3. Reference
参考文档的这一部分详细介绍了组成 Spring AMQP 的各种组件。 main chapter涵盖了开发 AMQP 应用程序的核心类。本部分还包括有关sample applications的章节。
3.1 使用 Spring AMQP
在本章中,我们将探讨作为使用 Spring AMQP 开发应用程序必不可少的组成部分的接口和类。
3.1.1 AMQP 抽象
Introduction
Spring AMQP 由几个模块组成,每个模块在发行版中均由 JAR 表示。这些模块是:spring-amqp 和 spring-rabbit。 * spring-amqp 模块包含org.springframework.amqp.core软件包。在该软件包中,您将找到代表核心 AMQP“模型”的类。我们的意图是提供不依赖任何特定 AMQP 代理实现或 Client 端库的通用抽象。最终用户代码将只能在抽象层上开发,因此在各个供应商的实现中将更具可移植性。这些抽象然后由特定于代理的模块(例如 spring-rabbit *)实现。当前只有 RabbitMQ 实施;但是,除了 RabbitMQ 之外,还使用 Apache Qpid 在.NET 中对抽象进行了验证。由于 AMQP 原则上在协议级别运行,因此 RabbitMQClient 端可以与支持相同协议版本的任何代理一起使用,但是我们目前不测试任何其他代理。
此处的概述假定您已经熟悉 AMQP 规范的基础知识。如果不是,请查看第 5 章,其他资源中列出的资源。
Message
0-9-1 AMQP 规范未定义消息类或接口。而是在执行诸如basicPublish()之类的操作时,将内容作为字节数组参数传递,并将其他属性作为单独的参数传递。 Spring AMQP 将 Message 类定义为更通用的 AMQP 域模型表示形式的一部分。 Message 类的目的是将正文和属性简单地封装在一个实例中,从而使 API 变得更简单。 Message 类的定义非常简单。
public class Message {
private final MessageProperties messageProperties;
private final byte[] body;
public Message(byte[] body, MessageProperties messageProperties) {
this.body = body;
this.messageProperties = messageProperties;
}
public byte[] getBody() {
return this.body;
}
public MessageProperties getMessageProperties() {
return this.messageProperties;
}
}
MessageProperties接口定义了几个常用属性,例如* messageId , timestamp , contentType 等。可以通过调用setHeader(String key, Object value)方法,使用用户定义的 header *扩展这些属性。
Tip
从版本1.5.7,1.6.11,1.7.4,2.0.0开始,如果消息正文是序列化的Serializable java 对象,则在执行toString()操作(例如在日志消息中)时,不再将其反序列化(默认情况下)。这是为了防止不安全的反序列化。默认情况下,仅反序列化java.util和java.lang类。若要恢复以前的行为,可以通过调用Message.addWhiteListPatterns(...)添加允许的类/包模式。支持一个简单的*通配符,例如com.foo.*, *.MyClass。无法反序列化的实体将在日志消息中用byte[<size>]表示。
Exchange
Exchange接口代表一个 AMQP 交换,这是消息生产者发送到的对象。代理的虚拟主机中的每个 Exchange 将具有唯一的名称以及一些其他属性:
public interface Exchange {
String getName();
String getExchangeType();
boolean isDurable();
boolean isAutoDelete();
Map<String, Object> getArguments();
}
如您所见,Exchange 还具有一个由ExchangeTypes中定义的常量表示的* type 。基本类型是:Direct,Topic,Fanout和Headers。在核心软件包中,您将找到每种类型的Exchange接口的实现。这些 Exchange 类型在处理队列绑定方面的行为各不相同。例如,直接交换允许队列由固定的路由键(通常是队列的名称)绑定。主题交换支持具有路由模式的绑定,这些路由模式可能分别包括**和*#通配符,分别用于 exactly-one 和 zero-or-more *。扇出交换发布到与其绑定的所有队列,而无需考虑任何路由键。有关这些和其他 Exchange 类型的更多信息,请查看第 5 章,其他资源。
Note
AMQP 规范还要求任何代理提供没有名称的“默认”直接交换。所有声明的队列将以其名称作为路由键绑定到该默认 Exchange。您将在第 3.1.4 节“ AmqpTemplate”中详细了解 Spring AMQP 中默认 Exchange 的用法。
Queue
Queue类代表消息使用者从中接收消息的组件。像各种 Exchange 类一样,我们的实现旨在作为这种核心 AMQP 类型的抽象表示。
public class Queue {
private final String name;
private volatile boolean durable;
private volatile boolean exclusive;
private volatile boolean autoDelete;
private volatile Map<String, Object> arguments;
/**
* The queue is durable, non-exclusive and non auto-delete.
*
* @param name the name of the queue.
*/
public Queue(String name) {
this(name, true, false, false);
}
// Getters and Setters omitted for brevity
}
请注意,构造函数采用队列名称。取决于实现方式,Management 模板可以提供用于生成唯一命名的队列的方法。这样的队列可用作“答复”地址或其他“临时”情况。因此,自动生成的 Queue 的* exclusive 和 autoDelete 属性都将设置为 true *。
Note
有关使用命名空间支持(包括队列参数)声明队列的信息,请参见第 3.1.10 节,“配置代理”中的队列部分。
Binding
假定生产者发送到 Exchange,而使用者从队列接收,则将队列连接到 Exchange 的绑定对于通过消息连接这些生产者和使用者至关重要。在 Spring AMQP 中,我们定义了一个Binding类来表示这些连接。让我们回顾一下将队列绑定到 Exchange 的基本选项。
您可以使用固定的路由密钥将队列绑定到 DirectExchange。
new Binding(someQueue, someDirectExchange, "foo.bar")
您可以使用路由模式将队列绑定到 TopicExchange。
new Binding(someQueue, someTopicExchange, "foo.*")
您可以使用路由键将队列绑定到 FanoutExchange。
new Binding(someQueue, someFanoutExchange)
我们还提供BindingBuilder以促进“Fluent 的 API”样式。
Binding b = BindingBuilder.bind(someQueue).to(someTopicExchange).with("foo.*");
Note
为了清楚起见,上面显示了 BindingBuilder 类,但是当对* bind()*方法使用静态导入时,此样式效果很好。
就其本身而言,Binding 类的实例只是保存有关连接的数据。换句话说,它不是“活动”组件。但是,正如您稍后将在第 3.1.10 节,“配置代理”中看到的那样,AmqpAdmin类可以使用绑定实例来实际触发代理上的绑定操作。另外,正如您将在同一部分中看到的那样,可以在@Configuration类中使用 Spring 的@Bean -style 定义 Binding 实例。还有一个方便的 Base Class,它进一步简化了用于生成与 AMQP 相关的 bean 定义的方法,并识别队列,交换和绑定,以便在应用程序启动时将它们全部在 AMQP 代理上声明。
AmqpTemplate也在核心包中定义。作为实际 AMQP 消息传递涉及的主要组件之一,将在其自己的部分中详细讨论(请参阅第 3.1.4 节“ AmqpTemplate”)。
3.1.2 连接和资源 Management
Introduction
尽管我们在上一节中描述的 AMQP 模型是通用的,并且适用于所有实现,但是当我们进行资源 Management 时,详细信息特定于代理实现。因此,在本节中,我们将集中讨论仅存在于“ spring-rabbit”模块中的代码,因为在这一点上,RabbitMQ 是唯一受支持的实现。
ConnectionFactory接口是用于 Management 与 RabbitMQ 代理的连接的中央组件。 ConnectionFactory实现的职责是提供org.springframework.amqp.rabbit.connection.Connection的实例,该实例是com.rabbitmq.client.Connection的包装器。我们提供的唯一具体实现是CachingConnectionFactory,默认情况下,它构建一个可以由应用程序共享的单个连接代理。可以共享连接,因为与 AMQP 进行消息传递的“工作单元”实际上是一个“通道”(在某些方面,这类似于 JMS 中的 Connection 和 Session 之间的关系)。可以想象,连接实例提供了createChannel方法。 CachingConnectionFactory实现支持这些通道的缓存,并且根据它们是否是事务性的,为通道维护单独的缓存。创建CachingConnectionFactory的实例时,可以通过构造函数提供* hostname 。还应该提供 username 和 password *属性。如果要配置通道缓存的大小(默认值为 25),则也可以在此处调用setChannelCacheSize()方法。
从* version 1.3 *开始,可以将CachingConnectionFactory配置为缓存连接以及通道。在这种情况下,每次对createConnection()的调用都会创建一个新连接(或从缓存中检索一个空闲的连接)。关闭连接会将其返回到缓存(如果尚未达到缓存大小)。在此类连接上创建的通道也将被缓存。在某些环境中,使用单独的连接可能很有用,例如从 HA 群集中使用负载,并与负载均衡器一起连接到不同的群集成员。将cacheMode设置为CacheMode.CONNECTION。
Note
这不限制连接数,它指定允许多少空闲打开连接。
从*版本 1.5.5 *开始,提供了一个新属性connectionLimit。设置此选项后,它将限制允许的连接总数。设置后,如果达到限制,则使用channelCheckoutTimeLimitawait 连接变为空闲。如果超过时间,则抛出AmqpTimeoutException。
Tip
当缓存模式为CONNECTION时,不支持队列的自动声明等(请参见称为“交换,队列和绑定的自动声明”的部分)。
另外,在编写本文时,默认情况下rabbitmq-client库为每个连接(5 个线程)创建一个固定的线程池。当使用大量连接时,应考虑在CachingConnectionFactory上设置自定义executor。然后,所有连接将使用同一执行程序,并且可以共享其线程。执行程序的线程池应该是无界的,或者应为预期的使用率进行适当设置(通常每个连接至少一个线程)。如果在每个连接上创建多个通道,则池大小将影响并发性,因此,变量(或简单缓存)线程池执行程序将是最合适的。
重要的是要了解,缓存大小(默认情况下)不是限制,而仅仅是可以缓存的通道数。高速缓存大小为 10,实际上可以使用任何数量的通道。如果使用了 10 个以上的通道并将它们全部返回到高速缓存,则 10 个通道将进入高速缓存;其余的将在物理上关闭。
从* version 1.6 *开始,默认的通道缓存大小已从 1 增加到 25.在大容量,多线程的环境中,小的缓存意味着将以较高的速率创建和关闭通道。增加默认缓存大小将避免这种开销。您应该通过 RabbitMQ Admin UI 监视正在使用的通道,如果看到许多正在创建和关闭的通道,请考虑进一步增加缓存大小。缓存将仅按需增长(以适应应用程序的并发要求),因此此更改不会影响现有的小批量应用程序。
从*版本 1.4.2 *开始,CachingConnectionFactory具有属性channelCheckoutTimeout。当此属性大于零时,channelCacheSize成为可在连接上创建的通道数的限制。如果达到限制,则调用线程将阻塞,直到某个通道可用或达到此超时为止,在这种情况下将引发AmqpTimeoutException。
Warning
框架内使用的通道(例如RabbitTemplate)将可靠地返回到缓存。如果您在框架外部创建通道(例如,通过直接访问连接并调用createChannel()),则必须(通过关闭)可靠地返回它们(可能在finally块中),以避免耗尽通道。
CachingConnectionFactory connectionFactory = new CachingConnectionFactory("somehost");
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
Connection connection = connectionFactory.createConnection();
使用 XML 时,配置可能如下所示:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.CachingConnectionFactory">
<constructor-arg value="somehost"/>
<property name="username" value="guest"/>
<property name="password" value="guest"/>
</bean>
Note
还有一个SingleConnectionFactory实现,仅在框架的单元测试代码中可用。它比CachingConnectionFactory更简单,因为它不缓存通道,但是由于缺乏性能和弹性,因此不适合在简单测试之外进行实际使用。如果出于某种原因发现需要实现自己的ConnectionFactory,则AbstractConnectionFactoryBase Class 可能会提供一个不错的起点。
可以使用 Rabbit 名称空间快速便捷地创建ConnectionFactory:
<rabbit:connection-factory id="connectionFactory"/>
在大多数情况下,这是可取的,因为框架可以为您选择最佳的默认值。创建的实例将是CachingConnectionFactory。请记住,通道的默认缓存大小为 25.如果要缓存更多通道,请通过* channelCacheSize *属性设置一个较大的值。在 XML 中,它看起来像这样:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.CachingConnectionFactory">
<constructor-arg value="somehost"/>
<property name="username" value="guest"/>
<property name="password" value="guest"/>
<property name="channelCacheSize" value="50"/>
</bean>
使用命名空间,您只需添加* channel-cache-size *属性即可:
<rabbit:connection-factory
id="connectionFactory" channel-cache-size="50"/>
默认的缓存模式是 CHANNEL,但是您可以将其配置为缓存连接。在这种情况下,我们使用connection-cache-size:
<rabbit:connection-factory
id="connectionFactory" cache-mode="CONNECTION" connection-cache-size="25"/>
主机和端口属性可以使用名称空间提供
<rabbit:connection-factory
id="connectionFactory" host="somehost" port="5672"/>
或者,如果在群集环境中运行,请使用地址属性。
<rabbit:connection-factory
id="connectionFactory" addresses="host1:5672,host2:5672"/>
这是一个自定义线程工厂的示例,该线程工厂在线程名称前加上rabbitmq-。
<rabbit:connection-factory id="multiHost" virtual-host="/bar" addresses="host1:1234,host2,host3:4567"
thread-factory="tf"
channel-cache-size="10" username="user" password="password" />
<bean id="tf" class="org.springframework.scheduling.concurrent.CustomizableThreadFactory">
<constructor-arg value="rabbitmq-" />
</bean>
从* 1.7 版本*开始,提供了ConnectionNameStrategy以便注入AbstractionConnectionFactory。生成的名称用于目标 RabbitMQ 连接的特定于应用程序的标识。如果 RabbitMQ 服务器支持,则连接名称将显示在 ManagementUI 中。此值不必是唯一的,也不能用作连接标识符,例如在 HTTP API 请求中。该值应该是人类可读的,并且是connection_name键下ClientProperties的一部分。可以用作简单的 Lambda:
connectionFactory.setConnectionNameStrategy(connectionFactory -> "MY_CONNECTION");
ConnectionFactory参数可用于通过某些逻辑来区分目标连接名称。默认情况下,AbstractConnectionFactory的beanName和内部计数器用于生成connection_name。 <rabbit:connection-factory>名称空间组件也随connection-name-strategy属性一起提供。
从* version 1.7.7 *开始,提供了一个AmqpResourceNotAvailableException,例如当SimpleConnection.createChannel()无法创建Channel时抛出该AmqpResourceNotAvailableException,因为达到了channelMax的限制并且缓存中没有可用的通道。可以在RetryPolicy中使用此异常,以在某些回退之后恢复操作。
配置基础 Client 端连接工厂
CachingConnectionFactory使用 RabbitClient 端ConnectionFactory的实例;在CachingConnectionFactory上设置等效属性时,会传递许多配置属性(例如host, port, userName, password, requestedHeartBeat, connectionTimeout)。要设置其他属性(例如clientProperties),请定义 Rabbit 工厂的实例,并使用CachingConnectionFactory的适当构造函数为其提供引用。如上所述使用命名空间时,请在connection-factory属性中提供对已配置工厂的引用。为方便起见,提供了工厂 bean 来帮助在 Spring 应用程序上下文中配置连接工厂,如下一节所述。
<rabbit:connection-factory
id="connectionFactory" connection-factory="rabbitConnectionFactory"/>
Note
默认情况下,4.0.xClient 端启用自动恢复;虽然与该功能兼容,但 Spring AMQP 拥有自己的恢复机制,通常不需要 Client 端恢复功能。建议禁用amqp-client自动恢复,以避免在代理可用但连接尚未恢复时获得AutoRecoverConnectionNotCurrentlyOpenException s。您可能会注意到此异常,例如,在RabbitTemplate中配置了RetryTemplate时,即使故障转移到集群中的另一个代理。由于自动恢复连接在计时器上恢复,因此使用 Spring AMQP 的恢复机制可以更快地恢复连接。从* version 1.7.1 *开始,Spring AMQP 禁用它,除非您显式创建自己的 RabbitMQ 连接工厂并将其提供给CachingConnectionFactory。 RabbitConnectionFactoryBean创建的 RabbitMQ ConnectionFactory实例默认情况下也会禁用该选项。
RabbitConnectionFactoryBean 和配置 SSL
从* version 1.4 *开始,提供了一个方便的RabbitConnectionFactoryBean,以使用依赖项注入在基础 Client 端连接工厂上方便地配置 SSL 属性。其他设置员仅委托给基础工厂。以前,您必须以编程方式配置 SSL 选项。
<rabbit:connection-factory id="rabbitConnectionFactory"
connection-factory="clientConnectionFactory"
host="${host}"
port="${port}"
virtual-host="${vhost}"
username="${username}" password="${password}" />
<bean id="clientConnectionFactory"
class="org.springframework.amqp.rabbit.connection.RabbitConnectionFactoryBean">
<property name="useSSL" value="true" />
<property name="sslPropertiesLocation" value="file:/secrets/rabbitSSL.properties"/>
</bean>
有关配置 SSL 的信息,请参考RabbitMQ Documentation。省略keyStore和trustStore配置以通过 SSL 进行连接而无需证书验证。密钥和信任库配置可以如下提供:
sslPropertiesLocation属性是 Spring Resource,它指向包含以下键的属性文件:
keyStore=file:/secret/keycert.p12
trustStore=file:/secret/trustStore
keyStore.passPhrase=secret
trustStore.passPhrase=secret
keyStore和truststore是指向 Store 的 Spring Resources。通常,此属性文件将由 os 保护,并且应用程序具有读取访问权限。
从 Spring AMQP *版本 1.5 *开始,可以直接在工厂 bean 上设置这些属性。如果同时提供了离散属性和sslPropertiesLocation,则后者中的属性将覆盖离散值。
路由连接工厂
从* version 1.3 *开始,引入了AbstractRoutingConnectionFactory。这提供了一种机制,可在运行时为多个ConnectionFactories配置 Map 并由某个lookupKey确定目标ConnectionFactory。通常,实现检查线程绑定上下文。为了方便起见,Spring AMQP 提供了SimpleRoutingConnectionFactory,它从SimpleResourceHolder获取当前线程绑定的lookupKey:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.SimpleRoutingConnectionFactory">
<property name="targetConnectionFactories">
<map>
<entry key="#{connectionFactory1.virtualHost}" ref="connectionFactory1"/>
<entry key="#{connectionFactory2.virtualHost}" ref="connectionFactory2"/>
</map>
</property>
</bean>
<rabbit:template id="template" connection-factory="connectionFactory" />
public class MyService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void service(String vHost, String payload) {
SimpleResourceHolder.bind(rabbitTemplate.getConnectionFactory(), vHost);
rabbitTemplate.convertAndSend(payload);
SimpleResourceHolder.unbind(rabbitTemplate.getConnectionFactory());
}
}
使用后解除绑定资源很重要。有关更多信息,请参见AbstractRoutingConnectionFactory的 JavaDocs。
从*版本 1.4 *开始,RabbitTemplate支持 SpEL sendConnectionFactorySelectorExpression和receiveConnectionFactorySelectorExpression属性,这些属性在每个 AMQP 协议交互操作(send,sendAndReceive,receive或receiveAndReply)上进行评估,对于提供的AbstractRoutingConnectionFactory解析为lookupKey值。表达式中可以使用 Bean 引用,例如"@vHostResolver.getVHost(#root)"。对于send操作,要发送的消息是根评估对象。对于receive操作,queueName 是根评估对象。
**路由算法为:如果 selectors 表达式为null,或者计算为null,或者提供的ConnectionFactory不是AbstractRoutingConnectionFactory的实例,则所有操作都像以前一样,取决于提供的ConnectionFactory实现。如果评估结果不是null,但是没有针对该lookupKey的目标ConnectionFactory,并且AbstractRoutingConnectionFactory配置为lenientFallback = true,则会发生相同的情况。当然,在AbstractRoutingConnectionFactory的情况下,它会回退到基于determineCurrentLookupKey()的routing实现。但是,如果lenientFallback = false,则抛出IllegalStateException。
命名空间支持还在<rabbit:template>组件上提供了send-connection-factory-selector-expression和receive-connection-factory-selector-expression属性。
同样从* version 1.4 *开始,您可以在侦听器容器中配置路由连接工厂。在这种情况下,队列名称列表将用作查找关键字。例如,如果您使用setQueueNames("foo", "bar")配置容器,则查找键将为"[foo,bar]"(无空格)。
从*版本 1.6.9 *开始,您可以使用侦听器容器上的setLookupKeyQualifier向查找键添加限定符。例如,这将允许侦听具有相同名称但在不同虚拟主机中的队列(每个虚拟主机中都有一个连接工厂)。
例如,在使用查找键限定符foo和侦听队列bar的容器的情况下,用于注册目标连接工厂的查找键将是foo[bar]。
队列相似性和 LocalizedQueueConnectionFactory
在群集中使用 HA 队列时,为了获得最佳性能,可能需要连接到主队列所在的物理代理。 CachingConnectionFactory可以配置多个代理地址;这是为了进行故障转移,Client 端将尝试按 Sequences 连接。 LocalizedQueueConnectionFactory使用 Management 插件提供的 REST API 来确定要控制队列的节点。然后,它创建(或从缓存中检索)CachingConnectionFactory,该CachingConnectionFactory将仅连接到该节点。如果连接失败,那么将确定新的主节点,并且使用者将连接到该主节点。 LocalizedQueueConnectionFactory配置有默认的连接工厂,以防无法确定队列的物理位置,在这种情况下,它将正常连接到群集。
LocalizedQueueConnectionFactory是RoutingConnectionFactory,而SimpleMessageListenerContainer使用队列名称作为查找关键字,如上面名为“路由连接工厂”的部分所述。
Note
由于这个原因(使用队列名称进行查找),只有在将容器配置为侦听单个队列时,才能使用LocalizedQueueConnectionFactory。
Note
必须在每个节点上启用 RabbitMQManagement 插件。
Warning
此连接工厂用于长期连接,例如SimpleMessageListenerContainer使用的连接。它不适用于短连接,例如用于RabbitTemplate,因为在构建连接之前调用 REST API 会产生开销。同样,对于发布操作,队列是未知的,并且无论如何该消息都会发布给所有集群成员,因此查找节点的逻辑几乎没有价值。
这是一个示例配置,使用 Spring Boot 的 RabbitProperties 配置工厂:
@Autowired
private RabbitProperties props;
private final String[] adminUris = { "http://host1:15672", "http://host2:15672" };
private final String[] nodes = { "[emailprotected]", "[emailprotected]" };
@Bean
public ConnectionFactory defaultConnectionFactory() {
CachingConnectionFactory cf = new CachingConnectionFactory();
cf.setAddresses(this.props.getAddresses());
cf.setUsername(this.props.getUsername());
cf.setPassword(this.props.getPassword());
cf.setVirtualHost(this.props.getVirtualHost());
return cf;
}
@Bean
public ConnectionFactory queueAffinityCF(
@Qualifier("defaultConnectionFactory") ConnectionFactory defaultCF) {
return new LocalizedQueueConnectionFactory(defaultCF,
StringUtils.commaDelimitedListToStringArray(this.props.getAddresses()),
this.adminUris, this.nodes,
this.props.getVirtualHost(), this.props.getUsername(), this.props.getPassword(),
false, null);
}
请注意,前三个参数是addresses,adminUris和nodes的数组。这些是适当的,因为当容器尝试连接到队列时,它确定队列在哪个节点上被控制,并连接到同一阵列位置中的地址。
发布者确认并return
通过将CachingConnectionFactory的publisherConfirms和publisherReturns属性分别设置为'true',可以支持确认和返回的消息。
设置这些选项后,工厂创建的Channel将被包装在PublisherCallbackChannel中,该_用于方便回调。当获得这样的 Channels 时,Client 端可以向Channel注册PublisherCallbackChannel.Listener。 PublisherCallbackChannel实现包含将确认/返回路由到适当的侦听器的逻辑。这些功能将在以下各节中进一步说明。
Tip
有关更多背景信息,请参阅 RabbitMQ 团队的以下博客文章介绍发布商确认。
记录 Channels 关闭事件
在 1.5 版中引入了一种使用户能够控制日志记录级别的机制。
CachingConnectionFactory使用默认策略记录通道关闭,如下所示:
正常通道关闭(200 OK)不会被记录。
如果通道由于被动队列声明失败而关闭,那么它将在调试级别记录。
如果通道由于
basic.consume由于特殊的使用者条件而被拒绝而关闭,则它将以 INFO 级别记录。其他所有日志均以 ERROR 级别记录。
若要修改此行为,请在其closeExceptionLogger属性中将自定义ConditionalExceptionLogger注入到CachingConnectionFactory中。
另请参见“Consumer 事件”部分。
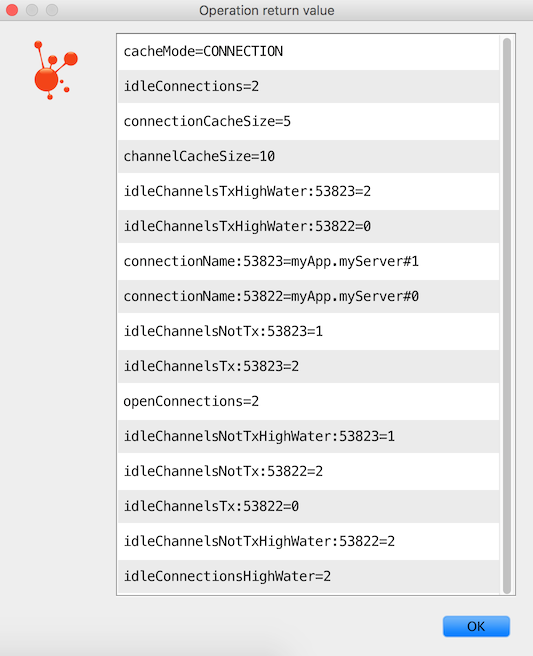
运行时缓存属性
从* version 1.6 *开始,CachingConnectionFactory现在通过getCacheProperties()方法提供了缓存统计信息。这些统计信息可用于调整缓存以在 Producing 对其进行优化。例如,高水位标记可用于确定是否应增加缓存大小。如果等于缓存大小,则可能要考虑进一步增加。
表 3.1. CacheMode.CHANNEL 的缓存属性
| Property | Meaning |
|---|---|
connectionName |
ConnectionNameStrategy生成的连接的名称。 |
channelCacheSize |
当前配置的允许空闲的最大通道数。 |
localPort |
连接的本地端口(如果有)。这可用于与 RabbitMQ Admin UI 上的连接/通道关联。 |
idleChannelsTx |
当前空闲(缓存)的事务通道的数量。 |
idleChannelsNotTx |
当前空闲(缓存)的非事务通道的数量。 |
idleChannelsTxHighWater |
已同时空闲(缓存)的最大事务通道数。 |
idleChannelsNotTxHighWater |
非事务通道的最大数量已被同时空闲(缓存)。 |
表 3.2. CacheMode.CONNECTION 的缓存属性
| Property | Meaning |
|---|---|
connectionName:<localPort> |
ConnectionNameStrategy生成的连接的名称。 |
openConnections |
表示与代理的连接的连接对象的数量。 |
channelCacheSize |
当前配置的允许空闲的最大通道数。 |
connectionCacheSize |
当前配置的允许空闲的最大连接数。 |
idleConnections |
当前空闲的连接数。 |
idleConnectionsHighWater |
并发空闲的最大连接数。 |
idleChannelsTx:<localPort> |
该连接当前空闲(缓存)的事务通道的数量。属性名称的 localPort 部分可用于与 RabbitMQ Admin UI 上的连接/通道关联。 |
