低延迟异步 Loggers
异步日志记录可以通过在单独的线程中执行 I/O 操作来提高应用程序的性能。 Log4j 2 在此方面进行了许多改进。
异步 Loggers 是 Log4j 2 的新增功能。它们的目的是尽快从对 Logger.log 的调用返回到应用程序。您可以选择使所有 Logger 异步,或混合使用同步 Logger 和异步 Logger。使所有 Logger 异步将提供最佳性能,而混合则可为您提供更大的灵 Active。
LMAX Disruptor 技术 。异步 Logger 在内部使用Disruptor(一种无锁的线程间通信库)代替队列,从而提高了吞吐量并降低了延迟。
作为异步 Logger 工作的一部分,“异步追加程序”已得到增强,可以在批处理结束时(队列为空时)刷新到磁盘。这产生与配置“ immediateFlush = true”相同的结果,即所有接收到的日志事件始终在磁盘上可用,但效率更高,因为它不需要在每个日志事件上都接触磁盘。 (异步 Appenders 在内部使用 ArrayBlockingQueue,并且不需要在 Classpath 上使用颠覆程序 jar.)
Trade-offs
尽管异步日志记录可以显着提高性能,但是在某些情况下,您可能希望选择同步日志记录。本节描述了异步日志记录的一些权衡。
Benefits
- 最高峰throughput。使用异步 Logger,您的应用程序可以记录消息的速度是同步 Logger 的 6-68 倍。
对于偶尔需要记录突发消息的应用程序,这尤其有趣。异步日志记录可以通过缩短直到可以记录下一条消息的 await 时间来帮助防止或缓解延迟高峰。如果将队列大小配置为足以处理突发事件,则异步日志记录将有助于防止应用程序在活动突然增加时落后(过多)。
- 降低日志记录响应时间latency。响应时间延迟是在给定的工作负载下,调用 Logger.log 返回所花费的时间。异步 Logger 的延迟始终低于同步 Logger 甚至是基于队列的异步附加器。
Drawbacks
错误处理。如果在记录过程中发生问题并且引发了异常,则异步 Logger 或附加器将这个问题发送给应用程序不太容易。通过配置 ExceptionHandler 可以部分缓解此问题,但这仍不能涵盖所有情况。因此,如果日志记录是业务逻辑的一部分,例如,如果您将 Log4j 用作审核日志记录框架,则建议同步记录这些审核消息。 (请注意,您仍然可以对它们进行combine操作,并使用异步日志记录进行调试/跟踪日志记录,以及对审计跟踪记录进行同步记录。)
在极少数情况下,必须注意可变消息。大多数时候,您无需为此担心。 Log4 将确保在调用 logger.debug()时,诸如 logger.debug(“ My object is{}”,myObject)之类的日志消息将使用 myObject 参数的状态。即使稍后修改 myObject,日志消息也不会更改。异步记录可变对象是安全的,因为 Log4j 内置的大多数Message实现都对参数进行快照。但是,有一些 exception:MapMessage和StructuredDataMessage在设计上是可变的:在创建消息对象之后,可以将字段添加到这些消息中。使用异步 Logger 或异步附加程序记录这些消息后,不应修改这些消息。您可能会或可能不会在结果日志输出中看到修改。同样,自定义Message实现应在设计时考虑异步使用,并在构造时对其参数进行快照,或记录其线程安全特性。
如果您的应用程序在 CPU 资源稀缺的环境中运行,例如具有一个 CPU 的单核计算机,则启动另一个线程不太可能获得更好的性能。
如果您的应用程序记录消息的持续速率快于基础附加程序的最大持续吞吐量,则队列将满,并且应用程序将以最慢的附加程序的速度结束记录。如果发生这种情况,请考虑选择faster appender或减少登录次数。如果这些都不是选项,则通过同步日志记录,您可能会获得更好的吞吐量和更少的延迟峰值。
使所有 Logger 异步化
Log4j-2.9 之后需要使用 disruptor-3.3.4.jar 或更高版本。在Log4j-2.9之前,需要使用 disruptor-3.0.0.jar 或更高版本。
这是最简单的配置,并提供最佳性能。要使所有 Logger 异步,请将干扰器 jar 添加到 Classpath,并将系统属性 log4j2.contextSelector 设置为 org.apache.logging.log4j.core.async.AsyncLoggerContextSelector。
