Correlation Optimizer
此页面记录了 Correlation Optimizer。它最初由HIVE-2206引入,并基于 YSmart [1]的思想。要打开此优化器,可以使用...
set hive.optimize.correlation=true;
1. Overview
在 Hadoop 环境中,将在分布式系统中评估提交给 Hive 的 SQL 查询。因此,在生成代表提交的 SQL 查询的查询运算符树之后,Hive 需要确定可以在单个节点中执行的任务中可以执行哪些操作。另外,由于 MapReduce 作业可以一次洗净数据数据,因此 Hive 还需要将树切割为多个 MapReduce 作业。重要的是,以良好的方式将运算符树切成多个 MapReduce,这样生成的计划才能有效地评估查询。
当为给定的 SQL 查询生成运算符树时,Hive 会确定何时通过可能需要对数据进行混洗的操作对数据进行混洗。例如,如果 Importing 表尚未通过连接列分配,则JOIN操作可能需要重新整理 Importing 数据。但是,在复杂的查询中,可能需要按 Sequences 重新整理 Importing 数据的操作的 Importing 数据可能已经被分区。例如,可能有类似SELECT t1.key, sum(value) FROM t1 JOIN t2 ON (t1.key = t2.key) GROUP BY t1.key的查询。在此示例中,JOIN操作和GROUP BY操作都可能需要对 Importing 数据进行混洗。但是,由于JOIN操作的输出是GROUP BY操作的 Importing,并且已经由t1.key进行了分区,因此我们不需要为GROUP BY操作重新整理数据。但是,Hive 无法识别JOIN操作和GROUP BY操作之间的这种关联,因此它将生成两个单独的 MapReduce 作业来评估此查询。基本上,我们不必为GROUP BY操作改组数据。在更复杂的查询中,不了解相关性的查询计划可能会产生效率很低的执行计划,并导致性能下降。
在将 Correlation Optimizer 集成到 Hive 中之前,Hive 具有 ReduceSink 重复数据删除优化器,它可以确定我们是否需要对链式运算符进行数据混排。但是,为了支持更复杂的运算符树,我们需要更通用的优化器和一种机制来正确执行优化的计划。因此,我们设计并实现了 Correlation Optimizer 和两个用于评估优化计划的运算符。值得注意的是,最好先使用 ReduceSink Deduplication Optimizer 处理简单案例,然后再使用 Correlation Optimizer 处理更复杂的案例。
