Performance
除了功能需求之外,选择日志记录库的重要原因通常是它满足非功能性需求(例如可靠性和性能)的程度。
此页面比较了许多日志记录框架(java.util.logging“ JUL”,Logback,Log4j 1.2 和 Log4j 2.6)的性能,并记录了 Log4j 2 功能的一些性能折衷。
Benchmarks
绩效对于不同的人可能意味着不同的事情。在这种情况下,通用术语是吞吐量和延迟:吞吐量是对容量的度量,可以用单个数字表示:在特定时间段内可以记录多少消息。响应时间延迟是记录消息所花费的时间。这不能用一个单一的数字表示,因为每个度量都有其自己的响应时间,而我们通常对异常值最感兴趣:异常数量是多少,异常大小是多少。
在评估日志记录框架的性能时,这些问题可能是有用的问题:
它的“峰值吞吐量”是多少?许多对外部事件做出反应的系统都需要记录突发消息,然后记录相对安静的时间段。该数字是在短时间内测得的最大吞吐量,可以让您对日志记录库处理突发的情况有所了解。对于需要以恒定的高速率进行大量日志记录的系统(例如批处理作业),这不太可能是有用的性能 Metrics。
最大持续吞吐量 是多少?这是长时间内的平均吞吐量。这是记录库容量“上限”的有用度量。不建议反应式应用程序实际以这种速率记录日志,因为在此负载下,它们可能会出现抖动和较大的响应时间尖峰。
-在各种负载下其“响应时间”行为是什么?对于需要及时响应外部事件的应用程序来说,这是最重要的问题。响应时间是记录消息所花费的总时间,是服务时间和 await 时间的总和。 “服务时间”是完成记录消息所需的时间。随着工作量的增加,服务时间通常变化不大:要做 X 数量的工作,总是要花 X 的时间。 “await 时间”是请求在服务之前必须在队列中 await 的时间。随着工作量的增加,await 时间通常会增加到服务时间的许多倍。
| 补充工具栏:为什么要关心响应时间延迟? | |||
| 通常测量和报告为延迟的实际上是服务时间,而忽略了服务时间峰值会增加许多后续事件的 await 时间。这可能会呈现比用户体验更为乐观的结果。 右图说明了乐观的服务时间比响应时间长得多。该图显示了同一系统在每秒 100,000 条消息的负载下的响应时间和服务时间。在 2400 万次测量中,只有约 50 次大于 250 微秒,不到 0.001%。在仅服务时间图中,这几乎是不可见的。但是,根据负载的不同,峰值后可能需要一段时间才能赶上。 响应时间图显示,实际上,受这些延迟影响的事件比仅服务时间所暗示的事件还要多。 要了解更多信息,请观看 Gil Tene 令人惊讶的演示文稿如何不测量延迟。 |
|||
记录库性能比较
异步日志记录-峰值吞吐量比较