默认情况下,异步 Logger 不会将location传递给 I/O 线程。如果您的布局或自定义过滤器之一需要位置信息,则需要在所有相关 Logger(包括根 Logger)的配置中设置“ includeLocation = true”。
不需要位置的配置可能如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Don't forget to set system property
-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
to make all loggers asynchronous. -->
<Configuration status="WARN">
<Appenders>
<!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. -->
<RandomAccessFile name="RandomAccessFile" fileName="async.log" immediateFlush="false" append="false">
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m %ex%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<Root level="info" includeLocation="false">
<AppenderRef ref="RandomAccessFile"/>
</Root>
</Loggers>
</Configuration>
当使用 AsyncLoggerContextSelector 使所有 Logger 异步时,请确保在配置中使用普通的\ 和\ 元素。 AsyncLoggerContextSelector 将使用与配置\ 或\ 时不同的机制来确保所有 Logger 都是异步的。后面的元素旨在将异步与同步 Logger 混合使用。如果同时使用这两种机制,则最终将有两个后台线程,您的应用程序将日志消息传递给线程 A,线程 A 将消息传递给线程 B,线程 B 随后将消息记录到磁盘。这可行,但是中间会有不必要的步骤。
您可以使用一些系统属性来控制异步日志记录子系统的各个方面。其中一些可用于调整日志记录性能。
还可以通过创建一个名为 log4j2.component.properties 的文件并将该文件包括在应用程序的 Classpath 中来指定以下属性。
请注意,在 Log4j 2.10.0 中,系统属性已重命名为更一致的样式。仍然支持所有旧属性名称,这些名称记录在here中。
系统属性以配置所有异步 Logger
| System Property | Default Value | Description |
|---|---|---|
| log4j2.asyncLoggerExceptionHandler | default handler | 实现 com.lmax.disruptor.ExceptionHandler 接口的类的完全限定名称。该类需要有一个公共的零参数构造函数。如果指定,则在记录消息时发生异常时将通知此类。 |
如果未指定,则默认异常处理程序将打印一条消息并将堆栈跟踪记录到标准错误输出流。
| log4j2.asyncLoggerRingBufferSize | 256 * 1024 |异步日志记录子系统使用的 RingBuffer 中的大小(插槽数)。使此值足够大以应对突发事件。最小大小为 128.RingBuffer 将在首次使用时进行预分配,并且在系统生命周期内不会增长或收缩。
当应用程序的日志记录速度快于基础附加程序无法满足的足够长的时间来填充队列时,其行为由AsyncQueueFullPolicy决定。
| log4j2.asyncLoggerWaitStrategy |超时|有效值:阻止,超时,睡眠,Yield。
块是一种对 await 日志事件的 I/O 线程使用锁定和条件变量的策略。当吞吐量和低延迟不如 CPU 资源那么重要时,可以使用块。建议用于资源受限/虚拟化的环境。
超时是阻止策略的一种变体,它将定期从锁定条件 await()调用中唤醒。这样可以确保,如果某种方式错过了通知,使用者线程不会卡住,而是会以较小的延迟延迟(默认为 10ms)恢复。
睡眠是一种策略,该策略首先旋转,然后使用 Thread.yield(),并最终在 I/O 线程 await 日志事件时停放 OS 和 JVM 将允许的最小数量的 nanos。睡眠是性能和 CPU 资源之间的良好折衷。此策略对应用程序线程的影响很小,以换取一些额外的延迟来实际记录消息。