idleChannelsNotTx:<localPort> |
该连接当前空闲(缓存)的非事务通道的数量。属性名称的 localPort 部分可用于与 RabbitMQ Admin UI 上的连接/通道关联。 |
| idleChannelsTxHighWater: | |
<localPort> |
同时空闲(缓存)的最大事务通道数。属性名称的 localPort 部分可用于与 RabbitMQ Admin UI 上的连接/通道关联。 |
| idleChannelsNotTxHighWater: <localPort> |
已同时空闲(缓存)的非事务通道的最大数量。属性名称的 localPort 部分可用于与 RabbitMQ Admin UI 上的连接/通道关联。 |
cacheMode属性(还包括CHANNEL或CONNECTION)。
图 3.1. JVisualVM 示例
RabbitMQ 自动连接/拓扑恢复
从 Spring AMQP 的第一个版本开始,该框架在代理发生故障的情况下提供了自己的连接和通道恢复。另外,如第 3.1.10 节,“配置代理”中所述,RabbitAdmin将在重新构建连接时重新声明任何基础结构 Bean(队列等)。因此,它不依赖amqp-client库现在提供的Auto Recovery。 Spring AMQP 现在使用amqp-client的4.0.x版本,默认情况下启用了自动恢复。如果愿意,Spring AMQP 仍可以使用其自己的恢复机制,在 Client 端中将其禁用(通过将基础RabbitMQ connectionFactory设置为false的automaticRecoveryEnabled属性)。但是,该框架与启用的自动恢复完全兼容。这意味着您在代码中创建的所有使用者(可能通过RabbitTemplate.execute())都可以自动恢复。
3.1.3 添加自定义 Client 端连接属性
CachingConnectionFactory现在允许您访问基础连接工厂,以允许例如设置自定义 Client 端属性:
connectionFactory.getRabbitConnectionFactory().getClientProperties().put("foo", "bar");
查看连接时,这些属性会显示在 RabbitMQManagement 员 UI 中。
3.1.4 AmqpTemplate
Introduction
与 Spring 框架和相关项目提供的许多其他高级抽象一样,Spring AMQP 提供了一个“模板”,该模板起着核心作用。定义主要操作的接口称为AmqpTemplate。这些操作涵盖了发送和接收消息的一般行为。换句话说,它们不是任何实现所独有的,因此名称中为“ AMQP”。另一方面,该接口的实现与 AMQP 协议的实现绑定在一起。与 JMS(本身是接口级 API)不同,AMQP 是线级协议。该协议的实现提供了自己的 Client 端库,因此模板接口的每种实现都将取决于特定的 Client 端库。当前,只有一个实现:RabbitTemplate。在下面的示例中,您经常会看到“ AmqpTemplate”的用法,但是当您查看配置示例或实例化模板和/或调用设置器的任何代码摘录时,您将看到实现类型(例如“ RabbitTemplate”)。
如上所述,AmqpTemplate接口定义了用于发送和接收消息的所有基本操作。在接下来的两个部分中,我们将分别探讨消息发送和接收。
另请参见名为“ AsyncRabbitTemplate”的部分。
添加重试功能
从*版本 1.3 *开始,您现在可以将RabbitTemplate配置为使用RetryTemplate来帮助处理代理连接性问题。有关完整信息,请参见spring-retry项目。以下仅是一个使用指数回退策略和默认值SimpleRetryPolicy的示例,它将在将异常抛出给调用方之前进行三次尝试。
使用 XML 名称空间:
<rabbit:template id="template" connection-factory="connectionFactory" retry-template="retryTemplate"/>
<bean id="retryTemplate" class="org.springframework.retry.support.RetryTemplate">
<property name="backOffPolicy">
<bean class="org.springframework.retry.backoff.ExponentialBackOffPolicy">
<property name="initialInterval" value="500" />
<property name="multiplier" value="10.0" />
<property name="maxInterval" value="10000" />
</bean>
</property>
</bean>
使用@Configuration:
@Bean
public AmqpTemplate rabbitTemplate();
RabbitTemplate template = new RabbitTemplate(connectionFactory());
RetryTemplate retryTemplate = new RetryTemplate();
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(500);
backOffPolicy.setMultiplier(10.0);
backOffPolicy.setMaxInterval(10000);
retryTemplate.setBackOffPolicy(backOffPolicy);
template.setRetryTemplate(retryTemplate);
return template;
}
从* version 1.4 *开始,除了retryTemplate属性之外,RabbitTemplate还支持recoveryCallback选项。用作RetryTemplate.execute(RetryCallback<T, E> retryCallback, RecoveryCallback<T>recoveryCallback)的第二个参数。
Note
RecoveryCallback在某种程度上受到限制,因为重试上下文仅包含lastThrowable字段。对于更复杂的用例,应该使用外部RetryTemplate,以便可以通过上下文的属性将其他信息传达给RecoveryCallback:
retryTemplate.execute(
new RetryCallback<Object, Exception>() {
@Override
public Object doWithRetry(RetryContext context) throws Exception {
context.setAttribute("message", message);
return rabbitTemplate.convertAndSend(exchange, routingKey, message);
}
}, new RecoveryCallback<Object>() {
@Override
public Object recover(RetryContext context) throws Exception {
Object message = context.getAttribute("message");
Throwable t = context.getLastThrowable();
// Do something with message
return null;
}
});
}
在这种情况下,您将 不 将RetryTemplate注入RabbitTemplate。
发布者确认并return
AmqpTemplate的RabbitTemplate实现支持发布者确认和return。
对于返回的消息,模板的mandatory属性必须设置为true,或者对于特定消息,mandatory-expression必须计算为true。此功能需要CachingConnectionFactory的publisherReturns属性设置为 true(请参见称为“发布者确认并返回”的部分)。通过调用setReturnCallback(ReturnCallback callback)注册RabbitTemplate.ReturnCallback,将返回值发送给 Client 端。回调必须实现此方法:
void returnedMessage(Message message, int replyCode, String replyText,
String exchange, String routingKey);
每个RabbitTemplate仅支持一个ReturnCallback。另请参见称为“答复超时”的部分。
对于发布者确认(又称发布者确认),模板需要一个CachingConnectionFactory,其publisherConfirms属性设置为 true。通过调用setConfirmCallback(ConfirmCallback callback)注册RabbitTemplate.ConfirmCallback来将确认发送到 Client 端。回调必须实现此方法:
void confirm(CorrelationData correlationData, boolean ack, String cause);
CorrelationData是 Client 端在发送原始消息时提供的对象。 ack对ack为 true,对nack为 false。对于nack,如果生成nack时原因可用,则原因可能包含 nack 的原因。一个示例是将消息发送到不存在的交换机时。在这种情况下,broker 关闭 Channel; cause中包含了关闭的原因。 cause已添加到*版本 1.4 *中。
RabbitTemplate仅支持一个ConfirmCallback。
Note
Rabbit 模板发送操作完成后,通道将关闭;如果连接工厂高速缓存已满(在高速缓存中有空间时,通道实际上并未关闭,并且返回/确认将正常进行),则这将阻止接收确认或返回。当缓存已满时,框架会将关闭延迟最多 5 秒钟,以便有时间接收确认/返回。使用确认时,将在收到最后一个确认时关闭通道。当仅使用回车时,通道将保持打开状态整整 5 秒钟。通常建议将连接工厂的channelCacheSize设置为足够大的值,以便将发布消息的通道返回到缓存中而不是将其关闭。您可以使用 RabbitMQManagement 插件监视 Channels 使用情况;如果看到通道快速打开/关闭,则应考虑增加缓存大小以减少服务器的开销。
Messaging integration
从* version 1.4 * RabbitMessagingTemplate开始,它构建在RabbitTemplate的基础上,提供了与 Spring Framework 消息传递抽象(即org.springframework.messaging.Message)的集成。这使您可以使用spring-messaging Message<?>抽象来发送和接收消息。其他 Spring 项目(例如 Spring Integration 和 Spring 的 STOMP 支持)使用了这种抽象。涉及两个消息转换器。一种在 Spring 消息Message<?>和 Spring AMQP 的Message抽象之间进行转换,另一种在 Spring AMQP 的Message抽象与基础 RabbitMQClient 端库所需的格式之间进行转换。默认情况下,消息有效负载由提供的RabbitTemplate的消息转换器转换。或者,您可以将自定义MessagingMessageConverter注入其他一些有效负载转换器:
MessagingMessageConverter amqpMessageConverter = new MessagingMessageConverter();
amqpMessageConverter.setPayloadConverter(myPayloadConverter);
rabbitMessagingTemplate.setAmqpMessageConverter(amqpMessageConverter);
已验证的用户 ID
从* version 1.6 *开始,模板现在支持user-id-expression(使用 Java 配置时为userIdExpression)。如果发送了一条消息,则在评估此表达式后将设置用户 id 属性(如果尚未设置)。评估的根对象是要发送的消息。
Examples:
<rabbit:template ... user-id-expression="'guest'" />
<rabbit:template ... user-id-expression="@myConnectionFactory.username" />
第一个示例是一个 Literals 表达式;第二个从应用程序上下文中的连接工厂 Bean 获取username属性。
3.1.5 发送消息
Introduction
发送邮件时,可以使用以下任何一种方法:
void send(Message message) throws AmqpException;
void send(String routingKey, Message message) throws AmqpException;
void send(String exchange, String routingKey, Message message) throws AmqpException;
我们可以从上面列出的最后一种方法开始讨论,因为它实际上是最明确的。它允许在运行时提供 AMQP 交换名称以及路由密钥。最后一个参数是负责实际创建 Message 实例的回调。使用此方法发送消息的示例可能如下所示:
amqpTemplate.send("marketData.topic", "quotes.nasdaq.FOO",
new Message("12.34".getBytes(), someProperties));
如果您计划大部分或所有时间使用模板实例发送到同一交换,则可以在模板本身上设置“交换”属性。在这种情况下,可以替代使用上面列出的第二种方法。以下示例在功能上等同于上一个示例:
amqpTemplate.setExchange("marketData.topic");
amqpTemplate.send("quotes.nasdaq.FOO", new Message("12.34".getBytes(), someProperties));
如果在模板上同时设置了“ exchange”和“ routingKey”属性,则可以使用仅接受Message的方法:
amqpTemplate.setExchange("marketData.topic");
amqpTemplate.setRoutingKey("quotes.nasdaq.FOO");
amqpTemplate.send(new Message("12.34".getBytes(), someProperties));
考虑交换和路由键属性的一种更好的方法是,显式方法参数将始终覆盖模板的默认值。实际上,即使您没有在模板上显式设置这些属性,也始终会存在默认值。在这两种情况下,默认值都是一个空字符串,但这实际上是一个明智的默认值。就路由密钥而言,并非一开始就总是必需的(例如,扇出交换)。此外,队列可以使用空字符串绑定到 Exchange。这些都是合法的方案,它们依赖模板的路由键属性的默认空字符串值。就 Exchange 名称而言,空字符串非常常用,因为 AMQP 规范将“默认 Exchange”定义为没有名称。由于所有队列都使用其名称作为绑定值自动绑定到该默认 Exchange(即直接 Exchange),因此上述第二种方法可用于通过默认 Exchange 简单地点对点消息传递到任何队列。只需提供队列名称作为“ routingKey”-通过在运行时提供 method 参数即可:
RabbitTemplate template = new RabbitTemplate(); // using default no-name Exchange
template.send("queue.helloWorld", new Message("Hello World".getBytes(), someProperties));
或者,如果您希望创建一个模板,该模板将主要或专门用于发布到单个 Queue,则以下内容是完全合理的:
RabbitTemplate template = new RabbitTemplate(); // using default no-name Exchange
template.setRoutingKey("queue.helloWorld"); // but we'll always send to this Queue
template.send(new Message("Hello World".getBytes(), someProperties));
Message Builder API
从*版本 1.3 *开始,MessageBuilder和MessagePropertiesBuilder提供了消息构建器 API;它们提供了一种方便的“流畅”的方式来创建消息或消息属性:
Message message = MessageBuilder.withBody("foo".getBytes())
.setContentType(MessageProperties.CONTENT_TYPE_TEXT_PLAIN)
.setMessageId("123")
.setHeader("bar", "baz")
.build();
or
MessageProperties props = MessagePropertiesBuilder.newInstance()
.setContentType(MessageProperties.CONTENT_TYPE_TEXT_PLAIN)
.setMessageId("123")
.setHeader("bar", "baz")
.build();
Message message = MessageBuilder.withBody("foo".getBytes())
.andProperties(props)
.build();
可以设置MessageProperties上定义的每个属性。其他方法包括setHeader(String key, String value),removeHeader(String key),removeHeaders()和copyProperties(MessageProperties properties)。每个属性设置方法都有一个set*IfAbsent()变体。在存在默认初始值的情况下,该方法名为set*IfAbsentOrDefault()。
提供了五个静态方法来创建初始消息构建器:
public static MessageBuilder withBody(byte[] body) (1)
public static MessageBuilder withClonedBody(byte[] body) (2)
public static MessageBuilder withBody(byte[] body, int from, int to) (3)
public static MessageBuilder fromMessage(Message message) (4)
public static MessageBuilder fromClonedMessage(Message message) (5)
- (1) 由构建器创建的消息将具有一个直接引用该参数的正文。
- (2) 由构建器创建的消息将具有一个主体,该主体是一个新数组,在参数中包含字节的副本。
- (3) 由构建器创建的消息将具有一个主体,该主体是一个新数组,其中包含来自参数的字节范围。有关更多详细信息,请参见
Arrays.copyOfRange()。 - (4) 由构建器创建的消息将具有直接引用自变量正文的正文。参数的属性将复制到新的
MessageProperties对象。 - (5) 由构建器创建的消息将具有一个主体,该主体是一个包含参数主体副本的新数组。参数的属性将复制到新的
MessageProperties对象。
public static MessagePropertiesBuilder newInstance() (1)
public static MessagePropertiesBuilder fromProperties(MessageProperties properties) (2)
public static MessagePropertiesBuilder fromClonedProperties(MessageProperties properties) (3)
- (1) 新的消息属性对象使用默认值初始化。
- (2) 构建器将使用提供的属性对象进行初始化,并且
build()将返回。 - (3) 参数的属性将复制到新的
MessageProperties对象。
使用AmqpTemplate的RabbitTemplate实现,每个send()方法都有一个重载版本,该重载版本带有一个额外的CorrelationData对象。启用发布者确认后,此对象将在第 3.1.4 节“ AmqpTemplate”中描述的回调中返回。这允许发送方将确认(确认或不确认)与发送的消息相关联。
从* version 1.6.7 *开始,引入了CorrelationAwareMessagePostProcessor接口,允许在转换消息后修改相关数据:
Message postProcessMessage(Message message, Correlation correlation);
同样从* version 1.6.7 *开始,提供了一个新的回调接口CorrelationDataPostProcessor;在所有MessagePostProcessor之后(在send()方法以及setBeforePublishPostProcessors()中提供的方法中提供)之后调用此方法。实现可以更新或替换send()方法(如果有)中提供的相关数据。 Message和原始CorrelationData(如果有)作为参数提供。
CorrelationData postProcess(Message message, CorrelationData correlationData);
Publisher Returns
当模板的mandatory属性为* true *时,返回的消息由第 3.1.4 节“ AmqpTemplate”中描述的回调提供。
从*版本 1.4 *开始,RabbitTemplate支持 SpEL mandatoryExpression属性,该属性针对每个请求消息进行评估,作为根评估对象,解析为boolean值。表达式中可以使用 Bean 引用,例如"@myBean.isMandatory(#root)"。
RabbitTemplate还可在发送和接收操作中内部使用发布者返回。有关更多信息,请参见称为“答复超时”的部分。
Batching
从*版本 1.4.2 *开始,引入了BatchingRabbitTemplate。这是RabbitTemplate的子类,具有重写的send方法,该方法根据BatchingStrategy批处理消息;仅当批次完成时,消息才会发送到 RabbitMQ。
public interface BatchingStrategy {
MessageBatch addToBatch(String exchange, String routingKey, Message message);
Date nextRelease();
Collection<MessageBatch> releaseBatches();
}
Warning
批处理数据保存在内存中;如果发生系统故障,未发送的消息可能会丢失。
提供了SimpleBatchingStrategy。它支持将消息发送到单个交换/路由键。它具有以下特性:
batchSize-批量发送之前的邮件数bufferLimit-批处理邮件的最大大小;如果超过batchSize,它将抢占batchSize并导致发送部分批次timeout-在没有新活动将消息添加到该批处理中之后将发送部分批处理的时间
SimpleBatchingStrategy通过在每个嵌入的消息之前添加 4 字节的二进制长度来格式化批处理。通过将springBatchFormat message 属性设置为lengthHeader4,将其传达给接收系统。
Tip
侦听器容器会自动分批处理成批的邮件(使用springBatchFormat邮件标题)。拒绝批次中的任何消息都将导致整个批次被拒绝。
3.1.6 接收消息
Introduction
消息接收总是比发送要复杂一些。接收Message有两种方法。比较简单的选项是使用轮询方法一次轮询单个Message。更复杂但更常见的方法是注册一个将按需异步接收Messages的侦听器。在接下来的两个小节中,我们将介绍每种方法的示例。
Polling Consumer
AmqpTemplate本身可用于轮询消息的接收。默认情况下,如果没有可用消息,则立即返回null;没有阻塞。从* version 1.5 *版本开始,您现在可以设置receiveTimeout(以毫秒为单位),并且 receive 方法将阻塞长达该时间,await 消息。小于零的值表示无限期阻塞(或至少直到与代理的连接丢失为止)。 *版本 1.6 *引入了receive方法的变体,允许在每次调用中传递超时。
Warning
由于接收操作会为每个消息创建一个新的QueueingConsumer,因此该技术实际上不适用于大容量环境;考虑使用异步使用者,或者对于这些用例,使用receiveTimeout为零。
有四种简单的* receive *方法。与发送方的 Exchange 一样,有一种方法要求直接在模板本身上设置默认队列属性,并且有一种方法在运行时接受队列参数。 *版本 1.6 *引入了变体,可以根据每个请求接受timeoutMillis覆盖receiveTimeout。
Message receive() throws AmqpException;
Message receive(String queueName) throws AmqpException;
Message receive(long timeoutMillis) throws AmqpException;
Message receive(String queueName, long timeoutMillis) throws AmqpException;
就像发送消息一样,AmqpTemplate拥有一些方便的方法来接收 POJO 而不是Message实例,并且实现将提供一种自定义MessageConverter的方法,该MessageConverter用于创建返回的Object:
Object receiveAndConvert() throws AmqpException;
Object receiveAndConvert(String queueName) throws AmqpException;
Message receiveAndConvert(long timeoutMillis) throws AmqpException;
Message receiveAndConvert(String queueName, long timeoutMillis) throws AmqpException;
与sendAndReceive方法类似,从* version 1.3 *开始,AmqpTemplate具有几种方便的receiveAndReply方法,用于同步接收,处理和回复消息:
<R, S> boolean receiveAndReply(ReceiveAndReplyCallback<R, S> callback)
throws AmqpException;
<R, S> boolean receiveAndReply(String queueName, ReceiveAndReplyCallback<R, S> callback)
throws AmqpException;
<R, S> boolean receiveAndReply(ReceiveAndReplyCallback<R, S> callback,
String replyExchange, String replyRoutingKey) throws AmqpException;
<R, S> boolean receiveAndReply(String queueName, ReceiveAndReplyCallback<R, S> callback,
String replyExchange, String replyRoutingKey) throws AmqpException;
<R, S> boolean receiveAndReply(ReceiveAndReplyCallback<R, S> callback,
ReplyToAddressCallback<S> replyToAddressCallback) throws AmqpException;
<R, S> boolean receiveAndReply(String queueName, ReceiveAndReplyCallback<R, S> callback,
ReplyToAddressCallback<S> replyToAddressCallback) throws AmqpException;
AmqpTemplate实现负责* receive 和 reply *阶段。在大多数情况下,您仅应提供ReceiveAndReplyCallback的实现以对接收到的消息执行一些业务逻辑,并在需要时构建回复对象或消息。注意,ReceiveAndReplyCallback可能返回null。在这种情况下,不会发送答复,并且receiveAndReply的工作方式类似于receive方法。这允许将同一队列用于混合消息,其中一些消息可能不需要回复。
仅当提供的回调不是ReceiveAndReplyMessageCallback的实例(提供原始消息交换 Contract)时,才应用自动消息(请求和答复)转换。
ReplyToAddressCallback对于需要自定义逻辑在运行时根据接收到的消息确定replyTo地址并从ReceiveAndReplyCallback进行回复的情况很有用。默认情况下,请求消息中的replyTo信息用于路由答复。
以下是基于 POJO 的接收和回复的示例…
boolean received =
this.template.receiveAndReply(ROUTE, new ReceiveAndReplyCallback<Order, Invoice>() {
public Invoice handle(Order order) {
return processOrder(order);
}
});
if (received) {
log.info("We received an order!");
}
Asynchronous Consumer
Tip
Spring AMQP 还通过使用@RabbitListenerComments 来支持带 Comments 的侦听器端点,并提供了开放的基础结构来以编程方式注册端点。到目前为止,这是设置异步使用者的最便捷方法,有关更多详细信息,请参见称为“Comments 驱动的侦听器端点”的部分。
Message Listener
对于异步消息接收,涉及一个专用组件(不是AmqpTemplate)。该组件是消息消耗回调的容器。我们将在短时间内查看容器及其属性,但是首先应该查看回调,因为这是您的应用程序代码将与消息传递系统集成的地方。从MessageListener接口的实现开始,回调有几个选项:
public interface MessageListener {
void onMessage(Message message);
}
如果您的回调逻辑出于任何原因依赖于 AMQP Channel 实例,则可以改用ChannelAwareMessageListener。看起来很相似,但是有一个额外的参数:
public interface ChannelAwareMessageListener {
void onMessage(Message message, Channel channel) throws Exception;
}
MessageListenerAdapter
如果您希望在应用程序逻辑和消息传递 API 之间保持更严格的分隔,则可以依靠框架提供的适配器实现。这通常称为“消息驱动的 POJO”支持。使用适配器时,仅需要提供对适配器本身应调用的实例的引用。
MessageListenerAdapter listener = new MessageListenerAdapter(somePojo);
listener.setDefaultListenerMethod("myMethod");
您可以继承适配器的子类并提供getListenerMethodName()的实现,以根据消息动态选择不同的方法。此方法有两个参数originalMessage和extractedMessage,后者是任何转换的结果。默认情况下,配置为SimpleMessageConverter;有关更多信息和其他可用转换器的信息,请参见名为“ SimpleMessageConverter”的部分。
从*版本 1.4.2 *开始,原始消息具有属性consumerQueue和consumerTag,这些属性可用于确定从哪个队列接收消息。
从* version 1.5 *开始,您可以配置使用者队列/标记到方法名称的 Map,以动态选择要调用的方法。如果 Map 中没有条目,我们将使用默认的侦听器方法。
Container
既然您已经看到了 Message-listening 回调的各种选项,我们就可以将注意力转向容器。基本上,容器处理“主动”职责,以便侦听器回调可以保持被动状态。容器是“生命周期”组件的一个示例。它提供了启动和停止的方法。配置容器时,实际上是在弥合 AMQP 队列和MessageListener实例之间的差距。您必须提供对ConnectionFactory的引用以及侦听器应从中使用 Messages 的队列名称或 Queue 实例。这是使用默认实现SimpleMessageListenerContainer的最基本示例:
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(rabbitConnectionFactory);
container.setQueueNames("some.queue");
container.setMessageListener(new MessageListenerAdapter(somePojo));
作为“活动”组件,最常见的是使用 bean 定义创建侦听器容器,以便它可以简单地在后台运行。这可以通过 XML 完成:
<rabbit:listener-container connection-factory="rabbitConnectionFactory">
<rabbit:listener queues="some.queue" ref="somePojo" method="handle"/>
</rabbit:listener-container>
或者,您可能更喜欢使用@Configuration 样式,该样式看起来与上面的实际代码片段非常相似:
@Configuration
public class ExampleAmqpConfiguration {
@Bean
public SimpleMessageListenerContainer messageListenerContainer() {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(rabbitConnectionFactory());
container.setQueueName("some.queue");
container.setMessageListener(exampleListener());
return container;
}
@Bean
public ConnectionFactory rabbitConnectionFactory() {
CachingConnectionFactory connectionFactory =
new CachingConnectionFactory("localhost");
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
return connectionFactory;
}
@Bean
public MessageListener exampleListener() {
return new MessageListener() {
public void onMessage(Message message) {
System.out.println("received: " + message);
}
};
}
}
从 RabbitMQ 版本 3.2 开始,代理现在支持使用者优先级(请参阅通过 RabbitMQ 使用 Consumer 优先级)。通过在使用者上设置x-priority参数可以启用此功能。 SimpleMessageListenerContainer现在支持设置使用者参数:
container.setConsumerArguments(Collections.