异步日志记录对于处理突发事件很有用。它的工作方式是由应用程序线程完成最少的工作量,以捕获日志事件中的所有必需信息,然后将此日志事件放入队列中,以供后台线程稍后进行处理。只要队列的大小足够大,应用程序线程就应该能够在日志记录调用上花费很少的时间,并很快地返回到业务逻辑。
事实证明,队列的选择对于峰值吞吐量至关重要。 Log4j 2 的异步 Logger 使用无锁数据结构,而 Logback,Log4j 1.2 和 Log4j 2 的异步附加器使用 ArrayBlockingQueue。对于阻塞队列,多线程应用程序在尝试使日志事件入队时通常会遇到锁争用。
下图说明了多线程方案中无锁数据结构对吞吐量的影响。 Log4j 2 随着线程数量的扩展而更好地扩展:具有更多线程的应用程序可以记录更多日志。其他日志记录库遭受锁争用,并且在记录更多线程时,总吞吐量保持恒定或下降。这意味着使用其他日志记录库,每个单独的线程将能够减少日志记录。
请记住,这是峰值吞吐量:Log4j 2 的异步日志 Logger 可以提供更高的吞吐量,但是,一旦队列已满,附加线程就需要 await,直到队列中的某个插槽可用为止,并且吞吐量将降至最大底层附加程序的持续吞吐量最大。
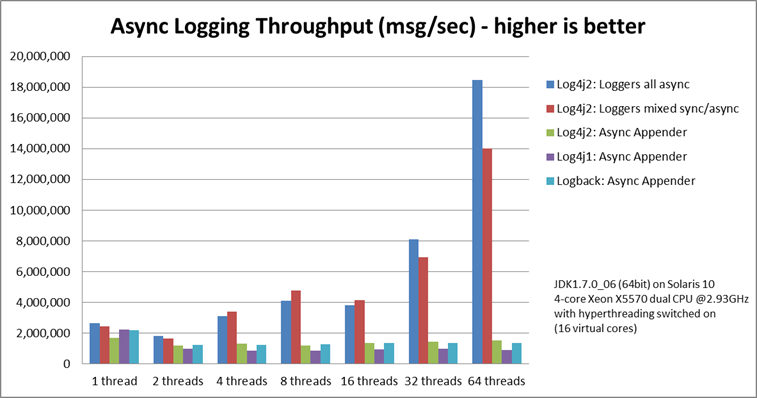
有关详细信息,请参见Async Loggers手册页。
异步记录响应时间
响应时间行为随工作负载和同时登录的线程数而有很大不同。 Async Loggers手册页和garbage-free logging手册页提供了一些图表,显示了在各种负载下的响应时间行为。
本节显示了另一个图表,该图表显示了在每秒 64,000 条消息的适度总负载下,同时记录 4 个线程的响应时间延迟行为。在这种负载以及这种硬件/ OS/JVM 配置下,锁争用和上下文切换所起的作用较小,并且暂停主要是由较小的垃圾收集引起的。垃圾收集的暂停持续时间和频率可以有很大的不同:在测试 Log4j 1.2.17 Async Appender 时,发生了 7 毫秒的 GC 暂停,而 Log4j 2 Async Appender 测试仅发生了 2 毫秒多的 GC 暂停。这不一定意味着一个比另一个更好。
通常,在我们测试的所有配置中,无垃圾异步 Logger 都具有最佳的响应时间行为。
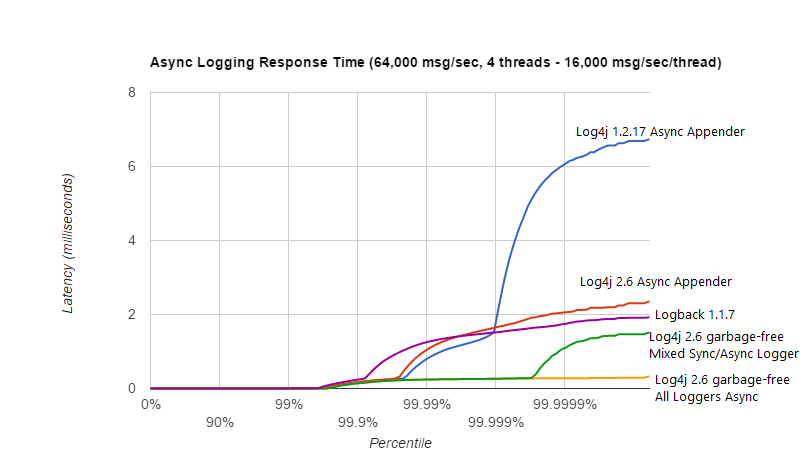
以上结果是通过 ResponseTimeTest 类获得的,该类可以在 Log4j 2 单元测试源目录中找到,该目录在具有 10 核 Xeon 的 RHEL 6.5(Linux 2.6.32-573.1.1.el6.x86_64)上的 JDK 1.8.0_45 上运行 CPU E5-2660 v3 @ 2.60GHz,超线程已打开(20 个虚拟内核)。
异步记录参数化消息
许多日志记录库提供用于记录参数化消息的 API。这使应用程序代码看起来像这样:
logger.debug("Entry number: {} is {}", i, entry[i]);
在上面的示例中,除非为 Logger 启用了 DEBUG 级别,否则不会创建完全格式化的消息文本。没有这个 API,您将需要三行代码来完成相同的工作:
if (logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + entry[i].toString());
}
如果启用了 DEBUG 级别,则有时需要格式化消息。当异步记录时,在后台线程有机会记录消息之前,应用程序线程可能会更改消息参数。这将在日志文件中显示错误的值。为防止这种情况,在将日志事件传递给后台线程之前,Log4j 2,Log4j 1.2 和 Logback 格式化了应用程序线程中的消息文本。
这是安全的事情,但是格式化会降低性能。下图比较了使用各种日志库的日志消息的吞吐量和参数。这些都是异步日志记录调用,因此这些数字不包括磁盘 I/O 的成本,而是峰值吞吐量。
JUL(java.util.logging)没有内置的异步处理程序。 MemoryHandler是最近的东西,因此我们将其包含在这里。 MemoryHandler 不会对当前参数状态进行快照(这只是保留对原始参数对象的引用)的安全措施,因此单线程处理时非常快。但是,当更多应用程序线程同时进行日志记录时,锁争用的成本将超过此收益。
与其他日志记录框架相比,Log4j 2 的 Async Logger 绝对数量上表现良好,但是请注意,消息格式化的成本随参数数量的增加而急剧增加。在这方面,Log4j 2 仍需改进:我们希望保持此成本不变。
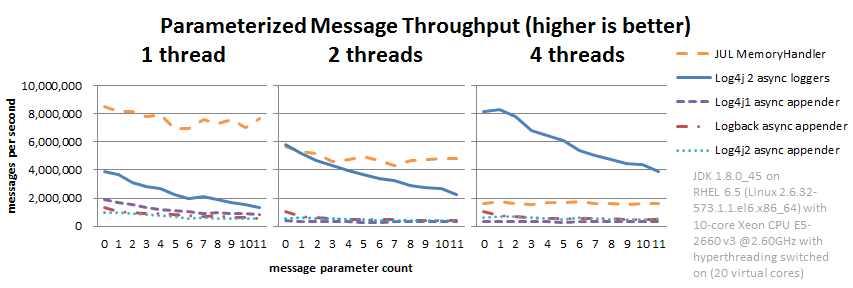
上面的结果适用于 JUL(java.util.logging)1.8.0_45,Log4j 2.6,Log4j 1.2.17 和 Logback 1.1.7,这些结果是使用JMH Java 基准测试工具获得的。请参阅 log4j-perf 模块中的 AsyncAppenderLog4j1Benchmark,AsyncAppenderLog4j2Benchmark,AsyncAppenderLogbackBenchmark,AsyncLoggersBenchmark 和 MemoryHandlerJULBenchmark 源代码。
带有呼叫者位置信息的异步记录
某些布局可以在进行日志记录调用的应用程序中显示类,方法和行号。在 Log4j 2 中,此类布局选项的示例为 HTML locationInfo或模式%C 或$ class,%F 或%file,%l 或%location,%L 或%line,%M 或%方法之一。为了提供呼叫者位置信息,日志记录库将对堆栈进行快照,并遍历堆栈跟踪以查找位置信息。