Yield 是一种策略,它在初始旋转后使用 Thread.yield()await 日志事件。良率是性能和 CPU 资源之间的一个很好的折衷,但是为了使消息更快地记录到磁盘,可能会使用比 Sleep 更多的 CPU。 |
| AsyncLogger.SynchronizeEnqueueWhenQueueFull |真实|当队列已满时,同步访问 Disruptor 环形缓冲区以阻止入队操作。当应用程序记录的日志超出了基础附加程序所能承受的速度并且环形缓冲区已满时,用户在 Disruptor v3.4.2 中遇到了过多的 CPU 使用率,尤其是在应用程序线程数大大超过内核数时。通过限制对入队操作的访问,可大大降低 CPU 利用率。当异步日志记录队列已满时,将此值设置为 false 可能会导致很高的 CPU 使用率。 |
| log4j2.asyncLoggerThreadNameStrategy |装箱|有效值:CACHED,UNCACHED。
默认情况下,AsyncLogger 将线程名称缓存在 ThreadLocal 变量中以提高性能。如果您的应用程序在运行时修改线程名称(使用 Thread.currentThread()。setName()),并且您想查看日志中反映的新线程名称,请指定 UNCACHED 选项。 |
| log4j2.clock | org.apache.logging.log4j.core.util.Clock 接口的系统时钟的实现,该接口用于在所有 Logger 都是异步的时为日志事件加时间戳。
默认情况下,在每个日志事件上都会调用 System.currentTimeMillis。
CachedClock 是针对低延迟应用程序的优化,该应用程序从时钟生成时间戳,该时钟每毫秒或每 1024 个日志事件(以先到者为准)在后台线程中更新其内部时间。这会稍微减少日志记录延迟,但会降低日志记录时间戳的准确性。除非您记录许多事件,否则可能会在日志时间戳之间看到 10-16 毫秒的“跳跃”。 Web 应用程序警告:使用后台线程可能会导致 Web 应用程序和 OSGi 应用程序出现问题,因此不建议将 CachedClock 用于此类应用程序。
您还可以指定实现 Clock 接口的自定义类的标准类名称。
即使基础追加程序无法跟上日志记录速率并且队列已满,也有一些系统属性可用于维持应用程序吞吐量。请参阅系统属性log4j2.asyncQueueFullPolicy 和 log4j2.discardThreshold的详细信息。
混 Contract 步 Logger 和异步 Logger
Log4j-2.9 和更高版本要求在 Classpath 上使用 disruptor-3.3.4.jar 或更高版本。在 Log4j-2.9 之前,需要使用 interrupter-3.0.0.jar 或更高版本。无需将系统属性“ Log4jContextSelector”设置为任何值。
同步和异步 Logger 可以在配置中组合。这样就给您带来了更多的灵 Active,但以牺牲一点性能为代价(与使所有 Logger 异步)相比。使用\ 或\ 配置元素来指定需要异步的 Logger。一个配置只能包含一个根 Logger( 或 元素),但是可以将异步和非异步 Logger 组合在一起。例如,包含\ 元素的配置文件也可以包含用于同步 Logger 的\ 和\ 元素。
默认情况下,异步 Logger 不会将location传递给 I/O 线程。如果您的布局或自定义过滤器之一需要位置信息,则需要在所有相关 Logger(包括根 Logger)的配置中设置“ includeLocation = true”。
混合了异步 Logger 的配置如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!-- No need to set system property "log4j2.contextSelector" to any value
when using <asyncLogger> or <asyncRoot>. -->
<Configuration status="WARN">
<Appenders>
<!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. -->
<RandomAccessFile name="RandomAccessFile" fileName="asyncWithLocation.log"
