query.timeout- 定义查询超时(以毫秒为单位)。
javax.persistence.fetchgraph- 定义一个* fetchgraph * EntityGraph。显式指定为
AttributeNodes的属性被视为FetchType.EAGER(通过连接提取或后续选择)。有关详细信息,请参见Fetching中的 EntityGraph 讨论。
- 定义一个* fetchgraph * EntityGraph。显式指定为
javax.persistence.loadgraph- 定义一个* loadgraph * EntityGraph。明确指定为 AttributeNodes 的属性被视为
FetchType.EAGER(通过连接提取或后续选择)。根据元数据中属性的定义,未指定的属性将被视为FetchType.LAZY或FetchType.EAGER。有关详细信息,请参见Fetching中的 EntityGraph 讨论。
- 定义一个* loadgraph * EntityGraph。明确指定为 AttributeNodes 的属性被视为
org.hibernate.cacheMode- 定义要使用的
CacheMode。参见org.hibernate.query.Query#setCacheMode。
- 定义要使用的
org.hibernate.cacheable- 定义查询是否可缓存。真假。参见
org.hibernate.query.Query#setCacheable。
- 定义查询是否可缓存。真假。参见
org.hibernate.cacheRegion- 对于可缓存的查询,定义要使用的特定缓存区域。参见
org.hibernate.query.Query#setCacheRegion。
- 对于可缓存的查询,定义要使用的特定缓存区域。参见
org.hibernate.comment- 定义 Comments 以应用于生成的 SQL。参见
org.hibernate.query.Query#setComment。
- 定义 Comments 以应用于生成的 SQL。参见
org.hibernate.fetchSize- 定义要使用的 JDBC fetch-size。参见
org.hibernate.query.Query#setFetchSize。
- 定义要使用的 JDBC fetch-size。参见
org.hibernate.flushMode- 定义要使用的特定于 Hibernate 的
FlushMode。请参见org.hibernate.query.Query#setFlushMode.(如果可能),请改用javax.persistence.Query#setFlushMode。
- 定义要使用的特定于 Hibernate 的
org.hibernate.readOnly- 定义此查询加载的实体和集合应标记为只读。参见
org.hibernate.query.Query#setReadOnly。
- 定义此查询加载的实体和集合应标记为只读。参见
执行查询之前需要完成的最后一件事情是绑定任何已定义参数的值。 JPA 定义了一组简化的参数绑定方法。本质上,它支持设置参数值(按名称/位置)和Calendar/Date类型的专用形式,另外还接受TemporalType。
例子 488. JPA 名称参数绑定
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" );
// For generic temporal field types (e.g. `java.util.Date`, `java.util.Calendar`)
// we also need to provide the associated `TemporalType`
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.createdOn > :timestamp" )
.setParameter( "timestamp", timestamp, TemporalType.DATE );
JPQL 样式的位置参数使用问号声明,后跟序号?1,?2。序数以 1 开头。与命名参数一样,位置参数也可以在查询中多次出现。
例子 489. JPA 位置参数绑定
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like ?1" )
.setParameter( 1, "J%" );
Note
最好不要在给定查询中混合参数绑定形式。
在执行方面,JPA Query提供了 3 种不同的方法来检索结果集。
Query#getResultList()-执行选择查询并返回结果列表。Query#getResultStream()-执行选择查询,并在结果上返回Stream。Query#getSingleResult()-执行选择查询并返回一个结果。如果结果不止一个,则会引发异常。
例子 490. JPA getResultList()结果
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.getResultList();
例子 491. JPA getResultStream()结果
try(Stream<Person> personStream = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name", Person.class )
.setParameter( "name", "J%" )
.getResultStream()) {
List<Person> persons = personStream
.skip( 5 )
.limit( 5 )
.collect( Collectors.toList() );
}
例子 492. JPA getSingleResult()
Person person = (Person) entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.getSingleResult();
15.2.2. 休眠查询 API
在 Hibernate 中,HQL 查询表示为org.hibernate.query.Query,它是从Session获得的。如果 HQL 是命名查询,则将使用Session#getNamedQuery;否则,将使用Session#getNamedQuery。否则需要Session#createQuery。
例子 493.获得一个休眠Query
org.hibernate.query.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name"
);
例子 494.获得一个命名查询的 Hibernate Query引用
org.hibernate.query.Query query = session.getNamedQuery( "get_person_by_name" );
Note
JPQL 语法不仅受到 HQL 的极大启发,而且许多 JPA API 也受到 Hibernate 的极大启发。这两个QueryContracts 非常相似。
然后可以使用 Query 接口来控制查询的执行。例如,我们可能要指定执行超时或控件缓存。
例子 495.基本查询用法-休眠
org.hibernate.query.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
// timeout - in seconds
.setTimeout( 2 )
// write to L2 caches, but do not read from them
.setCacheMode( CacheMode.REFRESH )
// assuming query cache was enabled for the SessionFactory
.setCacheable( true )
// add a comment to the generated SQL if enabled via the hibernate.use_sql_comments configuration property
.setComment( "+ INDEX(p idx_person_name)" );
有关完整的详细信息,请参见Query Javadocs。
Tip
这里的查询提示是数据库查询提示。根据Dialect#getQueryHintString将它们直接添加到生成的 SQL 中。
另一方面,查询提示的 JPA 概念指的是针对提供者的提示(休眠)。因此,即使它们的名称相同,也要注意它们的用途截然不同。另外,请注意,除非添加了代码的代码首先检查了 Dialect,否则 Hibernate 查询提示通常会使应用程序无法跨数据库移植。
Flushing中详细介绍了冲洗。 Locking中详细介绍了锁定。 Persistence Contexts涵盖了只读状态的概念。
Hibernate 还允许应用程序通过org.hibernate.transform.ResultTransformerContract 进入构建查询结果的过程。有关其他详细信息,请参见其Javadocs以及 Hibernate 提供的实现。
在执行查询之前,需要做的最后一件事是绑定查询中定义的任何参数的值。为此,查询定义了许多重载方法。最通用的形式采用该值以及“休眠类型”。
例子 496.休眠名称参数绑定
org.hibernate.query.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%", StringType.INSTANCE );
Hibernate 通常会根据查询中的上下文了解参数的预期类型。在前面的示例中,由于我们在与字符串类型的属性进行LIKE比较时使用了参数,因此 Hibernate 会自动推断类型;因此可以简化以上内容。
例子 497.休眠名称参数绑定(推断类型)
org.hibernate.query.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" );
也有用于绑定常见类型(例如字符串,布尔值,整数等)的简写形式。
例子 498.休眠名称参数绑定(简短形式)
org.hibernate.query.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name " +
" and p.createdOn > :timestamp" )
.setParameter( "name", "J%" )
.setParameter( "timestamp", timestamp, TemporalType.TIMESTAMP);
Tip
传统上,Hibernate 过去通过?符号来支持 JDBC 位置参数语法形式,而没有后面的序号。
除了将相同的值绑定到每个位置参数外,没有其他方法可以将两个这样的位置参数关联为“相同”,因此,不再支持此格式。
org.hibernate.query.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like ?" )
.setParameter( 1, "J%" );
在执行方面,Hibernate 提供了 4 种不同的方法。最常用的 2 种是
Query#list-执行选择查询并返回结果列表。Query#uniqueResult-执行选择查询并返回单个结果。如果结果不止一个,则会引发异常。
例子 499.休眠list()结果
List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.list();
也可以从Query提取单个结果。
例子 500.休眠uniqueResult()
Person person = (Person) session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.uniqueResult();
Note
如果经常使用唯一结果并且其基于的属性是唯一的,则您可能需要考虑 Map 自然 ID 并使用自然 ID 加载 API。有关此主题的更多信息,请参见Natural Ids。
15.2.3. 查询滚动
Hibernate 提供了其他的专用方法来滚动查询和使用服务器端游标处理结果。
Query#scroll与可滚动的ResultSet的 JDBC 概念协同工作。
Query#scroll方法已重载:
主要形式接受类型为
org.hibernate.ScrollMode的单个参数,该参数指示要使用的滚动类型。有关详细信息,请参见Javadocs。第二种形式不带参数,将使用
Dialect#defaultScrollMode表示的ScrollMode。
Query#scroll返回一个org.hibernate.ScrollableResults,该org.hibernate.ScrollableResults包装基础 JDBC(可滚动)ResultSet,并提供对结果的访问。与典型的仅向前ResultSet不同,ScrollableResults允许您在任何方向上导航ResultSet。
例子 501.滚动浏览包含实体的ResultSet
try ( ScrollableResults scrollableResults = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.scroll()
) {
while(scrollableResults.next()) {
Person person = (Person) scrollableResults.get()[0];
process(person);
}
}
Tip
由于此表单使 JDBC ResultSet保持打开状态,因此应用程序应通过调用close()方法(继承自java.io.Closeable,以便ScrollableResults与try-with-resources块一起使用)来指示何时完成ScrollableResults。
如果应用程序未关闭它,则 Hibernate 将在当前事务结束(提交或回滚)时自动关闭ScrollableResults内部使用的基础资源(例如ResultSet和PreparedStatement)。
但是,优良作法是显式关闭ScrollableResults。
Note
如果计划将Query#scroll与集合提取一起使用,则重要的是您的查询对结果进行显式排序,以便 JDBC 结果 Sequences 包含相关行。
Hibernate 还支持Query#iterate,当已知加载的条目已经存储在第二级缓存中时,它用于加载实体。进行迭代的想法是,仅匹配的标识符将在 SQL 查询中获得。从这些标识符中,通过二级缓存查找来解析标识符。如果这些第二级缓存查找失败,则将需要对数据库发出其他查询。
Note
对于加载某些二级缓存中确实已经存在的实体,此操作的性能可能会更好。在二级缓存中不存在许多实体的情况下,该操作几乎肯定会执行得更差。
从Query#iterate返回的Iterator实际上是一个特殊类型的迭代器:org.hibernate.engine.HibernateIterator。专门公开close()方法(再次继承自java.io.Closeable)。完成此Iterator的操作后,应通过强制转换为HibernateIterator或Closeable或调用Hibernate#close(java.util.Iterator)将其关闭。
从 5.2 开始,Hibernate 提供了对返回Stream的支持,以后可以将其用于转换基础ResultSet。
在内部,stream()的行为类似于Query#scroll,而基础结果由ScrollableResults支持。
可以使用Query#stream方法获取投影,方法如下:
例子 502.使用投影结果类型休眠stream()
try ( Stream<Object[]> persons = session.createQuery(
"select p.name, p.nickName " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.stream() ) {
persons
.map( row -> new PersonNames(
(String) row[0],
(String) row[1] ) )
.forEach( this::process );
}
当获取单个结果(例如Person实体而不是Stream<Object[]>)时,Hibernate 将计算出实际类型,因此结果为Stream<Person>。
例子 503.使用实体结果类型休眠stream()
try( Stream<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.stream() ) {
Map<Phone, List<Call>> callRegistry = persons
.flatMap( person -> person.getPhones().stream() )
.flatMap( phone -> phone.getCalls().stream() )
.collect( Collectors.groupingBy( Call::getPhone ) );
process(callRegistry);
}
Tip
就像使用ScrollableResults一样,您应该始终显式或使用try-with-resources块关闭 Hibernate Stream。
15.2.4. 查询流
从 2.2 版开始,JPA Query接口支持通过getResultStream方法返回Stream。
就像scroll方法一样,您可以使用 try-with-resources 块在关闭当前运行的持久性上下文之前关闭Stream。
从 Hibernate 5.4 开始,调用终端操作时Stream也会关闭,如以下示例所示。
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name", Person.class )
.setParameter( "name", "J%" )
.getResultStream()
.skip( 5 )
.limit( 5 )
.collect( Collectors.toList() );
调用collect方法后,将自动关闭Stream,因为如果Stream无法重用,则没有理由使基础 JDBC ResultSet保持打开状态。
15.3. 区分大小写
除 Java 类和属性的名称外,查询不区分大小写。因此,SeLeCT与sELEct与SELECT相同,但是org.hibernate.eg.FOO和org.hibernate.eg.Foo不同,foo.barSet和foo.BARSET也不同。
Note
本文档使用小写关键字作为查询示例中的约定。
15.4. 报表类型
HQL 和 JPQL 都允许执行SELECT,UPDATE和DELETE语句。 HQL 还允许INSERT语句,形式类似于 SQL INSERT FROM SELECT。
Tip
应注意何时执行UPDATE或DELETE语句。
Note
执行批量更新或删除操作时应小心,因为它们可能会导致数据库与活动持久性上下文中的实体之间出现不一致。通常,批量更新和删除操作仅应在新的持久性上下文中的事务内执行,或者应在获取或访问其状态可能受此类操作影响的实体之前执行。
— JPA 2.0 规范的第 4.10 节
15.5. 选择语句
HQL 中的SELECT语句的BNF为:
select_statement :: =
[select_clause]
from_clause
[where_clause]
[groupby_clause]
[having_clause]
[orderby_clause]
最简单的 HQL SELECT语句的形式为:
List<Person> persons = session.createQuery(
"from Person" )
.list();
Note
JPQL 中的 select 语句与 HQL 完全相同,只是 JPQL 需要select_clause,而 HQL 则不需要。
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p", Person.class )
.getResultList();
即使 HQL 不需要select_clause,也通常包括一个。对于简单查询,意图很明确,因此select_clause的预期结果很容易推断。但是在更复杂的查询中,情况并非总是如此。
通常最好明确指定意图。即使在解析 JPQL 查询时,Hibernate 实际上并没有强制select_clause存在,但是,对 JPA 可移植性感兴趣的应用程序应注意这一点。
15.6. 更新语句
UPDATE语句的 BNF 在 HQL 和 JPQL 中相同:
update_statement ::=
update_clause [where_clause]
update_clause ::=
UPDATE entity_name [[AS] identification_variable]
SET update_item {, update_item}*
update_item ::=
[identification_variable.]{state_field | single_valued_object_field} = new_value
new_value ::=
scalar_expression | simple_entity_expression | NULL
默认情况下,UPDATE语句不影响受影响实体的version或timestamp属性值。
但是,您可以通过使用versioned update强制 Hibernate 设置version或timestamp属性值。这是通过在UPDATE关键字之后添加VERSIONED关键字来实现的。
Note
版本更新是特定于 Hibernate 的功能,无法以可移植的方式工作。
自定义版本类型org.hibernate.usertype.UserVersionType不能与update versioned语句一起使用。
使用org.hibernate.query.Query或javax.persistence.Query的executeUpdate()执行UPDATE语句。该方法是为熟悉java.sql.PreparedStatement上的 JDBC executeUpdate()的人命名的。
executeUpdate()方法返回的int值指示受操作影响的实体数。这可能与数据库中受影响的行数相关或不相关。 HQL 批量操作可能会导致执行多个实际的 SQL 语句(例如,对于 joined-subclass)。返回的数字表示受该语句影响的实际实体数。使用 JOINED 继承层次结构,对子类之一的删除实际上可能不仅导致对该子类 Map 到的表的删除,而且还导致“根”表和“中间”表的删除。
例子 504. UPDATE 查询语句
int updatedEntities = entityManager.createQuery(
"update Person p " +
"set p.name = :newName " +
"where p.name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
int updatedEntities = session.createQuery(
"update Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
int updatedEntities = session.createQuery(
"update versioned Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
Tip
UPDATE和DELETE语句均不允许隐式联接。它们的形式也已经不允许显式连接。
15.7. 删除 Statements
DELETE语句的 BNF 在 HQL 和 JPQL 中相同:
delete_statement ::=
delete_clause [where_clause]
delete_clause ::=
DELETE FROM entity_name [[AS] identification_variable]
还可使用org.hibernate.query.Query或javax.persistence.Query的executeUpdate()方法执行DELETE语句。
15.8. 插入语句
HQL 还添加了定义INSERT语句的功能。
Note
没有与 HQL 样式的 INSERT 语句等效的 JPQL。
HQL INSERT语句的 BNF 为:
insert_statement ::=
insert_clause select_statement
insert_clause ::=
INSERT INTO entity_name (attribute_list)
attribute_list ::=
state_field[, state_field ]*
attribute_list与 SQL INSERT语句中的column specification类似。对于涉及 Map 继承的实体,只能在attribute_list中使用直接在命名实体上定义的属性。不允许超类属性,子类属性没有意义。换句话说,INSERT语句本质上是非多态的。
select_statement可以是任何有效的 HQL 选择查询,但请注意,返回类型必须与插入期望的类型匹配。当前,这是在查询编译期间检查的,而不是允许检查委托给数据库的。这可能会导致等价而非等价的休眠类型之间出现问题。例如,这可能导致 Map 为org.hibernate.type.DateType的属性与定义为org.hibernate.type.TimestampType的属性之间不匹配的问题,即使数据库可能没有区别或可能能够处理转换。
对于 id 属性,insert 语句为您提供两个选择。您可以在attribute_list中显式指定 id 属性,在这种情况下,其值是从相应的 select 表达式中获取的,或者在attribute_list中将其忽略,在这种情况下,将使用生成的值。仅当使用在“数据库中”运行的 id 生成器时,后一个选项才可用。尝试将此选项与任何“ in memory”类型生成器一起使用时,将在解析期间导致异常。
对于乐观锁定属性,insert 语句再次为您提供两个选择。您可以在attribute_list中指定属性,在这种情况下,其值是从相应的选择表达式中获取的,或者在attribute_list中省略它的值,在这种情况下,将使用由相应org.hibernate.type.VersionType定义的seed value。
例子 505. INSERT 查询语句
int insertedEntities = session.createQuery(
"insert into Partner (id, name) " +
"select p.id, p.name " +
"from Person p ")
.executeUpdate();
15.9. FROM 子句
FROM子句负责定义可用于其余查询的对象模型类型的范围。它也负责定义其余查询可用的所有“标识变量”。
15.10. 识别变量
标识变量通常称为别名。 FROM子句中对对象模型类的引用可以与一个标识变量相关联,然后可以在整个查询的其余部分中将该标识变量用于引用该类型。
在大多数情况下,声明标识变量是可选的,尽管声明它们通常是一种好习惯。
标识变量必须遵循 Java 标识符有效性的规则。
根据 JPQL,标识变量必须被视为不区分大小写。优良作法表示,在整个查询中应使用相同的大小写来引用给定的标识变量。换句话说,JPQL 表示它们可能不区分大小写,因此 Hibernate 必须能够对它们进行同样的处理,但这并不是一种好的做法。
15.11. 根实体引用
根实体引用或 JPA 称为range variable declaration的引用特别是对应用程序中 Map 实体类型的引用。它不能命名组件/可嵌入类型。关联(包括集合)以不同的方式处理,如稍后讨论。
根实体引用的 BNF 为:
root_entity_reference ::=
entity_name [AS] identification_variable
例子 506.简单查询例子
List<Person> persons = entityManager.createQuery(
"select p " +
"from org.hibernate.userguide.model.Person p", Person.class )
.getResultList();
我们看到查询正在定义对org.hibernate.userguide.model.Person对象模型类型的根实体引用。此外,它为该org.hibernate.userguide.model.Person引用声明了p的别名,这是标识变量。
通常,根实体引用仅表示entity name而不是实体类 FQN(完全限定名称)。默认情况下,实体名称是不合格的实体类名称,此处为Person。
例子 507.使用实体名称作为根实体参考的简单查询
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p", Person.class )
.getResultList();
即使命名同一个实体,也可以指定多个根实体引用。
例子 508.使用多个根实体引用的简单查询
List<Object[]> persons = entityManager.createQuery(
"select distinct pr, ph " +
"from Person pr, Phone ph " +
"where ph.person = pr and ph is not null", Object[].class)
.getResultList();
List<Person> persons = entityManager.createQuery(
"select distinct pr1 " +
"from Person pr1, Person pr2 " +
"where pr1.id <> pr2.id " +
" and pr1.address = pr2.address " +
" and pr1.createdOn < pr2.createdOn", Person.class )
.getResultList();
15.12. 显式联接
FROM子句还可以使用join关键字包含显式关系联接。这些联接可以是inner或left outer样式的联接。
例子 509.显式内部联接的例子
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"join pr.phones ph " +
"where ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.MOBILE )
.getResultList();
// same query but specifying join type as 'inner' explicitly
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"inner join pr.phones ph " +
"where ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.MOBILE )
.getResultList();
例子 510.显式的左(外)连接例子
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"left join pr.phones ph " +
"where ph is null " +
" or ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.getResultList();
// functionally the same query but using the 'left outer' phrase
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"left outer join pr.phones ph " +
"where ph is null " +
" or ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.getResultList();
HQL 还定义了WITH子句以限定连接条件。
Note
HQL 样式的 WITH 关键字特定于 Hibernate。 JPQL 为此功能定义了ON子句。
例子 511. HQL WITH子句联接例子
List<Object[]> personsAndPhones = session.createQuery(
"select pr.name, ph.number " +
"from Person pr " +
"left join pr.phones ph with ph.type = :phoneType " )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.list();
例子 512. JPQL ON子句联接例子
List<Object[]> personsAndPhones = entityManager.createQuery(
"select pr.name, ph.number " +
"from Person pr " +
"left join pr.phones ph on ph.type = :phoneType " )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.getResultList();
Note
重要的区别在于,在生成的 SQL 中,将WITH/ON子句的条件作为生成的 SQL 的ON子句的一部分,与本节中将 HQL/JPQL 条件作为WHERE子句的一部分的其他查询相反生成的 SQL。
在此特定示例中的区别可能并不那么重要。 with clause有时对于更复杂的查询是必需的。
显式联接可以引用关联或组件/嵌入的属性。对于组件/嵌入式属性,联接只是逻辑上的,与物理(SQL)联接不相关。有关集合值关联引用的更多信息,请参见集合成员参考。
显式联接的一个重要用例是定义FETCH JOIN,该FETCH JOIN覆盖联接关联的惰性。例如,给定名为Person的实体和具有phones的集合值的关联,JOIN FETCH还将在同一 SQL 查询中加载子集合:
例子 513.获取连接例子
// functionally the same query but using the 'left outer' phrase
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"left join fetch pr.phones ", Person.class )
.getResultList();
从示例中可以看到,通过在关键字join之后注入关键字fetch来指定访存联接。在该示例中,我们使用了左外部联接,因为我们还想返回没有订单的 Client。
也可以获取内部联接,但是内部联接会过滤掉根实体。在该示例中,使用内部联接将导致 Client 没有从结果中过滤出任何订单。
Tip
提取联接在子查询中无效。
提取加入集合值关联时要小心,该关联在任何方面都受到进一步限制(提取的集合也将受到限制)。因此,通常认为最佳做法是不为获取的联接分配标识变量,除非指定嵌套的获取联接。
抓取联接不应用于分页查询(例如setFirstResult()或setMaxResults()),也不应与scroll()或iterate()功能一起使用。
15.13. 隐式联接(路径表达式)
增加对查询可用的对象模型类型范围的另一种方法是通过使用隐式联接或路径表达式。
例子 514.简单的隐式联接例子
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"where ph.person.address = :address ", Phone.class )
.setParameter( "address", address )
.getResultList();
// same as
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"join ph.person pr " +
"where pr.address = :address ", Phone.class )
.setParameter( "address", address)
.getResultList();
隐式连接始终从identification variable开始,然后是导航运算符(.),再是由初始identification variable引用的对象模型类型的属性。在示例中,初始identification variable是ph,它是指Phone实体。 ph.person引用然后引用Phone实体的person属性。 person是关联类型,因此我们进一步导航到其 age 属性。
Tip
如果属性表示实体关联(非集合)或组件/嵌入式,则可以进一步浏览该引用。基本值和集合值的关联无法进一步导航。
如示例所示,隐式联接可以出现在FROM clause之外。但是,它们会影响FROM clause。
Note
隐式联接始终被视为内部联接。
对同一隐式联接的多个引用始终引用同一逻辑和物理(SQL)联接。
例子 515.重用隐式联接
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"where ph.person.address = :address " +
" and ph.person.createdOn > :timestamp", Phone.class )
.setParameter( "address", address )
.setParameter( "timestamp", timestamp )
.getResultList();
//same as
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"inner join ph.person pr " +
"where pr.address = :address " +
" and pr.createdOn > :timestamp", Phone.class )
.setParameter( "address", address )
.setParameter( "timestamp", timestamp )
.getResultList();
就像显式联接一样,隐式联接可以引用关联或组件/嵌入的属性。有关集合值关联引用的更多信息,请参见集合成员参考。
对于组件/嵌入式属性,联接只是逻辑上的,与物理(SQL)联接不相关。但是,与显式连接不同,隐式连接也可以引用基本状态字段,只要路径表达式在此结束。
15.14. Distinct
对于 JPQL 和 HQL,DISTINCT具有两个含义:
可以将其传递到数据库,以便从结果集中删除重复项
联接获取子集合时,可用于过滤出相同的父实体引用
15.14.1. 将 DISTINCT 与 SQL 投影配合使用
对于 SQL 投影,需要将DISTINCT传递到数据库,因为重复的条目需要先过滤掉,然后再返回数据库 Client 端。
例子 516.通过投影查询使用 DISTINCT 例子
List<String> lastNames = entityManager.createQuery(
"select distinct p.lastName " +
"from Person p", String.class)
.getResultList();
运行上面的查询时,Hibernate 生成以下 SQL 查询:
SELECT DISTINCT
p.last_name as col_0_0_
FROM person p
对于此特定用例,将DISTINCT关键字从 JPQL/HQL 传递到数据库是正确的做法。
15.14.2. 对实体查询使用 DISTINCT
DISTINCT还可以用于在与父实体一起获取子关联时过滤掉实体对象引用。
例子 517.对实体查询使用 DISTINCT 例子
List<Person> authors = entityManager.createQuery(
"select distinct p " +
"from Person p " +
"left join fetch p.books", Person.class)
.getResultList();
在这种情况下,使用DISTINCT是因为可能有多个Books实体与给定的Person关联。如果在数据库中数据库中有 3 Person s,而每个人有 2 Book s,则没有DISTINCT时,此查询将返回 6 Person s,因为 SQL 级别结果集的大小由连接的Book记录的数量给出。
但是,DISTINCT关键字也传递到数据库:
SELECT DISTINCT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
在这种情况下,不希望使用DISTINCT SQL 关键字,因为它进行了冗余的结果集排序,如在这篇博客文章中所述。为了解决此问题,Hibernate 5.2.2 添加了对HINT_PASS_DISTINCT_THROUGH实体查询提示的支持:
例子 518.对实体查询使用 DISTINCT 例子
List<Person> authors = entityManager.createQuery(
"select distinct p " +
"from Person p " +
"left join fetch p.books", Person.class)
.setHint( QueryHints.HINT_PASS_DISTINCT_THROUGH, false )
.getResultList();
有了此实体查询提示,Hibernate 将不会将DISTINCT关键字传递给 SQL 查询:
SELECT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
当使用HINT_PASS_DISTINCT_THROUGH实体查询提示时,Hibernate 仍然可以从查询结果中删除重复的父方实体。
15.15. 集合成员参考
对集合值关联的引用实际上是指该集合的“值”。
例子 519.集合引用例子
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Person pr " +
"join pr.phones ph " +
"join ph.calls c " +
"where pr.address = :address " +
" and c.duration > :duration", Phone.class )
.setParameter( "address", address )
.setParameter( "duration", duration )
.getResultList();
// alternate syntax
List<Phone> phones = session.createQuery(
"select ph " +
"from Person pr, " +
"in (pr.phones) ph, " +
"in (ph.calls) c " +
"where pr.address = :address " +
" and c.duration > :duration" )
.setParameter( "address", address )
.setParameter( "duration", duration )
.list();
在该示例中,标识变量ph实际上是指对象模型类型Phone,它是Person#phones关联的元素的类型。
该示例还显示了使用IN语法指定集合关联联接的替代语法。两种形式是等效的。应用程序选择使用哪种形式只是一个品味问题。
15.16. 特殊情况-限定路径表达式
我们之前说过,集合值关联实际上是指该集合的“值”。根据集合的类型,还提供了一组明确的资格表达。
例子 520.合格集合引用例子
@OneToMany(mappedBy = "phone")
@MapKey(name = "timestamp")
@MapKeyTemporal(TemporalType.TIMESTAMP )
private Map<Date, Call> callHistory = new HashMap<>();
// select all the calls (the map value) for a given Phone
List<Call> calls = entityManager.createQuery(
"select ch " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id ", Call.class )
.setParameter( "id", id )
.getResultList();
// same as above
List<Call> calls = entityManager.createQuery(
"select value(ch) " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id ", Call.class )
.setParameter( "id", id )
.getResultList();
// select all the Call timestamps (the map key) for a given Phone
List<Date> timestamps = entityManager.createQuery(
"select key(ch) " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id ", Date.class )
.setParameter( "id", id )
.getResultList();
// select all the Call and their timestamps (the 'Map.Entry') for a given Phone
List<Map.Entry<Date, Call>> callHistory = entityManager.createQuery(
"select entry(ch) " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id " )
.setParameter( "id", id )
.getResultList();
// Sum all call durations for a given Phone of a specific Person
Long duration = entityManager.createQuery(
"select sum(ch.duration) " +
"from Person pr " +
"join pr.phones ph " +
"join ph.callHistory ch " +
"where ph.id = :id " +
" and index(ph) = :phoneIndex", Long.class )
.setParameter( "id", id )
.setParameter( "phoneIndex", phoneIndex )
.getSingleResult();
VALUE
- 引用集合值。与未指定限定符相同。有助于明确显示意图。对任何类型的集合值引用有效。
INDEX
- 根据 HQL 规则,这对
Maps和Lists均有效,它们指定javax.persistence.OrderColumn注解以引用Map键或List位置(也称为OrderColumn值)。但是,JPQL 将其保留用于List情况,并为Map情况添加KEY。对 JPA 提供程序可移植性感兴趣的应用程序应意识到这一区别。
- 根据 HQL 规则,这对
KEY
- 仅对
Maps有效。指 Map 的键。如果键本身是实体,则可以进一步导航。
- 仅对
ENTRY
- 仅对
Maps有效。引用 Map 的逻辑java.util.Map.EntryTuples(键和值的组合)。ENTRY仅作为终端路径有效,并且仅适用于SELECT子句。
- 仅对
有关与集合相关的表达式的更多详细信息,请参见Collection-related expressions。
15.17. Polymorphism
HQL 和 JPQL 查询本质上是多态的。
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p ", Payment.class )
.getResultList();
该查询显式命名Payment实体。但是,Payment的所有子类也可用于查询。因此,如果CreditCardPayment和WireTransferPayment实体扩展了Payment类,则这三种类型都可用于实体查询,并且该查询将返回这三种类型的实例。
可以通过两种方式更改此行为:
通过限制查询以仅从子类实体中进行选择。
通过使用
org.hibernate.annotations.Polymorphism注解(全局和特定于 Hibernate)。有关此用例的更多信息,请参见@Polymorphism section。
Note
HQL 查询from java.lang.Object是完全有效的(尽管从性能角度来看不是很实用)!
它返回由应用程序 Map 定义的每个实体类型的每个对象。
15.18. Expressions
本质上,表达式是解析为基本或 Tuples 值的引用。
15.19. 识别变量
See FROM 子句.
15.20. 路径表达式
同样,请参见FROM 子句。
15.21. Literals
字符串 Literals 用单引号引起来。要转义字符串 Literals 中的单引号,请使用双单引号。
例子 521.字符串 Literals 的例子
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Joe'", Person.class)
.getResultList();
// Escaping quotes
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Joe''s'", Person.class)
.getResultList();
允许使用几种不同形式的数字 Literals。
例子 522.数字 Literals 例子
// simple integer literal
Person person = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id = 1", Person.class)
.getSingleResult();
// simple integer literal, typed as a long
Person person = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id = 1L", Person.class)
.getSingleResult();
// decimal notation
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 100.5", Call.class )
.getResultList();
// decimal notation, typed as a float
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 100.5F", Call.class )
.getResultList();
// scientific notation
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 1e+2", Call.class )
.getResultList();
// scientific notation, typed as a float
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 1e+2F", Call.class )
.getResultList();
Note
在科学计数形式中,E不区分大小写。
可以通过使用 Java 指定的相同后缀方法来实现特定类型。因此,L表示长整数,D表示双精度数,F表示浮点数。实际的后缀不区分大小写。
布尔 Literals 是TRUE和FALSE,再次不区分大小写。
枚举甚至可以作为 Literals 引用。必须使用标准的枚举类名称。尽管 JPQL 并未将其定义为受支持,但 HQL 也可以以相同的方式处理常量。
实体名称也可以用作 Literals。参见Entity type。
可以使用 JDBC 转义语法指定日期/时间 Literals:
{d 'yyyy-mm-dd'}日期{t 'hh:mm:ss'}次{ts 'yyyy-mm-dd hh:mm:ss[.millis]'}(毫秒为可选)用于时间戳记。
仅当底层 JDBC 驱动程序支持这些日期/时间 Literals 时,它们才起作用。
15.22. Arithmetic
算术运算也表示有效的表达式。
例子 523.数值算术例子
// select clause date/time arithmetic operations
Long duration = entityManager.createQuery(
"select sum(ch.duration) * :multiplier " +
"from Person pr " +
"join pr.phones ph " +
"join ph.callHistory ch " +
"where ph.id = 1L ", Long.class )
.setParameter( "multiplier", 1000L )
.getSingleResult();
// select clause date/time arithmetic operations
Integer years = entityManager.createQuery(
"select year( current_date() ) - year( p.createdOn ) " +
"from Person p " +
"where p.id = 1L", Integer.class )
.getSingleResult();
// where clause arithmetic operations
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where year( current_date() ) - year( p.createdOn ) > 1", Person.class )
.getResultList();
以下规则适用于算术运算的结果:
如果两个操作数之一为
Double/double,则结果为Double否则,如果两个操作数中的任何一个为
Float/float,则结果为Float否则,如果任一操作数为
BigDecimal,则结果为BigDecimal否则,如果两个操作数中的任何一个为
BigInteger,则结果为BigInteger(除法运算除外,在这种情况下,将不进一步定义结果类型)否则,如果两个操作数中的任何一个为
Long/long,则结果为Long(除法运算除外,在这种情况下,结果类型不再进一步定义)否则,(假设两个操作数都是整数类型)结果为
Integer(除法运算除外,在这种情况下,结果类型不再进一步定义)
还支持日期算术,尽管以更有限的方式。这是由于数据库支持方面的差异,部分原因是查询语言本身缺乏对INTERVAL定义的支持。
15.23. 串联(操作)
HQL 除了支持串联(CONCAT)功能之外,还定义了串联运算符。 JPQL 并未定义此属性,因此便携式应用程序应避免使用它。串联运算符取自 SQL 串联运算符(例如||)。
例子 524.串联操作例子
String name = entityManager.createQuery(
"select 'Customer ' || p.name " +
"from Person p " +
"where p.id = 1", String.class )
.getSingleResult();
有关concat()功能的详细信息,请参见Scalar functions。
15.24. 汇总功能
聚合函数也是 HQL 和 JPQL 中的有效表达式。语义与其对应的 SQL 相同。支持的聚合函数是:
COUNT(包括不同/所有限定词)- 结果类型始终为
Long。
- 结果类型始终为
AVG- 结果类型始终为
Double。
- 结果类型始终为
MIN- 结果类型与参数类型相同。
MAX- 结果类型与参数类型相同。
SUMSUM()函数的结果类型取决于要求和的值的类型。对于整数值(BigInteger除外),结果类型为Long。
对于浮点值(不是BigDecimal),结果类型为Double。对于BigInteger值,结果类型为BigInteger。对于BigDecimal值,结果类型为BigDecimal。
例子 525.聚合函数例子
Object[] callStatistics = entityManager.createQuery(
"select " +
" count(c), " +
" sum(c.duration), " +
" min(c.duration), " +
" max(c.duration), " +
" avg(c.duration) " +
"from Call c ", Object[].class )
.getSingleResult();
Long phoneCount = entityManager.createQuery(
"select count( distinct c.phone ) " +
"from Call c ", Long.class )
.getSingleResult();
List<Object[]> callCount = entityManager.createQuery(
"select p.number, count(c) " +
"from Call c " +
"join c.phone p " +
"group by p.number", Object[].class )
.getResultList();
聚集通常与分组一起出现。有关分组的信息,请参见Group by。
15.25. 标量函数
HQL 和 JPQL 都定义了一些可用的标准功能,而与使用的基础数据库无关。 HQL 还可以理解方言和应用程序定义的其他功能。
15.26. JPQL 标准化功能
这是 JPQL 支持定义的功能列表。对在 JPA 提供程序之间保持可移植性感兴趣的应用程序应坚持使用这些功能。
CONCAT
- 字符串串联函数。两个或多个字符串值的可变参数长度要串联在一起。
List<String> callHistory = entityManager.createQuery(
"select concat( p.number, ' : ' , cast(c.duration as string) ) " +
"from Call c " +
"join c.phone p", String.class )
.getResultList();
SUBSTRING
- 提取字符串值的一部分。第二个参数表示起始位置,其中 1 是字符串的第一个字符。第三个(可选)参数表示长度。
List<String> prefixes = entityManager.createQuery(
"select substring( p.number, 1, 2 ) " +
"from Call c " +
"join c.phone p", String.class )
.getResultList();
UPPER
- 大写指定的字符串。
List<String> names = entityManager.createQuery(
"select upper( p.name ) " +
"from Person p ", String.class )
.getResultList();
LOWER
- 小写指定的字符串。
List<String> names = entityManager.createQuery(
"select lower( p.name ) " +
"from Person p ", String.class )
.getResultList();
TRIM
- 遵循 SQL trim 函数的语义。
List<String> names = entityManager.createQuery(
"select trim( p.name ) " +
"from Person p ", String.class )
.getResultList();
LENGTH
- 返回字符串的长度。
List<Integer> lengths = entityManager.createQuery(
"select length( p.name ) " +
"from Person p ", Integer.class )
.getResultList();
LOCATE
- 在另一个字符串中找到一个字符串。第三个参数(可选)用于表示从其开始寻找的位置。
List<Integer> sizes = entityManager.createQuery(
"select locate( 'John', p.name ) " +
"from Person p ", Integer.class )
.getResultList();
ABS
- 计算数值的 math 绝对值。
List<Integer> abs = entityManager.createQuery(
"select abs( c.duration ) " +
"from Call c ", Integer.class )
.getResultList();
MOD
- 计算将第一个参数除以第二个参数的余数。
List<Integer> mods = entityManager.createQuery(
"select mod( c.duration, 10 ) " +
"from Call c ", Integer.class )
.getResultList();
SQRT
- 计算数值的 math 平方根。
List<Double> sqrts = entityManager.createQuery(
"select sqrt( c.duration ) " +
"from Call c ", Double.class )
.getResultList();
CURRENT_DATE
- 返回数据库的当前日期。
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.timestamp = current_date", Call.class )
.getResultList();
CURRENT_TIME
- 返回数据库的当前时间。
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.timestamp = current_time", Call.class )
.getResultList();
CURRENT_TIMESTAMP
- 返回数据库的当前时间戳。
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.timestamp = current_timestamp", Call.class )
.getResultList();
15.27. HQL 功能
除了使用 JPQL 标准化功能外,HQL 还提供了一些可用的附加功能,而与使用的基础数据库无关。
BIT_LENGTH
- 返回二进制数据的长度。
List<Number> bits = entityManager.createQuery(
"select bit_length( c.duration ) " +
"from Call c ", Number.class )
.getResultList();
CAST
- 执行 SQL 强制转换。强制转换目标应命名要使用的 HibernateMap 类型。有关更多信息,请参见第data types章。
List<String> durations = entityManager.createQuery(
"select cast( c.duration as string ) " +
"from Call c ", String.class )
.getResultList();
EXTRACT
- 对日期时间值执行 SQL 提取。提取会提取日期时间的一部分(例如年份)。
List<Integer> years = entityManager.createQuery(
"select extract( YEAR from c.timestamp ) " +
"from Call c ", Integer.class )
.getResultList();
请参阅下面的缩写形式。
YEAR
- 提取年份的缩写形式。
List<Integer> years = entityManager.createQuery(
"select year( c.timestamp ) " +
"from Call c ", Integer.class )
.getResultList();
MONTH
- 提取月份的缩写形式。
DAY
- 提取日的缩写形式。
HOUR
- 用于提取小时数的缩写提取形式。
MINUTE
- 用于提取分钟的缩写提取形式。
SECOND
- 用于提取第二种的缩写提取形式。
STR
- 用于将值转换为字符数据的缩写形式。
List<String> timestamps = entityManager.createQuery(
"select str( c.timestamp ) " +
"from Call c ", String.class )
.getResultList();
List<String> timestamps = entityManager.createQuery(
"select str( cast(duration as float) / 60, 4, 2 ) " +
"from Call c ", String.class )
.getResultList();
15.28. 用户定义的功能
休眠方言可以注册已知可用于该特定数据库产品的其他功能。这些功能也可以在 HQL(和 JPQL)中使用,尽管仅当使用 Hibernate 作为 JPA 提供程序时才可用)。但是,它们仅在使用该数据库方言时可用。旨在数据库可移植性的应用程序应避免使用此类中的功能。
应用程序开发人员还可以提供自己的功能集。这通常代表用户定义的 SQL 函数或 SQL 代码段的别名。此类函数声明是使用org.hibernate.boot.MetadataBuilder或旧版org.hibernate.cfg.Configuration的addSqlFunction()方法进行的。
现在,假设我们具有以下apply_vat PostgreSQL 用户定义函数:
例子 526. PostgreSQL 用户定义函数
statement.executeUpdate(
"CREATE OR REPLACE FUNCTION apply_vat(integer) RETURNS integer " +
" AS 'select cast(($1 * 1.2) as integer);' " +
" LANGUAGE SQL " +
" IMMUTABLE " +
" RETURNS NULL ON NULL INPUT;"
);
让我们考虑一下,我们在数据库中保留了以下实体:
例子 527.图书实体
Book book = new Book();
book.setIsbn( "978-9730228236" );
book.setTitle( "High-Performance Java Persistence" );
book.setAuthor( "Vlad Mihalcea" );
book.setPriceCents( 4500 );
entityManager.persist( book );
15.28.1. WHERE 子句中引用的用户定义函数
默认情况下,Hibernate 可以传递 JPQL/HQL 实体查询的 WHERE 子句中使用的任何用户定义函数。
例子 528.通过 WHERE 子句的用户定义函数
List<Book> books = entityManager.createQuery(
"select b " +
"from Book b " +
"where apply_vat(b.priceCents) = :price ", Book.class )
.setParameter( "price", 5400 )
.getResultList();
assertTrue( books
.stream()
.filter( book -> "High-Performance Java Persistence".equals( book.getTitle() ) )
.findAny()
.isPresent()
);
虽然这对于 Hibernate 来说很好,但是对于其他 JPA 提供程序来说可能是个问题。为此,JPA 提供了function JPQL 关键字,其工作原理如下。
例子 529.使用 JPQL function关键字
List<Book> books = entityManager.createQuery(
"select b " +
"from Book b " +
"where function('apply_vat', b.priceCents) = :price ", Book.class )
.setParameter( "price", 5400 )
.getResultList();
assertTrue( books
.stream()
.filter( book -> "High-Performance Java Persistence".equals( book.getTitle() ) )
.findAny()
.isPresent()
);
15.28.2. SELECT 子句中引用的用户定义函数
当在 JPQL/HQL 实体查询的 SELECT 子句中引用了用户定义的函数时,除非注册了该函数,否则 Hibernate 将无法再传递它。
例 530.使用MetadataBuilderContributor注册用户定义的函数
settings.put( "hibernate.metadata_builder_contributor",
(MetadataBuilderContributor) metadataBuilder ->
metadataBuilder.applySqlFunction(
"apply_vat",
new StandardSQLFunction(
"apply_vat",
StandardBasicTypes.INTEGER
)
)
);
现在已经注册了apply_vat,我们可以在 JPQL SELECT 子句中引用它。
例子 531. SELECT 子句中的用户定义函数
List<Tuple> books = entityManager.createQuery(
"select b.title as title, apply_vat(b.priceCents) as price " +
"from Book b " +
"where b.author = :author ", Tuple.class )
.setParameter( "author", "Vlad Mihalcea" )
.getResultList();
assertEquals( 1, books.size() );
Tuple book = books.get( 0 );
assertEquals( "High-Performance Java Persistence", book.get( "title" ) );
assertEquals( 5400, ((Number) book.get( "price" )).intValue() );
15.29. 与集合相关的表达式
有一些专门的表达式可用于集合值关联。通常,为了简明起见,这些仅仅是缩写形式或其他表达。
SIZE
- 计算集合的大小。等同于子查询!
