Apache HBase™参考指南
Preface
这是其随附的HBase版本的官方参考指南。
在这里,您可以找到有关 HBase 主题的 Authority 性文档(指当引用的 HBase 版本发布时的状态),也可以指向Javadoc或JIRA中可以找到相关信息的位置。
关于本指南
本参考指南正在进行中。可以在 HBase 源代码的_src/main/asciidoc 目录中找到本指南的源代码。该参考指南使用AsciiDoc进行了标记,最终的指南是根据这些AsciiDoc作为“站点”构建目标的一部分而生成的。运行
mvn site
生成此文档。欢迎对文档进行修改和改进。单击this link以针对 Apache HBase 提交新的文档错误,并预先选择了一些值。
撰写文档
有关 AsciiDoc 的概述以及开始为文档做出贡献的建议,请参见本文档后面的相关部分。
如果这是您首次涉足分布式计算领域,请多加注意...
如果这是您首次进入分布式计算的美好世界,那么您将处于一段有趣的时期。首先,分布式系统很难。使分布式系统嗡嗡声需要跨越系统(硬件和软件)和网络的不同技能。
群集操作可能会由于各种原因而打 ic,这是由于 HBase 本身中的错误,配置错误(HBase 的配置不正确,还有 os 配置错误)any 直至硬件问题(无论是网卡驱动程序中的错误还是 RAM 总线不足)导致的(要提到两个最近的硬件问题示例,这些问题表现为“ HBase 缓慢”)。如果您已将计算结果绑定到单个框,则还需要重新校准。这是一个很好的起点:分布式计算的谬误。
也就是说,不客气。
这是一个有趣的地方。
您好,HBase 社区。
Reporting Bugs
请使用JIRA报告与安全无关的错误。
为了保护现有的 HBase 安装不受新漏洞的影响,请 不要 使用 JIRA 报告与安全相关的错误。而是将您的报告发送到邮件列表private@hbase.apache.org,该列表允许任何人发送消息,但限制了可以阅读的人。该列表中的某人将与您联系以跟进您的报告。
支持和测试期望
在本指南中,短语/ supported /,/ notsupported /,/ tested /和/ not testing /出现在几个地方。为了清楚起见,这里简要说明了在 HBase 上下文中这些短语的一般含义。
Note
许多 Hadoop 供应商为 Apache HBase 提供了商业技术支持。这不是在 Apache HBase 项目的上下文中使用术语/ support /的意义。 Apache HBase 团队对您的 HBase 集群,您的配置或数据不承担任何责任。
Supported
- 在 Apache HBase 的上下文中,/ supported /表示 HBase 旨在按所述方式工作,并且与已定义行为或功能的偏差应报告为错误。
Not Supported
- 在 Apache HBase 的上下文中,/ notsupported /表示用例或使用模式不起作用,应将其视为反模式。如果您认为应该为给定的功能或使用模式重新考虑此指定,请提交 JIRA 或在其中一个邮件列表上进行讨论。
Tested
- 在 Apache HBase 的上下文中,/ tested /表示某个功能已包含在单元测试或集成测试中,并且已被证明可以按预期工作。
Not Tested
- 在 Apache HBase 的上下文中,/ nottested /表示功能或使用模式可能以给定方式工作,也可能无法工作,并且可能会或可能不会破坏您的数据或导致操作问题。这是一个未知数,并且无法保证。如果您可以提供证明/未测试的功能确实可以通过给定的方式工作的证据,请提交测试和/或 Metrics,以便其他用户可以确定此类功能或使用方式。
Getting Started
1. Introduction
Quickstart将使您在 HBase 的单节点独立实例上运行。
2.快速入门-独立 HBase
本节描述了单节点独立 HBase 的设置。一个独立实例具有所有 HBase 守护程序-主服务器,RegionServers 和 ZooKeeper-在单个 JVM 中运行并持久化到本地文件系统。这是我们最基本的部署配置文件。我们将向您展示如何使用hbase shell CLI 在 HBase 中创建表,如何在表中插入行,对表执行放置和扫描操作,启用或禁用表以及启动和停止 HBase。
除了下载 HBase 之外,此过程还需要不到 10 分钟的时间。
2.1. JDK 版本要求
HBase 要求安装 JDK。有关支持的 JDK 版本的信息,请参见Java。
2.2. HBase 入门
过程:以独立模式下载,配置和启动 HBase
从Apache 下载镜像列表中选择一个下载站点。单击建议的顶部链接。这将带您到* HBase Releases 的镜像。单击名为 stable 的文件夹,然后将以 .tar.gz 结尾的二进制文件下载到本地文件系统。现在不要下载以 src.tar.gz *结尾的文件。
解压缩下载的文件,然后转到新创建的目录。
$ tar xzvf hbase-2.1.9-bin.tar.gz
$ cd hbase-2.1.9/
- 在启动 HBase 之前,需要设置
JAVA_HOME环境变量。您可以通过 os 的常用机制来设置变量,但是 HBase 提供了一个中心机制* conf/hbase-env.sh 。编辑此文件,取消 Comments 以JAVA_HOME开头的行,并将其设置为适合您的 os 的位置。JAVA_HOME变量应设置为包含可执行文件 bin/java 的目录。大多数现代 Linuxos 都提供了一种机制,例如 RHEL 或 CentOS 上的/ usr/bin/alternatives,用于在诸如 Java 之类的可执行文件版本之间透明地进行切换。在这种情况下,可以将JAVA_HOME设置到包含指向 bin/java 的符号链接的目录,通常为/usr *。
JAVA_HOME=/usr
- 编辑* conf/hbase-site.xml ,它是主要的 HBase 配置文件。这时,您需要在本地文件系统上指定 HBase 和 ZooKeeper 写入数据的目录并确认一些风险。默认情况下,在/ tmp 下创建一个新目录。许多服务器配置为在重新引导时删除/tmp 的内容,因此您应该将数据存储在其他位置。以下配置会将 HBase 的数据存储在名为
testuser的用户的主目录的 hbase *目录中。将<property>标记粘贴在<configuration>标记下,该标记在新的 HBase 安装中应该为空。
示例 1.独立 HBase 的示例* hbase-site.xml *
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/testuser/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/testuser/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
<description>
Controls whether HBase will check for stream capabilities (hflush/hsync).
Disable this if you intend to run on LocalFileSystem, denoted by a rootdir
with the 'file://' scheme, but be mindful of the NOTE below.
WARNING: Setting this to false blinds you to potential data loss and
inconsistent system state in the event of process and/or node failures. If
HBase is complaining of an inability to use hsync or hflush it's most
likely not a false positive.
</description>
</property>
</configuration>
您不需要创建 HBase 数据目录。 HBase 将为您完成此任务。如果创建目录,HBase 将尝试进行迁移,这不是您想要的。
Note
上例中的* hbase.rootdir 指向 local 文件系统*中的目录。 “ file://”前缀是我们表示本地文件系统的方式。您应该牢记配置示例中的“警告”。在独立模式下,HBase 使用 Apache Hadoop 项目中的本地文件系统抽象。这种抽象不能提供 HBase 安全运行所需的持久性保证。这对于可以很好地控制群集故障成本的本地开发和测试用例来说是不错的选择。它不适用于生产部署;最终您将丢失数据。
要将 HBase 放置在现有 HDFS 实例上,请设置* hbase.rootdir 指向您实例上的目录:例如 hdfs://namenode.example.org:8020/hbase *。有关此变体的更多信息,请参见下面有关基于 HDFS 的独立 HBase 的部分。
- 提供* bin/start-hbase.sh 脚本是启动 HBase 的便捷方法。发出命令,如果一切顺利,则会在标准输出中记录一条消息,表明 HBase 已成功启动。您可以使用
jps命令来验证您有一个名为HMaster的正在运行的进程。在独立模式下,HBase 在此单个 JVM 中运行所有守护程序,即 HMaster,单个 HRegionServer 和 ZooKeeper 守护程序。转到 http://localhost:16010 *以查看 HBase Web UI。
Note
Java 需要安装并可用。如果收到指示未安装 Java 的错误,但该错误已在系统上(可能位于非标准位置),请编辑* conf/hbase-env.sh 文件并修改JAVA_HOME设置以指向该目录在系统上包含 bin/java *。
过程:首次使用 HBase
- 连接到 HBase。
使用位于 HBase 安装目录* bin/*中的hbase shell命令连接到正在运行的 HBase 实例。在此示例中,省略了启动 HBase Shell 时打印的一些用法和版本信息。 HBase Shell 提示符以>字符结尾。
$ ./bin/hbase shell
hbase(main):001:0>
- 显示 HBase Shell 帮助文本。
键入help并按 Enter,以显示 HBase Shell 的一些基本用法信息以及一些示例命令。请注意,表名,行,列都必须用引号引起来。
- 创建一个表。
使用create命令创建一个新表。您必须指定表名称和 ColumnFamily 名称。
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
- 列出有关表的信息
使用list命令确认您的表存在
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
现在,使用describe命令查看详细信息,包括配置默认值
hbase(main):003:0> describe 'test'
Table test is ENABLED
test
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE =>
'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'f
alse', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536'}
1 row(s)
Took 0.9998 seconds
- 将数据放入表中。
要将数据放入表中,请使用put命令。
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
在这里,我们插入三个值,一次插入一个。第一次插入位于row1的列cf:a处,值为value1。 HBase 中的列由列族前缀cf(在此示例中),冒号和列限定符后缀a(在本例中)组成。
- 一次扫描表中的所有数据。
从 HBase 获取数据的一种方法是扫描。使用scan命令扫描表中的数据。您可以限制扫描,但是目前,所有数据都已获取。
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds
- 获取单行数据。
要一次获取一行数据,请使用get命令。
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds
- 禁用表格。
如果要删除表或更改其设置,以及在其他情况下,则需要先使用disable命令禁用该表。您可以使用enable命令重新启用它。
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds
如果您测试了上面的enable命令,请再次禁用该表:
hbase(main):010:0> disable 'test'
0 row(s) in 1.1820 seconds
- 放下桌子。
要删除(删除)表,请使用drop命令。
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
- 退出 HBase Shell。
要退出 HBase Shell 并从群集断开连接,请使用quit命令。 HBase 仍在后台运行。
过程:停止 HBase
- 与提供* bin/start-hbase.sh 脚本以方便地启动所有 HBase 守护程序相同, bin/stop-hbase.sh *脚本将停止它们。
$ ./bin/stop-hbase.sh
stopping hbase....................
$
- 发出命令后,关闭进程可能需要几分钟。使用
jps确保已关闭 HMaster 和 HRegionServer 进程。
上面显示了如何启动和停止 HBase 的独立实例。在接下来的部分中,我们将简要概述 hbase 部署的其他模式。
2.3. 伪分布式本地安装
在通过quickstart独立模式工作之后,可以将 HBase 重新配置为以伪分布式模式运行。伪分布式模式意味着 HBase 仍完全在单个主机上运行,但是每个 HBase 守护程序(HMaster,HRegionServer 和 ZooKeeper)作为单独的进程运行:在独立模式下,所有守护程序都在一个 jvm 进程/实例中运行。默认情况下,除非您按照quickstart中所述配置hbase.rootdir属性,否则数据仍存储在*/tmp/*中。在本演练中,假设您有可用的 HDFS,我们将数据存储在 HDFS 中。您可以跳过 HDFS 配置,以 continue 将数据存储在本地文件系统中。
Hadoop Configuration
此过程假定您已在本地系统和/或远程系统上配置了 Hadoop 和 HDFS,并且它们正在运行并且可用。它还假定您正在使用 Hadoop2.Hadoop 文档中有关设置单节点群集的指南是一个很好的起点。
- 如果 HBase 正在运行,请停止它。
如果您刚刚完成quickstart并且 HBase 仍在运行,请停止它。此过程将创建一个全新的目录,HBase 将在该目录中存储其数据,因此之前创建的所有数据库都将丢失。
- Configure HBase.
编辑* hbase-site.xml *配置。首先,添加以下属性,该属性指示 HBase 在分布式模式下运行,每个守护程序一个 JVM 实例。
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
接下来,使用hdfs://// URI 语法将hbase.rootdir从本地文件系统更改为您的 HDFS 实例的地址。在此示例中,HDFS 在 localhost 上的端口 8020 上运行。请确保删除hbase.unsafe.stream.capability.enforce的条目或将其设置为 true。
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8020/hbase</value>
</property>
您无需在 HDFS 中创建目录。 HBase 将为您完成此任务。如果创建目录,HBase 将尝试进行迁移,这不是您想要的。
- Start HBase.
使用* bin/start-hbase.sh *命令启动 HBase。如果系统配置正确,则jps命令应显示正在运行的 HMaster 和 HRegionServer 进程。
- 检查 HDFS 中的 HBase 目录。
如果一切正常,HBase 将在 HDFS 中创建其目录。在上面的配置中,它存储在 HDFS 上的*/hbase/中。您可以在 Hadoop 的 bin/*目录中使用hadoop fs命令列出该目录。
$ ./bin/hadoop fs -ls /hbase
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs
- 创建一个表并用数据填充它。
您可以使用 HBase Shell 创建表,使用数据填充表,扫描表并从中获取值,方法与shell exercises相同。
- 启动和停止备用 HBase 主服务器(HMaster)。
Note
在生产环境中,在同一硬件上运行多个 HMaster 实例没有任何意义,就像在生产环境中运行伪分布式集群一样。此步骤仅用于测试和学习目的。
HMaster 服务器控制 HBase 群集。您最多可以启动 9 台备份 HMaster 服务器,这使 10 台 HMaster 总数(包括主服务器)在内。要启动备份 HMaster,请使用local-master-backup.sh。对于要启动的每个备份主服务器,添加一个代表该主服务器的端口偏移量的参数。每个 HMaster 使用两个端口(默认情况下为 16000 和 16010)。端口偏移量已添加到这些端口,因此,使用偏移量 2 时,备份 HMaster 将使用端口 16002 和 16012.以下命令使用端口 16002/16012、16003/16013 和 16005/16015 启动 3 个备份服务器。
$ ./bin/local-master-backup.sh start 2 3 5
要杀死备份主服务器而不杀死整个集群,您需要找到其进程 ID(PID)。 PID 存储在名称为*/tmp/hbase-USER-X-master.pid *的文件中。该文件的唯一内容是 PID。您可以使用kill -9命令杀死该 PID。以下命令将杀死端口偏移为 1 的主服务器,但使集群保持运行状态:
$ cat /tmp/hbase-testuser-1-master.pid |xargs kill -9
- 启动和停止其他 RegionServer
HRegionServer 按照 HMaster 的指示 Management 其 StoreFiles 中的数据。通常,群集中的每个节点都运行一个 HRegionServer。在同一系统上运行多个 HRegionServer 对于在伪分布式模式下进行测试很有用。 local-regionservers.sh命令允许您运行多个 RegionServer。它的工作方式与local-master-backup.sh命令类似,因为您提供的每个参数都代表实例的端口偏移量。每个 RegionServer 需要两个端口,默认端口为 16020 和 16030.由于 HBase 版本 1.1.0,HMaster 不使用区域服务器端口,因此剩下 10 个端口(16020 到 16029 和 16030 到 16039)用于 RegionServer。为了支持其他 RegionServer,请在运行脚本local-regionservers.sh之前将环境变量 HBASE_RS_BASE_PORT 和 HBASE_RS_INFO_BASE_PORT 设置为适当的值。例如对于基本端口,值为 16200 和 16300,可以在服务器上支持 99 个其他 RegionServer。以下命令启动四个附加的 RegionServer,它们在从 16022/16032(基本端口 16020/16030 加 2)开始的 Sequences 端口上运行。
$ .bin/local-regionservers.sh start 2 3 4 5
要手动停止 RegionServer,请使用带有_参数的local-regionservers.sh命令以及要停止的服务器偏移量。
$ .bin/local-regionservers.sh stop 3
- Stop HBase.
您可以使用* bin/stop-hbase.sh *命令以与quickstart过程相同的方式停止 HBase。
2.4. 高级-完全分布式
实际上,您需要一个完全分布式的配置来全面测试 HBase 并在实际场景中使用它。在分布式配置中,集群包含多个节点,每个节点运行一个或多个 HBase 守护程序。其中包括主实例和备份 Master 实例,多个 ZooKeeper 节点和多个 RegionServer 节点。
此高级快速入门为集群添加了两个以上的节点。架构如下:
表 1.分布式集群演示架构
| Node Name | Master | ZooKeeper | RegionServer |
|---|---|---|---|
| node-a.example.com | yes | yes | no |
| node-b.example.com | backup | yes | yes |
| node-c.example.com | no | yes | yes |
本快速入门假定每个节点都是虚拟机,并且它们都在同一网络上。假设您在该过程中配置的系统现在为node-a,则它以先前的快速入门伪分布式本地安装为基础。在 continue 之前,在node-a上停止 HBase。
Note
确保所有节点都具有完全的通信访问权限,并且没有适当的防火墙规则可能阻止它们相互通信。如果看到诸如no route to host之类的错误,请检查防火墙。
过程:配置无密码的 SSH 访问
node-a必须能够登录node-b和node-c(并本身)才能启动守护程序。完成此操作的最简单方法是在所有主机上使用相同的用户名,并配置从node-a到其他每个主机的无密码 SSH 登录。
- 在
node-a上,生成一个密钥对。
以将要运行 HBase 的用户身份登录后,使用以下命令生成 SSH 密钥对:
$ ssh-keygen -t rsa
如果命令成功执行,则将密钥对的位置打印到标准输出。公钥的默认名称是* id_rsa.pub *。
- 创建将在其他节点上保存共享密钥的目录。
在node-b和node-c上,以 HBase 用户身份登录,并在用户的主目录中创建* .ssh/*目录(如果尚不存在)。如果已经存在,请注意它可能已经包含其他密钥。
- 将公钥复制到其他节点。
通过使用scp或其他某种安全方式,将公钥从node-a安全复制到每个节点。在其他每个节点上,创建一个名为* .ssh/authorized_keys 的新文件(如果尚不存在),并将 id_rsa.pub *文件的内容附加到文件末尾。请注意,您还需要针对node-a本身执行此操作。
$ cat id_rsa.pub >> ~/.ssh/authorized_keys
- 测试无密码登录。
如果正确执行了该过程,则当您使用相同的用户名从node-a SSH 到其他任何一个节点时,不应该提示您 Importing 密码。
- 由于
node-b将运行备份主服务器,因此重复上述过程,在您看到node-a的任何地方都替换node-b。确保不要覆盖现有的* .ssh/authorized_keys *文件,而是使用>>运算符而不是>运算符将新密钥连接到现有文件上。
程序:准备node-a
node-a将运行您的主要主服务器和 ZooKeeper 进程,但不会运行 RegionServer。停止 RegionServer 从node-a启动。
- 编辑* conf/regionservers *并删除包含
localhost的行。添加带有node-b和node-c的主机名或 IP 地址的行。
即使您确实想在node-a上运行 RegionServer,也应使用其他服务器用来与其通信的主机名来引用它。在这种情况下,该值为node-a.example.com。这使您可以将任何主机名冲突将配置分发到群集的每个节点。保存文件。
- 将 HBase 配置为使用
node-b作为备份主机。
在* conf/中创建一个名为 backup-masters *的新文件,并在其中添加新行,其主机名为node-b。在此演示中,主机名是node-b.example.com。
- Configure ZooKeeper
实际上,您应该仔细考虑您的 ZooKeeper 配置。您可以在zookeeper部分中找到有关配置 ZooKeeper 的更多信息。此配置将指导 HBase 在群集的每个节点上启动和 ManagementZooKeeper 实例。
在node-a上,编辑* conf/hbase-site.xml *并添加以下属性。
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-a.example.com,node-b.example.com,node-c.example.com</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>
- 在配置中您将
node-a称为localhost的任何地方,请将引用更改为指向其他节点将用来引用node-a的主机名。在这些示例中,主机名是node-a.example.com。
程序:准备node-b和node-c
node-b将运行备份主服务器和 ZooKeeper 实例。
- 下载并解压缩 HBase。
将 HBase 下载并解压缩到node-b,就像对独立和伪分布式快速入门所做的那样。
- 将配置文件从
node-a复制到node-b和node-c。
群集的每个节点都需要具有相同的配置信息。将* conf/目录的内容复制到node-b和node-c上的 conf/*目录。
过程:启动和测试集群
- 确保 HBase 不在任何节点上运行。
如果您忘记从先前的测试中停止 HBase,则将出现错误。使用jps命令检查 HBase 是否在您的任何节点上运行。查找进程HMaster,HRegionServer和HQuorumPeer。如果它们存在,杀死它们。
- 启动集群。
在node-a上,发出start-hbase.sh命令。您的输出将类似于以下内容。
$ bin/start-hbase.sh
node-c.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-c.example.com.out
node-a.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-a.example.com.out
node-b.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-b.example.com.out
starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-node-a.example.com.out
node-c.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-c.example.com.out
node-b.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-b.example.com.out
node-b.example.com: starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-nodeb.example.com.out
ZooKeeper 首先启动,然后是主机,然后是 RegionServer,最后是备份主机。
- 验证进程正在运行。
在群集的每个节点上,运行jps命令,并验证每个服务器上是否正在运行正确的进程。如果将其他 Java 进程用于其他目的,则可能还会看到它们在服务器上运行。
node-a jps输出
$ jps
20355 Jps
20071 HQuorumPeer
20137 HMaster
node-b jps输出
$ jps
15930 HRegionServer
16194 Jps
15838 HQuorumPeer
16010 HMaster
node-c jps输出
$ jps
13901 Jps
13639 HQuorumPeer
13737 HRegionServer
ZooKeeper Process Name
HQuorumPeer进程是一个由 HBase 控制和启动的 ZooKeeper 实例。如果以这种方式使用 ZooKeeper,则每个群集节点只能使用一个实例,并且仅适用于测试。如果 ZooKeeper 在 HBase 外部运行,则该过程称为QuorumPeer。有关 ZooKeeper 配置的更多信息,包括将外部 ZooKeeper 实例与 HBase 一起使用,请参阅zookeeper部分。
- 浏览到 Web UI。
Web UI Port Changes
Web UI 端口更改
在低于 0.98.x 的 HBase 中,HBase Web UI 使用的 HTTP 端口从 Master 的 60010 和每个 RegionServer 的 60030 变为 Master 的 16010 和 RegionServer 的 16030.
如果一切设置正确,则应该可以使用网络浏览器连接到主服务器http://node-a.example.com:16010/或辅助主服务器http://node-b.example.com:16010/的 UI。如果可以通过localhost进行连接,但不能通过其他主机进行连接,请检查防火墙规则。您可以在其 IP 地址的端口 16030 上单击每个 RegionServer 的 Web UI,也可以单击主服务器的 Web UI 中的链接。
- 测试当节点或服务消失时会发生什么。
使用已配置的三节点群集,情况将不会非常灵活。您仍然可以通过终止关联的进程并查看日志来测试主要 Master 或 RegionServer 的行为。
2.5. 接下来去哪里
下一章configuration提供了有关不同 HBase 运行模式,运行 HBase 的系统要求以及用于设置分布式 HBase 群集的关键配置区域的更多信息。
Apache HBase 配置
本章在Getting Started章的基础上进一步扩展,以进一步说明 Apache HBase 的配置。请仔细阅读本章,尤其是Basic Prerequisites,以确保您的 HBase 测试和部署顺利进行。还要熟悉支持和测试期望。
3.配置文件
Apache HBase 使用与 Apache Hadoop 相同的配置系统。所有配置文件都位于* conf/*目录中,该目录需要与集群中的每个节点保持同步。
HBase 配置文件说明
backup-masters
- 默认情况下不存在。一个纯文本文件,其中列出了主机应在其上启动备份主机进程的主机,每行一台主机。
hadoop-metrics2-hbase.properties
- 用于连接 HBase Hadoop 的 Metrics2 框架。有关 Metrics2 的更多信息,请参见Hadoop Wiki 条目。默认情况下仅包含 Comments 掉的示例。
-
- hbase-env.cmd 和 hbase-env.sh *
- 用于 Windows 和 Linux/Unix 环境的脚本,用于设置 HBase 的工作环境,包括 Java 的位置,Java 选项和其他环境变量。该文件包含许多 Comments 掉的示例以提供指导。
hbase-policy.xml
- RPC 服务器用来对 Client 端请求做出授权决策的默认策略配置文件。仅在启用 HBase security时使用。
hbase-site.xml
- HBase 的主要配置文件。该文件指定了覆盖 HBase 默认配置的配置选项。您可以在* docs/hbase-default.xml *上查看(但不能编辑)默认配置文件。您还可以在 HBase Web UI 的“ HBase 配置”选项卡中查看群集的整个有效配置(默认值和替代值)。
log4j.properties
- 通过
log4j进行 HBase 日志记录的配置文件。
- 通过
regionservers
- 一个纯文本文件,其中包含应在 HBase 群集中运行 RegionServer 的主机列表。默认情况下,此文件包含单个条目
localhost。它应包含一列主机名或 IP 地址,每行一个,并且仅应包含localhost(如果群集中的每个节点都将在其localhost接口上运行 RegionServer)。
- 一个纯文本文件,其中包含应在 HBase 群集中运行 RegionServer 的主机列表。默认情况下,此文件包含单个条目
Checking XML Validity
在编辑 XML 时,最好使用支持 XML 的编辑器,以确保语法正确且 XML 格式正确。您还可以使用xmllintUtil 来检查 XML 格式是否正确。默认情况下,xmllint重排并将 XML 打印到标准输出。要检查格式是否正确并仅在存在错误的情况下打印输出,请使用命令xmllint -noout filename.xml。
Keep Configuration In Sync Across the Cluster
在分布式模式下运行时,对 HBase 配置进行编辑后,请确保将* conf/*目录的内容复制到群集的所有节点。 HBase 不会为您这样做。使用rsync,scp或其他安全机制将配置文件复制到您的节点。对于大多数配置,服务器需要重新启动才能获取更改。动态配置是一个 exception,下面将对此进行描述。
4.基本先决条件
本节列出了必需的服务和一些必需的系统配置。
Java
下表总结了在各种 Java 版本上部署的 HBase 社区的建议。Importing“是”是指测试的基本水平和愿意帮助诊断和解决您可能遇到的问题的意愿。同样,Importing“否”或“不支持”通常意味着,如果您遇到问题,社区可能会要求您在 continue 提供帮助之前更改 Java 环境。在某些情况下,还将注意有关限制的特定指南(例如,是否进行编译/单元测试工作,特定的操作问题等)。
Long Term Support JDKs are recommended
HBase 建议下游用户使用来自 OpenJDK 项目或供应商的标记为长期支持(LTS)的 JDK 版本。截至 2018 年 3 月,这意味着 Java 8 是唯一适用的版本,下一个可能进行测试的版本将是 2018 年第三季度附近的 Java 11.
表 2. Java 对发布线的支持
| HBase Version | JDK 7 | JDK 8 | JDK 9 | JDK 10 |
|---|---|---|---|---|
| 2.0 | Not Supported | yes | Not Supported | Not Supported |
| 1.3 | yes | yes | Not Supported | Not Supported |
| 1.2 | yes | yes | Not Supported | Not Supported |
Note
HBase 既不会构建也不会与 Java 6 一起运行。
Note
您必须在群集的每个节点上设置JAVA_HOME。 * hbase-env.sh *提供了一种方便的机制来执行此操作。
osUtil
ssh
- HBase 广泛使用 Secure Shell(ssh)命令和 Util 在群集节点之间进行通信。集群中的每个服务器都必须运行
ssh,以便可以 ManagementHadoop 和 HBase 守护程序。您必须能够使用共享密钥而不是密码通过 SSH 通过 SSH 从 Master 以及任何备份 Master 连接到所有节点,包括本地节点。您可以在“ 过程:配置无密码的 SSH 访问”中看到在 Linux 或 Unix 系统中进行此类设置的基本方法。如果您的群集节点使用 OS X,请参阅 Hadoop Wiki 上的SSH:设置远程桌面并启用自我登录部分。
- HBase 广泛使用 Secure Shell(ssh)命令和 Util 在群集节点之间进行通信。集群中的每个服务器都必须运行
DNS
- HBase 使用 localhost 名自报告其 IP 地址。
NTP
- 群集节点上的时钟应同步。少量的变化是可以接受的,但是较大的偏斜会导致不稳定和意外的行为。时间同步是检查集群中是否出现无法解释的问题的首要检查之一。建议您在群集上运行网络时间协议(NTP)服务或其他时间同步机制,并且所有节点都希望使用同一服务进行时间同步。请参阅* Linux 文档项目(TLDP)*的基本 NTP 配置来设置 NTP。
文件和进程数限制(ulimit)
- Apache HBase 是一个数据库。它要求能够一次打开大量文件。许多 Linux 发行版将允许单个用户打开的文件数限制为
1024(在旧版本的 OS X 中为256)。您可以通过以运行 HBase 的用户身份登录时运行命令ulimit -n来检查服务器上的此限制。如果限制太低,您可能会遇到的一些问题请参见故障排除部分。您可能还会注意到以下错误:
- Apache HBase 是一个数据库。它要求能够一次打开大量文件。许多 Linux 发行版将允许单个用户打开的文件数限制为
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: Exception increateBlockOutputStream java.io.EOFException
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: Abandoning block blk_-6935524980745310745_1391901
建议将 ulimit 至少提高到 10,000,但更可能是 10,240,因为该值通常以 1024 的倍数表示。每个 ColumnFamily 至少具有一个 StoreFile,如果该区域处于负载状态,则可能有六个以上的 StoreFile。所需的打开文件数取决于 ColumnFamilies 的数量和区域的数量。以下是用于计算 RegionServer 上打开文件的潜在数量的粗略公式。
计算打开文件的潜在数量
(StoreFiles per ColumnFamily) x (regions per RegionServer)
例如,假设一个模式每个区域有 3 个 ColumnFamily,每个 ColumnFamily 平均有 3 个 StoreFiles,并且每个 RegionServer 有 100 个区域,那么 JVM 将打开3 * 3 * 100 = 900文件 Descriptors,不计算打开的 JAR 文件,配置文件和其他文件。打开文件不会占用太多资源,并且允许用户打开太多文件的风险很小。
另一个相关的设置是允许用户一次运行的进程数。在 Linux 和 Unix 中,使用ulimit -u命令设置进程数。请勿将此与nproc命令混淆,该命令控制给定用户可用的 CPU 数量。在负载下,ulimit -u太低会导致 OutOfMemoryError 异常。
为运行 HBase 进程的用户配置文件 Descriptors 和进程的最大数量是一种 os 配置,而不是 HBase 配置。确保为实际运行 HBase 的用户更改设置也很重要。要查看哪个用户启动了 HBase,以及该用户的 ulimit 配置,请查看该实例的 HBase 日志的第一行。
示例 2. Ubuntu 上的ulimit设置
要在 Ubuntu 上配置 ulimit 设置,请编辑*/etc/security/limits.conf ,它是一个由空格分隔的四列文件。有关此文件格式的详细信息,请参考 limits.conf *的手册页。在以下示例中,第一行将具有用户名 hadoop 的 os 用户的打开文件(nofile)数量的软限制和硬限制都设置为 32768.第二行将同一用户的进程数设置为 32000.
hadoop - nofile 32768
hadoop - nproc 32000
仅当直接使用可插拔身份验证模块(PAM)环境时才应用设置。要将 PAM 配置为使用这些限制,请确保*/etc/pam.d/common-session *文件包含以下行:
session required pam_limits.so
Linux Shell
- HBase 附带的所有 shell 脚本都依赖GNU Bash shell。
Windows
- 不建议在 Windows 计算机上运行生产系统。
4.1. Hadoop
下表总结了每个 HBase 版本支持的 Hadoop 版本。此表中未出现的较旧版本被认为不支持,并且可能缺少必要的功能,而较新版本未经测试,但可能合适。
基于 HBase 的版本,您应该选择最合适的 Hadoop 版本。您可以使用 Apache Hadoop 或供应商的 Hadoop 发行版。这里没有区别。有关 Hadoop 供应商的信息,请参见Hadoop Wiki。
Hadoop 2.x is recommended.
Hadoop 2.x 速度更快,并且具有短路读取(请参见利用本地数据)等功能,这些功能将有助于改善 HBase 随机读取配置文件。 Hadoop 2.x 还包含重要的错误修复,这些错误修复将改善您的整体 HBase 体验。 HBase 不支持与 Hadoop 的早期版本一起运行。有关特定于不同 HBase 版本的要求,请参见下表。
Hadoop 3.x 仍处于早期访问版本中,尚未通过 HBase 社区针对生产用例的充分测试。
使用以下图例解释此表:
Hadoop 版本支持表
“ S” =支持
“ X” =不支持
“ NT” =未测试
| HBase-1.2.x | HBase-1.3.x | HBase-1.5.x | HBase-2.0.x | HBase-2.1.x | |
|---|---|---|---|---|---|
| Hadoop-2.4.x | S | S | X | X | X |
| Hadoop-2.5.x | S | S | X | X | X |
| Hadoop-2.6.0 | X | X | X | X | X |
| Hadoop-2.6.1+ | S | S | X | S | X |
| Hadoop-2.7.0 | X | X | X | X | X |
| Hadoop-2.7.1+ | S | S | S | S | S |
| Hadoop-2.8.[0-1] | X | X | X | X | X |
| Hadoop-2.8.2 | NT | NT | NT | NT | NT |
| Hadoop-2.8.3+ | NT | NT | NT | S | S |
| Hadoop-2.9.0 | X | X | X | X | X |
| Hadoop-2.9.1+ | NT | NT | NT | NT | NT |
| Hadoop-3.0.x | X | X | X | X | X |
| Hadoop-3.1.0 | X | X | X | X | X |
Hadoop Pre-2.6.1 and JDK 1.8 Kerberos
在 Kerberos 环境中使用 2.6.1 之前的 Hadoop 版本和 JDK 1.8 时,由于 Kerberos keytab 重新登录错误,HBase 服务器可能会失败并中止。 JDK 1.7 的较新版本(1.7.0_80)也存在此问题。有关更多详细信息,请参考HADOOP-10786。在这种情况下,请考虑升级到 Hadoop 2.6.1.
Hadoop 2.6.x
如果计划在 HDFS 加密区域上运行 HBase,则基于 2.6.x 行**的 Hadoop 发行版必须应用HADOOP-11710。否则将导致群集故障和数据丢失。 Apache Hadoop 版本 2.6.1 中提供了此补丁。
Hadoop 2.y.0 Releases
从 Hadoop 2.7.0 版本开始,Hadoop PMC 习惯于在其主要版本 2 发行行中召集新的次要版本,因为它们尚未稳定/尚未准备就绪。因此,HBase 明确建议下游用户避免在这些版本之上运行。请注意,Hadoop PMC 还为 2.8.1 版本提供了相同的警告。作为参考,请参阅Apache Hadoop 2.7.0,Apache Hadoop 2.8.0 版,Apache Hadoop 2.8.1 版和Apache Hadoop 2.9.0 版的发行公告。
Hadoop 3.0.x Releases
包含应用程序时间轴服务功能的 Hadoop 发行版可能会导致应用程序 Classpath 中出现意外版本的 HBase 类。计划使用 HBase 运行 MapReduce 应用程序的用户应确保其 YARN 服务中存在YARN-7190(当前已在 2.9.1 和 3.1.0 中修复)。
Hadoop 3.1.0 Release
Hadoop PMC 称 3.1.0 版本不稳定/无法投入生产。因此,HBase 明确建议下游用户避免在此版本之上运行。供参考,请参阅Hadoop 3.1.0 发布公告。
Replace the Hadoop Bundled With HBase!
由于 HBase 依赖 Hadoop,因此将 Hadoop jarBinding 在其* lib *目录下。Binding 的罐子只能在独立模式下使用。在分布式模式下,群集上的 Hadoop 版本与 HBase 下的 Hadoop 版本相匹配是“关键”的。将 HBase lib 目录中找到的 hadoop jar 替换为您在集群上运行的版本中的等效 hadoop jar,以避免版本不匹配的问题。确保在整个群集中替换 HBase 下的 jar。 Hadoop 版本不匹配问题有多种表现形式。如果 HBase 似乎挂起,请检查是否不匹配。
4.1.1. dfs.datanode.max.transfer.threads
HDFS DataNode 可以随时提供服务的文件数量上限。在执行任何加载之前,请确保已配置 Hadoop 的* conf/hdfs-site.xml *,并将dfs.datanode.max.transfer.threads值至少设置为以下值:
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
完成上述配置后,请务必重新启动 HDFS。
如果没有适当的配置,将导致外观异常。一种表现是对缺少块的抱怨。例如:
10/12/08 20:10:31 INFO hdfs.DFSClient: Could not obtain block
blk_XXXXXXXXXXXXXXXXXXXXXX_YYYYYYYY from any node: java.io.IOException: No live nodes
contain current block. Will get new block locations from namenode and retry...
另请参见casestudies.max.transfer.threads,请注意,此属性以前称为dfs.datanode.max.xcievers(例如Hadoop HDFS:被 Xciever 欺骗)。
4.2. ZooKeeper 要求
ZooKeeper 3.4.x 是必需的。
5. HBase 运行模式:独立和分布式
HBase 具有两种运行模式:standalone和distributed。开箱即用,HBase 以独立模式运行。无论使用哪种模式,都需要通过编辑 HBase * conf *目录中的文件来配置 HBase。至少,您必须编辑 conf/hbase-env.sh 来告诉 HBase 使用哪个 Java。在此文件中,您设置了 HBase 环境变量,例如JVM的 heapsize 和其他选项,日志文件的首选位置等。将 JAVA_HOME 设置为指向 Java 安装的根目录。
5.1. 独立的 HBase
这是默认模式。 quickstart部分介绍了独立模式。在独立模式下,HBase 不使用 HDFS(而是使用本地文件系统),而是在同一 JVM 中运行所有 HBase 守护程序和本地 ZooKeeper。 ZooKeeper 绑定到一个知名端口,因此 Client 端可以与 HBase 进行通信。
5.1.1. HDFS 上的独立 HBase
独立 hbase 上有时有用的变体是,所有守护程序都在一个 JVM 内运行,而不是持久化到本地文件系统,而是持久化到 HDFS 实例。
当您打算使用简单的部署概要文件时,可以考虑使用此概要文件,虽然负载很轻,但是数据必须在节点间来回移动。写入要复制数据的 HDFS 可以确保后者。
要配置此独立变体,请编辑* hbase-site.xml 设置 hbase.rootdir 以指向 HDFS 实例中的目录,然后将 hbase.cluster.distributed 设置为 false *。例如:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode.example.org:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>
5.2. Distributed
可以将分布式模式细分为分布式模式,但是所有守护程序都在单个节点上运行,也称为“ pseudo-distributed *”和“完全分布式”,其中,守护程序分布在群集中的所有节点上。 “伪分布式”与“完全分布式”的术语来自 Hadoop。
伪分布式模式可以针对本地文件系统运行,也可以针对* Hadoop 分布式文件系统*(HDFS)实例运行。全分布式模式只能在 HDFS 上运行。有关如何设置 HDFS 的信息,请参阅 Hadoop documentation。可以在http://www.alexjf.net/blog/distributed-systems/hadoop-yarn-installation-definitive-guide找到一个很好的在 Hadoop 2 上设置 HDFS 的演练。
5.2.1. Pseudo-distributed
Pseudo-Distributed Quickstart
快速入门已添加到“ quickstart”一章。参见quickstart-pseudo。本节中最初的某些信息已移至此处。
伪分布式模式只是在单个主机上运行的完全分布式模式。将此 HBase 配置仅用于测试和原型制作。不要将此配置用于生产或性能评估。
5.3. Fully-distributed
默认情况下,HBase 在独立模式下运行。提供独立模式和伪分布式模式都是为了进行小型测试。对于生产环境,建议使用分布式模式。在分布式模式下,HBase 守护程序的多个实例在群集中的多个服务器上运行。
就像在伪分布式模式下一样,完全分布式配置需要将hbase.cluster.distributed属性设置为true。通常,将hbase.rootdir配置为指向高可用性 HDFS 文件系统。
此外,还配置了群集,以便多个群集节点可以注册为 RegionServers,ZooKeeper QuorumPeers 和备份 HMaster 服务器。这些配置基础都在quickstart-fully-distributed中进行了演示。
Distributed RegionServers
通常,您的群集将包含运行在不同服务器上的多个 RegionServer,以及主和备份 Master 和 ZooKeeper 守护程序。主服务器上的* conf/regionservers *文件包含其 RegionServer 与该群集关联的主机列表。每个主机位于单独的行上。当主服务器启动或停止时,此文件中列出的所有主机都将启动和停止其 RegionServer 进程。
ZooKeeper 和 HBase
有关 HBase 的 ZooKeeper 设置说明,请参见ZooKeeper部分。
例子 3.例子分布式 HBase 集群
这是分布式 HBase 集群的基础知识* conf/hbase-site.xml 。用于实际工作的群集将包含更多自定义配置参数。大多数 HBase 配置指令具有默认值,除非在 hbase-site.xml *中覆盖了该值,否则将使用默认值。有关更多信息,请参见“ Configuration Files”。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode.example.org:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-a.example.com,node-b.example.com,node-c.example.com</value>
</property>
</configuration>
这是一个示例* conf/regionservers 文件,其中包含应在集群中运行 RegionServer 的节点的列表。这些节点需要安装 HBase,并且需要使用与主服务器相同的 conf/*目录内容
node-a.example.com
node-b.example.com
node-c.example.com
这是一个示例* conf/backup-masters *文件,其中包含应运行备份 Master 实例的每个节点的列表。除非主控主机不可用,否则备份主控实例将处于空闲状态。
node-b.example.com
node-c.example.com
分布式 HBase 快速入门
有关具有多个 ZooKeeper,备份 HMaster 和 RegionServer 实例的简单三节点群集配置的演练,请参阅quickstart-fully-distributed。
过程:HDFSClient 端配置
值得注意的是,如果您在 Hadoop 集群上进行了 HDFSClient 端配置更改(例如 HDFSClient 端的配置指令),而不是服务器端配置,则必须使用以下方法之一来使 HBase 能够查看和使用这些配置更改:
在* hbase-env.sh *中将指向
HADOOP_CONF_DIR的指针添加到HBASE_CLASSPATH环境变量。在* ${HBASE_HOME}/conf 下添加 hdfs-site.xml (或 hadoop-site.xml *)或更佳的符号链接的副本,或
如果只有少量的 HDFSClient 端配置,请将其添加到* hbase-site.xml *中。
此类 HDFSClient 端配置的示例为dfs.replication。例如,如果要以 5 的复制因子运行,除非您执行上述操作以使配置可用于 HBase,否则 HBase 将创建默认值为 3 的文件。
6.运行并确认安装
确保首先运行 HDFS。通过在HADOOP_HOME目录中运行* bin/start-hdfs.sh *来启动和停止 Hadoop HDFS 守护程序。您可以通过将put和get文件测试到 Hadoop 文件系统中来确保启动正确。 HBase 通常不使用 MapReduce 或 YARN 守护程序。这些不需要启动。
如果您正在 Management 自己的 ZooKeeper,请启动并确认其正在运行,否则 HBase 将在启动过程中为您启动 ZooKeeper。
使用以下命令启动 HBase:
bin/start-hbase.sh
从HBASE_HOME目录运行以上命令。
现在,您应该有一个正在运行的 HBase 实例。 HBase 日志可在* logs *子目录中找到。检查它们,特别是如果 HBase 无法启动。
HBase 还构建了一个列出重要属性的 UI。默认情况下,它部署在主主机上的端口 16010 上(HBase RegionServers 默认在端口 16020 上侦听,并在端口 16030 上构建一个信息性 HTTP 服务器)。如果主服务器在默认端口名为master.example.org的主机上运行,请将浏览器指向 http://master.example.org:16010 以查看 Web 界面。
HBase 启动后,请参见shell exercises部分,以了解如何创建表,添加数据,扫描插入以及最后禁用和删除表。
要在退出 HBase Shell 之后停止 HBase,请 Importing
$ ./bin/stop-hbase.sh
stopping hbase...............
关机可能需要一些时间才能完成。如果群集由许多计算机组成,则可能需要更长的时间。如果您正在运行分布式操作,请确保等到 HBase 完全关闭后再停止 Hadoop 守护程序。
7.默认配置
7.1. hbase-site.xml 和 hbase-default.xml
就像在 Hadoop 中将特定于站点的 HDFS 配置添加到* hdfs-site.xml 文件中一样,针对 HBase,特定于站点的自定义项也放入文件 conf/hbase-site.xml 中。有关可配置属性的列表,请参见下面的hbase 默认配置或在 src/main/resources 的 HBase 源代码中查看原始的 hbase-default.xml *源文件。
并非所有配置选项都将其显示在* hbase-default.xml *中。有些配置只会出现在源代码中。识别这些更改的唯一方法是通过代码审查。
当前,此处的更改将要求 HBase 重新启动群集以注意到更改。
7.2. HBase 默认配置
以下文档是使用默认的 hbase 配置文件* hbase-default.xml *作为源生成的。
hbase.tmp.dir- Description
本地文件系统上的临时目录。更改此设置以指向比'/ tmp'更永久的位置(java.io.tmpdir 的通常解析方法),因为在重新启动计算机时会清除'/ tmp'目录。
Default
${java.io.tmpdir}/hbase-${user.name}
hbase.rootdir- Description
区域服务器共享的目录,HBase 保留在该目录中。该 URL 应该是“完全限定”的,以包括文件系统方案。例如,要指定 HDFS 实例的 namenode 在端口 9000 上的 namenode.example.org 上运行的 HDFS 目录“/hbase”,请将此值设置为:hdfs://namenode.example.org:9000/hbase。默认情况下,我们会写入也设置了${hbase.tmp.dir}的内容(通常是/ tmp),因此请更改此配置,否则所有数据都会在计算机重新启动时丢失。
Default
${hbase.tmp.dir}/hbase
hbase.cluster.distributed- Description
群集将处于的模式。对于独立模式,可能的值为 false;对于分布式模式,可能的值为 true。如果为 false,则启动将在一个 JVM 中同时运行所有 HBase 和 ZooKeeper 守护程序。
Default
false
hbase.zookeeper.quorum- Description
ZooKeeper 集合中服务器的逗号分隔列表(此配置应已命名为 hbase.zookeeper.ensemble)。例如,“ host1.mydomain.com,host2.mydomain.com,host3.mydomain.com”。默认情况下,对于本地和伪分布式操作模式,此选项设置为 localhost。对于完全分布式的设置,应将其设置为 ZooKeeper 集成服务器的完整列表。如果在 hbase-env.sh 中设置了 HBASE_MANAGES_ZK,则这是 hbase 在群集启动/停止过程中将启动/停止 ZooKeeper 的服务器列表。在 Client 端,我们将获取此集成成员列表,并将其与 hbase.zookeeper.property.clientPort 配置放在一起。并将其作为 connectString 参数传递到 zookeeper 构造函数中。
Default
localhost
zookeeper.recovery.retry.maxsleeptime- Description
重试 Zookeeper 操作之前的最大睡眠时间(以毫秒为单位),此处需要一个最大时间,以使睡眠时间不会无限制地增长
Default
60000
hbase.local.dir- Description
本地文件系统上用作本地存储的目录。
Default
${hbase.tmp.dir}/local/
hbase.master.port- Description
HBase 主站应绑定的端口。
Default
16000
hbase.master.info.port- Description
HBase Master Web UI 的端口。如果您不希望运行 UI 实例,请设置为-1.
Default
16010
hbase.master.info.bindAddress- Description
HBase Master Web UI 的绑定地址
Default
0.0.0.0
hbase.master.logcleaner.plugins- Description
LogsCleaner 服务调用的以逗号分隔的 BaseLogCleanerDelegate 列表。这些 WAL 清理程序是按 Sequences 调用的,因此将修剪最多文件的清理程序放在前面。要实现自己的 BaseLogCleanerDelegate,只需将其放在 HBase 的 Classpath 中,然后在此处添加完全限定的类名。始终在列表中添加以上默认日志清除器。
Default
org.apache.hadoop.hbase.master.cleaner.TimeToLiveLogCleaner,org.apache.hadoop.hbase.master.cleaner.TimeToLiveProcedureWALCleaner
hbase.master.logcleaner.ttl- Description
WAL 在存档( {}/oldWALs)目录中保留多长时间,之后它将由主线程清除。该值以毫秒为单位。
Default
600000
hbase.master.procedurewalcleaner.ttl- Description
过程 WAL 将在存档目录中保留多长时间,之后将由主线程将其清除。该值以毫秒为单位。
Default
604800000
hbase.master.hfilecleaner.plugins- Description
由 HFileCleaner 服务调用的 BaseHFileCleanerDelegate 的逗号分隔列表。这些 HFiles 清理程序是按 Sequences 调用的,因此将修剪大多数文件的清理程序放在前面。要实现自己的 BaseHFileCleanerDelegate,只需将其放在 HBase 的 Classpath 中,然后在此处添加完全限定的类名。请始终在列表中添加上述默认日志清除器,因为它们将在 hbase-site.xml 中被覆盖。
Default
org.apache.hadoop.hbase.master.cleaner.TimeToLiveHFileCleaner
hbase.master.infoserver.redirect- Description
Master 是否侦听 Master Web UI 端口(hbase.master.info.port)并将请求重定向到 Master 和 RegionServer 共享的 Web UI 服务器。配置当 Master 服务于区域(不是默认值)时,这很有意义。
Default
true
hbase.master.fileSplitTimeout- Description
分割区域,在中止尝试之前要 await 文件分割步骤多长时间。默认值:600000.此设置以前在 hbase-1.x 中称为 hbase.regionserver.fileSplitTimeout。现在,Split 在主端运行,因此重命名(如果找到了“ hbase.master.fileSplitTimeout”设置,它将使用它来初始化当前的“ hbase.master.fileSplitTimeout”配置。
Default
600000
hbase.regionserver.port- Description
HBase RegionServer 绑定到的端口。
Default
16020
hbase.regionserver.info.port- Description
如果您不希望运行 RegionServer UI,请将 HBase RegionServer Web UI 的端口设置为-1.
Default
16030
hbase.regionserver.info.bindAddress- Description
HBase RegionServer Web UI 的地址
Default
0.0.0.0
hbase.regionserver.info.port.auto- Description
Master 或 RegionServer UI 是否应搜索要绑定的端口。如果 hbase.regionserver.info.port 已在使用中,则启用自动端口搜索。对于测试很有用,默认情况下处于关闭状态。
Default
false
hbase.regionserver.handler.count- Description
在 RegionServer 上旋转的 RPC 侦听器实例数。 Master 使用相同的属性来计算 master 处理程序的数量。过多的处理程序可能适得其反。将其设为 CPU 计数的倍数。如果大多数情况下是只读的,则处理程序计数接近 cpu 计数的效果很好。从两倍的 CPU 计数开始,然后从那里进行调整。
Default
30
hbase.ipc.server.callqueue.handler.factor- Description
确定呼叫队列数量的因素。值为 0 表示所有处理程序之间共享一个队列。值为 1 表示每个处理程序都有自己的队列。
Default
0.1
hbase.ipc.server.callqueue.read.ratio- Description
将呼叫队列划分为读写队列。指定的间隔(应在 0.0 到 1.0 之间)将乘以呼叫队列的数量。值为 0 表示不拆分呼叫队列,这意味着读取和写入请求都将被推送到同一组队列中。小于 0.5 的值表示读队列少于写队列。值为 0.5 表示将有相同数量的读取和写入队列。大于 0.5 的值表示将有比写队列更多的读队列。值 1.0 表示除一个队列外的所有队列均用于调度读取请求。示例:给定呼叫队列的总数为 10,读取比率为 0 表示:10 个队列将包含两个读取/写入请求。 read.ratio 为 0.3 表示:3 个队列仅包含读取请求,而 7 个队列仅包含写入请求。 read.ratio 为 0.5 意味着:5 个队列将仅包含读取请求,而 5 个队列将仅包含写入请求。 read.ratio 为 0.8 表示:8 个队列仅包含读取请求,而 2 个队列仅包含写入请求。 read.ratio 为 1 表示:9 个队列仅包含读取请求,而 1 个队列仅包含写入请求。
Default
0
hbase.ipc.server.callqueue.scan.ratio- Description
给定读取呼叫队列的数量(根据呼叫队列总数乘以 callqueue.read.ratio 计算得出),scan.ratio 属性会将读取呼叫队列分为小读取队列和长读取队列。小于 0.5 的值表示长读队列少于短读队列。值 0.5 表示将有相同数量的短读和长读队列。大于 0.5 的值表示长读取队列比短读取队列多。值为 0 或 1 表示对获取和扫描使用相同的队列集。示例:假设读取呼叫队列的总数为 8,则 scan.ratio 为 0 或 1 表示:8 个队列将同时包含长读取请求和短读取请求。 scan.ratio 为 0.3 表示:2 个队列将仅包含长读请求,而 6 个队列将仅包含短读请求。 scan.ratio 为 0.5 表示:4 个队列将仅包含长读请求,而 4 个队列将仅包含短读请求。 scan.ratio 为 0.8 表示:6 个队列将仅包含长读请求,而 2 个队列将仅包含短读请求。
Default
0
hbase.regionserver.msginterval- Description
从 RegionServer 到 Master 的消息之间的间隔(以毫秒为单位)。
Default
3000
hbase.regionserver.logroll.period- Description
无论提交多少编辑,我们都会滚动提交日志的时间段。
Default
3600000
hbase.regionserver.logroll.errors.tolerated- Description
在触发服务器异常终止之前,我们将允许的连续 WAL 关闭错误数。如果在日志滚动过程中关闭当前 WAL 写入器失败,则设置为 0 将导致区域服务器中止。即使是很小的值(2 或 3)也将使区域服务器克服瞬态 HDFS 错误。
Default
2
hbase.regionserver.hlog.reader.impl- Description
WAL 文件阅读器实现。
Default
org.apache.hadoop.hbase.regionserver.wal.ProtobufLogReader
hbase.regionserver.hlog.writer.impl- Description
WAL 文件编写器实现。
Default
org.apache.hadoop.hbase.regionserver.wal.ProtobufLogWriter
hbase.regionserver.global.memstore.size- Description
在阻止新更新并强制进行刷新之前,区域服务器中所有内存存储区的最大大小。默认为堆的 40%(0.4)。阻止更新并强制进行刷新,直到区域服务器中所有内存存储的大小达到 hbase.regionserver.global.memstore.size.lower.limit。此配置中的默认值有意保留为空,以保留旧的 hbase.regionserver.global.memstore.upperLimit 属性(如果存在)。
Default
none
hbase.regionserver.global.memstore.size.lower.limit- Description
强制刷新之前,区域服务器中所有内存存储区的最大大小。默认为 hbase.regionserver.global.memstore.size(0.95)的 95%。如果由于内存存储限制而阻止更新,则此值的 100%值将导致最小的刷新发生。此配置中的默认值有意保留为空,以保留旧的 hbase.regionserver.global.memstore.lowerLimit 属性(如果存在)。
Default
none
hbase.systemtables.compacting.memstore.type- Description
确定用于系统表(如 META,名称空间表等)的内存存储的类型。默认情况下,类型为 NONE,因此我们对所有系统表使用默认的内存存储。如果我们需要对系统表使用压缩存储区,则将此属性设置为 BASIC/EAGER
Default
NONE
hbase.regionserver.optionalcacheflushinterval- Description
编辑内容在自动刷新之前在内存中保留的最长时间。默认值 1 小时。将其设置为 0 以禁用自动刷新。
Default
3600000
hbase.regionserver.dns.interface- Description
区域服务器应从中报告其 IP 地址的网络接口的名称。
Default
default
hbase.regionserver.dns.nameserver- Description
区域服务器应使用该名称服务器(DNS)的主机名或 IP 地址来确定主机用于通讯和显示目的的主机名。
Default
default
hbase.regionserver.region.split.policy- Description
拆分策略确定何时应拆分区域。当前可用的其他各种拆分策略为 BusyRegionSplitPolicy,ConstantSizeRegionSplitPolicy,DisabledRegionSplitPolicy,DelimitedKeyPrefixRegionSplitPolicy,KeyPrefixRegionSplitPolicy 和 SteppingSplitPolicy。 DisabledRegionSplitPolicy 阻止手动区域分割。
Default
org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy
hbase.regionserver.regionSplitLimit- Description
区域数量的限制,之后将不再进行区域划分。这不是对区域数量的硬限制,但可作为区域服务器在特定限制后停止拆分的准则。默认设置为 1000.
Default
1000
zookeeper.session.timeout- Description
ZooKeeper 会话超时(以毫秒为单位)。它以两种不同的方式使用。首先,在 HBase 用于连接到集成体的 ZKClient 端中使用此值。 HBase 在启动 ZK 服务器时也使用它,并将其作为“ maxSessionTimeout”传递。参见https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html#ch_zkSessions。例如,如果 HBase 区域服务器连接到也由 HBaseManagement 的 ZK 集成,则会话超时将是此配置指定的会话超时。但是,连接到使用不同配置 Management 的集成服务器的区域服务器将受到该集成服务器的 maxSessionTimeout 的影响。因此,即使 HBase 可能建议使用 90 秒,该集合的最大超时值也可以低于此值,并且它将具有优先权。 ZK 随附的当前默认 maxSessionTimeout 为 40 秒,比 HBase 的低。
Default
90000
zookeeper.znode.parent- Description
ZooKeeper 中用于 HBase 的根 ZNode。配置有相对路径的所有 HBase 的 ZooKeeper 文件都将位于此节点下。默认情况下,所有 HBase 的 ZooKeeper 文件路径都配置有相对路径,因此除非更改,否则它们都将位于此目录下。
Default
/hbase
zookeeper.znode.acl.parent- Description
根 ZNode 用于访问控制列表。
Default
acl
hbase.zookeeper.dns.interface- Description
ZooKeeper 服务器应从中报告其 IP 地址的网络接口的名称。
Default
default
hbase.zookeeper.dns.nameserver- Description
ZooKeeper 服务器应使用其名称服务器(DNS)的主机名或 IP 地址来确定主机用于通信和显示目的的主机名。
Default
default
hbase.zookeeper.peerport- Description
ZooKeeper 对等方用来互相通信的端口。有关更多信息,请参见https://zookeeper.apache.org/doc/r3.3.3/zookeeperStarted.html#sc_RunningReplicatedZooKeeper。
Default
2888
hbase.zookeeper.leaderport- Description
ZooKeeper 用于领导者选举的端口。有关更多信息,请参见https://zookeeper.apache.org/doc/r3.3.3/zookeeperStarted.html#sc_RunningReplicatedZooKeeper。
Default
3888
hbase.zookeeper.property.initLimit- Description
ZooKeeper 的配置 zoo.cfg 中的属性。初始同步阶段可以进行的滴答声数量。
Default
10
hbase.zookeeper.property.syncLimit- Description
ZooKeeper 的配置 zoo.cfg 中的属性。在发送请求和获得确认之间可以经过的滴答数。
Default
5
hbase.zookeeper.property.dataDir- Description
ZooKeeper 的配置 zoo.cfg 中的属性。快照存储的目录。
Default
${hbase.tmp.dir}/zookeeper
hbase.zookeeper.property.clientPort- Description
ZooKeeper 的配置 zoo.cfg 中的属性。Client 端将连接的端口。
Default
2181
hbase.zookeeper.property.maxClientCnxns- Description
ZooKeeper 的配置 zoo.cfg 中的属性。限制单个 Client 端通过 IP 地址标识到 ZooKeeper 集成的单个成员的并发连接数(在套接字级别)。设置为高值可避免独立运行和伪分布式运行的 zk 连接问题。
Default
300
hbase.client.write.buffer- Description
BufferedMutator 写缓冲区的默认大小(以字节为单位)。较大的缓冲区会占用更多的内存-在 Client 端和服务器端,因为服务器会实例化传递的写缓冲区来处理它-但较大的缓冲区会减少制作的 RPC 数量。要估计服务器端使用的内存,请评估 hbase.client.write.buffer * hbase.regionserver.handler.count
Default
2097152
hbase.client.pause- Description
常规 Client 端暂停值。在运行重试失败的获取,区域查找等之前,主要用作 await 值。请参见 hbase.client.retries.number,以获取有关我们如何从此初始暂停量回退以及此暂停如何进行重试的描述。
Default
100
hbase.client.pause.cqtbe- Description
是否对 CallQueueTooBigException(cqtbe)使用特殊的 Client 端暂停。如果您观察到来自同一 RegionServer 的频繁 CQTBE 并且那里的呼叫队列保持满状态,则将此属性设置为比 hbase.client.pause 高的值。
Default
none
hbase.client.retries.number- Description
最大重试次数。用作所有可重试操作的最大值,例如获取单元格的值,开始行更新等。重试间隔是基于 hbase.client.pause 的粗略函数。首先,我们以该时间间隔重试,然后通过退避,我们很快就达到了每十秒钟重试一次的目的。有关备份如何增加的信息,请参见 HConstants#RETRY_BACKOFF。更改此设置和 hbase.client.pause 以适合您的工作量。
Default
15
hbase.client.max.total.tasks- Description
一个 HTable 实例将发送到群集的最大并发变异任务数。
Default
100
hbase.client.max.perserver.tasks- Description
单个 HTable 实例将发送到单个区域服务器的最大并发变异任务数。
Default
2
hbase.client.max.perregion.tasks- Description
Client 将维护到一个区域的最大并发突变任务数。也就是说,如果已经对该区域进行了 hbase.client.max.perregion.tasks 写入,则在完成某些写入之前,不会将新的 puts 发送到该区域。
Default
1
hbase.client.perserver.requests.threshold- Description
所有 Client 端线程(进程级别)中一台服务器的并发暂挂请求的最大数量。超出的请求将立即引发 ServerTooBusyException,以防止仅一台慢速区域服务器占用和阻止用户的线程。如果您使用固定数量的线程以同步方式访问 HBase,请将其设置为与线程数量相关的合适值将对您有所帮助。有关详情,请参见https://issues.apache.org/jira/browse/HBASE-16388。
Default
2147483647
hbase.client.scanner.caching- Description
如果未从(本地,Client 端)内存提供服务,则在扫描器上调用 next 时我们尝试获取的行数。此配置与 hbase.client.scanner.max.result.size 一起使用,以尝试有效地使用网络。默认情况下,默认值为 Integer.MAX_VALUE,以便网络将填充 hbase.client.scanner.max.result.size 定义的块大小,而不是受特定的行数限制,因为行的大小因表而异。如果您提前知道一次扫描不需要多于一定数量的行,则应通过 Scan#setCaching 将此配置设置为该行限制。较高的缓存值将启用更快的扫描程序,但会消耗更多的内存,并且当缓存为空时,对 next 的某些调用可能会花费越来越长的时间。请勿将此值设置为两次调用之间的时间大于扫描程序的超时时间;即 hbase.client.scanner.timeout.period
Default
2147483647
hbase.client.keyvalue.maxsize- Description
指定 KeyValue 实例的组合最大允许大小。这是为存储文件中保存的单个条目设置上限。由于无法拆分它们,因此有助于避免由于数据太大而无法进一步拆分区域。将其设置为最大区域大小的一小部分似乎是明智的。将其设置为零或更少将禁用检查。
Default
10485760
hbase.server.keyvalue.maxsize- Description
单个单元格的最大允许大小,包括值和所有关键组件。小于或等于 0 的值将禁用该检查。默认值为 10MB。这是一项安全设置,可以保护服务器免受 OOM 情况的影响。
Default
10485760
hbase.client.scanner.timeout.period- Description
Client 端扫描程序的租用期限(以毫秒为单位)。
Default
60000
hbase.client.localityCheck.threadPoolSize- Default
2
hbase.bulkload.retries.number- Description
最大重试次数。这是面对分裂操作时尝试进行的原子批量加载的最大迭代次数 0 表示永不放弃。
Default
10
hbase.master.balancer.maxRitPercent- Description
平衡时过渡区域的最大百分比。默认值为 1.0. 因此,没有平衡器节流。如果将此配置设置为 0.01,则表示平衡时最多有 1%的过渡区域。然后,平衡时群集的可用性至少为 99%。
Default
1.0
hbase.balancer.period- Description
区域平衡器在主服务器中运行的时间段。
Default
300000
hbase.normalizer.period- Description
区域规范化器在主服务器中运行的时间段。
Default
300000
hbase.regions.slop- Description
如果任何区域服务器具有平均(平均*斜率)区域,则重新平衡。在 StochasticLoadBalancer(默认负载均衡器)中,此参数的默认值为 0.001,而在其他负载均衡器(即 SimpleLoadBalancer)中默认值为 0.2.