immediateFlush="false" append="false">
<PatternLayout>
<Pattern>%d %p %class{1.} [%t] %location %m %ex%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<!-- pattern layout actually uses location, so we need to include it -->
<AsyncLogger name="com.foo.Bar" level="trace" includeLocation="true">
<AppenderRef ref="RandomAccessFile"/>
</AsyncLogger>
<Root level="info" includeLocation="true">
<AppenderRef ref="RandomAccessFile"/>
</Root>
</Loggers>
</Configuration>
您可以使用一些系统属性来控制异步日志记录子系统的各个方面。其中一些可用于调整日志记录性能。
还可以通过创建一个名为 log4j2.component.properties 的文件并将该文件包括在应用程序的 Classpath 中来指定以下属性。
请注意,在 Log4j 2.10 中,系统属性已重命名为更一致的样式。仍然支持所有旧属性名称,这些名称记录在here中。
配置混合的异步和常规 Logger 的系统属性
| System Property | Default Value | Description |
|---|---|---|
| log4j2.asyncLoggerConfigExceptionHandler | default handler | 实现 com.lmax.disruptor.ExceptionHandler 接口的类的完全限定名称。该类需要有一个公共的零参数构造函数。如果指定,则在记录消息时发生异常时将通知此类。 |
如果未指定,则默认异常处理程序将打印一条消息并将堆栈跟踪记录到标准错误输出流。
| log4j2.asyncLoggerConfigRingBufferSize | 256 * 1024 |异步日志记录子系统使用的 RingBuffer 中的大小(插槽数)。使此值足够大以应对突发事件。最小大小为 128.RingBuffer 将在首次使用时进行预分配,并且在系统生命周期内不会增长或收缩。
当应用程序的日志记录速度快于基础追加程序无法跟踪足够长的时间来填充队列时,行为由AsyncQueueFullPolicy确定。
| log4j2.asyncLoggerConfigWaitStrategy |超时|有效值:阻止,超时,睡眠,Yield。
块是一种对 await 日志事件的 I/O 线程使用锁定和条件变量的策略。当吞吐量和低延迟不如 CPU 资源那么重要时,可以使用块。建议用于资源受限/虚拟化的环境。
超时是阻止策略的一种变体,它将定期从锁定条件 await()调用中唤醒。这样可以确保,如果某种方式错过了通知,使用者线程不会卡住,而是会以较小的延迟延迟(默认为 10ms)恢复。
睡眠是一种策略,该策略首先旋转,然后使用 Thread.yield(),并最终在 I/O 线程 await 日志事件时停放 OS 和 JVM 将允许的最小数量的 nanos。睡眠是性能和 CPU 资源之间的良好折衷。此策略对应用程序线程的影响很小,以换取一些额外的延迟来实际记录消息。
Yield 是一种策略,它在初始旋转后使用 Thread.yield()await 日志事件。良率是性能和 CPU 资源之间的一个很好的折衷,但是为了使消息更快地记录到磁盘,可能会使用比 Sleep 更多的 CPU。 |
| AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull |真实|当队列已满时,同步访问 Disruptor 环形缓冲区以阻止入队操作。当应用程序记录的日志超出了基础附加程序所能承受的速度并且环形缓冲区已满时,用户在 Disruptor v3.4.2 中遇到了过多的 CPU 使用率,尤其是在应用程序线程数大大超过内核数时。通过限制对入队操作的访问,可大大降低 CPU 利用率。当异步日志记录队列已满时,将此值设置为 false 可能会导致很高的 CPU 使用率。 |