MAXELEMENT
- 可用于基本类型的集合。指通过应用
maxSQL 聚合确定的最大值。
- 可用于基本类型的集合。指通过应用
MAXINDEX
- 可用于索引集合。指通过应用
maxSQL 聚合确定的最大索引(键/位置)。
- 可用于索引集合。指通过应用
MINELEMENT
- 可用于基本类型的集合。指通过应用
minSQL 聚合确定的最小值。
- 可用于基本类型的集合。指通过应用
MININDEX
- 可用于索引集合。指通过应用
minSQL 聚合确定的最小索引(键/位置)。
- 可用于索引集合。指通过应用
ELEMENTS
- 用于指整个集合的元素。仅在 where 子句中允许。通常与
ALL,ANY或SOME限制结合使用。
- 用于指整个集合的元素。仅在 where 子句中允许。通常与
INDICES
- 与
elements相似,不同之处在于indices表达式整体上引用了集合索引(键/位置)。
- 与
例子 532.与集合有关的表达式例子
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where maxelement( p.calls ) = :call", Phone.class )
.setParameter( "call", call )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where minelement( p.calls ) = :call", Phone.class )
.setParameter( "call", call )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where maxindex( p.phones ) = 0", Person.class )
.getResultList();
// the above query can be re-written with member of
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where :phone member of p.phones", Person.class )
.setParameter( "phone", phone )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where :phone = some elements ( p.phones )", Person.class )
.setParameter( "phone", phone )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where exists elements ( p.phones )", Person.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where current_date() > key( p.callHistory )", Phone.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where current_date() > all elements( p.repairTimestamps )", Phone.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where 1 in indices( p.phones )", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where size( p.phones ) = 2", Person.class )
.getResultList();
索引运算符可以引用索引集合的元素(数组,列表和 Map)。
例子 533.索引运算符的例子
// indexed lists
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.phones[ 0 ].type = 'LAND_LINE'", Person.class )
.getResultList();
// maps
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.addresses[ 'HOME' ] = :address", Person.class )
.setParameter( "address", address)
.getResultList();
//max index in list
List<Person> persons = entityManager.createQuery(
"select pr " +
"from Person pr " +
"where pr.phones[ maxindex(pr.phones) ].type = 'LAND_LINE'", Person.class )
.getResultList();
另请参见特殊情况-限定路径表达式,因为有很多重叠之处。
15.30. 实体类型
我们还可以将实体的类型称为表达式。在处理实体继承层次结构时,这主要有用。可以使用TYPE函数表示类型,该函数用于引用表示实体的标识变量的类型。实体名称还用作引用实体类型的方式。另外,可以对实体类型进行参数化,在这种情况下,实体的 Java 类引用将被绑定为参数值。
例子 534.实体类型表达式的例子
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) = CreditCardPayment", Payment.class )
.getResultList();
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) = :type", Payment.class )
.setParameter( "type", WireTransferPayment.class)
.getResultList();
Note
HQL 还具有使用class关键字引用实体类型的旧式形式,尽管该旧式形式被认为已弃用,而赞成TYPE。
在示例中,旧版表单将使用p.class而不是type(p)。仅出于完整性目的提及它。
15.31. 案例表达
支持简单和搜索形式,以及两个 SQL 定义的缩写形式(NULLIF和COALESCE)
15.32. 简单的 CASE 表达式
简单形式具有以下语法:
CASE {operand} WHEN {test_value} THEN {match_result} ELSE {miss_result} END
例子 535.简单案例表达例子
List<String> nickNames = entityManager.createQuery(
"select " +
" case p.nickName " +
" when 'NA' " +
" then '<no nick name>' " +
" else p.nickName " +
" end " +
"from Person p", String.class )
.getResultList();
// same as above
List<String> nickNames = entityManager.createQuery(
"select coalesce(p.nickName, '<no nick name>') " +
"from Person p", String.class )
.getResultList();
15.33. 搜索的 CASE 表达式
搜索的表单具有以下语法:
CASE [ WHEN {test_conditional} THEN {match_result} ]* ELSE {miss_result} END
例子 536.搜索的事例表达式例子
List<String> nickNames = entityManager.createQuery(
"select " +
" case " +
" when p.nickName is null " +
" then " +
" case " +
" when p.name is null " +
" then '<no nick name>' " +
" else p.name " +
" end" +
" else p.nickName " +
" end " +
"from Person p", String.class )
.getResultList();
// coalesce can handle this more succinctly
List<String> nickNames = entityManager.createQuery(
"select coalesce( p.nickName, p.name, '<no nick name>' ) " +
"from Person p", String.class )
.getResultList();
15.34. 具有算术运算的 CASE 表达式
如果要在 CASE 表达式中使用算术运算,则需要将算术运算包装在括号中,如以下示例所示:
例子 537.带有算术运算例子的 case 表达式
List<Long> values = entityManager.createQuery(
"select " +
" case when p.nickName is null " +
" then (p.id * 1000) " +
" else p.id " +
" end " +
"from Person p " +
"order by p.id", Long.class)
.getResultList();
assertEquals(3, values.size());
assertEquals( 1L, (long) values.get( 0 ) );
assertEquals( 2000, (long) values.get( 1 ) );
assertEquals( 3000, (long) values.get( 2 ) );
Tip
如果不将算术表达式包装在(和)中,则实体查询解析器将无法解析算术运算符。
15.35. NULLIF 表达式
NULLIF 是 CASE 的缩写形式,如果认为其操作数相等,则返回 NULL。
例子 538. NULLIF 例子
List<String> nickNames = entityManager.createQuery(
"select nullif( p.nickName, p.name ) " +
"from Person p", String.class )
.getResultList();
// equivalent CASE expression
List<String> nickNames = entityManager.createQuery(
"select " +
" case" +
" when p.nickName = p.name" +
" then null" +
" else p.nickName" +
" end " +
"from Person p", String.class )
.getResultList();
15.36. COALESCE 表达式
COALESCE是缩写 CASE 表达式,它返回第一个非空操作数。我们在上面看到了COALESCE个示例。
15.37. SELECT 子句
SELECT子句标识要作为查询结果返回的对象和值。除非另有说明,否则Expressions中讨论的表达式都是有效的 select 表达式。有关根据SELECT子句中指定的值类型处理结果的信息,请参见休眠查询 API部分。
有一个特定的表达式类型仅在 select 子句中有效。 Hibernate 将此称为“动态实例化”。 JPQL 支持其中的某些功能,并将其称为“构造函数表达式”。
因此,我们将值包装在类型安全的 Java 对象中,而不是在这里处理Object[](再次参见休眠查询 API),该对象将作为查询结果返回。
例子 539.动态 HQL 和 JPQL 实例化
public class CallStatistics {
private final long count;
private final long total;
private final int min;
private final int max;
private final double avg;
public CallStatistics(long count, long total, int min, int max, double avg) {
this.count = count;
this.total = total;
this.min = min;
this.max = max;
this.avg = avg;
}
//Getters and setters omitted for brevity
}
CallStatistics callStatistics = entityManager.createQuery(
"select new org.hibernate.userguide.hql.CallStatistics(" +
" count(c), " +
" sum(c.duration), " +
" min(c.duration), " +
" max(c.duration), " +
" avg(c.duration)" +
") " +
"from Call c ", CallStatistics.class )
.getSingleResult();
Note
投影类必须在实体查询中完全合格,并且必须定义一个匹配的构造函数。
Tip
这里的类不需要 Map。它可以是 DTO 类。
如果它确实表示实体,则返回的实例将以 NEW 状态(不受 Management!)返回。
HQL 支持其他“动态实例化”功能。首先,查询可以指定为标量结果返回List而不是Object[]:
例子 540.动态实例化例子-列表
List<List> phoneCallDurations = entityManager.createQuery(
"select new list(" +
" p.number, " +
" c.duration " +
") " +
"from Call c " +
"join c.phone p ", List.class )
.getResultList();
此查询的结果将是List<List>,而不是List<Object[]>
HQL 还支持将标量结果包装在Map中。
例子 541.动态实例化例子-Map
List<Map> phoneCallTotalDurations = entityManager.createQuery(
"select new map(" +
" p.number as phoneNumber , " +
" sum(c.duration) as totalDuration, " +
" avg(c.duration) as averageDuration " +
") " +
"from Call c " +
"join c.phone p " +
"group by p.number ", Map.class )
.getResultList();
该查询的结果将是List<Map<String, Object>>而不是List<Object[]>。Map 的键由提供给选择表达式的别名定义。如果用户未分配别名,则关键字将是每个特定结果集列的索引(例如 0、1、2 等)。
15.38. Predicates
谓词构成 where 子句,having 子句和搜索到的大小写表达式的基础。它们是解析为真值(通常为TRUE或FALSE)的表达式,尽管涉及NULL的布尔比较通常会解析为UNKNOWN。
15.39. 关系比较
比较涉及比较运算符之一:=,>,>=,<,<=,<>。 HQL 还定义!=作为与<>同义的比较运算符。操作数应为相同类型。
例子 542.关系比较例子
// numeric comparison
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration < 30 ", Call.class )
.getResultList();
// string comparison
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'John%' ", Person.class )
.getResultList();
// datetime comparison
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.createdOn > '1950-01-01' ", Person.class )
.getResultList();
// enum comparison
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where p.type = 'MOBILE' ", Phone.class )
.getResultList();
// boolean comparison
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where p.completed = true ", Payment.class )
.getResultList();
// boolean comparison
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) = WireTransferPayment ", Payment.class )
.getResultList();
// entity value comparison
List<Object[]> phonePayments = entityManager.createQuery(
"select p " +
"from Payment p, Phone ph " +
"where p.person = ph.person ", Object[].class )
.getResultList();
比较还可以涉及子查询限定符:ALL,ANY,SOME。 SOME和ANY是同义词。
如果子查询结果中所有值的比较结果为 true,则ALL限定符将解析为 true。如果子查询结果为空,则解析为 false。
例子 543.所有子查询比较限定词例子
// select all persons with all calls shorter than 50 seconds
List<Person> persons = entityManager.createQuery(
"select distinct p.person " +
"from Phone p " +
"join p.calls c " +
"where 50 > all ( " +
" select duration" +
" from Call" +
" where phone = p " +
") ", Person.class )
.getResultList();
如果对子查询结果中的某些(至少其中一个)值的比较为 true,则ANY/SOME限定符将解析为 true。如果子查询结果为空,则解析为 false。
15.40. 空性谓词
它检查值是否为空。它可以应用于基本属性引用,实体引用和参数。 HQL 还允许将其应用于组件/可嵌入类型。
例子 544.空度检查例子
// select all persons with a nickname
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.nickName is not null", Person.class )
.getResultList();
// select all persons without a nickname
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.nickName is null", Person.class )
.getResultList();
15.41. 像谓词
对字符串值执行类似的比较。语法为:
like_expression ::=
string_expression
[NOT] LIKE pattern_value
[ESCAPE escape_character]
语义遵循类似 SQL 的表达式的语义。 pattern_value是要在string_expression中匹配的模式。就像 SQL 一样,pattern_value可以将_和%用作通配符。含义是相同的。 _符号与任何单个字符匹配,%与任意数量的字符匹配。
例子 545.像谓词例子
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Jo%'", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name not like 'Jo%'", Person.class )
.getResultList();
可选的escape 'escape character'用于指定转义字符,用于转义pattern_value中的_和%的特殊含义。当需要搜索包括_或%在内的模式时,这很有用。
语法的格式如下:'like_predicate' escape 'escape_symbol'因此,如果|是转义符号,并且我们要匹配所有以Dr_为前缀的存储过程,则类似的标准变为:'Dr|_%' escape '|':
例子 546.与转义符号一样
// find any person with a name starting with "Dr_"
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Dr|_%' escape '|'", Person.class )
.getResultList();
15.42. 谓词之间
类似于 SQL BETWEEN表达式,它检查该值是否在边界内。所有操作数应具有可比较的类型。
例子 547.在谓词例子之间
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"join p.phones ph " +
"where p.id = 1L and index(ph) between 0 and 3", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.createdOn between '1999-01-01' and '2001-01-02'", Person.class )
.getResultList();
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration between 5 and 20", Call.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name between 'H' and 'M'", Person.class )
.getResultList();
15.43. 谓语
IN谓词将检查特定值是否在值列表中。其语法为:
in_expression ::=
single_valued_expression [NOT] IN single_valued_list
single_valued_list ::=
constructor_expression | (subquery) | collection_valued_input_parameter
constructor_expression ::= (expression[, expression]*)
single_valued_expression的类型和single_valued_list中的各个值必须一致。
JPQL 在这里将有效类型限制为字符串,数字,日期,时间,时间戳和枚举类型,并且在 JPQL 中,single_valued_expression只能引用:
“状态字段”,它是简单属性的术语。具体来说,这不包括关联和组件/嵌入属性。
实体类型表达式。参见Entity type。
在 HQL 中,single_valued_expression可以引用更广泛的表达式类型集。允许单值关联,组件/嵌入式属性也是如此,尽管该功能取决于基础数据库中 Tuples 或“行值构造函数语法”的支持级别。此外,HQL 不会以任何方式限制值类型,尽管应用程序开发人员应注意,基于基础数据库供应商,不同类型可能会招致有限的支持。这很大程度上是 JPQL 限制的原因。
值列表可以来自许多不同的来源。在constructor_expression和collection_valued_input_parameter中,值列表不能为空;它必须包含至少一个值。
例子 548.在谓词例子中
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) in ( CreditCardPayment, WireTransferPayment )", Payment.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where type in ( 'MOBILE', 'LAND_LINE' )", Phone.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where type in :types", Phone.class )
.setParameter( "types", Arrays.asList( PhoneType.MOBILE, PhoneType.LAND_LINE ) )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select distinct p " +
"from Phone p " +
"where p.person.id in (" +
" select py.person.id " +
" from Payment py" +
" where py.completed = true and py.amount > 50 " +
")", Phone.class )
.getResultList();
// Not JPQL compliant!
List<Phone> phones = entityManager.createQuery(
"select distinct p " +
"from Phone p " +
"where p.person in (" +
" select py.person " +
" from Payment py" +
" where py.completed = true and py.amount > 50 " +
")", Phone.class )
.getResultList();
// Not JPQL compliant!
List<Payment> payments = entityManager.createQuery(
"select distinct p " +
"from Payment p " +
"where ( p.amount, p.completed ) in (" +
" (50, true )," +
" (100, true )," +
" (5, false )" +
")", Payment.class )
.getResultList();
15.44. 存在谓词
存在表达式测试子查询结果的存在。如果子查询结果包含值,则肯定形式返回 true。如果子查询结果为空,则取反的形式返回 true。
15.45. 空集合谓词
IS [NOT] EMPTY表达式适用于集合值的路径表达式。它检查特定集合是否具有任何关联的值。
例子 549.空集合表达式的例子
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.phones is empty", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.phones is not empty", Person.class )
.getResultList();
15.46. 集合成员谓词
[NOT] MEMBER [OF]表达式适用于集合值的路径表达式。它检查一个值是否是指定集合的成员。
例子 550.成员集合表达式的例子
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where 'Home address' member of p.addresses", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where 'Home address' not member of p.addresses", Person.class )
.getResultList();
15.47. 非谓词运算符
NOT运算符用于否定其后的谓词。如果以下谓词为 true,则 NOT 解析为 false。
Note
如果谓词为 true,则 NOT 解析为 false。如果谓词是未知的(例如NULL),则 NOT 也将解析为未知。
15.48. AND 谓词运算符
AND运算符用于组合 2 个谓词表达式。当且仅当两个谓词都解析为 true 时,AND 表达式的结果才为 true。如果任一谓词解析为未知,则 AND 表达式也解析为未知。否则,结果为假。
15.49. 或谓词运算符
OR运算符用于组合 2 个谓词表达式。如果一个谓词解析为 true,则 OR 表达式的结果为 true。如果两个谓词都解析为未知,则 OR 表达式解析为未知。否则,结果为假。
15.50. WHERE 子句
查询的WHERE子句由谓词组成,这些谓词 assert 每个潜在行中的值是否与当前过滤条件匹配。因此,where 子句限制从选择查询返回的结果,并限制更新和删除查询的范围。
15.51. 通过...分组
GROUP BY子句允许为各种价值组构建汇总结果。例如,请考虑以下查询:
例子 551.按例子分组
Long totalDuration = entityManager.createQuery(
"select sum( c.duration ) " +
"from Call c ", Long.class )
.getSingleResult();
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p.name, sum( c.duration ) " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p.name", Object[].class )
.getResultList();
//It's even possible to group by entities!
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p, sum( c.duration ) " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p", Object[].class )
.getResultList();
第一个查询检索所有订单的完整总数。第二个检索按每个 Client 分组的每个 Client 的总计。
在分组查询中,where 子句适用于未聚合的值(本质上,它确定是否将行放入聚合中)。 HAVING子句还限制结果,但是它对汇总值起作用。在按示例分组中,我们检索了所有人的Call持续时间总计。如果最终导致要处理的数据过多,我们可能希望将结果限制为仅针对总数超过 1000 的 Client:
例子 552.有例子
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p.name, sum( c.duration ) " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p.name " +
"having sum( c.duration ) > 1000", Object[].class )
.getResultList();
HAVING子句遵循与WHERE子句相同的规则,并且也由谓词组成。 HAVING在完成分组和聚合之后应用,而WHERE子句在之前应用。
15.52. Order 依据
查询的结果也可以排序。 ORDER BY子句用于指定用于对结果进行排序的所选值。被视为ORDER BY子句一部分有效的表达式类型包括:
state fields
component/embeddable attributes
标量表达式,例如算术运算,函数等。
在 select 子句中为任何以前的表达式类型声明的标识变量
此外,JPQL 表示必须在SELECT子句中命名ORDER BY子句中引用的所有值。 HQL 没有强制执行该限制,但是希望数据库具有可移植性的应用程序应注意,并非所有数据库都支持ORDER BY子句中的 select 子句中未引用的值。
排序中的各个表达式可以用ASC(升序)或DESC(降序)进行限定,以指示所需的排序方向。可以分别使用NULLS FIRST或NULLS LAST子句将空值放在排序集的前面或结尾。
例子 553.通过例子 Order
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"order by p.name", Person.class )
.getResultList();
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p.name, sum( c.duration ) as total " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p.name " +
"order by total", Object[].class )
.getResultList();
15.53. 只读实体
如entity immutability部分中所述,以只读模式获取实体比获取读写实体效率更高。即使实体是可变的,您仍然可以以只读模式获取它们,并受益于减少内存占用和加快刷新过程。
脏检查机制将跳过只读实体,如以下示例所示:
例子 554.只读实体查询例子
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"join c.phone p " +
"where p.number = :phoneNumber ", Call.class )
.setParameter( "phoneNumber", "123-456-7890" )
.setHint( "org.hibernate.readOnly", true )
.getResultList();
calls.forEach( c -> c.setDuration( 0 ) );
SELECT c.id AS id1_5_ ,
c.duration AS duration2_5_ ,
c.phone_id AS phone_id4_5_ ,
c.call_timestamp AS call_tim3_5_
FROM phone_call c
INNER JOIN phone p ON c.phone_id = p.id
WHERE p.phone_number = '123-456-7890'
如您所见,没有执行 SQL UPDATE。
您还可以使用 JPA @QueryHint注解将只读提示传递给命名查询。
例子 555.使用命名查询和只读提示来获取只读实体
@NamedQuery(
name = "get_read_only_person_by_name",
query = "select p from Person p where name = :name",
hints = {
@QueryHint(
name = "org.hibernate.readOnly",
value = "true"
)
}
)
Hibernate 本机 API 提供Query#setReadOnly方法,作为使用 JPA 查询提示的替代方法:
例子 556.只读实体本机查询例子
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"join c.phone p " +
"where p.number = :phoneNumber ", Call.class )
.setParameter( "phoneNumber", "123-456-7890" )
.unwrap( org.hibernate.query.Query.class )
.setReadOnly( true )
.getResultList();
15.54. 实体查询计划缓存
任何实体查询,无论是 JPQL 还是 Criteria API,都必须解析为 AST(抽象语法树),以便 Hibernate 可以生成正确的 SQL 语句。实体查询编译需要时间,因此,Hibernate 提供了一个查询计划缓存。
在执行实体查询时,Hibernate 首先检查计划缓存,只有在没有可用计划时,才会立即计算一个新计划。
可以通过以下配置属性来配置查询计划缓存:
hibernate.query.plan_cache_max_size- 此设置提供计划缓存的最大条目数。默认值为 2048.
hibernate.query.plan_parameter_metadata_max_size- 该设置给出了查询计划缓存所维护的
ParameterMetadataImpl个实例的最大数量。ParameterMetadataImpl对象封装了有关查询中遇到的参数的元数据。默认值为 128.
- 该设置给出了查询计划缓存所维护的
现在,如果您有许多 JPQL 或 Criteria API 查询,那么增加查询计划缓存大小是一个好主意,以便绝大多数执行实体查询可以跳过编译阶段,从而减少了执行时间。
为了更好地了解查询计划缓存的有效性,Hibernate 提供了一些可以使用的统计信息。有关更多详细信息,请查看查询计划缓存统计信息部分。
16. Criteria
标准查询为 HQL,JPQL 和本机 SQL 查询提供了类型安全的替代方法。
Tip
Hibernate 提供了较旧的旧版org.hibernate.Criteria API,应将其视为已弃用。
没有针对这些 API 的功能开发。最终,特定于 Hibernate 的 Criteria 功能将被移植为 JPA javax.persistence.criteria.CriteriaQuery的扩展。有关org.hibernate.Criteria API 的详细信息,请参见旧版休眠标准查询。
本章将重点介绍用于声明类型安全条件查询的 JPA API。
标准查询是一种编程的,类型安全的方式来表达查询。就使用接口和类表示查询的各个结构部分(例如查询本身,select 子句或排序依据等)而言,它们是类型安全的。就引用属性而言,它们也是类型安全的。正如我们将看到的。较旧的 Hibernate org.hibernate.Criteria查询 API 的用户将认识到通用方法,尽管我们认为 JPA API 会更胜一筹,因为它代表了从该 API 中学到的教训。
标准查询本质上是一个对象图,其中图的每个部分代表查询中越来越多的原子部分(随着我们向下浏览该图)。执行条件查询的第一步是构建该图。 javax.persistence.criteria.CriteriaBuilder界面是您在使用标准查询之前必须熟悉的第一件事。它的作用是为所有准则的各个部分提供工厂服务。您可以通过调用javax.persistence.EntityManagerFactory或javax.persistence.EntityManager的getCriteriaBuilder()方法来获得javax.persistence.criteria.CriteriaBuilder实例。
下一步是获取javax.persistence.criteria.CriteriaQuery。为此,可以使用javax.persistence.criteria.CriteriaBuilder上的三种方法之一来完成此操作:
<T> CriteriaQuery<T> createQuery( Class<T> resultClass )CriteriaQuery<Tuple> createTupleQuery()CriteriaQuery<Object> createQuery()
每种查询都有不同的用途,具体取决于查询结果的预期类型。
Note
JPA 规范的第 6 章(即 Criteria API)已经包含了与标准查询各个部分有关的大量参考资料。因此,与其在此处复制所有内容,不如看一下一些更广泛预期的 API 用法。
16.1. 键入条件查询
条件查询的类型(又称<T>)指示查询结果中的预期类型。这可能是一个实体,一个Integer或任何其他对象。
16.2. 选择一个实体
这可能是最常见的查询形式。该应用程序要选择实体实例。
例子 557.选择根实体
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> criteria = builder.createQuery( Person.class );
Root<Person> root = criteria.from( Person.class );
criteria.select( root );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Person> persons = entityManager.createQuery( criteria ).getResultList();
该示例使用createQuery()传递Person类引用,因为查询结果将是Person个对象。
Note
在此示例中,无需调用CriteriaQuery#select方法,因为* root *是隐含的选择,因为我们只有一个查询根。此处仅出于示例完整性的目的进行了此操作。
Person_.name参考是 JPA 元模型参考的静态形式的示例。我们将在本章中专门使用该表格。有关 JPA 静态元模型的更多详细信息,请参见Hibernate JPA 元模型生成器的文档。
16.3. 选择一个表达式
选择表达式的最简单形式是从实体中选择特定属性。但是此表达式也可能表示聚合,math 运算等。
例子 558.选择一个属性
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<String> criteria = builder.createQuery( String.class );
Root<Person> root = criteria.from( Person.class );
criteria.select( root.get( Person_.nickName ) );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<String> nickNames = entityManager.createQuery( criteria ).getResultList();
在此示例中,查询被键入为java.lang.String,因为这是结果的预期类型(Person#nickName属性的类型为java.lang.String)。由于查询可能包含对Person实体的多个引用,因此始终需要对属性引用进行限定。这是通过Root#get方法调用来完成的。
16.4. 选择多个值
实际上,有几种使用条件查询选择多个值的方法。我们将在此处探讨两个选项,但推荐的另一种方法是使用Tuples 条件查询中所述的 Tuples,或考虑包装查询,有关详细信息,请参见选择 Wrapper。
例子 559.选择一个数组
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Object[]> criteria = builder.createQuery( Object[].class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.select( builder.array( idPath, nickNamePath ) );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Object[]> idAndNickNames = entityManager.createQuery( criteria ).getResultList();
从技术上讲,这被归类为类型化查询,但是从处理结果中可以看出,这是一种误导。无论如何,这里的预期结果类型是一个数组。
然后,该示例使用javax.persistence.criteria.CriteriaBuilder的数组方法,该方法将各个选择明确组合为javax.persistence.criteria.CompoundSelection。
例子 560.使用multiselect选择一个数组
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Object[]> criteria = builder.createQuery( Object[].class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.multiselect( idPath, nickNamePath );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Object[]> idAndNickNames = entityManager.createQuery( criteria ).getResultList();
就像在选择一个数组中看到的那样,我们有一个类型化条件查询返回Object数组。这两个查询在功能上是等效的。第二个示例使用multiselect()方法,该方法的行为根据首次构建条件查询时给出的类型而略有不同,但是在这种情况下,它表示选择并返回* Object [] *。
16.5. 选择 Wrapper
选择多个值的另一种选择是改为选择一个将“包装”多个值的对象。回到那里的示例查询,而不是返回* [Person#id,Person#nickName] *的数组,而是声明一个保存这些值的类并将其用作返回对象。
例子 561.选择一个包装器
public class PersonWrapper {
private final Long id;
private final String nickName;
public PersonWrapper(Long id, String nickName) {
this.id = id;
this.nickName = nickName;
}
public Long getId() {
return id;
}
public String getNickName() {
return nickName;
}
}
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<PersonWrapper> criteria = builder.createQuery( PersonWrapper.class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.select( builder.construct( PersonWrapper.class, idPath, nickNamePath ) );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<PersonWrapper> wrappers = entityManager.createQuery( criteria ).getResultList();
首先,我们将看到用于包装结果值的包装对象的简单定义。具体来说,请注意构造函数及其参数类型。由于我们将返回PersonWrapper个对象,因此我们将PersonWrapper作为条件查询的类型。
此示例说明了用于构建包装器表达式的javax.persistence.criteria.CriteriaBuilder方法构造。对于结果中的每一行,我们都希望我们使用匹配的构造函数将PersonWrapper实例化为带有剩余参数的实例。然后将这个包装表达式作为选择传递。
16.6. Tuples 条件查询
选择多个值的更好方法是使用包装器(我们刚刚在选择 Wrapper中看到)或使用javax.persistence.TupleContract。
例子 562.选择一个 Tuples
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteria = builder.createQuery( Tuple.class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.multiselect( idPath, nickNamePath );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Tuple> tuples = entityManager.createQuery( criteria ).getResultList();
for ( Tuple tuple : tuples ) {
Long id = tuple.get( idPath );
String nickName = tuple.get( nickNamePath );
}
//or using indices
for ( Tuple tuple : tuples ) {
Long id = (Long) tuple.get( 0 );
String nickName = (String) tuple.get( 1 );
}
本示例说明了通过javax.persistence.Tuple界面访问查询结果。该示例使用javax.persistence.criteria.CriteriaBuilder的显式createTupleQuery()。另一种方法是使用createQuery( Tuple.class )。
就像使用多选选择阵列一样,我们再次看到multiselect()方法的使用。此处的区别在于javax.persistence.criteria.CriteriaQuery的类型定义为javax.persistence.Tuple,因此在这种情况下,复合选择被解释为 Tuples 元素。
javax.persistence.Tuple 契约提供对底层元素的三种访问方式:
typed
- 选择一个 Tuples示例说明了
tuple.get( idPath )和tuple.get( nickNamePath )调用中的这种访问方式。这允许基于用于构建标准的javax.persistence.TupleElement表达式对基础 Tuples 值进行类型化访问。
- 选择一个 Tuples示例说明了
positional
aliased
- 允许基于(可选)分配的别名访问基础 Tuples 值。示例查询未应用别名。别名将通过
javax.persistence.criteria.Selection上的 alias 方法应用。就像positional访问一样,既有类型化的(* Object get(String alias))和无类型化的( X get(String alias,Class type)*)形式。
- 允许基于(可选)分配的别名访问基础 Tuples 值。示例查询未应用别名。别名将通过
16.7. FROM 子句
CriteriaQuery对象定义对一个或多个实体,可嵌入或基本抽象架构类型的查询。查询的根对象是实体,通过导航可从中访问其他类型。
— JPA 规范,第 6.5.2 节“查询根”,第 262 页
Note
FROM 子句的所有各个部分(根,联接,路径)都实现javax.persistence.criteria.From接口。
16.8. Roots
根定义了查询中所有联接,路径和属性可用的基础。根始终是实体类型。通过重载javax.persistence.criteria.CriteriaQuery上的* from *方法来定义根并将其添加到条件中:
例子 563.根方法
<X> Root<X> from( Class<X> );
<X> Root<X> from( EntityType<X> );
例子 564.添加一个根例子
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> criteria = builder.createQuery( Person.class );
Root<Person> root = criteria.from( Person.class );
条件查询可以定义多个根,其作用是在新添加的根与其他根之间创建笛卡尔乘积。这是定义Person和Partner实体之间的笛卡尔积的示例:
例子 565.添加多个根例子
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteria = builder.createQuery( Tuple.class );
Root<Person> personRoot = criteria.from( Person.class );
Root<Partner> partnerRoot = criteria.from( Partner.class );
criteria.multiselect( personRoot, partnerRoot );
Predicate personRestriction = builder.and(
builder.equal( personRoot.get( Person_.address ), address ),
builder.isNotEmpty( personRoot.get( Person_.phones ) )
);
Predicate partnerRestriction = builder.and(
builder.like( partnerRoot.get( Partner_.name ), prefix ),
builder.equal( partnerRoot.get( Partner_.version ), 0 )
);
criteria.where( builder.and( personRestriction, partnerRestriction ) );
List<Tuple> tuples = entityManager.createQuery( criteria ).getResultList();
16.9. Joins
联接允许从其他javax.persistence.criteria.From导航到关联或嵌入的属性。连接是由javax.persistence.criteria.From接口的许多重载* join *方法创建的。
例子 566.连接例子
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Phone> criteria = builder.createQuery( Phone.class );
Root<Phone> root = criteria.from( Phone.class );
// Phone.person is a @ManyToOne
Join<Phone, Person> personJoin = root.join( Phone_.person );
// Person.addresses is an @ElementCollection
Join<Person, String> addressesJoin = personJoin.join( Person_.addresses );
criteria.where( builder.isNotEmpty( root.get( Phone_.calls ) ) );
List<Phone> phones = entityManager.createQuery( criteria ).getResultList();
16.10. Fetches
就像在 HQL 和 JPQL 中一样,条件查询可以指定与所有者一起提取关联的数据。提取是通过javax.persistence.criteria.From接口的许多重载* fetch *方法创建的。
例子 567.加入获取例子
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Phone> criteria = builder.createQuery( Phone.class );
Root<Phone> root = criteria.from( Phone.class );
// Phone.person is a @ManyToOne
Fetch<Phone, Person> personFetch = root.fetch( Phone_.person );
// Person.addresses is an @ElementCollection
Fetch<Person, String> addressesJoin = personFetch.fetch( Person_.addresses );
criteria.where( builder.isNotEmpty( root.get( Phone_.calls ) ) );
List<Phone> phones = entityManager.createQuery( criteria ).getResultList();
Note
从技术上讲,嵌入属性总是与它们的所有者一起获取。但是,为了定义对* Phone#addresses *的提取,我们需要一个javax.persistence.criteria.Fetch,因为默认情况下元素集合是LAZY。
16.11. 路径表达式
Note
根,联接和访存本身也是路径表达式。
16.12. 使用参数
例子 568.参数例子
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> criteria = builder.createQuery( Person.class );
Root<Person> root = criteria.from( Person.class );
ParameterExpression<String> nickNameParameter = builder.parameter( String.class );
criteria.where( builder.equal( root.get( Person_.nickName ), nickNameParameter ) );
TypedQuery<Person> query = entityManager.createQuery( criteria );
query.setParameter( nickNameParameter, "JD" );
List<Person> persons = query.getResultList();
使用javax.persistence.criteria.CriteriaBuilder的参数方法来获取参数引用。然后使用参数引用将参数值绑定到javax.persistence.Query。
16.13. 使用分组依据
例子 569.按例子分组
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteria = builder.createQuery( Tuple.class );
Root<Person> root = criteria.from( Person.class );
criteria.groupBy(root.get("address"));
criteria.multiselect(root.get("address"), builder.count(root));
List<Tuple> tuples = entityManager.createQuery( criteria ).getResultList();
for ( Tuple tuple : tuples ) {
String name = (String) tuple.get( 0 );
Long count = (Long) tuple.get( 1 );
}
17.本机 SQL 查询
您也可以使用数据库的本地 SQL 方言来表达查询。如果要使用特定于数据库的功能,例如窗口函数,通用表表达式(CTE)或 Oracle 中的CONNECT BY选项,此功能将非常有用。它还提供了从直接基于 SQL/JDBC 的应用程序到 Hibernate/JPA 的干净迁移路径。 Hibernate 还允许您为所有创建,更新,删除和检索操作指定手写 SQL(包括存储过程)。
17.1. 使用 JPA 创建本机查询
本地 SQL 查询的执行是通过NativeQuery接口控制的,该接口是通过调用Session.createNativeQuery()获得的。以下各节介绍如何使用此 API 进行查询。
17.2. 标量查询
最基本的 SQL 查询是获取标量(列)值的列表。
例子 570. JPA 本机查询选择所有列
List<Object[]> persons = entityManager.createNativeQuery(
"SELECT * FROM Person" )
.getResultList();
例子 571.具有自定义列选择的 JPA 本机查询
List<Object[]> persons = entityManager.createNativeQuery(
"SELECT id, name FROM Person" )
.getResultList();
for(Object[] person : persons) {
Number id = (Number) person[0];
String name = (String) person[1];
}
例子 572.休眠本机查询选择所有列
List<Object[]> persons = session.createNativeQuery(
"SELECT * FROM Person" )
.list();
例子 573.带有自定义列选择的休眠本地查询
List<Object[]> persons = session.createNativeQuery(
"SELECT id, name FROM Person" )
.list();
for(Object[] person : persons) {
Number id = (Number) person[0];
String name = (String) person[1];
}
这些将返回List的Object数组(Object[]),其中PERSON表中的每一列都有标量值。 Hibernate 将使用java.sql.ResultSetMetadata来推断返回的标量值的实际 Sequences 和类型。
为了避免使用ResultSetMetadata的开销,或者只是更明确地说明返回的内容,可以使用addScalar():
例子 574.具有显式结果集选择的休眠本机查询
List<Object[]> persons = session.createNativeQuery(
"SELECT * FROM Person" )
.addScalar( "id", LongType.INSTANCE )
.addScalar( "name", StringType.INSTANCE )
.list();
for(Object[] person : persons) {
Long id = (Long) person[0];
String name = (String) person[1];
}
尽管它仍返回Object数组,但此查询将不再使用ResultSetMetadata,因为它显式地从基础ResultSet分别获取id和name列作为BigInteger和String。这也意味着即使查询仍在使用*并且ResultSet包含的列多于三个列出的列,也将仅返回这两列。
可以省略所有或某些标量的类型信息。
例子 575. Hibernate 本地查询的结果集选择是部分显式的
List<Object[]> persons = session.createNativeQuery(
"SELECT * FROM Person" )
.addScalar( "id", LongType.INSTANCE )
.addScalar( "name" )
.list();
for(Object[] person : persons) {
Long id = (Long) person[0];
String name = (String) person[1];
}
这基本上与以前的查询相同,但是现在使用ResultSetMetaData确定name的类型,而明确指定id的类型。
从ResultSetMetaData返回的java.sql.Types如何 Map 到 Hibernate 类型由Dialect控制。如果未 Map 特定类型,或未生成预期类型,则可以通过在方言中调用registerHibernateType对其进行自定义。
17.3. 实体查询
上面的查询都是关于返回标量值的,基本上是从ResultSet返回* raw *值。
例子 576. JPA 本机查询选择实体
List<Person> persons = entityManager.createNativeQuery(
"SELECT * FROM Person", Person.class )
.getResultList();
例子 577.休眠本机查询选择实体
List<Person> persons = session.createNativeQuery(
"SELECT * FROM Person" )
.addEntity( Person.class )
.list();
假设Person被 Map 为具有id,name,nickName,address,createdOn和version列的类,则以下查询还将返回List,其中每个元素都是Person实体。
例子 578. JPA 本机查询选择具有显式结果集的实体
List<Person> persons = entityManager.createNativeQuery(
"SELECT id, name, nickName, address, createdOn, version " +
"FROM Person", Person.class )
.getResultList();
例子 579.休眠的本机查询选择带有显式结果集的实体
List<Person> persons = session.createNativeQuery(
"SELECT id, name, nickName, address, createdOn, version " +
"FROM Person" )
.addEntity( Person.class )
.list();
17.4. 处理关联和集合
如果该实体是通过many-to-one或子端one-to-oneMap 到另一个实体的,则在执行本机查询时还需要返回该实体,否则,将发生数据库特定的“未找到列”错误。
例子 580. JPA 本机查询选择具有多对一关联的实体
List<Phone> phones = entityManager.createNativeQuery(
"SELECT id, phone_number, phone_type, person_id " +
"FROM Phone", Phone.class )
.getResultList();
例子 581.休眠本机查询选择具有多对一关联的实体
List<Phone> phones = session.createNativeQuery(
"SELECT id, phone_number, phone_type, person_id " +
"FROM Phone" )
.addEntity( Phone.class )
.list();
这将使Phone#person正常运行,因为many-to-one或one-to-one关联将使用将在首次导航时初始化的代理。
可以热切地加入Phone和Person实体,以避免可能的额外往返来初始化many-to-one关联。
例子 582.休眠的本机查询选择具有多对一关联的实体
List<Object[]> tuples = session.createNativeQuery(
"SELECT * " +
"FROM Phone ph " +
"JOIN Person pr ON ph.person_id = pr.id" )
.addEntity("phone", Phone.class )
.addJoin( "pr", "phone.person")
.list();
for(Object[] tuple : tuples) {
Phone phone = (Phone) tuple[0];
Person person = (Person) tuple[1];
assertNotNull( person.getName() );
}
SELECT
*
FROM
Phone ph
JOIN
Person pr
ON ph.person_id = pr.id
Note
从关联的 SQL 查询中可以看出,Hibernate 无需任何额外的数据库往返就可以构造实体层次结构。
默认情况下,使用addJoin()方法时,结果集将包含两个连接的实体。要构建实体层次结构,您需要使用ROOT_ENTITY或DISTINCT_ROOT_ENTITY ResultTransformer。
例子 583.休眠的本机查询选择具有多对一关联和ResultTransformer的实体
List<Person> persons = session.createNativeQuery(
"SELECT * " +
"FROM Phone ph " +
"JOIN Person pr ON ph.person_id = pr.id" )
.addEntity("phone", Phone.class )
.addJoin( "pr", "phone.person")
.setResultTransformer( Criteria.ROOT_ENTITY )
.list();
for(Person person : persons) {
person.getPhones();
}
Note
由于ROOT_ENTITY ResultTransformer,上述查询将返回父级作为根实体。
请注意,您添加了别名* pr *,以便能够指定联接的目标属性路径。可以对集合(例如Phone#calls one-to-many关联)进行相同的热切加入。
例子 584. JPA 本机查询选择具有一对多关联的实体
List<Phone> phones = entityManager.createNativeQuery(
"SELECT * " +
"FROM Phone ph " +
"JOIN phone_call c ON c.phone_id = ph.id", Phone.class )
.getResultList();
for(Phone phone : phones) {
List<Call> calls = phone.getCalls();
}
SELECT *
FROM phone ph
JOIN call c ON c.phone_id = ph.id
例子 585.休眠的本机查询选择具有一对多关联的实体
List<Object[]> tuples = session.createNativeQuery(
"SELECT * " +
"FROM Phone ph " +
"JOIN phone_call c ON c.phone_id = ph.id" )
.addEntity("phone", Phone.class )
.addJoin( "c", "phone.calls")
.list();
for(Object[] tuple : tuples) {
Phone phone = (Phone) tuple[0];
Call call = (Call) tuple[1];
}
SELECT *
FROM phone ph
JOIN call c ON c.phone_id = ph.id
在此阶段,您正在达到本机查询所能达到的极限,而没有开始增强 SQL 查询以使其在 Hibernate 中可用。返回多个相同类型的实体或默认别名/列名称不够用时,可能会出现问题。
17.5. 返回多个实体
到目前为止,假定结果集的列名与 Map 文档中指定的列名相同。对于连接多个表的 SQL 查询,这可能会出现问题,因为相同的列名可能出现在多个表中。
以下查询需要列别名注入,否则将抛出NonUniqueDiscoveredSqlAliasException。
例子 586. JPA 本机查询选择具有相同列名的实体
List<Object> entities = entityManager.createNativeQuery(
"SELECT * " +
"FROM Person pr, Partner pt " +
"WHERE pr.name = pt.name" )
.getResultList();
例子 587. Hibernate 本机查询选择具有相同列名的实体
List<Object> entities = session.createNativeQuery(
"SELECT * " +
"FROM Person pr, Partner pt " +
"WHERE pr.name = pt.name" )
.list();
该查询旨在返回所有具有相同名称的Person和Partner实例。由于两个实体 Map 到相同的列名(例如id,name,version),因此名称冲突导致查询失败。同样,在某些数据库上,返回的列别名很可能采用pr.id,pr.name等形式,它们不等于 Map 中指定的列(id和name)。
以下形式不易受到列名重复的影响:
例子 588.休眠本机查询选择具有相同列名和别名的实体
List<Object> entities = session.createNativeQuery(
"SELECT {pr.*}, {pt.*} " +
"FROM Person pr, Partner pt " +
"WHERE pr.name = pt.name" )
.addEntity( "pr", Person.class)
.addEntity( "pt", Partner.class)
.list();
Note
JPA 中没有这样的等效项,因为javax.persistence.Query接口没有定义等效的addEntity方法。
上面使用的{pr.} 和{pt. }表示法是“所有属性”的简写。另外,您可以显式列出这些列,但是即使在这种情况下,Hibernate 也会为每个属性注入 SQL 列别名。列别名的占位符只是表别名限定的属性名称。
17.6. 别名和属性参考
在大多数情况下,需要上述别名注入。对于与更复杂的 Map 有关的查询,例如复合属性,继承标识符,集合等,可以使用允许 Hibernate 注入适当别名的特定别名。
下表显示了可以使用别名注入的不同方式。请注意,结果中的别名仅是示例,使用时每个别名将具有唯一且可能不同的名称。
表 9.别名注入名称
| Description | Syntax | Example |
|---|---|---|
| 一个简单的属性 | {[aliasname].[propertyname]} |
A_NAME as {item.name} |
| 复合属性 | {[aliasname].[componentname].[propertyname]} |
CURRENCY as {item.amount.currency}, VALUE as {item.amount.value} |
| 实体的歧视者 | {[aliasname].class} |
DISC as {item.class} |
| 实体的所有属性 | {[aliasname].*} |
{item.*} |
| 收集钥匙 | {[aliasname].key} |
ORGID as {coll.key} |
| 集合的 ID | {[aliasname].id} |
EMPID as {coll.id} |
| 集合的元素 | {[aliasname].element} |
XID as {coll.element} |
| 集合中元素的属性 | {[aliasname].element.[propertyname]} |
NAME as {coll.element.name} |
| 集合中元素的所有属性 | {[aliasname].element.*} |
{coll.element.*} |
| 集合的所有属性 | {[aliasname].*} |
{coll.*} |
17.7. 返回的 DTO(数据传输对象)
可以将ResultTransformer应用于本机 SQL 查询,从而允许其返回非托管实体。
例子 589.休眠本机查询选择 DTO
public class PersonSummaryDTO {
private Number id;
private String name;
//Getters and setters are omitted for brevity
public Number getId() {
return id;
}
public void setId(Number id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
List<PersonSummaryDTO> dtos = session.createNativeQuery(
"SELECT p.id as \"id\", p.name as \"name\" " +
"FROM Person p")
.setResultTransformer( Transformers.aliasToBean( PersonSummaryDTO.class ) )
.list();
Note
JPA 中没有此类等效项,因为javax.persistence.Query接口未定义setResultTransformer方法等效项。
上面的查询将返回已实例化的PersonSummaryDTO列表,并将id和name的值注入其相应的属性或字段中。
17.8. 处理继承
查询作为继承的一部分 Map 的实体的本机 SQL 查询必须包含 Base Class 及其所有子类的所有属性。
例子 590.休眠本机查询选择子类
List<CreditCardPayment> payments = session.createNativeQuery(
"SELECT * " +
"FROM Payment p " +
"JOIN CreditCardPayment cp on cp.id = p.id" )
.addEntity( CreditCardPayment.class )
.list();
Note
JPA 中没有这样的等效项,因为javax.persistence.Query接口没有定义等效的addEntity方法。
17.9. Parameters
本机 SQL 查询支持位置参数和命名参数:
例子 591.带参数的 JPA 本机查询
List<Person> persons = entityManager.createNativeQuery(
"SELECT * " +
"FROM Person " +
"WHERE name like :name", Person.class )
.setParameter("name", "J%")
.getResultList();
例子 592.带参数的休眠本机查询
List<Person> persons = session.createNativeQuery(
"SELECT * " +
"FROM Person " +
"WHERE name like :name" )
.addEntity( Person.class )
.setParameter("name", "J%")
.list();
17.10. 命名 SQL 查询
还可以在 Map 期间定义命名 SQL 查询,并以与命名 HQL 查询完全相同的方式进行调用。在这种情况下,您无需再致电addEntity()。
JPA 为此定义了javax.persistence.NamedNativeQuery注解,而 Hibernate org.hibernate.annotations.NamedNativeQuery注解对其进行了扩展并添加了以下属性:
flushMode()- 查询的刷新模式。默认情况下,它使用当前的持久性上下文刷新模式。
cacheable()- 查询(结果)是否可缓存。默认情况下,不缓存查询。
cacheRegion()- 如果查询结果是可缓存的,请命名要使用的查询缓存区域。
fetchSize()- JDBC 驱动程序每次数据库行程获取的行数。缺省值由 JDBC 驱动程序提供。
timeout()- 查询超时(以秒为单位)。默认情况下,没有超时。
callable()- SQL 查询是否表示对过程/函数的调用?默认为 false。
comment()- 添加到 SQL 查询中的 Comments,用于调整执行计划。
cacheMode()- 用于此查询的缓存模式。这是指查询返回的实体/集合。默认值为
CacheModeType.NORMAL。
- 用于此查询的缓存模式。这是指查询返回的实体/集合。默认值为
readOnly()- 结果是否应为只读。默认情况下,查询不是只读的,因此实体存储在持久性上下文中。
17.10.1. 选择标量值的命名 SQL 查询
要获取给定表的单个列,命名查询如下所示:
例子 593.单标量值NamedNativeQuery
@NamedNativeQuery(
name = "find_person_name",
query =
"SELECT name " +
"FROM Person "
),
例子 594. JPA 命名本机查询选择一个标量值
List<String> names = entityManager.createNamedQuery(
"find_person_name" )
.getResultList();
例子 595. Hibernate 命名本机查询选择一个标量值
List<String> names = session.getNamedQuery(
"find_person_name" )
.list();
选择多个标量值是这样完成的:
例子 596.多个标量值NamedNativeQuery
@NamedNativeQuery(
name = "find_person_name_and_nickName",
query =
"SELECT " +
" name, " +
" nickName " +
"FROM Person "
),
在不指定显式结果类型的情况下,Hibernate 将采用Object数组:
例子 597. JPA 命名本机查询选择多个标量值
List<Object[]> tuples = entityManager.createNamedQuery(
"find_person_name_and_nickName" )
.getResultList();
for(Object[] tuple : tuples) {
String name = (String) tuple[0];
String nickName = (String) tuple[1];
}
例子 598. Hibernate 命名本机查询选择多个标量值
List<Object[]> tuples = session.getNamedQuery(
"find_person_name_and_nickName" )
.list();
for(Object[] tuple : tuples) {
String name = (String) tuple[0];
String nickName = (String) tuple[1];
}
可以使用 DTO 存储结果标量值:
例子 599. DTO 存储多个标量值
public class PersonNames {
private final String name;
private final String nickName;
public PersonNames(String name, String nickName) {
this.name = name;
this.nickName = nickName;
}
public String getName() {
return name;
}
public String getNickName() {
return nickName;
}
}
例子 600.多个标量值NamedNativeQuery和ConstructorResult
@NamedNativeQuery(
name = "find_person_name_and_nickName_dto",
query =
"SELECT " +
" name, " +
" nickName " +
"FROM Person ",
resultSetMapping = "name_and_nickName_dto"
),
@SqlResultSetMapping(
name = "name_and_nickName_dto",
classes = @ConstructorResult(
targetClass = PersonNames.class,
columns = {
@ColumnResult(name = "name"),
@ColumnResult(name = "nickName")
}
)
)
例子 601. JPA 命名本机查询将多个标量值选择到 DTO 中
List<PersonNames> personNames = entityManager.createNamedQuery(
"find_person_name_and_nickName_dto" )
.getResultList();
例子 602.休眠的命名本机查询选择多个标量值到 DTO 中
List<PersonNames> personNames = session.getNamedQuery(
"find_person_name_and_nickName_dto" )
.list();
您还可以使用@NamedNativeQuery Hibernate 注解通过各种配置(例如访存模式,可缓存性,超时间隔)来自定义命名查询。
例子 603.使用ConstructorResult和 Hibernate NamedNativeQuery的多个标量值
@NamedNativeQueries({
@NamedNativeQuery(
name = "get_person_phone_count",
query = "SELECT pr.name AS name, count(*) AS phoneCount " +
"FROM Phone p " +
"JOIN Person pr ON pr.id = p.person_id " +
"GROUP BY pr.name",
resultSetMapping = "person_phone_count",
timeout = 1,
readOnly = true
),
})
@SqlResultSetMapping(
name = "person_phone_count",
classes = @ConstructorResult(
targetClass = PersonPhoneCount.class,
columns = {
@ColumnResult(name = "name"),
@ColumnResult(name = "phoneCount")
}
)
)
例子 604.休眠NamedNativeQuery命名本机查询,将多个标量值选择到 DTO 中
List<PersonPhoneCount> personNames = session.getNamedNativeQuery(
"get_person_phone_count")
.getResultList();
17.10.2. 命名 SQL 查询选择实体
考虑以下命名查询:
例子 605.单一实体NamedNativeQuery
@NamedNativeQuery(
name = "find_person_by_name",
query =
"SELECT " +
" p.id AS \"id\", " +
" p.name AS \"name\", " +
" p.nickName AS \"nickName\", " +
" p.address AS \"address\", " +
" p.createdOn AS \"createdOn\", " +
" p.version AS \"version\" " +
"FROM Person p " +
"WHERE p.name LIKE :name",
resultClass = Person.class
),
结果集 Map 声明此本地查询检索的实体。实体的每个字段都绑定到一个 SQL 别名(或列名)。实体的所有字段(包括子类和相关实体的外键列)都必须存在于 SQL 查询中。字段定义是可选的,只要它们 Map 到与在 class 属性上声明的列名称相同的列名即可。
可以按以下步骤执行此命名的本机查询:
例子 606. JPA 命名本机实体查询
List<Person> persons = entityManager.createNamedQuery(
"find_person_by_name" )
.setParameter("name", "J%")
.getResultList();
例子 607.休眠命名本机实体查询
List<Person> persons = session.getNamedQuery(
"find_person_by_name" )
.setParameter("name", "J%")
.list();
要连接多个实体,您需要为要查询 SQL 的每个实体使用SqlResultSetMapping。
例子 608.联合实体NamedNativeQuery
@NamedNativeQuery(
name = "find_person_with_phones_by_name",
query =
"SELECT " +
" pr.id AS \"pr.id\", " +
" pr.name AS \"pr.name\", " +
" pr.nickName AS \"pr.nickName\", " +
" pr.address AS \"pr.address\", " +
" pr.createdOn AS \"pr.createdOn\", " +
" pr.version AS \"pr.version\", " +
" ph.id AS \"ph.id\", " +
" ph.person_id AS \"ph.person_id\", " +
" ph.phone_number AS \"ph.number\", " +
" ph.phone_type AS \"ph.type\" " +
"FROM Person pr " +
"JOIN Phone ph ON pr.id = ph.person_id " +
"WHERE pr.name LIKE :name",
resultSetMapping = "person_with_phones"
)
@SqlResultSetMapping(
name = "person_with_phones",
entities = {
@EntityResult(
entityClass = Person.class,
fields = {
@FieldResult( name = "id", column = "pr.id" ),
@FieldResult( name = "name", column = "pr.name" ),
@FieldResult( name = "nickName", column = "pr.nickName" ),
@FieldResult( name = "address", column = "pr.address" ),
@FieldResult( name = "createdOn", column = "pr.createdOn" ),
@FieldResult( name = "version", column = "pr.version" ),
}
),
@EntityResult(
entityClass = Phone.class,
fields = {
@FieldResult( name = "id", column = "ph.id" ),
@FieldResult( name = "person", column = "ph.person_id" ),
@FieldResult( name = "number", column = "ph.number" ),
@FieldResult( name = "type", column = "ph.type" ),
}
)
}
),
例子 609.具有联合关联的 JPA 命名本机实体查询
List<Object[]> tuples = entityManager.createNamedQuery(
"find_person_with_phones_by_name" )
.setParameter("name", "J%")
.getResultList();
for(Object[] tuple : tuples) {
Person person = (Person) tuple[0];
Phone phone = (Phone) tuple[1];
}
例子 610.带有联合关联的休眠命名本机实体查询
List<Object[]> tuples = session.getNamedQuery(
"find_person_with_phones_by_name" )
.setParameter("name", "J%")
.list();
for(Object[] tuple : tuples) {
Person person = (Person) tuple[0];
Phone phone = (Phone) tuple[1];
}
最后,如果与相关实体的关联涉及复合主键,则应将@FieldResult元素用于每个外键列。 @FieldResult名称由关系的属性名称,后跟点(“.”),后跟名称或主键的字段或属性组成。对于此示例,将使用以下实体:
例子 611.具有复合键和命名本机查询的实体关联
@Embeddable
public class Dimensions {
private int length;
private int width;
//Getters and setters are omitted for brevity
}
@Embeddable
public class Identity implements Serializable {
private String firstname;
private String lastname;
//Getters and setters are omitted for brevity
public boolean equals(Object o) {
if ( this == o ) return true;
if ( o == null || getClass() != o.getClass() ) return false;
final Identity identity = (Identity) o;
if ( !firstname.equals( identity.firstname ) ) return false;
if ( !lastname.equals( identity.lastname ) ) return false;
return true;
}
public int hashCode() {
int result;
result = firstname.hashCode();
result = 29 * result + lastname.hashCode();
return result;
}
}
@Entity
public class Captain {
@EmbeddedId
private Identity id;
//Getters and setters are omitted for brevity
}
@Entity
@NamedNativeQueries({
@NamedNativeQuery(name = "find_all_spaceships",
query =
"SELECT " +
" name as \"name\", " +
" model, " +
" speed, " +
" lname as lastn, " +
" fname as firstn, " +
" length, " +
" width, " +
" length * width as surface, " +
" length * width * 10 as volume " +
"FROM SpaceShip",
resultSetMapping = "spaceship"
)
})
@SqlResultSetMapping(
name = "spaceship",
entities = @EntityResult(
entityClass = SpaceShip.class,
fields = {
@FieldResult(name = "name", column = "name"),
@FieldResult(name = "model", column = "model"),
@FieldResult(name = "speed", column = "speed"),
@FieldResult(name = "captain.lastname", column = "lastn"),
@FieldResult(name = "captain.firstname", column = "firstn"),
@FieldResult(name = "dimensions.length", column = "length"),
@FieldResult(name = "dimensions.width", column = "width"),
}
),
columns = {
@ColumnResult(name = "surface"),
@ColumnResult(name = "volume")
}
)
public class SpaceShip {
@Id
private String name;
private String model;
private double speed;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumns({
@JoinColumn(name = "fname", referencedColumnName = "firstname"),
@JoinColumn(name = "lname", referencedColumnName = "lastname")
})
private Captain captain;
private Dimensions dimensions;
//Getters and setters are omitted for brevity
}
例子 612. JPA 命名本机实体查询,具有连接的关联和组合键
List<Object[]> tuples = entityManager.createNamedQuery(
"find_all_spaceships" )
.getResultList();
for(Object[] tuple : tuples) {
SpaceShip spaceShip = (SpaceShip) tuple[0];
Number surface = (Number) tuple[1];
Number volume = (Number) tuple[2];
}
例子 613. Hibernate 命名本机实体查询,具有联接和组合键
List<Object[]> tuples = session.getNamedQuery(
"find_all_spaceships" )
.list();
for(Object[] tuple : tuples) {
SpaceShip spaceShip = (SpaceShip) tuple[0];
Number surface = (Number) tuple[1];
Number volume = (Number) tuple[2];
}
17.11. 在本机 SQL 查询中解析全局编录和架构
当使用多个数据库目录和模式时,Hibernate 提供了设置全局目录或模式的可能性,这样您就不必为每个实体都明确地声明它。
例子 614.设置全局目录和模式
<property name="hibernate.default_catalog" value="crm"/>
<property name="hibernate.default_schema" value="analytics"/>
这样,我们可以在每个 JPQL,HQL 或 Criteria API 查询中隐含全局 crm 目录和 analytics 模式。
但是,对于本机查询,SQL 查询将按原样传递,因此,每当引用数据库表时,都需要显式设置全局编录和架构。幸运的是,Hibernate 允许您使用以下占位符解析当前的全局目录和架构:
{h-catalog}
- 解析当前的
hibernate.default_catalog配置属性值。
- 解析当前的
{h-schema}
- 解析当前的
hibernate.default_schema配置属性值。
- 解析当前的
{h-domain}
- 解析当前的
hibernate.default_catalog和hibernate.default_schema配置属性值(例如 catalog.schema)。
- 解析当前的
使用这些占位符,您可以隐含每个本机查询的目录,架构,或者隐含目录和架构。
因此,在运行以下本机查询时:
@NamedNativeQuery(
name = "last_30_days_hires",
query =
"select * " +
"from {h-domain}person " +
"where age(hired_on) < '30 days'",
resultClass = Person.class
)
Hibernate 将根据默认目录和架构的值来解析{h-domain}占位符:
SELECT *
FROM crm.analytics.person
WHERE age(hired_on) < '30 days'
17.12. 使用存储过程进行查询
Hibernate 通过存储过程和功能为查询提供支持。存储过程参数使用IN参数类型声明,结果可以用OUT参数类型REF_CURSOR标记,也可以像函数一样返回结果。
例子 615.具有OUT参数类型的 MySQL 存储过程
statement.executeUpdate(
"CREATE PROCEDURE sp_count_phones (" +
" IN personId INT, " +
" OUT phoneCount INT " +
") " +
"BEGIN " +
" SELECT COUNT(*) INTO phoneCount " +
" FROM Phone p " +
" WHERE p.person_id = personId; " +
"END"
);
要使用此存储过程,可以执行以下 JPA 2.1 查询:
例子 616.使用 JPA 调用具有OUT参数类型的 MySQL 存储过程
StoredProcedureQuery query = entityManager.createStoredProcedureQuery( "sp_count_phones");
query.registerStoredProcedureParameter( "personId", Long.class, ParameterMode.IN);
query.registerStoredProcedureParameter( "phoneCount", Long.class, ParameterMode.OUT);
query.setParameter("personId", 1L);
query.execute();
Long phoneCount = (Long) query.getOutputParameterValue("phoneCount");
例子 617.使用 Hibernate 调用具有OUT参数类型的 MySQL 存储过程
Session session = entityManager.unwrap( Session.class );
ProcedureCall call = session.createStoredProcedureCall( "sp_count_phones" );
call.registerParameter( "personId", Long.class, ParameterMode.IN ).bindValue( 1L );
call.registerParameter( "phoneCount", Long.class, ParameterMode.OUT );
Long phoneCount = (Long) call.getOutputs().getOutputParameterValue( "phoneCount" );
assertEquals( Long.valueOf( 2 ), phoneCount );
如果存储过程直接输出结果而没有OUT参数类型:
例子 618.没有OUT参数类型的 MySQL 存储过程
statement.executeUpdate(
"CREATE PROCEDURE sp_phones(IN personId INT) " +
"BEGIN " +
" SELECT * " +
" FROM Phone " +
" WHERE person_id = personId; " +
"END"
);
您可以按以下方式检索上述 MySQL 存储过程的结果:
例子 619.使用 JPA 调用 MySQL 存储过程并获取没有OUT参数类型的结果集
StoredProcedureQuery query = entityManager.createStoredProcedureQuery( "sp_phones");
query.registerStoredProcedureParameter( 1, Long.class, ParameterMode.IN);
query.setParameter(1, 1L);
List<Object[]> personComments = query.getResultList();
例子 620.调用 MySQL 存储过程并使用 Hibernate 来获取没有OUT参数类型的结果集
Session session = entityManager.unwrap( Session.class );
ProcedureCall call = session.createStoredProcedureCall( "sp_phones" );
call.registerParameter( 1, Long.class, ParameterMode.IN ).bindValue( 1L );
Output output = call.getOutputs().getCurrent();
List<Object[]> personComments = ( (ResultSetOutput) output ).getResultList();
对于REF_CURSOR个结果集,我们将考虑以下 Oracle 存储过程:
例子 621. Oracle REF_CURSOR存储过程
statement.executeUpdate(
"CREATE OR REPLACE PROCEDURE sp_person_phones ( " +
" personId IN NUMBER, " +
" personPhones OUT SYS_REFCURSOR ) " +
"AS " +
"BEGIN " +
" OPEN personPhones FOR " +
" SELECT *" +
" FROM phone " +
" WHERE person_id = personId; " +
"END;"
);
Tip
REF_CURSOR结果集仅受某些关系数据库(例如 Oracle 和 PostgreSQL)支持,而其他数据库系统 JDBC 驱动程序可能不支持此功能。
可以使用标准的 Java Persistence API 调用此函数:
例子 622.使用 JPA 调用 Oracle REF_CURSOR存储过程
StoredProcedureQuery query = entityManager.createStoredProcedureQuery( "sp_person_phones" );
query.registerStoredProcedureParameter( 1, Long.class, ParameterMode.IN );
query.registerStoredProcedureParameter( 2, Class.class, ParameterMode.REF_CURSOR );
query.setParameter( 1, 1L );
query.execute();
List<Object[]> postComments = query.getResultList();
例子 623.使用 Hibernate 调用 Oracle REF_CURSOR存储过程
Session session = entityManager.unwrap(Session.class);
ProcedureCall call = session.createStoredProcedureCall( "sp_person_phones");
call.registerParameter(1, Long.class, ParameterMode.IN).bindValue(1L);
call.registerParameter(2, Class.class, ParameterMode.REF_CURSOR);
Output output = call.getOutputs().getCurrent();
List<Object[]> postComments = ( (ResultSetOutput) output ).getResultList();
assertEquals(2, postComments.size());
如果数据库定义了 SQL 函数:
例子 624. MySQL 函数
statement.executeUpdate(
"CREATE FUNCTION fn_count_phones(personId integer) " +
"RETURNS integer " +
"DETERMINISTIC " +
"READS SQL DATA " +
"BEGIN " +
" DECLARE phoneCount integer; " +
" SELECT COUNT(*) INTO phoneCount " +
" FROM Phone p " +
" WHERE p.person_id = personId; " +
" RETURN phoneCount; " +
"END"
);
由于当前的StoredProcedureQuery实现尚不支持 SQL 函数,因此我们需要使用 JDBC 语法。
Note
此限制已得到确认,并将通过HHH-10530问题解决。
例子 625.调用一个 MySQL 函数
final AtomicReference<Integer> phoneCount = new AtomicReference<>();
Session session = entityManager.unwrap( Session.class );
session.doWork( connection -> {
try (CallableStatement function = connection.prepareCall(
"{ ? = call fn_count_phones(?) }" )) {
function.registerOutParameter( 1, Types.INTEGER );
function.setInt( 2, 1 );
function.execute();
phoneCount.set( function.getInt( 1 ) );
}
} );
Note
存储过程查询不能以setFirstResult()/setMaxResults()进行分页。
由于这些服务器可以返回多个结果集和更新计数,因此 Hibernate 将迭代结果并将结果集的第一个结果作为其返回值,因此其他所有内容都将被丢弃。
对于 SQL Server,如果可以在过程中启用SET NOCOUNT ON,则效率可能更高,但这不是必需的。
17.13. 使用命名查询来调用存储过程
就像使用 SQL 语句一样,您也可以使用命名查询来调用存储过程。为此,JPA 定义了@NamedStoredProcedureQueryComments。
例子 626. Oracle REF_CURSOR命名查询存储过程
@NamedStoredProcedureQueries(
@NamedStoredProcedureQuery(
name = "sp_person_phones",
procedureName = "sp_person_phones",
parameters = {
@StoredProcedureParameter(
name = "personId",
type = Long.class,
mode = ParameterMode.IN
),
@StoredProcedureParameter(
name = "personPhones",
type = Class.class,
mode = ParameterMode.REF_CURSOR
)
}
)
)
调用此存储过程很简单,如以下示例所示。
例子 627.使用名为 JPA 的查询调用 Oracle REF_CURSOR存储过程
List<Object[]> postComments = entityManager
.createNamedStoredProcedureQuery( "sp_person_phones" )
.setParameter( "personId", 1L )
.getResultList();
17.14. 用于 CRUD 的自定义 SQL(创建,读取,更新和删除)
Hibernate 可以将自定义 SQL 用于 CRUD 操作。可以在语句级别或单个列级别覆盖 SQL。本节描述语句替代。有关列,请参见列转换器:读取和写入表达式。
下面的示例演示如何使用 Comments 定义自定义 SQL 操作。 @SQLInsert,@SQLUpdate和@SQLDelete覆盖给定实体的 INSERT,UPDATE,DELETE 语句。对于 SELECT 子句,必须定义@Loader以及用于加载基础表记录的@NamedNativeQuery。
对于集合,Hibernate 允许定义一个自定义@SQLDeleteAll,该自定义@SQLDeleteAll用于删除与给定父实体关联的所有子记录。为了过滤集合,@WhereComments 允许自定义基础 SQL WHERE 子句。
例子 628.自定义 CRUD
@Entity(name = "Person")
@SQLInsert(
sql = "INSERT INTO person (name, id, valid) VALUES (?, ?, true) ",
check = ResultCheckStyle.COUNT
)
@SQLUpdate(
sql = "UPDATE person SET name = ? where id = ? "
)
@SQLDelete(
sql = "UPDATE person SET valid = false WHERE id = ? "
)
@Loader(namedQuery = "find_valid_person")
@NamedNativeQueries({
@NamedNativeQuery(
name = "find_valid_person",
query = "SELECT id, name " +
"FROM person " +
"WHERE id = ? and valid = true",
resultClass = Person.class
)
})
public static class Person {
@Id
@GeneratedValue
private Long id;
private String name;
@ElementCollection
@SQLInsert(
sql = "INSERT INTO person_phones (person_id, phones, valid) VALUES (?, ?, true) ")
@SQLDeleteAll(
sql = "UPDATE person_phones SET valid = false WHERE person_id = ?")