2. Examples
首先,让我们看三个例子。对于每个查询,我们都会显示 Hive 生成的原始运算符树和优化的运算符树。简而言之,我们仅显示以下运算符,即FileSinkOperator (FS),GroupByOperator (AGG),HashTableSinkOperator (HT),JoinOperator (JOIN),MapJoinOperator (MJ)和ReduceSinkOperator (RS)。此外,在每个查询中,我们都会添加 Comments(例如/ * JOIN1 * /),以指示操作所属的操作员树中的节点。
2.1 示例 1
SELECT tmp1.key, count(*)
FROM (SELECT key, avg(value) AS avg
FROM t1
GROUP BY /*AGG1*/ key) tmp1
JOIN /*JOIN1*/ t1 ON (tmp1.key = t2.key)
WHERE t1.value > tmp1.avg
GROUP BY /*AGG2*/ tmp1.key;
Hive 生成的原始运算符树如下所示。
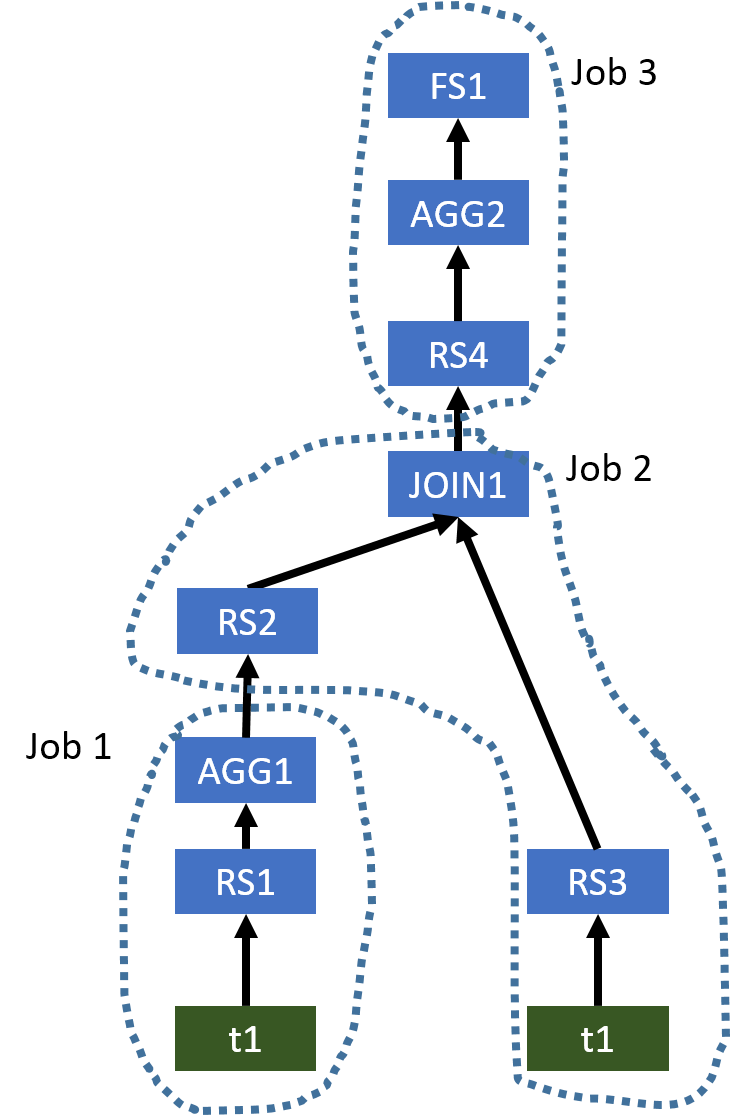
图 1:Hive 生成的示例 1 的原始运算符树
该计划使用三个 MapReduce 作业来评估此查询。但是,AGG1,JOIN1和AGG2都要求列key是用于对数据进行混排的分区列。因此,我们不需要以相同的方式对数据进行 3 次重排。我们只需要将数据混洗一次,因此需要一个 MapReduce 作业。优化的运算符树如下所示。
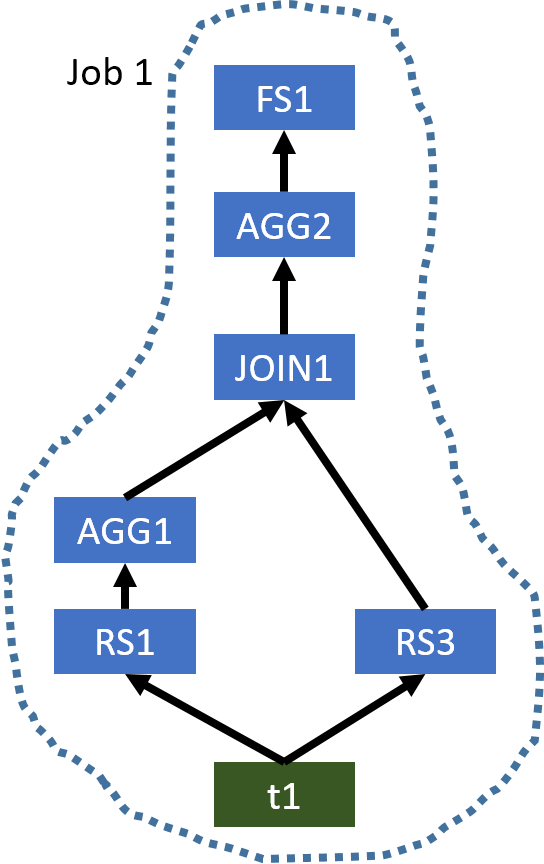
图 2:示例 1 的优化运算符树
由于AGG1的 Importing 表和JOIN1的左表均为t1,因此当我们使用单个 MapReduce 作业评估此查询时,Hive 只需要扫描t1一次。而在原始计划中,t1在两个 MapReduce 作业中使用,因此被扫描了两次。
2.2 示例 2
SELECT tmp1.key, count(*)
FROM t1
JOIN /*JOIN1*/ (SELECT key, avg(value) AS avg
FROM t1