<String, Object> singletonMap("x-priority", Integer.valueOf(10)));
为了方便起见,名称空间在listener元素上提供了priority属性:
<rabbit:listener-container connection-factory="rabbitConnectionFactory">
<rabbit:listener queues="some.queue" ref="somePojo" method="handle" priority="10" />
</rabbit:listener-container>
从*版本 1.3 *开始,可以在运行时修改正在侦听容器的队列。参见第 3.1.18 节“侦听器容器队列”。
auto-delete Queues
如果将容器配置为侦听auto-delete队列,或者该队列具有x-expires选项,或者在 Broker 上配置了Time-To-Live策略,则当容器停止(最后一个使用者被取消)时,代理会将队列删除。在* version 1.3 *之前,由于缺少队列,因此无法重新启动容器。 RabbitAdmin仅在连接关闭/打开时自动重新声明队列等,而在容器停止/启动时不会发生这种情况。
从* version 1.3 *开始,容器现在将在启动过程中使用RabbitAdmin重新声明所有丢失的队列。
您还可以结合使用条件声明(称为“有条件的声明”的部分)和auto-startup="false" admin 来将队列声明推迟到容器启动之前。
<rabbit:queue id="otherAnon" declared-by="containerAdmin" />
<rabbit:direct-exchange name="otherExchange" auto-delete="true" declared-by="containerAdmin">
<rabbit:bindings>
<rabbit:binding queue="otherAnon" key="otherAnon" />
</rabbit:bindings>
</rabbit:direct-exchange>
<rabbit:listener-container id="container2" auto-startup="false">
<rabbit:listener id="listener2" ref="foo" queues="otherAnon" admin="containerAdmin" />
</rabbit:listener-container>
<rabbit:admin id="containerAdmin" connection-factory="rabbitConnectionFactory"
auto-startup="false" />
在这种情况下,队列和交换由具有auto-startup="false"的containerAdmin声明,因此在上下文初始化期间不声明元素。同样,由于相同的原因,容器没有启动。稍后启动容器时,它将使用对containerAdmin的引用来声明元素。
Batched Messages
侦听器容器自动分批处理了批处理的邮件(使用springBatchFormat邮件标题)。拒绝批次中的任何消息都将导致整个批次被拒绝。有关批处理的更多信息,请参见称为“批处理”的部分。
Consumer Events
从* version 1.5 *版本开始,只要侦听器(使用者)遇到某种故障,SimpleMessageListenerContainer就会发布应用程序事件。事件ListenerContainerConsumerFailedEvent具有以下属性:
container-Consumer 遇到问题的侦听器容器。reason-失败的 Literals 原因。fatal-指示失败是否致命的布尔值;根据retryInterval,在非致命异常的情况下,容器将尝试重新启动使用者。throwable-被捕获的Throwable。
通过实现ApplicationListener<ListenerContainerConsumerFailedEvent>可以消耗这些事件。
Note
concurrentConsumers大于 1 时,所有使用者都将发布系统范围的事件(例如连接失败)。
如果使用者由于默认情况下仅使用其队列而失败以及发布事件而失败,则会发出WARN日志。要更改此日志记录行为,请在SimpleMessageListenerContainer的exclusiveConsumerExceptionLogger属性中提供一个自定义ConditionalExceptionLogger。另请参见名为“记录通道关闭事件”的部分。
致命错误始终记录在ERROR级别;这是不可修改的。
在容器生命周期的各个阶段还发布了其他一些事件:
AsyncConsumerStartedEvent(开始使用 Consumer 时)AsyncConsumerRestartedEvent(当使用者在失败后重新启动时-仅SimpleMessageListenerContainer)AsyncConsumerTerminatedEvent(当 Consumer 正常停止时)AsyncConsumerStoppedEvent(当使用者停止时-仅SimpleMessageListenerContainer)ConsumeOkEvent(当从代理接收到consumeOk时,包含队列名和consumerTag)ListenerContainerIdleEvent(请参阅“检测空闲的异步用户”一节)
Consumer Tags
从*版本 1.4.5 *开始,您现在可以提供一种生成 Consumer 标签的策略。默认情况下,Consumer 标签将由代理生成。
public interface ConsumerTagStrategy {
String createConsumerTag(String queue);
}
队列可用,因此可以(可选)在标记中使用该队列。
注解驱动的侦听器端点
Introduction
从* version 1.4 *开始,异步接收消息的最简单方法是使用带 Comments 的侦听器端点基础结构。简而言之,它允许您将托管 bean 的方法公开为 Rabbit 侦听器端点。
@Component
public class MyService {
@RabbitListener(queues = "myQueue")
public void processOrder(String data) {
...
}
}
上面示例的想法是,只要在org.springframework.amqp.core.Queue“ myQueue”上有消息可用,就会相应地调用processOrder方法(在这种情况下,使用消息的有效负载)。
带 Comments 的端点基础结构使用RabbitListenerContainerFactory在幕后为每种带 Comments 的方法创建一个消息侦听器容器。
在上面的示例中,myQueue必须已经存在并绑定到某些交换。从* version 1.5.0 *开始,只要应用程序上下文中存在RabbitAdmin,就可以自动声明和绑定队列。
Note
可以为 Comments 属性(queues等)指定属性占位符(${some.property})或 SpEL 表达式(#{someExpression})。有关为什么可能使用 SpEL 而不是属性占位符的示例,请参见名为“侦听多个队列”的部分。
@Component
public class MyService {
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "myQueue", durable = "true"),
exchange = @Exchange(value = "auto.exch", ignoreDeclarationExceptions = "true"),
key = "orderRoutingKey")
)
public void processOrder(String data) {
...
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue,
exchange = @Exchange(value = "auto.exch"),
key = "invoiceRoutingKey")
)
public void processInvoice(String data) {
...
}
}
在第一个示例中,如果需要,队列myQueue将与交换机一起自动声明(持久),并与路由键绑定到交换机。在第二个示例中,将声明并绑定一个匿名(专有,自动删除)队列。可以提供多个QueueBinding条目,从而允许侦听器侦听多个队列。
此机制仅支持 DIRECT,FANOUT,TOPIC 和 HEADERS 交换类型。需要更高级的配置时,请使用常规的@Bean定义。
请注意第一个示例中关于 Transaction 所的ignoreDeclarationExceptions。例如,这允许绑定到可能具有不同设置(例如internal)的现有交换机。默认情况下,现有 Transaction 所的属性必须匹配。
从* version 1.6 *开始,您现在可以在@QueueBindingComments 中为队列,交换和绑定指定参数。例如:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "auto.headers", autoDelete = "true",
arguments = @Argument(name = "x-message-ttl", value = "10000",
type = "java.lang.Integer")),
exchange = @Exchange(value = "auto.headers", type = ExchangeTypes.HEADERS, autoDelete = "true"),
arguments = {
@Argument(name = "x-match", value = "all"),
@Argument(name = "foo", value = "bar"),
@Argument(name = "baz")
})
)
public String handleWithHeadersExchange(String foo) {
...
}
请注意,该队列的x-message-ttl参数设置为 10 秒。由于参数类型不是String,因此我们必须指定其类型;在这种情况下Integer。与所有此类声明一样,如果队列已经存在,则参数必须与队列中的参数匹配。对于 Headers 交换,我们设置绑定参数以匹配将 Headersfoo设置为bar且 Headersbaz必须存在任何值的消息。 x-match参数表示必须同时满足两个条件。
参数名称,值和类型可以是属性占位符(${...})或 SpEL 表达式(#{...})。 name必须解析为String; type的表达式必须解析为Class或类的完全限定名称。 value必须解析为可以由DefaultConversionService转换为类型的内容(例如上例中的x-message-ttl)。
如果名称解析为null或空String,则该@Argument将被忽略。
Meta-Annotations
有时您可能想对多个侦听器使用相同的配置。为了减少样板配置,可以使用元 Comments 来创建自己的侦听器 Comments:
@Target({ElementType.TYPE, ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@RabbitListener(bindings = @QueueBinding(
value = @Queue,
exchange = @Exchange(value = "metaFanout", type = ExchangeTypes.FANOUT)))
public @interface MyAnonFanoutListener {
}
public class MetaListener {
@MyAnonFanoutListener
public void handle1(String foo) {
...
}
@MyAnonFanoutListener
public void handle2(String foo) {
...
}
}
在此示例中,由@MyAnonFanoutListenerComments 创建的每个侦听器都将匿名自动删除队列绑定到扇出交换机metaFanout。元 Comments 机制很简单,因为不检查用户定义 Comments 上的属性-因此您不能覆盖元 Comments 中的设置。当需要更高级的配置时,请使用正常的@Bean定义。
启用侦听器端点 Comments
要启用对@RabbitListenerComments 的支持,请将@EnableRabbit添加到您的@Configuration类中。
@Configuration
@EnableRabbit
public class AppConfig {
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory() {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory());
factory.setConcurrentConsumers(3);
factory.setMaxConcurrentConsumers(10);
return factory;
}
}
默认情况下,基础结构将查找名为rabbitListenerContainerFactory的 bean 作为工厂用来创建消息侦听器容器的源。在这种情况下,无需考虑 RabbitMQ 基础结构设置,就可以使用 3 个线程的核心轮询大小和 10 个线程的最大池大小来调用processOrder方法。
可以自定义侦听器容器工厂以使用每个 Comments,或者可以通过实现RabbitListenerConfigurer接口配置显式默认值。仅当至少一个端点在没有特定容器工厂的情况下注册时才需要使用默认值。有关完整的详细信息和示例,请参见 javadoc。
如果您更喜欢 XML 配置,请使用<rabbit:annotation-driven>元素。
<rabbit:annotation-driven/>
<bean id="rabbitListenerContainerFactory"
class="org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory">
<property name="connectionFactory" ref="connectionFactory"/>
<property name="concurrentConsumers" value="3"/>
<property name="maxConcurrentConsumers" value="10"/>
</bean>
Comments 方法的消息转换
调用侦听器之前,管道中有两个转换步骤。第一个使用MessageConverter将传入的 Spring AMQP Message转换为* spring-messaging * Message。调用目标方法时,如有必要,消息有效负载将转换为方法参数类型。
第一步的默认MessageConverter是 Spring AMQP SimpleMessageConverter,它处理到String和java.io.Serializable对象的转换。所有其他都保留为byte[]。在下面的讨论中,我们将此称为消息转换器。
第二步的默认转换器是GenericMessageConverter,它委派给转换服务(DefaultFormattingConversionService的实例)。在下面的讨论中,我们将此称为方法参数转换器。
要更改* message converter *,只需将其作为属性添加到容器工厂 bean 中:
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory() {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
...
factory.setMessageConverter(new Jackson2JsonMessageConverter());
...
return factory;
}
这将配置一个 Jackson2 转换器,该转换器希望出现 Headers 信息以指导转换。
您也可以考虑使用ContentTypeDelegatingMessageConverter,它可以处理不同 Content Type 的转换。
在大多数情况下,除非必须使用自定义ConversionService,否则不必自定义* method arguments converter *。
在* 1.6 之前的版本中,必须在消息头中提供用于转换 JSON 的类型信息,或者需要自定义ClassMapper。从 version 1.6 *开始,如果没有类型信息 Headers,则可以从目标方法参数中推断类型。
Note
此类型推断仅在方法级别适用于@RabbitListener。
有关更多信息,请参见名为“ Jackson2JsonMessageConverter”的部分。
如果您希望自定义* method arguments converter *,则可以按照以下步骤进行:
@Configuration
@EnableRabbit
public class AppConfig implements RabbitListenerConfigurer {
...
@Bean
public DefaultMessageHandlerMethodFactory myHandlerMethodFactory() {
DefaultMessageHandlerMethodFactory factory = new DefaultMessageHandlerMethodFactory();
factory.setMessageConverter(new GenericMessageConverter(myConversionService()));
return factory;
}
@Bean
public ConversionService myConversionService() {
DefaultConversionService conv = new DefaultConversionService();
conv.addConverter(mySpecialConverter());
return conv;
}
@Override
public void configureRabbitListeners(RabbitListenerEndpointRegistrar registrar) {
registrar.setMessageHandlerMethodFactory(myHandlerMethodFactory());
}
...
}
Tip
对于多方法侦听器(请参见称为“多方法侦听器”的部分),方法的选择基于消息转换后的消息有效负载**;仅在选择方法后才调用“方法参数转换器”。
程序化端点注册
RabbitListenerEndpoint提供 Rabbit 端点的模型,并负责为该模型配置容器。除了RabbitListenerComments 检测到的端点外,基础结构还允许您以编程方式配置端点。
@Configuration
@EnableRabbit
public class AppConfig implements RabbitListenerConfigurer {
@Override
public void configureRabbitListeners(RabbitListenerEndpointRegistrar registrar) {
SimpleRabbitListenerEndpoint endpoint = new SimpleRabbitListenerEndpoint();
endpoint.setQueueNames("anotherQueue");
endpoint.setMessageListener(message -> {
// processing
});
registrar.registerEndpoint(endpoint);
}
}
在上面的示例中,我们使用了SimpleRabbitListenerEndpoint来提供实际的MessageListener进行调用,但是您也可以构建自己的描述自定义调用机制的端点变量。
应该注意的是,您也可以完全跳过@RabbitListener的使用,而仅通过 RabbitListenerConfigurer 以编程方式注册端点。
带 Comments 的端点方法签名
到目前为止,我们已经在端点中注入了一个简单的 String,但实际上它可以具有非常灵活的方法签名。让我们重写它,以使用自定义 Headers 注入Order:
@Component
public class MyService {
@RabbitListener(queues = "myQueue")
public void processOrder(Order order, @Header("order_type") String orderType) {
...
}
}
这些是您可以在侦听器端点中注入的主要元素:
原始的org.springframework.amqp.core.Message。
收到消息的com.rabbitmq.client.Channel
org.springframework.messaging.Message代表传入的 AMQP 消息。请注意,此消息同时包含自定义 Headers 和标准 Headers(由AmqpHeaders定义)。
Note
从* version 1.6 *开始,入站deliveryModeHeaders 现在在名称为AmqpHeaders.RECEIVED_DELIVERY_MODE而不是AmqpHeaders.DELIVERY_MODE的 Headers 中可用。
@Header-带 Comments 的方法参数以提取特定的 Headers 值,包括标准 AMQPHeaders。
@Headers-带 Comments 的参数,也必须可分配给java.util.Map以访问所有 Headers。
不是受支持类型之一(即Message和Channel)的未 Comments 元素被视为有效负载。您可以通过用@PayloadComments 参数来使其明确。您还可以通过添加额外的@Valid来启用验证。
注入 Spring 的 Message 抽象的能力特别有用,它可以受益于存储在特定于传输的消息中的所有信息,而无需依赖于特定于传输的 API。
@RabbitListener(queues = "myQueue")
public void processOrder(Message<Order> order) { ...
}
DefaultMessageHandlerMethodFactory提供了方法参数的处理,可以进一步对其进行自定义以支持其他方法参数。转换和验证支持也可以在那里定制。
例如,如果要在处理订单之前确保其有效,则可以使用@ValidComments 有效负载,并按以下方式配置必要的验证器:
@Configuration
@EnableRabbit
public class AppConfig implements RabbitListenerConfigurer {
@Override
public void configureRabbitListeners(RabbitListenerEndpointRegistrar registrar) {
registrar.setMessageHandlerMethodFactory(myHandlerMethodFactory());
}
@Bean
public DefaultMessageHandlerMethodFactory myHandlerMethodFactory() {
DefaultMessageHandlerMethodFactory factory = new DefaultMessageHandlerMethodFactory();
factory.setValidator(myValidator());
return factory;
}
}
收听多个队列
使用queues属性时,可以指定关联的容器可以侦听多个队列。您可以使用@HeaderComments 使从中接收消息的队列名称可用于 POJO 方法:
@Component
public class MyService {
@RabbitListener(queues = { "queue1", "queue2" } )
public void processOrder(String data, @Header(AmqpHeaders.CONSUMER_QUEUE) String queue) {
...
}
}
从* version 1.5 *版本开始,您可以使用属性占位符和 SpEL 来外部化队列名称:
@Component
public class MyService {
@RabbitListener(queues = "#{'${property.with.comma.delimited.queue.names}'.split(',')}" )
public void processOrder(String data, @Header(AmqpHeaders.CONSUMER_QUEUE) String queue) {
...
}
}
在 1.5 版之前,只能以这种方式指定一个队列;每个队列都需要一个单独的属性。
Reply Management
MessageListenerAdapter中的现有支持已经允许您的方法具有非空返回类型。在这种情况下,调用的结果将封装在一条消息中,该消息要么以原始消息的ReplyToAddressHeaders 中指定的地址发送,要么以侦听器上配置的默认地址发送。现在可以使用消息传递抽象的@SendToComments 设置默认地址。
假设我们的processOrder方法现在应该返回OrderStatus,则可以按照以下方式编写它以自动发送回复:
@RabbitListener(destination = "myQueue")
@SendTo("status")
public OrderStatus processOrder(Order order) {
// order processing
return status;
}
如果需要以与传输无关的方式设置其他 Headers,则可以返回Message,例如:
@RabbitListener(destination = "myQueue")
@SendTo("status")
public Message<OrderStatus> processOrder(Order order) {
// order processing
return MessageBuilder
.withPayload(status)
.setHeader("code", 1234)
.build();
}
@SendTo值假定为模式exchange/routingKey之后的回复exchange和routingKey对,其中那些部分之一可以省略。有效值为:
foo/bar-回复要交换和路由的密钥。
foo/-replyTo 交换和默认(空)routingKey。
bar或/bar-ReplyTo routingKey 和默认(空)交换。
/或为空-ReplyTo 默认交换和默认 routingKey。
@SendTo也可以不带value属性使用。这种情况下等于一个空的 sendTo 模式。仅当入站邮件没有replyToAddress属性时才使用@SendTo。
从* version 1.5 *开始,@SendTo值可以是 bean 初始化 SpEL 表达式,例如…
@RabbitListener(queues = "test.sendTo.spel")
@SendTo("#{spelReplyTo}")
public String capitalizeWithSendToSpel(String foo) {
return foo.toUpperCase();
}
...
@Bean
public String spelReplyTo() {
return "test.sendTo.reply.spel";
}
该表达式的计算结果必须为String,它可以是简单的队列名称(发送到默认交换机)或采用如上所述的exchange/routingKey形式。
Note
初始化期间,对#{...}表达式求值一次。
对于动态回复路由,消息发送者应包括reply_to消息属性或使用下面描述的备用运行时 SpEL 表达式。
从* version 1.6 *开始,@SendTo可以是 SpEL 表达式,它会在运行时针对请求和回复进行评估:
@RabbitListener(queues = "test.sendTo.spel")
@SendTo("!{'some.reply.queue.with.' + result.queueName}")
public Bar capitalizeWithSendToSpel(Foo foo) {
return processTheFooAndReturnABar(foo);
}
SpEL 表达式的运行时性质由!{...}分隔符指示。表达式的评估上下文#root对象具有三个属性:
request-o.s.amqp.core.Message请求对象。source-转换后的o.s.messaging.Message<?>。result-方法结果。
该上下文具有一个 map 属性访问器,一个标准类型转换器和一个 bean 解析器,从而允许引用上下文中的其他 bean(例如@someBeanName.determineReplyQ(request, result))。
总而言之,#{...}在初始化期间被评估一次,其中#root对象是应用程序上下文; bean 由它们的名称引用。对于每条消息,在运行时都会对!{...}进行评估,其根对象具有上述属性,并且使用其名称(以@作为前缀)引用 bean。
Multi-Method Listeners
从* version 1.5.0 *开始,现在可以在类级别指定@RabbitListenerComments。与新的@RabbitHandler注解一起,这允许单个侦听器根据传入消息的有效负载类型来调用不同的方法。最好用一个例子来描述:
@RabbitListener(id="multi", queues = "someQueue")
public class MultiListenerBean {
@RabbitHandler
@SendTo("my.reply.queue")
public String bar(Bar bar) {
...
}
@RabbitHandler
public String baz(Baz baz) {
...
