附录 B.元数据架构
B.1 Overview
Spring Batch 元数据表与 Java 中表示它们的 Domain 对象非常匹配。例如,JobInstance,JobExecution,JobParameters和StepExecution分别 Map 到 BATCH_JOB_INSTANCE,BATCH_JOB_EXECUTION,BATCH_JOB_EXECUTION_PARAMS 和 BATCH_STEP_EXECUTION。 ExecutionContext同时 Map 到 BATCH_JOB_EXECUTION_CONTEXT 和 BATCH_STEP_EXECUTION_CONTEXT。 JobRepository负责将每个 Java 对象保存并存储到正确的表中。以下附录详细描述了元数据表,以及创建元数据表时做出的许多设计决策。查 Watch 下面的各种表创建语句时,重要的是要意识到所使用的数据类型应尽可能通用。 Spring Batch 提供了许多模式作为示例,由于各个数据库供应商对数据类型的处理方式不同,所有模式都有不同的数据类型。以下是所有 6 个表格及其相互关系的 ERD 模型:
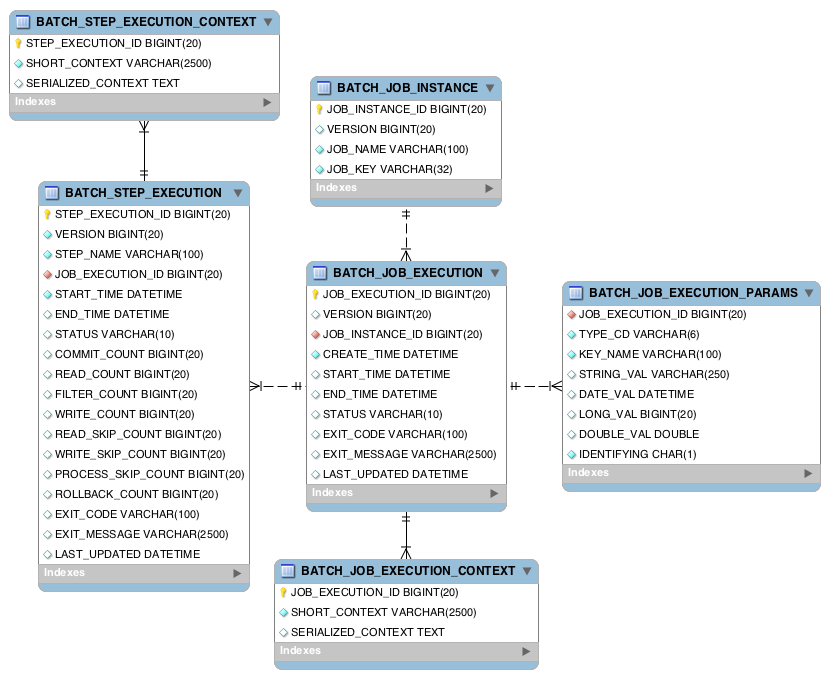
B.1.1 DDL 脚本示例
Spring Batch Core JAR 文件包含用于为多个数据库平台创建关系表的示例脚本(依次由作业存储库工厂 Bean 或等效名称空间自动检测到)。这些脚本可以按原样使用,也可以根据需要使用其他索引和约束进行修改。文件名的格式为schema-*.sql,其中“ *”是目标数据库平台的简称。脚本位于org.springframework.batch.core包中。
B.1.2 Version
本附录中讨论的许多数据库表都包含一个 version 列。该列很重要,因为 Spring Batch 在处理数据库更新时采用了乐观锁定策略。这意味着每次“触摸”(更新)一条记录时,version 列中的值就会增加 1.当存储库返回尝试保存值时,如果版本号已更改,它将抛出OptimisticLockingFailureException,表示并发访问存在错误。该检查是必需的,因为即使不同的批处理作业可能在不同的计算机上运行,它们都使用相同的数据库表。
B.1.3 Identity
BATCH_JOB_INSTANCE,BATCH_JOB_EXECUTION 和 BATCH_STEP_EXECUTION 均包含以_ID 结尾的列。这些字段充当其各自表的主键。但是,它们不是数据库生成的密钥,而是由单独的序列生成的。这是必要的,因为在将一个域对象插入数据库后,需要在实际对象上设置给出的密钥,以便可以在 Java 中对其进行唯一标识。较新的数据库驱动程序(Jdbc 3.0 及更高版本)通过数据库生成的密钥支持此功能,但并非必需使用序列。模式的每个变体将包含以下形式:
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;
许多数据库供应商不支持序列。在这些情况下,将使用变通方法,例如以下针对 MySQL 的方法:
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);
在上述情况下,将使用表格代替每个序列。然后,Spring 核心类MySQLMaxValueIncrementer将按此 Sequences 递增一列,以提供类似的功能。
B.2 BATCH_JOB_INSTANCE
BATCH_JOB_INSTANCE 表保存与JobInstance相关的所有信息,并用作整个层次结构的顶部。以下通用 DDL 语句用于创建它:
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL ,
JOB_KEY VARCHAR(2500)
);
下面是表格中各列的说明:
JOB_INSTANCE_ID:将标识实例的唯一 ID,它也是主键。此列的值应通过在
JobInstance上调用getId方法来获取。版本:请参见上一节。
JOB_NAME:从
Job对象获得的作业的名称。因为需要标识实例,所以它不能为 null。JOB_KEY:
JobParameters的序列化,可以唯一地标识同一作业的单独实例。 (具有相同作业名称的JobInstances必须具有不同的JobParameters,并因此具有不同的 JOB_KEY 值)。
B.3 BATCH_JOB_EXECUTION_PARAMS
BATCH_JOB_EXECUTION_PARAMS 表保存与JobParameters对象有关的所有信息。它包含传递给Job的 0 个或多个键/值对,并用作运行作业的参数的记录。对于有助于生成作业身份的每个参数,将 IDENTIFYING 标志设置为 true。应该注意的是,该表已被规范化。没有为每种类型创建单独的表,而是有一个表,其中的一列指示类型:
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
以下是每列的说明:
JOB_EXECUTION_ID:来自 BATCH_JOB_EXECUTION 表的外键,指示参数条目所属的作业执行。应当注意,每次执行可能存在多个行(即键/值对)。
TYPE_CD:存储的值类型的字符串表示形式,可以是字符串,日期,长整数或双精度型。因为必须知道类型,所以不能为 null。
KEY_NAME:参数键。
STRING_VAL:参数值(如果类型为字符串)。
DATE_VAL:参数值(如果类型为日期)。
LONG_VAL:参数值(如果类型为 long)。
DOUBLE_VAL:参数值(如果类型为 double)。
IDENTIFYING:标志,指示参数是否促成相关
JobInstance的身份。
值得注意的是,该表没有主键。这仅仅是因为该框架没有用,因此不需要它。如果用户选择这样做,则可以添加一个数据库生成的密钥,而不会引起框架本身的任何问题。
B.4 BATCH_JOB_EXECUTION
BATCH_JOB_EXECUTION 表包含与JobExecution对象有关的所有信息。每次运行Job时,此表中总会有一个新的JobExecution和一个新行:
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;
以下是每列的说明:
JOB_EXECUTION_ID:主键唯一标识此执行。可通过调用
JobExecution对象的getId方法获得此列的值。版本:请参见上一节。
JOB_INSTANCE_ID:来自 BATCH_JOB_INSTANCE 表的外键,指示此执行所属的实例。每个实例可能有多个执行。
CREATE_TIME:表示创建执行时间的时间戳。
START_TIME:表示执行开始时间的时间戳。
END_TIME:时间戳,表示执行完成的时间,无论成功或失败。即使作业当前未在运行,此列中的值为空也表明存在某种类型的错误,并且框架无法执行最后的保存,然后再失败。
状态:表示执行状态的字符串。可以是 COMPLETED,STARTED 等。此列的对象表示形式是
BatchStatus枚举。EXIT_CODE:表示执行的退出代码的字符串。对于命令行作业,可以将其转换为数字。
EXIT_MESSAGE:表示作业如何退出的更详细描述的字符串。在发生故障的情况下,这可能包括尽可能多的堆栈跟踪。
LAST_UPDATED:时间戳记,表示最后一次执行被持久化的时间。
B.5 BATCH_STEP_EXECUTION
BATCH_STEP_EXECUTION 表包含与StepExecution对象有关的所有信息。该表在许多方面与 BATCH_JOB_EXECUTION 表非常相似,并且对于每个JobExecution创建的每个JobExecution总是至少存在一个条目:
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME TIMESTAMP NOT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
以下是每列的说明:
STEP_EXECUTION_ID:主键,唯一标识此执行。该列的值应该可以通过调用
StepExecution对象的getId方法来获得。版本:请参见上一节。
STEP_NAME:此执行所属的步骤的名称。
JOB_EXECUTION_ID:来自 BATCH_JOB_EXECUTION 表的外键,指示此 StepExecution 所属的 JobExecution。对于给定的
Step名称,给定的JobExecution可能只有一个StepExecution。START_TIME:表示执行开始时间的时间戳。
END_TIME:时间戳,表示执行完成的时间,无论成功或失败。即使作业当前未在运行,此列中的值为空也表明存在某种类型的错误,并且框架无法执行最后的保存,然后再失败。
状态:表示执行状态的字符串。可以是 COMPLETED,STARTED 等。此列的对象表示形式是
BatchStatus枚举。COMMIT_COUNT:在此执行过程中步骤提交事务的次数。
READ_COUNT:在此执行期间读取的 Item 数。
FILTER_COUNT:从该执行中筛选出的 Item 数。
WRITE_COUNT:在此执行期间写入和提交的 Item 数。
READ_SKIP_COUNT:在此执行期间读取时跳过的 Item 数。
WRITE_SKIP_COUNT:在此执行期间写入时跳过的 Item 数。
PROCESS_SKIP_COUNT:在此执行期间的处理过程中跳过的 Item 数。
ROLLBACK_COUNT:此执行期间的回滚数。请注意,此计数包括每次回滚发生的时间,包括用于重试的回滚和跳过恢复过程中的回滚。