GROUP BY /*AGG1*/ key) tmp1 ON (t1.key = tmp1.key)
JOIN /*JOIN1*/ t2 ON (tmp1.key = t2.key)
WHERE t2.value > tmp1.avg
GROUP BY /*AGG2*/ t1.key;
Hive 生成的原始运算符树如下所示。
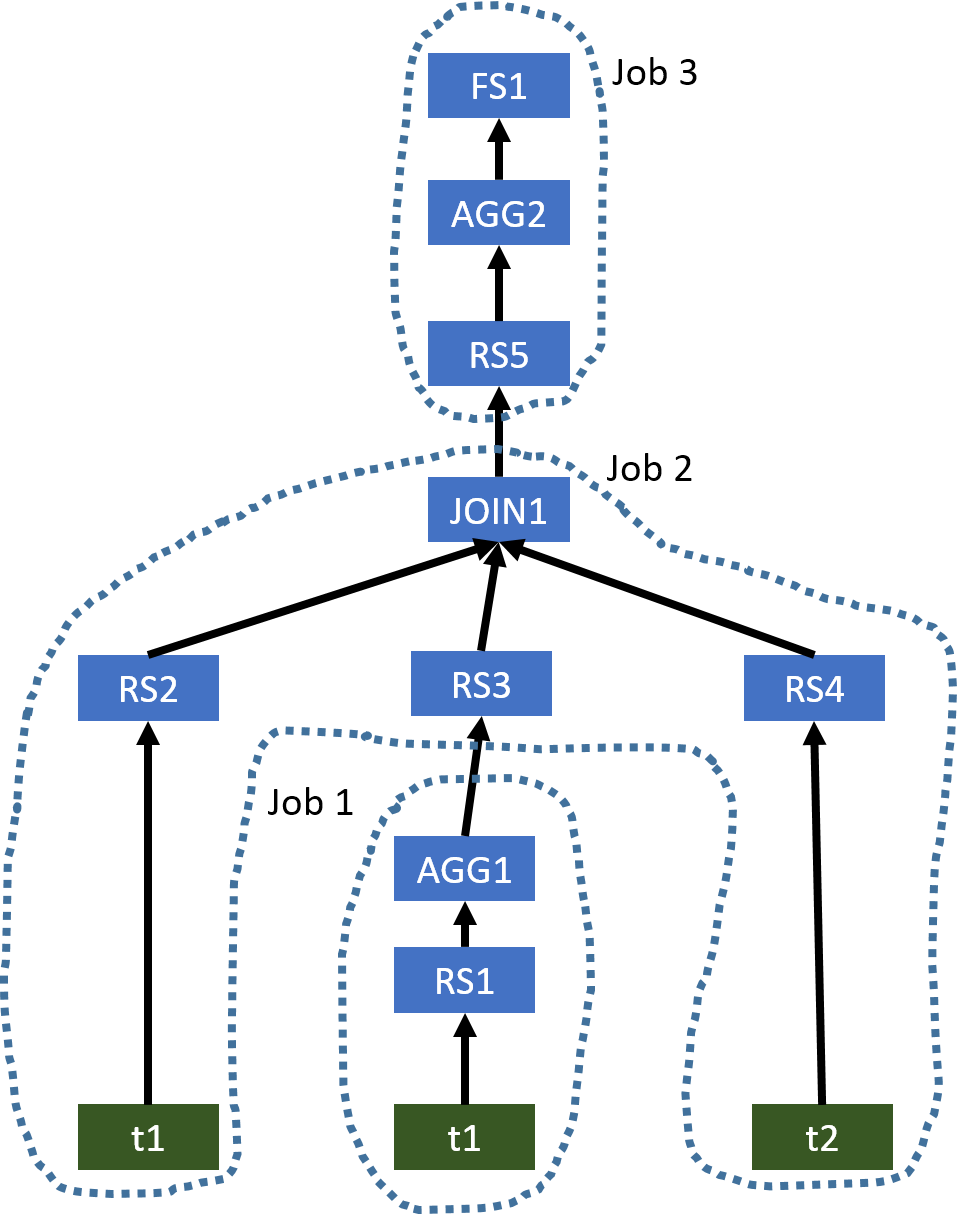
图 3:Hive 生成的示例 2 的原始运算符树
该示例与示例 1 相似。优化的运算符树仅需要一个 MapReduce 作业,如下所示。
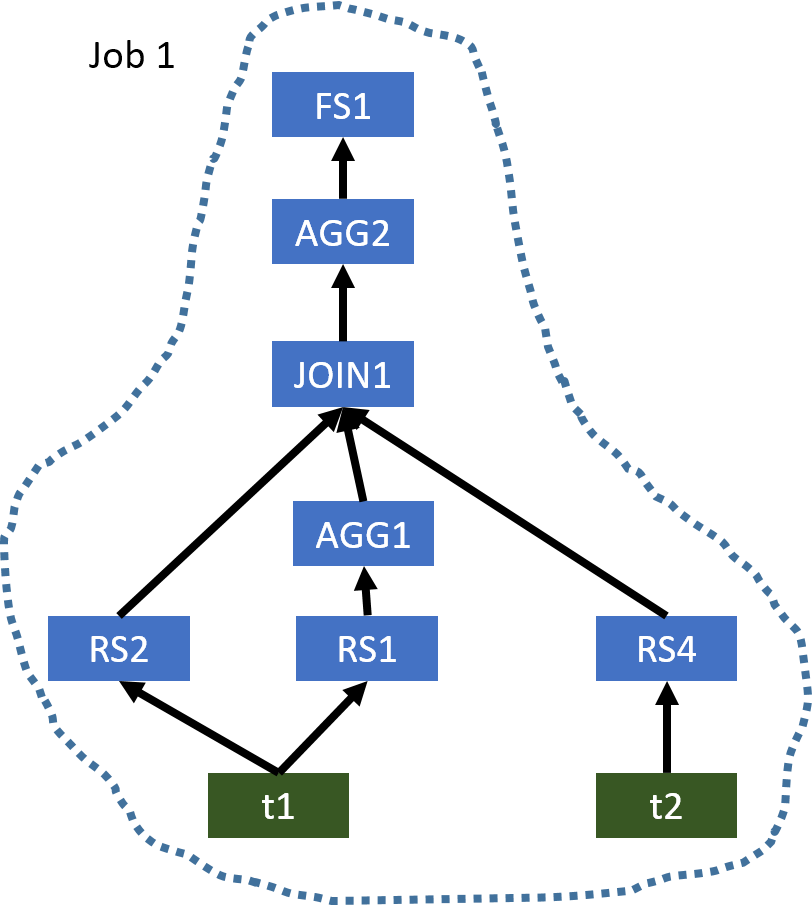
图 4:示例 2 的优化运算符树
2.3 示例 3
SELECT count(distinct ws1.ws_order_number) as order_count,
sum(ws1.ws_ext_ship_cost) as total_shipping_cost,
sum(ws1.ws_net_profit) as total_net_profit
FROM web_sales ws1
JOIN /*MJ1*/ customer_address ca ON (ws1.ws_ship_addr_sk = ca.ca_address_sk)
JOIN /*MJ2*/ web_site s ON (ws1.ws_web_site_sk = s.web_site_sk)
JOIN /*MJ3*/ date_dim d ON (ws1.ws_ship_date_sk = d.d_date_sk)
LEFT SEMI JOIN /*JOIN4*/ (SELECT ws2.ws_order_number as ws_order_number
FROM web_sales ws2 JOIN /*JOIN1*/ web_sales ws3
ON (ws2.ws_order_number = ws3.ws_order_number)
WHERE ws2.ws_warehouse_sk <> ws3.ws_warehouse_sk) ws_wh1
ON (ws1.ws_order_number = ws_wh1.ws_order_number)
LEFT SEMI JOIN /*JOIN4*/ (SELECT wr_order_number
FROM web_returns wr
JOIN /*JOIN3*/ (SELECT ws4.ws_order_number as ws_order_number