Default
0.001
hbase.server.thread.wakefrequency- Description
两次搜索工作之间的睡眠时间(以毫秒为单位)。用作日志线程等服务线程的睡眠间隔。
Default
10000
hbase.server.versionfile.writeattempts- Description
在终止之前尝试重试几次尝试写入版本文件。每次尝试都由 hbase.server.thread.wakefrequency 毫秒分隔。
Default
3
hbase.hregion.memstore.flush.size- Description
如果内存大小超过此字节数,则将内存存储刷新到磁盘。值由运行每个 hbase.server.thread.wakefrequency 的线程检查。
Default
134217728
hbase.hregion.percolumnfamilyflush.size.lower.bound.min- Description
如果使用了 FlushLargeStoresPolicy 并且有多个列族,那么每次我们达到内存存储区的总限制时,我们都会找出所有其内存存储区超出“下限”的列族,并仅刷新它们,同时将其他存储区保留在内存中。默认情况下,“下界”将为“ hbase.hregion.memstore.flush.size/column_family_number”,除非该属性的值大于该值。如果没有一个家族的内存大小超过下限,则将刷新所有内存(就像往常一样)。
Default
16777216
hbase.hregion.preclose.flush.size- Description
如果在关闭时某个区域中的存储器大小等于或大于此大小,则在设置区域已关闭标志并使该区域脱机之前,运行“预冲洗”以清除存储器。关闭时,在关闭标志下运行刷新以清空内存。在这段时间内,该地区处于离线状态,我们没有进行任何写操作。如果 memstore 内容很大,则刷新可能需要很长时间才能完成。预刷新的目的是在放置关闭标志并使区域脱机之前清理掉大部分的内存存储,因此在关闭标志下运行的刷新几乎没有作用。
Default
5242880
hbase.hregion.memstore.block.multiplier- Description
如果 memstore 具有 hbase.hregion.memstore.block.multiplier 乘以 hbase.hregion.memstore.flush.size 字节,则阻止更新。防止更新流量激增期间失控的存储器。如果没有上限,则内存存储将进行填充,以便在刷新结果刷新文件时需要花费很长时间来压缩或拆分,或更糟糕的是,我们 OOME。
Default
4
hbase.hregion.memstore.mslab.enabled- Description
启用 MemStore-Local Allocation Buffer,该功能可防止在重写入负载下发生堆碎片。这可以减少大堆上停止世界 GC 暂停的频率。
Default
true
hbase.hregion.max.filesize- Description
最大 HFile 大小。如果区域的 HFiles 大小的总和超过了该值,则该区域将一分为二。
Default
10737418240
hbase.hregion.majorcompaction- Description
两次大压实之间的时间,以毫秒为单位。设置为 0 以禁用基于时间的自动专业压缩。用户请求的基于大小的大型压缩仍将运行。将该值乘以 hbase.hregion.majorcompaction.jitter 可以使压缩在给定的时间范围内在某个随机时间开始。默认值为 7 天,以毫秒为单位。如果大型压缩在您的环境中造成破坏,则可以将其配置为在部署的非高峰时间运行,或者通过将此参数设置为 0 来禁用基于时间的大型压缩,并在 cron 作业或其他作业中运行大型压缩外部机制。
Default
604800000
hbase.hregion.majorcompaction.jitter- Description
应用于 hbase.hregion.majorcompaction 的乘数,使压缩在 hbase.hregion.majorcompaction 的任一侧发生给定的时间。数量越小,紧缩将发生在 hbase.hregion.majorcompaction 间隔上。
Default
0.50
hbase.hstore.compactionThreshold- Description
如果在任何一个 Store 中都存在超过此数目的 StoreFile(每次刷新 MemStore 都会写入一个 StoreFile),则会运行压缩以将所有 StoreFile 重写为一个 StoreFile。较大的值会延迟压缩,但是当压缩确实发生时,则需要更长的时间才能完成。
Default
3
hbase.hstore.flusher.count- Description
刷新线程数。如果线程较少,则将对 MemStore 刷新进行排队。如果线程更多,则将并行执行刷新,从而增加 HDFS 的负载,并可能导致更多的压缩。
Default
2
hbase.hstore.blockingStoreFiles- Description
如果在任何一个 Store 中都存在超过此数目的 StoreFile(每次刷新 MemStore 都写入一个 StoreFile),则将阻止对此区域进行更新,直到压缩完成或超过 hbase.hstore.blockingWaitTime。
Default
16
hbase.hstore.blockingWaitTime- Description
达到 hbase.hstore.blockingStoreFiles 定义的 StoreFile 限制后,区域将阻止更新的时间。经过此时间后,即使压缩尚未完成,该区域也将停止阻止更新。
Default
90000
hbase.hstore.compaction.min- Description
运行压缩之前必须符合压缩条件的最小 StoreFiles 数。调整 hbase.hstore.compaction.min 的目标是避免最终产生太多无法压缩的微小 StoreFiles。每次在存储中有两个 StoreFiles 时,将此值设置为 2 都会导致较小的压缩,这可能不合适。如果将此值设置得太高,则所有其他值都需要相应地进行调整。在大多数情况下,默认值为适当。在以前的 HBase 版本中,参数 hbase.hstore.compaction.min 命名为 hbase.hstore.compactionThreshold。
Default
3
hbase.hstore.compaction.max- Description
无论合格的 StoreFiles 数量如何,一次较小的压缩将选择的 StoreFiles 的最大数量。有效地,hbase.hstore.compaction.max 的值控制完成一次压缩的时间长度。将其设置为更大意味着压缩中将包含更多 StoreFiles。在大多数情况下,默认值为适当。
Default
10
hbase.hstore.compaction.min.size- Description
小于此大小的 StoreFile(或使用 ExploringCompactionPolicy 时选择的 StoreFiles)始终可以进行较小的压缩。大小更大的 HFile 由 hbase.hstore.compaction.ratio 评估以确定它们是否合格。因为此限制表示所有小于此值的 StoreFiles 的“自动包含”限制,所以在需要大量写入 1-2 MB 范围的 StoreFiles 的写繁重环境中,可能需要减小此值,因为每个 StoreFile 都将作为目标。进行压缩,生成的 StoreFiles 可能仍小于最小大小,需要进一步压缩。如果降低此参数,则比率检查将更快地触发。这解决了早期版本的 HBase 中遇到的一些问题,但是在大多数情况下不再需要更改此参数。默认值:128 MB,以字节为单位。
Default
134217728
hbase.hstore.compaction.max.size- Description
大于此大小的 StoreFile(或使用 ExploringCompactionPolicy 时选择的 StoreFiles)将被排除在压缩之外。增大 hbase.hstore.compaction.max.size 的效果较小,而较大的 StoreFiles 则不会经常压缩。如果您认为压缩过于频繁而没有太多好处,则可以尝试提高此值。默认值:LONG.MAX_VALUE 的值,以字节为单位。
Default
9223372036854775807
hbase.hstore.compaction.ratio- Description
对于较小的压缩,此比率用于确定大于 hbase.hstore.compaction.min.size 的给定 StoreFile 是否适合压缩。它的作用是限制大型 StoreFiles 的压缩。 hbase.hstore.compaction.ratio 的值表示为浮点十进制。很大的比例(例如 10)将产生一个巨大的 StoreFile。相反,较低的值(例如.25)将产生类似于 BigTable 压缩算法的行为,从而产生四个 StoreFiles。建议在 1.0 到 1.4 之间使用一个适中的值。调整此值时,您要平衡写入成本和读取成本。将值提高(到 1.4 之类)会增加写入成本,因为您将压缩更大的 StoreFiles。但是,在读取期间,HBase 将需要搜索较少的 StoreFiles 来完成读取。如果您无法利用布隆过滤器,请考虑使用这种方法。否则,您可以将此值降低到 1.0 之类,以减少写入的背景成本,并使用 Bloom 过滤器控制读取期间接触到的 StoreFiles 的数量。在大多数情况下,默认值为适当。
Default
1.2F
hbase.hstore.compaction.ratio.offpeak- Description
允许您设置不同的比率(默认情况下更具侵略性),以确定非高峰时段压缩中是否包含较大的 StoreFiles。以与 hbase.hstore.compaction.ratio 相同的方式工作。仅在同时启用了 hbase.offpeak.start.hour 和 hbase.offpeak.end.hour 的情况下适用。
Default
5.0F
hbase.hstore.time.to.purge.deletes- Description
延迟清除带有 Future 时间戳记的删除标记的时间。如果未设置或设置为 0,则所有删除标记(包括带有 Future 时间戳记的标记)将在下一次主要压缩期间清除。否则,将保留删除标记,直到在标记的时间戳加上此设置的值之后发生的主要压缩为止(以毫秒为单位)。
Default
0
hbase.offpeak.start.hour- Description
非高峰时间的开始,表示为 0 到 23 之间的一个整数(包括 0 和 23)。设置为-1 可禁用非峰值。
Default
-1
hbase.offpeak.end.hour- Description
非高峰时段的结束时间,以 0 到 23 之间的一个整数表示,包括 0 和 23.设置为-1 可禁用非峰值。
Default
-1
hbase.regionserver.thread.compaction.throttle- Description
有两种不同的线程池用于压缩,一种用于大压缩,另一种用于小压缩。这有助于保持精简表(例如 hbase:meta)的紧缩。如果压缩大于此阈值,它将进入大型压缩池。在大多数情况下,默认值为适当。默认值:2 x hbase.hstore.compaction.max x hbase.hregion.memstore.flush.size(默认为 128MB)。值字段假定 hbase.hregion.memstore.flush.size 的值与默认值保持不变。
Default
2684354560
hbase.regionserver.majorcompaction.pagecache.drop- Description
指定是否通过主要压缩将读取/写入的页面丢弃到系统页面缓存中。将其设置为 true 有助于防止大型压缩污染页面缓存,这几乎总是需要的,尤其是对于内存/存储比率低/中等的群集。
Default
true
hbase.regionserver.minorcompaction.pagecache.drop- Description
指定是否通过较小的压缩将读取/写入的页面丢弃到系统页面缓存中。将其设置为 true 有助于防止较小的压缩对页面缓存造成污染,这在内存与存储比率低或写入量很大的群集中最有用。当大量读取都在最近写入的数据上时,您可能希望在中等到低的写入工作量下将其设置为 false。
Default
true
hbase.hstore.compaction.kv.max- Description
刷新或压缩时要批量读取和写入的 KeyValue 的最大数量。如果您有较大的键值和内存不足异常问题,请将其设置为较低,如果行宽且较小的行,请将其设置为较高。
Default
10
hbase.storescanner.parallel.seek.enable- Description
在 StoreScanner 中启用 StoreFileScanner 并行查找功能,该功能可以减少特殊情况下的响应延迟。
Default
false
hbase.storescanner.parallel.seek.threads- Description
如果启用了并行查找功能,则为默认线程池大小。
Default
10
hfile.block.cache.size- Description
分配给 StoreFile 使用的块缓存的最大堆的百分比(-Xmx 设置)。默认值为 0.4 表示分配 40%。设置为 0 以禁用,但不建议这样做;您至少需要足够的缓存来保存存储文件索引。
Default
0.4
hfile.block.index.cacheonwrite- Description
这允许在写入索引时将非根多级索引块放入块高速缓存中。
Default
false
hfile.index.block.max.size- Description
当多级块索引中的叶级,中间级或根级索引块的大小增长到该大小时,将写出该块并开始一个新块。
Default
131072
hbase.bucketcache.ioengine- Description
存储桶式缓存内容的位置。其中之一:堆,文件,文件或 mmap。如果是一个或多个文件,请将其设置为 file:PATH_TO_FILE。 mmap 表示内容将在 mmaped 文件中。使用 mmap:PATH_TO_FILE。有关更多信息,请参见http://hbase.apache.org/book.html#offheap.blockcache。
Default
none
hbase.bucketcache.size- Description
EITHER 代表要提供给缓存的总堆内存大小的百分比的浮点数(如果<1.0),或者,它是 BucketCache 的总容量(以兆字节为单位)。默认值:0.0
Default
none
hbase.bucketcache.bucket.sizes- Description
以逗号分隔的存储区存储区大小列表。可以是多种尺寸。按从小到大的 Sequences 列出块大小。您使用的大小将取决于您的数据访问模式。必须为 256 的倍数,否则当您从缓存中读取数据时,将遇到“ java.io.IOException:无效的 HFile 块魔术”。如果在此处未指定任何值,则将选择代码中设置的默认存储桶大小(请参见 BucketAllocator#DEFAULT_BUCKET_SIZES)。
Default
none
hfile.format.version- Description
用于新文件的 HFile 格式版本。第 3 版增加了对 hfiles 中标签的支持(请参阅http://hbase.apache.org/book.html#hbase.tags)。另请参阅配置“ hbase.replication.rpc.codec”。
Default
3
hfile.block.bloom.cacheonwrite- Description
为复合 Bloom 过滤器的内联块启用写时缓存。
Default
false
io.storefile.bloom.block.size- Description
复合布隆过滤器的单个块(“块”)的字节大小。此大小是近似值,因为 Bloom 块只能插入数据块边界,并且每个数据块的键数有所不同。
Default
131072
hbase.rs.cacheblocksonwrite- Description
块完成后是否应将 HFile 块添加到块缓存中。
Default
false
hbase.rpc.timeout- Description
这是为 RPC 层定义的,HBaseClient 端应用程序需要花费多长时间(毫秒)来进行远程调用以使超时。它使用 ping 来检查连接,但最终将抛出 TimeoutException。
Default
60000
hbase.client.operation.timeout- Description
操作超时是一个顶级限制(毫秒),可确保 Table 中的阻止操作不会超过此限制。在每个操作中,如果 rpc 请求由于超时或其他原因而失败,它将重试直到成功或抛出 RetriesExhaustedException。但是,如果阻塞的总时间在重试用尽之前达到了操作超时,它将提前中断并抛出 SocketTimeoutException。
Default
1200000
hbase.cells.scanned.per.heartbeat.check- Description
在两次心跳检查之间扫描的细胞数。心跳检查在扫描处理期间进行,以确定服务器是否应停止扫描以便将心跳消息发送回 Client 端。心跳消息用于在长时间运行的扫描期间保持 Client 端-服务器连接保持活动状态。较小的值表示心跳检查将更频繁地发生,因此将对扫描的执行时间提供更严格的限制。较大的值表示心跳检查发生的频率较低
Default
10000
hbase.rpc.shortoperation.timeout- Description
这是“ hbase.rpc.timeout”的另一个版本。对于群集内的那些 RPC 操作,我们依靠此配置为短操作设置短超时限制。例如,区域服务器尝试向活动主服务器报告的较短 rpc 超时时间可以使主服务器故障转移过程更快。
Default
10000
hbase.ipc.client.tcpnodelay- Description
设置 rpc 套接字连接没有延迟。参见http://docs.oracle.com/javase/1.5.0/docs/api/java/net/Socket.html#getTcpNoDelay(
Default
true
hbase.regionserver.hostname- Description
此配置适用于 maven:除非您真的知道自己在做什么,否则请不要设置其值。设置为非空值时,它表示基础服务器的(外部)主机名。有关详情,请参见https://issues.apache.org/jira/browse/HBASE-12954。
Default
none
hbase.regionserver.hostname.disable.master.reversedns- Description
此配置适用于 maven:除非您真的知道自己在做什么,否则请不要设置其值。设置为 true 时,regionserver 将使用当前节点的主机名作为服务器名,而 HMaster 将跳过反向 DNS 查找,而是使用 regionserver 发送的主机名。请注意,此配置和 hbase.regionserver.hostname 是互斥的。有关更多详细信息,请参见https://issues.apache.org/jira/browse/HBASE-18226。
Default
false
hbase.master.keytab.file- Description
kerberos keytab 文件的完整路径,用于登录已配置的 HMaster 服务器主体。
Default
none
hbase.master.kerberos.principal- Description
例如“ hbase/_HOST@EXAMPLE.COM”。用来运行 HMaster 进程的 Kerberos 主体名称。主体名称应采用以下格式:user/hostname @ DOMAIN。如果将“ _HOST”用作主机名部分,它将被正在运行的实例的实际主机名替换。
Default
none
hbase.regionserver.keytab.file- Description
kerberos keytab 文件的完整路径,用于登录已配置的 HRegionServer 服务器主体。
Default
none
hbase.regionserver.kerberos.principal- Description
例如“ hbase/_HOST@EXAMPLE.COM”。用来运行 HRegionServer 进程的 Kerberos 主体名称。主体名称应采用以下格式:user/hostname @ DOMAIN。如果将“ _HOST”用作主机名部分,它将被正在运行的实例的实际主机名替换。该主体的条目必须存在于 hbase.regionserver.keytab.file 中指定的文件中
Default
none
hadoop.policy.file- Description
RPC 服务器用来对 Client 端请求做出授权决策的策略配置文件。仅在启用 HBase 安全性时使用。
Default
hbase-policy.xml
hbase.superuser- Description
在整个集群中,无论存储的 ACL 如何,都被授予完全特权的用户或组(以逗号分隔)的列表。仅在启用 HBase 安全性时使用。
Default
none
hbase.auth.key.update.interval- Description
服务器中认证令牌的主密钥的更新间隔(以毫秒为单位)。仅在启用 HBase 安全性时使用。
Default
86400000
hbase.auth.token.max.lifetime- Description
认证令牌到期的最大生存时间(以毫秒为单位)。仅在启用 HBase 安全性时使用。
Default
604800000
hbase.ipc.client.fallback-to-simple-auth-allowed- Description
当 Client 端配置为尝试安全连接,但尝试连接到不安全的服务器时,该服务器可能会指示 Client 端切换到 SASL SIMPLE(不安全)身份验证。此设置控制 Client 端是否将接受来自服务器的此指令。如果为 false(默认值),则 Client 端将不允许回退到 SIMPLE 身份验证,并将中止连接。
Default
false
hbase.ipc.server.fallback-to-simple-auth-allowed- Description
当服务器配置为需要安全连接时,它将使用 SASL SIMPLE(不安全)身份验证拒绝来自 Client 端的连接尝试。此设置允许安全服务器在 Client 端请求时接受来自 Client 端的 SASL SIMPLE 连接。如果为 false(默认值),则服务器将不允许回退到 SIMPLE 身份验证,并且将拒绝连接。警告:在将 Client 端转换为安全身份验证时,仅应将此设置用作临时措施。为了安全操作,必须将其禁用。
Default
false
hbase.display.keys- Description
如果将其设置为 true,则 webUI 会显示所有开始/结束键,作为表详细信息,区域名称等的一部分。如果将其设置为 false,则将隐藏键。
Default
true
hbase.coprocessor.enabled- Description
启用或禁用协处理器加载。如果为“ false”(禁用),则将忽略任何其他与协处理器相关的配置。
Default
true
hbase.coprocessor.user.enabled- Description
启用或禁用用户(aka 表)协处理器加载。如果为“ false”(禁用),则将忽略表 Descriptors 中的任何表协处理器属性。如果“ hbase.coprocessor.enabled”为“ false”,则此设置无效。
Default
true
hbase.coprocessor.region.classes- Description
默认情况下,在所有表上加载的逗号分隔的协处理器列表。对于任何重写协处理器方法,将按 Sequences 调用这些类。在实现自己的协处理器之后,只需将其放在 HBase 的 Classpath 中,然后在此处添加完全限定的类名即可。也可以通过设置 HTableDescriptor 来按需加载协处理器。
Default
none
hbase.coprocessor.master.classes- Description
逗号分隔的 org.apache.hadoop.hbase.coprocessor.MasterObserver 协处理器列表,默认情况下在活动 HMaster 进程中加载。对于任何已实现的协处理器方法,将按 Sequences 调用列出的类。在实现自己的 MasterObserver 之后,只需将其放入 HBase 的 Classpath 中,并在此处添加完全限定的类名。
Default
none
hbase.coprocessor.abortonerror- Description
设置为 true 会导致在协处理器无法加载,初始化失败或引发意外的 Throwable 对象时导致托管服务器(主服务器或区域服务器)中止。将其设置为 false 将允许服务器 continue 执行,但是有问题的协处理器的系统范围状态将变得不一致,因为它将仅在一部分服务器中正确执行,因此这仅对调试有用。
Default
true
hbase.rest.port- Description
HBase REST 服务器的端口。
Default
8080
hbase.rest.readonly- Description
定义启动 REST 服务器的模式。可能的值是:false:允许所有 HTTP 方法-GET/PUT/POST/DELETE。 true:仅允许 GET 方法。
Default
false
hbase.rest.threads.max- Description
REST 服务器线程池的最大线程数。池中的线程被重用以处理 REST 请求。这控制了并发处理的最大请求数。这可能有助于控制 REST 服务器使用的内存,以避免 OOM 问题。如果线程池已满,则传入的请求将排队,并 await 一些空闲线程。
Default
100
hbase.rest.threads.min- Description
REST 服务器线程池的最小线程数。线程池始终至少具有这些线程数,因此 REST 服务器已准备就绪,可以处理传入的请求。
Default
2
hbase.rest.support.proxyuser- Description
允许运行 REST 服务器以支持代理用户模式。
Default
false
hbase.defaults.for.version.skip- Description
设置为 true 可以跳过“ hbase.defaults.for.version”检查。将其设置为 true 可以在 Maven 生成的另一端以外的环境中使用。即在 IDE 中运行。您需要将此布尔值设置为 true 以避免看到 RuntimeException 投诉:“ hbase-default.xml 文件似乎适用于旧版本的 HBase( ${}),此版本为 X.X.X-SNAPSHOT”
Default
false
hbase.table.lock.enable- Description
设置为 true 以启用将锁锁定在 zookeeper 中以进行模式更改操作。来自主服务器的表锁定可防止将并发模式修改为损坏的表状态。
Default
true
hbase.table.max.rowsize- Description
未设置行内扫描标志的“获取”或“扫描”单行的最大大小(以字节为单位)(默认为 1 Gb)。如果行大小超过此限制,则将 RowTooBigException 抛出给 Client 端。
Default
1073741824
hbase.thrift.minWorkerThreads- Description
线程池的“核心大小”。在每个连接上都会创建新线程,直到创建了这么多线程。
Default
16
hbase.thrift.maxWorkerThreads- Description
线程池的最大大小。当挂起的请求队列溢出时,将创建新线程,直到它们的数量达到该数量为止。此后,服务器开始断开连接。
Default
1000
hbase.thrift.maxQueuedRequests- Description
在队列中 await 的未决 Thrift 连接的最大数量。如果池中没有空闲线程,则服务器会将请求排队。仅当队列溢出时,才添加新线程,直到 hbase.thrift.maxQueuedRequests 线程。
Default
1000
hbase.regionserver.thrift.framed- Description
在服务器端使用 Thrift TFramedTransport。对于节俭服务器,这是建议的传输方式,并且在 Client 端需要类似的设置。将其更改为 false 将选择默认传输方式,当由于 THRIFT-601 发出格式错误的请求时,该传输方式容易受到 DoS 攻击。
Default
false
hbase.regionserver.thrift.framed.max_frame_size_in_mb- Description
使用成帧传输时的默认帧大小,以 MB 为单位
Default
2
hbase.regionserver.thrift.compact- Description
使用 Thrift TCompactProtocol 二进制序列化协议。
Default
false
hbase.rootdir.perms- Description
安全(kerberos)设置中根数据子目录的 FS 权限。当 master 启动时,它将创建具有此权限的 rootdir 或设置不匹配的权限。
Default
700
hbase.wal.dir.perms- Description
安全(kerberos)设置中的根 WAL 目录的 FS 权限。当 master 启动时,它将使用此权限创建 WAL 目录,或者在不匹配时设置权限。
Default
700
hbase.data.umask.enable- Description
启用(如果为 true),应将文件权限分配给由 regionserver 写入的文件
Default
false
hbase.data.umask- Description
hbase.data.umask.enable 为 true 时应用于写入数据文件的文件权限
Default
000
hbase.snapshot.enabled- Description
设置为 true 以允许拍摄/还原/克隆快照。
Default
true
hbase.snapshot.restore.take.failsafe.snapshot- Description
设置为 true 以在还原操作之前进行快照。如果发生故障,将使用拍摄的快照来还原以前的状态。在还原操作结束时,此快照将被删除
Default
true
hbase.snapshot.restore.failsafe.name- Description
还原操作获取的故障安全快照的名称。您可以使用\ {},\ {}和\ {}变量根据要还原的内容创建名称。
Default
hbase-failsafe-{snapshot.name}-{restore.timestamp}
hbase.server.compactchecker.interval.multiplier- Description
该数字确定我们进行扫描以查看是否有必要进行压缩的频率。通常,压缩是在某些事件(例如 memstore 刷新)之后完成的,但是,如果区域一段时间未收到大量写入,或者由于不同的压缩策略,则可能需要定期检查它。检查之间的间隔是 hbase.server.compactchecker.interval.multiplier 乘以 hbase.server.thread.wakefrequency。
Default
1000
hbase.lease.recovery.timeout- Description
在放弃之前,我们 awaitdfs 租赁恢复的总时间为多长时间。
Default
900000
hbase.lease.recovery.dfs.timeout- Description
dfs 之间恢复租约调用的时间。应该大于名称节点作为数据节点的一部分发出块恢复命令所花费的时间总和; dfs.heartbeat.interval 以及主数据节点所花费的时间,在死数据节点上执行块恢复到超时;通常是 dfs.client.socket-timeout。有关更多信息,请参见 HBASE-8389 的末尾。
Default
64000
hbase.column.max.version- Description
新的列族 Descriptors 将使用此值作为要保留的默认版本数。
Default
1
dfs.client.read.shortcircuit- Description
如果设置为 true,则此配置参数启用短路本地读取。
Default
false
dfs.domain.socket.path- Description
如果 dfs.client.read.shortcircuit 设置为 true,这是 UNIX 域套接字的路径,该套接字将用于 DataNode 与本地 HDFSClient 端之间的通信。如果此路径中存在字符串“ _PORT”,它将被 DataNode 的 TCP 端口替换。请注意托管共享域套接字的目录的权限; dfsclient 将向 HBase 用户以外的其他用户开放。
Default
none
hbase.dfs.client.read.shortcircuit.buffer.size- Description
如果未设置 DFSClient 配置 dfs.client.read.shortcircuit.buffer.size,我们将使用此处配置的短路读取默认直接字节缓冲区大小。 DFSClient 本机默认值为 1MB; HBase 保持其 HDFS 文件处于打开状态,因此文件块数* 1MB 很快就开始增加,并由于直接内存不足而威胁了 OOME。因此,我们将其设置为默认值。使其>在 HColumnDescriptor 中设置的默认 hbase 块大小,通常为 64k。
Default
131072
hbase.regionserver.checksum.verify- Description
如果设置为 true(默认值),则 HBase 会验证 hfile 块的校验和。 HBase 在写出 hfile 时,将校验和与数据内联。 HDFS(在撰写本文时)将校验和写入数据文件之外的单独文件,这需要额外的查找。设置该标志可节省一些 I/O。设置此标志时,将在 hfile 流上内部禁用 HDFS 的校验和验证。如果 hbase-checksum 验证失败,我们将切换回使用 HDFS 校验和(因此请不要禁用 HDFS 校验和!此外,此功能仅适用于 hfile,不适用于 WAL)。如果将此参数设置为 false,则 hbase 将不会验证任何校验和,而是取决于 HDFSClient 端中进行的校验和验证。
Default
true
hbase.hstore.bytes.per.checksum- Description
hfile 块中 HBase 级别校验和的新创建校验和块中的字节数。
Default
16384
hbase.hstore.checksum.algorithm- Description
用于计算校验和的算法的名称。可能的值为 NULL,CRC32,CRC32C。
Default
CRC32C
hbase.client.scanner.max.result.size- Description
调用扫描仪的下一个方法时返回的最大字节数。请注意,当单行大于此限制时,该行仍将完全返回。默认值为 2MB,适合 1ge 网络。对于更快和/或高延迟的网络,此值应增加。
Default
2097152
hbase.server.scanner.max.result.size- Description
调用扫描仪的下一个方法时返回的最大字节数。请注意,当单行大于此限制时,该行仍将完全返回。默认值为 100MB。这是一项安全设置,可以保护服务器免受 OOM 情况的影响。
Default
104857600
hbase.status.published- Description
此设置激活主服务器发布区域服务器状态。当区域服务器停止运行并开始恢复时,主服务器会将此信息推送到 Client 端应用程序,以使它们立即断开连接,而不必 await 超时。
Default
false
hbase.status.publisher.class- Description
使用多播消息实现状态发布。
Default
org.apache.hadoop.hbase.master.ClusterStatusPublisher$MulticastPublisher
hbase.status.listener.class- Description
使用多播消息实现状态侦听器。
Default
org.apache.hadoop.hbase.client.ClusterStatusListener$MulticastListener
hbase.status.multicast.address.ip- Description
用于通过多播发布状态的多播地址。
Default
226.1.1.3
hbase.status.multicast.address.port- Description
组播端口,用于通过组播发布状态。
Default
16100
hbase.dynamic.jars.dir- Description
区域服务器无需重新启动即可从其动态加载自定义过滤器 JAR 的目录。但是,已经加载的过滤器/协处理器类不会被卸载。有关更多详细信息,请参见 HBASE-1936.不适用于协处理器。
Default
${hbase.rootdir}/lib
hbase.security.authentication- Description
控制是否为 HBase 启用安全身份验证。可能的值为“简单”(不进行身份验证)和“ kerberos”。
Default
simple
hbase.rest.filter.classes- Description
REST 服务的 Servlet 过滤器。
Default
org.apache.hadoop.hbase.rest.filter.GzipFilter
hbase.master.loadbalancer.class- Description
当周期发生时用于执行区域平衡的类。有关其工作原理的更多信息,请参见类 Comments。http://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/master/balancer/StochasticLoadBalancer.html它将 DefaultLoadBalancer 替换为默认值(因为重命名为 SimpleLoadBalancer)。
Default
org.apache.hadoop.hbase.master.balancer.StochasticLoadBalancer
hbase.master.loadbalance.bytable- Description
平衡器运行时的因子表名称。默认值:false。
Default
false
hbase.master.normalizer.class- Description
发生周期时用于执行区域规范化的类。有关其工作原理的更多信息,请参见类 Commentshttp://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/master/normalizer/SimpleRegionNormalizer.html
Default
org.apache.hadoop.hbase.master.normalizer.SimpleRegionNormalizer
hbase.rest.csrf.enabled- Description
设置为 true 以启用针对跨站点请求伪造(CSRF)的保护
Default
false
hbase.rest-csrf.browser-useragents-regex- Description
通过将 hbase.rest.csrf.enabled 设置为 true 为 REST 服务器启用跨站点请求伪造(CSRF)保护时,用逗号分隔的正则表达式列表,用于与 HTTP 请求的 User-AgentHeaders 匹配。如果传入的 User-Agent 与这些正则表达式中的任何一个匹配,则该请求被视为由浏览器发送,因此强制执行 CSRF 防护。如果请求的用户代理与这些正则表达式都不匹配,则认为该请求是由浏览器以外的其他设备(例如脚本化自动化)发送的。在这种情况下,CSRF 并不是潜在的攻击媒介,因此无法执行预防措施。这有助于实现与尚未更新为发送 CSRF 预防 Headers 的现有自动化的向后兼容性。
Default
Mozilla.,Opera.
hbase.security.exec.permission.checks- Description
如果启用此设置并且基于 ACL 的访问控制处于活动状态(AccessController 协处理器既可以作为系统协处理器安装,也可以作为表协处理器安装在表上),那么如果所有相关用户需要执行协处理器端点的能力,则必须授予他们 EXEC 特权电话。像任何其他权限一样,EXEC 特权可以全局授予用户,也可以基于每个表或每个命名空间授予用户。有关协处理器端点的更多信息,请参见 HBase 在线手册的协处理器部分。有关使用 AccessController 授予或撤消权限的更多信息,请参见 HBase 在线手册的安全性部分。
Default
false
hbase.procedure.regionserver.classes- Description
逗号分隔的 org.apache.hadoop.hbase.procedure.RegionServerProcedureManager 过程 Management 器列表,默认情况下在活动 HRegionServer 进程中加载。生命周期方法(init/start/stop)将由活动的 HRegionServer 进程调用,以执行特定的全局受阻过程。在实现自己的 RegionServerProcedureManager 之后,只需将其放在 HBase 的 Classpath 中,然后在此处添加完全限定的类名。
Default
none
hbase.procedure.master.classes- Description
逗号分隔的 org.apache.hadoop.hbase.procedure.MasterProcedureManager 过程 Management 器列表,默认情况下在活动 HMaster 进程上加载。过程由其签名标识,用户可以使用签名和即时名称来触发全局障碍过程的执行。在实现自己的 MasterProcedureManager 之后,只需将其放入 HBase 的 Classpath 中,然后在此处添加完全限定的类名即可。
Default
none
hbase.coordinated.state.manager.class- Description
实现协调状态 Management 器的类的全限定名称。
Default
org.apache.hadoop.hbase.coordination.ZkCoordinatedStateManager
hbase.regionserver.storefile.refresh.period- Description
刷新辅助区域的存储文件的时间段(以毫秒为单位)。 0 表示此功能被禁用。一旦辅助区域刷新了该区域中的文件列表(没有通知机制),辅助区域就会从主服务器看到新文件(通过刷新和压缩)。但是过于频繁的刷新可能会导致额外的 Namenode 压力。如果文件刷新的时间不能超过 HFile TTL(hbase.master.hfilecleaner.ttl),则拒绝请求。还建议通过此设置将 HFile TTL 配置为更大的值。
Default
0
hbase.region.replica.replication.enabled- Description
是否启用了到辅助区域副本的异步 WAL 复制。如果启用此功能,将创建一个名为“ region_replica_replication”的复制对等方,它将复制日志尾部并将突变复制到具有区域复制> 1 的表的区域副本中。如果启用一次,则禁用此复制还需要禁用复制使用 Shell 或 Admin java 类的对等体。到辅助区域副本的复制通过标准的群集间复制进行。
Default
false
hbase.http.filter.initializers- Description
用逗号分隔的类名称列表。列表中的每个类都必须扩展 org.apache.hadoop.hbase.http.FilterInitializer。相应的过滤器将被初始化。然后,该筛选器将应用于所有面向用户的 jsp 和 servlet 网页。列表的 Sequences 定义了过滤器的 Sequences。默认的 StaticUserWebFilter 添加由 hbase.http.staticuser.user 属性定义的用户主体。
Default
org.apache.hadoop.hbase.http.lib.StaticUserWebFilter
hbase.security.visibility.mutations.checkauths- Description
如果启用此属性,将检查可见性表达式中的标签是否与发出突变的用户相关联
Default
false
hbase.http.max.threads- Description
HTTP Server 将在其 ThreadPool 中创建的最大线程数。
Default
16
hbase.replication.rpc.codec- Description
启用复制时要使用的编解码器,以便也复制标签。与 HFileV3 一起使用,后者支持其中的标签。如果未使用标签,或者使用的 hfile 版本为 HFileV2,则可以将 KeyValueCodec 用作复制编解码器。请注意,在没有标签的情况下使用 KeyValueCodecWithTags 进行复制不会造成任何危害。
Default
org.apache.hadoop.hbase.codec.KeyValueCodecWithTags
hbase.replication.source.maxthreads- Description
任何复制源用于将编辑并行传送到接收器的最大线程数。这也限制了每个复制批处理分成的块数。较大的值可以提高主群集和从群集之间的复制吞吐量。默认值 10 几乎不需要更改。
Default
10
hbase.http.staticuser.user- Description
呈现内容时在静态 Web 筛选器上作为筛选条件的用户名。 HDFS Web UI(用于浏览文件的用户)是一个示例用法。
Default
dr.stack
hbase.regionserver.handler.abort.on.error.percent- Description
区域服务器 RPC 线程无法中止 RS 的百分比。 -1 禁用中止; 0 即使有一个处理程序死亡,也中止; 0.x 仅在此百分比的处理程序已死亡时才中止; 1 只有中止所有处理程序的人都死了。
Default
0.5
hbase.mob.file.cache.size- Description
要缓存的已打开文件处理程序的数量。较大的值将为每个 mob 文件缓存提供更多的文件处理程序,从而有利于读取,并减少频繁的文件打开和关闭操作。但是,如果设置得太高,则可能导致“打开的文件处理程序太多”。默认值为 1000.
Default
1000
hbase.mob.cache.evict.period- Description
暴民缓存逐出已缓存的暴徒文件之前的时间(以秒为单位)。默认值为 3600 秒。
Default
3600
hbase.mob.cache.evict.remain.ratio- Description
当缓存的 mob 文件的数量超过 hbase.mob.file.cache.size 时,将触发逐出后保留的缓存文件的比例(介于 0.0 和 1.0 之间)。默认值为 0.5f。
Default
0.5f
hbase.master.mob.ttl.cleaner.period- Description
ExpiredMobFileCleanerChore 运行的周期。单位是第二。默认值为一天。 MOB 文件名仅使用文件创建时间中的日期部分。我们用这段时间来确定文件的 TTL 到期时间。因此,TTL 过期文件的删除可能会延迟。最大延迟时间可能是 24 小时。
Default
86400
hbase.mob.compaction.mergeable.threshold- Description
如果 mob 文件的大小小于此值,则将其视为小文件,需要在 mob 压缩中合并。默认值为 1280MB。
Default
1342177280
hbase.mob.delfile.max.count- Description
mob 压缩中允许的最大 del 文件数。在 mob 压缩中,当现有 del 文件的数量大于此值时,将合并它们,直到 del 文件的数量不大于该值。预设值为 3.
Default
3
hbase.mob.compaction.batch.size- Description
一批 mob 压缩中允许的 mob 文件的最大数量。暴民压缩将小暴民文件合并为大暴民文件。如果小文件的数量很大,则合并中可能会导致“打开的文件处理程序太多”。合并必须分批进行。该值限制了一批 mob 压缩中选择的 mob 文件的数量。默认值为 100.
Default
100
hbase.mob.compaction.chore.period- Description
MobCompactionChore 运行的时间。单位是第二。默认值为一周。
Default
604800
hbase.mob.compactor.class- Description
实现 mob 压缩器,默认之一是 PartitionedMobCompactor。
Default
org.apache.hadoop.hbase.mob.compactions.PartitionedMobCompactor
hbase.mob.compaction.threads.max- Description
MobCompactor 中使用的最大线程数。
Default
1
hbase.snapshot.master.timeout.millis- Description
快照过程执行的主服务器超时。
Default
300000
hbase.snapshot.region.timeout- Description
区域服务器将线程保留在快照请求池中的 await 时间。
Default
300000
hbase.rpc.rows.warning.threshold- Description
批处理操作中的行数,如果超过该行,将记录警告。
Default
5000
hbase.master.wait.on.service.seconds- Description
默认值为 5 分钟。进行 30 秒的测试。有关某些上下文,请参见 HBASE-19794.
Default
30
7.3. hbase-env.sh
在此文件中设置 HBase 环境变量。示例包括在 HBase 守护程序启动时传递 JVM 的选项,例如堆大小和垃圾收集器配置。您还可以为 HBase 配置,日志目录,niceness,ssh 选项,在何处查找进程 pid 文件等设置配置。在* conf/hbase-env.sh *中打开文件并仔细阅读其内容。每个选项都有充分的文档记录。如果希望在启动时由 HBase 守护程序读取环境变量,请在此处添加您自己的环境变量。
此处的更改将要求群集重新启动,以便 HBase 注意到更改。
7.4. log4j.properties
编辑此文件以更改 HBase 文件的滚动速率并更改 HBase 记录消息的级别。
尽管可以通过 HBase UI 更改特定守护程序的日志级别,但此处的更改将要求 HBase 重新启动集群以注意到更改。
7.5. Client 端配置和依赖关系连接到 HBase 集群
如果您以独立模式运行 HBase,则无需配置任何配置即可让 Client 端正常工作,前提是它们都在同一台计算机上。
由于 HBase Master 可能会四处移动,因此 Client 端可以通过向 ZooKeeper 查找当前的关键位置来进行引导。 ZooKeeper 是保留所有这些值的位置。因此,Client 在执行其他任何操作之前,需要先确定 ZooKeeper 合奏的位置。通常,此合奏位置保留在* hbase-site.xml *中,并由 Client 端从CLASSPATH获取。
如果要配置 IDE 以运行 HBaseClient 端,则应在 Classpath 中包括* conf/目录,以便可以找到 hbase-site.xml 设置(或添加 src/test/resources *以选择测试使用的 hbase-site.xml)。
对于使用 Maven 的 Java 应用程序,建议在连接到集群时包括 hbase-shaded-client 模块依赖项:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-shaded-client</artifactId>
<version>2.0.0</version>
</dependency>
仅用于 Client 端的基本示例* hbase-site.xml *可能如下所示:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>example1,example2,example3</value>
<description>The directory shared by region servers.
</description>
</property>
</configuration>
7.5.1. JavaClient 端配置
JavaClient 端使用的配置保存在HBaseConfiguration实例中。
HBaseConfiguration HBaseConfiguration.create();的工厂方法在调用时将读取在 Client 端CLASSPATH上找到的第一个* hbase-site.xml 的内容(如果存在)(调用还将包括任何 hbase-default.xml *找到了; * hbase-default.xml 放在 hbase.XXXjar 内。也可以直接指定配置,而不必从 hbase-site.xml *中读取。例如,以编程方式为集群设置 ZooKeeper 集成,请执行以下操作:
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "localhost"); // Here we are running zookeeper locally
如果多个 ZooKeeper 实例构成了 ZooKeeper 集合,则可以在逗号分隔的列表中指定它们(就像在* hbase-site.xml *文件中一样)。然后可以将此填充的Configuration实例传递给Table,依此类推。
7.6. 超时设定
HBase 提供了各种各样的超时设置,以限制各种远程操作的执行时间。
hbase.rpc.timeout
hbase.rpc.read.timeout
hbase.rpc.write.timeout
hbase.client.operation.timeout
hbase.client.meta.operation.timeout
hbase.client.scanner.timeout.period
hbase.rpc.timeout属性限制了单个 RPC 调用在超时之前可以运行多长时间。要微调与读取或写入相关的 RPC 超时,请设置hbase.rpc.read.timeout和hbase.rpc.write.timeout配置属性。如果没有这些属性,将使用hbase.rpc.timeout。
较高级别的超时是hbase.client.operation.timeout,它对于每个 Client 端调用均有效。例如,由于hbase.rpc.timeout而导致 RPC 调用超时失败时,它将重试,直到达到hbase.client.operation.timeout。可以通过设置hbase.client.meta.operation.timeout配置值来微调系统表的 Client 端操作超时。如果未设置,则其值将使用hbase.client.operation.timeout。
扫描操作的超时控制不同。使用hbase.client.scanner.timeout.period属性设置此超时时间。
8.配置示例
8.1. 基本的分布式 HBase 安装
这是一个分布式十节点群集的基本配置示例:在此示例中,节点通过节点example9命名为example0,example1等。 * HBase 主节点和 HDFS NameNode 在节点example0上运行。 * RegionServer 在节点example1-example9上运行。 * 3 节点的 ZooKeeper 集成在默认端口上的example1,example2和example3上运行。 * ZooKeeper 数据保存在目录/export/zookeeper *中。
下面我们显示在 HBase * conf *目录中找到的主要配置文件-hbase-site.xml , regionservers 和 hbase-env.sh *的外观。
8.1.1. hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>example1,example2,example3</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/zookeeper</value>
<description>Property from ZooKeeper config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://example0:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
</description>
</property>
</configuration>
8.1.2. regionservers
在此文件中,列出将运行 RegionServers 的节点。在我们的例子中,这些节点是example1-example9。
example1
example2
example3
example4
example5
example6
example7
example8
example9
8.1.3. hbase-env.sh
- hbase-env.sh *文件中的以下各行显示了如何设置
JAVA_HOME环境变量(HBase 必需)以及如何将堆设置为 4 GB(而不是默认值 1 GB)。如果您复制并粘贴此示例,请确保调整JAVA_HOME以适合您的环境。
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0/
# The maximum amount of heap to use. Default is left to JVM default.
export HBASE_HEAPSIZE=4G
使用 rsync 将* conf *目录的内容复制到群集的所有节点。
9.重要配置
下面我们列出了一些重要的配置。我们将本节分为所需的配置和值得一看的推荐配置。
9.1. 所需配置
9.1.1. 大集群配置
如果您的群集具有很多区域,则在主服务器启动后,Regionserver 可能会短暂签入,而所有其他 RegionServer 都将滞后。该第一台要签入的服务器将被分配所有非最佳区域。为防止发生上述情况,请将hbase.master.wait.on.regionservers.mintostart属性从其默认值 1 上调。有关更多详细信息,请参见HBASE-6389 修改条件以确保主服务器在开始区域分配之前 await 足够数量的区域服务器。
9.2. 推荐配置
9.2.1. ZooKeeper 配置
zookeeper.session.timeout
默认超时为 90 秒(以毫秒为单位)。这意味着,如果服务器崩溃,则主服务器将在 90 秒后通知崩溃并开始恢复。您可能需要将超时调整为一分钟或更短,以便主服务器能够更快地注意到故障。更改此值之前,请确保已控制 JVM 垃圾收集配置,否则,持续超过 ZooKeeper 会话超时的长时间垃圾收集将占用 RegionServer。 (这样做可能会很好-如果 RegionServer 长时间处于 GC 中,您可能希望恢复在服务器上开始)。
要更改此配置,请编辑* hbase-site.xml *,在集群中复制更改的文件,然后重新启动。
我们将此值设置得很高,以免我们不得不在邮件列表中提出问题,以询问为什么在大规模导入期间 RegionServer 出现故障。通常的原因是他们的 JVM 未调整,并且正在运行很长的 GC 暂停。我们的想法是,当用户熟悉 HBase 时,我们不必为他们省却所有复杂性。稍后,当他们构建起一定的信心时,他们便可以使用这样的配置。
ZooKeeper 实例数
See zookeeper.
9.2.2. HDFS 配置
dfs.datanode.failed.volumes.tolerated
这是* hdfs-default.xml *说明中的“…在 DataNode 停止提供服务之前允许失败的卷数。默认情况下,任何卷故障都会导致数据节点关闭”。您可能希望将其设置为可用磁盘数量的一半。
hbase.regionserver.handler.count
此设置定义保持打开状态以响应对用户表的传入请求的线程数。经验法则是,当每个请求的有效负载接近 MB 时(大放置,使用大缓存进行扫描),此数字应保持较低;当有效负载较小(获取,小放置,ICV,删除)时,请保持较高的数字。正在进行的查询的总大小受设置hbase.ipc.server.max.callqueue.size的限制。
如果有效负载很小,可以安全地将该数目设置为最大数量的传入 Client 端,典型示例是为网站提供服务的群集,因为通常不对 put 进行缓冲,并且大多数操作都可以得到。
将该设置保持在较高状态是危险的,原因是区域服务器中当前正在发生的所有 put 的总大小可能会对其内存施加过多压力,甚至触发 OutOfMemoryError。在内存不足的情况下运行的 RegionServer 会触发其 JVM 的垃圾收集器更频繁地运行,直到 GC 暂停变得明显为止(原因是,用于保留所有请求有效负载的所有内存都不能被废弃,垃圾收集器尝试)。一段时间后,整个群集的吞吐量会受到影响,因为命中该 RegionServer 的每个请求都将花费更长的时间,从而使问题更加严重。
您可以通过在单个 RegionServer 上rpc.logging然后尾随其日志(排队的请求占用内存)来了解您是否拥有过多的处理程序。
9.2.3. 大内存机器的配置
HBase 带有合理,保守的配置,几乎可以在人们可能要测试的所有计算机类型上使用。如果您有较大的计算机(HBase 具有 8G 和较大的堆),则以下配置选项可能会有所帮助。去做。
9.2.4. Compression
您应该考虑启用 ColumnFamily 压缩。有几个选项几乎是无摩擦的,并且在大多数情况下,它们通过减小 StoreFiles 的大小从而减少 I/O 来提高性能。
有关更多信息,请参见compression。
9.2.5. 配置 WAL 文件的大小和数量
如果 RS 发生故障,HBase 使用wal来恢复尚未刷新到磁盘的内存存储数据。这些 WAL 文件应配置为略小于 HDFS 块(默认情况下,HDFS 块为 64Mb,WAL 文件为~60Mb)。
HBase 对 WAL 文件的数量也有限制,旨在确保在恢复过程中不会有太多数据需要重播。需要根据 memstore 配置设置此限制,以便所有必需的数据都适合。建议分配足够的 WAL 文件以至少存储那么多的数据(当所有内存存储都快用完时)。例如,对于 16Gb RS 堆,默认内存存储设置(0.4)和默认 WAL 文件大小(~60Mb),16Gb * 0.4/60,WAL 文件计数的起点是~109.但是,由于并非所有存储器都始终都已满,因此可以分配较少的 WAL 文件。
9.2.6. 托管拆分
HBase 通常根据* hbase-default.xml 和 hbase-site.xml *配置文件中的设置来处理区域划分。重要设置包括hbase.regionserver.region.split.policy,hbase.hregion.max.filesize,hbase.regionserver.regionSplitLimit。分割的一种简化视图是,当区域增长到hbase.hregion.max.filesize时,将对其进行分割。对于大多数使用模式,应使用自动拆分。有关手动区域分割的更多信息,请参见手动区域分割决策。
您可以选择自己 Management 拆分,而不是让 HBase 自动拆分区域。如果您非常了解密钥空间,则可以手动 Management 拆分,否则让 HBase 为您确定拆分的位置。手动拆分可以减轻区域创建和负载下的移动。它还使区域边界是已知且不变的(如果禁用区域划分)。如果使用手动拆分,则更容易进行基于时间的交错压缩,以分散网络 IO 负载。
禁用自动拆分
要禁用自动拆分,可以在群集配置或表配置中将区域拆分策略设置为org.apache.hadoop.hbase.regionserver.DisabledRegionSplitPolicy。
Automatic Splitting Is Recommended
如果禁用自动拆分以诊断问题或在数据快速增长期间,建议在情况变得更稳定时重新启用它们。Management 区域分裂自己的潜在好处并非没有争议。
确定预分割区域的最佳数量
预分割区域的最佳数量取决于您的应用程序和环境。一个好的经验法则是从每个服务器 10 个预分割区域开始,并观察数据随时间增长的情况。最好在区域太少的一侧犯错误,然后再进行滚动拆分。最佳区域数取决于您所在区域中最大的 StoreFile。如果数据量增加,则最大的 StoreFile 的大小将随时间增加。目的是使最大区域足够大,以使压缩选择算法仅在定时大压缩期间对其进行压缩。否则,集群可能会同时受到大量区域的压缩风暴。重要的是要了解数据增长会导致压缩风暴,而不是手动拆分决定。
如果将区域分成太多大区域,则可以通过配置HConstants.MAJOR_COMPACTION_PERIOD来增加主要压缩间隔。 org.apache.hadoop.hbase.util.RegionSplitterUtil 还提供所有区域的网络 IO 安全滚动拆分。
9.2.7. 托管压缩
默认情况下,大型压缩计划为每 7 天运行一次。
如果需要精确控制大型压缩的时间和频率,则可以禁用托管大型压缩。有关详细信息,请参见compaction.parameters表中的hbase.hregion.majorcompaction条目。
Do Not Disable Major Compactions
对于 StoreFile 清理,绝对必需进行大压缩。请勿完全禁用它们。您可以通过 HBase shell 或Admin API手动运行主要压缩。
有关压缩和 zipfile 选择过程的更多信息,请参阅compaction。
9.2.8. 投机执行
默认情况下,MapReduce 任务的推测执行是打开的,对于 HBase 群集,通常建议在系统级关闭推测执行,除非在特定情况下需要它,可以在每个作业中对其进行配置。将属性mapreduce.map.speculative和mapreduce.reduce.speculative设置为 false。
9.3. 其他配置
9.3.1. Balancer
平衡器是一种定期操作,在主服务器上运行,以重新分配群集上的区域。它是通过hbase.balancer.period配置的,默认值为 300000(5 分钟)。
有关 LoadBalancer 的更多信息,请参见master.processes.loadbalancer。
9.3.2. 禁用块缓存
不要关闭块缓存(您可以通过将hfile.block.cache.size设置为零来关闭它)。目前,如果您这样做的话,我们做得并不好,因为 RegionServer 会花所有的时间一遍又一遍地加载 HFile 索引。如果您的工作组对块缓存不利,请至少调整块缓存的大小,以使 HFile 索引保留在缓存中(您可以通过调查 RegionServer UI 来大致了解所需的大小;您将请参阅网页顶部附近的索引块大小)。
9.3.3. Nagle 或小包装问题
如果在针对 HBase 的操作中偶尔会出现 40ms 左右的延迟,请尝试 Nagles 的设置。例如,请参见用户邮件列表线程缓存设置为 1 时扫描性能不一致以及其中引用的问题,其中设置notcpdelay可以提高扫描速度。您可能还会看到HBASE-7008 将扫描仪缓存设置为更好的默认值尾部的图形,其中我们的 Lars Hofhansl 尝试打开和关闭 Nagle 来测量效果的各种数据大小。
9.3.4. 更好的平均恢复时间(MTTR)
本节介绍的配置将使服务器在出现故障后更快地恢复。请参阅 Deveraj Das 和 Nicolas Liochon 博客文章HBase 平均恢复时间(MTTR)简介的简要介绍。
问题HBASE-8354 强制 Namenode 进入具有租约恢复请求的循环杂乱无章,但对于低超时问题以及如何导致更快的恢复(包括对添加到 HDFS 的修复程序的引用),最后有很多很好的讨论。阅读 Varun Sharma 的 Comment。以下建议的配置是 Varun 的建议经过提炼和测试的。确保您在最新版本的 HDFS 上运行,因此您具有他所引用的修复程序,并且自己添加了可帮助 HBase MTTR 的 HDFS(例如,HDFS-3703,HDFS-3712 和 HDFS-4791)。 Hadoop 1 后期有一些)。在 RegionServer 中设置以下内容。
<property>
<name>hbase.lease.recovery.dfs.timeout</name>
<value>23000</value>
<description>How much time we allow elapse between calls to recover lease.
Should be larger than the dfs timeout.</description>
</property>
<property>
<name>dfs.client.socket-timeout</name>
<value>10000</value>
<description>Down the DFS timeout from 60 to 10 seconds.</description>
</property>
在 NameNode/DataNode 端,设置以下内容以启用 HDFS-3703,HDFS-3912 中引入的“陈旧性”。
<property>
<name>dfs.client.socket-timeout</name>
<value>10000</value>
<description>Down the DFS timeout from 60 to 10 seconds.</description>
</property>
<property>
<name>dfs.datanode.socket.write.timeout</name>
<value>10000</value>
<description>Down the DFS timeout from 8 * 60 to 10 seconds.</description>
</property>
<property>
<name>ipc.client.connect.timeout</name>
<value>3000</value>
<description>Down from 60 seconds to 3.</description>
</property>
<property>
<name>ipc.client.connect.max.retries.on.timeouts</name>
<value>2</value>
<description>Down from 45 seconds to 3 (2 == 3 retries).</description>
</property>
<property>
<name>dfs.namenode.avoid.read.stale.datanode</name>
<value>true</value>
<description>Enable stale state in hdfs</description>
</property>
<property>
<name>dfs.namenode.stale.datanode.interval</name>
<value>20000</value>
<description>Down from default 30 seconds</description>
</property>
<property>
<name>dfs.namenode.avoid.write.stale.datanode</name>
<value>true</value>
<description>Enable stale state in hdfs</description>
</property>
9.3.5. JMX
JMX(JavaManagement 扩展)提供了内置的工具,使您可以监视和 ManagementJava VM。要从远程系统启用监视和 Management,在启动 Java VM 时,需要设置系统属性com.sun.management.jmxremote.port(要用来启用 JMX RMI 连接的端口号)。有关更多信息,请参见official documentation。从历史上看,除了上面提到的端口之外,JMX 还打开了两个附加的随机 TCP 侦听端口,这可能会导致端口冲突问题。 (有关详情,请参见HBASE-10289)
或者,您可以使用 HBase 提供的基于协处理器的 JMX 实现。要启用它,请在* hbase-site.xml *中添加以下属性:
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.JMXListener</value>
</property>
Note
请勿同时为 Java VM 设置com.sun.management.jmxremote.port。
当前,它支持 Master 和 RegionServer Java VM。默认情况下,JMX 侦听 TCP 端口 10102,您可以使用以下属性进一步配置端口:
<property>
<name>regionserver.rmi.registry.port</name>
<value>61130</value>
</property>
<property>
<name>regionserver.rmi.connector.port</name>
<value>61140</value>
</property>
在大多数情况下,注册表端口可以与连接器端口共享,因此您只需要配置 regionserver.rmi.registry.port。但是,如果要使用 SSL 通信,则必须将 2 个端口配置为不同的值。
默认情况下,密码验证和 SSL 通信是禁用的。要启用密码验证,您需要更新* hbase-env.sh *,如下所示:
export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.authenticate=true \
-Dcom.sun.management.jmxremote.password.file=your_password_file \
-Dcom.sun.management.jmxremote.access.file=your_access_file"
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE "
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE "
请参阅* $ JRE_HOME/lib/management *下的示例密码/访问文件。
要通过密码验证启用 SSL 通信,请执行以下步骤:
#1. generate a key pair, stored in myKeyStore
keytool -genkey -alias jconsole -keystore myKeyStore
#2. export it to file jconsole.cert
keytool -export -alias jconsole -keystore myKeyStore -file jconsole.cert
#3. copy jconsole.cert to jconsole client machine, import it to jconsoleKeyStore
keytool -import -alias jconsole -keystore jconsoleKeyStore -file jconsole.cert
然后像下面这样更新* hbase-env.sh *:
export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=true \
-Djavax.net.ssl.keyStore=/home/tianq/myKeyStore \
-Djavax.net.ssl.keyStorePassword=your_password_in_step_1 \
-Dcom.sun.management.jmxremote.authenticate=true \
-Dcom.sun.management.jmxremote.password.file=your_password file \
-Dcom.sun.management.jmxremote.access.file=your_access_file"
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE "
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE "
最后,使用密钥库在 Client 端上启动jconsole:
jconsole -J-Djavax.net.ssl.trustStore=/home/tianq/jconsoleKeyStore
Note
要在 Master 上启用 HBase JMX 实现,还需要在* hbase-site.xml *中添加以下属性:
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.JMXListener</value>
</property>
端口配置的相应属性是master.rmi.registry.port(默认情况下为 10101)和master.rmi.connector.port(默认情况下与 Registry.port 相同)
10.动态配置
可以更改配置的子集,而无需重新启动服务器。在 HBase Shell 中,操作update_config和update_all_config将提示服务器或所有服务器重新加载配置。
当前,正在运行的服务器中只能更改所有配置的一部分。这些是这些配置:
表 3.配置支持动态更改
| Key |
|---|
| hbase.ipc.server.fallback-to-simple-auth-allowed |
| hbase.cleaner.scan.dir.concurrent.size |
| hbase.regionserver.thread.compaction.large |
| hbase.regionserver.thread.compaction.small |
| hbase.regionserver.thread.split |
| hbase.regionserver.throughput.controller |
| hbase.regionserver.thread.hfilecleaner.throttle |
| hbase.regionserver.hfilecleaner.large.queue.size |
| hbase.regionserver.hfilecleaner.small.queue.size |
| hbase.regionserver.hfilecleaner.large.thread.count |
| hbase.regionserver.hfilecleaner.small.thread.count |
| hbase.regionserver.hfilecleaner.thread.timeout.msec |
| hbase.regionserver.hfilecleaner.thread.check.interval.msec |
| hbase.regionserver.flush.throughput.controller |
| hbase.hstore.compaction.max.size |
| hbase.hstore.compaction.max.size.offpeak |
| hbase.hstore.compaction.min.size |
| hbase.hstore.compaction.min |
| hbase.hstore.compaction.max |
| hbase.hstore.compaction.ratio |
| hbase.hstore.compaction.ratio.offpeak |
| hbase.regionserver.thread.compaction.throttle |
| hbase.hregion.majorcompaction |
| hbase.hregion.majorcompaction.jitter |
| hbase.hstore.min.locality.to.skip.major.compact |
| hbase.hstore.compaction.date.tiered.max.storefile.age.millis |
| hbase.hstore.compaction.date.tiered.incoming.window.min |
| hbase.hstore.compaction.date.tiered.window.policy.class |
| hbase.hstore.compaction.date.tiered.single.output.for.minor.compaction |
| hbase.hstore.compaction.date.tiered.window.factory.class |
| hbase.offpeak.start.hour |
| hbase.offpeak.end.hour |
| hbase.oldwals.cleaner.thread.size |
| hbase.oldwals.cleaner.thread.timeout.msec |
| hbase.oldwals.cleaner.thread.check.interval.msec |
| hbase.procedure.worker.keep.alive.time.msec |
| hbase.procedure.worker.add.stuck.percentage |
| hbase.procedure.worker.monitor.interval.msec |
| hbase.procedure.worker.stuck.threshold.msec |
| hbase.regions.slop |
| hbase.regions.overallSlop |
| hbase.balancer.tablesOnMaster |
| hbase.balancer.tablesOnMaster.systemTablesOnly |
| hbase.util.ip.to.rack.determiner |
| hbase.ipc.server.max.callqueue.length |
| hbase.ipc.server.priority.max.callqueue.length |
| hbase.ipc.server.callqueue.type |
| hbase.ipc.server.callqueue.codel.target.delay |
| hbase.ipc.server.callqueue.codel.interval |
| hbase.ipc.server.callqueue.codel.lifo.threshold |
| hbase.master.balancer.stochastic.maxSteps |
| hbase.master.balancer.stochastic.stepsPerRegion |
| hbase.master.balancer.stochastic.maxRunningTime |
| hbase.master.balancer.stochastic.runMaxSteps |
| hbase.master.balancer.stochastic.numRegionLoadsToRemember |
| hbase.master.loadbalance.bytable |
| hbase.master.balancer.stochastic.minCostNeedBalance |
| hbase.master.balancer.stochastic.localityCost |
| hbase.master.balancer.stochastic.rackLocalityCost |
| hbase.master.balancer.stochastic.readRequestCost |
| hbase.master.balancer.stochastic.writeRequestCost |
| hbase.master.balancer.stochastic.memstoreSizeCost |
| hbase.master.balancer.stochastic.storefileSizeCost |
| hbase.master.balancer.stochastic.regionReplicaHostCostKey |
| hbase.master.balancer.stochastic.regionReplicaRackCostKey |
| hbase.master.balancer.stochastic.regionCountCost |
| hbase.master.balancer.stochastic.primaryRegionCountCost |
| hbase.master.balancer.stochastic.moveCost |
| hbase.master.balancer.stochastic.maxMovePercent |
| hbase.master.balancer.stochastic.tableSkewCost |
Upgrading
升级时不能跳过主要版本。如果要从 0.98.x 版本升级到 2.x,则必须先从 0.98.x 升级到 1.2.x,然后再从 1.2.x 升级到 2.x。
查看Apache HBase 配置,尤其是Hadoop。熟悉支持和测试期望。
11. HBase 版本号和兼容性
11.1. 理想的语义版本控制
从 1.0.0 版本开始,HBase 正在朝Semantic Versioning进行版本控制。综上所述:
给定版本号 MAJOR.MINOR.PATCH,增加:
当您进行不兼容的 API 更改时的主要版本,
以向后兼容的方式添加功能时的 MINOR 版本,并且
进行向后兼容的错误修复时的 PATCH 版本。
预发布和构建元数据的其他标签可作为 MAJOR.MINOR.PATCH 格式的 extensions 使用。
Compatibility Dimensions
除了通常的 API 版本控制注意事项之外,HBase 还具有我们需要考虑的其他兼容性维度。
Client 端-服务器有线协议兼容性
允许更新 Client 端和服务器不同步。
我们只能先升级服务器。即服务器将与旧 Client 端向后兼容,这样新的 API 就可以了。
示例:用户应该能够使用旧 Client 端连接到升级的群集。
服务器-服务器协议兼容性
不同版本的服务器可以共存于同一群集中。
服务器之间的有线协议兼容。
复制和日志拆分等分布式任务的工作程序可以共存于同一群集中。
相关协议(例如使用 ZK 进行协调)也不会更改。
示例:用户可以执行滚动升级。
文件格式兼容性
支持文件格式向后和向前兼容
示例:作为 HBase 升级的一部分,文件,ZK 编码,目录布局会自动升级。用户可以降级到较旧的版本,并且一切将 continue 工作。
Client 端 API 兼容性
允许更改或删除现有的 Client 端 API。
对于整个主要版本,都需要弃用 API,然后再进行更改/删除。
例如:API 在 2.0.1 中已弃用,并在 4.0.0 中被标记为删除。另一方面,在 2.0.0 中弃用的 API 可以在 3.0.0 中删除。
修补程序版本中提供的 API 将在所有更高的修补程序版本中提供。但是,可能会添加新的 API,而这些 API 在较早的修补程序版本中将不可用。
补丁版本中引入的新 API 将仅以与源兼容的方式添加\ [1]:即,实现公共 API 的代码将 continue 编译。
示例:使用新近弃用的 API 的用户无需使用 HBase API 调用即可修改应用程序代码,直到下一个主要版本。 *
Client 端二进制兼容性
写入给定补丁程序版本中可用的 API 的 Client 端代码可以针对更高版本的补丁程序的新 jar 保持不变(无需重新编译)。
写入给定补丁程序版本中可用的 API 的 Client 端代码可能无法与早期补丁程序版本中的旧 jar 一起运行。
示例:旧的已编译 Client 端代码将与新的 jar 一起使用。
如果 Client 端实现了 HBase 接口,则可能需要重新编译才能升级到较新的次要版本(有关不兼容更改的警告,请参阅发行说明)。将尽一切努力提供默认的实现,因此不会出现这种情况。
服务器端受限 API 兼容性(取自 Hadoop)
内部 API 被标记为稳定,不断 Developing 或不稳定
这意味着协处理器和插件(可插拔的类,包括复制)的二进制兼容性,只要它们仅使用标记的接口/类即可。
示例:旧的编译的协处理器,过滤器或插件代码将与新的 jar 一起使用。
Dependency Compatibility
HBase 的升级将不需要对依赖项目进行不兼容的升级,除了 Apache Hadoop。
HBase 的升级将不需要 Java 运行时的不兼容升级。
示例:将 HBase 升级到支持* Dependency Compatibility *的版本将不需要您升级 Apache ZooKeeper 服务。
示例:如果当前的 HBase 版本支持在 JDK 8 上运行,则升级到支持* Dependency Compatibility *的版本也将在 JDK 8 上运行。
Hadoop Versions
以前,我们尝试维护底层 Hadoop 服务的依赖项兼容性,但在过去几年中,这已证明是站不住脚的。当 HBase 项目尝试维持对 Hadoop 较早版本的支持时,我们删除了“支持”的次要版本号,这些次要版本无法 continue 查看其发行版。此外,Hadoop 项目有一套自己的兼容性指南,这意味着在某些情况下,必须更新到较新的受支持的次要版本,可能会破坏我们的一些兼容性承诺。
Operational Compatibility
Metric changes
服务的行为变化
通过
/jmx/端点公开的 JMX API
Summary
修补程序升级是一种替代产品。与 Java 二进制文件和源代码不兼容的任何更改都将不允许。\ [2]在补丁程序发行版中降级版本可能不兼容。
较小的升级不需要修改应用程序/Client 端代码。理想情况下,这将是直接替换,但如果使用新的 jar,则必须重新编译 Client 端代码,协处理器,过滤器等。
重大升级使 HBase 社区可以进行重大更改。
*表 4.兼容性列表\ [3] *
| Major | Minor | Patch | |
| Client 端-服务器线兼容性 | N | Y | Y |
| Server-Server Compatibility | N | Y | Y |
| 文件格式兼容性 | N [4] | Y | Y |
| Client 端 API 兼容性 | N | Y | Y |
| Client 二进制兼容性 | N | N | Y |
| 服务器端受限 API 兼容性 | |||
| Stable | N | Y | Y |
| Evolving | N | N | Y |
| Unstable | N | N | N |
| Dependency Compatibility | N | Y | Y |
| Operational Compatibility | N | N | Y |
11.1.1. HBase API 表面
HBase 有很多 API 要点,但是对于上面的兼容性矩阵,我们区分了 Client API,Limited Private API 和 Private API。 HBase 使用Apache Yetus 受众 Comments指导下游对稳定性的期望。
InterfaceAudience(javadocs):捕获目标受众,可能的值包括:
公共:对最终用户和外部项目安全
LimitedPrivate:用于我们希望可插拔的内部组件,例如协处理器
私有:严格用于 HBase 本身定义为
IA.Private的类可用作声明为IA.LimitedPrivate的接口的参数或返回值。将IA.Private对象视为不透明;不要尝试直接访问其方法或字段。
InterfaceStability(javadocs):描述允许哪些类型的接口更改。可能的值包括:
稳定:接口固定,预计不会改变
不断 Developing:将来的次要版本界面可能会发生变化
不稳定:界面可能随时更改
请记住 HBase 项目中InterfaceAudience和InterfaceStability注解之间的以下交互:
IA.Public类具有固有的稳定性,并遵守与升级类型(主要,次要或补丁)有关的稳定性保证。IA.LimitedPrivate类应始终使用给定的InterfaceStability值之一进行 Comments。如果不是,则应假定它们为IS.Unstable。IA.Private类应视为隐式不稳定,不能保证发行版之间的稳定性。HBaseClient 端 API
- HBaseClient 端 API 包含所有标有 InterfaceAudience.Public 接口的类或方法。 hbase-client 和从属模块中的所有主要类都具有 InterfaceAudience.Public,InterfaceAudience.LimitedPrivate 或 InterfaceAudience.Private 标记。并非其他模块(hbase-server 等)中的所有类都具有标记。如果一个类未使用其中之一进行 Comments,则假定该类为 InterfaceAudience.Private 类。
HBase LimitedPrivate API
- LimitedPrivate 注解随附了一组接口的目标使用者。这些使用者是协处理器,凤凰,复制终结点实现或类似者。此时,HBase 仅保证补丁程序版本之间的这些接口的源和二进制兼容性。
HBase 专用 API
- 所有使用 InterfaceAudience 进行 Comments 的类。私有或不具有 Comments 的所有类仅供 HBase 内部使用。接口和方法签名可以随时更改。如果您依赖于标记为“专用”的特定接口,则应打开“ jira”以建议将接口更改为“公共”或“有限私有”,或为此目的公开的接口。
Binary Compatibility
当我们说两个 HBase 版本兼容时,是指这些版本是有线和二进制兼容的。兼容的 HBase 版本意味着 Client 端可以与兼容但版本不同的服务器通信。这也意味着您可以换掉一个版本的 jar,然后用另一个兼容版本的 jar 替换它们,所有这些都可以使用。除非另有说明,否则 HBase 点版本(主要)是二进制兼容的。您可以安全地在二进制兼容版本之间进行滚动升级。即跨维护版本:例如从 1.2.4 到 1.2.6. 请参阅 HBase 开发邮件列表上的链接:[版本之间的兼容性是否还意味着二进制兼容性?]。
11.2. 滚动升级
滚动升级是一次更新群集中的服务器的过程。如果 HBase 版本是二进制或有线兼容的,则可以跨 HBase 版本滚动升级。有关此含义的更多信息,请参见二进制/有线兼容版本之间的滚动升级。粗略地讲,滚动升级是每个服务器的正常停止,更新软件然后重新启动的操作。您为集群中的每个服务器执行此操作。通常,先升级主服务器,然后再升级 RegionServers。有关可以帮助使用滚动升级过程的工具,请参见Rolling Restart。
例如,在下面的内容中,HBase 被符号链接到实际的 HBase 安装。升级时,在对群集进行滚动重启之前,我们将符号链接更改为指向新的 HBase 软件版本,然后运行
$ HADOOP_HOME=~/hadoop-2.6.0-CRC-SNAPSHOT ~/hbase/bin/rolling-restart.sh --config ~/conf_hbase
滚动重新启动脚本将首先正常停止并重新启动主服务器,然后依次停止每个 RegionServer。由于符号链接已更改,因此在重新启动时,服务器将使用新的 HBase 版本启动。随着滚动升级的进行,请检查日志中是否有错误。
二进制/有线兼容版本之间的滚动升级
除非另有说明,否则 HBase 次要版本是二进制兼容的。您可以在 HBase 点版本之间执行Rolling Upgrades。例如,可以通过在整个群集中进行滚动升级来从 1.2.6 升级到 1.2.4,将 1.2.4 二进制文件替换为 1.2.6 二进制文件。
在下面的特定于次要版本的部分中,我们指出了版本与 wire/protocol 兼容的地方,在这种情况下,还可以执行Rolling Upgrades。
12. Rollback
有时,尝试升级时事情并没有按计划进行。本节说明如何对早期 HBase 版本执行“回滚”。请注意,仅在主要版本和某些次要版本之间才需要这样做。您应该始终能够在同一次要版本的 HBase 修补程序版本之间“降级”。这些说明可能要求您在开始升级过程之前采取步骤,因此请务必先通读本节。
12.1. Caveats
回滚与降级
本节介绍如何在 HBase 次要和主要版本之间的升级上执行回滚。在本文档中,回滚指的是获取升级后的集群并将其还原到旧版本的过程,同时会丢失自升级以来发生的所有更改。相比之下,群集“降级”会将升级后的群集还原到旧版本,同时保留自升级以来写入的所有数据。当前,我们仅提供回滚 HBase 群集的说明。此外,仅在执行升级之前遵循以下说明时,回滚才有效。
当这些说明讨论先决条件群集服务(即 HDFS)的回滚与降级时,应将服务版本与降级的退化情况相同。
Replication
除非您执行所有服务回滚,否则 HBase 群集将丢失用于 HBase 复制的所有已配置对等项。如果为集群配置了 HBase 复制,则在遵循这些说明之前,应记录所有复制对等体。执行回滚后,应将每个记录的对等方添加回群集中。有关启用 HBase 复制,列出对等方以及添加对等方的更多信息,请参见Management 和配置群集复制。还请注意,自升级以来写入集群的数据可能已经复制或可能尚未复制到任何对等点。确定哪些对等点(如果有)已看到复制数据并回滚这些对等点中的数据,超出了本指南的范围。
Data Locality
除非您执行所有服务回滚,否则执行回滚过程可能会破坏 Region Server 的所有位置。您应该期望性能下降,直到群集有时间进行压缩以恢复数据局部性为止。 (可选)您可以强制压缩以加快生成群集负载的速度,从而加快此过程。
Configurable Locations
以下说明假定 HBase 数据目录和 HBase znode 的默认位置。这两个位置都是可配置的,并且在 continue 之前,您应该验证集群中使用的值。如果您使用不同的值,则只需将默认值替换为在配置中找到的值即可.* HBase 数据目录是通过键“ hbase.rootdir”配置的,其默认值为“/hbase”。 * HBase znode 是通过键“ zookeeper.znode.parent”配置的,其默认值为“/hbase”。
12.2. 所有服务回滚
如果要同时执行 HDFS 和 ZooKeeper 服务的回滚,则 HBase 的数据将在此过程中回滚。
Requirements
- 能够回滚 HDFS 和 ZooKeeper
Before upgrade
升级前不需要其他步骤。作为一种额外的预防措施,您可能希望使用 distcp 从要升级的群集中备份 HBase 数据。为此,请遵循“ HDFS 降级后回滚”的“升级前”部分中的步骤,但复制到另一个 HDFS 实例,而不是复制到同一实例中。
执行回滚
Stop HBase
对 HDFS 和 ZooKeeper 执行回滚(HBase 应该保持停止状态)
将已安装的 HBase 版本更改为以前的版本
Start HBase
验证 HBase 内容-使用 HBase Shell 列出表并扫描一些已知值。
12.3. HDFS 回滚和 ZooKeeper 降级后的回滚
如果您要回滚 HDFS 但要通过 ZooKeeper 降级,则 HBase 将处于不一致状态。您必须确保集群没有启动,直到完成此过程。
Requirements
能够回滚 HDFS
降级 ZooKeeper 的能力
Before upgrade
升级前不需要其他步骤。作为一种额外的预防措施,您可能希望使用 distcp 从要升级的群集中备份 HBase 数据。为此,请遵循“ HDFS 降级后回滚”的“升级前”部分中的步骤,但复制到另一个 HDFS 实例,而不是复制到同一实例中。
执行回滚
Stop HBase
对 HDFS 执行回滚,对 ZooKeeper 进行降级(HBase 应该保持停止状态)
将已安装的 HBase 版本更改为以前的版本
清除与 HBase 相关的 ZooKeeper 信息。警告:此步骤将永久破坏所有复制对等。有关更多信息,请参见“警告”下有关“ HBase 复制”的部分。
从 ZooKeeper 中清除 HBase 信息
[hpnewton@gateway_node.example.com ~]$ zookeeper-client -server zookeeper1.example.com:2181,zookeeper2.example.com:2181,zookeeper3.example.com:2181
Welcome to ZooKeeper!
JLine support is disabled
rmr /hbase
quit
Quitting...
Start HBase
验证 HBase 内容-使用 HBase Shell 列出表并扫描一些已知值。
12.4. HDFS 降级后回滚
如果要执行 HDFS 降级,则无论 ZooKeeper 是经过回滚,降级还是重新安装,都需要遵循这些说明。
Requirements
能够降级 HDFS
升级前的集群必须能够运行 MapReduce 作业
HDFS 超级用户访问
HDFS 中至少有两个 HBase 数据目录副本的足够空间
Before upgrade
在开始升级过程之前,您必须完整备份 HBase 的后备数据。以下说明涵盖了备份当前 HDFS 实例中的数据。或者,您可以使用 distcp 命令将数据复制到另一个 HDFS 群集。
停止 HBase 集群
使用distcp command作为 HDFS 超级用户将 HBase 数据目录复制到备份位置(如下所示,在启用安全性的群集上)
使用 distcp 备份 HBase 数据目录
[hpnewton@gateway_node.example.com ~]$ kinit -k -t hdfs.keytab hdfs@EXAMPLE.COM
[hpnewton@gateway_node.example.com ~]$ hadoop distcp /hbase /hbase-pre-upgrade-backup
- Distcp 将启动 mapreduce 作业以处理以分布式方式复制文件。检查 distcp 命令的输出,以确保此作业成功完成。
执行回滚
Stop HBase
对 HDFS 执行降级,对 ZooKeeper 执行降级/回滚(HBase 应该保持停止状态)
将已安装的 HBase 版本更改为以前的版本
以 HDFS 超级用户的身份从升级之前还原 HBase 数据目录(如下所示,在启用安全性的群集上)。如果您将数据备份到另一个 HDFS 群集上而不是本地上,则需要使用 distcp 命令将其复制回当前 HDFS 群集上。
恢复 HBase 数据目录
[hpnewton@gateway_node.example.com ~]$ kinit -k -t hdfs.keytab hdfs@EXAMPLE.COM
[hpnewton@gateway_node.example.com ~]$ hdfs dfs -mv /hbase /hbase-upgrade-rollback
[hpnewton@gateway_node.example.com ~]$ hdfs dfs -mv /hbase-pre-upgrade-backup /hbase
- 清除与 HBase 相关的 ZooKeeper 信息。警告:此步骤将永久破坏所有复制对等。有关更多信息,请参见“警告”下有关“ HBase 复制”的部分。
从 ZooKeeper 中清除 HBase 信息
[hpnewton@gateway_node.example.com ~]$ zookeeper-client -server zookeeper1.example.com:2181,zookeeper2.example.com:2181,zookeeper3.example.com:2181
Welcome to ZooKeeper!
JLine support is disabled
rmr /hbase
quit
Quitting...
Start HBase
验证 HBase 内容-使用 HBase Shell 列出表并扫描一些已知值。
13.升级路径
13.1. 从 1.x 升级到 2.x
在本节中,我们将首先指出与之前的稳定 HBase 版本相比的重大更改,然后介绍升级过程。请务必仔细阅读前者,以免出现意外。
13.1.1. 注意事项的变化!
首先,我们将介绍升级到 HBase 2.0 时可能会遇到的部署/操作更改。之后,我们将调出下游应用程序的更改。请注意,“操作”部分介绍了协处理器。另请注意,本节并不旨在传达您可能感兴趣的有关新功能的信息。有关更改的完整摘要,请参阅源版本工件中计划升级到的版本的 CHANGES.txt 文件。
更新到 HBase 2.0 中的基本必备条件最低要求
如第Basic Prerequisites节所述,HBase 2.0 至少需要 Java 8 和 Hadoop 2.6. HBase 社区建议确保在升级 HBase 版本之前,先决条件已完成所有必需的升级。
HBCK 必须与 HBase 服务器版本匹配
您“不得”对 HBase 2.0 集群使用 HBCK 的 HBase 1.x 版本。 HBCK 与 HBase 服务器版本紧密相关。对 HBase 2.0 群集使用较早版本的 HBCK 工具将以不可恢复的方式破坏性地更改该群集。
从 HBase 2.0 开始,HBCK(也称为 HBCK1 或 hbck1 *)是一种只读工具,可以报告某些非公共系统内部组件的状态。您不应该依赖这些内部组件的格式或内容来在 HBase 版本之间保持一致。
要了解有关 HBCK 更换的信息,请参阅Apache HBase 运营 Management中的HBase HBCK2。
HBase 2.0 中不再有配置设置
以下配置设置不再适用或不可用。有关详细信息,请参见详细的发行说明。
hbase.config.read.zookeeper.config(有关迁移的详细信息,请参见ZooKeeper 配置不再从 zoo.cfg 中读取)
hbase.zookeeper.useMulti(HBase 现在始终使用 ZK 的多功能功能)
hbase.rpc.client.threads.max
hbase.rpc.client.nativetransport
hbase.fs.tmp.dir
hbase.bucketcache.combinedcache.enabled
hbase.bucketcache.ioengine 不再支持“堆”值。
hbase.bulkload.staging.dir
严格来说,hbase.balancer.tablesOnMaster 并未删除,但其含义已发生根本变化,用户不应设置它。有关详细信息,请参见“主托管区域”功能已损坏且不受支持部分。
hbase.master.distributed.log.replay 有关详细信息,请参见删除了“分布式日志重播”功能部分
hbase.regionserver.disallow.writes.when.recovering 有关详细信息,请参见删除了“分布式日志重播”功能部分
hbase.regionserver.wal.logreplay.batch.size 有关详细信息,请参见删除了“分布式日志重播”功能部分
hbase.master.catalog.timeout
hbase.regionserver.catalog.timeout
hbase.metrics.exposeOperationTimes
hbase.metrics.showTableName
hbase.online.schema.update.enable(HBase 现在始终支持此功能)
hbase.thrift.htablepool.size.max
在 HBase 2.0 中重命名的配置属性
以下属性已重命名。尝试设置旧属性将在运行时被忽略。
表 5.重命名属性
| Old name | New name |
|---|---|
| hbase.rpc.server.nativetransport | hbase.netty.nativetransport |
| hbase.netty.rpc.server.worker.count | hbase.netty.worker.count |
| hbase.hfile.compactions.discharger.interval | hbase.hfile.compaction.discharger.interval |
| hbase.hregion.percolumnfamilyflush.size.lower.bound | hbase.hregion.percolumnfamilyflush.size.lower.bound.min |
HBase 2.0 中具有不同默认值的配置设置
以下配置设置更改了其默认值。在适用的情况下,给出了用于还原 HBase 1.2 行为的值。
hbase.security.authorization 现在默认为 false。设置为 true 可恢复与以前的默认行为相同的行为。
hbase.client.retries.number 现在设置为 10.以前是 35.建议下游用户使用 Client 端超时,如Timeout settings部分所述。
hbase.client.serverside.retries.multiplier 现在设置为 3.以前是 10.建议下游用户使用 Client 端超时,如Timeout settings部分所述。
hbase.master.fileSplitTimeout 现在设置为 10 分钟。以前是 30 秒。
hbase.regionserver.logroll.multiplier 现在设置为 0.5. 以前是 0.95. 此更改与以下块大小加倍相关。结合起来,这两个配置更改应该使 WAL 的大小与 hbase-1.x 中的 WAL 大小相同,但是小块的发生率应该降低,因为在达到块大小阈值之前我们无法滚动 WAL。参见HBASE-19148进行讨论。
hbase.regionserver.hlog.blocksize 的默认值是 WAL 目录的 HDFS 默认块大小的 2 倍。以前,它等于 WAL 目录的 HDFS 默认块大小。
hbase.client.start.log.errors.counter 更改为 5.以前是 9.
hbase.ipc.server.callqueue.type 更改为“ fifo”。在 HBase 版本 1.0-1.2 中,这是“最后期限”。在 1.x 之前和之后的版本中,它已经默认为'fifo'。
默认情况下,hbase.hregion.memstore.chunkpool.maxsize 为 1.0. 以前是 0.0. 实际上,这意味着以前我们在内存存储处于堆状态时不会使用块池,而现在我们会使用。有关 MSLAB 块池的更多信息,请参见GC 长时间停顿部分。
hbase.master.cleaner.interval 现在设置为 10 分钟。以前是 1 分钟。
现在,hbase.master.procedure.threads 将默认为可用 CPU 数量的 1/4,但不少于 16 个线程。以前,线程数等于 CPU 数。
hbase.hstore.blockingStoreFiles 现在是 16.以前是 10.
hbase.http.max.threads 现在是 16.以前是 10.
hbase.client.max.perserver.tasks 现在是 2.以前是 5.
hbase.normalizer.period 现在是 5 分钟。以前是 30 分钟。
hbase.regionserver.region.split.policy 现在是 SteppingSplitPolicy。以前,它是 IncreasingToUpperBoundRegionSplitPolicy。
Replication.source.ratio 现在为 0.5. 以前是 0.1.
“主托管区域”功能已损坏且不受支持
HBase 1.y 中可用的功能“ Master 充当区域服务器”和相关的后续工作在 HBase 2.y 中不起作用,由于 Master 初始化上的死锁,不应在生产设置中使用。建议下游用户将相关配置设置视为实验性功能,而该功能不适合生产设置。
相关更改的简要摘要:
主人默认不再携带地区
hbase.balancer.tablesOnMaster 是一个布尔值,默认为 false(如果它持有表的 HBase 1.x 列表,则默认为 false)
hbase.balancer.tablesOnMaster.systemTablesOnly 是布尔值,可将用户表保持为主状态。默认为假
那些希望复制旧服务器列表配置的用户应该部署一个独立的 RegionServer 进程,然后依赖 Region Server Groups
删除了“分布式日志重播”功能
分布式日志重播功能已损坏,已从 HBase 2.y 中删除。结果,所有相关的配置,Metrics,RPC 字段和日志记录也已删除。请注意,在运行 HBase 1.0 时发现该功能不可靠,默认情况下未使用此功能,当我们开始忽略将其打开的配置(HBASE-14465)时,该功能已在 HBase 1.2.0 中有效删除。如果当前正在使用该功能,请确保执行干净关机,确保所有 DLR 工作已完成,并在升级之前禁用该功能。
前缀树编码已删除
前缀树编码已从 HBase 2.0.0(HBASE-19179)中删除。在 hbase-1.2.7,hbase-1.4.0 和 hbase-1.3.2 中已弃用(最新!)。
由于未积极维护此功能,因此删除了该功能。如果有兴趣恢复这种以降低写入速度为代价来改善随机读取延迟的便利功能,请在* dev 的 hbase dot apache dot org *处编写 HBase 开发人员列表。
在升级到 HBase 2.0 之前,需要从所有表中删除前缀树编码。为此,首先需要将编码从 PREFIX_TREE 更改为 HBase 2.0 支持的其他格式。之后,您必须对以前使用 PREFIX_TREE 编码的表进行压缩。要检查哪些列族使用的数据块编码不兼容,可以使用Pre-Upgrade Validator。
Changed metrics
以下 Metrics 已更改名称:
- 以前以“ AssignmentManger” [sic]的名义发布的 Metrics 现在以“ AssignmentManager”的名义发布
以下 Metrics 已更改其含义:
基于每个区域服务器发布的度量标准'blockCacheEvictionCount'不再包括由于其所在的 hfile 无效(例如,通过压缩)而从缓存中删除的块。
Metrics“ totalRequestCount”每个请求增加一次;之前,它增加了请求中携带的
Actions的数量;例如如果一个请求是由四个 Get 和两个 Put 组成的multi,则我们将'totalRequestCount'增加 6;现在无论如何我们都增加一。期望在 hbase-2.0.0 中看到该 Metrics 的较低值。现在,“ readRequestCount”对返回非空行的读取进行计数,在较旧的 hbase 中,无论是否为 Result,我们都会增加“ readRequestCount”。如果对不存在的行的请求,则此更改将使读取请求图的配置文件平坦。 YCSB 读取繁重的工作负载可以执行此操作,具体取决于数据库的加载方式。
以下 Metrics 已删除:
- 与分布式日志重播功能有关的 Metrics 不再存在。通常在区域服务器上下文中以“重播”名称找到它们。有关详细信息,请参见删除了“分布式日志重播”功能部分。
添加了以下 Metrics:
- “ totalRowActionRequestCount”是区域行操作的总数,该操作汇总了读写操作。
Changed logging
HBase-2.0.0 现在使用slf4j作为其日志记录前端。以前,我们使用log4j (1.2)。对于大多数情况而言,过渡应该是无缝的。 slf4j 很好地解释了* log4j.properties *日志记录配置文件,因此您不会注意到日志系统发出的任何差异。
也就是说,您的* log4j.properties *可能需要刷新。例如,请参见HBASE-20351,其中陈旧的日志配置文件表现为 netty 配置,并在 DEBUG 级别上作为每个 shell 命令调用的前导转储。
ZooKeeper 配置不再从 zoo.cfg 中读取
HBase 不再选择读取与 ZooKeeper 相关的配置设置的'zoo.cfg'文件。如果以前使用“ hbase.config.read.zookeeper.config”配置来实现此功能,则应在添加前缀“ hbase.zookeeper.property”的同时将所有需要的设置迁移到 hbase-site.xml 文件。每个属性名称。
权限变更
以下与权限相关的更改是更改的语义或默认值:
现在,授予用户的权限将与该用户的现有权限合并,而不是覆盖它们。 (有关详细信息,请参见HBASE-17472 的发行说明)
区域服务器组命令(在 1.4.0 中添加)现在需要 Management 员权限。
大多数 Admin API 不适用于 HBase 2.0 之前的 Client 端的 HBase 2.0 群集
从 HBase 2.0 之前的 Client 端使用许多 Management 命令时,这些命令不起作用。这包括一个具有 HBase 2.0 之前版本的库 jar 的 HBase Shell。您将需要计划中断使用 ManagementAPI 和命令,直到您还可以更新到所需的 Client 端版本。
从 HBase 2.0 之前的 Client 端执行以下 Client 端操作不适用于 HBase 2.0 群集:
list_procedures
split
merge_region
list_quotas
enable_table_replication
disable_table_replication
快照相关命令
在 1.0 中不推荐使用的 Management 命令已被删除。
在 1.0 中不推荐使用的以下命令已被删除。列出了替换命令(如果适用)。
- 'hlog'命令已被删除。下游用户应改为使用“ wal”命令。
区域服务器内存消耗发生变化。
从 HBase 1.4 之前的版本升级的用户应阅读区域服务器内存消耗发生变化。部分中的说明。
此外,HBase 2.0 更改了跟踪内存存储器以进行刷新决策的方式。以前,数据大小和存储开销都用于计算冲刷阈值的利用率。现在,仅使用数据大小来做出这些按区域的决策。在 Global 范围内,存储开销的增加用于做出有关强制刷新的决策。
用于拆分和合并的 Web UI 对行前缀进行操作
以前,Web UI 在表状态页上包含功能,可以根据编码的区域名称合并或拆分。在 HBase 2.0 中,该功能通过使用行前缀来起作用。
从 HBase 1.4 之前的复制用户的特殊升级
用户在运行 1.4.0 发行版之前使用复制的 HBase 版本时,请务必阅读复制对等方的 TableCFs 配置部分中的说明。
HBase Shell 更改
HBase shell 命令依赖于 Binding 的 JRuby 实例。Binding 的 JRuby 已从 1.6.8 版本更新到 9.1.10.0 版本。表示从 Ruby 1.8 到 Ruby 2.3.3 的更改,后者为用户脚本引入了不兼容的语言更改。
现在,HBase Shell 命令将忽略早期 HBase 1.4 发行版中的“ --return-values”标志。相反,shell 始终表现出好像已传递该标志的行为。如果您希望避免在控制台中打印表达式结果,则应按照irbrc部分中的说明更改 IRB 配置。
HBase 2.0 中的协处理器 API 已更改
已对所有协处理器 API 进行重构,以提高对二进制 API 兼容性的支持能力,以支持将来的 HBase 版本。如果您或您依赖的应用程序具有自定义的 HBase 协处理器,则应阅读HBASE-18169 的发行说明以获得升级到 HBase 2.0 之前需要进行的更改的详细信息。
例如,如果您在 HBase 1.2 中具有 BaseRegionObserver,则至少需要对其进行更新以实现 RegionObserver 和 RegionCoprocessor 并添加方法
...
