在启用云的应用程序中使用 Log4j
十二要素应用程序
十二要素应用的日志记录准则指出,所有日志都应无缓冲地路由到 stdout。由于这是最不常见的分母,因此保证可以在所有应用程序中使用。但是,与任何一组通用准则一样,选择最小公分母方法是有代价的。 Java 应用程序中的一些成本包括:
Java 堆栈跟踪是多行日志消息。标准 docker 日志驱动程序无法正确处理这些问题。请参阅Docker 问题#22920,它已关闭,并显示消息“无关”。解决方案是:使用不支持多行日志消息的 docker 日志驱动程序 b。使用不会产生多行消息的日志记录格式,c。从 Log4j 直接登录到日志记录转发器或聚合器,并绕过 Docker 日志记录驱动程序。
在 Docker 中登录到 stdout 时,日志事件会通过 Java 的标准输出处理传递,然后将其定向到 os,以便可以将输出通过管道传递到文件中。从这些基准测试结果可以看出,所有这些操作的开销比仅直接写入文件要慢得多,在这些基准测试结果中,重复输出的日志记录到 stdout 的速度比直接写入文件要慢 16-20 倍。通过在配备 2.9GHz Intel Core i9 处理器和 1TB SSD 的 2018 年 MacBook Pro 上运行Output Benchmark可获得以下结果。但是,仅凭这些结果就不足以反对写入标准输出流,因为每个日志记录调用仅占 14-25 微秒,而写入文件时只有 1.5 微秒。
Benchmark Mode Cnt Score Error Units
OutputBenchmark.console thrpt 20 39291.885 ± 3370.066 ops/s
OutputBenchmark.file thrpt 20 654584.309 ± 59399.092 ops/s
OutputBenchmark.redirect thrpt 20 70284.576 ± 7452.167 ops/s
- 使用诸如 log4j-audit 之类的框架执行审核日志记录时,需要保证交付审核事件。许多用于写入输出的选项(包括写入标准输出流)不能保证交付。在这些情况下,必须将事件传递给“转发者”,该转发者仅在将事件放置在持久存储中(例如 Apache Flume 或 Apache Kafka 将执行的操作)时才确认接收。
Logging Approaches
本页上讨论的所有解决方案都基于以下想法:日志文件不能永久驻留在文件系统上,并且所有日志事件都应路由到一个或多个用于报告和警报的日志分析工具。有很多方法可以转发和收集要发送到日志分析工具的事件。
请注意,任何绕过 Docker 日志记录驱动程序的方法都需要 Log4j 的Docker Loookup,以允许将 Docker 属性注入到日志事件中。
登录到标准输出流
如上所述,对于在 docker 容器中运行的应用程序,这是推荐的 12 因素方法。如果 Java 应用程序将记录异常,则 Log4j 团队不建议使用此方法。
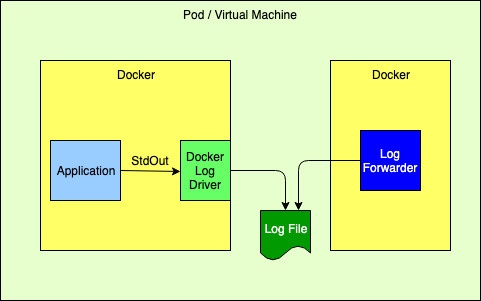
使用 Docker Fluentd 日志记录驱动程序登录到标准输出流
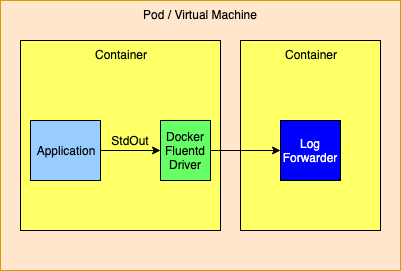
Docker 提供了备用logging drivers,例如gelf或fluentd,可用于将标准输出流重定向到日志转发器或日志聚合器。
路由到日志转发器时,预计转发器将具有与应用程序相同的生存期。如果转发器失败,则 Management 工具也应终止依赖于该转发器的其他容器。
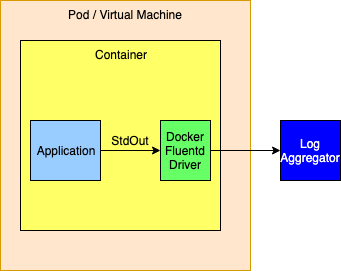
或者,可以将日志记录驱动程序配置为将事件直接路由到日志记录聚合器。通常这不是一个好主意,因为日志记录驱动程序仅允许配置一个主机和端口。 docker 文档尚不清楚,但推断无法发送日志事件时将删除日志事件,因此如果需要高度可用的解决方案,则不应使用此方法。
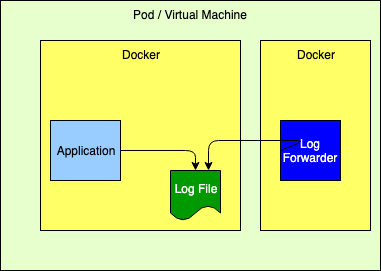
登录到文件
尽管这不是推荐的 12 因子方法,但它的效果非常好。但是,它要求应用程序声明日志文件将驻留的卷,然后将日志转发器配置为尾随这些文件。还必须注意自动 Management 用于日志的磁盘空间,Log4j 可以通过对RollingFileAppender进行 Delete 操作来执行这些磁盘空间。
通过 TCP 直接发送到日志转发器
将日志直接发送到 Log Forwarder 很简单,因为通常只需要在 SocketAppender 上以适当的布局配置转发器的主机和端口即可。
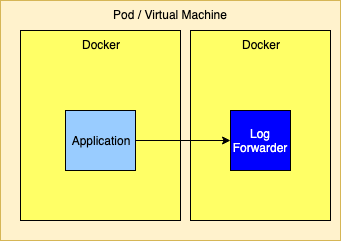
通过 TCP 直接发送到 Log Aggregator
与将日志发送到转发器相似,日志也可以发送到聚合器集群。但是,设置此过程并非那么简单,因为要使其高度可用,必须使用一组聚合器。但是,SocketAppender 当前只能使用单个主机和端口进行配置。为了在主聚合器发生故障时进行故障转移,必须将 SocketAppender 封装在FailoverAppender内,该FailoverAppender也将配置辅助聚合器。另一个选择是让 SocketAppender 指向可以转发到 Log Aggregator 的高可用性代理。
