13. Spring Batch Integration
Many users of Spring Batch may encounter requirements that are outside the scope of Spring Batch, yet may be efficiently and concisely implemented using Spring Integration. Conversely, Spring Batch users may encounter Spring Batch requirements and need a way to efficiently integrate both frameworks. In this context several patterns and use-cases emerge and Spring Batch Integration will address those requirements.
The line between Spring Batch and Spring Integration is not always clear, but there are guidelines that one can follow. Principally, these are: think about granularity, and apply common patterns. Some of those common patterns are described in this reference manual section.
Adding messaging to a batch process enables automation of operations, and also separation and strategizing of key concerns. For example a message might trigger a job to execute, and then the sending of the message can be exposed in a variety of ways. Or when a job completes or fails that might trigger a message to be sent, and the consumers of those messages might have operational concerns that have nothing to do with the application itself. Messaging can also be embedded in a job, for example reading or writing items for processing via channels. Remote partitioning and remote chunking provide methods to distribute workloads over an number of workers.
Some key concepts that we will cover are:
Since Spring Batch Integration 1.3, dedicated XML Namespace support was added, with the aim to provide an easier configuration experience. In order to activate the namespace, add the following namespace declarations to your Spring XML Application Context file:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch-int="http://www.springframework.org/schema/batch-integration"
xsi:schemaLocation="
http://www.springframework.org/schema/batch-integration
http://www.springframework.org/schema/batch-integration/spring-batch-integration.xsd">
...
</beans>A fully configured Spring XML Application Context file for Spring Batch Integration may look like the following:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:int="http://www.springframework.org/schema/integration"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:batch-int="http://www.springframework.org/schema/batch-integration"
xsi:schemaLocation="
http://www.springframework.org/schema/batch-integration
http://www.springframework.org/schema/batch-integration/spring-batch-integration.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd">
...
</beans>Appending version numbers to the referenced XSD file is also allowed but, as a version-less declaration will always use the latest schema, we generally don't recommend appending the version number to the XSD name. Adding a version number, for instance, would create possibly issues when updating the Spring Batch Integration dependencies as they may require more recent versions of the XML schema.
When starting batch jobs using the core Spring Batch API you basically have 2 options:
Command line via the
CommandLineJobRunnerProgramatically via either
JobOperator.start()orJobLauncher.run().
For example, you may want to use the CommandLineJobRunner when invoking Batch Jobs using a shell script. Alternatively, you may use the JobOperator directly, for example when using Spring Batch as part of a web application. However, what about more complex use-cases? Maybe you need to poll a remote (S)FTP server to retrieve the data for the Batch Job. Or your application has to support multiple different data sources simultaneously. For example, you may receive data files not only via the web, but also FTP etc. Maybe additional transformation of the input files is needed before invoking Spring Batch.
Therefore, it would be much more powerful to execute the batch job using Spring Integration and its numerous adapters. For example, you can use a File Inbound Channel Adapter to monitor a directory in the file-system and start the Batch Job as soon as the input file arrives. Additionally you can create Spring Integration flows that use multiple different adapters to easily ingest data for your Batch Jobs from multiple sources simultaneously using configuration only. Implementing all these scenarios with Spring Integration is easy as it allow for an decoupled event-driven execution of the JobLauncher.
Spring Batch Integration provides the JobLaunchingMessageHandler class that you can use to launch batch jobs. The input for the JobLaunchingMessageHandler is provided by a Spring Integration message, which payload is of type JobLaunchRequest. This class is a wrapper around the Job that needs to be launched as well as the JobParameters necessary to launch the Batch job.
The following image illustrates the typical Spring Integration message flow in order to start a Batch job. The EIP (Enterprise IntegrationPatterns) website provides a full overview of messaging icons and their descriptions.