EXIT_CODE:表示执行的退出代码的字符串。对于命令行作业,可以将其转换为数字。
EXIT_MESSAGE:表示作业如何退出的更详细描述的字符串。在发生故障的情况下,这可能包括尽可能多的堆栈跟踪。
LAST_UPDATED:时间戳记,表示最后一次执行被持久化的时间。
B.6 BATCH_JOB_EXECUTION_CONTEXT
BATCH_JOB_EXECUTION_CONTEXT 表保存与Job的ExecutionContext相关的所有信息。每个JobExecution恰好有一个Job ExecutionContext,并且它包含特定作业执行所需的所有作业级别数据。该数据通常表示故障后必须检索的状态,以便JobInstance可以从“中断处开始”。
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
以下是每列的说明:
JOB_EXECUTION_ID:表示上下文所属的
JobExecution的外键。与给定执行相关联的行可能不止一个。SHORT_CONTEXT:SERIALIZED_CONTEXT 的字符串版本。
SERIALIZED_CONTEXT:整个上下文,已序列化。
B.7 BATCH_STEP_EXECUTION_CONTEXT
BATCH_STEP_EXECUTION_CONTEXT 表保存与Step的ExecutionContext相关的所有信息。每个StepExecution恰好有一个ExecutionContext,并且它包含执行特定步骤所需要保留的所有数据。此数据通常表示故障后必须检索的状态,以便JobInstance可以从中断处开始。
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;
以下是每列的说明:
STEP_EXECUTION_ID:外键,表示上下文所属的
StepExecution。与给定执行相关联的行可能不止一个。SHORT_CONTEXT:SERIALIZED_CONTEXT 的字符串版本。
SERIALIZED_CONTEXT:整个上下文,已序列化。
B.8 Archiving
因为每次运行批处理作业时多个表中都有条目,所以通常为元数据表创建一个归档策略。这些表本身旨在显示过去发生的情况的记录,并且通常不会影响任何作业的运行,但有几个与重新启动有关的显着异常:
框架将使用元数据表来确定是否已运行过特定的 JobInstance。如果已运行,并且该作业不可重新启动,则将引发异常。
如果未成功完成就删除 JobInstance 的条目,则框架将认为作业是新的,而不是重新启动。
如果重新启动作业,则框架将使用已持久保存到 ExecutionContext 的所有数据来还原作业的状态。因此,从表中删除所有未成功完成的作业的条目将阻止它们在正确的位置重新启动。
B.9 国际字符和多字节字符
如果您在业务处理中使用多字节字符集(例如 Chines 或 Cyrillic),那么这些字符可能需要保留在 Spring Batch 模式中。许多用户发现,只需将架构更改为VARCHAR列的长度的两倍就足够了。其他人更喜欢用max-varchar-length配置一半的max-varchar-length列长度就足够了。一些用户还报告说,他们在架构定义中使用NVARCHAR代替VARCHAR。最佳结果将取决于数据库平台和在本地配置数据库服务器的方式。
B.10 为元数据表构建索引的建议
Spring Batch 为几个常见数据库平台的 Core jar 文件中的元数据表提供了 DDL 示例。索引声明未包含在该 DDL 中,因为用户可能希望根据自己的精确平台,本地约定以及如何操作作业的业务要求来构建索引的方式有所不同。下表提供了一些指示,这些指示是 Spring Batch 提供的 Dao 实现将在 WHERE 子句中使用哪些列,以及它们的使用频率,以便各个 Item 可以对索引制定自己的想法。
表 B.1.SQL 语句中的 where 子句(不包括主键)及其大致使用频率.
| 默认表名 | Where Clause | Frequency |
| BATCH_JOB_INSTANCE | JOB_NAME =吗?和 JOB_KEY =? | 每次启动工作 |
| BATCH_JOB_EXECUTION | JOB_INSTANCE_ID =? | 每次重新启动作业 |
| BATCH_EXECUTION_CONTEXT | EXECUTION_ID =吗?和 KEY_NAME =吗? | 在提交间隔上,也就是大块 |
| BATCH_STEP_EXECUTION | 版本=? | 在提交间隔上,又称为块(以及步骤的开始和结束) |
| BATCH_STEP_EXECUTION | STEP_NAME =吗?和 JOB_EXECUTION_ID =? | 在执行每个步骤之前 |