HiveServer2
HiveServer2(HS2)是一个服务器接口,使远程 Client 端可以对 Hive 执行查询并检索结果(更详细的介绍here)。基于 Thrift RPC 的当前实现是HiveServer的改进版本,并支持多 Client 端并发和身份验证。它旨在为 JDBC 和 ODBC 等开放 APIClient 端提供更好的支持。
HiveServer2 的 Thrift 接口定义语言(IDL)在https://github.com/apache/hive/blob/trunk/service/if/TCLIService.thrift可用。
Thrift 文档可在http://thrift.apache.org/docs/获得。
本文档介绍了如何设置服务器。 HiveServer2Client 端文档中描述了如何在该服务器上使用 Client 端。
Version
在 Hive 版本 0.11 中引入。参见HIVE-2935。
如何配置
hive-site.xml 文件中的配置属性
hive.server2.thrift.min.worker.threads –辅助线程的最小数量,默认为 5.
hive.server2.thrift.max.worker.threads –工作线程的最大数量,默认为 500.
hive.server2.thrift.port –要侦听的 TCP 端口号,默认为 10000.
hive.server2.thrift.bind.host –要绑定的 TCP 接口。
有关可以为 HiveServer2 设置的其他属性,请参见配置属性文档中的 HiveServer2。
可选的环境设置
HIVE_SERVER2_THRIFT_BIND_HOST –要绑定的可选 TCP 主机接口。覆盖配置文件设置。
HIVE_SERVER2_THRIFT_PORT –侦听的可选 TCP 端口号,默认为 10000.覆盖配置文件设置。
以 HTTP 模式运行
HiveServer2 支持通过 HTTP 传输发送 Thrift RPC 消息(从 Hive 0.13 开始,请参见HIVE-4752)。这对于支持 Client 端和服务器之间的代理中介(例如,出于负载平衡或安全原因)特别有用。当前,您可以在 TCP 模式或 HTTP 模式下运行 HiveServer2,但不能同时在两种模式下运行。对于相应的 JDBC URL,请检查以下链接:HiveServer2Client 端-JDBC 连接 URL。使用以下设置来启用和配置 HTTP 模式:
| Setting | Default | Description |
|---|---|---|
| hive.server2.transport.mode | binary | 设置为 http 以启用 HTTP 传输模式 |
| hive.server2.thrift.http.port | 10001 | 要侦听的 HTTP 端口号 |
| hive.server2.thrift.http.max.worker.threads | 500 | 服务器池中的最大工作线程数 |
| hive.server2.thrift.http.min.worker.threads | 5 | 服务器池中的最小工作线程 |
| hive.server2.thrift.http.path | cliservice | 服务端点 |
基于 Cookie 的身份验证
HIVE-9709和HIVE-9710为 HTTP 模式下的 HiveServer2 引入了基于 cookie 的身份验证。与此更改关联的 HiveServer2 参数(hive.server2.thrift.http.cookie.*)可以找到here。
可选的全局初始化文件
可以将全局初始化文件放置在已配置的hive.server2.global.init.file.location位置(从 Hive 0.14 开始,请参见HIVE-5160,HIVE-7497和HIVE-8138)。这可以是初始文件本身的路径,也可以是预期名为“ .hiverc”的初始文件的目录。
初始化文件列出了将为此 HiveServer2 实例的用户运行的一组命令,例如注册一组标准的 jar 和函数。
Logging Configuration
HiveServer2 操作日志可用于 BeelineClient 端(从 Hive 0.14 开始)。这些参数配置日志记录:
hive.server2.logging.operation.verbose(配置单元为 0.14 至 1.1)
hive.server2.logging.operation.level(Hive 1.2 及更高版本)
如何开始
$HIVE_HOME/bin/hiveserver2
OR
$HIVE_HOME/bin/hive --service hiveserver2
Usage Message
-H或--help选项显示用法消息,例如:
$HIVE_HOME/bin/hive --service hiveserver2 -H
Starting HiveServer2
usage: hiveserver2
-H,--help Print help information
--hiveconf <property=value> Use value for given property
Authentication/Security Configuration
HiveServer2 支持带有(不带有)SASL,Kerberos(GSSAPI),通过 LDAP,可插拔自定义认证和可插拔认证模块(PAM,受支持的 Hive 0.13 起)的匿名(不认证)。
Configuration
Authentication mode:
hive.server2.authentication –身份验证模式,默认为 NONE。选项为 NONE(使用普通 SASL),NOSASL,KERBEROS,LDAP,PAM 和 CUSTOM。
为 KERBEROS 模式设置以下内容:
hive.server2.authentication.kerberos.principal –服务器的 Kerberos 主体。
hive.server2.authentication.kerberos.keytab –服务器主体的密钥表。
为 LDAP 模式设置以下内容:
hive.server2.authentication.ldap.url – LDAP URL(例如,ldap://hostname.com:389)。
hive.server2.authentication.ldap.baseDN – LDAP 基本 DN。 (对于 AD 是可选的.)
hive.server2.authentication.ldap.Domain – LDAP 域。 (配置单元 0.12.0 和更高版本.)