下图显示了从单个线程异步登录时捕获呼叫者位置信息对性能的影响。我们的测试表明,捕获调用者的位置对所有日志记录库都具有类似的影响,并将异步日志记录的速度降低了大约 30-100 倍。
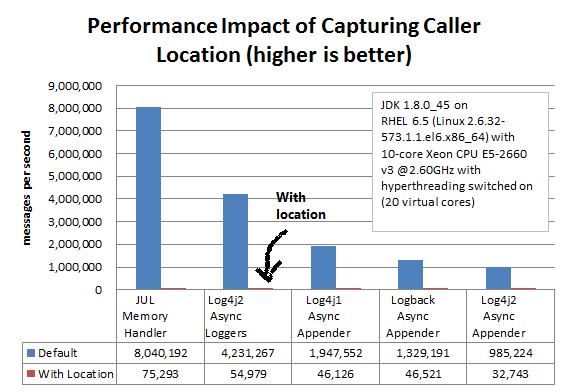
上面的结果适用于 JUL(java.util.logging)1.8.0_45,Log4j 2.6,Log4j 1.2.17 和 Logback 1.1.7,这些结果是使用JMH Java 基准测试工具获得的。请参阅 log4j-perf 模块中的 AsyncAppenderLog4j1LocationBenchmark,AsyncAppenderLog4j2LocationBenchmark,AsyncAppenderLogbackLocationBenchmark,AsyncLoggersLocationBenchmark 和 MemoryHandlerJULLocationBenchmark 源代码。
同步文件记录-持续吞吐量比较
本节讨论记录到文件的最大持续吞吐量。在任何系统中,最大的持续吞吐量取决于其最慢的组件。对于日志记录,这是附加程序,在此进行消息格式化和磁盘 I/O。因此,我们将研究简单的同步记录到文件,而没有队列或后台线程。
下图比较了 Oracle Java 1.8.0_45 上 Log4j 2.6 的 RandomAccessFile 附加器与 Log4j 1.2.17,Logback 1.1.7 和 Java util 日志(JUL)的相应文件附加器。对于支持此功能的所有 Logger,将 InstantFlush 设置为 false。 JUL 结果是针对 XMLFormatter 的(在我们的测量中,它约为 SimpleFormatter 的两倍)。
当同时记录更多线程时,Log4j 2 的持续吞吐量会下降一点,但是其细粒度的锁定会有所回报,并且吞吐量保持相对较高。在多线程应用程序中,其他日志记录框架的吞吐量急剧下降:Log4j 1.2 的单线程容量为 1/4,Logback 的单线程容量为 1/10,JUL 从 1/4 稳定地降至 1 /随着添加更多线程,其单线程吞吐量的十分之一。
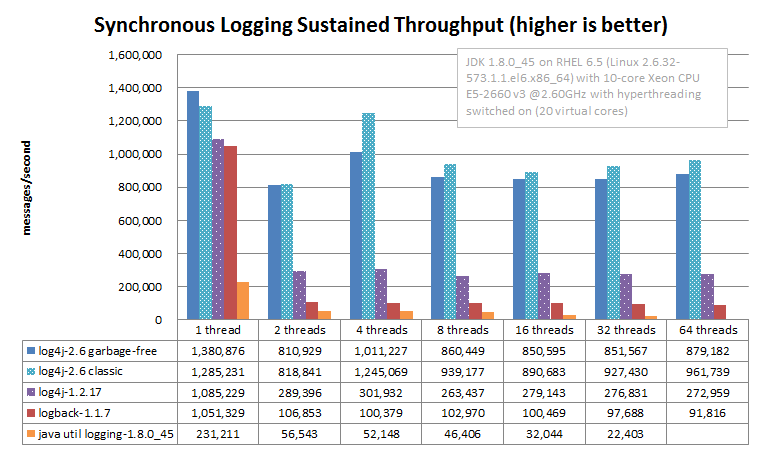
上面的同步日志记录吞吐量结果是使用JMH Java 基准测试工具获得的。请参阅 log4j-perf 模块中的 FileAppenderBenchmark 源代码。
同步文件记录-响应时间比较
同步文件日志记录的响应时间随工作负载和线程数的不同而变化很大。以下是每秒 32,000 个事件的工作负载示例,其中 2 个线程每秒记录 16,000 个事件。
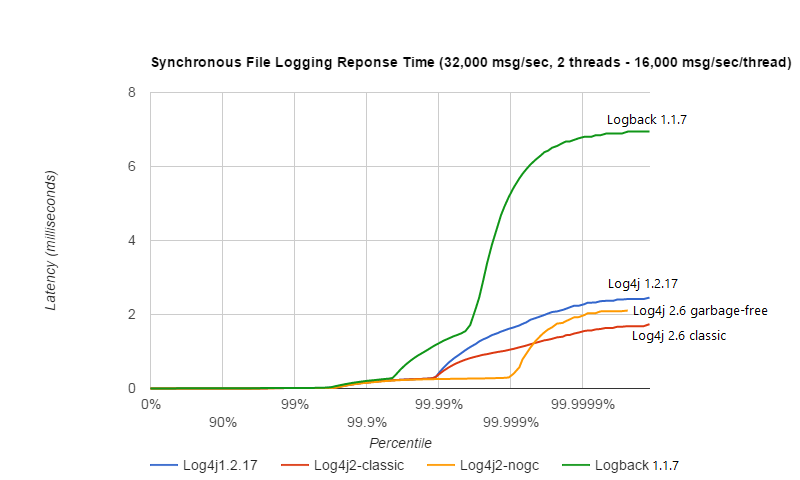