FROM web_sales ws4 JOIN /*JOIN2*/ web_sales ws5
ON (ws4.ws_order_number = ws5.ws_order_number)
WHERE ws4.ws_warehouse_sk <> ws5.ws_warehouse_sk) ws_wh2
ON (wr.wr_order_number = ws_wh2.ws_order_number)) tmp1
ON (ws1.ws_order_number = tmp1.wr_order_number)
WHERE d.d_date >= '2001-05-01' and
d.d_date <= '2001-06-30' and
ca.ca_state = 'NC' and
s.web_company_name = 'pri';
Hive 生成的原始运算符树如下所示。
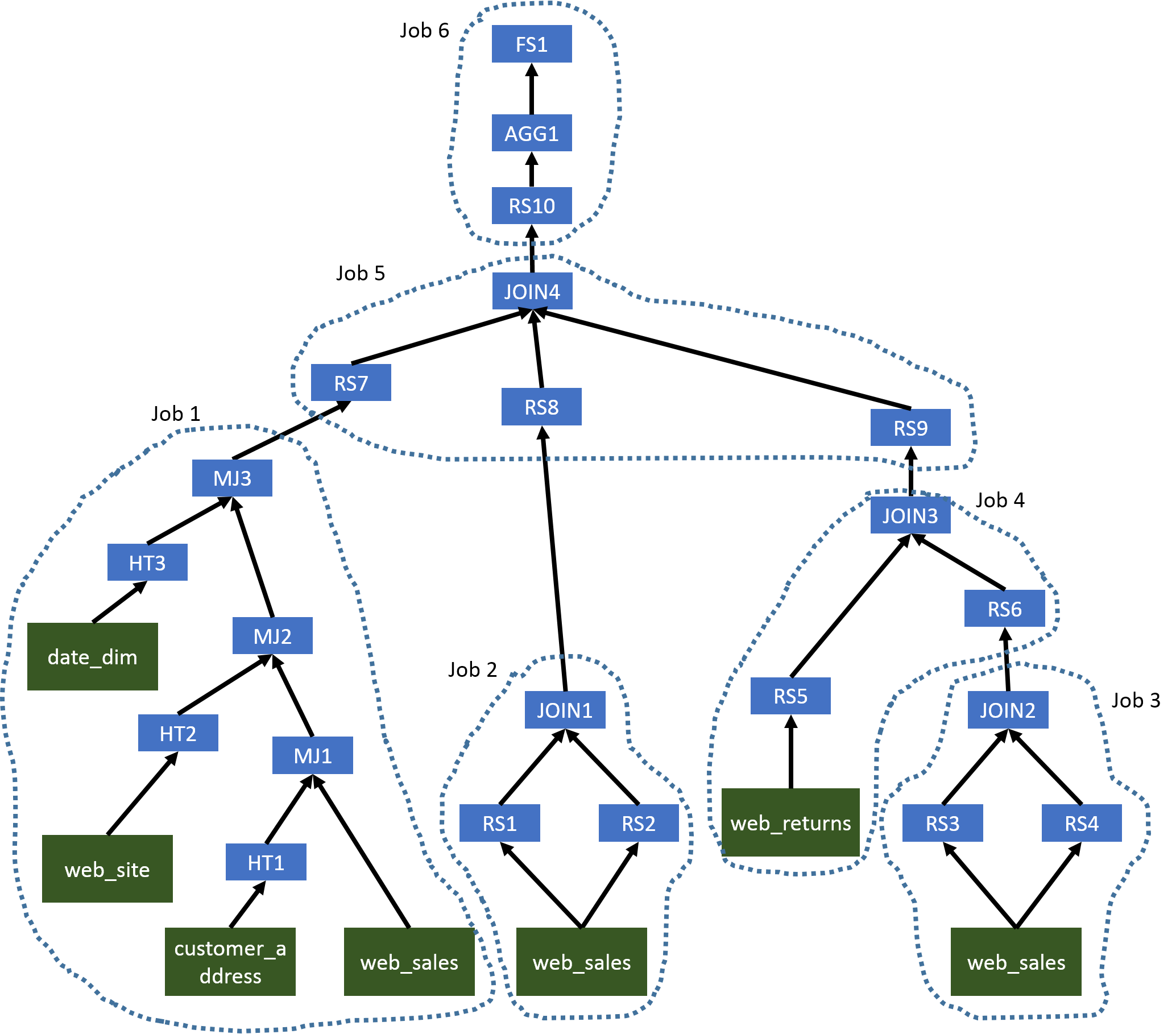
图 5:Hive 生成的示例 3 的原始运算符树
在这个复杂的查询中,我们首先将有几个 MapJoins(MJ1,MJ2和MJ3),可以在同一 Map 阶段对其进行评估。由于JOIN1,JOIN2,JOIN3和JOIN4使用与连接键相同的列,因此我们可以使用单个 MapReduce 作业来评估AGG1之前的所有运算符。第二个 MapReduce 作业将生成最终结果。优化的运算符树如下所示。
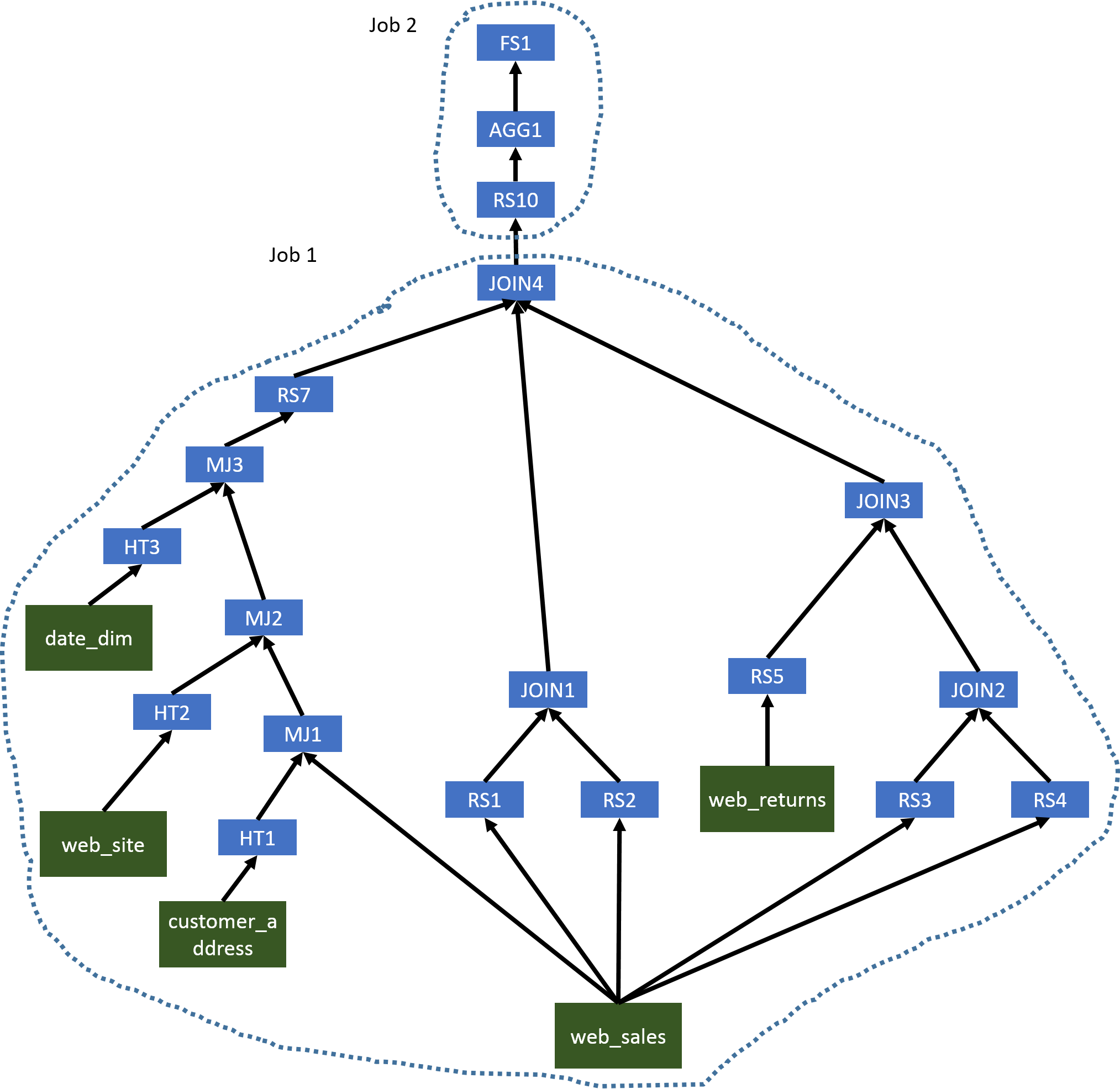
图 6:示例 3 的优化运算符树
3.查询内相关
在 Hive 中,需要在分布式系统中评估提交的 SQL 查询。在评估查询时,有时可能需要重新整理数据。根据不同数据操作的性质,Hive 中的运算符可以分为两类。
不需要数据混排的运算符。示例为
TableScanOperator,SelectOperator和FilterOperator。需要数据混排的运算符。例子是
GroupByOperator和JoinOperator。
对于需要数据改组的操作员,Hive 将添加一个或多个ReduceSinkOperators作为该操作员的父级(ReduceSinkOperators的数量取决于需要数据改组的操作员的 Importing 数量)。那些ReduceSinkOperators形成了 Map 阶段和 Reduce 阶段之间的边界。然后,Hive 将操作员树切割成多个片段(MapReduce 任务),并且每个片段都可以在 MapReduce 作业中执行。