@Where( clause = "valid = true" )
private List<String> phones = new ArrayList<>();
//Getters and setters are omitted for brevity
}
在上面的示例中,Map 了实体,以便条目被软删除(记录不会从数据库中删除,而是用一个标志标记行的有效性)。 Person实体受益于自定义 INSERT,UPDATE 和 DELETE 语句,这些语句将相应地更新valid列。自定义@Loader仅用于检索有效的Person行。
phones集合也是如此。每当修改集合时,都会使用@SQLDeleteAll和SQLInsert查询。
Note
您还可以使用自定义 CRUD 语句调用存储过程。唯一的要求是将callable属性设置为true。
为了检查执行是否正确,Hibernate 允许您定义以下三种策略之一:
none:不执行任何检查;存储过程应在违反约束时失败。
count:使用
executeUpdate()方法调用返回的行计数来检查更新是否成功。参数:类似于 count,但使用
CallableStatement输出参数。
要定义结果检查样式,请使用check参数。
Tip
参数 Sequences 很重要,并且由 Hibernate 处理属性的 Sequences 定义。您可以通过启用调试日志记录来查看预期的 Sequences,因此 Hibernate 可以打印出用于创建,更新和删除实体的静态 SQL。
要查看预期的 Sequences,请记住不要通过 Comments 或 Map 文件包括您的自定义 SQL,因为这将覆盖 Hibernate 生成的静态 SQL。
也可以使用@org.hibernate.annotations.Table和sqlInsert,sqlUpdate,sqlDelete属性来覆盖辅助表的 SQL 语句。
例 629.覆盖辅助表的 SQL 语句
@Entity(name = "Person")
@Table(name = "person")
@SQLInsert(
sql = "INSERT INTO person (name, id, valid) VALUES (?, ?, true) "
)
@SQLDelete(
sql = "UPDATE person SET valid = false WHERE id = ? "
)
@SecondaryTable(name = "person_details",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "person_id"))
@org.hibernate.annotations.Table(
appliesTo = "person_details",
sqlInsert = @SQLInsert(
sql = "INSERT INTO person_details (image, person_id, valid) VALUES (?, ?, true) ",
check = ResultCheckStyle.COUNT
),
sqlDelete = @SQLDelete(
sql = "UPDATE person_details SET valid = false WHERE person_id = ? "
)
)
@Loader(namedQuery = "find_valid_person")
@NamedNativeQueries({
@NamedNativeQuery(
name = "find_valid_person",
query = "SELECT " +
" p.id, " +
" p.name, " +
" pd.image " +
"FROM person p " +
"LEFT OUTER JOIN person_details pd ON p.id = pd.person_id " +
"WHERE p.id = ? AND p.valid = true AND pd.valid = true",
resultClass = Person.class
)
})
public static class Person {
@Id
@GeneratedValue
private Long id;
private String name;
@Column(name = "image", table = "person_details")
private byte[] image;
//Getters and setters are omitted for brevity
}
Tip
SQL 是直接在数据库中执行的,因此您可以使用任何喜欢的方言。但是,如果使用特定于数据库的 SQL,这将降低 Map 的可移植性。
您还可以使用存储过程来自定义 CRUD 语句。
假设以下存储过程:
例子 630. Oracle 存储过程软删除一个给定的实体
statement.executeUpdate(
"CREATE OR REPLACE PROCEDURE sp_delete_person ( " +
" personId IN NUMBER ) " +
"AS " +
"BEGIN " +
" UPDATE person SET valid = 0 WHERE id = personId; " +
"END;"
);}
实体可以使用此存储过程来软删除有问题的实体:
例 631.自定义实体 delete 语句以使用 Oracle 存储过程=
@SQLDelete(
sql = "{ call sp_delete_person( ? ) } ",
callable = true
)
Note
使用存储过程而不是 SQL 语句时,需要设置callable属性。
18. Spatial
18.1. Overview
Hibernate Spatial 最初是作为 Hibernate 的通用扩展而开发的,用于处理地理数据。从 5.0 开始,Hibernate Spatial 现在已成为 Hibernate ORM 项目的一部分,它使您能够以标准化方式处理地理数据。
Hibernate Spatial 为地理数据存储和查询功能提供了标准化的跨数据库接口。它支持 OGC 简单功能规范中描述的大多数功能。支持的数据库是 Oracle 10g/11g,PostgreSQL/PostGIS,MySQL,Microsoft SQL Server 和 H2/GeoDB。
空间数据类型不是 Java 标准库的一部分,而 JDBC 规范中却没有。多年来,JTS出现了事实上标准以填补这一空白。 JTS 是简单功能规范(SFS)的实现。另一方面,许多数据库都实现了 SQL/MM-第 3 部分:空间数据规范-相关但范围更广的规范。最大的区别是 SFS 限于投影平面中的 2D 几何形状(尽管 JTS 支持 3D 坐标),而 SQL/MM 支持 2、3 或 4 维坐标空间。
Hibernate Spatial 支持两种不同的几何模型:JTS和geolatte-geom。如前所述,JTS 是事实上的标准。 Geolatte-geom(也由 Hibernate Spatial 的首席开发人员编写)是一个更新的库,它支持 SQL/MM 中指定的许多功能,但 JTS 中不可用(例如,对 4D 几何的支持以及对扩展的 WKT/WKB 格式的支持)。 。 Geolatte-geom 还为数据库本机类型实现了编码器/解码器。 Geolatte-geom 与 JTS 具有良好的互操作性。例如,将 Geolatte geometry转换为 JTS`几何不需要复制坐标。它还将空间处理委托给 JTS。
无论您使用 JTS 还是 Geolatte-geom,Hibernate 空间都会将数据库空间类型 Map 到您选择的几何模型。但是,它将始终使用 Geolatte-geom 来解码数据库本机类型。
Hibernate Spatial 还使 HQL 和 Criteria Query API 中提供了许多空间功能。这些函数在 SQL/MM 中都指定为 SFS,并且通常在具有空间支持的数据库中实现(请参见Hibernate Spatial 方言功能支持)
18.2. Configuration
Hibernate Spatial 需要一些配置才能开始使用它。
18.2.1. Dependency
您需要在构建环境中包括hibernate-spatial依赖项。对于 Maven,您需要添加以下依赖项:
例子 632. Maven 依赖
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-spatial</artifactId>
<version>${hibernate.version}</version>
</dependency>
18.2.2. Dialects
Hibernate Spatial 扩展了 Hibernate ORM 方言,以便在 HQL 和 JPQL 中可以使用数据库的空间功能。因此,例如,我们不使用PostgreSQL82Dialect,而是使用该方言的 Hibernate SpatialextensionsPostgisDialect。
例子 633.指定空间方言
<property
name="hibernate.dialect"
value="org.hibernate.spatial.dialect.postgis.PostgisDialect"
/>
并非所有数据库都支持 Hibernate Spatial 定义的所有功能。下表概述了每个数据库提供的功能。如果功能是在简单功能说明中定义的,则说明引用了相关部分。
表 10. Hibernate Spatial 方言功能支持
| Function | Description | PostgresSQL | Oracle 10g/11g | MySQL | SQLServer | GeoDB (H2) | DB2 |
| 几何基本功能 | |||||||
int dimension(Geometry) |
SFS §2.1.1.1 | ||||||
String geometrytype(Geometry) |
SFS §2.1.1.1 | ||||||
int srid(Geometry) |
SFS §2.1.1.1 | ||||||
Geometry envelope(Geometry) |
SFS §2.1.1.1 | ||||||
String astext(Geometry) |
SFS §2.1.1.1 | ||||||
byte[] asbinary(Geometry) |
SFS §2.1.1.1 | ||||||
boolean isempty(Geometry) |
SFS §2.1.1.1 | ||||||
boolean issimple(Geometry) |
SFS §2.1.1.1 | ||||||
Geometry boundary(Geometry) |
SFS §2.1.1.1 | ||||||
| 测试几何对象之间空间关系的函数 | |||||||
boolean equals(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean disjoint(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean intersects(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean touches(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean crosses(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean within(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean contains(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean overlaps(Geometry, Geometry) |
SFS §2.1.1.2 | ||||||
boolean relate(Geometry, Geometry, String) |
SFS §2.1.1.2 | ||||||
| 支持空间分析的功能 | |||||||
double distance(Geometry, Geometry) |
SFS §2.1.1.3 | ||||||
Geometry buffer(Geometry, double) |
SFS §2.1.1.3 | ||||||
Geometry convexhull(Geometry) |
SFS §2.1.1.3 | (1) | |||||
Geometry intersection(Geometry, Geometry) |
SFS §2.1.1.3 | (1) | |||||
Geometry geomunion(Geometry, Geometry) |
SFS§2.1.1.3(从 unions 重命名) | (1) | |||||
Geometry difference(Geometry, Geometry) |
SFS §2.1.1.3 | (1) | |||||
Geometry symdifference(Geometry, Geometry) |
SFS §2.1.1.3 | (1) | |||||
| 常见的非 SFS 功能 | |||||||
boolean dwithin(Geometry, Geometry, double) |
如果几何之间的距离在指定范围内,则返回 true | ||||||
Geometry transform(Geometry, int) |
返回一个新几何,其坐标转换为整型参数引用的 SRID | ||||||
| 空间聚集函数 | |||||||
Geometry extent(Geometry) |
返回一个边界框,该边界框限制了返回的几何图形集 | ||||||
(1)参数几何必须具有相同的维数。
Postgis
- 对于 1.3 及更高版本的 Postgis,最好使用的方言是
org.hibernate.spatial.dialect.postgis.PostgisDialect。
- 对于 1.3 及更高版本的 Postgis,最好使用的方言是
这会将 HQL 空间功能转换为 Postgis SQL/MM 兼容功能。对于不兼容 SQL/MM 的 Postgis v1.3 之前的较早版本,提供了方言org.hibernate.spatial.dialect.postgis.PostgisNoSQLMM。
MySQL
- MySQL 有几种方言:
MySQLSpatialDialectHibernate
MySQLDialect的空间扩展版本MySQL5SpatialDialect- Hibernate
MySQL5Dialect的空间扩展版本
- Hibernate
MySQLSpatial56Dialect- Hibernate
MySQL55Dialect的空间扩展版本。
- Hibernate
Note
5.6.1 之前的 MySQL 版本仅对空间运算符提供有限支持。大多数运算符仅考虑几何的最小边界矩形(MBR),而不考虑几何本身。
当 MySQL 引入ST_*空间运算符时,这一点在 5.6.1 版本中有所改变。方言MySQLSpatial56Dialect使用这些更新的,更精确的运算符。
因此,这些方言可能会产生与其他空间方言不同的结果。
有关更多信息,请参见 MySQL 参考指南中的此页面(尤其是测试几何对象之间空间关系的函数部分)。
Oracle10g/11g
- 当前只有一种 Oracle 空间方言:
OracleSpatial10gDialect扩展了 Hibernate 方言Oracle10gDialect。该方言已在SDO_GEOMETRY空间数据库类型的 Oracle 10g 和 Oracle 11g 上进行了测试。
- 当前只有一种 Oracle 空间方言:
可以使用 Hibernate 属性配置此方言:
hibernate.spatial.connection_finder- 要使用的
ConnectionFinder的完全合格的类名(请参见下文)。
- 要使用的
The ConnectionFinder interface
将几何转换为 SDO_GEOMETRY 时,SDOGeometryType需要访问OracleConnection对象。但是,在某些环境中,OracleConnection不可用(例如,因为 Java EE 容器或连接池代理将连接对象包装在其自己的Connection实现中)。 ConnectionFinder知道如何从传递到准备好的语句的包装器或代理 Connection 对象中检索OracleConnection。
当传递的对象还不是OracleConnection时,默认实现将尝试通过递归反射来检索OracleConnection。它将搜索返回Connection对象的方法,执行这些方法并检查结果。如果结果为OracleConnection类型,则返回该对象。否则,它将重复执行。
在某些情况下,此策略已足够。如果没有,您可以在 Classpath 上提供您自己的接口实现,并在hibernate.spatial.connection_finder属性中对其进行配置。请注意,实现必须是线程安全的,并且具有默认的无参数构造函数。
SQL Server
- 在 SQL Server 2008 及更高版本中,方言
SqlServer2008Dialect支持GEOMETRY类型。
- 在 SQL Server 2008 及更高版本中,方言
Note
当前不支持GEOGRAPHY类型。
GeoDB (H2)
GeoDBDialect支持 GeoDB H2 内存数据库的空间扩展。
Note
该方言已使用 GeoDB 0.7 版进行了测试
DB2
DB2SpatialDialect支持 DB2 LUW 数据库的空间扩展。该方言已通过 DB2 LUW 11.1 进行了测试。该方言不支持 DB2 for z/OS 或 DB2 面向列的数据库。
Note
为了使用 DB2 Hibernate Spatial 功能,必须首先执行以下 SQL 语句,该语句将允许 DB2 接受扩展的已知文本(EWKT)数据并返回 EWKT 数据。一种方法是将这些语句复制到 ewkt.sql 之类的文件中,并在 DB2 命令窗口中使用“ db2 -tvf ewkt.sql”之类的命令来执行。
create or replace function db2gse.asewkt(geometry db2gse.st_geometry)
returns clob(2G)
specific db2gse.asewkt1
language sql
deterministic
no external action
reads sql data
return 'srid=' || varchar(db2gse.st_srsid(geometry)) || ';' || db2gse.st_astext(geometry);
create or replace function db2gse.geomfromewkt(instring varchar(32000))
returns db2gse.st_geometry
specific db2gse.fromewkt1
language sql
deterministic
no external action
reads sql data
return db2gse.st_geometry(
substr(instring,posstr(instring,';')+1, length(instring) - posstr(instring,';')),
integer(substr(instring,posstr(instring,'=')+1,posstr(instring,';')-(posstr(instring,'=')+1))));
create transform for db2gse.st_geometry ewkt (
from sql with function db2gse.asewkt(db2gse.st_geometry),
to sql with function db2gse.geomfromewkt(varchar(32000)) );
drop transform db2_program for db2gse.st_geometry;
create transform for db2gse.st_geometry db2_program (
from sql with function db2gse.asewkt(db2gse.st_geometry),
to sql with function db2gse.geomfromewkt(varchar(32000)) );
18.3. Types
Hibernate Spatial 具有以下类型:
jts_geometry
- 由
org.hibernate.spatial.JTSGeometryType处理,它将数据库几何列类型 Map 到org.locationtech.jts.geom.Geometry实体属性类型。
- 由
geolatte_geometry
- 由
org.hibernate.spatial.GeolatteGeometryType处理,它将数据库几何列类型 Map 到org.geolatte.geom.Geometry实体属性类型。
- 由
只需将属性声明为 JTS 或 Geolatte-geom Geometry,Hibernate Spatial 就会使用相关类型对其进行 Map。
这是使用 JTS 的示例:
例子 634.类型 Map
import org.locationtech.jts.geom.Point;
@Entity(name = "Event")
public static class Event {
@Id
private Long id;
private String name;
private Point location;
//Getters and setters are omitted for brevity
}
现在,我们可以像对待任何其他类型一样对待空间几何形状。
例子 635.创建一个点
Event event = new Event();
event.setId( 1L);
event.setName( "Hibernate ORM presentation");
Point point = geometryFactory.createPoint( new Coordinate( 10, 5 ) );
event.setLocation( point );
entityManager.persist( event );
空间方言定义了 HQL 和 JPQL 查询中都可用的许多查询功能。下面我们展示了如何使用within函数查找给定空间范围或窗口内的所有对象。
例子 636.查询几何
Polygon window = geometryFactory.createPolygon( coordinates );
Event event = entityManager.createQuery(
"select e " +
"from Event e " +
"where within(e.location, :window) = true", Event.class)
.setParameter("window", window)
.getSingleResult();
19. Multitenancy
19.1. 什么是多租户?
通常,术语“多租户”用于软件开发,以表示一种体系结构,在该体系结构中,应用程序的单个运行实例同时为多个 Client 端(租户)提供服务。这在 SaaS 解决方案中非常普遍。在这些系统中,隔离与各种租户有关的信息(数据,定制等)是一个特殊的挑战。这包括存储在数据库中的每个租户所拥有的数据。我们将重点关注的是最后一部分,有时也称为多租户数据。
19.2. 多租户数据方法
在这些多租户系统中,有三种隔离信息的主要方法,这些方法与不同的数据库模式定义和 JDBC 设置紧密结合。
Note
每种多租户策略都有优点和缺点以及特定的技术和注意事项。这些主题超出了本文档的范围。
19.2.1. 单独的数据库
每个租户的数据都保存在物理上独立的数据库实例中。 JDBC 连接将专门指向每个数据库,因此任何池都是固定的。在这里,一种通用的应用程序方法是为每个租户定义一个 JDBC 连接池,并根据与当前登录用户相关联的“租户标识符”来选择要使用的池。
19.2.2. 单独的架构
每个租户的数据都保存在单个数据库实例上的不同数据库架构中。这里有两种不同的方法来定义 JDBC 连接:
连接可以专门指向每个架构,就像我们使用
Separate database方法看到的那样。如果驱动程序支持在连接 URL 中命名默认架构,或者如果池化机制支持命名用于其连接的架构,则此选项是一个选项。使用这种方法,我们将为每个租户提供一个不同的 JDBC 连接池,其中将根据与当前登录用户关联的“租户标识符”来选择要使用的池。连接可以指向数据库本身(使用某些默认模式),但是可以使用 SQL
SET SCHEMA(或类似命令)更改连接。使用这种方法,我们将有一个用于为所有租户提供服务的 JDBC 连接池,但是在使用连接之前,将对其进行更改以引用由与当前登录用户相关联的“租户标识符”命名的架构。
19.3. 分区(区分)数据
所有数据都保存在单个数据库架构中。每个租户的数据通过使用分区值或区分符进行分区。此区分符的复杂度可能从简单的列值到复杂的 SQL 公式。同样,此方法将使用单个连接池为所有租户提供服务。但是,在这种方法中,应用程序需要更改发送到数据库的每个 SQL 语句,以引用“租户标识符”鉴别符。
19.4. Hibernate 中的多租户
将 Hibernate 与多租户数据一起使用归结为一个 API,然后是集成件。像往常一样,Hibernate 努力使 API 保持简单并与任何底层集成复杂性隔离。实际上,通过打开租户标识符作为打开任何会话的一部分来定义 API。
例子 637.从SessionFactory指定租户标识符
private void doInSession(String tenant, Consumer<Session> function) {
Session session = null;
Transaction txn = null;
try {
session = sessionFactory
.withOptions()
.tenantIdentifier( tenant )
.openSession();
txn = session.getTransaction();
txn.begin();
function.accept(session);
txn.commit();
} catch (Throwable e) {
if ( txn != null ) txn.rollback();
throw e;
} finally {
if (session != null) {
session.close();
}
}
}
此外,在指定配置时,应使用hibernate.multiTenancy设置来命名org.hibernate.MultiTenancyStrategy。 Hibernate 将根据您指定的策略类型执行验证。这里的策略与上面讨论的隔离方法相关。
NONE
- (默认)不期望多租户。实际上,如果使用此策略打开会话时指定了租户标识符,则认为是错误。
SCHEMA
- 与单独的架构方法相关。尝试使用此策略尝试在没有租户标识符的情况下打开会话是错误的。此外,必须指定
MultiTenantConnectionProvider。
- 与单独的架构方法相关。尝试使用此策略尝试在没有租户标识符的情况下打开会话是错误的。此外,必须指定
DATABASE
- 与单独的数据库方法相关。尝试使用此策略尝试在没有租户标识符的情况下打开会话是错误的。此外,必须指定
MultiTenantConnectionProvider。
- 与单独的数据库方法相关。尝试使用此策略尝试在没有租户标识符的情况下打开会话是错误的。此外,必须指定
DISCRIMINATOR
- 与分区(区分器)方法相关。尝试使用此策略尝试在没有租户标识符的情况下打开会话是错误的。该策略尚未实施,您可以通过HHH-6054 吉拉问题跟踪其进度。
19.4.1. MultiTenantConnectionProvider
当使用 DATABASE 或 SCHEMA 方法时,Hibernate 需要能够以租户特定的方式获得连接。
这就是MultiTenantConnectionProviderContract 的角色。应用程序开发人员将需要提供此 Contract 的实施。
它的大多数方法都是非常不言自明的。唯一可能不是getAnyConnection和releaseAnyConnection。还必须注意,这些方法不接受承租方标识符。 Hibernate 在启动期间使用这些方法来执行各种配置,主要是通过java.sql.DatabaseMetaData对象。
可以使用多种方式指定要使用的MultiTenantConnectionProvider:
使用
hibernate.multi_tenant_connection_provider设置。它可以命名MultiTenantConnectionProvider实例,MultiTenantConnectionProvider实现类引用或MultiTenantConnectionProvider实现类名称。直接传递给
org.hibernate.boot.registry.StandardServiceRegistryBuilder。如果以上选项都不匹配,但设置确实指定了
hibernate.connection.datasource值,则 Hibernate 会假定它应使用特定的DataSourceBasedMultiTenantConnectionProviderImpl实现,该实现在许多合理的假设下运行(在应用服务器内部运行且每个租户使用一个javax.sql.DataSource)。有关更多详细信息,请参见其Javadocs。
以下示例描绘了一个处理多个ConnectionProvider的MultiTenantConnectionProvider实现。
例子 638.一个MultiTenantConnectionProvider实现
public class ConfigurableMultiTenantConnectionProvider
extends AbstractMultiTenantConnectionProvider {
private final Map<String, ConnectionProvider> connectionProviderMap =
new HashMap<>( );
public ConfigurableMultiTenantConnectionProvider(
Map<String, ConnectionProvider> connectionProviderMap) {
this.connectionProviderMap.putAll( connectionProviderMap );
}
@Override
protected ConnectionProvider getAnyConnectionProvider() {
return connectionProviderMap.values().iterator().next();
}
@Override
protected ConnectionProvider selectConnectionProvider(String tenantIdentifier) {
return connectionProviderMap.get( tenantIdentifier );
}
}
ConfigurableMultiTenantConnectionProvider的设置如下:
例子 639.一个MultiTenantConnectionProvider用法例子
private void init() {
registerConnectionProvider( FRONT_END_TENANT );
registerConnectionProvider( BACK_END_TENANT );
Map<String, Object> settings = new HashMap<>( );
settings.put( AvailableSettings.MULTI_TENANT, multiTenancyStrategy() );
settings.put( AvailableSettings.MULTI_TENANT_CONNECTION_PROVIDER,
new ConfigurableMultiTenantConnectionProvider( connectionProviderMap ) );
sessionFactory = sessionFactory(settings);
}
protected void registerConnectionProvider(String tenantIdentifier) {
Properties properties = properties();
properties.put( Environment.URL,
tenantUrl(properties.getProperty( Environment.URL ), tenantIdentifier) );
DriverManagerConnectionProviderImpl connectionProvider =
new DriverManagerConnectionProviderImpl();
connectionProvider.configure( properties );
connectionProviderMap.put( tenantIdentifier, connectionProvider );
}
使用多租户时,可以在不同的租户之间保存具有相同标识符的实体:
例子 640.在不同的租户中保存具有相同标识符的实体的例子
doInSession( FRONT_END_TENANT, session -> {
Person person = new Person( );
person.setId( 1L );
person.setName( "John Doe" );
session.persist( person );
} );
doInSession( BACK_END_TENANT, session -> {
Person person = new Person( );
person.setId( 1L );
person.setName( "John Doe" );
session.persist( person );
} );
19.4.2. CurrentTenantIdentifierResolver
org.hibernate.context.spi.CurrentTenantIdentifierResolver是 Hibernate 能够解决应用程序视为当前租户标识符的 Contract。使用的实现可以通过其setCurrentTenantIdentifierResolver方法直接传递给Configuration,也可以通过hibernate.tenant_identifier_resolver设置指定。
在两种情况下使用CurrentTenantIdentifierResolver:
第一种情况是应用程序将
org.hibernate.context.spi.CurrentSessionContext功能与多租户结合使用。对于当前会话功能,如果 Hibernate 在范围内找不到现有的会话,则需要打开一个会话。但是,在多租户环境中打开会话时,必须指定租户标识符。这是CurrentTenantIdentifierResolver发挥作用的地方; Hibernate 将咨询您提供的实现,以确定在打开会话时要使用的租户标识符。在这种情况下,要求提供CurrentTenantIdentifierResolver。另一种情况是您不想一直明确指定租户标识符。如果已指定
CurrentTenantIdentifierResolver,则 Hibernate 将使用它来确定打开会话时要使用的默认租户标识符。
另外,如果CurrentTenantIdentifierResolver实现为其validateExistingCurrentSessions方法返回true,则 Hibernate 将确保在范围内找到的所有现有会话都具有匹配的租户标识符。仅当在当前会话设置中使用CurrentTenantIdentifierResolver时,此功能才有意义。
19.4.3. Caching
Hibernate 中的多租户支持与 Hibernate 二级缓存无缝配合。用于缓存数据的密钥对租户标识符进行编码。
Note
当前,模式导出实际上不适用于多租户。
JPAmaven 组正在为即将发布的规范版本定义多租户支持。
19.4.4. 多租户 Hibernate 会话配置
使用多租户时,您可能需要不同地配置每个特定于租户的Session。例如,每个租户可以指定不同的时区配置。
例子 641.注册特定于租户的时区信息
registerConnectionProvider( FRONT_END_TENANT, TimeZone.getTimeZone( "UTC" ) );
registerConnectionProvider( BACK_END_TENANT, TimeZone.getTimeZone( "CST" ) );
registerConnectionProvider方法用于定义特定于租户的上下文。
例子 642. registerConnectionProvider方法用于定义特定于租户的上下文
protected void registerConnectionProvider(String tenantIdentifier, TimeZone timeZone) {
Properties properties = properties();
properties.put(
Environment.URL,
tenantUrl( properties.getProperty( Environment.URL ), tenantIdentifier )
);
DriverManagerConnectionProviderImpl connectionProvider =
new DriverManagerConnectionProviderImpl();
connectionProvider.configure( properties );
connectionProviderMap.put( tenantIdentifier, connectionProvider );
timeZoneTenantMap.put( tenantIdentifier, timeZone );
}
对于我们的示例,特定于租户的上下文保存在connectionProviderMap和timeZoneTenantMap中。
private Map<String, ConnectionProvider> connectionProviderMap = new HashMap<>();
private Map<String, TimeZone> timeZoneTenantMap = new HashMap<>();
现在,在构建 Hibernate Session时,除了传递租户标识符之外,我们还可以将Session配置为使用特定于租户的时区。
例子 643.可以使用特定于租户的上下文来配置 Hibernate Session
private void doInSession(String tenant, Consumer<Session> function, boolean useTenantTimeZone) {
Session session = null;
Transaction txn = null;
try {
SessionBuilder sessionBuilder = sessionFactory
.withOptions()
.tenantIdentifier( tenant );
if ( useTenantTimeZone ) {
sessionBuilder.jdbcTimeZone( timeZoneTenantMap.get( tenant ) );
}
session = sessionBuilder.openSession();
txn = session.getTransaction();
txn.begin();
function.accept( session );
txn.commit();
}
catch (Throwable e) {
if ( txn != null ) {
txn.rollback();
}
throw e;
}
finally {
if ( session != null ) {
session.close();
}
}
}
因此,如果我们将useTenantTimeZone参数设置为true,则 Hibernate 将使用特定于租户的时区来保留Timestamp属性。如下面的示例所示,即使当前运行的 JVM 使用不同的时区,也已成功检索Timestamp。
例子 644. useTenantTimeZone允许您在提供的时区中保留Timestamp
doInSession( FRONT_END_TENANT, session -> {
Person person = new Person();
person.setId( 1L );
person.setName( "John Doe" );
person.setCreatedOn( LocalDateTime.of( 2018, 11, 23, 12, 0, 0 ) );
session.persist( person );
}, true );
doInSession( BACK_END_TENANT, session -> {
Person person = new Person();
person.setId( 1L );
person.setName( "John Doe" );
person.setCreatedOn( LocalDateTime.of( 2018, 11, 23, 12, 0, 0 ) );
session.persist( person );
}, true );
doInSession( FRONT_END_TENANT, session -> {
Timestamp personCreationTimestamp = (Timestamp) session
.createNativeQuery(
"select p.created_on " +
"from Person p " +
"where p.id = :personId" )
.setParameter( "personId", 1L )
.getSingleResult();
assertEquals(
Timestamp.valueOf( LocalDateTime.of( 2018, 11, 23, 12, 0, 0 ) ),
personCreationTimestamp
);
}, true );
doInSession( BACK_END_TENANT, session -> {
Timestamp personCreationTimestamp = (Timestamp) session
.createNativeQuery(
"select p.created_on " +
"from Person p " +
"where p.id = :personId" )
.setParameter( "personId", 1L )
.getSingleResult();
assertEquals(
Timestamp.valueOf( LocalDateTime.of( 2018, 11, 23, 12, 0, 0 ) ),
personCreationTimestamp
);
}, true );
但是,在后台,我们可以看到 Hibernate 在特定于租户的时区中保存了created_on属性。下面的示例向您显示Timestamp已保存在 UTC 时区中,因此偏移量显示在测试输出中。
例子 645.在useTenantTimeZone属性设置为false的情况下,在租户特定的时区中提取Timestamp
doInSession( FRONT_END_TENANT, session -> {
Timestamp personCreationTimestamp = (Timestamp) session
.createNativeQuery(
"select p.created_on " +
"from Person p " +
"where p.id = :personId" )
.setParameter( "personId", 1L )
.getSingleResult();
log.infof(
"The created_on timestamp value is: [%s]",
personCreationTimestamp
);
long timeZoneOffsetMillis =
Timestamp.valueOf( LocalDateTime.of( 2018, 11, 23, 12, 0, 0 ) ).getTime() -
personCreationTimestamp.getTime();
assertEquals(
TimeZone.getTimeZone(ZoneId.systemDefault()).getRawOffset(),
timeZoneOffsetMillis
);
log.infof(
"For the current time zone: [%s], the UTC time zone offset is: [%d]",
TimeZone.getDefault().getDisplayName(), timeZoneOffsetMillis
);
}, false );
SELECT
p.created_on
FROM
Person p
WHERE
p.id = ?
-- binding parameter [1] as [BIGINT] - [1]
-- extracted value ([CREATED_ON] : [TIMESTAMP]) - [2018-11-23 10:00:00.0]
-- The created_on timestamp value is: [2018-11-23 10:00:00.0]
-- For the current time zone: [Eastern European Time], the UTC time zone offset is: [7200000]
请注意,对于Eastern European Time时区,执行测试时的时区偏移为 2 小时。
20. OSGi
20.1. OSGi 规范和环境
Hibernate 针对 OSGi 4.3 规范或更高版本。由于我们依赖 OSGi 的BundleWiring进行实体/Map 扫描,因此有必要从 4.3 开始,超过 4.2.
Hibernate 在 OSGi 中支持三种类型的配置。
容器 Management 的 JPA Container-Managed JPA
非托管的 JPA Unmanaged JPA
非托管原生Unmanaged Native
20.2. hibernate-osgi
不是将 OSGi 功能嵌入到休眠核心和子模块中,而是创建了 hibernate-osgi。它是有目的地分离的,隔离了所有 OSGi 依赖项。它提供了特定于 OSGi 的ClassLoader(将容器的ClassLoader与核心和``聚合在一起),JPA 持久性提供程序,SessionFactory/EntityManagerFactory引导程序,实体/Map 扫描程序以及服务 Management。
20.3. features.xml
Apache Karaf 环境倾向于大量使用其“功能”概念,该功能是一组专注于简明功能的特定于订单的 Binding 软件。这些功能通常在features.xml文件中定义。 Hibernate 产生并发布自己的features.xml,该features.xml定义了核心hibernate-orm以及可选功能的其他功能(缓存,Envers 等)。它包含在二进制发行版中,并已部署到 JBoss Nexus 存储库(使用org.hibernate groupId 和hibernate-osgiartifactId 和karaf.xml分类器)。
请注意,我们的功能使用与其包装的相同 ORM 工件版本进行版本控制。另外,请注意,作为基于 PaxExam 的集成测试的一部分,这些功能已针对 Karaf 3.0.3 进行了严格测试。但是,它们也可能会在其他版本上使用。
从理论上讲,hibernate-osgi 支持各种 OSGi 容器,例如 Equinox。在这种情况下,请使用features.xm作为激活所需 Binding 包及其正确 Sequences 的参考。但是,请注意,Karaf 会自动启动许多 Binding 软件,其中一些 Binding 软件需要在替代产品上手动安装。
20.4. QuickStarts/Demos
这三种配置在hibernate-demos项目中都有一个 QuickStart/Demo:
20.5. 容器 Management 的 JPA
Enterprise OSGi 规范包括容器 Management 的 JPA。容器负责发现 Binding 中的持久性单元,并自动创建EntityManagerFactory(每个PersistenceUnit一个EntityManagerFactory)。它使用已向 OSGi PersistenceProvider服务注册了自己的 JPA 提供程序(hibernate-osgi)。
20.6. 企业 OSGi JPA 容器
为了利用容器 Management 的 JPA,Enterprise OSGi JPA 容器必须在运行时处于活动状态。在 Karaf 中,这表示即装即用的 Aries JPA(只需激活jpa和transaction功能)。最初,我们打算将那些依赖项包含在我们自己的features.xml中。然而,在卡拉夫和白羊队的指导下,它被撤出。这使 Hibernate OSGi 可以移植,并且不直接与 Aries 版本绑定,而不必让用户选择要使用的版本。
话虽如此,QuickStart/Demo 项目包含一个示例features.xml,该示例显示了需要在 Karaf 中激活哪些功能才能支持此环境。如前所述,仅将其用作参考!
20.7. persistence.xml
与任何其他 JPA 设置类似,您的 Binding 包必须包含persistence.xml文件。通常位于META-INF。
20.8. DataSource
Enterprise OSGi JPA 的典型用法是在容器中安装DataSource。Binding 商品的persistence.xml通过 JNDI 调出DataSource。例如,您可以安装以下 H2 DataSource。您可以手动部署DataSource(Karaf 的目录为deploy),也可以通过“蓝图包”(blueprint:file:/[PATH]/datasource-h2.xml)部署。
例子 646. datasource-h2.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
First install the H2 driver using:
> install -s mvn:com.h2database/h2/1.3.163
Then copy this file to the deploy folder
-->
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0">
<bean id="dataSource" class="org.h2.jdbcx.JdbcDataSource">
<property name="URL" value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE"/>
<property name="user" value="sa"/>
<property name="password" value=""/>
</bean>
<service interface="javax.sql.DataSource" ref="dataSource">
<service-properties>
<entry key="osgi.jndi.service.name" value="jdbc/h2ds"/>
</service-properties>
</service>
</blueprint>
然后DataSource由您的persistence.xml持久性单元使用。以下内容在 Karaf 中有效,但名称可能需要在其他容器中进行调整。
例子 647. META-INF/persistence.xml
<jta-data-source>osgi:service/javax.sql.DataSource/(osgi.jndi.service.name=jdbc/h2ds)</jta-data-source>
20.9. Binding 包导入
您的 Binding 商品清单至少需要导入:
javax.persistenceorg.hibernate.proxy和javassist.util.proxy,因为 Hibernate 可以返回代理以进行延迟初始化(Javassist 增强功能发生在实体的ClassLoader上)。
20.10. 获取实体
获取EntityManager的最简单,最受支持的方法是使用 Binding 软件中的 OSGi OSGI-INF/blueprint/blueprint.xml。容器使用您的持久性单元的名称,然后自动将EntityManager实例注入给定的 bean 属性。
例子 648. OSGI-INF/blueprint/blueprint.xml
<?xml version="1.0" encoding="UTF-8"?>
<blueprint xmlns:jpa="http://aries.apache.org/xmlns/jpa/v1.0.0"
xmlns:tx="http://aries.apache.org/xmlns/transactions/v1.0.0"
default-activation="eager"
xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0">
<!-- This gets the container-managed EntityManager and injects it into the DataPointServiceImpl bean.