以上结果是通过 ResponseTimeTest 类获得的,该类可以在 Log4j 2 单元测试源目录中找到,该目录在具有 10 核 Xeon 的 RHEL 6.5(Linux 2.6.32-573.1.1.el6.x86_64)上的 JDK 1.8.0_45 上运行 CPU E5-2660 v3 @ 2.60GHz,超线程已打开(20 个虚拟内核)。
按级别过滤
日志记录框架提供的最基本的筛选是按日志级别进行筛选。当完全关闭日志记录或仅针对一组级别关闭日志记录时,日志请求的成本包括许多方法调用以及一个整数比较。与 Log4j 不同,Log4j 2 Logger 不会“遍历层次结构”。Logger 直接指向最匹配 Logger 名称的 Logger 配置。首次创建 Logger 时,这会产生额外的开销,但会减少每次使用 Logger 时的开销。
Advanced Filtering
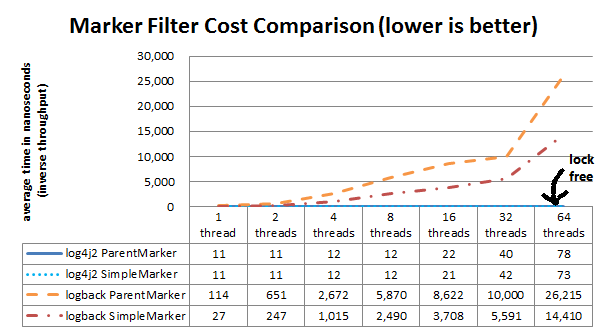
Logback 和 Log4j 2 均支持高级过滤。 Logback 将它们称为 TurboFilters,而 Log4j 2 具有单个 Filter 对象。进阶筛选功能提供了在事件传递给 Appender 之前,不仅使用 Level 来过滤 LogEvents 的功能。但是,这种灵 Active 确实要付出一些代价。由于多线程也会影响高级过滤的性能,因此下表显示了基于标记或标记父级的过滤性能的差异。
“简单标记”比较会检查没有参考其他标记的标记是否与请求的标记匹配。 “父标记”比较将检查确实引用了其他标记的标记是否与请求的标记匹配。
看起来 SLF4J 中的粗粒度同步会影响多线程方案中的性能。参见SLF4J-240。
Log4j 和 Logback 还支持对 Log4j ThreadContext 中的值进行筛选,而支持 Logback 对 MDC 中的值进行筛选。下图显示,对于 ThreadContext 筛选器,Log4j 2 和 Logback 之间的性能差异很小。
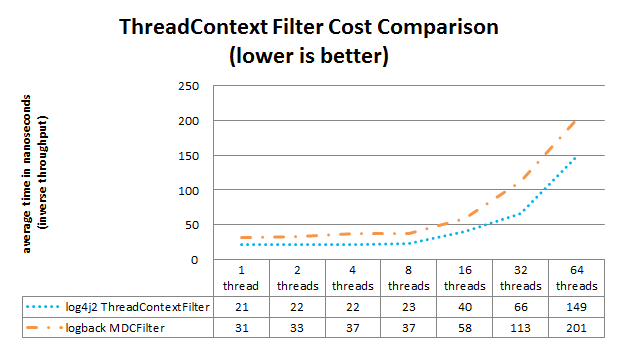
上面的过滤器比较结果是使用JMH Java 基准测试工具获得的。有关这些基准的详细信息,请参见 log4j-perf 模块中的 MarkerFilterBenchmark 和 MDCFilterBenchmark。
Trade-offs
要使用哪个 Log4j 2 Appender?
假设您选择 Log4j 2 作为日志记录框架,接下来您可能会对学习选择特定 Log4j 2 配置的性能折衷感兴趣。例如,有三个用于记录到文件的附加程序:File,RandomAccessFile 和 MemoryMappedFile 附加程序。您应该使用哪一个?