对于复杂的查询,多个 MapReduce 任务可能使用一个 Importing 表。在这种情况下,使用原始运算符树时,将多次加载该表。此外,在生成那些ReduceSinkOperators时,Hive 不会考虑是否需要进行数据混排的相应运算符确实需要重新分区的 Importing 数据。例如,在原始运算符树Example 1(Figure 1)中,AGG1,JOIN1和AGG2要求以相同的方式对数据进行混洗,因为它们全部都要求key列为其对应的ReduceSinkOperators中的分区列。但是,Hive 无法识别AGG1,JOIN1和AGG2之间的这种关联,并且仍会生成三个 MapReduce 任务。
关联优化器旨在利用上述两个 qeury 内部关联。
Importing 相关性:原始运算符树中的多个 MapReduce 任务使用一个 Importing 表。
作业流关联:两个相关的 MapReduce 任务以相同的方式对数据进行混洗。
4.相关性检测
在 Hive 中,每个查询都有一个或多个终端运算符,它们是运算符树中的最后一个运算符。这些终端操作员称为 FileSinkOperatos。为了便于说明,如果操作员 A 在另一个操作员 B 的 FileSinkOperato 路径上,则 A 是 B 的下游,而 B 是 A 的上游。
对于像Figure 1中所示的给定运算符树,Correlation Optimizer 开始以深度优先的方式从那些 FileSinkOperatos 访问树中的运算符。遍历树的树停在每个 ReduceSinkOperator 上。然后,相关性检测器通过递归的方式找到最远的相关上游 ReduceSinkOperator,从而开始从该 ReduceSinkOperator 及其兄弟姐妹中找到相关性。如果我们可以找到任何相关的上游 ReduceSinkOperator,我们就会找到一个相关。当前,存在三个条件来确定上游 ReduceSinkOperator 和下游 ReduceSinkOperator 是否相关,分别是
这两个 ReduceSinkOperators 发出的行以相同的方式排序;
这两个 ReduceSinkOperators 发出的行以相同的方式分区;和
这些 ReduceSinkOperators 在数量减少器上没有任何冲突。
有兴趣的 Reader 可以参考我们的implementation以获得详细信息。
