1. 常见批处理模式
一些批处理作业可以纯粹从 Spring Batch 中的现成组件中组装。例如,可以将ItemReader和ItemWriter实现配置为涵盖各种场景。但是,在大多数情况下,必须编写自定义代码。应用程序开发人员的主要 API 入口点是Tasklet,ItemReader,ItemWriter和各种侦听器接口。大多数简单的批处理作业都可以使用 Spring Batch ItemReader的现成 Importing,但是通常情况下,在处理和编写过程中存在自定义问题,需要开发人员实现ItemWriter或ItemProcessor。
在本章中,我们提供了一些自定义业务逻辑中常见模式的示例。这些示例主要具有侦听器接口。应当注意,如果合适,ItemReader或ItemWriter也可以实现侦听器接口。
1.1.记录 Item 处理和故障
一个常见的用例是需要逐个步骤对错误进行特殊处理,可能需要登录到特殊通道或将记录插入数据库中。面向块的Step(从 step factory Bean 创建)使用户可以使用简单的ItemReadListener来解决read上的错误,并使用ItemWriteListener来解决write上的错误。以下代码段说明了一个记录读取和写入失败的侦听器:
public class ItemFailureLoggerListener extends ItemListenerSupport {
private static Log logger = LogFactory.getLog("item.error");
public void onReadError(Exception ex) {
logger.error("Encountered error on read", e);
}
public void onWriteError(Exception ex, List<? extends Object> items) {
logger.error("Encountered error on write", ex);
}
}
实现此侦听器后,必须向其注册一个步骤,如以下示例所示:
XML Configuration
<step id="simpleStep">
...
<listeners>
<listener>
<bean class="org.example...ItemFailureLoggerListener"/>
</listener>
</listeners>
</step>
Java Configuration
@Bean
public Step simpleStep() {
return this.stepBuilderFactory.get("simpleStep")
...
.listener(new ItemFailureLoggerListener())
.build();
}
Tip
如果您的侦听器以onError()方法执行任何操作,则它必须位于要回滚的事务内。如果您需要在onError()方法内部使用事务性资源,例如数据库,请考虑向该方法添加声明性事务(有关详细信息,请参见《 Spring Core 参考指南》),并将其传播属性的值设置为REQUIRES_NEW。
1.2.由于业务原因手动停止作业
Spring Batch 通过JobLauncher接口提供了stop()方法,但这实际上是供操作员而非应用程序程序员使用的。有时,从业务逻辑中停止作业执行更方便或更有意义。
最简单的方法是抛出RuntimeException(既不会无限期重试,也不会跳过)。例如,可以使用自定义异常类型,如以下示例所示:
public class PoisonPillItemProcessor<T> implements ItemProcessor<T, T> {
@Override
public T process(T item) throws Exception {
if (isPoisonPill(item)) {
throw new PoisonPillException("Poison pill detected: " + item);
}
return item;
}
}
停止执行步骤的另一种简单方法是从ItemReader返回null,如以下示例所示:
public class EarlyCompletionItemReader implements ItemReader<T> {
private ItemReader<T> delegate;
public void setDelegate(ItemReader<T> delegate) { ... }
public T read() throws Exception {
T item = delegate.read();
if (isEndItem(item)) {
return null; // end the step here
}
return item;
}
}
前面的示例实际上是基于CompletionPolicy策略的默认实现的,该默认实现在要处理的物料为null时发出完整批次的 signal。可以实现更复杂的完成策略,并将其通过SimpleStepFactoryBean注入到Step中,如以下示例所示:
XML Configuration
<step id="simpleStep">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="10"
chunk-completion-policy="completionPolicy"/>
</tasklet>
</step>
<bean id="completionPolicy" class="org.example...SpecialCompletionPolicy"/>
Java Configuration
@Bean
public Step simpleStep() {
return this.stepBuilderFactory.get("simpleStep")