}
@RabbitHandler
public String qux(@Header("amqp_receivedRoutingKey") String rk, @Payload Qux qux) {
...
}
}
在这种情况下,如果转换后的有效负载是Bar,Baz或Qux,则将调用单独的@RabbitHandler方法。重要的是要了解系统必须能够基于有效负载类型识别唯一方法。检查该类型是否可分配给没有 Comments 或带有@PayloadComments 的单个参数。注意,与上述方法级别@RabbitListener中讨论的方法签名相同。
请注意,必须在每种方法上都指定@SendTo(如果需要);在类级别不支持此功能。
@Repeatable @RabbitListener
从* version 1.6 *开始,@RabbitListenerComments 用@Repeatable标记。这意味着 Comments 可以多次出现在相同的 Comments 元素(方法或类)上。在这种情况下,将为每个 Comments 创建一个单独的侦听器容器,每个 Comments 都调用相同的侦听器@Bean。 Java 8 或更高版本可以使用可重复的注解;当使用 Java 7 或更早版本时,通过使用@RabbitListeners“容器”Comments 以及@RabbitListenerComments 数组可以达到相同的效果。
代理@RabbitListener 和泛型
如果打算代理您的服务(例如@Transactional),则在接口具有通用参数时需要注意一些事项。具有通用接口和特定实现,例如:
interface TxService<P> {
String handle(P payload, String header);
}
static class TxServiceImpl implements TxService<Foo> {
@Override
@RabbitListener(...)
public String handle(Foo foo, String rk) {
...
}
}
您必须切换到 CGLIB 目标类代理,因为接口handle方法的实际实现是 bridge 方法。对于事务 Management,使用 Comments 选项@EnableTransactionManagement(proxyTargetClass = true)来配置 CGLIB 的使用。在这种情况下,必须在实现中的目标方法上声明所有 Comments:
static class TxServiceImpl implements TxService<Foo> {
@Override
@Transactional
@RabbitListener(...)
public String handle(@Payload Foo foo, @Header("amqp_receivedRoutingKey") String rk) {
...
}
}
Container Management
为 Comments 创建的容器未在应用程序上下文中注册。您可以通过在RabbitListenerEndpointRegistry bean 上调用getListenerContainers()获得所有容器的集合。然后,您可以遍历此集合,例如,停止/启动所有容器或在注册表本身上调用Lifecycle方法,这将在每个容器上调用操作。
您还可以使用id,getListenerContainer(String id)获得对单个容器的引用;例如registry.getListenerContainer("multi")(由上面的代码段创建的容器)。
从* 1.5.2 *版本开始,您可以使用getListenerContainerIds()获得id s 已注册容器。
从* version 1.5 *开始,您现在可以将group分配给RabbitListener端点上的容器。这提供了一种获取容器子集引用的机制。添加group属性会使类型为Collection<MessageListenerContainer>的 bean 注册到具有组名的上下文中。
线程和异步使用者
异步使用者涉及许多不同的线程。
当RabbitMQ Client传递新消息时,将使用SimpleMessageListener中配置的TaskExecutor的线程来调用MessageListener。如果未配置,则使用SimpleAsyncTaskExecutor。如果使用池 Actuator,请确保池大小足以处理配置的并发。
Note
使用默认的SimpleAsyncTaskExecutor时,对于调用侦听器的线程,侦听器容器beanName用作threadNamePrefix。这对日志分析很有用;通常建议在日志记录附加程序配置中始终包含线程名称。通过SimpleMessageListenerContainer上的taskExecutor属性专门提供TaskExecutor时,将按原样使用它,而无需进行修改。建议您使用类似的技术来命名由自定义TaskExecutor bean 定义创建的线程,以帮助在日志消息中标识线程。
创建连接时,在CachingConnectionFactory中配置的Executor被传递到RabbitMQ Client,并且其线程用于将新消息传递到侦听器容器。在编写本文时,如果未配置它,则 Client 端使用内部线程池执行程序,该执行程序的池大小为 5.
RabbitMQ client使用ThreadFactory为低级 I/O(套接字)操作创建线程。要修改此工厂,您需要配置基础 RabbitMQ ConnectionFactory,如名为“配置基础 Client 端连接工厂”的部分中所述。
检测空闲的异步使用者
尽管效率很高,但异步使用者的一个问题是检测它们何时处于空闲状态-如果一段时间内没有消息到达,则用户可能希望采取某些措施。
从* version 1.6 *开始,现在可以将侦听器容器配置为在一段时间没有消息传递的情况下发布ListenerContainerIdleEvent。容器空闲时,每idleEventInterval毫秒将发布一次事件。
要配置此功能,请在容器上设置idleEventInterval:
xml
<rabbit:listener-container connection-factory="connectionFactory"
...
idle-event-interval="60000"
...
>
<rabbit:listener id="container1" queue-names="foo" ref="myListener" method="handle" />
</rabbit:listener-container>
Java
@Bean
public SimpleMessageListenerContainer(ConnectionFactory connectionFactory) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(connectionFactory);
...
container.setIdleEventInterval(60000L);
...
return container;
}
@RabbitListener
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory() {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(rabbitConnectionFactory());
factory.setIdleEventInterval(60000L);
...
return factory;
}
在每种情况下,容器闲置时每分钟将发布一次事件。
Event Consumption
您可以通过实现ApplicationListener捕获这些事件-可以是常规侦听器,也可以是仅侦听仅接收此特定事件的监听器。您还可以使用 Spring Framework 4.2 中引入的@EventListener。
以下示例将@RabbitListener和@EventListener合并为一个类。重要的是要了解,应用程序侦听器将获取所有容器的事件,因此,如果您要基于哪个容器处于空闲状态采取特定的操作,则可能需要检查侦听器 ID。您也可以为此使用@EventListener condition。
事件具有 4 个属性:
source-侦听器容器实例id-侦听器 ID(或容器 Bean 名称)idleTime-事件发布时容器空闲的时间queueNames-容器侦听的队列的名称
public class Listener {
@RabbitListener(id="foo", queues="#{queue.name}")
public String listen(String foo) {
return foo.toUpperCase();
}
@EventListener(condition = "event.listenerId == 'foo'")
public void onApplicationEvent(ListenerContainerIdleEvent event) {
...
}
}
Tip
事件侦听器将看到所有容器的事件;因此,在上面的示例中,我们根据侦听器 ID 缩小了接收到的事件的范围。
Warning
如果希望使用 idle 事件停止列表器容器,则不应在调用侦听器的线程上调用container.stop()-这将导致延迟和不必要的日志消息。相反,您应该将事件传递给另一个线程,该线程可以随后停止容器。
3.1.7 消息转换器
Introduction
AmqpTemplate还定义了几种发送和接收将委派给MessageConverter的消息的方法。 MessageConverter本身非常简单。它为每个方向提供了一种方法:一种用于将消息转换成消息,而另一种用于将消息转换成消息。请注意,转换为消息时,除了对象之外,您还可以提供属性。 “对象”参数通常对应于消息正文。
public interface MessageConverter {
Message toMessage(Object object, MessageProperties messageProperties)
throws MessageConversionException;
Object fromMessage(Message message) throws MessageConversionException;
}
下面列出了AmqpTemplate上的相关消息发送方法。它们比我们之前讨论的方法更简单,因为它们不需要Message实例。相反,MessageConverter负责通过将提供的对象转换为Message主体的字节数组,然后添加任何提供的MessageProperties来“创建”每个Message。
void convertAndSend(Object message) throws AmqpException;
void convertAndSend(String routingKey, Object message) throws AmqpException;
void convertAndSend(String exchange, String routingKey, Object message)
throws AmqpException;
void convertAndSend(Object message, MessagePostProcessor messagePostProcessor)
throws AmqpException;
void convertAndSend(String routingKey, Object message,
MessagePostProcessor messagePostProcessor) throws AmqpException;
void convertAndSend(String exchange, String routingKey, Object message,
MessagePostProcessor messagePostProcessor) throws AmqpException;
在接收方,只有两种方法:一种接受队列名称,另一种依赖于已设置的模板的“ queue”属性。
Object receiveAndConvert() throws AmqpException;
Object receiveAndConvert(String queueName) throws AmqpException;
Note
称为“异步 Consumer”的部分中提到的MessageListenerAdapter也使用MessageConverter。
SimpleMessageConverter
MessageConverter策略的默认实现称为SimpleMessageConverter。如果您未明确配置替代方案,那么 RabbitTemplate 实例将使用此转换器。它处理基于文本的内容,序列化的 Java 对象和简单的字节数组。
从邮件转换
如果 ImportingMessage 的 Content Type 以“ text”开头(例如“ text/plain”),则还将检查 content-encoding 属性,以确定将 Message 主体字节数组转换为 Java String 时要使用的字符集。 。如果未在 Importing 消息上设置任何内容编码属性,则默认情况下它将使用“ UTF-8”字符集。如果需要覆盖该默认设置,则可以配置SimpleMessageConverter的实例,设置其“ defaultCharset”属性,然后将其注入RabbitTemplate实例。
如果 ImportingMessage 的 content-type 属性值设置为“ application/x-java-serialized-object”,则SimpleMessageConverter将尝试将字节数组反序列化(重新水化)为 Java 对象。虽然这可能对简单的原型制作很有用,但通常不建议您依赖 Java 序列化,因为它会导致生产者和使用者之间的紧密耦合。当然,它也排除了使用非 Java 系统的任何一方。由于 AMQP 是线级协议,因此不幸的是,由于此类限制而失去了很多优势。在接下来的两节中,我们将探讨一些无需依赖 Java 序列化即可传递富域对象内容的替代方法。
对于所有其他 Content Type,SimpleMessageConverter将直接以字节数组形式返回消息正文内容。
有关重要信息,请参见称为“ Java 反序列化”的部分。
转换为邮件
从任意 Java 对象转换为消息时,SimpleMessageConverter同样处理字节数组,字符串和可序列化的实例。它将把这些转换成字节(对于字节数组,没有任何转换),并将相应地设置 content-type 属性。如果要转换的对象与这些类型之一不匹配,则消息正文将为 null。
SerializerMessageConverter
该转换器与SimpleMessageConverter相似,不同之处在于它可以与其他 Spring Framework Serializer和Deserializer实现一起进行application/x-java-serialized-object转换配置。
有关重要信息,请参见称为“ Java 反序列化”的部分。
Jackson2JsonMessageConverter
转换为邮件
如前一节所述,通常不建议依赖 Java 序列化。 JSON(JavaScript 对象表示法)是一种更常见且更灵活且可跨不同语言和平台移植的替代方法。可以在任何RabbitTemplate实例上配置该转换器,以覆盖其对SimpleMessageConverter默认实例的使用。 Jackson2JsonMessageConverter使用com.fasterxml.jackson 2.x 库。
<bean class="org.springframework.amqp.rabbit.core.RabbitTemplate">
<property name="connectionFactory" ref="rabbitConnectionFactory"/>
<property name="messageConverter">
<bean class="org.springframework.amqp.support.converter.Jackson2JsonMessageConverter">
<!-- if necessary, override the DefaultClassMapper -->
<property name="classMapper" ref="customClassMapper"/>
</bean>
</property>
</bean>
如上所示,默认情况下Jackson2JsonMessageConverter使用DefaultClassMapper。类型信息被添加到MessageProperties(并从中检索)。如果入站邮件的MessageProperties中不包含类型信息,但是您知道所需的类型,则可以使用defaultType属性配置静态类型。
<bean id="jsonConverterWithDefaultType"
class="o.s.amqp.support.converter.Jackson2JsonMessageConverter">
<property name="classMapper">
<bean class="org.springframework.amqp.support.converter.DefaultClassMapper">
<property name="defaultType" value="foo.PurchaseOrder"/>
</bean>
</property>
</bean>
从邮件转换
根据发送系统添加到 Headers 的类型信息,将入站消息转换为对象。
在* 1.6 之前的版本中,如果不存在类型信息,则转换将失败。从 version 1.6 *开始,如果缺少类型信息,则转换器将使用 Jackson 的默认值(通常是 Map)转换 JSON。
同样,从* version 1.6 *开始,当使用@RabbitListenerComments(在方法上)时,推断的类型信息将添加到MessageProperties;这使转换器可以转换为目标方法的参数类型。仅当存在一个不带 Comments 的参数或一个带有@PayloadComments 的参数时,才适用。在分析期间会忽略类型为Message的参数。
Tip
默认情况下,推断的类型信息将覆盖发送系统创建的入站__TypeId__和相关 Headers。这允许接收系统自动转换为其他域对象。仅当参数类型是具体的(不是抽象或接口)或来自java.util包时才适用。在所有其他情况下,将使用__TypeId__和相关的 Headers。在某些情况下,您可能希望覆盖默认行为并始终使用__TypeId__信息。例如,假设您有一个带有Foo参数的@RabbitListener,但消息中包含一个Bar,它是Foo的子类(具体来说)。推断的类型将不正确。要处理这种情况,请将Jackson2JsonMessageConverter上的TypePrecedence属性设置为TYPE_ID而不是默认的INFERRED。该属性实际上位于转换器的DefaultJackson2JavaTypeMapper上,但是为方便起见,在转换器上提供了一个 setter。如果注入自定义类型 Map 器,则应改为在 Map 器上设置属性。
Note
从Message转换时,传入的MessageProperties.getContentType()必须兼容 JSON(使用逻辑contentType.contains("json"))。否则,将发出WARN日志消息Could not convert incoming message with content-type [...],并按byte[]的原样返回message.getBody()。因此,为了满足 Consumer 方面的Jackson2JsonMessageConverter要求,生产者必须添加contentType消息属性,例如作为application/json,text/x-json或者只是使用Jackson2JsonMessageConverter,它将自动设置标题。
@RabbitListener
public void foo(Foo foo) {...}
@RabbitListener
public void foo(@Payload Foo foo, @Header("amqp_consumerQueue") String queue) {...}
@RabbitListener
public void foo(Foo foo, o.s.amqp.core.Message message) {...}
@RabbitListener
public void foo(Foo foo, o.s.messaging.Message<Foo> message) {...}
@RabbitListener
public void foo(Foo foo, String bar) {...}
@RabbitListener
public void foo(Foo foo, o.s.messaging.Message<?> message) {...}
在上面的前四种情况下,转换器将尝试转换为Foo类型。第五个示例无效,因为我们无法确定哪个参数应接收消息有效负载。对于第六个示例,由于通用类型为WildcardType,因此将应用 Jackson 的默认值。
但是,您可以创建一个自定义转换器,并使用targetMethod message 属性来确定将 JSON 转换为哪种类型。
Note
仅当在方法级别声明@RabbitListenerComments 时,才能实现这种类型推断。对于类级别@RabbitListener,转换后的类型用于选择要调用的@RabbitHandler方法。因此,基础结构提供了targetObject消息属性,定制转换器可以使用该属性来确定类型。
Tip
从* version 1.6.11 *开始,Jackson2JsonMessageConverter以及DefaultJackson2JavaTypeMapper(DefaultClassMapper)提供trustedPackages选项来克服Serialization Gadgets漏洞。默认情况下,为了向后兼容,Jackson2JsonMessageConverter信任所有软件包-将*用于该选项。
MarshallingMessageConverter
另一个选择是MarshallingMessageConverter。它委派给Marshaller和Unmarshaller策略接口的 Spring OXM 库实现。您可以阅读有关该库here的更多信息。就配置而言,仅提供构造函数参数是最常见的,因为Marshaller的大多数实现也将实现Unmarshaller。
<bean class="org.springframework.amqp.rabbit.core.RabbitTemplate">
<property name="connectionFactory" ref="rabbitConnectionFactory"/>
<property name="messageConverter">
<bean class="org.springframework.amqp.support.converter.MarshallingMessageConverter">
<constructor-arg ref="someImplemenationOfMarshallerAndUnmarshaller"/>
</bean>
</property>
</bean>
ContentTypeDelegatingMessageConverter
此类是在*版本 1.4.2 *中引入的,并允许基于MessageProperties中的 content type 属性委派到特定的MessageConverter。默认情况下,如果没有contentType属性,或者没有与任何已配置的转换器匹配的值,它将委派给SimpleMessageConverter。
<bean id="contentTypeConverter" class="ContentTypeDelegatingMessageConverter">
<property name="delegates">
<map>
<entry key="application/json" value-ref="jsonMessageConverter" />
<entry key="application/xml" value-ref="xmlMessageConverter" />
</map>
</property>
</bean>
Java Deserialization
Tip
从不受信任的来源反序列化 Java 对象时,可能存在一个漏洞。
如果您接受来自content-type application/x-java-serialized-object的不可信来源的消息,则应考虑配置允许反序列化哪些程序包/类。当将SimpleMessageConverter和SerializerMessageConverter配置为隐式或通过配置使用DefaultDeserializer时,这适用于SimpleMessageConverter和SerializerMessageConverter。
默认情况下,白名单为空,这意味着将反序列化所有类。
您可以设置模式列表,例如foo.*,foo.bar.Baz或*.MySafeClass。
模式将按 Sequences 检查,直到找到匹配项。如果没有匹配项,则抛出SecurityException。
使用这些转换器上的whiteListPatterns属性设置模式。
邮件属性转换器
MessagePropertiesConverter策略接口用于在 Rabbit Client BasicProperties和 Spring AMQP MessageProperties之间进行转换。默认实现(DefaultMessagePropertiesConverter)通常可以满足大多数目的,但是您可以根据需要实现自己的实现。当大小不超过1024字节时,默认属性转换器会将LongString类型的BasicProperties元素转换为String。较大的LongString不进行转换(请参见下文)。可以使用构造函数参数来覆盖此限制。
从* version 1.6 *开始,长于长字符串限制(默认值为 1024)的 Headers 现在默认由DefaultMessagePropertiesConverter保留为LongString。您可以通过getBytes[],toString()或getStream()方法访问内容。
以前,DefaultMessagePropertiesConverter将此类 Headers“转换”为DataInputStream(实际上只是引用了LongString的DataInputStream)。在输出时,此 Headers 未转换(除非转换为字符串,例如通过在流上调用toString()来转换为[email protected])。
现在,大的传入LongStringHeaders 也可以在输出中正确“转换”(默认情况下)。
提供了一个新的构造函数,使您可以配置转换器以像以前一样工作:
/**
* Construct an instance where LongStrings will be returned
* unconverted or as a java.io.DataInputStream when longer than this limit.
* Use this constructor with 'true' to restore pre-1.6 behavior.
* @param longStringLimit the limit.
* @param convertLongLongStrings LongString when false,
* DataInputStream when true.