Assumes DataPointServiceImpl has an "entityManager" field with a getter and setter. -->
<bean id="dpService" class="org.hibernate.osgitest.DataPointServiceImpl">
<jpa:context unitname="managed-jpa" property="entityManager"/>
<tx:transaction method="*" value="Required"/>
</bean>
<service ref="dpService" interface="org.hibernate.osgitest.DataPointService"/>
</blueprint>
20.11. 非托管 JPA
Hibernate 还支持不受 OSGi 容器 Management 的 JPA 的使用。ClientBinding 包负责 ManagementEntityManagerFactory和``。
20.12. persistence.xml
与任何其他 JPA 设置类似,您的 Binding 包必须包含persistence.xml文件。通常位于META-INF。
20.13. Binding 包导入
您的 Binding 商品清单至少需要导入:
javax.persistenceorg.hibernate.proxy和javassist.util.proxy,因为 Hibernate 可以返回代理以进行延迟初始化(Javassist 增强功能在运行时在实体的ClassLoader上发生)JDBC 驱动程序包(示例:
org.h2)org.osgi.framework,是发现EntityManagerFactory的必要条件(如下所述)
20.14. 获取 EntityMangerFactory
hibernate-osgi使用 JPA PersistenceProvider接口名称注册 OSGi 服务,该服务引导并创建特定于 OSGi 环境的EntityManagerFactory。
Tip
通过服务而不是手动创建EntityManagerFactory是至关重要的。该服务处理 OSGi ClassLoader,发现的扩展点,扫描等。保证手动创建EntityManagerFactory不会在运行时起作用!
例子 649.发现/使用EntityManagerFactory
public class HibernateUtil {
private EntityManagerFactory emf;
public EntityManager getEntityManager() {
return getEntityManagerFactory().createEntityManager();
}
private EntityManagerFactory getEntityManagerFactory() {
if ( emf == null ) {
Bundle thisBundle = FrameworkUtil.getBundle(
HibernateUtil.class
);
BundleContext context = thisBundle.getBundleContext();
ServiceReference serviceReference = context.getServiceReference(
PersistenceProvider.class.getName()
);
PersistenceProvider persistenceProvider = ( PersistenceProvider ) context
.getService(
serviceReference
);
emf = persistenceProvider.createEntityManagerFactory(
"YourPersistenceUnitName",
null
);
}
return emf;
}
}
20.15. 非托管本地
还支持本地 Hibernate 使用。Client 端 Binding 包负责 ManagementSessionFactory和Session。
20.16. Binding 包导入
您的 Binding 商品清单至少需要导入:
javax.persistenceorg.hibernate.proxy和javassist.util.proxy,因为 Hibernate 可以返回代理以进行延迟初始化(Javassist 增强功能在运行时在实体的ClassLoader上发生)JDBC 驱动程序包(示例:
org.h2)org.osgi.framework,是发现SessionFactory的必要条件(如下所述)org.hibernate.*软件包(如有必要)(例如:cfg,标准,服务等)
20.17. 获取 SessionFactory
hibernate-osgi使用SessionFactory接口名称注册 OSGi 服务,该服务引导并创建特定于 OSGi 环境的SessionFactory。
Tip
通过服务而不是手动创建SessionFactory是至关重要的。该服务处理 OSGi ClassLoader,发现的扩展点,扫描等。手动创建SessionFactory保证在运行期间不起作用!
例子 650.发现/使用SessionFactory
public class HibernateUtil {
private SessionFactory sf;
public Session getSession() {
return getSessionFactory().openSession();
}
private SessionFactory getSessionFactory() {
if ( sf == null ) {
Bundle thisBundle = FrameworkUtil.getBundle(
HibernateUtil.class
);
BundleContext context = thisBundle.getBundleContext();
ServiceReference sr = context.getServiceReference(
SessionFactory.class.getName()
);
sf = ( SessionFactory ) context.getService( sr );
}
return sf;
}
}
20.18. 可选模块
unmanaged-native演示项目显示了可选 Hibernate 模块的用法。每个模块都添加了必须首先手动或通过其他功能激活的其他依赖项 Binding 包。从 ORM 4.2 开始,完全支持 Envers。在 4.3 中添加了对 C3P0,Proxool,EhCache 和 Infinispan 的支持。但是,它们的第 3 方库当前都无法在 OSGi 中工作(很多ClassLoader问题,等等)。我们正在跟踪 JIRA 中的问题。
20.19. 延伸点
存在多个 Contract,以允许应用程序与 Hibernate 功能集成并扩展它们。大多数应用程序都使用 JDK 服务来提供其实现。 hibernate-osgi通过 OSGi 服务支持相同的扩展。实施并注册这三种配置中的任何一种。 hibernate-osgi将在EntityManagerFactory/SessionFactory引导过程中发现并整合它们。支持的扩展点如下。服务注册期间应使用指定的接口。
org.hibernate.integrator.spi.Integrator- (从 4.2 版开始)
org.hibernate.boot.registry.selector.StrategyRegistrationProvider- (从 4.3 版开始)
org.hibernate.boot.model.TypeContributor- (从 4.3 版开始)
JTA's
javax.transaction.TransactionManager和javax.transaction.UserTransaction(从 4.2 开始)。但是,这些通常是由 OSGi 容器提供的。
注册扩展点实现的最简单方法是通过blueprint.xml文件。将OSGI-INF/blueprint/blueprint.xml添加到您的 Classpath 中。 Envers 的蓝图就是一个很好的例子:
例子 651. blueprint.xml 中的例子扩展点注册
<!--
~ Hibernate, Relational Persistence for Idiomatic Java
~
~ License: GNU Lesser General Public License (LGPL), version 2.1 or later.
~ See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
-->
<blueprint default-activation="eager"
xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0">
<bean id="integrator" class="org.hibernate.envers.boot.internal.EnversIntegrator"/>
<service ref="integrator" interface="org.hibernate.integrator.spi.Integrator"/>
<bean id="typeContributor"
class="org.hibernate.envers.boot.internal.TypeContributorImpl"/>
<service ref="typeContributor" interface="org.hibernate.boot.model.TypeContributor"/>
</blueprint>
扩展点也可以通过BundleContext#registerService(通常在您的BundleActivator#start内)以编程方式注册。
20.20. Caveats
从技术上讲,Enterprise OSGi JPA 和非托管 Hibernate JPA 使用支持多个持久性单元。但是,我们目前无法在 OSGi 中支持此功能。在 Hibernate 4 中,每个 HibernateBinding 包仅使用一个 OSGi 专用
ClassLoader实例,这主要是由于大量使用静态 TCCLUtil。我们希望在 Hibernate 5 中支持一个 OSGiClassLoader持久性单元。支持扫描以查找未明确列出的实体和 Map。但是,它们必须与您的持久性单元位于同一个 Binding 包中(无论如何还是非常典型的)。我们的 OSGi
ClassLoader仅考虑“请求 Binding 包”(因此要求使用服务来创建EntityManagerFactory/SessionFactory),而不是尝试扫描所有可用 Binding 包。这主要是出于版本控制,碰撞保护等方面的考虑。即使您的
persistence.xml明确将exclude-unlisted-classes设置为false,某些容器(例如 Aries)对于PersistenceUnitInfo#excludeUnlistedClasses始终返回 true。他们声称,这是为了保护 JPA 提供程序免于实施扫描(“我们为您处理”),即使在许多情况下我们仍然希望支持它也是如此。解决方法是将hibernate.archive.autodetection设置为例如hbm,class。这告诉休眠状态忽略excludeUnlistedClasses值并扫描*.hbm.xml和实体。扫描当前不支持
package-info.java上的带 Comments 的程序包。当前,主要使用 Apache Karaf 和 Apache Aries JPA 对 Hibernate OSGi 进行测试。 Equinox,Gemini 和其他容器提供商需要进行其他测试。
Hibernate ORM 具有许多当前不提供 OSGi 清单的依赖项。快速入门教程大量使用了第三方 Binding 包(SpringSource,ServiceMix)或
wrap:…运算符。
21. Envers
21.1. Basics
要审核在实体上执行的更改,您仅需要两件事:
Classpath 上的
hibernate-enversjar实体上的
@AuditedComments。
Tip
与以前的版本不同,您不再需要在 Hibernate 配置文件中指定侦听器。仅将 Envers jar 放在 Classpath 上就足够了,因为侦听器将自动注册。
就这样。您可以像往常一样创建,修改和删除实体。
Tip
Envers 当前不支持使用 JPA 的CriteriaUpdate和CriteriaDelete批量操作,这是因为实体的生命周期事件是如何分派的。应避免此类操作,因为它们不会被 Envers 捕获,并导致不完整的审核历史记录。
如果查看为您的实体生成的架构,或查看 Hibernate 保留的数据,您会注意到没有任何更改。但是,对于每个审计实体,都会引入一个新表entity_table_AUD,每当您提交事务时,该表都会存储历史数据。
Note
如果hibernate.hbm2ddl.auto选项设置为create,create-drop或update,则 Envers 自动创建审核表。还可以使用使用 Hibernate hbm2ddl 工具生成 Envers 模式中的 Ant 任务生成适当的 DDL 语句。
考虑到我们有一个Customer实体,当使用AuditedComments 对其进行 Comments 时,Hibernate 将使用hibernate.hbm2ddl.auto模式工具生成以下表:
例子 652.基本 Envers 实体 Map
@Audited
@Entity(name = "Customer")
public static class Customer {
@Id
private Long id;
private String firstName;
private String lastName;
@Temporal( TemporalType.TIMESTAMP )
@Column(name = "created_on")
@CreationTimestamp
private Date createdOn;
//Getters and setters are omitted for brevity
}
create table Customer (
id bigint not null,
created_on timestamp,
firstName varchar(255),
lastName varchar(255),
primary key (id)
)
create table Customer_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint,
created_on timestamp,
firstName varchar(255),
lastName varchar(255),
primary key (id, REV)
)
create table REVINFO (
REV integer generated by default as identity,
REVTSTMP bigint,
primary key (REV)
)
alter table Customer_AUD
add constraint FK5ecvi1a0ykunrriib7j28vpdj
foreign key (REV)
references REVINFO
您可以使用@Audited来仅 Comments 一些持久属性,而不是 Comments 整个类并审核所有属性。这将仅审核这些属性。
现在,考虑先前的Customer实体,让我们看看在插入,更新和删除相关实体时 Envers 审计的工作方式。
例子 653.审核实体INSERT的操作
Customer customer = new Customer();
customer.setId( 1L );
customer.setFirstName( "John" );
customer.setLastName( "Doe" );
entityManager.persist( customer );
insert
into
Customer
(created_on, firstName, lastName, id)
values
(?, ?, ?, ?)
-- binding parameter [1] as [TIMESTAMP] - [Mon Jul 24 17:21:32 EEST 2017]
-- binding parameter [2] as [VARCHAR] - [John]
-- binding parameter [3] as [VARCHAR] - [Doe]
-- binding parameter [4] as [BIGINT] - [1]
insert
into
REVINFO
(REV, REVTSTMP)
values
(?, ?)
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [BIGINT] - [1500906092803]
insert
into
Customer_AUD
(REVTYPE, created_on, firstName, lastName, id, REV)
values
(?, ?, ?, ?, ?, ?)
-- binding parameter [1] as [INTEGER] - [0]
-- binding parameter [2] as [TIMESTAMP] - [Mon Jul 24 17:21:32 EEST 2017]
-- binding parameter [3] as [VARCHAR] - [John]
-- binding parameter [4] as [VARCHAR] - [Doe]
-- binding parameter [5] as [BIGINT] - [1]
-- binding parameter [6] as [INTEGER] - [1]
例子 654.审计实体UPDATE操作
Customer customer = entityManager.find( Customer.class, 1L );
customer.setLastName( "Doe Jr." );
update
Customer
set
created_on=?,
firstName=?,
lastName=?
where
id=?
-- binding parameter [1] as [TIMESTAMP] - [2017-07-24 17:21:32.757]
-- binding parameter [2] as [VARCHAR] - [John]
-- binding parameter [3] as [VARCHAR] - [Doe Jr.]
-- binding parameter [4] as [BIGINT] - [1]
insert
into
REVINFO
(REV, REVTSTMP)
values
(?, ?)
-- binding parameter [1] as [BIGINT] - [2]
-- binding parameter [2] as [BIGINT] - [1500906092853]
insert
into
Customer_AUD
(REVTYPE, created_on, firstName, lastName, id, REV)
values
(?, ?, ?, ?, ?, ?)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [TIMESTAMP] - [2017-07-24 17:21:32.757]
-- binding parameter [3] as [VARCHAR] - [John]
-- binding parameter [4] as [VARCHAR] - [Doe Jr.]
-- binding parameter [5] as [BIGINT] - [1]
-- binding parameter [6] as [INTEGER] - [2]
例子 655.审计实体DELETE操作
Customer customer = entityManager.getReference( Customer.class, 1L );
entityManager.remove( customer );
delete
from
Customer
where
id = ?
-- binding parameter [1] as [BIGINT] - [1]
insert
into
REVINFO
(REV, REVTSTMP)
values
(?, ?)
-- binding parameter [1] as [BIGINT] - [3]
-- binding parameter [2] as [BIGINT] - [1500906092876]
insert
into
Customer_AUD
(REVTYPE, created_on, firstName, lastName, id, REV)
values
(?, ?, ?, ?, ?, ?)
-- binding parameter [1] as [INTEGER] - [2]
-- binding parameter [2] as [TIMESTAMP] - [null]
-- binding parameter [3] as [VARCHAR] - [null]
-- binding parameter [4] as [VARCHAR] - [null]
-- binding parameter [5] as [BIGINT] - [1]
-- binding parameter [6] as [INTEGER] - [3]
REVTYPE列的值取自RevisionType枚举。
表 11. REVTYPE列值
| 数据库列值 | 关联的RevisionType枚举值 |
Description |
| 0 | ADD |
插入了数据库表行。 |
| 1 | MOD |
数据库表行已更新。 |
| 2 | DEL |
数据库表行已删除。 |
可以使用AuditReader接口访问实体的审计(历史),该接口可以通过AuditReaderFactory打开EntityManager或Session来获取。
例 656.获取Customer实体的修订列表
List<Number> revisions = doInJPA( this::entityManagerFactory, entityManager -> {
return AuditReaderFactory.get( entityManager ).getRevisions(
Customer.class,
1L
);
} );
select
c.REV as col_0_0_
from
Customer_AUD c
cross join
REVINFO r
where
c.id = ?
and c.REV = r.REV
order by
c.REV asc
-- binding parameter [1] as [BIGINT] - [1]
使用以前获取的修订,我们现在可以检查该特定修订的Customer实体的状态:
例子 657.获得Customer实体的第一个修订版
Customer customer = (Customer) AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, revisions.get( 0 ) )
.getSingleResult();
assertEquals("Doe", customer.getLastName());
select
c.id as id1_1_,
c.REV as REV2_1_,
c.REVTYPE as REVTYPE3_1_,
c.created_on as created_4_1_,
c.firstName as firstNam5_1_,
c.lastName as lastName6_1_
from
Customer_AUD c
where
c.REV = (
select
max( c_max.REV )
from
Customer_AUD c_max
where
c_max.REV <= ?
and c.id = c_max.id
)
and c.REVTYPE <> ?
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [INTEGER] - [2]
执行上述 SQL 查询时,有两个参数:
revision_number
- 第一个参数标记我们感兴趣的修订版本号,或者标记直到该特定修订版本为止的最新版本。
revision_type
- 第二个参数指定我们对
DELRevisionType不感兴趣,以便将删除的条目过滤掉。
- 第二个参数指定我们对
与UPDATE语句关联的第二个修订版也是如此。
例子 658.获得Customer实体的第二个修订版本
Customer customer = (Customer) AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, revisions.get( 1 ) )
.getSingleResult();
assertEquals("Doe Jr.", customer.getLastName());
对于已删除的实体修订版,Envers 会引发NoResultException,因为该实体在该修订版中不再有效。
例子 659.获得Customer实体的第三个修订版
try {
Customer customer = (Customer) AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, revisions.get( 2 ) )
.getSingleResult();
fail("The Customer was deleted at this revision: " + revisions.get( 2 ));
}
catch (NoResultException expected) {
}
您可以使用forEntitiesAtRevision(Class<T> cls,字符串 entityName,数字修订,布尔值 includeDeletions)方法来获取已删除的实体修订,以便除实体标识符之外的所有属性都将成为null,而不是NoResultException。
例子 660.在没有得到NoResultException的情况下获得Customer实体的第三个修订版
Customer customer = (Customer) AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision(
Customer.class,
Customer.class.getName(),
revisions.get( 2 ),
true )
.getSingleResult();
assertEquals( Long.valueOf( 1L ), customer.getId() );
assertNull( customer.getFirstName() );
assertNull( customer.getLastName() );
assertNull( customer.getCreatedOn() );
有关提供的其他功能的详细信息,请参见Javadocs。
21.2. 配置属性
可以配置 Hibernate Envers 行为的各个方面,例如表名等。
org.hibernate.envers.audit_table_prefix- 字符串,将在被审核实体的名称之前添加以创建实体名称,并将包含审核信息。
org.hibernate.envers.audit_table_suffix(默认值:_AUD)- 字符串,该字符串将附加到被审核实体的名称上以创建实体名称,并将包含审核信息。
如果审核表名称为 Person 的实体,则默认情况下,Envers 会生成Person_AUD表来存储历史数据。
org.hibernate.envers.revision_field_name(默认值:REV)- 审核实体中将保留修订号的字段名称。
org.hibernate.envers.revision_type_field_name(默认值:REVTYPE)- 审核实体中将保留修订类型的字段的名称(当前可以是
add,mod,del)。
- 审核实体中将保留修订类型的字段的名称(当前可以是
org.hibernate.envers.revision_on_collection_change(默认值:true)- 当非所有关系字段更改时是否应生成修订(可以是一对多关系中的集合,也可以是一对一关系中使用
mappedBy属性的字段)。
- 当非所有关系字段更改时是否应生成修订(可以是一对多关系中的集合,也可以是一对一关系中使用
org.hibernate.envers.do_not_audit_optimistic_locking_field(默认值:true)- 设置为 true 时,将不会自动审核用
@VersionComments 的用于乐观锁定的属性(它们的历史记录将不会被存储;通常不会存储它)。
- 设置为 true 时,将不会自动审核用
org.hibernate.envers.store_data_at_delete(默认值:false)- 删除实体时,应将实体数据存储在修订版中(而不是仅将 id 和所有其他属性存储为 null)。
通常不需要,因为数据存在于上一个修订版中。但是,有时在上一个修订版中访问它会更容易,更有效(然后,删除之前包含的实体的数据将存储两次)。
org.hibernate.envers.default_schema(默认值:null-与正在审核的表相同的架构)- 应用于审核表的默认架构名称。
可以使用@AuditTable( schema = "…" )Comments 覆盖。
如果不存在,则该架构将与被审核表的架构相同。
org.hibernate.envers.default_catalog(默认值:null-与要审核的表相同的目录)- 审计表应使用的默认目录名称。
可以使用@AuditTable( catalog = "…" )Comments 覆盖。
如果不存在,则目录将与普通表的目录相同。
org.hibernate.envers.audit_strategy(默认值:org.hibernate.envers.strategy.DefaultAuditStrategy)- 保留审核数据时应使用的审核策略。缺省值仅存储修改实体的修订版本。
另一种方法是org.hibernate.envers.strategy.ValidityAuditStrategy存储开始修订和结束修订。这些共同定义了审核行何时有效,因此命名为 ValidityAuditStrategy。
org.hibernate.envers.audit_strategy_validity_end_rev_field_name(默认值:REVEND)- 将在审核实体中保存最终修订版本号的列名称。仅当使用有效性审核策略时,此属性才有效。
org.hibernate.envers.audit_strategy_validity_store_revend_timestamp(默认值:false)- 除了最终修订本身之外,是否还应存储最终修订的时间戳,直到该数据有效为止。能够通过使用表分区从关系数据库中清除旧的 Audit 记录,这很有用。
分区需要表中存在一列。仅当使用ValidityAuditStrategy时才评估此属性。
org.hibernate.envers.audit_strategy_validity_revend_timestamp_field_name(默认值:REVEND_TSTMP)- 直到数据有效的最终修订的时间戳的列名。仅在使用
ValidityAuditStrategy且org.hibernate.envers.audit_strategy_validity_store_revend_timestamp计算为 true 时使用。
- 直到数据有效的最终修订的时间戳的列名。仅在使用
org.hibernate.envers.use_revision_entity_with_native_id(默认值:true)- 布尔值标志,用于确定修订号生成策略。修订版实体的默认实现使用本机标识符生成器。
如果当前数据库引擎不支持标识列,建议用户将此属性设置为 false。
在这种情况下,修订号是由预配置的org.hibernate.id.enhanced.SequenceStyleGenerator创建的。参见:org.hibernate.envers.DefaultRevisionEntity和org.hibernate.envers.enhanced.SequenceIdRevisionEntity。
org.hibernate.envers.track_entities_changed_in_revision(默认值:false)- 应该跟踪在每个修订版中已修改的实体类型。默认实现创建
REVCHANGES表,该表存储已修改的持久对象的实体名称。单个记录封装了修订标识符(REVINFO表的外键)和字符串值。有关更多信息,请参阅修订期间修改的跟踪实体名称和查询在给定版本中修改的实体类型。
- 应该跟踪在每个修订版中已修改的实体类型。默认实现创建
org.hibernate.envers.global_with_modified_flag(默认值:false,可以用@Audited( withModifiedFlag = true )分别覆盖)- 是否应为所有审核实体和所有属性存储属性修改标志。
设置为 true 时,将为所有属性在审核表中创建一个附加的布尔列,并在给定修订版本中更改给定属性时填充信息。
设置为 false 时,可以使用@AuditedComments 将此类列添加到选定的实体或属性。
有关更多信息,请参阅在属性级别跟踪实体更改和查询修改给定属性的实体修订。
org.hibernate.envers.modified_flag_suffix(默认值:_MOD)- 存储“ Modified Flags”的列的后缀。
例如,默认情况下,名为“ age”的属性将获得列名为“ age_MOD”的修改标志。
org.hibernate.envers.modified_column_naming_strategy(默认值:org.hibernate.envers.boot.internal.LegacyModifiedColumnNamingStrategy)- 用于审核元数据中的已修改标志列的命名策略。
org.hibernate.envers.embeddable_set_ordinal_field_name(默认值:SETORDINAL)- 用于存储可嵌入元素集中的更改 Sequences 的列的名称。
org.hibernate.envers.cascade_delete_revision(默认值:false)- 在删除修订条目时,请删除关联的审核实体的数据。需要数据库支持才能删除级联行。
org.hibernate.envers.allow_identifier_reuse(默认值:false)- 当应用程序重用已删除实体的标识符时,保证适当的有效性审计策略行为。每个标识符只存在一个结束日期为
null的行。
- 当应用程序重用已删除实体的标识符时,保证适当的有效性审计策略行为。每个标识符只存在一个结束日期为
org.hibernate.envers.original_id_prop_name(默认值:originalId)- 指定审核表 Map 使用的复合 ID 密钥属性名称。
org.hibernate.envers.find_by_revision_exact_match(默认值:false)- 指定接受修订号参数的
AuditReader#find方法是基于模糊匹配还是完全匹配行为来查找结果。
- 指定接受修订号参数的
旧的(传统)行为一直是执行模糊匹配,如果主键存在修订版本号小于或等于修订方法参数的修订,则这些方法将返回匹配项。当您要基于另一个实体的修订号查找不相关实体的快照时,此行为很好。
启用此选项后,新的(可选)行为会强制查询执行完全匹配。为了使这些方法返回非null值,对于具有指定主键和修订号的实体,必须存在修订条目。否则结果将为null。
Tip
最近添加了以下配置选项,应将其视为实验性的:
org.hibernate.envers.track_entities_changed_in_revisionorg.hibernate.envers.using_modified_flagorg.hibernate.envers.modified_flag_suffixorg.hibernate.envers.modified_column_naming_strategyorg.hibernate.envers.original_id_prop_nameorg.hibernate.envers.find_by_revision_exact_match
21.3. 其他 MapComments
可以使用@AuditTableComments 按实体设置审核表的名称。将此 Comments 添加到每个审核的实体可能很乏味,因此,如果可能的话,最好使用前缀/后缀。
如果您具有包含辅助表的 Map,则将以相同的方式(通过添加前缀和后缀)为它们生成审核表。如果要覆盖此行为,可以使用@SecondaryAuditTable和@SecondaryAuditTables注解。
如果您想覆盖从@MappedSuperclass或嵌入式组件继承的某些字段/属性的审核行为,则可以在组件的子类型或使用站点上应用@AuditOverride注解。
如果要审核用@OneToMany和@JoinColumnMap 的关系,请参阅Mapping exceptions以获取可能要使用的其他@AuditJoinTableComments 的描述。
如果要审核不审核目标实体的关系(例如,像字典一样的实体即不会更改且不必审核),只需用@Audited( targetAuditMode = RelationTargetAuditMode.NOT_AUDITED )进行 Comments。然后,在读取实体的历史版本时,该关系将始终指向与“当前”相关的实体。默认情况下,当数据库中不存在“当前”实体时,Envers 会抛出javax.persistence.EntityNotFoundException。应用@NotFound( action = NotFoundAction.IGNORE )Comments 可使异常静音,并分配空值。因此解决方案导致一对一关系的隐性渴望加载。
如果您要审核实体的超类的属性,而这些属性未经过明确审核(它们在任何属性或类上都没有@AuditedComments),则可以设置@AuditOverride( forClass = SomeEntity.class, isAudited = true/false )Comments。
Note
@AuditedComments 还具有auditParents属性,但现在不推荐使用@AuditOverride。
21.4. 选择审核策略
完成基本配置后,重要的是选择将用于保留和检索审核信息的审核策略。在持久性能和查询审计信息的性能之间需要权衡。当前,有两种审计策略。
- 默认审核策略将审核数据与开始修订版一起保留。对于在审核表中插入,更新或删除的每一行,将在审核表中插入一行或多行,以及有效性的开始修订。插入后,审计表中的行永远不会更新。审核信息查询使用子查询来选择审核表中的适用行。
Tip
众所周知,这些子查询很慢并且很难索引。
- 替代方法是有效性审核策略。此策略存储审核信息的开始修订和结束修订。对于在审核表中插入,更新或删除的每一行,将在审核表中插入一行或多行,以及有效性的开始修订。但是同时,先前审核行的结束修订字段(如果可用)设置为此修订。然后,对审核信息的查询可以使用“开始和结束修订之间”,而不是默认审核策略所使用的子查询。
此策略的结果是,由于涉及额外的更新,因此保留审核信息的速度会稍慢一些,但是检索审核信息的速度会快很多。
Tip
可以通过添加额外的索引来进一步改善。
21.4.1. 配置 ValidityAuditStrategy
为了更好地可视化ValidityAuditStrategy的工作方式,请考虑以下练习,在其中重播Customer实体的先前审核日志记录示例。
首先,您需要配置ValidityAuditStrategy:
例子 661.配置ValidityAuditStrategy
options.put(
EnversSettings.AUDIT_STRATEGY,
ValidityAuditStrategy.class.getName()
);
如果您使用的是persistence.xml配置文件,则 Map 将如下所示:
<property
name="org.hibernate.envers.audit_strategy"
value="org.hibernate.envers.strategy.ValidityAuditStrategy"
/>
配置ValidityAuditStrategy后,将自动生成以下架构:
例子 662.启用ValidityAuditStrategy的架构
create table Customer (
id bigint not null,
created_on timestamp,
firstName varchar(255),
lastName varchar(255),
primary key (id)
)
create table Customer_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint,
REVEND integer,
created_on timestamp,
firstName varchar(255),
lastName varchar(255),
primary key (id, REV)
)
create table REVINFO (
REV integer generated by default as identity,
REVTSTMP bigint,
primary key (REV)
)
alter table Customer_AUD
add constraint FK5ecvi1a0ykunrriib7j28vpdj
foreign key (REV)
references REVINFO
alter table Customer_AUD
add constraint FKqd4fy7ww1yy95wi4wtaonre3f
foreign key (REVEND)
references REVINFO
如您所见,REVEND列及其外键被添加到REVINFO表中。
当针对ValidityAuditStrategy重新运行以前的Customer审核日志查询时,我们得到以下结果:
例子 663.获得Customer实体的第一个修订版
select
c.id as id1_1_,
c.REV as REV2_1_,
c.REVTYPE as REVTYPE3_1_,
c.REVEND as REVEND4_1_,
c.created_on as created_5_1_,
c.firstName as firstNam6_1_,
c.lastName as lastName7_1_
from
Customer_AUD c
where
c.REV <= ?
and c.REVTYPE <> ?
and (
c.REVEND > ?
or c.REVEND is null
)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [INTEGER] - [2]
-- binding parameter [3] as [INTEGER] - [1]
Note
与默认策略相比,ValidityAuditStrategy生成的查询更简单,可以呈现更好的 SQL 执行计划。
21.5. 修订日志
当 Envers 启动新修订时,它将创建一个新修订实体,该实体存储有关修订的信息。
默认情况下,仅包括:
revision number
- 整数值(
int/Integer或long/Long)。本质上,是修订的主键。
- 整数值(
Warning
修订号值应该“总是”不断增加且永不溢出。
Envers 提供的默认实现使用int数据类型,其上限为Integer.MAX_VALUE。用户考虑此上限对于您的应用程序是否可行至关重要。如果需要很大的范围,请考虑使用long数据类型的自定义修订版实体 Map。
如果修订号达到其上限并变为负数,则将抛出AuditException导致当前事务回滚。这样可以确保审核历史记录保持有效状态,可以由 Envers Query API 查询。
revision timestamp
- 代表进行修订的时间的
long/Long或java.util.Date值。当使用java.util.Date而不是long/Long作为修订时间戳时,请注意不要将其存储到会降低精度的列数据类型中。
- 代表进行修订的时间的
Envers 将此信息作为实体处理。默认情况下,它使用自己的内部类作为实体,Map 到REVINFO表。但是,您可以提供自己的方法来收集此信息,这可能有助于捕获其他详细信息,例如谁进行了更改或发出请求的 IP 地址。要完成这项工作,需要做两件事:
- 首先,您需要将要使用的实体告知 Envers。您的实体必须使用
@org.hibernate.envers.RevisionEntityComments。它必须定义上述两个属性,分别用@org.hibernate.envers.RevisionNumber和@org.hibernate.envers.RevisionTimestampComments。如果需要,您可以从org.hibernate.envers.DefaultRevisionEntity继承所有这些必需的行为。
只需像常规实体一样添加自定义修订版实体,Envers 就会“找到它” **。
Note
有多个标记为@org.hibernate.envers.RevisionEntity的实体是错误的。
- 其次,您需要告诉 Envers 如何创建由
org.hibernate.envers.RevisionListener接口的newRevision(对象 versionEntity)方法处理的修订实体的实例。
您可以通过使用 value 属性在@org.hibernate.envers.RevisionEntity注解中指定它来告诉 Envers 您的自定义org.hibernate.envers.RevisionListener实现要使用。如果您无法通过@RevisionEntity访问RevisionListener类(例如,它存在于其他模块中),请将org.hibernate.envers.revision_listener属性设置为其完全限定的类名。配置参数定义的类名称将覆盖修订实体的 value 属性。
考虑到我们有一个CurrentUserUtil,用于存储当前登录的用户:
例子 664.CurrentUserUtil
public static class CurrentUser {
public static final CurrentUser INSTANCE = new CurrentUser();
private static final ThreadLocal<String> storage = new ThreadLocal<>();
public void logIn(String user) {
storage.set( user );
}
public void logOut() {
storage.remove();
}
public String get() {
return storage.get();
}
}
现在,我们需要提供一个自定义@RevisionEntity来存储当前登录的用户
例子 665.自定义@RevisionEntity例子
@Entity(name = "CustomRevisionEntity")
@Table(name = "CUSTOM_REV_INFO")
@RevisionEntity( CustomRevisionEntityListener.class )
public static class CustomRevisionEntity extends DefaultRevisionEntity {
private String username;
public String getUsername() {
return username;
}
public void setUsername( String username ) {
this.username = username;
}
}
有了自定义的RevisionEntity实现,我们只需要提供RevisionEntity实现即可充当RevisionEntity实例的工厂。
例子 666.自定义@RevisionListener例子
public static class CustomRevisionEntityListener implements RevisionListener {
public void newRevision( Object revisionEntity ) {
CustomRevisionEntity customRevisionEntity =
( CustomRevisionEntity ) revisionEntity;
customRevisionEntity.setUsername(
CurrentUser.INSTANCE.get()
);
}
}
生成数据库架构时,Envers 将创建以下RevisionEntity表:
例子 667.自动生成的RevisionEntity Envers 表
create table CUSTOM_REV_INFO (
id integer not null,
timestamp bigint not null,
username varchar(255),
primary key (id)
)
您可以在适当位置看到username列。
现在,在插入Customer实体时,Envers 会生成以下语句:
例子 668.使用定制的@RevisionEntity实例进行审核
CurrentUser.INSTANCE.logIn( "Vlad Mihalcea" );
doInJPA( this::entityManagerFactory, entityManager -> {
Customer customer = new Customer();
customer.setId( 1L );
customer.setFirstName( "John" );
customer.setLastName( "Doe" );
entityManager.persist( customer );
} );
CurrentUser.INSTANCE.logOut();
insert
into
Customer
(created_on, firstName, lastName, id)
values
(?, ?, ?, ?)
-- binding parameter [1] as [TIMESTAMP] - [Thu Jul 27 15:45:00 EEST 2017]
-- binding parameter [2] as [VARCHAR] - [John]
-- binding parameter [3] as [VARCHAR] - [Doe]
-- binding parameter [4] as [BIGINT] - [1]
insert
into
CUSTOM_REV_INFO
(timestamp, username, id)
values
(?, ?, ?)
-- binding parameter [1] as [BIGINT] - [1501159500888]
-- binding parameter [2] as [VARCHAR] - [Vlad Mihalcea]
-- binding parameter [3] as [INTEGER] - [1]
insert
into
Customer_AUD
(REVTYPE, created_on, firstName, lastName, id, REV)
values
(?, ?, ?, ?, ?, ?)
-- binding parameter [1] as [INTEGER] - [0]
-- binding parameter [2] as [TIMESTAMP] - [Thu Jul 27 15:45:00 EEST 2017]
-- binding parameter [3] as [VARCHAR] - [John]
-- binding parameter [4] as [VARCHAR] - [Doe]
-- binding parameter [5] as [BIGINT] - [1]
-- binding parameter [6] as [INTEGER] - [1]
如上面的示例所示,正确设置了用户名并将其传播到CUSTOM_REV_INFO表。
Warning
从 5.2 版开始不推荐使用此策略.替代方法是使用版本 5.3 起提供的依赖项注入.
使用org.hibernate.envers.RevisionListener的另一种方法是改为调用org.hibernate.envers.AuditReader接口的getCurrentRevision(Class<T>versionEntityClass,布尔值持久化)方法来获取当前修订,并用所需的信息填充它。
该方法接受一个persist参数,该参数指示在从该方法返回之前是否应保留修订实体:
true确保返回的实体可以访问其标识符值(修订号),但是无论是否更改了任何审核的实体,修订版实体都将保留。
false表示修订版本号将为
null,但是只有在某些审核实体已更改的情况下,修订版本实体才会保留。
Note
从 Hibernate Envers 5.3 开始,现在支持RevisionListener的依赖项注入。
此功能取决于各种依赖性框架,例如 CDI 和 Spring,以在 Hibernate ORM 引导期间提供必要的实现以支持注入。如果没有提供合格的实现,则RevisionListener将被构造为不注入。
21.6. 修订期间修改的跟踪实体名称
默认情况下,不会跟踪在每个修订版中已更改的实体类型。这意味着有必要查询存储审计数据的所有表,以检索在指定修订期间所做的更改。 Envers 提供了一种简单的机制来创建REVCHANGES表,该表存储已修改的持久对象的实体名称。单个记录封装了修订标识符(REVINFO表的外键)和字符串值。
可以通过三种不同方式启用对已修改实体名称的跟踪:
将
org.hibernate.envers.track_entities_changed_in_revision参数设置为true。在这种情况下,org.hibernate.envers.DefaultTrackingModifiedEntitiesRevisionEntity将隐式用作修订日志实体。创建扩展
org.hibernate.envers.DefaultTrackingModifiedEntitiesRevisionEntity类的自定义修订版实体。
@Entity(name = "CustomTrackingRevisionEntity")
@Table(name = "TRACKING_REV_INFO")
@RevisionEntity
public static class CustomTrackingRevisionEntity
extends DefaultTrackingModifiedEntitiesRevisionEntity {
}
- 用
@org.hibernate.envers.ModifiedEntityNamesComments 标记自定义修订实体的适当字段。该属性必须为Set<String>类型。
@Entity(name = "CustomTrackingRevisionEntity")
@Table(name = "TRACKING_REV_INFO")
@RevisionEntity
public static class CustomTrackingRevisionEntity extends DefaultRevisionEntity {
@ElementCollection
@JoinTable(
name = "REVCHANGES",
joinColumns = @JoinColumn( name = "REV" )
)
@Column( name = "ENTITYNAME" )
@ModifiedEntityNames
private Set<String> modifiedEntityNames = new HashSet<>();
public Set<String> getModifiedEntityNames() {
return modifiedEntityNames;
}
}
考虑到我们有一个Customer实体,如以下示例所示:
例子 669. Customer重命名之前的实体
@Audited
@Entity(name = "Customer")
public static class Customer {
@Id
private Long id;
private String firstName;
private String lastName;
@Temporal( TemporalType.TIMESTAMP )
@Column(name = "created_on")
@CreationTimestamp
private Date createdOn;
//Getters and setters are omitted for brevity
}
如果Customer实体类名称更改为ApplicationCustomer,则 Envers 将使用先前的实体类名称在REVCHANGES表中插入新记录:
例子 670.重命名后的Customer实体
@Audited
@Entity(name = "Customer")
public static class ApplicationCustomer {
@Id
private Long id;
private String firstName;
private String lastName;
@Temporal( TemporalType.TIMESTAMP )
@Column(name = "created_on")
@CreationTimestamp
private Date createdOn;
//Getters and setters are omitted for brevity
}
insert
into
REVCHANGES
(REV, ENTITYNAME)
values
(?, ?)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [VARCHAR] - [org.hibernate.userguide.envers.EntityTypeChangeAuditTest$Customer]
选择了上面列出的方法之一的用户可以使用查询在给定版本中修改的实体类型中描述的 API 来检索在指定版本中修改的所有实体。
还允许用户实施跟踪已修改实体类型的自定义机制。在这种情况下,他们应将自己的org.hibernate.envers.EntityTrackingRevisionListener接口实现作为@org.hibernate.envers.RevisionEntityComments 的值传递。
EntityTrackingRevisionListener接口公开了一种方法,该方法会在当前版本边界内添加,修改或删除受审核实体实例时进行通知。
例子 671. EntityTrackingRevisionListener实现
public static class CustomTrackingRevisionListener implements EntityTrackingRevisionListener {
@Override
public void entityChanged(Class entityClass,
String entityName,
Serializable entityId,
RevisionType revisionType,
Object revisionEntity ) {
String type = entityClass.getName();
( (CustomTrackingRevisionEntity) revisionEntity ).addModifiedEntityType( type );
}
@Override
public void newRevision( Object revisionEntity ) {
}
}
CustomTrackingRevisionListener将完全限定的类名添加到CustomTrackingRevisionEntity的modifiedEntityTypes属性中。
例子 672. RevisionEntity使用自定义EntityTrackingRevisionListener
@Entity(name = "CustomTrackingRevisionEntity")
@Table(name = "TRACKING_REV_INFO")
@RevisionEntity( CustomTrackingRevisionListener.class )
public static class CustomTrackingRevisionEntity {
@Id
@GeneratedValue
@RevisionNumber
private int customId;
@RevisionTimestamp
private long customTimestamp;
@OneToMany(
mappedBy="revision",
cascade={
CascadeType.PERSIST,
CascadeType.REMOVE
}
)
private Set<EntityType> modifiedEntityTypes = new HashSet<>();
public Set<EntityType> getModifiedEntityTypes() {
return modifiedEntityTypes;
}
public void addModifiedEntityType(String entityClassName ) {
modifiedEntityTypes.add( new EntityType( this, entityClassName ) );
}
}
CustomTrackingRevisionEntity包含ModifiedTypeRevisionEntity的@OneToMany列表
例子 673. EntityType封装了类名修改之前的实体类型名
@Entity(name = "EntityType")
public static class EntityType {
@Id
@GeneratedValue
private Integer id;
@ManyToOne
private CustomTrackingRevisionEntity revision;
private String entityClassName;
private EntityType() {
}
public EntityType(CustomTrackingRevisionEntity revision, String entityClassName) {
this.revision = revision;
this.entityClassName = entityClassName;
}
//Getters and setters are omitted for brevity
}
现在,在获取CustomTrackingRevisionEntity时,您可以访问以前的实体类名称。
例子 674.通过CustomTrackingRevisionEntity获取EntityType
AuditReader auditReader = AuditReaderFactory.get( entityManager );
List<Number> revisions = auditReader.getRevisions(
ApplicationCustomer.class,
1L
);
CustomTrackingRevisionEntity revEntity = auditReader.findRevision(
CustomTrackingRevisionEntity.class,
revisions.get( 0 )
);
Set<EntityType> modifiedEntityTypes = revEntity.getModifiedEntityTypes();
assertEquals( 1, modifiedEntityTypes.size() );
EntityType entityType = modifiedEntityTypes.iterator().next();
assertEquals(
Customer.class.getName(),
entityType.getEntityClassName()
);
21.7. 在属性级别跟踪实体更改
默认情况下,Envers 存储的唯一信息是已修改实体的修订版。通过这种方法,用户可以根据实体属性的历史值创建审核查询。有时,当您还对更改类型(不仅是结果值)感兴趣时,为每个修订存储其他元数据很有用。
修订期间修改的跟踪实体名称中描述的功能可以告诉您在给定修订版中哪些实体已被修改。
此处描述的功能使它更进一步。 * Modification Flags *(标记)使 Envers 能够跟踪给定版本中已审计实体的哪些属性被修改。
可以通过以下方式在属性级别启用跟踪实体更改:
将
org.hibernate.envers.global_with_modified_flag配置属性设置为true。此全局开关将导致为所有审核实体的所有审核属性存储添加的修改标志。在属性或实体上使用
@Audited( withModifiedFlag = true )。
与此功能相关的权衡是,审核表的大小增加了,并且审核写入期间的性能下降很少,几乎可以忽略不计。这是由于以下事实:每个跟踪的属性都必须在架构中具有一个随附的布尔列,该布尔列用于存储有关属性修改的信息。当然,相应地填写这些列是 Enver 的工作-无需开发人员进行其他工作。由于提到的成本,建议在需要时使用上述粒度配置工具有选择地启用该功能。
例子 675.用于在属性级别跟踪实体更改的 Map
@Audited(withModifiedFlag = true)
@Entity(name = "Customer")
public static class Customer {
@Id
private Long id;
private String firstName;
private String lastName;
@Temporal( TemporalType.TIMESTAMP )
@Column(name = "created_on")
@CreationTimestamp
private Date createdOn;
//Getters and setters are omitted for brevity
}
create table Customer_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint,
created_on timestamp,
createdOn_MOD boolean,
firstName varchar(255),
firstName_MOD boolean,
lastName varchar(255),
lastName_MOD boolean,
primary key (id, REV)
)
如您所见,每个属性在审核日志中都有_MOD列(例如createdOn_MOD)。
例子 676.跟踪实体在属性级别的变化
Customer customer = entityManager.find( Customer.class, 1L );
customer.setLastName( "Doe Jr." );
update
Customer
set
created_on = ?,
firstName = ?,
lastName = ?
where
id = ?
-- binding parameter [1] as [TIMESTAMP] - [2017-07-31 15:58:20.342]
-- binding parameter [2] as [VARCHAR] - [John]
-- binding parameter [3] as [VARCHAR] - [Doe Jr.]
-- binding parameter [4] as [BIGINT] - [1]
insert
into
REVINFO
(REV, REVTSTMP)
values
(null, ?)
-- binding parameter [1] as [BIGINT] - [1501505900439]
insert
into
Customer_AUD
(REVTYPE, created_on, createdOn_MOD, firstName, firstName_MOD, lastName, lastName_MOD, id, REV)
values
(?, ?, ?, ?, ?, ?, ?, ?, ?)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [TIMESTAMP] - [2017-07-31 15:58:20.342]
-- binding parameter [3] as [BOOLEAN] - [false]
-- binding parameter [4] as [VARCHAR] - [John]
-- binding parameter [5] as [BOOLEAN] - [false]
-- binding parameter [6] as [VARCHAR] - [Doe Jr.]
-- binding parameter [7] as [BOOLEAN] - [true]
-- binding parameter [8] as [BIGINT] - [1]
-- binding parameter [9] as [INTEGER] - [2]
要查看如何使用“修改的标志”,请查看使用它们的非常简单的查询 API:查询修改给定属性的实体修订。
21.8. 选择策略以跟踪属性级别更改
默认情况下,Envers 使用legacy修改的列命名策略。此策略旨在根据以下规则集添加列:
如果使用
@AuditedComments 属性,并且指定了* modifiedColumnName *属性,则该列将直接基于提供的名称。如果未使用
@AuditedComments 属性,或者未提供* modifiedColumnName *属性,则该列将以 java 类属性命名,并附加配置的后缀,默认为_MOD。
尽管此策略没有性能上的缺点,但确实给那些希望保持一致而不冗长的用户带来了困扰。让我们以以下实体 Map 为例。
@Audited(withModifiedFlags = true)
@Entity
public class Customer {
@Id
private Integer id;
@Column(name = "customer_name")
private String name;
}
这种 Map 实际上会导致各列之间的命名不一致,有关将如何在customer_name中存储模型名称的信息,请参见下文,但是跟踪该列在版本之间是否发生变化的修改后的列名为name_MOD。
CREATE TABLE Customer_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint not null,
customer_name varchar(255),
name_MOD boolean,
primary key(id, REV)
)
另一种名为improved的策略旨在解决这些不一致的列命名问题。此策略使用以下规则集:
属性是基本类型(单列值属性)
如果属性 Map 中提供了一个,则直接使用* modifiedColumnName *
- 否则,请使用已解析的 ORM 列名,并附加修改后的标志后缀配置值
属性是使用单列与外键的关联(到一个 Map)
如果属性 Map 中提供了一个,则直接使用* modifiedColumnName *
- 否则,请使用已解析的 ORM 列名,并附加修改后的标志后缀配置值
属性是使用多列的外键的关联(到一个 Map)
如果属性 Map 中提供了一个,则直接使用* modifiedColumnName *
- 否则,请使用属性名称加上修改后的标志后缀配置值
财产是可嵌入的
如果属性 Map 中提供了一个,则直接使用* modifiedColumnName *
- 否则,请使用属性名称加上修改后的标志后缀配置值
使用此策略时,相同的CustomerMap 将生成以下表模式:
CREATE TABLE Customer_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint not null,
customer_name varchar(255),
customer_name_MOD boolean,
primary key(id, REV)
)
当已经将 Envers 与已修改的列标志功能一起使用时,建议不要立即启用新策略,因为将需要更改架构。您将需要手动迁移现有模式以遵守上述规则,或者对使用该功能的现有列使用@AuditedComments 上的显式* modifiedColumnName *属性。
要配置自定义策略实施或使用改进的策略,将需要设置配置选项org.hibernate.envers.modified_column_naming_strategy。此选项可以是ModifiedColumnNameStrategy实现的完全限定的类名,也可以是两个提供的实现中的legacy或improved的全限定类名。
21.9. Queries
您可以认为历史数据具有两个维度:
horizontal
- 给定版本的数据库状态。因此,您可以查询实体,它们的版本为 N。
vertical
- 实体发生更改的修订。因此,您可以查询给定实体已更改的修订。
Envers 中的查询与 Hibernate Criteria 查询类似,因此,如果您熟悉它们,则使用 Envers 查询会容易得多。
当前查询实现的主要限制是您无法遍历关系。您只能在相关实体的 ID 上指定约束,并且只能在关系的“拥有”端指定约束。但是,在将来的版本中将对此进行更改。
Note
在许多情况下,对审计数据的查询要比对“实时”数据的相应查询慢得多,因为尤其是对于默认审计策略,它们涉及相关的子选择。
使用有效性审计策略时,查询在速度和可能性上都得到了改进,该策略存储实体的开始和结束修订。有关更详细的讨论,请参见配置 ValidityAuditStrategy。
21.10. 查询给定版本的类的实体
此类查询的入口点是:
例子 677.在给定的版本中获取Customer实体
Customer customer = (Customer) AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, revisions.get( 0 ) )
.getSingleResult();
assertEquals("Doe", customer.getLastName());
21.11. 使用过滤条件查询实体
然后,您可以通过添加限制(可以使用AuditEntity factory 类获得)来指定返回的实体应满足的限制。
例如,仅选择firstName属性等于“ John”的实体:
例 678.获取具有给定firstName属性值的Customer审核日志
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, true, true )
.add( AuditEntity.property( "firstName" ).eq( "John" ) )
.getResultList();
assertEquals(2, customers.size());
assertEquals( "Doe", customers.get( 0 ).getLastName() );
assertEquals( "Doe Jr.", customers.get( 1 ).getLastName() );
并且,要仅选择其关系与给定实体相关的实体,可以使用目标实体或其标识符。
例子 679.获取Customer实体,它们的address属性匹配给定的实体引用
Address address = entityManager.getReference( Address.class, 1L );
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, true, true )
.add( AuditEntity.property( "address" ).eq( address ) )
.getResultList();
assertEquals(2, customers.size());
select
c.id as id1_3_,
c.REV as REV2_3_,
c.REVTYPE as REVTYPE3_3_,
c.REVEND as REVEND4_3_,
c.created_on as created_5_3_,
c.firstName as firstNam6_3_,
c.lastName as lastName7_3_,
c.address_id as address_8_3_
from
Customer_AUD c
where
c.address_id = ?
order by
c.REV asc
-- binding parameter [1] as [BIGINT] - [1]
即使我们提供标识符而不是目标实体引用,也会生成相同的 SQL。
例子 680.获得Customer实体,它们的address标识符与给定的实体标识符匹配
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, true, true )
.add( AuditEntity.relatedId( "address" ).eq( 1L ) )
.getResultList();
assertEquals(2, customers.size());
除了严格的相等匹配之外,您还可以使用IN子句来提供多个实体标识符:
例子 681.获得Customer实体,它们的address标识符与给定的实体标识符之一匹配
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, true, true )
.add( AuditEntity.relatedId( "address" ).in( new Object[] { 1L, 2L } ) )
.getResultList();
assertEquals(2, customers.size());
select
c.id as id1_3_,
c.REV as REV2_3_,
c.REVTYPE as REVTYPE3_3_,
c.REVEND as REVEND4_3_,
c.created_on as created_5_3_,
c.firstName as firstNam6_3_,
c.lastName as lastName7_3_,
c.address_id as address_8_3_
from
Customer_AUD c
where
c.address_id in (
? , ?