如果使用的日志聚合器是 Apache Flume 或 Apache Kafka(或类似的),则为这些支持的 Appender 配置了主机和端口列表,因此高可用性不是问题。
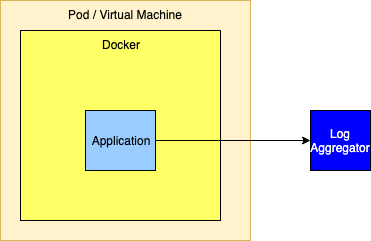
使用 ElasticSearch,Logstash 和 Kibana 进行日志记录
以下配置已通过 ELK 堆栈进行了测试,并且可以正常工作。
Log4j Configuration
使用具有 GELF 布局的套接字附加器。请注意,如果套接字附加器使用的主机名具有与其 DNS 条目相关联的多个 IP 地址,则套接字附加器将在需要时对它们全部失败。
<Socket name="Elastic" host="${sys:elastic.search.host}" port="12222" protocol="tcp" bufferedIo="true">
<GelfLayout includeStackTrace="true" host="${hostName}" includeThreadContext="true" includeNullDelimiter="true"
compressionType="OFF">
<ThreadContextIncludes>requestId,sessionId,loginId,userId,ipAddress,callingHost</ThreadContextIncludes>
<MessagePattern>%d [%t] %-5p %X{requestId, sessionId, loginId, userId, ipAddress} %C{1.}.%M:%L - %m%n</MessagePattern>
<KeyValuePair key="containerId" value="${docker:containerId:-}"/>
<KeyValuePair key="application" value="$${lower:${spring:spring.application.name:-spring}}"/>
<KeyValuePair key="kubernetes.serviceAccountName" value="${k8s:accountName:-}"/>
<KeyValuePair key="kubernetes.containerId" value="${k8s:containerId:-}"/>
<KeyValuePair key="kubernetes.containerName" value="${k8s:containerName:-}"/>
<KeyValuePair key="kubernetes.host" value="${k8s:host:-}"/>
<KeyValuePair key="kubernetes.labels.app" value="${k8s:labels.app:-}"/>
<KeyValuePair key="kubernetes.labels.pod-template-hash" value="${k8s:labels.podTemplateHash:-}"/>
<KeyValuePair key="kubernetes.master_url" value="${k8s:masterUrl:-}"/>
<KeyValuePair key="kubernetes.namespaceId" value="${k8s:namespaceId:-}"/>
<KeyValuePair key="kubernetes.namespaceName" value="${k8s:namespaceName:-}"/>
<KeyValuePair key="kubernetes.podID" value="${k8s:podId:-}"/>
<KeyValuePair key="kubernetes.podIP" value="${k8s:podIp:-}"/>
<KeyValuePair key="kubernetes.podName" value="${k8s:podName:-}"/>
<KeyValuePair key="kubernetes.imageId" value="${k8s:imageId:-}"/>
<KeyValuePair key="kubernetes.imageName" value="${k8s:imageName:-}"/>
</GelfLayout>
</Socket>
Logstash Configuration
input {
gelf {
host => "localhost"
use_tcp => true
use_udp => false
port => 12222
type => "gelf"