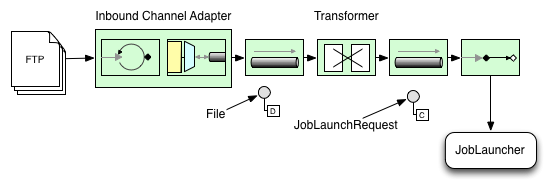
package io.spring.sbi;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.integration.launch.JobLaunchRequest;
import org.springframework.integration.annotation.Transformer;
import org.springframework.messaging.Message;
import java.io.File;
public class FileMessageToJobRequest {
private Job job;
private String fileParameterName;
public void setFileParameterName(String fileParameterName) {
this.fileParameterName = fileParameterName;
}
public void setJob(Job job) {
this.job = job;
}
@Transformer
public JobLaunchRequest toRequest(Message<File> message) {
JobParametersBuilder jobParametersBuilder =
new JobParametersBuilder();
jobParametersBuilder.addString(fileParameterName,
message.getPayload().getAbsolutePath());
return new JobLaunchRequest(job, jobParametersBuilder.toJobParameters());
}
}When a Batch Job is being executed, a JobExecution instance is returned. This instance can be used to determine the status of an execution. If a JobExecution was able to be created successfully, it will always be returned, regardless of whether or not the actual execution was successful.
The exact behavior on how the JobExecution instance is returned depends on the provided TaskExecutor. If a synchronous (single-threaded) TaskExecutor implementation is used, the JobExecution response is only returned after the job completes. When using an asynchronous TaskExecutor, the JobExecution instance is returned immediately. Users can then take the id of JobExecution instance (JobExecution.getJobId()) and query the JobRepository for the job's updated status using the JobExplorer. For more information, please refer to the Spring Batch reference documentation on Querying the Repository .
The following configuration will create a file inbound-channel-adapter to listen for CSV files in the provided directory, hand them off to our transformer (FileMessageToJobRequest), launch the job via the Job Launching Gateway then simply log the output of the JobExecution via the logging-channel-adapter.
<int:channel id="inboundFileChannel"/>
<int:channel id="outboundJobRequestChannel"/>
<int:channel id="jobLaunchReplyChannel"/>
<int-file:inbound-channel-adapter id="filePoller"
channel="inboundFileChannel"
directory="file:/tmp/myfiles/"
filename-pattern="*.csv">
<int:poller fixed-rate="1000"/>
</int-file:inbound-channel-adapter>
<int:transformer input-channel="inboundFileChannel"
output-channel="outboundJobRequestChannel">
<bean class="io.spring.sbi.FileMessageToJobRequest">
<property name="job" ref="personJob"/>
<property name="fileParameterName" value="input.file.name"/>
</bean>
</int:transformer>
<batch-int:job-launching-gateway request-channel="outboundJobRequestChannel"
reply-channel="jobLaunchReplyChannel"/>
<int:logging-channel-adapter channel="jobLaunchReplyChannel"/>Now that we are polling for files and launching jobs, we need to configure for example our Spring Batch ItemReader to utilize found file represented by the job parameter "input.file.name":
<bean id="itemReader" class="org.springframework.batch.item.file.FlatFileItemReader"
scope="step">
<property name="resource" value="file://#{jobParameters['input.file.name']}"/>
...
</bean>The main points of interest here are injecting the value of #{jobParameters['input.file.name']} as the Resource property value and setting the ItemReader bean to be of Step scope to take advantage of the late binding support which allows access to the jobParameters variable.
idIdentifies the underlying Spring bean definition, which is an instance of either:EventDrivenConsumerPollingConsumer
The exact implementation depends on whether the component's input channel is a:
SubscribableChannelorPollableChannel
auto-startupBoolean flag to indicate that the endpoint should start automatically on startup. The default istrue.request-channelThe inputMessageChannelof this endpoint.reply-channelMessage Channelto which the resultingJobExecutionpayload will be sent.reply-timeoutAllows you to specify how long this gateway will wait for the reply message to be sent successfully to the reply channel before throwing an exception. This attribute only applies when the channel might block, for example when using a bounded queue channel that is currently full. Also, keep in mind that when sending to aDirectChannel, the invocation will occur in the sender's thread. Therefore, the failing of the send operation may be caused by other components further downstream. Thereply-timeoutattribute maps to thesendTimeoutproperty of the underlyingMessagingTemplateinstance. The attribute will default, if not specified, to-1, meaning that by default, the Gateway will wait indefinitely. The value is specified in milliseconds.job-launcherPass in a customJobLauncherbean reference. This attribute is optional. If not specified the adapter will re-use the instance that is registered under the idjobLauncher. If no default instance exists an exception is thrown.orderSpecifies the order for invocation when this endpoint is connected as a subscriber to aSubscribableChannel.