)
order by
c.REV asc
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [BIGINT] - [2]
您可以限制结果的数量,对其进行排序,并以通常的方式设置汇总和预测(分组除外)。查询完成后,可以通过调用getSingleResult()或getResultList()方法获得结果。
完整的查询可以看起来像这样:
例子 682.使用过滤和分页获取Customer实体
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, true, true )
.addOrder( AuditEntity.property( "lastName" ).desc() )
.add( AuditEntity.relatedId( "address" ).eq( 1L ) )
.setFirstResult( 1 )
.setMaxResults( 2 )
.getResultList();
assertEquals(1, customers.size());
select
c.id as id1_3_,
c.REV as REV2_3_,
c.REVTYPE as REVTYPE3_3_,
c.REVEND as REVEND4_3_,
c.created_on as created_5_3_,
c.firstName as firstNam6_3_,
c.lastName as lastName7_3_,
c.address_id as address_8_3_
from
Customer_AUD c
where
c.address_id = ?
order by
c.lastName desc
limit ?
offset ?
21.12. 查询修订,给定类的实体已更改
此类查询的入口点是:
AuditQuery query = AuditReaderFactory.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, false, true );
您可以按照与上一个查询相同的方式向该查询添加约束。
还有一些其他可能性:
使用
AuditEntity.revisionNumber(),您可以在修订号上指定约束,预测和 Sequences,在其中修订了审计实体。类似地,使用
AuditEntity.revisionProperty( propertyName )可以在修订实体的属性上指定约束,投影和 Sequences,该属性对应于修改了审核实体的修订。AuditEntity.revisionType()使您能够像上面那样访问修订的类型(ADD,MOD,DEL)。
使用这些方法,您可以按修订号对查询结果进行排序,将投影数设置为投影或限制为大于或小于指定值等。例如,以下查询将选择最小的修订号,在该实体上版本号 2 之后,ID 为entityId的类别MyEntity已更改:
Number revision = (Number) AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, false, true )
.addProjection( AuditEntity.revisionNumber().min() )
.add( AuditEntity.id().eq( 1L ) )
.add( AuditEntity.revisionNumber().gt( 2 ) )
.getSingleResult();
您可以在修订查询中使用的第二个附加功能是“最大化” /“最小化”属性的功能。
例如,如果要选择createdOn属性值大于给定值的最小修订版本,则可以运行以下查询:
Number revision = (Number) AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, false, true )
.addProjection( AuditEntity.revisionNumber().min() )
.add( AuditEntity.id().eq( 1L ) )
.add(
AuditEntity.property( "createdOn" )
.minimize()
.add( AuditEntity.property( "createdOn" )
.ge(
Timestamp.from(
LocalDateTime.now()
.minusDays( 1 )
.toInstant( ZoneOffset.UTC )
)
)
)
)
.getSingleResult();
minimize()和maximize()方法返回一个条件,您可以向其添加约束,具有* maximized / minimized *属性的实体必须满足这些条件。
您可能还注意到创建查询时传递了两个布尔参数。
selectEntitiesOnly- 第一个参数仅在未设置显式投影时才有效。
如果为 true,则查询结果将为实体列表(在满足指定约束的修订版中已更改)。
如果为 false,则结果将是三个元素数组的列表:
第一个元素将是更改后的实体实例。
第二个将是包含修订数据的实体(如果未使用任何自定义实体,则将是
DefaultRevisionEntity的实例)。第三个将是修订的类型(
RevisionType枚举的值之一:ADD,MOD,DEL)。selectDeletedEntities- 第二个参数指定结果中是否应包含删除实体的修订。
如果是,则此类实体的修订版类型为DEL,除id之外的所有属性都将设置为null。
另一个有用的功能是AggregatedAuditExpression#computeAggregationInInstanceContext()。这可用于基于实体实例主键创建聚合查询。
例如,如果要查找所有 Client,但只想检索具有最大修订号的实例,则可以使用以下查询:
List<Customer> results = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, true, false )
.add( AuditEntity.revisionNumber().maximize().computeAggregationInInstanceContext() )
.getResultList();
换句话说,结果集将包含Customer个实例的列表,每个主键一个。每个实例会将每个Customer主键的经审核的属性数据保存在最大修订版本号处。
21.13. 查询修改给定属性的实体修订
对于上述两种类型的查询,可以使用称为hasChanged()和hasNotChanged()的特殊Audit条件,这些条件利用了在属性级别跟踪实体更改中描述的功能。
让我们看一下可以从这两个条件中受益的各种查询。
首先,您必须确保您的实体可以跟踪修改标志:
例子 683.仅在审计日志记录跟踪实体属性修改标志时有效
@Audited( withModifiedFlag = true )
以下查询将返回lastName属性已更改的具有给定id的Customer实体的所有修订。
例子 684.获取lastName属性已更改的所有Customer版本
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, false, true )
.add( AuditEntity.id().eq( 1L ) )
.add( AuditEntity.property( "lastName" ).hasChanged() )
.getResultList();
select
c.id as id1_3_0_,
c.REV as REV2_3_0_,
defaultrev1_.REV as REV1_4_1_,
c.REVTYPE as REVTYPE3_3_0_,
c.REVEND as REVEND4_3_0_,
c.created_on as created_5_3_0_,
c.createdOn_MOD as createdO6_3_0_,
c.firstName as firstNam7_3_0_,
c.firstName_MOD as firstNam8_3_0_,
c.lastName as lastName9_3_0_,
c.lastName_MOD as lastNam10_3_0_,
c.address_id as address11_3_0_,
c.address_MOD as address12_3_0_,
defaultrev1_.REVTSTMP as REVTSTMP2_4_1_
from
Customer_AUD c cross
join
REVINFO defaultrev1_
where
c.id = ?
and c.lastName_MOD = ?
and c.REV=defaultrev1_.REV
order by
c.REV asc
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [BOOLEAN] - [true]
使用此查询,我们将不会获得未触及lastName的所有其他修订。从 SQL 查询中,您可以看到 WHERE 子句中正在使用lastName_MOD列,因此,前面提到的跟踪修改标志的要求。
当然,没有什么可以阻止用户将hasChanged条件与一些其他条件组合在一起。
例子 685.获取lastName属性已更改而firstName属性未更改的所有Customer版本
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forRevisionsOfEntity( Customer.class, false, true )
.add( AuditEntity.id().eq( 1L ) )
.add( AuditEntity.property( "lastName" ).hasChanged() )
.add( AuditEntity.property( "firstName" ).hasNotChanged() )
.getResultList();
select
c.id as id1_3_0_,
c.REV as REV2_3_0_,
defaultrev1_.REV as REV1_4_1_,
c.REVTYPE as REVTYPE3_3_0_,
c.REVEND as REVEND4_3_0_,
c.created_on as created_5_3_0_,
c.createdOn_MOD as createdO6_3_0_,
c.firstName as firstNam7_3_0_,
c.firstName_MOD as firstNam8_3_0_,
c.lastName as lastName9_3_0_,
c.lastName_MOD as lastNam10_3_0_,
c.address_id as address11_3_0_,
c.address_MOD as address12_3_0_,
defaultrev1_.REVTSTMP as REVTSTMP2_4_1_
from
Customer_AUD c cross
join
REVINFO defaultrev1_
where
c.id=?
and c.lastName_MOD=?
and c.firstName_MOD=?
and c.REV=defaultrev1_.REV
order by
c.REV asc
-- binding parameter [1] as [BIGINT] - [1]
-- binding parameter [2] as [BOOLEAN] - [true]
-- binding parameter [3] as [BOOLEAN] - [false]
要在给定的revisionNumber上更改Customer实体,并修改lastName且未修改firstName,我们必须使用forEntitiesModifiedAtRevision查询:
例子 686.如果lastName属性已更改而firstName属性未更改,则获取给定修订的Customer实体
Customer customer = (Customer) AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesModifiedAtRevision( Customer.class, 2 )
.add( AuditEntity.id().eq( 1L ) )
.add( AuditEntity.property( "lastName" ).hasChanged() )
.add( AuditEntity.property( "firstName" ).hasNotChanged() )
.getSingleResult();
select
c.id as id1_3_,
c.REV as REV2_3_,
c.REVTYPE as REVTYPE3_3_,
c.REVEND as REVEND4_3_,
c.created_on as created_5_3_,
c.createdOn_MOD as createdO6_3_,
c.firstName as firstNam7_3_,
c.firstName_MOD as firstNam8_3_,
c.lastName as lastName9_3_,
c.lastName_MOD as lastNam10_3_,
c.address_id as address11_3_,
c.address_MOD as address12_3_
from
Customer_AUD c
where
c.REV=?
and c.id=?
and c.lastName_MOD=?
and c.firstName_MOD=?
-- binding parameter [1] as [INTEGER] - [2]
-- binding parameter [2] as [BIGINT] - [1]
-- binding parameter [3] as [BOOLEAN] - [true]
-- binding parameter [4] as [BOOLEAN] - [false]
21.14. 查询实体的修订版,包括已修改的属性名称
Note
这里描述的此功能仍被认为是实验性的。它会根据用户反馈在将来的发行版中进行更改,以提高其实用性。
有时,查询实体修订并确定修订的所有属性而不必使用hasChanged()和hasNotChanged()标准发出多个查询可能很有用。
现在,您可以使用以下查询轻松获得此信息:
例子 687.查询实体修订,包括修改后的属性名称。
List results = AuditReaderFactory.get( entityManager )
.createQuery()
.forRevisionsOfEntityWithChanges( Customer.class, false )
.add( AuditEntity.id().eq( 1L ) )
.getResultList();
for ( Object entry : results ) {
final Object[] array = (Object[]) entry;
final Set<String> propertiesChanged = (Set<String>) array[3];
for ( String propertyName : propertiesChanged ) {
/* Do something useful with the modified property `propertyName` */
}
}
21.15. 查询在给定版本中修改的实体类型
Note
仅当启用了跟踪更改的实体类型的默认机制(请参见修订期间修改的跟踪实体名称)时,才能使用以下方法。
此基本查询允许检索在指定版本中更改的实体名称和相应的 Java 类:
例子 688.检索实体名称和对应的 Java 类在指定的修订版中已更改
assertEquals(
"org.hibernate.userguide.envers.EntityTypeChangeAuditTest$Customer",
AuditReaderFactory
.get( entityManager )
.getCrossTypeRevisionChangesReader()
.findEntityTypes( 1 )
.iterator().next()
.getFirst()
);
assertEquals(
"org.hibernate.userguide.envers.EntityTypeChangeAuditTest$ApplicationCustomer",
AuditReaderFactory
.get( entityManager )
.getCrossTypeRevisionChangesReader()
.findEntityTypes( 2 )
.iterator().next()
.getFirst()
);
其他查询(也可以从org.hibernate.envers.CrossTypeRevisionChangesReader访问):
List<Object> findEntities(Number)- 返回在给定修订中已更改(添加,更新和删除)的所有审核实体的快照。执行
N + 1个 SQL 查询,其中N是在指定修订版中修改的许多不同实体类。
- 返回在给定修订中已更改(添加,更新和删除)的所有审核实体的快照。执行
List<Object> findEntities(Number, RevisionType)- 返回在给定修订中按修改类型过滤的所有更改(添加,更新或删除)的审核实体的快照。执行
N + 1个 SQL 查询,其中N是在指定修订版中修改的许多不同实体类。
- 返回在给定修订中按修改类型过滤的所有更改(添加,更新或删除)的审核实体的快照。执行
Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType(Number)- 返回包含按修改操作(例如添加,更新和删除)分组的实体快照列表的 Map。执行
3N + 1个 SQL 查询,其中N是在指定修订版中修改的许多不同实体类。
- 返回包含按修改操作(例如添加,更新和删除)分组的实体快照列表的 Map。执行
21.16. 使用实体关系联接查询实体
Warning
关系联接查询被认为是实验性的,可能会在将来的版本中进行更改。
审计查询支持基于实体关系应用约束,预测和排序操作的功能。为了遍历审计查询中的实体关系,您必须使用具有联接类型的关系遍历 API。
Note
只有在使用JoinType.LEFT或JoinType.INNER时,关系联接才能应用于many-to-one和one-to-oneMap。
创建实体关系联接查询的基础如下:
例子 689. INNER JOIN 实体审核查询
AuditQuery innerJoinAuditQuery = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, 1 )
.traverseRelation( "address", JoinType.INNER );
例子 690. LEFT JOIN 实体审核查询
AuditQuery innerJoinAuditQuery = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, 1 )
.traverseRelation( "address", JoinType.LEFT );
像任何其他查询一样,可以添加约束以限制结果。
例如,要查找给定修订版中地址在România中的所有Customer实体,可以使用以下查询:
例子 691.用 WHERE 子句谓词过滤联接关系
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, 1 )
.traverseRelation( "address", JoinType.INNER )
.add( AuditEntity.property( "country" ).eq( "România" ) )
.getResultList();
select
c.id as id1_3_,
c.REV as REV2_3_,
c.REVTYPE as REVTYPE3_3_,
c.REVEND as REVEND4_3_,
c.created_on as created_5_3_,
c.firstName as firstNam6_3_,
c.lastName as lastName7_3_,
c.address_id as address_8_3_
from
Customer_AUD c
inner join
Address_AUD a
on (
c.address_id=a.id
or (
c.address_id is null
)
and (
a.id is null
)
)
where
c.REV<=?
and c.REVTYPE<>?
and (
c.REVEND>?
or c.REVEND is null
)
and a.REV<=?
and a.country=?
and (
a.REVEND>?
or a.REVEND is null
)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [INTEGER] - [2]
-- binding parameter [3] as [INTEGER] - [1]
-- binding parameter [4] as [INTEGER] - [1]
-- binding parameter [5] as [VARCHAR] - [România]
-- binding parameter [6] as [INTEGER] - [1]
也可以遍历实体图中的第一个关系。
例如,要查找给定修订版的所有Customer实体,其中 address 属性的 country 属性为România:
例子 692.用 WHERE 子句谓词过滤嵌套的连接关系
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, 1 )
.traverseRelation( "address", JoinType.INNER )
.traverseRelation( "country", JoinType.INNER )
.add( AuditEntity.property( "name" ).eq( "România" ) )
.getResultList();
assertEquals( 1, customers.size() );
select
cu.id as id1_5_,
cu.REV as REV2_5_,
cu.REVTYPE as REVTYPE3_5_,
cu.REVEND as REVEND4_5_,
cu.created_on as created_5_5_,
cu.firstName as firstNam6_5_,
cu.lastName as lastName7_5_,
cu.address_id as address_8_5_
from
Customer_AUD cu
inner join
Address_AUD a
on (
cu.address_id=a.id
or (
cu.address_id is null
)
and (
a.id is null
)
)
inner join
Country_AUD co
on (
a.country_id=co.id
or (
a.country_id is null
)
and (
co.id is null
)
)
where
cu.REV<=?
and cu.REVTYPE<>?
and (
cu.REVEND>?
or cu.REVEND is null
)
and a.REV<=?
and (
a.REVEND>?
or a.REVEND is null
)
and co.REV<=?
and co.name=?
and (
co.REVEND>?
or co.REVEND is null
)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [INTEGER] - [2]
-- binding parameter [3] as [INTEGER] - [1]
-- binding parameter [4] as [INTEGER] - [1]
-- binding parameter [5] as [INTEGER] - [1]
-- binding parameter [6] as [INTEGER] - [1]
-- binding parameter [7] as [VARCHAR] - [România]
-- binding parameter [8] as [INTEGER] - [1]
约束也可以添加到嵌套连接关系的属性中,例如测试null。
例如,以下查询说明了如何查找给定修订版中在Cluj-Napoca中具有address或address的所有Customer实体没有没有任何国家实体引用:
例子 693.使用多个谓词过滤联接关系
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, 1 )
.traverseRelation( "address", JoinType.LEFT, "a" )
.add(
AuditEntity.or(
AuditEntity.property( "a", "city" ).eq( "Cluj-Napoca" ),
AuditEntity.relatedId( "country" ).eq( null )
)
)
.getResultList();
select
c.id as id1_5_,
c.REV as REV2_5_,
c.REVTYPE as REVTYPE3_5_,
c.REVEND as REVEND4_5_,
c.created_on as created_5_5_,
c.firstName as firstNam6_5_,
c.lastName as lastName7_5_,
c.address_id as address_8_5_
from
Customer_AUD c
left outer join
Address_AUD a
on (
c.address_id=a.id
or (
c.address_id is null
)
and (
a.id is null
)
)
where
c.REV<=?
and c.REVTYPE<>?
and (
c.REVEND>?
or c.REVEND is null
)
and (
a.REV is null
or a.REV<=?
and (
a.REVEND>?
or a.REVEND is null
)
)
and (
a.city=?
or a.country_id is null
)
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [INTEGER] - [2]
-- binding parameter [3] as [INTEGER] - [1]
-- binding parameter [4] as [INTEGER] - [1]
-- binding parameter [5] as [INTEGER] - [1]
-- binding parameter [6] as [VARCHAR] - [Cluj-Napoca]
Note
查询可以使用up方法来导航回实体图。
析取标准也可以应用于关系联接查询。
例如,以下查询将查找给定版本的所有Customer实体,其中国家/地区名称为România或Customer居住于Cluj-Napoca:
例子 694.使用多个谓词过滤一个嵌套的连接关系
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, 1 )
.traverseRelation( "address", JoinType.INNER, "a" )
.traverseRelation( "country", JoinType.INNER, "cn" )
.up()
.up()
.add(
AuditEntity.disjunction()
.add( AuditEntity.property( "a", "city" ).eq( "Cluj-Napoca" ) )
.add( AuditEntity.property( "cn", "name" ).eq( "România" ) )
)
.addOrder( AuditEntity.property( "createdOn" ).asc() )
.getResultList();
select
cu.id as id1_5_,
cu.REV as REV2_5_,
cu.REVTYPE as REVTYPE3_5_,
cu.REVEND as REVEND4_5_,
cu.created_on as created_5_5_,
cu.firstName as firstNam6_5_,
cu.lastName as lastName7_5_,
cu.address_id as address_8_5_
from
Customer_AUD cu
inner join
Address_AUD a
on (
cu.address_id=a.id
or (
cu.address_id is null
)
and (
a.id is null
)
)
inner join
Country_AUD co
on (
a.country_id=co.id
or (
a.country_id is null
)
and (
co.id is null
)
)
where
cu.REV<=?
and cu.REVTYPE<>?
and (
cu.REVEND>?
or cu.REVEND is null
)
and (
a.city=?
or co.name=?
)
and a.REV<=?
and (
a.REVEND>?
or a.REVEND is null
)
and co.REV<=?
and (
co.REVEND>?
or co.REVEND is null
)
order by
cu.created_on asc
-- binding parameter [1] as [INTEGER] - [1]
-- binding parameter [2] as [INTEGER] - [2]
-- binding parameter [3] as [INTEGER] - [1]
-- binding parameter [4] as [VARCHAR] - [Cluj-Napoca]
-- binding parameter [5] as [VARCHAR] - [România]
-- binding parameter [6] as [INTEGER] - [1]
-- binding parameter [7] as [INTEGER] - [1]
-- binding parameter [8] as [INTEGER] - [1]
-- binding parameter [9] as [INTEGER] - [1]
最后,该示例说明了如何在单个约束中比较相关实体属性。
假设Customer和Address之前的更改如下:
例子 695.更改Address以匹配Country名称
Customer customer = entityManager.createQuery(
"select c " +
"from Customer c " +
"join fetch c.address a " +
"join fetch a.country " +
"where c.id = :id", Customer.class )
.setParameter( "id", 1L )
.getSingleResult();
customer.setLastName( "Doe Sr." );
customer.getAddress().setCity(
customer.getAddress().getCountry().getName()
);
以下查询显示如何查找address属性的city属性等于关联的country属性的name的Customer实体。
例子 696.使用多个谓词过滤嵌套的连接关系
List<Number> revisions = AuditReaderFactory.get( entityManager ).getRevisions(
Customer.class,
1L
);
List<Customer> customers = AuditReaderFactory
.get( entityManager )
.createQuery()
.forEntitiesAtRevision( Customer.class, revisions.get( revisions.size() - 1 ) )
.traverseRelation( "address", JoinType.INNER, "a" )
.traverseRelation( "country", JoinType.INNER, "cn" )
.up()
.up()
.add( AuditEntity.property( "a", "city" ).eqProperty( "cn", "name" ) )
.getResultList();
select
cu.id as id1_5_,
cu.REV as REV2_5_,
cu.REVTYPE as REVTYPE3_5_,
cu.REVEND as REVEND4_5_,
cu.created_on as created_5_5_,
cu.firstName as firstNam6_5_,
cu.lastName as lastName7_5_,
cu.address_id as address_8_5_
from
Customer_AUD cu
inner join
Address_AUD a
on (
cu.address_id=a.id
or (
cu.address_id is null
)
and (
a.id is null
)
)
inner join
Country_AUD cr
on (
a.country_id=cr.id
or (
a.country_id is null
)
and (
cr.id is null
)
)
where
cu.REV<=?
and cu.REVTYPE<>?
and a.city=cr.name
and (
cu.REVEND>?
or cu.REVEND is null
)
and a.REV<=?
and (
a.REVEND>?
or a.REVEND is null
)
and cr.REV<=?
and (
cr.REVEND>?
or cr.REVEND is null
)
-- binding parameter [1] as [INTEGER] - [2]
-- binding parameter [2] as [INTEGER] - [2]
-- binding parameter [3] as [INTEGER] - [2]
-- binding parameter [4] as [INTEGER] - [2]
-- binding parameter [5] as [INTEGER] - [2]
-- binding parameter [6] as [INTEGER] - [2]
-- binding parameter [7] as [INTEGER] - [2]
21.17. 在不加载实体的情况下查询修订信息
有时,加载有关修订的信息以找出执行特定修订的人员或了解修改了哪些实体名称可能很有用,但是不需要有关相关已审核实体的变更日志。该 API 提供了一种有效的方式来获取修订信息实体日志,而无需实例化实际的实体本身。
这是一个简单的示例:
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity( DefaultRevisionEntity.class, true )
.add( AuditEntity.revisionNumber().between( 1, 25 ) );
该查询将返回 1 到 25 之间的所有修订信息实体,包括那些与删除有关的修订。如果不需要删除,则将false作为第二个参数传递。
请注意,此查询使用DefaultRevisionEntity类类型。所提供的类将根据用于配置 Envers 的配置属性或您是否提供自己的修订版实体而有所不同。通常,将使用此 API 的用户可能会提供自定义修订版实体实现,以获取每个修订版维护的自定义信息。
21.18. 有条件的审计
Envers 使用org.hibernate.envers.event.spi包中的一系列事件侦听器,对各种 Hibernate 事件(例如post update,post insert等)作出反应,从而持久保留审核数据。默认情况下,如果 Envers jar 位于 Classpath 中,则事件侦听器将自动注册到 Hibernate。
可以通过重写某些 Envers 事件侦听器来实现条件审核。要使用自定义的 Envers 事件侦听器,需要执行以下步骤:
通过将
hibernate.envers.autoRegisterListenersHibernate 属性设置为false来关闭自动 Envers 事件侦听器注册。为适当的事件侦听器创建子类。例如,如果要有条件地审核实体插入,请扩展
org.hibernate.envers.event.spi.EnversPostInsertEventListenerImpl类。将条件审核逻辑放在子类中,如果应执行审核,则调用 super 方法。创建自己的
org.hibernate.integrator.spi.Integrator实现,类似于org.hibernate.envers.boot.internal.EnversIntegrator。使用事件侦听器类而不是默认类。为了使 Hibernate 启动时自动使用 Integration 器,您需要在 jar 中添加一个
META-INF/services/org.hibernate.integrator.spi.Integrator文件。该文件应包含实现接口的类的完全限定名称。
Note
hibernate.listeners.envers.autoRegister的使用已被弃用。应该使用新的hibernate.envers.autoRegisterListeners配置设置。
21.19. 了解 Envers 模式
对于每个审核实体(即,对于包含至少一个审核字段的每个实体),创建一个审核表。默认情况下,审计表的名称是通过在原始表名称中添加“ _AUD”后缀来创建的,但是可以通过使用@org.hibernate.envers.AuditTableComments 在配置属性或每个实体中指定其他后缀/前缀来覆盖此表。
审核表包含以下列:
id
- 原始实体的
id(在复合主键的情况下,此字段可以超过一列)。
- 原始实体的
revision number
- 一个整数,与修订实体表中的修订号匹配。
revision type
org.hibernate.envers.RevisionType枚举序号说明更改是否表示 INSERT,UPDATE 或 DELETE。
audited fields
- 来自原始实体的属性。
审核表的主键是实体的原始 ID 和修订号的组合,因此在给定的修订版中,给定的实体实例最多可以有一个历史条目。
当前实体数据存储在原始表和审核表中。但是,这是数据的重复,因为此解决方案使查询系统功能更加强大,并且由于内存便宜,因此希望这对用户而言不会成为主要缺点。
审核表中具有实体 ID ID,修订版N和数据D的行表示:具有 ID ID的实体的数据D从修订版N起。因此,如果要在版本M处找到实体,则必须在审核表中搜索行,该行的版本号小于或等于M,但应尽可能大。如果找不到这样的行,或者找到带有“已删除”标记的行,则表示该版本不存在该实体。
“修订类型”字段当前可以具有三个值:0,1和2,分别表示ADD,MOD和DEL。修订版本为DEL的行将仅包含实体的 ID,不包含任何数据(所有字段NULL),因为该行仅用作标记,表明“此实体在该修订版本中已删除”。
此外,还有一个修订实体表,其中包含有关全局修订的信息。默认情况下,生成的表名为REVINFO,仅包含两列:ID和TIMESTAMP。在每个新修订版本(即,在事务的每次提交中)都会在此表中插入一行,这会更改审核的数据。可以配置该表的名称,可以如Revision Log所述实现其列的名称以及添加其他列。
Note
尽管 Global 修订版是提供正确审核关系的好方法,但有人指出,这可能是经常修改数据的系统的瓶颈。
一种可行的解决方案是引入一个选项,使实体“本地修订”,即将为其独立创建修订。这将无法启用正确的关系版本控制,但没有REVINFO表也可以使用。
另一种可能性是引入“修订组”的概念,它将共享相同修订号的实体分组。每个这样的组必须由一个或多个强连接的组件组成,这些组件属于由实体之间的关系引起的实体图。
在论坛上,欢迎您就此发表意见。
21.20. 使用 Hibernate hbm2ddl 工具生成 Envers 模式
如果您想使用 Hibernate 生成数据库模式文件,则也只需要使用 hbm2ddl。
此任务将生成所有实体的定义,这两个实体都由 Envers 审核,而没有被 Envers 审核。
有关更多信息,请参见Schema generation章。
对于以下实体,Hibernate 将生成以下数据库架构:
例子 697.使用多个谓词过滤嵌套联接关系
@Audited
@Entity(name = "Customer")
public static class Customer {
@Id
private Long id;
private String firstName;
private String lastName;
@Temporal( TemporalType.TIMESTAMP )
@Column(name = "created_on")
@CreationTimestamp
private Date createdOn;
@ManyToOne(fetch = FetchType.LAZY)
private Address address;
//Getters and setters omitted for brevity
}
@Audited
@Entity(name = "Address")
public static class Address {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Country country;
private String city;
private String street;
private String streetNumber;
//Getters and setters omitted for brevity
}
@Audited
@Entity(name = "Country")
public static class Country {
@Id
private Long id;
private String name;
//Getters and setters omitted for brevity
}
create table Address (
id bigint not null,
city varchar(255),
street varchar(255),
streetNumber varchar(255),
country_id bigint,
primary key (id)
)
create table Address_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint,
REVEND integer,
city varchar(255),
street varchar(255),
streetNumber varchar(255),
country_id bigint,
primary key (id, REV)
)
create table Country (
id bigint not null,
name varchar(255),
primary key (id)
)
create table Country_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint,
REVEND integer,
name varchar(255),
primary key (id, REV)
)
create table Customer (
id bigint not null,
created_on timestamp,
firstName varchar(255),
lastName varchar(255),
address_id bigint,
primary key (id)
)
create table Customer_AUD (
id bigint not null,
REV integer not null,
REVTYPE tinyint,
REVEND integer,
created_on timestamp,
firstName varchar(255),
lastName varchar(255),
address_id bigint,
primary key (id, REV)
)
create table REVINFO (
REV integer generated by default as identity,
REVTSTMP bigint,
primary key (REV)
)
alter table Address
add constraint FKpr4rl83u5fv832kdihl6w3kii
foreign key (country_id)
references Country
alter table Address_AUD
add constraint FKgwp5sek4pjb4awy66sp184hrv
foreign key (REV)
references REVINFO
alter table Address_AUD
add constraint FK52pqkpismfxg2b9tmwtncnk0d
foreign key (REVEND)
references REVINFO
alter table Country_AUD
add constraint FKrix4g8hm9ui6sut5sy86ujggr
foreign key (REV)
references REVINFO
alter table Country_AUD
add constraint FKpjeqmdccv22y1lbtswjb84ghi
foreign key (REVEND)
references REVINFO
alter table Customer
add constraint FKfok4ytcqy7lovuiilldbebpd9
foreign key (address_id)
references Address
alter table Customer_AUD
add constraint FK5ecvi1a0ykunrriib7j28vpdj
foreign key (REV)
references REVINFO
alter table Customer_AUD
add constraint FKqd4fy7ww1yy95wi4wtaonre3f
foreign key (REVEND)
references REVINFO
21.21. Map 异常
21.21.1. 什么是不支持
不支持袋子,因为袋子中可能包含非唯一元素。坚持一袋``违反了关系数据库的原则,即每个表都是一组 Tuples。
但是,在使用 bag 的情况下(需要连接表),如果存在重复元素,则对应于元素的两个 Tuples 将相同。尽管 Hibernate 允许这样做,但是由于唯一的约束冲突,在尝试持久化两个相同元素时,Envers(或更准确地说是数据库连接器)将引发异常。
如果需要 bag 语义,至少有两种方法可以解决:
使用带有
@javax.persistence.OrderColumn注解的索引集合。通过
@CollectionIdComments 为您的元素提供唯一的 ID。
21.21.2. 什么不是,将支持
- 带有
@CollectionId标识符列的手袋样式集合(请参阅HHH-3950)。
21.22. @OneToMany 和@JoinColumn
当使用这两个 CommentsMap 集合时,Hibernate 不会生成联接表。但是,Envers 必须这样做,以便当您阅读相关实体已更改的修订时,不会得到错误的结果。
为了能够命名附加的联接表,有一个特殊的注解:@AuditJoinTable,其语义与 JPA @JoinTable相似。
一种特殊情况是将关系 Map 为@OneToMany和__2 分别 Map 到@ManyToOne和@JoinColumn( insertable = false, updatable = false。实际上,这种关系是双向的,但是所有权是集合。
要使用 Envers 正确审核此类关系,可以使用@AuditMappedBy注解。它使您可以指定反向属性(使用mappedBy元素)。如果是索引集合,则索引列也必须 Map 到引用的实体中(使用@Column( insertable = false, updatable = false )并使用positionMappedBy进行指定。此 Comments 只会影响 Envers 的工作方式。请注意,该 Comments 是实验性的,将来可能会更改。
21.23. 高级:审核表分区
21.24. 审核表分区的好处
由于审核表会无限期地增长,因此它们很快就会变得很大。当审核表已增长到一定限制(每个 RDBMS 和/或 os 不同)时,开始使用表分区是有意义的。 SQL 表分区提供了许多优点,包括但不限于:
通过选择性地将行移动到各个分区(甚至清除旧行),提高了查询性能。
更快的数据加载,索引创建等
21.25. 适用于审计表分区的列
通常,SQL 表必须在表中存在的列上进行分区。通常,使用* end 版本或 end 版本时间戳*列对审计表进行分区是有意义的。
Note
最终版本信息不适用于默认的AuditStrategy。
因此,需要以下 Envers 配置选项:
org.hibernate.envers.audit_strategy = org.hibernate.envers.strategy.ValidityAuditStrategy
org.hibernate.envers.audit_strategy_validity_store_revend_timestamp = true
(可选)您还可以使用以下属性覆盖默认值:
org.hibernate.envers.audit_strategy_validity_end_rev_field_name
org.hibernate.envers.audit_strategy_validity_revend_timestamp_field_name
有关更多信息,请参见Configuration Properties。
应将最终修订信息用于审核表分区的原因是基于这样的假设,即审核表应按照“相关程度的提高”进行分区,如下所示:
几个分区的审核数据不是很重要(或不再重要)。它可以存储在慢速介质上,甚至可能最终被清除。
审计数据的某些分区可能是相关的。
一个最可能相关的审计数据分区。应该将其存储在最快的介质上,以便进行读取和写入。
21.26. 审核表分区示例
为了确定“相关程度增加”的合适列,请考虑一个未命名机构的工资注册的简化示例。
当前,薪水表包含某人 X 的以下行:
表 12.薪金表
| Year | Salary (USD) |
|---|---|
| 2006 | 3300 |
| 2007 | 3500 |
| 2008 | 4000 |
| 2009 | 4500 |
当前会计年度(2010 年)的薪水未知。该机构要求记录一个会计年度的所有注册薪金变动(即审计追踪)。其背后的理由是,在特定日期做出的决定是基于当时的注册工资。并且在任何时候都必须能够重现在特定日期做出特定决定的原因。
提供了以下审核信息,按发生 Sequences 排序:
表 13.薪金-审计表
| Year | Revision type | Revision timestamp | Salary (USD) | 结束修订时间戳 |
|---|---|---|---|---|
| 2006 | ADD | 2007-04-01 | 3300 | null |
| 2007 | ADD | 2008-04-01 | 35 | 2008-04-02 |
| 2007 | MOD | 2008-04-02 | 3500 | null |
| 2008 | ADD | 2009-04-01 | 3700 | 2009-07-01 |
| 2008 | MOD | 2009-07-01 | 4100 | 2010-02-01 |
| 2008 | MOD | 2010-02-01 | 4000 | null |
| 2009 | ADD | 2010-04-01 | 4500 | null |
21.27. 确定合适的分区列
要对该数据进行分区,必须定义“相关级别”。考虑以下:
- 对于 2006 会计年度,仅进行了一次修订。它具有所有审计行中最古老的修订时间戳,但仍应视为具有相关性,因为它是薪资表中该会计年度的最新修订(修订修订时间戳为空)。
另外,请注意,如果在 2011 年更新 2006 会计年度的薪水(这可能要到会计年度后至少 10 年才能更新),并且审计信息将移至慢速磁盘(基于修订时间戳的期限)。请记住,在这种情况下,Envers 将必须更新最新审计行的“ 结束修订时间戳记”。
- 2007 会计年度的薪水中有两个修订版本,它们的修订时间戳几乎相同,而最终修订时间戳不同。
乍一看,很明显,第一次修订是一个错误,可能不相关。 2007 年唯一相关的修订版是*“结束修订版时间戳记”值为 null 的修订版。
基于上述内容,很明显,只有“最终修订时间戳记”适用于审计表分区。 修订时间戳不合适。
21.28. 确定合适的分区方案
工资表的可能分区方案如下:
结束修订时间戳年= 2008
- 此分区包含无关紧要的审核数据。
结束修订时间戳年= 2009
- 此分区包含可能相关的审核数据。
结束修订时间戳记年> = 2010 或 null
- 此分区包含最相关的审核数据。
此分区方案还涵盖了“最终修订时间戳记”更新的潜在问题,如果修改了审核表中的行,则会发生此问题。即使 Envers 在修改之时将审核行的* end 修订时间戳记*更新为系统日期,审核行仍将保留在同一分区(“扩展存储桶”)中。
在 2011 年的某个时候,最后一个分区(或“扩展存储桶”)被分为两个新分区:
最终修订时间戳年= 2010:此分区包含可能相关的审核数据(2011 年)。
结束修订时间戳记年> = 2011 或为空:此分区包含最有趣的审核数据,并且是新的“扩展存储段”。
21.29. 启用链接
JIRA 问题追踪器(添加有关 Envers 的问题时,请确保选择“ envers”组件!)
22.数据库可移植性注意事项
22.1. 可移植性基础
数据库可移植性是 Hibernate 的卖点之一(实际上是整个对象/关系 Map)。这可能意味着内部 IT 用户从一个数据库供应商迁移到另一数据库供应商,也可能意味着框架或可部署的应用程序消耗了 Hibernate 来使其用户同时定位多个数据库产品。不管确切的情况如何,基本思想都是希望 Hibernate 在无需更改代码的情况下帮助您在任意数量的数据库上运行,并且最好在不更改 Map 元数据的情况下运行。
22.2. Dialect
Hibernate 可移植性的第一行是方言,它是org.hibernate.dialect.DialectContract 的一种特殊形式。方言封装了 Hibernate 必须如何与特定数据库通信以完成某些任务(例如获取序列值或构造 SELECT 查询)的所有差异。 Hibernate 为许多最受欢迎的数据库 Binding 了多种方言。如果您发现您的特定数据库不在其中,那么编写自己的数据库并不难。
22.3. 方言解析
最初,Hibernate 始终要求用户指定要使用的方言。如果用户希望同时使用其构建目标多个数据库,那将是有问题的。通常,这要求其用户配置 Hibernate 方言或定义自己的设置该值的方法。
从版本 3.2 开始,Hibernate 引入了基于从java.sql.Connection到该数据库的java.sql.DatabaseMetaData自动检测要使用的方言的概念。这要好得多,只不过此解决方案仅限于 Hibernate 提前知道的数据库,而绝不是可配置或可重写的。
从版本 3.3 开始,Hibernate 具有更强大的方法,它可以依靠一系列实现org.hibernate.dialect.resolver.DialectResolver的委托来自动确定要使用的方言,而org.hibernate.dialect.resolver.DialectResolver仅定义了一个方法:
public Dialect resolveDialect(DatabaseMetaData metaData) throws JDBCConnectionException
这里的基本约定是,如果解析器“理解”给定的数据库元数据,则它将返回相应的 Dialect;如果不是,则返回 null,然后过程 continue 到下一个解析器。签名还将org.hibernate.exception.JDBCConnectionException标识为可能被抛出。此处的JDBCConnectionException被解释为表示非临时(也称为不可恢复)连接问题,用于指示立即停止解决解析问题。所有其他异常都会导致警告并 continue 进行下一个解析器。
关于这些解析器的最酷的部分是用户还可以注册自己的自定义解析器,该解析器将在内置的 Hibernate 解析器之前进行处理。这在许多不同情况下可能有用:
除了 Hibernate 本身附带的方言外,它还可以轻松集成以自动检测方言。
当识别特定数据库时,它允许您指定使用自定义方言。
要注册一个或多个解析器,只需使用“ hibernate.dialect_resolvers”配置设置(请参见org.hibernate.cfg.Environment上的DIALECT_RESOLVERS常量)指定它们(用逗号,制表符或空格分隔)。
22.4. 标识符生成
考虑数据库之间的可移植性时,另一个重要的决定是选择要使用的标识符生成策略。最初,Hibernate 为此目的提供了* native 生成器,该生成器旨在根据基础数据库的功能在 sequence , identity 或 table *策略之间进行选择。
但是,当针对某些支持* identity 生成的数据库而某些不支持 identity *生成的数据库时,这种方法会带来隐患。 * identity *的生成依赖于 IDENTITY(或自动递增)列的 SQL 定义来 Management 标识符值。这就是所谓的“插入后”生成策略,因为插入实际上必须在我们知道标识符值之前发生。
由于 Hibernate 依赖于此标识符值来在持久性上下文中唯一引用实体,因此无论当前的事务语义如何,它都必须在用户请求实体与会话相关联时立即发出插入(例如,通过save()或persist())。
Note
一旦更好地理解了它的含义,Hibernate 就会稍作更改,因此在可行的情况下,现在可以延迟插入。
潜在的问题是,在这些情况下,应用程序本身的实际语义会发生变化。
从版本 3.2.3 开始,Hibernate 附带了一组enhanced标识符生成器,它们以非常不同的方式针对可移植性。
Note
具体来说,有 2 个 Binding 的增强生成器:
org.hibernate.id.enhanced.SequenceStyleGeneratororg.hibernate.id.enhanced.TableGenerator
这些生成器背后的思想是将标识符值生成的实际语义移植到不同的数据库中。例如,org.hibernate.id.enhanced.SequenceStyleGenerator通过使用表模拟了序列在不支持序列的数据库上的行为。
22.5. 数据库功能
Warning
在数据库功能方面,Hibernate 可以从改进中受益。
就可移植性方面而言,当前的功能处理在 HQL 中运行良好,但是在所有其他方面都非常缺乏。
用户可以通过多种方式引用 SQL 函数。但是,并非所有数据库都支持相同的功能集。 Hibernate 提供了一种将逻辑函数名 Map 到委托的方法,该委托知道如何呈现该特定函数,甚至可能使用完全不同的物理函数调用。
Tip
从技术上讲,SQL 函数注册是通过org.hibernate.dialect.function.SQLFunctionRegistry类处理的,该类旨在允许用户提供自定义函数定义而不必提供自定义方言。到目前为止,此特定行为尚未完全完成。
它的实现方式是使用户可以以编程方式向org.hibernate.cfg.Configuration注册功能,并且这些功能将被 HQL 识别。
22.6. 类型 Map
待办事项:也记录以下内容
22.6.1. BLOB/CLOBMap
22.6.2. 布尔 Map
JPA portability
HQL/JPQL differences
naming strategies
basic types
简单 ID 类型
生成的 ID 类型
复合 ID 和多对一
“嵌入式复合标识符”
23. Statistics
Hibernate 可以收集各种统计信息,这可以帮助您更好地了解 Hibernate 在幕后所做的事情。
默认情况下,不收集统计信息,因为这会导致额外的处理和内存开销。要指示 Hibernate 开始收集统计信息,您需要将hibernate.generate_statistics配置属性设置为true:
<property
name="hibernate.generate_statistics"
value="true"
/>
23.1. org.hibernate.stat.Statistics 方法
可以通过Statistics接口使用 Hibernate 统计信息,该接口公开了以下方法:
23.1.1. 一般统计方法
isStatisticsEnabled- 是否启用统计信息?