* @since 1.6
*/
public DefaultMessagePropertiesConverter(int longStringLimit, boolean convertLongLongStrings) { ... }
同样从* version 1.6 *开始,新属性correlationIdString已添加到MessageProperties。以前,当从 RabbitMQClient 端使用BasicProperties来回转换时,执行了不必要的byte[] <-> String转换,因为MessageProperties.correlationId是byte[]但BasicProperties使用String。 (最终,RabbitMQClient 端使用 UTF-8 将 String 转换为字节以放入协议消息中)。
为了提供最大的向后兼容性,已将新属性correlationIdPolicy添加到DefaultMessagePropertiesConverter。这需要一个DefaultMessagePropertiesConverter.CorrelationIdPolicy枚举参数。默认情况下,它设置为BYTES,它复制了以前的行为。
对于入站邮件:
STRING-仅 Map 了correlationIdString属性BYTES-仅 Map 了correlationId属性BOTH-Map 了两个属性
对于出站邮件:
STRING-仅 Map 了correlationIdString属性BYTES-仅 Map 了correlationId属性BOTH-将同时考虑这两个属性,其中 String 属性优先
同样从* version 1.6 *开始,入站deliveryMode属性不再 Map 到MessageProperties.deliveryMode,而是 Map 到MessageProperties.receivedDeliveryMode。同样,入站userId属性不再 Map 到MessageProperties.userId,而是 Map 到MessageProperties.receivedUserId。如果将相同的MessageProperties对象用于出站消息,则这些更改是为了避免这些属性的意外传播。
3.1.8 修改邮件-压缩等
存在许多扩展点,您可以在其中对消息执行某些处理,可以将其发送到 RabbitMQ 之前,也可以在接收到消息之后立即进行处理。
从第 3.1.7 节“消息转换器”可以看出,这样的扩展点位于AmqpTemplate convertAndReceive操作中,您可以在其中提供MessagePostProcessor。例如,在转换 POJO 之后,使用MessagePostProcessor可以在Message上设置自定义 Headers 或属性。
从*版本 1.4.2 *开始,附加的扩展点已添加到RabbitTemplate-setBeforePublishPostProcessors()和setAfterReceivePostProcessors()。第一个使后处理器能够在发送到 RabbitMQ 之前立即运行。使用批处理(请参见称为“批处理”的部分)时,将在组装批处理之后和发送批处理之前调用此方法。收到消息后立即调用第二个。
这些扩展点用于压缩等功能,为此,提供了多个MessagePostProcessor:
GZipPostProcessor
ZipPostProcessor
用于在发送之前压缩消息,以及
GUnzipPostProcessor
UnzipPostProcessor
用于解压缩收到的消息。
同样,SimpleMessageListenerContainer也具有setAfterReceivePostProcessors()方法,从而允许在容器接收到消息后执行解压缩。
3.1.9 请求/回复消息
Introduction
AmqpTemplate还提供了各种sendAndReceive方法,这些方法接受与单向发送操作(交换,routingKey 和 Message)相同的自变量。这些方法对于请求/答复方案非常有用,因为它们在发送之前处理必要的“答复”属性的配置,并且可以在为此目的内部创建的互斥队列上侦听答复消息。
将MessageConverter应用于请求和答复时,也可以使用类似的请求/答复方法。这些方法被命名为convertSendAndReceive。有关更多详细信息,请参见AmqpTemplate的 Javadoc。
从版本 1.5.0 *开始,每个sendAndReceive方法变体都有一个重载版本CorrelationData。与正确配置的连接工厂一起,这可以使发布者收到操作的发送方的确认。有关更多信息,请参见称为“发布者确认并返回”的部分。
Reply Timeout
默认情况下,send 和 receive 方法将在 5 秒后超时并返回 null。可以通过设置replyTimeout属性来修改。从* version 1.5 *开始,如果将mandatory属性设置为 true(或者对于特定消息,mandatory-expression的评估结果为true),则如果无法将消息传递到队列,则会抛出AmqpMessageReturnedException。此异常具有returnedMessage,replyCode,replyText属性,以及用于发送的exchange和routingKey。
Note
此功能使用发布者的return,并且可以通过将CachingConnectionFactory上的publisherReturns设置为 true 来启用此功能(请参见称为“发布者确认并返回”的部分)。另外,您一定不能在RabbitTemplate上注册自己的ReturnCallback。
RabbitMQ 直接回复
Tip
从*版本 3.4.0 *开始,RabbitMQ 服务器现在支持Direct reply-to;这消除了固定答复队列的主要原因(以避免为每个请求创建临时队列)。从 Spring AMQP 版本 1.4.1 开始 ,默认情况下将使用直接答复(如果服务器支持),而不是创建临时答复队列。如果未提供replyQueue(或将其设置为名称amq.rabbitmq.reply-to),则RabbitTemplate将自动检测是否支持直接回复,然后使用它还是使用临时回复队列。使用直接答复时,不需要reply-listener,也不应配置。
命名队列(amq.rabbitmq.reply-to除外)仍支持回复侦听器,从而可以控制回复并发等。
从* version 1.6 *版本开始,如果由于某种原因您希望为每个答复使用一个临时的,排他的,自动删除队列,请将useTemporaryReplyQueues属性设置为true。如果您设置replyAddress,则将忽略此属性。
通过将RabbitTemplate子类化并覆盖useDirectReplyTo(),可以更改是否使用直接回复的决定以使用不同的标准。该方法仅被调用一次。发送第一个请求时。
邮件与回复队列的相关性
使用固定的答复队列(不是amq.rabbitmq.reply-to)时,有必要提供相关数据,以便将答复与请求相关。参见RabbitMQ 远程过程调用(RPC)。默认情况下,标准correlationId属性将用于保存相关数据。但是,如果希望使用自定义属性来保存相关数据,则可以在\ 上设置correlation-key属性。将该属性显式设置为correlationId与省略该属性相同。当然,Client 端和服务器必须将相同的 Headers 用于关联数据。
Note
Spring AMQP 1.1 版对此数据使用了自定义属性spring_reply_correlation。如果希望使用当前版本恢复到此行为,或者为了保持与使用 1.1 的其他应用程序的兼容性,必须将属性设置为spring_reply_correlation。
回复侦听器容器
当使用* 3.4.0 *之前的 RabbitMQ 版本时,每个答复都会使用一个新的临时队列。但是,可以在模板上配置单个回复队列,这样可以提高效率,并且还可以在该队列上设置参数。但是,在这种情况下,您还必须提供\ 子元素。此元素为答复队列提供一个侦听器容器,其中模板为侦听器。<listener-container/>上允许的所有第 3.1.15 节“消息侦听器容器配置”属性都在元素上允许,但从模板配置继承的 connection-factory 和 message-converter 除外。
Tip
如果您运行应用程序的多个实例或使用多个RabbitTemplate,则每个对象都必须使用唯一的答复队列-RabbitMQ 无法从队列中选择消息,因此,如果它们都使用相同的队列,则每个实例会争夺答复,但不一定会收到自己的答复。
<rabbit:template id="amqpTemplate"
connection-factory="connectionFactory"
reply-queue="replies"
reply-address="replyEx/routeReply">
<rabbit:reply-listener/>
</rabbit:template>
尽管容器和模板共享连接工厂,但是它们不共享通道,因此不会在同一事务(如果是事务性)内执行请求和答复。
Note
在版本 1.5.0 *之前,reply-address属性不可用,始终使用默认交换和reply-queue名称作为路由键来路由答复。这仍然是默认设置,但是您现在可以指定新的reply-address属性。 reply-address可以包含格式为<exchange>/<routingKey>的地址,并且答复将被路由到指定的 exchange 并被路由到与 routing key 绑定的队列。 reply-address优先于reply-queue。 <reply-listener>必须配置为单独的<listener-container>组件,当仅使用reply-address时,无论如何reply-address和reply-queue(或<listener-container>上的queues属性)必须在逻辑上引用同一队列。
在此配置下,SimpleListenerContainer用于接收回复; RabbitTemplate是MessageListener。如上所示,当使用<rabbit:template/>名称空间元素定义模板时,解析器会将模板中的容器和连线定义为侦听器。
Note
当模板不使用固定的replyQueue(或使用直接答复-参见“ RabbitMQ 直接回复”部分)时,则不需要侦听器容器。使用 RabbitMQ * 3.4.0 *或更高版本时,直接reply-to是首选机制。
如果将RabbitTemplate定义为<bean/>,或者使用@Configuration类将其定义为@Bean,或者以编程方式创建模板,则需要自己定义并连接答复侦听器容器。如果您无法执行此操作,则模板将永远不会收到答复,并且最终将超时并返回空值作为对sendAndReceive方法的调用的答复。
从* version 1.5 *开始,RabbitTemplate将检测是否已将其配置为MessageListener以接收答复。否则,尝试发送和接收带有回复地址的消息将失败,并带有IllegalStateException(因为将永远不会收到回复)。
此外,如果使用简单的replyAddress(队列名称),则回复侦听器容器将验证它正在侦听具有相同名称的队列。如果回复地址是交换和路由密钥,则将无法执行此检查,并且将写入调试日志消息。
Tip
自己连接回复侦听器和模板时,重要的是要确保模板的replyQueue和容器的queues(或queueNames)属性引用同一队列。该模板将回复队列插入到出站邮件replyTo属性中。
以下是如何手动连接 bean 的示例。
<bean id="amqpTemplate" class="org.springframework.amqp.rabbit.core.RabbitTemplate">
<constructor-arg ref="connectionFactory" />
<property name="exchange" value="foo.exchange" />
<property name="routingKey" value="foo" />
<property name="replyQueue" ref="replyQ" />
<property name="replyTimeout" value="600000" />
</bean>
<bean class="org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer">
<constructor-arg ref="connectionFactory" />
<property name="queues" ref="replyQ" />
<property name="messageListener" ref="amqpTemplate" />
</bean>
<rabbit:queue id="replyQ" name="my.reply.queue" />
@Bean
public RabbitTemplate amqpTemplate() {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory());
rabbitTemplate.setMessageConverter(msgConv());
rabbitTemplate.setReplyQueue(replyQueue());
rabbitTemplate.setReplyTimeout(60000);
return rabbitTemplate;
}
@Bean
public SimpleMessageListenerContainer replyListenerContainer() {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory());
container.setQueues(replyQueue());
container.setMessageListener(amqpTemplate());
return container;
}
@Bean
public Queue replyQueue() {
return new Queue("my.reply.queue");
}
这个测试用例中显示了连接固定的答复队列的RabbitTemplate以及处理请求并返回答复的“远程”侦听器容器的完整示例。
Tip
当回复超时(replyTimeout)时,sendAndReceive()方法返回 null。
在版本 1.3.6 *之前,仅记录了对超时消息的最新答复。现在,如果收到延迟答复,则拒绝该答复(模板抛出AmqpRejectAndDontRequeueException)。如果将答复队列配置为将拒绝的消息发送到死信交换,则可以检索答复以供以后分析。只需使用等于答复队列名称的路由密钥将队列绑定到配置的死信交换。
有关配置无效字母的更多信息,请参考RabbitMQ 死信文档。您还可以查看FixedReplyQueueDeadLetterTests测试用例作为示例。
AsyncRabbitTemplate
- 1.6 版*引入了
AsyncRabbitTemplate。它具有与AmqpTemplate相似的sendAndReceive(和convertSendAndReceive)方法,但是它们不是阻塞而是返回ListenableFuture。
sendAndReceive方法返回RabbitMessageFuture; convertSendAndReceive方法返回RabbitConverterFuture。
您可以稍后在以后调用get()来同步检索结果,也可以注册将与结果异步调用的回调。
@Autowired
private AsyncRabbitTemplate template;
...
public void doSomeWorkAndGetResultLater() {
...
ListenableFuture<String> future = this.template.convertSendAndReceive("foo");
// do some more work
String reply = null;
try {
reply = future.get();
}
catch (ExecutionException e) {
...
}
...
}
public void doSomeWorkAndGetResultAsync() {
...
RabbitConverterFuture<String> future = this.template.convertSendAndReceive("foo");
future.addCallback(new ListenableFutureCallback<String>() {
@Override
public void onSuccess(String result) {
...
}
@Override
public void onFailure(Throwable ex) {
...
}
});
...
}
如果设置了mandatory,并且消息无法传递,则将来会抛出ExecutionException,原因为AmqpMessageReturnedException,该原因封装了返回的消息和有关返回的信息。
如果设置了enableConfirms,则将来将具有属性confirm,该属性本身是ListenableFuture<Boolean>,其中true表示发布成功。如果确认 Future 为假,则RabbitFuture将具有另一个属性nackCause-失败的原因(如果有)。
Tip
如果在回复后收到确认,则发布者确认将被丢弃-因为回复表示成功发布。
在模板上设置receiveTimeout属性以使答复超时(默认为30000-30 秒)。如果发生超时,将来将以AmqpReplyTimeoutException结束。
模板实现SmartLifecycle;在有待处理的回复时停止模板将导致待处理的Future s 被取消。
使用 AMQP 进行远程处理
Spring 框架具有一般的远程处理功能,允许远程过程调用(RPC)使用各种传输方式。 Spring-AMQP 支持类似的机制,Client 端上为AmqpProxyFactoryBean,服务器上为AmqpInvokerServiceExporter。这提供了基于 AMQP 的 RPC。在 Client 端,如上所述使用RabbitTemplate;在服务器端,调用程序(配置为MessageListener)接收消息,调用配置的服务,并使用入站消息的replyTo信息返回答复。
可以将 Client 端工厂 bean 注入到任何 bean 中(使用其serviceInterface);然后,Client 端可以调用代理上的方法,从而通过 AMQP 进行远程执行。
Note
对于默认的MessageConverter,方法参数和返回值必须是Serializable的实例。
在服务器端,AmqpInvokerServiceExporter同时具有AmqpTemplate和MessageConverter属性。当前,未使用模板的MessageConverter。如果需要提供自定义消息转换器,则应使用messageConverter属性提供它。在 Client 端,可以将自定义消息转换器添加到AmqpTemplate,使用其amqpTemplate属性将其提供给AmqpProxyFactoryBean。
Client 端和服务器配置示例如下所示。
<bean id="client"
class="org.springframework.amqp.remoting.client.AmqpProxyFactoryBean">
<property name="amqpTemplate" ref="template" />
<property name="serviceInterface" value="foo.ServiceInterface" />
</bean>
<rabbit:connection-factory id="connectionFactory" />
<rabbit:template id="template" connection-factory="connectionFactory" reply-timeout="2000"
routing-key="remoting.binding" exchange="remoting.exchange" />
<rabbit:admin connection-factory="connectionFactory" />
<rabbit:queue name="remoting.queue" />
<rabbit:direct-exchange name="remoting.exchange">
<rabbit:bindings>
<rabbit:binding queue="remoting.queue" key="remoting.binding" />
</rabbit:bindings>
</rabbit:direct-exchange>
<bean id="listener"
class="org.springframework.amqp.remoting.service.AmqpInvokerServiceExporter">
<property name="serviceInterface" value="foo.ServiceInterface" />
<property name="service" ref="service" />
<property name="amqpTemplate" ref="template" />
</bean>
<bean id="service" class="foo.ServiceImpl" />
<rabbit:connection-factory id="connectionFactory" />
<rabbit:template id="template" connection-factory="connectionFactory" />
<rabbit:queue name="remoting.queue" />
<rabbit:listener-container connection-factory="connectionFactory">
<rabbit:listener ref="listener" queue-names="remoting.queue" />
</rabbit:listener-container>
Tip
AmqpInvokerServiceExporter只能处理格式正确的消息,例如从AmqpProxyFactoryBean发送的消息。如果收到无法解释的消息,则将发送序列化的RuntimeException作为答复。如果邮件没有replyToAddress属性,则如果未配置“死信交换”,则该邮件将被拒绝并永久丢失。
Note
默认情况下,如果无法传递请求消息,则调用线程最终将超时并抛出RemoteProxyFailureException。超时默认为 5 秒,可以通过在RabbitTemplate上设置replyTimeout属性来修改。从* version 1.5 *版本开始,将mandatory属性设置为 true,并在连接工厂上启用返回(请参见称为“发布者确认并返回”的部分),调用线程将抛出AmqpMessageReturnedException。有关更多信息,请参见称为“答复超时”的部分。
3.1.10 配置代理
Introduction
AMQP 规范描述了如何使用协议在代理上配置队列,交换和绑定。这些可从 0.8 规范及更高版本移植的操作位于org.springframework.amqp.core软件包的AmqpAdmin界面中。该类的 RabbitMQ 实现位于org.springframework.amqp.rabbit.core包中的RabbitAdmin。
AmqpAdmin 界面基于使用 Spring AMQP 域抽象的基础,如下所示:
public interface AmqpAdmin {
// Exchange Operations
void declareExchange(Exchange exchange);
void deleteExchange(String exchangeName);
// Queue Operations
Queue declareQueue();
String declareQueue(Queue queue);
void deleteQueue(String queueName);
void deleteQueue(String queueName, boolean unused, boolean empty);
void purgeQueue(String queueName, boolean noWait);
// Binding Operations
void declareBinding(Binding binding);
void removeBinding(Binding binding);
Properties getQueueProperties(String queueName);
}
getQueueProperties()方法返回有关队列的一些有限信息(消息计数和使用者计数)。返回的属性的键在RabbitTemplate(QUEUE_NAME,QUEUE_MESSAGE_COUNT,QUEUE_CONSUMER_COUNT)中可用作常量。 RabbitMQ REST API在QueueInfo对象中提供了更多信息。
no-arg declareQueue()方法使用自动生成的名称在代理上定义队列。此自动生成的队列的其他属性是exclusive=true,autoDelete=true和durable=false。
declareQueue(Queue queue)方法采用Queue对象,并返回声明的队列的名称。如果提供的Queue的name属性为空 String,则代理将使用生成的名称声明队列,并将该名称返回给调用方。 Queue对象本身未更改。此功能只能通过直接调用RabbitAdmin以编程方式使用。Management 员不支持通过在应用程序上下文中声明性地定义队列来自动声明它。
这与AnonymousQueue相反,在AnonymousQueue中,框架生成唯一的(UUID)名称,并将durable设置为false和exclusive,autoDelete设置为true。具有name空属性或缺少name属性的<rabbit:queue/>将始终创建AnonymousQueue。
请参阅名为“ AnonymousQueue”的部分,以了解为什么AnonymousQueue优先于代理生成的队列名称,以及如何控制名称的格式。声明性队列必须具有固定的名称,因为它们可能在上下文中的其他地方(例如,在侦听器中)被引用:
<rabbit:listener-container>
<rabbit:listener ref="listener" queue-names="#{someQueue.name}" />
</rabbit:listener-container>
See 称为“交换,队列和绑定的自动声明”的部分.
该接口的 RabbitMQ 实现是 RabbitAdmin,当使用 Spring XML 进行配置时,它将如下所示:
<rabbit:connection-factory id="connectionFactory"/>
<rabbit:admin id="amqpAdmin" connection-factory="connectionFactory"/>
当CachingConnectionFactory缓存模式为CHANNEL(默认设置)时,RabbitAdmin实现会自动在同一ApplicationContext中声明的Queues,Exchanges和Bindings的惰性声明。向代理打开Connection时,这些组件将声明为 s0on。有一些名称空间功能使此操作非常方便,例如在“股票”samples 应用程序中,我们具有:
<rabbit:queue id="tradeQueue"/>
<rabbit:queue id="marketDataQueue"/>
<fanout-exchange name="broadcast.responses"
xmlns="http://www.springframework.org/schema/rabbit">
<bindings>
<binding queue="tradeQueue"/>
</bindings>
</fanout-exchange>
<topic-exchange name="app.stock.marketdata"
xmlns="http://www.springframework.org/schema/rabbit">
<bindings>
<binding queue="marketDataQueue" pattern="${stocks.quote.pattern}"/>
</bindings>
</topic-exchange>
在上面的示例中,我们使用匿名队列(实际上内部只是队列,其名称由框架而不是由代理生成),并通过 ID 引用它们。我们还可以使用显式名称声明 Queue,这些名称也用作上下文中其 bean 定义的标识符。例如。
<rabbit:queue name="stocks.trade.queue"/>
Tip
您可以同时提供 id 和 name 属性。这使您可以通过独立于队列名称的 ID 来引用队列(例如,在绑定中)。它还允许使用标准 Spring 功能,例如属性占位符和 SpEL 表达式作为队列名称。使用名称作为 Bean 标识符时,这些功能不可用。
可以使用其他参数配置队列,例如* x-message-ttl 或 x-ha-policy *。使用名称空间支持,它们以<rabbit:queue-arguments>元素的形式以实参名称/实参值对的 Map 的形式提供。
<rabbit:queue name="withArguments">
<rabbit:queue-arguments>
<entry key="x-ha-policy" value="all"/>
</rabbit:queue-arguments>
</rabbit:queue>
默认情况下,参数被假定为字符串。对于其他类型的参数,需要提供类型。
<rabbit:queue name="withArguments">
<rabbit:queue-arguments value-type="java.lang.Long">
<entry key="x-message-ttl" value="100"/>
</rabbit:queue-arguments>
</rabbit:queue>
提供混合类型的参数时,将为每个入口元素提供类型:
<rabbit:queue name="withArguments">
<rabbit:queue-arguments>
<entry key="x-message-ttl">
<value type="java.lang.Long">100</value>
</entry>
<entry key="x-ha-policy" value="all"/>
</rabbit:queue-arguments>
</rabbit:queue>
在 Spring Framework 3.2 和更高版本中,这可以更简洁地声明:
<rabbit:queue name="withArguments">
<rabbit:queue-arguments>
<entry key="x-message-ttl" value="100" value-type="java.lang.Long"/>
<entry key="x-ha-policy" value="all"/>
</rabbit:queue-arguments>
</rabbit:queue>
Tip
RabbitMQ 代理将不允许声明参数不匹配的队列。例如,如果一个queue已经不存在time to live参数,而您尝试使用key="x-message-ttl" value="100"对其进行声明,则将引发异常。
默认情况下,发生任何异常时,RabbitAdmin将立即停止处理所有声明。这可能会导致下游问题-例如“监听器容器”初始化失败,因为未声明另一个队列(在错误的队列之后定义)。
可以通过将RabbitAdmin上的ignore-declaration-exceptions属性设置为true来修改此行为。此选项指示RabbitAdmin记录异常,并 continue 声明其他元素。使用 Java 配置RabbitAdmin时,此属性为ignoreDeclarationExceptions。这是适用于所有元素的全局设置,队列,交换和绑定具有类似的属性,仅适用于那些元素。
在*版本 1.6 *之前,仅当通道上出现IOException时(例如,当前属性与所需属性之间不匹配时),此属性才生效。现在,此属性对任何异常(包括TimeoutException等)都生效。
此外,任何声明异常都会导致发布DeclarationExceptionEvent,这是一个ApplicationEvent,上下文中的任何ApplicationListener都可以使用它。该事件包含对 admin,正在声明的元素和Throwable的引用。
从* version 1.3 *开始,可以将HeadersExchange配置为在多个 Headers 上匹配;您还可以指定是否必须匹配任何 Headers:
<rabbit:headers-exchange name="headers-test">
<rabbit:bindings>
<rabbit:binding queue="bucket">
<rabbit:binding-arguments>
<entry key="foo" value="bar"/>
<entry key="baz" value="qux"/>
<entry key="x-match" value="all"/>
</rabbit:binding-arguments>
</rabbit:binding>
</rabbit:bindings>
</rabbit:headers-exchange>
从* version 1.6 *开始,Exchanges可以配置为internal标志(默认为false),并且可以通过RabbitAdmin在 Broker 上正确配置这样的Exchange(如果应用程序上下文中存在)。如果用于交换的internal标志是true,RabbitMQ 将不允许 Client 端使用交换。这对于无用信函交换或交换到交换绑定非常有用,在这种情况下,您不希望发行人直接使用交换。
要查看如何使用 Java 配置 AMQP 基础结构,请查看 Stock 示例应用程序,其中有@Configuration类AbstractStockRabbitConfiguration,而该类又具有RabbitClientConfiguration和RabbitServerConfiguration子类。 AbstractStockRabbitConfiguration的代码如下所示
@Configuration
public abstract class AbstractStockAppRabbitConfiguration {
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory =
new CachingConnectionFactory("localhost");
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
return connectionFactory;
}
@Bean
public RabbitTemplate rabbitTemplate() {
RabbitTemplate template = new RabbitTemplate(connectionFactory());
template.setMessageConverter(jsonMessageConverter());
configureRabbitTemplate(template);
return template;
}
@Bean
public MessageConverter jsonMessageConverter() {
return new JsonMessageConverter();
}
@Bean
public TopicExchange marketDataExchange() {
return new TopicExchange("app.stock.marketdata");
}
// additional code omitted for brevity
}
在 Stock 应用程序中,使用以下@Configuration 类配置服务器:
@Configuration
public class RabbitServerConfiguration extends AbstractStockAppRabbitConfiguration {
@Bean
public Queue stockRequestQueue() {
return new Queue("app.stock.request");
}
}
这是@Configuration类的整个继承链的结尾。最终结果是 TopicExchange 和 Queue 将在应用程序启动时声明给代理。在服务器配置中,没有将 TopicExchange 绑定到队列,这是在 Client 端应用程序中完成的。但是,库存请求队列自动绑定到 AMQP 默认交换-此行为由规范定义。
Client 端@Configuration类更加有趣,如下所示。
@Configuration
public class RabbitClientConfiguration extends AbstractStockAppRabbitConfiguration {
@Value("${stocks.quote.pattern}")
private String marketDataRoutingKey;
@Bean
public Queue marketDataQueue() {
return amqpAdmin().declareQueue();
}
/**
* Binds to the market data exchange.
* Interested in any stock quotes
* that match its routing key.