在相关检测期间,JoinOperator 或 UnionOperator 可以将分支引入搜索路径。对于 JoinOperator 来说,其父代都是 ReduceSinkOperators。当检测器到达 JoinOperator 时,它将检查此 JoinOperator 的所有父级是否都与下游的 ReduceSinkOperator 相关。由于 JoinOperator 包含一个或多个 2 向 Join 操作,对于 ReduceXinkOperator,我们可以根据 Join 方法中这些 ReduceSinkOperator 的 Join 类型和位置,来确定在同一 Join 操作中出现的另一个 ReduceSinkOperator 是否相关联。
如果 ReduceSinkOperator 代表 INNER JOIN,LEFT OUTER JOIN 或 LEFT SEMI JOIN 的左表,则代表右表的 ReduceSinkOperator 也被认为是相关的。和
如果 ReduceSinkOperator 代表 INNER JOIN 的右表或 RIGHT OUTER JOIN,则代表左表的 ReduceSinkOperator 也被认为是相关的。
使用这两个规则,我们开始从每个在 Join 子句中出现列的 ReduceSinkOperator 中分析 JoinOperator 的父级 ReduceSinkOperator,然后我们可以递归找到所有相关的 ReduceSinkOperator。如果我们发现所有父级 ReduceSinkOperator 与每个在 Join 子句中出现列的 ReduceSinkOperator 相关,我们将在该分支上 continue 进行相关性检测。否则,我们将确定 JoinOperator 的 ReduceSinkOperator 没有关联,并在此分支上停止关联检测。
对于 UnionOperator 而言,其任何 parent 都不是 ReduceSinkOperator。因此,我们检查是否可以为此 UnionOperator 的每个父分支找到相关的 ReduceSinkOperators。如果任何分支都没有 ReduceSinkOperator,我们将确定在此 UnionOperator 的父分支中没有找到任何相关的 ReduceSinkOperator。
在相关性检测过程中,检测器可能会访问 JoinOperator,稍后它将转换为 Map Join。在这种情况下,检测器将停止搜索包含此 Map Join 的分支。例如,