When this Gateway is receiving messages from a PollableChannel, you must either provide a global default Poller or provide a Poller sub-element to the Job Launching Gateway:
<batch-int:job-launching-gateway request-channel="queueChannel"
reply-channel="replyChannel" job-launcher="jobLauncher">
<int:poller fixed-rate="1000"/>
</batch-int:job-launching-gateway>As Spring Batch jobs can run for long times, providing progress information will be critical. For example, stake-holders may want to be notified if a some or all parts of a Batch Job has failed. Spring Batch provides support for this information being gathered through:
Active polling or
Event-driven, using listeners.
When starting a Spring Batch job asynchronously, e.g. by using the Job Launching Gateway, a JobExecution instance is returned. Thus, JobExecution.getJobId() can be used to continuously poll for status updates by retrieving updated instances of the JobExecution from the JobRepository using the JobExplorer. However, this is considered sub-optimal and an event-driven approach should be preferred.
Therefore, Spring Batch provides listeners such as:
StepListener
ChunkListener
JobExecutionListener
In the following example, a Spring Batch job was configured with a StepExecutionListener. Thus, Spring Integration will receive and process any step before/after step events. For example, the received StepExecution can be inspected using a Router. Based on the results of that inspection, various things can occur for example routing a message to a Mail Outbound Channel Adapter, so that an Email notification can be send out based on some condition.
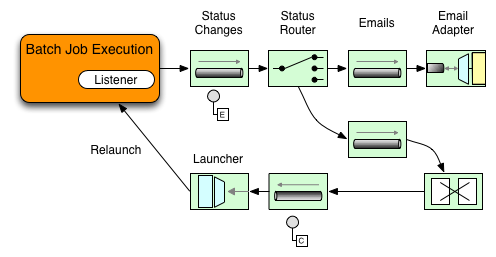
Below is an example of how a listener is configured to send a message to a Gateway for StepExecution events and log its output to a logging-channel-adapter:
First create the notifications integration beans:
<int:channel id="stepExecutionsChannel"/>
<int:gateway id="notificationExecutionsListener"
service-interface="org.springframework.batch.core.StepExecutionListener"
default-request-channel="stepExecutionsChannel"/>
<int:logging-channel-adapter channel="stepExecutionsChannel"/>Then modify your job to add a step level listener:
<job id="importPayments">
<step id="step1">
<tasklet ../>
<chunk ../>
<listeners>
<listener ref="notificationExecutionsListener"/>
</listeners>
</tasklet>
...
</step>
</job>Asynchronous Processors help you to to scale the processing of items. In the asynchronous processor use-case, an AsyncItemProcessor serves as a dispatcher, executing the ItemProcessor's logic for an item on a new thread. The Future is passed to the AsynchItemWriter to be written once the processor completes.
Therefore, you can increase performance by using asynchronous item processing, basically allowing you to implement fork-join scenarios. The AsyncItemWriter will gather the results and write back the chunk as soon as all the results become available.
Configuration of both the AsyncItemProcessor and AsyncItemWriter are simple, first the AsyncItemProcessor:
<bean id="processor"
class="org.springframework.batch.integration.async.AsyncItemProcessor">
<property name="delegate">
<bean class="your.ItemProcessor"/>
</property>
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor"/>
</property>
</bean>The property "delegate" is actually a reference to your ItemProcessor bean and the "taskExecutor" property is a reference to the TaskExecutor of your choice.
Then we configure the AsyncItemWriter:
<bean id="itemWriter"
class="org.springframework.batch.integration.async.AsyncItemWriter">
<property name="delegate">
<bean id="itemWriter" class="your.ItemWriter"/>
</property>
</bean>Again, the property "delegate" is actually a reference to your ItemWriter bean.