*/
@Bean
public Binding marketDataBinding() {
return BindingBuilder.bind(
marketDataQueue()).to(marketDataExchange()).with(marketDataRoutingKey);
}
// additional code omitted for brevity
}
Client 端正在通过AmqpAdmin上的declareQueue()方法声明另一个队列,并且该 Client 端使用在属性文件中外部化的路由模式将该队列绑定到市场数据交换。
用于队列和交换的 Builder API
*版本 1.6 *引入了便捷的 fluent API,用于在使用 Java 配置时配置Queue和Exchange对象:
@Bean
public Queue queue() {
return QueueBuilder.nonDurable("foo")
.autoDelete()
.exclusive()
.withArgument("foo", "bar")
.build();
}
@Bean
public Exchange exchange() {
return ExchangeBuilder.directExchange("foo")
.autoDelete()
.internal()
.withArgument("foo", "bar")
.build();
}
有关更多信息,请参见org.springframework.amqp.core.QueueBuilder和org.springframework.amqp.core.ExchangeBuilder的 javadocs。
声明交换,队列和绑定的集合
从* version 1.5 *版本开始,现在可以通过重现一个集合,用一个@Bean声明多个实体。
仅考虑第一个元素为Declarable的集合,并且仅处理此类集合中的Declarable个元素。
@Configuration
public static class Config {
@Bean
public ConnectionFactory cf() {
return new CachingConnectionFactory("localhost");
}
@Bean
public RabbitAdmin admin(ConnectionFactory cf) {
return new RabbitAdmin(cf);
}
@Bean
public DirectExchange e1() {
return new DirectExchange("e1", false, true);
}
@Bean
public Queue q1() {
return new Queue("q1", false, false, true);
}
@Bean
public Binding b1() {
return BindingBuilder.bind(q1()).to(e1()).with("k1");
}
@Bean
public List<Exchange> es() {
return Arrays.<Exchange>asList(
new DirectExchange("e2", false, true),
new DirectExchange("e3", false, true)
);
}
@Bean
public List<Queue> qs() {
return Arrays.asList(
new Queue("q2", false, false, true),
new Queue("q3", false, false, true)
);
}
@Bean
public List<Binding> bs() {
return Arrays.asList(
new Binding("q2", DestinationType.QUEUE, "e2", "k2", null),
new Binding("q3", DestinationType.QUEUE, "e3", "k3", null)
);
}
@Bean
public List<Declarable> ds() {
return Arrays.<Declarable>asList(
new DirectExchange("e4", false, true),
new Queue("q4", false, false, true),
new Binding("q4", DestinationType.QUEUE, "e4", "k4", null)
);
}
}
Tip
在某些情况下,此功能可能会导致不良的副作用,因为 Management 员必须遍历所有Collection<?> bean。从*版本 1.7.7、2.0.4 *开始,可以通过将 admin 属性declareCollections设置为false来禁用此功能。
Conditional Declaration
默认情况下,所有队列,交换和绑定都由应用程序上下文中的所有RabbitAdmin个实例(具有auto-startup="true")声明。
Note
从 1.2 版本开始,可以有条件地声明这些元素。当应用程序连接到多个代理并且需要指定应与哪个代理进行声明的特定元素时,这特别有用。
表示这些元素的类实现Declarable,它具有两种方法:shouldDeclare()和getDeclaringAdmins()。 RabbitAdmin使用这些方法来确定特定实例是否应实际处理其Connection上的声明。
这些属性可用作名称空间中的属性,如以下示例所示。
<rabbit:admin id="admin1" connection-factory="CF1" />
<rabbit:admin id="admin2" connection-factory="CF2" />
<rabbit:queue id="declaredByBothAdminsImplicitly" />
<rabbit:queue id="declaredByBothAdmins" declared-by="admin1, admin2" />
<rabbit:queue id="declaredByAdmin1Only" declared-by="admin1" />
<rabbit:queue id="notDeclaredByAny" auto-declare="false" />
<rabbit:direct-exchange name="direct" declared-by="admin1, admin2">
<rabbit:bindings>
<rabbit:binding key="foo" queue="bar"/>
</rabbit:bindings>
</rabbit:direct-exchange>
Note
auto-declare属性默认为true,如果未提供declared-by(或为空),则所有RabbitAdmin都将声明该对象(只要 Management 员的auto-startup属性为 true;默认)。
同样,您可以使用基于 Java 的@Configuration来达到相同的效果。在此示例中,组件将由admin1而不是admin2声明:
@Bean
public RabbitAdmin admin() {
RabbitAdmin rabbitAdmin = new RabbitAdmin(cf1());
rabbitAdmin.afterPropertiesSet();
return rabbitAdmin;
}
@Bean
public RabbitAdmin admin2() {
RabbitAdmin rabbitAdmin = new RabbitAdmin(cf2());
rabbitAdmin.afterPropertiesSet();
return rabbitAdmin;
}
@Bean
public Queue queue() {
Queue queue = new Queue("foo");
queue.setAdminsThatShouldDeclare(admin());
return queue;
}
@Bean
public Exchange exchange() {
DirectExchange exchange = new DirectExchange("bar");
exchange.setAdminsThatShouldDeclare(admin());
return exchange;
}
@Bean
public Binding binding() {
Binding binding = new Binding("foo", DestinationType.QUEUE, exchange().getName(), "foo", null);
binding.setAdminsThatShouldDeclare(admin());
return binding;
}
AnonymousQueue
通常,当需要唯一命名的,排他的自动删除队列时,建议使用AnonymousQueue代替代理定义的队列名称(使用""作为Queue名称将导致代理生成队列名称)。
这是因为:
构建与代理的连接时,实际上会声明队列。这些 bean 创建并连接在一起很长时间之后;使用队列的 bean 需要知道其名称。实际上,启动应用程序时,代理甚至可能没有运行。
如果由于某种原因失去了与代理的连接,则 Management 员将重新声明具有相同名称的
AnonymousQueue。如果使用代理声明的队列,则队列名称将更改。
从* version 1.5.3 *开始,您可以控制AnonymousQueue s 使用的队列名称的格式。
默认情况下,队列名称是UUID的字符串表示形式;例如:07afcfe9-fe77-4983-8645-0061ec61a47a。
您现在可以在构造函数参数中提供AnonymousQueue.NamingStrategy实现:
@Bean
public Queue anon1() {
return new AnonymousQueue(new AnonymousQueue.Base64UrlNamingStrategy());
}
@Bean
public Queue anon2() {
return new AnonymousQueue(new AnonymousQueue.Base64UrlNamingStrategy("foo-"));
}
第一个将生成以spring.gen-为前缀的队列名称,后跟UUID的 base64 表示形式,例如spring.gen-MRBv9sqISkuCiPfOYfpo4g。第二个将生成以foo-为前缀的队列名称,后跟UUID的 base64 表示形式。
base64 编码使用 RFC 4648 中的“ URL 和文件名安全字母”;尾随的填充字符(=)被删除。
您可以提供自己的命名策略,从而可以在队列名称中包含其他信息(例如,应用程序,Client 端主机)。
从* version 1.6 *开始,可以在使用 XML 配置时指定命名策略。 naming-strategy属性存在于实现AnonymousQueue.NamingStrategy的 Bean 引用的<rabbit:queue>元素上。
<rabbit:queue id="uuidAnon" />
<rabbit:queue id="springAnon" naming-strategy="springNamer" />
<rabbit:queue id="customAnon" naming-strategy="customNamer" />
<bean id="springNamer" class="org.springframework.amqp.core.AnonymousQueue.Base64UrlNamingStrategy" />
<bean id="customNamer" class="org.springframework.amqp.core.AnonymousQueue.Base64UrlNamingStrategy">
<constructor-arg value="custom.gen-" />
</bean>
第一个使用 UUID 的字符串表示形式创建名称。第二个创建类似spring.gen-MRBv9sqISkuCiPfOYfpo4g的名称。第三个创建类似custom.gen-MRBv9sqISkuCiPfOYfpo4g的名称。
当然,您可以提供自己的命名策略 bean。
3.1.11 邮件交换延迟
- 1.6 版*引入了对延迟的消息交换插件的支持
Note
该插件目前被标记为实验性,但已经可用了一年多的时间(在撰写本文时)。如果需要更改插件,我们将在可行的情况下尽快添加对此类更改的支持。因此,Spring AMQP 中的这种支持也应视为试验性的。此功能已通过 RabbitMQ 3.6.0 和插件的 0.0.1 版进行了测试。
要使用RabbitAdmin声明延迟交换,只需将交换 bean 上的delayed属性设置为 true。 RabbitAdmin将使用交换类型(Direct,Fanout等)来设置x-delayed-type参数,并使用x-delayed-message类型声明交换。
使用 XML 配置交换 bean 时,delayed属性(默认false)也可用。
<rabbit:topic-exchange name="topic" delayed="true" />
要发送延迟的消息,只需通过MessageProperties设置x-delayHeaders 即可:
MessageProperties properties = new MessageProperties();
properties.setDelay(15000);
template.send(exchange, routingKey,
MessageBuilder.withBody("foo".getBytes()).andProperties(properties).build());
or
rabbitTemplate.convertAndSend(exchange, routingKey, "foo", new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setDelay(15000);
return message;
}
});
要检查消息是否延迟,请使用MessageProperties上的getReceivedDelay()方法。这是一个单独的属性,可以避免意外传播到由 Importing 消息生成的输出消息。
3.1.12 RabbitMQ REST API
启用 Management 插件后,RabbitMQ 服务器将公开 REST API 来监视和配置代理。现在提供了API 的 Java 绑定。通常,您可以直接使用该 API,但是提供了一个方便包装器,以将熟悉的 Spring AMQP Queue,Exchange和Binding域对象与该 API 一起使用。直接使用com.rabbitmq.http.client.Client API(分别为QueueInfo,ExchangeInfo和BindingInfo)时,这些对象可获得更多信息。 RabbitManagementTemplate提供以下操作:
public interface AmqpManagementOperations {
void addExchange(Exchange exchange);
void addExchange(String vhost, Exchange exchange);
void purgeQueue(Queue queue);
void purgeQueue(String vhost, Queue queue);
void deleteQueue(Queue queue);
void deleteQueue(String vhost, Queue queue);
Queue getQueue(String name);
Queue getQueue(String vhost, String name);
List<Queue> getQueues();
List<Queue> getQueues(String vhost);
void addQueue(Queue queue);
void addQueue(String vhost, Queue queue);
void deleteExchange(Exchange exchange);
void deleteExchange(String vhost, Exchange exchange);
Exchange getExchange(String name);
Exchange getExchange(String vhost, String name);
List<Exchange> getExchanges();
List<Exchange> getExchanges(String vhost);
List<Binding> getBindings();
List<Binding> getBindings(String vhost);
List<Binding> getBindingsForExchange(String vhost, String exchange);
}
有关更多信息,请参考 javadocs。
3.1.13 异常处理
RabbitMQ JavaClient 端的许多操作都可能引发已检查的异常。例如,在很多情况下,可能会引发 IOExceptions。 RabbitTemplate,SimpleMessageListenerContainer 和其他 Spring AMQP 组件将捕获这些 Exception,并将其转换为我们的运行时层次结构中的 Exception 之一。这些在* org.springframework.amqp *包中定义,并且 AmqpException 是层次结构的基础。
当侦听器引发异常时,它将包裹在ListenerExecutionFailedException中,通常,消息将被代理拒绝并重新排队。将defaultRequeueRejected设置为 false 将导致消息被丢弃(或路由到无效信件交换)。如称为“消息侦听器和异步情况”的部分中所述,侦听器可以抛出AmqpRejectAndDontRequeueException以有条件地控制此行为。
但是,存在一类错误,侦听器无法控制该行为。当遇到无法转换的消息(例如无效的content_encoding头)时,在消息到达用户代码之前会引发一些异常。将defaultRequeueRejected设置为true(默认值),此类消息将一遍又一遍地传递。在*版本 1.3.2 *之前,用户需要编写自定义ErrorHandler,如第 3.1.13 节“异常处理”中所述,以避免这种情况。
从* version 1.3.2 *开始,默认的ErrorHandler现在是ConditionalRejectingErrorHandler,它将拒绝(而不是重新排队)由于不可恢复的错误而失败的消息:
o.s.amqp...MessageConversionExceptiono.s.messaging...MessageConversionExceptiono.s.messaging...MethodArgumentNotValidExceptiono.s.messaging...MethodArgumentTypeMismatchExceptionjava.lang.NoSuchMethodExceptionjava.lang.ClassCastException
使用MessageConverter转换传入消息有效负载时,可以引发第一个。如果 Map 到@RabbitListener方法时需要其他转换,则转换服务可能会抛出第二个错误。如果在侦听器中使用了验证(例如@Valid)并且验证失败,则可能会抛出第三个。如果将入站消息转换为对目标方法不正确的类型,则可能会抛出第四个错误。例如,将参数声明为Message<Foo>,但接收到Message<Bar>。
在*版本 1.6.3 *中添加了第五和第六。
可以使用FatalExceptionStrategy配置此错误处理程序的实例,以便用户可以提供自己的条件消息拒绝规则,例如从 Spring Retry(称为“消息侦听器和异步情况”的部分)到BinaryExceptionClassifier的委托实现。此外,ListenerExecutionFailedException现在具有failedMessage属性,可以在决策中使用该属性。如果FatalExceptionStrategy.isFatal()方法返回true,则错误处理程序将抛出AmqpRejectAndDontRequeueException。当确定异常是致命的时,默认值FatalExceptionStrategy会记录一条警告消息。
从*版本 1.6.3 *开始,将用户异常添加到致命列表的便捷方法是子类ConditionalRejectingErrorHandler.DefaultExceptionStrategy并重写方法isUserCauseFatal(Throwable cause)以针对致命异常返回 true。
3.1.14 Transactions
Introduction
Spring Rabbit 框架支持同步和异步用例中的自动事务 Management,具有许多不同的语义,可以pass 语句方式选择这些语义,这是 Spring 事务的现有用户所熟悉的。这使许多(如果不是大多数)常见的消息传递模式非常易于实现。
有两种方法可以向框架发出所需的事务语义。在RabbitTemplate和SimpleMessageListenerContainer中都有一个标志channelTransacted,如果为 true,则指示框架使用事务通道并根据结果以提交或回滚来结束所有操作(发送或接收),并带有表示回滚的异常。 。另一个 signal 是使用 Spring 的PlatformTransactionManager实现之一提供外部事务,作为正在进行的操作的上下文。如果在框架发送或接收消息时已经有一个事务在进行中,并且channelTransacted标志为 true,则将消息事务的提交或回滚推迟到当前事务结束为止。如果channelTransacted标志为 false,则没有事务语义适用于消息传递操作(它是自动确认的)。
channelTransacted标志是配置时间设置:创建 AMQP 组件时,通常在应用程序启动时声明并处理一次。原则上,外部事务是动态的,因为系统会在运行时响应当前的线程状态,但实际上,当将事务声明性地分层到应用程序时,外部事务通常也是配置设置。
对于带有RabbitTemplate的同步用例,外部事务由调用方根据喜好以声明性或强制性方式提供(通常的 Spring 事务模型)。声明性方法的示例(通常首选,因为它是非侵入性的),其中模板已使用channelTransacted=true配置:
@Transactional
public void doSomething() {
String incoming = rabbitTemplate.receiveAndConvert();
// do some more database processing...
String outgoing = processInDatabaseAndExtractReply(incoming);
rabbitTemplate.convertAndSend(outgoing);
}
在标记为@Transactional 的方法内,将 String 有效负载作为消息主体进行接收,转换和发送,因此,如果数据库处理因异常而失败,则传入消息将返回给代理,而传出消息将不会被发送。这适用于在 Transaction 方法链中使用RabbitTemplate进行的任何操作(例如,除非直接操纵Channel以尽早提交 Transaction)。
对于带有SimpleMessageListenerContainer的异步用例,如果需要外部事务,则容器在设置侦听器时必须请求它。为了表明需要进行外部 Transaction,用户在配置容器后向其提供PlatformTransactionManager的实现。例如:
@Configuration
public class ExampleExternalTransactionAmqpConfiguration {
@Bean
public SimpleMessageListenerContainer messageListenerContainer() {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(rabbitConnectionFactory());
container.setTransactionManager(transactionManager());
container.setChannelTransacted(true);
container.setQueueName("some.queue");
container.setMessageListener(exampleListener());
return container;
}
}
在上面的示例中,添加了事务 Management 器作为从另一个 bean 定义(未显示)注入的依赖项,并且channelTransacted标志也设置为 true。结果是,如果侦听器因异常而失败,则事务将回滚,并且消息也将返回给代理。重要的是,如果事务提交失败(例如,数据库约束错误或连接问题),则 AMQP 事务也将回滚,并将消息返回给代理。这有时被称为“尽力而为第一阶段提交”,是可靠消息传递的一种非常强大的模式。如果在上面的示例中将channelTransacted标志设置为 false(这是默认设置),则仍将为侦听器提供外部事务,但是所有消息传递操作将被自动确认,因此结果是即使提交消息传递操作也是如此在业务操作上回滚。
Conditional Rollback
在版本 1.6.6 *之前,使用外部事务 Management 器(例如 JDBC)时,将回滚规则添加到容器的transactionAttribute无效;异常总是回滚事务。
另外,在容器的通知链中使用transaction advice时,条件回滚不是很有用,因为所有侦听器异常都包装在ListenerExecutionFailedException中。
第一个问题已得到纠正,现在可以正确应用规则。此外,现在提供了ListenerFailedRuleBasedTransactionAttribute;它是RuleBasedTransactionAttribute的子类,唯一的区别是它知道ListenerExecutionFailedException并将该异常的原因用于规则。该 Transaction 属性可以直接在容器中使用,也可以通过 Transaction 通知使用。
使用此规则的示例如下:
@Bean
public AbstractMessageListenerContainer container() {
...
container.setTransactionManager(transactionManager);
RuleBasedTransactionAttribute transactionAttribute =
new ListenerFailedRuleBasedTransactionAttribute();
transactionAttribute.setRollbackRules(Collections.singletonList(
new NoRollbackRuleAttribute(DontRollBackException.class)));
container.setTransactionAttribute(transactionAttribute);
...
}
关于回滚收到的邮件的 Comments
AMQP 事务仅适用于发送给代理的消息和确认,因此,在对 Spring 事务进行回滚并且已接收到消息时,Spring AMQP 要做的不仅是回滚事务,而且还手动拒绝消息(有点小问题,但这不是规范所称的)。对消息拒绝采取的操作与事务无关,并且取决于defaultRequeueRejected属性(默认为true)。有关拒绝失败消息的更多信息,请参阅称为“消息侦听器和异步情况”的部分。
有关 RabbitMQ 事务及其限制的更多信息,请参阅RabbitMQbroker 语义。
Note
在 RabbitMQ 2.7.0 之前,此类消息(以及通道关闭或中止时未确认的任何消息)在 Rabbit Broker 上排在队列的后面,因为 2.7.0 版以来,被拒绝的消息都在前面与 JMS 回滚消息的方式类似。
Note
本地事务之间和提供TransactionManager时,事务回滚时的消息重新排队不一致。在前一种情况下,将应用常规的重新排队逻辑(AmqpRejectAndDontRequeueException或defaultRequeueRejected=false)(请参阅称为“消息侦听器和异步情况”的部分);使用事务 Management 器,该消息将在回滚时无条件重新排队。从* version 1.7.1 *开始,可以通过将容器的alwaysRequeueWithTxManagerRollback属性设置为false来启用一致的行为;在 2.0 中默认为false。参见第 3.1.15 节“消息侦听器容器配置”。
使用 RabbitTransactionManager
RabbitTransactionManager是在外部事务内执行并与外部事务同步的 Rabbit 操作的替代方法。该事务 Management 器是PlatformTransactionManager接口的实现,应与单个 Rabbit ConnectionFactory 一起使用。
Tip
此策略无法提供 XA 事务,例如为了在消息传递和数据库访问之间共享事务。
需要应用程序代码来通过ConnectionFactoryUtils.getTransactionalResourceHolder(ConnectionFactory, boolean)而不是随后的 Channel 创建一个标准Connection.createChannel()来通过ConnectionFactoryUtils.getTransactionalResourceHolder(ConnectionFactory, boolean)检索事务型 Rabbit 资源。使用 Spring AMQP 的RabbitTemplate时,它将自动检测线程绑定的 Channel 并自动参与其事务。
使用 Java 配置,您可以使用以下命令设置新的 RabbitTransactionManager:
@Bean
public RabbitTransactionManager rabbitTransactionManager() {
return new RabbitTransactionManager(connectionFactory);
}
如果您更喜欢使用 XML 配置,请在 XML Application Context 文件中声明以下 bean:
<bean id="rabbitTxManager"
class="org.springframework.amqp.rabbit.transaction.RabbitTransactionManager">
<property name="connectionFactory" ref="connectionFactory"/>
</bean>
3.1.15 邮件侦听器容器配置
用于配置与 Transaction 和服务质量有关的SimpleMessageListenerContainer的选项很多,其中一些彼此交互。
下表显示了使用命名空间配置<rabbit:listener-container/>时的容器属性名称及其等效属性名称(在括号中)。
命名空间未公开某些属性。由N/A表示的属性。
表 3.3. 消息侦听器容器的配置选项
| Property (Attribute) | Description |
|---|---|
(group) |
仅在使用名称空间时才可用。指定后,将使用该名称注册类型为Collection<MessageListenerContainer>的 bean,并将每个<listener/>元素的容器添加到集合中。例如,这允许通过遍历集合来启动/停止容器组。如果多个<listener-container/>元素具有相同的组值,则集合中的容器是所有指定容器的集合。 |
| channelTransacted | |
(channel-transacted) |
布尔值标志,表示应在事务中(手动或自动)确认所有消息 |
| acknowledgeMode (确认) |
NONE =将不发送任何 signal(与channelTransacted=true不兼容)。 RabbitMQ 之所以称其为“自动确认”,是因为代理假定所有消息都已确认,而无需使用者采取任何措施。MANUAL =侦听器必须通过调用Channel.basicAck()来确认所有消息。AUTO =容器将自动确认该消息,除非MessageListener引发异常。请注意,acknowledgeMode是 channelTransacted 的补充-如果处理了通道,则代理除了确认外还需要提交通知。这是默认模式。另请参见txSize。 |
| transactionManager (事务 Management 器) |
用于侦听器操作的外部事务 Management 器。也是 channelTransacted 的补充-如果Channel被 Transaction,则其事务将与外部事务同步。 |
| prefetchCount (预取) |
在一个套接字框架中从代理接受的消息数。越高,消息传递的速度越快,但是非 Sequences 处理的风险也越高。忽略acknowledgeMode是否为 NONE。如有必要,它将增加以匹配txSize。 |
| shutdownTimeout (N/A) |
容器关闭时(例如,其封闭的ApplicationContext已关闭),它将 await 处理机上消息直至达到此限制。默认为 5 秒。 |
 |
|
| forceCloseChannel (N/A) |
如果使用者未在shutdownTimeout内响应关闭,则为true,则通道将关闭,从而导致任何未确认的消息重新排队。默认值false。 |
| txSize (transaction-size) |
与acknowledgeMode AUTO 一起使用时,容器将尝试处理多达此数量的消息,然后再发送 ack(await 每个消息直到接收超时设置)。这也是在提交 TransactionChannel 时的情况。如果prefetchCount小于txSize,它将增加以匹配txSize。 |
| receiveTimeout (接收超时) |
await 每条消息的最长时间。如果 replyMode = NONE,则影响很小-容器只是旋转并要求另一条消息。对于具有txSize > 1的事务Channel,它具有最大的影响,因为它可能导致已经超时的过期之前未确认已消耗的消息。 |
| autoStartup (自动启动) |
标志,指示容器应在ApplicationContext执行时启动(作为SmartLifecycle回调的一部分,该回调在所有 bean 初始化之后发生)。默认值为 true,但是如果您的代理在启动时可能不可用,则将其设置为 false,然后在您知道代理已准备好时,稍后手动调用start()。 |
| phase (阶段) |
当 autoStartup 为 true 时,此容器应在其中启动和停止的生命周期阶段。值越低,此容器将越早启动,而其停止就越晚。默认值为 Integer.MAX_VALUE,表示容器将尽可能晚地启动并尽快停止。 |
| adviceChain (advice-chain) |
适用于侦听器执行的 AOP Advice 数组。这可以用于解决其他交叉问题,例如在 broker 死亡的情况下自动重试。请注意,只要代理仍然存在,则由CachingConnectionFactory处理 AMQP 错误后的简单重新连接。 |
| taskExecutor (task-executor) |
对用于执行侦听器调用程序的 Spring TaskExecutor(或标准 JDK 1.5 Executor)的引用。默认是使用内部托管线程的 SimpleAsyncTaskExecutor。 |
| errorHandler (错误处理程序) |
对 ErrorHandler 策略的引用,该策略用于处理在 MessageListener 执行期间可能发生的任何未捕获的异常。默认值:ConditionalRejectingErrorHandler |
| concurrentConsumers (并发) |
每个侦听器最初启动的并发使用者数。参见第 3.1.16 节“侦听器并发”。 |
| maxConcurrentConsumers (max-concurrency) |
根据需要启动的并发使用者的最大数量。必须大于或等于* concurrentConsumers *。参见第 3.1.16 节“侦听器并发”。 |
| concurrency (不适用) |
m-n每个侦听器的并发使用者范围(最小,最大)。如果仅提供n,则n是固定数量的使用者。参见第 3.1.16 节“侦听器并发”。 |
| consumerStartTimeout (N/A) |
await 使用者线程启动的时间(以毫秒为单位)。如果这段时间过去,则会写入错误日志;例如,如果配置的taskExecutor没有足够的线程来支持容器concurrentConsumers,则可能发生这种情况。参见称为“线程和异步使用者”的部分。默认值 60000(60 秒)。 |
| startConsumerMin Interval (min-start-interval) |
以毫秒为单位启动每个新 Consumer 之前必须经过的时间。参见第 3.1.16 节“侦听器并发”。默认值 10000(10 秒)。 |
| stopConsumerMinInterval (min-stop-interval) |
在检测到一个空闲的使用者之后,从停止最后一个使用者以来,在停止使用者之前必须经过的时间(以毫秒为单位)。参见第 3.1.16 节“侦听器并发”。默认值 60000(1 分钟)。 |
| consecutiveActiveTrigger (min-conecutive-active) |
在考虑启动新使用者时,使用者接收到的连续消息的最小数量,并且没有发生接收超时。还受* txSize *影响。参见第 3.1.16 节“侦听器并发”。默认值 10 |
| consecutiveIdleTrigger (最小连续空闲) |
Consumer 在考虑停止 Consumer 之前必须经历的最小接收超时数。还受* txSize *影响。参见第 3.1.16 节“侦听器并发”。默认值 10 |
| connectionFactory (连接工厂) |
对ConnectionFactory的引用;使用 XML 名称空间进行配置时,默认引用的 bean 名称为“ rabbitConnectionFactory”。 |
| defaultRequeueRejected (requeue-rejected) |
确定是否应重新排队因为侦听器引发异常而被拒绝的消息。默认* true *。 |
| recoveryInterval (recovery-interval) |
确定由于非致命性原因而无法启动 Consumer 的尝试之间的时间间隔(以毫秒为单位)。默认值* 5000 *。与recoveryBackOff互斥。 |
| recoveryBackOff (恢复后退) |
将BackOff指定为启动 Consumer 的两次尝试之间的间隔(如果该 Consumer 由于非致命原因而无法启动)。默认值为FixedBackOff,每 5 秒无限制重试。与recoveryInterval互斥。 |
| exclusive (独占) |
确定此容器中的单个使用者是否具有对队列的独占访问权。如果为真,则容器的并发性必须为 1.如果另一个使用者具有独占访问权,则容器将根据recovery-interval或recovery-back-off尝试恢复该使用者。使用命名空间时,此属性与队列名称一起显示在\ <>元素上。默认* false *。 |
| rabbitAdmin (admin) |
当侦听器容器侦听至少一个自动删除队列并且在启动过程中被发现丢失时,该容器将使用RabbitAdmin声明队列以及任何相关的绑定和交换。如果将此类元素配置为使用条件声明(请参见称为“有条件的声明”的部分),则容器必须使用配置为声明这些元素的 Management 员。在此处指定该 Management 员;仅在将自动删除队列与条件声明一起使用时才需要。如果您不希望在启动容器之前声明自动删除队列,请在 Management 员上将auto-startup设置为false。缺省为RabbitAdmin,它将声明所有非条件元素。 |
| missingQueuesFatal (missing-queues-fatal) |
从*版本 1.3.5 *开始,SimpleMessageListenerContainer具有此新属性。设置为 true(默认)时,如果代理上没有配置的队列可用,则认为这是致命的。这会导致应用程序上下文在启动期间无法初始化;同样,在容器运行时删除队列时,默认情况下,使用者将进行 3 次重试以连接到队列(间隔为 5 秒),并在尝试失败时停止容器。这在以前的版本中不可配置。 设置为 false时,在进行 3 次重试后,容器将进入恢复模式,并出现其他问题,例如代理关闭。容器将尝试根据recoveryInterval属性进行恢复。在每次恢复尝试期间,每个使用者将再次尝试 4 次,以 5 秒为间隔被动声明队列。此过程将无限期 continue。您还可以使用属性 bean 来为所有容器全局设置属性,如下所示: <util:properties id="spring.amqp.global.properties"> <prop key="smlc.missing.queues.fatal">false</prop> </util:properties> 此全局属性将不会应用于设置了明确的 missingQueuesFatal属性的任何容器。可以使用以下属性覆盖默认的重试属性(每 5 秒重试 3 次)。 |
| mismatchedQueuesFatal (mismatched-queues-fatal) |
在*版本 1.6 *中添加了它。容器启动时,如果此属性为 true(默认值:false),则容器将检查上下文中声明的所有队列是否与代理上已经存在的队列兼容。如果存在不匹配的属性(例如auto-delete)或参数(例如x-message-ttl),则容器(和应用程序上下文)将不会以致命异常开头。如果在恢复过程中(例如在丢失连接后)检测到问题,则容器将被停止。 应用程序上下文中必须有一个 RabbitAdmin(或使用rabbitAdmin属性在容器上专门配置的一个);否则,此属性必须为false。 |
Note
如果代理在初始启动期间不可用,则容器将启动,并且在构建连接时将检查条件。
[!TIP]
将针对上下文中的所有队列进行检查,而不仅仅是对特定侦听器配置为使用的队列进行检查。如果希望将检查限制为仅由容器使用的队列,则应为容器配置单独的RabbitAdmin,并使用rabbitAdmin属性提供对其的引用。有关更多信息,请参见称为“有条件的声明”的部分。
|
|possibleAuthenticationFailureFatal
> (可能的身份验证失败致命消息)|设置为true(默认值)时,如果在连接过程中抛出PossibleAuthenticationFailureException,则认为是致命的。这会导致应用程序上下文在启动期间无法初始化。
> 从*版本 1.7.4 开始。
> 设置为false时,在进行 3 次重试后,容器将进入恢复模式,并出现其他问题,例如代理关闭。容器将尝试根据recoveryInterval属性进行恢复。在每次恢复尝试期间,每个使用者将再次尝试 4 次以启动。此过程将无限期地 continue。
|autoDeclare
> (自动声明)|从版本 1.4 开始,SimpleMessageListenerContainer具有此新属性。
> 设置为true(默认值)时,如果容器在启动过程中检测到至少缺少一个队列,则可能会使用RabbitAdmin重新声明所有 AMQP 对象(队列,交换,绑定),可能是因为它是auto-delete或已过期队列,但是如果队列由于某种原因丢失,将 continue 进行重新声明。若要禁用此行为,请将此属性设置为false。请注意,如果缺少所有队列,容器将无法启动。
> [!NOTE]
在 1.6 版之前,如果上下文中有多个 Management 员,则容器将随机选择一个。如果没有 Management 员,它将在内部创建一个。无论哪种情况,都可能导致意外结果。从 version 1.6 开始,要使autoDeclare起作用,上下文中必须恰好有一个RabbitAdmin,或者必须使用rabbitAdmin属性在容器上配置对特定实例的引用。
|
|declarationRetries
> (declaration-retries)|从版本 1.4.3,1.3.9 *开始,SimpleMessageListenerContainer具有此新属性。 * 1.5.x 版本中提供了 namespace 属性。
> 被动队列声明失败时的重试尝试次数。被动队列声明发生在使用者启动时,或者在从多个队列中消费时,在初始化期间并非所有队列都可用时。重试用尽后,如果无法(由于任何原因)被动声明任何已配置队列,则容器行为由上面的'missingQueuesFatal+1611++1612++1613++1616++1619++1620+`可以将容器配置为使用一致的消息拒绝行为,而不管是否配置了事务 Management 器。
3.1.16 侦听器并发
默认情况下,侦听器容器将启动一个使用者,该使用者将从队列中接收消息。
在检查上一节中的表时,您将看到许多控制并发性的属性/属性。最简单的是concurrentConsumers,它仅创建(固定)数量的使用者,该使用者将同时处理消息。
在*版本 1.3.0 *之前,这是唯一可用的设置,必须停止容器并再次启动容器才能更改设置。
从*版本 1.3.0 *开始,您现在可以动态调整concurrentConsumers属性。如果在容器运行时更改它,则将根据需要添加或删除使用者,以适应新设置。
此外,已添加新属性maxConcurrentConsumers,并且容器将根据工作负载动态调整并发性。这与四个附加属性一起工作:consecutiveActiveTrigger,startConsumerMinInterval,consecutiveIdleTrigger,stopConsumerMinInterval。使用默认设置,增加使用方的算法如下:
如果尚未达到maxConcurrentConsumers且现有使用者已连续 10 个周期处于活动状态,并且自启动最后一个使用者以来至少经过了 10 秒钟,则将启动新使用者。如果 Consumer 在txSize * receiveTimeout毫秒内收到至少一条消息,则认为该 Consumer 处于活动状态。
在默认设置下,减少使用方的算法如下:
如果运行的concurrentConsumers个以上,并且使用方检测到 10 个连续超时(空闲),并且最后一个使用方在至少 60 秒前停止,则使用方将被停止。超时取决于receiveTimeout和txSize属性。如果使用者在txSize * receiveTimeout毫秒内未收到任何消息,则认为该使用者处于空闲状态。因此,在默认超时(1 秒)和txSize为 4 的情况下,将在 40 秒的空闲时间后考虑停止使用程序(4 个超时对应于 1 个空闲检测)。
Note
实际上,只有整个容器闲置一段时间后,Consumer 才会停止使用。这是因为 broker 将在所有活跃的 Consumer 之间共享其工作。
3.1.17 独家 Consumer
同样从* version 1.3 *开始,可以为侦听器容器配置一个单独的使用者。这样可以防止其他容器从队列中使用,直到当前使用方被取消为止。这样的容器的并发必须为 1.