在Figure 5中,检测器知道 MJ1,MJ2 和 MJ3 将被转换为 Map Joins。
5.操作员树转换
在关联中,存在两种 ReduceSinkOperators。第一种类型的 ReduceSinkOperators 在查询运算符树的底层,需要将行运行到混洗阶段。例如,在Figure 1中,RS1 和 RS3 是底层的 ReduceSinkOperators。第二类 ReduceSinkOperator 是不必要的,可以从优化的运算符树中删除。例如,在Figure 1中,RS2 和 RS4 是不必要的 ReduceSinkOperators。因为 Reduce 阶段的 Importing 行可能需要转发到不同的运算符,并且这些 Importing 行来自单个流,所以我们添加了一个称为 DemuxOperator 的新运算符,以将 Reduce 阶段的 Importing 行分派给相应的运算符。在运算符树转换中,我们首先将底层的 ReduceSinkOperators 的子级连接到 DemuxOperator,并重新分配底层的 ReduceSinkOperators 的标签(DemuxOperator 是底层的 ReduceSinkOperators 的唯一子级)。在 DemuxOperator 中,我们记录了两个 Map。第一个称为 newTagToOldTag,它将分配给底层的 ReduceSinkOperators 的那些新标签 Map 到其原始标签。这些原始标签是使 JoinOperator 正常工作所必需的。第二个 Map 称为 newTagToChildIndex,它将这些新标记 Map 到子索引。通过此 Map,DemuxOperator 可以基于该行的标签知道需要转发该行的正确运算符。运算符树转换的第二步是删除那些不必要的 ReduceSinkOperators。为了使 Reduce 阶段中的运算符树正确工作,我们在这些不必要的 ReduceSinkOperators 的原始位置添加了一个名为 MuxOperator 的新运算符。值得注意的是,如果一个运算符有多个不必要的 ReduceSinkOperators 作为其父级,我们只会添加一个 MuxOperator。
6.在 Reduce 阶段执行优化的操作员树