@Override
public Optional<RegionObserver> getRegionObserver() {
return Optional.of(this);
}
...
HBase 2.0 不能再写入 HFile v2 文件。
HBase 简化了我们内部的 HFile 处理。结果,我们不能再写比默认版本 3 更早的 HFile 版本。升级用户之前,应确保 hbase-site.xml 中的 hfile.format.version 未设置为 2.否则,将导致区域服务器故障。 HBase 仍可以读取以旧版本 2 格式编写的 HFile。
HBase 2.0 无法再读取基于序列文件的 WAL 文件。
HBase 无法再读取以 Apache Hadoop 序列文件格式编写的不赞成使用的 WAL 文件。应将 hbase.regionserver.hlog.reader.impl 和 hbase.regionserver.hlog.reader.impl 配置条目设置为使用基于 Protobuf 的 WAL 读取器/写入器类。自 HBase 0.96 起,此实现已成为默认设置,因此对于大多数下游用户而言,旧的 WAL 文件不应该成为问题。
干净关闭群集应确保没有 WAL 文件。如果不确定给定的 WAL 文件格式,则可以在 HBase 群集脱机时使用hbase wal命令解析文件。在 HBase 2.0 中,此命令将无法读取基于序列文件的 WAL。有关该工具的更多信息,请参见WALPrettyPrinter部分。
过滤器行为的变化
过滤器 ReturnCode NEXT_ROW 已重新定义为跳至当前族的下一行,而不是所有族的下一行。这更合理,因为 ReturnCode 是 Store 级别的概念,而不是区域级别的概念。
下游 HBase 2.0 用户应使用 shadeClient 端
强烈建议下游用户依赖 Maven 坐标 org.apache.hbase:hbase-shaded-client 进行运行时使用。该工件包含与 HBase 集群通信时所需的所有实现细节,同时最大程度地减少了公开的第三方依赖项的数量。
请注意,此工件在 org.apache.hadoop 包空间中公开了一些类(例如 o.a.h.configuration.Configuration),以便我们可以保持与公共 API 的源兼容性。包括了这些类,以便可以对其进行更改以使用与其余 HBaseClient 端代码相同的重新定位的第三方依赖关系。如果需要在代码中“还”使用 Hadoop,则应确保所有与 Hadoop 相关的 jar 在 Classpath 中的 HBaseClient 端 jar 之前。
MapReduce 的下游 HBase 2.0 用户必须切换到新工件
HBase 与 Apache Hadoop MapReduce 集成的下游用户必须切换到依赖 org.apache.hbase:hbase-shaded-mapreduce 模块进行运行时使用。从历史上看,下游用户依赖于这些类的 org.apache.hbase:hbase-server 或 org.apache.hbase:hbase-shaded-server 工件。不再支持这两种用法,并且在大多数情况下将在运行时失败。
请注意,此工件在 org.apache.hadoop 包空间中公开了一些类(例如 o.a.h.configuration.Configuration),以便我们可以保持与公共 API 的源兼容性。包括了这些类,以便可以对其进行更改以使用与其余 HBaseClient 端代码相同的重新定位的第三方依赖关系。如果需要在代码中“还”使用 Hadoop,则应确保所有与 Hadoop 相关的 jar 在 Classpath 中的 HBaseClient 端 jar 之前。
对运行时 Classpath 的重大更改
HBase 的许多内部依赖项已从运行时 Classpath 中更新或删除。不遵循下游 HBase 2.0 用户应使用 shadeClient 端中的指导的下游 Client 端用户将必须检查 Maven 引入的依赖关系集以产生影响。 LimitedPrivate 协处理器 API 的下游用户将需要检查运行时环境的影响。有关我们过去一直在协调兼容的运行时版本方面遇到的问题的第三方库的新处理方法的详细信息,请参见参考指南HBase-第三方依赖关系和 shade/重定位。
Client 端 API 对源代码和二进制兼容性的多项重大更改
用于 HBase 的 JavaClient 端 API 进行了许多更改,这些更改破坏了源代码兼容性和二进制兼容性,有关详细信息,请参阅要升级到的版本的兼容性检查报告。
跟踪实施变更
HBase 跟踪功能的支持实现已从 Apache HTrace 3 更新为 HTrace 4,其中包括一些重大更改。尽管 HTrace 3 和 HTrace 4 可以在同一运行时中共存,但它们不会相互集成,从而导致跟踪信息脱节。
升级期间对 HBase 进行的内部更改足以进行编译,但是尚未确认跟踪功能没有任何退步。请考虑此功能在不久的将来过期。
如果您以前依赖于与 HBase 操作集成的 Client 端跟踪,则建议您也将用法升级到 HTrace 4.
HFile 失去向前兼容性
由 2.0.0、2.0.1、2.1.0 生成的 HFile 与 1.4.6-,1.3.2.1-,1.2.6.1-和其他非活动版本不向前兼容。为什么 HFile 失去兼容性是新版本(2.0.0、2.0.1、2.1.0)中的 hbase 使用 protobuf 序列化/反序列化 TimeRangeTracker(TRT),而旧版本使用 DataInput/DataOutput。为了解决这个问题,我们必须将HBASE-21012放入 2.x,并将HBASE-21013放入 1.x。有关更多信息,请检查HBASE-21008。
Performance
考虑到读写路径已发生重大变化,升级到 hbase-2.0.0 时,性能概要文件可能会发生变化。在发布时,根据上下文的不同,写入可能会变慢,而读取结果可能会相同或好得多。准备花些时间进行调整(请参阅Apache HBase 性能调优)。性能也是一个需要积极审查的领域,因此希望在以后的发行版中有所改进(请参阅HBASE-20188 测试性能)。
默认压缩吞吐量
HBase 2.x 带有默认的压缩执行速度限制。此限制是按 RegionServer 定义的。在以前的 HBase 版本中,默认情况下压缩的运行速度没有限制。对压缩的吞吐量施加限制应确保来自 RegionServer 的操作更加稳定。
请注意,此限制是每个 RegionServer 而不是每个压缩。
吞吐量限制定义为每秒写入的字节范围,并允许在给定的上下限内变化。 RegionServers 观察压实的当前吞吐量,并应用线性公式相对于外部压力在上下限内调整允许的吞吐量。对于压实,外部压力定义为相对于允许的最大存储文件数的存储文件数。存储文件越多,压实压力越高。
此吞吐量的配置由以下属性控制。
下限由
hbase.hstore.compaction.throughput.lower.bound定义,默认为 10 MB/s(10485760)。上限由
hbase.hstore.compaction.throughput.higher.bound定义,默认为 20 MB/s(20971520)。
要将这种行为恢复为早期版本的 HBase 的无限制压缩吞吐量,请将以下属性设置为对压缩没有限制的实现。
hbase.regionserver.throughput.controller=org.apache.hadoop.hbase.regionserver.throttle.NoLimitThroughputController
13.1.2. 将协处理器升级到 2.0
协处理器在 2.0 中进行了重大更改,从类层次结构的顶层设计更改到更改/删除的方法,接口等(父 jira:2.0.0 发行之前的 HBASE-18169 协处理器修复和清理)。如此广泛的变化的一些原因:
传递接口而不是实现;例如 TableDescriptor 代替 HTableDescriptor,Region 代替 HRegion(HBASE-18241将 client.Table 和 client.Admin 更改为不使用 HTableDescriptor)。
设计重构,因此实施者需要填写的模板更少,因此我们可以进行更多的编译时检查(HBASE-17732)
从协处理器 API 清除协议缓冲区(HBASE-18859,HBASE-16769等)
减少我们向协处理器公开的内容,删除过于私有而无法公开的内部钩子(例如HBASE-18453 CompactionRequest 不应直接公开给用户; HBASE-18298 RegionServerServices CP 公开的接口清理;等等)
要在 2.0 中使用协处理器,应针对新的 API 重建它们,否则它们将无法加载,并且 HBase 进程将死亡。
升级协处理器的建议更改 Sequences:
直接实现观察者接口,而不是扩展 Base * Observer 类。将
Foo extends BaseXXXObserver更改为Foo implements XXXObserver。 (HBASE-17312)。通过遵循this example适应从继承到合成(HBASE-17732)的设计更改。
getTable()已从 CoprocessorEnvrionment 中删除,协处理器应自行 ManagementTable 实例。
在 hbase-example 模块here中可以找到使用新 API 编写协处理器的一些示例。
最后,如果某个 api 被更改/删除以一种无法弥补的方式使您烦恼,并且有充分的理由将其重新添加,请通知我们(dev@hbase.apache.org)。
13.1.3. 从 1.x 滚动升级到 2.x
滚动升级目前是一项实验功能。他们的测试很有限。我们有限的经验中可能还没有发现一些极端的情况,因此如果您走这条 Route,请务必小心。下一节从 1.x 升级到 2.x 的过程中描述的停止/升级/启动是最安全的 Route。
也就是说,以下是 1.4 群集滚动升级的说明。
Pre-Requirements
升级到最新的 1.4.x 版本。 1.4 版之前的版本也可以使用,但未经测试,因此,除非您是 maven 并且熟悉区域分配和崩溃处理,否则请先升级到 1.4.3,然后再升级到 2.x。有关如何升级到 1.4.x 的信息,请参见从 1.4 之前的版本升级到 1.4部分。
确保启用了 zk-less 分配,即将
hbase.assignment.usezk设置为false。这是最重要的。它允许 1.x 主机向 2.x 区域服务器分配/取消分配区域。请参阅HBASE-11059的发行说明部分,以了解如何从基于 zk 的分配迁移到不包含 zk 的分配。我们已经测试了从 1.4.3 到 2.1.0 的滚动升级,但是如果您想升级到 2.0.x,它也应该可以使用。
Instructions
卸载区域服务器并将其升级到 2.1.0. 设置HBASE-17931后,元区域和其他系统表的区域将立即移到该区域服务器。如果没有,请手动将它们移动到新的区域服务器。这很重要,因为
meta 区域的模式是硬编码的,如果 meta 在旧的区域服务器上,则新的区域服务器将无法访问它,因为它没有某些族,例如表状态。
较低版本的 Client 端可以与较高版本的服务器进行通信,反之亦然。如果元区域在旧的区域服务器上,则新的区域服务器将使用具有较高版本的 Client 端与具有较低版本的服务器进行通信,这可能会带来奇怪的问题。
滚动升级所有其他区域服务器。
Upgrading masters.
在滚动升级过程中,区域服务器会崩溃是可以的。 1.x 主服务器可以将区域分配给 1.x 和 2.x 区域服务器,并且HBASE-19166解决了一个问题,因此 1.x 区域服务器也可以读取由 2.x 区域服务器编写的 WAL 并将它们拆分。
Note
在进行升级之前,请仔细阅读注意事项的变化!部分。确保不使用 2.0 中已删除的功能,例如,前缀树编码,旧的 hfile 格式等。它们都可能导致升级失败,并使群集处于中间状态并且难以恢复。
Note
如果您成功执行此处方,请向开发人员列表发送一份有关您的经验的 Comments,并/或使用可能发生的任何偏差更新以上内容,以便其他人从您的努力中受益。
13.1.4. 从 1.x 升级到 2.x 的过程
要升级现有的 HBase 1.x 群集,您应该:
彻底关闭现有 1.x 群集
Update coprocessors
首先升级主角色
Upgrade RegionServers
(最终)升级 Client 端
13.2. 从 1.4 之前的版本升级到 1.4
13.2.1. 区域服务器内存消耗发生变化。
从 HBase 1.4 之前的版本升级的用户应注意,对于最大 32G 的堆大小(使用 CompressedOops),memstore 对象(KeyValue,对象和数组头大小等)对堆使用情况的估计已变得更加准确,从而导致实际上,它们下降了 10-50%。由于“屑”冲洗,这也导致冲洗和压实的次数减少。 YMMV。结果,在刷新之前,memstore 的实际堆使用量可能最多增加 100%。如果已根据观察到的使用情况调整了区域服务器的配置内存限制,则此更改可能导致更糟的 GC 行为,甚至导致 OutOfMemory 错误。将环境属性(不是 hbase-site.xml)“ hbase.memorylayout.use.unsafe”设置为 false 以禁用。
13.2.2. 复制对等方的 TableCFs 配置
在 1.4 之前,表名不能包含复制对等方的 TableCFs 配置的名称空间。通过将 TableCF 添加到存储在 Zookeeper 中的 ReplicationPeerConfig 中,可以修复该问题。因此,升级到 1.4 时,必须首先更新 Zookeeper 上的原始 ReplicationPeerConfig 数据。当您的群集具有带有 TableCFs 配置的复制对等方时,有四个升级步骤。
禁用复制对等方。
如果 master 具有写复制对等 znode 的权限,则直接滚动更新 master。如果不是,请使用 TableCFsUpdater 工具更新复制对等方的配置。
$ bin/hbase org.apache.hadoop.hbase.replication.master.TableCFsUpdater update
滚动更新区域服务器。
启用复制对等方。
Notes:
- 无法使用旧 Client 端(1.4 之前的版本)更改复制对等方的配置。由于 Client 端将配置直接写入 Zookeeper,因此旧 Client 端将丢失 TableCFs 的配置。并且旧 Client 端将 TableCFs 配置写入旧 tablecfs znode,它将不适用于新版本的 regionserver。
13.2.3. 原始扫描现在忽略 TTL
现在,执行原始扫描将返回根据 TTL 设置过期的结果。
13.3. 从 1.3 之前的版本升级到 1.3
如果在 Kerberos 下运行集成测试,请参见[upgrade2.0.it.kerberos]。
13.4. 升级到 1.x
请参阅专门针对要升级到的 HBase 版本发布的文档,以获取有关升级过程的详细信息。
Apache HBase Shell
Apache HBase Shell 是(J)Ruby的 IRB,其中添加了一些 HBase 特定命令。在 IRB 中可以执行的任何操作,都应该可以在 HBase Shell 中执行。
要运行 HBase Shell,请执行以下操作:
$ ./bin/hbase shell
键入help,然后键入<RETURN>以查看 Shell 命令和选项的列表。至少浏览帮助输出末尾的段落,以了解如何将变量和命令参数 ImportingHBase shell;特别注意表名,行和列等必须加引号。
有关基本 Shell 程序操作的示例,请参见shell exercises。
这是 Rajeshbabu Chintaguntla 精心格式化的所有 shell 命令清单。
14.使用 Ruby 编写脚本
有关编写 Apache HBase 脚本的示例,请查看 HBase * bin 目录。查看以*。rb *结尾的文件。要运行这些文件之一,请执行以下操作:
$ ./bin/hbase org.jruby.Main PATH_TO_SCRIPT
15.在非交互模式下运行 Shell
HBase Shell 中已添加了新的非交互模式(HBASE-11658)。非交互模式将捕获 HBase Shell 命令的退出状态(成功或失败),并将该状态传递回命令解释器。 ,则 HBase Shell 只会返回自己的退出状态,成功几乎总是0。
要调用非交互模式,请将-n或--non-interactive选项传递给 HBase Shell。
16. OS 脚本中的 HBase Shell
您可以在 os 脚本解释器(例如 Bash shell)中使用 HBase shell,而 Bash shell 是大多数 Linux 和 UNIX 发行版的默认命令解释器。以下准则使用 Bash 语法,但可以进行调整以与 C 样式的 shell(例如 csh 或 tcsh)一起使用,并且可以进行修改以与 Microsoft Windows 脚本解释器一起使用。欢迎提交。
Note
以这种方式生成 HBase Shell 命令的速度很慢,因此在决定何时将 HBase 操作与 os 命令行结合使用时要牢记这一点。
例子 4.将命令传递给 HBase Shell
您可以使用echo命令和|(管道)运算符以非交互模式(请参见hbase.shell.noninteractive)将命令传递给 HBase Shell。确保在 HBase 命令中转义字符,否则这些字符会被 Shell 解释。下面的示例已截断了某些调试级别的输出。
$ echo "describe 'test1'" | ./hbase shell -n
Version 0.98.3-hadoop2, rd5e65a9144e315bb0a964e7730871af32f5018d5, Sat May 31 19:56:09 PDT 2014
describe 'test1'
DESCRIPTION ENABLED
'test1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'NON true
E', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0',
VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIO
NS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS =>
'false', BLOCKSIZE => '65536', IN_MEMORY => 'false'
, BLOCKCACHE => 'true'}
1 row(s) in 3.2410 seconds
要取消所有输出,请将其回显到*/dev/null:*
$ echo "describe 'test'" | ./hbase shell -n > /dev/null 2>&1
例子 5.检查脚本命令的结果
由于脚本并非旨在以交互方式运行,因此您需要一种方法来检查命令是失败还是成功。 HBase Shell 使用标准约定,即对于成功的命令返回0的值,对于失败的命令返回一些非零的值。 Bash 将命令的返回值存储在名为$?的特殊环境变量中。由于该变量每次在 Shell 运行任何命令时都会被覆盖,因此您应将结果存储在脚本定义的其他变量中。
这是一个幼稚的脚本,它显示了一种存储返回值并基于该值进行决策的方法。
#!/bin/bash
echo "describe 'test'" | ./hbase shell -n > /dev/null 2>&1
status=$?
echo "The status was " $status
if ($status == 0); then
echo "The command succeeded"
else
echo "The command may have failed."
fi
return $status
16.1. 检查脚本中的成功或失败
获得退出代码0意味着您编写的命令肯定成功。但是,获得非零的退出代码并不一定意味着命令失败。该命令可能已经成功,但是 Client 端失去了连接,或者其他事件掩盖了其成功。这是因为 RPC 命令是 Stateless 的。确保操作状态的唯一方法是检查。例如,如果您的脚本创建了一个表,但是返回了一个非零的退出值,则应在再次尝试创建表之前检查该表是否已实际创建。
17.从命令文件中读取 HBase Shell 命令
您可以将 HBase Shell 命令 Importing 到文本文件中,每行一个命令,然后将该文件传递给 HBase Shell。
示例命令文件
create 'test', 'cf'
list 'test'
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'
put 'test', 'row4', 'cf:d', 'value4'
scan 'test'
get 'test', 'row1'
disable 'test'
enable 'test'
例子 6.指示 HBase Shell 执行命令
将路径传递到命令文件作为hbase shell命令的唯一参数。每个命令都会执行,并显示其输出。如果脚本中未包含exit命令,则会返回到 HBase shell 提示符。无法以编程方式检查每个单独的命令是否成功。另外,尽管您看到了每个命令的输出,但命令本身并未回显到屏幕,因此可能很难将命令与其输出对齐。
$ ./hbase shell ./sample_commands.txt
0 row(s) in 3.4170 seconds
TABLE
test
1 row(s) in 0.0590 seconds
0 row(s) in 0.1540 seconds
0 row(s) in 0.0080 seconds
0 row(s) in 0.0060 seconds
0 row(s) in 0.0060 seconds
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1407130286968, value=value1
row2 column=cf:b, timestamp=1407130286997, value=value2
row3 column=cf:c, timestamp=1407130287007, value=value3
row4 column=cf:d, timestamp=1407130287015, value=value4
4 row(s) in 0.0420 seconds
COLUMN CELL
cf:a timestamp=1407130286968, value=value1
1 row(s) in 0.0110 seconds
0 row(s) in 1.5630 seconds
0 row(s) in 0.4360 seconds
18.将 VM 选项传递到命令行 Management 程序
您可以使用HBASE_SHELL_OPTS环境变量将 VM 选项传递给 HBase Shell。您可以在环境中进行设置,例如通过编辑*~/ .bashrc *,或将其设置为启动 HBase Shell 的命令的一部分。以下示例仅在运行 HBase Shell 的 VM 的生命周期内设置了几个与垃圾回收相关的变量。该命令应全部在同一行上运行,但为了便于阅读,请使用\字符将其破坏。
$ HBASE_SHELL_OPTS="-verbose:gc -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDateStamps \
-XX:+PrintGCDetails -Xloggc:$HBASE_HOME/logs/gc-hbase.log" ./bin/hbase shell
19.覆盖启动 HBase Shell 的配置
从 hbase-2.0.5/hbase-2.1.3/hbase-2.2.0/hbase-1.4.10/hbase-1.5.0 开始,您可以通过传递前缀的键/值来传递或覆盖hbase-*.xml中指定的 hbase 配置在命令行上使用-D,如下所示:
$ ./bin/hbase shell -Dhbase.zookeeper.quorum=ZK0.remote.cluster.example.org,ZK1.remote.cluster.example.org,ZK2.remote.cluster.example.org -Draining=false
...
hbase(main):001:0> @shell.hbase.configuration.get("hbase.zookeeper.quorum")
=> "ZK0.remote.cluster.example.org,ZK1.remote.cluster.example.org,ZK2.remote.cluster.example.org"
hbase(main):002:0> @shell.hbase.configuration.get("raining")
=> "false"
20. Shell 技巧
20.1. 表变量
HBase 0.95 添加了 shell 命令,这些命令为表提供了 jruby 样式的面向对象的引用。以前,作用于表的所有 shell 命令都具有一种程序样式,该样式始终将表的名称作为参数。 HBase 0.95 引入了将表分配给 jruby 变量的功能。该表引用可用于执行数据读写操作,例如放置,扫描以及获取良好的 Management 功能,例如禁用,删除,描述表。
例如,以前您总是要指定一个表名:
hbase(main):000:0> create 't', 'f'
0 row(s) in 1.0970 seconds
hbase(main):001:0> put 't', 'rold', 'f', 'v'
0 row(s) in 0.0080 seconds
hbase(main):002:0> scan 't'
ROW COLUMN+CELL
rold column=f:, timestamp=1378473207660, value=v
1 row(s) in 0.0130 seconds
hbase(main):003:0> describe 't'
DESCRIPTION ENABLED
't', {NAME => 'f', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_ true
SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2
147483647', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false
', BLOCKCACHE => 'true'}
1 row(s) in 1.4430 seconds
hbase(main):004:0> disable 't'
0 row(s) in 14.8700 seconds
hbase(main):005:0> drop 't'
0 row(s) in 23.1670 seconds
hbase(main):006:0>
现在,您可以将表分配给变量,并在 jruby shell 代码中使用结果。
hbase(main):007 > t = create 't', 'f'
0 row(s) in 1.0970 seconds
=> Hbase::Table - t
hbase(main):008 > t.put 'r', 'f', 'v'
0 row(s) in 0.0640 seconds
hbase(main):009 > t.scan
ROW COLUMN+CELL
r column=f:, timestamp=1331865816290, value=v
1 row(s) in 0.0110 seconds
hbase(main):010:0> t.describe
DESCRIPTION ENABLED
't', {NAME => 'f', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_ true
SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2
147483647', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false
', BLOCKCACHE => 'true'}
1 row(s) in 0.0210 seconds
hbase(main):038:0> t.disable
0 row(s) in 6.2350 seconds
hbase(main):039:0> t.drop
0 row(s) in 0.2340 seconds
如果已经创建了表,则可以使用 get_table 方法将表分配给变量:
hbase(main):011 > create 't','f'
0 row(s) in 1.2500 seconds
=> Hbase::Table - t
hbase(main):012:0> tab = get_table 't'
0 row(s) in 0.0010 seconds
=> Hbase::Table - t
hbase(main):013:0> tab.put 'r1' ,'f', 'v'
0 row(s) in 0.0100 seconds
hbase(main):014:0> tab.scan
ROW COLUMN+CELL
r1 column=f:, timestamp=1378473876949, value=v
1 row(s) in 0.0240 seconds
hbase(main):015:0>
列表功能也得到了扩展,以便它以字符串形式返回表名列表。然后,您可以使用 jruby 根据这些名称对表操作进行脚本编写。 list_snapshots 命令的行为也类似。
hbase(main):016 > tables = list('t.*')
TABLE
t
1 row(s) in 0.1040 seconds
=> #<#<Class:0x7677ce29>:0x21d377a4>
hbase(main):017:0> tables.map { |t| disable t ; drop t}
0 row(s) in 2.2510 seconds
=> [nil]
hbase(main):018:0>
20.2. irbrc
在主目录中为自己创建一个* .irbrc *文件。添加自定义项。命令历史是一个有用的命令,因此命令可在 Shell 调用之间保存:
$ more .irbrc
require 'irb/ext/save-history'
IRB.conf[:SAVE_HISTORY] = 100
IRB.conf[:HISTORY_FILE] = "#{ENV['HOME']}/.irb-save-history"
如果要避免将将每个表达式求值的结果打印到 stderr,例如,从“ list”命令返回的表数组:
$ echo "IRB.conf[:ECHO] = false" >>~/.irbrc
请参阅* .irbrc *的ruby文档,以了解其他可能的配置。
20.3. 将数据记录到时间戳
要将日期“ 08/08/16 20:56:29”从 hbase 日志转换为时间戳,请执行以下操作:
hbase(main):021:0> import java.text.SimpleDateFormat
hbase(main):022:0> import java.text.ParsePosition
hbase(main):023:0> SimpleDateFormat.new("yy/MM/dd HH:mm:ss").parse("08/08/16 20:56:29", ParsePosition.new(0)).getTime() => 1218920189000
要走另一个方向:
hbase(main):021:0> import java.util.Date
hbase(main):022:0> Date.new(1218920189000).toString() => "Sat Aug 16 20:56:29 UTC 2008"
以与 HBase 日志格式完全相同的格式输出将使SimpleDateFormat有点混乱。
20.4. 查询 Shell 程序配置
hbase(main):001:0> @shell.hbase.configuration.get("hbase.rpc.timeout")
=> "60000"
要在 Shell 中设置配置:
hbase(main):005:0> @shell.hbase.configuration.setInt("hbase.rpc.timeout", 61010)
hbase(main):006:0> @shell.hbase.configuration.get("hbase.rpc.timeout")
=> "61010"
20.5. 使用 HBase Shell 进行预拆分表
通过 HBase Shell create命令创建表时,可以使用各种选项来预分割表。
最简单的方法是在创建表时指定分割点数组。请注意,当将字符串 Literals 指定为拆分点时,它们将基于字符串的基础字节表示形式创建拆分点。因此,当指定分割点“ 10”时,我们实际上是在指定字节分割点“\x31\30”。
分割点将定义n+1个区域,其中n是分割点数。最低的区域将包含从最低可能的按键到第一个分割点按键的所有按键,但不包括这些按键。下一个区域将包含从第一个分割点到下一个分割点的键,但不包括下一个分割点的键。对于所有拆分点,该操作将一直持续到最后。从最后的分割点到最大可能的键将定义最后一个区域。
hbase>create 't1','f',SPLITS => ['10','20','30']
在上面的示例中,将使用列族“ f”创建表“ t1”,该列族被预分割为四个区域。请注意,第一个区域将包含从' x00'到' x30'的所有键(因为' x31'是'1'的 ASCII 码)。
您可以使用以下变体在文件中传递分割点。在此示例中,从与本地文件系统上的本地路径相对应的文件中读取拆分。文件中的每一行都指定一个分割点键。
hbase>create 't14','f',SPLITS_FILE=>'splits.txt'
其他选项是根据所需的区域数量和分割算法自动计算分割。 HBase 提供了用于根据统一拆分或基于十六进制密钥拆分密钥范围的算法,但是您可以提供自己的拆分算法来细分密钥范围。
# create table with four regions based on random bytes keys
hbase>create 't2','f1', { NUMREGIONS => 4 , SPLITALGO => 'UniformSplit' }
# create table with five regions based on hex keys
hbase>create 't3','f1', { NUMREGIONS => 5, SPLITALGO => 'HexStringSplit' }
由于 HBase Shell 实际上是 Ruby 环境,因此您可以使用简单的 Ruby 脚本通过算法计算拆分。
# generate splits for long (Ruby fixnum) key range from start to end key
hbase(main):070:0> def gen_splits(start_key,end_key,num_regions)
hbase(main):071:1> results=[]
hbase(main):072:1> range=end_key-start_key
hbase(main):073:1> incr=(range/num_regions).floor
hbase(main):074:1> for i in 1 .. num_regions-1
hbase(main):075:2> results.push([i*incr+start_key].pack("N"))
hbase(main):076:2> end
hbase(main):077:1> return results
hbase(main):078:1> end
hbase(main):079:0>
hbase(main):080:0> splits=gen_splits(1,2000000,10)
=> ["\000\003\r@", "\000\006\032\177", "\000\t'\276", "\000\f4\375", "\000\017B<", "\000\022O{", "\000\025\\\272", "\000\030i\371", "\000\ew8"]
hbase(main):081:0> create 'test_splits','f',SPLITS=>splits
0 row(s) in 0.2670 seconds
=> Hbase::Table - test_splits
请注意,HBase Shell 命令truncate有效地删除并使用默认选项重新创建了表,该默认选项将丢弃任何预分割。如果需要截断一个预分割表,则必须显式删除并重新创建该表以重新指定自定义分割选项。
20.6. Debug
20.6.1. Shell 调试开关
您可以在 Shell 中设置调试开关以查看更多输出。更多有关异常的堆栈跟踪—当您运行命令时:
hbase> debug <RETURN>
20.6.2. 调试日志级别
要在 Shell 中启用 DEBUG 级别的日志记录,请使用-d选项启动它。
$ ./bin/hbase shell -d
20.7. Commands
20.7.1. count
Count 命令返回表中的行数。当配置正确的 CACHE 时,速度非常快
hbase> count '<tablename>', CACHE => 1000
上面的计数一次获取 1000 行。如果行很大,请将 CACHE 设置为较低。默认值为一次获取一行。
Data Model
在 HBase 中,数据存储在具有行和列的表中。这是与关系数据库(RDBMS)的术语重叠,但这并不是一个有用的类比。相反,将 HBase 表视为多维 Map 可能会有所帮助。
HBase 数据模型术语
Table
- 一个 HBase 表由多行组成。
Row
- HBase 中的一行由一个行键和一个或多个与之相关联的列组成。行在存储时按行键按字母 Sequences 排序。因此,行键的设计非常重要。目标是以相关行彼此靠近的方式存储数据。常见的行密钥模式是网站域。如果行键是域,则可能应该将它们反向存储(org.apache.www,org.apache.mail,org.apache.jira)。这样,所有 Apache 域在表中彼此靠近,而不是根据子域的第一个字母散布开。
Column
- HBase 中的列由列族和列限定符组成,它们由
:(冒号)字符分隔。
- HBase 中的列由列族和列限定符组成,它们由
Column Family
- 出于性能考虑,列族实际上将一组列及其值并置在一起。每个列族都有一组存储属性,例如是否应将其值缓存在内存中,如何压缩其数据或对其行键进行编码等。表中的每一行都具有相同的列族,尽管给定的行可能不会在给定的列族中存储任何内容。
Column Qualifier
- 将列限定符添加到列族,以提供给定数据段的索引。给定列族
content,列限定符可能是content:html,另一个可能是content:pdf。尽管列族在创建表时是固定的,但列限定符是可变的,并且行之间的差异可能很大。
- 将列限定符添加到列族,以提供给定数据段的索引。给定列族
Cell
- 单元格是行,列族和列限定符的组合,并包含一个值和一个时间戳,代表该值的版本。
Timestamp
- 时间戳与每个值一起写入,并且是值的给定版本的标识符。默认情况下,时间戳表示写入数据时在 RegionServer 上的时间,但是在将数据放入单元格时,可以指定其他时间戳值。
21.概念视图
您可以在 Jim R. Wilson 的博客文章了解 HBase 和 BigTable中阅读有关 HBase 数据模型的非常容易理解的解释。 Amandeep Khurana 的 PDF 基本模式设计简介中提供了另一个很好的解释。
可能有助于阅读不同的观点,以便对 HBase 模式设计有深入的了解。链接的文章所涵盖的内容与本节中的内容相同。
下面的示例是对BigTable论文第 2 页的格式的略微修改形式。有一个名为webtable的表,该表包含两行(com.cnn.www和com.example.www)以及三个名为contents,anchor和people的列族。在此示例中,对于第一行(com.cnn.www),anchor包含两列(anchor:cssnsi.com,anchor:my.look.ca),而contents包含一列(contents:html)。本示例包含具有行键com.cnn.www的行的 5 个版本和具有行键com.example.www的行的一个版本。 contents:html列限定符包含给定网站的整个 HTML。 anchor列族的限定符每个都包含链接到该行表示的站点的外部站点,以及该链接的锚点中使用的文本。 people列族表示与该站点关联的人员。
Column Names
按照惯例,列名由其列族前缀和* qualifier 组成。例如,列 contents:html 由列族contents和html限定符组成。冒号(:)将列族与列族 qualifier *分隔开。
*表 6.表webtable *
| Row Key | Time Stamp | ColumnFamily contents |
ColumnFamily anchor |
ColumnFamily people |
|---|---|---|---|---|
| "com.cnn.www" | t9 | anchor:cnnsi.com =“ CNN” | ||
| "com.cnn.www" | t8 | anchor:my.look.ca =“ CNN.com” | ||
| "com.cnn.www" | t6 | contents:html =“<html>…” | ||
| "com.cnn.www" | t5 | contents:html =“<html>…” | ||
| "com.cnn.www" | t3 | contents:html =“<html>…” | ||
| "com.example.www" | t5 | contents:html =“<html>…” | people:author =“ John Doe” | |
该表中看起来为空的单元格在 HBase 中不占用空间,或实际上不存在。这就是使 HBase“稀疏”的原因。表格视图不是查看 HBase 中数据的唯一可能方法,甚至不是最准确的方法。以下代表与多维 Map 相同的信息。这仅是出于说明目的的模型,可能并非严格准确。
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}
22.物理视图
尽管从概念上讲,表可以看作是行的稀疏集合,但它们实际上是按列族存储的。可以随时将新的列限定符(column_family:column_qualifier)添加到现有的列族。
*表 7. ColumnFamily anchor *
| Row Key | Time Stamp | 列族anchor |
|---|---|---|
| "com.cnn.www" | t9 | anchor:cnnsi.com = "CNN" |
| "com.cnn.www" | t8 | anchor:my.look.ca = "CNN.com" |
*表 8. ColumnFamily contents *
| Row Key | Time Stamp | ColumnFamily contents: |
|---|---|---|
| "com.cnn.www" | t6 | contents:html =“<html>…” |
| "com.cnn.www" | t5 | contents:html =“<html>…” |
| "com.cnn.www" | t3 | contents:html =“<html>…” |
概念视图中显示的空单元格根本不存储。因此,在时间戳t8处对contents:html列的值的请求将不返回任何值。同样,在时间戳t9处请求anchor:my.look.ca值的请求将不返回任何值。但是,如果未提供时间戳,则将返回特定列的最新值。给定多个版本,最新的也是找到的第一个版本,因为时间戳以降序存储。因此,如果未指定时间戳,则对com.cnn.www行中所有列的值的请求将是:来自时间戳t6的contents:html的值,来自时间戳t9的anchor:cnnsi.com的值,来自时间戳t8的anchor:my.look.ca的值。
有关 Apache HBase 如何存储数据的内部信息,请参阅regions.arch。
23. Namespace
命名空间是表的逻辑分组,类似于关系数据库系统中的数据库。这种抽象为即将到来的多租户相关功能奠定了基础:
配额 Management(HBASE-8410)-限制名称空间可以消耗的资源(即区域,表)数量。
命名空间安全 Management(HBASE-9206)-为租户提供另一级别的安全 Management。
区域服务器组(HBASE-6721)-可以将名称空间/表固定到 RegionServers 的子集上,从而保证了粗略的隔离级别。
23.1. 命名空间 Management
可以创建,删除或更改名称空间。命名空间成员资格是在表创建期间通过指定以下格式的标准表名来确定的:
<table namespace>:<table qualifier>
例子 7.例子
#Create a namespace
create_namespace 'my_ns'
#create my_table in my_ns namespace
create 'my_ns:my_table', 'fam'
#drop namespace
drop_namespace 'my_ns'
#alter namespace
alter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
23.2. sched 义的名称空间
有两个 sched 义的特殊名称空间:
hbase-系统名称空间,用于包含 HBase 内部表
默认-没有显式指定名称空间的表将自动落入该名称空间
例子 8.例子
#namespace=foo and table qualifier=bar
create 'foo:bar', 'fam'
#namespace=default and table qualifier=bar
create 'bar', 'fam'
24. Table
表是在架构定义时预先声明的。
25. Row
行键是未解释的字节。行按字典 Sequences 排序,最低 Sequences 在表中排在最前面。空字节数组用于表示表名称空间的开始和结束。
26.列族
Apache HBase 中的列分为列族。列族的所有列成员都具有相同的前缀。例如,* courses:history 列和 courses:math 列都是 courses 列家族的成员。冒号(:)分隔了列族和列族限定符。列族前缀必须由* printable 字符组成。限定尾巴,列族 qualifier *,可以由任意字节组成。列族必须在架构定义时预先声明,而不必在架构时定义列,但可以在表启动并运行时即时对其进行构想。
实际上,所有列族成员都一起存储在文件系统上。由于调整和存储规范是在列族级别上完成的,因此建议所有列族成员都具有相同的常规访问模式和大小 Feature。
27. Cells
*{row, column, version} *Tuples 在 HBase 中恰好指定了cell。单元格内容是未解释的字节
28.数据模型操作
四个主要的数据模型操作是“获取”,“放置”,“扫描”和“删除”。通过Table个实例应用操作。
28.1. Get
28.2. Put
Put可以将新行添加到表中(如果键是新键),也可以更新现有行(如果键已存在)。通过Table.put(非 writeBuffer)或Table.batch(non-writeBuffer)执行看跌期权
28.3. Scans
Scan允许针对指定属性在多行上进行迭代。
以下是“扫描表”实例的示例。假设一个表中填充了键为“ row1”,“ row2”,“ row3”的行,然后填充了另一组键为“ abc1”,“ abc2”和“ abc3”的行。以下示例显示如何设置 Scan 实例以返回以“ row”开头的行。
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Table table = ... // instantiate a Table instance
Scan scan = new Scan();
scan.addColumn(CF, ATTR);
scan.setRowPrefixFilter(Bytes.toBytes("row"));
ResultScanner rs = table.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// process result...
}
} finally {
rs.close(); // always close the ResultScanner!
}
请注意,通常,最简单的指定扫描特定停止点的方法是使用InclusiveStopFilter类。
28.4. Delete
Delete从表中删除一行。删除是通过Table.delete执行的。
HBase 不会就地修改数据,因此删除操作通过创建称为* tombstones *的新标记来处理。这些墓碑以及固定价格将在大压实时清理干净。
有关删除列版本的更多信息,请参见version.delete;有关压缩的更多信息,请参见compaction。
29. Versions
*{row, column, version} *Tuples 在 HBase 中恰好指定了cell。可能会有无数的单元格,其中行和列相同,但单元格地址仅在其版本维度上有所不同。
当行键和列键表示为字节时,使用长整数指定版本。通常,此 long 包含一些时间实例,例如java.util.Date.getTime()或System.currentTimeMillis()返回的那些实例,即:当前时间与 1970 年 1 月 1 日午夜之间的差(以毫秒为单位)。
HBase 版本维以降序存储,因此从存储文件中读取时,将首先找到最新值。
在 HBase 中,关于cell版本的语义存在很多混乱。特别是:
如果对一个单元的多次写入具有相同版本,则只有最后一次写入是可获取的。
可以按非递增版本 Sequences 写入单元格。
下面我们描述 HBase 中版本维度当前的工作方式。有关 HBase 版本的讨论,请参见HBASE-2406。 HBase 中的弯曲时间可以很好地阅读 HBase 中的版本或时间维度。与此处提供的版本相比,它具有有关版本控制的更多详细信息。
在撰写本文时,本文提到的限制“在现有时间戳上覆盖值” *在 HBase 中不再适用。这部分基本上是 Bruno Dumon 撰写的这篇文章的提要。
29.1. 指定要存储的版本数
给定列存储的最大版本数是列架构的一部分,并在创建表时指定,或通过alter命令,通过HColumnDescriptor.DEFAULT_VERSIONS指定。在 HBase 0.96 之前,保留的默认版本数是3,但在 0.96 和更高版本中已更改为1。
示例 9.修改列族的最大版本数
本示例使用 HBase Shell 保留列系列f1中所有列的最多 5 个版本。您也可以使用HColumnDescriptor。
hbase> alter 't1′, NAME => 'f1′, VERSIONS => 5
例子 10.修改一个列族的最小版本数
您还可以指定每个列系列要存储的最小版本数。默认情况下,它设置为 0,这意味着该功能被禁用。下面的示例通过 HBase Shell 将列系列f1到2的所有列上的最小版本数设置为。您也可以使用HColumnDescriptor。
hbase> alter 't1′, NAME => 'f1′, MIN_VERSIONS => 2
从 HBase 0.98.2 开始,可以通过在* hbase-site.xml *中设置hbase.column.max.version来为所有新创建的列保留的最大版本数指定全局默认值。参见hbase.column.max.version。
29.2. 版本和 HBase 操作
在本节中,我们研究每个核心 HBase 操作的版本维度的行为。
29.2.1. Get/Scan
获取是在“扫描”之上实现的。以下对Get的讨论同样适用于Scans。
默认情况下,即,如果您未指定任何显式版本,则在执行get时,将返回其版本值最大的单元格(该单元格可能不是最新写入的单元格,请参阅下文)。可以通过以下方式修改默认行为:
返回多个版本,请参见Get.setMaxVersions()
返回最新版本以外的版本,请参见Get.setTimeRange()
要检索小于或等于给定值的最新版本,从而在某个时间点给出记录的“最新”状态,只需使用 0 到所需版本的范围并将最大版本设置为 1 。
29.2.2. 默认获取示例
以下 Get 将仅检索该行的当前版本
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(Bytes.toBytes("row1"));
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); // returns current version of value
29.2.3. 版本化获取示例
下面的 Get 将返回该行的最后 3 个版本。
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(Bytes.toBytes("row1"));
get.setMaxVersions(3); // will return last 3 versions of row
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); // returns current version of value
List<KeyValue> kv = r.getColumn(CF, ATTR); // returns all versions of this column
29.2.4. Put
进行认沽通常会在某个时间戳记上创建cell的新版本。默认情况下,系统使用服务器的currentTimeMillis,但是您可以自己在每个列级别上指定版本(=长整数)。这意味着您可以分配过去或将来的时间,或将 long 值用于非时间目的。
要覆盖现有值,请在与要覆盖的单元格完全相同的行,列和版本上进行放置。
隐式版本示例
HBase 将使用当前时间对以下 Put 进行隐式版本控制。
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Put put = new Put(Bytes.toBytes(row));
put.add(CF, ATTR, Bytes.toBytes( data));
table.put(put);
显式版本示例
下面的 Put 具有明确设置的版本时间戳。
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Put put = new Put( Bytes.toBytes(row));
long explicitTimeInMs = 555; // just an example
put.add(CF, ATTR, explicitTimeInMs, Bytes.toBytes(data));
table.put(put);
注意:HBase 在内部使用版本时间戳记来进行生存时间计算。通常最好避免自己设置此时间戳。首选使用行的单独时间戳属性,或将时间戳作为行键的一部分,或两者兼而有之。
29.2.5. Delete
有三种不同类型的内部删除标记。请参阅 Lars Hofhansl 的博客,以了解有关他尝试添加另一个在 HBase 中扫描:前缀删除标记的尝试。
删除:用于特定版本的列。
删除列:适用于列的所有版本。
删除族:针对特定 ColumnFamily 的所有列
删除整行时,HBase 会在内部为每个 ColumnFamily(即不是每个单独的列)创建一个逻辑删除。
通过创建墓碑标记来删除工作。例如,假设我们要删除一行。为此,您可以指定一个版本,否则默认使用currentTimeMillis。这意味着删除版本小于或等于此版本的所有单元格。 HBase 永远不会在适当位置修改数据,例如,删除操作不会立即删除(或标记为已删除)存储文件中与删除条件相对应的条目。而是编写了一个所谓的“墓碑”,它将掩盖已删除的值。当 HBase 进行重大压缩时,将处理逻辑删除以实际删除无效值以及逻辑删除本身。如果删除行时指定的版本大于该行中任何值的版本,则可以考虑删除整个行。
有关删除和版本控制如何交互的详细讨论,请参阅用户邮件列表上的带时间戳记放置→Deleteall→带时间戳记放置失败 up 线程。
另请参阅keyvalue,以获取有关内部 KeyValue 格式的更多信息。
除非在列族中设置了KEEP_DELETED_CELLS选项(请参见保留删除的单元格),否则在下次存储的主要压缩期间将删除删除标记。要使删除保持可配置的时间,可以通过* hbase-site.xml *中的 hbase.hstore.time.to.purge.deletes 属性设置删除 TTL。如果未设置hbase.hstore.time.to.purge.deletes或将其设置为 0,则所有删除标记(包括将来带有时间戳的标记)将在下一次主要压缩期间清除。否则,将保留将来带有时间戳的删除标记,直到在该标记的时间戳加上hbase.hstore.time.to.purge.deletes的值所表示的时间之后的主要压缩为止(以毫秒为单位)。
Note
此行为表示对 HBase 0.94 中引入的意外更改的修复,并在HBASE-10118中进行了修复。所做的更改已反向移植到 HBase 0.94 和更新的分支中。
29.3. HBase-2.0.0 中的可选新版本和删除行为
在hbase-2.0.0中,操作员可以通过将列 Descriptors 属性NEW_VERSION_BEHAVIOR设置为 true 来指定备用版本并删除处理(要在列族 Descriptors 上设置属性,必须先禁用该表,然后更改列族 Descriptors;有关详细信息,请参见保留删除的单元格)在列族 Descriptors 上编辑属性的示例)。
“新版本行为”消除了下面列出的限制,即如果在相同的位置(即相同的行,列族,限定词和时间戳记)(无论先到达哪个位置),Delete总是会遮盖Put。版本记帐也发生了变化,因为删除的版本被视为总版本数。这样做是为了确保在进行大型压实时不会改变结果。请参见HBASE-15968和链接的问题进行讨论。
目前,使用此新配置运行需要花费很多;我们在每次比较时都将 Cell MVCC 包括在内,因此可以消耗更多的 CPU。减速将取决于。在测试中,我们发现性能下降了 0%到 25%。
如果要复制,建议您使用新的串行复制功能(请参阅HBASE-9465;串行复制功能未将其放入hbase-2.0.0,但应在后续的 hbase-2.x 版本中提供),就像现在突变到达的 Sequences 一样是一个因素。
29.4. 电流限制
hbase-2.0.0 中解决了以下限制。请参见上面的HBase-2.0.0 中的可选新版本和删除行为部分。
29.4.1. 删除面膜放置
删除蒙版看跌期权,甚至是 Importing 删除后发生的看跌期权。参见HBASE-2256。请记住,删除操作会写入一个墓碑,该墓碑只有在下一次大型压缩运行之后才会消失。假设您删除了所有内容⇐T。此后,您将使用时间戳记 do T 进行新的放置。此放置,即使它在删除后发生,也将被删除逻辑删除掩盖。进行认沽不会失败,但是当您进行认沽时,您会注意到认沽没有任何效果。大型压实运行后,它将重新开始工作。如果您使用不断增加的版本来放置新的看跌期权,这些问题应该不会成为问题。但是,即使您不在乎时间,它们也可能发生:只需删除并立即放置就可以了,它们有可能在同一毫秒内发生。
29.4.2. 重大压缩会更改查询结果
…在 t1,t2 和 t3 处创建三个单元格版本,最大版本设置为 2.因此,在获取所有版本时,将仅返回 t2 和 t3 处的值。但是,如果您在 t2 或 t3 删除该版本,则 t1 的版本将再次出现。显然,一旦进行了重大压实,这种行为就不会再出现了……(请参阅HBase 中的弯曲时间中的垃圾收集)。
30.排序 Sequences
所有数据模型操作 HBase 都按排序 Sequences 返回数据。首先是按行,然后是 ColumnFamily,然后是列限定符,最后是时间戳(按相反 Sequences 排序,因此首先返回最新记录)。
31.列元数据
在 ColumnFamily 的内部 KeyValue 实例之外没有任何列元数据存储。因此,尽管 HBase 不仅可以支持每行大量列,而且还可以支持行之间的异构列集,但是您有责任跟踪列名。
获取 ColumnFamily 存在的一组完整列的唯一方法是处理所有行。有关 HBase 如何在内部存储数据的更多信息,请参见keyvalue。
32. Joins
HBase 是否支持联接是 dist 列表上的一个常见问题,并且有一个简单的答案:它至少在 RDBMS 支持联接的方式上不支持(例如,在 SQL 中使用等联接或外部联接) )。如本章所述,HBase 中的读取数据模型操作是 Get 和 Scan。
但是,这并不意味着您的应用程序不支持等效的联接功能,而是您必须自己做。两种主要策略是在写入 HBase 时对数据进行非规范化,或者在应用程序或 MapReduce 代码中具有查找表并在 HBase 表之间进行联接(正如 RDBMS 所演示的那样,有几种策略可用于此操作,具体取决于表,例如,嵌套循环与哈希联接)。那么哪种方法最好呢?这取决于您要尝试执行的操作,因此,没有一个适用于每个用例的答案。
33. ACID
参见ACID Semantics。拉尔斯·霍夫汉斯(Lars Hofhansl)也已在HBase 中的 ACID上写了一个 Comments。
HBase 和架构设计
可以在 Ian Varley 的硕士论文没有关系:非关系数据库的混合祝福中找到有关各种非 rdbms 数据存储的优缺点建模的很好的介绍。如果您有一点时间了解 HBase 模式建模与 RDBMS 中的建模方法有何不同,那么现在它有点过时了,但是请阅读大量的背景知识。另外,请阅读keyvalue以了解 HBase 如何在内部存储数据,以及schema.casestudies的部分。
Cloud Bigtable 网站设计架构上的文档相关且做得很好,在 HBase 上同样可以从中汲取教训。只需将所有引用的值除以~10 即可获得适用于 HBase 的内容:它表示单个值的大小可能约为 10MB,HBase 可以做类似的事情-如果可能的话,最好减小它-并指出 Cloud Bigtable 中最多 100 个列族,在 HBase 上建模时认为大约 10 个。
另请参见 Robert Yokota 的HBase 应用程序原型(其他 HBasers 完成的工作的更新),以获取对在 HBase 模型之上运行良好的用例的有用分类。
34.模式创建
可以使用 Java API 中的Apache HBase Shell或Admin创建或更新 HBase 模式。
进行 ColumnFamily 修改时,必须禁用表,例如:
Configuration config = HBaseConfiguration.create();
Admin admin = new Admin(conf);
TableName table = TableName.valueOf("myTable");
admin.disableTable(table);
HColumnDescriptor cf1 = ...;
admin.addColumn(table, cf1); // adding new ColumnFamily
HColumnDescriptor cf2 = ...;
admin.modifyColumn(table, cf2); // modifying existing ColumnFamily
admin.enableTable(table);
有关配置 Client 端连接的更多信息,请参见client dependencies。
Note
0.92.x 代码库支持联机模式更改,但是 0.90.x 代码库要求禁用该表。
34.1. 架构更新
当对 Tables 或 ColumnFamilies 进行更改(例如,区域大小,块大小)时,这些更改将在下次进行重大压缩时生效,并且 StoreFiles 将被重写。
有关 StoreFiles 的更多信息,请参见store。
35.表架构的经验法则
有许多不同的数据集,具有不同的访问模式和服务级别期望。因此,这些经验法则只是一个概述。阅读完此列表后,请阅读本章的其余部分以获取更多详细信息。
目标区域的大小在 10 到 50 GB 之间。
争取使单元格的大小不超过 10 MB,如果使用mob,则不超过 50 MB。否则,请考虑将单元数据存储在 HDFS 中,并将指向数据的指针存储在 HBase 中。
典型的架构每个表具有 1 到 3 个列族。 HBase 表不应设计为模仿 RDBMS 表。
对于带有 1 或 2 个列族的表,大约 50-100 个区域是一个不错的数字。请记住,区域是列族的连续段。
列的姓氏应尽可能短。为每个值存储列族名称(忽略前缀编码)。它们不应该像典型的 RDBMS 中那样具有自我说明性和描述性。
如果要存储基于时间的机器数据或日志记录信息,并且行键是基于设备 ID 或服务 ID 加上时间的,那么您可能会遇到一种模式,即较旧的数据区域在一定期限内永远不会进行其他写入。在这种情况下,最终会出现少量活动区域和大量较旧的区域,而这些区域没有新的写入操作。对于这些情况,您可以容忍更多区域,因为资源消耗仅由活动区域驱动。
如果只有一个列族忙于写操作,则只有该列族会占用内存。分配资源时要注意写模式。
RegionServer 大小调整的经验法则
Lars Hofhansl 写了一篇很棒的blog post关于 RegionServer 内存大小。结果是您可能需要比您认为需要的更多的内存。他探讨了区域大小,存储区大小,HDFS 复制因子以及其他要检查的因素的影响。
Note
就个人而言,除非您的工作负载非常繁重,否则我将把每台机器可以由 HBase 专门提供的最大磁盘空间放在 6T 左右。在这种情况下,Java 堆应为 32GB(20G 区域,128M 内存存储,其余为默认值)。
—拉尔斯·霍夫汉斯(Lars Hofhansl)
http://hadoop-hbase.blogspot.com/2013/01/hbase-region-server-memory-sizing.html
36.关于列族的数量
HBase 当前不能很好地处理超过两个或三个列族的任何事物,因此请保持架构中列族的数量少。当前,刷新和压缩是在每个区域的基础上进行的,因此,如果一个列族承载着大量要进行刷新的数据,即使相邻族族携带的数据量很小,也将对其进行刷新。当存在许多色谱柱系列时,冲洗和压实相互作用会导致一堆不必要的 I/O(通过更改冲洗和压实以在每个色谱柱族的基础上解决)。有关压缩的更多信息,请参见Compaction。
如果可以,请尝试使用一个列族。仅在通常以列为范围的数据访问的情况下才引入第二和第三列族。也就是说,您查询一个列族或另一个列族,但通常一次不会同时查询两个。
36.1. ColumnFamilies 的基数
在单个表中存在多个 ColumnFamilies 的地方,请注意基数(即行数)。如果 ColumnFamilyA 具有 100 万行,而 ColumnFamilyB 具有 10 亿行,则 ColumnFamilyA 的数据可能会分布在许多区域(和 RegionServers)中。这使得对 ColumnFamilyA 进行批量扫描的效率较低。
37.行键设计
37.1. Hotspotting
HBase 中的行按行键按字典 Sequences 排序。该设计针对扫描进行了优化,使您可以将相关的行或将一起读取的行彼此靠近存储。但是,设计不当的行键是* hotspotting *的常见来源。当大量 Client 端流量定向到群集的一个节点或仅几个节点时,就会发生热点。此流量可能表示读取,写入或其他操作。流量使负责托管该区域的单台计算机不堪重负,从而导致性能下降并可能导致区域不可用。这也可能对由同一区域服务器托管的其他区域产生不利影响,因为该主机无法满足请求的负载。设计数据访问模式很重要,这样才能充分,均匀地利用群集。
为了防止写入时出现热点,请设计行键,以使确实确实需要在同一区域中的行存在,但从更大的角度看,数据将被写入整个集群的多个区域中,而不是一次写入一个区域中。下面介绍了一些避免热点的常用技术,以及它们的一些优点和缺点。
Salting
从这种意义上讲,加盐与加密无关,而是指将随机数据添加到行密钥的开头。在这种情况下,加盐是指在行键上添加一个随机分配的前缀,以使其与行键的排序方式不同。可能的前缀数量与您要在其上分布数据的区域数量相对应。如果您有一些“热”行键模式在其他分布更均匀的行中反复出现,则盐析会有所帮助。考虑下面的示例,该示例表明加盐可以将写入负载分散到多个 RegionServer 中,并说明对读取的某些负面影响。
例子 11.加盐的例子
假设您具有以下行键列表,并且对表进行了拆分,以使字母表中的每个字母都有一个区域。前缀“ a”是一个区域,前缀“ b”是另一个区域。在此表中,所有以'f'开头的行都在同一区域中。本示例重点介绍具有以下键的行:
foo0001
foo0002
foo0003
foo0004
现在,假设您想将它们分布在四个不同的区域。您决定使用四种不同的盐:a,b,c和d。在这种情况下,这些字母前缀中的每个字母将位于不同的区域。应用盐后,将改为使用以下行键。由于您现在可以写入四个单独的区域,因此从理论上讲,写入时的吞吐量是所有写入相同区域时的吞吐量的四倍。
a-foo0003
b-foo0001
c-foo0004
d-foo0002
然后,如果您添加另一行,则会随机为其分配四个可能的盐值之一,并最终靠近现有行之一。
a-foo0003
b-foo0001
c-foo0003
c-foo0004
d-foo0002
由于此分配是随机的,因此,如果要按字典 Sequences 检索行,则需要做更多的工作。这样,盐化会尝试增加写入的吞吐量,但会在读取期间增加成本。
Hashing
代替随机分配,您可以使用单向* hash *,这将使给定的行始终使用相同的前缀“加盐”,以这种方式将负载分散到 RegionServer 上,但允许在读。使用确定性哈希允许 Client 端重建完整的行键,并使用 Get 操作正常检索该行。
例子 12.散列例子
给定上面盐化示例中的相同情况,您可以改为应用单向哈希,这将导致键foo0003的行始终且可预测地接收a前缀。然后,要检索该行,您将已经知道密钥。您还可以优化事物,例如使某些对密钥始终位于同一区域。
倒转钥匙
防止热点的第三个常见技巧是反转固定宽度或数字行键,以使变化最频繁的部分(最低有效位)在第一位。这有效地使行键随机化,但牺牲了行排序属性。
请参阅 Phoenix 项目的https://communities.intel.com/community/itpeernetwork/datastack/blog/2013/11/10/discussion-on-designing-hbase-tables和关于盐渍表的文章,以及HBASE-11682的 Comments 中的讨论,以获取有关避免热点的更多信息。
37.2. 单调增加行键/时间序列数据
在汤姆·怀特(Tom White)的书Hadoop:Authority 指南(O'Reilly)的 HBase 章节中,有一个优化注意事项,用于注意一种现象,在该现象中,导入过程步调一致,所有 Client 都在一致地敲击桌子的一个区域(因此,单个节点),然后移动到下一个区域,依此类推。随着单调增加行键(即使用时间戳),这种情况将会发生。请参见 IKai Lan 的漫画,内容是为何在类似 BigTable 的数据存储区单调增加值是不好的中单调增加行键会出现问题。可以通过将 Importing 记录随机化为不按排序 Sequences 来缓解单调递增键在单个区域上的堆积,但是通常最好避免使用时间戳或序列(例如 1、2、3)作为行键。
如果确实需要将时间序列数据上传到 HBase,则应学习OpenTSDB作为成功示例。它的页面描述了它在 HBase 中使用的schema。 OpenTSDB 中的密钥格式实际上是[metric_type] [event_timestamp],乍一看与以前关于不使用时间戳作为密钥的建议相矛盾。但是,不同之处在于时间戳不在密钥的* lead *位置,而设计假设是存在数十个或数百个(或更多)不同的度量标准类型。因此,即使连续 Importing 数据流具有多种度量标准类型,Put 也会分布在表中区域的各个点上。
有关某些行键设计示例,请参见schema.casestudies。
37.3. 尝试最小化行和列的大小
在 HBase 中,值总是随其坐标一起传送;当单元格值通过系统时,将始终伴随其行,列名和时间戳。如果行名和列名很大,尤其是与单元格值的大小相比,则可能会遇到一些有趣的情况。马克·利莫特(Marc Limotte)在HBASE-3551尾部描述的情况就是这种情况(推荐!)。其中,保留在 HBase 存储文件(StoreFile (HFile))上以方便随机访问的索引可能最终会占用 HBase 分配的 RAM 的大块,因为单元值坐标很大。上面引用的 Comments 中的 Mark 表示建议增大块大小,以便存储文件索引中的条目以较大的间隔发生,或者修改表模式,从而使行和列名更小。压缩还将使索引更大。请参阅用户邮件列表上的问题 storefileIndexSize线程。
在大多数情况下,效率低下并不重要。不幸的是,这是他们这样做的情况。无论为 ColumnFamilies,属性和行键选择了哪种模式,它们都可以在数据中重复数十亿次。
有关 HBase 内部存储数据的更多信息,请参见keyvalue,以了解为什么这很重要。
37.3.1. 列族
尝试使 ColumnFamily 名称尽可能的小,最好是一个字符(例如,“ d”表示数据/默认值)。
有关 HBase 内部存储数据的更多信息,请参见KeyValue,以了解为什么这很重要。
37.3.2. Attributes
尽管详细的属性名称(例如“ myVeryImportantAttribute”)更易于阅读,但更喜欢将较短的属性名称(例如“ via”)存储在 HBase 中。
有关 HBase 内部存储数据的更多信息,请参见keyvalue,以了解为什么这很重要。
37.3.3. 行键长度
请尽量缩短它们,以使它们仍然可用于所需的数据访问(例如,获取与扫描)。对于数据访问无用的短键并不比具有更好的获取/扫描属性的长键更好。设计行键时需要权衡取舍。
37.3.4. 字节模式
长为 8 个字节。您可以在这八个字节中存储最多 18,446,744,073,709,551,615 个无符号数。如果将此数字存储为字符串-(假定每个字符一个字节),则需要将近 3 倍的字节。
不服气吗?下面是一些示例代码,您可以自己运行。
// long
//
long l = 1234567890L;
byte[] lb = Bytes.toBytes(l);
System.out.println("long bytes length: " + lb.length); // returns 8
String s = String.valueOf(l);
byte[] sb = Bytes.toBytes(s);
System.out.println("long as string length: " + sb.length); // returns 10
// hash
//
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] digest = md.digest(Bytes.toBytes(s));
System.out.println("md5 digest bytes length: " + digest.length); // returns 16
String sDigest = new String(digest);
byte[] sbDigest = Bytes.toBytes(sDigest);
System.out.println("md5 digest as string length: " + sbDigest.length); // returns 26
不幸的是,使用类型的二进制表示形式会使您的数据难以在代码外部读取。例如,这是在增加值时在 Shell 中看到的内容:
hbase(main):001:0> incr 't', 'r', 'f:q', 1
COUNTER VALUE = 1
hbase(main):002:0> get 't', 'r'
COLUMN CELL
f:q timestamp=1369163040570, value=\x00\x00\x00\x00\x00\x00\x00\x01
1 row(s) in 0.0310 seconds
Shell 程序会尽力打印字符串,在这种情况下,它决定只打印十六进制。区域名称中的行键也会发生同样的情况。如果您知道要存储的内容,可以这样做,但是如果可以将任意数据放在相同的单元格中,则可能也无法读取。这是主要的权衡。
37.4. 反向时间戳
Reverse Scan API
HBASE-4811实现了一个 API 来反向扫描表或表中的范围,从而减少了优化架构以进行正向或反向扫描的需要。 HBase 0.98 和更高版本中提供了此功能。有关更多信息,请参见Scan.setReversed()。
数据库处理中的一个常见问题是快速找到值的最新版本。使用反向时间戳作为键的一部分的技术可以在此问题的特殊情况下极大地帮助您。这项技术还可以在汤姆·怀特(Tom White)的《 Hadoop:Authority 指南》(O'Reilly)的 HBase 一章中找到,该技术包括将(Long.MAX_VALUE - timestamp)附加到任何密钥的末尾,例如[key] [reverse_timestamp]。
通过执行[key]扫描并获取第一条记录,可以找到表中[key]的最新值。由于 HBase 键是按排序 Sequences 排列的,因此此键在[key]的任何较旧的行键之前进行排序,因此是第一个。
此技术将代替版本数来使用,而版本数的目的是“永久”(或很长时间)保留所有版本,同时使用相同的 Scan 技术快速获取对任何其他版本的访问权限。
37.5. Rowkey 和 ColumnFamilies
行键的作用域为 ColumnFamilies。因此,相同的行键可以存在于表中的每个 ColumnFamily 中而不会发生冲突。
37.6. 行键的不变性
行键不能更改。可以在表中“更改”它们的唯一方法是删除行然后将其重新插入。这是 HBase dist-list 上的一个相当普遍的问题,因此第一次(和/或在插入大量数据之前)正确获取行键是值得的。
37.7. RowKey 与区域分割之间的关系
如果您预先分割了表格,那么了解行键如何在区域边界上分布至关重要。作为说明为什么如此重要的示例,请考虑使用可显示的十六进制字符作为键的开头位置的示例(例如,“ 0000000000000000”到“ ffffffffffffffff”)。通过Bytes.split运行这些关键范围(这是在Admin.createTable(byte[] startKey, byte[] endKey, numRegions)中为 10 个区域创建区域时使用的分割策略,将产生以下分割…
48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 // 0
54 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 // 6
61 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -68 // =
68 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -126 // D
75 75 75 75 75 75 75 75 75 75 75 75 75 75 75 72 // K
82 18 18 18 18 18 18 18 18 18 18 18 18 18 18 14 // R
88 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -44 // X
95 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -102 // _
102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 // f
(请注意:引导字节在右侧列为 Comments.)鉴于第一个拆分为'0',最后一个拆分为'f',一切都很好,对吗?没那么快。
问题在于所有数据都将在前两个区域和最后一个区域堆积,从而造成“块状”(可能还有“热”)区域问题。要了解原因,请参考ASCII Table。 “ 0”是字节 48,而“ f”是字节 102,但是字节值(字节 58 至 96)之间有巨大的差距,永远不会出现在此键空间中,因为唯一的值是[0-9]和[af]。因此,中间区域将永远不会被使用。为了使该示例键空间能够进行预拆分,需要自定义拆分定义(即,不依赖于内置拆分方法)。
第 1 课:预分割表通常是最佳实践,但是您需要以可在键空间中访问所有区域的方式预分割表。尽管此示例演示了十六进制键空间的问题,但* any *键空间也可能发生相同的问题。了解您的数据。
第 2 课:虽然通常不建议这样做,但是只要在键空间中可访问所有创建的区域,使用十六进制键(更常见的是可显示的数据)仍可与预分割表一起使用。
总结这个例子,下面是一个例子,说明如何为十六进制键预先创建适当的分割:
public static boolean createTable(Admin admin, HTableDescriptor table, byte[][] splits)
throws IOException {
try {
admin.createTable( table, splits );
return true;
} catch (TableExistsException e) {
logger.info("table " + table.getNameAsString() + " already exists");
// the table already exists...
return false;
}
}
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {
byte[][] splits = new byte[numRegions-1][];
BigInteger lowestKey = new BigInteger(startKey, 16);
BigInteger highestKey = new BigInteger(endKey, 16);
BigInteger range = highestKey.subtract(lowestKey);
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);
for(int i=0; i < numRegions-1;i++) {
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
byte[] b = String.format("%016x", key).getBytes();
splits[i] = b;
}
return splits;
}
38.版本号
38.1. 最大版本数
通过HColumnDescriptor为每个列族配置了要存储的最大行版本数。最高版本的默认值为 1.这是一个重要的参数,因为如Data Model部分所述,HBase 不会*覆盖行值,而是按时间(和限定符)每行存储不同的值。大型压缩期间将删除多余的版本。取决于应用程序的需要,最大版本的数量可能需要增加或减少。
不建议将最大版本数设置为过高的级别(例如,数百个或更多),除非您非常喜欢那些旧值,因为这会大大增加 StoreFile 的大小。
38.2. 最低版本数
与最大行版本数类似,通过HColumnDescriptor为每个列族配置要保留的最小行版本数。最低版本的默认值为 0,这表示该功能已禁用。最小行版本数参数与生存时间参数一起使用,并且可以与行版本数参数结合使用,以进行诸如“保留最后 T 分钟的数据,最多 N 个版本,但至少应保持个版本在*左右(其中 M 是最小行版本数的值,M <N)。仅当为列族启用生存时间时才应设置此参数,并且该参数必须小于行版本的数目。
39.支持的数据类型
HBase 通过Put和Result支持“ bytes-in/bytes-out”接口,因此任何可以转换为字节数组的内容都可以存储为值。Importing 可以是字符串,数字,复杂对象甚至是图像,只要它们可以呈现为字节即可。
值的大小有实际限制(例如,在 HBase 中存储 10-50MB 对象可能会要求太多);在邮件列表中搜索有关此主题的对话。 HBase 中的所有行均符合Data Model,其中包括版本控制。设计时要考虑到这一点,以及 ColumnFamily 的块大小。
39.1. Counters
需要特别提及的一种受支持的数据类型是“计数器”(即进行原子原子递增的能力)。参见Table中的Increment。
计数器同步是在 RegionServer 上完成的,而不是在 Client 端上完成的。
40. Joins
如果您有多个表,请不要忘记将Joins的潜力纳入模式设计。
41.生存时间(TTL)
ColumnFamilies 可以设置以秒为单位的 TTL 长度,并且一旦达到到期时间,HBase 将自动删除行。这适用于行的“所有”版本-甚至是当前版本。在 HBase 中为该行编码的 TTL 时间以 UTC 指定。
较小的压缩会删除仅包含过期行的存储文件。将hbase.store.delete.expired.storefile设置为false将禁用此功能。将最小版本数设置为非 0 也会禁用此功能。
有关更多信息,请参见HColumnDescriptor。
HBase 的最新版本还支持设置每个单元的生存时间。有关更多信息,请参见HBASE-10560。使用 mutation#setTTL 将单元 TTL 作为属性提交给突变请求(追加,增量,放置等)。如果设置了 TTL 属性,它将应用于通过该操作在服务器上更新的所有单元。单元 TTL 处理和 ColumnFamily TTL 之间有两个显着差异:
单元 TTL 以毫秒为单位而不是秒。
单元 TTL 不能将单元的有效寿命延长到 ColumnFamily 级别 TTL 设置之外。
42.保留已删除的单元格
默认情况下,删除标记可 traceback 到时间的开始。因此,即使“获取”或“扫描”操作指示放置删除标记之前的时间范围,Get或Scan操作也不会看到已删除的单元格(行或列)。
ColumnFamilies 可以选择保留删除的单元格。在这种情况下,只要这些操作指定的时间范围在会影响该单元格的任何删除的时间戳记之前结束,仍然可以检索已删除的单元格。即使存在删除操作,也可以进行时间点查询。
删除的单元格仍然受 TTL 的约束,并且删除的单元格永远不会超过“最大版本数”。新的“原始”扫描选项将返回所有已删除的行和删除标记。
使用 HBase Shell 更改KEEP_DELETED_CELLS的值
hbase> hbase> alter 't1′, NAME => 'f1′, KEEP_DELETED_CELLS => true
例子 13.使用 API 改变KEEP_DELETED_CELLS的值
...
HColumnDescriptor.setKeepDeletedCells(true);
...
让我们说明在表上设置KEEP_DELETED_CELLS属性的基本效果。
First, without:
create 'test', {NAME=>'e', VERSIONS=>2147483647}
put 'test', 'r1', 'e:c1', 'value', 10
put 'test', 'r1', 'e:c1', 'value', 12
put 'test', 'r1', 'e:c1', 'value', 14
delete 'test', 'r1', 'e:c1', 11
hbase(main):017:0> scan 'test', {RAW=>true, VERSIONS=>1000}
ROW COLUMN+CELL
r1 column=e:c1, timestamp=14, value=value
r1 column=e:c1, timestamp=12, value=value
r1 column=e:c1, timestamp=11, type=DeleteColumn
r1 column=e:c1, timestamp=10, value=value
1 row(s) in 0.0120 seconds
hbase(main):018:0> flush 'test'
0 row(s) in 0.0350 seconds
hbase(main):019:0> scan 'test', {RAW=>true, VERSIONS=>1000}
ROW COLUMN+CELL
r1 column=e:c1, timestamp=14, value=value
r1 column=e:c1, timestamp=12, value=value
r1 column=e:c1, timestamp=11, type=DeleteColumn
1 row(s) in 0.0120 seconds
hbase(main):020:0> major_compact 'test'
0 row(s) in 0.0260 seconds
hbase(main):021:0> scan 'test', {RAW=>true, VERSIONS=>1000}
ROW COLUMN+CELL
r1 column=e:c1, timestamp=14, value=value
r1 column=e:c1, timestamp=12, value=value
1 row(s) in 0.0120 seconds
请注意如何释放删除单元格。
现在,让我们只在表上设置KEEP_DELETED_CELLS来运行相同的测试(您可以执行表或每个列家庭):
hbase(main):005:0> create 'test', {NAME=>'e', VERSIONS=>2147483647, KEEP_DELETED_CELLS => true}
0 row(s) in 0.2160 seconds
=> Hbase::Table - test
hbase(main):006:0> put 'test', 'r1', 'e:c1', 'value', 10
0 row(s) in 0.1070 seconds
hbase(main):007:0> put 'test', 'r1', 'e:c1', 'value', 12
0 row(s) in 0.0140 seconds
hbase(main):008:0> put 'test', 'r1', 'e:c1', 'value', 14
0 row(s) in 0.0160 seconds
hbase(main):009:0> delete 'test', 'r1', 'e:c1', 11
0 row(s) in 0.0290 seconds
hbase(main):010:0> scan 'test', {RAW=>true, VERSIONS=>1000}
ROW COLUMN+CELL
r1 column=e:c1, timestamp=14, value=value
r1 column=e:c1, timestamp=12, value=value
r1 column=e:c1, timestamp=11, type=DeleteColumn
r1 column=e:c1, timestamp=10, value=value
1 row(s) in 0.0550 seconds
hbase(main):011:0> flush 'test'
0 row(s) in 0.2780 seconds
hbase(main):012:0> scan 'test', {RAW=>true, VERSIONS=>1000}
ROW COLUMN+CELL
r1 column=e:c1, timestamp=14, value=value
r1 column=e:c1, timestamp=12, value=value
r1 column=e:c1, timestamp=11, type=DeleteColumn
r1 column=e:c1, timestamp=10, value=value
1 row(s) in 0.0620 seconds
hbase(main):013:0> major_compact 'test'
0 row(s) in 0.0530 seconds
hbase(main):014:0> scan 'test', {RAW=>true, VERSIONS=>1000}
ROW COLUMN+CELL
r1 column=e:c1, timestamp=14, value=value
r1 column=e:c1, timestamp=12, value=value
r1 column=e:c1, timestamp=11, type=DeleteColumn
r1 column=e:c1, timestamp=10, value=value
1 row(s) in 0.0650 seconds
KEEP_DELETED_CELLS 是避免“仅”删除单元的原因是删除标记时,将其从 HBase 中删除。因此,启用 KEEP_DELETED_CELLS 后,如果您编写的版本超过配置的最大值,或者您拥有 TTL 并且单元格超出配置的超时时间,则删除的单元格将被删除。
43.二级索引和备用查询路径
该部分的标题也可能是“如果我的表行键看起来像* this 但我也想查询我的表 that *怎么办”。 dist 列表上的一个常见示例是其中行键的格式为“ user-timestamp”,但是对于特定时间范围内的用户活动有报告要求。因此,由用户进行选择很容易,因为它处于键的引导位置,而时间却不然。
解决这个问题的最佳方法没有一个答案,因为这取决于……
用户数
数据大小和数据到达率
灵活的报告要求(例如,完全临时的日期选择与预先配置的范围)
所需的查询执行速度(例如,对于某些临时报告,90 秒对于某些人来说可能是合理的,而对于另一些报告则可能太长)
解决方案还受群集大小以及必须在解决方案上投入多少处理能力的影响。常用技术在下面的小节中。这是方法的综合列表,但并不详尽。
二级索引需要额外的群集空间和处理也就不足为奇了。这正是 RDBMS 中发生的情况,因为创建备用索引的操作需要空间和处理周期来进行更新。 RDBMS 产品在这方面更先进,可以立即处理替代索引 Management。但是,HBase 在较大的数据量时可更好地扩展,因此这是一个功能折衷。
实施任何一种方法时,请注意Apache HBase 性能调优。
此外,请在此分发列表线程HBase,邮件#用户-Stargate HBase中查看 David Butler 的回复。
43.1. 筛选查询
根据情况,可能适合使用Client 请求过滤器。在这种情况下,不会创建二级索引。但是,请勿尝试从应用程序(即单线程 Client 端)对大型表进行全面扫描。
43.2. 定期更新二级索引
可以在另一个表中创建二级索引,该表通过 MapReduce 作业定期更新。该作业可以在一天之内执行,但是根据负载策略,它仍可能与主数据表不同步。
有关更多信息,请参见mapreduce.example.readwrite。
43.3. 双写二级索引
另一种策略是在将数据发布到集群时构建辅助索引(例如,写入数据表,写入索引表)。如果在已经存在数据表之后采用这种方法,那么对于具有 MapReduce 作业的辅助索引,将需要进行引导(请参见secondary.indexes.periodic)。
43.4. 汇总表
在时间范围很广的地方(例如,长达一年的报告),并且数据量很大,因此汇总表是一种常见的方法。这些将通过 MapReduce 作业生成到另一个表中。
有关更多信息,请参见mapreduce.example.summary。
43.5. 协处理器二级索引
协处理器的行为类似于 RDBMS 触发器。这些以 0.92 添加。有关更多信息,请参见coprocessors
44. Constraints
HBase 当前在传统(SQL)数据库中支持“约束”。约束的建议用法是针对表中的属性执行业务规则(例如,确保值在 1 到 10 的范围内)。约束也可以用于强制执行引用完整性,但是强烈建议不要这样做,因为这会大大降低启用完整性检查的表的写吞吐量。从 0.94 版开始,可以在Constraint上找到有关使用约束的大量文档。
45.模式设计案例研究
下面将描述一些使用 HBase 的典型数据摄取用例,以及如何进行行键设计和构造。注意:这仅是潜在方法的说明,而不是详尽的清单。了解您的数据,并了解您的处理要求。
强烈建议您先阅读HBase 和架构设计的其余部分,然后再阅读这些案例研究。
描述了以下案例研究:
日志数据/时间序列数据
在类固醇上记录数据/时间序列
Customer/Order
高/宽/中方案设计
List Data
45.1. 案例研究-日志数据和时间序列数据
假设正在收集以下数据元素。
Hostname
Timestamp
Log event
Value/message
我们可以将它们存储在名为 LOG_DATA 的 HBase 表中,但是行键是什么?从这些属性中,行键将是主机名,时间戳和日志事件的某种组合-但是具体是什么?