.<String, String>chunk(new SpecialCompletionPolicy())
.reader(reader())
.writer(writer())
.build();
}
另一种方法是在StepExecution中设置一个标志,该标志由 Item 处理之间的框架中的Step实现检查。要实现此替代方案,我们需要访问当前的StepExecution,这可以通过实现StepListener并将其注册到Step来实现。以下示例显示了设置标志的侦听器:
public class CustomItemWriter extends ItemListenerSupport implements StepListener {
private StepExecution stepExecution;
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
public void afterRead(Object item) {
if (isPoisonPill(item)) {
stepExecution.setTerminateOnly(true);
}
}
}
设置该标志后,默认行为是该步骤抛出JobInterruptedException。可以通过StepInterruptionPolicy控制此行为。但是,唯一的选择是引发或不引发异常,因此这始终是工作的异常结束。
1.3.添加页脚记录
通常,在写入平面文件时,在完成所有处理之后,必须在文件末尾附加“页脚”记录。可以使用 Spring Batch 提供的FlatFileFooterCallback接口来实现。 FlatFileFooterCallback(及其对应的FlatFileHeaderCallback)是FlatFileItemWriter的可选属性,可以将其添加到 Item 编写器中,如以下示例所示:
XML Configuration
<bean id="itemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="headerCallback" ref="headerCallback" />
<property name="footerCallback" ref="footerCallback" />
</bean>
Java Configuration
@Bean
public FlatFileItemWriter<String> itemWriter(Resource outputResource) {
return new FlatFileItemWriterBuilder<String>()
.name("itemWriter")
.resource(outputResource)
.lineAggregator(lineAggregator())
.headerCallback(headerCallback())
.footerCallback(footerCallback())
.build();
}
页脚回调接口只有一种必须在编写页脚时调用的方法,如以下接口定义所示:
public interface FlatFileFooterCallback {
void writeFooter(Writer writer) throws IOException;
}
1.3.1.编写摘要页脚
涉及页脚记录的常见要求是在输出过程中汇总信息,并将此信息附加到文件末尾。此页脚通常用作文件的摘要或提供校验和。
例如,如果批处理作业正在将Trade条记录写入平面文件,并且要求将所有Trades的总数放在页脚中,则可以使用以下ItemWriter实现:
public class TradeItemWriter implements ItemWriter<Trade>,
FlatFileFooterCallback {
private ItemWriter<Trade> delegate;
private BigDecimal totalAmount = BigDecimal.ZERO;
public void write(List<? extends Trade> items) throws Exception {
BigDecimal chunkTotal = BigDecimal.ZERO;
for (Trade trade : items) {
chunkTotal = chunkTotal.add(trade.getAmount());
}
delegate.write(items);
// After successfully writing all items
totalAmount = totalAmount.add(chunkTotal);
}
public void writeFooter(Writer writer) throws IOException {
writer.write("Total Amount Processed: " + totalAmount);
}
public void setDelegate(ItemWriter delegate) {...}
}
此TradeItemWriter存储一个totalAmount值,该值随每个写入的Trade项中的amount增加。在处理最后一个Trade之后,框架调用writeFooter,这会将totalAmount放入文件中。请注意,write方法使用了临时变量chunkTotal,该临时变量将Trade总量存储在块中。这样做是为了确保,如果write方法中发生跳过,则totalAmount保持不变。只有在write方法的末尾,一旦确保不引发任何异常,就可以更新totalAmount。
为了调用writeFooter方法,必须将TradeItemWriter(实现FlatFileFooterCallback)连接到FlatFileItemWriter作为footerCallback。以下示例显示了如何执行此操作:
XML Configuration
<bean id="tradeItemWriter" class="..TradeItemWriter">
<property name="delegate" ref="flatFileItemWriter" />
</bean>
<bean id="flatFileItemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator" ref="lineAggregator"/>
<property name="footerCallback" ref="tradeItemWriter" />
</bean>
Java Configuration
@Bean
public TradeItemWriter tradeItemWriter() {
TradeItemWriter itemWriter = new TradeItemWriter();
itemWriter.setDelegate(flatFileItemWriter(null));
return itemWriter;
}
@Bean
public FlatFileItemWriter<String> flatFileItemWriter(Resource outputResource) {
return new FlatFileItemWriterBuilder<String>()
.name("itemWriter")
.resource(outputResource)
.lineAggregator(lineAggregator())
.footerCallback(tradeItemWriter())
.build();
}
到目前为止,只有在无法重新启动Step的情况下,TradeItemWriter的写入方式才能正确运行。这是因为该类是有状态的(因为它存储了totalAmount),但是totalAmount没有持久化到数据库中。因此,在重新启动的情况下无法检索到它。为了使此类可重启,应将ItemStream接口与方法open和update一起实现,如以下示例所示:
public void open(ExecutionContext executionContext) {
if (executionContext.containsKey("total.amount") {
totalAmount = (BigDecimal) executionContext.get("total.amount");
}
}
public void update(ExecutionContext executionContext) {
executionContext.put("total.amount", totalAmount);
}
在该对象持久保存到数据库之前,更新方法将totalAmount的最新版本存储到ExecutionContext。 open 方法从ExecutionContext中检索任何现有的totalAmount并将其用作处理的起点,从而允许TradeItemWriter在重新启动时重新启动,而在上一次运行Step时它停止了。
1.4.基于驱动查询的 ItemReader
在关于 Reader 和 Writer 的章节中,讨论了使用分页的数据库 Importing。许多数据库供应商,例如 DB2,都具有极其悲观的锁定策略,如果正在读取的表也需要由联机应用程序的其他部分使用,则会导致问题。此外,在非常大的数据集上打开游标会导致某些供应商的数据库出现问题。因此,许多 Item 更喜欢使用“驱动查询”方法来读取数据。这种方法通过遍历键而不是遍历需要返回的整个对象而起作用,如下图所示:
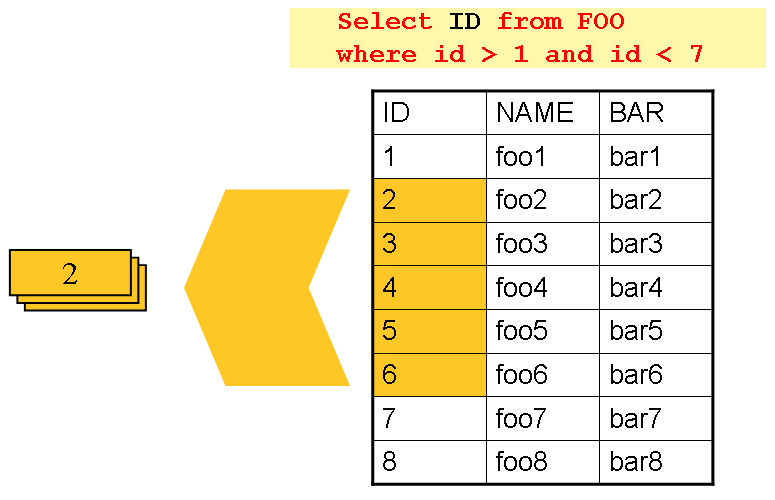
图 1.驱动查询作业
如您所见,上图中显示的示例使用与基于游标的示例相同的“ FOO”表。但是,不是选择整个行,而是在 SQL 语句中选择了 ID。因此,不是从read返回FOO对象,而是返回Integer。然后可以使用该数字查询“详细信息”,它是一个完整的Foo对象,如下图所示:
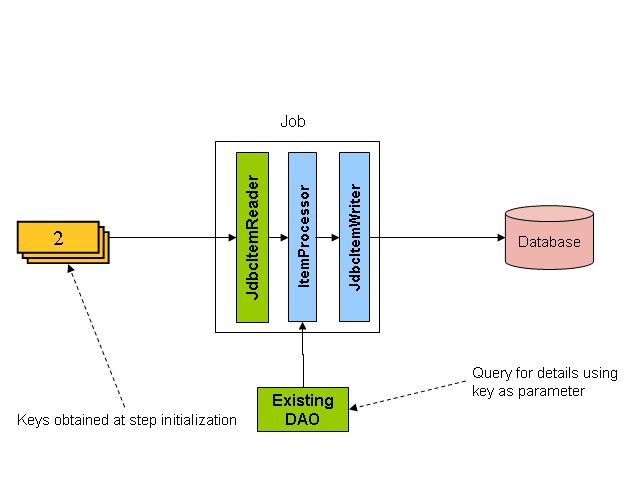
图 2.驾驶查询示例
应该使用ItemProcessor将从驾驶查询中获得的键转换为完整的“ Foo”对象。现有的 DAO 可以用于根据密钥查询完整的对象。
1.5.多行记录
虽然平面文件通常将每个记录限制在一行中,但通常一个文件中的记录可能会跨越具有多种格式的多行。以下文件摘录显示了这种安排的示例:
HEA;0013100345;2007-02-15
NCU;Smith;Peter;;T;20014539;F
BAD;;Oak Street 31/A;;Small Town;00235;IL;US
FOT;2;2;267.34
以“ HEA”开头的行和以“ FOT”开头的行之间的所有内容均被视为一条记录。为了正确处理此情况,必须考虑以下几点:
ItemReader不能一次读取一个记录,而必须将多行记录的每一行作为一个组读取,以便可以将其完整地传递给ItemWriter。每种线型可能需要不同地标记。
由于一条记录跨越多行,并且由于我们可能不知道有多少行,因此ItemReader必须小心以始终读取整个记录。为此,应实现自定义ItemReader作为FlatFileItemReader的包装,如以下示例所示:
XML Configuration
<bean id="itemReader" class="org.spr...MultiLineTradeItemReader">
<property name="delegate">
<bean class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="data/iosample/input/multiLine.txt" />