setStatisticsEnabled(boolean b)- 根据提供的参数启用统计信息。
clear- 重置所有统计信息。
logSummary- 将当前统计信息的摘要打印到应用程序日志中。
getStartTime- 从最初创建此 Statistics 实例或上次调用
clear()以来的毫秒数(JVM 标准currentTimeMillis())。
- 从最初创建此 Statistics 实例或上次调用
23.1.2. 汇总统计方法
getQueries- 获取执行的查询字符串。 Hibernate 统计信息跟踪的最大查询数由
hibernate.statistics.query_max_size属性给出。
- 获取执行的查询字符串。 Hibernate 统计信息跟踪的最大查询数由
getEntityStatistics(String entityName)- 查找给定名称的实体统计信息。
getCollectionStatistics(String role)- 获取每个角色的集合统计信息(集合名称)。
getNaturalIdStatistics(String entityName)- 获取给定实体的特定于 Hibernate 的自然 ID 解析统计信息。
getQueryStatistics(String queryString)- 获取给定查询字符串(JPQL/HQL 或本机 SQL)的统计信息。
getDomainDataRegionStatistics(String regionName)- 获取每个域数据(实体,集合,自然 ID)区域的二级缓存统计信息。
getQueryRegionStatistics(String regionName)- 获取每个查询区域的二级缓存统计信息。
getCacheRegionStatistics(String regionName)- 获取域数据或查询结果区域的统计信息(此方法同时检查两者,如果存在则更喜欢域数据区域)。
23.1.3. SessionFactory 统计方法
getEntityNames- 获取使用当前
SessionFactory配置的所有实体的名称。
- 获取使用当前
getCollectionRoleNames- 获取使用当前
SessionFactory配置的所有集合角色的名称。
- 获取使用当前
23.1.4. 会话统计方法
getSessionCloseCount- Global 已关闭的会话数。
getSessionOpenCount- 已打开的全局会话数。
getFlushCount- 获取执行的刷新操作的全局数量(手动或自动)。
23.1.5. JDBC 统计方法
getPrepareStatementCount- Hibernate 获取的 JDBC 准备的语句数。
getCloseStatementCount- Hibernate 发布的 JDBC 准备的语句数。
getConnectCount- 获取由 Hibernate 会话获取的全局连接数(实际使用的连接数可能会少得多,具体取决于您是否使用连接池)。
23.1.6. Transaction 统计方法
getSuccessfulTransactionCount- 成功完成的事务数。
getTransactionCount- 我们知道已完成的 Transaction 数量。
23.1.7. 并发控制统计方法
getOptimisticFailureCount- 发生的 Hibernate
StaleObjectStateExceptions 或 JPAOptimisticLockExceptions 的数量。
- 发生的 Hibernate
23.1.8. 实体统计方法
getEntityDeleteCount- 获取实体删除的全局数量。
getEntityInsertCount- 获取实体插入的全局数量。
getEntityLoadCount- 获取实体加载的全局数量。
getEntityFetchCount- 获取实体获取的全局数量。
getEntityUpdateCount- 获取实体更新的 Global 数量。
23.1.9. collections 统计方法
getCollectionLoadCount- 加载的全局集合数。
getCollectionFetchCount- 已获取的 Global 收藏数量。
getCollectionUpdateCount- 已更新的全局集合数。
getCollectionRemoveCount- 已删除的全局集合数。
getCollectionRecreateCount- 重新创建的集合的 Global 数量。
23.1.10. 查询统计方法
getQueryExecutionCount- 获取已执行查询的全局数目。
getQueryExecutionMaxTime- 获取最慢查询的时间(以毫秒为单位)。
getQueryExecutionMaxTimeQueryString- 获取最慢查询的查询字符串。
getQueryPlanCacheHitCount- 获取成功从缓存中检索的查询计划的全局数量。
getQueryPlanCacheMissCount- 获取在缓存中 找不到 的全局查询计划查找数。
23.1.11. 自然 ID 统计方法
getNaturalIdQueryExecutionCount- 获取针对数据库执行的自然 ID 查询的全局数目。
getNaturalIdQueryExecutionMaxTime- 获取针对数据库执行的自然 ID 查询的全局最大查询时间。
getNaturalIdQueryExecutionMaxTimeRegion- 获取最大自然 ID 查询时间的区域。
getNaturalIdQueryExecutionMaxTimeEntity- 获取最大自然 ID 查询时间的实体。
23.1.12. 二级缓存统计方法
getSecondLevelCacheRegionNames- 获取所有第二级域数据缓存区域名称。
getSecondLevelCacheHitCount- 从缓存中成功检索的可缓存实体/集合的全局数量。
getSecondLevelCacheMissCount- 在缓存中找不到并从数据库加载的可缓存实体/集合的全局数量。
getSecondLevelCachePutCount- 放入缓存的全局可缓存实体/集合的数量。
二级缓存自然 ID 统计方法
getNaturalIdCacheHitCount- 获取成功从缓存中检索的缓存自然 ID 查找的全局数量。
getNaturalIdCacheMissCount- 获取在缓存中 找不到 的缓存自然 ID 查找的全局数量。
getNaturalIdCachePutCount- 获取放入缓存的全局可缓存自然 ID 查找数。
二级缓存查询统计方法
getQueryCacheHitCount- 获取从缓存成功检索的缓存查询的全局数量。
getQueryCacheMissCount- 获取在缓存中 找不到 的缓存查询的全局数量。
getQueryCachePutCount- 获取放入缓存的全局可缓存查询数。
二级缓存时间戳统计方法
getUpdateTimestampsCacheHitCount- 获取成功从缓存中检索的全局时间戳数。
getUpdateTimestampsCacheMissCount- 获取在缓存中找不到的全局时间戳请求。
getUpdateTimestampsCachePutCount- 获取放入缓存的全局时间戳数。
23.2. 查询统计信息的最大大小
传统上,启用统计信息后,Hibernate 会存储所有已执行的查询。但是,这是一个非常糟糕的默认值,因为如果您的应用程序运行数百万个不同的查询,您将有可能耗尽内存。
因此,为了限制 Hibernate 统计信息可以容纳的查询数量,添加了hibernate.statistics.query_max_size属性。默认情况下,保留的最大查询数量为 5000 ,但是您可以通过hibernate.statistics.query_max_size属性来增加此值。
因此,如果您的应用程序大量使用了 JPA Criteria API,或者您仅拥有大量查询,则可能需要提高Statistics实例存储的最大查询数量。
如果已达到最大查询数量,则 Hibernate 使用最近最少使用(LRU)策略为新查询条目腾出空间。
23.3. 查询计划缓存统计信息
每个实体查询(无论是 JPQL/HQL 还是 Criteria API)都被编译为 AST(抽象语法树),并且此过程是资源密集型的。为了加快实体查询的执行速度,Hibernate 提供了一个查询计划缓存,以便可以重用已编译的计划。
要监视查询计划缓存,您需要以下统计信息。
23.3.1. 查询计划缓存全局统计信息
Statistics实例提供了两个全局计数器,这些计数器可以使您总体了解查询计划缓存的有效性。
getQueryPlanCacheHitCountgetQueryPlanCacheMissCount
如果命中计数高而未命中计数低,则查询计划缓存有效,并且绝大多数实体查询均由查询计划缓存提供服务,而不是反复编译。
23.3.2. 查询计划缓存查询级统计
您可以通过Statistics对象的getQueryStatistics(String queryString)方法获得QueryStatistics实例,该实例存储以下查询计划缓存 Metrics:
getPlanCacheHitCount- 从缓存中成功获取的查询计划的数量。
getQueryPlanCacheMissCount- 从缓存中获取的查询计划的数量(不是)。
getQueryPlanCacheMissCount- 为该特定查询编译计划所花费的总时间。
24. Configurations
24.1. 策略配置
许多配置设置定义了 Hibernate 用于各种目的的可插拔策略。这些策略类型设置中的许多配置接受各种形式的定义。有关此类配置设置的文档,请参见此处。在这种情况下可用的表格类型包括:
简称(如果已定义)
- 某些内置策略实现具有相应的简称
strategy instance
- 可以指定要使用的策略实施的实例
策略类参考
- 要使用的策略实施的
java.lang.Class参考
- 要使用的策略实施的
策略类别名称
- 要使用的策略实施的类名称(
java.lang.String)
- 要使用的策略实施的类名称(
24.2. 常规配置
hibernate.dialect(例如org.hibernate.dialect.PostgreSQL94Dialect)- Hibernate Dialect的类名,Hibernate 可以从该类名生成针对特定关系数据库优化的 SQL。
在大多数情况下,Hibernate 可以根据 JDBC 驱动程序返回的 JDBC 元数据选择正确的Dialect实现。
hibernate.current_session_context_class(例如jta,thread,managed或实现org.hibernate.context.spi.CurrentSessionContext的自定义类)- 为* current *
Session的作用域提供自定义策略。
- 为* current *
确切的“当前”含义的定义由使用中的CurrentSessionContext实现控制。
请注意,为了向后兼容,如果未配置CurrentSessionContext,但配置了 JTA,则默认为JTASessionContext。
24.3. 符合 JPA
hibernate.jpa.compliance.transaction(例如true或false(默认值))- 此设置控制 Hibernate
Transaction是否应按照 JPAjavax.persistence.EntityTransaction的规范定义进行操作,因为它扩展了 JPA 一个。
- 此设置控制 Hibernate
hibernate.jpa.compliance.query(例如true或false(默认值))- 控制 Hibernate 对
javax.persistence.Query(JPQL,条件和本机查询)的处理是否应严格遵循 JPA 规范。
- 控制 Hibernate 对
这既包括解析或翻译查询,也包括对javax.persistence.Query方法的调用以引发规范定义的异常,而 Hibernate 则不然。
hibernate.jpa.compliance.list(例如true或false(默认值))- 控制 Hibernate 是否应将其认为的“袋子”(
org.hibernate.collection.internal.PersistentBag)识别为列表(org.hibernate.collection.internal.PersistentList)或袋子。
- 控制 Hibernate 是否应将其认为的“袋子”(
如果启用,我们会将其识别为仅缺少javax.persistence.OrderColumn的列表(将应用其默认值)。
hibernate.jpa.compliance.closed(例如true或false(默认值))- JPA 在调用先前已关闭的
javax.persistence.EntityManager和javax.persistence.EntityManagerFactory对象上的特定方法时定义特定的异常。
- JPA 在调用先前已关闭的
此设置控制将使用 JPA 规范定义的行为还是 Hibernate 行为。
如果启用,则 Hibernate 将以 JPA 指定的方式运行,并在规范要求时抛出异常。
hibernate.jpa.compliance.proxy(例如true或false(默认值))- JPA 规范说,访问数据库中没有关联表行的实体代理时,应抛出
javax.persistence.EntityNotFoundException。
- JPA 规范说,访问数据库中没有关联表行的实体代理时,应抛出
传统上,由于我们已经知道标识符值,因此 Hibernate 在访问其标识符时不会初始化实体代理,因此可以节省数据库往返时间。
如果启用,则 Hibernate 即使在访问其标识符时也将初始化实体代理。
hibernate.jpa.compliance.global_id_generators(例如true或false(默认值))- JPA 规范说,TableGenerator 和 SequenceGenerator 名称的范围对于持久性单元是全局的(跨所有生成器类型)。
传统上,Hibernate 会考虑本地范围内的名称。
如果启用,则@TableGenerator和@SequenceGenerator使用的名称将被视为全局名称,因此使用相同的名称配置两个不同的生成器将导致在启动时抛出java.lang.IllegalArgumentException。
24.4. 数据库连接属性
hibernate.connection.driver_class或javax.persistence.jdbc.driver(例如org.postgresql.Driver)- 命名 JDBC
Driver类名。
- 命名 JDBC
hibernate.connection.url或javax.persistence.jdbc.url(例如jdbc:postgresql:hibernate_orm_test)- 命名 JDBC 连接 URL。
hibernate.connection.username或javax.persistence.jdbc.user- 命名 JDBC 连接用户名。
hibernate.connection.password或javax.persistence.jdbc.password- 命名 JDBC 连接密码。
hibernate.connection.isolation(例如REPEATABLE_READ或Connection.TRANSACTION_REPEATABLE_READ)- 命名 JDBC 连接事务隔离级别。
hibernate.connection.autocommit(例如true或false(默认值))- 命名从在某些 ConnectionProvider 隐式创建的连接池返回的 JDBC 连接的初始自动提交模式。
另请参见hibernate.connection.provider_disables_autocommit的讨论。
hibernate.connection.provider_disables_autocommit(例如true或false(默认值))- 指示用户的承诺,无论从数据提供者或其他某种连接池机制支持该提供者,当 Hibernate 从配置的 ConnectionProvider 获得的连接都已自动提交时,将禁用自动提交。通常,在以下情况下会发生这种情况:
Hibernate 已配置为从基础数据源获取连接,并且该数据源已配置为在其托管连接上禁用自动提交。
Hibernate 配置为从非 DataSource 连接池获取连接,并且该连接池已配置为禁用自动提交。对于 Hibernate 提供的实现,这将取决于
hibernate.connection.autocommit设置的值。
Hibernate 将此保证作为选择退出某些可能会对性能产生影响的操作的机会(尽管这种影响通常可以忽略不计)。具体来说,当通过 Hibernate 或 JPA 事务 API 启动事务时,Hibernate 通常会立即从提供程序获取连接,并且:
通过调用
Connection#getAutocommit来检查 Connection 最初是否处于自动提交模式,以了解释放时如何清理 Connection。通过调用
Connection#setAutocommit(false)启动 JDBC 事务。
如果我们知道 ConnectionProvider 将始终返回禁用了自动提交的连接,则可以跳过这两个步骤。这就是此设置的目的。通过将其设置为true,可以延迟Connection的获取,直到需要执行第一个 SQL 语句为止。连接获取延迟使您可以减少数据库连接的租用时间,因此可以增加事务吞吐量。
实际上,当从提供程序获取的 Connections Hibernate 没有禁用自动提交时,将此值设置为true是不适当的。
这样做将导致 Hibernate 在任何 JDBC/SQL 事务之外执行 SQL 操作。
hibernate.connection.handling_mode- 指定 Hibernate 在获取和释放方面应如何 ManagementJDBC 连接。此配置属性取代
hibernate.connection.acquisition_mode和hibernate.connection.release_mode。
- 指定 Hibernate 在获取和释放方面应如何 ManagementJDBC 连接。此配置属性取代
连接处理模式策略由PhysicalConnectionHandlingMode枚举定义。
该配置可以是PhysicalConnectionHandlingMode引用,也可以是不区分大小写的String表示形式。
有关PhysicalConnectionHandlingMode和 Hibernate 连接处理的更多详细信息,请查看Connection handling部分。
hibernate.connection.acquisition_mode(例如immediate)
Note
不推荐使用此设置。您应该改用hibernate.connection.handling_mode。
指定 Hibernate 如何获取 JDBC 连接。可能的值由org.hibernate.ConnectionAcquisitionMode给出。
通常应该只配置此或hibernate.connection.release_mode,而不要同时配置两者。
hibernate.connection.release_mode(例如auto(默认值))
Note
不推荐使用此设置。您应该改用hibernate.connection.handling_mode。
指定 Hibernate 应该如何释放 JDBC 连接。可能的值由当前事务模式(对于 JDBC 事务为after_transaction,对于 JTA 事务为after_statement)给出。
通常应该只配置此或hibernate.connection.acquisition_mode,而不要同时配置两者。
hibernate.connection.datasource- 可以找到
javax.sql.DataSource的javax.sql.DataSource实例或 JNDI 名称。
- 可以找到
对于 JNDI 名称,ses 也是hibernate.jndi.class,hibernate.jndi.url,hibernate.jndi。
hibernate.connection- 命名用于定义任意 JDBC 连接属性的前缀。创建连接时,这些属性将传递给 JDBC 提供程序。
hibernate.connection.provider_class(例如org.hibernate.hikaricp.internal. HikariCPConnectionProvider)- 命名ConnectionProvider以用于获取 JDBC 连接。
Can reference:
ConnectionProvider的实例Class<? extends ConnectionProvider>对象参考实现
ConnectionProvider的类的完全限定名称
由于遗留原因,设置名称中会出现“ class”一词。但是,它可以接受实例。
hibernate.jndi.class- 命名 JNDI
javax.naming.InitialContext类。
- 命名 JNDI
hibernate.jndi.url(例如java:global/jdbc/default)- 命名 JNDI 提供程序/连接 URL。
hibernate.jndi- 命名用于定义任意 JNDI
javax.naming.InitialContext属性的前缀。
- 命名用于定义任意 JNDI
这些属性将传递给javax.naming.InitialContext#InitialContext(java.util.Hashtable)方法。
24.4.1. 休眠内部连接池选项
hibernate.connection.initial_pool_size(例如 1(默认值))- 内置的 Hibernate 连接池的最小连接数。
hibernate.connection.pool_size(例如 20(默认值))- 内置的 Hibernate 连接池的最大连接数。
hibernate.connection.pool_validation_interval(例如 30(默认值))- 两次连续池验证之间的秒数。在验证期间,池大小可以根据连接获取请求计数增加或减少。
24.5. c3p0 属性
hibernate.c3p0.min_size(例如 1)- C3P0 连接池的最小大小。指的是c3p0 minPoolSize 设置。
hibernate.c3p0.max_size(例如 5)- C3P0 连接池的最大大小。指的是c3p0 maxPoolSize 设置。
hibernate.c3p0.timeout(例如 30)- C3P0 连接池的最大空闲时间。指的是c3p0 maxIdleTime 设置。
hibernate.c3p0.max_statements(例如 5)- C3P0 语句缓存的最大大小。指的是c3p0 maxStatements 设置。
hibernate.c3p0.acquire_increment(例如 2)- 池中没有可用连接时一次获取的连接数。指的是c3p0 获取增量设置。
hibernate.c3p0.idle_test_period(例如 5)- 验证 C3P0 池连接之前的空闲时间。指的是c3p0 idleConnectionTestPeriod 设置。
hibernate.c3p0- 设置前缀,用于指示需要传递给基础 c3p0 连接池的其他 c3p0 属性。
24.6. Map 属性
24.6.1. 表资格选项
hibernate.default_catalog(例如目录名称)- 使用生成的 SQL 中的给定目录来限定不合格的表名。
hibernate.default_schema(例如,架构名称)- 使用生成的 SQL 中的给定架构或表空间来限定不合格的表名。
hibernate.schema_name_resolver(例如org.hibernate.engine.jdbc.env.spi.SchemaNameResolver实现类的完全限定名称)- 默认情况下,Hibernate 使用org.hibernate.dialect.Dialect#getSchemaNameResolver。您可以通过提供SchemaNameResolver接口的自定义实现来自定义模式名称的解析方式。
24.6.2. 标识符选项
hibernate.id.new_generator_mappings(例如true(默认值)或false)- 表示新的IdentifierGenerator是否用于
AUTO,TABLE和SEQUENCE的设置。
- 表示新的IdentifierGenerator是否用于
现有应用程序可能需要禁用此设置(将其设置为false),以实现从 3.x 和 4.x 到 5.x 的升级兼容性。
hibernate.use_identifier_rollback(例如true或false(默认值))- 如果为 true,则删除对象时,生成的标识符属性将重置为默认值。
hibernate.id.optimizer.pooled.preferred(例如none,hilo,legacy-hilo,pooled(默认值),pooled-lo,pooled-lotl或Optimizer实现的标准名称)- 当生成器指定了增量大小并且未明确指定优化器时,应首选哪个“池式”优化器?
hibernate.id.generator.stored_last_used(例如true(默认值)或false)- 如果为 true,则
@TableGenerator使用的表中存储的值是最后使用的值;如果为 false,则该值是要使用的下一个值。
- 如果为 true,则
hibernate.model.generator_name_as_sequence_name(例如true(默认值)或false)- 如果为 true,则在找不到匹配的
@SequenceGenerator或TableGenerator时,应将@GeneratedValue注解的generator属性指定的值用作序列/表名称。
- 如果为 true,则在找不到匹配的
默认值为true,表示默认情况下会将@GeneratedValue.generator()用作序列/表名称。使用旧版hibernate_sequence名称从早期版本迁移的用户应禁用此设置。
hibernate.ejb.identifier_generator_strategy_provider(例如,完全限定的类名或实际的IdentifierGeneratorStrategyProvider实例)- 此设置允许您提供实现
org.hibernate.jpa.spi.IdentifierGeneratorStrategyProvider接口的实例或类,因此您可以提供一组IdentifierGenerator策略,以覆盖 Hibernate Core 默认策略。
- 此设置允许您提供实现
hibernate.id.disable_delayed_identity_inserts(例如true或false(默认值))- 如果为 true,则使用生成的标识符(身份/序列)的插入将永远不会延迟,并且始终会立即插入。如果您遇到
DelayedPostInsertIdentifier的任何错误,应使用此方法,并应将其视为“临时”修复程序。请向我们报告导致问题的 Map,以便我们检查默认算法以查看是否应包含您的用例。
- 如果为 true,则使用生成的标识符(身份/序列)的插入将永远不会延迟,并且始终会立即插入。如果您遇到
默认值为false,这意味着 Hibernate 将使用一种算法来确定插入是否可以延迟或是否应该立即执行插入。
24.6.3. 报价选项
hibernate.globally_quoted_identifiers(例如true或false(默认值))- 所有数据库标识符都应加引号。
hibernate.globally_quoted_identifiers_skip_column_definitions(例如true或false(默认值))- 假设
hibernate.globally_quoted_identifiers为true,这将允许全局引用跳过javax.persistence.Column,javax.persistence.JoinColumn等定义的列定义,并且虽然避免了由于全局引用而导致对列定义的引用,但仍可以在 Comments/ xml 中显式引用它们 Map。
- 假设
hibernate.auto_quote_keyword(例如true或false(默认值))- 指定是否自动引用被视为关键字的任何名称。
24.6.4. 鉴别器选项
hibernate.discriminator.implicit_for_joined(例如true或false(默认值))- Hibernate 的遗留行为是不使用区分符进行联合继承(Hibernate 不需要区分符)。但是,某些 JPA 提供程序确实需要区分符来处理连接继承,因此,出于可移植性考虑,此功能也已添加到 Hibernate 中。
因为要确保旧版应用程序也能 continue 正常工作,所以在处理“隐式”鉴别符 Map 方面,这使我们陷入了困境。解决方案是假定没有鉴别符元数据意味着遵循传统行为(除非*启用此设置)。
启用此设置后,Hibernate 会将没有标识符的元数据解释为对这些缺少的 Comments 使用 JPA 定义的默认值的指示。
有关其他背景信息,请参见 Hibernate Jira 问题HHH-6911。
hibernate.discriminator.ignore_explicit_for_joined(例如true或false(默认值))- Hibernate 的遗留行为是不使用区分符进行联合继承(Hibernate 不需要区分符)。但是,某些 JPA 提供程序确实需要区分符来处理连接继承,因此,出于可移植性考虑,此功能也已添加到 Hibernate 中。
现有的应用程序(隐式或显式)依赖于 Hibernate,而忽略联接继承层次结构上的任何DiscriminatorColumn声明。通过此设置,这些应用程序可以保持与联接继承配对时被忽略的DiscriminatorColumnComments 的旧行为。
有关其他背景信息,请参见 Hibernate Jira 问题HHH-6911。
24.6.5. 命名策略
hibernate.implicit_naming_strategy(例如default(默认值),jpa,legacy-jpa,legacy-hbm,component-path)- 用于指定要使用的ImplicitNamingStrategy类。为此设置定义了以下简称:
defaultjpalegacy-jpalegacy-hbmcomponent-path
如果此属性恰好为空,则后备方法是使用default策略。
hibernate.physical_naming_strategy(例如org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl(默认值))- 用于指定要使用的PhysicalNamingStrategy类。
24.6.6. 元数据扫描选项
hibernate.archive.scanner- 传递Scanner的实现。默认情况下,使用StandardScanner。
Accepts:
实际的
Scanner实例对实现
Scanner的类的引用实现
Scanner的 Class 的完全限定名称hibernate.archive.interpreter- 传递ArchiveDescriptorFactory以用于扫描过程。
Accepts:
实际的
ArchiveDescriptorFactory实例对实现
ArchiveDescriptorFactory的类的引用实现
ArchiveDescriptorFactory的 Class 的完全限定名称
请参阅Scanner上有关预期构造函数形式的信息。
hibernate.archive.autodetection(例如hbm,class(默认值))- 标识以逗号分隔的值列表,这些值指示我们在扫描期间应自动检测到的 Map 类型。
允许的值包括:
class扫描类别(例如
.class)以提取实体 Map 元数据hbm- 扫描
hbmMap 文件(例如hbm.xml)以提取实体 Map 元数据
- 扫描
默认情况下,将扫描 HBM,Comments 和 JPA XMLMap。
使用 JPA 时,要禁用所有实体类的自动扫描,必须将exclude-unlisted-classes persistence.xml元素设置为 true。因此,在将exclude-unlisted-classes设置为 true 时,仅考虑在persistence.xml配置文件中显式声明的类。
hibernate.mapping.precedence(例如hbm,class(默认值))- 用于指定处理元数据源的 Sequences。值是一个定界列表,其元素由MetadataSourceType定义。
默认值为hbm,class,因此首先处理hbm.xml个文件,然后处理 Comments(与orm.xmlMap 结合)。
使用 JPA 时,XMLMap 将覆盖以相同实体属性为目标的冲突 CommentsMap。
24.6.7. JDBC 相关的选项
hibernate.use_nationalized_character_data(例如true或false(默认值))- 对所有基于字符串/ Clob 的属性(字符串,char,clob,文本等)启用民族化字符支持。
hibernate.jdbc.lob.non_contextual_creation(例如true或false(默认值))- 我们是否不应该使用上下文 LOB 创建(又基于
java.sql.Connection#createBlob()等)? HANA,H2 和 PostgreSQL 的默认值为true。
- 我们是否不应该使用上下文 LOB 创建(又基于
hibernate.jdbc.time_zone(例如ZoneId的java.util.TimeZone,java.time.ZoneId或String表示)- 除非指定,否则 JDBC 驱动程序将使用默认的 JVM 时区。如果通过此设置配置了其他时区,则 JDBC PreparedStatement#setTimestamp将根据指定的时区使用
Calendar实例。
- 除非指定,否则 JDBC 驱动程序将使用默认的 JVM 时区。如果通过此设置配置了其他时区,则 JDBC PreparedStatement#setTimestamp将根据指定的时区使用
hibernate.dialect.oracle.prefer_long_raw(例如true或false(默认值))- 此设置仅适用于 Oracle Dialect,它指定是将
byte[]还是Byte[]数组 Map 到已弃用的LONG RAW(当此配置属性值为true时)还是 Map 到BLOB列类型(当此配置属性值为false时)。
- 此设置仅适用于 Oracle Dialect,它指定是将
24.6.8. Bean 验证选项
javax.persistence.validation.factory(例如javax.validation.ValidationFactory实现)- 指定用于 Bean 验证的
javax.validation.ValidationFactory实现。
- 指定用于 Bean 验证的
hibernate.check_nullability(例如true或false)- 启用可空性检查。如果标记为 not-null 的属性为 null,则引发异常。
如果在 Classpath 中存在 Bean 验证并且使用了 Hibernate Annotations,则默认为false,否则为true。
hibernate.validator.apply_to_ddl(例如true(默认值)或false)- 如果启用了自动模式生成,则 Bean 验证约束将应用于 DDL。换句话说,数据库模式将反映 Bean 验证约束。
要禁用向 DDL 的约束传播,请在配置文件中设置hibernate.validator.apply_to_ddl到false。这种需求非常罕见,不建议这样做。
24.6.9. 杂项选项
hibernate.create_empty_composites.enabled(例如true或false(默认值))- 当其所有属性值均为
null时,启用复合/可嵌入对象的实例化。默认(和历史)行为是当null引用的所有属性均为null时将用于表示该组合。
- 当其所有属性值均为
这是一项实验性功能,存在已知问题。在稳定之前,不得在 Producing 使用它。有关详细信息,请参见 Hibernate Jira 问题HHH-11936。
hibernate.entity_dirtiness_strategy(例如,完全限定的类名或实际的CustomEntityDirtinessStrategy实例)- 设置以标识要使用的
org.hibernate.CustomEntityDirtinessStrategy。
- 设置以标识要使用的
hibernate.default_entity_mode(例如pojo(默认值)或dynamic-map)- 从此
SessionFactory打开的所有会话的实体表示形式的默认值EntityMode,默认值pojo。
- 从此
24.7. 字节码增强属性
hibernate.enhancer.enableDirtyTracking(例如true或false(默认值))- 在运行时字节码增强中启用脏跟踪功能。
hibernate.enhancer.enableLazyInitialization(例如true或false(默认值))- 在运行时字节码增强中启用延迟加载功能。这样,即使是基本类型(例如
@Basic(fetch = FetchType.LAZY)也可以延迟获取。
- 在运行时字节码增强中启用延迟加载功能。这样,即使是基本类型(例如
hibernate.enhancer.enableAssociationManagement(例如true或false(默认值))- 在运行时字节码增强中启用关联 Management 功能,当仅更改一侧时,该功能会自动同步双向关联。
hibernate.bytecode.provider(例如bytebuddy(默认值))- BytecodeProvider内置实现风格。当前,只有
bytebuddy和javassist是有效值。
- BytecodeProvider内置实现风格。当前,只有
hibernate.bytecode.use_reflection_optimizer(例如true或false(默认值))- 我们应该使用反射优化吗?反射优化器实现ReflectionOptimizer接口,并改进了实体实例化和属性 getter/setter 调用。
hibernate.bytecode.enforce_legacy_proxy_classnames(例如true或false(默认值))- 其他一些库(例如 Spring)过去依赖于用于运行时生成的代理类的特定命名模式。将此设置为
true以使代理类名称符合旧模式。
- 其他一些库(例如 Spring)过去依赖于用于运行时生成的代理类的特定命名模式。将此设置为
24.8. 查询设定
hibernate.query.plan_cache_max_size(例如2048(默认值))- 最大条目数,包括:HQLQueryPlan,FilterQueryPlan,NativeSQLQueryPlan。
由QueryPlanCache维护。
hibernate.query.plan_parameter_metadata_max_size(例如128(默认值))- 与
ParameterMetadata关联的强引用的最大数量由QueryPlanCache维护。
- 与
hibernate.order_by.default_null_ordering(例如none,first或last)- 在
ORDER BY子句中定义空值的优先级。默认值为none,这在 RDBMS 实现之间有所不同。
- 在
hibernate.discriminator.force_in_select(例如true或false(默认值))- 对于未明确说明的实体,是否应将区分符强制放入 SQL 选择中?
hibernate.query.substitutions(例如true=1,false=0)- 将 Hibernate 查询转换为 SQL 时要使用的以逗号分隔的令牌替换列表。
hibernate.query.factory_class(例如org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory(默认值)或org.hibernate.hql.internal.classic.ClassicQueryTranslatorFactory)- 选择 HQL 解析器实现。
hibernate.query.jpaql_strict_compliance(例如true或false(默认值))- 从 Hibernate 查询中的令牌 Map 到 SQL 令牌,例如函数或 Literals 名称。
我们应该严格遵守 JPA 查询语言(JPQL)语法,还是更广泛地支持 Hibernate 的所有超集(HQL)?
将此设置为true可能会导致有效的 HQL 引发异常,因为它违反了 JPQL 子集。
hibernate.query.startup_check(例如true(默认值)或false)- 启动期间是否应检查命名查询?
hibernate.proc.param_null_passing(例如true或false(默认值))null参数绑定是否应作为ProcedureCall处理的一部分传递给数据库过程/函数调用的全局设置。隐式地,Hibernate 不会通过null,其目的是允许应用任何默认参数值。
这定义了一个全局设置,然后可以通过org.hibernate.procedure.ParameterRegistration#enablePassingNulls(boolean)对每个参数进行控制。
值为true(传递 NULL)或false(不传递 NULL)。
hibernate.jdbc.log.warnings(例如true或false)- 启用提取 JDBC 语句警告进行日志记录。默认值由
org.hibernate.dialect.Dialect#isJdbcLogWarningsEnabledByDefault()给出。
- 启用提取 JDBC 语句警告进行日志记录。默认值由
hibernate.session_factory.statement_inspector(例如,完全限定的类名,实例或Class对象引用)- 命名要应用于当前
SessionFactory创建的每个Session的StatementInspector实现。
- 命名要应用于当前
可以引用StatementInspector实例,StatementInspector实现Class引用或StatementInspector实现类名(完全合格的类名)。
hibernate.query.validate_parameters(例如true(默认值)或false)- 通过 JPA
javax.persistence.EntityManagerFactory引导会话时,可以使用此配置属性禁用org.hibernate.query.Query#setParameter执行的参数验证。
- 通过 JPA
hibernate.criteria.literal_handling_mode(例如AUTO(默认值),BIND或INLINE)- 默认情况下,条件查询将绑定参数用于所有非数字值的 Literals。但是,为了增加 JDBC 语句缓存的可能性,您可能还希望对数字值使用绑定参数。
org.hibernate.query.criteria.LiteralHandlingMode#BIND模式将对任何 Literals 值使用绑定变量。 org.hibernate.query.criteria.LiteralHandlingMode#INLINE模式将按原样内联 Literals 值。
为防止 SQL 注入,切勿将org.hibernate.query.criteria.LiteralHandlingMode#INLINE与 String 变量一起使用。始终在org.hibernate.query.criteria.LiteralHandlingMode#INLINE模式下使用常量。
有效的选项由org.hibernate.query.criteria.LiteralHandlingMode枚举定义。默认值为org.hibernate.query.criteria.LiteralHandlingMode#AUTO。
hibernate.query.fail_on_pagination_over_collection_fetch(例如true或false(默认值))- 在将要执行对集合获取的内存中分页时引发异常。
默认禁用。设置为 true 启用。
24.8.1. 多表批量 HQL 操作
hibernate.hql.bulk_id_strategy(例如,完全限定的类名,实例或Class对象引用)- 提供自定义的org.hibernate.hql.spi.id.MultiTableBulkIdStrategy实现,以处理多表批量 HQL 操作。
hibernate.hql.bulk_id_strategy.global_temporary.drop_tables(例如true或false(默认值))- 对于不支持本地表而仅支持全局表的数据库,此配置属性允许您关闭
SessionFactory或EntityManagerFactory时,删除用于多表批量 HQL 操作的全局表。
- 对于不支持本地表而仅支持全局表的数据库,此配置属性允许您关闭
hibernate.hql.bulk_id_strategy.persistent.drop_tables(例如true或false(默认值))- PersistentTableBulkIdStrategy使用此配置属性,该属性模拟不支持临时表的数据库的临时表。它遵循类似于全局临时表的 ANSI SQL 定义的模式,其中使用“会话 ID”列来分割来自各个会话的行。
使用此配置属性,可以在SessionFactory或EntityManagerFactory关闭时,删除用于多表批量 HQL 操作的表。
hibernate.hql.bulk_id_strategy.persistent.schema(例如,数据库架构名称.默认情况下,使用hibernate.default_schema.)- PersistentTableBulkIdStrategy使用此配置属性,该属性模拟不支持临时表的数据库的临时表。它遵循类似于全局临时表的 ANSI SQL 定义的模式,其中使用“会话 ID”列来分割来自各个会话的行。
此配置属性定义用于存储用于批量 HQL 操作的临时表的数据库架构。
hibernate.hql.bulk_id_strategy.persistent.catalog(例如,数据库目录名称.默认情况下,使用hibernate.default_catalog.)- PersistentTableBulkIdStrategy使用此配置属性,该属性模拟不支持临时表的数据库的临时表。它遵循类似于全局临时表的 ANSI SQL 定义的模式,其中使用“会话 ID”列来分割来自各个会话的行。
此配置属性定义用于存储用于批量 HQL 操作的临时表的数据库目录。
hibernate.legacy_limit_handler(例如true或false(默认值))- 该设置指示是否使用
org.hibernate.dialect.pagination.LimitHandler实现牺牲性能优化以允许旧版 4.x 限制行为。
- 该设置指示是否使用
旧版 4.x 行为通过避免使用偏移量值而倾向于在内存中执行分页,该值总体上是较差的性能。在 5.x 中,限制处理程序的行为会提高性能,因此,如果方言不支持偏移量,则会引发异常。
hibernate.query.conventional_java_constants(例如true(默认值)或false)- 该设置指示 Java 常量是否遵循Java 命名约定。
默认值为true。如果使用非常规的 Java 常量,则现有的应用程序可能希望禁用此设置(将其设置为false)。但是,由于 Hibernate 无法确定是否应将别名视为 Java 常量,因此使用非常规 Java 常量会产生很大的性能开销。
查看HHH-4959了解更多详细信息。
24.9. 批处理属性
hibernate.jdbc.batch_size(例如 5)- 最大 JDBC 批处理大小。非零值将启用批量更新。
hibernate.order_inserts(例如true或false(默认值))- 强制 Hibernate 通过插入项的主键值对 SQL 插入进行排序。使用级联时,这将保留批处理。
hibernate.order_updates(例如true或false(默认值))- 强制 Hibernate 通过要更新的项的主键值对 SQL 更新进行排序。这在使用级联时保留了批处理,并减少了高并发系统中事务死锁的可能性。
hibernate.jdbc.batch_versioned_data(例如true(默认值)或false)- 版本化的实体是否应包括在批处理中?
如果您的 JDBC 驱动程序从 executeBatch()返回正确的行数,则将此属性设置为true。此选项通常是安全的,但默认情况下处于禁用状态。如果启用,则 Hibernate 将批处理的 DML 用于自动版本化的数据。
hibernate.batch_fetch_style(例如LEGACY(默认值))- 命名要使用的BatchFetchStyle。
可以指定BatchFetchStyle名称(不区分大小写)或BatchFetchStyle实例。 LEGACY是默认值。
hibernate.jdbc.batch.builder(例如BatchBuilder实现类类型的完整名称或实际的对象实例)- 命名要使用的BatchBuilder实现。
24.9.1. 获取属性
hibernate.max_fetch_depth(例如0和3之间的值)- 为单端关联设置外部联接获取树的最大深度。单端关联是一对一或多对一关联。值
0禁用默认的外部联接获取。
- 为单端关联设置外部联接获取树的最大深度。单端关联是一对一或多对一关联。值
hibernate.default_batch_fetch_size(例如4,8或16)- Hibernate 批量提取关联的默认大小(可以批量提取延迟提取的关联,以防止出现 N 1 个查询问题)。
hibernate.jdbc.fetch_size(例如0或整数)- 非零值通过调用
Statement.setFetchSize()确定 JDBC 的获取大小。
- 非零值通过调用
hibernate.jdbc.use_scrollable_resultset(例如true或false)- 使 Hibernate 使用 JDBC2 可滚动结果集。此属性仅与用户提供的 JDBC 连接有关。否则,Hibernate 将使用连接元数据。
hibernate.jdbc.use_streams_for_binary(例如true或false(默认值))- 向 JDBC 写入
binary或serializable类型或从 JDBC 读取binary或serializable类型时,请使用流。这是系统级别的属性。
- 向 JDBC 写入
hibernate.jdbc.use_get_generated_keys(例如true或false)- 允许 Hibernate 在插入后使用 JDBC3
PreparedStatement.getGeneratedKeys()检索本机生成的键。您需要 JDBC3 驱动程序和 JRE1.4. 如果您的驱动程序在 Hibernate 标识符生成器方面有问题,请禁用此属性。默认情况下,它尝试从连接元数据中检测驱动程序功能。
- 允许 Hibernate 在插入后使用 JDBC3
hibernate.jdbc.wrap_result_sets(例如true或false(默认值))- 启用 JDBC 结果集的包装,以加快损坏的 JDBC 驱动程序的列名查找。
hibernate.enable_lazy_load_no_trans(例如true或false(默认值))- 在给定的事务持久性上下文之外初始化惰性代理或集合。
尽管启用此配置可以使LazyInitializationException消失,但最好使用获取计划,该计划可确保在关闭 Session 之前正确初始化所有属性。
实际上,无论如何您都不应该启用此设置。
24.10. 语句记录和统计
24.10.1. SQL 语句记录
hibernate.show_sql(例如true或false(默认值))- 将所有 SQL 语句写入控制台。这是将日志类别
org.hibernate.SQL设置为调试的替代方法。
- 将所有 SQL 语句写入控制台。这是将日志类别
hibernate.format_sql(例如true或false(默认值))- 在日志和控制台中漂亮地打印 SQL。
hibernate.use_sql_comments(例如true或false(默认值))- 如果为 true,则 Hibernate 会在 SQL 内生成 Comments,以便于调试。
24.10.2. 统计设置
hibernate.generate_statistics(例如true或false)- 使 Hibernate 收集统计信息以进行性能调整。
hibernate.stats.factory(例如StatisticsFactory实现或实际实例的全限定名称)StatisticsFactory允许您自定义如何收集休眠统计信息。
hibernate.session.events.log(例如true或false)- 用于控制是否在所有
Sessions上启用org.hibernate.engine.internal.StatisticalLoggingSessionEventListener的设置(除非为给定的Session明确禁用)。
- 用于控制是否在所有
此设置的默认值由hibernate.generate_statistics的值确定,这意味着如果启用了统计信息,则默认情况下也会启用会话 Metrics 的日志记录。
24.11. 缓存属性
hibernate.cache.region.factory_class(例如jcache)- 快捷方式名称(例如
jcache,ehcache)或RegionFactory实现类的标准名称。
- 快捷方式名称(例如
hibernate.cache.default_cache_concurrency_strategy- 当使用
@javax.persistence.Cacheable,@org.hibernate.annotations.Cache或@org.hibernate.annotations.Cache覆盖全局设置时,该设置用于提供要使用的默认CacheConcurrencyStrategy的名称。
- 当使用
hibernate.cache.use_minimal_puts(例如true(默认值)或false)- 优化第二级缓存操作以最大程度地减少写入,但需要更频繁地读取。这对于群集缓存最有用,并且默认情况下对于群集缓存实现启用。
hibernate.cache.use_query_cache(例如true或false(默认值))- 启用查询缓存。您仍然需要将单个查询设置为可缓存。
hibernate.cache.use_second_level_cache(例如true(默认值)或false)- 启用/禁用默认情况下启用的二级缓存,尽管默认的
RegionFactor是NoCachingRegionFactory(这意味着没有实际的缓存实现)。
- 启用/禁用默认情况下启用的二级缓存,尽管默认的
hibernate.cache.query_cache_factory(例如,完全限定的类名称)- 自定义QueryCacheFactory界面。默认值为内置
StandardQueryCacheFactory。
- 自定义QueryCacheFactory界面。默认值为内置
hibernate.cache.region_prefix(例如字符串)- 二级缓存区域名称的前缀。
hibernate.cache.use_structured_entries(例如true或false(默认值))- 强制 Hibernate 以更易于理解的格式将数据存储在二级缓存中。
hibernate.cache.auto_evict_collection_cache(例如true或false(默认值:false))- 当在
ManyToOne集合中的元素被添加/更新/删除而未适当地 ManagementOneToMany端的更改时,启用自动撤消双向关联的集合缓存。
- 当在
hibernate.cache.use_reference_entries(例如true或false)- 优化第二级缓存操作,以将不具有关联的不可变实体(也称为“引用”)直接存储到缓存中。在这种情况下,可以避免拆卸和深复制操作。此属性的默认值为
false。
- 优化第二级缓存操作,以将不具有关联的不可变实体(也称为“引用”)直接存储到缓存中。在这种情况下,可以避免拆卸和深复制操作。此属性的默认值为
hibernate.ejb.classcache(例如hibernate.ejb.classcache.org.hibernate.ejb.test.Item=read-write)- 为指定区域设置关联的实体类缓存并发策略。高速缓存配置应遵循以下模式
hibernate.ejb.classcache.<fully.qualified.Classname> = usage[, region],其中用法是所使用的高速缓存策略,并对高速缓存区域名称进行区域划分。
- 为指定区域设置关联的实体类缓存并发策略。高速缓存配置应遵循以下模式
hibernate.ejb.collectioncache(例如hibernate.ejb.collectioncache.org.hibernate.ejb.test.Item.distributors=read-write, RegionName)- 为指定区域设置关联的集合缓存并发策略。高速缓存配置应遵循以下模式
hibernate.ejb.collectioncache.<fully.qualified.Classname>.<role> = usage[, region],其中用法是所使用的高速缓存策略,并对高速缓存区域名称进行区域划分。
- 为指定区域设置关联的集合缓存并发策略。高速缓存配置应遵循以下模式
24.12. Infinispan 属性
有关如何自定义 Infinispan 二级缓存提供程序的更多详细信息,请查看Infinispan 用户指南。
24.13. Transaction 属性
hibernate.transaction.jta.platform(例如JBossAS,BitronixJtaPlatform)- 命名用于与 JTA 系统集成的JtaPlatform实现。可以引用JtaPlatform实例或JtaPlatform实现类的名称。
hibernate.jta.prefer_user_transaction(例如true或false(默认值))- 我们应该更喜欢使用
org.hibernate.engine.transaction.jta.platform.spi.JtaPlatform#retrieveUserTransaction而不是org.hibernate.engine.transaction.jta.platform.spi.JtaPlatform#retrieveTransactionManager吗?
- 我们应该更喜欢使用
hibernate.transaction.jta.platform_resolver- 命名要使用的JtaPlatformResolver实现。
hibernate.jta.cacheTransactionManager(例如true(默认值)或false)- 配置值键,用于指示可以安全缓存。
hibernate.jta.cacheUserTransaction(例如true或false(默认值))- 配置值键,用于指示可以安全缓存。
hibernate.transaction.flush_before_completion(例如true或false(默认值))- 导致在事务的完成阶段之前刷新会话。如果可能,请改用内置的自动会话上下文 Management。
hibernate.transaction.auto_close_session(例如true或false(默认值))- 使会话在事务的完成阶段之后关闭。如果可能,请改用内置的自动会话上下文 Management。
hibernate.transaction.coordinator_class- 命名用于创建TransactionCoordinator实例的TransactionCoordinatorBuilder的实现。
可以是TransactionCoordinatorBuilder实例,TransactionCoordinatorBuilder实现Class引用,TransactionCoordinatorBuilder实现类名(完全限定的名称)或简称。
为此设置定义了以下简称:
jdbc通过调用
java.sql.ConnectionManagementTransaction(非 JPA 应用程序默认)。jta- 通过 JTAManagementTransaction。参见Java EE 引导。
如果 JPA 应用程序未提供hibernate.transaction.coordinator_class的设置,则 Hibernate 将基于持久性单元的事务类型自动构建适当的事务协调器。
如果非 JPA 应用程序未提供hibernate.transaction.coordinator_class的设置,则 Hibernate 将使用jdbc作为默认值。如果应用程序实际使用基于 JTA 的事务,则此默认值将导致问题。使用基于 JTA 的事务的非 JPA 应用程序应显式设置hibernate.transaction.coordinator_class=jta或提供构建TransactionCoordinator的自定义TransactionCoordinatorBuilder,以正确地与基于 JTA 的事务进行协调。
hibernate.jta.track_by_thread(例如true(默认值)或false)- 事务可以由另一个线程(“按线程跟踪”)而不是原始应用程序回滚。这样的示例包括由后台收割线程处理的 JTA 事务超时。
处理这种情况的能力要求每次调用 Session 时都要检查线程 ID,因此启用它肯定会对性能产生影响。
hibernate.transaction.factory_classWarning
这是旧版设置,已过时,您应改用
hibernate.transaction.jta.platform。
hibernate.jta.allowTransactionAccess(例如true(默认值)或false)- 由于 JPA 规范禁止此行为,因此即使使用 JTA,它也允许访问基础的
org.hibernate.Transaction。
- 由于 JPA 规范禁止此行为,因此即使使用 JTA,它也允许访问基础的
如果此配置属性设置为true,则授予对基础org.hibernate.Transaction的访问权限。如果将其设置为false,则将无法访问org.hibernate.Transaction。
除非通过 JPA 引导Session,否则默认行为是允许访问。
24.14. 多租户设置
hibernate.multiTenancy(例如NONE(默认值),SCHEMA,DATABASE和DISCRIMINATOR(尚未实现))- 正在使用的多租户策略。
hibernate.multi_tenant_connection_provider(例如true或false(默认值))- 命名要使用的MultiTenantConnectionProvider实现。由于
MultiTenantConnectionProvider也是一项服务,因此可以直接通过StandardServiceRegistryBuilder进行配置。
- 命名要使用的MultiTenantConnectionProvider实现。由于
hibernate.tenant_identifier_resolver- 命名一个CurrentTenantIdentifierResolver实现以解析当前的租户标识符,以便调用
SessionFactory#openSession()将获得连接到正确的租户的Session。
- 命名一个CurrentTenantIdentifierResolver实现以解析当前的租户标识符,以便调用
可以是CurrentTenantIdentifierResolver实例,CurrentTenantIdentifierResolver实现Class对象引用或CurrentTenantIdentifierResolver实现类名称。
hibernate.multi_tenant.datasource.identifier_for_any(例如true或false(默认值))- 当
hibernate.connection.datasource属性值解析为javax.naming.Context对象时,此配置属性定义用于查找DataSource的 JNDI 名称,该DataSource用于访存初始Connection,该Connection用于访问基础数据库的数据库元数据(在这种情况下,没有租户 ID,例如启动过程)。
- 当
24.15. 自动模式生成
hibernate.hbm2ddl.auto(例如none(默认值),create-only,drop,create,create-drop,validate和update)- 设置为在
SessionFactory生命周期中自动执行SchemaManagementTool动作。有效选项由Action枚举的externalHbm2ddlName值定义的:
- 设置为在
none将不执行任何操作。
create-only- 将创建数据库创建。
drop- 数据库删除将被生成。
create- 将创建数据库删除,然后创建数据库。
create-drop- 删除架构,并在 SessionFactory 启动时重新创建它。此外,在 SessionFactory 关闭时删除架构。
validate- 验证数据库架构。
update- 更新数据库架构。
javax.persistence.schema-generation.database.action(例如none(默认值),create-only,drop,create,create-drop,validate和update)- 设置为在
SessionFactory生命周期中自动执行SchemaManagementTool动作。有效选项由Action枚举的externalJpaName值定义的:
- 设置为在
none将不执行任何操作。
create- 将创建数据库创建。
drop- 数据库删除将被生成。
drop-and-create- 将创建数据库删除,然后创建数据库。
javax.persistence.schema-generation.scripts.action(例如none(默认值),create-only,drop,create,create-drop,validate和update)- 设置执行
SchemaManagementTool个动作,将命令写入 DDL 脚本文件。有效选项由Action枚举的externalJpaName值定义的:
- 设置执行
none将不执行任何操作。
create- 将创建数据库创建。
drop- 数据库删除将被生成。
drop-and-create- 将创建数据库删除,然后创建数据库。
javax.persistence.schema-generation-connection- 允许传递特定的
java.sql.Connection实例供SchemaManagementTool使用。
- 允许传递特定的
javax.persistence.database-product-name- 在与基础数据库的连接不可用的情况下(也就是主要在生成脚本中),指定数据库提供程序的名称。在这种情况下,必须指定此设置的值*。
此设置的值应与目标数据库的java.sql.DatabaseMetaData#getDatabaseProductName()返回的值匹配。
此外,可能需要指定javax.persistence.database-major-version和/或javax.persistence.database-minor-version才能准确了解如何生成所需的架构命令。
javax.persistence.database-major-version- 指定基础数据库的主版本,如目标数据库的
java.sql.DatabaseMetaData#getDatabaseMajorVersion返回。
- 指定基础数据库的主版本,如目标数据库的
在javax.persistence.database-product-name不能提供足够区分的情况下,该值用于帮助更精确地确定如何为基础数据库执行模式生成任务。
javax.persistence.database-minor-version- 指定基础数据库的次版本,由
java.sql.DatabaseMetaData#getDatabaseMinorVersion返回目标数据库。
- 指定基础数据库的次版本,由
在javax.persistence.database-product-name和javax.persistence.database-major-version没有提供足够区别的情况下,该值用于帮助更精确地确定如何为基础数据库执行模式生成任务。
javax.persistence.schema-generation.create-source- 指定是否基于对象/关系 Map 元数据,DDL 脚本或两者的组合来确定用于模式创建的模式生成命令。有关有效值集,请参见SourceType。
如果未指定任何值,则假定默认值如下:
如果指定了源脚本(每个
javax.persistence.schema-generation.create-script-source),则假定script否则,假定为
metadatajavax.persistence.schema-generation.drop-source- 指定是否要基于对象/关系 Map 元数据,DDL 脚本或两者的组合来确定用于模式删除的模式生成命令。有关有效值集,请参见SourceType。
如果未指定任何值,则假定默认值如下:
如果指定了源脚本(每个
javax.persistence.schema-generation.create-script-source),则假定script选项否则,假定为
metadatajavax.persistence.schema-generation.create-script-source- 将
create脚本文件指定为为读取 DDL 脚本文件而配置的java.io.Reader或为 DDL 脚本指定文件java.net.URL的字符串。
- 将
Hibernate 过去也出于类似目的接受hibernate.hbm2ddl.import_files,但是javax.persistence.schema-generation.create-script-source应该比hibernate.hbm2ddl.import_files更可取。
javax.persistence.schema-generation.drop-script-source- 将
drop脚本文件指定为为读取 DDL 脚本文件而配置的java.io.Reader或为 DDL 脚本指定文件java.net.URL的字符串。
- 将
javax.persistence.schema-generation.scripts.create-target- 对于
javax.persistence.schema-generation.scripts.action值指示应将架构创建命令写入 DDL 脚本文件的情况,javax.persistence.schema-generation.scripts.create-target指定为 DDL 脚本的输出配置的java.io.Writer或指定 DDL 脚本的文件 URL 的字符串。
- 对于
javax.persistence.schema-generation.scripts.drop-target- 对于
javax.persistence.schema-generation.scripts.action值指示应将架构删除命令写入 DDL 脚本文件的情况,javax.persistence.schema-generation.scripts.drop-target指定为 DDL 脚本的输出配置的java.io.Writer或为 DDL 脚本指定文件 URL 的字符串。
- 对于
javax.persistence.hibernate.hbm2ddl.import_files(例如import.sql(默认值))- 包含在
SessionFactory创建期间执行的 SQL DML 语句的可选文件的名称,以逗号分隔。文件 Sequences 很重要,给定文件的语句在下一个语句之前执行。
- 包含在
仅在创建模式时才执行这些语句,这意味着将hibernate.hbm2ddl.auto设置为create,create-drop或update。 javax.persistence.schema-generation.create-script-source/javax.persistence.schema-generation.drop-script-source应该是首选。
javax.persistence.sql-load-script-sourcehibernate.hbm2ddl.import_files的 JPA 变体。指定配置为读取 SQL 加载脚本的java.io.Reader或指定 SQL 加载脚本的文件java.net.URL的字符串。 “ SQL 加载脚本”是执行一些数据库初始化(INSERT 等)的脚本。
hibernate.hbm2ddl.import_files_sql_extractor- 引用ImportSqlCommandExtractor实现类,用于解析
javax.persistence.schema-generation.create-script-source,javax.persistence.schema-generation.drop-script-source或hibernate.hbm2ddl.import_files定义的源/导入文件。
- 引用ImportSqlCommandExtractor实现类,用于解析
引用可以引用实例,实现ImportSqlCommandExtractor的类或ImportSqlCommandExtractor实现的全限定名称。如果给出了完全限定的名称,则实现必须提供一个无参数的构造函数。
默认值为SingleLineSqlCommandExtractor。
hibernate.hbm2ddl.create_namespaces(例如true或false(默认值))- 指定是否也自动创建数据库模式/目录。
javax.persistence.create-database-schemas(例如true或false(默认值))hibernate.hbm2ddl.create_namespaces的 JPA 变体。指定除了创建数据库对象(表,序列,约束等)之外,持久性提供程序是否还将创建数据库模式。如果持久性提供程序要在数据库中创建架构或生成包含“ CREATE SCHEMA”命令的 DDL,则此布尔属性的值应设置为true。
如果未提供此属性(或显式为false),则提供程序不应尝试创建数据库模式。
hibernate.hbm2ddl.schema_filter_provider- 用于指定数据库架构上的
create,drop,migrate和validate操作要使用的SchemaFilterProvider。SchemaFilterProvider提供可用于将这些操作的范围限制为特定名称空间,表和序列的过滤器。默认情况下包括所有对象。
- 用于指定数据库架构上的
hibernate.hbm2ddl.jdbc_metadata_extraction_strategy(例如grouped(默认值)或individually)- 设置选择用于访问 JDBC 元数据的策略。有效的选项由JdbcMetadaAccessStrategy枚举的
strategy值定义:
- 设置选择用于访问 JDBC 元数据的策略。有效的选项由JdbcMetadaAccessStrategy枚举的
groupedSchemaMigrator和SchemaValidator执行一次
java.sql.DatabaseMetaData#getTables(String, String, String, String[])调用以检索所有数据库表,以确定所有javax.persistence.Entity是否具有对应的 Map 数据库表。此策略可能要求提供hibernate.default_schema和/或hibernate.default_catalog。individually- SchemaMigrator和SchemaValidator对每个
javax.persistence.Entity执行一次java.sql.DatabaseMetaData#getTables(String, String, String, String[])调用,以确定是否存在相应的数据库表。
- SchemaMigrator和SchemaValidator对每个
hibernate.hbm2ddl.delimiter(例如;)- 标识用于在脚本输出中分隔模式 Management 语句的定界符。
hibernate.schema_management_tool(例如,架构名称)- 用于指定用于执行模式 Management 的
SchemaManagementTool。默认值为HibernateSchemaManagementTool。
- 用于指定用于执行模式 Management 的
hibernate.synonyms(例如true或false(默认值))- 如果启用,则允许架构更新和验证以支持同义词。由于这可能会返回重复的表(尤其是在 Oracle 中),因此默认情况下处于禁用状态。
hibernate.hbm2ddl.extra_physical_table_types(例如BASE TABLE)- 标识以逗号分隔的值列表,以指定默认的
TABLE值以外的其他表类型,以识别为通过架构更新,创建和验证定义物理表。
- 标识以逗号分隔的值列表,以指定默认的
hibernate.schema_update.unique_constraint_strategy(例如DROP_RECREATE_QUIETLY,RECREATE_QUIETLY,SKIP)- 唯一列和唯一键在大多数方言中都使用唯一约束。
SchemaUpdate需要创建这些约束,但是数据库对查找现有约束的支持极为不一致。此外,未明确命名的唯一约束使用随机生成的字符。
- 唯一列和唯一键在大多数方言中都使用唯一约束。
因此,UniqueConstraintSchemaUpdateStrategy提供以下选项:
DROP_RECREATE_QUIETLY默认选项。尝试删除,然后(重新)创建每个唯一约束。忽略任何引发的异常。
RECREATE_QUIETLY- 尝试(重新)创建唯一约束,而忽略如果约束已经存在则抛出的异常。
SKIP- 不要尝试在架构更新上创建唯一约束。
hibernate.hbm2ddl.charset_name(例如Charset.defaultCharset())- 定义用于所有 Importing/输出模式生成资源的字符集(编码)。默认情况下,Hibernate 使用
Charset.defaultCharset()给出的默认字符集。此配置属性允许您覆盖默认的 JVM 设置,以便您可以指定在读写模式生成资源(例如,文件,URL)时使用哪种编码。
- 定义用于所有 Importing/输出模式生成资源的字符集(编码)。默认情况下,Hibernate 使用
hibernate.hbm2ddl.halt_on_error(例如true或false(默认值))- 模式迁移工具是否应因错误而停止,因此终止引导过程。默认情况下,即使架构迁移引发异常,也会创建
EntityManagerFactory或SessionFactory。为了防止出现这种默认行为,请将此属性值设置为true。
- 模式迁移工具是否应因错误而停止,因此终止引导过程。默认情况下,即使架构迁移引发异常,也会创建
24.16. 异常处理
hibernate.jdbc.sql_exception_converter(例如,实施SQLExceptionConverter的类的全限定名称)- SQLExceptionConverter用于将
SQLExceptions转换为 Hibernate 的JDBCException层次结构。默认为使用配置的Dialect的首选SQLExceptionConverter。
- SQLExceptionConverter用于将
hibernate.native_exception_handling_51_compliance(例如true或false(默认值))- 指示通过 Hibernate 的本机引导构建的
SessionFactory的异常处理是否应与 Hibernate ORM 5.1 中的本机异常处理相同。设置为true时,HibernateException将不会根据 JPA 规范进行包装或转换。对于通过 JPA 引导程序构建的SessionFactory,此设置将被忽略。
- 指示通过 Hibernate 的本机引导构建的
24.17. 会议活动
hibernate.session.events.auto- 实现
SessionEventListener接口的全限定类名。
- 实现
hibernate.session_factory.interceptor(例如org.hibernate.EmptyInterceptor(默认值))- 命名要应用于当前
org.hibernate.SessionFactory创建的每个Session的Interceptor实现。
- 命名要应用于当前
Can reference:
Interceptor个实例Interceptor实现Class对象参考Interceptor实现类名称hibernate.ejb.interceptor(例如hibernate.session_factory.interceptor(默认值))Warning
弃用的设置。请改用
hibernate.session_factory.session_scoped_interceptor。
hibernate.session_factory.session_scoped_interceptor(例如,完全合格的类名称或类参考)- 命名要应用于
org.hibernate.SessionFactory并传播到从SessionFactory创建的每个Session的org.hibernate.Interceptor实现。
- 命名要应用于
此设置标识将应用于从SessionFactory打开的每个Session的Interceptor实现,但是与hibernate.session_factory.interceptor不同的是,每个Session使用Interceptor的唯一实例。
Can reference:
Interceptor个实例Interceptor实现Class对象参考java.util.function.Supplier实例,用于检索Interceptor实例
Note
具体来说,此设置无法命名Interceptor实例。
hibernate.ejb.interceptor.session_scoped(例如,完全合格的类名称或类参考)Warning
弃用的设置。请改用
hibernate.session_factory.session_scoped_interceptor。
可选的 Hibernate 拦截器。
拦截器实例特定于给定的 Session 实例(因此不是线程安全的),必须实现org.hibernate.Interceptor并具有无参数构造函数。
此属性不能与hibernate.ejb.interceptor组合。
hibernate.ejb.session_factory_observer(例如,完全合格的类名称或类参考)- 指定要应用于 SessionFactory 的
SessionFactoryObserver。该类必须具有无参数构造函数。
- 指定要应用于 SessionFactory 的
hibernate.ejb.event(例如hibernate.ejb.event.pre-load=com.acme.SecurityListener,com.acme.AuditListener)- 给定事件类型的事件侦听器列表。事件侦听器列表是用逗号分隔的完全限定的类名称列表。
24.18. JMX 设置
hibernate.jmx.enabled(例如true或false(默认值))- Enable JMX.