45.1.1. Rowkey 引导位置的时间戳
行键[timestamp][hostname][log-event]受到单调增加行键/时间序列数据中描述的单调增加的行键问题的困扰。
通过在时间戳上执行 mod 操作,在 dist 列表中经常提到另一种关于“存储桶”时间戳的模式。如果面向时间的扫描很重要,那么这可能是一种有用的方法。必须注意存储桶的数量,因为这将需要相同数量的扫描才能返回结果。
long bucket = timestamp % numBuckets;
to construct:
[bucket][timestamp][hostname][log-event]
如上所述,要为特定时间范围选择数据,将需要为每个存储桶执行一次扫描。例如,100 个存储桶将在键空间中提供广泛的分布,但是需要 100 次扫描才能获取单个时间戳的数据,因此需要权衡取舍。
45.1.2. 主持人在行键领导位置
如果有大量主机在键空间上分布写入和读取,则行键[hostname][log-event][timestamp]是候选键。如果按主机名扫描是优先级,则此方法将很有用。
45.1.3. 时间戳还是反向时间戳?
如果最重要的访问路径是提取最新事件,则将时间戳存储为反向时间戳(例如timestamp = Long.MAX_VALUE – timestamp)将创建能够对[hostname][log-event]进行扫描以获得最新捕获的事件的属性。
两种方法都没有错,仅取决于最适合这种情况的方法。
Reverse Scan API
HBASE-4811实现了一个 API 来反向扫描表或表中的范围,从而减少了优化架构以进行正向或反向扫描的需要。 HBase 0.98 和更高版本中提供了此功能。有关更多信息,请参见Scan.setReversed()。
45.1.4. 可变长度还是固定长度的行键?
重要的是要记住,行键标记在 HBase 的每一列上。如果主机名是a并且事件类型是e1,则结果行键将非常小。但是,如果提取的主机名是myserver1.mycompany.com且事件类型是com.package1.subpackage2.subsubpackage3.ImportantService怎么办?
在行键中使用某些替换可能很有意义。至少有两种方法:散列和数字。在“行键引导位置的主机名”示例中,它可能看起来像这样:
带有哈希的复合行键:
[主机名的 MD5 哈希] = 16 个字节
[事件类型的 MD5 哈希] = 16 个字节
[时间戳] = 8 个字节
带有数字替换的复合行键:
对于这种方法,除了 LOG_DATA 外,还需要另一个查询表,称为 LOG_TYPES。 LOG_TYPES 的行键为:
[type](例如,指示主机名与事件类型的字节)[bytes]可变长度字节,用于原始主机名或事件类型。
此行键的列可能是带有指定数字的长整数,可以使用HBase counter获得
因此,生成的复合行键将为:
[用主机名替换长] = 8 个字节
[事件类型的长整数替换] = 8 个字节
[时间戳] = 8 个字节
在散列或数字替换方法中,主机名和事件类型的原始值可以存储为列。
45.2. 案例研究-类固醇上的日志数据和时间序列数据
这实际上是 OpenTSDB 方法。 OpenTSDB 所做的是重写数据,并在特定时间段内将行打包到列中。有关详细说明,请参见:HBaseCon2012 中的http://opentsdb.net/schema.html和OpenTSDB 的经验教训。
但这就是一般概念的工作方式:例如,以这种方式摄取数据……
[hostname][log-event][timestamp1]
[hostname][log-event][timestamp2]
[hostname][log-event][timestamp3]
每个详细事件都有单独的行键,但可以这样重写…
[hostname][log-event][timerange]
并将上述每个事件转换为以相对于开始时间范围的时间偏移(例如每 5 分钟)存储的列。这显然是一种非常先进的处理技术,但是 HBase 使这成为可能。
45.3. 案例研究-Client/订单
假设使用 HBase 存储 Client 和订单信息。提取了两种核心记录类型:Client 记录类型和订单记录类型。
Client 记录类型将包括您通常期望的所有内容:
Customer number
Customer name
地址(例如,城市,State,邮政编码)
电话 Numbers 等
订单记录类型将包括以下内容:
Customer number
Order number
Sales date
一系列嵌套对象,用于运输位置和行项目(有关详细信息,请参见订单对象设计)
假设 Client 编号和销售订单的组合唯一地标识了一个订单,那么这两个属性将组成行键,特别是一个组合键,例如:
[customer number][order number]
用于 ORDER 表。但是,还有更多的设计决策:* raw *值是行键的最佳选择吗?
日志数据用例中的相同设计问题在这里也面临着我们。Client 编号的键空间是什么,格式是什么(例如,数字?字母数字?),因为在 HBase 中使用固定长度的键以及可以在键空间中支持合理分布的键是有利的,类似选项出现:
带有哈希的复合行键:
[Client 编号的 MD5] = 16 字节
[订单号的 MD5] = 16 个字节
复合数字/哈希组合行键:
[用 Client 编号代替长] = 8 个字节
[订单号的 MD5] = 16 个字节
45.3.1. 单桌?多张桌子?
传统的设计方法将为 Client 和销售提供单独的表格。另一种选择是将多种记录类型打包到一个表中(例如 CUSTOMER)。
Client 记录类型行键:
[customer-id]
[type] =表示 Client 记录类型为“ 1”的类型
订单记录类型行键:
[customer-id]
[类型] =指示订单记录类型为“ 2”的类型
[order]
这种特殊的 Client 方法的优点是,可以通过 ClientID 来组织许多不同的记录类型(例如,一次扫描可以为您提供有关该 Client 的所有信息)。缺点是扫描特定的记录类型并不容易。
45.3.2. 订单对象设计
现在我们需要解决如何对 Order 对象建模。假定类结构如下:
Order
- (一个订单可以有多个发货地点
LineItem
- (ShippingLocation 可以有多个 LineItem
存储此数据有多种选择。
Completely Normalized
使用这种方法,将为 ORDER,SHIPPING_LOCATION 和 LINE_ITEM 提供单独的表。
上面描述了 ORDER 表的行键:schema.casestudies.custorder
SHIPPING_LOCATION 的复合行键如下所示:
[order-rowkey][shipping location number](例如,第一地点,第二地点等)
LINE_ITEM 表的复合行键如下所示:
[order-rowkey][shipping location number](例如,第一地点,第二地点等)[line item number](例如,第一个订单项,第二个订单项等)
这种标准化的模型很可能是 RDBMS 的方法,但这并不是 HBase 的唯一选择。这种方法的缺点是要检索有关任何订单的信息,您将需要:
进入订单的 ORDER 表
在 SHIPPING_LOCATION 表上扫描该订单以获取 ShippingLocation 实例
在 LINE_ITEM 上扫描每个送货地点
当然,这是 RDBMS 会在后台进行的操作,但是由于 HBase 中没有联接,因此您只需要了解这一事实。
具有记录类型的单个表
使用这种方法,将存在一个单个表 ORDER,其中包含
订单行键如上所述:schema.casestudies.custorder
[order-rowkey][ORDER record type]
ShippingLocation 复合行键将如下所示:
[order-rowkey][SHIPPING record type][shipping location number](例如,第一地点,第二地点等)
LineItem 复合行键将如下所示:
[order-rowkey][LINE record type][shipping location number](例如,第一地点,第二地点等)[line item number](例如,第一个订单项,第二个订单项等)
Denormalized
“具有记录类型的单表”方法的一种变体是对某些对象层次结构进行非规范化和扁平化,例如将 ShippingLocation 属性折叠到每个 LineItem 实例上。
LineItem 复合行键将如下所示:
[order-rowkey][LINE record type][line item number](例如,第一个订单项,第二个订单项等,请务必注意整个订单中的商品是唯一的)
而 LineItem 列将如下所示:
itemNumber
quantity
price
shipToLine1(从 ShippingLocation 规范化)
shipToLine2(从 ShippingLocation 规范化)
shipToCity(从 ShippingLocation 规范化)
shipToState(从 ShippingLocation 规范化)
shipToZip(从 ShippingLocation 规范化)
这种方法的优点是对象层次结构不太复杂,但是缺点之一是万一这些信息发生更改,更新就会变得更加复杂。
Object BLOB
通过这种方法,整个 Order 对象图以一种或另一种方式被视为 BLOB。例如,上面描述了 ORDER 表的行键:schema.casestudies.custorder,并且一个名为“ order”的列将包含一个可以反序列化的对象,其中包含一个容器 Order,ShippingLocations 和 LineItems。
这里有许多选项:JSON,XML,Java 序列化,Avro,Hadoop 可写文件等。它们都是相同方法的变体:将对象图编码为字节数组。如果对象模型发生更改,以确保仍可以从 HBase 中读出较旧的持久化结构,则应谨慎使用此方法以确保向后兼容。
专业人士能够以最少的 I/OManagement 复杂的对象图(例如,在此示例中为单个“每个订单获取 HBase Get”),但缺点包括上述关于序列化向后兼容性,序列化的语言依赖性(例如 Java 序列化)的警告仅适用于 JavaClient 端),必须对整个对象进行反序列化以在 BLOB 中获取任何信息这一事实,以及使诸如 Hive 之类的框架无法与此类自定义对象一起使用的困难。
45.4. 案例研究-“高/宽/中”方案设计精简
本节将描述出现在 dist 列表中的其他架构设计问题,特别是有关高大桌子的问题。这些是一般准则,而不是法律-每个应用程序都必须考虑自己的需求。
45.4.1. 行与版本
一个常见的问题是,是应该使用行还是 HBase 的内置版本控制。上下文通常是要保留行的“很多”版本的位置(例如,该位置明显高于 HBase 默认的 1 个最大版本)。行方法将需要在行键的某些部分中存储时间戳,以便它们不会在每次连续更新时被覆盖。
首选项:行(通常而言)。
45.4.2. 行与列
另一个常见的问题是,人们应该选择行还是列。上下文通常在宽表的极端情况下使用,例如具有 1 行具有 1 百万个属性,或具有 1 百万行具有 1 个每列的属性。
首选项:行(通常而言)。需要明确的是,该准则是在非常广泛的情况下使用的,而不是在需要存储几十或数百列的标准用例中使用的。但是,这两个选项之间还有一条中间路径,那就是“行作为列”。
45.4.3. 行作为列
行与列之间的中间路径是将某些行的数据打包成独立的行。 OpenTSDB 是这种情况的最佳示例,其中单行代表定义的时间范围,然后将离散事件视为列。这种方法通常更复杂,并且可能需要重新写入数据的额外复杂性,但是具有 I/O 高效的优势。有关此方法的概述,请参见schema.casestudies.log-steroids。
45.5. 案例研究-列表数据
以下是来自用户 dist-list 的一个相当常见的问题的交流:如何在 Apache HBase 中处理每个用户的列表数据。
- 题 **** *
我们正在研究如何在 HBase 中存储大量(每个用户)列表数据,并且试图找出哪种访问模式最有意义。一种选择是将大多数数据存储在一个密钥中,因此我们可以得到以下内容:
<FixedWidthUserName><FixedWidthValueId1>:"" (no value)
<FixedWidthUserName><FixedWidthValueId2>:"" (no value)
<FixedWidthUserName><FixedWidthValueId3>:"" (no value)
我们拥有的另一个选择是完全使用以下方法:
<FixedWidthUserName><FixedWidthPageNum0>:<FixedWidthLength><FixedIdNextPageNum><ValueId1><ValueId2><ValueId3>...
<FixedWidthUserName><FixedWidthPageNum1>:<FixedWidthLength><FixedIdNextPageNum><ValueId1><ValueId2><ValueId3>...
每行将包含多个值。因此,在一种情况下,读取前三十个值将是:
scan { STARTROW => 'FixedWidthUsername' LIMIT => 30}
在第二种情况下
get 'FixedWidthUserName\x00\x00\x00\x00'
通常的使用模式是只读取这些列表的前 30 个值,而很少的访问量会更深入地读取列表。有些用户在这些列表中的总价值为 30 英镑,而有些用户则有数百万(即幂律分布)
单值格式似乎会在 HBase 上占用更多空间,但会提供一些改进的检索/分页灵 Active。与获取扫描分页相比,通过获取分页是否会有明显的性能优势?
我最初的理解是,如果我们的分页大小未知(并且缓存设置适当),则扫描应该更快,但是如果我们始终需要相同的页面大小,则扫描应该更快。我最终听到不同的人告诉我关于性能的相反的事情。我假设页面大小相对一致,因此对于大多数用例,我们可以保证在固定页面长度的情况下只需要一页数据。我还要假设我们不经常进行更新,但是可能在这些列表的中间插入了插入(这意味着我们需要更新所有后续行)。
感谢您的帮助/建议/后续问题。
- 回答 **** *
如果我理解正确,那么您最终将尝试以“用户,valueid,值”的形式存储三 Tuples,对吗?例如:
"user123, firstname, Paul",
"user234, lastname, Smith"
(但是用户名是固定宽度,而 valueid 是固定宽度)。
并且,您的访问模式如下:“对于用户 X,列出接下来的 30 个值,以 valueid Y 开头”。那正确吗?这些值应该按 valueid 排序返回吗?
tl; dr 版本是每个用户值可能只包含一行,并且除非您确实确定需要,否则不要自行构建复杂的行内分页方案。
您的两个选择反映了人们在设计 HBase 模式时遇到的一个常见问题:我应该“高”还是“宽”?您的第一个架构是“高层”:每一行代表一个用户一个值,因此表中有很多行针对每个用户。行键是用户 valueid,并且(大概)将有一个单列限定符,表示“值”。如果您要按行键按排序 Sequences 扫描行(这是我上面的问题,关于这些 ID 是否正确排序),这很好。您可以从任何用户 valueid 开始扫描,然后读取下一个 30,然后完成扫描。您要放弃的是能够为一个用户在所有行周围拥有事务保证,但这听起来并不是您需要的。通常建议以这种方式进行操作(请参见https://hbase.apache.org/book.html#schema.smackdown)。
第二个选项是“宽”:使用不同的限定词(其中的限定词是 valueid)将一堆值存储在一行中。这样做的简单方法是仅将一个用户的所有值存储在一行中。我猜您跳到了“分页”版本,因为您假设在单行中存储数百万列会降低性能,这可能是正确的,也可能不是正确的。只要您不打算在单个请求中执行太多操作,或者执行诸如扫描并返回该行中所有单元格之类的操作,从根本上讲,这应该不会更糟。Client 端具有允许您获取特定列列的方法。
请注意,两种情况都不会比另一种情况占用更多的磁盘空间。您只是将标识信息的一部分“左移”(左移至选项 1 中的行键)或向右(右移至选项 2 中的列限定符)。在幕后,每个键/值仍然存储整个行键和列族名称。 (如果这有点令人困惑,请花一个小时,观看 Lars George 的精彩视频,了解理解 HBase 模式设计:http://www.youtube.com/watch?v=_HLoH_PgrLk)。
如您所注意到的,手动分页版本具有更多的复杂性,例如必须跟踪每个页面中有多少东西,如果插入新值则需要重新排序等等。这似乎要复杂得多。在极高的吞吐量下,它可能具有一些轻微的速度优势(或劣势!),要 true 知道这一点,唯一的方法就是尝试一下。如果您没有时间同时构建和比较它,我的建议是从最简单的选项开始(每个用户值一行)。从简单开始并进行迭代! :)
46.操作和性能配置选项
46.1. 调整 HBase 服务器 RPC 处理
将
hbase.regionserver.handler.count(在hbase-site.xml中)设置为核心 x 主轴以实现并发。(可选)将呼叫队列分为不同的读取和写入队列以区分服务。参数
hbase.ipc.server.callqueue.handler.factor指定呼叫队列的数量:0表示一个共享队列1表示每个处理程序一个队列。0和1之间的值与处理程序的数量成比例地分配队列的数量。例如,值.5在每两个处理程序之间共享一个队列。
使用
hbase.ipc.server.callqueue.read.ratio(0.98 中的hbase.ipc.server.callqueue.read.share)将呼叫队列分为读写队列:0.5表示将有相同数量的读写队列< 0.5多于读> 0.5写多于读
设置
hbase.ipc.server.callqueue.scan.ratio(HBase 1.0)将读取调用队列分为小读和长读队列:0 .5 表示短读和长读队列的数量相同
< 0.5以便阅读更多> 0.5以便阅读更多
46.2. 禁用 Nagle for RPC
禁用 Nagle 的算法。延迟的 ACK 可能会使 RPC 往返时间增加约 200 毫秒。设置以下参数:
在 Hadoop 的
core-site.xml中:ipc.server.tcpnodelay = trueipc.client.tcpnodelay = true
在 HBase 的
hbase-site.xml中:hbase.ipc.client.tcpnodelay = truehbase.ipc.server.tcpnodelay = true
46.3. 限制服务器故障影响
尽快检测到区域服务器故障。设置以下参数:
在
hbase-site.xml中,将zookeeper.session.timeout设置为 30 秒或更短以进行绑定故障检测(20-30 秒是一个好的开始)。注意:Zookeeper 的
sessionTimeout被限制为tickTime的 2 倍至 20 倍(ZooKeeper 使用的基本时间单位为毫秒,默认值为 2000ms.用于执行心跳,并且最小会话超时将是 tickTime 的两倍) 。检测并避免不健康或出现故障的 HDFS 数据节点:在
hdfs-site.xml和hbase-site.xml中,设置以下参数:dfs.namenode.avoid.read.stale.datanode = truedfs.namenode.avoid.write.stale.datanode = true
46.4. 在服务器端进行优化以降低延迟
当 RegionServer 通过利用 HDFS 的短路本地读工具从 HDFS 读取数据时,跳过网络上的本地块。请注意如何在连接的数据节点和 dfsclient 端(即在 RegionServer 上)都必须完成设置,以及两端如何都需要加载 hadoop 本机.so库。配置完 hadoop 设置后,将* dfs.client.read.shortcircuit 设置为 true ,并配置了数据节点和 dfsclient 共享并重新启动的 dfs.domain.socket.path *路径,然后配置 regionserver/dfsclient 端。
在
hbase-site.xml中,设置以下参数:dfs.client.read.shortcircuit = truedfs.client.read.shortcircuit.skip.checksum = true,因此我们不会将校验和加倍(HBase 自己执行校验和以保存在 i/os 上.有关此内容,请参见hbase.regionserver.checksum.verify。dfs.domain.socket.path以匹配为数据节点设置的内容。dfs.client.read.shortcircuit.buffer.size = 131072避免 OOME 很重要-hbase 有一个默认值(如果未设置),请参见hbase.dfs.client.read.shortcircuit.buffer.size;其默认值为 131072.
确保数据局部性。在
hbase-site.xml中,设置hbase.hstore.min.locality.to.skip.major.compact = 0.7(表示 0.7 <= n <= 1)确保 DataNode 具有足够的处理程序以进行块传输。在
hdfs-site.xml中,设置以下参数:dfs.datanode.max.xcievers >= 8192dfs.datanode.handler.count =锭数
重新启动后检查 RegionServer 日志。如果配置错误,您应该只会看到投诉。否则,短路读取将在后台安静地运行。它没有提供度量标准,因此没有光学手段可以证明它的有效性,但是读取延迟应该显示出明显的改善,尤其是在良好的数据局部性,大量随机读取以及数据集大于可用缓存的情况下。
您可能会使用的其他高级配置,包括dfs.client.read.shortcircuit.streams.cache.size和dfs.client.socketcache.capacity,尤其是在日志中抱怨短路功能时。这些选项的文档很少。您必须阅读源代码。
有关短路读取的更多信息,请参见 Colin 推出的旧博客改进的本地本地读取如何为 Hadoop 带来更好的性能和安全性。 HDFS-347问题还引起了有趣的阅读,显示了 HDFS 社区的最佳状态(有一些 Comment)。
46.5. JVM 调整
46.5.1. 调整 JVM GC 以降低收集延迟
使用 CMS 收集器:
-XX:+UseConcMarkSweepGC保持伊甸园空间尽可能小,以最小化平均收集时间。例:
-XX:CMSInitiatingOccupancyFraction=70
针对低收集延迟而不是吞吐量进行优化:
-Xmn512m并行收集伊甸园:
-XX:+UseParNewGC避免在压力下收集:
-XX:+UseCMSInitiatingOccupancyOnly限制每个请求的扫描器结果大小,使所有内容都适合幸存者空间,但不保有任期。在
hbase-site.xml中,将hbase.client.scanner.max.result.size设置为伊甸园空间的 1/8(使用-Xmn512m这是~51MB)设置小于幸存者空间
max.result.sizexhandler.count
46.5.2. os 级调整
- 关闭透明大页面(THP):
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
设置
vm.swappiness = 0将
vm.min_free_kbytes设置为至少 1GB(较大的内存系统为 8GB)禁用
vm.zone_reclaim_mode = 0的 NUMA 区域回收
47.特殊情况
47.1. 对于快速失败胜于 await 的应用程序
在 Client 端的
hbase-site.xml中,设置以下参数:设置
hbase.client.pause = 1000设置
hbase.client.retries.number = 3如果您想越过拆分和区域移动,请大幅提高
hbase.client.retries.number(> = 20)设置 RecoverableZookeeper 重试次数:
zookeeper.recovery.retry = 1(不重试)
在服务器端的
hbase-site.xml中,设置 Zookeeper 会话超时以检测服务器故障:zookeeper.session.timeout⇐30 秒(20-30 很好)。
47.2. 对于可以容忍一些过时信息的应用程序
HBase 时间轴一致性(HBASE-10070) 启用只读副本后,区域(副本)的只读副本将分布在群集上。一个 RegionServer 服务于默认副本或主副本,这是唯一可以服务于写操作的副本。其他 RegionServer 服务于辅助副本,跟在主要 RegionServer 之后,并且仅查看已提交的更新。辅助副本是只读的,但可以在主副本进行故障转移时立即为读取提供服务,从而将读取可用性的时间从几秒钟缩短到了几毫秒。自 4.4.0 起,Phoenix 支持时间轴一致性。
部署 HBase 1.0.0 或更高版本。
在服务器端启用时间轴一致的副本。
使用以下方法之一设置时间轴一致性:
使用
ALTER SESSION SET CONSISTENCY = 'TIMELINE'- 在 JDBC 连接字符串中将连接属性
Consistency设置为timeline
- 在 JDBC 连接字符串中将连接属性
47.3. 更多信息
有关操作和性能模式设计选项的更多信息,请参见“性能”部分perf.schema,例如布隆过滤器,表配置的区域大小,压缩和块大小。
HBase 和 MapReduce
Apache MapReduce 是用于分析大量数据的软件框架。由Apache Hadoop提供。 MapReduce 本身不在本文档的范围之内。开始使用 MapReduce 的好地方是https://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html。 MapReduce 版本 2(MR2)现在是YARN的一部分。
本章讨论在 HBase 中对数据使用 MapReduce 时需要采取的特定配置步骤。此外,它还讨论了 HBase 和 MapReduce 作业之间的其他交互作用和问题。最后,它讨论了 MapReduce 的Cascading和alternative API。
mapred and mapreduce
与 MapReduce 本身一样,HBase 中有两个 mapreduce 软件包:* org.apache.hadoop.hbase.mapred 和 org.apache.hadoop.hbase.mapreduce 。前者执行旧式 API,后者执行新模式。后者具有更多功能,尽管您通常可以在较早的软件包中找到等效的软件包。选择 MapReduce 部署随附的软件包。如有疑问或从头开始,请选择 org.apache.hadoop.hbase.mapreduce 。在下面的 Comments 中,我们指的是 o.a.h.h.mapreduce ,但如果使用的是 o.a.h.h.mapred *,则将其替换。
48. HBase,MapReduce 和 CLASSPATH
默认情况下,部署到 MapReduce 群集的 MapReduce 作业无法访问$HBASE_CONF_DIR下的 HBase 配置或 HBase 类。
要为 MapReduce 作业提供所需的访问权限,可以将* hbase-site.xml 添加到_ $ HADOOP_HOME/conf 并将 HBase jar 添加到 $ HADOOP_HOME/lib 目录。然后,您需要在整个集群中复制这些更改。或者,您可以编辑 $ HADOOP_HOME/conf/hadoop-env.sh *并将 hbase 依赖项添加到HADOOP_CLASSPATH变量中。不推荐使用这两种方法,因为这会使用 HBase 引用污染您的 Hadoop 安装。它还要求您重新启动 Hadoop 群集,然后 Hadoop 才能使用 HBase 数据。
推荐的方法是让 HBase 添加其依赖项 jar 并使用HADOOP_CLASSPATH或-libjars。
从 HBase 0.90.x开始,HBase 将其依赖项 JAR 添加到作业配置本身。依赖项仅需要在本地CLASSPATH上可用,然后从这里将它们拾取并 Binding 到部署到 MapReduce 集群的胖作业 jar 中。一个基本技巧就是将完整的 hbaseClasspath(包括所有 hbase 和从属 jar 以及配置)传递给 mapreduce 作业运行器,让 hbaseUtil 从完整的 Classpath 中挑选出将它们添加到 MapReduce 作业配置中所需的内容(请参阅源代码)。 TableMapReduceUtil#addDependencyJars(org.apache.hadoop.mapreduce.Job))。
以下示例对名为usertable的表运行 Binding 的 HBase RowCounter MapReduce 作业。它将_base 设置为HADOOP_CLASSPATH,以便 hbase 需要在 MapReduce 上下文中运行(包括 hbase-site.xml 等配置文件)。确保为您的系统使用正确版本的 HBase JAR。用本地 hbase 安装版本替换下面命令行中的 VERSION 字符串。反引号(````符号)使 Shell 执行子命令,将hbase classpath的输出设置为HADOOP_CLASSPATH。本示例假定您使用兼容 BASH 的 Shell。
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-VERSION.jar \
org.apache.hadoop.hbase.mapreduce.RowCounter usertable
上面的命令将针对 hadoop 配置所指向的集群上的本地配置所指向的 hbase 集群启动行计数 mapreduce 作业。
hbase-mapreduce.jar的主要驱动程序是列出了 hbase 附带的一些基本 mapreduce 任务的驱动程序。例如,假设您的安装是 hbase 2.0.0-SNAPSHOT:
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-2.0.0-SNAPSHOT.jar
An example program must be given as the first argument.
Valid program names are:
CellCounter: Count cells in HBase table.
WALPlayer: Replay WAL files.
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster.
export: Write table data to HDFS.
exportsnapshot: Export the specific snapshot to a given FileSystem.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table.
verifyrep: Compare the data from tables in two different clusters. WARNING: It doesn't work for incrementColumnValues'd cells since the timestamp is changed after being appended to the log.
您可以将上面列出的短名称用于 mapreduce 作业,就像下面重新运行行计数器作业一样(同样,假设您的安装是 hbase 2.0.0-SNAPSHOT):
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-2.0.0-SNAPSHOT.jar \
rowcounter usertable
您可能会发现感兴趣的更具选择性的hbase mapredcp工具输出;它列出了针对 hbase 安装运行基本 mapreduce 作业所需的最少 jar 集合。它不包括配置。如果希望 MapReduce 作业找到目标集群,则可能需要添加它们。一旦开始执行任何实质操作,您可能还必须将指针添加到额外的 jar。只需在运行hbase mapredcp时通过传递系统属性-Dtmpjars来指定其他功能。
对于不打包依赖项或不调用TableMapReduceUtil#addDependencyJars的作业,以下命令结构是必需的:
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf hadoop jar MyApp.jar MyJobMainClass -libjars $(${HBASE_HOME}/bin/hbase mapredcp | tr ':' ',') ...
Note
如果您从其构建目录而不是安装位置运行 HBase,则该示例可能无法正常工作。您可能会看到类似以下的错误:
java.lang.RuntimeException: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper
如果发生这种情况,请尝试按以下方式修改命令,以便它使用构建环境中* target/*目录中的 HBase JAR。
$ HADOOP_CLASSPATH=${HBASE_BUILD_HOME}/hbase-mapreduce/target/hbase-mapreduce-VERSION-SNAPSHOT.jar:`${HBASE_BUILD_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_BUILD_HOME}/hbase-mapreduce/target/hbase-mapreduce-VERSION-SNAPSHOT.jar rowcounter usertable
Notice to MapReduce users of HBase between 0.96.1 and 0.98.4
使用 HBase 的某些 MapReduce 作业无法启动。该症状是与以下内容类似的异常:
Exception in thread "main" java.lang.IllegalAccessError: class
com.google.protobuf.ZeroCopyLiteralByteString cannot access its superclass
com.google.protobuf.LiteralByteString
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:792)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at
org.apache.hadoop.hbase.protobuf.ProtobufUtil.toScan(ProtobufUtil.java:818)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.convertScanToString(TableMapReduceUtil.java:433)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:186)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:147)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:270)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:100)
...
这是由HBASE-9867中引入的优化导致的,该优化无意中引入了 classloader 依赖项。
这会同时使用-libjars选项和“胖罐”(将其运行时依赖项打包在嵌套lib文件夹中的那些文件)影响这两个作业。
为了满足新的类加载器要求,hbase-protocol.jar必须包含在 Hadoop 的 Classpath 中。有关解决 Classpath 错误的最新建议,请参见HBase,MapReduce 和 CLASSPATH。出于历史目的包括以下内容。
这可以在系统范围内解决,方法是通过符号链接在 Hadoop 的 lib 目录中包含对hbase-protocol.jar的引用,或者将 jar 复制到新位置。
也可以在每个作业启动时通过在作业提交时将其包含在HADOOP_CLASSPATH环境变量中来实现。启动打包其依赖项的作业时,以下所有三个作业启动命令均满足此要求:
$ HADOOP_CLASSPATH=/path/to/hbase-protocol.jar:/path/to/hbase/conf hadoop jar MyJob.jar MyJobMainClass
$ HADOOP_CLASSPATH=$(hbase mapredcp):/path/to/hbase/conf hadoop jar MyJob.jar MyJobMainClass
$ HADOOP_CLASSPATH=$(hbase classpath) hadoop jar MyJob.jar MyJobMainClass
对于不打包依赖关系的 jar,以下命令结构是必需的:
$ HADOOP_CLASSPATH=$(hbase mapredcp):/etc/hbase/conf hadoop jar MyApp.jar MyJobMainClass -libjars $(hbase mapredcp | tr ':' ',') ...
有关此问题的进一步讨论,另请参见HBASE-10304。
49. MapReduce 扫描缓存
TableMapReduceUtil 现在恢复在传入的 Scan 对象上设置扫描程序缓存(将结果返回给 Client 端之前缓存的行数)的选项。由于 HBase 0.95(HBASE-11558)中的错误,该功能丢失了。对于 HBase 0.98.5 和 0.96.3 是固定的。选择扫描仪缓存的优先 Sequences 如下:
在扫描对象上设置的缓存设置。
通过配置选项
hbase.client.scanner.caching指定的缓存设置,可以在* hbase-site.xml *中手动设置,也可以通过助手方法TableMapReduceUtil.setScannerCaching()设置。默认值
HConstants.DEFAULT_HBASE_CLIENT_SCANNER_CACHING设置为100。
优化缓存设置是 Client 端 await 结果的时间与 Client 端需要接收的结果集数量之间的平衡。如果缓存设置太大,Client 端可能会 await 很长时间,甚至请求可能会超时。如果设置太小,则扫描需要分多次返回结果。如果您将扫描视为铲子,则较大的缓存设置类似于较大的铲子,而较小的缓存设置等效于进行更多铲斗以填充铲斗。
上面提到的优先级列表允许您设置合理的默认值,并为特定操作覆盖它。
有关更多详细信息,请参见Scan的 API 文档。
50.Binding 的 HBase MapReduce 作业
HBase JAR 还可以用作某些 Binding 的 MapReduce 作业的驱动程序。要了解 Binding 的 MapReduce 作业,请运行以下命令。
$ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar
An example program must be given as the first argument.
Valid program names are:
copytable: Export a table from local cluster to peer cluster
completebulkload: Complete a bulk data load.
export: Write table data to HDFS.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table
每个有效的程序名称都是 Binding 的 MapReduce 作业。要运行作业之一,请在以下示例之后对命令建模。
$ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar rowcounter myTable
51. HBase 作为 MapReduce 作业数据源和数据接收器
HBase 可用作 MapReduce 作业的数据源TableInputFormat和数据接收器TableOutputFormat或MultiTableOutputFormat。编写可读取或写入 HBase 的 MapReduce 作业时,建议将TableMapper和/或TableReducer子类化。有关基本用法,请参见“禁止执行”直通类IdentityTableMapper和IdentityTableReducer。有关更多示例,请参见RowCounter或查看org.apache.hadoop.hbase.mapreduce.TestTableMapReduce单元测试。
如果运行将 HBase 用作源或接收器的 MapReduce 作业,则需要在配置中指定源和接收器表及列的名称。
当您从 HBase 读取数据时,TableInputFormat向 HBase 请求区域列表并创建一个 Map,该 Map 可以是map-per-region或mapreduce.job.mapsMap,以较小者为准。如果您的工作只有两个 Map,请将mapreduce.job.maps增大到大于区域数的数字。如果您在每个节点上运行 TaskTracer/NodeManager 和 RegionServer,则 Map 将在相邻的 TaskTracker/NodeManager 上运行。写入 HBase 时,应避免执行 Reduce 步骤,然后从 Map 内写回 HBase。当您的工作不需要 MapReduce 对 Map 发出的数据执行的排序和排序规则时,此方法将起作用。插入时,HBase 会“排序”,因此除非您需要,否则就不会进行点双重排序(并在 MapReduce 群集周围进行数据改组)。如果不需要精简,则 Map 可能会在作业结束时发出为报告而处理的记录计数,或者将精简数量设置为零并使用 TableOutputFormat。如果在您的情况下运行 Reduce 步骤有意义,则通常应使用多个 reducer,以便将负载分散到 HBase 群集中。
一个新的 HBase 分区程序HRegionPartitioner可以与现有区域数量一样多的 reducer 运行。 HRegionPartitioner 适用于表较大且上传完成后不会大大改变现有区域数的情况。否则,请使用默认分区程序。
52.批量导入期间直接写入 HFile
如果要导入到新表中,则可以绕过 HBase API 并将内容直接写入文件系统,并格式化为 HBase 数据文件(HFiles)。您的导入将运行得更快,也许要快一个数量级。有关此机制如何工作的更多信息,请参见Bulk Loading。
53. RowCounter 示例
包含的RowCounter MapReduce 作业使用TableInputFormat并对指定表中的所有行进行计数。要运行它,请使用以下命令:
$ ./bin/hadoop jar hbase-X.X.X.jar
这将调用 HBase MapReduce 驱动程序类。从提供的工作中选择rowcounter。这会将行计数器使用建议打印到标准输出。指定表名,要计数的列和输出目录。如果您遇到 Classpath 错误,请参见HBase,MapReduce 和 CLASSPATH。
54.Map 任务拆分
54.1. 默认的 HBase MapReduce 拆分器
当TableInputFormat用于在 MapReduce 作业中为 HBase 表提供源代码时,其拆分器将为该表的每个区域执行 Map 任务。因此,如果表中有 100 个区域,则该作业将有 100 个 Map 任务-无论在“扫描”中选择了多少列族。
54.2. 定制分离器
对于那些对实现自定义拆分器感兴趣的人,请参见TableInputFormatBase中的getSplits方法。这就是 Map 任务分配的逻辑所在。
55. HBase MapReduce 示例
55.1. HBase MapReduce 阅读示例
以下是以只读方式将 HBase 用作 MapReduce 源的示例。具体来说,有一个 Mapper 实例,但没有 Reducer,并且没有从 Mapper 发出任何东西。该工作的定义如下:
Configuration config = HBaseConfiguration.create();
Job job = new Job(config, "ExampleRead");
job.setJarByClass(MyReadJob.class); // class that contains mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
...
TableMapReduceUtil.initTableMapperJob(
tableName, // input HBase table name
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper
null, // mapper output key
null, // mapper output value
job);
job.setOutputFormatClass(NullOutputFormat.class); // because we aren't emitting anything from mapper
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
…Map 器实例将扩展TableMapper…
public static class MyMapper extends TableMapper<Text, Text> {
public void map(ImmutableBytesWritable row, Result value, Context context) throws InterruptedException, IOException {
// process data for the row from the Result instance.
}
}
55.2. HBase MapReduce 读/写示例
以下是通过 MapReduce 将 HBase 用作源和接收器的示例。此示例将简单地将数据从一个表复制到另一个表。
Configuration config = HBaseConfiguration.create();
Job job = new Job(config,"ExampleReadWrite");
job.setJarByClass(MyReadWriteJob.class); // class that contains mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
sourceTable, // input table
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper class
null, // mapper output key
null, // mapper output value
job);
TableMapReduceUtil.initTableReducerJob(
targetTable, // output table
null, // reducer class
job);
job.setNumReduceTasks(0);
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
需要说明TableMapReduceUtil在做什么,尤其是对于减速器。 TableOutputFormat用作 outputFormat 类,并且在配置上设置了几个参数(例如TableOutputFormat.OUTPUT_TABLE),并将 reducer 输出键设置为ImmutableBytesWritable,reducer 值设置为Writable。这些可以由程序员在作业和配置上设置,但是TableMapReduceUtil试图使事情变得更容易。
以下是示例 Map 器,它将创建一个Put并匹配 ImportingResult并发出它。注意:这就是 CopyTableUtil 的作用。
public static class MyMapper extends TableMapper<ImmutableBytesWritable, Put> {
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
// this example is just copying the data from the source table...
context.write(row, resultToPut(row,value));
}
private static Put resultToPut(ImmutableBytesWritable key, Result result) throws IOException {
Put put = new Put(key.get());
for (KeyValue kv : result.raw()) {
put.add(kv);
}
return put;
}
}
实际上没有 reducer 步骤,因此TableOutputFormat负责将Put发送到目标表。
这只是一个示例,开发人员可以选择不使用TableOutputFormat并自己连接到目标表。
55.3. 具有多表输出的 HBase MapReduce 读/写示例
TODO:MultiTableOutputFormat的示例。
55.4. HBase MapReduce 汇总到 HBase 示例
以下示例将 HBase 用作 MapReduce 源和接收器,并进行了总结。本示例将对一个表中值的不同实例的数量进行计数,并将这些汇总计数写入另一个表中。
Configuration config = HBaseConfiguration.create();
Job job = new Job(config,"ExampleSummary");
job.setJarByClass(MySummaryJob.class); // class that contains mapper and reducer
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
sourceTable, // input table
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper class
Text.class, // mapper output key
IntWritable.class, // mapper output value
job);
TableMapReduceUtil.initTableReducerJob(
targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1); // at least one, adjust as required
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
在此示例 Map 器中,选择具有字符串值的列作为要汇总的值。该值用作从 Map 器发出的键,并且IntWritable代表实例计数器。
public static class MyMapper extends TableMapper<Text, IntWritable> {
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR1 = "attr1".getBytes();
private final IntWritable ONE = new IntWritable(1);
private Text text = new Text();
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
String val = new String(value.getValue(CF, ATTR1));
text.set(val); // we can only emit Writables...
context.write(text, ONE);
}
}
在化简器中,对“ 1”进行计数(就像其他任何执行此操作的 MR 示例一样),然后发出Put。
public static class MyTableReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
public static final byte[] CF = "cf".getBytes();
public static final byte[] COUNT = "count".getBytes();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int i = 0;
for (IntWritable val : values) {
i += val.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.add(CF, COUNT, Bytes.toBytes(i));
context.write(null, put);
}
}
55.5. HBase MapReduce 摘要文件示例
这与上面的摘要示例非常相似,不同的是,它使用 HBase 作为 MapReduce 源,但使用 HDFS 作为接收器。区别在于作业设置和减速机。Map 器保持不变。
Configuration config = HBaseConfiguration.create();
Job job = new Job(config,"ExampleSummaryToFile");
job.setJarByClass(MySummaryFileJob.class); // class that contains mapper and reducer
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
sourceTable, // input table
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper class
Text.class, // mapper output key
IntWritable.class, // mapper output value
job);
job.setReducerClass(MyReducer.class); // reducer class
job.setNumReduceTasks(1); // at least one, adjust as required
FileOutputFormat.setOutputPath(job, new Path("/tmp/mr/mySummaryFile")); // adjust directories as required
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}
如上所述,在此示例中,以前的 Mapper 可以不变地运行。至于 Reducer,它是一个“通用” Reducer,而不是扩展 TableMapper 和发出 Puts。
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int i = 0;
for (IntWritable val : values) {
i += val.get();
}
context.write(key, new IntWritable(i));
}
}
55.6. HBase MapReduce 摘要到不带减速器的 HBase
如果将 HBase 用作化简器,也可以不使用化简器执行摘要。
HBase 目标表将需要存在以用于作业摘要。 Table 方法incrementColumnValue将用于自动增加值。从性能的角度来看,最好保留一个值 Map 表,并为每个 Map 任务增加其值,并在 Map 器的cleanup方法期间对每个键进行一次更新。但是,您的里程可能会有所不同,具体取决于要处理的行数和唯一键。
最后,汇总结果在 HBase 中。
55.7. HBase MapReduce 到 RDBMS 的摘要
有时,为 RDBMS 生成摘要更合适。对于这些情况,可以通过定制化简器直接向 RDBMS 生成摘要。 setup方法可以连接到 RDBMS(可以通过上下文中的自定义参数传递连接信息),而 cleanup 方法可以关闭连接。
了解该工作的减速器数量会影响汇总实现至关重要,因此您必须将其设计到减速器中。具体来说,它是设计为作为单例(一个减速器)运行还是作为多个减速器运行。对与错都取决于您的用例。认识到分配给该作业的减速器越多,将构建到 RDBMS 的更多同时连接-这将扩展,但仅限于一点。
public static class MyRdbmsReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private Connection c = null;
public void setup(Context context) {
// create DB connection...
}
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// do summarization
// in this example the keys are Text, but this is just an example
}
public void cleanup(Context context) {
// close db connection
}
}
最后,汇总结果将写入您的 RDBMS 表。
56.访问 MapReduce 作业中的其他 HBase 表
尽管该框架当前允许一个 HBase 表作为 MapReduce 作业的 Importing,但可以通过在 Mapper 的 setup 方法中创建 Table 实例,在 MapReduce 作业中将其他 HBase 表作为查找表等进行访问。
public class MyMapper extends TableMapper<Text, LongWritable> {
private Table myOtherTable;
public void setup(Context context) {
// In here create a Connection to the cluster and save it or use the Connection
// from the existing table
myOtherTable = connection.getTable("myOtherTable");
}
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
// process Result...
// use 'myOtherTable' for lookups
}
57.投机执行
通常建议对使用 HBase 作为源的 MapReduce 作业关闭推测执行。这既可以通过每个作业通过属性来完成,也可以在整个群集上完成。特别是对于长时间运行的作业,推测性执行将创建重复的 Map 任务,这会将您的数据双重写入 HBase。这可能不是您想要的。
有关更多信息,请参见spec.ex。
58. Cascading
Cascading是 MapReduce 的替代 API,它实际上使用 MapReduce,但允许您以简化的方式编写 MapReduce 代码。
以下示例显示了将数据“下沉”到 HBase 群集中的级联Flow。同样的hBaseTap API 也可以用于“获取”数据。
// read data from the default filesystem
// emits two fields: "offset" and "line"
Tap source = new Hfs( new TextLine(), inputFileLhs );
// store data in an HBase cluster
// accepts fields "num", "lower", and "upper"
// will automatically scope incoming fields to their proper familyname, "left" or "right"
Fields keyFields = new Fields( "num" );
String[] familyNames = {"left", "right"};
Fields[] valueFields = new Fields[] {new Fields( "lower" ), new Fields( "upper" ) };
Tap hBaseTap = new HBaseTap( "multitable", new HBaseScheme( keyFields, familyNames, valueFields ), SinkMode.REPLACE );
// a simple pipe assembly to parse the input into fields
// a real app would likely chain multiple Pipes together for more complex processing
Pipe parsePipe = new Each( "insert", new Fields( "line" ), new RegexSplitter( new Fields( "num", "lower", "upper" ), " " ) );
// "plan" a cluster executable Flow
// this connects the source Tap and hBaseTap (the sink Tap) to the parsePipe
Flow parseFlow = new FlowConnector( properties ).connect( source, hBaseTap, parsePipe );
// start the flow, and block until complete
parseFlow.complete();
// open an iterator on the HBase table we stuffed data into
TupleEntryIterator iterator = parseFlow.openSink();
while(iterator.hasNext())
{
// print out each tuple from HBase
System.out.println( "iterator.next() = " + iterator.next() );
}
iterator.close();
保护 Apache HBase
Reporting Security Bugs
Note
为了保护现有的 HBase 安装不受攻击,请 不要 使用 JIRA 报告与安全性有关的错误。而是将您的报告发送到邮件列表private@hbase.apache.org,该列表允许任何人发送消息,但限制了可以阅读的人。该列表中的某人将与您联系以跟进您的报告。
HBase 遵守 Apache Software Foundation 关于已报告漏洞的 Policy,该 Policy 可在http://apache.org/security/获得。
如果您希望发送加密的报告,则可以使用为常规 ASF 安全列表提供的 GPG 详细信息。这可能会增加对报告的响应时间。
59. Web UI 安全
HBase 提供了一些机制来保护 HBase 的各个组件和方面以及它与 Hadoop 基础结构的其余部分以及 Hadoop 外部的 Client 端和资源之间的关系。
59.1. 将安全 HTTP(HTTPS)用于 Web UI
默认的 HBase 安装会为主服务器和区域服务器的 Web UI 使用不安全的 HTTP 连接。要改为启用安全的 HTTP(HTTPS)连接,请在* hbase-site.xml *中将hbase.ssl.enabled设置为true。这不会更改 Web UI 使用的端口。要更改给定 HBase 组件的 Web UI 的端口,请在 hbase-site.xml 中配置该端口的设置。这些设置是:
hbase.master.info.porthbase.regionserver.info.port
If you enable HTTPS, clients should avoid using the non-secure HTTP connection.
如果启用安全 HTTP,则 Client 端应使用https:// URL 连接到 HBase。使用http:// URL 的 Client 端将收到200的 HTTP 响应,但不会接收任何数据。记录以下异常:
javax.net.ssl.SSLException: Unrecognized SSL message, plaintext connection?
这是因为同一端口用于 HTTP 和 HTTPS。
HBase 将 Jetty 用于 Web UI。如果不修改 Jetty 本身,似乎无法配置 Jetty 将一个端口重定向到同一主机上的另一个端口。有关更多信息,请参见 Nick Dimiduk 在此Stack Overflow线程上的贡献。如果您知道如何解决此问题而又不为 HTTPS 打开第二个端口,那么不胜感激。
59.2. 使用 SPNEGO 通过 Web UI 进行 Kerberos 身份验证
可以通过在* hbase-site.xml *中使用hbase.security.authentication.ui属性配置 SPNEGO 来启用对 HBase Web UI 的 Kerberos 身份验证。启用此身份验证需要将 HBase 还配置为对 RPC 使用 Kerberos 身份验证(例如hbase.security.authentication = kerberos)。
<property>
<name>hbase.security.authentication.ui</name>
<value>kerberos</value>
<description>Controls what kind of authentication should be used for the HBase web UIs.</description>
</property>
<property>
<name>hbase.security.authentication</name>
<value>kerberos</value>
<description>The Kerberos keytab file to use for SPNEGO authentication by the web server.</description>
</property>
存在许多属性,可以为 Web 服务器配置 SPNEGO 身份验证:
<property>
<name>hbase.security.authentication.spnego.kerberos.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
<description>Required for SPNEGO, the Kerberos principal to use for SPNEGO authentication by the
web server. The _HOST keyword will be automatically substituted with the node's
hostname.</description>
</property>
<property>
<name>hbase.security.authentication.spnego.kerberos.keytab</name>
<value>/etc/security/keytabs/spnego.service.keytab</value>
<description>Required for SPNEGO, the Kerberos keytab file to use for SPNEGO authentication by the
web server.</description>
</property>
<property>
<name>hbase.security.authentication.spnego.kerberos.name.rules</name>
<value></value>
<description>Optional, Hadoop-style `auth_to_local` rules which will be parsed and used in the
handling of Kerberos principals</description>
</property>
<property>
<name>hbase.security.authentication.signature.secret.file</name>
<value></value>
<description>Optional, a file whose contents will be used as a secret to sign the HTTP cookies
as a part of the SPNEGO authentication handshake. If this is not provided, Java's `Random` library
will be used for the secret.</description>
</property>
59.3. 定义 Web UI 的 Management 员
在上一节中,我们介绍了如何通过 SPNEGO 启用 Web UI 的身份验证。但是,Web UI 的某些部分可用于影响 HBase 群集的可用性和性能。因此,希望确保只有那些具有适当权限的人员才能与这些敏感端点进行交互。
HBase 允许通过 hbase-site.xml 中的用户名或组列表定义 Management 员
<property>
<name>hbase.security.authentication.spnego.admin.users</name>
<value></value>
</property>
<property>
<name>hbase.security.authentication.spnego.admin.groups</name>
<value></value>
</property>
给定 core-site.xml 中的 Hadoop auth_to_local规则,用户名是 Kerberos 身份 Map 到的用户名。此处的组是与 Map 的用户名关联的 Unix 组。
请考虑以下情形,以描述配置属性的运行方式。考虑在 Kerberos KDC 中定义的三个用户:
alice@COMPANY.COMbob@COMPANY.COMcharlie@COMPANY.COM
缺省的 Hadoop auth_to_local规则将这些主体 Map 到“短名称”:
alicebobcharlie
Unix 组成员资格定义alice是组admins的成员。 bob和charlie不是admins组的成员。
<property>
<name>hbase.security.authentication.spnego.admin.users</name>
<value>charlie</value>
</property>
<property>
<name>hbase.security.authentication.spnego.admin.groups</name>
<value>admins</value>
</property>
根据上述配置,由于alice是admins组的成员,因此允许alice访问 Web UI 中的敏感端点。 charlie也被允许访问敏感的端点,因为在配置中他被明确列为 Management 员。 bob不允许访问敏感端点,因为他不是admins组的成员,也不通过hbase.security.authentication.spnego.admin.users被列为显式 Management 员用户,但仍可以在 Web UI 中使用任何非敏感端点。
如果不言而喻:未经身份验证的用户将无法访问 Web UI 的任何部分。
59.4. 其他与 UI 安全相关的配置
尽管这对于 HBase 开发人员而言是明显的反模式,但是开发人员承认 HBase 配置(包括 Hadoop 配置文件)可能包含敏感信息。这样,用户可能会发现他们不想向所有经过身份验证的用户公开 HBase 服务级别的配置。他们可能将 HBase 配置为要求用户必须是 Management 员才能通过 HBase UI 访问服务级别配置。默认情况下,此配置为“ false”(任何经过身份验证的用户都可以访问该配置)。
希望更改此设置的用户可以在其 hbase-site.xml 中设置以下内容:
<property>
<name>hbase.security.authentication.ui.config.protected</name>
<value>true</value>
</property>
60.对 Apache HBase 的安全 Client 端访问
较新的 Apache HBase 版本(> = 0.92)支持 Client 端的可选 SASL 身份验证。另请参见 Matteo Bertozzi 在了解 Apache HBase 中的用户身份验证和授权上的文章。
这说明了如何设置 Apache HBase 和 Client 端以连接到安全的 HBase 资源。
60.1. Prerequisites
Hadoop 身份验证配置
- 要使用强身份验证运行 HBase RPC,必须将
hbase.security.authentication设置为kerberos。在这种情况下,还必须在 core-site.xml 中将hadoop.security.authentication设置为kerberos。否则,您将对 HBase 使用强身份验证,而不对基础 HDFS 使用强身份验证,这将抵消任何好处。
- 要使用强身份验证运行 HBase RPC,必须将
Kerberos KDC
- 您需要有一个有效的 Kerberos KDC。
60.2. 服务器端配置以确保安全运行
首先,请参考security.prerequisites并确保基础 HDFS 配置是安全的。
将以下内容添加到群集中每台服务器计算机上的hbase-site.xml文件中:
<property>
<name>hbase.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.token.TokenProvider</value>
</property>
部署这些配置更改时,需要完全关闭并重新启动 HBase 服务。
60.3. 用于安全操作的 Client 端配置
首先,请参考Prerequisites并确保基础 HDFS 配置是安全的。
将以下内容添加到每个 Client 端的hbase-site.xml文件中:
<property>
<name>hbase.security.authentication</name>
<value>kerberos</value>
</property>
在 2.2.0 版之前,必须先通过kinit命令从 KDC 或 keytab 登录 Client 端环境,然后才能与 HBase 群集进行通信。
从 2.2.0 开始,Client 端可以在hbase-site.xml中指定以下配置:
<property>
<name>hbase.client.keytab.file</name>
<value>/local/path/to/client/keytab</value>
</property>
<property>
<name>hbase.client.keytab.principal</name>
<value>foo@EXAMPLE.COM</value>
</property>
然后,应用程序可以自动执行登录和凭据续订作业,而不会受到 Client 端的干扰。
这是一项可选功能,升级到 2.2.0 的 Client 端只要保持未设置hbase.client.keytab.file和hbase.client.keytab.principal,仍可以保持其登录和凭证续订逻辑已在旧版本中进行。
请注意,如果 Client 端和服务器端站点文件中的hbase.security.authentication不匹配,则 Client 端将无法与群集进行通信。
一旦为安全 RPC 配置了 HBase,就可以选择配置加密通信。为此,请将以下内容添加到每个 Client 端的hbase-site.xml文件中:
<property>
<name>hbase.rpc.protection</name>
<value>privacy</value>
</property>
也可以在每个连接的基础上设置此配置属性。在提供给Table的Configuration中进行设置:
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
conf.set("hbase.rpc.protection", "privacy");
try (Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf(tablename))) {
.... do your stuff
}
预计加密通信的性能会降低约 10%。
60.4. 用于安全操作的 Client 端配置-Thrift Gateway
将以下内容添加到每个 Thrift 网关的hbase-site.xml文件中:
<property>
<name>hbase.thrift.keytab.file</name>
<value>/etc/hbase/conf/hbase.keytab</value>
</property>
<property>
<name>hbase.thrift.kerberos.principal</name>
<value>$USER/_HOST@HADOOP.LOCALDOMAIN</value>
<!-- TODO: This may need to be HTTP/_HOST@<REALM> and _HOST may not work.
You may have to put the concrete full hostname.
-->
</property>
<!-- Add these if you need to configure a different DNS interface from the default -->
<property>
<name>hbase.thrift.dns.interface</name>
<value>default</value>
</property>
<property>
<name>hbase.thrift.dns.nameserver</name>
<value>default</value>
</property>
分别用适当的凭据和密钥表代替* $ USER 和 $ KEYTAB *。
为了使用 Thrift API 主体与 HBase 进行交互,还必须将hbase.thrift.kerberos.principal添加到acl表中。例如,要给 Thrift API 主体thrift_server进行 Management 访问,这样的命令就足够了:
grant 'thrift_server', 'RWCA'
有关 ACL 的更多信息,请参见访问控制标签(ACL)部分
Thrift 网关将使用提供的凭据对 HBase 进行身份验证。 Thrift 网关本身不会执行任何身份验证。所有通过 Thrift 网关的 Client 端访问都将使用 Thrift 网关的凭据并拥有其特权。
60.5. 配置 Thrift Gateway 以代表 Client 端进行身份验证
用于安全操作的 Client 端配置-Thrift Gateway介绍了如何使用固定用户向 HBase 认证 ThriftClient 端。或者,您可以配置 Thrift 网关代表 Client 端对 HBase 进行身份验证,并使用代理用户访问 HBase。对于 Thrift 1,此设置是在HBASE-11349中实现的;对于 Thrift 2,此实现是在HBASE-11474中实现的。
Limitations with Thrift Framed Transport
如果您使用框架传输,则您将无法利用此功能,因为 SASL 目前不适用于 Thrift 框架传输。
要启用它,请执行以下操作。
通过遵循用于安全操作的 Client 端配置-Thrift Gateway中描述的过程,确保 Thrift 在安全模式下运行。
确保将 HBase 配置为允许代理用户,如REST 网关模拟配置中所述。
对于每个运行 Thrift 网关的集群节点,在* hbase-site.xml *中,将属性
hbase.thrift.security.qop设置为以下三个值之一:privacy-身份验证,完整性和机密性检查。integrity-身份验证和完整性检查authentication-仅验证检查重新启动 Thrift 网关进程以使更改生效。如果节点正在运行 Thrift,则
jps命令的输出将列出ThriftServer进程。要在节点上停止 Thrift,请运行命令bin/hbase-daemon.sh stop thrift。要在节点上启动 Thrift,请运行命令bin/hbase-daemon.sh start thrift。
60.6. 配置 Thrift 网关以使用 doAs 功能
配置 Thrift Gateway 以代表 Client 端进行身份验证描述了如何配置 Thrift 网关以代表 Client 端对 HBase 进行身份验证,以及如何使用代理用户访问 HBase。此方法的局限性在于,在使用特定的一组凭据初始化 Client 端之后,它无法在会话期间更改这些凭据。 doAs功能提供了一种灵活的方式来使用同一 Client 端模拟多个主体。此功能已在 Thrift 1 的HBASE-12640中实现,但当前不适用于 Thrift 2.
要启用doAs功能 ,请将以下内容添加到每个 Thrift 网关的* hbase-site.xml *文件中:
<property>
<name>hbase.regionserver.thrift.http</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.support.proxyuser</name>
<value>true/value>
</property>
要在使用doAs模拟时允许代理用户 ,请将以下内容添加到每个 HBase 节点的* hbase-site.xml *文件中:
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hadoop.proxyuser.$USER.groups</name>
<value>$GROUPS</value>
</property>
<property>
<name>hadoop.proxyuser.$USER.hosts</name>
<value>$GROUPS</value>
</property>
查看demo client,以全面了解如何在 Client 端中使用此功能。
60.7. 用于安全操作的 Client 端配置-REST 网关
将以下内容添加到每个 REST 网关的hbase-site.xml文件中:
<property>
<name>hbase.rest.keytab.file</name>
<value>$KEYTAB</value>
</property>
<property>
<name>hbase.rest.kerberos.principal</name>
<value>$USER/_HOST@HADOOP.LOCALDOMAIN</value>
</property>
分别用适当的凭据和密钥表代替* $ USER 和 $ KEYTAB *。
REST 网关将使用提供的凭据对 HBase 进行身份验证。
为了使用 REST API 主体与 HBase 进行交互,还必须将hbase.rest.kerberos.principal添加到acl表中。例如,要授予 REST API 主体rest_server的 Management 访问权限,只需执行以下命令即可:
grant 'rest_server', 'RWCA'
有关 ACL 的更多信息,请参见访问控制标签(ACL)部分
HBase REST 网关支持SPNEGO HTTP 身份验证以便 Client 端访问网关。要为 Client 端访问启用 REST 网关 Kerberos 身份验证,请将以下内容添加到每个 REST 网关的hbase-site.xml文件中。
<property>
<name>hbase.rest.support.proxyuser</name>
<value>true</value>
</property>
<property>
<name>hbase.rest.authentication.type</name>
<value>kerberos</value>
</property>
<property>
<name>hbase.rest.authentication.kerberos.principal</name>
<value>HTTP/_HOST@HADOOP.LOCALDOMAIN</value>
</property>
<property>
<name>hbase.rest.authentication.kerberos.keytab</name>
<value>$KEYTAB</value>
</property>
<!-- Add these if you need to configure a different DNS interface from the default -->
<property>
<name>hbase.rest.dns.interface</name>
<value>default</value>
</property>
<property>
<name>hbase.rest.dns.nameserver</name>
<value>default</value>
</property>
将 keytab 替换为* $ KEYTAB *的 HTTP。
HBase REST 网关支持不同的“ hbase.rest.authentication.type”:简单,kerberos。您还可以通过实现 Hadoop AuthenticationHandler 来实现自定义身份验证,然后将完整的类名称指定为“ hbase.rest.authentication.type”值。有关更多信息,请参阅SPNEGO HTTP 身份验证。
60.8. REST 网关模拟配置
默认情况下,REST 网关不支持模拟。它以上一节中配置的用户身份代表 Client 端访问 HBase。对于 HBase 服务器,所有请求均来自 REST 网关用户。实际用户未知。您可以打开模拟支持。通过模拟,REST 网关用户是代理用户。 HBase 服务器知道每个请求的实际/实际用户。因此,它可以应用适当的授权。
要打开 REST 网关模拟,我们需要配置 HBase 服务器(主服务器和区域服务器)以允许代理用户。配置 REST 网关以启用模拟。
要允许代理用户,请将以下内容添加到每个 HBase 服务器的hbase-site.xml文件中:
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hadoop.proxyuser.$USER.groups</name>
<value>$GROUPS</value>
</property>
<property>
<name>hadoop.proxyuser.$USER.hosts</name>
<value>$GROUPS</value>
</property>
将 REST 网关代理用户替换为* $ USER ,并将允许的组列表替换为 $ GROUPS *。
要启用 REST 网关模拟,请将以下内容添加到每个 REST 网关的hbase-site.xml文件中。
<property>
<name>hbase.rest.authentication.type</name>
<value>kerberos</value>
</property>
<property>
<name>hbase.rest.authentication.kerberos.principal</name>
<value>HTTP/_HOST@HADOOP.LOCALDOMAIN</value>
</property>
<property>
<name>hbase.rest.authentication.kerberos.keytab</name>
<value>$KEYTAB</value>
</property>
将 keytab 替换为* $ KEYTAB *的 HTTP。
61.对 Apache HBase 的简单用户访问
较新的 Apache HBase 版本(> = 0.92)支持 Client 端的可选 SASL 身份验证。另请参见 Matteo Bertozzi 在了解 Apache HBase 中的用户身份验证和授权上的文章。
这描述了如何设置 Apache HBase 和 Client 端以简化用户对 HBase 资源的访问。
61.1. 简单访问与安全访问
以下部分显示了如何设置简单的用户访问。简单的用户访问不是操作 HBase 的安全方法。此方法用于防止用户犯错误。它可用于在开发系统上模拟访问控制,而无需设置 Kerberos。
此方法不能用于防止恶意或黑客攻击。要使 HBase 抵御这些类型的攻击,必须将 HBase 配置为安全操作。请参考安全的 Client 端访问 Apache HBase部分,并完成其中描述的所有步骤。
61.2. Prerequisites
None
61.3. 服务器端配置,用于简单的用户访问操作
将以下内容添加到群集中每台服务器计算机上的hbase-site.xml文件中:
<property>
<name>hbase.security.authentication</name>
<value>simple</value>
</property>
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
对于 0.94,将以下内容添加到群集中每台服务器计算机上的hbase-site.xml文件中:
<property>
<name>hbase.rpc.engine</name>
<value>org.apache.hadoop.hbase.ipc.SecureRpcEngine</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
部署这些配置更改时,需要完全关闭并重新启动 HBase 服务。
61.4. Client 端配置,用于简单的用户访问操作
将以下内容添加到每个 Client 端的hbase-site.xml文件中:
<property>
<name>hbase.security.authentication</name>
<value>simple</value>
</property>
对于 0.94,将以下内容添加到群集中每台服务器计算机上的hbase-site.xml文件中:
<property>
<name>hbase.rpc.engine</name>
<value>org.apache.hadoop.hbase.ipc.SecureRpcEngine</value>
</property>
请注意,如果 Client 端和服务器端站点文件中的hbase.security.authentication不匹配,则 Client 端将无法与群集进行通信。
61.4.1. 简单用户访问操作的 Client 端配置-Thrift Gateway
Thrift 网关用户将需要访问。例如,要授予 Thrift API 用户thrift_server的 Management 访问权限,则需要执行以下命令:
grant 'thrift_server', 'RWCA'
有关 ACL 的更多信息,请参见访问控制标签(ACL)部分
Thrift 网关将使用提供的凭据对 HBase 进行身份验证。 Thrift 网关本身不会执行任何身份验证。所有通过 Thrift 网关的 Client 端访问都将使用 Thrift 网关的凭据并拥有其特权。
61.4.2. 用于简单用户访问操作的 Client 端配置-REST 网关
REST 网关将使用提供的凭据对 HBase 进行身份验证。 REST 网关本身不会执行任何身份验证。通过 REST 网关进行的所有 Client 端访问都将使用 REST 网关的凭据并拥有其特权。
REST 网关用户将需要访问。例如,要授予 REST API 用户rest_server的 Management 访问权限,只需执行以下命令即可:
grant 'rest_server', 'RWCA'
有关 ACL 的更多信息,请参见访问控制标签(ACL)部分
Client 端应该可以通过 SPNEGO HTTP 身份验证以直通方式通过 REST 网关通过 HBase 群集进行身份验证。这是 Future 的工作。
62.确保对 HDFS 和 ZooKeeper 的访问
安全的 HBase 需要安全的 ZooKeeper 和 HDFS,以便用户无法从 HBase 下访问和/或修改元数据和数据。 HBase 使用 HDFS(或配置的文件系统)来保留其数据文件以及预写日志(WAL)和其他数据。 HBase 使用 ZooKeeper 来存储一些元数据用于操作(主地址,表锁,恢复状态等)。
62.1. 保护 ZooKeeper 数据
ZooKeeper 具有可插入的身份验证机制,以允许使用不同方法从 Client 端进行访问。 ZooKeeper 甚至可以同时允许经过身份验证和未经身份验证的 Client 端。可以通过为每个 znode 提供访问控制列表(ACL)来限制对 znode 的访问。 ACL 包含两个组件,身份验证方法和主体。 ACL 不是分层实施的。有关详情,请参见ZooKeeper 程序员指南。
HBase 守护程序通过 SASL 和 kerberos 向 ZooKeeper 进行身份验证(请参阅ZooKeeper 的 SASL 身份验证)。 HBase 设置 znode ACL,以便只有 HBase 用户和配置的 hbase 超级用户(hbase.superuser)可以访问和修改数据。在将 ZooKeeper 用于服务发现或与 Client 端共享状态的情况下,由 HBase 创建的 znodes 也将允许任何人(无论身份验证如何)读取这些 znodes(clusterId,主地址,元位置等),但只能读取 HBase。用户可以修改它们。
62.2. 保护文件系统(HDFS)数据
所有 Management 的数据都保存在文件系统(hbase.rootdir)的根目录下。应该限制对文件系统中数据和 WAL 文件的访问,以使用户无法绕过 HBase 层,并可以窥视文件系统中的基础数据文件。 HBase 假定使用的文件系统(HDFS 或其他文件系统)强制执行权限。如果没有提供足够的文件系统保护(包括授权和身份验证),则 HBase 级别的授权控制(ACL,可见性标签等)将变得毫无意义,因为用户始终可以从文件系统访问数据。
HBase 对其根目录强制执行类似 posix 的权限 700(rwx------)。这意味着只有 HBase 用户可以读取或写入 FS 中的文件。可以通过在 hbase-site.xml 中配置hbase.rootdir.perms来更改默认设置。需要重新启动活动主服务器,以便更改使用的权限。对于 1.2.0 之前的版本,您可以检查是否提交了 HBASE-13780,如果没有提交,则可以根据需要手动设置根目录的权限。使用 HDFS,命令将是:
sudo -u hdfs hadoop fs -chmod 700 /hbase
如果您使用其他hbase.rootdir,则应更改/hbase。
在安全模式下,应该配置 SecureBulkLoadEndpoint 并将其用于正确地将从 MR 作业创建的用户文件处理到 HBase 守护程序和 HBase 用户。用于批量加载的分布式文件系统中的登台目录(hbase.bulkload.staging.dir,默认为/tmp/hbase-staging)应具有(模式 711 或rwx—x—x),以便用户可以访问在该父目录下创建的登台目录,但不能执行任何其他操作。有关如何配置 SecureBulkLoadEndPoint 的信息,请参见安全散装。
63.确保对您的数据的访问
在 HBaseClient 端与服务器进程和网关之间配置了安全身份验证之后,需要考虑数据本身的安全性。 HBase 提供了几种保护数据的策略:
基于角色的访问控制(RBAC)使用熟悉的角色范例来控制哪些用户或组可以读写给定的 HBase 资源或执行协处理器端点。
可见性标签允许您标记单元格并控制对标记单元格的访问,以进一步限制谁可以读取或写入数据的某些子集。可见性标签存储为标签。有关更多信息,请参见hbase.tags。
HFiles 和 WAL 中基础文件系统上静态数据的透明加密。这样可以保护您的静态数据,使其免受攻击者的攻击,这些攻击者可以访问基础文件系统,而无需更改 Client 端的实现。它还可以防止因磁盘配置不当而造成的数据泄漏,这对于法律和法规遵从性很重要。
下面讨论了每个功能的服务器端配置,Management 和实现细节,以及所有性能折衷。最后给出了一个示例安全配置,以显示所有这些功能一起使用,就像它们在现实世界中一样。
Warning
HBase 中的安全性的各个方面都在积极开发中并且正在迅速 Developing。您为数据安全性采用的任何策略都应进行彻底测试。此外,其中一些功能仍处于试验开发阶段。要利用其中的许多功能,您必须正在运行 HBase 0.98 并使用 HFile v3 文件格式。
Protecting Sensitive Files
本节中的几个过程要求您在群集节点之间复制文件。复制密钥,配置文件或其他包含敏感字符串的文件时,请使用安全方法,例如ssh,以避免泄漏敏感数据。
过程:服务器端基本配置
- 通过在* hbase-site.xml *中将
hfile.format.version设置为 3 来启用 HFile v3.这是 HBase 1.0 及更高版本的默认设置。
<property>
<name>hfile.format.version</name>
<value>3</value>
</property>
- 如security.prerequisites和ZooKeeper 的 SASL 身份验证中所述,为 RPC 和 ZooKeeper 启用 SASL 和 Kerberos 身份验证。
63.1. Tags
标签是 HFile v3 的功能。标签是一条元数据,它是单元的一部分,与键,值和版本分开。标签是实现细节,它为其他与安全相关的功能(如单元级 ACL 和可见性标签)奠定了基础。标记存储在 HFiles 本身中。将来可能会使用标签来实现其他 HBase 功能。您不需要对标签了解太多,就可以使用它们启用的安全功能。
63.1.1. 实施细节
每个单元格可以具有零个或多个标签。每个标签都有一个类型和实际的标签字节数组。
正如可以对行键,列族,限定符和值进行编码(请参见data.block.encoding.types)一样,也可以对标签进行编码。您可以在列族级别启用或禁用标记编码,并且默认情况下启用。使用HColumnDescriptor#setCompressionTags(boolean compressTags)方法来 Management 列族的编码设置。您还需要为列系列启用 DataBlockEncoder,以使标签编码生效。
如果还启用了 WAL 压缩,则可以通过在* hbase-site.xml *中将hbase.regionserver.wal.tags.enablecompression的值设置为true来启用 WAL 中每个标签的压缩。标签压缩使用字典编码。
在 RegionServers 上服务器端运行的协处理器可以对单元标签执行 get 和 set 操作。在回读响应之前,标记在 RPC 层被剥离,因此 Client 端看不到这些标记。使用 WAL 加密时,不支持标签压缩。
63.2. 访问控制标签(ACL)
63.2.1. 这个怎么运作
HBase 中的 ACL 基于用户在组中的成员身份或从组中排除,以及给定组的访问给定资源的权限。 ACL 被实现为称为 AccessController 的协处理器。
HBase 不维护私有组 Map,而是依赖 Hadoop 组 Map 器*,该组 Map 器在 LDAP 或 Active Directory 等目录中的实体与 HBase 用户之间进行 Map。任何受支持的 Hadoop 组 Map 器都将起作用。然后,向用户授予针对资源(全局,名称空间,表,单元或端点)的特定权限(读取,写入,执行,创建,Management)。
Note
启用 Kerberos 和访问控制后,将对 Client 端对 HBase 的访问进行身份验证,并且用户数据为私有数据,除非已明确授予访问权限。
HBase 具有比关系数据库更简单的安全模型,尤其是在 Client 端操作方面。例如,插入(新记录)和更新(现有记录)之间没有区别,因为两者都折叠成 Put。
了解访问级别
HBase 访问级别相互独立授予,并允许在给定范围内进行不同类型的操作。
读取(R)-可以读取给定范围的数据
写入(W)-可以在给定范围内写入数据
-
- Execute(X)*-可以在给定范围内执行协处理器端点
创建(C)-可以在给定范围内创建表或删除表(甚至包括未创建的表)
-
- Admin(A)*-可以执行群集操作,例如平衡群集或在给定范围内分配区域
可能的范围是:
超级用户-超级用户可以对任何资源执行 HBase 中可用的任何操作。在群集上运行 HBase 的用户是超级用户,在 HMaster 的* hbase-site.xml *中分配给配置属性
hbase.superuser的任何主体也是如此。-
- Global -在 global *范围内授予的权限允许 Management 员对集群的所有表进行操作。
名称空间-在名称空间范围内授予的权限适用于给定名称空间内的所有表。
表-在表范围内授予的权限适用于给定表中的数据或元数据。
-
- ColumnFamily -在 ColumnFamily *范围内授予的权限适用于该 ColumnFamily 中的单元格。
-
- Cell -在 cell *范围内授予的权限适用于该确切的单元格坐标(键,值,时间戳)。这允许策略与数据一起 Developing。
要更改特定单元格上的 ACL,请使用新 ACL 将更新后的单元格写入原始单元格的精确坐标。
如果您具有多版本架构,并且想要在所有可见版本上更新 ACL,则需要为所有可见版本编写新的单元格。该应用程序可以完全控制策略的演变。
上述规则的 exception 是append和increment处理。追加和递增操作中可以携带 ACL。如果该运算中包含一个,则它将应用于append或increment的结果。否则,将保留要添加或递增的现有单元的 ACL。
访问级别和范围的组合创建了可以授予用户的可能访问级别的矩阵。在生产环境中,根据完成特定工作所需的条件来考虑访问级别很有用。下表描述了一些常见 HBase 用户类型的访问级别。重要的是,不要授予超出给定用户执行其所需任务所需权限的访问权限。
超级用户-在生产系统中,只有 HBase 用户应具有超级用户访问权限。在开发环境中,Management 员可能需要超级用户访问权限才能快速控制和 Management 集群。但是,这种类型的 Management 员通常应该是全局 Management 员,而不是超级用户。
全局 Management 员-全局 Management 员可以执行任务并访问 HBase 中的每个表。在典型的生产环境中,Management 员不应具有对表中数据的读取或写入权限。
具有 Management 员权限的全局 Management 员可以在群集上执行群集范围内的操作,例如平衡,分配或取消分配区域,或调用显式主要压缩。这是操作角色。
具有“创建”权限的全局 Management 员可以在 HBase 中创建或删除任何表。这更像是 DBA 类型的角色。
在生产环境中,不同的用户可能只有 Admin 和 Create 权限之一。
Warning
在当前的实现中,具有Admin权限的 Global Admin 可以授予自己对表的Read和Write权限,并获得对该表数据的访问权限。因此,仅将Global Admin权限授予实际需要它们的受信任用户。
还应注意,具有Create权限的Global Admin可以在 ACL 表上执行Put操作,模拟grant或revoke并绕过Global Admin权限的授权检查。
由于这些问题,请谨慎授予Global Admin特权。
名称空间 Management 员-具有
Create权限的名称空间 Management 员可以在该名称空间中创建或删除表,以及获取和还原快照。具有Admin权限的名称空间 Management 员可以对该名称空间内的表执行诸如拆分或主要压缩之类的操作。表 Management 员-表 Management 员只能在该表上执行 Management 操作。具有
Create权限的表 Management 员可以从该表创建快照或从快照还原该表。具有Admin权限的表 Management 员可以在该表上执行拆分或重大压缩等操作。用户-用户可以读取或写入数据,或同时读取和写入数据。如果被授予
Executable权限,则用户还可以执行协处理器端点。
表 9.访问级别的真实示例
| Job Title | Scope | Permissions | Description |
|---|---|---|---|
| Senior Administrator | Global | Access, Create | Management 集群并授予初级 Management 员访问权限。 |
| Junior Administrator | Global | Create | 创建表并授予表 Management 员访问权限。 |
| Table Administrator | Table | Access | 从操作角度维护表。 |
| Data Analyst | Table | Read | 从 HBase 数据创建报告。 |
| Web Application | Table | Read, Write | 将数据放入 HBase 并使用 HBase 数据执行操作。 |
ACL Matrix
有关 ACL 如何 Map 到特定 HBase 操作和任务的更多详细信息,请参见附录 ACL 矩阵。
Implementation Details
单元级 ACL 使用标签实现(请参见Tags)。为了使用单元级别的 ACL,您必须使用 HFile v3 和 HBase 0.98 或更高版本。
由 HBase 创建的文件归运行 HBase 进程的 os 用户所有。要与 HBase 文件进行交互,应使用 API 或批量加载工具。
HBase 不在 HBase 内部对“角色”建模。而是可以授予组名权限。这允许通过组成员资格对角色进行外部建模。通过 Hadoop 组 Map 服务在 HBase 外部创建和操作组。
Server-Side Configuration
作为前提,执行过程:服务器端基本配置中的步骤。
通过在* hbase-site.xml *中设置以下属性来安装和配置 AccessController 协处理器。这些属性采用类列表。
Note
如果将 AccessController 与 VisibilityController 一起使用,则 AccessController 必须在列表中排在第一位,因为在两个组件都处于活动状态的情况下,VisibilityController 会将其系统表上的访问控制委托给 AccessController。有关将两者一起使用的示例,请参见安全配置示例。
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController, org.apache.hadoop.hbase.security.token.TokenProvider</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.security.exec.permission.checks</name>
<value>true</value>
</property>
(可选)您可以通过将hbase.rpc.protection设置为privacy来启用传输安全性。这需要 HBase 0.98.4 或更高版本。
- 在 Hadoop 名称节点的* core-site.xml *中设置 Hadoop 组 Map 器。这是 Hadoop 文件,而不是 HBase 文件。根据您的站点需求对其进行自定义。以下是一个示例。
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.LdapGroupsMapping</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.url</name>
<value>ldap://server</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.user</name>
<value>Administrator@example-ad.local</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.password</name>
<value>****</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.base</name>
<value>dc=example-ad,dc=local</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.user</name>
<value>(&(objectClass=user)(sAMAccountName={0}))</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.group</name>
<value>(objectClass=group)</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.member</name>
<value>member</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.group.name</name>
<value>cn</value>
</property>
(可选)启用提前评估策略。在 HBase 0.98.0 之前,如果未授予用户访问列系列或至少一个列限定符的权限,则将引发 AccessDeniedException。 HBase 0.98.0 删除了此异常,以便允许单元级别的特殊授予。要恢复 HBase 0.98.0-0.98.6 中的旧行为,请在* hbase-site.xml *中将
hbase.security.access.early_out设置为true。在 HBase 0.98.6 中,默认值已返回true。分发配置并重新启动集群以使更改生效。
要测试您的配置,请以给定用户身份登录 HBase Shell,并使用
whoami命令报告您的用户所属的组。在此示例中,该用户被报告为services组的成员。
hbase> whoami
service (auth:KERBEROS)
groups: services
Administration
可以从 HBase Shell 或通过 API 执行 Management 任务。
API Examples
下面的许多 API 示例均来自源文件* hbase-server/src/test/java/org/apache/hadoop/hbase/security/access/TestAccessController.java 和 hbase-server/src/test/java/org/apache/hadoop/hbase/security/access/SecureTestUtil.java *。
示例及其来源文件均不是公共 HBase API 的一部分,并且仅出于说明目的而提供。有关使用说明,请参阅官方 API。
- 用户和组 Management
用户和组在目录的 HBase 外部维护。
- 授予对命名空间,表,列族或单元格的访问权限
授予语句有几种不同类型的语法。第一个,也是最熟悉的,如下,表和列族是可选的:
grant 'user', 'RWXCA', 'TABLE', 'CF', 'CQ'
可以通过相同的方式为组和用户授予访问权限,但是组前面带有@符号。以相同的方式,以相同的方式指定表和名称空间,但是名称空间以@符号为前缀。
如本例所示,还可以在单个语句中授予对同一资源的多个权限。第一个子句将用户 Map 到 ACL,第二个子句指定资源。
Note
HBase Shell 在单元级别授予和撤消访问的支持是用于测试和验证支持,不应用于生产用途,因为它不会将权限应用于尚不存在的单元。应用单元格级别权限的正确方法是在存储值时在应用程序代码中进行操作。
ACL 粒度和评估 Sequences
从最小粒度到最精细粒度对 ACL 进行评估,并且在达到授予许可的 ACL 时,评估将停止。这意味着单元 ACL 不会以较小的粒度覆盖 ACL。
例子 14. HBase Shell
- Global:
hbase> grant '@admins', 'RWXCA'
- Namespace:
hbase> grant 'service', 'RWXCA', '@test-NS'
- Table:
hbase> grant 'service', 'RWXCA', 'user'
- Column Family:
hbase> grant '@developers', 'RW', 'user', 'i'
- Column Qualifier:
hbase> grant 'service, 'RW', 'user', 'i', 'foo'
- Cell:
授予单元 ACL 的语法使用以下语法:
grant <table>, \
{ '<user-or-group>' => \
'<permissions>', ... }, \
{ <scanner-specification> }
*<user-or-group> *是用户名或组名,如果是组,则以
@作为前缀。*<permissions> *是包含任何或所有“ RWXCA”的字符串,尽管只有 R 和 W 在单元格范围内才有意义。
*<scanner-specification> *是'scan'shell 命令使用的扫描仪规范语法和约定。有关扫描仪规格的一些示例,请发出以下 HBase Shell 命令。
hbase> help "scan"
如果需要启用 ACL 单元格,则 hbase-site.xml 中的 hfile.format.version 选项应大于或等于 3,并且 hbase.security.access.early_out 选项应设置为 false。在“ pii”列中与过滤器匹配的单元格上,对“ testuser”用户具有访问权限,对“开发者”组具有读/写访问权限。
hbase> grant 'user', \
{ '@developers' => 'RW', 'testuser' => 'R' }, \
{ COLUMNS => 'pii', FILTER => "(PrefixFilter ('test'))" }
Shell 程序将使用给定的标准运行扫描程序,用新的 ACL 重写找到的单元,然后将其存储回其精确坐标。
例子 15. API
下面的示例显示如何在表级别授予访问权限。
public static void grantOnTable(final HBaseTestingUtility util, final String user,
final TableName table, final byte[] family, final byte[] qualifier,
final Permission.Action... actions) throws Exception {
SecureTestUtil.updateACLs(util, new Callable<Void>() {
@Override
public Void call() throws Exception {
try (Connection connection = ConnectionFactory.createConnection(util.getConfiguration());
Table acl = connection.getTable(AccessControlLists.ACL_TABLE_NAME)) {
BlockingRpcChannel service = acl.coprocessorService(HConstants.EMPTY_START_ROW);
AccessControlService.BlockingInterface protocol =
AccessControlService.newBlockingStub(service);
AccessControlUtil.grant(null, protocol, user, table, family, qualifier, false, actions);
}
return null;
}
});
}
要在单元级别授予权限,可以使用Mutation.setACL方法:
Mutation.setACL(String user, Permission perms)
Mutation.setACL(Map<String, Permission> perms)
具体来说,此示例为特定 Put 操作中包含的任何单元格上的名为user1的用户提供读取权限:
put.setACL("user1", new Permission(Permission.Action.READ))
- 撤消命名空间,表,列族或单元格中的访问控制
revoke命令和 API 是 Grant 命令和 API 的双胞胎,语法完全相同。唯一的 exception 是您不能撤消单元级别的权限。您只能撤消先前已授予的访问权限,并且revoke语句与显式拒绝资源不同。
Note
HBase Shell 对授予和撤消访问的支持是用于测试和验证支持,不应用于生产用途,因为它不会将权限应用于尚不存在的单元。正确应用单元级别权限的方法是在存储值时在应用程序代码中进行操作。
例子 16.撤销对表的访问
public static void revokeFromTable(final HBaseTestingUtility util, final String user,
final TableName table, final byte[] family, final byte[] qualifier,
final Permission.Action... actions) throws Exception {
SecureTestUtil.updateACLs(util, new Callable<Void>() {
@Override
public Void call() throws Exception {
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table acl = connection.getTable(util.getConfiguration(), AccessControlLists.ACL_TABLE_NAME);
try {
BlockingRpcChannel service = acl.coprocessorService(HConstants.EMPTY_START_ROW);
AccessControlService.BlockingInterface protocol =
AccessControlService.newBlockingStub(service);
ProtobufUtil.revoke(protocol, user, table, family, qualifier, actions);
} finally {
acl.close();
}
return null;
}
});
}
- 显示用户的有效权限
HBase Shell
hbase> user_permission 'user'
hbase> user_permission '.*'
hbase> user_permission JAVA_REGEX
例子 17. API
public static void verifyAllowed(User user, AccessTestAction action, int count) throws Exception {
try {
Object obj = user.runAs(action);
if (obj != null && obj instanceof List<?>) {
List<?> results = (List<?>) obj;
if (results != null && results.isEmpty()) {
fail("Empty non null results from action for user '" ` user.getShortName() ` "'");
}
assertEquals(count, results.size());
}
} catch (AccessDeniedException ade) {
fail("Expected action to pass for user '" ` user.getShortName() ` "' but was denied");
}
}
63.3. 可见性标签
可见性标签控件只能用于允许与给定标签关联的用户或主体读取或访问带有该标签的单元格。例如,您可能标记了单元格top-secret,而只将对该标签的访问权限授予了managers组。可见性标签是使用标签实现的,标签是 HFile v3 的一项功能,可让您按单元存储元数据。标签是字符串,可以使用逻辑运算符(&,|或!)并使用括号将标签组合为表达式。除了基本格式正确之外,HBase 不会对表达式进行任何形式的验证。可见性标签本身没有含义,可以用来表示敏感度级别,特权级别或任何其他任意语义。
如果用户的标签与单元格的标签或表达式不匹配,则拒绝用户访问该单元格。
在 HBase 0.98.6 和更高版本中,可见性标签和表达式支持 UTF-8 编码。使用org.apache.hadoop.hbase.security.visibility.VisibilityClient类提供的addLabels(conf, labels)方法创建标签并通过“扫描”或“获取”在“授权”中传递标签时,标签可以包含 UTF-8 字符以及可见性标签中通常使用的逻辑运算符,并带有普通的 Java 表示法,而无需任何其他操作转义方法。但是,当您通过 Mutation 传递 CellVisibility 表达式时,如果使用 UTF-8 字符或逻辑运算符,则必须使用CellVisibility.quote()方法将该表达式括起来。参见TestExpressionParser和源文件* hbase-client/src/test/java/org/apache/hadoop/hbase/client/TestScan.java *。
用户在 Put 操作期间向单元格添加可见性表达式。在默认配置中,用户不需要访问标签即可为其标记单元格。此行为由配置选项hbase.security.visibility.mutations.checkauths控制。如果将此选项设置为true,则用户必须将与突变相关的用户正在修改的标签与该用户相关联,否则该突变将失败。在“获取”或“扫描”过程中确定用户是否有权读取标记的单元格,并过滤掉不允许用户读取的结果。这将产生与返回结果相同的 I/O 损失,但会减少网络上的负载。
还可以在“删除”操作期间指定可见性标签。有关可见性标签和删除的详细信息,请参见HBASE-10885。
当 RegionServer 首次接收到请求时,用户的有效标签集将构建在 RPC 上下文中。用户与标签关联的方式是可插入的。默认插件会通过添加到“获取”或“扫描”中的“授权”中指定的标签,并根据主叫用户的已认证标签列表检查这些标签。当 Client 端传递未经用户验证的标签时,默认插件会将其删除。您可以通过Get#setAuthorizations(Authorizations(String,…))和Scan#setAuthorizations(Authorizations(String,…));方法传递用户身份验证标签的子集。
可以向组授予与用户相同的可见性标签。组以@符号为前缀。当检查用户的可见性标签时,服务器将包括用户所属的组的可见性标签以及用户自己的标签。当使用 API VisibilityClient#getAuths或 Shell 命令get_auths检索用户的可见性标签时,我们将仅返回专门为该用户添加的标签,而不是组级别标签。
可见性标签访问检查由 VisibilityController 协处理器执行。您可以使用界面VisibilityLabelService提供自定义实现和/或控制将可见性标签与单元格一起存储的方式。有关一个示例,请参见源文件* hbase-server/src/test/java/org/apache/hadoop/hbase/security/visibility/TestVisibilityLabelsWithCustomVisLabService.java *。
可见性标签可以与 ACL 结合使用。
Note
必须先明确定义标签,然后才能在可见性标签中使用它们。请参阅以下示例,了解如何完成此操作。
Note
当前尚无法确定已将哪些标签应用于单元格。有关详情,请参见HBASE-12470。
Note
可见性标签当前不适用于超级用户。
表 10.可见性表达的示例
| Expression | Interpretation |
|---|---|
fulltime |
允许访问与全职标签关联的用户。 |
!public |
允许访问未与公共标签关联的用户。 |
( secret | topsecret ) & !probationary |
允许访问与 Secret 或最高机密标签关联但与试用标签不关联的用户。 |
63.3.1. 服务器端配置
作为前提,执行过程:服务器端基本配置中的步骤。
通过在* hbase-site.xml *中设置以下属性来安装和配置 VisibilityController 协处理器。这些属性采用类名列表。
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.visibility.VisibilityController</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.visibility.VisibilityController</value>
</property>
Note
如果同时使用 AccessController 和 VisibilityController 协处理器,则 AccessController 必须排在列表的首位,因为在两个组件都处于活动状态的情况下,VisibilityController 会将其系统表上的访问控制委托给 AccessController。
- Adjust Configuration
默认情况下,用户可以使用任何标签来标记单元格,包括与它们不相关的标签,这意味着用户可以放置他无法读取的数据。例如,即使用户未与该标签相关联,用户也可以使用(假设的)“最高机密”标签对其进行标签。如果只希望用户能够使用与其关联的标签来标记单元格,请将hbase.security.visibility.mutations.checkauths设置为true。在这种情况下,如果突变使用了用户未关联的标签,则它将失败。
- 分发配置并重新启动集群以使更改生效。
63.3.2. Administration
可以使用 HBase Shell 或 Java API 执行 Management 任务。为了定义可见性标签列表并将标签与用户相关联,HBase Shell 可能更简单。
API Examples
本节中的许多 Java API 示例均来自源文件* hbase-server/src/test/java/org/apache/hadoop/hbase/security/visibility/TestVisibilityLabels.java *。有关更多上下文,请参考该文件或 API 文档。
这些示例或它们的源文件均不是公共 HBase API 的一部分,并且仅出于说明目的而提供。有关使用说明,请参阅官方 API。
- 定义可见性标签列表
HBase Shell
hbase> add_labels [ 'admin', 'service', 'developer', 'test' ]
例子 18. Java API
public static void addLabels() throws Exception {
PrivilegedExceptionAction<VisibilityLabelsResponse> action = new PrivilegedExceptionAction<VisibilityLabelsResponse>() {
public VisibilityLabelsResponse run() throws Exception {
String[] labels = { SECRET, TOPSECRET, CONFIDENTIAL, PUBLIC, PRIVATE, COPYRIGHT, ACCENT,
UNICODE_VIS_TAG, UC1, UC2 };
try {
VisibilityClient.addLabels(conf, labels);
} catch (Throwable t) {
throw new IOException(t);
}
return null;
}
};
SUPERUSER.runAs(action);
}
- 将标签与用户相关联
HBase Shell
hbase> set_auths 'service', [ 'service' ]
hbase> set_auths 'testuser', [ 'test' ]
hbase> set_auths 'qa', [ 'test', 'developer' ]
hbase> set_auths '@qagroup', [ 'test' ]
例子 19. Java API
public void testSetAndGetUserAuths() throws Throwable {
final String user = "user1";
PrivilegedExceptionAction<Void> action = new PrivilegedExceptionAction<Void>() {
public Void run() throws Exception {
String[] auths = { SECRET, CONFIDENTIAL };
try {
VisibilityClient.setAuths(conf, auths, user);
} catch (Throwable e) {
}
return null;
}
...