即使基础追加程序无法跟上日志记录速率并且队列已满,也有一些系统属性可用于维持应用程序吞吐量。请参阅系统属性log4j2.asyncQueueFullPolicy 和 log4j2.discardThreshold的详细信息。
位置,位置,位置...
如果其中一个布局配置了与位置相关的属性(例如 HTML locationInfo),或者配置了模式%C 或$ class,%F 或%file,%l 或%location,%L 或%line,%M 或%方法之一,则 Log4j 会获取堆栈的快照,并遍历堆栈跟踪以查找位置信息。
这是一项昂贵的操作:对于同步 Logger,速度要慢 1.3-5 倍。同步 Logger 在获取此堆栈快照之前会 await 尽可能长的时间。如果不需要位置,将永远不会拍摄快照。
但是,异步 Logger 需要在将日志消息传递到另一个线程之前做出决定。之后,位置信息将丢失。对于异步 Logger 而言,获取堆栈跟踪快照的performance impact甚至更高:有位置的记录比没有位置的记录慢 30-100 倍。因此,默认情况下,异步 Logger 和异步附加器不包含位置信息。
您可以通过指定 includeLocation =“ true”覆盖 Logger 或异步附加程序配置中的默认行为。
异步日志记录性能
下面的吞吐量性能结果来自运行 PerfTest,MTPerfTest 和 PerfTestDriver 类,这些类可以在 Log4j 2 单元测试源目录中找到。对于吞吐量测试,使用的方法是:
首先,通过记录 200,000 条 500 个字符的日志消息来预热 JVM。
重复预热 10 次,然后 await10 秒以使 I/O 线程赶上并耗尽缓冲区。
测量执行 Logger.log 的 256 * 1024/threadCount 调用所需的时间,并以每秒的消息数表示结果。
重复测试 5 次并取平均值。
以下结果是使用 log4j-2.0-beta5,disruptor-3.0.0.beta3,log4j-1.2.17 和 logback-1.0.10 获得的。
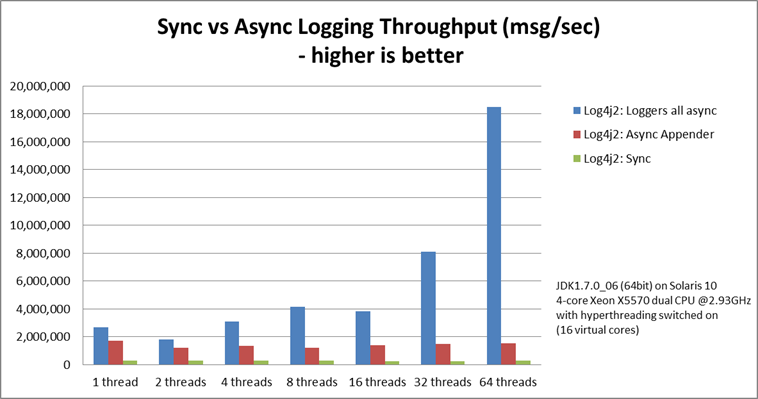
记录峰值吞吐量
下图比较了同步 Logger,异步附加器和异步 Logger 的吞吐量。这是所有线程在一起的总吞吐量。在具有 64 个线程的测试中,异步 Logger 比异步附加器快 12 倍,比同步 Logger 快 68 倍。
异步 Logger 的吞吐量随线程数的增加而增加,而同步 Logger 和异步附加程序都具有或多或少的恒定吞吐量,而与执行记录的线程数无关。
与其他日志记录程序包的异步吞吐量比较
我们还将异步 Logger 的峰值吞吐量与其他日志记录包(尤其是 log4j-1.2.17 和 logback-1.0.10)中可用的同步 Logger 和异步附加程序进行了比较,结果相似。对于异步附加程序,添加更多线程时,所有线程的总日志记录吞吐量大致保持不变。在多线程方案中,异步 Logger 可以更有效地利用计算机上可用的多个内核。
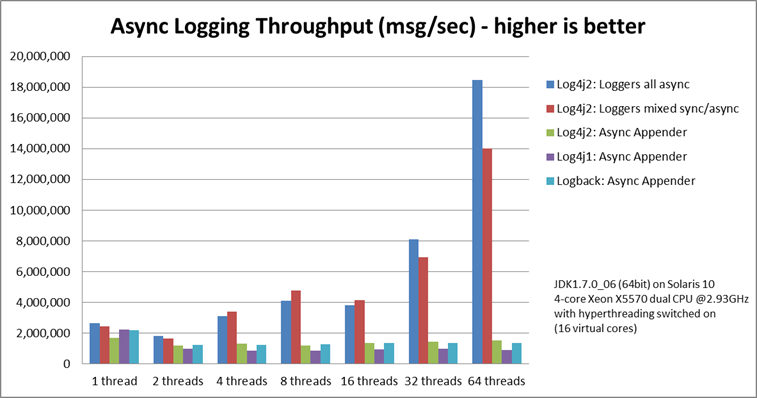
在具有 JDK1.7.0_06 的 Solaris 10(64 位)上,打开了超线程的 4 核 Xeon X5570 双 CPU @ 2.93Ghz(16 个虚拟核):
每个线程的吞吐量(以消息/秒为单位)
| Logger | 1 thread | 2 threads | 4 threads | 8 threads | 16 threads | 32 threads | 64 threads |
|---|---|---|---|---|---|---|---|
| Log4j 2:Logger 全部异步 | 2,652,412 | 909,119 | 776,993 | 516,365 | 239,246 | 253,791 | 288,997 |
| Log4j 2:Logger 混 Contract 步/异步 | 2,454,358 | 839,394 | 854,578 | 597,913 | 261,003 | 216,863 | 218,937 |
| Log4j 2:异步追加程序 | 1,713,429 | 603,019 | 331,506 | 149,408 | 86,107 | 45,529 | 23,980 |
| Log4j1:异步追加程序 | 2,239,664 | 494,470 | 221,402 | 109,314 | 60,580 | 31,706 | 14,072 |