hibernate.jmx.usePlatformServer(例如true或false(默认值))- 使用
ManagementFactory#getPlatformMBeanServer()返回的平台 MBeanServer。
- 使用
hibernate.jmx.agentId- 关联的
MBeanServer的代理标识符。
- 关联的
hibernate.jmx.defaultDomain- 关联的
MBeanServer的域名。
- 关联的
hibernate.jmx.sessionFactoryNameSessionFactory名称附加到可 ManagementBean 所注册到的对象名称上。如果为 null,则使用hibernate.session_factory_name配置值。
org.hibernate.core- 默认对象域附加到可 ManagementBean 所注册到的对象名称上。
24.19. JACC 设置
hibernate.jacc.enabled(例如true或false(默认值))- 是否启用了 JACC?
hibernate.jacc(例如hibernate.jacc.allowed.org.jboss.ejb3.test.jacc.AllEntity)- 属性名称定义角色(例如
allowed)和实体类名称(例如org.jboss.ejb3.test.jacc.AllEntity),而属性值定义授权的动作(例如insert,update,read)。
- 属性名称定义角色(例如
hibernate.jacc_context_id- 一个字符串,用于标识要返回其 PolicyConfiguration 接口的策略上下文。传递给此参数的值不能为 null。
24.20. ClassLoaders 属性
hibernate.classLoaders- Hibernate 用于定义
java.util.Collection<ClassLoader>或ClassLoader实例,Hibernate 应该将其用于类加载和资源查找。
- Hibernate 用于定义
hibernate.classLoader.application- 命名用于加载用户应用程序类的
ClassLoader。
- 命名用于加载用户应用程序类的
hibernate.classLoader.resourcesClassLoaderHibernate 用于执行资源加载的名称。
hibernate.classLoader.hibernate- 命名负责加载 Hibernate 类的
ClassLoader。默认情况下,这是加载此类的ClassLoader。
- 命名负责加载 Hibernate 类的
hibernate.classLoader.environment- 命名当 Hibernate 无法在
hibernate.classLoader.application或hibernate.classLoader.hibernate上找到类时使用的ClassLoader。
- 命名当 Hibernate 无法在
24.21. 引导程序属性
hibernate.integrator_provider(例如IntegratorProvider的全限定名)- 用于定义Integrator的列表,该列表在引导过程中用于集成各种服务。
hibernate.strategy_registration_provider(例如StrategyRegistrationProviderList的全限定名)- 用于定义StrategyRegistrationProvider的列表,该列表在引导过程中用于提供策略 selectors 的注册。
hibernate.type_contributors(例如TypeContributorList的全限定名)- 用于定义TypeContributor的列表,该列表在引导过程中用于提供类型。
hibernate.persister.resolver(例如PersisterClassResolver或PersisterClassResolver实例的全限定名称)- 用于定义
PersisterClassResolver接口的实现,该接口可用于自定义实体或集合的持久化方式。
- 用于定义
hibernate.persister.factory(例如PersisterFactory或PersisterFactory实例的全限定名称)- 像
PersisterClassResolver一样,PersisterFactory可用于自定义实体或集合的持久化方式。
- 像
hibernate.service.allow_crawling(例如true(默认值)或false)- 搜寻所有可用的服务绑定,以替代注册给定的 Hibernate
Service。
- 搜寻所有可用的服务绑定,以替代注册给定的 Hibernate
hibernate.metadata_builder_contributor(例如MetadataBuilderContributor的实例,类或完全限定的类名称)- 用于定义实例,MetadataBuilderContributor的类或完全限定的类名,当通过 JPA
EntityManagerFactory引导时,可用于配置MetadataBuilder。
- 用于定义实例,MetadataBuilderContributor的类或完全限定的类名,当通过 JPA
24.22. 杂项属性
hibernate.dialect_resolvers- 命名其他DialectResolver实现以向标准DialectFactory注册。
hibernate.session_factory_name(例如 JNDI 名称)- 用于命名休眠
SessionFactory的设置。只要在每个 JVM 上使用相同的名称,对SessionFactory进行命名就可以在 JVM 之间对其进行正确的序列化。
- 用于命名休眠
如果hibernate.session_factory_name_is_jndi设置为true,这也是SessionFactory在启动时绑定到 JNDI 的名称,并且可以从 JNDI 获得该名称。
hibernate.session_factory_name_is_jndi(例如true(默认值)或false)hibernate.session_factory_name定义的值是否表示org.hibernate.SessionFactory应绑定并可访问的 JNDI 名称空间?
默认为true,以实现向后兼容。如果出于序列化目的需要命名 SessionFactory,但在运行时环境中不存在可写的 JNDI 上下文,或者如果用户只是不想使用 JNDI,则将其设置为false。
hibernate.ejb.entitymanager_factory_name(例如,默认情况下使用持久性单元名称,否则使用随机生成的 UUID)- 在内部,Hibernate 使用
EntityManagerFactoryRegistry跟踪所有EntityManagerFactory实例。该名称用作识别给定EntityManagerFactory参考的键。
- 在内部,Hibernate 使用
hibernate.ejb.cfgfile(例如hibernate.cfg.xml(默认值))- 用于配置 Hibernate 的 XML 配置文件。
hibernate.ejb.discard_pc_on_close(例如true或false(默认值))- 如果为 true,则将丢弃持久性上下文(在调用该方法时,请考虑
clear())。否则,持久性上下文将一直保持活动状态,直到事务完成:所有对象都将保持托管状态,并且所有更改都将与数据库同步(默认为 false,即 await 事务完成)。
- 如果为 true,则将丢弃持久性上下文(在调用该方法时,请考虑
hibernate.ejb.metamodel.population(例如enabled或disabled或ignoreUnsupported(默认值))- 该设置指示是否构建 JPA 类型。
接受三个值:
enabled
做构建。
disabled
- 不要进行构建。
ignoreUnsupported
- 进行构建,但忽略任何会导致失败的非 JPA 功能(例如
@Any注解)。
- 进行构建,但忽略任何会导致失败的非 JPA 功能(例如
hibernate.jpa.static_metamodel.population(例如enabled或disabled或skipUnsupported(默认值))- 该设置控制我们是否查找 JPA 静态元模型类并填充它们。
接受三个值:
enabled
做人口。
disabled
- 不做人口。
skipUnsupported
- 进行填充,但忽略任何会导致填充失败的非 JPA 功能(例如
@AnyComments)。
- 进行填充,但忽略任何会导致填充失败的非 JPA 功能(例如
hibernate.delay_cdi_access(例如true或false(默认值))- 定义对 CDI
BeanManager的延迟访问。从 5.1 开始,首选的 CDI 自举方式是通过ExtendedBeanManager。
- 定义对 CDI
hibernate.resource.beans.container(例如,完全限定的类名称)- 标识要使用的显式
org.hibernate.resource.beans.container.spi.BeanContainer。
- 标识要使用的显式
请注意,对于基于 CDI 的容器,不需要进行设置。只需通过BeanManager传递BeanManager即可使用,并可以选择指定hibernate.delay_cdi_access。
此设置更适合于集成非 CDI bean 容器,例如 Spring。
hibernate.allow_update_outside_transaction(例如true或false(默认值))- 允许在事务边界之外执行更新操作的设置。
接受两个值:
true
允许从事务中清除更新
false
- 不允许
hibernate.collection_join_subquery(例如true(默认值)或false)- 指示是否应将收集表上的新 JOIN 重写为子查询的设置。
hibernate.allow_refresh_detached_entity(例如true(使用 Hibernate 本机引导时的默认值)或false(使用 JPA 引导时的默认值)- 即使从 JPA
javax.persistence.EntityManager获得org.hibernate.Session,也允许在分离的实例上调用javax.persistence.EntityManager#refresh(entity)或Session#refresh(entity)的设置。
- 即使从 JPA
hibernate.use_entity_where_clause_for_collections(例如true(默认值)或false)- 设置控制在加载该类型的实体的一对多或多对多集合时,是否考虑使用
@Where(clause = "…")或<entity … where="…">Map 的实体的“ where”子句。
- 设置控制在加载该类型的实体的一对多或多对多集合时,是否考虑使用
hibernate.event.merge.entity_copy_observer(例如disallow(默认值),allow,log(仅用于测试目的)或标准的类名)- 该设置指定在合并时检测到同一持久性实体(“实体副本”)的多种表示形式时,Hibernate 将如何响应。
可能的值为:
disallow
如果检测到实体副本,则抛出
IllegalStateExceptionallow
- 对检测到的每个实体副本执行合并操作
log
- (仅用于测试)对检测到的每个实体副本执行合并操作,并记录有关实体副本的信息。此设置要求为EntityCopyAllowedLoggedObserver启用 DEBUG 日志记录。
此外,应用程序可以通过提供EntityCopyObserver的实现并将hibernate.event.merge.entity_copy_observer设置为类名来自定义行为。当此属性设置为allow或log时,Hibernate 将在级联合并操作时合并检测到的每个实体副本。在合并每个实体副本的过程中,Hibernate 将从每个实体副本到与cascade = CascadeType.MERGE或cascade = CascadeType.ALL关联的合并操作进行级联。当合并另一个实体副本时,由于合并一个实体副本而导致的实体状态将被覆盖。
有关更多详细信息,请查看Merge gotchas部分。
24.23. 启用属性
hibernate.envers.autoRegisterListeners(例如true(默认值)或false)- 设置为
false时,Envers 实体侦听器不再自动注册,因此您需要在引导过程中手动注册它们。
- 设置为
hibernate.integration.envers.enabled(例如true(默认值)或false)- 启用或禁用 Hibernate Envers
Service集成。
- 启用或禁用 Hibernate Envers
hibernate.listeners.envers.autoRegister- 旧版设置。请改用
hibernate.envers.autoRegisterListeners或hibernate.integration.envers.enabled。
- 旧版设置。请改用
24.24. 空间特性
hibernate.integration.spatial.enabled(例如true(默认值)或false)- 启用或禁用 Hibernate Spatial
Service集成。
- 启用或禁用 Hibernate Spatial
hibernate.spatial.connection_finder(例如org.geolatte.geom.codec.db.oracle.DefaultConnectionFinder)- 定义实现
org.geolatte.geom.codec.db.oracle.ConnectionFinder接口的类的标准名称。
- 定义实现
24.25. 内部性质
以下配置属性在内部使用,您可能不必在应用程序中对其进行配置。
hibernate.enable_specj_proprietary_syntax(例如true或false(默认值))- 启用或禁用与 JPA 规范不同的 SpecJ 专有 Map 语法。仅在性能测试期间使用。
hibernate.temp.use_jdbc_metadata_defaults(例如true(默认值)或false)- 此设置用于控制当数据库可能不可用时(主要是在工具使用方面),是否应参考 JDBC 元数据来确定某些设置默认值。
hibernate.connection_provider.injection_data- 要注入的连接提供程序设置(
Map实例)在当前配置的连接提供程序中。
- 要注入的连接提供程序设置(
hibernate.jandex_index- 命名要使用的 Jandex
org.jboss.jandex.Index实例。
- 命名要使用的 Jandex
25.MapComments
25.1. JPA 注解
25.1.1. @Access
@Access注解用于指定关联的实体类,Map 的超类或可嵌入的类或实体属性的访问类型。
有关更多信息,请参见Access type部分。
25.1.2. @AssociationOverride
@AssociationOverrideComments 用于覆盖从 Map 的超类或可嵌入对象继承的关联 Map(例如@ManyToOne,@OneToOne,@OneToMany,@ManyToMany)。
有关更多信息,请参见覆盖可嵌入类型部分。
25.1.3. @AssociationOverrides
@AssociationOverrides用于对多个@AssociationOverrideComments 进行分组。
25.1.4. @AttributeOverride
@AttributeOverrideComments 用于覆盖从 Map 超类或可嵌入对象继承的属性 Map。
有关更多信息,请参见覆盖可嵌入类型部分。
25.1.5. @AttributeOverrides
@AttributeOverrides用于对多个@AttributeOverrideComments 进行分组。
25.1.6. @Basic
@Basic注解用于将基本属性类型 Map 到数据库列。
有关更多信息,请参见Basic types章。
25.1.7. @Cacheable
@Cacheable注解用于指定是否将实体存储在二级缓存中。
如果persistence.xml shared-cache-mode XML 属性设置为ENABLE_SELECTIVE,则只有带有@CacheableComments 的实体将存储在第二级缓存中。
如果shared-cache-mode XML 属性值为DISABLE_SELECTIVE,则标记为@CacheableComments 的实体将不会存储在二级缓存中,而所有其他实体都将存储在缓存中。
有关更多信息,请参见Caching章。
25.1.8. @CollectionTable
@CollectionTable注解用于指定存储基本或可嵌入类型集合的值的数据库表。
有关更多信息,请参见可嵌入类型的集合部分。
25.1.9. @Column
@Column注解用于指定基本实体属性和数据库表列之间的 Map。
有关更多信息,请参见@Column annotation部分。
25.1.10. @ColumnResult
@ColumnResultComments 与@SqlResultSetMapping或@ConstructorResultComments 结合使用,以 Map 给定 SELECT 查询的 SQL 列。
有关更多信息,请参见具有命名本机查询的实体关联部分。
25.1.11. @ConstructorResult
@ConstructorResultComments 与@SqlResultSetMappingComments 结合使用,将给定 SELECT 查询的列 Map 到某个对象构造函数。
有关更多信息,请参见具有 ConstructorResult 的多个标量值 NamedNativeQuery部分。
25.1.12. @Convert
@ConvertComments 用于指定AttributeConverter实现,该实现用于转换当前带 Comments 的基本属性。
如果AttributeConverter使用autoApply,则将自动转换具有相同目标类型的所有实体属性。
有关更多信息,请参见AttributeConverter部分。
25.1.13. @Converter
@ConverterComments 用于指定当前 Comments 的AttributeConverter实现可用作 JPA 基本属性转换器。
如果autoApply属性设置为true,那么 JPA 提供程序将自动转换具有与当前转换器所定义的 Java 类型相同的所有 Java 基本属性。
有关更多信息,请参见AttributeConverter部分。
25.1.14. @Converts
@Converts注解用于对多个@Convert注解进行分组。
有关更多信息,请参见AttributeConverter部分。
25.1.15. @DiscriminatorColumn
@DiscriminatorColumn注解用于指定SINGLE_TABLE和JOINED继承策略的标识符列名称和discriminator type。
有关更多信息,请参见Discriminator部分。
25.1.16. @DiscriminatorValue
@DiscriminatorValueComments 用于指定鉴别符列的值用于 Map 当前带 Comments 的实体。
有关更多信息,请参见Discriminator部分。
25.1.17. @ElementCollection
@ElementCollection注解用于指定基本或可嵌入类型的集合。
有关更多信息,请参见Collections部分。
25.1.18. @Embeddable
@Embeddable注解用于指定可嵌入的类型。与基本类型一样,可嵌入类型没有任何身份,由其拥有的实体进行 Management。
有关更多信息,请参见Embeddables部分。
25.1.19. @Embedded
@Embedded注解用于指定给定的实体属性表示可嵌入类型。
有关更多信息,请参见Embeddables部分。
25.1.20. @EmbeddedId
@EmbeddedId注解用于指定实体标识符为可嵌入类型。
有关更多信息,请参见具有@EmbeddedId 的复合标识符部分。
25.1.21. @Entity
@EntityComments 用于指定当前带 Comments 的类表示实体类型。与基本类型和可嵌入类型不同,实体类型具有标识,其状态由基础持久性上下文 Management。
有关更多信息,请参见Entity部分。
25.1.22. @EntityListeners
@EntityListeners注解用于指定当前被注解的实体使用的回调侦听器类的数组。
有关更多信息,请参见JPA callbacks部分。
25.1.23. @EntityResult
@EntityResultComments 与@SqlResultSetMappingComments 一起用于将选定的列 Map 到实体。
有关更多信息,请参见具有命名本机查询的实体关联部分。
25.1.24. @Enumerated
@EnumeratedComments 用于指定实体属性表示枚举类型。
有关更多信息,请参见@枚举基本类型部分。
25.1.25. @ExcludeDefaultListeners
@ExcludeDefaultListenersComments 用于指定当前带 Comments 的实体跳过对任何默认侦听器的调用。
有关更多信息,请参见排除默认实体侦听器部分。
25.1.26. @ExcludeSuperclassListeners
@ExcludeSuperclassListenersComments 用于指定当前带 Comments 的实体跳过其超类声明的侦听器的调用。
有关更多信息,请参见排除默认实体侦听器部分。
25.1.27. @FieldResult
@FieldResultComments 与@EntityResultComments 一起用于将选定的列 Map 到某些特定实体的字段。
有关更多信息,请参见具有命名本机查询的实体关联部分。
25.1.28. @ForeignKey
@ForeignKey注解用于指定@JoinColumnMap 的关联外键。 @ForeignKey注解仅在启用了自动模式生成工具时使用,在这种情况下,它允许您自定义基础外键定义。
有关更多信息,请参见@ManyToOne 与@ForeignKey部分。
25.1.29. @GeneratedValue
@GeneratedValueComments 指定使用标识列,数据库序列或表生成器自动生成实体标识符值。 Hibernate 即使对UUID标识符也支持@GeneratedValueMap。
有关更多信息,请参见Automatically-generated identifiers部分。
25.1.30. @Id
@IdComments 指定实体标识符。实体必须始终具有一个标识符属性,该属性在给定的持久性上下文中加载该实体时使用。
有关更多信息,请参见Identifiers部分。
25.1.31. @IdClass
如果当前实体定义了复合标识符,则使用@IdClassComments。单独的类封装了所有标识符属性,这些标识符属性由当前实体 Map 进行镜像。
有关更多信息,请参见具有@IdClass 的复合标识符部分。
25.1.32. @Index
自动化模式生成工具使用@IndexComments 来创建数据库索引。
有关更多信息,请参见Columns index章。
25.1.33. @Inheritance
@Inheritance注解用于指定给定实体类层次结构的继承策略。
有关更多信息,请参见Inheritance部分。
25.1.34. @JoinColumn
@JoinColumnComments 用于指定加入实体关联或可嵌入集合时使用的 FOREIGN KEY 列。
有关更多信息,请参见@ManyToOne 和@JoinColumn部分。
25.1.35. @JoinColumns
@JoinColumns注解用于对多个@JoinColumn注解进行分组,当使用复合标识符 Map 实体关联或可嵌入的集合时,将使用这些注解。
25.1.36. @JoinTable
@JoinTableComments 用于指定其他两个数据库表之间的链接表。
有关更多信息,请参见@JoinTable mapping部分。
25.1.37. @Lob
@LobComments 用于指定当前带 Comments 的实体属性表示大型对象类型。
有关更多信息,请参见BLOB mapping部分。
25.1.38. @ManyToMany
@ManyToMany注解用于指定多对多数据库关系。
有关更多信息,请参见@ManyToMany mapping部分。
25.1.39. @ManyToOne
@ManyToOne注解用于指定多对一数据库关系。
有关更多信息,请参见@ManyToOne mapping部分。
25.1.40. @MapKey
@MapKey注解用于指定java.util.Map关联的键,其键类型是主键或表示 Map 值的实体的属性。
有关更多信息,请参见@MapKey mapping部分。
25.1.41. @MapKeyClass
@MapKeyClass注解用于指定java.util.Map关联的 Map 关键字的类型。
有关更多信息,请参见@MapKeyClass mapping部分。
25.1.42. @MapKeyColumn
@MapKeyColumnComments 用于指定数据库列,该数据库列存储 Map 键为基本类型的java.util.Map关联的键。
有关@MapKeyColumnComments 用法的示例,请参见@MapKeyTypeMap 部分。
25.1.43. @MapKeyEnumerated
@MapKeyEnumerated注解用于指定java.util.Map关联的键是 Java 枚举。
有关更多信息,请参见@MapKeyEnumerated mapping部分。
25.1.44. @MapKeyJoinColumn
@MapKeyJoinColumn注解用于指定java.util.Map关联的关键字是实体关联。Map 键列是链接表中的 FOREIGN KEY,该链接表还将Map所有者的表与Map值所在的表连接在一起。
有关更多信息,请参见@MapKeyJoinColumn mapping部分。
25.1.45. @MapKeyJoinColumns
当java.util.Map关联密钥使用复合标识符时,@MapKeyJoinColumnsComments 用于对多个@MapKeyJoinColumnMap 进行分组。
25.1.46. @MapKeyTemporal
@MapKeyTemporalComments 用于指定java.util.Map关联的关键字是@TemporalType(例如DATE,TIME,TIMESTAMP)。
有关更多信息,请参见@MapKeyTemporal mapping部分。
25.1.47. @MappedSuperclass
@MappedSuperclassComments 用于指定任何子类实体继承当前 Comments 的类型属性。
有关更多信息,请参见@MappedSuperclass部分。
25.1.48. @MapsId
@MapsIdComments 用于指定实体标识符由当前 Comments 的@ManyToOne或@OneToOne关联 Map。
有关更多信息,请参见@MapsId mapping部分。
25.1.49. @NamedAttributeNode
@NamedAttributeNodeComments 用于指定实体图需要获取的每个单独的属性节点。
有关更多信息,请参见Fetch graph部分。
25.1.50. @NamedEntityGraph
@NamedEntityGraphComments 用于指定实体图,实体查询可使用该图来覆盖默认的提取计划。
有关更多信息,请参见Fetch graph部分。
25.1.51. @NamedEntityGraphs
@NamedEntityGraphs注解用于对多个@NamedEntityGraph注解进行分组。
25.1.52. @NamedNativeQueries
@NamedNativeQueries注解用于对多个@NamedNativeQuery注解进行分组。
有关更多信息,请参见自定义 CRUDMap部分。
25.1.53. @NamedNativeQuery
@NamedNativeQuery注解用于指定本机 SQL 查询,以后可以通过其名称检索。
有关更多信息,请参见自定义 CRUDMap部分。
25.1.54. @NamedQueries
@NamedQueries注解用于对多个@NamedQuery注解进行分组。
25.1.55. @NamedQuery
@NamedQuery注解用于指定 JPQL 查询,以后可以通过其名称检索该查询。
有关更多信息,请参见@NamedQuery部分。
25.1.56. @NamedStoredProcedureQueries
@NamedStoredProcedureQueries注解用于对多个@NamedStoredProcedureQuery注解进行分组。
25.1.57. @NamedStoredProcedureQuery
@NamedStoredProcedureQuery注解用于指定存储过程查询,以后可以通过其名称检索该查询。
有关更多信息,请参见使用命名查询来调用存储过程部分。
25.1.58. @NamedSubgraph
@NamedSubgraphComments 用于在实体图中指定子图。
有关更多信息,请参见Fetch subgraph部分。
25.1.59. @OneToMany
@OneToMany注解用于指定一对多数据库关系。
有关更多信息,请参见@OneToMany mapping部分。
25.1.60. @OneToOne
@OneToOne注解用于指定一对一的数据库关系。
有关更多信息,请参见@OneToOne mapping部分。
25.1.61. @OrderBy
@OrderByComments 用于指定在获取当前带 Comments 的集合时用于排序的实体属性。
有关更多信息,请参见@OrderBy mapping部分。
25.1.62. @OrderColumn
@OrderColumnComments 用于指定应在数据库中实现当前 Comments 收集 Sequences。
有关更多信息,请参见@OrderColumn mapping部分。
25.1.63. @PersistenceContext
@PersistenceContext注解用于指定需要作为依赖项注入的EntityManager。
有关更多信息,请参见@PersistenceContext mapping部分。
25.1.64. @PersistenceContexts
@PersistenceContexts注解用于对多个@PersistenceContext注解进行分组。
25.1.65. @PersistenceProperty
@PersistenceProperty注解用于@PersistenceContext注解,以声明创建EntityManager实例时传递到基础容器的 JPA 提供程序属性。
有关更多信息,请参见@PersistenceProperty mapping部分。
25.1.66. @PersistenceUnit
@PersistenceUnit注解用于指定需要作为依赖项注入的EntityManagerFactory。
有关更多信息,请参见@PersistenceUnit mapping部分。
25.1.67. @PersistenceUnits
@PersistenceUnits注解用于对多个@PersistenceUnit注解进行分组。
25.1.68. @PostLoad
@PostLoad注解用于指定在加载实体后触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.69. @PostPersist
@PostPersist注解用于指定在持久保存实体后触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.70. @PostRemove
@PostRemove注解用于指定在删除实体后触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.71. @PostUpdate
@PostUpdateComments 用于指定在更新实体后触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.72. @PrePersist
@PrePersist注解用于指定在持久保存实体之前触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.73. @PreRemove
@PreRemove注解用于指定在删除实体之前触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.74. @PreUpdate
@PreUpdate注解用于指定在更新实体之前触发的回调方法。
有关更多信息,请参见JPA callbacks部分。
25.1.75. @PrimaryKeyJoinColumn
@PrimaryKeyJoinColumnComments 用于指定当前带 Comments 的实体的主键列还是其他某个实体(例如JOINED继承策略中的 Base Class 表,辅助表 Map 中的主表或父级)的外键@OneToOne关系中的表格)。
有关更多信息,请参见@PrimaryKeyJoinColumn mapping部分。
25.1.76. @PrimaryKeyJoinColumns
@PrimaryKeyJoinColumns注解用于对多个@PrimaryKeyJoinColumn注解进行分组。
25.1.77. @QueryHint
@QueryHint注解用于指定@NamedQuery或@NamedNativeQuery注解使用的 JPA 提供程序提示。
有关更多信息,请参见@QueryHint部分。
25.1.78. @SecondaryTable
@SecondaryTableComments 用于为当前带 Comments 的实体指定辅助表。
有关更多信息,请参见@SecondaryTable mapping部分。
25.1.79. @SecondaryTables
@SecondaryTables注解用于对多个@SecondaryTable注解进行分组。
25.1.80. @SequenceGenerator
@SequenceGeneratorComments 用于指定当前被 Comments 实体的标识符生成器使用的数据库序列。
有关更多信息,请参见@SequenceGenerator mapping部分。
25.1.81. @SqlResultSetMapping
@SqlResultSetMapping注解用于指定本机 SQL 查询或存储过程的ResultSetMap。
有关更多信息,请参见SqlResultSetMapping mapping部分。
25.1.82. @SqlResultSetMappings
@SqlResultSetMappingsComments 是多个@SqlResultSetMappingComments 组。
25.1.83. @StoredProcedureParameter
@StoredProcedureParameter注解用于指定@NamedStoredProcedureQuery的参数。
有关更多信息,请参见使用命名查询来调用存储过程部分。
25.1.84. @Table
@TableComments 用于指定当前带 Comments 的实体的主表。
有关更多信息,请参见@Table mapping部分。
25.1.85. @TableGenerator
@TableGeneratorComments 用于指定当前被 Comments 实体的身份生成器使用的数据库表。
有关更多信息,请参见@TableGenerator mapping部分。
25.1.86. @Temporal
@TemporalComments 用于指定当前 Comments 的java.util.Date或java.util.Calendar实体属性的TemporalType。
有关更多信息,请参见基本时间类型章。
25.1.87. @Transient
@Transient注解用于指定不应保留给定的实体属性。
有关更多信息,请参见@Transient mapping部分。
25.1.88. @UniqueConstraint
@UniqueConstraintComments 用于为与当前带 Comments 的实体相关联的主表或辅助表指定唯一的约束,该约束将由自动模式生成器包括在内。
有关更多信息,请参见列唯一约束章。
25.1.89. @Version
@Version注解用于指定用于乐观锁定的 version 属性。
有关更多信息,请参见乐观锁 Map部分。
25.2. 休眠 Comments
25.2.1. @AccessType
@AccessTypeComments 已弃用。您应该使用 JPA @Access或 Hibernate 本机@AttributeAccessorComments。
25.2.2. @Any
@Any注解用于定义“任意一对一”关联,该关联可以指向几种实体类型之一。
有关更多信息,请参见@Any mapping部分。
25.2.3. @AnyMetaDef
@AnyMetaDef注解用于提供有关@Any或@ManyToAnyMap 的元数据。
有关更多信息,请参见@Any mapping部分。
25.2.4. @AnyMetaDefs
@AnyMetaDefs注解用于对多个@AnyMetaDef注解进行分组。
25.2.5. @AttributeAccessor
@AttributeAccessor注解用于指定自定义PropertyAccessStrategy。
仅应用于命名自定义PropertyAccessStrategy。对于属性/字段访问类型,应首选 JPA @Access注解。
但是,如果将此注解与 value =“ property”或 value =“ field”一起使用,它将充当 JPA @Access注解的相应用法。
25.2.6. @BatchSize
@BatchSize注解用于指定批量加载惰性集合条目的大小。
有关更多信息,请参见Batch fetching部分。
25.2.7. @Cache
@Cache注解用于指定根实体或集合的CacheConcurrencyStrategy。
有关更多信息,请参见Caching章。
25.2.8. @Cascade
@Cascade注解用于将 Hibernate 特定的CascadeType策略(例如CascadeType.LOCK,CascadeType.SAVE_UPDATE,CascadeType.REPLICATE)应用于给定的关联。
对于 JPA 级联,请改用javax.persistence.CascadeType。
当结合使用 JPA 和 Hibernate CascadeType策略时,Hibernate 将合并两组级联。
有关更多信息,请参见Cascading章。
25.2.9. @Check
@CheckComments 用于指定可以在类级别定义的任意 SQL CHECK 约束。
有关更多信息,请参见Database-level checks章。
25.2.10. @CollectionId
@CollectionId注解用于指定 idbag 集合的标识符列。
您可能要改用 JPA @OrderColumn。
25.2.11. @CollectionType
@CollectionType注解用于指定自定义集合类型。
集合也可以命名为@Type,它定义了集合元素的休眠类型。
有关更多信息,请参见自定义集合类型章。
25.2.12. @ColumnDefault
@ColumnDefaultComments 用于指定使用自动模式生成器时要应用的DEFAULT DDL 值。
使用 JPA @Column注解的definition属性可以实现相同的行为。
有关更多信息,请参见数据库列的默认值章。
25.2.13. @Columns
@Columns注解用于对多个 JPA @Column注解进行分组。
有关更多信息,请参见@Columns mapping部分。
25.2.14. @ColumnTransformer
@ColumnTransformerComments 用于自定义如何从数据库读取或写入给定的列值。
有关更多信息,请参见@ColumnTransformer mapping部分。
25.2.15. @ColumnTransformers
@ColumnTransformersComments 用于将多个@ColumnTransformerComments 分组。
25.2.16. @CreationTimestamp
@CreationTimestampComments 用于指定必须使用当前 JVM 时间戳值初始化当前 Comments 的时间类型。
有关更多信息,请参见@CreationTimestamp mapping部分。
25.2.17. @DiscriminatorFormula
@DiscriminatorFormulaComments 用于指定 Hibernate @Formula来解析继承标识符值。
有关更多信息,请参见@DiscriminatorFormula部分。
25.2.18. @DiscriminatorOptions
@DiscriminatorOptions注解用于提供force和insert Discriminator 属性。
有关更多信息,请参见Discriminator部分。
25.2.19. @DynamicInsert
@DynamicInsert注解用于指定每当要保留实体时都应生成INSERT SQL 语句。
默认情况下,Hibernate 使用设置所有表列的缓存INSERT语句。当使用@DynamicInsertComments 对实体进行 Comments 时,PreparedStatement将仅包含非 null 列。
有关@DynamicInsert工作原理的更多信息,请参见@CreationTimestamp mapping部分。
25.2.20. @DynamicUpdate
@DynamicUpdateComments 用于指定每当修改实体时都应生成UPDATE SQL 语句。
默认情况下,Hibernate 使用设置所有表列的缓存UPDATE语句。当使用@DynamicUpdateComments 对实体进行 Comments 时,PreparedStatement将仅包括其值已更改的列。
有关更多信息,请参见@DynamicUpdate部分。
Note
为了重新连接分离的实体,如果没有@SelectBeforeUpdateComments,也无法进行动态更新。
25.2.21. @Entity
@EntityComments 已弃用。请改用 JPA @Entity注解。
25.2.22. @Fetch
@FetchComments 用于指定用于当前 Comments 的关联的特定于 Hibernate 的FetchMode(例如JOIN,SELECT,SUBSELECT)。
有关更多信息,请参见@Fetch mapping部分。
25.2.23. @FetchProfile
@FetchProfile注解用于指定自定义提取配置文件,类似于 JPA 实体图。
有关更多信息,请参见Fetch mapping部分。
25.2.24. @FetchProfile.FetchOverride
@FetchProfile.FetchOverride注解与@FetchProfile注解一起使用,它用于覆盖特定实体关联的获取策略。
有关更多信息,请参见Fetch profile部分。
25.2.25. @FetchProfiles
@FetchProfiles注解用于对多个@FetchProfile注解进行分组。
25.2.26. @Filter
@Filter注解用于将过滤器添加到集合的实体或目标实体。
有关更多信息,请参见Filter mapping部分。
25.2.27. @FilterDef
@FilterDefComments 用于指定@Filter定义(名称,默认条件和参数类型,如果有的话)。
有关更多信息,请参见Filter mapping部分。
25.2.28. @FilterDefs
@FilterDefs注解用于对多个@FilterDef注解进行分组。
25.2.29. @FilterJoinTable
@FilterJoinTable注解用于将@Filter功能添加到联接表集合中。
有关更多信息,请参见FilterJoinTable mapping部分。
25.2.30. @FilterJoinTables
@FilterJoinTables注解用于对多个@FilterJoinTable注解进行分组。
25.2.31. @Filters
25.2.32. @ForeignKey
@ForeignKeyComments 已弃用。请改用 JPA 2.1 @ForeignKey注解。
25.2.33. @Formula
@Formula注解用于指定要填充给定实体属性而执行的 SQL 片段。
有关更多信息,请参见@Formula mapping部分。
25.2.34. @Generated
@Generated注解用于指定当前已注解的实体属性是由数据库生成的。
有关更多信息,请参见@Generated mapping部分。
25.2.35. @GeneratorType
@GeneratorTypeComments 用于为当前 Comments 的生成的属性提供ValueGenerator和GenerationTime。
有关更多信息,请参见@GeneratorType mapping部分。
25.2.36. @GenericGenerator
@GenericGeneratorComments 可用于配置任何 Hibernate 标识符生成器。
有关更多信息,请参见@GenericGenerator mapping部分。
25.2.37. @GenericGenerators
@GenericGenerators注解用于对多个@GenericGenerator注解进行分组。
25.2.38. @Immutable
@ImmutableComments 用于指定带 Comments 的实体,属性或集合是不可变的。
有关更多信息,请参见@Immutable mapping部分。
25.2.39. @Index
@IndexComments 已弃用。请改用 JPA @Index注解。
25.2.40. @IndexColumn
@IndexColumnComments 已弃用。请改用 JPA @OrderColumn注解。
25.2.41. @JoinColumnOrFormula
@JoinColumnOrFormulaComments 用于指定通过 FOREIGN KEY 连接(例如@JoinColumn)或使用给定 SQL 公式的结果(例如@JoinFormula)来解析实体关联。
有关更多信息,请参见@JoinColumnOrFormula mapping部分。
25.2.42. @JoinColumnsOrFormulas
@JoinColumnsOrFormulas注解用于对多个@JoinColumnOrFormula注解进行分组。
25.2.43. @JoinFormula
当关联没有专用的 FOREIGN KEY 列时,@JoinFormulaComments 将替代@JoinColumn。
有关更多信息,请参见@JoinFormula mapping部分。
25.2.44. @LazyCollection
@LazyCollection注解用于指定给定集合的延迟获取行为。可能的值由LazyCollectionOption枚举给出:
TRUE- 在请求状态时加载它。
FALSE- 认真加载它。
EXTRA- 优先选择额外的查询而不是完整的集合加载。
TRUE和FALSE值已弃用,因为您应该使用@ElementCollection,@OneToMany或@ManyToMany集合的 JPA FetchType属性。
EXTRA值在 JPA 规范中没有等效项,即使在首次访问该集合时,也可以避免加载整个集合。使用辅助查询分别获取每个元素。
有关更多信息,请参见@LazyCollection mapping部分。
25.2.45. @LazyGroup
@LazyGroupComments 用于指定应将实体属性与属于同一组的所有其他属性一起获取。
要延迟加载实体属性,需要增强字节码。默认情况下,所有非集合属性都加载到一个名为“ DEFAULT”的组中。
当访问组中的一个属性时,此注解允许定义不同的属性组以一起初始化。
有关更多信息,请参见@LazyGroup mapping部分。
25.2.46. @LazyToOne
@LazyToOneComments 用于指定由LazyToOneOption表示的惰性选项,可用于@OneToOne或@ManyToOne关联。
LazyToOneOption定义了以下替代方法:
FALSE
- 认真加载关联。因为 JPA
FetchType.EAGER提供了相同的行为,所以不需要这一行为。
- 认真加载关联。因为 JPA
NO_PROXY
- 该选项将在返回真实实体对象时延迟获取关联。
PROXY
- 此选项将延迟获取关联,同时返回代理。
有关更多信息,请参见@LazyToOneMap 示例部分。
25.2.47. @ListIndexBase
@ListIndexBase注解用于为存储在数据库中的列表索引指定起始值。
默认情况下,从零开始存储List个索引。通常与@OrderColumn结合使用。
有关更多信息,请参见@ListIndexBase mapping部分。
25.2.48. @Loader
@Loader注解用于覆盖用于加载实体的默认SELECT查询。
有关更多信息,请参见自定义 CRUDMap部分。
25.2.49. @ManyToAny
@ManyToAny注解用于在动态解析目标类型时指定多对一关联。
有关更多信息,请参见@ManyToAny mapping部分。
25.2.50. @MapKeyType
@MapKeyType注解用于指定 Map 密钥类型。
有关更多信息,请参见@MapKeyType mapping部分。
25.2.51. @MetaValue
@MetaValue注解用于@AnyMetaDef注解,以指定给定的标识符值和实体类型之间的关联。
有关更多信息,请参见@Any mapping部分。
25.2.52. @NamedNativeQueries
@NamedNativeQueries注解用于对多个@NamedNativeQuery注解进行分组。
25.2.53. @NamedNativeQuery
@NamedNativeQueryComments 使用 Hibernate 特定功能扩展了 JPA @NamedNativeQuery,例如:
此特定查询的刷新模式
是否应缓存查询,以及应使用哪个缓存区域
所选实体
CacheModeType策略JDBC
Statement获取大小JDBC
Statement执行超时如果查询是
CallableStatement,则以存储过程或数据库函数为目标应该将什么 SQL 级别的 Comments 发送到数据库
如果查询是只读的,则不会将结果实体存储到当前运行的持久性上下文中
有关更多信息,请参见Hibernate @NamedNativeQuery部分。
25.2.54. @NamedQueries
@NamedQueries注解用于对多个@NamedQuery注解进行分组。
25.2.55. @NamedQuery
@NamedQueryComments 使用 Hibernate 特定功能扩展了 JPA @NamedQuery,例如:
此特定查询的刷新模式
是否应缓存查询,以及应使用哪个缓存区域
所选实体
CacheModeType策略JDBC
Statement获取大小JDBC
Statement执行超时如果查询是
CallableStatement,则以存储过程或数据库函数为目标应该将什么 SQL 级别的 Comments 发送到数据库
如果查询是只读的,则不会将结果实体存储到当前运行的持久性上下文中
有关更多信息,请参见@NamedQuery部分。
25.2.56. @Nationalized
@NationalizedComments 用于指定当前 Comments 的属性是字符类型(例如String,Character,Clob),该字符类型存储在民族化的列类型(NVARCHAR,NCHAR,NCLOB)中。
有关更多信息,请参见@Nationalized mapping部分。
25.2.57. @NaturalId
@NaturalIdComments 用于指定当前带 Comments 的属性是实体自然 ID 的一部分。
有关更多信息,请参见Natural Ids部分。
25.2.58. @NaturalIdCache
@NaturalIdCacheComments 用于指定与带 Comments 的实体关联的自然 id 值应存储在第二级缓存中。
有关更多信息,请参见@NaturalIdCache mapping部分。
25.2.59. @NotFound
@NotFoundComments 用于指定在给定关联中找不到元素时的NotFoundAction策略。
NotFoundAction定义了两种可能性:
EXCEPTION- 如果找不到元素(默认和推荐),则会引发异常。
IGNORE- 在数据库中找不到该元素时,请忽略该元素。
有关更多信息,请参见@NotFound mapping部分。
25.2.60. @OnDelete
@OnDeleteComments 用于指定当前 Comments 的集合,数组或联接的子类采用的删除策略。自动模式生成工具使用此 Comments 来生成适当的 FOREIGN KEY DDL 级联指令。
OnDeleteAction枚举定义了两种可能的策略:
CASCADE
- 使用数据库的 FOREIGN KEY 级联功能。
NO_ACTION
- 不采取行动。
有关更多信息,请参见@OnDelete cascade章。
25.2.61. @OptimisticLock
@OptimisticLockComments 用于指定当前 Comments 的属性是否将在修改后触发实体版本增量。
有关更多信息,请参见Excluding attributes部分。
25.2.62. @OptimisticLocking
@OptimisticLockingComments 用于指定当前带 Comments 的实体的乐观锁定策略。
OptimisticLockType枚举定义了四种可能的策略:
NONE
- 隐式乐观锁定机制已禁用。
VERSION
- 隐式乐观锁定机制正在使用专用版本列。
ALL
- 隐式的乐观锁定机制将 all 属性用作
UPDATE和DELETESQL 语句的扩展 WHERE 子句限制的一部分。
- 隐式的乐观锁定机制将 all 属性用作
DIRTY
- 隐式的乐观锁定机制将 dirty 属性(已修改的属性)用作对
UPDATE和DELETESQL 语句的扩展 WHERE 子句限制的一部分。
- 隐式的乐观锁定机制将 dirty 属性(已修改的属性)用作对
有关更多信息,请参见无版本乐观锁定部分。
25.2.63. @OrderBy
@OrderByComments 用于指定用于对当前带 Comments 的集合进行排序的 SQL 排序指令。
它与 JPA @OrderByComments 不同,因为 JPAComments 需要 JPQL 排序片段,而不是 SQL 指令。
有关更多信息,请参见@OrderBy mapping部分。
25.2.64. @ParamDef
@ParamDefComments 与@FilterDef结合使用,以便可以使用运行时提供的参数值来自定义 Hibernate Filter。
有关更多信息,请参见Filter mapping部分。
25.2.65. @Parameter
@ParameterComments 是用于参数化其他 Comments(例如@CollectionType,@GenericGenerator和@Type,@TypeDef)的通用参数(基本上是键/值组合)。
25.2.66. @Parent
@Parent注解用于指定当前已注解的可嵌入属性引用了所属实体。
有关更多信息,请参见@Parent mapping部分。
25.2.67. @Persister
@Persister注解用于指定自定义实体或集合持久性。
对于实体,自定义持久程序必须实现EntityPersister接口。
对于集合,自定义持久程序必须实现CollectionPersister接口。
有关更多信息,请参见@Persister mapping部分。
25.2.68. @Polymorphism
@PolymorphismComments 用于定义PolymorphismType Hibernate 将应用于实体层次结构。
PolymorphismType选项有两个:
EXPLICIT
- 仅在明确询问时才检索当前带 Comments 的实体。
IMPLICIT
- 如果检索到其任何超级实体,则检索当前带 Comments 的实体。这是默认选项。
有关更多信息,请参见@Polymorphism部分。
25.2.69. @Proxy
@ProxyComments 用于为当前带 Comments 的实体指定自定义代理实现。
有关更多信息,请参见@Proxy mapping部分。
25.2.70. @RowId
@RowIdComments 用于指定用作ROWID * pseudocolumn *的数据库列。例如,Oracle 定义了ROWID pseudocolumn,它提供每个表行的地址。
根据 Oracle 文档,ROWID是访问表中单行的最快方法。
有关更多信息,请参见@RowId mapping部分。
25.2.71. @SelectBeforeUpdate
@SelectBeforeUpdateComments 用于指定当重新连接分离的实体时确定是否执行更新时,从数据库中选择当前已 Comments 的实体状态。
有关@SelectBeforeUpdate工作原理的更多信息,请参见OptimisticLockType.DIRTY mapping部分。
25.2.72. @Sort
@SortComments 已弃用。请改用 Hibernate 特定的@SortComparator或@SortNaturalComments。
25.2.73. @SortComparator
@SortComparator注解用于指定Comparator以对Set/Map内存进行排序。
有关更多信息,请参见@SortComparator mapping部分。
25.2.74. @SortNatural
@SortNaturalComments 用于指定应使用自然排序对Set/Map进行排序。
有关更多信息,请参见@SortNatural mapping部分。
25.2.75. @Source
@SourceComments 与指示时间戳值SourceType的@Version时间戳实体属性一起使用。
SourceType提供两个选项:
DB
- 从数据库获取时间戳。
VM
- 从当前的 JVM 获取时间戳。
有关更多信息,请参见数据库生成的版本时间戳 Map部分。
25.2.76. @SQLDelete
@SQLDeleteComments 用于为当前带 Comments 的实体或集合指定自定义 SQL DELETE语句。
有关更多信息,请参见自定义 CRUDMap部分。
25.2.77. @SQLDeleteAll
删除当前带 Comments 集合的所有元素时,@SQLDeleteAllComments 用于指定自定义 SQL DELETE语句。
有关更多信息,请参见自定义 CRUDMap部分。
25.2.78. @SqlFragmentAlias
@SqlFragmentAliasComments 用于为 Hibernate @Filter指定别名。
然后可以使用{alias}(例如{myAlias})占位符在@Filter condition子句中使用别名(例如myAlias)。
有关更多信息,请参见@SqlFragmentAlias mapping部分。
25.2.79. @SQLInsert
@SQLInsertComments 用于为当前带 Comments 的实体或集合指定自定义 SQL INSERT语句。
有关更多信息,请参见自定义 CRUDMap部分。
25.2.80. @SQLUpdate
@SQLUpdateComments 用于为当前带 Comments 的实体或集合指定自定义 SQL UPDATE语句。
有关更多信息,请参见自定义 CRUDMap部分。
25.2.81. @Subselect
@SubselectComments 用于使用自定义 SQL SELECT语句指定不可变的只读实体。
有关更多信息,请参见将实体 Map 到 SQL 查询部分。
25.2.82. @Synchronize
@Synchronize注解通常与@Subselect注解一起使用,以指定@Subselect SQL 查询使用的数据库表的列表。
有了这些信息,当持久性上下文针对@Subselect SQL 查询使用的数据库表安排了一些插入/更新/删除操作时,只要要执行针对@Subselect实体的查询,Hibernate 就会正确触发实体刷新。
因此,在针对@Subselect实体执行实体查询时,@SynchronizeComments 可防止派生实体返回陈旧数据。
有关更多信息,请参见将实体 Map 到 SQL 查询部分。
25.2.83. @Table
@Table注解用于为 JPA @Table注解指定其他信息,例如自定义INSERT,UPDATE或DELETE语句或特定的FetchMode。
有关特定于 Hibernate 的@TableMap 的更多信息,请参见@SecondaryTable mapping部分。
25.2.84. @Tables
25.2.85. @Target
当前 Comments 的关联使用接口类型时,@TargetComments 用于指定显式目标实现。
有关更多信息,请参见@Target mapping部分。
25.2.86. @Tuplizer
@TuplizerComments 用于为当前带 Comments 的实体或可嵌入的实体指定自定义修整器。
对于实体,辅导者必须实现EntityTuplizer接口。
对于可嵌入对象,guides 者必须实现ComponentTuplizer接口。
有关更多信息,请参见@Tuplizer mapping部分。
25.2.87. @Tuplizers
@Tuplizers注解用于对多个@Tuplizer注解进行分组。
25.2.88. @Type
@TypeComments 用于指定当前 Comments 的基本属性所使用的 Hibernate @Type。
有关更多信息,请参见@Type mapping部分。
25.2.89. @TypeDef
@TypeDef注解用于指定@Type定义,以后可将其重新用于多个基本属性 Map。
有关更多信息,请参见@TypeDef mapping部分。
25.2.90. @TypeDefs
@TypeDefs注解用于对多个@TypeDef注解进行分组。
25.2.91. @UpdateTimestamp
@UpdateTimestampComments 用于指定每当拥有实体被修改时,都应使用当前的 JVM 时间戳更新当前 Comments 的时间戳属性。
java.util.Datejava.util.Calendarjava.sql.Datejava.sql.Timejava.sql.Timestamp
有关更多信息,请参见@UpdateTimestamp mapping部分。
25.2.92. @ValueGenerationType
@ValueGenerationTypeComments 用于指定将当前 Comments 类型用作生成器 Comments 类型。
有关更多信息,请参见@ValueGenerationType mapping部分。
25.2.93. @Where