- 清除用户标签
HBase Shell
hbase> clear_auths 'service', [ 'service' ]
hbase> clear_auths 'testuser', [ 'test' ]
hbase> clear_auths 'qa', [ 'test', 'developer' ]
hbase> clear_auths '@qagroup', [ 'test', 'developer' ]
例子 20. Java API
...
auths = new String[] { SECRET, PUBLIC, CONFIDENTIAL };
VisibilityLabelsResponse response = null;
try {
response = VisibilityClient.clearAuths(conf, auths, user);
} catch (Throwable e) {
fail("Should not have failed");
...
}
- 将标签或表达式应用于单元格
仅在写入数据时才应用标签。标签与单元的给定版本相关联。
HBase Shell
hbase> set_visibility 'user', 'admin|service|developer', { COLUMNS => 'i' }
hbase> set_visibility 'user', 'admin|service', { COLUMNS => 'pii' }
hbase> set_visibility 'user', 'test', { COLUMNS => [ 'i', 'pii' ], FILTER => "(PrefixFilter ('test'))" }
Note
HBase Shell 支持将标签或权限应用于单元格是为了进行测试和验证支持,不应将其用于生产用途,因为它不会将标签应用于尚不存在的单元格。正确应用单元格级别标签的方法是在存储值时在应用程序代码中进行操作。
例子 21. Java API
static Table createTableAndWriteDataWithLabels(TableName tableName, String... labelExps)
throws Exception {
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Table table = NULL;
try {
table = TEST_UTIL.createTable(tableName, fam);
int i = 1;
List<Put> puts = new ArrayList<Put>();
for (String labelExp : labelExps) {
Put put = new Put(Bytes.toBytes("row" + i));
put.add(fam, qual, HConstants.LATEST_TIMESTAMP, value);
put.setCellVisibility(new CellVisibility(labelExp));
puts.add(put);
i++;
}
table.put(puts);
} finally {
if (table != null) {
table.flushCommits();
}
}
63.3.3. 读取带有标签的单元格
发出“扫描”或“获取”时,HBase 使用您的默认授权集来过滤掉您无权访问的单元。超级用户可以使用set_auths HBase Shell 命令或VisibilityClient.setAuths()方法来设置给定用户的默认授权集。
您可以通过在 HBase Shell 中传递 AUTHORIZATIONS 选项或在Scan.setAuthorizations()方法(如果使用 API)的情况下在“扫描”或“获取”过程中指定其他授权。该授权将与您的默认设置结合在一起作为附加过滤器。它将进一步过滤您的结果,而不是授予您其他授权。
HBase Shell
hbase> get_auths 'myUser'
hbase> scan 'table1', AUTHORIZATIONS => ['private']
例子 22. Java API
...
public Void run() throws Exception {
String[] auths1 = { SECRET, CONFIDENTIAL };
GetAuthsResponse authsResponse = null;
try {
VisibilityClient.setAuths(conf, auths1, user);
try {
authsResponse = VisibilityClient.getAuths(conf, user);
} catch (Throwable e) {
fail("Should not have failed");
}
} catch (Throwable e) {
}
List<String> authsList = new ArrayList<String>();
for (ByteString authBS : authsResponse.getAuthList()) {
authsList.add(Bytes.toString(authBS.toByteArray()));
}
assertEquals(2, authsList.size());
assertTrue(authsList.contains(SECRET));
assertTrue(authsList.contains(CONFIDENTIAL));
return null;
}
...
63.3.4. 实施自己的可见性标签算法
解释为给定的获取/扫描请求验证的标签是一种可插入的算法。
您可以使用属性hbase.regionserver.scan.visibility.label.generator.class指定一个或多个自定义插件。第一个ScanLabelGenerator的输出将是下一个ScanLabelGenerator的 Importing,直到列表末尾。
默认实现是在HBASE-12466中实现的,它将加载两个插件FeedUserAuthScanLabelGenerator和DefinedSetFilterScanLabelGenerator。参见读取带有标签的单元格。
63.3.5. 将可见性标签复制为字符串
如以上各节所述,接口VisibilityLabelService可用于实现在单元格中存储可见性表达式的另一种方式。启用复制的群集还必须将可见性表达式复制到对等群集。如果将DefaultVisibilityLabelServiceImpl用作VisibilityLabelService的实现,则基于标签表中存储的每个可见性标签的序号,所有可见性表达式都将转换为相应的表达式。在复制过程中,可见细胞也将以基于序数的表达完整地复制。对等群集可能不具有相同的labels表,并且具有相同的可见性标签 SequencesMap。在这种情况下,复制普通字母毫无意义。如果复制以字符串形式传输的可见性表达式来进行复制会更好。要将可见性表达式作为字符串复制到对等集群,请创建一个RegionServerObserver配置,该配置基于VisibilityLabelService接口的实现而起作用。通过以下配置,可以将可见性表达式作为字符串复制到对等群集。有关更多详细信息,请参见HBASE-11639。
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.security.visibility.VisibilityController$VisibilityReplication</value>
</property>
63.4. 静态数据的透明加密
HBase 提供了一种机制,用于保护驻留在 HDFS 或另一个分布式文件系统中的 HFiles 和 WAL 中的静态数据。两层体系结构用于灵活和非侵入式密钥旋转。 “透明”表示在 Client 端不需要更改任何实现。写入数据时,将对其进行加密。读取后,将按需解密。
63.4.1. 这个怎么运作
Management 员为群集设置一个主密钥,该主密钥存储在密钥提供程序中,该密钥提供程序可用于每个受信任的 HBase 进程,包括 Management 工作站上的 HMaster,RegionServers 和 Client 端(例如 HBase Shell)。默认密钥提供程序已与 Java KeyStore API 以及任何支持它的密钥 Management 系统集成在一起。其他自定义密钥提供程序实现也是可能的。密钥检索机制在* hbase-site.xml *配置文件中配置。主密钥可以存储在群集服务器上,受安全的 KeyStore 文件保护,也可以存储在外部密钥服务器上,或者存储在硬件安全模块中。 HBase 进程会通过配置的密钥提供程序根据需要解析此主密钥。
接下来,可以通过创建或修改列 Descriptors 以包括两个附加属性,在模式中为每个列系列指定加密使用:加密算法的名称(当前仅支持“ AES”),以及可选的用集群主密钥包装(加密)的数据密钥。如果没有为 ColumnFamily 显式配置数据密钥,则 HBase 将为每个 HFile 创建一个随机数据密钥。与替代方案相比,这提供了安全性方面的增量改进。除非需要提供显式的数据密钥,例如在使用给定的数据密钥生成用于批量导入的加密 HFile 的情况下,否则仅在 ColumnFamily 模式元数据中指定加密算法,然后让 HBase 根据需要创建数据密钥。每列族键可促进低冲击的增量键旋转,并减小键材料外部泄漏的范围。包装的数据密钥存储在 ColumnFamily 架构元数据中,并存储在 Column Family 的每个 HFile 中,并使用集群主密钥进行加密。配置列系列进行加密后,所有新的 HFile 将被写入加密状态。为确保对所有 HFile 进行加密,请在启用此功能后触发重大压缩。
打开 HFile 时,将从 HFile 中提取数据密钥,并使用群集主密钥对其进行解密,然后将其用于解密 HFile 的其余部分。如果主密钥不可用,则 HFile 将不可读。如果远程用户由于 HDFS 权限的某些失效或从不当丢弃的媒体而以某种方式获得了对 HFile 数据的访问权限,则将无法解密数据密钥或文件数据。
也可以对 WAL 进行加密。即使 WAL 是瞬态的,在基础文件系统遭到破坏的情况下,也有必要对 WALEdits 进行加密以避免对加密列族的 HFile 保护。启用 WAL 加密后,所有 WAL 都会被加密,无论相关的 HFile 是否已加密。
63.4.2. 服务器端配置
此过程假定您正在使用默认的 Java 密钥库实现。如果您使用的是自定义实现,请查看其文档并进行相应调整。
- 使用
keytoolUtil 为 AES 加密创建适当长度的 Secret 密钥。
$ keytool -keystore /path/to/hbase/conf/hbase.jks \
-storetype jceks -storepass **** \
-genseckey -keyalg AES -keysize 128 \
-alias <alias>
将 **** **替换为密钥库文件的密码,并将\ 替换为 HBase 服务帐户的用户名或任意字符串。如果使用任意字符串,则需要配置 HBase 才能使用它,下面将对此进行介绍。指定适当的密钥大小。不要为密钥指定单独的密码,而是在出现提示时按 Return 键。
- 在密钥文件上设置适当的权限,并将其分发给所有 HBase 服务器。
上一个命令在 HBase 的* conf/目录中创建了一个名为 hbase.jks *的文件。对此文件设置权限和所有权,以使只有 HBase 服务帐户用户可以读取该文件,并将密钥安全地分发给所有 HBase 服务器。
- 配置 HBase 守护程序。
在区域服务器上的* hbase-site.xml *中设置以下属性,以将 HBase 守护程序配置为使用由 KeyStore 文件支持的密钥提供程序或检索集群主密钥。在下面的示例中,将 **** **替换为密码。
<property>
<name>hbase.crypto.keyprovider</name>
<value>org.apache.hadoop.hbase.io.crypto.KeyStoreKeyProvider</value>
</property>
<property>
<name>hbase.crypto.keyprovider.parameters</name>
<value>jceks:///path/to/hbase/conf/hbase.jks?password=****</value>
</property>
默认情况下,HBase 服务帐户名将用于解析群集主密钥。但是,您可以使用任意别名存储它(在keytool命令中)。在这种情况下,请将以下属性设置为您使用的别名。
<property>
<name>hbase.crypto.master.key.name</name>
<value>my-alias</value>
</property>
您还需要确保您的 HFiles 使用 HFile v3,以便使用透明加密。这是 HBase 1.0 及更高版本的默认配置。对于以前的版本,请在* hbase-site.xml *文件中设置以下属性。
<property>
<name>hfile.format.version</name>
<value>3</value>
</property>
(可选)您可以使用其他密码提供程序,即 Java 密码学加密(JCE)算法提供程序或自定义 HBase 密码实现。
JCE:
安装签名的 JCE 提供程序(支持具有 128 位密钥的
AES/CTR/NoPadding模式)以最高优先级将其添加到 JCE 站点配置文件* $ JAVA_HOME/lib/security/java.security *中。
更新* hbase-site.xml *中的
hbase.crypto.algorithm.aes.provider和hbase.crypto.algorithm.rng.provider选项。
自定义 HBase 密码:
实施
org.apache.hadoop.hbase.io.crypto.CipherProvider。将实现添加到服务器 Classpath。
更新* hbase-site.xml *中的
hbase.crypto.cipherprovider。
配置 WAL 加密。
通过设置以下属性,在每个 RegionServer 的* hbase-site.xml 中配置 WAL 加密。您也可以将它们包含在 HMaster 的 hbase-site.xml *中,但是 HMaster 没有 WAL,因此不会使用它们。
<property>
<name>hbase.regionserver.hlog.reader.impl</name>
<value>org.apache.hadoop.hbase.regionserver.wal.SecureProtobufLogReader</value>
</property>
<property>
<name>hbase.regionserver.hlog.writer.impl</name>
<value>org.apache.hadoop.hbase.regionserver.wal.SecureProtobufLogWriter</value>
</property>
<property>
<name>hbase.regionserver.wal.encryption</name>
<value>true</value>
</property>
- 在* hbase-site.xml *文件上配置权限。
由于密钥库密码存储在 hbase-site.xml 中,因此需要确保只有 HBase 用户才能使用文件所有权和权限读取* hbase-site.xml *文件。
- 重新启动集群。
将新的配置文件分发到所有节点,然后重新启动集群。
63.4.3. Administration
可以在 HBase Shell 或 Java API 中执行 Management 任务。
Java API
本节中的 Java API 示例摘自源文件* hbase-server/src/test/java/org/apache/hadoop/hbase/util/TestHBaseFsckEncryption.java *。 。
这些示例以及它们的源文件均不是公共 HBase API 的一部分,并且仅出于说明目的而提供。有关使用说明,请参阅官方 API。
在列族上启用加密
- 要在列族上启用加密,可以使用 HBase Shell 或 Java API。启用加密后,触发一次重大压缩。当主要压缩完成时,将对 HFiles 进行加密。
旋转数据键
- 要旋转数据键,请首先在列 Descriptors 中更改 ColumnFamily 键,然后触发主要压缩。压缩完成后,将使用新的数据密钥重新加密所有 HFile。在压缩完成之前,仍然可以使用旧密钥读取旧的 HFile。
在使用随机数据密钥和指定密钥之间切换
- 如果您将列族配置为使用特定键,并且想要返回使用对该列族使用随机生成的键的默认行为,请使用 Java API 更改
HColumnDescriptor,以使键ENCRYPTION_KEY不会发送任何值。
- 如果您将列族配置为使用特定键,并且想要返回使用对该列族使用随机生成的键的默认行为,请使用 Java API 更改
旋转万能钥匙
- 要旋转主密钥,请首先生成并分发新密钥。然后,更新密钥库以包含新的主密钥,并使用其他别名将旧的主密钥保留在密钥库中。接下来,将后备配置为* hbase-site.xml *文件中的旧主密钥。
63.5. 安全散装
安全模式下的批量加载比普通设置要复杂得多,因为 Client 端必须将 MapReduce 作业生成的文件的所有权转移到 HBase。安全大容量加载由名为SecureBulkLoadEndpoint的协处理器实现,协处理器使用由配置属性hbase.bulkload.staging.dir配置的暂存目录,该暂存目录默认为*/tmp/hbase-staging/*。
安全批量加载算法
- 仅一次,创建一个可在世界范围内遍历并由运行 HBase 的用户拥有的登台目录(模式 711 或
rwx—x—x)。该目录的清单将类似于以下内容:
$ ls -ld /tmp/hbase-staging
drwx--x--x 2 hbase hbase 68 3 Sep 14:54 /tmp/hbase-staging
用户将数据写到该用户拥有的安全输出目录中。例如,*/user/foo/data *。
在内部,HBase 创建一个 Secret 的登台目录,该目录可以全局读取/写入(
-rwxrwxrwx, 777)。例如,*/tmp/hbase-staging/averylongandrandomdirectoryname *。该目录的名称和位置不向用户公开。 HBaseManagement 此目录的创建和删除。用户使数据可 Global 读取和写入,然后将其移动到随机暂存目录中,然后调用
SecureBulkLoadClient#bulkLoadHFiles方法。
安全性的强度在于 Secret 目录的长度和随机性。
要启用安全的批量加载,请将以下属性添加到* hbase-site.xml *。
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.bulkload.staging.dir</name>
<value>/tmp/hbase-staging</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.token.TokenProvider,
org.apache.hadoop.hbase.security.access.AccessController,org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint</value>
</property>
63.6. 安全启用
在 hbase-2.x 之后,默认的“ hbase.security.authorization”已更改。在 hbase-2.x 之前,它默认为 true,而在更高版本的 HBase 中,默认值为 false。因此,要启用 hbase 授权,必须在* hbase-site.xml *中配置以下属性。参见HBASE-19483;
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
64.安全配置示例
此配置示例包括对 HFile v3,ACL,可见性标签的支持,以及对静态数据和 WAL 的透明加密。所有选项已在上面的部分中单独讨论。
例子 23. * hbase-site.xml *中的例子安全设置
<!-- HFile v3 Support -->
<property>
<name>hfile.format.version</name>
<value>3</value>
</property>
<!-- HBase Superuser -->
<property>
<name>hbase.superuser</name>
<value>hbase,admin</value>
</property>
<!-- Coprocessors for ACLs and Visibility Tags -->
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController,
org.apache.hadoop.hbase.security.visibility.VisibilityController,
org.apache.hadoop.hbase.security.token.TokenProvider</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController,
org.apache.hadoop.hbase.security.visibility.VisibilityController</value>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<!-- Executable ACL for Coprocessor Endpoints -->
<property>
<name>hbase.security.exec.permission.checks</name>
<value>true</value>
</property>
<!-- Whether a user needs authorization for a visibility tag to set it on a cell -->
<property>
<name>hbase.security.visibility.mutations.checkauth</name>
<value>false</value>
</property>
<!-- Secure RPC Transport -->
<property>
<name>hbase.rpc.protection</name>
<value>privacy</value>
</property>
<!-- Transparent Encryption -->
<property>
<name>hbase.crypto.keyprovider</name>
<value>org.apache.hadoop.hbase.io.crypto.KeyStoreKeyProvider</value>
</property>
<property>
<name>hbase.crypto.keyprovider.parameters</name>
<value>jceks:///path/to/hbase/conf/hbase.jks?password=***</value>
</property>
<property>
<name>hbase.crypto.master.key.name</name>
<value>hbase</value>
</property>
<!-- WAL Encryption -->
<property>
<name>hbase.regionserver.hlog.reader.impl</name>
<value>org.apache.hadoop.hbase.regionserver.wal.SecureProtobufLogReader</value>
</property>
<property>
<name>hbase.regionserver.hlog.writer.impl</name>
<value>org.apache.hadoop.hbase.regionserver.wal.SecureProtobufLogWriter</value>
</property>
<property>
<name>hbase.regionserver.wal.encryption</name>
<value>true</value>
</property>
<!-- For key rotation -->
<property>
<name>hbase.crypto.master.alternate.key.name</name>
<value>hbase.old</value>
</property>
<!-- Secure Bulk Load -->
<property>
<name>hbase.bulkload.staging.dir</name>
<value>/tmp/hbase-staging</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.token.TokenProvider,
org.apache.hadoop.hbase.security.access.AccessController,org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint</value>
</property>
示例 24. Hadoop 中的示例组 Map 器* core-site.xml *
调整这些设置以适合您的环境。
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.LdapGroupsMapping</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.url</name>
<value>ldap://server</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.user</name>
<value>Administrator@example-ad.local</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.password</name>
<value>****</value> <!-- Replace with the actual password -->
</property>
<property>
<name>hadoop.security.group.mapping.ldap.base</name>
<value>dc=example-ad,dc=local</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.user</name>
<value>(&(objectClass=user)(sAMAccountName={0}))</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.group</name>
<value>(objectClass=group)</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.member</name>
<value>member</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.group.name</name>
<value>cn</value>
</property>
Architecture
65. Overview
65.1. NoSQL?
HBase 是一种“ NoSQL”数据库。 “ NoSQL”是一个通用术语,表示该数据库不是支持 SQL 作为其主要访问语言的 RDBMS,但是 NoSQL 数据库的类型很多:BerkeleyDB 是本地 NoSQL 数据库的示例,而 HBase 在很大程度上分布式数据库。从技术上讲,HBase 实际上比“数据库”更像是“数据存储”,因为它缺少您在 RDBMS 中发现的许多功能,例如类型化的列,二级索引,触发器和高级查询语言等。
但是,HBase 具有支持线性和模块化缩放的许多功能。 HBase 群集通过添加在商品类服务器上托管的 RegionServer 来扩展。例如,如果一个群集从 10 个 RegionServers 扩展到 20 个,则它在存储和处理能力方面都会翻倍。 RDBMS 可以很好地扩展,但是只能扩展到一个点-特别是单个数据库服务器的大小-为了获得最佳性能,需要专用的硬件和存储设备。注意的 HBase 功能包括:
高度一致的读/写:HBase 不是“最终一致”的数据存储。这使得它非常适合诸如高速计数器聚合之类的任务。
自动分片:HBase 表通过区域分布在群集上,并且随着数据的增长,区域会自动拆分和重新分布。
自动 RegionServer 故障转移
Hadoop/HDFS 集成:HBase 开箱即用地支持 HDFS 作为其分布式文件系统。
MapReduce:HBase 支持通过 MapReduce 大规模并行化处理,以将 HBase 用作源和接收器。
JavaClient 端 API:HBase 支持易于使用的 Java API 进行编程访问。
Thrift/REST API:HBase 还为非 Java 前端支持 Thrift 和 REST。
块缓存和 Bloom 过滤器:HBase 支持块缓存和 Bloom 过滤器,以进行大量查询优化。
运营 Management:HBase 提供了内置的网页,以提供运营见解以及 JMXMetrics。
65.2. 什么时候应该使用 HBase?
HBase 并不适合所有问题。
首先,请确保您有足够的数据。如果您有数亿或数十亿行,那么 HBase 是一个很好的选择。如果您只有数千行/百万行,则使用传统的 RDBMS 可能是一个更好的选择,原因是您的所有数据都可能在单个节点(或两个节点)上结束,而集群的其余部分可能处于停顿状态闲。
其次,确保没有 RDBMS 提供的所有其他功能(例如,类型化的列,二级索引,事务,高级查询语言等),您就可以生存。不能简单地通过更改将基于 RDBMS 构建的应用程序“移植”到 HBase。例如 JDBC 驱动程序。考虑从 RDBMS 迁移到 HBase,作为与端口相对的完整重新设计。
第三,确保您有足够的硬件。即使少于 5 个 DataNode(由于诸如 HDFS 块复制(默认值为 3)之类的东西)加上一个 NameNode,HDFS 也不能很好地处理。
HBase 在笔记本电脑上可以很好地独立运行-但这仅应视为开发配置。
65.3. HBase 和 Hadoop/HDFS 有什么区别?
HDFS是非常适合存储大文件的分布式文件系统。它的文档指出,它不是通用文件系统,并且不提供文件中快速的单个记录查找。另一方面,HBase 构建在 HDFS 之上,并为大型表提供快速记录查找(和更新)。有时这可能是概念上的混乱点。 HBase 在内部将数据放入 HDFS 上存在的索引“ StoreFiles”中,以进行高速查找。有关 HBase 如何实现其目标的更多信息,请参见Data Model和本章的其余部分。
66.目录表
目录表hbase:meta作为 HBase 表存在,并已从 HBase Shell 的list命令中过滤掉,但实际上是一个表,与其他表一样。
66.1. hbase:meta
hbase:meta表(以前称为.META.)保留了系统中所有区域的列表,并且hbase:meta的位置存储在 ZooKeeper 中。
hbase:meta表结构如下:
Key
- 格式的区域密钥(
[table],[region start key],[region id])
Values
info:regioninfo(此区域的序列化HRegionInfo实例)info:server(包含该区域的 RegionServer 的服务器:端口)info:serverstartcode(包含该区域的 RegionServer 进程的开始时间)
当表正在拆分时,将创建另外两个列,分别称为info:splitA和info:splitB。这些列代表两个子区域。这些列的值也是序列化的 HRegionInfo 实例。分割区域后,最终将删除该行。
Note on HRegionInfo
空键用于表示表的开始和结束。起始键为空的区域是表中的第一个区域。如果某个区域同时具有空的开始键和空的结束键,则它是表中唯一的区域
在(极有可能)需要对目录元数据进行编程处理的情况下,请参阅RegionInfo.parseFromUtil。
66.2. 启动排序
首先,在 ZooKeeper 中查找hbase:meta的位置。接下来,使用服务器和起始码值更新hbase:meta。
有关 region-RegionServer 分配的信息,请参见Region-RegionServer Assignment。
67. Client
HBaseClient 端找到正在服务的特定行范围的 RegionServer。它通过查询hbase:meta表来实现。有关详情,请参见hbase:meta。找到所需的区域后,Client 端将联系为该区域提供服务的 RegionServer,而不是通过主服务器,并发出读取或写入请求。此信息被缓存在 Client 端中,因此后续请求无需经过查找过程。如果由主负载平衡器重新分配了区域,或者由于 RegionServer 已经失效,则 Client 端将重新查询目录表以确定用户区域的新位置。
有关主服务器对 HBaseClient 端通信的影响的更多信息,请参见Runtime Impact。
Management 功能通过Admin实例完成
67.1. 集群连接
API 在 HBase 1.0 中已更改。有关连接配置的信息,请参见Client 端配置和依赖关系连接到 HBase 集群。
67.1.1. 自 HBase 1.0.0 起的 API
它已被清理,并且为用户提供了针对接口而不是针对特定类型的接口。在 HBase 1.0 中,从ConnectionFactory获取Connection对象,然后根据需要从中获取Table,Admin和RegionLocator的实例。完成后,关闭获得的实例。最后,请确保在退出前清理Connection实例。 Connections是重量级对象,但是是线程安全的,因此您可以为应用程序创建一个对象并保留该实例。 Table,Admin和RegionLocator实例是轻量级的。随心所欲创建,然后通过关闭它们立即放手。有关新 HBase 1.0 API 的用法示例,请参见Client 端软件包 Javadoc 描述。
67.1.2. HBase 1.0.0 之前的 API
HTable的实例是与 1.0.0 之前的 HBase 群集进行交互的方式。 * Table实例不是线程安全的*。在任何给定时间,只有一个线程可以使用 Table 的实例。创建表实例时,建议使用相同的HBaseConfiguration实例。这将确保将 ZooKeeper 和套接字实例共享到 RegionServer,这通常是您所需要的。例如,这是首选:
HBaseConfiguration conf = HBaseConfiguration.create();
HTable table1 = new HTable(conf, "myTable");
HTable table2 = new HTable(conf, "myTable");
与此相反:
HBaseConfiguration conf1 = HBaseConfiguration.create();
HTable table1 = new HTable(conf1, "myTable");
HBaseConfiguration conf2 = HBaseConfiguration.create();
HTable table2 = new HTable(conf2, "myTable");
有关如何在 HBaseClient 端中处理连接的更多信息,请参见ConnectionFactory。
Connection Pooling
对于需要高端多线程访问的应用程序(例如,可以在单个 JVM 中服务多个应用程序线程的 Web 服务器或应用程序服务器),您可以预先创建Connection,如以下示例所示:
例子 25.预创建一个Connection
// Create a connection to the cluster.
Configuration conf = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf(tablename))) {
// use table as needed, the table returned is lightweight
}
HTablePool is Deprecated
本指南的先前版本讨论了HTablePool,在 HBase 0.94、0.95 和 0.96 中已不推荐使用HTablePool,在 0.98.1 中通过HBASE-6580或HConnection对其进行了删除,而在 HBase 1.0 中已通过Connection弃用了。请改用Connection。
67.2. WriteBuffer 和批处理方法
在 HBase 1.0 和更高版本中,不推荐使用HTable,而推荐使用Table。 Table不使用自动刷新。要进行缓冲写入,请使用 BufferedMutator 类。
在 HBase 2.0 和更高版本中,HTable不使用 BufferedMutator 执行Put操作。有关更多信息,请参考HBASE-18500。
有关写持久性的其他信息,请查看ACID semantics页。
有关_或Delete s 批处理的细粒度控制,请参见 Table 上的batch方法。
67.3. 异步 Client 端
它是 HBase 2.0 中引入的新 API,旨在提供异步访问 HBase 的功能。
您可以从ConnectionFactory获得AsyncConnection,然后从其中获取一个异步表实例以访问 HBase。完成后,关闭AsyncConnection实例(通常在程序退出时)。
对于异步表,大多数方法与旧的Table接口具有相同的含义,希望返回值通常用 CompletableFuture 包装。我们这里没有任何缓冲区,因此没有用于异步表的 close 方法,您不需要关闭它。而且它是线程安全的。
扫描有几个区别:
仍然有一个
getScanner方法返回ResultScanner。您可以按旧方式使用它,它的工作方式类似于旧ClientAsyncPrefetchScanner。有一个
scanAll方法将立即返回所有结果。它旨在为小型扫描提供一种更简单的方法,您通常希望一次获得整个结果。观察者模式。有一种扫描方法接受
ScanResultConsumer作为参数。它将结果传递给 Consumer。
请注意,AsyncTable接口已被模板化。 template 参数指定扫描使用的ScanResultConsumerBase的类型,这意味着观察者样式扫描 API 有所不同。两种类型的扫描使用者是ScanResultConsumer和AdvancedScanResultConsumer。
ScanResultConsumer需要一个单独的线程池,该线程池用于执行注册到返回的 CompletableFuture 的回调。因为使用单独的线程池可以释放 RPC 线程,所以回调可以随意执行任何操作。如果回调不快速或有疑问,请使用此选项。
AdvancedScanResultConsumer在框架线程内执行回调。不允许在回调中执行耗时的工作,否则可能会阻塞框架线程并造成非常严重的性能影响。顾名思义,它是为想要编写高性能代码的高级用户设计的。有关如何使用org.apache.hadoop.hbase.client.example.HttpProxyExample编写完全异步代码的信息,请参见org.apache.hadoop.hbase.client.example.HttpProxyExample。
67.4. 异步 Management
您可以从ConnectionFactory获得AsyncConnection,然后从其中获得AsyncAdmin实例以访问 HBase。请注意,有两种getAdmin方法可获取AsyncAdmin实例。一种方法有一个额外的线程池参数,用于执行回调。它是为普通用户设计的。另一个方法不需要线程池,并且所有回调都在框架线程内执行,因此不允许在回调中执行耗时的工作。它是为高级用户设计的。
默认的getAdmin方法将返回一个使用默认配置的AsyncAdmin实例。如果要自定义一些配置,则可以使用getAdminBuilder方法获取用于创建AsyncAdmin实例的AsyncAdminBuilder。用户可以自由地设置他们关心的配置来创建一个新的AsyncAdmin实例。
对于AsyncAdmin接口,大多数方法与旧Admin接口具有相同的含义,希望返回值通常用 CompletableFuture 包装。
对于大多数 Management 员操作,完成返回的 CompletableFuture 后,这意味着 Management 员操作也已完成。但是对于压缩操作,这仅意味着压缩请求已发送到 HBase,并且可能需要一些时间才能完成压缩操作。对于rollWALWriter方法,这仅意味着 rollWALWriter 请求已发送到区域服务器,并且可能需要一些时间才能完成rollWALWriter操作。
对于区域名称,我们仅接受byte[]作为参数类型,它可以是完整的区域名称或编码的区域名称。对于服务器名称,我们仅接受ServerName作为参数类型。对于表名,我们仅接受TableName作为参数类型。对于list*操作,如果要进行正则表达式匹配,我们仅接受Pattern作为参数类型。
67.5. 外部 Client
有关非 JavaClient 端和自定义协议的信息,请参见Apache HBase 外部 API
68.Client 端请求过滤器
Get和Scan实例可以用filters进行配置,这些实例将应用在 RegionServer 上。
过滤器可能会造成混乱,因为类型很多,最好通过了解过滤器功能组来进行过滤。
68.1. Structural
结构过滤器包含其他过滤器。
68.1.1. FilterList
FilterList代表过滤器列表,过滤器之间的关系为FilterList.Operator.MUST_PASS_ALL或FilterList.Operator.MUST_PASS_ONE。以下示例显示了两个过滤器之间的“或”(检查同一属性上的“我的值”或“我的其他值”)。
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE);
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(
cf,
column,
CompareOperator.EQUAL,
Bytes.toBytes("my value")
);
list.add(filter1);
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(
cf,
column,
CompareOperator.EQUAL,
Bytes.toBytes("my other value")
);
list.add(filter2);
scan.setFilter(list);
68.2. 栏值
68.2.1. SingleColumnValueFilter
SingleColumnValueFilter(请参阅:https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/SingleColumnValueFilter.html)可用于测试列值的等效性(CompareOperaor.EQUAL),不等式(CompareOperaor.NOT_EQUAL)或范围(例如CompareOperaor.GREATER)。以下是测试列与字符串值“ my value”的等效性的示例…
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
Bytes.toBytes("my value")
);
scan.setFilter(filter);
68.2.2. ColumnValueFilter
作为对 SingleColumnValueFilter 的补充,在 HBase-2.0.0 版本中引入了 ColumnValueFilter 仅获取匹配的单元格,而 SingleColumnValueFilter 获取匹配的单元格所属的整行(具有其他列和值)。 ColumnValueFilter 的构造函数的参数与 SingleColumnValueFilter 相同。
ColumnValueFilter filter = new ColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
Bytes.toBytes("my value")
);
scan.setFilter(filter);
注意。对于诸如“等于 family:qualifier:value”之类的简单查询,我们强烈建议使用以下方式,而不是使用 SingleColumnValueFilter 或 ColumnValueFilter:
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("family"), Bytes.toBytes("qualifier"));
ValueFilter vf = new ValueFilter(CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("value")));
scan.setFilter(vf);
...
此扫描将限制为指定的列'family:qualifier',避免扫描不相关的族和列,它们具有更好的性能,并且ValueFilter是用于进行值过滤的条件。
但是如果本书以外的查询要复杂得多,那么请视情况做出您的选择。
68.3. 列值比较器
在 Filter 包中有几个 Comparator 类值得特别提及。这些比较器与其他过滤器一起使用,例如SingleColumnValueFilter。
68.3.1. RegexStringComparator
RegexStringComparator支持用于值比较的正则表达式。
RegexStringComparator comp = new RegexStringComparator("my."); // any value that starts with 'my'
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
comp
);
scan.setFilter(filter);
有关Java 支持的 RegEx 模式的信息,请参见 Oracle JavaDoc。
68.3.2. SubstringComparator
SubstringComparator可用于确定值中是否存在给定的子字符串。比较不区分大小写。
SubstringComparator comp = new SubstringComparator("y val"); // looking for 'my value'
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
comp
);
scan.setFilter(filter);
68.3.3. BinaryPrefixComparator
68.3.4. BinaryComparator
See BinaryComparator.
68.4. 键值元数据
由于 HBase 在内部将数据存储为键值对,因此键值元数据过滤器会评估行的键(即 ColumnFamily:Column 限定符)的存在,而不是上一节中的值。
68.4.1. FamilyFilter
FamilyFilter可用于对 ColumnFamily 进行过滤。通常,与使用过滤器相比,在“扫描”中选择 ColumnFamilies 更好。
68.4.2. QualifierFilter
QualifierFilter可用于根据列(即限定符)名称进行过滤。
68.4.3. ColumnPrefixFilter
ColumnPrefixFilter可用于根据列名(即限定符)的开头部分进行过滤。
ColumnPrefixFilter 在与每一行和每个涉及的列族匹配的前缀的第一列之前搜索。它可用于有效地获取非常宽的行中的列的子集。
注意:同一列限定符可用于不同的列族。该过滤器返回所有匹配的列。
示例:查找行和族中以“ abc”开头的所有列
Table t = ...;
byte[] row = ...;
byte[] family = ...;
byte[] prefix = Bytes.toBytes("abc");
Scan scan = new Scan(row, row); // (optional) limit to one row
scan.addFamily(family); // (optional) limit to one family
Filter f = new ColumnPrefixFilter(prefix);
scan.setFilter(f);
scan.setBatch(10); // set this if there could be many columns returned
ResultScanner rs = t.getScanner(scan);
for (Result r = rs.next(); r != null; r = rs.next()) {
for (KeyValue kv : r.raw()) {
// each kv represents a column
}
}
rs.close();
68.4.4. MultipleColumnPrefixFilter
MultipleColumnPrefixFilter的行为类似于 ColumnPrefixFilter,但允许指定多个前缀。
与 ColumnPrefixFilter 一样,MultipleColumnPrefixFilter 可以高效地搜索与最低前缀匹配的第一列,并且还可以搜索前缀之间的列的过去范围。它可用于有效地从非常宽的行中获取不连续的列集。
示例:查找行和族中以“ abc”或“ xyz”开头的所有列
Table t = ...;
byte[] row = ...;
byte[] family = ...;
byte[][] prefixes = new byte[][] {Bytes.toBytes("abc"), Bytes.toBytes("xyz")};
Scan scan = new Scan(row, row); // (optional) limit to one row
scan.addFamily(family); // (optional) limit to one family
Filter f = new MultipleColumnPrefixFilter(prefixes);
scan.setFilter(f);
scan.setBatch(10); // set this if there could be many columns returned
ResultScanner rs = t.getScanner(scan);
for (Result r = rs.next(); r != null; r = rs.next()) {
for (KeyValue kv : r.raw()) {
// each kv represents a column
}
}
rs.close();
68.4.5. ColumnRangeFilter
ColumnRangeFilter允许有效的行内扫描。
ColumnRangeFilter 可以针对每个涉及的列族向前搜索第一个匹配列。它可用于有效地获取非常宽的行的列的“切片”。即您连续有一百万列,但您只想查看 bbbb-bbdd 列。
注意:同一列限定符可用于不同的列族。该过滤器返回所有匹配的列。
示例:查找“ bbbb”(包括)和“ bbdd”(包括)之间的行和族的所有列
Table t = ...;
byte[] row = ...;
byte[] family = ...;
byte[] startColumn = Bytes.toBytes("bbbb");
byte[] endColumn = Bytes.toBytes("bbdd");
Scan scan = new Scan(row, row); // (optional) limit to one row
scan.addFamily(family); // (optional) limit to one family
Filter f = new ColumnRangeFilter(startColumn, true, endColumn, true);
scan.setFilter(f);
scan.setBatch(10); // set this if there could be many columns returned
ResultScanner rs = t.getScanner(scan);
for (Result r = rs.next(); r != null; r = rs.next()) {
for (KeyValue kv : r.raw()) {
// each kv represents a column
}
}
rs.close();
注意:在 HBase 0.92 中引入
68.5. RowKey
68.5.1. RowFilter
通常最好在 Scan 上使用 startRow/stopRow 方法进行行选择,但是也可以使用RowFilter。
68.6. Utility
68.6.1. FirstKeyOnlyFilter
这主要用于行数作业。参见FirstKeyOnlyFilter。
69. Master
HMaster是主服务器的实现。主服务器负责监视群集中的所有 RegionServer 实例,并且是所有元数据更改的接口。在分布式群集中,主服务器通常在NameNode上运行。 J Mohamed Zahoor 在此博客文章HBase HMaster 体系结构中进一步介绍了 Master Architecture。
69.1. 启动行为
如果在多主服务器环境中运行,则所有主服务器都将竞争运行集群。如果活动的主服务器失去了在 ZooKeeper 中的租约(或主服务器关闭),则剩余的主服务器将争夺主服务器角色。
69.2. 运行时影响
常见的分发列表问题涉及当主服务器崩溃时,HBase 群集会发生什么情况。因为 HBaseClient 端直接与 RegionServer 通信,所以群集仍可以在“稳定状态”下运行。此外,每个Catalog Tables,hbase:meta作为 HBase 表存在,并且不驻留在主服务器中。但是,主服务器控制着关键功能,例如 RegionServer 故障转移和完成区域划分。因此,尽管在没有 Master 的情况下群集仍可以短时间运行,但应该尽快重新启动 Master。
69.3. Interface
HMasterInterface公开的方法主要是面向元数据的方法:
表(createTable,modifyTable,removeTable,启用,禁用)
ColumnFamily(addColumn,modifyColumn,removeColumn)
区域(移动,分配,取消分配)例如,当调用
Admin方法disableTable时,它由主服务器提供服务。
69.4. Processes
主服务器运行几个后台线程:
69.4.1. LoadBalancer
周期性地,当没有过渡区域时,负载均衡器将运行并移动区域以平衡集群的负载。有关配置此属性的信息,请参见Balancer。
有关区域分配的更多信息,请参见Region-RegionServer Assignment。
69.4.2. CatalogJanitor
定期检查并清理hbase:meta表。有关元表的更多信息,请参见hbase:meta。
69.5. MasterProcWAL
HMaster 将 Management 操作及其运行状态(例如,崩溃的服务器的处理,表的创建以及其他 DDL)记录到其自己的 WAL 文件中。 WAL 存储在 MasterProcWALs 目录下。主 WAL 与 RegionServer WAL 不同。保持 Master WAL 保持不变,我们可以运行状态机,该状态机可在 Master 故障发生时保持弹性。例如,如果 HMaster 在创建表的过程中遇到问题并失败,则下一个活动的 HMaster 可以接管上一个中断的 HMaster,并完成操作。从 hbase-2.0.0 开始,引入了新的 AssignmentManager(AKA AMv2),HMaster 处理区域分配操作,服务器崩溃处理,平衡等操作,全部通过 AMv2 保留所有状态并过渡到 MasterProcWAL,而不是进入 ZooKeeper。我们在 hbase-1.x 中进行。
如果您想了解有关新的 AssignmentManager 的更多信息,请参见开发人员的 AMv2 说明(和程序框架(Pv2): HBASE-12439作为其基础)。
69.5.1. MasterProcWAL 的配置
这是影响 MasterProcWAL 操作的配置列表。您不必更改默认值。
hbase.procedure.store.wal.periodic.roll.msec- Description
产生新的 WAL 的频率
Default
1h (3600000 in msec)
hbase.procedure.store.wal.roll.threshold- Description
WAL 滚动之前的大小阈值。每当 WAL 达到此大小或自上次日志滚动起经过上述时间(1 小时)后,HMaster 将生成一个新的 WAL。
Default
32MB (33554432 in byte)
hbase.procedure.store.wal.warn.threshold- Description
如果 WAL 的数量超过此阈值,则滚动时,以下消息应在 WARN 级别的 HMaster 日志中出现。
procedure WALs count=xx above the warning threshold 64. check running procedures to see if something is stuck.
Default
64
hbase.procedure.store.wal.max.retries.before.roll- Description
将插槽(记录)同步到其基础存储(例如 HDFS)时的最大重试次数。每次尝试时,以下消息应出现在 HMaster 日志中。
unable to sync slots, retry=xx
Default
3
hbase.procedure.store.wal.sync.failure.roll.max- Description
在上述 3 次重试之后,滚动日志并将重试计数重置为 0,随即开始一组新的重试。此配置控制在同步失败时日志滚动的最大尝试次数。也就是说,HMaster 总共不能同步 9 次。一旦超过,以下日志应出现在 HMaster 日志中。
Sync slots after log roll failed, abort.
Default
3
70. RegionServer
HRegionServer是 RegionServer 实现。它负责服务和 Management 区域。在分布式群集中,RegionServer 在DataNode上运行。
70.1. Interface
HRegionRegionInterface公开的方法同时包含面向数据和区域维护方法:
数据(获取,放置,删除,下一个等)
区域(splitRegion,compactRegion 等)例如,当在表上调用
Admin方法majorCompact时,Client 端实际上会遍历指定表的所有区域,并直接向每个区域请求大压缩。
70.2. Processes
RegionServer 运行各种后台线程:
70.2.1. CompactSplitThread
检查是否有裂痕并处理较小的压实。
70.2.2. MajorCompactionChecker
检查重大压实。
70.2.3. MemStoreFlusher
定期将 MemStore 中的内存中写入刷新到 StoreFiles。
70.2.4. LogRoller
定期检查 RegionServer 的 WAL。
70.3. Coprocessors
在 0.92 中添加了协处理器。有完整的协处理器博客概述发布。文档最终将移至该参考指南,但是博客是当前可用的最新信息。
70.4. 块缓存
HBase 提供了两种不同的 BlockCache 实现来缓存从 HDFS 读取的数据:默认的堆上LruBlockCache和BucketCache(通常是堆外)。本节讨论每种实现的优缺点,如何选择适当的选项以及每种实现的配置选项。
Block Cache Reporting: UI
有关缓存部署的详细信息,请参见 RegionServer UI。查看配置,大小,当前使用情况,缓存时间,甚至有关块计数和类型的详细信息。
70.4.1. 缓存选择
LruBlockCache是原始实现,并且完全在 Java 堆中。 BucketCache是可选的,主要用于使块缓存数据不在堆中,尽管BucketCache也可以是文件支持的缓存。
启用 BucketCache 时,将启用两层缓存系统。我们以前将层描述为“ L1”和“ L2”,但是从 hbase-2.0.0 开始不赞成使用此术语。 “ L1”缓存引用 LruBlockCache 的实例,“ L2”引用堆外的 BucketCache。相反,当启用 BucketCache 时,所有 DATA 块都保留在 BucketCache 层中,元块(INDEX 和 BLOOM 块)在LruBlockCache中处于堆中状态。这两个层的 Management 以及指示块之间如何移动的策略由CombinedBlockCache完成。
70.4.2. 常规缓存配置
除了缓存实现本身之外,您还可以设置一些常规配置选项来控制缓存的执行方式。参见CacheConfig。设置任何这些选项之后,请重新启动或滚动重新启动群集,以使配置生效。检查日志中是否有错误或意外行为。
另请参见块缓存的预取选项,其中讨论了HBASE-9857中引入的新选项。
70.4.3. LruBlockCache 设计
LruBlockCache 是一个 LRU 缓存,其中包含三个级别的块优先级,以允许进行扫描抵抗和内存中的 ColumnFamilies:
单一访问优先级:首次从 HDFS 加载块时,它通常具有此优先级,它将成为驱逐期间要考虑的第一个组的一部分。优点是,与获得更多使用的块相比,扫描的块更有可能被驱逐。
多路访问优先级:如果再次访问先前优先级组中的块,则它将升级到该优先级。因此,它是驱逐期间考虑的第二组的一部分。
内存中访问优先级:如果将块的族配置为“内存中”,则无论访问该对象的次数如何,它都是该优先级的一部分。目录表的配置如下。该小组是驱逐期间考虑的最后一个小组。
要将列族标记为内存中,请调用
HColumnDescriptor.setInMemory(true);
如果是通过 Java 创建表格,或者在 Shell 中创建或更改表格时设置IN_MEMORY ⇒ true:
hbase(main):003:0> create 't', {NAME => 'f', IN_MEMORY => 'true'}
有关更多信息,请参见 LruBlockCache 源。
70.4.4. LruBlockCache 的用法
默认情况下,所有用户表都启用块缓存,这意味着任何读取操作都将加载 LRU 缓存。这对于许多用例而言可能是好的,但是通常需要进行进一步的调整才能获得更好的性能。一个重要的概念是工作台尺寸或 WSS,它是:“计算问题答案所需的内存量”。对于网站,这就是在短时间内回答查询所需的数据。
计算 HBase 中可用于缓存的内存量的方法是:
number of region servers * heap size * hfile.block.cache.size * 0.99
块高速缓存的默认值为 0.4,它表示可用堆的 40%。最后一个值(99%)是 LRU 缓存中默认的可接受的加载因子,在此之后开始逐出。之所以将其包含在此等式中,是因为说有可能使用 100%的可用内存是不切实际的,因为这会使进程从加载新块的位置开始阻塞。这里有些例子:
一台将堆大小设置为 1 GB 并且默认块高速缓存大小的区域服务器将具有 405 MB 的块高速缓存可用。
20 区域服务器的堆大小设置为 8 GB,默认块缓存大小将具有 63.3 的块缓存。
100 区域服务器(堆大小设置为 24 GB,块缓存大小为 0.5)将具有约 1.16 TB 的块缓存。
您的数据不是块缓存的唯一居民。以下是您可能需要考虑的其他事项:
Catalog Tables
hbase:meta表被强制进入块缓存,并且具有内存中优先级,这意味着它们更难以驱逐。
Note
hbase:meta 表可以占用几个 MB,具体取决于区域的数量。
HFiles Indexes
-
- HFile *是 HBase 用于在 HDFS 中存储数据的文件格式。它包含一个多层索引,该索引使 HBase 无需读取整个文件即可查找数据。这些索引的大小是块大小(默认为 64KB),键的大小和要存储的数据量的因素。对于大数据集,每个区域服务器大约有 1GB 的数据是很常见的,尽管并非所有数据都将存储在缓存中,因为 LRU 会驱逐未使用的索引。
-
Keys
- 存储的值仅是图片的一半,因为每个值都与其键(行键,家庭限定符和时间戳)一起存储。参见尝试最小化行和列的大小。
Bloom Filters
- 就像 HFile 索引一样,那些数据结构(启用时)存储在 LRU 中。
当前,推荐的衡量 HFile 索引和 Bloom 过滤器大小的方法是查看区域服务器 Web UI 并签出相关 Metrics。对于密钥,可以使用 HFile 命令行工具进行采样并查找平均密钥大小度量标准。从 HBase 0.98.3 开始,您可以在 UI 的特殊“块缓存”部分中查看有关 BlockCache 统计信息和 Metrics 的详细信息。
当 WSS 不能容纳在内存中时,通常不宜使用块缓存。例如,当您在所有区域服务器的块缓存中都有 40GB 的可用空间,但需要处理 1TB 的数据时,就是这种情况。原因之一是驱逐产生的流失将不必要地触发更多垃圾收集。这是两个用例:
完全随机读取模式:在这种情况下,您几乎不会在短时间内访问同一行两次,因此命中缓存块的机会接近 0.在这样的表上设置块缓存会浪费内存和 CPU 周期,因此它将产生更多垃圾以供 JVM 处理。有关监视 GC 的更多信息,请参见JVM 垃圾收集日志。
Map 表:在典型的 MapReduce 作业中,Importing 一个表,每行将只读取一次,因此无需将它们放入块缓存中。扫描对象可以选择通过 setCaching 方法将其关闭(将其设置为 false)。如果您需要快速随机读取访问权限,则仍可以在此表上保持块缓存打开状态。一个例子是计算服务于实时流量的表中的行数,缓存该表的每个块都会造成巨大的用户流失,并且肯定会逐出当前正在使用的数据。
仅缓存 META 块(fscache 中的 DATA 块)
一种有趣的设置是仅缓存 META 块,并在每次访问时读取 DATA 块。如果 DATA 块适合 fscache,则当跨非常大的数据集进行完全随机访问时,此替代方法可能有意义。要启用此设置,请更改表并为每个列族设置BLOCKCACHE ⇒ 'false'。您仅针对此列系列“禁用” BlockCache。您永远不能禁用 META 块的缓存。从HBASE-4683 始终缓存索引和 Bloom 块开始,即使 BlockCache 被禁用,我们也将缓存 META 块。
70.4.5. 堆外块缓存
如何启用 BucketCache
BucketCache 的通常部署是通过 Management 类来进行的,该 Management 类设置了两个缓存层:由 LruBlockCache 实现的堆上缓存和由 BucketCache 实现的第二个缓存。默认情况下,Management 类为CombinedBlockCache。前面的链接描述了 CombinedBlockCache 实现的缓存“策略”。简而言之,它通过将元数据块(INDEX 和 BLOOM)保留在堆上 LruBlockCache 层中而工作,而 DATA 块则保留在 BucketCache 层中。
Pre-hbase-2.0.0 versions
- 与本地堆上的 LruBlockCache 相比,在 hbase-2.0.0 之前的版本中从 BucketCache 进行抓取时,抓取总是会变慢。但是,随着时间的流逝,延迟往往不太规律,因为在使用 BucketCache 时,由于它 Management 的是 BlockCache 分配而不是 GC,因此垃圾收集较少。如果以非堆模式部署 BucketCache,则该内存完全不受 GCManagement。这就是为什么要在 2.0.0 之前的版本中使用 BucketCache 的原因,因此延迟较小,可以减少 GC 和堆碎片,从而可以安全地使用更多的内存。请参阅 Nick Dimiduk 的BlockCache 101,以进行堆上和堆外测试的比较。另请参见比较 BlockCache 部署,它发现如果您的数据集适合您的 LruBlockCache 部署,请使用它,否则,如果您遇到高速缓存搅动(或者您希望高速缓存存在于 Java GC 的可变范围之外),请使用 BucketCache。
在 2.0.0 之前的版本中,可以配置 BucketCache,以便它接收 LruBlockCache 收回的victim。首先将所有数据和索引块缓存在 L1 中。当从 L1 驱逐时,块(或victims)将移至 L2.通过(HColumnDescriptor.setCacheDataInL1(true)或在 Shell 中设置cacheDataInL1,创建或修改列系列,并将CACHE_DATA_IN_L1设置为 true:
hbase(main):003:0> create 't', {NAME => 't', CONFIGURATION => {CACHE_DATA_IN_L1 => 'true'}}
hbase-2.0.0+ versions
- HBASE-11425 更改了 HBase 的读取路径,因此可以将读取的数据保留在堆外,从而避免将缓存的数据复制到 Java 堆上。参见Offheap read-path。在 hbase-2.0.0 中,堆外延迟接近堆上缓存延迟,并且具有不激发 GC 的附加优势。
从 HBase 2.0.0 起,L1 和 L2 的概念已被弃用。当 BucketCache 打开时,DATA 块将始终转到 BucketCache,而 INDEX/BLOOM 块将转到堆 LRUBlockCache。 cacheDataInL1支持已被删除。
BucketCache Block Cache 可以* off-heap , file 或 mmaped *文件模式进行部署。
您可以通过hbase.bucketcache.ioengine设置进行设置。将其设置为offheap将使 BucketCache 进行堆外分配,而 ioengine 设置file:PATH_TO_FILE将指示 BucketCache 使用文件缓存(尤其是当您将一些快速 I/O 附加到包装盒(例如 SSD)时,此方法很有用)。从 2.0.0 版开始,可能有多个文件支持 BucketCache。当高速缓存大小要求很高时,这特别有用。对于多个备份文件,请将 ioengine 配置为files:PATH_TO_FILE1,PATH_TO_FILE2,PATH_TO_FILE3。 BucketCache 可以配置为也使用 Map 文件。为此,将 ioengine 配置为mmap:PATH_TO_FILE。
可以部署分层设置,在此我们绕过 CombinedBlockCache 策略,并让 BucketCache 充当 L1 LruBlockCache 的严格 L2 缓存。对于这种设置,请将hbase.bucketcache.combinedcache.enabled设置为false。在此模式下,从 L1 逐出时,块进入 L2.缓存块时,首先将其缓存在 L1 中。当我们寻找缓存的块时,我们首先在 L1 中查找,如果找不到,则搜索 L2.让我们将此部署格式称为* Raw L1 L2 *。注意:此 L1 L2 模式已从 2.0.0 中删除。使用 BucketCache 时,严格来说将是 DATA 缓存,而 LruBlockCache 将缓存 INDEX/META 块。
其他 BucketCache 配置包括:指定一个位置,以在重新启动后将缓存持久化,使用多少个线程来写入缓存,等等。有关配置选项和说明,请参见CacheConfig.html类。
要检查它是否启用,请查找描述高速缓存设置的日志行。它将详细介绍 BucketCache 的部署方式。另请参见用户界面。它将详细介绍缓存分层及其配置。
BucketCache 示例配置
本示例提供了 4 GB 的堆外 BucketCache 和 1 GB 的堆上高速缓存的配置。
配置在 RegionServer 上执行。
设置hbase.bucketcache.ioengine和hbase.bucketcache.size> 0 将启用CombinedBlockCache。让我们假设 RegionServer 已设置为与 5G 堆一起运行:HBASE_HEAPSIZE=5g。
- 首先,编辑 RegionServer 的* hbase-env.sh *并将
HBASE_OFFHEAPSIZE设置为大于所需堆外大小的值,在这种情况下为 4 GB(表示为 4G)。让我们将其设置为 5G。对于我们的堆外缓存,这将是 4G;对于堆外内存的任何其他用途,它将是 1G(除了 BlockCache 之外还有其他堆外内存用户;例如,RegionServer 中的 DFSClient 可以使用堆外内存)。参见HBase 中的直接内存使用情况。
HBASE_OFFHEAPSIZE=5G
- 接下来,将以下配置添加到 RegionServer 的* hbase-site.xml *中。
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.2</value>
</property>
<property>
<name>hbase.bucketcache.size</name>
<value>4196</value>
</property>
- 重新启动或滚动重新启动群集,并检查日志中是否有任何问题。
在上面,我们将 BucketCache 设置为 4G。我们将堆上的 LruBlockCache 配置为具有 RegionServer 堆大小的 20%(0.2)(0.2 * 5G = 1G)。换句话说,您可以像通常一样配置 L1 LruBlockCache(就像没有 L2 缓存一样)。
HBASE-10641引入了在 HBase 0.98 及更高版本中为 BucketCache 的存储桶配置多个大小的功能。要配置多个存储桶大小,请将新属性hfile.block.cache.sizes(而不是hfile.block.cache.size)配置为以逗号分隔的块大小列表,从最小到最大 Sequences 排列,没有空格。目的是根据您的数据访问模式优化存储桶大小。以下示例配置了大小为 4096 和 8192 的存储桶。
<property>
<name>hfile.block.cache.sizes</name>
<value>4096,8192</value>
</property>
Direct Memory Usage In HBase
默认最大直接内存因 JVM 而异。传统上,它是 64M 或与分配堆大小(-Xmx)有某种关系,或者根本没有限制(显然是 JDK7)。 HBase 服务器使用直接内存,特别是短路读取(请参见利用本地数据),托管的 DFSClient 将分配直接内存缓冲区。 DFSClient 使用多少并不容易量化。它是打开的 HFiles * hbase.dfs.client.read.shortcircuit.buffer.size的数量,其中hbase.dfs.client.read.shortcircuit.buffer.size在 HBase 中设置为 128k-请参阅* hbase-default.xml 默认配置。如果进行堆外块缓存,则将使用直接内存。 RPCServer 使用 ByteBuffer 池。从 2.0.0 开始,这些缓冲区是堆外 ByteBuffer。启动 JVM,请确保 conf/hbase-env.sh *中的-XX:MaxDirectMemorySize设置考虑了堆外 BlockCache(hbase.bucketcache.size),DFSClient 使用情况,RPC 端 ByteBufferPool 最大大小。这必须比堆外 BlockCache 大小和 ByteBufferPool 最大大小的总和高一些。在测试中可以分配额外的 1-2 GB 的最大直接内存大小。直接内存是 Java 进程堆的一部分,与-Xmx 分配的对象堆是分开的。 MaxDirectMemorySize分配的值不得超过物理 RAM,并且由于其他内存要求和系统限制,可能小于总可用 RAM。
通过查看 UI 中的“服务器度量标准:内存”选项卡,您可以查看配置了 RegionServer 的堆内存(堆上和堆外/直接堆)以及在任何时候使用了多少内存。也可以通过 JMX 获得。特别是,服务器当前使用的直接内存可以在java.nio.type=BufferPool,name=direct bean 上找到。 Terracotta 在 Java 中使用好写表示使用堆外内存。它是针对其产品 BigMemory 的,但是提到的许多问题通常适用于任何试图摆脱困境的尝试。看看这个。
hbase.bucketcache.percentage.in.combinedcache
这是 HBase 1.0 之前的配置已删除,因为它令人困惑。您可以将其设置为 0.0 到 1.0 之间的一个 Float 值。默认值为 0.9. 如果部署使用 CombinedBlockCache,则 LruBlockCache L1 大小计算为(1 - hbase.bucketcache.percentage.in.combinedcache) * size-of-bucketcache,而 BucketCache 大小为hbase.bucketcache.percentage.in.combinedcache * size-of-bucket-cache。如果“桶高速缓存”的大小本身是配置hbase.bucketcache.size的值(如果hbase.bucketcache.size在 0 到 1.0 之间),则将其配置为兆字节或hbase.bucketcache.size * -XX:MaxDirectMemorySize。
在 1.0 中,它应该更简单。使用hfile.block.cache.size setting(不是最佳名称)将 Onheap LruBlockCache 的大小设置为 Java 堆的一部分,并且如上以绝对兆字节为单位设置 BucketCache。
70.4.6. 压缩块缓存
HBASE-11331引入了惰性 BlockCache 解压缩,简称为压缩 BlockCache。启用压缩的 BlockCache 后,数据和编码的数据块将以其磁盘上的格式缓存在 BlockCache 中,而不是在缓存之前进行解压缩和解密。
对于承载超过缓存容量的更多数据的 RegionServer,通过 SNAPPY 压缩启用此功能已显示出将吞吐量提高 50%,平均延迟提高 30%,同时将垃圾收集增加 80%,并将总 CPU 负载增加 30%。 2%。有关如何衡量和实现性能的更多详细信息,请参见 HBASE-11331.对于托管可以舒适地容纳在缓存中的数据的 RegionServer,或者如果您的工作负载对额外的 CPU 或垃圾收集负载敏感,则可能会收到较少的收益。
默认情况下,压缩的 BlockCache 是禁用的。要启用它,请在所有 RegionServer 上的* hbase-site.xml *中将hbase.block.data.cachecompressed设置为true。
70.5. RegionServer 堆读取/写入路径
70.5.1. 堆读取路径
在 hbase-2.0.0 中,HBASE-11425更改了 HBase 的读取路径,因此它可以将读取的数据保留在堆外,从而避免将缓存的数据复制到 Java 堆上。由于减少了垃圾的产生,因此减少了 GC 暂停,因此清除起来也更少。堆外读取路径的性能与堆上 LRU 缓存的性能类似/更好。从 HBase 2.0.0 开始,此功能可用。如果 BucketCache 处于file模式,则与本地堆上的 LruBlockCache 相比,访存将始终较慢。有关更多详细信息和测试结果,请参见下面的博客,该报告的读取路径为改善 Apache HBase 中的读取路径:第 1 部分,共 2 部分和Producing 的 Offheap 读取路径-阿里巴巴的故事
对于端到端的堆读取路径,首先应该有一个堆备用的堆外块缓存(BC)。将'hbase.bucketcache.ioengine'配置为* hbase-site.xml 中的堆。还要使用hbase.bucketcache.size config 指定 BC 的总容量。请记住在 hbase-env.sh *中调整'HBASE_OFFHEAPSIZE'的值。这就是我们为 RegionServer java 进程指定最大可能的堆外内存分配的方式。这应该大于堆外 BC 大小。请记住,hbase.bucketcache.ioengine没有默认值,这意味着 BC 默认情况下为 OFF(请参阅HBase 中的直接内存使用情况)。
接下来要调整的是 RPC 服务器端的 ByteBuffer 池。该池中的缓冲区将用于累积单元字节并创建结果单元块,以发送回 Client 端。 hbase.ipc.server.reservoir.enabled可用于打开或关闭此池。默认情况下,此池为 ON 并且可用。 HBase 将创建堆 ByteBuffer 并将其池化。如果要在读取路径中进行端到端的堆换,请确保不要将其关闭。如果关闭此池,则服务器将在堆上创建临时缓冲区以累积单元字节并生成结果单元块。这可能会影响高读取负载的服务器上的 GC。用户可以根据池中有多少个缓冲区以及每个 ByteBuffer 的大小来调整此池。使用配置hbase.ipc.server.reservoir.initial.buffer.size调整每个缓冲区的大小。默认值为 64 KB。
如果读取模式是随机的行读取负载,并且与 64 KB 相比,每行的大小都较小,请尝试减小此大小。当结果大小大于一个 ByteBuffer 大小时,服务器将尝试获取一个以上的缓冲区,并使结果单元块脱离其中。当池中的缓冲区用完时,服务器最终将创建临时的堆上缓冲区。
可以使用配置'hbase.ipc.server.reservoir.initial.max'调整池中 ByteBuffer 的最大数量。其值默认为配置的 64 *区域服务器处理程序(请参见 config'hbase.regionserver.handler.count')。math 计算的结果是,默认情况下,我们将 2 MB 作为每个读取结果的结果单元块大小,并且每个处理程序都将处理读取。对于 2 MB 的大小,我们需要 32 个缓冲区,每个缓冲区的大小为 64 KB(请参阅池中的默认缓冲区大小)。因此,每个处理程序需要 32 个 ByteBuffers(BB)。我们将此大小分配为最大 BB 数的两倍,以便一个处理程序可以创建响应并将其传递给 RPC Responder 线程,然后处理新请求以创建新的响应单元块(使用缓冲池)。即使响应者无法立即发送回第一个 TCP 响应,我们的计数也应允许我们池中仍然有足够的缓冲区,而不必在堆上创建临时缓冲区。再次对于较小的随机行读取,调整此最大计数。有延迟创建的缓冲区,该计数是要合并的最大计数。
如果即使使端到端读取路径脱离堆之后仍然看到 GC 问题,请在适当的缓冲池中查找问题。检查以下具有 INFO 级别的 RegionServer 日志:
Pool already reached its max capacity : XXX and no free buffers now. Consider increasing the value for 'hbase.ipc.server.reservoir.initial.max' ?