| 注销:异步 Appender | 2,206,907 | 624,082 | 307,500 | 160,096 | 85,701 | 43,422 | 21,303 |
| Log4j 2:同步 | 273,536 | 136,523 | 67,609 | 34,404 | 15,373 | 7,903 | 4,253 |
| Log4j1: Synchronous | 326,894 | 105,591 | 57,036 | 30,511 | 13,900 | 7,094 | 3,509 |
| Logback: Synchronous | 178,063 | 65,000 | 34,372 | 16,903 | 8,334 | 3,985 | 1,967 |
在具有 JDK1.7.0_11 的 Windows 7(64 位)上,打开了超线程的 2 核 Intel i5-3317u CPU @ 1.70Ghz(4 个虚拟核):
每个线程的吞吐量(以消息/秒为单位)
| Logger | 1 thread | 2 threads | 4 threads | 8 threads | 16 threads | 32 threads |
|---|---|---|---|---|---|---|
| Log4j 2:Logger 全部异步 | 1,715,344 | 928,951 | 1,045,265 | 1,509,109 | 1,708,989 | 773,565 |
| Log4j 2:Logger 混 Contract 步/异步 | 571,099 | 1,204,774 | 1,632,204 | 1,368,041 | 462,093 | 908,529 |
| Log4j 2:异步追加程序 | 1,236,548 | 1,006,287 | 511,571 | 302,230 | 160,094 | 60,152 |
| Log4j1:异步追加程序 | 1,373,195 | 911,657 | 636,899 | 406,405 | 202,777 | 162,964 |
| 注销:异步 Appender | 1,979,515 | 783,722 | 582,935 | 289,905 | 172,463 | 133,435 |
| Log4j 2:同步 | 281,250 | 225,731 | 129,015 | 66,590 | 34,401 | 17,347 |
| Log4j1: Synchronous | 147,824 | 72,383 | 32,865 | 18,025 | 8,937 | 4,440 |
| Logback: Synchronous | 149,811 | 66,301 | 32,341 | 16,962 | 8,431 | 3,610 |
响应时间延迟
| 该部分已被 Log4j 2.6 版本重写。以前的版本仅报告服务时间,而不报告响应时间。有关效果为何过于乐观,请参见效果页面上的response time侧栏。此外,以前的版本报告了平均延迟,这没有意义,因为延迟不是正态分布。最后,本节的先前版本仅报告了高达 99.99%的测量值的最大延迟,而没有告诉您最坏的 0.01%的测量值有多糟糕。这是不幸的,因为在响应时间方面,“异常值”通常很重要。从此版本中,我们将尝试做得更好,并报告整个百分比范围内的响应时间延迟,包括所有异常值。感谢 Gil Tene 的如何不测量延迟演示。 (现在我们知道为什么这也称为“哦 s#@ t!”演示文稿.) |
Response time是在特定负载下记录消息所花费的时间。通常被称为延迟的实际上是服务时间:执行操作所花费的时间。这掩盖了一个事实,即服务时间的一个高峰会增加许多后续操作的排队延迟。服务时间很容易衡量(并且通常看起来很不错),但对用户而言却无关紧要,因为它省去了 await 服务的时间。因此,我们报告响应时间:服务时间加 await 时间。
下面的响应时间测试结果全部来自运行 ResponseTimeTest 类,可以在 Log4j 2 单元测试源目录中找到该类。如果您想自己运行这些测试,请使用以下命令行选项:
-Xms1G -Xmx1G(防止在测试期间调整堆大小)
-DLog4jContextSelector = org.apache.logging.log4j.core.async.AsyncLoggerContextSelector -DAsyncLogger.WaitStrategy = busyspin(使用异步 Logger.BusySpinawait 策略可减少一些抖动.)