@Where注解用于指定在获取实体或集合时使用的自定义 SQL WHERE子句。
有关更多信息,请参见@Where mapping部分。
25.2.94. @WhereJoinTable
@WhereJoinTable注解用于指定在获取联接集合表时使用的自定义 SQL WHERE子句。
有关更多信息,请参见@WhereJoinTable mapping部分。
26.性能调优和最佳做法
每个企业系统都是唯一的。但是,拥有非常高效的数据访问层是许多企业应用程序的普遍要求。 Hibernate 具有多种功能,可以帮助您调整数据访问层。
26.1. 模式 Management
尽管 Hibernate 为hibernate.hbm2ddl.auto配置属性提供了update选项,但是此功能不适用于生产环境。
使用自动模式迁移工具(例如Flyway,Liquibase),您可以使用任何特定于数据库的 DDL 功能(例如规则,触发器,分区表)。每个迁移都应具有一个关联的脚本,该脚本与应用程序源代码一起存储在版本控制系统中。
如果将应用程序部署在类似生产的 QA 环境中,并且部署按预期进行,那么将部署推送到生产环境应该很简单,因为已经测试了最新的架构迁移。
Tip
您应该始终使用自动模式迁移工具,并将所有迁移脚本存储在版本控制系统中。
26.2. Logging
无论何时使用代表您生成 SQL 语句的框架,都必须确保生成的语句首先是您想要的。
日志记录语句有多种选择。您可以通过配置基础日志记录框架来记录语句。对于 Log4j,可以使用以下附加程序:
### log just the SQL
log4j.logger.org.hibernate.SQL=debug
### log JDBC bind parameters ###
log4j.logger.org.hibernate.type=trace
log4j.logger.org.hibernate.type.descriptor.sql=trace
但是,还有其他一些选择,例如使用 datasource-proxy 或 p6spy。使用 JDBC Driver或DataSource代理的优点是您可以超越简单的 SQL 日志记录:
语句执行时间
JDBC 批处理记录
使用DataSource代理的另一个优点是,您可以在测试时声明已执行语句的数量。这样,当自动检测到 N 1 查询问题时,可以使集成测试失败。
Tip
尽管简单的语句记录很好,但使用datasource-proxy或p6spy甚至更好。
26.3. JDBC 批处理
JDBC 允许我们批处理多个 SQL 语句,并将它们发送到单个请求中到数据库服务器。这样可以节省数据库往返次数,因此是大大减少响应时间。
不仅可以批处理INSERT和UPDATE语句,甚至可以批处理DELETE语句。对于INSERT和UPDATE语句,请确保已具备所有正确的配置属性,例如对插入和更新进行排序以及为版本化数据激活批处理。请查看this article了解有关此主题的更多详细信息。
对于DELETE语句,没有选择对父语句和子语句进行排序的选项,因此级联会干扰 JDBC 批处理过程。
与其他任何不能自动生成 SQL 语句的框架不同,Hibernate 使Batching chapter中指示的激活 JDBC 级批处理变得非常容易。
26.4. Mapping
选择正确的 Map 对于高性能数据访问层非常重要。从标识符生成器到关联,有许多选项可供选择,但是从性能的角度来看,并非所有选择都是平等的。
26.4.1. Identifiers
关于标识符,您可以选择自然 ID 或合成密钥。
对于自然标识符, assigned 标识符生成器是正确的选择。
对于合成密钥,应用程序开发人员可以选择随机生成的固定大小序列(例如 UUID)或自然标识符。自然标识符非常实用,比 UUID 标识符更紧凑,因此有多个生成器可供选择:
IDENTITYSEQUENCETABLE
尽管TABLE生成器解决了可移植性问题,但实际上它的性能很差,因为它需要使用单独的事务和行级锁来模拟数据库序列。因此,通常在IDENTITY和SEQUENCE之间进行选择。
Tip
如果基础数据库支持序列,则应始终将其用作 Hibernate 实体标识符。
仅当关系数据库不支持序列(例如 MySQL 5.7)时,才应使用IDENTITY生成器。但是,请记住,IDENTITY生成器禁用了INSERT语句的 JDBC 批处理。
如果您使用的是SEQUENCE生成器,则应该使用在 Hibernate 5 中默认启用的增强型标识符生成器。 pooled 和 pooled-lo 优化器对于减少数量非常有用。每个数据库事务写入多个实体时的数据库往返次数。
26.4.2. Associations
JPA 提供了四种实体关联类型:
@ManyToOne@OneToOne@OneToMany@ManyToMany
还有一个@ElementCollection用于可嵌入对象的集合。
由于对象关联可以是双向的,因此存在许多可能的关联组合。但是,从数据库的角度来看,并非每种可能的关联类型都是有效的。
Tip
关联 Map 越接近底层数据库关系,它将执行得越好。
另一方面,关联 Map 越奇特,效率低下的机会就越大。
因此,@ManyToOne和@OneToOne子方关联最好代表FOREIGN KEY关系。
父端@OneToOne关联需要增强字节码,以便可以延迟加载关联。否则,即使关联标记为FetchType.LAZY,也始终会获取父级关联。
因此,最好使用@MapsIdMap@OneToOne关联,以便在子实体和父实体之间共享PRIMARY KEY。当使用@MapsId时,父侧关联变得多余,因为可以使用父实体标识符轻松获取子实体。
对于集合,关联可以是:
unidirectional
bidirectional
对于单向集合,Set是最佳选择,因为它们生成最有效的 SQL 语句。单向List s 的效率比@ManyToOne关联低。
双向关联通常是更好的选择,因为@ManyToOne端控制关联。
可嵌入的集合(@ElementCollection)是单向关联,因此Set s 是最有效的,其次是有序的List s,而包(无序的List s)的效率最低。
@ManyToManyComments 很少是一个不错的选择,因为它将双方都视为单向关联。
因此,最好按照具有链接实体生命周期的双向多对多部分中所示 Map 链接表。每个FOREIGN KEY列将 Map 为@ManyToOne关联。在每个父侧,双向@OneToMany关联将 Map 到链接实体中的上述@ManyToOne关系。
Tip
仅仅因为您对集合具有支持,并不意味着您必须将任何一对多数据库关系转换为一个集合。
有时,一个@ManyToOne关联就足够了,并且该集合可以简单地由一个易于分页或过滤的实体查询代替。
26.5. Inheritance
JPA 提供SINGLE_TABLE,JOINED和TABLE_PER_CLASS来处理继承 Map,并且每种策略都有其优点和缺点。
SINGLE_TABLE在执行的 SQL 语句方面表现最佳。但是,您不能在列级使用NOT NULL约束。您仍然可以使用触发器和规则来强制执行此类约束,但这并不是那么简单。JOINED解决了数据完整性问题,因为每个子类都与一个不同的表相关联。多态查询或@OneToManyBase Class 关联在此策略下效果不佳。但是,多态@ManyToOne关联很好,它们可以提供很多价值。应避免使用
TABLE_PER_CLASS,因为它无法呈现有效的 SQL 语句。
26.6. Fetching
Tip
对于绝大多数 JPA 应用程序而言,获取太多数据是性能的首要问题。
Hibernate 支持实体查询(JPQL/HQL 和 Criteria API)和本机 SQL 语句。实体查询仅在您需要修改获取的实体时才有用,因此可从自动脏检查机制中受益。
对于只读事务,应该获取 DTO 预测,因为它们允许您选择满足特定业务用例所需的任意多列。这具有许多好处,例如,由于不需要 ManagementDTO 投影,因此可以减轻当前正在运行的持久性上下文的负担。
26.6.1. 提取关联
与关联相关,有两种主要的获取策略:
EAGERLAZY
EAGER提取几乎总是一个错误的选择。
Tip
在 JPA 之前,默认情况下,Hibernate 以前将所有关联都设为LAZY。但是,当 JPA 1.0 规范出现时,人们认为并非所有提供程序都将使用代理。因此,默认情况下@ManyToOne和@OneToOne关联现在为EAGER。
EAGER提取策略不能在每个查询的基础上被覆盖,因此即使您不需要该关联,也总是可以对其进行检索。此外,如果您忘记在 JPQL 查询中使用JOIN FETCH EAGER关联,则 Hibernate 将使用辅助语句对其进行初始化,这反过来可能导致 N 1 个查询问题。
因此,应避免EAGER提取。因此,最好将所有关联都默认标记为LAZY。
但是,LAZY关联必须在访问之前初始化。否则,将引发LazyInitializationException。处理LazyInitializationException的方法有好有坏。
处理LazyInitializationException的最佳方法是在关闭持久性上下文之前获取所有必需的关联。 JOIN FETCH指令适用于@ManyToOne和OneToOne关联,最多可用于一个集合(例如@OneToMany或@ManyToMany)。如果需要获取多个集合,则为了避免使用笛卡尔积,应该使用通过查询LAZY关联或调用Hibernate#initialize(Object proxy)方法触发的辅助查询。
26.7. Caching
Hibernate 具有两个缓存层:
提供应用程序级可重复读取的第一级缓存(持久性上下文)。
第二级缓存与应用程序级缓存不同,它不存储实体集合,但存储归一化的脱水实体条目。
一级缓存不是“本身”的缓存解决方案,它对于确保READ COMMITTED隔离级别更为有用。
虽然第一级缓存是短暂的,但在底层EntityManager关闭时会清除,但第二级缓存绑定到EntityManagerFactory。一些第二级缓存提供程序为群集提供支持。因此,节点仅需要存储整个缓存数据的子集。
尽管由于从缓存而不是从数据库中检索实体,第二级缓存可以减少事务响应时间,但是还有其他选项可以实现相同的目标,并且在跳转到第二级缓存层之前,您应该考虑这些替代方案:
调整基础数据库缓存,以使工作集适合内存,从而减少磁盘 I/O 流量。
通过 JDBC 批处理,语句缓存,索引优化数据库语句可以减少平均响应时间,因此也可以提高吞吐量。
数据库复制也是增加只读事务吞吐量的非常有价值的选择。
在适当调整数据库后,为了进一步减少平均响应时间并增加系统吞吐量,应用程序级缓存变得不可避免。
通常,键值应用程序级缓存(如Memcached或Redis)是存储数据聚合的常见选择。如果您可以复制键值存储中的所有数据,则可以选择关闭数据库系统进行维护,而不会完全失去可用性,因为仍然可以从缓存中提供只读流量。
使用应用程序级缓存的主要挑战之一是确保跨实体聚合的数据一致性。这就是二级缓存的解决方法。二级缓存与 Hibernate 紧密集成,可以提供更好的数据一致性,因为条目是以标准化的方式进行缓存的,就像在关系数据库中一样。与键值存储中级联的高速缓存条目失效相反,更改父实体仅需要单条目高速缓存更新。
二级缓存提供了四种缓存并发策略:
READ_ONLYNONSTRICT_READ_WRITEREAD_WRITETRANSACTIONAL
READ_WRITE是一种非常好的默认并发策略,因为它在不影响吞吐量的情况下提供了强大的一致性保证。 TRANSACTIONAL并发策略使用 JTA。因此,当实体经常被修改时,它更合适。
READ_WRITE和TRANSACTIONAL均使用直写式缓存,而NONSTRICT_READ_WRITE是直读式缓存策略。因此,如果经常更改实体,NONSTRICT_READ_WRITE不太适合。
使用群集时,第二级缓存条目分布在多个节点上。使用Infinispan 分布式缓存时,只有READ_WRITE和NONSTRICT_READ_WRITE可用于读写缓存。请记住,NONSTRICT_READ_WRITE提供的一致性保证较弱,因为可能会进行陈旧的更新。
Note
有关 Hibernate Performance Tuning 的更多信息,请查看 Devoxx France 的High-Performance Hibernate演示文稿。
27.旧版自举
引导 SessionFactory 的旧方法是通过org.hibernate.cfg.Configuration对象。 Configuration从本质上讲是一个点,用于指定构建SessionFactory的各个方面:从设置,Map 到策略等的所有内容。我喜欢将Configuration视为一个大锅,在其中添加了很多东西(Map,设置等),然后我们最终得到SessionFactory.
Note
遗留引导机制存在一些重大缺陷,导致其弃用并开发了新方法,将在Native Bootstrapping中进行讨论。
Configuration已过时,但仍可以使用,其形式有限,可以消除这些缺点。 “在幕后”,Configuration使用新的引导代码,因此此处的可用内容在自动发现方面也可用。
您可以通过直接实例化Configuration来获取它。然后,您可以指定描述您的应用程序对象模型及其到 SQL 数据库的 Map 的 Map 元数据(XMLMap 文档,带 Comments 的类)。
Configuration cfg = new Configuration()
// addResource does a classpath resource lookup
.addResource( "Item.hbm.xml" )
.addResource( "Bid.hbm.xml" )
// calls addResource using "/org/hibernate/auction/User.hbm.xml"
.addClass( org.hibernate.auction.User.class )
// parses Address class for mapping annotations
.addAnnotatedClass( Address.class )
// reads package-level (package-info.class) annotations in the named package
.addPackage( "org.hibernate.auction" )
.setProperty( "hibernate.dialect", "org.hibernate.dialect.H2Dialect" )
.setProperty( "hibernate.connection.datasource", "java:comp/env/jdbc/test" )
.setProperty( "hibernate.order_updates", "true" );
还有其他方法可以指定配置信息,包括:
将名为 hibernate.properties 的文件放在 Classpath 的根目录中
将 java.util.Properties 的实例传递给
Configuration#setProperties通过
hibernate.cfg.xml文件使用 Java
-Dproperty=value的系统属性
28. Migration
将配置方法 Map 到新 API 中的相应方法。
Configuration#addFile |
Configuration#addFile |
Configuration#add(XmlDocument) |
Configuration#add(XmlDocument) |
Configuration#addXML |
Configuration#addXML |
Configuration#addCacheableFile |
Configuration#addCacheableFile |
Configuration#addURL |
Configuration#addURL |
Configuration#addInputStream |
Configuration#addInputStream |
Configuration#addResource |
Configuration#addResource |
Configuration#addClass |
Configuration#addClass |
Configuration#addAnnotatedClass |
Configuration#addAnnotatedClass |
Configuration#addPackage |
Configuration#addPackage |
Configuration#addJar |
Configuration#addJar |
Configuration#addDirectory |
Configuration#addDirectory |
Configuration#registerTypeContributor |
Configuration#registerTypeContributor |
Configuration#registerTypeOverride |
Configuration#registerTypeOverride |
Configuration#setProperty |
Configuration#setProperty |
Configuration#setProperties |
Configuration#setProperties |
Configuration#addProperties |
Configuration#addProperties |
Configuration#setNamingStrategy |
Configuration#setNamingStrategy |
Configuration#setImplicitNamingStrategy |
Configuration#setImplicitNamingStrategy |
Configuration#setPhysicalNamingStrategy |
Configuration#setPhysicalNamingStrategy |
Configuration#configure |
Configuration#configure |
Configuration#setInterceptor |
Configuration#setInterceptor |
Configuration#setEntityNotFoundDelegate |
Configuration#setEntityNotFoundDelegate |
Configuration#setSessionFactoryObserver |
Configuration#setSessionFactoryObserver |
Configuration#setCurrentTenantIdentifierResolver |
Configuration#setCurrentTenantIdentifierResolver |
29.旧版域模型
例子 698.在hbm.xml中声明版本属性
<!--
~ Hibernate, Relational Persistence for Idiomatic Java
~
~ License: GNU Lesser General Public License (LGPL), version 2.1 or later.
~ See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
-->
<version
column="version_column"
name="propertyName"
type="typename"
access="field|property|ClassName"
unsaved-value="null|negative|undefined"
generated="never|always"
insert="true|false"
node="element-name|@attribute-name|element/@attribute|."
/>
| column | 包含版本号的列的名称。可选,默认为属性名称。 |
| name | 持久类的属性的名称。 |
| type | 版本号的类型。可选,默认为integer。 |
| access | Hibernate 的访问属性值的策略。可选,默认为property。 |
| unsaved-value | 表示实例是新实例化的,因此未保存。这将其与在先前会话中保存或加载的分离实例区分开。默认值undefined指示应使用标识符属性值。可选的。 |
| generated | 指示版本属性值是由数据库生成的。可选,默认为never。 |
| insert | 是否在 SQL insert语句中包括version列。默认值为true,但是如果数据库列定义为默认值0,则可以将其设置为false。 |
例子 699. hbm.xml中的 timestamp 元素
<!--
~ Hibernate, Relational Persistence for Idiomatic Java
~
~ License: GNU Lesser General Public License (LGPL), version 2.1 or later.
~ See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
-->
<timestamp
column="timestamp_column"
name="propertyName"
access="field|property|ClassName"
unsaved-value="null|undefined"
source="vm|db"
generated="never|always"
node="element-name|@attribute-name|element/@attribute|."
/>
| column | 包含时间戳的列的名称。可选,默认为属性名称 |
| name | 持久类的 Java 类型Date或Timestamp的 JavaBeans 样式属性的名称。 |
| access | Hibernate 用于访问属性值的策略。可选,默认为property。 |
| unsaved-value | 一个版本属性,指示实例是新实例化的并且尚未保存。这将其与在先前会话中保存或加载的分离实例区分开。默认值undefined表示 Hibernate 使用标识符属性值。 |
| source | Hibernate 是从数据库还是从当前 JVM 检索时间戳。基于数据库的时间戳会产生开销,因为 Hibernate 每次都需要查询数据库以确定增量下一个值。但是,在群集环境中使用数据库派生的时间戳更加安全。并非所有数据库方言都支持数据库当前时间戳的检索。其他人也可能由于缺乏精确度而无法安全锁定。 |
| generated | 时间戳属性值是否由数据库生成。可选,默认为never。 |
30.旧版休眠标准查询
Tip
本附录介绍了旧的 Hibernate org.hibernate.Criteria API,应将其视为已弃用。
新的开发应该集中在 JPA javax.persistence.criteria.CriteriaQuery API 上。最终,特定于 Hibernate 的条件功能将被移植为 JPA javax.persistence.criteria.CriteriaQuery的扩展。有关 JPA API 的详细信息,请参见Criteria。
Hibernate 具有直观,可扩展的条件查询 API。
30.1. 创建一个条件实例
接口org.hibernate.Criteria代表针对特定持久性类的查询。 Session是Criteria个实例的工厂。
Criteria crit = sess.createCriteria( Cat.class );
crit.setMaxResults( 50 );
List cats = crit.list();
30.2. JPA 与 Hibernate 实体名称
使用Session#createCriteria(字符串实体名称)或 StatelessSession#createCriteria(字符串实体名称)时, entityName 表示基础实体的标准名称,而不是 JPA @Entity注解的name属性表示的名称。
考虑到您具有以下实体:
@Entity(name = "ApplicationEvent")
public static class Event {
@Id
private Long id;
private String name;
}
如果将 JPA 实体名称提供给旧的 Criteria 查询:
List<Event> events = entityManager.unwrap( Session.class )
.createCriteria( "ApplicationEvent" )
.list();
Hibernate 将抛出以下MappingException:
org.hibernate.MappingException: Unknown entity: ApplicationEvent
另一方面,Hibernate 实体名称(完全合格的类名称)可以正常工作:
List<Event> events = entityManager.unwrap( Session.class )
.createCriteria( Event.class.getName() )
.list();
有关此主题的更多信息,请查看HHH-2597 JIRA 问题。
30.3. 缩小结果集
单个查询条件是接口org.hibernate.criterion.Criterion的实例。 org.hibernate.criterion.Restrictions类定义用于获取某些内置Criterion类型的工厂方法。
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.like( "name", "Fritz%" ) )
.add( Restrictions.between( "weight", minWeight, maxWeight ) )
.list();
限制可以按逻辑分组。
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.like( "name", "Fritz%" ) )
.add( Restrictions.or(
Restrictions.eq( "age", new Integer(0) ),
Restrictions.isNull( "age" ) )
)
.list();
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.in( "name", new String[] { "Fritz", "Izi", "Pk" } ) )
.add( Restrictions.disjunction()
.add( Restrictions.isNull("age") )
.add( Restrictions.eq("age", new Integer(0) ) )
.add( Restrictions.eq("age", new Integer(1) ) )
.add( Restrictions.eq("age", new Integer(2) ) )
) )
.list();
有一系列内置的标准类型(Restrictions个子类)。最有用的Restrictions之一允许您直接指定 SQL。
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.sqlRestriction(
"lower({alias}.name) like lower(?)", "Fritz%", Hibernate.STRING )
)
.list();
{alias}占位符将替换为查询实体的行别名。
您还可以从Property实例获取条件。您可以通过调用Property.forName()来创建Property:
Property age = Property.forName( "age" );
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.disjunction()
.add( age.isNull() )
.add( age.eq( new Integer(0) ) )
.add( age.eq( new Integer(1) ) )
.add( age.eq( new Integer(2) ) )
) )
.add( Property.forName("name").in( new String[] { "Fritz", "Izi", "Pk" } ) )
.list();
30.4. 排序结果
您可以使用org.hibernate.criterion.Order对结果进行排序。
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.like( "name", "F%" ) )
.addOrder( Order.asc( "name" ).nulls( NullPrecedence.LAST ) )
.addOrder( Order.desc( "age" ) )
.setMaxResults( 50 )
.list();
List cats = sess.createCriteria( Cat.class )
.add( Property.forName( "name" ).like( "F%" ) )
.addOrder( Property.forName( "name" ).asc() )
.addOrder( Property.forName( "age" ).desc() )
.setMaxResults( 50 )
.list();
30.5. Associations
通过使用createCriteria()导航关联,可以指定对相关实体的约束:
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.like( "name", "F%" ) )
.createCriteria( "kittens" )
.add( Restrictions.like( "name", "F%" ) )
.list();
第二个createCriteria()返回一个新的Criteria实例,该实例引用kittens集合中的元素。
还有一种在某些情况下有用的替代形式:
List cats = sess.createCriteria( Cat.class )
.createAlias( "kittens", "kt" )
.createAlias( "mate", "mt" )
.add( Restrictions.eqProperty( "kt.name", "mt.name" ) )
.list();
请注意,createAlias()不会创建Criteria的新实例。
前两个查询返回的Cat个实例所保存的小猫集合不被条件预先过滤。如果您只想检索符合条件的小猫,则必须使用ResultTransformer。
List cats = sess.createCriteria( Cat.class )
.createCriteria( "kittens", "kt" )
.add( Restrictions.eq( "name", "F%" ) )
.setResultTransformer( Criteria.ALIAS_TO_ENTITY_MAP )
.list();
Iterator iter = cats.iterator();
while ( iter.hasNext() ) {
Map map = (Map) iter.next();
Cat cat = (Cat) map.get( Criteria.ROOT_ALIAS );
Cat kitten = (Cat) map.get( "kt" );
}
此外,您可以使用左外部联接来操纵结果集:
List cats = session.createCriteria( Cat.class )
.createAlias( "mate", "mt", Criteria.LEFT_JOIN, Restrictions.like( "mt.name", "good%" ) )
.addOrder( Order.asc( "mt.age" ) )
.list();
这将返回所有Cat,并且其配偶的名称按其配偶的年龄排序(以“好”开头),以及所有没有配偶的猫。当需要在返回复杂/大型结果集之前对数据库进行排序或限制时,这很有用,并且可以删除许多必须执行多个查询并将结果由 Java 合并到内存中的实例。
如果没有此功能,首先需要在一个查询中加载所有没有伴侣的猫。然后,第二个查询将需要检索其名称以“好”开头的按伴侣年龄分类的伴侣的猫。第三,在内存中,列表需要手动连接。
30.6. 动态关联获取
您可以在运行时使用setFetchMode()指定关联获取语义。
List cats = sess.createCriteria( Cat.class )
.add( Restrictions.like( "name", "Fritz%" ) )
.setFetchMode( "mate", FetchMode.EAGER )
.setFetchMode( "kittens", FetchMode.EAGER )
.list();
此查询将通过外部联接同时获取mate和kittens。
30.7. Components
要添加对嵌入式组件属性的限制,在创建Restriction时,组件属性名称应放在属性名称之前。条件对象应该在拥有实体上创建,而不能在组件本身上创建。例如,假设Cat具有组件属性fullName以及子属性firstName和lastName:
List cats = session.createCriteria( Cat.class )
.add( Restrictions.eq( "fullName.lastName", "Cattington" ) )
.list();
注意:这在查询组件集合时不适用,请参阅下面的Collections。
30.8. Collections
在对集合使用条件时,有两种不同的情况。一种是如果集合包含实体(例如<one-to-many/>或<many-to-many/>)或组件(<composite-element/>),第二种是集合是否包含标量值(<element/>)。在第一种情况下,语法如上文Associations部分中所述,我们在其中限制kittens集合。本质上,我们针对 collection 属性创建Criteria对象,并使用该实例限制实体或组件属性。
为了查询基本值的集合,我们仍然针对该集合创建Criteria对象,但是要引用该值,我们使用特殊属性“元素”。对于索引集合,我们还可以使用特殊属性“索引”来引用 index 属性。
List cats = session.createCriteria( Cat.class )
.createCriteria( "nickNames" )
.add( Restrictions.eq( "elements", "BadBoy" ) )
.list();
30.9. 查询示例
类别org.hibernate.criterion.Example允许您从给定实例构造查询条件。
Cat cat = new Cat();
cat.setSex( 'F' );
cat.setColor( Color.BLACK );
List results = session.createCriteria( Cat.class )
.add( Example.create( cat ) )
.list();
版本属性,标识符和关联将被忽略。默认情况下,排除空值属性。
您可以调整Example的应用方式。
Example example = Example.create( cat )
.excludeZeroes() //exclude zero valued properties
.excludeProperty( "color" ) //exclude the property named "color"
.ignoreCase() //perform case insensitive string comparisons
.enableLike(); //use like for string comparisons
List results = session.createCriteria( Cat.class )
.add( example )
.list();
您甚至可以使用示例将条件放置在关联的对象上。
List results = session.createCriteria( Cat.class )
.add( Example.create( cat ) )
.createCriteria( "mate" )
.add( Example.create( cat.getMate() )
)
.list();
30.10. 投影,汇总和分组
org.hibernate.criterion.Projections类是Projection个实例的工厂。您可以通过调用setProjection()将投影应用于查询。
List results = session.createCriteria( Cat.class )
.setProjection( Projections.rowCount() )
.add( Restrictions.eq( "color", Color.BLACK ) )
.list();
List results = session.createCriteria( Cat.class )
.setProjection( Projections.projectionList()
.add( Projections.rowCount() )
.add( Projections.avg( "weight" ) )
.add( Projections.max( "weight" ) )
.add( Projections.groupProperty( "color" ) )
)
.list();
在条件查询中,没有明确的“分组依据”。某些投影类型被定义为* grouping projections *,它们也出现在 SQL group by子句中。
可以将别名分配给投影,以便可以在限制或 Sequences 中引用投影值。这是两种不同的方法来执行此操作:
List results = session.createCriteria( Cat.class )
.setProjection( Projections.alias( Projections.groupProperty( "color" ), "colr" ) )
.addOrder( Order.asc( "colr" ) )
.list();
List results = session.createCriteria( Cat.class )
.setProjection( Projections.groupProperty( "color" ).as( "colr" ) )
.addOrder( Order.asc( "colr" ) )
.list();
alias()和as()方法只是将投影实例包装在Projection的另一个别名实例中。作为快捷方式,可以在将投影添加到投影列表时分配别名:
List results = session.createCriteria( Cat.class )
.setProjection( Projections.projectionList()
.add( Projections.rowCount(), "catCountByColor" )
.add( Projections.avg( "weight" ), "avgWeight" )
.add( Projections.max( "weight" ), "maxWeight" )
.add( Projections.groupProperty( "color" ), "color" )
)
.addOrder( Order.desc( "catCountByColor" ) )
.addOrder( Order.desc( "avgWeight" ) )
.list();
List results = session.createCriteria( Domestic.class, "cat" )
.createAlias( "kittens", "kit" )
.setProjection( Projections.projectionList()
.add( Projections.property( "cat.name" ), "catName" )
.add( Projections.property( "kit.name" ), "kitName" )
)
.addOrder( Order.asc( "catName" ) )
.addOrder( Order.asc( "kitName" ) )
.list();
您也可以使用Property.forName()来表达预测:
List results = session.createCriteria( Cat.class )
.setProjection( Property.forName( "name" ) )
.add( Property.forName( "color" ).eq( Color.BLACK ) )
.list();
List results = session.createCriteria( Cat.class )
.setProjection(Projections.projectionList()
.add( Projections.rowCount().as( "catCountByColor" ) )
.add( Property.forName( "weight" ).avg().as( "avgWeight" ) )
.add( Property.forName( "weight" ).max().as( "maxWeight" ) )
.add( Property.forName( "color" ).group().as( "color" ) )
)
.addOrder( Order.desc( "catCountByColor" ) )
.addOrder( Order.desc( "avgWeight" ) )
.list();
30.11. 分离的查询和子查询
DetachedCriteria类允许您在会话范围之外创建查询,然后使用任意Session执行查询。
DetachedCriteria query = DetachedCriteria.forClass( Cat.class )
.add( Property.forName( "sex" ).eq( 'F' ) );
Session session = ....;
Transaction txn = session.beginTransaction();
List results = query.getExecutableCriteria( session ).setMaxResults( 100 ).list();
txn.commit();
session.close();
DetachedCriteria也可以用于表示子查询。可以通过Subqueries或Property获得Criterion个涉及子查询的实例。
DetachedCriteria avgWeight = DetachedCriteria.forClass( Cat.class )
.setProjection( Property.forName( "weight" ).avg() );
session.createCriteria( Cat.class )
.add( Property.forName( "weight" ).gt( avgWeight ) )
.list();
DetachedCriteria weights = DetachedCriteria.forClass( Cat.class )
.setProjection( Property.forName( "weight" ) );
session.createCriteria( Cat.class )
.add( Subqueries.geAll( "weight", weights ) )
.list();
相关子查询也是可能的:
DetachedCriteria avgWeightForSex = DetachedCriteria.forClass( Cat.class, "cat2" )
.setProjection( Property.forName( "weight" ).avg() )
.add( Property.forName( "cat2.sex" ).eqProperty( "cat.sex" ) );
session.createCriteria( Cat.class, "cat" )
.add( Property.forName( "weight" ).gt( avgWeightForSex ) )
.list();
基于子查询的多列限制示例:
DetachedCriteria sizeQuery = DetachedCriteria.forClass( Man.class )
.setProjection( Projections.projectionList()
.add( Projections.property( "weight" ) )
.add( Projections.property( "height" ) )
)
.add( Restrictions.eq( "name", "John" ) );
session.createCriteria( Woman.class )
.add( Subqueries.propertiesEq( new String[] { "weight", "height" }, sizeQuery ) )
.list();
30.12. 通过自然标识符查询
对于大多数查询(包括条件查询),查询缓存效率不高,因为查询缓存失效发生得太频繁了。但是,存在一种特殊的查询,您可以在其中优化缓存失效算法:通过恒定的自然键进行查找。在某些应用程序中,这种查询经常发生。 Criteria API 为此用例提供了特殊的规定。
首先,使用<natural-id>Map 您实体的自然键,然后启用二级缓存。
<class name="User">
<cache usage="read-write"/>
<id name="id">
<generator class="increment"/>
</id>
<natural-id>
<property name="name"/>
<property name="org"/>
</natural-id>
<property name="password"/>
</class>
此功能不适用于具有* mutable *自然键的实体。
启用 Hibernate 查询缓存后,Restrictions.naturalId()允许您使用更有效的缓存算法。
session.createCriteria( User.class )
.add( Restrictions.naturalId()
.set( "name", "gavin" )
.set( "org", "hb" )
)
.setCacheable( true )
.uniqueResult();
31.旧版休眠本机查询
31.1. 旧式命名 SQL 查询
还可以在 Map 期间定义命名 SQL 查询,并以与命名 HQL 查询完全相同的方式进行调用。在这种情况下,您无需再致电addEntity()。
例子 700.使用<sql-query>Map 元素的命名 SQL 查询
<sql-query name = "persons">
<return alias="person" class="eg.Person"/>
SELECT person.NAME AS {person.name},
person.AGE AS {person.age},
person.SEX AS {person.sex}
FROM PERSON person
WHERE person.NAME LIKE :namePattern
</sql-query>
例子 701.一个命名查询的执行
List people = session
.getNamedQuery( "persons" )
.setParameter( "namePattern", namePattern )
.setMaxResults( 50 )
.list();
<return-join>元素用于连接关联,而<load-collection>元素用于定义初始化集合的查询。
例子 702.具有关联的命名 sql 查询
<sql-query name = "personsWith">
<return alias="person" class="eg.Person"/>
<return-join alias="address" property="person.mailingAddress"/>
SELECT person.NAME AS {person.name},
person.AGE AS {person.age},
person.SEX AS {person.sex},
address.STREET AS {address.street},
address.CITY AS {address.city},
address.STATE AS {address.state},
address.ZIP AS {address.zip}
FROM PERSON person
JOIN ADDRESS address
ON person.ID = address.PERSON_ID AND address.TYPE='MAILING'
WHERE person.NAME LIKE :namePattern
</sql-query>
命名的 SQL 查询可能返回标量值。您必须使用<return-scalar>元素声明列别名和 Hibernate 类型:
例子 703.命名查询返回一个标量
<sql-query name = "mySqlQuery">
<return-scalar column = "name" type="string"/>
<return-scalar column = "age" type="long"/>
SELECT p.NAME AS name,
p.AGE AS age,
FROM PERSON p WHERE p.NAME LIKE 'Hiber%'
</sql-query>
您可以在<resultset>元素中外部化结果集 Map 信息,这将使您可以在多个命名查询中或通过setResultSetMapping() API 重用它们。
例子 704.<resultset>Map 用于外部化 Map 信息
<resultset name = "personAddress">
<return alias="person" class="eg.Person"/>
<return-join alias="address" property="person.mailingAddress"/>
</resultset>
<sql-query name = "personsWith" resultset-ref="personAddress">
SELECT person.NAME AS {person.name},
person.AGE AS {person.age},
person.SEX AS {person.sex},
address.STREET AS {address.street},
address.CITY AS {address.city},
address.STATE AS {address.state},
address.ZIP AS {address.zip}
FROM PERSON person
JOIN ADDRESS address
ON person.ID = address.PERSON_ID AND address.TYPE='MAILING'
WHERE person.NAME LIKE :namePattern
</sql-query>
或者,您可以直接在 Java 代码中使用 hbm 文件中的结果集 Map 信息。
例子 705.以编程方式指定结果 Map 信息
List cats = session
.createSQLQuery( "select {cat.*}, {kitten.*} from cats cat, cats kitten where kitten.mother = cat.id" )
.setResultSetMapping( "catAndKitten" )
.list();
31.2. 旧版返回属性,用于明确指定列/别名
您可以明确地告诉 Hibernate 与<return-property>一起使用哪些列别名,而不是使用{}语法让 Hibernate 注入自己的别名。例如:
<sql-query name = "mySqlQuery">
<return alias = "person" class = "eg.Person">
<return-property name = "name" column = "myName"/>
<return-property name = "age" column = "myAge"/>
<return-property name = "sex" column = "mySex"/>
</return>
SELECT person.NAME AS myName,
person.AGE AS myAge,
person.SEX AS mySex,
FROM PERSON person WHERE person.NAME LIKE :name
</sql-query>
<return-property>也适用于多列。这解决了{}语法的局限性,该局限性不允许对多列属性进行精细控制。
<sql-query name = "organizationCurrentEmployments">
<return alias = "emp" class = "Employment">
<return-property name = "salary">
<return-column name = "VALUE"/>
<return-column name = "CURRENCY"/>
</return-property>
<return-property name = "endDate" column = "myEndDate"/>
</return>
SELECT EMPLOYEE AS {emp.employee}, EMPLOYER AS {emp.employer},
STARTDATE AS {emp.startDate}, ENDDATE AS {emp.endDate},
REGIONCODE as {emp.regionCode}, EID AS {emp.id}, VALUE, CURRENCY
FROM EMPLOYMENT
WHERE EMPLOYER = :id AND ENDDATE IS NULL
ORDER BY STARTDATE ASC
</sql-query>
在此示例中,<return-property>与{}语法结合使用进行注入。这使用户可以选择他们要如何引用列和属性。
如果 Map 中有一个标识符,则必须使用<return-discriminator>指定标识符列。
31.3. 旧版存储过程用于查询
Hibernate 通过存储过程和功能为查询提供支持。以下大多数文档对于两者都是等效的。存储过程/函数必须返回结果集作为第一个输出参数,才能与 Hibernate 一起使用。在 Oracle 9 和更高版本中,这样的存储函数的示例如下:
CREATE OR REPLACE FUNCTION selectAllEmployments
RETURN SYS_REFCURSOR
AS
st_cursor SYS_REFCURSOR;
BEGIN
OPEN st_cursor FOR
SELECT EMPLOYEE, EMPLOYER,
STARTDATE, ENDDATE,
REGIONCODE, EID, VALUE, CURRENCY
FROM EMPLOYMENT;
RETURN st_cursor;
END;
要在 Hibernate 中使用此查询,您需要通过命名查询将其 Map。
<sql-query name = "selectAllEmployees_SP" callable = "true">
<return alias="emp" class="Employment">
<return-property name = "employee" column = "EMPLOYEE"/>
<return-property name = "employer" column = "EMPLOYER"/>
<return-property name = "startDate" column = "STARTDATE"/>
<return-property name = "endDate" column = "ENDDATE"/>
<return-property name = "regionCode" column = "REGIONCODE"/>
<return-property name = "id" column = "EID"/>
<return-property name = "salary">
<return-column name = "VALUE"/>
<return-column name = "CURRENCY"/>
</return-property>
</return>
{ ? = call selectAllEmployments() }
</sql-query>
存储过程当前仅返回标量和实体。不支持<return-join>和<load-collection>。
31.4. 使用存储过程的旧规则/限制
除非遵循某些过程/功能规则,否则您不能在 Hibernate 中使用存储过程。如果他们不遵守这些规则,则无法在 Hibernate 中使用。如果仍然要使用这些过程,则必须通过session.doWork()执行它们。
每个数据库的规则都不同,因为数据库供应商具有不同的存储过程语义/语法。
存储过程查询不能以setFirstResult()/setMaxResults()进行分页。
推荐的调用形式为标准 SQL92:{ ? = call functionName(<parameters>) }或{ ? = call procedureName(<parameters>}。不支持本机调用语法。
对于 Oracle,适用以下规则:
函数必须返回结果集。
过程的第一个参数必须是返回结果集的
OUT。这是通过在 Oracle 9 或 10 中使用SYS_REFCURSOR类型完成的。在 Oracle 中,您需要定义REF CURSOR类型。有关更多信息,请参见 Oracle 文献。
对于 Sybase 或 MS SQL Server,适用以下规则:
该过程必须返回结果集。注意,由于这些服务器可以返回多个结果集和更新计数,因此 Hibernate 将迭代结果并将结果集的第一个结果作为其返回值。其他一切将被丢弃。
如果您可以在过程中启用
SET NOCOUNT ON,则可能会更有效,但这不是必需的。
31.5. 旧版自定义 SQL,用于创建,更新和删除
Hibernate 可以使用自定义 SQL 进行创建,更新和删除操作。可以在语句级别或单个列级别覆盖 SQL。本节描述语句替代。有关列,请参见列转换器:读取和写入表达式。下面的示例演示如何使用 Comments 定义自定义 SQL 操作。
例子 706.定制 CRUD XML
<class name = "Person">
<id name = "id">
<generator class = "increment"/>
</id>
<property name = "name" not-null = "true"/>
<sql-insert>INSERT INTO PERSON (NAME, ID) VALUES ( UPPER(?), ? )</sql-insert>
<sql-update>UPDATE PERSON SET NAME=UPPER(?) WHERE ID=?</sql-update>
<sql-delete>DELETE FROM PERSON WHERE ID=?</sql-delete>
</class>
Note
如果希望调用存储过程,请确保在基于注解和基于 XML 的 Map 中都将callable属性设置为true。
为了检查执行是否正确,Hibernate 允许您定义以下三种策略之一:
none:不执行任何检查;预计存储过程将因问题而失败
计数:使用行数检查更新是否成功
参数:类似于 COUNT,但使用输出参数而不是标准机制
要定义结果检查样式,请使用check参数,该参数再次在 Comments 和 xml 中可用。
最后但并非最不重要的一点是,在大多数情况下,需要使用存储过程来返回插入,更新和删除的行数。 Hibernate 始终将第一个语句参数注册为 CUD 操作的数字输出参数:
例子 707.存储过程及其返回值
CREATE OR REPLACE FUNCTION updatePerson (uid IN NUMBER, uname IN VARCHAR2)
RETURN NUMBER IS
BEGIN
update PERSON
set
NAME = uname,
where
ID = uid;
return SQL%ROWCOUNT;
END updatePerson;
31.6. 旧版自定义 SQL 进行加载
您还可以声明自己的 SQL(或 HQL)查询以进行实体加载。与插入,更新和删除一样,这可以在单独的列级别上完成,如 For 列中所述,请参见列转换器:读取和写入表达式或在语句级别。这是一个语句级别覆盖的示例:
<sql-query name = "person">
<return alias = "pers" class = "Person" lock-mode= "upgrade"/>
SELECT NAME AS {pers.name}, ID AS {pers.id}
FROM PERSON
WHERE ID=?
FOR UPDATE
</sql-query>
如前所述,这只是一个命名查询声明。您可以在类 Map 中引用此命名查询:
<class name = "Person">
<id name = "id">
<generator class = "increment"/>
</id>
<property name = "name" not-null = "true"/>
<loader query-ref = "person"/>
</class>
这甚至适用于存储过程。
您甚至可以为集合加载定义查询:
<set name = "employments" inverse = "true">
<key/>
<one-to-many class = "Employment"/>
<loader query-ref = "employments"/>
</set>
<sql-query name = "employments">
<load-collection alias = "emp" role = "Person.employments"/>
SELECT {emp.*}
FROM EMPLOYMENT emp
WHERE EMPLOYER = :id
ORDER BY STARTDATE ASC, EMPLOYEE ASC
</sql-query>
您还可以定义一个实体加载器,该实体加载器通过联接获取来加载集合:
<sql-query name = "person">
<return alias = "pers" class = "Person"/>
<return-join alias = "emp" property = "pers.employments"/>
SELECT NAME AS {pers.*}, {emp.*}
FROM PERSON pers
LEFT OUTER JOIN EMPLOYMENT emp
ON pers.ID = emp.PERSON_ID
WHERE ID=?
</sql-query>
32. References
[PoEAA] Martin Fowler。 企业应用架构的模式。 Addison-Wesley 出版公司。 2003.
[JPwH] Christian Bauer 和 Gavin King。 Java Persistence with Hibernate,第二版。曼宁出版社(Manning Publications Co.),2015 年。