}
}
filter {
# These are GELF/Syslog logging levels as defined in RFC 3164. Map the integer level to its human readable format.
translate {
field => "[level]"
destination => "[levelName]"
dictionary => {
"0" => "EMERG"
"1" => "ALERT"
"2" => "CRITICAL"
"3" => "ERROR"
"4" => "WARN"
"5" => "NOTICE"
"6" => "INFO"
"7" => "DEBUG"
}
}
}
output {
# (Un)comment for debugging purposes
# stdout { codec => rubydebug }
# Modify the hosts value to reflect where elasticsearch is installed.
elasticsearch {
hosts => ["http://localhost:9200/"]
index => "app-%{application}-%{+YYYY.MM.dd}"
}
}
Kibana
通过上述配置,消息字段将包含完全格式化的日志事件,就像在文件 Appender 中出现的一样。 ThreadContext 属性,custome 字段,线程名称等都将在每个可用于过滤的日志事件上用作属性。
Management 日志记录配置
Spring Boot 为日志记录配置提供了另一种最不常用的分母方法。它可以让您设置应用程序中各种 Logger 的日志级别,这些日志级别可以通过 Spring 提供的 REST 端点进行动态更新。尽管这在很多情况下都有效,但它不支持 Log4j 的任何更高级的过滤功能。例如,由于它不能添加或修改除 Logger 日志级别以外的任何过滤器,因此无法进行更改以允许临时记录特定用户或 Client 的所有日志事件(请参见DynamicThresholdFilter或ThreadContextMapFilter)或任何其他类型的日志。更改过滤器。此外,在微服务集群环境中,很有可能需要将这些更改同时传播到多个服务器。试图通过 REST 调用实现这一目标可能很困难。
从第一个版本开始,Log4j 就支持通过文件进行重新配置。从 Log4j 2.12.0 开始,Log4j 还支持通过 HTTP(S)访问配置并通过使用 HTTP“ If-Modified-Since”头监视文件的更改。从 2.0.3 和 2.1.1 版本开始,一个补丁也已集成到 Spring Cloud Config 中,以纪念 If-Modified-SinceHeaders。另外,log4j-spring-cloud-config 项目将侦听 Spring Cloud Bus 发布的更新事件,然后验证配置文件已被修改,因此不需要通过 HTTP 进行轮询。
Log4j 还支持复合配置。跨微服务分布的分布式应用程序可以共享一个公共配置文件,该文件可用于控制诸如为特定用户启用调试日志记录之类的操作。
尽管 Log4j 重新配置自身以对日志记录配置文件进行更改,但是用于更新日志记录的标准 Spring Boot REST 端点仍然可以工作,这些 REST 端点所做的任何更改都将丢失。
有关 log4j-spring-cloud-config-client 集成的更多信息,请参见Log4j Spring Cloud ConfigClient 端。
与 Spring Boot 集成
Log4j 通过两种方式与 Spring Boot 集成:
Spring 查找可用于从 Log4j 配置文件访问 Spring 应用程序配置。
尝试解析 log4j 系统属性时,Log4j 将访问 Spring 配置。
这两个都要求在应用程序中包含 log4j-spring-cloud-client jar。
与 Docker 集成
Docker 容器中使用 Docker 日志记录驱动程序进行日志记录的应用程序可以在格式化日志事件中包含特殊属性,如自定义日志驱动程序输出所述。 Log4j 通过Docker Lookup提供类似的功能。有关 Log4j 的 Docker 支持的更多信息,也可以在Log4j-Docker处找到。
与 Kubernetes 集成
由 KubernetesManagement 的应用程序可以绕过 Docker/Kubernetes 日志记录基础结构,并直接登录到 Sidecar 转发器或日志记录聚合器集群,同时仍然使用 Log4j 2 Kubernetes Lookup包括所有 kubernetes 属性。有关 Log4j 的 Kubernetes 支持的更多信息,也可以在Log4j-Kubernetes找到。
Appender Performance
下表中的数字表示应用程序调用 logger.debug 100,000 次所需的时间(以秒为单位)。这些数字仅包括交付到特别指出的端点所花费的时间,而许多数字不包括可供查看的实际时间。所有测量均在配备 2.9 GHz Intel Core I9 处理器,6 个物理和 12 个逻辑核心,32 GB 的 2400 MHz DDR4 RAM 和 1 TB 的 Apple SSD 的 MacBook Pro 上执行。 Docker 使用的 VM 由 VMWare FusionManagement,并具有 4 个 CPU 和 2 GB 的 RAM。这些数字应用于相对性能比较,因为另一个系统上的结果可能会有很大差异。