有关 Hive 1.3.0 和更高版本中的其他 LDAP 配置参数,请参见HiveServer2 中的 LDAP Atn 提供程序对用户和组过滤器的支持。
为自定义模式设置以下内容:
hive.server2.custom.authentication.class –实现org.apache.hive.service.auth.PasswdAuthenticationProvider接口的自定义身份验证类。
对于 PAM 模式,请参见下面的PAM 部分。
Impersonation
默认情况下,HiveServer2 以提交查询的用户身份执行查询处理。但是,如果以下参数设置为 false,则查询将以hiveserver2进程运行的用户身份运行。
hive.server2.enable.doAs –模拟连接的用户,默认为 true。
为防止在不安全模式下发生内存泄漏,请通过将以下参数设置为 true 来禁用文件系统缓存(请参阅HIVE-4501):
fs.hdfs.impl.disable.cache –禁用 HDFS 文件系统缓存,默认为 false。
fs.file.impl.disable.cache –禁用本地文件系统缓存,默认为 false。
Integrity/Confidentiality Protection
启用了 Hive JDBC 驱动程序和 HiveServer2 之间的通信的完整性保护和机密性保护(不只是默认的身份验证)(从 Hive 0.12 开始,请参阅HIVE-4911)。您可以使用SASL QOP属性进行配置。
仅当使用 Kerberos 进行 HiveServer2 的 HS2Client 端(JDBC/ODBC 应用程序)身份验证时才使用 Kerberos。
必须将
hive-site.xml中的 hive.server2.thrift.sasl.qop 设置为有效的QOP值之一(“ auth”,“ auth-int”或“ auth-conf”)。
SSL Encryption
支持 SSL 加密(从 Hive 0.13 开始,请参阅HIVE-5351)。要启用,请在hive-site.xml中设置以下配置:
hive.server2.use.SSL-将此设置为 true。
hive.server2.keystore.path –将此设置为您的密钥库路径。
hive.server2.keystore.password –将此设置为您的密钥库密码。
Note
如果 hive.server2.transport.mode 是二进制文件,而 hive.server2.authentication 是 KERBEROS,则 SSL 加密在 Hive 2.0 之前不起作用。将 hive.server2.thrift.sasl.qop 设置为 auth-conf 以启用加密。有关详情,请参见HIVE-14019。
使用自签名证书设置 SSL
使用以下步骤创建和验证用于 HiveServer2 的自签名 SSL 证书:
使用以下命令创建自签名证书并将其添加到密钥库文件中:keytool -genkey -alias example.com -keyalg RSA -keystore keystore.jks -keysize 2048 确保自签名证书中使用的名称与 HiveServer2 将在其中运行的主机名匹配。
列出密钥库条目以验证是否已添加证书。请注意,密钥库可以包含多个此类证书:keytool -list -keystore keystore.jks
将此证书从 keystore.jks 导出到证书文件:keytool -export -alias example.com -file example.com.crt -keystore keystore.jks
将此证书添加到 Client 端的信任库中以构建信任:keytool -import -trustcacerts -alias example.com -file example.com.crt -keystore truststore.jks
验证证书在 truststore.jks 中是否存在:keytool -list -keystore truststore.jks
然后启动 HiveServer2,并尝试使用以下命令与 Beeline 连接:jdbc:hive2://<host>:\ /<database>; ssl = true; sslTrustStore =<path-to-truststore>; trustStorePassword =<truststore-password>