<property name="lineMapper">
<bean class="org.spr...DefaultLineMapper">
<property name="lineTokenizer" ref="orderFileTokenizer"/>
<property name="fieldSetMapper" ref="orderFieldSetMapper"/>
</bean>
</property>
</bean>
</property>
</bean>
Java Configuration
@Bean
public MultiLineTradeItemReader itemReader() {
MultiLineTradeItemReader itemReader = new MultiLineTradeItemReader();
itemReader.setDelegate(flatFileItemReader());
return itemReader;
}
@Bean
public FlatFileItemReader flatFileItemReader() {
FlatFileItemReader<Trade> reader = new FlatFileItemReaderBuilder<Trade>()
.name("flatFileItemReader")
.resource(new ClassPathResource("data/iosample/input/multiLine.txt"))
.lineTokenizer(orderFileTokenizer())
.fieldSetMapper(orderFieldSetMapper())
.build();
return reader;
}
为了确保正确标记每行,这对于定长 Importing 尤其重要,可以在委托FlatFileItemReader上使用PatternMatchingCompositeLineTokenizer。有关更多详细信息,请参见Reader 和 Writer 一章中的 FlatFileItemReader。然后,委托 Reader 使用PassThroughFieldSetMapper将每行的FieldSet传递回包装ItemReader,如以下示例所示:
XML Content
<bean id="orderFileTokenizer" class="org.spr...PatternMatchingCompositeLineTokenizer">
<property name="tokenizers">
<map>
<entry key="HEA*" value-ref="headerRecordTokenizer" />
<entry key="FOT*" value-ref="footerRecordTokenizer" />
<entry key="NCU*" value-ref="customerLineTokenizer" />
<entry key="BAD*" value-ref="billingAddressLineTokenizer" />
</map>
</property>
</bean>
Java Content
@Bean
public PatternMatchingCompositeLineTokenizer orderFileTokenizer() {
PatternMatchingCompositeLineTokenizer tokenizer =
new PatternMatchingCompositeLineTokenizer();
Map<String, LineTokenizer> tokenizers = new HashMap<>(4);
tokenizers.put("HEA*", headerRecordTokenizer());
tokenizers.put("FOT*", footerRecordTokenizer());
tokenizers.put("NCU*", customerLineTokenizer());
tokenizers.put("BAD*", billingAddressLineTokenizer());
tokenizer.setTokenizers(tokenizers);
return tokenizer;
}
此包装器必须能够识别记录的结尾,以便它可以连续地对其委托调用read()直到到达结尾。对于读取的每一行,包装器应构建要返回的 Item。到达页脚后,可以将商品退回以交付给ItemProcessor和ItemWriter,如以下示例所示:
private FlatFileItemReader<FieldSet> delegate;
public Trade read() throws Exception {
Trade t = null;
for (FieldSet line = null; (line = this.delegate.read()) != null;) {
String prefix = line.readString(0);
if (prefix.equals("HEA")) {
t = new Trade(); // Record must start with header
}
else if (prefix.equals("NCU")) {
Assert.notNull(t, "No header was found.");
t.setLast(line.readString(1));
t.setFirst(line.readString(2));
...
}
else if (prefix.equals("BAD")) {
Assert.notNull(t, "No header was found.");
t.setCity(line.readString(4));
t.setState(line.readString(6));
...