The integration approaches discussed so far suggest use-cases where Spring Integration wraps Spring Batch like an outer-shell. However, Spring Batch can also use Spring Integration internally. Using this approach, Spring Batch users can delegate the processing of items or even chunks to outside processes. This allows you to offload complex processing. Spring Batch Integration provides dedicated support for:
Remote Chunking
Remote Partitioning
Taking things one step further, one can also externalize the chunk processing using the ChunkMessageChannelItemWriter which is provided by Spring Batch Integration which will send items out and collect the result. Once sent, Spring Batch will continue the process of reading and grouping items, without waiting for the results. Rather it is the responsibility of the ChunkMessageChannelItemWriter to gather the results and integrate them back into the Spring Batch process.
Using Spring Integration you have full control over the concurrency of your processes, for instance by using a QueueChannel instead of a DirectChannel. Furthermore, by relying on Spring Integration's rich collection of Channel Adapters (E.g. JMS or AMQP), you can distribute chunks of a Batch job to external systems for processing.
A simple job with a step to be remotely chunked would have a configuration similar to the following:
<job id="personJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="200"/>
</tasklet>
...
</step>
</job>The ItemReader reference would point to the bean you would like to use for reading data on the master. The ItemWriter reference points to a special ItemWriter "ChunkMessageChannelItemWriter" as described above. The processor (if any) is left off the master configuration as it is configured on the slave. The following configuration provides a basic master setup. It's advised to check any additional component properties such as throttle limits and so on when implementing your use case.
<bean id="connectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory">
<property name="brokerURL" value="tcp://localhost:61616"/>
</bean>
<int-jms:outbound-channel-adapter id="requests" destination-name="requests"/>
<bean id="messagingTemplate"
class="org.springframework.integration.core.MessagingTemplate">
<property name="defaultChannel" ref="requests"/>
<property name="receiveTimeout" value="2000"/>
</bean>
<bean id="itemWriter"
class="org.springframework.batch.integration.chunk.ChunkMessageChannelItemWriter"
scope="step">
<property name="messagingOperations" ref="messagingTemplate"/>
<property name="replyChannel" ref="replies"/>
</bean>
<bean id="chunkHandler"
class="org.springframework.batch.integration.chunk.RemoteChunkHandlerFactoryBean">
<property name="chunkWriter" ref="itemWriter"/>
<property name="step" ref="step1"/>
</bean>
<int:channel id="replies">
<int:queue/>
</int:channel>
<int-jms:message-driven-channel-adapter id="jmsReplies"
destination-name="replies"
channel="replies"/>This configuration provides us with a number of beans. We configure our messaging middleware using ActiveMQ and inbound/outbound JMS adapters provided by Spring Integration. As shown, our itemWriter bean which is referenced by our job step utilizes the ChunkMessageChannelItemWriter for writing chunks over the configured middleware.
Now lets move on to the slave configuration:
<bean id="connectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory">
<property name="brokerURL" value="tcp://localhost:61616"/>
</bean>
<int:channel id="requests"/>
<int:channel id="replies"/>
<int-jms:message-driven-channel-adapter id="jmsIn"
destination-name="requests"
channel="requests"/>
<int-jms:outbound-channel-adapter id="outgoingReplies"
destination-name="replies"
channel="replies">
</int-jms:outbound-channel-adapter>
<int:service-activator id="serviceActivator"
input-channel="requests"
output-channel="replies"
ref="chunkProcessorChunkHandler"
method="handleChunk"/>
<bean id="chunkProcessorChunkHandler"
class="org.springframework.batch.integration.chunk.ChunkProcessorChunkHandler">
<property name="chunkProcessor">
<bean class="org.springframework.batch.core.step.item.SimpleChunkProcessor">
<property name="itemWriter">
<bean class="io.spring.sbi.PersonItemWriter"/>
</property>
<property name="itemProcessor">
<bean class="io.spring.sbi.PersonItemProcessor"/>
</property>
</bean>
</property>
</bean>Most of these configuration items should look familiar from the master configuration. Slaves do not need access to things like the Spring Batch JobRepository nor access to the actual job configuration file. The main bean of interest is the "chunkProcessorChunkHandler". The chunkProcessor property of ChunkProcessorChunkHandler takes a configured SimpleChunkProcessor which is where you would provide a reference to your ItemWriter and optionally your ItemProcessor that will run on the slave when it receives chunks from the master.