- hbase-env.sh 中 HBASE_OFFHEAPSIZE *的设置也应在 RPC 端考虑此堆外缓冲池。我们需要将 RegionServer 的最大堆外大小配置为略大于此最大池大小和堆外缓存大小的总和。 TCP 层还需要创建直接字节缓冲区以进行 TCP 通信。此外,DFSClient 端将需要一些备用资源来完成其工作,尤其是在配置了短路读取的情况下。在测试中可以分配额外的 1-2 GB 的最大直接内存大小。
如果您正在使用协处理器,并且在读取结果中引用了单元,则不要将对这些单元的引用存储在 CP 钩子方法的范围之外。有时,CP 需要存储有关单元的信息(如其行键),以便在下一个 CP 钩子调用等中进行考虑。在这种情况下,请根据用例克隆整个 Cell 的必填字段。 [请参阅 CellUtil#cloneXXX(Cell)API]
70.5.2. 堆写入路径
TODO
70.6. RegionServer 拆分实施
当写入请求由区域服务器处理时,它们会堆积在称为* memstore 的内存存储系统中。内存存储填满后,其内容将作为其他存储文件写入磁盘。此事件称为 memstore flush *。随着存储文件的累积,RegionServer 会将它们compact打包成更少,更大的文件。每次刷新或压缩完成后,该区域中存储的数据量已更改。 RegionServer 会查询区域拆分策略以确定该区域是否太大或由于其他特定于策略的原因而被拆分。如果策略建议,则将区域划分请求加入队列。
从逻辑上讲,分割区域的过程很简单。我们在区域的键空间中找到一个合适的点,该区域应将区域分成两半,然后在该点将区域的数据分为两个新区域。但是,该过程的细节并不简单。发生拆分时,新创建的“子区域”不会立即将所有数据重写为新文件。相反,它们创建类似于符号链接文件的小文件Reference files,这些文件根据拆分点指向父存储文件的顶部或底部。参考文件的使用与常规数据文件一样,但是只考虑了一半的记录。仅当没有更多对父区域的不可变数据文件的引用时,才可以分割区域。这些参考文件将通过压缩逐步清除,因此该区域将停止引用其父文件,并且可以进一步拆分。
尽管分割区域是 RegionServer 做出的本地决定,但是分割过程本身必须与许多参与者协调。 RegionServer 在拆分前后会通知 Master,更新.META.表,以便 Client 端可以发现新的子分区,并重新排列 HDFS 中的目录结构和数据文件。拆分是一个多任务过程。为了在发生错误时启用回滚,RegionServer 会在内存中保留有关执行状态的日志。 RegionServer 拆分过程中说明了 RegionServer 执行拆分的步骤。每个步骤均标有其步骤编号。来自 RegionServers 或 Master 的操作以红色显示,而来自 Client 端的操作以绿色显示。
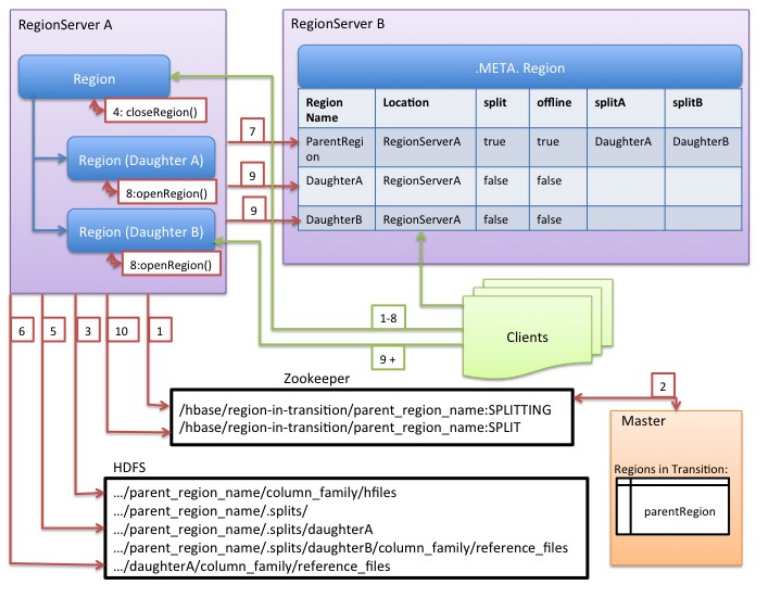
图 1. RegionServer 拆分过程
RegionServer 在本地决定分割区域,并准备分割。 SPLIT TRANSACTION 已开始. 作为第一步,RegionServer 在表上获取一个共享的读锁,以防止在拆分过程中修改架构。然后,它在 zookeeper 中的
/hbase/region-in-transition/region-name下创建一个 znode,并将 znode 的状态设置为SPLITTING。主节点了解此 znode,因为它具有父
region-in-transitionznode 的监视程序。RegionServer 在 HDFS 中父级的
region目录下创建一个名为.splits的子目录。RegionServer 关闭父区域,并在其本地数据结构中将该区域标记为脱机。 分割区域现在离线. 此时,到达父区域的 Client 请求将抛出
NotServingRegionException。Client 端将重试一些退避。关闭区域被冲洗。RegionServer 在
.splits目录下为子区域 A 和 B 创建区域目录,并创建必要的数据结构。然后,它将拆分存储文件,这意味着它会在父区域中为每个存储文件创建两个参考文件。这些参考文件将指向父区域的文件。RegionServer 在 HDFS 中创建实际的区域目录,并移动每个子级的参考文件。
RegionServer 向
.META.表发送Put请求,以在.META.表中将父级设置为脱机并添加有关子区域的信息。此时,在.META.中将没有针对女儿的单独条目。如果 Client 扫描.META.,他们将看到父区域已拆分,但直到它们出现在.META.之前,他们才知道这些子区域。此外,如果此Put至.META。成功后,parent 将被有效分割。如果 RegionServer 在此 RPC 成功之前失败,则 Master 和下一个打开该区域的 Region Server 将清除有关区域拆分的脏状态。但是,在.META.更新后,区域拆分将由 Master 进行前滚。RegionServer 并行打开子节点 A 和 B。
RegionServer 将子 A 和 B 添加到
.META.,以及它承载区域的信息。 分割区域(与 parent 相关的女儿)现在在线上. 此刻之后,Client 可以发现新区域并向他们发出请求。Client 端在本地缓存.META.条目,但是当它们向 RegionServer 或.META.发出请求时,其缓存将失效,并且他们将从.META.了解新的区域。RegionServer 将 ZooKeeper 中的 znode
/hbase/region-in-transition/region-name更新为状态SPLIT,以便主服务器可以了解它。如果需要,平衡器可以将子区域自由地重新分配给其他区域服务器。 拆分 Transaction 现已完成.拆分后,
.META.和 HDFS 仍将包含对父区域的引用。当子区域中的压缩重写数据文件时,这些引用将被删除。主服务器中的垃圾收集任务会定期检查子区域是否仍引用父区域的文件。否则,父区域将被删除。
70.7. 预写日志(WAL)
70.7.1. Purpose
*提前写入日志(WAL)*将对 HBase 中数据的所有更改记录到基于文件的存储中。在正常操作下,由于数据更改从 MemStore 移至 StoreFiles,因此不需要 WAL。但是,如果在刷新 MemStore 之前 RegionServer 崩溃或变得不可用,则 WAL 确保可以重播对数据的更改。如果写入 WAL 失败,则修改数据的整个操作将失败。
HBase 使用WAL接口的实现。通常,每个 RegionServer 仅存在一个 WAL 实例。exception 是携带* hbase:meta *的 RegionServer; * meta *表具有自己的专用 WAL。 RegionServer 将 Puts 和 Deletes 记录到其 WAL 中,然后为受影响的Store记录这些 Mutations MemStore。
The HLog
在 2.0 之前的版本中,HBase 中 WAL 的接口名为HLog。在 0.94 中,HLog 是 WAL 实施的名称。您可能会在针对这些较早版本量身定制的文档中找到对 HLog 的引用。
WAL 位于 HDFS 的*/hbase/WALs/*目录中,每个区域都有子目录。
有关预写日志概念的更多常规信息,请参阅 Wikipedia Write-Ahead Log文章。
70.7.2. WAL 提供商
在 HBase 中,有许多 WAL 实施(或“提供程序”)。每个标签都有一个简短的名称标签(不幸的是,它并不总是具有描述性)。您可以在* hbase-site.xml 中设置提供程序,并将 WAL 提供程序简称作为 hbase.wal.provider 属性上的值(使用 hbase.wal.meta_provider 为* hbase:meta 设置提供程序属性,否则它使用* hbase.wal.provider *配置的相同提供程序。
-
- asyncfs : 默认 自 hbase-2.0.0(HBASE-15536,HBASE-14790)以来的新功能。这个 AsyncFSWAL *提供程序在 RegionServer 日志中标识自己,它基于新的非阻塞 dfsclient 实现。它当前驻留在 hbase 代码库中,但目的是将其移回 HDFS 本身。 WAL 编辑将同时(“扇出”)样式写入每个 DataNode 上的每个 WAL 块副本,而不是像默认 Client 端那样在链接的管道中写入。延迟应该更好。有关实现的更多详细信息,请参见幻灯片 14 向前的小米上的 Apache HBase 改进和实践。
-
- filesystem :这是 hbase-1.x 发行版中的默认设置。它构建在阻塞的 DFSClient 上,并以经典的 DFSCLient 管道模式写入副本。在日志中,它标识为 FSHLog 或 FSHLogProvider *。
-
- multiwal :此提供程序由 asyncfs 或 filesystem 的多个实例组成。有关 multiwal *的更多信息,请参见下一部分。
在 RegionServer 日志中查找类似下面的行,以查看到哪个提供程序(下面显示了默认的 AsyncFSWALProvider):
2018-04-02 13:22:37,983 INFO [regionserver/ve0528:16020] wal.WALFactory: Instantiating WALProvider of type class org.apache.hadoop.hbase.wal.AsyncFSWALProvider
Note
由于* AsyncFSWAL 侵入了 DFSClient 实现的内部,因此即使升级了简单的补丁程序,也可以通过升级 hadoop 依赖项轻松地将其破坏。因此,如果您未明确指定 wal 提供程序,则我们将首先尝试使用 asyncfs ,如果失败,我们将回退使用 filesystem 。并注意这可能并不总是有效,因此如果由于启动 AsyncFSWAL 的问题而无法启动 HBase,请在配置文件中显式指定 filesystem *。
Note
EC 支持已添加到 hadoop-3.x 中,并且与 WAL 不兼容,因为 EC 输出流不支持 hflush/hsync。为了在 EC 目录中创建非 EC 文件,我们需要对* FileSystem *使用基于生成器的新创建 API,但是它仅在 hadoop-2.9 中引入,对于 HBase,我们仍然需要支持 hadoop-2.7 。X。因此,在找到解决方法之前,请不要对 WAL 目录启用 EC。
70.7.3. MultiWAL
每个 RegionServer 使用单个 WAL,RegionServer 必须串行写入 WAL,因为 HDFS 文件必须是 Sequences 的。这导致 WAL 成为性能瓶颈。
HBase 1.0 在HBASE-5699中引入了对 MultiWal 的支持。 MultiWAL 允许 RegionServer 通过在基础 HDFS 实例中使用多个管道来并行写入多个 WAL 流,这将增加写入期间的总吞吐量。并行化是通过按区域对传入编辑进行分区来完成的。因此,当前的实现将无助于增加单个区域的吞吐量。
使用原始 WAL 实现的 RegionServer 和使用 MultiWAL 实现的 RegionServer 都可以处理任意一组 WAL 的恢复,因此可以通过滚动重启来实现零停机配置更新。
Configure MultiWAL
要为 RegionServer 配置 MultiWAL,请通过粘贴以下 XML 将属性hbase.wal.provider的值设置为multiwal:
<property>
<name>hbase.wal.provider</name>
<value>multiwal</value>
</property>
重新启动 RegionServer,以使更改生效。
要为 RegionServer 禁用 MultiWAL,请取消设置该属性,然后重新启动 RegionServer。
70.7.4. 沃尔冲洗
TODO (describe).
70.7.5. 沃尔玛分裂
RegionServer 服务于许多区域。区域服务器中的所有区域共享相同的活动 WAL 文件。 WAL 文件中的每个编辑都包含有关它属于哪个区域的信息。当打开一个区域时,需要重播 WAL 文件中属于该区域的编辑。因此,必须按区域对 WAL 文件中的编辑进行分组,以便可以重播特定集以重新生成特定区域中的数据。按地区对 WAL 编辑进行分组的过程称为日志拆分。如果区域服务器发生故障,这是恢复数据的关键过程。
日志拆分是由 HMaster 在群集启动期间完成的,或者由 ServerShutdownHandler 在区域服务器关闭时完成的。为了保证一致性,在恢复数据之前,受影响的区域将不可用。必须恢复并重放所有 WAL 编辑,然后才能再次使给定区域可用。结果,受日志拆分影响的区域在该过程完成之前不可用。
过程:逐步拆分日志
- */hbase/WALs /<host>,\ ,\ *目录已重命名。
重命名目录非常重要,因为即使 HMaster 认为它已关闭,RegionServer 可能仍处于启动状态并接受请求。如果 RegionServer 没有立即响应,并且没有对其 ZooKeeper 会话进行心跳检测,则 HMaster 可能会将其解释为 RegionServer 故障。重命名日志目录可确保活动的但繁忙的 RegionServer 仍在使用的现有有效 WAL 文件不会被意外写入。
新目录根据以下模式命名:
/hbase/WALs/<host>,<port>,<startcode>-splitting
此类重命名目录的示例可能如下所示:
/hbase/WALs/srv.example.com,60020,1254173957298-splitting
- 每个日志文件被拆分,一次一个。
日志拆分器一次读取日志文件中的一个编辑条目,并将每个编辑条目放入与该编辑区域相对应的缓冲区中。同时,拆分器启动多个写程序线程。编写器线程将拾取相应的缓冲区,并将缓冲区中的编辑条目写入到临时恢复的编辑文件中。临时编辑文件使用以下命名模式存储到磁盘:
/hbase/<table_name>/<region_id>/recovered.edits/.temp
该文件用于将所有编辑存储在该区域的 WAL 日志中。日志拆分完成后,*。temp *文件将重命名为写入该文件的第一个日志的序列 ID。
为了确定是否已写入所有编辑,将序列 ID 与最后写入 HFile 的编辑序列进行比较。如果上次编辑的序列大于或等于文件名中包含的序列 ID,则很明显,已完成对编辑文件的所有写操作。
- 日志拆分完成后,将每个受影响的区域分配给 RegionServer。
打开区域后,将检查* recovered.edits *文件夹中是否有恢复的编辑文件。如果存在任何此类文件,请通过阅读编辑内容并将它们保存到 MemStore 来重放它们。重放所有编辑文件后,会将 MemStore 的内容写入磁盘(HFile),然后删除编辑文件。
日志拆分期间的错误处理
如果将hbase.hlog.split.skip.errors选项设置为true,则错误将按以下方式处理:
分割期间遇到的任何错误都将被记录。
有问题的 WAL 日志将移至 hbase
rootdir下的* .corrupt *目录中,WAL 的处理将 continue
如果hbase.hlog.split.skip.errors选项设置为false,则为默认值,将传播异常,并且拆分将记录为失败。参见HBASE-2958 将 hbase.hlog.split.skip.errors 设置为 false 时,分割失败,仅此而已。如果设置了此标志,我们需要做的不仅仅是失败分割。
拆分崩溃的 RegionServer 的 WAL 时如何处理 EOFException
如果在拆分日志时发生 EOFException,则即使hbase.hlog.split.skip.errors设置为false,拆分也会 continue 进行。在读取要拆分的文件集中的最后一个日志时,可能会出现 EOFException,因为 RegionServer 可能在崩溃时正在写入记录。有关背景,请参见HBASE-2643 图如何处理 eof 拆分日志
日志拆分期间的性能改进
WAL 日志的拆分和恢复可能会占用大量资源,并且会花费很长时间,具体取决于崩溃中涉及的 RegionServer 的数量和区域的大小。开发启用或禁用分布式日志拆分是为了提高日志拆分期间的性能。
启用或禁用分布式日志拆分
从 HBase 0.92 开始,默认情况下启用分布式日志处理。该设置由hbase.master.distributed.log.splitting属性控制,该属性可以设置为true或false,但默认为true。
分布式日志拆分,分步进行
配置分布式日志拆分后,HMaster 控制该过程。 HMaster 在日志拆分过程中注册每个 RegionServer,拆分日志的实际工作由 RegionServer 完成。 分布式日志拆分,分步进行中描述的日志拆分的一般过程仍然适用于此。
如果启用了分布式日志处理,则在启动群集时,HMaster 将创建一个* split log manager *实例。
拆分日志 Management 器 Management 所有需要扫描和拆分的日志文件。
拆分日志 Management 器将所有日志作为任务放置到 ZooKeeper splitWAL 节点(*/hbase/splitWAL *)中。
您可以通过发出以下
zkCli命令来查看 splitWAL 的内容。显示示例输出。
ls /hbase/splitWAL
[hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost8.sample.com%2C57020%2C1340474893275-splitting%2Fhost8.sample.com%253A57020.1340474893900,
hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost3.sample.com%2C57020%2C1340474893299-splitting%2Fhost3.sample.com%253A57020.1340474893931,
hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost4.sample.com%2C57020%2C1340474893287-splitting%2Fhost4.sample.com%253A57020.1340474893946]
输出包含一些非 ASCII 字符。解码后,它看起来要简单得多:
[hdfs://host2.sample.com:56020/hbase/WALs
/host8.sample.com,57020,1340474893275-splitting
/host8.sample.com%3A57020.1340474893900,
hdfs://host2.sample.com:56020/hbase/WALs
/host3.sample.com,57020,1340474893299-splitting
/host3.sample.com%3A57020.1340474893931,
hdfs://host2.sample.com:56020/hbase/WALs
/host4.sample.com,57020,1340474893287-splitting
/host4.sample.com%3A57020.1340474893946]
该清单表示要扫描和拆分的 WAL 文件名,这是日志拆分任务的列表。
- 拆分日志 Management 器监视日志拆分任务和工作程序。
拆分日志 Management 器负责以下正在进行的任务:
一旦拆分日志 Management 器将所有任务发布到 splitWAL znode,它就会监视这些任务节点并 await 它们被处理。
检查是否有排队 await 死亡的拆分日志工作程序。如果发现无响应的工作人员主张任务,它将重新提交这些任务。如果由于某些 ZooKeeper 异常而导致重新提交失败,则已死亡的工作程序将再次排队 await 重试。
检查是否有未分配的任务。如果找到任何内容,它将创建一个临时重新扫描节点,以便通过
nodeChildrenChangedZooKeeper 事件通知每个拆分日志工作程序重新扫描未分配的任务。检查已分配但已过期的任务。如果找到任何内容,它们将再次移回到
TASK_UNASSIGNED状态,以便可以重试。这些任务有可能分配给了慢工,或者可能已经完成。这不是问题,因为日志拆分任务具有幂等性。换句话说,同一日志拆分任务可以多次处理而不会引起任何问题。拆分日志 Management 器不断监视 HBase 拆分日志 znode。如果任何拆分日志任务节点数据已更改,则拆分日志 Management 器将检索节点数据。节点数据包含任务的当前状态。您可以使用
zkCliget命令来检索任务的当前状态。在下面的示例输出中,输出的第一行显示当前未分配任务。
get /hbase/splitWAL/hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost6.sample.com%2C57020%2C1340474893287-splitting%2Fhost6.sample.com%253A57020.1340474893945
unassigned host2.sample.com:57000
cZxid = 0×7115
ctime = Sat Jun 23 11:13:40 PDT 2012
...
根据数据已更改的任务的状态,拆分日志 Management 器执行以下操作之一:
如果任务未分配,请重新提交
对任务执行心跳(如果已分配)
如果任务已辞职,请重新提交或失败(请参见任务失败的原因)
如果任务完成但有错误,请重新提交或使任务失败(请参见任务失败的原因)
如果由于错误而无法完成任务,请重新提交或使任务失败(请参见任务失败的原因)
如果任务成功完成或失败,则将其删除
Reasons a Task Will Fail
任务已被删除。
该节点不再存在。
日志状态 Management 器无法将任务状态移动到
TASK_UNASSIGNED。重新提交的次数超过了重新提交的阈值。
- 每个 RegionServer 的拆分日志工作器都执行日志拆分任务。
每个 RegionServer 运行一个名为* split log worker *的守护程序线程,该线程负责拆分日志。守护程序线程在 RegionServer 启动时启动,并进行注册以监视 HBase znode。如果任何 splitWAL znode 子级发生更改,它将通知正在睡眠的工作线程唤醒并抓取更多任务。如果某个工作程序的当前任务的节点数据已更改,则该工作程序会检查该任务是否已由其他工作程序执行。如果是这样,工作线程将停止当前任务的工作。
工作程序会持续监视 splitWAL znode。当出现新任务时,拆分日志工作程序将检索任务路径并检查每个路径,直到找到未声明的任务并尝试声明该任务。如果索赔成功,它将尝试执行任务并根据拆分结果更新任务的state属性。此时,拆分日志工作程序将扫描另一个无人认领的任务。
拆分日志工作程序如何处理任务
它查询任务状态,并且仅在任务处于“ TASK_UNASSIGNED”状态时才采取措施。
如果任务处于
TASK_UNASSIGNED状态,则工作程序会尝试自行将状态设置为TASK_OWNED。如果无法设置状态,则其他工作人员将尝试获取它。如果任务仍未分配,则拆分日志 Management 器还将要求所有工作人员稍后重新扫描。如果工作人员成功获得任务的所有权,它将尝试再次获取任务状态,以确保它确实是异步获取的。同时,它启动一个拆分任务 Actuator 来执行实际工作:
获取 HBase 根文件夹,在根目录下创建一个 temp 文件夹,然后将日志文件拆分到 temp 文件夹。
如果拆分成功,则任务 Actuator 将任务设置为状态
TASK_DONE。如果工作程序捕获到意外的 IOException,则该任务将设置为状态
TASK_ERR。如果工作人员正在关闭,请将任务设置为状态
TASK_RESIGNED。如果任务是由其他工作人员执行的,则只需记录下来即可。
拆分日志 Management 器监视未完成的任务。
当所有任务成功完成时,拆分日志 Management 器将返回。如果所有任务均因某些失败而完成,则拆分日志 Management 器将引发异常,以便可以重试日志拆分。由于异步实现,在极少数情况下,拆分日志 Management 器无法跟踪某些已完成的任务。因此,它会定期检查其任务图中或 ZooKeeper 中是否还有未完成的任务。如果未找到,它将引发异常,以便可以立即重试日志拆分,而不必挂在这里 await 不会发生的事情。
70.7.6. WAL 压缩
可以使用 LRU 词典压缩来压缩 WAL 的内容。这可以用于加快 WAL 复制到不同数据节点的速度。该词典最多可以存储 215 个元素;超过此数字后,驱逐开始。
要启用 WAL 压缩,请将hbase.regionserver.wal.enablecompression属性设置为true。此属性的默认值为false。默认情况下,启用 WAL 压缩后会启用 WAL 标签压缩。您可以通过将hbase.regionserver.wal.tags.enablecompression属性设置为'false'来关闭 WAL 标签压缩。
WAL 压缩的一个可能弊端是,如果 WAL 中的最后一个块在写入中间终止,我们将丢失更多数据。如果在最后一个块中添加了新的字典条目,但由于突然终止而使修改后的字典无法保留,则读取最后一个块可能无法解析最后写入的条目。
70.7.7. Durability
可以在每个突变或表格的基础上设置耐久性。选项包括:
-
- SKIP_WAL *:请勿将 Mutations 写入 WAL(请参阅下一部分禁用 WAL)。
-
- ASYNC_WAL *:异步写入 WAL;不要阻止 Client 端 await 将其写入文件系统的同步,而是立即返回。编辑变为可见。同时,在后台,Mutation 将在以后的某个时间刷新到 WAL。该选项当前可能会丢失数据。请参阅 HBASE-16689.
-
- SYNC_WAL *: 默认 。在我们将成功返回给 Client 端之前,每次编辑都会同步到 HDFS。
-
- FSYNC_WAL *:在我们将成功返回给 Client 端之前,每个编辑都会同步到 HDFS 和文件系统。
不要将 Mutation 或 Table 的* ASYNC_WAL 选项与 AsyncFSWAL *编写器混淆;不幸的是,它们是不同的选择
70.7.8. 禁用 WAL
可以禁用 WAL,以提高某些特定情况下的性能。但是,禁用 WAL 会使您的数据处于危险之中。推荐这样做的唯一情况是在大负载期间。这是因为,如果发生问题,可以重新运行大容量负载,而不会丢失数据。
通过调用 HBaseClient 端字段Mutation.writeToWAL(false)来禁用 WAL。使用Mutation.setDurability(Durability.SKIP_WAL)和 Mutation.getDurability()方法来设置和获取字段的值。无法仅对特定表禁用 WAL。
Warning
如果对大容量负载以外的任何其他功能禁用 WAL,则数据将受到威胁。
71. Regions
区域是表的可用性和分布的基本元素,并且由每个列族的存储组成。对象的层次结构如下:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
有关写入 HDFS 时 HBase 文件的外观的说明,请参见浏览 HBase 对象的 HDFS。
71.1. 区域数量注意事项
通常,HBase 被设计为在每个服务器上以少量(20-200)个相对较大(5-20Gb)的区域运行。注意事项如下:
71.1.1. 为什么要保持我的地区计数低?
通常,出于多种原因,您希望在 HBase 上保持较低的区域计数。通常,每个 RegionServer 大约 100 个区域产生了最佳结果。以下是一些使区域计数保持较低的原因:
MSLAB(MemStore 本地分配缓冲区)每个 MemStore 需要 2MB(每个区域每个家庭 2MB)。 1000 个具有 2 个系列的区域使用 3.9GB 的堆,甚至还没有存储数据。注意:2MB 值是可配置的。
如果您以几乎相同的速率填充所有区域,则全局内存使用情况会导致当您拥有太多区域时会强制进行微小刷新,进而产生压缩。您想要做的最后一件事就是重写相同的数据数十次。一个示例是平均填充 1000 个区域(一个家庭),让我们考虑一下 5GB 的全局 MemStore 使用量的下限(区域服务器将有很大的堆)。一旦达到 5GB,它将强制刷新最大的区域,这时他们几乎应该都拥有约 5MB 的数据,以便刷新该数量。稍后插入 5MB,它将刷新另一个区域,该区域现在将有 5MB 以上的数据,依此类推。当前,这是限制区域数量的主要因素。有关详细公式,请参见每个 RS 的区域数-上限。
主人对很多地区都过敏,将需要大量时间来分配它们并分批移动它们。原因是它在 ZK 的使用上很繁重,并且目前还不是很同步(可以 true 改进--并且在 0.96 HBase 中进行了很多改进)。
在旧版本的 HBase(HFile v2 之前的版本,0.90 及更低版本)中,少数 RS 上的大量区域可能导致存储文件索引增加,从而增加堆使用率,并可能在 RS 上造成内存压力或 OOME
另一个问题是区域数量对 MapReduce 作业的影响。每个 HBase 区域通常有一个 Map 器。因此,每个 RS 仅托管 5 个区域可能不足以为 MapReduce 作业获得足够数量的任务,而 1000 个区域将生成太多任务。
有关配置准则,请参见确定区域数和大小。
71.2. 区域-区域服务器分配
本节介绍如何将区域分配给 RegionServers。
71.2.1. Startup
HBase 启动时,区域分配如下(简短版本):
主机在启动时调用
AssignmentManager。AssignmentManager查看hbase:meta中的现有区域分配。如果区域分配仍然有效(即,如果 RegionServer 仍然在线),则保留该分配。
如果分配无效,则调用
LoadBalancerFactory来分配区域。负载平衡器(HBase 1.0 中默认为StochasticLoadBalancer)将区域分配给 RegionServer。hbase:meta在 RegionServer 打开区域时使用 RegionServer 分配(如果需要)和 RegionServer 起始代码(RegionServer 进程的开始时间)进行更新。
71.2.2. Failover
当 RegionServer 发生故障时:
由于 RegionServer 已关闭,因此这些区域立即变得不可用。
主服务器将检测到 RegionServer 发生故障。
区域分配将被视为无效,并将像启动 Sequences 一样重新分配。
机上查询将重试,并且不会丢失。
在以下时间内,操作将切换到新的 RegionServer:
ZooKeeper session timeout + split time + assignment/replay time
71.2.3. 区域负载平衡
LoadBalancer可以定期移动区域。
71.2.4. 区域状态转换
HBase 为每个区域维护一个状态,并将该状态保留在hbase:meta中。 hbase:meta区域本身的状态保留在 ZooKeeper 中。您可以在 Master Web UI 中查看过渡区域的状态。以下是可能的区域状态列表。
可能的区域 State
OFFLINE:该地区离线且未开放OPENING:该区域正在开放中OPEN:区域已打开,RegionServer 已通知主服务器FAILED_OPEN:RegionServer 无法打开区域CLOSING:该区域正在关闭中CLOSED:RegionServer 已关闭区域并通知主服务器FAILED_CLOSE:RegionServer 无法关闭区域SPLITTING:RegionServer 通知主服务器该区域正在拆分SPLIT:RegionServer 通知主服务器该区域已完成分割SPLITTING_NEW:此区域正在通过拆分进行创建MERGING:RegionServer 通知主服务器此区域正在与另一个区域合并MERGED:RegionServer 通知主服务器此区域已被合并MERGING_NEW:此区域是通过合并两个区域来创建的
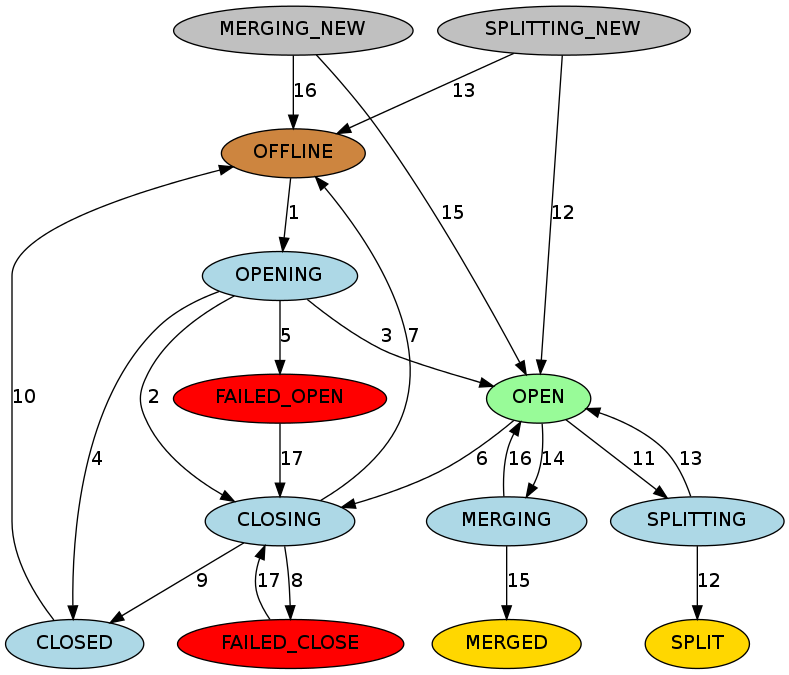
图 2.区域状态转换
Graph Legend
棕色:离线状态,一种特殊的状态,可以是瞬态的(在打开之前关闭后),终端的状态(禁用表的区域)或初始的状态(新创建的表的区域)
Palegreen:在线状态表明区域可以满足请求
浅蓝色:瞬态
红色:故障状态需要 OPS 注意
黄金:地区的最终状态已拆分/合并
灰色:通过拆分/合并创建的区域的初始状态
过渡状态说明
主服务器将区域从
OFFLINE状态移动到OPENING状态,然后尝试将该区域分配给 RegionServer。 RegionServer 可能会或可能未收到开放区域请求。主服务器重试将打开的区域请求发送到 RegionServer,直到 RPC 通过或主服务器用尽重试。 RegionServer 收到打开区域请求后,RegionServer 开始打开区域。如果主服务器用尽了重试时间,则即使 RegionServer 开始打开区域,主服务器也可以通过将区域移到
CLOSING状态并尝试关闭区域来阻止 RegionServer 打开区域。RegionServer 打开区域后,它将 continue 尝试通知主服务器,直到主服务器将区域移到
OPEN状态并通知 RegionServer。该地区现已开放。如果 RegionServer 无法打开区域,则会通知主服务器。主服务器将区域移到
CLOSED状态,并尝试在其他 RegionServer 上打开区域。如果主服务器无法在一定数量的区域中的任何一个上打开该区域,它将把该区域移到
FAILED_OPEN状态,并且直到操作员从 HBase shell 介入或服务器死机之前,不采取其他措施。主机将区域从
OPEN状态移到CLOSING状态。保留该区域的 RegionServer 可能会或可能未收到关闭区域请求。主服务器重试将关闭请求发送到服务器,直到 RPC 通过或主服务器用尽重试。如果 RegionServer 不在线或抛出
NotServingRegionException,则主服务器将区域移到OFFLINE状态,然后将其重新分配给其他 RegionServer。如果 RegionServer 处于联机状态,但在主服务器用尽重试后仍无法访问,则主服务器将区域移至
FAILED_CLOSE状态,并且在操作员从 HBase shell 进行干预或服务器死机之前不采取进一步措施。如果 RegionServer 得到关闭区域请求,它将关闭区域并通知主服务器。主服务器将区域移到
CLOSED状态,然后将其重新分配给其他 RegionServer。在分配区域之前,如果主区域处于
CLOSED状态,则主节点会自动将其移至OFFLINE状态。当 RegionServer 将要分割区域时,它将通知主服务器。主服务器将要从
OPEN分割的区域移动到SPLITTING状态,并将要创建的两个新区域添加到 RegionServer。这两个区域最初处于SPLITTING_NEW状态。通知主服务器后,RegionServer 开始分割区域。一旦超过了返回点,RegionServer 会再次通知主服务器,以便主服务器可以更新
hbase:meta表。但是,主服务器不会更新区域状态,直到服务器通知它已完成拆分为止。如果拆分成功,则将拆分区域从SPLITTING移到SPLIT状态,并将两个新区域从SPLITTING_NEW移到OPEN状态。如果拆分失败,则拆分区域将从
SPLITTING移回到OPEN状态,并且创建的两个新区域也从SPLITTING_NEW移到OFFLINE状态。当 RegionServer 即将合并两个区域时,它将首先通知主服务器。主服务器将要合并的两个区域从
OPEN状态移动到MERGING状态,并将将合并区域的内容保存到 RegionServer 的新区域。新区域最初处于MERGING_NEW状态。通知主服务器后,RegionServer 开始合并两个区域。一旦超过了不可返回的点,RegionServer 将再次通知主服务器,以便主服务器可以更新 META。但是,在 RegionServer 通知其合并已完成之前,主服务器不会更新区域状态。如果合并成功,则两个合并区域将从
MERGING状态移到MERGED状态,新区域从MERGING_NEW状态移到OPEN状态。如果合并失败,则两个合并的区域将从
MERGING移回到OPEN状态,而为保存合并区域的内容而创建的新区域从MERGING_NEW移至OFFLINE状态。对于处于
FAILED_OPEN或FAILED_CLOSE状态的区域,当操作员通过 HBase Shell 重新分配它们时,主服务器尝试再次将其关闭。
71.3. 区域服务器区域
随着时间的流逝,Region-RegionServer 的本地性是通过 HDFS 块复制来实现的。在选择写入副本的位置时,HDFSClient 端默认情况下会执行以下操作:
第一个副本写入本地节点
将第二个副本写入另一个机架上的随机节点
第三个副本与第二个副本位于相同的机架上,但在随机选择的不同节点上
随后的副本将写入群集中的随机节点上。请参阅此页面上的“复制品放置:初生婴儿步骤” *:HDFS Architecture
因此,HBase 最终在冲洗或压实之后实现了区域的局部性。在 RegionServer 故障转移情况下,可能会向 RegionServer 分配具有 nonlocalStoreFiles 的区域(因为所有副本都不是本地的),但是当在该区域中写入新数据或压缩表并重写 StoreFiles 时,它们将成为 RegionServer 的“本地”。
有关更多信息,请参见本页上的“复制品放置:第一个婴儿步骤” *:HDFS Architecture以及HBase 和 HDFS 的本地性上的 Lars George 的博客。
71.4. 区域分割
区域达到配置的阈值时会分裂。下面我们简短地讨论该主题。有关更详细的说明,请参见我们的 Enis Soztutar 的Apache HBase 区域拆分和合并。
拆分在 RegionServer 上独立运行;即大师不参加。 RegionServer 分割一个区域,使分割的区域脱机,然后将子区域添加到hbase:meta,在父级的托管 RegionServer 上打开子区域,然后将分割结果报告给主服务器。有关如何手动 Management 拆分的信息(以及执行此操作的原因),请参见Managed Splitting。
71.4.1. 自定义拆分策略
您可以使用自定义RegionSplitPolicy(HBase 0.94)覆盖默认的拆分策略。通常,自定义拆分策略应扩展 HBase 的默认拆分策略:IncreasingToUpperBoundRegionSplitPolicy。
该策略可以通过 HBase 配置全局设置,也可以基于每个表设置。
在* hbase-site.xml *中全局配置拆分策略
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>
使用 Java API 在表上配置拆分策略
HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
----
使用 HBase Shell 在表上配置拆分策略
hbase> create 'test', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'cf1'}
可以通过使用的 HBaseConfiguration 或在每个表的基础上全局设置策略:
HTableDescriptor myHtd = ...;
myHtd.setValue(HTableDescriptor.SPLIT_POLICY, MyCustomSplitPolicy.class.getName());
Note
DisabledRegionSplitPolicy策略阻止手动区域划分。
71.5. 手动区域分割
可以在创建表(预拆分)时或在以后作为 Management 操作手动拆分表。您可能出于以下一个或多个原因而选择拆分区域。可能还有其他合理的原因,但是需要手动拆分表也可能会导致方案设计出现问题。
手动拆分表的原因
您的数据按时间序列或其他类似的算法排序,该算法在表末尾对新数据进行排序。这意味着保存最后一个区域的区域服务器始终处于负载状态,而其他区域服务器则处于空闲状态或大部分处于空闲状态。另请参见单调增加行键/时间序列数据。
您在表的一个区域中构建了一个意外的热点。例如,如果某名人的新闻出现,跟踪名人搜索的应用可能会被名人的大量搜索所淹没。有关此特定方案的更多讨论,请参见perf.one.region。
在群集中的 RegionServer 数量大大增加之后,可以快速分散负载。
在散装货物之前,这可能会导致跨区域的异常负载和不均匀负载。
有关完全手动 Management 拆分的危险和潜在好处的讨论,请参见Managed Splitting。
Note
DisabledRegionSplitPolicy策略阻止手动区域划分。
71.5.1. 确定分割点
手动拆分表的目的是在仅凭好的行键设计无法解决问题的情况下,提高在整个群集之间平衡负载的机会。请记住,划分区域的方式非常取决于数据的 Feature。可能是您已经知道拆分表的最佳方法。如果不是,则拆分表的方式取决于键的类型。
Alphanumeric Rowkeys
- 如果行键以字母或数字开头,则可以在字母或数字边界处拆分表。例如,以下命令创建一个表,该表具有在每个元音处分开的区域,因此第一个区域具有 A-D,第二个区域具有 E-H,第三个区域具有 I-N,第四个区域具有 O-V,第五个区域具有 U-Z。
使用自定义算法
- HBase 提供了 RegionSplitter 工具,并使用* SplitAlgorithm *为您确定分割点。作为参数,您可以为其指定算法,所需的区域数和列族。它包括三种拆分算法。第一个是
HexStringSplit算法,它假定行键是十六进制字符串。第二种是DecimalStringSplit算法,它假定行键是在 00000000 到 99999999 之间的十进制字符串。第三种UniformSplit假定行键是随机字节数组。您可能需要使用提供的SplitAlgorithm作为模型来开发自己的SplitAlgorithm。
- HBase 提供了 RegionSplitter 工具,并使用* SplitAlgorithm *为您确定分割点。作为参数,您可以为其指定算法,所需的区域数和列族。它包括三种拆分算法。第一个是
71.6. 在线区域合并
Master 和 RegionServer 都参与在线区域合并的事件。Client 端将合并的 RPC 发送给主服务器,然后主服务器将这些区域一起移动到 RegionServer,在该服务器上负载更重的区域驻留在该服务器上。最终,主服务器将合并请求发送到此 RegionServer,然后运行该合并。与区域拆分过程相似,区域合并作为 RegionServer 上的本地事务运行。它使区域脱机,然后合并文件系统上的两个区域,从hbase:meta原子删除合并的区域,然后将合并的区域添加到hbase:meta,在 RegionServer 上打开合并的区域,然后将合并报告给主服务器。
HBase Shell 中区域合并的示例
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME', true
这是一个异步操作,调用会立即返回,而无需 await 合并完成。传递true作为可选的第三个参数将强制合并。通常,只有相邻区域可以合并。 force参数将覆盖此行为,并且仅供 maven 使用。
71.7. Store
一个 Store 托管一个 MemStore 和 0 个或多个 StoreFiles(HFiles)。Store 对应于给定区域的表的列族。
71.7.1. MemStore
MemStore 保留对 Store 的内存中修改。修改是单元格/键值。当请求刷新时,当前的 MemStore 将移至快照并被清除。 HBasecontinue 从新的 MemStore 和备份快照提供编辑,直到刷新程序报告刷新成功为止。此时,快照将被丢弃。请注意,发生刷新时,属于同一区域的 MemStores 将全部被刷新。
71.7.2. MemStore 冲洗
可以在下面列出的任何条件下触发 MemStore 刷新。最小刷新单位是每个区域,而不是单个 MemStore 级别。
当 MemStore 达到
hbase.hregion.memstore.flush.size指定的大小时,所有属于其区域的 MemStore 将被刷新到磁盘。当 MemStore 的整体使用量达到
hbase.regionserver.global.memstore.upperLimit所指定的值时,来自各个区域的 MemStores 将被刷新到磁盘上,以减少 RegionServer 中的 MemStore 的整体使用量。
刷新 Sequences 基于区域的 MemStore 使用量的降序。
区域将刷新其 MemStore,直到整个 MemStore 使用量降至hbase.regionserver.global.memstore.lowerLimit或略低于hbase.regionserver.global.memstore.lowerLimit为止。
- 当给定区域服务器的 WAL 中的 WAL 日志条目数达到
hbase.regionserver.max.logs中指定的值时,来自各个区域的 MemStores 将被刷新到磁盘上,以减少 WAL 中的日志数。
刷新 Sequences 基于时间。
具有最旧 MemStores 的区域将首先刷新,直到 WAL 计数降至hbase.regionserver.max.logs以下。
71.7.3. Scans
当 Client 端对表发出扫描时,HBase 会生成
RegionScanner个对象(每个区域一个)来满足扫描请求。RegionScanner对象包含StoreScanner对象的列表,每个列族一个。每个
StoreScanner对象还包含与相应列族的每个 StoreFile 和 HFile 对应的StoreFileScanner对象的列表,以及用于 MemStore 的KeyValueScanner对象的列表。这两个列表合并为一个,然后按升序排序,列表末尾有 MemStore 的扫描对象。
构造
StoreFileScanner对象时,该对象与MultiVersionConcurrencyControl读取点(即当前memstoreTS)相关联,从而过滤掉超出读取点的所有新更新。
71.7.4. StoreFile(HFile)
StoreFiles 是数据存放的地方。
HFile Format
- HFile *文件格式基于BigTable [2006]文件中描述的 SSTable 文件和 Hadoop 的TFile(单元测试套件和压缩工具直接取自 TFile)。 Schubert Zhang 在HFile:存储已排序键-值对的块索引文件格式上的博客文章全面介绍了 HBase 的 HFile。 Matteo Bertozzi 还提供了一个有用的描述HBase I/O:HFile。
有关更多信息,请参见 HFile 源代码。另请参阅具有内联块的 HBase 文件格式(版本 2)以获取有关 0.92 中包含的 HFile v2 格式的信息。
HFile Tool
要查看 HFile 内容的文本版本,可以使用hbase hfile工具。Importing 以下内容以查看用法:
$ ${HBASE_HOME}/bin/hbase hfile
例如,要查看文件* hdfs://10.81.47.41:8020/hbase/default/TEST/1418428042/DSMP/4759508618286845475 *的内容,请键入以下内容:
$ ${HBASE_HOME}/bin/hbase hfile -v -f hdfs://10.81.47.41:8020/hbase/default/TEST/1418428042/DSMP/4759508618286845475
如果不选择-v,则仅在 HFile 上看到摘要。查看使用hfile工具的其他用途。
HDFS 上的 StoreFile 目录结构
有关目录结构在 HDFS 上的外观的更多信息,请参阅浏览 HBase 对象的 HDFS。
71.7.5. Blocks
StoreFiles 由块组成。块大小是按每个 ColumnFamily 配置的。
压缩在 StoreFiles 中的块级别进行。有关压缩的更多信息,请参见HBase 中的压缩和数据块编码。
有关块的更多信息,请参见 HFileBlock 源代码。
71.7.6. KeyValue
KeyValue 类是 HBase 中数据存储的核心。 KeyValue 包装一个字节数组,并将偏移量和长度放入传递的数组中,该数组指定从何处开始将内容解释为 KeyValue。
字节数组中的 KeyValue 格式为:
keylength
valuelength
key
value
密钥进一步分解为:
rowlength
行(即行键)
columnfamilylength
columnfamily
columnqualifier
timestamp
键类型(例如 Put,Delete,DeleteColumn,DeleteFamily)
KeyValue 实例不跨块分割。例如,如果有一个 8 MB 的键值,则即使块大小为 64kb,该键值也将作为一个连贯的块读入。有关更多信息,请参见 KeyValue 源代码。
Example
为了强调以上几点,请检查同一行的两个不同列的两次看跌期权的处理情况:
Importing#1:
rowkey=row1, cf:attr1=value1Importing#2:
rowkey=row1, cf:attr2=value2
即使这些用于同一行,也会为每列创建一个 KeyValue:
推杆 1 的关键部分:
rowlength -----------→ 4row -----------------→ row1columnfamilylength --→ 2columnfamily --------→ cfcolumnqualifier -----→ attr1timestamp -----------→ server time of Putkeytype -------------→ Put
推杆 2 的关键部分:
rowlength -----------→ 4row -----------------→ row1columnfamilylength --→ 2columnfamily --------→ cfcolumnqualifier -----→ attr2timestamp -----------→ server time of Putkeytype -------------→ Put
了解行键,ColumnFamily 和列(也称为 columnqualifier)嵌入在 KeyValue 实例中非常重要。这些标识符越长,则 KeyValue 越大。
71.7.7. Compaction
Ambiguous Terminology
-
- StoreFile *是 HFile 的外观。在压缩方面,过去似乎普遍使用 StoreFile。
-
- Store *与 ColumnFamily 相同。 StoreFiles 与 Store 或 ColumnFamily 相关。
如果要了解有关 StoreFiles 与 HFiles 和 Stores 与 ColumnFamilies 的更多信息,请参见HBASE-11316。
当 MemStore 达到给定大小(hbase.hregion.memstore.flush.size)时,它将其内容刷新到 StoreFile。存储中的 StoreFiles 数量随时间增加。 * Compaction *是一项操作,通过将它们合并在一起来减少存储中 StoreFile 的数量,从而提高读取操作的性能。压缩可能会占用大量资源,并且取决于许多因素,压缩可能会帮助或阻碍性能。
压实分为两类:次要和主要。次要和主要压实在以下方面有所不同。
较小的压缩通常会选择少量的较小的相邻 StoreFile,然后将它们重写为单个 StoreFile。由于潜在的副作用,较小的压缩不会丢弃(过滤掉)删除或过期的版本。有关如何处理与压缩有关的删除和版本的信息,请参见压缩和删除和压缩和版本。较小压缩的最终结果是给定 Store 的 StoreFiles 更少,更大。
“重大压缩”的最终结果是每个 Store 一个 StoreFile。大型压缩还处理删除标记和最大版本。有关如何处理与压缩有关的删除和版本的信息,请参见压缩和删除和压缩和版本。
压缩和删除
在 HBase 中发生显式删除时,实际上不会删除数据。而是写一个墓碑标记。逻辑删除标记可防止查询返回数据。在大型压缩期间,实际上会删除数据,并从 StoreFile 中删除逻辑删除标记。如果由于 TTL 过期而导致删除,则不会创建逻辑删除。而是,过期的数据将被过滤掉,并且不会写回到压缩的 StoreFile 中。
压缩和版本
创建列族时,可以通过指定HColumnDescriptor.setMaxVersions(int versions)来指定要保留的最大版本数。默认值为3。如果存在超过指定最大数量的版本,则多余的版本将被滤除,并且不会写回到压缩的 StoreFile 中。
Major Compactions Can Impact Query Results
在某些情况下,如果明确删除较新的版本,则可能会无意中恢复较旧的版本。有关详细说明,请参见重大压缩会更改查询结果。这种情况只有在压实完成之前才有可能。
从理论上讲,大型压实可以提高性能。但是,在高负载的系统上,大型压缩可能需要不适当数量的资源,并对性能产生不利影响。在默认配置中,大型压缩将自动计划为每 7 天运行一次。有时这不适用于 Producing 的系统。您可以手动 Management 主要压缩。参见Managed Compactions。
压缩不执行区域合并。有关区域合并的更多信息,请参见Merge。
Compaction Switch
我们可以在区域服务器上打开和关闭压缩。关闭压缩还会中断任何当前正在进行的压缩。可以使用 hbase shell 中的“ compaction_switch”命令动态地完成此操作。如果从命令行完成,则此设置将在服务器重新启动时丢失。要持久保存跨区域服务器的更改,请修改 hbase-site.xml 中的配置 hbase.regionserver .compaction.enabled 并重新启动 HBase。
压缩策略-HBase 0.96.x 和更高版本
压缩大型 StoreFiles 或一次压缩太多 StoreFiles 可能会导致更多的 IO 负载,而群集无法处理而又不会造成性能问题。 HBase 选择压缩中要包括的 StoreFiles(以及压缩是次要压缩还是次要压缩)的方法称为* compaction policy *。
在 HBase 0.96.x 之前,只有一种压缩策略。该原始压缩策略仍可作为RatioBasedCompactionPolicy使用。新的压缩默认策略ExploringCompactionPolicy随后被反向移植到 HBase 0.94 和 HBase 0.95,并且是 HBase 0.96 和更高版本中的默认默认策略。它是在HBASE-7842中实现的。简而言之,ExploringCompactionPolicy尝试选择最佳的 StoreFiles 组以最少的工作量进行压缩,而RatioBasedCompactionPolicy选择符合条件的第一组。
无论使用哪种压缩策略,文件选择都由几个可配置的参数控制,并且以多步方法进行。这些参数将在上下文中进行解释,然后在一个表中给出,该表显示了它们的描述,默认值以及更改它们的含义。
Being Stuck
当 MemStore 太大时,需要将其内容刷新到 StoreFile。但是,存储库配置有数量限制 StoreFiles hbase.hstore.blockingStoreFiles,如果数量过多,则 MemStore 刷新必须 await,直到 StoreFile 计数减少一次或多次压缩。如果 MemStore 太大并且 StoreFiles 的数量也太多,则该算法被称为“卡住”。默认情况下,我们将 await 最多hbase.hstore.blockingWaitTime毫秒的压缩。如果这段时间到期,即使我们超出hbase.hstore.blockingStoreFiles计数,我们也将 continue 刷新。
增大hbase.hstore.blockingStoreFiles计数将允许进行刷新,但是包含许多 StoreFiles 的 Store 可能具有更高的读取延迟。尝试弄清为什么紧缩没有跟上。是导致这种情况的写入突增,还是定期发生,并且群集的写入量配置不足?
ExploringCompactionPolicy 算法
ExploringCompactionPolicy 算法在选择压缩最有利的位置之前,先考虑每个可能的相邻 StoreFile 组。
ExploringCompactionPolicy 效果特别好的一种情况是,当您批量加载数据并且批量加载创建的 StoreFiles 比 StoreFiles 更大时,StoreFiles 保留的数据早于批量加载的数据。每次需要压缩时,这都会“欺骗” HBase 选择执行大型压缩,并导致大量额外开销。借助 ExploringCompactionPolicy,大型压缩的发生频率要低得多,因为小型压缩更为有效。
通常,在大多数情况下,ExploringCompactionPolicy 是正确的选择,因此是默认的压缩策略。您还可以将 ExploringCompactionPolicy 与实验:条带压缩一起使用。
可以在 hbase-server/src/main/java/org/apache/hadoop/hbase/regionserver/compactions/ExploringCompactionPolicy.java 中检查此策略的逻辑。以下是 ExploringCompactionPolicy 的逻辑的逐步介绍。
列出 Store 中所有现有的 StoreFiles。该算法的其余部分将过滤此列表,以提供将被选择进行压缩的 HFiles 子集。
如果这是用户请求的压缩,请尝试执行请求的压缩类型,而不管通常选择什么类型。注意,即使用户请求进行大压缩,也可能无法进行大压缩。这可能是因为并非列族中的所有 StoreFile 都可以压缩,或者是因为列族中的存储太多。
某些 StoreFiles 会自动排除在考虑范围之外。这些包括:
大于
hbase.hstore.compaction.max.size的 StoreFiles由批量加载操作(明确排除压缩)创建的 StoreFiles。您可以决定从压缩中排除批量加载产生的 StoreFiles。为此,请在批量加载操作期间指定
hbase.mapreduce.hfileoutputformat.compaction.exclude参数。遍历步骤 1 中的列表,并列出所有可能的 StoreFiles 集以压缩在一起。潜在集是列表中的
hbase.hstore.compaction.min个连续 StoreFiles 的分组。对于每个集合,执行一些完整性检查,并确定这是否是可以完成的最佳压缩:如果此集中的 StoreFiles 数量(而不是 StoreFiles 的大小)小于
hbase.hstore.compaction.min或大于hbase.hstore.compaction.max,请忽略它。将这组 StoreFiles 的大小与到目前为止在列表中找到的最小压缩的大小进行比较。如果这组 StoreFiles 的大小代表可以完成的最小压缩,则在算法“卡住”的情况下存储它以用作备用,否则将不选择 StoreFiles。参见Being Stuck。
对这组 StoreFiles 中的每个 StoreFile 进行基于大小的完整性检查。
如果此 StoreFile 的大小大于
hbase.hstore.compaction.max.size,请忽略它。- 如果大小大于或等于
hbase.hstore.compaction.min.size,请根据基于文件的比率对其进行完整性检查,以查看它是否太大而无法考虑。
- 如果大小大于或等于
在以下情况下,完整性检查成功:
此集合中只有一个 StoreFile,或者
对于每个 StoreFile,其大小乘以
hbase.hstore.compaction.ratio(如果配置了非高峰时间且处于非高峰时间,则为hbase.hstore.compaction.ratio.offpeak)小于集合中其他 HFile 大小的总和。如果仍在考虑这组 StoreFiles,请将其与先前选择的最佳压缩方式进行比较。如果更好,请用此替代以前选择的最佳压实。
处理完所有可能的压实列表后,执行发现的最佳压实。如果没有选择要压缩的 StoreFiles,但是有多个 StoreFiles,则假定算法被卡住(请参阅Being Stuck),如果是,则执行在步骤 3 中发现的最小压缩。
RatioBasedCompactionPolicy Algorithm
RatioBasedCompactionPolicy 是 HBase 0.96 之前的唯一压缩策略,尽管 ExploringCompactionPolicy 现在已回迁到 HBase 0.94 和 0.95. 要使用 RatioBasedCompactionPolicy 而不是 ExploringCompactionPolicy,请在* hbase-site.xml 文件中将hbase.hstore.defaultengine.compactionpolicy.class设置为RatioBasedCompactionPolicy。要切换回 ExploringCompactionPolicy,请从 hbase-site.xml *中删除设置。
下一节将逐步介绍用于在 RatioBasedCompactionPolicy 中选择要压缩的 StoreFiles 的算法。
第一阶段是创建所有候选压缩列表。将创建一个列表,列出所有尚未在压缩队列中的 StoreFiles,并且所有 StoreFiles 都比当前正在压缩的最新文件新。此 StoreFiles 列表按序列 ID 排序。序列 ID 在将 Put 附加到预写日志(WAL)时生成,并存储在 HFile 的元数据中。
检查算法是否卡住(请参见Being Stuck,如果是,则强行进行大压缩。这是一个关键区域,其中ExploringCompactPolicy 算法通常比 RatioBasedCompactionPolicy 更好。
如果压缩是用户请求的,请尝试执行请求的压缩类型。请注意,如果并非所有 HFile 都不能进行压缩,或者存在太多 StoreFile(大于
hbase.hstore.compaction.max),则可能无法进行大型压缩。某些 StoreFiles 会自动排除在考虑范围之外。这些包括:
大于
hbase.hstore.compaction.max.size的 StoreFiles由批量加载操作(明确排除压缩)创建的 StoreFiles。您可以决定从压缩中排除批量加载产生的 StoreFiles。为此,请在批量加载操作期间指定
hbase.mapreduce.hfileoutputformat.compaction.exclude参数。大型压缩中允许的最大 StoreFiles 数量由
hbase.hstore.compaction.max参数控制。如果列表中包含的存储文件数量超过此数目,则将执行次要压缩,即使原本会进行次要压缩也是如此。但是,即使要压缩的存储文件超过hbase.hstore.compaction.max个,仍然会发生用户要求的主要压缩。如果列表包含少于
hbase.hstore.compaction.min个要压缩的 StoreFiles,则中止小型压缩。请注意,可以在单个 HFile 上执行主要压缩。它的功能是删除删除和过期的版本,并重置 StoreFile 上的位置。hbase.hstore.compaction.ratio参数的值乘以小于给定文件的 StoreFiles 之和,以确定是否在次要压缩期间选择该 StoreFile 进行压缩。例如,如果 hbase.hstore.compaction.ratio 为 1.2,FileX 为 5MB,FileY 为 2MB,FileZ 为 3MB:
5 <= 1.2 x (2 + 3) or 5 <= 6
在这种情况下,FileX 可以进行较小的压缩。如果 FileX 为 7MB,则不适合进行较小的压缩。此比率有利于较小的 StoreFile。如果还配置了hbase.offpeak.start.hour和hbase.offpeak.end.hour,则可以使用参数hbase.hstore.compaction.ratio.offpeak来配置在非高峰时段使用的其他比率。
- 如果上一次大型压缩的时间太久了,并且要压缩的 StoreFile 不止一个,那么将运行一次大型压缩,即使原本可能是次要的压缩也是如此。默认情况下,两次大压实之间的最大时间为 7 天,加上或减去 4.8 小时,并在这些参数内随机确定。在 HBase 0.96 之前,主要压实时间为 24 小时。请参阅下表中的
hbase.hregion.majorcompaction来调整或禁用基于时间的主要压缩。
压缩算法使用的参数
该表包含用于压缩的主要配置参数。此列表并不详尽。要从默认值调整这些参数,请编辑* hbase-default.xml *文件。有关所有可用配置参数的完整列表,请参见config.files。
hbase.hstore.compaction.min- 运行压缩之前必须符合压缩条件的最小 StoreFiles 数。调整
hbase.hstore.compaction.min的目的是避免最终产生太多无法压缩的微小 StoreFiles。每次在存储中有两个 StoreFiles 时,将此值设置为 2 都会导致较小的压缩,这可能不合适。如果将此值设置得太高,则所有其他值都需要相应地进行调整。在大多数情况下,默认值为适当。在以前的 HBase 版本中,参数hbase.hstore.compaction.min称为hbase.hstore.compactionThreshold。
- 运行压缩之前必须符合压缩条件的最小 StoreFiles 数。调整
默认 :3
hbase.hstore.compaction.max- 无论合格的 StoreFiles 数量如何,一次较小的压缩将选择的 StoreFiles 的最大数量。实际上,
hbase.hstore.compaction.max的值控制完成一次压缩的时间长度。将其设置为更大意味着压缩中将包含更多 StoreFiles。在大多数情况下,默认值为适当。
- 无论合格的 StoreFiles 数量如何,一次较小的压缩将选择的 StoreFiles 的最大数量。实际上,
默认 :10
hbase.hstore.compaction.min.size- 小于此大小的 StoreFile 将始终有资格进行较小的压缩。
hbase.hstore.compaction.ratio将评估此大小或更大的 StoreFile,以确定它们是否符合条件。因为此限制表示所有小于此值的 StoreFiles 的“自动包含”限制,所以在需要大量写入 1-2 MB 范围的文件的写繁重环境中,可能需要减小此值,因为每个 StoreFile 都将作为目标。进行压缩,生成的 StoreFiles 可能仍小于最小大小,需要进一步压缩。如果降低此参数,则比率检查将更快地触发。这解决了早期版本的 HBase 中遇到的一些问题,但是在大多数情况下不再需要更改此参数。
- 小于此大小的 StoreFile 将始终有资格进行较小的压缩。
默认 :128 MB
hbase.hstore.compaction.max.size- 大于此大小的 StoreFile 将从压缩中排除。提高
hbase.hstore.compaction.max.size的效果是,较少且较大的 StoreFiles 不会经常压缩。如果您认为压缩过于频繁而没有太多好处,则可以尝试提高此值。
- 大于此大小的 StoreFile 将从压缩中排除。提高
默认 :Long.MAX_VALUE
hbase.hstore.compaction.ratio- 对于较小的压缩,该比率用于确定大于
hbase.hstore.compaction.min.size的给定 StoreFile 是否适合压缩。它的作用是限制大型 StoreFile 的压缩。hbase.hstore.compaction.ratio的值表示为浮点十进制。
- 对于较小的压缩,该比率用于确定大于
很大的比例(例如 10)将产生一个巨大的 StoreFile。相反,值.25 将产生类似于 BigTable 压缩算法的行为,从而产生四个 StoreFiles。
建议在 1.0 到 1.4 之间使用一个适中的值。调整此值时,您要平衡写入成本和读取成本。将值提高(到 1.4 之类)会增加写入成本,因为您将压缩更大的 StoreFiles。但是,在读取期间,HBase 将需要搜索较少的 StoreFiles 来完成读取。如果您无法利用Bloom Filters,请考虑使用这种方法。
或者,您可以将此值降低到 1.0 之类,以减少写入的背景成本,并用于限制读取期间接触的 StoreFiles 数量。在大多数情况下,默认值为适当。
默认 :1.2F
hbase.hstore.compaction.ratio.offpeak- 如果还配置了非高峰时间,则在非高峰期压缩期间使用的压缩率(请参见下文)。表示为浮点小数。这样可以在设定的时间段内进行更积极的压缩(如果将其设置为低于
hbase.hstore.compaction.ratio,则进行更不积极的压缩)。如果禁用了非高峰则忽略(默认)。这与hbase.hstore.compaction.ratio相同。
- 如果还配置了非高峰时间,则在非高峰期压缩期间使用的压缩率(请参见下文)。表示为浮点小数。这样可以在设定的时间段内进行更积极的压缩(如果将其设置为低于
默认 :5.0F
hbase.offpeak.start.hour- 非高峰时间的开始,表示为 0 到 23 之间的一个整数(包括 0 和 23)。设置为-1 可禁用非峰值。
默认 :-1(已禁用)
hbase.offpeak.end.hour- 非高峰时段的结束时间,以 0 到 23 之间的一个整数表示,包括 0 和 23.设置为-1 可禁用非峰值。
默认 :-1(已禁用)
hbase.regionserver.thread.compaction.throttle- 有两种不同的线程池用于压缩,一种用于大压缩,另一种用于小压缩。这有助于保持精简表(例如
hbase:meta)的快速压缩。如果压缩大于此阈值,它将进入大型压缩池。在大多数情况下,默认值为适当。
- 有两种不同的线程池用于压缩,一种用于大压缩,另一种用于小压缩。这有助于保持精简表(例如
默认 :2 x hbase.hstore.compaction.max x hbase.hregion.memstore.flush.size(默认为128)
hbase.hregion.majorcompaction- 两次大压实之间的时间,以毫秒为单位。设置为 0 以禁用基于时间的自动专业压缩。用户请求的基于大小的大型压缩仍将运行。将该值乘以
hbase.hregion.majorcompaction.jitter可以使压缩在给定的时间范围内在某个随机时间开始。
- 两次大压实之间的时间,以毫秒为单位。设置为 0 以禁用基于时间的自动专业压缩。用户请求的基于大小的大型压缩仍将运行。将该值乘以
默认 :7 天(604800000毫秒)
hbase.hregion.majorcompaction.jitter- 应用于 hbase.hregion.majorcompaction 的乘数,使压缩在
hbase.hregion.majorcompaction的任一侧发生给定的时间。数量越小,压缩将更接近hbase.hregion.majorcompaction间隔。表示为浮点小数。
- 应用于 hbase.hregion.majorcompaction 的乘数,使压缩在
默认 :.50F
zipfile 选择
Legacy Information
由于历史原因保留了本节,并涉及在 HBase 0.96.x 之前进行压缩的方式。如果启用RatioBasedCompactionPolicy Algorithm,仍然可以使用此行为。有关压缩在 HBase 0.96.x 和更高版本中的工作方式的信息,请参见Compaction。
为了了解选择 StoreFile 的核心算法,Store 源代码中有一些 ASCII 技巧可以用作参考。
它已被复制到下面:
/* normal skew:
*
* older ----> newer
* _
* | | _
* | | | | _
* --|-|- |-|- |-|---_-------_------- minCompactSize
* | | | | | | | | _ | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
*/
Important knobs:
hbase.hstore.compaction.ratiozipfile 选择算法中使用的比率(默认为 1.2f)。hbase.hstore.compaction.min(在 HBase v 0.90 中,这称为hbase.hstore.compactionThreshold)(文件)为进行压缩而选择的每个存储的最小 StoreFile 数量(默认为 2)。hbase.hstore.compaction.max(文件)每次压缩的最大存储文件数(默认为 10)。hbase.hstore.compaction.min.size(字节)任何小于此设置的 StoreFile 都会自动成为压缩对象。默认为hbase.hregion.memstore.flush.size(128 mb)。hbase.hstore.compaction.max.size(.92)(字节)大于此设置且自动排除的任何 StoreFile(默认为 Long.MAX_VALUE)。
次要压缩 StoreFile 选择逻辑基于大小,并在file ⇐ sum(smaller_files) * hbase.hstore.compaction.ratio时选择要压缩的文件。
次要 zipfile 的选择-示例 1(基本示例)
此示例反映了单元测试TestCompactSelection的示例。
hbase.hstore.compaction.ratio= 1.0fhbase.hstore.compaction.min= 3(文件)hbase.hstore.compaction.max= 5(文件)hbase.hstore.compaction.min.size= 10(字节)hbase.hstore.compaction.max.size= 1000(字节)
存在以下 StoreFiles:每个 100、50、23、12 和 12 个字节(最旧到最新)。使用上述参数,将选择进行次压缩的文件为 23、12 和 12.
Why?
100 →否,因为 sum(50,23,12,12)* 1.0 = 97.
50 →否,因为 sum(23,12,12)* 1.0 = 47.
23 →是,因为 sum(12,12)* 1.0 = 24.
12 →是,因为已包含以前的文件,并且没有超过文件的最大限制 5
12 →是,因为已包含上一个文件,并且没有超过最大文件数限制 5.
选择次要 zipfile-示例 2(zipfile 不足)
此示例反映了单元测试TestCompactSelection的示例。
hbase.hstore.compaction.ratio= 1.0fhbase.hstore.compaction.min= 3(文件)hbase.hstore.compaction.max= 5(文件)hbase.hstore.compaction.min.size= 10(字节)hbase.hstore.compaction.max.size= 1000(字节)
存在以下 StoreFiles:每个 100、25、12 和 12 个字节(最旧到最新)。使用以上参数,将不会开始压缩。
Why?
100 →否,因为 sum(25,12,12)* 1.0 = 47
25 →否,因为 sum(12,12)* 1.0 = 24
12 →否。因为 sum(12)* 1.0 = 12,所以只有 2 个文件要压缩,小于 3 个阈值
12 →否。因为以前的 StoreFile 是候选文件,但是没有足够的文件要压缩
次要 zipfile 的选择-示例 3(将文件限制为压缩)
此示例反映了单元测试TestCompactSelection的示例。
hbase.hstore.compaction.ratio= 1.0fhbase.hstore.compaction.min= 3(文件)hbase.hstore.compaction.max= 5(文件)hbase.hstore.compaction.min.size= 10(字节)hbase.hstore.compaction.max.size= 1000(字节)
存在以下 StoreFiles:每个 7、6、5、4、3、2 和 1 个字节(最旧到最新)。使用以上参数,将选择进行次压缩的文件为 7、6、5、4、3.
Why?