}
else if (prefix.equals("FOT")) {
return t; // Record must end with footer
}
}
Assert.isNull(t, "No 'END' was found.");
return null;
}
1.6.执行系统命令
许多批处理作业要求从批处理作业中调用外部命令。调度程序可以单独启动此过程,但是有关运行的通用元数据的优势将丢失。此外,也需要将多步骤作业拆分为多个作业。
由于这种需求非常普遍,因此 Spring Batch 提供了Tasklet实现来调用系统命令,如以下示例所示:
XML Configuration
<bean class="org.springframework.batch.core.step.tasklet.SystemCommandTasklet">
<property name="command" value="echo hello" />
<!-- 5 second timeout for the command to complete -->
<property name="timeout" value="5000" />
</bean>
Java Configuration
@Bean
public SystemCommandTasklet tasklet() {
SystemCommandTasklet tasklet = new SystemCommandTasklet();
tasklet.setCommand("echo hello");
tasklet.setTimeout(5000);
return tasklet;
}
1.7.未找到 Importing 时处理步骤完成
在许多批处理方案中,在数据库或文件中找不到要处理的行并不是 exception。 Step仅被视为未找到任何工作,并完成了 0 项读取。 Spring Batch 中提供的所有ItemReader实现都是默认使用此方法。如果即使在存在 Importing 的情况下也什么也不写的情况下,这可能会导致一些混乱(通常在文件名错误或出现类似问题时发生)。因此,应检查元数据本身,以确定发现框架要处理多少工作。但是,如果找不到任何 Importing 被认为是 exceptions 怎么办?在这种情况下,最好的方法是以编程方式检查元数据中是否有未处理的 Item 并导致失败。因为这是一个常见的用例,所以 Spring Batch 为监听器提供了恰好此功能,如NoWorkFoundStepExecutionListener的类定义所示:
public class NoWorkFoundStepExecutionListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
if (stepExecution.getReadCount() == 0) {
return ExitStatus.FAILED;
}
return null;
}
}
前面的StepExecutionListener在“ afterStep”阶段检查StepExecution的readCount属性,以确定是否未读取任何 Item。在这种情况下,将返回退出代码 FAILED,表明Step应该失败。否则,将返回null,这不会影响Step的状态。
1.8.将数据传递到将来的步骤
将信息从一个步骤传递到另一步骤通常很有用。这可以通过ExecutionContext完成。要注意的是,有两个ExecutionContexts:一个在Step级别,一个在Job级别。 Step ExecutionContext仅保留到步长,而Job ExecutionContext保留到整个Job。另一方面,每次Step提交一个块时Step ExecutionContext被更新,而Job ExecutionContext仅在每个Step的末尾被更新。
这种分离的结果是在执行Step时必须将所有数据都放在Step ExecutionContext中。这样做可确保在Step运行时正确存储数据。如果将数据存储到Job ExecutionContext,则在Step执行期间不会将其保留。如果Step失败,则该数据将丢失。
public class SavingItemWriter implements ItemWriter<Object> {
private StepExecution stepExecution;
public void write(List<? extends Object> items) throws Exception {
// ...
ExecutionContext stepContext = this.stepExecution.getExecutionContext();
stepContext.put("someKey", someObject);
}
@BeforeStep
public void saveStepExecution(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
}
为了使数据可供将来的Steps使用,必须在完成该步骤后将其“提升”到Job ExecutionContext。 Spring Batch 为此提供了ExecutionContextPromotionListener。必须为侦听器配置与必须提升的ExecutionContext中的数据相关的键。也可以选择为其配置升级代码的退出代码模式列表(默认为COMPLETED)。与所有侦听器一样,它必须在Step上注册,如以下示例所示:
XML Configuration
<job id="job1">
<step id="step1">
<tasklet>
<chunk reader="reader" writer="savingWriter" commit-interval="10"/>
</tasklet>
<listeners>
<listener ref="promotionListener"/>
</listeners>
</step>
<step id="step2">
...
</step>
</job>
<beans:bean id="promotionListener" class="org.spr....ExecutionContextPromotionListener">
<beans:property name="keys">
<list>
<value>someKey</value>
</list>
</beans:property>
</beans:bean>
Java Configuration
@Bean
public Job job1() {
return this.jobBuilderFactory.get("job1")
.start(step1())
.next(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(reader())
.writer(savingWriter())
.listener(promotionListener())
.build();
}
@Bean
public ExecutionContextPromotionListener promotionListener() {
ExecutionContextPromotionListener listener = new ExecutionContextPromotionListener();
listener.setKeys(new String[] {"someKey" });
return listener;
}
最后,必须从Job ExecutionContext检索保存的值,如以下示例所示:
public class RetrievingItemWriter implements ItemWriter<Object> {
private Object someObject;
public void write(List<? extends Object> items) throws Exception {
// ...
}
@BeforeStep
public void retrieveInterstepData(StepExecution stepExecution) {
JobExecution jobExecution = stepExecution.getJobExecution();
ExecutionContext jobContext = jobExecution.getExecutionContext();
this.someObject = jobContext.get("someKey");
}
}