经典模式: -Dlog4j2.enable.threadlocals = false -Dlog4j2.enable.direct.encoders = false
无垃圾模式: -Dlog4j2.enable.threadlocals = true -Dlog4j2.enable.direct.encoders = true-XX:CompileCommand=dontinline,org.apache.logging.log4j.core.async.perftest.NoOpIdleStrategy::idle
-verbose:gc -XX:PrintGCDetails -XX:PrintGCDateStamps -XX:PrintTenuringDistribution -XX:PrintGCApplicationConcurrentTime -XX:PrintGCApplicationStoppedTime(用于监视 GC 和安全点暂停)
下图将 Logback 1.1.7,Log4j 1.2.17 中基于 ArrayBlockingQueue 的异步附加程序的响应时间延迟与 Log4j 2.6 提供的异步日志记录的各种选项进行了比较。在使用 16 个线程的每秒 128,000 条消息的工作负载下(每个日志以每秒 8,000 条消息的速度记录),我们看到 Logback 1.1.7,Log4j 1.2.17 经历的延迟峰值比 Log4j 2 大几个数量级。
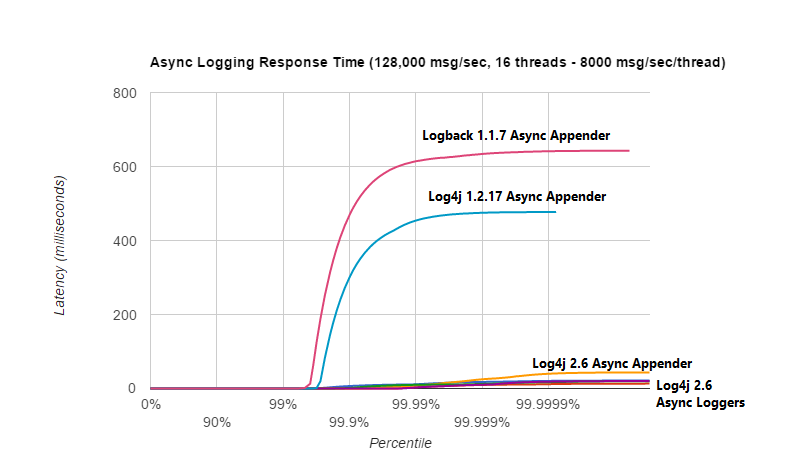
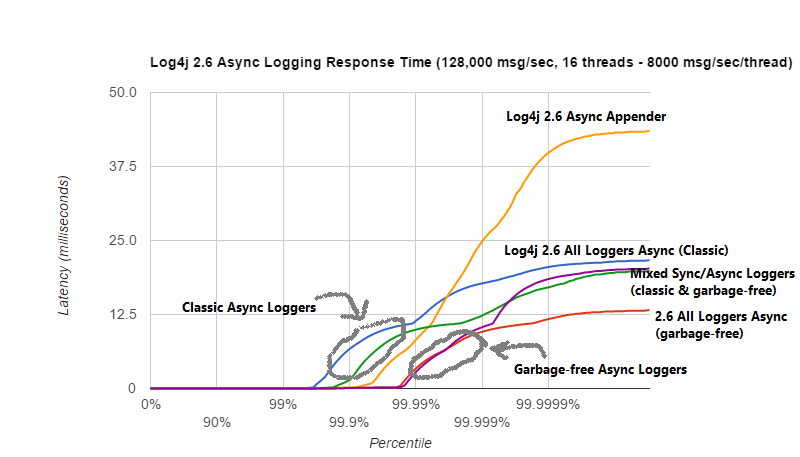
下图放大了同一测试的 Log4j 2 结果。我们看到,基于 ArrayBlockingQueue 的异步 Appender 的最坏情况响应时间最高。 Garbage-free异步 Logger 的响应时间性能最佳。
Under The Hood
异步 Logger 是使用LMAX Disruptor线程间消息传递库实现的。从 LMAX 网站:
Note
...使用队列在系统各阶段之间传递数据会引入延迟,因此我们专注于优化该区域。 Disruptor 是我们研究和测试的结果。我们发现 CPU 级别的高速缓存未命中以及需要内核仲裁的锁都非常昂贵,因此我们创建了一个框架,该框架对其运行的硬件具有“机械同情”,并且是无锁的。
可以找到here与 java.util.concurrent.ArrayBlockingQueue 进行的 LMAX Disruptor 内部性能比较。