如果您只在乎性能,则下图显示最佳选择是 MemoryMappedFile 追加器或 RandomAccessFile 追加器。请记住以下几点:
MemoryMappedFile 附加程序尚无滚动变体。
当日志文件大小超过 MemoryMappedFile 的区域长度时,需要重新 Map 文件。这可能是非常昂贵的操作,如果区域很大,则需要花费几秒钟。
MemoryMappedFile 附加器从头开始创建一个预大小的文件,并逐渐填充它。这会混淆诸如 tail 之类的工具。许多此类工具无法与内存 Map 文件配合使用。
在 Windows 上,使用 RandomAccessFile 附加程序创建的文件上的 tail 之类的工具可以对该文件持有锁,这可能会阻止 Log4j 在重新启动应用程序时再次打开该文件。在期望使用 tail 等工具查看日志文件内容的同时定期重启应用程序的开发环境中,文件附加器可能是性能和灵 Active 之间的合理权衡。对于生产环境,性能可能具有更高的优先级。
下图显示了 Log4j 2.6 中控制台和文件附加器的持续吞吐量,并提供 2.5 性能以供参考。
事实证明,与 Log4j 2.5 相比,2.6 中的无垃圾文本编码逻辑使这些附加程序的性能得到了提高。过去,RandomAccessFile 附加程序明显更快,尤其是在多线程方案中,但是在 2.6 版本中,文件附加程序的性能有所提高,并且这两个附加程序之间的性能差异较小。
另一个要点是记录到控制台的性能拖动可以有多少。考虑记录到文件并使用诸如 tail 之类的工具实时观察文件更改。
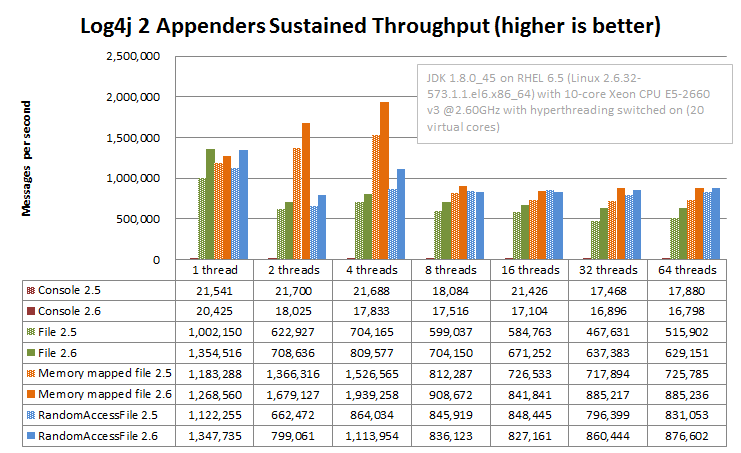
在 Windows 上,结果相似,但在多线程方案中,RandomAccessFile 和 MemoryMappedFile 附加器的性能优于纯文件附加器。 Windows 上的绝对值更高:我们不知道为什么,但是 Windows 似乎比 Linux 处理锁争用更好。
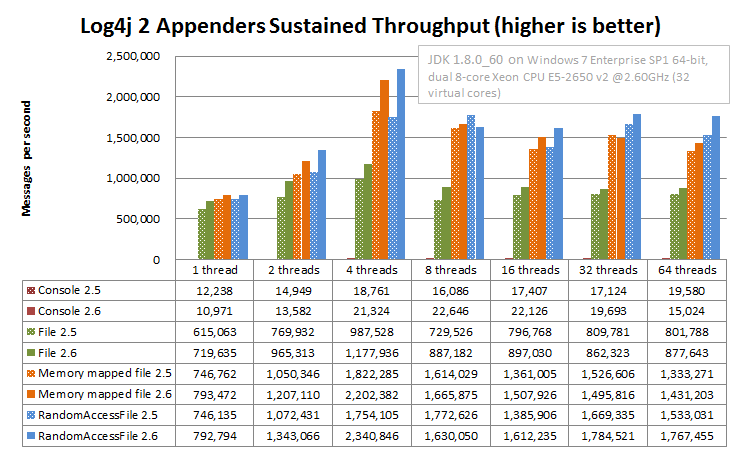
上面的 Log4j 2 附加程序比较结果是使用JMH Java 基准测试工具获得的。请参阅 log4j-perf 模块中的 Log4j2AppenderComparisonBenchmark 源代码。