使用独占使用者时,其他容器将根据recoveryInterval属性尝试从队列中进行消耗,如果尝试失败,则记录警告。
3.1.18 侦听器容器队列
*版本 1.3 *引入了许多改进,以处理侦听器容器中的多个队列。
必须将容器配置为侦听至少一个队列。以前也是如此,但是现在可以在运行时添加和删除队列。处理完任何预提取的消息后,容器将回收(取消并重新创建)使用者。请参见方法addQueues,addQueueNames,removeQueues和removeQueueNames。删除队列时,必须至少保留一个队列。
使用者现在可以在任何队列可用的情况下启动-以前,如果任何队列不可用,容器将停止。现在,只有在没有可用队列的情况下才是这种情况。如果并非所有队列都可用,则容器将尝试每 60 秒被动声明(并消耗)丢失的队列。
同样,如果使用者从代理收到取消通知(例如,如果删除队列),则该使用者将尝试恢复,并且恢复的使用者将 continue 处理来自任何其他已配置队列的消息。以前,取消一个队列会取消整个使用方,最终,由于缺少队列,容器将停止。
如果希望永久删除队列,则应在删除队列之前或之后更新容器,以避免将来尝试从中使用该容器。
3.1.19 弹性:从错误和代理失败中恢复
Introduction
Spring AMQP 提供的一些关键(也是最流行的)高级功能与协议错误或代理失败时的恢复和自动重新连接有关。我们已经在本指南中看到了所有相关组件,但是应该有助于将它们放在一起,并分别指出功能和恢复方案。
主要重新连接功能由CachingConnectionFactory本身启用。使用RabbitAdmin自动声明功能通常也很有益。另外,如果您关心保证交付,则可能还需要在RabbitTemplate和SimpleMessageListenerContainer中使用channelTransacted标志,在SimpleMessageListenerContainer中也使用AcknowledgeMode.AUTO(如果是您自己动手,也可以使用手册)。
自动声明交换,队列和绑定
RabbitAdmin组件可以在启动时声明交换,队列和绑定。它通过ConnectionListener懒惰地执行此操作,因此,如果启动时不存在代理,则无关紧要。第一次使用Connection(例如,通过发送消息)时,监听器将触发并应用 Management 功能。在侦听器中执行自动声明的另一个好处是,如果由于任何原因(例如代理死亡,网络故障等)而断开连接,则在重新构建连接时将再次应用它们。
Note
以这种方式声明的队列必须具有固定名称;由框架明确声明或由AnonymousQueue s 生成。匿名队列是非持久的,独占的和自动删除的。
Tip
仅当CachingConnectionFactory缓存模式为CHANNEL(默认设置)时才执行自动声明。存在此限制是因为排他队列和自动删除队列绑定到该连接。
同步操作失败和重试选项
如果您使用RabbitTemplate(例如)以同步 Sequences 失去与代理的连接,那么 Spring AMQP 将抛出AmqpException(通常但并非总是AmqpIOException)。我们不会试图掩盖存在问题的事实,因此您必须能够捕获并响应异常。如果您怀疑连接丢失并且不是您的错,那么最简单的操作就是再次尝试该操作。您可以手动执行此操作,也可以查看使用 Spring Retry 处理(命令式或声明式)重试。
Spring Retry 提供了几个 AOP 拦截器,并提供了很大的灵 Active 来指定重试的参数(尝试次数,异常类型,退避算法等)。 Spring AMQP 还为 AMQP 用例提供了一种方便的工厂 bean,以方便的形式创建 Spring Retry 拦截器,并带有强类型的回调接口,可用于实现自定义恢复逻辑。有关更多详细信息,请参见StatefulRetryOperationsInterceptor和StatelessRetryOperationsInterceptor的 Javadocs 和属性。如果没有事务或在重试回调中启动了事务,则 Stateless 重试是合适的。请注意,Stateless 重试比有状态重试更易于配置和分析,但是如果存在正在进行的事务必须回滚或肯定要回滚,则通常不适合使用。在事务中间断开连接应该具有与回滚相同的效果,因此对于重新连接(在较高的堆栈上启动事务开始),有状态重试通常是最佳选择。
从* version 1.3 *开始,提供了一个构建器 API,以帮助使用 Java(或在@Configuration类中)组装这些拦截器,例如:
@Bean
public StatefulRetryOperationsInterceptor interceptor() {
return RetryInterceptorBuilder.stateful()
.maxAttempts(5)
.backOffOptions(1000, 2.0, 10000) // initialInterval, multiplier, maxInterval
.build();
}
这种方式只能配置一部分重试功能。更多高级功能需要将RetryTemplate配置为 Spring bean。有关可用策略及其配置的完整信息,请参见Spring 重试 Javadocs。
消息侦听器和异步情况
如果MessageListener因业务异常而失败,则该异常由消息侦听器容器处理,然后返回到侦听另一条消息。如果故障是由断开的连接(不是业务异常)引起的,则必须取消并重新启动为侦听器收集消息的使用者。 SimpleMessageListenerContainer无缝处理此问题,并留下一条日志说正在重新启动侦听器。实际上,它会无休止地循环尝试重新启动使用者,并且只有当使用者表现得很差时,它才会放弃。副作用是,如果在容器启动时代理关闭,则它将 continue 尝试直到可以构建连接为止。
与协议错误和断开连接相反,业务异常处理可能需要更多考虑和一些自定义配置,尤其是在使用事务和/或容器确认的情况下。在 2.8.x 之前,RabbitMQ 没有死信行为的定义,因此默认情况下,由于业务异常而被拒绝或回滚的消息可以无限地重新发送。为了限制 Client 端的重传次数,一种选择是侦听器的建议链中的StatefulRetryOperationsInterceptor。拦截器可以具有实现自定义死信动作的恢复回调:适用于您的特定环境的任何东西。
另一种选择是将容器的 rejectRequeued 属性设置为 false。这将导致所有失败的消息被丢弃。当使用 RabbitMQ 2.8.x 或更高版本时,这也有助于将消息传递到 Dead Letter Exchange。
或者,您可以抛出AmqpRejectAndDontRequeueException;不管defaultRequeueRejected属性的设置如何,都可以防止消息重新排队。
通常,将两种技术结合使用。在建议链中使用StatefulRetryOperationsInterceptor,而在MessageRecover处抛出AmqpRejectAndDontRequeueException。所有重试都用尽后,将调用MessageRecover。默认值MessageRecoverer仅消耗错误消息并发出 WARN 消息。在这种情况下,该消息将被确认,并且不会发送到死信交换(如果有的话)。
从* version 1.3 *版本开始,提供了一个新的RepublishMessageRecoverer,以允许在重试用尽后发布失败的消息:
@Bean
RetryOperationsInterceptor interceptor() {
return RetryInterceptorBuilder.stateless()
.maxAttempts(5)
.recoverer(new RepublishMessageRecoverer(amqpTemplate(), "bar", "baz"))
.build();
}
RepublishMessageRecoverer在消息头中发布带有其他信息的消息,例如异常消息,堆栈跟踪,原始交换和路由密钥。可以通过创建子类并覆盖additionalHeaders()来添加其他标题。
重试的异常分类
Spring Retry 在确定哪些异常可以调用重试方面具有很大的灵 Active。默认配置将重试所有异常。鉴于用户异常将包含在ListenerExecutionFailedException中,因此我们需要确保分类检查异常原因。默认分类器仅查看顶级异常。
从 Spring Retry 1.0.3 开始,BinaryExceptionClassifier具有属性traverseCauses(默认false)。当true时,它将遍历异常原因,直到找到匹配项或没有原因为止。
要使用此分类器进行重试,请使用使用最大尝试次数的构造函数创建的SimpleRetryPolicy,Exception的Map和布尔值(traverseCauses),然后将此策略注入RetryTemplate。
3.1.20 Debugging
Spring AMQP 提供了广泛的日志记录,尤其是在DEBUG级别。
如果希望监视应用程序和代理之间的 AMQP 协议,可以使用 WireShark 之类的工具,该工具具有用于解码协议的插件。另外,RabbitMQ JavaClient 端带有一个非常有用的类Tracer。默认情况下,以main身份运行时,它将侦听端口 5673 并连接到 localhost 上的端口 5672.只需运行它,然后更改连接工厂配置以连接到 localhost 上的端口 5673.它在控制台上显示解码的协议。有关更多信息,请参考Tracer javadocs。
3.2 记录子系统 AMQP Appender
该框架为几个流行的日志子系统提供日志附加程序:
log4j(从 Spring AMQP *版本 1.1 *开始)(已弃用)
logback(从 Spring AMQP *版本 1.4 *开始)
log4j2(从 Spring AMQP *版本 1.6 *开始)
附加程序使用日志子系统的常规机制配置,可用属性在以下各节中指定。
3.2.1 通用属性
以下属性可用于所有追加程序:
表 3.4. 常用的附加属性
| Property | Default | Description |
|---|---|---|
exchangeName |
logs |
要将日志事件发布到的交换的名称。 |
exchangeType |
topic |
将日志事件发布到的交换类型-仅在附加程序声明交换时才需要。参见declareExchange。 |
routingKeyPattern |
%c.%p |
记录子系统模式格式,用于生成路由密钥。 |
applicationId |
`` | 应用程序 ID-如果模式包含%X{applicationId},则添加到路由键。 |
senderPoolSize |
2 |
用于发布日志事件的线程数。 |
maxSenderRetries |
30 |
如果代理不可用或存在其他错误,请重试发送消息多少次。重试延迟如下:N ^ log(N),其中N是重试编号。 |
addresses |
`` | 代理地址的逗号分隔列表:host:port[,host:port]*-覆盖host和port。 |
host |
localhost |
要连接的 RabbitMQ 主机。 |
port |
5672 |
要连接的 RabbitMQ 端口。 |
virtualHost |
/ |
要连接的 RabbitMQ 虚拟主机。 |
username |
guest |
RabbitMQ 用户连接为。 |
password |
guest |
该用户的 RabbitMQ 密码。 |
contentType |
text/plain |
日志消息的content-type属性。 |
contentEncoding |
`` | 日志消息的content-encoding属性。 |
declareExchange |
false |
启动此附加程序时是否声明已配置的交换。另请参见durable和autoDelete。 |
durable |
true |
当declareExchange为true时,持久标记设置为此值。 |
autoDelete |
false |
当declareExchange为true时,自动删除标志设置为此值。 |
charset |
null |
将 String 转换为 byte []时使用的字符集,默认为 null(使用系统默认字符集)。如果当前平台不支持该字符集,那么我们将使用系统字符集。 |
deliveryMode |
PERSISTENT |
PERSISTENT 或 NON_PERSISTENT 确定 RabbitMQ 是否应保留消息。 |
generateId |
false |
用于确定messageId属性是否设置为唯一值。 |
clientConnectionProperties |
null |
逗号分隔的key:value对列表,用于与 RabbitMQ 连接的自定义 Client 端属性。 |
3.2.2 Log4j Appender
示例 log4j.properties 代码片段.
log4j.appender.amqp.addresses=foo:5672,bar:5672
log4j.appender.amqp=org.springframework.amqp.rabbit.log4j.AmqpAppender
log4j.appender.amqp.applicationId=myApplication
log4j.appender.amqp.routingKeyPattern=%X{applicationId}.%c.%p
log4j.appender.amqp.layout=org.apache.log4j.PatternLayout
log4j.appender.amqp.layout.ConversionPattern=%d %p %t [%c] - <%m>%n
log4j.appender.amqp.generateId=true
log4j.appender.amqp.charset=UTF-8
log4j.appender.amqp.durable=false
log4j.appender.amqp.deliveryMode=NON_PERSISTENT
log4j.appender.amqp.declareExchange=true
Note
不推荐使用此附加程序,并将在* version 2.0 *中将其删除。
3.2.3 Log4j2 Appender
示例 log4j2.xml 代码片段.
<Appenders>
...
<RabbitMQ name="rabbitmq"
addresses="foo:5672,bar:5672" user="guest" password="guest" virtualHost="/"
exchange="log4j2" exchangeType="topic" declareExchange="true" durable="true" autoDelete="false"
applicationId="myAppId" routingKeyPattern="%X{applicationId}.%c.%p"
contentType="text/plain" contentEncoding="UTF-8" generateId="true" deliveryMode="NON_PERSISTENT"
charset="UTF-8"
senderPoolSize="3" maxSenderRetries="5">
</RabbitMQ>
</Appenders>
Tip
从* versions 1.6.10,1.7.3 *开始,默认情况下,log4j2 Appender 将消息发布到调用线程上的 RabbitMQ。这是因为 log4j2 默认情况下不创建线程安全事件。如果代理关闭,则maxSenderRetries将用于重试,两次重试之间没有延迟。如果希望恢复以前在单独的线程(senderPoolSize)上发布消息的行为,请将async属性设置为true。但是,您还需要将 log4j2 配置为使用DefaultLogEventFactory而不是ReusableLogEventFactory。一种方法是设置系统属性-Dlog4j2.enable.threadlocals=false。如果将异步发布与ReusableLogEventFactory一起使用,则事件很可能由于串扰而被破坏。
3.2.4 Logback Appender
示例 logback.xml 片段.
<appender name="AMQP" class="org.springframework.amqp.rabbit.logback.AmqpAppender">
<layout>
<pattern><![CDATA[ %d %p %t [%c] - <%m>%n ]]></pattern>
</layout>
<addresses>foo:5672,bar:5672</addresses>
<abbreviation>36</abbreviation>
<includeCallerData>false</includeCallerData>
<applicationId>myApplication</applicationId>
<routingKeyPattern>%property{applicationId}.%c.%p</routingKeyPattern>
<generateId>true</generateId>
<charset>UTF-8</charset>
<durable>false</durable>
<deliveryMode>NON_PERSISTENT</deliveryMode>
<declareExchange>true</declareExchange>
</appender>
从* version 1.7.1 *开始,Logback AmqpAppender提供了includeCallerData选项,默认情况下为false。提取呼叫者数据可能会非常昂贵,因为日志事件必须创建一个 throwable 并对其进行检查以确定呼叫位置。因此,默认情况下,将事件添加到事件队列时,不会提取与事件关联的呼叫者数据。您可以通过将includeCallerData属性设置为true来配置附加程序以包括调用方数据。
3.2.5 自定义消息
默认情况下,AMQP 附加程序将填充以下消息属性:* deliveryMode * contentType * contentEncoding(如果已配置)* messageId(如果已配置generateId 日志事件的时间戳) appId(如果已配置 applicationId)
此外,它们还会填充标题:日志事件的类别名称日志事件的级别线程发生日志事件的线程的名称位置日志事件调用的堆栈跟踪*所有 MDC 属性的副本
每个追加程序都可以被子类化,从而允许您在发布之前修改消息。
自定义日志消息.
public class MyEnhancedAppender extends AmqpAppender {
@Override
public Message postProcessMessageBeforeSend(Message message, Event event) {
message.getMessageProperties().setHeader("foo", "bar");
return message;
}
}
3.2.6 自定义 Client 端属性
简单字符串属性
每个追加程序都支持将 Client 端属性添加到 RabbitMQ 连接。
log4j.
log4j.appender.amqp.clientConnectionProperties=foo:bar,baz:qux
logback.
<appender name="AMQP" ...>
...
<clientConnectionProperties>foo:bar,baz:qux</clientConnectionProperties>
...
</appender>
log4j2.
<Appenders>
...
<RabbitMQ name="rabbitmq"
...
clientConnectionProperties="foo:bar,baz:qux"
...