7 →是,因为 sum(6,5,4,3,2,1)* 1.0 =21.而且,7 小于最小大小
6 →是,因为 sum(5,4,3,2,1)* 1.0 =15.而且,6 小于最小大小。
5 →是,因为 sum(4,3,2,1)* 1.0 =10.而且,5 小于最小大小。
4 →是,因为 sum(3,2,1)* 1.0 =6.而且,4 小于最小大小。
3 →是,因为 sum(2,1)* 1.0 =3.而且,3 小于最小大小。
2 →否。因为选择了上一个文件并且 2 个小于最小大小,但已达到要压缩的最大文件数,因此是候选。
1 →否。候选,因为选择了上一个文件,且 1 小于最小大小,但已达到要压缩的最大文件数。
Impact of Key Configuration Options
现在,此信息包含在压缩算法使用的参数的配置参数表中。
日期分层压缩
日期分层压缩是一种可感知日期的存储文件压缩策略,它有利于对时间序列数据进行时间范围扫描。
何时使用日期分层压缩
考虑在有限的时间范围内使用日期分层压缩进行读取,尤其是对最近数据的扫描
请勿用于
不受时间限制的随机获取
频繁删除和更新
频繁出现乱序的数据写入会产生长尾巴,尤其是带有 Future 时间戳记的写入
频繁散装,时间范围重叠严重
Performance Improvements
性能测试表明,在有限的时间范围内,尤其是对最近数据的扫描,时间范围扫描的性能大大提高。
启用日期分层压缩
您可以通过将表或列族的hbase.hstore.engine.class设置为org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine来启用日期分层压缩。
如果使用所有默认设置,则还需要将hbase.hstore.blockingStoreFiles设置为较高的数字,例如 60,而不是默认值 12)。如果更改参数,请使用 1.5~2 x 预计文件数,预计文件数=每层窗口数 x 层数传入窗口最小文件寿命
您还需要将hbase.hstore.compaction.max设置为与hbase.hstore.blockingStoreFiles相同的值,以取消阻止主要压缩。
过程:启用日期分层压缩
- 在 HBase Shell 中运行以下命令之一。将表名
orders_table替换为表名。
alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine', 'hbase.hstore.blockingStoreFiles' => '60', 'hbase.hstore.compaction.min'=>'2', 'hbase.hstore.compaction.max'=>'60'}
alter 'orders_table', {NAME => 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine', 'hbase.hstore.blockingStoreFiles' => '60', 'hbase.hstore.compaction.min'=>'2', 'hbase.hstore.compaction.max'=>'60'}}
create 'orders_table', 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine', 'hbase.hstore.blockingStoreFiles' => '60', 'hbase.hstore.compaction.min'=>'2', 'hbase.hstore.compaction.max'=>'60'}
- 如果需要,配置其他选项。有关更多信息,请参见配置日期分层压缩。
过程:禁用日期分层压缩
- 将
hbase.hstore.engine.class选项设置为 nil 或org.apache.hadoop.hbase.regionserver.DefaultStoreEngine。两种选择都具有相同的效果。确保将其他选项也设置为原始设置。
alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DefaultStoreEngine', 'hbase.hstore.blockingStoreFiles' => '12', 'hbase.hstore.compaction.min'=>'6', 'hbase.hstore.compaction.max'=>'12'}}
当您以任何一种方式更改存储引擎时,都可能会在大多数区域上执行重大压缩。在新表上不需要这样做。
配置日期分层压缩
日期分层压缩的每个设置都应在表或列族级别上配置。如果使用 HBase Shell,则常规命令模式如下:
alter 'orders_table', CONFIGURATION => {'key' => 'value', ..., 'key' => 'value'}}
Tier Parameters
您可以通过更改以下参数的设置来配置日期层:
表 11.日期层参数
| Setting | Notes |
|---|---|
hbase.hstore.compaction.date.tiered.max.storefile.age.millis |
max-timestamp 小于此值的文件将不再压缩。默认值为 Long.MAX_VALUE。 |
hbase.hstore.compaction.date.tiered.base.window.millis |
基本窗口大小(以毫秒为单位)。默认为 6 小时。 |
hbase.hstore.compaction.date.tiered.windows.per.tier |
每层的窗口数。默认值为 4. |
hbase.hstore.compaction.date.tiered.incoming.window.min |
在进入的窗口中压缩的文件最少。将其设置为窗口中的预期文件数,以避免浪费的压缩。默认值为 6. |
hbase.hstore.compaction.date.tiered.window.policy.class |
在同一时间窗口内选择存储文件的策略。它不适用于传入的窗口。探索压缩时的默认设置。这是为了避免浪费的压缩。 |
Compaction Throttler
使用分层压缩时,群集中的所有服务器将同时将 Windows 升级到更高的层,因此建议使用压缩限制:将hbase.regionserver.throughput.controller设置为org.apache.hadoop.hbase.regionserver.compactions.PressureAwareCompactionThroughputController。
Note
有关日期分层压缩的更多信息,请参考设计规范,网址为https://docs.google.com/document/d/1_AmlNb2N8Us1xICsTeGDLKIqL6T-oHoRLZ323MG_uy8
实验性:条带压缩
条纹压缩是 HBase 0.98 中添加的一项实验功能,旨在改善大区域或不均匀分布的行键的压缩。为了实现更小和/或更详细的压缩,区域内的 StoreFiles 分别针对该区域的几个行键子范围或“条”进行维护。条带对其余的 HBase 透明,因此对 HFiles 或数据的其他操作无需修改即可工作。
条带压缩会更改 HFile 布局,从而在区域内创建子区域。这些次区域更容易压实,应减少主要压实。这种方法减轻了较大区域的挑战。
条带压缩与Compaction完全兼容,并且可以与 ExploringCompactionPolicy 或 RatioBasedCompactionPolicy 结合使用。可以为现有表启用它,并且如果以后禁用该表,该表将 continue 正常运行。
何时使用条带压缩
如果满足以下任一条件,请考虑使用条带压缩:
大区域。您可以获得较小区域的积极影响,而无需增加 MemStore 的额外开销和区域 Management 开销。
非统一密钥,例如密钥中的时间维度。仅接收新密钥的条带需要压缩。如果有的话,旧数据将不会经常压缩
Performance Improvements
性能测试表明,读取的性能有所提高,并且读取和写入的性能差异大大降低。在较大的非均匀行键区域(例如哈希前缀的时间戳键)上,可以看到总体的长期性能改进。在已经很大的桌子上,这些性能提升最为明显。性能改进可能会扩展到区域拆分。
启用条带压缩
您可以通过将表hbase.hstore.engine.class设置为org.apache.hadoop.hbase.regionserver.StripeStoreEngine来为表或列族启用条带压缩。您还需要将hbase.hstore.blockingStoreFiles设置为一个较高的数字,例如 100(而不是默认值 10)。
过程:启用条带压缩
- 在 HBase Shell 中运行以下命令之一。将表名
orders_table替换为表名。
alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.StripeStoreEngine', 'hbase.hstore.blockingStoreFiles' => '100'}
alter 'orders_table', {NAME => 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.StripeStoreEngine', 'hbase.hstore.blockingStoreFiles' => '100'}}
create 'orders_table', 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.StripeStoreEngine', 'hbase.hstore.blockingStoreFiles' => '100'}
如果需要,配置其他选项。有关更多信息,请参见配置条带压缩。
启用表格。
过程:禁用条带压缩
- 将
hbase.hstore.engine.class选项设置为 nil 或org.apache.hadoop.hbase.regionserver.DefaultStoreEngine。两种选择都具有相同的效果。
alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'rg.apache.hadoop.hbase.regionserver.DefaultStoreEngine'}
- 启用表格。
在以任何一种方式更改存储引擎后启用大表时,可能会在大多数区域上执行大型压缩。在新表上不需要这样做。
配置条带压缩
条带压缩的每个设置都应在表或列族级别上进行配置。如果使用 HBase Shell,则常规命令模式如下:
alter 'orders_table', CONFIGURATION => {'key' => 'value', ..., 'key' => 'value'}}
区域和条纹大小
您可以根据区域大小来配置条带大小。默认情况下,您的新区域将从一个条纹开始。在条带变得太大(16 x MemStore 刷新大小)之后的下一次压缩中,将其分成两个条带。条带分割随着区域的增长而 continue,直到区域足够大以至于可以分割为止。
您可以针对自己的数据改进此模式。一个好的规则是,目标是至少 1 GB 的条带大小,对于统一的行键,大约 8-12 条带。例如,如果您的区域为 30 GB,则可能需要 12 x 2.5 GB 的条带。
表 12.条带大小设置
| Setting | Notes |
|---|---|
hbase.store.stripe.initialStripeCount |
启用条带压缩时要创建的条带数量。您可以按以下方式使用它: |
对于相对统一的行键,如果您从上面知道了大致的目标条带数量,则可以通过从几个条带(2、5、10…)开始避免开销的分散。如果早期数据不能代表整个行密钥分配,那么效率将不那么高。
对于具有大量数据的现有表,此设置将有效地预先分割条带。
对于诸如哈希前缀的连续密钥之类的密钥,每个区域具有一个以上的哈希前缀,预分割可能是有意义的。
| hbase.store.stripe.sizeToSplit |条带在分割前增长的最大大小。根据上面的大小考虑,将其与hbase.store.stripe.splitPartCount结合使用以控制目标条带大小(sizeToSplit = splitPartsCount * target stripe size)。
| hbase.store.stripe.splitPartCount |拆分条带时要创建的新条带数。默认值为 2,适用于大多数情况。对于非一致的行键,您可以尝试将数字增加到 3 或 4,以将到达的更新隔离到该区域的较窄切片中,而无需进行其他拆分。
MemStore 大小设置
默认情况下,刷新会根据现有的条带边界和要刷新的行键从一个 MemStore 创建多个文件。这种方法最大程度地减少了写放大,但是如果 MemStore 很小并且有很多条带,则可能是不希望的,因为文件太小了。
在这种情况下,您可以将hbase.store.stripe.compaction.flushToL0设置为true。这将导致 MemStore 刷新创建单个文件。当至少hbase.store.stripe.compaction.minFilesL0个此类文件(默认为 4 个)累积时,它们将被压缩为带状文件。
常规压缩配置和条带压缩
适用于常规压缩的所有设置(请参阅压缩算法使用的参数)都适用于条带压缩。最小和最大文件数是个 exception,默认情况下将其设置为较高的值,因为带区中的文件较小。要控制它们以进行条带压缩,请使用hbase.store.stripe.compaction.minFiles和hbase.store.stripe.compaction.maxFiles,而不要使用hbase.hstore.compaction.min和hbase.hstore.compaction.max。
72.批量加载
72.1. Overview
HBase 包括几种将数据加载到表中的方法。最直接的方法是使用 MapReduce 作业中的TableOutputFormat类,或使用常规 Client 端 API。但是,这些方法并不总是最有效的方法。
批量加载功能使用 MapReduce 作业以 HBase 的内部数据格式输出表数据,然后将生成的 StoreFiles 直接加载到正在运行的集群中。与仅使用 HBase API 相比,使用大容量加载将占用更少的 CPU 和网络资源。
72.2. 批量负荷限制
由于批量加载绕过了写入路径,因此 WAL 不会作为该过程的一部分被写入。复制通过读取 WAL 文件来进行,因此它不会看到批量加载的数据-使用Put.setDurability(SKIP_WAL)的编辑也是如此。一种处理方法是将原始文件或 HFile 运送到另一个群集,然后在该群集中执行其他处理。
72.3. 批量加载架构
HBase 批量加载过程包括两个主要步骤。
72.3.1. 通过 MapReduce 作业准备数据
批量加载的第一步是使用HFileOutputFormat2从 MapReduce 作业生成 HBase 数据文件(StoreFiles)。此输出格式以 HBase 的内部存储格式写出数据,以便以后可以将它们非常有效地加载到群集中。
为了有效运行,必须配置HFileOutputFormat2,以便每个输出 HFile 都适合单个区域。为此,其输出将被批量加载到 HBase 中的作业使用 Hadoop 的TotalOrderPartitioner类将 Map 输出划分为键空间的不相交范围,该范围与表中区域的键范围相对应。
HFileOutputFormat2包含便利功能configureIncrementalLoad(),该功能会根据表格的当前区域边界自动设置TotalOrderPartitioner。
72.3.2. 完成数据加载
在准备好数据导入之后,可以通过将importtsv工具与“ importtsv.bulk.output”选项一起使用,或者通过某些其他 MapReduce 作业使用HFileOutputFormat,使用completebulkload工具将数据导入到正在运行的集群中。此命令行工具遍历准备好的数据文件,并为每个文件确定文件所属的区域。然后,它与采用 HFile 的适当 RegionServer 联系,将其移入其存储目录并将数据提供给 Client 端。
如果在批量装载准备期间或准备和完成步骤之间区域边界发生了变化,则completebulkloadUtil 将自动将数据文件拆分为与新边界相对应的片段。此过程的效率不是最佳,因此用户应注意最大程度地减少准备大容量负载和将其导入群集之间的延迟,尤其是在其他 Client 端通过其他方式同时加载数据时。
$ hadoop jar hbase-server-VERSION.jar completebulkload [-c /path/to/hbase/config/hbase-site.xml] /user/todd/myoutput mytable
如果 CLASSPATH 中尚未提供-c config-file选项,则该文件可用于指定包含适当 hbase 参数的文件(例如,hbase-site.xml)(此外,如果 zookeeper 是,则 CLASSPATH 必须包含具有 zookeeper 配置文件的目录.不受 HBaseManagement)。
Note
如果目标表在 HBase 中尚不存在,则此工具将自动创建表。
72.4. 也可以看看
有关引用的 Util 的更多信息,请参见ImportTsv和CompleteBulkLoad。
有关批量加载当前状态的最新博客,请参见如何:使用 HBase 批量加载以及原因。
72.5. 高级用法
尽管importtsv工具在许多情况下很有用,但高级用户可能希望以编程方式生成数据,或从其他格式导入数据。首先,请进入ImportTsv.java并检查 JavaDoc for HFileOutputFormat。
批量加载的导入步骤也可以通过编程完成。有关更多信息,请参见LoadIncrementalHFiles类。
73. HDFS
由于 HBase 在 HDFS 上运行(并且每个 StoreFile 都作为文件写在 HDFS 上),因此重要的是了解 HDFS 体系结构,尤其是在如何存储文件,处理故障转移和复制块方面。
有关更多信息,请参见HDFS Architecture上的 Hadoop 文档。
73.1. NameNode
NameNode 负责维护文件系统元数据。有关更多信息,请参见上面的 HDFS 体系结构链接。
73.2. DataNode
数据节点负责存储 HDFS 块。有关更多信息,请参见上面的 HDFS 体系结构链接。
74.时间轴一致的高可用读取
Note
当前的作业 Management 员 V2不适用于区域副本,因此此功能可能会失效。请谨慎使用。
74.1. Introduction
从结构上讲,HBase 从一开始就始终具有强大的一致性保证。所有读取和写入均通过单个区域服务器进行路由,这可以确保所有写入均按 Sequences 进行,并且所有读取都可以看到最新提交的数据。
但是,由于将读取单次归位到单个位置,因此如果服务器不可用,则托管在区域服务器中的表的区域在一段时间内将变得不可用。区域恢复过程分为三个阶段-检测,分配和恢复。其中,检测时间通常最长,根据 ZooKeeper 会话超时,当前检测时间约为 20-30 秒。在这段时间内和恢复完成之前,Client 端将无法读取区域数据。
但是,对于某些用例,数据可以是只读的,或者可以接受对某些陈旧数据的读取。借助时间轴一致的高可用读取,HBase 可以用于这类对延迟敏感的用例,在这些用例中,应用程序预期在读取完成上有时间限制。
为了实现读取的高可用性,HBase 提供了一个称为* regionplication *的功能。在此模型中,对于表的每个区域,将在不同的 RegionServers 中打开多个副本。默认情况下,区域复制设置为 1,因此仅部署一个区域副本,并且与原始模型不会有任何更改。如果区域复制设置为 2 或更多,则主服务器将分配表区域的副本。负载平衡器可确保区域副本不会共同托管在同一区域服务器和同一机架中(如果可能)。
单个区域的所有副本都将从 0 开始具有唯一的 copy_id。具有 copy_id == 0 的区域副本称为主要区域,其他次要区域或次要区域。只有主服务器才能接受来自 Client 端的写入,并且主服务器将始终包含最新的更改。由于所有写操作仍必须经过主要区域,因此这些写操作并不是很高的可用性(这意味着如果该区域不可用,它们可能会阻塞一段时间)。
74.2. 时间线一致性
通过此功能,HBase 引入了一致性定义,可以为每个读取操作(获取或扫描)提供一致性定义。
public enum Consistency {
STRONG,
TIMELINE
}
Consistency.STRONG是 HBase 提供的默认一致性模型。如果表的区域复制= 1,或者在具有区域副本的表中,但读取是在这种一致性下进行的,则读取始终由主要区域执行,因此与先前的行为不会有任何变化,并且 Client 总是观察最新的数据。
如果使用Consistency.TIMELINE进行读取,则读取的 RPC 将首先发送到主区域服务器。间隔很短的时间(hbase.client.primaryCallTimeout.get,默认为 10ms)后,如果主区域未响应,则还将发送用于辅助区域副本的并行 RPC。此后,从首先完成的 RPC 中返回结果。如果响应是从主区域副本返回的,则我们始终可以知道数据是最新的。为此,已添加 Result.isStale()API 以检查过时性。如果结果来自辅助区域,则 Result.isStale()将设置为 true。然后,用户可以检查该字段以可能推断出数据。
在语义方面,由 HBase 实现的 TIMELINE 一致性在以下方面不同于纯粹的最终一致性:
单一归宿和有序更新:无论是否进行区域复制,在写入方面,仍然只有 1 个定义的副本(主副本)可以接受写入。该副本负责命令编辑并防止冲突。这保证了不同的副本不会同时提交两次不同的写入,并且数据会发散。这样,就无需进行读取修复或上次时间戳获胜的冲突解决方案。
辅助节点还按照主要节点提交编辑的 Sequences 来应用编辑。这样,辅助数据库将在任何时间点包含主数据库数据的快照。这类似于 RDBMS 复制,甚至类似于 HBase 自己的多数据中心复制,但是在单个群集中。
在读取方面,Client 端可以检测读取是来自最新数据还是陈旧数据。此外,Client 端可以在每次操作的基础上发出具有不同一致性要求的读取,以确保其自身的语义保证。
如果 Client 端首先观察到一个二级副本的读取,然后观察另一个二级副本的读取,则 Client 端仍然可以无序观察编辑,并且可以及时返回。区域副本没有粘性,也没有基于事务 ID 的保证。如果需要,可以稍后执行。
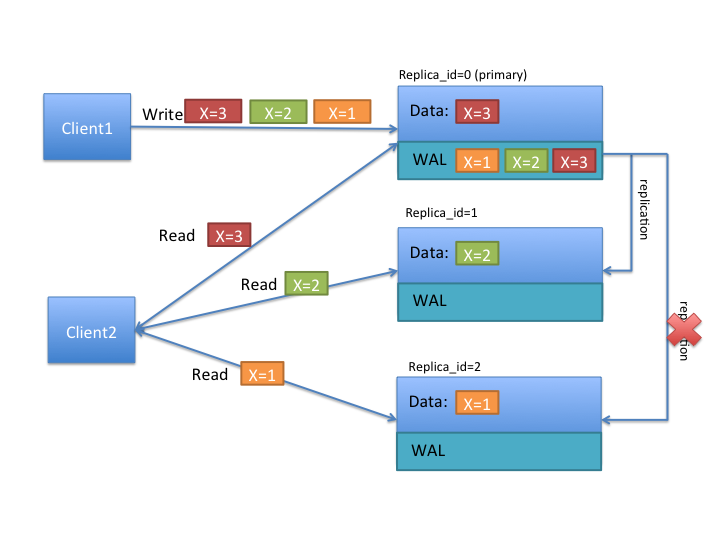
图 3.时间线一致性
为了更好地理解 TIMELINE 语义,让我们看一下上面的图。假设有两个 Client 端,第一个 Client 端首先写 x = 1,然后写 x = 2,然后写 x = 3.如上所述,所有写操作均由主区域副本处理。这些写操作将保存在预写日志(WAL)中,并异步复制到其他副本中。在上图中,请注意,replica_id = 1 接收了 2 个更新,并且其数据显示 x = 2,而 replica_id = 2 仅接收了一个更新,并且其数据显示 x = 1.
如果 client1 以 STRONG 一致性读取,则它将仅与 copy_id = 0 对话,因此可以保证观察到 x = 3 的最新值。如果 Client 端发出 TIMELINE 一致性读取,则 RPC 将转到所有副本(在主超时之后),并且第一个响应的结果将返回。因此,Client 可以将 1、2 或 3 视为 x 的值。假设主要区域发生故障,并且日志复制无法持续一段时间。如果 Client 端以 TIMELINE 一致性进行多次读取,则她可以先观察 x = 2,然后观察 x = 1,依此类推。
74.3. Tradeoffs
托管二级区域以实现读取可用性会带来一些折衷,应根据每个用例仔细评估。以下是优点和缺点。
Advantages
只读表的高可用性
高可用性的陈旧读取
能够以非常高的百分位数(99.9%)延迟执行非常低延迟的读取,以实现陈旧的读取
Disadvantages
区域复制> 1 的表的 Double/Triple MemStore 用法(取决于区域复制计数)
增加的块缓存使用率
用于日志复制的额外网络流量
副本的额外备份 RPC
为了提供来自多个副本的区域数据,HBase 在区域服务器中以辅助模式打开区域。在辅助模式下打开的区域将与主区域副本共享相同的数据文件,但是每个辅助区域副本将拥有自己的 MemStore,以保留未刷新的数据(仅主区域可以进行刷新)。另外,为了服务于来自次级区域的读取,数据文件的块也可以被高速缓存在用于次级区域的块高速缓存中。
74.4. 代码在哪里
此功能分两个阶段(阶段 1 和 2)提供。第一阶段针对 HBase-1.0.0 版本及时完成。意味着使用 HBase-1.0.x,可以使用标记为阶段 1 的所有功能。阶段 2 在 HBase-1.1.0 中提交,这意味着 1.1.0 之后的所有 HBase 版本都应包含阶段 2 项。
74.5. 将写入传播到区域副本
如上所述,写入仅转到主要区域副本。为了将写操作从主要区域副本传播到辅助区域,有两种不同的机制。对于只读表,您不需要使用以下任何方法。禁用和启用表应该使数据在所有区域副本中可用。对于可变表,您必须仅使用以下机制之一:存储文件刷新器或异步 wal 复制。建议使用后者。
74.5.1. StoreFile 刷新器
第一种机制是 HBase-1.0 中引入的存储文件刷新器。存储文件刷新器是每个区域服务器的一个线程,该线程定期运行,并对辅助区域副本的主区域的存储文件执行刷新操作。如果启用,刷新器将确保辅助区域副本及时从主区域中看到新的已刷新,压缩或批量加载的文件。但是,这意味着只能从辅助区域副本中读取刷新的数据,并且在运行刷新器之后,使辅助数据库在较长时间内落后于主数据库。
要启用此功能,应将hbase.regionserver.storefile.refresh.period配置为非零值。请参阅下面的“配置”部分。
74.5.2. Asnyc WAL 复制
第二种机制是通过“异步 WAL 复制”功能来完成对辅助文件写入的传播,并且仅在 HBase-1.1 中可用。这与 HBase 的多数据中心复制类似,但是来自区域的数据被复制到辅助区域。每个辅助副本始终以与主区域提交它们的 Sequences 相同的 Sequences 接收和观察写入。从某种意义上说,这种设计可以被认为是“集群内复制”,其中数据复制到辅助区域以保持最新状态,而不是复制到另一个数据中心。数据文件在主区域和其他副本之间共享,因此没有额外的存储开销。但是,辅助区域的存储器中将有最近未刷新的数据,这会增加内存开销。主区域也将刷新,压缩和批量装入事件写入其 WAL,这些事件也通过 wal 复制复制到辅助区域。当他们观察到刷新/压缩或批量加载事件时,辅助区域将重播该事件以拾取新文件并删除旧文件。
以与主要区域相同的 Sequences 提交写入操作可确保次区域不会与主要区域数据分开,但是由于日志复制是异步的,因此在次区域中数据仍可能是陈旧的。由于此功能充当复制端点,因此性能和 await 时间特性预计与集群间复制相似。
默认情况下,“异步 WAL 复制”为“禁用”。您可以通过将hbase.region.replica.replication.enabled设置为true来启用此功能。首次创建区域复制> 1 的表时,Asyn WAL 复制功能将添加一个名为region_replica_replication的新复制对等体作为复制对等体。启用后,如果要禁用此功能,则需要执行以下两项操作:*将hbase-site.xml中的配置属性hbase.region.replica.replication.enabled设置为 false(请参见下面的配置部分)*使用 hbase shell 或Admin类在群集中禁用名为region_replica_replication的复制对等项:
hbase> disable_peer 'region_replica_replication'
74.6. 存储文件 TTL
在上述两种写传播方法中,主数据库的存储文件都将在与主区域无关的辅助数据库中打开。因此,对于主要压缩的文件,辅助文件可能仍会引用这些文件进行读取。这两个功能都使用 HFileLinks 来引用文件,但是(至今)没有任何保护措施可以保证不会过早删除文件。因此,作为防护,应将配置属性hbase.master.hfilecleaner.ttl设置为较大的值,例如 1 小时,以确保不会收到针对复制请求的 IOExceptions。
74.7. META 表区域的区域复制
当前,尚未对 META 表的 WAL 执行异步 WAL 复制。元表的辅助副本仍从持久性存储文件中刷新自身。因此,需要将hbase.regionserver.meta.storefile.refresh.period设置为某个非零值以刷新元存储文件。请注意,此配置的配置不同于hbase.regionserver.storefile.refresh.period。
74.8. 内存记帐
辅助区域副本引用主区域副本的数据文件,但是它们具有自己的内存存储区(在 HBase-1.1 中),并且还使用块缓存。但是,一个区别是,当二级存储区的内存存在内存压力时,二级存储区副本无法刷新数据。他们只能在主要区域进行刷新并将此刷新复制到辅助区域时释放内存存储内存。由于在区域服务器中托管某些区域的主副本,而在某些区域托管第二副本,因此这些副本可能导致对同一主机中主区域的额外刷新。在极端情况下,将没有内存可用于通过 wal 复制添加来自主数据库的新写入。为了阻止这种情况(并且由于辅助服务器无法自行刷新),允许辅助服务器通过执行文件系统列表操作从主服务器上拾取新文件,并可能删除其内存来进行“存储文件刷新”。仅当最大的辅助区域副本的内存大小至少是主副本的最大内存大小的hbase.region.replica.storefile.refresh.memstore.multiplier(默认 4 倍)倍时,才执行此刷新。一个警告是,如果执行此操作,则辅助数据库可以观察到跨列族的部分行更新(因为列族是独立刷新的)。默认值应该很好,以便不要经常执行此操作。如果需要,可以将该值设置为一个较大的值以禁用此功能,但是请注意,这可能会导致复制永远停止。
74.9. 辅助副本故障转移
当辅助区域副本首次联机或进行故障转移时,它可能已从其内存存储中进行了一些编辑。由于辅助副本的恢复处理方式不同,因此辅助副本必须确保在分配后开始为请求提供服务之前,它不会及时返回。为此,辅助节点 await 直到观察到完整的刷新周期(开始刷新,提交刷新)或从主要节点复制的“区域打开事件”。在这种情况发生之前,辅助区域副本将通过抛出 IOException 消息“该区域的读取已禁用”来拒绝所有读取请求。但是,其他副本可能仍然可以读取,因此不会对具有 TIMELINE 一致性的 rpc 造成任何影响。为了加快恢复速度,辅助区域在打开时将触发来自主要区域的刷新请求。如果需要,可使用配置属性hbase.region.replica.wait.for.primary.flush(默认情况下启用)来禁用此功能。
74.10. 配置属性
要使用高可用性读取,应在hbase-site.xml文件中设置以下属性。没有启用或禁用区域副本的特定配置。相反,您可以更改每个表的区域副本数,以在创建表或使用 alter table 时增加或减少。以下配置用于使用异步 wal 复制和 3 的元副本。
74.10.1. 服务器端属性
<property>
<name>hbase.regionserver.storefile.refresh.period</name>
<value>0</value>
<description>
The period (in milliseconds) for refreshing the store files for the secondary regions. 0 means this feature is disabled. Secondary regions sees new files (from flushes and compactions) from primary once the secondary region refreshes the list of files in the region (there is no notification mechanism). But too frequent refreshes might cause extra Namenode pressure. If the files cannot be refreshed for longer than HFile TTL (hbase.master.hfilecleaner.ttl) the requests are rejected. Configuring HFile TTL to a larger value is also recommended with this setting.
</description>
</property>
<property>
<name>hbase.regionserver.meta.storefile.refresh.period</name>
<value>300000</value>
<description>
The period (in milliseconds) for refreshing the store files for the hbase:meta tables secondary regions. 0 means this feature is disabled. Secondary regions sees new files (from flushes and compactions) from primary once the secondary region refreshes the list of files in the region (there is no notification mechanism). But too frequent refreshes might cause extra Namenode pressure. If the files cannot be refreshed for longer than HFile TTL (hbase.master.hfilecleaner.ttl) the requests are rejected. Configuring HFile TTL to a larger value is also recommended with this setting. This should be a non-zero number if meta replicas are enabled (via hbase.meta.replica.count set to greater than 1).
</description>
</property>
<property>
<name>hbase.region.replica.replication.enabled</name>
<value>true</value>
<description>
Whether asynchronous WAL replication to the secondary region replicas is enabled or not. If this is enabled, a replication peer named "region_replica_replication" will be created which will tail the logs and replicate the mutations to region replicas for tables that have region replication > 1. If this is enabled once, disabling this replication also requires disabling the replication peer using shell or Admin java class. Replication to secondary region replicas works over standard inter-cluster replication.
</description>
</property>
<property>
<name>hbase.region.replica.replication.memstore.enabled</name>
<value>true</value>
<description>
If you set this to `false`, replicas do not receive memstore updates from
the primary RegionServer. If you set this to `true`, you can still disable
memstore replication on a per-table basis, by setting the table's
`REGION_MEMSTORE_REPLICATION` configuration property to `false`. If
memstore replication is disabled, the secondaries will only receive
updates for events like flushes and bulkloads, and will not have access to
data which the primary has not yet flushed. This preserves the guarantee
of row-level consistency, even when the read requests `Consistency.TIMELINE`.
</description>
</property>
<property>
<name>hbase.master.hfilecleaner.ttl</name>
<value>3600000</value>
<description>
The period (in milliseconds) to keep store files in the archive folder before deleting them from the file system.</description>
</property>
<property>
<name>hbase.meta.replica.count</name>
<value>3</value>
<description>
Region replication count for the meta regions. Defaults to 1.
</description>
</property>
<property>
<name>hbase.region.replica.storefile.refresh.memstore.multiplier</name>
<value>4</value>
<description>
The multiplier for a "store file refresh" operation for the secondary region replica. If a region server has memory pressure, the secondary region will refresh it's store files if the memstore size of the biggest secondary replica is bigger this many times than the memstore size of the biggest primary replica. Set this to a very big value to disable this feature (not recommended).
</description>
</property>
<property>
<name>hbase.region.replica.wait.for.primary.flush</name>
<value>true</value>
<description>
Whether to wait for observing a full flush cycle from the primary before start serving data in a secondary. Disabling this might cause the secondary region replicas to go back in time for reads between region movements.
</description>
</property>
还需要记住的一件事是,区域副本放置策略仅由默认平衡器StochasticLoadBalancer强制执行。如果在 hbase-site.xml(hbase.master.loadbalancer.class)中使用自定义负载平衡器属性,则区域的副本可能最终将托管在同一服务器中。
74.10.2. Client 端属性
确保为将使用区域副本的所有 Client 端(和服务器)设置以下内容。
<property>
<name>hbase.ipc.client.specificThreadForWriting</name>
<value>true</value>
<description>
Whether to enable interruption of RPC threads at the client side. This is required for region replicas with fallback RPC's to secondary regions.
</description>
</property>
<property>
<name>hbase.client.primaryCallTimeout.get</name>
<value>10000</value>
<description>
The timeout (in microseconds), before secondary fallback RPC's are submitted for get requests with Consistency.TIMELINE to the secondary replicas of the regions. Defaults to 10ms. Setting this lower will increase the number of RPC's, but will lower the p99 latencies.
</description>
</property>
<property>
<name>hbase.client.primaryCallTimeout.multiget</name>
<value>10000</value>
<description>
The timeout (in microseconds), before secondary fallback RPC's are submitted for multi-get requests (Table.get(List<Get>)) with Consistency.TIMELINE to the secondary replicas of the regions. Defaults to 10ms. Setting this lower will increase the number of RPC's, but will lower the p99 latencies.
</description>
</property>
<property>
<name>hbase.client.replicaCallTimeout.scan</name>
<value>1000000</value>
<description>
The timeout (in microseconds), before secondary fallback RPC's are submitted for scan requests with Consistency.TIMELINE to the secondary replicas of the regions. Defaults to 1 sec. Setting this lower will increase the number of RPC's, but will lower the p99 latencies.
</description>
</property>
<property>
<name>hbase.meta.replicas.use</name>
<value>true</value>
<description>
Whether to use meta table replicas or not. Default is false.
</description>
</property>
注意 HBase-1.0.x 用户应使用hbase.ipc.client.allowsInterrupt而不是hbase.ipc.client.specificThreadForWriting。
74.11. 用户界面
在主用户界面中,还显示了表的区域副本以及主要区域。您会注意到,区域的副本将共享相同的开始键和结束键以及相同的区域名称前缀。唯一的区别是附加的 copy_id(编码为十六进制),而区域编码的名称将不同。您还可以查看 UI 中明确显示的副本 ID。
74.12. 使用区域复制创建表
区域复制是每个表的属性。默认情况下,所有表都有REGION_REPLICATION = 1,这意味着每个区域只有一个副本。您可以通过在表 Descriptors 中提供REGION_REPLICATION属性来设置和更改表每个区域的副本数。
74.12.1. Shell
create 't1', 'f1', {REGION_REPLICATION => 2}
describe 't1'
for i in 1..100
put 't1', "r#{i}", 'f1:c1', i
end
flush 't1'
74.12.2. Java
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf("test_table"));
htd.setRegionReplication(2);
...
admin.createTable(htd);
您还可以使用setRegionReplication()并更改表来增加,减少表的区域复制。
74.13. 阅读 API 和用法
74.13.1. Shell
您可以使用 Consistency.TIMELINE 语义在 Shell 中进行读取,如下所示
hbase(main):001:0> get 't1','r6', {CONSISTENCY => "TIMELINE"}
您可以模拟区域服务器暂停或变得不可用,并从辅助副本进行读取:
$ kill -STOP <pid or primary region server>
hbase(main):001:0> get 't1','r6', {CONSISTENCY => "TIMELINE"}
使用扫描也很相似
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}
74.13.2. Java
您可以设置“获取”和“扫描”的一致性,并执行请求,如下所示。
Get get = new Get(row);
get.setConsistency(Consistency.TIMELINE);
...
Result result = table.get(get);
您还可以传递多个获取:
Get get1 = new Get(row);
get1.setConsistency(Consistency.TIMELINE);
...
ArrayList<Get> gets = new ArrayList<Get>();
gets.add(get1);
...
Result[] results = table.get(gets);
And Scans:
Scan scan = new Scan();
scan.setConsistency(Consistency.TIMELINE);
...
ResultScanner scanner = table.getScanner(scan);
您可以通过调用Result.isStale()方法来检查结果是否来自主要区域:
Result result = table.get(get);
if (result.isStale()) {
...
}
74.14. Resources
有关设计和实现的更多信息,请参见 jira 问题:HBASE-10070
HBaseCon 2014 演讲:HBase 使用时间轴一致的区域副本读取高可用性还包含一些细节,而slides。
75.存储中型对象(MOB)
数据有多种大小,将所有数据(包括图像和文档等二进制数据)保存在 HBase 中是理想的。从技术上讲,HBase 可以处理单元大小大于 100 KB 的二进制对象,但 HBase 的常规读写路径已针对小于 100KB 的值进行了优化。当 HBase 处理超过此阈值的大量对象(此处称为中型对象或 MOB)时,由于拆分和压缩导致的写入放大会降低性能。使用 MOB 时,理想情况下,您的对象应介于 100KB 和 10MB 之间(请参见FAQ)。 HBase **** FIX_VERSION_NUMBER **** 添加了对更好地 Management 大量 MOB 的支持,同时保持了性能,一致性和较低的操作开销。 MOB 支持由HBASE-11339中完成的工作提供。要使用 MOB,您需要使用HFile 版本 3。 (可选)为每个 RegionServer 配置 MOB 文件读取器的缓存设置(请参见配置 MOB 缓存),然后配置特定列以保存 MOB 数据。无需更改 Client 端代码即可利用 HBase MOB 支持。该功能对 Client 端是透明的。
MOB compaction
MemStore 刷新后,会将 MOB 数据刷新到 MOB 文件中。一段时间后,会有很多 MOB 文件。为了减少 MOB 文件的数量,有一项定期任务将小 MOB 文件压缩为大文件(MOB 压缩)。
75.1. 配置 MOB 的列
您可以在 HBase Shell 中或通过 Java API 将表配置为在表创建或更改期间支持 MOB。两个相关属性是布尔值IS_MOB和MOB_THRESHOLD,这是将对象视为 MOB 的字节数。只需IS_MOB。如果未指定MOB_THRESHOLD,则使用默认阈值 100 KB。
使用 HBase Shell 为 MOB 配置列
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400}
示例 26.使用 Java API 为 MOB 配置列
...
HColumnDescriptor hcd = new HColumnDescriptor("f");
hcd.setMobEnabled(true);
...
hcd.setMobThreshold(102400L);
...
75.2. 配置 MOB 压缩策略
默认情况下,将某一天的 MOB 文件压缩为一个大的 MOB 文件。为了进一步减少 MOB 文件数,还支持其他 MOB 压缩策略。
每日策略-将一天的 MOB 文件压缩为一个大 MOB 文件(默认策略)每周策略-将一周的 MOB 文件压缩为一个大 MOB 文件每月策略-将一个月的 MOB 文件压缩为一个大 MOB 文件
使用 HBase Shell 配置 MOB 压缩策略
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'daily'}
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'weekly'}
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'monthly'}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'daily'}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'weekly'}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'monthly'}
75.3. 配置 MOB 压缩可合并阈值
如果 mob 文件的大小小于此值,则将其视为小文件,需要在 mob 压缩中合并。默认值为 1280MB。
<property>
<name>hbase.mob.compaction.mergeable.threshold</name>
<value>10000000000</value>
</property>
75.4. 测试 MOB
提供了 Utilorg.apache.hadoop.hbase.IntegrationTestIngestWithMOB来帮助测试 MOB 功能。该 Util 如下运行:
$ sudo -u hbase hbase org.apache.hadoop.hbase.IntegrationTestIngestWithMOB \
-threshold 1024 \
-minMobDataSize 512 \
-maxMobDataSize 5120
threshold是将单元格视为 MOB 的阈值。默认值为 1 kB,以字节表示。minMobDataSize是 MOB 数据大小的最小值。默认值为 512 B,以字节表示。maxMobDataSize是 MOB 数据大小的最大值。默认值为 5 kB,以字节为单位。
75.5. 配置 MOB 缓存
由于与 HFiles 的数量相比,随时都可以有大量的 MOB 文件,因此 MOB 文件并不总是保持打开状态。 MOB 文件读取器高速缓存是一种 LRU 高速缓存,它可使最近使用的 MOB 文件保持打开状态。若要在每个 RegionServer 上配置 MOB 文件读取器的缓存,请将以下属性添加到 RegionServer 的hbase-site.xml,自定义配置以适合您的环境,然后重新启动或滚动重新启动 RegionServer。
例子 27.例子 MOB 缓存配置
<property>
<name>hbase.mob.file.cache.size</name>
<value>1000</value>
<description>
Number of opened file handlers to cache.
A larger value will benefit reads by providing more file handlers per mob
file cache and would reduce frequent file opening and closing.
However, if this is set too high, this could lead to a "too many opened file handers"
The default value is 1000.
</description>
</property>
<property>
<name>hbase.mob.cache.evict.period</name>
<value>3600</value>
<description>
The amount of time in seconds after which an unused file is evicted from the
MOB cache. The default value is 3600 seconds.
</description>
</property>
<property>
<name>hbase.mob.cache.evict.remain.ratio</name>
<value>0.5f</value>
<description>
A multiplier (between 0.0 and 1.0), which determines how many files remain cached
after the threshold of files that remains cached after a cache eviction occurs
which is triggered by reaching the `hbase.mob.file.cache.size` threshold.
The default value is 0.5f, which means that half the files (the least-recently-used
ones) are evicted.
</description>
</property>
75.6. MOB 优化任务
75.6.1. 手动压缩 MOB 文件
若要手动压缩 MOB 文件,而不是 awaitconfiguration触发压缩,请使用compact或major_compact HBase Shell 命令。这些命令要求第一个参数为表名,并以列族作为第二个参数。并将压缩类型作为第三个参数。
hbase> compact 't1', 'c1', 'MOB'
hbase> major_compact 't1', 'c1', 'MOB'
这些命令也可以通过Admin.compact和Admin.majorCompact方法获得。
75.7. MOB 架构
本部分来自HBASE-11339中的信息。有关更多信息,请参见该问题的附件“ 基础 MOB 设计-v5.pdf”。
75.7.1. Overview
MOB 功能通过将大于配置阈值的值存储在正常区域之外,从而避免了拆分,合并和最重要的是正常压缩,从而降低了已配置列系列的总体 IO 负载。
第一次将单元格写入区域时,无论值大小如何,都将其存储在 WAL 和 memstore 中。当来自配置为使用 MOB 的列族的内存存储最终被刷新时,将同时写入两个 hfile。值小于阈值大小的单元格将写入正常区域 hfile。值大于阈值的单元格将被写入特殊的 MOB hfile 中,并且还将 MOB 参考单元格写入正常区域 HFile 中。
MOB 参考单元格与其所基于的单元格具有相同的密钥。参考单元格的值由两部分元数据组成:实际值的大小和包含原始单元格的 MOB hfile。除了最初写入 HBase 的任何标签之外,参考单元还附加了两个附加标签。第一个是标记标记,表示该单元格是 MOB 参考。以后可以使用它专门扫描参考单元。第二个在写出 MOB hfile 时存储名称空间和表。此标签用于优化在一系列 HBase 快照操作(参考 HBASE-12332)之后,MOB 系统如何在 MOB hfile 中找到基础值。请注意,标记仅在 HBase 服务器中可用,并且默认情况下不会通过 RPC 发送。
给定表的所有 MOB hfile 在不直接服务于请求的逻辑区域内进行 Management。通过刷新或 MOB 压缩创建这些 MOB hfile 时,它们将放置在 hbase 根目录下专用于名称空间,表,mob 逻辑区域和列族的专用 mob 数据区域中。通常,这意味着路径的结构如下:
%HBase Root Dir%/mobdir/data/%namespace%/%table%/%logical region%/%column family%/
使用默认配置,默认名称空间中名为“ some_table”的示例表具有启用了 MOB 的列族“ foo”,此 HDFS 目录将为
/hbase/mobdir/data/default/some_table/372c1b27e3dc0b56c3a031926e5efbe9/foo/
这些 MOB hfile 由 HBase 主服务器中的特殊杂项维护,而不是由任何单独的 Region Server 维护。具体来说,这些杂务负责执行 TTL 并将其压缩。请注意,这种压缩主要是控制 HDFS 中文件的总数,因为我们对 MOB 数据的操作假设是它很少更新或删除。
当由于压缩过程而不再需要给定的 MOB hfile 时,就像任何普通的 hfile 一样将其归档。由于表的 mob 区域独立于所有普通区域,因此可以在常规归档存储区域中与它们共存:
/hbase/archive/data/default/some_table/372c1b27e3dc0b56c3a031926e5efbe9/foo/
负责最终从正常区域删除不需要的归档文件的 hfile 清理工作同样也将处理这些 MOB hfile。
75.8. MOB 故障排除
75.8.1. 通过 HBase Shell 检索 MOB 元数据
在对 MOB 系统中的故障进行故障排除时,可以通过在扫描中指定特殊属性来通过 HBase Shell 检索一些内部信息。
hbase(main):112:0> scan 'some_table', {STARTROW => '00012-example-row-key', LIMIT => 1,
hbase(main):113:1* CACHE_BLOCKS => false, ATTRIBUTES => { 'hbase.mob.scan.raw' => '1',
hbase(main):114:2* 'hbase.mob.scan.ref.only' => '1' } }
将 MOB 内部信息存储为四个字节,以表示基础单元值的大小,然后将其存储为包含基础单元值的 MOB HFile 名称的 UTF8 字符串。请注意,默认情况下,此序列化结构的整体将通过 HBase Shell 的二进制字符串转换器传递。这意味着组成该值大小的字节很可能被写入为转义的不可打印字节值,例如' x03',除非它们恰好对应于 ASCII 字符。
让我们看一个具体的例子:
hbase(main):112:0> scan 'some_table', {STARTROW => '00012-example-row-key', LIMIT => 1,
hbase(main):113:1* CACHE_BLOCKS => false, ATTRIBUTES => { 'hbase.mob.scan.raw' => '1',
hbase(main):114:2* 'hbase.mob.scan.ref.only' => '1' } }
ROW COLUMN+CELL
00012-example-row-key column=foo:bar, timestamp=1511179764, value=\x00\x02|\x94d41d8cd98f00b204
e9800998ecf8427e19700118ffd9c244fe69488bbc9f2c77d24a3e6a
1 row(s) in 0.0130 seconds
在这种情况下,前四个字节是\x00\x02|\x94,它对应于字节[0x00, 0x02, 0x7C, 0x94]。 (请注意,第三个字节被打印为 ASCII 字符“ |”.)被解码为整数,这使我们的基础值大小为 162,964 字节。
其余字节为我们提供了一个 HFile 名称,即“ d41d8cd98f00b204e9800998ecf8427e19700118ffd9c244fe69488bbc9f2c77d24a3e6a”。该 HFile 很可能存储在此特定表的指定 MOB 存储区域中。但是,如果此表来自已还原的快照,则文件也可能位于存档区域中。此外,如果该表来自其他表的克隆快照,则该文件可能位于该源表的活动或归档区域中。正如上面对 MOB 参考单元格的解释中提到的,区域服务器将在发现 MOB HFile 时使用服务器端标签来优化查看正确原始表的 mob 和存档区域。由于您的扫描是在 Client 端进行的,因此无法检索该标记,您将需要已经知道表格的谱系,或者需要在所有表格中进行搜索。
假设您已通过 HBase 超级用户权限认证为用户,则可以搜索它:
$> hdfs dfs -find /hbase -name \
d41d8cd98f00b204e9800998ecf8427e19700118ffd9c244fe69488bbc9f2c77d24a3e6a
/hbase/mobdir/data/default/some_table/372c1b27e3dc0b56c3a031926e5efbe9/foo/d41d8cd98f00b204e9800998ecf8427e19700118ffd9c244fe69488bbc9f2c77d24a3e6a
75.8.2. 将列族移出 MOB
如果要禁用列族上的 MOB,则必须确保指示 HBase 在关闭功能之前将数据从 MOB 系统中迁移出来。如果这样做失败,则 HBase 会将内部 MOB 元数据返回给应用程序,因为它不知道需要解析实际值。
以下过程将安全地迁移基础数据,而无需群集中断。应用配置设置并重新加载区域时,Client 端将看到许多重试。
步骤:停止 MOB 维护,更改 MOB 阈值,通过压缩重写数据
通过将
hbase.mob.file.compaction.chore.period设置为0来确保母版中的 MOB 压缩繁琐。应用此配置更改将需要滚动重启 HBase Master。这将需要对主动主服务器进行至少一次故障转移,这可能会导致重试执行 HBaseManagement 操作的 Client 端。确保在此迁移期间,没有通过 HBase Shell 为表发布任何 MOB 压缩。
使用 HBase Shell 可以将要迁移的列系列的 MOB 大小阈值更改为大于列系列中存在的最大单元格的值。例如。给定一个名为“ some_table”的表和一个名为“ foo”的列族,我们可以选择一个千兆字节作为任意“大于存储的值”:
hbase(main):011:0> alter 'some_table', {NAME => 'foo', MOB_THRESHOLD => '1000000000'}
Updating all regions with the new schema...
9/25 regions updated.
25/25 regions updated.
Done.
0 row(s) in 3.4940 seconds
请注意,如果您仍在提取数据,则必须确保此阈值大于您可能写入的任何单元格值; MAX_INT 将是一个安全的选择。
- 在桌子上进行大夯实。具体来说,您是在执行“常规”压缩而不是 MOB 压缩。
hbase(main):012:0> major_compact 'some_table'
0 row(s) in 0.2600 seconds
- 监视主要压实的结束。由于压缩是异步处理的,因此您需要使用 Shell 首先查看压缩的开始,然后再查看结束。
HBase 首先应该说正在发生“主要”压缩。
hbase(main):015:0> @hbase.admin(@formatter).instance_eval do
hbase(main):016:1* p @admin.get_compaction_state('some_table').to_string
hbase(main):017:2* end
"MAJOR"
压实完成后,结果应打印为“ NONE”。
hbase(main):015:0> @hbase.admin(@formatter).instance_eval do
hbase(main):016:1* p @admin.get_compaction_state('some_table').to_string
hbase(main):017:2* end
"NONE"
- 运行* mobrefs *Util,以确保没有 MOB 单元。具体来说,该工具将启动 Hadoop MapReduce 作业,当我们成功重写所有数据时,该作业将显示 0Importing 记录的作业计数器。
$> HADOOP_CLASSPATH=/etc/hbase/conf:$(hbase mapredcp) yarn jar \
/some/path/to/hbase-shaded-mapreduce.jar mobrefs mobrefs-report-output some_table foo
...
19/12/10 11:38:47 INFO impl.YarnClientImpl: Submitted application application_1575695902338_0004
19/12/10 11:38:47 INFO mapreduce.Job: The url to track the job: https://rm-2.example.com:8090/proxy/application_1575695902338_0004/
19/12/10 11:38:47 INFO mapreduce.Job: Running job: job_1575695902338_0004
19/12/10 11:38:57 INFO mapreduce.Job: Job job_1575695902338_0004 running in uber mode : false
19/12/10 11:38:57 INFO mapreduce.Job: map 0% reduce 0%
19/12/10 11:39:07 INFO mapreduce.Job: map 7% reduce 0%
19/12/10 11:39:17 INFO mapreduce.Job: map 13% reduce 0%
19/12/10 11:39:19 INFO mapreduce.Job: map 33% reduce 0%
19/12/10 11:39:21 INFO mapreduce.Job: map 40% reduce 0%
19/12/10 11:39:22 INFO mapreduce.Job: map 47% reduce 0%
19/12/10 11:39:23 INFO mapreduce.Job: map 60% reduce 0%
19/12/10 11:39:24 INFO mapreduce.Job: map 73% reduce 0%
19/12/10 11:39:27 INFO mapreduce.Job: map 100% reduce 0%
19/12/10 11:39:35 INFO mapreduce.Job: map 100% reduce 100%
19/12/10 11:39:35 INFO mapreduce.Job: Job job_1575695902338_0004 completed successfully
19/12/10 11:39:35 INFO mapreduce.Job: Counters: 54
...
Map-Reduce Framework
Map input records=0
...
19/12/09 22:41:28 INFO mapreduce.MobRefReporter: Finished creating report for 'some_table', family='foo'
如果数据尚未成功移出,则此报告将显示非零数量的 Importing 记录和 mob 单元数。
$> HADOOP_CLASSPATH=/etc/hbase/conf:$(hbase mapredcp) yarn jar \
/some/path/to/hbase-shaded-mapreduce.jar mobrefs mobrefs-report-output some_table foo
...
19/12/10 11:44:18 INFO impl.YarnClientImpl: Submitted application application_1575695902338_0005
19/12/10 11:44:18 INFO mapreduce.Job: The url to track the job: https://busbey-2.gce.cloudera.com:8090/proxy/application_1575695902338_0005/
19/12/10 11:44:18 INFO mapreduce.Job: Running job: job_1575695902338_0005
19/12/10 11:44:26 INFO mapreduce.Job: Job job_1575695902338_0005 running in uber mode : false
19/12/10 11:44:26 INFO mapreduce.Job: map 0% reduce 0%
19/12/10 11:44:36 INFO mapreduce.Job: map 7% reduce 0%
19/12/10 11:44:45 INFO mapreduce.Job: map 13% reduce 0%
19/12/10 11:44:47 INFO mapreduce.Job: map 27% reduce 0%
19/12/10 11:44:48 INFO mapreduce.Job: map 33% reduce 0%
19/12/10 11:44:50 INFO mapreduce.Job: map 40% reduce 0%
19/12/10 11:44:51 INFO mapreduce.Job: map 53% reduce 0%
19/12/10 11:44:52 INFO mapreduce.Job: map 73% reduce 0%
19/12/10 11:44:54 INFO mapreduce.Job: map 100% reduce 0%
19/12/10 11:44:59 INFO mapreduce.Job: map 100% reduce 100%
19/12/10 11:45:00 INFO mapreduce.Job: Job job_1575695902338_0005 completed successfully
19/12/10 11:45:00 INFO mapreduce.Job: Counters: 54
...
Map-Reduce Framework
Map input records=1
...
MOB
NUM_CELLS=1
...
19/12/10 11:45:00 INFO mapreduce.MobRefReporter: Finished creating report for 'some_table', family='foo'
如果发生这种情况,则应确认已禁用 MOB 压缩,并确认选择了足够大的 MOB 阈值,然后重做主要的压缩步骤。
- 当* mobrefs *报告显示 MOB 系统中不再存储任何数据时,您可以安全地更改列族配置,从而禁用 MOB 功能。
hbase(main):017:0> alter 'some_table', {NAME => 'foo', IS_MOB => 'false'}
Updating all regions with the new schema...
8/25 regions updated.
25/25 regions updated.
Done.
0 row(s) in 2.9370 seconds
列系列不再显示已启用 MOB 功能后,可以安全地再次启动 MOB 维护工作。通过从配置文件中删除默认值
hbase.mob.file.compaction.chore.period或将其恢复为开始此过程之前的任何自定义值,可以允许该默认值用于hbase.mob.file.compaction.chore.period。一旦禁用了列族的 MOB 功能,就不会有内部 HBase 进程在该列族特定的 MOB 存储区域中查找数据。在压缩过程之前,那里仍然存在数据,这些数据将值重新写入了 HBase 的数据区域。您可以作为 HBase 超级用户直接在 HDFS 中检查此残留数据。
$ hdfs dfs -count /hbase/mobdir/data/default/some_table
4 54 9063269081 /hbase/mobdir/data/default/some_table
该数据是虚 Pseudo,可能会被回收。您应该将其放在一边,验证应用程序在表中的视图,然后将其删除。
In-memory Compaction
76. Overview
内存压缩(A.K.A 手风琴)是 hbase-2.0.0 中的新功能。它最初是在手风琴:HBase 具有内存压缩功能的 Apache HBase Blog 上引入的。引用博客:
Note
手风琴将 LSM 主体[* Log-Structured-Merge Tree *,HBase 所基于的设计模式]重新应用于 MemStore,以消除数据仍在 RAM 中时的冗余和其他开销。这样做可以减少刷新到 HDFS 的频率,从而减少写放大和总体磁盘占用空间。使用较少的刷新,由于 MemStore 溢出而导致写操作停顿的频率降低,因此提高了写性能。磁盘上较少的数据还意味着对块缓存的压力较小,命中率较高,并最终改善了读取响应时间。最后,较少的磁盘写入也意味着在后台发生较少的压缩,即从生产(读取和写入)工作中窃取了较少的周期。总而言之,可以将内存压缩的效果看作是使系统整体运行更快的催化剂。
开发人员视图位于手风琴:内存中压缩的开发人员视图。
当高数据流失率时,内存中压缩最有效。当数据仍在内存中时,可以消除覆盖或过度版本。如果所有写操作都是唯一的,则可能会拖慢写吞吐量(内存压缩会占用 CPU)。我们建议您在部署到生产环境之前进行测试和比较。
在本节中,我们描述如何启用手风琴和可用的配置。
77. Enabling
要启用内存中压缩,请在每个您希望其行为的列系列上设置* IN_MEMORY_COMPACTION *属性。 * IN_MEMORY_COMPACTION *属性可以具有四个值之一。
-
- NONE *:不进行内存压缩。
-
- BASIC *:基本策略启用刷新并保持刷新流水线,直到我们超过管线最大阈值,然后刷新到磁盘。没有内存中的压缩,但是当数据从大量的原生 ConcurrentSkipListMap 数据类型移动到更紧凑(更有效)的数据类型时,可以帮助提高吞吐量。
-
- EAGER :这是 BASIC *策略加上刷新的内存内压缩(很像对 hfile 的磁盘上压缩);在压缩时,我们应用磁盘上的规则来消除版本,重复项,ttl'd 单元等。
自适应:自适应压缩可适应工作量。它根据数据中重复单元的比率应用索引压缩或数据压缩。实验性的。
要在表* radish 的 info 列族上启用 BASIC ,请禁用该表并将属性添加到 info *列族,然后重新启用:
hbase(main):002:0> disable 'radish'
Took 0.5570 seconds
hbase(main):003:0> alter 'radish', {NAME => 'info', IN_MEMORY_COMPACTION => 'BASIC'}
Updating all regions with the new schema...
All regions updated.
Done.
Took 1.2413 seconds
hbase(main):004:0> describe 'radish'
Table radish is DISABLED
radish
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536', METADATA => {
'IN_MEMORY_COMPACTION' => 'BASIC'}}
1 row(s)
Took 0.0239 seconds
hbase(main):005:0> enable 'radish'
Took 0.7537 seconds
请注意 IN_MEMORY_COMPACTION 属性如何显示为* METADATA *Map 的一部分。
还有一个全局配置* hbase.hregion.compacting.memstore.type ,您可以在 hbase-site.xml 文件中进行设置。使用它来设置创建新表时的默认值(在创建列系列 Store 时,我们首先查看列系列配置以查找 IN_MEMORY_COMPACTION 设置,如果没有,则参考 hbase.hregion.使用其内容的 compacting.memstore.type 值;默认值为 BASIC *)。
默认情况下,新的 hbase 系统表将具有* BASIC 内存中压缩集。否则,在创建新表时,将 hbase.hregion.compacting.memstore.type 设置为 NONE (注意,在系统表创建后设置此值不会产生 traceback 作用;您必须更改您的表将内存属性设置为 NONE *)。
通过将配置的区域刷新大小(在表 Descriptors 中设置或从* hbase.hregion.memstore.flush.size 中读取)除以列系列的数量,然后乘以 hbase,可以计算出内存中刷新发生的时间。 memstore.inmemoryflush.threshold.factor *。默认值为 0.014.
监视管道承载的刷新次数,以使其适合于内存存储大小的范围,但您也可以通过设置* hbase.hregion.compacting.pipeline.segments.limit *来设置刷新总数的最大值。默认值为 2.
创建列系列存储时,它会说明有效的存储类型。在撰写本文时,已有一个古老的* DefaultMemStore 填充了 ConcurrentSkipListMap ,然后刷新到磁盘或新的 CompactingMemStore ,该实现提供了这种新的内存压缩功能。这是 RegionServer 的一条日志行,显示名为 family 的列系列存储,配置为使用 CompactingMemStore *:
Note how the IN_MEMORY_COMPACTION attribute shows as part of the _METADATA_ map.
2018-03-30 11:02:24,466 INFO [Time-limited test] regionserver.HStore(325): Store=family, memstore type=CompactingMemStore, storagePolicy=HOT, verifyBulkLoads=false, parallelPutCountPrintThreshold=10
在 CompactingMemStore 类(* org.apache.hadoop.hbase.regionserver.CompactingMemStore *)上启用 TRACE 级别的日志记录,以查看其操作的详细信息。
Synchronous Replication
78. Background
当前replication在 HBase 中处于异步状态。因此,如果主群集崩溃,则从群集可能没有最新数据。如果用户想要强一致性,那么他们将无法切换到从集群。
79. Design
请参阅HBASE-19064上的设计文档
80.操作与维护
Case.1 设置两个同步复制群集
-
- 在源集群和对等集群中都添加一个同步对等体。
-
对于源集群:
hbase> add_peer '1', CLUSTER_KEY => 'lg-hadoop-tst-st01.bj:10010,lg-hadoop-tst-st02.bj:10010,lg-hadoop-tst-st03.bj:10010:/hbase/test-hbase-slave', REMOTE_WAL_DIR=>'hdfs://lg-hadoop-tst-st01.bj:20100/hbase/test-hbase-slave/remoteWALs', TABLE_CFS => {"ycsb-test"=>[]}
对于对等集群:
hbase> add_peer '1', CLUSTER_KEY => 'lg-hadoop-tst-st01.bj:10010,lg-hadoop-tst-st02.bj:10010,lg-hadoop-tst-st03.bj:10010:/hbase/test-hbase', REMOTE_WAL_DIR=>'hdfs://lg-hadoop-tst-st01.bj:20100/hbase/test-hbase/remoteWALs', TABLE_CFS => {"ycsb-test"=>[]}
Note
对于同步复制,当前的实现要求我们对源群集和对等群集具有相同的对等 ID。需要注意的另一件事是:对等方不支持群集级,命名空间级或 cf 级复制,现在仅支持表级复制。
- 将对等集群转换为 STANDBY 状态
hbase> transit_peer_sync_replication_state '1', 'STANDBY'
- 将源集群转换为活动状态
hbase> transit_peer_sync_replication_state '1', 'ACTIVE'
现在,同步复制已成功设置。 HBaseClient 端只能请求源集群,如果请求对等集群,则现在处于 STANDBY 状态的对等集群将拒绝读/写请求。
Case.2 备用群集崩溃时如何操作
- 如果备用群集已崩溃,它将无法为活动群集写入远程 WAL。因此,我们需要将源集群转换为 DOWNGRANDE_ACTIVE 状态,这意味着源集群将不再写任何远程 WAL,但是常规复制(异步复制)仍然可以正常工作,它将新写入的 WAL 排队,但是复制块直到对等群集返回。
hbase> transit_peer_sync_replication_state '1', 'DOWNGRADE_ACTIVE'
一旦对等集群恢复正常,我们可以将源集群转换为 ACTIVE,以确保复制将是同步的。
hbase> transit_peer_sync_replication_state '1', 'ACTIVE'
Case.3 活动群集崩溃时如何操作
- 如果活动集群已崩溃(现在可能无法访问),那么让我们将备用集群转换为 DOWNGRANDE_ACTIVE 状态,然后,我们应该将来自 Client 端的所有请求重定向到 DOWNGRADE_ACTIVE 集群。
hbase> transit_peer_sync_replication_state '1', 'DOWNGRADE_ACTIVE'
如果崩溃的群集又回来了,我们只需要将其直接转移到 STANDBY。否则,如果将群集迁移到 DOWNGRADE_ACTIVE,则与当前 ACTIVE 群集相比,原始 ACTIVE 群集可能具有冗余数据。因为我们设计了同时写入源集群 WAL 和远程集群 WAL 的设计,所以源集群 WAL 可能比远程集群拥有更多的数据,从而导致数据不一致。将 ACTIVE 转换为 STANDBY 的过程没有问题,因为我们将跳过重放原始 WAL。
hbase> transit_peer_sync_replication_state '1', 'STANDBY'
之后,我们可以立即将 DOWNGRADE_ACTIVE 集群升级为 ACTIVE,以确保复制将是同步的。
hbase> transit_peer_sync_replication_state '1', 'ACTIVE'
Apache HBase API
本章提供有关使用 HBase 本机 API 执行操作的信息。该信息并不详尽,除了用户 API 参考之外,还提供了快速参考。此处的示例并不全面或不完整,应仅用于说明目的。
Apache HBase 还可以使用多个外部 API。有关更多信息,请参见Apache HBase 外部 API。
81. Examples
例子 28.使用 Java 创建,修改和删除表
package com.example.hbase.admin;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.io.compress.Compression.Algorithm;
public class Example {
private static final String TABLE_NAME = "MY_TABLE_NAME_TOO";
private static final String CF_DEFAULT = "DEFAULT_COLUMN_FAMILY";
public static void createOrOverwrite(Admin admin, HTableDescriptor table) throws IOException {
if (admin.tableExists(table.getTableName())) {
admin.disableTable(table.getTableName());
admin.deleteTable(table.getTableName());
}
admin.createTable(table);
}
public static void createSchemaTables(Configuration config) throws IOException {
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
HTableDescriptor table = new HTableDescriptor(TableName.valueOf(TABLE_NAME));
table.addFamily(new HColumnDescriptor(CF_DEFAULT).setCompressionType(Algorithm.NONE));
System.out.print("Creating table. ");
createOrOverwrite(admin, table);
System.out.println(" Done.");
}
}
public static void modifySchema (Configuration config) throws IOException {
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
TableName tableName = TableName.valueOf(TABLE_NAME);
if (!admin.tableExists(tableName)) {
System.out.println("Table does not exist.");
System.exit(-1);
}
HTableDescriptor table = admin.getTableDescriptor(tableName);
// Update existing table
HColumnDescriptor newColumn = new HColumnDescriptor("NEWCF");
newColumn.setCompactionCompressionType(Algorithm.GZ);
newColumn.setMaxVersions(HConstants.ALL_VERSIONS);
admin.addColumn(tableName, newColumn);
// Update existing column family
HColumnDescriptor existingColumn = new HColumnDescriptor(CF_DEFAULT);
existingColumn.setCompactionCompressionType(Algorithm.GZ);
existingColumn.setMaxVersions(HConstants.ALL_VERSIONS);
table.modifyFamily(existingColumn);
admin.modifyTable(tableName, table);
// Disable an existing table
admin.disableTable(tableName);
// Delete an existing column family
admin.deleteColumn(tableName, CF_DEFAULT.getBytes("UTF-8"));
// Delete a table (Need to be disabled first)
admin.deleteTable(tableName);
}
}
public static void main(String... args) throws IOException {
Configuration config = HBaseConfiguration.create();
//Add any necessary configuration files (hbase-site.xml, core-site.xml)
config.addResource(new Path(System.getenv("HBASE_CONF_DIR"), "hbase-site.xml"));
config.addResource(new Path(System.getenv("HADOOP_CONF_DIR"), "core-site.xml"));
createSchemaTables(config);
modifySchema(config);
}
}
Apache HBase 外部 API
本章将介绍通过非 Java 语言和自定义协议对 Apache HBase 的访问。有关使用本机 HBase API 的信息,请参阅用户 API 参考和HBase APIs章。
82. REST
代表性状态转移(REST)于 2000 年在 Roy Fielding 博士论文中提出,该论文是 HTTP 规范的主要作者之一。
REST 本身不在本文档的讨论范围内,但是通常,REST 允许通过绑定到 URL 本身的 API 进行 Client 端-服务器交互。本节讨论如何配置和运行 HBase 附带的 REST 服务器,该服务器将 HBase 表,行,单元格和元数据公开为 URL 指定的资源。杰西·安德森(Jesse Anderson)在方法:使用 Apache HBase REST 接口上也有一系列不错的博客。
82.1. 启动和停止 REST 服务器
随附的 REST 服务器可以作为守护程序运行,该守护程序启动嵌入式 Jetty Servlet 容器并将 Servlet 部署到其中。使用以下命令之一在前台或后台启动 REST 服务器。端口是可选的,默认为 8080.
# Foreground
$ bin/hbase rest start -p <port>
# Background, logging to a file in $HBASE_LOGS_DIR
$ bin/hbase-daemon.sh start rest -p <port>
要停止 REST 服务器,如果在前台运行,请使用 Ctrl-C;如果在后台运行,请使用以下命令。
$ bin/hbase-daemon.sh stop rest
82.2. 配置 REST 服务器和 Client 端
有关为 SSL 配置 REST 服务器和 Client 端以及 REST 服务器模拟doAs的信息,请参阅配置 Thrift Gateway 以代表 Client 端进行身份验证和保护 Apache HBase章节的其他部分。
82.3. 使用 REST 端点
以下示例使用占位符服务器 http://example.com:8000,并且以下命令都可以使用curl或wget命令运行。您可以通过不为纯文本添加标题或为 XML 添加标题“ Accept:text/xml”,为 JSON 添加“ Accept:application/json”或“ Accept:”来请求纯文本(默认),XML 或 JSON 输出。 application/x-protobuf”以用于协议缓冲区。
Note
除非指定,否则使用GET请求进行查询,使用PUT或POST请求进行创建或变异,使用DELETE进行删除。
表 13.集群范围内的端点
| Endpoint | HTTP Verb | Description | Example |
|---|---|---|---|
/version/cluster |
GET |
在此群集上运行的 HBase 版本 | curl -vi -X GET \ |
-H“接受:text/xml” "http://example.com:8000/version/cluster" |
|||
/status/cluster |
GET |
集群状态 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/status/cluster" |
/ |
GET |
所有非系统表的列表 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/" |
表 14.命名空间端点
| Endpoint | HTTP Verb | Description | Example |
|---|---|---|---|
/namespaces |
GET |
列出所有名称空间 | curl -vi -X GET \ |
-H“接受:text/xml” "http://example.com:8000/namespaces/" |
|||
/namespaces/namespace |
GET |
描述特定的名称空间 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/namespaces/special_ns" |
/namespaces/namespace |
POST |
创建新的命名空间 | curl -vi -X POST -H“接受:text/xml” "example.com:8000/namespaces/special_ns" |
/namespaces/namespace/tables |
GET |
列出特定命名空间中的所有表 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/namespaces/special_ns/tables" |
/namespaces/namespace |
PUT |
更改现有名称空间。当前未使用。 | curl -vi -X PUT -H“接受:text/xml” "http://example.com:8000/namespaces/special_ns |
/namespaces/namespace |
DELETE |
删除名称空间。名称空间必须为空。 | curl -vi -X DELETE -H“接受:text/xml” "example.com:8000/namespaces/special_ns" |
表 15.表端点
| Endpoint | HTTP Verb | Description | Example |
|---|---|---|---|
/table/schema |
GET |
描述指定表的架构。 | curl -vi -X GET \ |
-H“接受:text/xml” "http://example.com:8000/users/schema" |
|||
/table/schema |
POST |
使用提供的模式片段更新现有表 | curl -vi -X POST -H“接受:text/xml” -H“Content Type:text/xml” -d'<?xml version="1.0" encoding="UTF-8"?> <TableSchema name="users"> <ColumnSchema name="cf" KEEP_DELETED_CELLS="true" /> </TableSchema>' "http://example.com:8000/users/schema" |
/table/schema |
PUT |
创建新表,或替换现有表的模式 | curl -vi -X PUT -H“接受:text/xml” -H“Content Type:text/xml” -d'<?xml version="1.0" encoding="UTF-8"?> <TableSchema name="users"> <ColumnSchema name="cf" /> </TableSchema>' "http://example.com:8000/users/schema" |
/table/schema |
DELETE |
删除表。您必须使用/table/schema端点,而不仅仅是/table/。 |
curl -vi -X DELETE -H“接受:text/xml” "http://example.com:8000/users/schema" |
/table/regions |
GET |
列出表区域 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/users/regions |
表 16. Get操作的端点
| Endpoint | HTTP Verb | Description | Example |
|---|---|---|---|
/table/row |
GET |
获取单行的所有列。值是 Base-64 编码的。这需要“ Accept”请求 Headers,该 Headers 的类型可以容纳多个列(例如 xml,json 或 protobuf)。 | curl -vi -X GET \ |
-H“接受:text/xml” "http://example.com:8000/users/row1" |
|||
/table/row/column:qualifier/timestamp |
GET |
获取单个列的值。值是 Base-64 编码的。 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/users/row1/cf:a/1458586888395" |
/table/row/column:qualifier |
GET |
获取单个列的值。值是 Base-64 编码的。 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/users/row1/cf:a" curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/users/row1/cf:a/" |
/table/row/column:qualifier/?v=number_of_versions |
GET |
多获取给定单元格的指定数量的版本。值是 Base-64 编码的。 | curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/users/row1/cf:a?v=2" |
表 17. Scan操作的端点
| Endpoint | HTTP Verb | Description | Example |
|---|---|---|---|
/table/scanner/ |
PUT |
获取扫描仪对象。所有其他扫描操作都需要。将批处理参数调整为扫描应在批处理中返回的行数。请参见下一个向过滤器添加过滤器的示例。扫描程序端点 URL 在 HTTP 响应中以Location的形式返回。该表中的其他示例假定扫描程序端点为http://example.com:8000/users/scanner/145869072824375522207。 |
curl -vi -X PUT \ |
-H“接受:text/xml” -H“Content Type:text/xml” -d'<Scanner batch="1"/>' "http://example.com:8000/users/scanner/" |
|||
/table/scanner/ |
PUT |
要为“扫描程序”对象提供过滤器或以其他任何方式配置“扫描程序”,您可以创建一个文本文件并将过滤器添加到该文件。例如,要仅返回键以\ u123</codeph>开头并且使用批处理大小为 100 的行,则过滤文件如下所示: [source,xml] ----<Scanner batch="100"><filter>{ "type": "PrefixFilter", "value": "u123" }</filter></Scanner> ---- 将文件传递给 curl请求的-d参数。 |
curl -vi -X PUT -H“接受:text/xml” -H“ Content-Type:文本/ xml” -d @ filter.txt "http://example.com:8000/users/scanner/" |
/table/scanner/scanner-id |
GET |
从扫描仪获取下一批。单元格值是字节编码的。如果扫描仪已耗尽,则返回 HTTP 状态204。 |
curl -vi -X GET -H“接受:text/xml” "http://example.com:8000/users/scanner/145869072824375522207" |
table/scanner/scanner-id |
DELETE |
删除扫描仪并释放其使用的资源。 | curl -vi -X DELETE -H“接受:text/xml” "http://example.com:8000/users/scanner/145869072824375522207" |
表 18. Put操作的端点
| Endpoint | HTTP Verb | Description | Example |
|---|---|---|---|
/table/row_key |
PUT |
在表中写一行。行,列限定符和值都必须使用 Base-64 编码。要编码字符串,请使用base64命令行 Util。要解码字符串,请使用base64 -d。有效负载在--data参数中,而/users/fakerow值是占位符。通过将多个行添加到<CellSet>元素来插入它们。您还可以将要插入的数据保存到文件中,然后使用类似-d @filename.txt的语法将其传递给-d参数。 |
curl -vi -X PUT \ |
-H“接受:text/xml” -H“Content Type:text/xml” -d'<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <CellSet> <Row key="cm93NQo="> <Cell column="Y2Y6ZQo="> dmFsdWU1Cg == </Cell> </Row> </CellSet>' "http://example.com:8000/users/fakerow" curl -vi -X PUT -H“接受:text/json” -H“Content Type:text/json” -d'{"Row":[{"key":"cm93NQo=", "Cell": [{"column":"Y2Y6ZQo=", "$":"dmFsdWU1Cg=="}]}]}'' "example.com:8000/users/fakerow" |
82.4. REST XML 模式
<schema xmlns="http://www.w3.org/2001/XMLSchema" xmlns:tns="RESTSchema">
<element name="Version" type="tns:Version"></element>
<complexType name="Version">
<attribute name="REST" type="string"></attribute>
<attribute name="JVM" type="string"></attribute>
<attribute name="OS" type="string"></attribute>
<attribute name="Server" type="string"></attribute>
<attribute name="Jersey" type="string"></attribute>
</complexType>
<element name="TableList" type="tns:TableList"></element>
<complexType name="TableList">
<sequence>
<element name="table" type="tns:Table" maxOccurs="unbounded" minOccurs="1"></element>
</sequence>
</complexType>
<complexType name="Table">
<sequence>
<element name="name" type="string"></element>
</sequence>
</complexType>
<element name="TableInfo" type="tns:TableInfo"></element>
<complexType name="TableInfo">
<sequence>
<element name="region" type="tns:TableRegion" maxOccurs="unbounded" minOccurs="1"></element>
</sequence>
<attribute name="name" type="string"></attribute>
</complexType>
<complexType name="TableRegion">
<attribute name="name" type="string"></attribute>
<attribute name="id" type="int"></attribute>
<attribute name="startKey" type="base64Binary"></attribute>
<attribute name="endKey" type="base64Binary"></attribute>
<attribute name="location" type="string"></attribute>
</complexType>
<element name="TableSchema" type="tns:TableSchema"></element>
<complexType name="TableSchema">
<sequence>
<element name="column" type="tns:ColumnSchema" maxOccurs="unbounded" minOccurs="1"></element>
</sequence>
<attribute name="name" type="string"></attribute>
<anyAttribute></anyAttribute>
</complexType>
<complexType name="ColumnSchema">
<attribute name="name" type="string"></attribute>
<anyAttribute></anyAttribute>
</complexType>
<element name="CellSet" type="tns:CellSet"></element>
<complexType name="CellSet">
<sequence>
<element name="row" type="tns:Row" maxOccurs="unbounded" minOccurs="1"></element>
</sequence>
</complexType>
<element name="Row" type="tns:Row"></element>
<complexType name="Row">
<sequence>
<element name="key" type="base64Binary"></element>
<element name="cell" type="tns:Cell" maxOccurs="unbounded" minOccurs="1"></element>
</sequence>
</complexType>
<element name="Cell" type="tns:Cell"></element>
<complexType name="Cell">
<sequence>
<element name="value" maxOccurs="1" minOccurs="1">
<simpleType><restriction base="base64Binary">
</simpleType>
</element>
</sequence>
<attribute name="column" type="base64Binary" />
<attribute name="timestamp" type="int" />
</complexType>
<element name="Scanner" type="tns:Scanner"></element>
<complexType name="Scanner">
<sequence>
<element name="column" type="base64Binary" minOccurs="0" maxOccurs="unbounded"></element>
</sequence>
<sequence>
<element name="filter" type="string" minOccurs="0" maxOccurs="1"></element>
</sequence>
<attribute name="startRow" type="base64Binary"></attribute>
<attribute name="endRow" type="base64Binary"></attribute>
<attribute name="batch" type="int"></attribute>
<attribute name="startTime" type="int"></attribute>
<attribute name="endTime" type="int"></attribute>
</complexType>
<element name="StorageClusterVersion" type="tns:StorageClusterVersion" />
<complexType name="StorageClusterVersion">
<attribute name="version" type="string"></attribute>
</complexType>
<element name="StorageClusterStatus"
type="tns:StorageClusterStatus">
</element>
<complexType name="StorageClusterStatus">
<sequence>
<element name="liveNode" type="tns:Node"
maxOccurs="unbounded" minOccurs="0">
</element>
<element name="deadNode" type="string" maxOccurs="unbounded"
minOccurs="0">
</element>
</sequence>
<attribute name="regions" type="int"></attribute>
<attribute name="requests" type="int"></attribute>
<attribute name="averageLoad" type="float"></attribute>
</complexType>
<complexType name="Node">
<sequence>
<element name="region" type="tns:Region"
maxOccurs="unbounded" minOccurs="0">
</element>
</sequence>
<attribute name="name" type="string"></attribute>
<attribute name="startCode" type="int"></attribute>
<attribute name="requests" type="int"></attribute>
<attribute name="heapSizeMB" type="int"></attribute>
<attribute name="maxHeapSizeMB" type="int"></attribute>
</complexType>
<complexType name="Region">
<attribute name="name" type="base64Binary"></attribute>
<attribute name="stores" type="int"></attribute>
<attribute name="storefiles" type="int"></attribute>
<attribute name="storefileSizeMB" type="int"></attribute>
<attribute name="memstoreSizeMB" type="int"></attribute>
<attribute name="storefileIndexSizeMB" type="int"></attribute>
</complexType>
</schema>
82.5. REST Protobufs 模式
message Version {
optional string restVersion = 1;
optional string jvmVersion = 2;
optional string osVersion = 3;
optional string serverVersion = 4;
optional string jerseyVersion = 5;
}
message StorageClusterStatus {
message Region {
required bytes name = 1;
optional int32 stores = 2;
optional int32 storefiles = 3;
optional int32 storefileSizeMB = 4;
optional int32 memstoreSizeMB = 5;
optional int32 storefileIndexSizeMB = 6;
}
message Node {
required string name = 1; // name:port
optional int64 startCode = 2;
optional int32 requests = 3;
optional int32 heapSizeMB = 4;
optional int32 maxHeapSizeMB = 5;
repeated Region regions = 6;
}
// node status
repeated Node liveNodes = 1;
repeated string deadNodes = 2;
// summary statistics
optional int32 regions = 3;
optional int32 requests = 4;
optional double averageLoad = 5;
}
message TableList {
repeated string name = 1;
}
message TableInfo {
required string name = 1;
message Region {
required string name = 1;
optional bytes startKey = 2;
optional bytes endKey = 3;
optional int64 id = 4;
optional string location = 5;
}
repeated Region regions = 2;
}
message TableSchema {
optional string name = 1;
message Attribute {
required string name = 1;
required string value = 2;
}
repeated Attribute attrs = 2;
repeated ColumnSchema columns = 3;
// optional helpful encodings of commonly used attributes
optional bool inMemory = 4;
optional bool readOnly = 5;
}
message ColumnSchema {
optional string name = 1;
message Attribute {
required string name = 1;
required string value = 2;
}
repeated Attribute attrs = 2;
// optional helpful encodings of commonly used attributes
optional int32 ttl = 3;
optional int32 maxVersions = 4;
optional string compression = 5;
}
message Cell {
optional bytes row = 1; // unused if Cell is in a CellSet
optional bytes column = 2;
optional int64 timestamp = 3;
optional bytes data = 4;
}
message CellSet {
message Row {
required bytes key = 1;
repeated Cell values = 2;
}
repeated Row rows = 1;
}
message Scanner {
optional bytes startRow = 1;
optional bytes endRow = 2;
repeated bytes columns = 3;
optional int32 batch = 4;
optional int64 startTime = 5;
optional int64 endTime = 6;
}
83. Thrift
有关 Thrift 的文档已移至节俭 API 和过滤器语言。
84. C/C Apache HBaseClient 端
FB 的 Chip Turner 编写了一个纯 C/CClient 端。 看看这个。
CClient 端实现。看HBASE-14850。
85.通过 HBase 使用 Java 数据对象(JDO)
Java 数据对象(JDO)是使用普通的旧 Java 对象(POJO)表示持久数据来访问数据库中持久数据的一种标准方法。
Dependencies
此代码示例具有以下依赖关系:
HBase 0.90.x 或更高版本
commons-beanutils.jar (https://commons.apache.org/)
commons-pool-1.5.5.jar (https://commons.apache.org/)
HBase 0.90(https://github.com/hbase-trx/hbase-transactional-tableindexed)的事务表索引
下载hbase-jdo
从http://code.google.com/p/hbase-jdo/下载代码。
例子 29. JDO 例子
本示例使用 JDO 创建表和索引,将行插入表中,获取行,获取列值,执行查询,以及执行一些其他 HBase 操作。
package com.apache.hadoop.hbase.client.jdo.examples;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Hashtable;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.tableindexed.IndexedTable;
import com.apache.hadoop.hbase.client.jdo.AbstractHBaseDBO;
import com.apache.hadoop.hbase.client.jdo.HBaseBigFile;
import com.apache.hadoop.hbase.client.jdo.HBaseDBOImpl;
import com.apache.hadoop.hbase.client.jdo.query.DeleteQuery;
import com.apache.hadoop.hbase.client.jdo.query.HBaseOrder;
import com.apache.hadoop.hbase.client.jdo.query.HBaseParam;
import com.apache.hadoop.hbase.client.jdo.query.InsertQuery;
import com.apache.hadoop.hbase.client.jdo.query.QSearch;
import com.apache.hadoop.hbase.client.jdo.query.SelectQuery;
import com.apache.hadoop.hbase.client.jdo.query.UpdateQuery;
/**
* Hbase JDO Example.
*
* dependency library.
* - commons-beanutils.jar
* - commons-pool-1.5.5.jar
* - hbase0.90.0-transactionl.jar
*
* you can expand Delete,Select,Update,Insert Query classes.
*
*/
public class HBaseExample {
public static void main(String[] args) throws Exception {
AbstractHBaseDBO dbo = new HBaseDBOImpl();
//*drop if table is already exist.*
if(dbo.isTableExist("user")){
dbo.deleteTable("user");
}
//*create table*
dbo.createTableIfNotExist("user",HBaseOrder.DESC,"account");
//dbo.createTableIfNotExist("user",HBaseOrder.ASC,"account");
//create index.
String[] cols={"id","name"};
dbo.addIndexExistingTable("user","account",cols);
//insert
InsertQuery insert = dbo.createInsertQuery("user");
UserBean bean = new UserBean();
bean.setFamily("account");
bean.setAge(20);
bean.setEmail("ncanis@gmail.com");
bean.setId("ncanis");
bean.setName("ncanis");
bean.setPassword("1111");
insert.insert(bean);
//select 1 row
SelectQuery select = dbo.createSelectQuery("user");
UserBean resultBean = (UserBean)select.select(bean.getRow(),UserBean.class);
// select column value.
String value = (String)select.selectColumn(bean.getRow(),"account","id",String.class);
// search with option (QSearch has EQUAL, NOT_EQUAL, LIKE)
// select id,password,name,email from account where id='ncanis' limit startRow,20
HBaseParam param = new HBaseParam();
param.setPage(bean.getRow(),20);
param.addColumn("id","password","name","email");
param.addSearchOption("id","ncanis",QSearch.EQUAL);
select.search("account", param, UserBean.class);
// search column value is existing.
boolean isExist = select.existColumnValue("account","id","ncanis".getBytes());
// update password.
UpdateQuery update = dbo.createUpdateQuery("user");
Hashtable<String, byte[]> colsTable = new Hashtable<String, byte[]>();
colsTable.put("password","2222".getBytes());
update.update(bean.getRow(),"account",colsTable);
//delete
DeleteQuery delete = dbo.createDeleteQuery("user");
delete.deleteRow(resultBean.getRow());
////////////////////////////////////
// etc
// HTable pool with apache commons pool
// borrow and release. HBasePoolManager(maxActive, minIdle etc..)
IndexedTable table = dbo.getPool().borrow("user");
dbo.getPool().release(table);
// upload bigFile by hadoop directly.
HBaseBigFile bigFile = new HBaseBigFile();
File file = new File("doc/movie.avi");
FileInputStream fis = new FileInputStream(file);
Path rootPath = new Path("/files/");
String filename = "movie.avi";
bigFile.uploadFile(rootPath,filename,fis,true);
// receive file stream from hadoop.