选择性停用 SSL 协议版本
要禁用特定的 SSL 协议版本,请使用以下步骤:
运行 openssl ciphers -v(如果不使用 openssl,则运行相应的命令)以查看所有协议版本。
除 1 之外,可能还需要执行其他步骤才能查看 HiveServer2 日志,以查看运行 HiveServer2 的节点支持的所有协议。为此,请在 HiveServer2 日志文件中搜索“启用 SSL 服务器套接字的协议:”。
将所有需要禁用的 SSL 协议添加到 hive.ssl.protocol.blacklist。确保 hiveserver2-site.xml 中的属性不会覆盖 hive-site.xml 中的属性。
可插拔身份验证模块(PAM)
Warning
如果用户的密码已过期,用于提供 PAM 身份验证模式的JPAM库可能导致 HiveServer2 关闭。发生这种情况是由于 JPAM 调用了本机代码中的段错误/核心转储。在其他情况下,一些用户也报告了登录期间崩溃。建议使用 LDAP 或 KERBEROS。
提供了对 PAM 的支持(从 Hive 0.13 开始,请参阅HIVE-6466)。要配置 PAM:
下载相关架构的JPAM本机库。
解压缩 libjpam.so 并将其复制到系统上的目录( )。
将目录添加到 LD_LIBRARY_PATH 环境变量中,如下所示:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<libjmap-directory>对于某些 PAM 模块,您必须确保运行 HiveServer2 进程的用户可以读取
/etc/shadow和/etc/login.defs文件。
最后,在hive-site.xml中设置以下配置:
hive.server2.authentication –将此设置为 PAM。
hive.server2.authentication.pam.services –将此设置为将使用的逗号分隔的 PAM 服务列表。请注意,/ etc/pam.d 中必须存在与 PAM 服务同名的文件。
设置 HiveServer2 作业凭据提供程序
从 Hive 2.2.0 开始(请参阅HIVE-14822),Hiveserver2 支持 MR 和 Spark 作业的特定于作业的 hadoop 凭据提供程序。通过 Hadoop 凭据提供程序使用加密密码时,HiveServer2 需要将足够的信息转发到作业配置,以便跨集群启动的作业可以读取这些机密。此外,HiveServer2 可能具有作业不应该拥有的 Secret,例如 Hive Metastore 数据库密码。如果您的工作需要访问诸如 S3 凭据之类的机密,则可以使用以下配置步骤配置它们:
在 HDFS 中的安全位置使用 Hadoop 凭据提供程序 API 创建特定于作业的密钥库。该密钥库应包含作业所需的配置的加密密钥/值对。例如:对于 S3 凭证,密钥库应包含 fs.s3a.secret.key 和 fs.s3a.access.key 及其相应值。
解密密钥库的密码应设置为 HiveServer2 环境变量,称为 HIVE_JOB_CREDSTORE_PASSWORD
将 hive.server2.job.credential.provider.path 设置为 URL,以指向在上面的(1)中创建的密钥库的类型和位置。如果没有特定于作业的密钥库,则 HiveServer2 将使用 core-site.xml 中的 hadoop.credential.provider.path 使用一组。
如果未提供在步骤 2 中设置的使用环境变量的密码,则 HiveServer2 将使用 HADOOP_CREDSTORE_PASSWORD 环境变量(如果可用)。
HiveServer2 现在将修改使用 MR 或 Spark 执行引擎启动的作业的作业配置,以包括作业凭证提供程序,以便作业任务可以使用机密访问加密的密钥库。
hive.server2.job.credential.provider.path –将此设置为您的特定于作业的 hadoop 凭据提供程序。例如:jceks://hdfs/user/hive/secret/jobcreds.jceks。
HIVE_JOB_CREDSTORE_PASSWORD –将此 HiveServer2 环境变量设置为上面设置的特定于作业的 Hadoop 凭证提供程序密码。