</RabbitMQ>
</Appenders>
这些属性是用逗号分隔的key:value对列表。键和值不能包含逗号或冒号。
查看连接时,这些属性将显示在 RabbitMQManagement 员 UI 上。
Log4j 和 Logback 的高级技术
使用 log4j 和 logback 附加程序,可以对附加程序进行子类化,从而允许您在构建连接之前修改 Client 端连接属性:
自定义 Client 端连接属性.
public class MyEnhancedAppender extends AmqpAppender {
private String foo;
@Override
protected void updateConnectionClientProperties(Map<String, Object> clientProperties) {
clientProperties.put("foo", this.foo);
}
public void setFoo(String foo) {
this.foo = foo;
}
}
对于 log4j2,将log4j.appender.amqp.foo=bar添加到 log4j.properties 以设置属性。对于 logback,将<foo>bar</foo>添加到 logback.xml。
当然,对于像此示例这样的简单 String 属性,可以使用先前的技术;子类允许更丰富的属性(例如添加Map或数字属性)。
对于 log4j2,由于 log4j2 使用静态工厂方法的方式,因此不支持子类。
3.3 示例应用程序
3.3.1 Introduction
SpringAMQPsamples项目包括两个示例应用程序。第一个是一个简单的“ Hello World”示例,该示例演示了同步和异步消息接收。它为了解基本组件提供了一个极好的起点。第二个示例基于一个股票 Transaction 用例,以演示在实际应用中常见的交互类型。在本章中,我们将快速介绍每个示例,以便您可以专注于最重要的组件。这些示例都是基于 Maven 的,因此您应该能够将它们直接导入任何支持 Maven 的 IDE(例如SpringSource 工具套件)。
3.3.2 Hello World
Introduction
Hello World 示例演示了同步和异步消息接收。您可以将* spring-rabbit-helloworld *示例导入 IDE,然后按照下面的讨论进行操作。
Synchronous Example
在* src/main/java 目录中,导航到 org.springframework.amqp.helloworld *包。打开 HelloWorldConfiguration 类,请注意它在类级别包含@ConfigurationComments,在方法级别包含一些@BeanComments。这是 Spring 基于 Java 的配置的示例。您可以阅读有关here的更多信息。
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory =
new CachingConnectionFactory("localhost");
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
return connectionFactory;
}
该配置还包含一个实例RabbitAdmin,该实例默认情况下查找类型为 Exchange,Queue 或 Binding 的任何 bean,然后在代理上声明它们。实际上,在 HelloWorldConfiguration 中生成的“ helloWorldQueue” bean 只是一个示例,因为它是 Queue 的一个实例。
@Bean
public Queue helloWorldQueue() {
return new Queue(this.helloWorldQueueName);
}
回顾“ rabbitTemplate” bean 配置,您将看到它已将 helloWorldQueue 的名称设置为其“ queue”属性(用于接收消息)和其“ routingKey”属性(用于发送消息)。
现在,我们已经探索了配置,让我们看一下实际使用这些组件的代码。首先,从同一包中打开 Producer 类。它包含一个 main()方法,用于在其中创建 Spring ApplicationContext。
public static void main(String[] args) {
ApplicationContext context =
new AnnotationConfigApplicationContext(RabbitConfiguration.class);
AmqpTemplate amqpTemplate = context.getBean(AmqpTemplate.class);
amqpTemplate.convertAndSend("Hello World");
System.out.println("Sent: Hello World");
}
如您在上面的示例中所看到的,AmqpTemplate bean 被检索并用于发送消息。由于 Client 端代码应尽可能依赖接口,因此类型为 AmqpTemplate 而不是 RabbitTemplate。即使在 HelloWorldConfiguration 中创建的 bean 是 RabbitTemplate 的实例,依靠接口也意味着此代码更可移植(可以独立于代码更改配置)。由于调用了 convertAndSend()方法,因此模板将委派给其 MessageConverter 实例。在这种情况下,它使用默认的 SimpleMessageConverter,但是可以为 HelloWorldConfiguration 中定义的“ rabbitTemplate” bean 提供不同的实现。
现在打开 Consumer 类。实际上,它共享相同的配置 Base Class,这意味着它将共享“ rabbitTemplate” bean。这就是为什么我们同时使用“ routingKey”(用于发送)和“ queue”(用于接收)来配置该模板的原因。如您在第 3.1.4 节“ AmqpTemplate”中所见,您可以改为将* routingKey 参数传递给 send 方法,并将 queue *参数传递给 receive 方法。Consumer 代码基本上是生产者的镜像,调用 receiveAndConvert()而不是 convertAndSend()。
public static void main(String[] args) {
ApplicationContext context =
new AnnotationConfigApplicationContext(RabbitConfiguration.class);
AmqpTemplate amqpTemplate = context.getBean(AmqpTemplate.class);
System.out.println("Received: " + amqpTemplate.receiveAndConvert());
}
如果您运行生产者,然后运行 Consumer,您应该在控制台输出中看到消息“ Received:Hello World”。
Asynchronous Example
现在,我们已经遍历了同步 Hello World 示例,是时候 continue 使用稍微更高级但功能更强大的选项了。经过一些修改,Hello World 示例可以提供一个异步接收的示例,也就是 消息驱动的 POJO 。实际上,有一个子软件包可以提供确切的信息:org.springframework.amqp.samples.helloworld.async。
再一次,我们将从发送方开始。打开 ProducerConfiguration 类,注意它创建了一个“ connectionFactory”和“ rabbitTemplate” bean。这次,由于配置专用于消息发送端,因此我们甚至不需要任何队列定义,并且 RabbitTemplate 仅设置了* routingKey *属性。回想一下,邮件是发送到 Exchange 的,而不是直接发送到队列的。 AMQP 默认交换是没有名称的直接交换。所有队列都以其名称作为路由键绑定到该默认 Exchange。这就是为什么我们只需要在此处提供路由密钥的原因。
public RabbitTemplate rabbitTemplate() {
RabbitTemplate template = new RabbitTemplate(connectionFactory());
template.setRoutingKey(this.helloWorldQueueName);
return template;
}
由于此示例将演示异步消息接收,因此产生方将设计为连续发送消息(如果它是像同步版本一样的每次执行消息模型,那么实际上它不是消息-驱动的 Consumer)。负责连续发送消息的组件被定义为 ProducerConfiguration 中的内部类。它配置为每 3 秒执行一次。
static class ScheduledProducer {
@Autowired
private volatile RabbitTemplate rabbitTemplate;
private final AtomicInteger counter = new AtomicInteger();
@Scheduled(fixedRate = 3000)
public void sendMessage() {
rabbitTemplate.convertAndSend("Hello World " + counter.incrementAndGet());
}
}
您不需要了解所有细节,因为 true 的重点应该放在接收方(我们将在稍后进行介绍)。但是,如果您还不熟悉 Spring 3.0 任务计划支持,则可以了解更多信息here。简短的故事是 ProducerConfiguration 中的“ postProcessor” bean 正在向调度程序注册任务。
现在,让我们转到接收方。为了强调消息驱动的 POJO 行为,将从响应消息的组件开始。该类称为 HelloWorldHandler。
public class HelloWorldHandler {
public void handleMessage(String text) {
System.out.println("Received: " + text);
}
}
显然,这是一个 POJO。它不扩展任何 Base Class,不实现任何接口,甚至不包含任何导入。 Spring AMQP MessageListenerAdapter 正在将其“适配”到 MessageListener 接口。然后可以在 SimpleMessageListenerContainer 上配置该适配器。对于此示例,在 ConsumerConfiguration 类中创建容器。您可以在其中看到包装在适配器中的 POJO。
@Bean
public SimpleMessageListenerContainer listenerContainer() {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory());
container.setQueueName(this.helloWorldQueueName);
container.setMessageListener(new MessageListenerAdapter(new HelloWorldHandler()));
return container;
}
SimpleMessageListenerContainer 是 Spring 生命周期组件,默认情况下将自动启动。如果查看 Consumer 类,将看到它的 main()方法只包含用于创建 ApplicationContext 的单行引导程序。生产者的 main()方法也是单行引导程序,因为使用@ScheduledComments 其方法的组件也将自动开始执行。您可以按任何 Sequences 启动生产者和使用者,并且您应该看到每 3 秒发送和接收一条消息。
3.3.3 股票 Transaction
与“ Hello World”示例相比,“股票 Transaction”示例展示了更高级的消息传递场景。但是,配置非常相似-涉及更多。由于我们已经详细介绍了 Hello World 配置,因此在此我们将重点介绍使此示例与众不同的地方。有一个将市场数据(股票报价)推送到主题 Transaction 所的服务器。然后,Client 可以通过将队列与路由模式(例如“ app.stock.quotes.nasdaq.*”)绑定在一起来订阅市场数据供稿。该演示的另一个主要 Feature 是由 Client 端发起并由服务器处理的请求-答复“股票 Transaction”交互。这涉及由 Client 在订单请求消息本身内发送的私有“ replyTo”队列。
服务器的核心配置在 org.springframework.amqp.rabbit.stocks.config.server 软件包内的 RabbitServerConfiguration 类中。它扩展了 AbstractStockAppRabbitConfiguration。在那里定义了服务器和 Client 端的公共资源,包括市场数据 Topic Exchange(名称为* app.stock.marketdata )和服务器为股票 Transaction 而公开的队列(名称为)。 app.stock.request *)。在该通用配置文件中,您还将看到在 RabbitTemplate 上配置了 JsonMessageConverter。
服务器特定的配置由两部分组成。首先,它在 RabbitTemplate 上配置市场数据交换,因此不需要在每次发送消息的调用中都提供该交换名称。它在基本配置类中定义的抽象回调方法中执行此操作。
public void configureRabbitTemplate(RabbitTemplate rabbitTemplate) {
rabbitTemplate.setExchange(MARKET_DATA_EXCHANGE_NAME);
}
其次,声明库存请求队列。在这种情况下,它不需要任何显式绑定,因为它将绑定到默认的无名称交换,并以其自己的名称作为路由键。如前所述,AMQP 规范定义了该行为。
@Bean
public Queue stockRequestQueue() {
return new Queue(STOCK_REQUEST_QUEUE_NAME);
}
既然您已经看到了服务器的 AMQP 资源的配置,请导航到* src/test/java 目录下的 org.springframework.amqp.rabbit.stocks 包。在那里,您将看到提供 main()方法的实际 Server 类。它基于 server-bootstrap.xml 配置文件创建一个 ApplicationContext。在这里,您将看到发布虚拟市场数据的计划任务。该配置依赖于 Spring 3.0 的“任务”名称空间支持。引导程序配置文件还会导入其他一些文件。最有趣的是 server-messaging.xml ,它直接位于 src/main/resources 下。在这里,您将看到负责处理股票 Transaction 请求的“ messageListenerContainer” bean。最后,看看在“ server-handlers.xml”中定义的“ serverHandler” bean(也在 src/main/resources *中)。该 bean 是 ServerHandler 类的实例,并且是消息驱动的 POJO 的一个很好的示例,该 POJO 也能够发送答复消息。请注意,它本身并不与框架或任何 AMQP 概念耦合。它只是接受一个 TradeRequest 并返回一个 TradeResponse。
public TradeResponse handleMessage(TradeRequest tradeRequest) { ...
}
现在,我们已经看到了服务器的最重要的配置和代码,下面我们来看 Client 端。最好的起点可能是* org.springframework.amqp.rabbit.stocks.config.client *包中的 RabbitClientConfiguration。请注意,它声明了两个队列而没有提供显式名称。
@Bean
public Queue marketDataQueue() {
return amqpAdmin().declareQueue();
}
@Bean
public Queue traderJoeQueue() {
return amqpAdmin().declareQueue();
}
这些是专用队列,唯一名称将自动生成。Client 端使用第一个生成的队列绑定到服务器公开的市场数据交换。回想一下,在 AMQP 中,Consumer 与队列交互,而生产者与 Exchange 交互。队列与 Exchange 的“绑定”是指示代理将消息从给定 Exchange 传递或路由到队列的内容。由于市场数据交换是主题交换,因此可以使用路由模式来表示绑定。 RabbitClientConfiguration 使用 Binding 对象声明该对象,并使用 BindingBuilder 的流畅 API 生成该对象。
@Value("${stocks.quote.pattern}")
private String marketDataRoutingKey;
@Bean
public Binding marketDataBinding() {
return BindingBuilder.bind(
marketDataQueue()).to(marketDataExchange()).with(marketDataRoutingKey);
}
请注意,实际值已在属性文件(src/main/resources 下的“ client.properties”)中外部化,并且我们正在使用 Spring 的@ValueComments 注入该值。这通常是一个好主意,因为否则该值将被硬编码在一个类中,并且无需重新编译就无法修改。在这种情况下,可以更轻松地运行 Client 端的多个版本,同时更改用于绑定的路由模式。让我们现在尝试。
首先运行 org.springframework.amqp.rabbit.stocks.Server,然后运行 org.springframework.amqp.rabbit.stocks.Client。您应该看到纳斯达克股票的虚拟报价,因为与 client.properties 中的* stocks.quote.pattern 关键字关联的当前值为 app.stock.quotes.nasdaq。 **** 现在,在保持现有服务器和 Client 端运行的同时,将该属性值更改为* app.stock.quotes.nyse.**并启动另一个 Client 实例。您应该看到第一个 Client 仍在接收纳斯达克报价,而第二个 Client 仍在接收纽约证券 Transaction 所报价。相反,您可以更改模式以获取所有股票甚至单个股票代码。
我们将探讨的最后一个功能是从 Client 的角度进行请求-答复交互。回想一下,我们已经看到 ServerHandler 接受 TradeRequest 对象并返回 TradeResponse 对象。Client 端上的相应代码是* org.springframework.amqp.rabbit.stocks.gateway *包中的 RabbitStockServiceGateway。它委托给 RabbitTemplate 以便发送消息。
public void send(TradeRequest tradeRequest) {
getRabbitTemplate().convertAndSend(tradeRequest, new MessagePostProcessor() {
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setReplyTo(new Address(defaultReplyToQueue));
try {
message.getMessageProperties().setCorrelationId(
UUID.randomUUID().toString().getBytes("UTF-8"));
}
catch (UnsupportedEncodingException e) {
throw new AmqpException(e);
}
return message;
}
});
}
请注意,在发送消息之前,它会设置“ replyTo”地址。它提供了由上面显示的“ traderJoeQueue” bean 定义生成的队列。这是 StockServiceGateway 类本身的@Bean 定义。
@Bean
public StockServiceGateway stockServiceGateway() {
RabbitStockServiceGateway gateway = new RabbitStockServiceGateway();
gateway.setRabbitTemplate(rabbitTemplate());
gateway.setDefaultReplyToQueue(traderJoeQueue());
return gateway;
}
如果不再运行服务器和 Client 端,请立即启动它们。尝试发送* 100 TCKR *格式的请求。经过短暂的人为延迟,模拟了请求的“处理”,您应该看到一条确认消息出现在 Client 端上。
3.4 测试支持
3.4.1 Introduction
为异步应用程序编写集成必须比测试更简单的应用程序复杂。当诸如@RabbitListenerComments 之类的抽象引入图片时,这变得更加复杂。问题是如何验证发送消息后,侦听器是否按预期收到了消息。
框架本身具有许多单元测试和集成测试。一些使用模拟,其他使用与实时 RabbitMQ 代理的集成测试。您可以咨询这些测试以获取有关测试方案的一些想法。
Spring AMQP *版本 1.6 *引入了spring-rabbit-test jar,它提供了对测试其中一些更复杂场景的支持。预计该项目将随着时间的推移而扩展,但是我们需要社区的反馈,以便为测试所需的功能提出建议。请使用JIRA或GitHub Issues提供此类反馈。
3.4.2 Mockito 答案\ <?>实现
当前有两种Answer<?>实现可帮助进行测试:
第一个LatchCountDownAndCallRealMethodAnswer提供了Answer<Void>,该Answer<Void>返回null并递减锁存器。
LatchCountDownAndCallRealMethodAnswer answer = new LatchCountDownAndCallRealMethodAnswer(2);
doAnswer(answer)
.when(listener).foo(anyString(), anyString());
...
assertTrue(answer.getLatch().await(10, TimeUnit.SECONDS));
第二个参数LambdaAnswer<T>提供了一种机制,可以选择调用 real 方法,并提供了基于InvocationOnMock和结果(如果有的话)返回自定义结果的机会。
public class Foo {
public String foo(String foo) {
return foo.toUpperCase();
}
}
Foo foo = spy(new Foo());
doAnswer(new LambdaAnswer<String>(true, (i, r) -> r + r))
.when(foo).foo(anyString());
assertEquals("FOOFOO", foo.foo("foo"));
doAnswer(new LambdaAnswer<String>(true, (i, r) -> r + i.getArguments()[0]))
.when(foo).foo(anyString());
assertEquals("FOOfoo", foo.foo("foo"));
doAnswer(new LambdaAnswer<String>(false, (i, r) ->
"" + i.getArguments()[0] + i.getArguments()[0])).when(foo).foo(anyString());
assertEquals("foofoo", foo.foo("foo"));
使用 Java 7 或更早版本时:
doAnswer(new LambdaAnswer<String>(true, new ValueToReturn<String>() {
@Override
public String apply(InvocationOnMock i, String r) {
return r + r;
}
})).when(foo).foo(anyString());
3.4.3 @RabbitListenerTest 和 RabbitListenerTestHarness
用@RabbitListenerTestComments 您的@Configuration类之一将使框架用子类RabbitListenerTestHarness替换标准RabbitListenerAnnotationBeanPostProcessor(它还将通过@EnableRabbit启用@RabbitListener检测)。
RabbitListenerTestHarness通过两种方式增强了侦听器-将其包装在Mockito Spy中,从而启用了正常的Mockito存根和验证操作。它还可以向侦听器添加Advice,以允许访问所引发的参数,结果和/或异常。您可以通过@RabbitListenerTest上的属性来控制启用其中的哪一项(或全部启用)。提供后者用于访问有关调用的低级数据-它还支持阻塞测试线程,直到调用异步侦听器为止。
Tip
final @RabbitListener无法发现或建议使用方法;同样,只能监视或建议具有id属性的侦听器。
让我们看一些例子。
Using spy:
@Configuration
@RabbitListenerTest
public class Config {
@Bean
public Listener listener() {
return new Listener();
}
...
}
public class Listener {
@RabbitListener(id="foo", queues="#{queue1.name}")
public String foo(String foo) {
return foo.toUpperCase();
}
@RabbitListener(id="bar", queues="#{queue2.name}")
public void foo(@Payload String foo, @Header("amqp_receivedRoutingKey") String rk) {
...
}
}
public class MyTests {
@Autowired
private RabbitListenerTestHarness harness; (1)
@Test
public void testTwoWay() throws Exception {
assertEquals("FOO", this.rabbitTemplate.convertSendAndReceive(this.queue1.getName(), "foo"));
Listener listener = this.harness.getSpy("foo"); (2)
assertNotNull(listener);
verify(listener).foo("foo");
}
@Test
public void testOneWay() throws Exception {
Listener listener = this.harness.getSpy("bar");
assertNotNull(listener);
LatchCountDownAndCallRealMethodAnswer answer = new LatchCountDownAndCallRealMethodAnswer(2); (3)
doAnswer(answer).when(listener).foo(anyString(), anyString()); (4)
this.rabbitTemplate.convertAndSend(this.queue2.getName(), "bar");
this.rabbitTemplate.convertAndSend(this.queue2.getName(), "baz");
assertTrue(answer.getLatch().await(10, TimeUnit.SECONDS));
verify(listener).foo("bar", this.queue2.getName());
verify(listener).foo("baz", this.queue2.getName());
}
}
- (1) 将线束注入测试用例中,以便我们可以访问 Spy。
- (2) 获取对 Spy 的引用,以便我们可以验证它是否按预期被调用。由于这是一个发送和接收操作,因此无需挂起测试线程,因为它已在
RabbitTemplate中挂起,await 答复。 - (3) 在这种情况下,我们仅使用发送操作,因此我们需要一个闩锁来 await 对容器线程上的侦听器的异步调用。我们使用Answer<?>实现之一来帮助您。
- (4) 配置 Spy 以调用
Answer。
使用捕获建议:
@Configuration
@ComponentScan
@RabbitListenerTest(spy = false, capture = true)
public class Config {
}
@Service
public class Listener {
private boolean failed;
@RabbitListener(id="foo", queues="#{queue1.name}")
public String foo(String foo) {
return foo.toUpperCase();
}
@RabbitListener(id="bar", queues="#{queue2.name}")
public void foo(@Payload String foo, @Header("amqp_receivedRoutingKey") String rk) {
if (!failed && foo.equals("ex")) {
failed = true;
throw new RuntimeException(foo);
}
failed = false;
}
}
public class MyTests {
@Autowired
private RabbitListenerTestHarness harness; (1)
@Test
public void testTwoWay() throws Exception {
assertEquals("FOO", this.rabbitTemplate.convertSendAndReceive(this.queue1.getName(), "foo"));
InvocationData invocationData =
this.harness.getNextInvocationDataFor("foo", 0, TimeUnit.SECONDS); (2)
assertThat(invocationData.getArguments()[0], equalTo("foo")); (3)
assertThat((String) invocationData.getResult(), equalTo("FOO"));
}
@Test
public void testOneWay() throws Exception {
this.rabbitTemplate.convertAndSend(this.queue2.getName(), "bar");
this.rabbitTemplate.convertAndSend(this.queue2.getName(), "baz");
this.rabbitTemplate.convertAndSend(this.queue2.getName(), "ex");
InvocationData invocationData =
this.harness.getNextInvocationDataFor("bar", 10, TimeUnit.SECONDS); (4)
Object[] args = invocationData.getArguments();
assertThat((String) args[0], equalTo("bar"));
assertThat((String) args[1], equalTo(queue2.getName()));
invocationData = this.harness.getNextInvocationDataFor("bar", 10, TimeUnit.SECONDS);
args = invocationData.getArguments();
assertThat((String) args[0], equalTo("baz"));
invocationData = this.harness.getNextInvocationDataFor("bar", 10, TimeUnit.SECONDS);
args = invocationData.getArguments();
assertThat((String) args[0], equalTo("ex"));
assertEquals("ex", invocationData.getThrowable().getMessage()); (5)
}
}
- (1) 将线束注入测试用例中,以便我们可以访问 Spy。
- (2) 使用
harness.getNextInvocationDataFor()来检索调用数据-在这种情况下,由于它是一个请求/答复方案,因此无需 await 任何时间,因为测试线程已挂在RabbitTemplate中 await 结果。 - (3) 然后,我们可以验证参数和结果是否符合预期。
- (4) 这次我们需要一些时间来 await 数据,因为它是对容器线程的异步操作,因此我们需要挂起测试线程。
- (5) 侦听器引发异常时,在调用数据的
throwable属性中可用。
3.4.4 JUnit @Rules
Spring AMQP *版本 1.7 *提供了一个额外的 jar spring-rabbit-junit;这个 jar 包含几个 Util@Rule,可以在运行 JUnit 测试时使用。
BrokerRunning
BrokerRunning提供了一种机制,当代理未运行时(默认情况下为localhost),测试可以成功进行。
它还具有 Util 方法来初始化/清空队列,以及删除队列和交换。
Usage:
@ClassRule
public static BrokerRunning brokerRunning = BrokerRunning.isRunningWithEmptyQueues("foo", "bar");
@AfterClass
public void tearDown() {
brokerRunning.removeTestQueues("some.other.queue.too") // removes foo, bar as well
}
有几种isRunning...静态方法(例如isBrokerAndManagementRunning())可以验证代理是否启用了 Management 插件。
配置规则
有时候,如果没有代理,您希望测试失败,例如每晚配置项构建。要在运行时禁用规则,请将环境变量RABBITMQ_SERVER_REQUIRED设置为true。
您可以通过几种方式覆盖代理属性,例如主机名:
- Setters
@ClassRule
public static BrokerRunning brokerRunning = BrokerRunning.isRunningWithEmptyQueues("foo", "bar");
static {
brokerRunning.setHostName("10.0.0.1")
}
@AfterClass
public static void tearDown() {
brokerRunning.removeTestQueues("some.other.queue.too") // removes foo, bar as well
}
- Environment Variables
提供了以下环境变量:
public static final String BROKER_ADMIN_URI = "RABBITMQ_TEST_ADMIN_URI";
public static final String BROKER_HOSTNAME = "RABBITMQ_TEST_HOSTNAME";
public static final String BROKER_PORT = "RABBITMQ_TEST_PORT";
public static final String BROKER_USER = "RABBITMQ_TEST_USER";
public static final String BROKER_PW = "RABBITMQ_TEST_PASSWORD";
public static final String BROKER_ADMIN_USER = "RABBITMQ_TEST_ADMIN_USER";
public static final String BROKER_ADMIN_PW = "RABBITMQ_TEST_ADMIN_PASSWORD";
这些将覆盖默认设置(对于 amqp 来说是localhost:5672,对于 ManagementREST API 来说是http://localhost:15672/api/)。
更改主机名会影响 amqp 和 ManagementREST API 连接(除非显式设置了 admin uri)。
BrokerRunning还提供了static方法:setEnvironmentVariableOverrides,您可以在其中传递包含这些变量的 Map;它们覆盖系统环境变量。如果您希望对多个测试套件中的测试使用不同的配置,这可能会很有用。重要说明:在调用任何创建规则实例的isRunning()静态方法之前,必须先调用该方法。变量值将应用于此后创建的所有实例。调用clearEnvironmentVariableOverrides()以将规则重置为使用默认值(包括任何实际的环境变量)。
在测试用例中,可以在创建连接工厂时使用这些属性:
@Bean
public ConnectionFactory rabbitConnectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setHost(brokerRunning.getHostName());
connectionFactory.setPort(brokerRunning.getPort());
connectionFactory.setUsername(brokerRunning.getUser());
connectionFactory.setPassword(brokerRunning.getPassword());
return connectionFactory;
}
LongRunningIntegrationTest
LongRunningIntegrationTest是禁用长时间运行测试的规则;您可能要在开发人员系统上使用此功能,但请确保在例如夜间 CI 构建中禁用该规则。
Usage:
@Rule
public LongRunningIntegrationTest longTests = new LongRunningIntegrationTest();
要在运行时禁用规则,请将环境变量RUN_LONG_INTEGRATION_TESTS设置为true。