可以在 Log4j source repository的 log4j-spring-cloud-config/log4j-spring-cloud-config-samples 目录下找到使用的示例应用程序。
| Test | 1 Thread | 2 Threads | 4 Threads | 8 Threads |
|---|---|---|---|---|
| Flume Avro | ||||
| -批量大小 1-JSON | 49.11 | 46.54 | 46.70 | 44.92 |
| -批次大小 1-RFC5424 | 48.30 | 45.79 | 46.31 | 45.50 |
| -批量大小 100-JSON | 6.33 | 3.87 | 3.57 | 3.84 |
| -批次大小 100-RFC5424 | 6.08 | 3.69 | 3.22 | 3.11 |
| -批量大小 1000-JSON | 4.83 | 3.20 | 3.02 | 2.11 |
| -批次大小 1000-RFC5424 | 4.70 | 2.40 | 2.37 | 2.37 |
| Flume Embedded | ||||
| - RFC5424 | 3.58 | 2.10 | 2.10 | 2.70 |
| - JSON | 4.20 | 2.49 | 3.53 | 2.90 |
| Kafka 本地 JSON | ||||
| -sendSync 为 true | 58.46 | 38.55 | 19.59 | 19.01 |
| -sendSync 错误 | 9.8 | 10.8 | 12.23 | 11.36 |
| Console | ||||
| -JSON/Kubernetes | 3.03 | 3.11 | 3.04 | 2.51 |
| - JSON | 2.80 | 2.74 | 2.54 | 2.35 |
| -DockerFluent 的驱动程序 | 10.65 | 9.92 | 10.42 | 10.27 |
| Rolling File | ||||
| - RFC5424 | 1.65 | 0.94 | 1.22 | 1.55 |
| - JSON | 1.90 | 0.95 | 1.57 | 1.94 |
| TCP-Fluent 位-JSON | 2.34 | 2.167 | 1.67 | 2.50 |
| Async Logger | ||||
| -TCP-Fluent 位-JSON | 0.90 | 0.58 | 0.36 | 0.48 |
| -控制台-JSON | 0.83 | 0.57 | 0.55 | 0.61 |
| -Flume Avro-1000-JSON | 0.76 | 0.37 | 0.45 | 0.68 |
Notes:
Flume Avro-缓冲由批次大小控制。当遥控器确认批次已写入其通道时,每个发送都完成。这些数字似乎表明 Flume Avro 可以受益于使用 RPCClients 池,至少对于 batchSize 为 1 而言。
Flume Embedded-本质上是异步的,因为它写入内存缓冲区。目前尚不清楚为什么性能不能接近 AsyncLogger 结果。
Kafka 与应用程序在同一台笔记本电脑上以独立模式运行。如果将 sendSync 设置为 true,则需要 awaitKafka 对每个日志事件的确认。
控制台-Docker 将 System.out 重定向到文件。测试表明,如果将其写入终端屏幕,速度会慢得多。
滚动文件-测试使用默认的 8K 缓冲区大小。
TCP 到 Fluent 位-套接字附加器使用 8K 的默认缓冲区大小。
异步 Logger-所有这些都写入循环缓冲区并返回到应用程序。实际的 I/O 将在单独的线程上进行。如果写入事件的执行速度比创建事件的执行速度慢,则最终缓冲区将被填满,并以与写入日志事件相同的速度执行日志记录。
Logging Recommendations
除非绝对需要保证交付,否则请使用异步日志记录。如性能数字所示,只要日志记录的数量不足以填满循环缓冲区,日志记录的开销对于应用程序来说几乎是不明显的。
如果考虑整体性能,或者您需要对多行事件(例如堆栈跟踪)进行正确处理,则可以通过 TCP 记录到充当日志转发器的协同容器中,或者直接记录到日志聚合器中,如用 ELK 记录所示。使用
Log4j Docker Lookup 将容器信息添加到每个日志事件。无论何时需要保证交付,请使用批处理大小为 1 的 Flume Avro 或其他 appender(例如 kafka Appender 且 syncSend 设置为 true),仅在下游代理确认收到事件后才返回控制。请注意,使用 Appender 单独写入每个事件应保持最少,因为它比发送缓冲事件慢得多。
不建议在容器中记录文件。这样做需要在 Docker 配置中声明一个卷,并且该文件必须由日志转发器拖尾。但是,它的性能比记录到标准输出流更好。如果不是通过 TCP 进行日志记录,并且需要正确的多行处理,请考虑使用此选项。