临时目录 Management
HiveServer2 允许配置临时目录的各个方面,Hive 使用这些目录来存储临时输出和计划。
Configuration Properties
以下是可以配置的与临时目录相关的属性:
ClearDanglingScratchDir Tool
可以运行工具 cleardanglingscratchdir 来清理因不正确关闭 Hive 而留下的任何悬挂的暂存目录,例如,当虚拟机重新启动时,Hive 没有机会运行关闭钩子。
hive --service cleardanglingscratchdir [-r] [-v] [-s scratchdir]
-r dry-run mode, which produces a list on console
-v verbose mode, which prints extra debugging information
-s if you are using non-standard scratch directory
该工具会测试暂存目录是否正在使用,如果没有,则将其删除。这依赖于 HDFS 写锁来检测是否正在使用临时目录。 HDFSClient 端打开一个 HDFS 文件($scratchdir/inuse.lck)进行写入,并且仅在关闭会话时将其关闭。 cleardanglingscratchdir 将尝试打开$scratchdir/inuse.lck进行写入,以测试相应的 HiveCli/HiveServer2 是否仍在运行。如果使用锁,则不会清除暂存目录。如果锁可用,则暂存目录将被清除。请注意,NameNode 最多可能需要 10 分钟才能从死掉的 HiveCli/HiveServer2 中回收临时文件锁的租约,此时,如果再次运行, cleardanglingscratchdir 将能够删除它.**
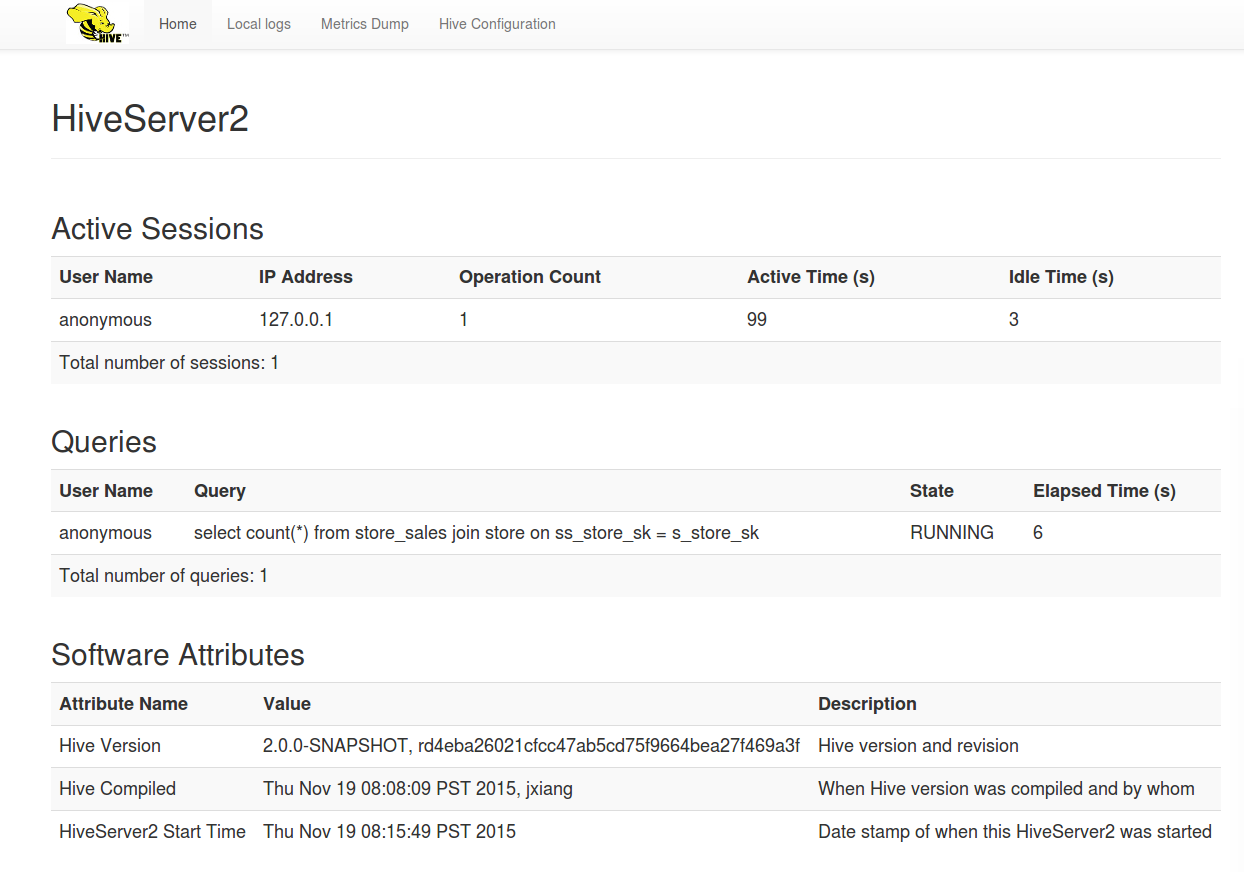
HiveServer2 的 Web UI
Version
在 Hive 2.0.0 中引入。请参阅HIVE-12338及其子任务。
HiveServer2 的 Web 用户界面(UI)提供配置,日志记录,Metrics 和活动会话信息。默认情况下,Web UI 在端口 10002(127.0.0.1:10002)上可用。
Web UI 的Configuration properties可以是在 hive-site.xml 中定制,包括 hive.server2.webui.host,hive.server2.webui.port,hive.server2.webui.max.threads 等。
可以使用“Metrics 转储”标签查看Hive Metrics。
可以使用“本地日志”标签查看Logs。
该接口当前正在使用HIVE-12338开发。
PythonClient 端驱动程序
HiveServer2 的 PythonClient 端驱动程序位于https://github.com/BradRuderman/pyhs2(感谢 Brad)。它包括所有必需的软件包,例如 SASL 和 Thrift 包装器。
该驱动程序已通过认证可与 Python 2.6 及更高版本一起使用。
要使用pyhs2驱动程序:
pip install pyhs2
and then:
import pyhs2
with pyhs2.connect(host='localhost',
port=10000,
authMechanism="PLAIN",
user='root',
password='test',
database='default') as conn:
with conn.cursor() as cur:
#Show databases
print cur.getDatabases()
#Execute query
cur.execute("select * from table")
#Return column info from query
print cur.getSchema()
#Fetch table results
for i in cur.fetch():
print i
您可以在user@hive.apache.org 邮件列表上讨论此驱动程序。
RubyClient 端驱动程序
github 上的https://github.com/forward3d/rbhive提供了 RubyClient 端驱动程序。