在 Reduce 阶段,ExecReducer 将首先将所有 reduceImporting 行转发到 DemuxOperator。当前,reduce 阶段运算符树中的阻塞运算符共享相同的密钥。其他案例将在以后的工作中得到支持。然后,DemuxOperator 会将行转发到其相应的运算符。因为 Reduce 计划优化的 Correlation Optimizer 可以是树形结构,所以我们需要协调该树中的运算符以使 Reduce 阶段正常工作。此协调机制在 ExecDriver,DemuxOperator 和 MuxOperator 中实现。
将新行发送到 ExecDriver 时,它将通过检查那些键列的值来检查是否需要启动新的一组行。如果要出现一组新的行,它将首先调用 DemuxOperator.endGroup。然后,DemuxOperator 将要求其子级处理其缓冲的行,并将 endGroup 调用传播到运算符树。最后,DemuxOperator 将 processGroup 调用传播到操作员树。通常,操作员中 processGroup 的实现只会将此调用传播到其子级。 MuxOperator 是覆盖 processGroup 的那个。当 MuxOperator 获得 processGroup 调用时,它将检查其所有父操作符是否都已调用此调用。如果是这样,它将要求其子代生成结果并将 processGroup 传播到其子代。将 processGroup 传播到所有运算符后,DemuxOperator.endGroup 将返回,并且 ExecDriver 会将 startGroup 传播到运算符树。
对于发送到 ExecDriver 的每一行,它还具有一个由 Map 阶段的相应 RediceSinkOperator 分配的标签。在行组(行具有相同的键)中,行也按其标签排序。当 DemuxOperator 看到一个新标签时,它知道与小于此新标签的标签相关联的所有子运算符在当前行组中将没有任何 Importing。因此,它可以更早地调用这些运算符的 endGroup 和 processGroup。使用此逻辑,在行组中,操作符树中每个操作符的 Importing 行也按标记排序,这是 JoinOperator 所必需的。此逻辑还使运算符缓冲区中的行尽快发出,从而避免了由于缓冲不必要的行而造成的不必要的内存占用。
7.相关的 Jiras
雨伞吉拉是HIVE-3667。
7.1 已解决的 Jiras
7.2 未解决的 Jiras
8. References
- 李如宝,罗天罗,尹怀,王福生,何永强,张晓东。 YSmart:另一个从 SQL 到 MapReduce 的转换器,ICCDS,2011 年