For more information, please also consult the Spring Batch manual, specifically the chapter on Remote Chunking .
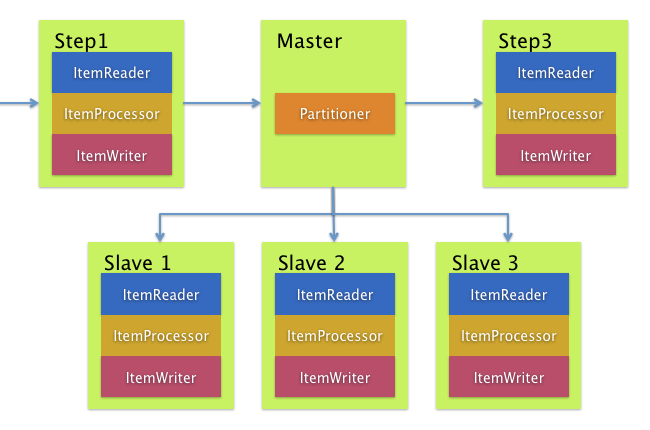
Remote Partitioning, on the other hand, is useful when the problem is not the processing of items, but the associated I/O represents the bottleneck. Using Remote Partitioning, work can be farmed out to slaves that execute complete Spring Batch steps. Thus, each slave has its own ItemReader, ItemProcessor and ItemWriter. For this purpose, Spring Batch Integration provides the MessageChannelPartitionHandler.
This implementation of the PartitionHandler interface uses MessageChannel instances to send instructions to remote workers and receive their responses. This provides a nice abstraction from the transports (E.g. JMS or AMQP) being used to communicate with the remote workers.
The reference manual section Remote Partitioning provides an overview of the concepts and components needed to configure Remote Partitioning and shows an example of using the default TaskExecutorPartitionHandler to partition in separate local threads of execution. For Remote Partitioning to multiple JVM's, two additional components are required:
Remoting fabric or grid environment
A PartitionHandler implementation that supports the desired remoting fabric or grid environment
Similar to Remote Chunking JMS can be used as the "remoting fabric" and the PartitionHandler implementation to be used as described above is the MessageChannelPartitionHandler. The example shown below assumes an existing partitioned job and focuses on the MessageChannelPartitionHandler and JMS configuration:
<bean id="partitionHandler"
class="org.springframework.batch.integration.partition.MessageChannelPartitionHandler">
<property name="stepName" value="step1"/>
<property name="gridSize" value="3"/>
<property name="replyChannel" ref="outbound-replies"/>
<property name="messagingOperations">
<bean class="org.springframework.integration.core.MessagingTemplate">
<property name="defaultChannel" ref="outbound-requests"/>
<property name="receiveTimeout" value="100000"/>
</bean>
</property>
</bean>
<int:channel id="outbound-requests"/>
<int-jms:outbound-channel-adapter destination="requestsQueue"
channel="outbound-requests"/>
<int:channel id="inbound-requests"/>
<int-jms:message-driven-channel-adapter destination="requestsQueue"
channel="inbound-requests"/>
<bean id="stepExecutionRequestHandler"
class="org.springframework.batch.integration.partition.StepExecutionRequestHandler">
<property name="jobExplorer" ref="jobExplorer"/>
<property name="stepLocator" ref="stepLocator"/>
</bean>
<int:service-activator ref="stepExecutionRequestHandler" input-channel="inbound-requests"
output-channel="outbound-staging"/>
<int:channel id="outbound-staging"/>
<int-jms:outbound-channel-adapter destination="stagingQueue"
channel="outbound-staging"/>
<int:channel id="inbound-staging"/>
<int-jms:message-driven-channel-adapter destination="stagingQueue"
channel="inbound-staging"/>
<int:aggregator ref="partitionHandler" input-channel="inbound-staging"
output-channel="outbound-replies"/>
<int:channel id="outbound-replies">
<int:queue/>
</int:channel>
<bean id="stepLocator"
class="org.springframework.batch.integration.partition.BeanFactoryStepLocator" />Also ensure the partition handler attribute maps to the partitionHandler bean:
<job id="personJob">
<step id="step1.master">
<partition partitioner="partitioner" handler="partitionHandler"/>
...
</step>
</job>