Path p = new Path(rootPath,filename);
InputStream is = bigFile.path2Stream(p,4096);
}
}
86. Scala
86.1. 设置 Classpath
要将 Scala 与 HBase 一起使用,您的 CLASSPATH 必须包含 HBase 的 Classpath 以及代码所需的 Scala JAR。首先,在运行 HBase RegionServer 进程的服务器上使用以下命令来获取 HBase 的 Classpath。
$ ps aux |grep regionserver| awk -F 'java.library.path=' {'print $2'} | awk {'print $1'}
/usr/lib/hadoop/lib/native:/usr/lib/hbase/lib/native/Linux-amd64-64
设置$CLASSPATH环境变量以包括在上一步中找到的路径,以及scala-library.jar的路径以及项目所需的每个其他与 Scala 相关的 JAR。
$ export CLASSPATH=$CLASSPATH:/usr/lib/hadoop/lib/native:/usr/lib/hbase/lib/native/Linux-amd64-64:/path/to/scala-library.jar
86.2. Scala SBT 文件
您的build.sbt文件需要以下resolvers和libraryDependencies才能与 HBase 一起使用。
resolvers += "Apache HBase" at "https://repository.apache.org/content/repositories/releases"
resolvers += "Thrift" at "https://people.apache.org/~rawson/repo/"
libraryDependencies ++= Seq(
"org.apache.hadoop" % "hadoop-core" % "0.20.2",
"org.apache.hbase" % "hbase" % "0.90.4"
)
86.3. 示例 Scala 代码
本示例列出了 HBase 表,创建了一个新表,并向其中添加了一行。
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Connection,ConnectionFactory,HBaseAdmin,HTable,Put,Get}
import org.apache.hadoop.hbase.util.Bytes
val conf = new HBaseConfiguration()
val connection = ConnectionFactory.createConnection(conf);
val admin = connection.getAdmin();
// list the tables
val listtables=admin.listTables()
listtables.foreach(println)
// let's insert some data in 'mytable' and get the row
val table = new HTable(conf, "mytable")
val theput= new Put(Bytes.toBytes("rowkey1"))
theput.add(Bytes.toBytes("ids"),Bytes.toBytes("id1"),Bytes.toBytes("one"))
table.put(theput)
val theget= new Get(Bytes.toBytes("rowkey1"))
val result=table.get(theget)
val value=result.value()
println(Bytes.toString(value))
87. Jython
87.1. 设置 Classpath
要将 Jython 与 HBase 一起使用,您的 CLASSPATH 必须包括 HBase 的 Classpath 以及代码所需的 Jython JAR。
将路径设置为包含项目所需的jython.jar以及每个其他与 Jython 相关的 JAR 的目录。然后导出指向$ JYTHON_HOME env 的 HBASE_CLASSPATH。变量。
$ export HBASE_CLASSPATH=/directory/jython.jar
使用 Classpath 中的 HBase 和 Hadoop JAR 启动 Jython shell:$ bin/hbase org.python.util.jython
87.2. Jython 代码示例
例子 30.用 Jython 创建,填充,获取和删除表
下面的 Jython 代码示例检查表(如果存在),将其删除然后创建。然后,使用数据填充表并获取数据。
import java.lang
from org.apache.hadoop.hbase import HBaseConfiguration, HTableDescriptor, HColumnDescriptor, TableName
from org.apache.hadoop.hbase.client import Admin, Connection, ConnectionFactory, Get, Put, Result, Table
from org.apache.hadoop.conf import Configuration
# First get a conf object. This will read in the configuration
# that is out in your hbase-*.xml files such as location of the
# hbase master node.
conf = HBaseConfiguration.create()
connection = ConnectionFactory.createConnection(conf)
admin = connection.getAdmin()
# Create a table named 'test' that has a column family
# named 'content'.
tableName = TableName.valueOf("test")
table = connection.getTable(tableName)
desc = HTableDescriptor(tableName)
desc.addFamily(HColumnDescriptor("content"))
# Drop and recreate if it exists
if admin.tableExists(tableName):
admin.disableTable(tableName)
admin.deleteTable(tableName)
admin.createTable(desc)
# Add content to 'column:' on a row named 'row_x'
row = 'row_x'
put = Put(row)
put.addColumn("content", "qual", "some content")
table.put(put)
# Now fetch the content just added, returns a byte[]
get = Get(row)
result = table.get(get)
data = java.lang.String(result.getValue("content", "qual"), "UTF8")
print "The fetched row contains the value '%s'" % data
例子 31.使用 Jython 进行表扫描
本示例扫描表并返回与给定的家庭限定词匹配的结果。
import java.lang
from org.apache.hadoop.hbase import TableName, HBaseConfiguration
from org.apache.hadoop.hbase.client import Connection, ConnectionFactory, Result, ResultScanner, Table, Admin
from org.apache.hadoop.conf import Configuration
conf = HBaseConfiguration.create()
connection = ConnectionFactory.createConnection(conf)
admin = connection.getAdmin()
tableName = TableName.valueOf('wiki')
table = connection.getTable(tableName)
cf = "title"
attr = "attr"
scanner = table.getScanner(cf)
while 1:
result = scanner.next()
if not result:
break
print java.lang.String(result.row), java.lang.String(result.getValue(cf, attr))
Thrift API 和过滤器语言
Apache Thrift是一个跨平台,跨语言的开发框架。 HBase 包括 Thrift API 和过滤器语言。 Thrift API 依赖于 Client 端和服务器进程。
您可以按照用于安全操作的 Client 端配置-Thrift Gateway和配置 Thrift Gateway 以代表 Client 端进行身份验证中的过程在服务器和 Client 端上配置 Thrift 以进行安全身份验证。
本章的其余部分讨论了 Thrift API 提供的过滤器语言。
88.过滤器语言
HBase 0.92 中引入了节俭过滤器语言。通过 Thrift 或在 HBase Shell 中访问 HBase 时,它允许您执行服务器端过滤。您可以通过在 Shell 程序中使用scan help命令找到有关 Shell 程序集成的更多信息。
您将过滤器指定为字符串,该字符串在服务器上进行解析以构造过滤器。
88.1. 通用过滤器字符串语法
一个简单的过滤器表达式表示为一个字符串:
"FilterName (argument, argument,... , argument)"
请牢记以下语法准则。
指定过滤器的名称,然后在括号中指定逗号分隔的参数列表。
如果参数表示字符串,则应将其括在单引号(
')中。表示布尔值,整数或比较运算符的参数(例如 <, >或!=)不应用引号引起来
过滤器名称必须是一个单词。允许使用所有 ASCII 字符,但空格,单引号和括号除外。
过滤器的参数可以包含任何 ASCII 字符。如果参数中包含单引号,则必须在前面加上一个附加的单引号。
88.2. 复合过滤器和运算符
Binary Operators
AND- 如果使用
AND运算符,则键值必须同时满足两个过滤条件。
- 如果使用
OR- 如果使用
OR运算符,则键值必须满足至少一个过滤器。
- 如果使用
Unary Operators
SKIP- 对于特定行,如果任何键值均未通过过滤条件,则将跳过整行。
WHILE- 对于特定行,将运行键值,直到达到失败的过滤条件的键值为止。
例子 32.复合运算符
您可以组合多个运算符来创建过滤器的层次结构,例如以下示例:
(Filter1 AND Filter2) OR (Filter3 AND Filter4)
88.3. 评估 Sequences
括号的优先级最高。
一元运算符
SKIP和WHILE在其后,并且具有相同的优先级。二进制运算符跟随。
AND的优先级最高,其次是OR。
例子 33.优先例子
Filter1 AND Filter2 OR Filter
is evaluated as
(Filter1 AND Filter2) OR Filter3
Filter1 AND SKIP Filter2 OR Filter3
is evaluated as
(Filter1 AND (SKIP Filter2)) OR Filter3
您可以使用括号来显式控制评估的 Sequences。
88.4. 比较运算符
提供了以下比较运算符:
LESS (<)
LESS_OR_EQUAL (⇐)
EQUAL (=)
NOT_EQUAL (!=)
GREATER_OR_EQUAL (>=)
GREATER (>)
NO_OP(无操作)
Client 端应使用符号( <, ⇐, =, !=, >,> =)表示比较运算符。
88.5. Comparator
比较器可以是以下任意一个:
-
- BinaryComparator *-使用 Bytes.compareTo(byte [],byte [])在字典上与指定的字节数组进行比较
-
- BinaryPrefixComparator *-在字典上与指定的字节数组进行比较。它仅比较该字节数组的长度。
RegexStringComparator *-使用给定的正则表达式将其与指定的字节数组进行比较。此比较器仅 EQUAL 和 NOT_EQUAL 比较有效
-
- SubStringComparator *-测试给定的子字符串是否出现在指定的字节数组中。比较不区分大小写。此比较器仅 EQUAL 和 NOT_EQUAL 比较有效
比较器的一般语法为:ComparatorType:ComparatorValue
各种比较器的 ComparatorType 如下:
-
- BinaryComparator *-二进制
-
- BinaryPrefixComparator *-binaryprefix
-
- RegexStringComparator *-正则表达式
-
- SubStringComparator *-子字符串
ComparatorValue 可以是任何值。
Example ComparatorValues
binary:abc将匹配在字典上大于“ abc”的所有内容binaryprefix:abc将匹配在字典上前三个字符等于“ abc”的所有字符regexstring:ab*yz将匹配所有不以“ ab”开头且以“ yz”结尾的内容substring:abc123将匹配所有以子字符串“ abc123”开头的内容
88.6. 使用过滤器语言的示例 PHPClient 端程序
<?
$_SERVER['PHP_ROOT'] = realpath(dirname(__FILE__).'/..');
require_once $_SERVER['PHP_ROOT'].'/flib/__flib.php';
flib_init(FLIB_CONTEXT_SCRIPT);
require_module('storage/hbase');
$hbase = new HBase('<server_name_running_thrift_server>', <port on which thrift server is running>);
$hbase->open();
$client = $hbase->getClient();
$result = $client->scannerOpenWithFilterString('table_name', "(PrefixFilter ('row2') AND (QualifierFilter (>=, 'binary:xyz'))) AND (TimestampsFilter ( 123, 456))");
$to_print = $client->scannerGetList($result,1);
while ($to_print) {
print_r($to_print);
$to_print = $client->scannerGetList($result,1);
}
$client->scannerClose($result);
?>
88.7. 过滤字符串示例
"PrefixFilter ('Row') AND PageFilter (1) AND FirstKeyOnlyFilter ()"将返回符合以下条件的所有键值对:包含键值的行应带有前缀* Row *
键值必须位于表格的第一行
键值对必须是该行中的第一个键值
"(RowFilter (=, 'binary:Row 1') AND TimeStampsFilter (74689, 89734)) OR ColumnRangeFilter ('abc', true, 'xyz', false))"将返回符合以下两个条件的所有键值对:键值位于具有行键*行 1 *的行中
键值的时间戳记必须为 74689 或 89734.
或者它必须满足以下条件:
键值对必须位于按字典 Sequences> = abc 和<xyz 的列中
如果该行中的任何一个值都不为 0,则
"SKIP ValueFilter (0)"将跳过整行
88.8. 个别过滤器语法
KeyOnlyFilter
- 该过滤器不接受任何参数。它仅返回每个键值的键组成部分。
FirstKeyOnlyFilter
- 该过滤器不接受任何参数。它仅返回每行的第一个键值。
PrefixFilter
- 此过滤器采用一个参数–行键的前缀。它仅返回以指定行前缀开头的行中存在的那些键值
ColumnPrefixFilter
- 该过滤器采用一个参数–列前缀。它仅返回存在于以指定列前缀开头的列中的那些键值。列前缀的格式必须为:
"qualifier"。
- 该过滤器采用一个参数–列前缀。它仅返回存在于以指定列前缀开头的列中的那些键值。列前缀的格式必须为:
MultipleColumnPrefixFilter
- 此过滤器采用列前缀列表。它返回存在于以任何指定列前缀开头的列中的键值。每个列前缀都必须采用以下形式:
"qualifier"。
- 此过滤器采用列前缀列表。它返回存在于以任何指定列前缀开头的列中的键值。每个列前缀都必须采用以下形式:
ColumnCountGetFilter
- 此过滤器接受一个参数-一个限制。它返回表中的第一个限制列数。
PageFilter
- 此过滤器采用一个参数–页面大小。它从表中返回页面大小的行数。
ColumnPaginationFilter
- 该过滤器采用两个参数–限制和偏移量。它在偏移列数之后返回限制列数。它对所有行都执行此操作。
InclusiveStopFilter
- 该过滤器采用一个参数–行键,停止扫描。它返回直到指定行为止的行中存在的所有键值。
TimeStampsFilter
- 该过滤器采用时间戳列表。它返回那些时间戳与任何指定时间戳匹配的键值。
RowFilter
- 该过滤器带有一个比较运算符和一个比较器。它使用比较运算符将每个行键与比较器进行比较,如果比较返回 true,则返回该行中的所有键值。
Family Filter
- 该过滤器带有一个比较运算符和一个比较器。它使用比较运算符将每个列族名称与比较器进行比较,如果比较结果为 true,则返回该列族中的所有单元格。
QualifierFilter
- 该过滤器带有一个比较运算符和一个比较器。它使用比较运算符将每个限定符名称与比较器进行比较,如果比较返回 true,则将返回该列中的所有键值。
ValueFilter
- 该过滤器带有一个比较运算符和一个比较器。它使用比较运算符将每个值与比较器进行比较,如果比较返回 true,则返回该键值。
DependentColumnFilter
- 该过滤器接受两个参数-家庭和限定词。它尝试在每一行中定位此列,并返回该行中所有具有相同时间戳的键值。如果该行不包含指定的列-该行中的任何键值均不会返回。
SingleColumnValueFilter
- 该过滤器包含一个列族,一个限定符,一个比较运算符和一个比较器。如果找不到指定的列,则将运行该行的所有列。如果找到该列并且与比较器的比较返回 true,则将发出该行的所有列。如果条件失败,则不会发出该行。
SingleColumnValueExcludeFilter
- 该过滤器采用相同的参数,其行为与 SingleColumnValueFilter 相同–但是,如果找到该列且条件通过,则将发出该行的所有列,但测试列的值除外。
ColumnRangeFilter
- 此过滤器仅用于选择其列在 minColumn 和 maxColumn 之间的键。它还需要两个布尔变量来指示是否包括 minColumn 和 maxColumn。
Apache HBase 协处理器
HBase 协处理器是根据 Google BigTable 的协处理器实现建模的(http://research.google.com/people/jeff/SOCC2010-keynote-slides.pdf第 41-42 页。)。
协处理器框架提供了用于在 Management 数据的 RegionServer 上直接运行自定义代码的机制。正在努力缩小 HBase 的实现与 BigTable 的体系结构之间的差距。有关更多信息,请参见HBASE-4047。
本章中的信息主要来自以下资源,并且大量重复使用:
赖明杰的博客文章Coprocessor Introduction。
Gaurav Bhardwaj 的博客文章HBase 协处理器的使用方法。
Use Coprocessors At Your Own Risk
协处理器是 HBase 的高级功能,仅供系统开发人员使用。因为协处理器代码直接在 RegionServer 上运行并且可以直接访问您的数据,所以它们会带来数据损坏,中间人攻击或其他恶意数据访问的风险。尽管尚在HBASE-4047上进行工作,但目前尚无机制可防止协处理器破坏数据。
- 此外,没有资源隔离,因此,一个意图良好但行为不当的协处理器会严重降低群集的性能和稳定性。
89.协处理器概述
在 HBase 中,您使用Get或Scan来获取数据,而在 RDBMS 中,您使用 SQL 查询。为了仅获取相关数据,请使用 HBase Filter对其进行过滤,而在 RDBMS 中则使用WHERE谓词。
提取数据后,您可以对其进行计算。此范例适用于具有数千行和几列的“小数据”。但是,当您扩展到数十亿行和数百万列时,在网络上移动大量数据将在网络层造成瓶颈,并且 Client 端需要足够强大并且有足够的内存来处理大量数据,并且计算。此外,Client 端代码可能会变得庞大而复杂。
在这种情况下,协处理器可能有意义。您可以将业务计算代码放入协处理器中,该协处理器在 RegionServer 上与数据位于相同的位置,然后将结果返回给 Client 端。
这只是使用协处理器可以带来好处的一种情况。以下是一些类推,可能有助于解释协处理器的某些好处。
89.1. 协处理器类比
触发器和存储过程
- 观察者协处理器类似于 RDBMS 中的触发器,因为它在特定事件(例如
Get或Put)发生之前或之后执行代码。端点协处理器类似于 RDBMS 中的存储过程,因为它允许您对 RegionServer 本身而不是 Client 端上的数据执行自定义计算。
- 观察者协处理器类似于 RDBMS 中的触发器,因为它在特定事件(例如
MapReduce
- MapReduce 的工作原理是将计算移至数据位置。协处理器在相同的主体上运行。
AOP
- 如果您熟悉面向方面的编程(AOP),则可以将协处理器视为通过在将请求传递给最终目的地(甚至更改目的地)之前拦截请求然后运行一些自定义代码来应用建议。
89.2. 协处理器实现概述
您的类应该实现协处理器接口之一Coprocessor,RegionObserver,CoprocessorService-仅举几例。
使用 HBase Shell 静态地(从配置中)或动态地加载协处理器。有关更多详细信息,请参见Loading Coprocessors。
从 Client 端代码调用协处理器。 HBase 透明地处理协处理器。
coprocessor软件包中提供了框架 API。
90.协处理器的类型
90.1. 观察者协处理器
观察者协处理器在特定事件发生之前或之后触发。在事件之前发生的观察者使用以pre前缀开头的方法,例如prePut。事件发生后立即发生的观察者会覆盖以post前缀开头的方法,例如postPut。
90.1.1. 观察者协处理器的用例
Security
- 在执行
Get或Put操作之前,您可以使用preGet或prePut方法检查权限。
- 在执行
Referential Integrity
- HBase 不直接支持 RDBMS 参考完整性的概念,也称为外键。您可以使用协处理器来强制这种完整性。例如,如果您有一条业务规则,即对
users表的每个插入都必须在user_daily_attendance表中带有相应的条目,则可以实现协处理器以对user使用prePut方法将记录插入user_daily_attendance。
- HBase 不直接支持 RDBMS 参考完整性的概念,也称为外键。您可以使用协处理器来强制这种完整性。例如,如果您有一条业务规则,即对
Secondary Indexes
- 您可以使用协处理器来维护二级索引。有关更多信息,请参见SecondaryIndexing。
90.1.2. 观察者协处理器的类型
RegionObserver
- RegionObserver 协处理器使您可以观察区域上的事件,例如
Get和Put操作。参见RegionObserver。
- RegionObserver 协处理器使您可以观察区域上的事件,例如
RegionServerObserver
- RegionServerObserver 允许您观察与 RegionServer 操作相关的事件,例如启动,停止或执行合并,提交或回滚。参见RegionServerObserver。
MasterObserver
- MasterObserver 允许您观察与 HBase Master 相关的事件,例如表创建,删除或架构修改。参见MasterObserver。
WalObserver
- WalObserver 允许您观察与写入预写日志(WAL)有关的事件。参见WALObserver。
Examples提供了观察者协处理器的工作示例。
90.2. 端点协处理器
端点处理器使您可以在数据位置执行计算。参见Coprocessor Analogy。一个例子是需要为跨越数百个区域的整个表计算运行平均值或求和。
与观察者协处理器不同,在观察者协处理器中代码是透明运行的,必须使用Table或HTable中可用的CoprocessorService()方法显式调用端点协处理器。
从 HBase 0.96 开始,端点协处理器是使用 Google 协议缓冲区(protobuf)实现的。有关 protobuf 的更多详细信息,请参见 Google 的协议缓冲区指南。用 0.94 版编写的端点协处理器与 0.96 版或更高版本不兼容。参见HBASE-5448)。要将 HBase 群集从 0.94 或更早版本升级到 0.96 或更晚版本,您需要重新实现协处理器。
协处理器端点不应使用 HBase 内部结构,而应仅使用公共 API。理想情况下,CPEP 应该仅取决于接口和数据结构。这并非总是可能的,但是请注意,这样做会使 Endpoint 变脆,随着 HBase 内部结构的 Developing 而易于损坏。Comments 为私有或不断 Developing 的 HBase 内部 API 不必在删除之前遵守关于弃用的语义版本控制规则或通用 Java 规则。虽然没有生成的 protobuf 文件,但是 hbaseSpectator 注解-“它们是由 protobuf 协议工具创建的,该工具对 HBase 的工作一无所知”-应将它们视为@InterfaceAudience.Private,因此易于更改。
Examples提供了端点协处理器的工作示例。
91.加载协处理器
为了使协处理器可用于 HBase,必须“静态”加载(通过 HBase 配置)或动态(使用 HBase Shell 或 Java API)。
91.1. 静态加载
请按照以下步骤静态加载您的协处理器。请记住,必须重新启动 HBase 才能卸载已静态加载的协处理器。
在* hbase-site.xml *中定义协处理器,带有一个带有和一个子元素的\ 元素。<name>应该是以下之一:
hbase.coprocessor.region.classes用于 RegionObservers 和端点。hbase.coprocessor.wal.classesfor WALObservers。hbase.coprocessor.master.classes(用于 MasterObservers)。
\ 必须包含协处理器的实现类的标准类名。
例如,要加载协处理器(在类 SumEndPoint.java 中实现),您必须在 RegionServer 的“ hbase-site.xml”文件(通常位于“ conf”目录下)中创建以下条目:
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.myname.hbase.coprocessor.endpoint.SumEndPoint</value>
</property>
如果为加载指定了多个类别,则类别名称必须用逗号分隔。框架尝试使用默认的类加载器加载所有配置的类。因此,jar 文件必须驻留在服务器端 HBaseClasspath 上。
以这种方式加载的协处理器将在所有表的所有区域上处于活动状态。这些也称为系统协处理器。首先列出的协处理器将被分配优先级Coprocessor.Priority.SYSTEM。列表中的每个后续协处理器将其优先级值加 1(这会降低其优先级,因为优先级具有整数的自然排序 Sequences)。
可以在 hbase-site.xml 中手动覆盖这些优先级值。如果您要保证协处理器会陆续执行,这将很有用。例如,在以下配置中,除非与另一个协处理器并列,否则SumEndPoint将保证排在最后:
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.myname.hbase.coprocessor.endpoint.SumEndPoint|2147483647</value>
</property>
当调用注册的观察者时,框架将按照其优先级的排序 Sequences 执行其回调方法。
领带被任意 break。
将您的代码放在 HBase 的 Classpath 上。一种简单的方法是将 jar(包含您的代码和所有依赖项)放入 HBase 安装的
lib/目录中。Restart HBase.
91.2. 静态卸货
从
hbase-site.xml删除协处理器的\ 元素(包括子元素)。Restart HBase.
(可选)从 Classpath 或 HBase 的
lib/目录中删除协处理器的 JAR 文件。
91.3. 动态加载
您还可以动态加载协处理器,而无需重新启动 HBase。这似乎比静态加载更好,但是动态加载的协处理器是按表加载的,并且仅对加载它们的表可用。因此,动态加载的表有时称为 Table Coprocessor 。
此外,动态加载协处理器还充当表上的架构更改,并且必须使表脱机以加载协处理器。
有三种方法可以动态加载协处理器。
Assumptions
以下提到的指令进行以下假设:
一个名为
coprocessor.jar的 JAR 包含协处理器实现及其所有依赖项。HDFS 的
hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar等位置提供了 JAR。
91.3.1. 使用 HBase Shell
- 使用 HBase Shell 禁用表:
hbase> disable 'users'
- 使用如下命令加载协处理器:
hbase alter 'users', METHOD => 'table_att', 'Coprocessor'=>'hdfs://<namenode>:<port>/
user/<hadoop-user>/coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823|
arg1=1,arg2=2'
协处理器框架将尝试从协处理器表属性值中读取类信息。该值包含由竖线(|)字符分隔的四条信息。
文件路径:包含协处理器实现的 jar 文件必须位于所有区域服务器都可以读取的位置。
您可以将文件复制到每个区域服务器上的本地磁盘上,但是建议将其存储在 HDFS 中。
HBASE-14548允许指定包含 jar 或一些通配符的目录,例如:hdfs://<namenode>:\ /user /<hadoop-user> /或 hdfs://<namenode>:\ /user /<hadoop-user>/*。罐。请注意,如果指定了目录,则会添加目录中的所有 jar 文件(.jar)。它不会在子目录中搜索文件。如果要指定目录,请不要使用通配符。此增强功能也适用于通过 JAVA API 的用法。类名:协处理器的完整类名。
优先级:整数。框架将使用优先级确定在同一钩子上注册的所有已配置观察者的执行 Sequences。该字段可以留为空白。在这种情况下,框架将分配默认优先级值。
参数(可选):该字段传递给协处理器实现。这是可选的。
启用表格。
hbase(main):003:0> enable 'users'
- 验证是否已加载协处理器:
hbase(main):04:0> describe 'users'
协处理器应该在TABLE_ATTRIBUTES中列出。
91.3.2. 使用 Java API(所有 HBase 版本)
以下 Java 代码显示了如何使用HTableDescriptor的setValue()方法在users表上加载协处理器。
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.setValue("COPROCESSOR$1", path + "|"
+ RegionObserverExample.class.getCanonicalName() + "|"
+ Coprocessor.PRIORITY_USER);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
91.3.3. 使用 Java API(仅适用于 HBase 0.96)
在 HBase 0.96 和更高版本中,HTableDescriptor的addCoprocessor()方法提供了一种更轻松的方式来动态加载协处理器。
TableName tableName = TableName.valueOf("users");
Path path = new Path("hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar");
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.addCoprocessor(RegionObserverExample.class.getCanonicalName(), path,
Coprocessor.PRIORITY_USER, null);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
Warning
无法保证框架会成功加载给定的协处理器。例如,shell 命令既不能保证 jar 文件位于特定位置,也不能验证给定的类是否实际上包含在 jar 文件中。
91.4. 动态卸载
91.4.1. 使用 HBase Shell
- 禁用表格。
hbase> disable 'users'
- 更改表以删除协处理器。
hbase> alter 'users', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
- 启用表格。
hbase> enable 'users'
91.4.2. 使用 Java API
通过使用setValue()或addCoprocessor()方法重新加载表定义,而无需设置协处理器的值。这将删除连接到表的所有协处理器。
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
在 HBase 0.96 和更高版本中,您可以改用HTableDescriptor类的removeCoprocessor()方法。
92. Examples
HBase 提供了 Observer 协处理器的示例。
下面给出一个更详细的示例。
这些示例假定一个名为users的表,该表具有两个列族personalDet和salaryDet,其中包含个人和薪水详细信息。下面是users表的图形表示。
表 19.用户表
| personalDet | salaryDet | |||||
|---|---|---|---|---|---|---|
| rowkey | name | lastname | dob | gross | net | allowances |
| admin | Admin | Admin | ||||
| cdickens | Charles | Dickens | 02/07/1812 | 10000 | 8000 | 2000 |
92.1. 观察者示例
以下观察者协处理器可防止在users表的Get或Scan中返回用户admin的详细信息。
编写实现RegionObserver类的类。
重写
preGetOp()方法(不建议使用preGet()方法)以检查 Client 端是否已查询值admin的行键。如果是这样,则返回空结果。否则,请正常处理请求。将您的代码和依赖项放在 JAR 文件中。
将 JAR 放在 HBase 可以找到的 HDFS 中。
加载协处理器。
编写一个简单的程序对其进行测试。
以下是上述步骤的实现:
public class RegionObserverExample implements RegionObserver {
private static final byte[] ADMIN = Bytes.toBytes("admin");
private static final byte[] COLUMN_FAMILY = Bytes.toBytes("details");
private static final byte[] COLUMN = Bytes.toBytes("Admin_det");
private static final byte[] VALUE = Bytes.toBytes("You can't see Admin details");
@Override
public void preGetOp(final ObserverContext<RegionCoprocessorEnvironment> e, final Get get, final List<Cell> results)
throws IOException {
if (Bytes.equals(get.getRow(),ADMIN)) {
Cell c = CellUtil.createCell(get.getRow(),COLUMN_FAMILY, COLUMN,
System.currentTimeMillis(), (byte)4, VALUE);
results.add(c);
e.bypass();
}
}
}
覆盖preGetOp()仅适用于Get操作。您还需要覆盖preScannerOpen()方法以从扫描结果中过滤admin行。
@Override
public RegionScanner preScannerOpen(final ObserverContext<RegionCoprocessorEnvironment> e, final Scan scan,
final RegionScanner s) throws IOException {
Filter filter = new RowFilter(CompareOp.NOT_EQUAL, new BinaryComparator(ADMIN));
scan.setFilter(filter);
return s;
}
此方法有效,但有副作用。如果 Client 端在其扫描中使用了筛选器,则该筛选器将替换为该筛选器。相反,您可以从扫描中明确删除任何admin结果:
@Override
public boolean postScannerNext(final ObserverContext<RegionCoprocessorEnvironment> e, final InternalScanner s,
final List<Result> results, final int limit, final boolean hasMore) throws IOException {
Result result = null;
Iterator<Result> iterator = results.iterator();
while (iterator.hasNext()) {
result = iterator.next();
if (Bytes.equals(result.getRow(), ROWKEY)) {
iterator.remove();
break;
}
}
return hasMore;
}
92.2. 端点范例
仍然使用users表,此示例使用端点协处理器实现了协处理器来计算所有员工薪金的总和。
- 创建一个定义您的服务的“ .proto”文件。
option java_package = "org.myname.hbase.coprocessor.autogenerated";
option java_outer_classname = "Sum";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
option optimize_for = SPEED;
message SumRequest {
required string family = 1;
required string column = 2;
}
message SumResponse {
required int64 sum = 1 [default = 0];
}
service SumService {
rpc getSum(SumRequest)
returns (SumResponse);
}
- 执行
protoc命令,从上述.proto'文件生成 Java 代码。
$ mkdir src
$ protoc --java_out=src ./sum.proto
这将生成一个类调用Sum.java。
- 编写一个类,以扩展生成的服务类,实现
Coprocessor和CoprocessorService类,并覆盖 service 方法。
Warning
如果从hbase-site.xml加载协处理器,然后使用 HBase Shell 再次加载同一协处理器,则会再次加载该协处理器。同一类将存在两次,并且第二个实例的 ID 较高(因此优先级较低)。结果是有效地忽略了重复协处理器。
public class SumEndPoint extends Sum.SumService implements Coprocessor, CoprocessorService {
private RegionCoprocessorEnvironment env;
@Override
public Service getService() {
return this;
}
@Override
public void start(CoprocessorEnvironment env) throws IOException {
if (env instanceof RegionCoprocessorEnvironment) {
this.env = (RegionCoprocessorEnvironment)env;
} else {
throw new CoprocessorException("Must be loaded on a table region!");
}
}
@Override
public void stop(CoprocessorEnvironment env) throws IOException {
// do nothing
}
@Override
public void getSum(RpcController controller, Sum.SumRequest request, RpcCallback<Sum.SumResponse> done) {
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(request.getFamily()));
scan.addColumn(Bytes.toBytes(request.getFamily()), Bytes.toBytes(request.getColumn()));
Sum.SumResponse response = null;
InternalScanner scanner = null;
try {
scanner = env.getRegion().getScanner(scan);
List<Cell> results = new ArrayList<>();
boolean hasMore = false;
long sum = 0L;
do {
hasMore = scanner.next(results);
for (Cell cell : results) {
sum = sum + Bytes.toLong(CellUtil.cloneValue(cell));
}
results.clear();
} while (hasMore);
response = Sum.SumResponse.newBuilder().setSum(sum).build();
} catch (IOException ioe) {
ResponseConverter.setControllerException(controller, ioe);
} finally {
if (scanner != null) {
try {
scanner.close();
} catch (IOException ignored) {}
}
}
done.run(response);
}
}
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("users");
Table table = connection.getTable(tableName);
final Sum.SumRequest request = Sum.SumRequest.newBuilder().setFamily("salaryDet").setColumn("gross").build();
try {
Map<byte[], Long> results = table.coprocessorService(
Sum.SumService.class,
null, /* start key */
null, /* end key */
new Batch.Call<Sum.SumService, Long>() {
@Override
public Long call(Sum.SumService aggregate) throws IOException {
BlockingRpcCallback<Sum.SumResponse> rpcCallback = new BlockingRpcCallback<>();
aggregate.getSum(null, request, rpcCallback);
Sum.SumResponse response = rpcCallback.get();
return response.hasSum() ? response.getSum() : 0L;
}
}
);
for (Long sum : results.values()) {
System.out.println("Sum = " + sum);
}
} catch (ServiceException e) {
e.printStackTrace();
} catch (Throwable e) {
e.printStackTrace();
}
加载协处理器。
编写 Client 端代码以调用协处理器。
93.部署协处理器的准则
Bundling Coprocessors
- 您可以将协处理器的所有类 Binding 到 RegionServer 的 Classpath 上的单个 JAR 中,以便于部署。否则,请将所有依赖项放在 RegionServer 的 Classpath 上,以便可以在 RegionServer 启动期间加载它们。 RegionServer 的 Classpath 在 RegionServer 的
hbase-env.sh文件中设置。
- 您可以将协处理器的所有类 Binding 到 RegionServer 的 Classpath 上的单个 JAR 中,以便于部署。否则,请将所有依赖项放在 RegionServer 的 Classpath 上,以便可以在 RegionServer 启动期间加载它们。 RegionServer 的 Classpath 在 RegionServer 的
Automating Deployment
- 您可以使用诸如 Puppet,Chef 或 Ansible 之类的工具将协处理器的 JAR 运送到 RegionServers 文件系统上的所需位置,然后重新启动每个 RegionServer,以自动进行协处理器部署。此类设置的详细信息不在本文档的讨论范围之内。
更新协处理器
- 部署给定协处理器的新版本并不像禁用它,替换 JAR 并重新启用协处理器那样简单。这是因为除非删除所有当前对 JVM 的引用,否则无法在 JVM 中重新加载它。由于当前的 JVM 引用了现有的协处理器,因此必须通过重新启动 RegionServer 来重新启动 JVM 才能替换它。这种行为预计不会改变。
Coprocessor Logging
- 协处理器框架没有提供用于标准 Java 日志记录之外的日志记录的 API。
Coprocessor Configuration
- 如果您不想从 HBase Shell 加载协处理器,则可以将其配置属性添加到
hbase-site.xml。在使用 HBase Shell中,设置了两个参数:arg1=1,arg2=2。这些可能已被添加到hbase-site.xml,如下所示:
- 如果您不想从 HBase Shell 加载协处理器,则可以将其配置属性添加到
<property>
<name>arg1</name>
<value>1</value>
</property>
<property>
<name>arg2</name>
<value>2</value>
</property>
然后,您可以使用如下代码读取配置:
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("users");
Table table = connection.getTable(tableName);
Get get = new Get(Bytes.toBytes("admin"));
Result result = table.get(get);
for (Cell c : result.rawCells()) {
System.out.println(Bytes.toString(CellUtil.cloneRow(c))
+ "==> " + Bytes.toString(CellUtil.cloneFamily(c))
+ "{" + Bytes.toString(CellUtil.cloneQualifier(c))
+ ":" + Bytes.toLong(CellUtil.cloneValue(c)) + "}");
}
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result res : scanner) {
for (Cell c : res.rawCells()) {
System.out.println(Bytes.toString(CellUtil.cloneRow(c))
+ " ==> " + Bytes.toString(CellUtil.cloneFamily(c))
+ " {" + Bytes.toString(CellUtil.cloneQualifier(c))
+ ":" + Bytes.toLong(CellUtil.cloneValue(c))
+ "}");
}
}
94.限制协处理器使用
在多租户环境中,限制任意用户协处理器可能是一个大问题。 HBase 提供了一系列选项来确保仅预期的协处理器正在运行:
hbase.coprocessor.enabled:启用或禁用所有协处理器。这将限制 HBase 的功能,因为禁用所有协处理器将禁用某些安全提供程序。受此影响的示例协处理器为org.apache.hadoop.hbase.security.access.AccessController。hbase.coprocessor.user.enabled:启用或禁用在表上加载协处理器(即用户协处理器)。- 通过
hbase-site.xml中的以下可调参数,可以静态加载协处理器,并可以选择调整其优先级:
- 通过
hbase.coprocessor.regionserver.classes:区域服务器加载的以逗号分隔的协处理器列表hbase.coprocessor.region.classes:RegionObserver 和 Endpoint 协处理器的逗号分隔列表hbase.coprocessor.user.region.classes:所有区域加载的以逗号分隔的协处理器列表hbase.coprocessor.master.classes:由主服务器加载的协处理器的逗号分隔列表(MasterObserver 协处理器)hbase.coprocessor.wal.classes:要加载的以逗号分隔的 WALObserver 协处理器列表hbase.coprocessor.abortonerror:如果协处理器应该发生IOError以外的错误,是否终止加载了协处理器的守护程序。如果将其设置为 false,并且访问控制器协处理器应该出现致命错误,则将绕过该协处理器,因此在安全安装中,建议将其设置为true;但是,对于用户协处理器,可以在每个表的基础上重写此操作,以确保它们不会中止其运行区域服务器,而是在出错时卸载。hbase.coprocessor.region.whitelist.paths:可用逗号分隔的列表,用于加载org.apache.hadoop.hbase.security.access.CoprocessorWhitelistMasterObserver,从而可以使用以下选项将可从其加载协处理器的路径列入白名单。
Classpath 上的协处理器被隐式列入白名单
*通配所有协处理器路径整个文件系统(例如
hdfs://my-cluster/)FilenameUtils.wildcardMatch要评估的通配符路径
注意:Path 是否可以指定方案(例如
file:///usr/hbase/lib/coprocessors或所有文件系统/usr/hbase/lib/coprocessors)
Apache HBase 性能调优
95.os
95.1. Memory
RAM,RAM,RAM。不要饿死 HBase。
95.2. 64-bit
使用 64 位平台(和 64 位 JVM)。
95.3. Swapping
当心交换。将swappiness设置为 0.
95.4. CPU
确保已将 Hadoop 设置为使用本机硬件校验和。参见链接:[hadoop.native.lib]。
96. Network
避免网络问题降低 Hadoop 和 HBase 性能的最重要因素可能是所使用的交换硬件,当您将群集大小增加一倍或两倍时,在项目范围内早期做出的决策可能会导致严重问题。
要考虑的重要事项:
设备的交换能力
连接的系统数
Uplink capacity
96.1. 单开关
此配置中最重要的一个因素是,硬件的交换能力能够处理可能由连接到交换机的所有系统生成的流量。某些价格较低的商品硬件的交换容量可能会比完整交换机所使用的交换容量慢。
96.2. 多个开关
多个交换机是架构中的潜在陷阱。价格较低的硬件最常见的配置是从一台交换机到另一台交换机的简单 1Gbps 上行链路。这个经常被忽略的瓶颈很容易成为集群通信的瓶颈。特别是对于同时读取和写入大量数据的 MapReduce 作业,跨此上行链路的通信可能会饱和。
缓解此问题非常简单,可以通过多种方式实现:
对要构建的集群规模使用适当的硬件。
使用更大的单交换机配置,即单个 48 端口而不是 2 个 24 端口
为上行链路配置端口中继,以利用多个接口来增加跨交换机带宽。
96.3. 多个机架
多个机架配置具有与多个交换机相同的潜在问题,并且可能在两个主要方面导致性能下降:
开关容量性能不佳
到另一个机架的上行链路不足
如果机架中的交换机具有适当的交换能力以全速处理所有主机,则下一个最可能出现的问题将是通过在机架中放置更多的群集而引起的。跨多个机架时避免问题的最简单方法是使用端口中继来创建到其他机架的绑定上行链路。但是,此方法的缺点在于可能使用的端口的开销。这样的一个例子是,创建一个从机架 A 到机架 B 的 8Gbps 端口通道,使用 24 个端口中的 8 个在机架之间进行通信会给您带来较差的 ROI,但是使用的端口数太少可能意味着您没有从中获得最大的收益 Cluster。
在机架之间使用 10Gbe 链接将大大提高性能,并且假设您的交换机支持 10Gbe 上行链路或允许使用扩展卡,则可以为上行链路分配机器的端口。
96.4. 网络接口
所有网络接口是否正常运行?你确定吗?请参阅案例研究 1(单个节点上的性能问题)中的故障排除案例研究。
96.5. 网络一致性和分区容限
CAP Theorem表示分布式系统可以维护以下三个 Feature 中的两个:-* C * onsistency-所有节点都可以看到相同的数据。 -* A * vailability-每个请求都收到有关成功还是失败的响应。 -* P *定位公差-system 即使某些组件对其他组件不可用,系统仍将 continue 运行。
HBase 支持一致性和分区容忍度,因此必须做出决定。 Coda Hale 在http://codahale.com/you-cant-sacrifice-partition-tolerance/中解释了为什么分区容限如此重要。
Robert Yokota 使用一种名为Jepson的自动化测试框架,以 Aphyr 的打电话给我,可能的话系列为模型,对面对网络分区的 HBase 的分区容限进行了测试。结果以blog post和addendum表示,表明 HBase 正确执行。
97. Java
97.1. 垃圾收集器和 Apache HBase
97.1.1. GC 长时间停顿
在他的演示文稿避免使用带有 MemStore 本地分配缓冲区的完整 GC中,Todd Lipcon 描述了 HBase 中常见的两种情况(尤其是在加载过程中)的世界停止垃圾回收; CMS 的故障模式和旧堆带来的碎片化。
要解决第一个问题,请通过添加-XX:CMSInitiatingOccupancyFraction并将其设置为默认值,从而比默认值更早启动 CMS。从 60%或 70%开始(降低阈值越低,完成 GC 越多,使用的 CPU 越多)。为了解决第二个碎片问题,Todd 添加了一个实验工具(MSLAB),必须在 Apache HBase 0.90.x 中显式启用它(在 Apache 0.92.x HBase 中默认为* on *)。将Configuration中的hbase.hregion.memstore.mslab.enabled设置为 true。有关背景和详细信息,请参见引用的幻灯片。最新的 JVM 最好考虑碎片问题,因此请确保您正在运行最新版本。在消息识别由碎片引起的并发模式故障中阅读。请注意,启用后,每个 MemStore 实例将至少占用一个 MSLAB 内存实例。如果您有成千上万个区域或许多区域,每个区域都有许多列族,则 MSLAB 的这种分配可能会占您堆分配的很大一部分,在极端情况下会导致您成为 OOME。在这种情况下,请禁用 MSLAB,或降低其使用的内存量,或使每台服务器的 Float 区域更少。
如果您的工作量繁重,请查看HBASE-8163 MemStoreChunkPool:使用 MSLAB 时对 JAVA GC 的改进。它描述了在写重负载期间降低新 GC 数量的配置。如果您未安装 HBASE-8163,并且正在尝试改善年轻的 GC 时间,则可以考虑的一个窍门-由我们的 Liang Xie 提供-由* hbase-env.sh *中设置 GC 配置-XX:PretenureSizeThreshold小于hbase.hregion.memstore.mslab.chunksize的大小,因此 MSLAB 分配直接在终身空间中发生,而不是在年轻一代中首先发生。您之所以这样做,是因为这些 MSLAB 分配很可能会使它变成老一代,而不是在伊甸空间中支付 s0 和 s1 之间的副本的价格,然后在 MSLAB 拥有之后从年轻一代复制到老一代取得了足够的任期,节省了一点 YGC 流失并直接分配给旧 Generator。
长 GC 的其他来源可以是 JVM 本身的日志记录。见消除由后台 IO 流量引起的大型 JVM GC 暂停
有关 GC 日志的更多信息,请参见JVM 垃圾收集日志。
考虑还启用堆外块缓存。已显示这可以减少 GC 暂停时间。见Block Cache
98. HBase 配置
See Recommended Configurations.
98.1. 提高百分之九十九
Try link:[hedged_reads].
98.2. Management 压实
对于较大的系统,您可能需要考虑 Managementlink:[compacts and splits]。
98.3. hbase.regionserver.handler.count
See [hbase.regionserver.handler.count].
98.4. hfile.block.cache.size
参见[hfile.block.cache.size]。 RegionServer 进程的内存设置。
98.5. 块缓存的预取选项
如果设置了 Column family 或 RegionServer 属性,则HBASE-9857添加一个新选项以在打开 BlockCache 时预取 HFile 内容。此选项可用于 HBase 0.98.3 及更高版本。目的是使用内存中的表数据,在打开高速缓存后尽可能快地预热 BlockCache,而不将预取视为高速缓存未命中。这对于快速读取非常有用,但是如果要预加载的数据不适合 BlockCache,则不是一个好主意。这对于调整预取对 IO 的影响以及所有数据块进入缓存之前的时间非常有用。
要在给定的列族上启用预取,可以使用 HBase Shell 或 API。
使用 HBase Shell 启用预取
hbase> create 'MyTable', { NAME => 'myCF', PREFETCH_BLOCKS_ON_OPEN => 'true' }
例子 34.使用 API 启用预取
// ...
HTableDescriptor tableDesc = new HTableDescriptor("myTable");
HColumnDescriptor cfDesc = new HColumnDescriptor("myCF");
cfDesc.setPrefetchBlocksOnOpen(true);
tableDesc.addFamily(cfDesc);
// ...
请参阅CacheConfig的 API 文档。
要查看预取的运行情况,请在 hbase-2.0 的org.apache.hadoop.hbase.io.hfile.HFileReaderImpl或 HBase 的早期版本的 hbase-1.x 的org.apache.hadoop.hbase.io.hfile.HFileReaderV2上启用 TRACE 级别的日志记录。
98.6. hbase.regionserver.global.memstore.size
参见[hbase.regionserver.global.memstore.size]。通常根据需要针对 RegionServer 进程调整此内存设置。
98.7. hbase.regionserver.global.memstore.size.lower.limit
参见[hbase.regionserver.global.memstore.size.lower.limit]。通常根据需要针对 RegionServer 进程调整此内存设置。
98.8. hbase.hstore.blockingStoreFiles
参见[hbase.hstore.blockingStoreFiles]。如果 RegionServer 日志中存在阻塞,则增加该值可能会有所帮助。
98.9. hbase.hregion.memstore.block.multiplier
参见[hbase.hregion.memstore.block.multiplier]。如果有足够的 RAM,增加它可以有所帮助。
98.10. hbase.regionserver.checksum.verify
让 HBase 将校验和写入数据块,并在每次读取时省去执行校验和查找的麻烦。
参见[hbase.regionserver.checksum.verify],[hbase.hstore.bytes.per.checksum]和[hbase.hstore.checksum.algorithm]。有关更多信息,请参见HBASE-5074 支持 HBase 块缓存中的校验和上的发行说明。
98.11. 调整 callQueue 选项
HBASE-11355引入了几种可以提高性能的 callQueue 调整机制。有关一些基准测试信息,请参见 JIRA。
要增加呼叫队列的数量,请将hbase.ipc.server.num.callqueue设置为大于1的值。要将呼叫队列拆分为单独的读取和写入队列,请将hbase.ipc.server.callqueue.read.ratio设置为0和1之间的值。此因素将队列加权为写入(如果低于 0.5)或读取(如果高于 0.5)。另一种说法是,该因素决定了将拆分队列的百分比用于读取。以下示例说明了一些可能性。请注意,无论使用哪种设置,您始终至少有一个写队列。
缺省值
0不会拆分队列。值
.3将 30%的队列用于读取,将 60%的队列用于写入。给定hbase.ipc.server.num.callqueue的值10,将使用 3 个队列进行读取,将 7 个队列用于写入。值
.5使用相同数量的读取队列和写入队列。给定hbase.ipc.server.num.callqueue的值10,将使用 5 个队列进行读取,将 5 个队列用于写入。值
.6将 60%的队列用于读取,将 30%的队列用于读取。给定hbase.ipc.server.num.callqueue的值10,将使用 7 个队列进行读取,将 3 个队列用于写入。值
1.0使用一个队列处理写请求,所有其他队列处理读请求。高于1.0的值与1.0的作用相同。给定hbase.ipc.server.num.callqueue的值10,将使用 9 个队列进行读取,使用 1 个队列进行写入。
您还可以通过设置hbase.ipc.server.callqueue.scan.ratio选项拆分读取队列,以便将单独的队列用于短读取(来自 Get 操作)和长读取(来自 Scan 操作)。此选项是介于 0 和 1 之间的因子,该因子确定用于“获取”和“扫描”的读取队列的比率。如果值小于.5,则更多队列用于 Gets,如果值大于.5,则更多队列用于扫描。无论使用什么设置,至少一个读取队列都将用于 Get 操作。
值
0不会拆分读取队列。值
.3将 60%的读取队列用于 Gets,将 30%的扫描用于 Scans。给定hbase.ipc.server.num.callqueue的20值和hbase.ipc.server.callqueue.read.ratio的.5值,将使用 10 个队列进行读取,在这 10 个队列中,将使用 7 个队列进行 Gets,将 3 个用于扫描。值为
.5时,一半的读取队列用于获取,一半用于扫描。给定hbase.ipc.server.num.callqueue的值20和hbase.ipc.server.callqueue.read.ratio的值.5,则将使用 10 个队列进行读取,在这 10 个队列中,将有 5 个用于 Gets,将 5 个用于 Scans。值
.6将 30%的读取队列用于 Gets,将 60%的扫描用于 Scans。给定hbase.ipc.server.num.callqueue的20值和hbase.ipc.server.callqueue.read.ratio的.5值,将使用 10 个队列进行读取,在这 10 个队列中,将使用 3 个队列进行 Gets,将 7 个用于扫描。值
1.0使用除读取队列以外的所有读取队列进行扫描。给定hbase.ipc.server.num.callqueue的20值和hbase.ipc.server.callqueue.read.ratio的``值,将使用 10 个队列进行读取,在这 10 个队列中,将 1 个用于 Gets,将 9 个用于 Scans。
您可以使用新选项hbase.ipc.server.callqueue.handler.factor以编程方式调整队列数量:
值
0使用所有处理程序之间的单个共享队列。值
1为每个处理程序使用一个单独的队列。介于
0和1之间的值可将队列数量与处理程序数量进行调整。例如,值.5在每两个处理程序之间共享一个队列。
具有更多队列,例如在每个处理程序只有一个队列的情况下,可以减少将任务添加到队列或从队列中选择任务时的争用。折衷方案是,如果您有一些队列中包含长时间运行的任务,则处理程序可能最终会从该队列中 await 执行,而不是处理另一个具有 await 任务的队列。
为了使这些值在给定的 RegionServer 上生效,必须重新启动 RegionServer。这些参数仅用于测试目的,应谨慎使用。
99. ZooKeeper
有关配置 ZooKeeper 的信息,请参见ZooKeeper,并参阅有关拥有专用磁盘的部分。
100.架构设计
100.1. 列族数
See 关于列族的数量.
100.2. 键和属性长度
参见尝试最小化行和列的大小。有关压缩警告,另请参见However…。
100.3. 表区域大小
如果某些表要求的区域大小与配置的默认区域大小不同,则可以通过HTableDescriptor上的setFileSize在每个表上设置区域大小。
有关更多信息,请参见确定区域数和大小。
100.4. 布隆过滤器
以其创建者 Burton Howard Bloom 命名的 Bloom 过滤器是一种数据结构,旨在预测给定元素是否为数据集的成员。布隆过滤器的肯定结果并不总是准确的,但肯定会得出负面结果。 Bloom 过滤器被设计为对于足够大的数据集“足够准确”,以至于常规的散列机制将是不切实际的。有关一般布隆过滤器的更多信息,请参阅http://en.wikipedia.org/wiki/Bloom_filter。
就 HBase 而言,Bloom 筛选器提供了一种轻量级的内存结构,以减少给定 Get 操作(Bloom 筛选器不适用于 Scans)的磁盘读取次数,仅减少可能包含所需行的 StoreFiles。潜在的性能增益随并行读取的数量而增加。
Bloom 筛选器本身存储在每个 HFile 的元数据中,不需要更新。当由于将区域部署到 RegionServer 而打开 HFile 时,Bloom 筛选器将加载到内存中。
HBase 包括一些调整机制,用于折叠 Bloom 滤波器以减小尺寸并将假阳性率保持在所需范围内。
在HBASE-1200中引入了 Bloom 过滤器。从 HBase 0.96 开始,默认情况下启用基于行的 Bloom 筛选器。 (HBASE-8450)
有关与 HBase 相关的 Bloom 过滤器的更多信息,请参阅Bloom Filters以获得更多信息,或进行以下 Quora 讨论:HBase 中的 bloom 过滤器如何使用?。
100.4.1. 何时使用布隆过滤器
从 HBase 0.96 开始,默认情况下启用基于行的 Bloom 筛选器。您可以选择禁用它们或更改某些表以使用行列 Bloom 过滤器,具体取决于数据的特性以及如何将其加载到 HBase 中。
要确定 Bloom 筛选器是否可能产生积极影响,请检查 RegionServerMetrics 中的blockCacheHitRatio的值。如果启用了布隆过滤器,则blockCacheHitRatio的值应增加,因为布隆过滤器正在过滤出绝对不需要的块。
您可以选择为行或行列组合启用 Bloom 筛选器。如果通常扫描整个行,则行列组合将不会提供任何好处。基于行的 Bloom 筛选器可以对行列 Get 进行操作,但反之则不能。但是,如果您有大量的列级 Put,使得每个 StoreFile 中都可能存在一行,则基于行的过滤器将始终返回正结果,并且没有任何好处。除非每行有一列,否则行列 Bloom 过滤器需要更多空间才能存储更多键。当每个数据条目的大小至少为几千字节时,Bloom 过滤器最有效。
当您的数据存储在一些较大的 StoreFiles 中时,开销将减少,以避免在低级扫描找到特定的行期间出现额外的磁盘 IO。
Bloom 过滤器需要在删除时重新构建,因此可能不适用于具有大量删除操作的环境。
100.4.2. 启用布隆过滤器
在列族上启用了布隆过滤器。您可以使用 HColumnDescriptor 的 setBloomFilterType 方法或使用 HBase API 来执行此操作。有效值为NONE,ROW(默认值)或ROWCOL。有关ROW与ROWCOL的更多信息,请参见何时使用布隆过滤器。另请参阅HColumnDescriptor的 API 文档。
以下示例创建一个表并在colfam1列系列上启用 ROWCOL Bloom 过滤器。
hbase> create 'mytable',{NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
100.4.3. 配置布隆过滤器的服务器级行为
您可以在* hbase-site.xml *中配置以下设置。
| Parameter | Default | Description |
|---|---|---|
| io.storefile.bloom.enabled | yes | 设置为 no 可在出现问题时在服务器范围内终止 Bloom 过滤器 |
| io.storefile.bloom.error.rate | .01 | 布隆过滤器的平均误报率。折叠用于维持误报率。用百分比的十进制表示形式表示。 |
| io.storefile.bloom.max.fold | 7 | 保证的最大折叠率。不需要更改此设置,不建议这样做。 |
| io.storefile.bloom.max.keys | 128000000 | 对于默认(单块)Bloom 过滤器,这指定了最大密钥数。 |
| io.storefile.delete.family.bloom.enabled | true | 主开关启用 Delete Family Bloom 过滤器并将其存储在 StoreFile 中。 |
| io.storefile.bloom.block.size | 131072 | 目标 Bloom 块大小。大约此大小的布隆过滤器块与数据块交织。 |
| hfile.block.bloom.cacheonwrite | false | 为复合 Bloom 过滤器的内联块启用写时缓存。 |
100.5. 列家庭块大小
可以为表中的每个 ColumnFamily 配置块大小,默认为 64k。较大的像元值需要较大的块大小。块大小与生成的 StoreFile 索引之间存在反比关系(即,如果块大小加倍,则生成的索引应大致减半)。
有关更多信息,请参见HColumnDescriptor和Store。
100.6. 内存中列系列
ColumnFamilies 可以选择定义为内存中。像其他任何 ColumnFamily 一样,数据仍保留在磁盘上。内存中的块在Block Cache中具有最高优先级,但是不能保证整个表都将在内存中。
有关更多信息,请参见HColumnDescriptor。
100.7. Compression
生产系统应在其 ColumnFamily 定义中使用压缩。有关更多信息,请参见HBase 中的压缩和数据块编码。
100.7.1. However…
压缩会压缩磁盘上的数据。当它在内存中(例如,在 MemStore 中)或在线(例如,在 RegionServer 和 Client 之间传输)时,它会膨胀。因此,虽然使用 ColumnFamily 压缩是一种最佳实践,但是它并不能完全消除过大的键,过大的 ColumnFamily 名称或过大的列名称的影响。
有关架构设计技巧,请参见尝试最小化行和列的大小,有关 HBase 内部存储数据的更多信息,请参见KeyValue。
101. HBase 通用模式
101.1. Constants
当人们开始使用 HBase 时,他们倾向于编写如下代码:
Get get = new Get(rowkey);
Result r = table.get(get);
byte[] b = r.getValue(Bytes.toBytes("cf"), Bytes.toBytes("attr")); // returns current version of value
但是,尤其是在内部循环(和 MapReduce 作业)中,将 columnFamily 和 column-name 反复转换为字节数组的代价令人惊讶。最好对字节数组使用常量,如下所示:
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(rowkey);
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); // returns current version of value
102.写入 HBase
102.1. 批量加载
如果可以,请使用批量加载工具。参见Bulk Loading。否则,请注意以下内容。
102.2. 表创建:预创建区域
默认情况下,HBase 中的表最初是使用一个区域创建的。对于批量导入,这意味着所有 Client 端都将写入同一区域,直到该区域足够大以在群集中拆分并分布为止。加快批量导入过程的一种有用模式是预先创建空白区域。在这方面要保守一些,因为太多区域实际上会降低性能。
有两种使用 HBase API 预先创建分割的方法。第一种方法是依靠默认的Admin策略(在Bytes.split中实现)…
byte[] startKey = ...; // your lowest key
byte[] endKey = ...; // your highest key
int numberOfRegions = ...; // # of regions to create
admin.createTable(table, startKey, endKey, numberOfRegions);
另一种使用 HBase API 的方法是自己定义拆分…
byte[][] splits = ...; // create your own splits
admin.createTable(table, splits);
通过指定拆分选项,可以使用 HBase Shell 创建表来达到类似的效果。
# create table with specific split points
hbase>create 't1','f1',SPLITS => ['\x10\x00', '\x20\x00', '\x30\x00', '\x40\x00']
# create table with four regions based on random bytes keys
hbase>create 't2','f1', { NUMREGIONS => 4 , SPLITALGO => 'UniformSplit' }
# create table with five regions based on hex keys
create 't3','f1', { NUMREGIONS => 5, SPLITALGO => 'HexStringSplit' }
有关了解您的键空间和预创建区域的问题,请参见RowKey 与区域分割之间的关系。有关手动预分割区域的讨论,请参见手动区域分割决策。有关使用 HBase Shell 预分割表的更多详细信息,请参见使用 HBase Shell 进行预拆分表。
102.3. 表创建:延迟日志刷新
使用预写日志(WAL)的看跌期权的默认行为是将立即写入WAL个编辑。如果使用了延迟的日志刷新,则 WAL 编辑将保留在内存中,直到刷新周期。这样做的好处是聚合和异步WAL-写入,但是潜在的缺点是,如果 RegionServer 崩溃,则尚未刷新的编辑将丢失。但是,与完全不使用 Put 一起使用 WAL 相比,这更安全。
可以通过HTableDescriptor在表上配置延迟的日志刷新。 hbase.regionserver.optionallogflushinterval的默认值为 1000ms。
102.4. HBaseClient 端:关闭看跌期权的 WAL
一个常见的请求是禁用 WAL 以提高看跌期权的性能。这仅适用于大容量负载,因为在区域服务器崩溃的情况下,通过删除 WAL 的保护会给您的数据带来风险。崩溃时可以重新运行大容量负载,数据丢失的风险很小。
Warning
如果对大容量负载以外的任何其他功能禁用 WAL,则数据将受到威胁。
通常,最好将 WAL 用于看跌期权,而在需要考虑装载吞吐量的情况下,请改用批量装载技术。对于正常的看跌期权,您不太可能看到性能提高超过风险。要禁用 WAL,请参阅禁用 WAL。
102.5. HBaseClient 端:按 RegionServer 分组放置
除了使用 writeBuffer 之外,当前在 MASTER 上对Put`s by RegionServer can reduce the number of client RPC calls per writeBuffer flush. There is a utility `HTableUtil进行分组,但是您可以复制该文件或为仍在 0.90.x 或更早版本上的人实现自己的版本。
102.6. MapReduce:跳过 Reducer
当从 MR 作业(例如,使用TableOutputFormat)将大量数据写入 HBase 表时,尤其是从 Map 器发出 Put 的位置时,请跳过 Reducer 步骤。使用 Reducer 步骤时,Mapper 的所有输出(Put)将被后台处理到磁盘,然后排序/混编到其他很有可能不在节点上的 Reducer。直接写入 HBase 效率更高。
对于将 HBase 用作源和接收器的汇总作业,则写入将来自 Reducer 步骤(例如,汇总值然后写入结果)。这是与上述情况不同的处理问题。
102.7. 反模式:一个热点地区
如果您一次将所有数据都写入一个区域,请重新阅读有关处理时间序列数据的部分。
另外,如果您正在预分割区域,并且即使您的键没有单调增加,所有数据仍在单个区域中仍整理,请确认您的键空间确实适用于分割策略。出于多种原因,区域可能看起来“很好地分开”,但不适用于您的数据。当 HBaseClient 端直接与 RegionServer 通信时,可以通过RegionLocator.getRegionLocation获得。
参见表创建:预创建区域和HBase Configurations
103.从 HBase 读取
如果您遇到性能问题,邮件列表可以提供帮助。例如,以下是解决阅读时间问题的一个不错的常规线程:HBase 随机读取延迟> 100ms
103.1. 扫描缓存
例如,如果将 HBase 用作 MapReduce 作业的 Importing 源,请确保 MapReduce 作业的 ImportingScan实例将setCaching设置为大于默认值(即 1)。使用默认值意味着 Map 任务将为每个已处理的记录回调到区域服务器。例如,将此值设置为 500,将一次将 500 行传输到要处理的 Client 端。拥有较大的缓存值是有成本/收益的,因为对于 Client 端和 RegionServer 而言,它在内存上的开销更大,因此,增大值并不总是更好。
103.1.1. 扫描 MapReduce 作业中的缓存
MapReduce 作业中的扫描设置值得特别注意。如果在 Client 端返回到 RegionServer 获取下一组数据之前需要花费更长的时间处理一批记录,则 Map 任务中可能会发生超时(例如 UnknownScannerException)。发生此问题的原因是每行都发生了非平凡的处理。如果您快速处理行,请将缓存设置得更高。如果您处理行的速度较慢(例如,每行写入很多转换),则将缓存设置得较低。
在非 MapReduce 用例中也可能发生超时(即,单线程 HBaseClient 端执行扫描),但是 MapReduce 作业中经常执行的处理会加剧此问题。
103.2. 扫描属性选择
每当使用扫描来处理大量行时(尤其是用作 MapReduce 源时),请注意选择了哪些属性。如果调用了scan.addFamily,则指定 ColumnFamily 中的所有**属性将返回给 Client 端。如果仅要处理少量可用属性,则应在 Importing 扫描中仅指定那些属性,因为对于大型数据集,属性过度选择对性能的影响不小。
103.3. 避免扫描寻道
当使用scan.addColumn明确选择了列时,HBase 将安排搜索操作以在选定的列之间进行搜索。如果行中的列很少,而每列中只有几个版本,则效率可能很低。如果至少不搜索超过 5-10 列/版本或 512-1024 字节,则搜索操作通常会较慢。
为了机会性地向前看一些列/版本,以查看是否可以在安排搜索操作之前以这种方式找到下一个列/版本,可以在“扫描”对象上设置新的属性Scan.HINT_LOOKAHEAD。下面的代码指示 RegionServer 在计划搜索之前尝试 next 的两次迭代:
Scan scan = new Scan();
scan.addColumn(...);
scan.setAttribute(Scan.HINT_LOOKAHEAD, Bytes.toBytes(2));
table.getScanner(scan);
103.4. MapReduce-Importing 分割
对于使用 HBase 表作为源的 MapReduce 作业,如果存在一种模式,其中“慢速”Map 任务似乎具有相同的 Importing 拆分(即,服务数据的 RegionServer),请参阅案例研究 1(单个节点上的性能问题)中的疑难解答案例研究。
103.5. 关闭结果扫描仪
这与提高性能无关,而是“避免”性能问题。如果您忘记关闭ResultScanners,可能会在 RegionServers 上引起问题。始终在 try/catch 块中包含 ResultScanner 处理。
Scan scan = new Scan();
// set attrs...
ResultScanner rs = table.getScanner(scan);
try {
for (Result r = rs.next(); r != null; r = rs.next()) {
// process result...
} finally {
rs.close(); // always close the ResultScanner!
}
table.close();
103.6. 块缓存
可以通过setCacheBlocks方法将Scan个实例设置为使用 RegionServer 中的块缓存。对于 Importing 扫描到 MapReduce 作业,该值应为false。对于经常访问的行,建议使用块缓存。
通过将块缓存移到堆外来缓存更多数据。见堆外块缓存
103.7. 行键的最佳加载
当执行只需要行键的表scan时(不需要族,限定词,值或时间戳),使用setFilter将带有MUST_PASS_ALL运算符的 FilterList 添加到扫描器。过滤器列表应同时包含FirstKeyOnlyFilter和KeyOnlyFilter。使用此筛选器组合将导致在最坏的情况下,RegionServer 从磁盘读取单个值,并且对于单行,到 Client 端的网络通信量最少。
103.8. 并发:监控数据传播
当执行大量并发读取时,请监视目标表的数据传播。如果目标表的区域太少,则可能会从太少的节点提供读取服务。
参见表创建:预创建区域和HBase Configurations
103.9. 布隆过滤器
启用 Bloom Filters 可以节省您进入磁盘的时间,并可以帮助提高读取延迟。
Bloom filters是在HBase-1200 添加 BloomFilters中开发的。有关开发过程的说明(“为什么是静态绽放而不是动态绽放”),以及有关与 HBase 中的绽放有关的独特属性的概述以及可能的 Future 方向,请参见HBASE-1200所附文件HBase 中的 BloomFilters的*“开发过程”部分。 。这里描述的 Bloom 过滤器实际上是 HBase 中 Bloom 的第二版。在最高 0.19.x 的版本中,HBase 具有基于欧盟委员会一实验室项目 034819完成的工作的动态 Bloom 选项。 HBase 开花工作的核心后来被带入 Hadoop 以实现 org.apache.hadoop.io.BloomMapFile。 HBase Blooms 的版本 1 从来没有那么好过。版本 2 是从头开始重写的,尽管它还是从一个实验室的工作开始。
另请参见Bloom Filters。
103.9.1. Bloom StoreFile 占用空间
布隆过滤器向StoreFile常规FileInfo数据结构添加一个条目,然后向StoreFile元数据部分添加两个额外的条目。
StoreFile''FileInfo 数据结构中的 BloomFilter
FileInfo的BLOOM_FILTER_TYPE条目设置为NONE,ROW或ROWCOL.
StoreFile 元数据中的 BloomFilter 条目
BLOOM_FILTER_META保留 Bloom 大小,使用的哈希函数等。它的大小很小,并在StoreFile.Reader加载时缓存
BLOOM_FILTER_DATA是实际的 Bloomfilter 数据。按需获取。存储在 LRU 缓存中(如果已启用)(默认情况下已启用)。
103.9.2. 布隆过滤器配置
io.storefile.bloom.enabled 全局终止开关
发生故障时,Configuration中的io.storefile.bloom.enabled用作终止开关。默认值= true。
io.storefile.bloom.error.rate
io.storefile.bloom.error.rate =平均误报率。默认值= 1%。每个布满条目将速率降低½(例如,降至 0.5%)== 1 位。
io.storefile.bloom.max.fold
io.storefile.bloom.max.fold =保证的最小折叠率。大多数人应该不要管它。默认值= 7,或者可以折叠至少为原始大小的 1/128.有关此选项含义的更多信息,请参见文档HBase 中的 BloomFilters的*“开发过程”部分。
103.10. 对冲读取
对冲读取是 Hadoop 2.4.0 中带有HDFS-5776的 HDFS 的功能。通常,为每个读取请求生成一个线程。但是,如果启用了树篱读取,则 Client 端将 await 一些可配置的时间,如果读取未返回,则 Client 端将针对相同数据的不同块副本生成第二个读取请求。使用第一个读取返回的对象,而另一个读取请求则被丢弃。
套期读取是“ ...非常擅长消除异常数据节点,这反过来使它们成为对延迟敏感的设置的很好选择。但是,如果您正在寻求最大化吞吐量,则套期读取往往会导致负载放大,因为事情通常会变慢。简而言之,要注意的是,当您在接近某个吞吐量阈值的情况下运行时,性能会非优雅地下降。” (引用自 Ashu Pachauri,在 HBASE-17083 中)。
在启用对冲读取的情况下运行时要记住的其他问题包括:
它们可能导致网络拥塞。见HBASE-17083
确保将线程池设置为足够大,以防止在线程池上阻塞成为瓶颈(再次参见HBASE-17083)
(从 Yu Li 到 HBASE-17083)
由于 HBase RegionServer 是 HDFSClient 端,因此可以通过在 RegionServer 的 hbase-site.xml 中添加以下属性并调整值以适合您的环境来在 HBase 中启用对冲读取。
对冲读取的配置
dfs.client.hedged.read.threadpool.size-专用于服务被套期读取的线程数。如果将其设置为 0(默认值),则会禁用树篱读取。dfs.client.hedged.read.threshold.millis-产生第二个读取线程之前要 await 的毫秒数。
例子 35.对冲读取配置例子
<property>
<name>dfs.client.hedged.read.threadpool.size</name>
<value>20</value> <!-- 20 threads -->
</property>
<property>
<name>dfs.client.hedged.read.threshold.millis</name>
<value>10</value> <!-- 10 milliseconds -->
</property>
使用以下 Metrics 来调整群集上对冲读取的设置。有关更多信息,请参见HBase Metrics。
对冲读取的 Metrics
树篱读取操作-树篱读取线程已触发的次数。这可能表明读取请求通常很慢,或者套期读取触发得太快。
树篱 ReadOpsWin-树篱读取线程比原始线程快的次数。这可能表明给定的 RegionServer 在处理请求时遇到问题。
104.从 HBase 删除
104.1. 使用 HBase 表作为队列
HBase 表有时用作队列。在这种情况下,必须格外注意定期对以这种方式使用的桌子进行大夯实。如Data Model中所述,将行标记为已删除会创建其他 StoreFile,然后需要在读取时对其进行处理。墓碑仅通过大压实清理。
另请参见Compaction和Admin.majorCompact。
104.2. 删除 RPC 行为
请注意,Table.delete(Delete)不使用 writeBuffer。它将在每次调用时执行 RegionServer RPC。对于大量删除,请考虑Table.delete(List)。
105. HDFS
因为 HBase 在HDFS上运行,所以了解它的工作方式以及对 HBase 的影响非常重要。
105.1. 低延迟阅读的当前问题
HDFS 的原始用例是批处理。因此,从历史上看,低延迟读取并不是优先事项。随着 Apache HBase 越来越多的采用,这种情况正在改变,并且已经在进行一些改进。参见HBase 的 HDFS 改进伞 Jira 票。
105.2. 利用本地数据
由于 Hadoop 1.0.0(也是 0.22.1、0.23.1,CDH3u3 和 HDP 1.0)通过HDFS-2246进行操作,因此 DFSClient 可能会“短路”并直接从磁盘读取数据,而不是通过数据是本地的。对于 HBase 而言,这意味着 RegionServer 可以直接从其计算机的磁盘读取数据,而不必打开套接字与 DataNode 进行通信,而后者通常要快得多。参见京东的Performance Talk。另请参见HBase,邮件#dev-读取短路线程以获取有关短路读取的更多讨论。
要启用“短路”读取,将取决于您的 Hadoop 版本。最初的短路读取补丁在HDFS-347的 Hadoop 2 中得到了很大的改进。有关新旧实现之间差异的详细信息,请参见http://blog.cloudera.com/blog/2013/08/how-improved-short-circuit-local-reads-bring-better-performance-and-security-to-hadoop/。有关如何启用后一种更好的短路版本,请参见Hadoop 短路读取配置页面。例如,这是一个最低配置。启用添加到* hbase-site.xml *的短路读取:
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
<description>
This configuration parameter turns on short-circuit local reads.
</description>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/home/stack/sockets/short_circuit_read_socket_PORT</value>
<description>
Optional. This is a path to a UNIX domain socket that will be used for
communication between the DataNode and local HDFS clients.
If the string "_PORT" is present in this path, it will be replaced by the
TCP port of the DataNode.
</description>
</property>
请注意托管共享域套接字的目录的权限; dfsclient 将向 hbase 用户以外的其他用户开放。
如果您正在旧 Hadoop 上运行,则该旧 Hadoop 不含HDFS-347但具有HDFS-2246,则必须设置两个配置。首先,需要修改 hdfs-site.xml。将属性dfs.block.local-path-access.user设置为可以使用快捷方式的* only *用户。这必须是启动 HBase 的用户。然后在 hbase-site.xml 中将dfs.client.read.shortcircuit设置为true
服务(至少是 HBase RegionServers)将需要重新启动才能使用新配置。
dfs.client.read.shortcircuit.buffer.size
当在流量很高的 HBase 上运行时,此值的默认值太高。在 HBase 中,如果尚未设置此值,则将其从默认值 1M 设置为 128k(从 HBase 0.98.0 和 0.96.1 开始)。参见带有本地短路读取(ssr)的 Hadoop 2 上的 HBASE-8143 HBase 导致 OOM)。 HBase 中的 Hadoop DFSClient 将为其打开的* each *块分配此大小的直接字节缓冲区;鉴于 HBase 始终保持其 HDFS 文件保持打开状态,这可以迅速增加。
105.3. HBase 与 HDFS 的性能比较
dist 列表上一个相当普遍的问题是,为什么 HBase 在批处理上下文中(例如,作为 MapReduce 源或接收器)不像 HDFS 文件那样具有高性能。简短的答案是 HBase 比 HDFS 做更多的事情(例如读取键值,返回最新行或指定的时间戳等),因此 HBase 在此处理上下文中比 HDFS 慢 4-5 倍。有改进的余地,随着时间的流逝,这种差距将不断缩小,但是在这种用例中,HDFS 总是会更快。
106. Amazon EC2
性能问题在 Amazon EC2 环境中很常见,因为它是一个共享环境。您不会看到与专用服务器相同的吞吐量。就在 EC2 上运行测试而言,出于相同原因多次运行它们(即,这是一个共享环境,并且您不知道服务器上还发生了什么)。
如果您正在使用 EC2 并将性能问题发布到 dist-list 上,请事先声明这一事实,因为 EC2 问题实际上是一类单独的性能问题。
107.并置 HBase 和 MapReduce
通常建议对 HBase 和 MapReduce 使用不同的群集。一个更好的限定条件是:不要并置用于处理实时请求且 MR 工作量很大的 HBase。 OLTP 和 OLAP 优化的系统有相互矛盾的要求,一个会输给另一个,通常是前者。例如,对延迟敏感的短磁盘读取将不得不在较长的读取之后排队 await,而较长的读取则试图挤出尽可能多的吞吐量。写入 HBase 的 MR 作业还将生成刷新和压缩,从而使Block Cache中的块无效。
如果需要处理来自 MR 中实时 HBase 群集的数据,则可以将CopyTable附带增量,或使用复制在 OLAP 群集上实时获取新数据。在最坏的情况下,如果您确实需要同时配置两者,请将 MR 设置为使用比通常配置更少的 Map 和 Reduce 插槽,可能只有一个。
当将 HBase 用于 OLAP 操作时,最好以一种强化的方式进行设置,例如配置较高的 ZooKeeper 会话超时并为 MemStores 提供更多的内存(这种说法是,由于工作负载大,因此块缓存不会被大量使用)通常是长时间扫描)。
108.个案研究
有关性能和故障排除案例研究,请参阅Apache HBase 案例研究。
Profiler Servlet
109. Background
HBASE-21926 引入了一个新的 servlet,它支持通过 async-profiler 进行集成分析。
110. Prerequisites
转到https://github.com/jvm-profiling-tools/async-profiler,下载适合您的平台的版本,然后安装在每个群集主机上。
在环境中将ASYNC_PROFILER_HOME设置(放置在 hbase-env.sh 中)到 async-profiler 安装位置的根目录,或在 HBase 守护程序的命令行中将其作为系统属性-Dasync.profiler.home=/path/to/async-profiler传递。
111. Usage
一旦满足先决条件,就可以通过 HBase UI 或与信息服务器的直接交互来访问 async-profiler。
Examples:
收集当前进程的 30 秒 CPU 配置文件(返回 FlameGraph svg)
curl http://localhost:16030/prof收集当前进程的 1 分钟 CPU 配置文件并以树格式(html)
curl http://localhost:16030/prof?output=tree&duration=60输出收集当前进程的 30 秒堆分配配置文件(返回 FlameGraph svg)
curl http://localhost:16030/prof?event=alloc收集当前进程的锁争用配置文件(返回 FlameGraph svg)
curl http://localhost:16030/prof?event=lock
async-profiler 支持以下事件类型。使用“事件”参数进行指定。默认值为“ cpu”。并非所有 os 都支持所有类型。
Perf events:
cpu
page-faults
context-switches
cycles
instructions
cache-references
cache-misses
branches
branch-misses
bus-cycles
L1-dcache-load-misses
LLC-load-misses
dTLB-load-misses
Java events:
alloc
lock
支持以下输出格式。使用“输出”参数进行指定。默认值为“ flamegraph”。
Output formats:
摘要:基本概要分析统计信息的转储。
跟踪:呼叫跟踪。
扁平:扁平轮廓(前 N 种热方法)。
折叠:以 FlameGraph 脚本使用的格式折叠的呼叫跟踪。这是调用堆栈的集合,其中每一行都是用分号分隔的帧列表,后跟一个计数器。
svg:SVG 格式的 FlameGraph。
tree:HTML 格式的调用树。
jfr:Java Flight Recorder 格式的呼叫跟踪。
“ duration”参数指定生成输出之前收集跟踪数据的时间(以秒为单位)。默认值为 10 秒。
112. UI
在用户界面中,顶部菜单中有一个新条目“ Profiler”,它将运行默认操作,该操作用于分析本地进程的 CPU 使用情况三十秒钟,然后生成 FlameGraph SVG 输出。
113. Notes
查询参数pid可用于指定要分析的特定进程的进程 ID。如果缺少此参数,将分析嵌入信息服务器的本地进程。不是 JVM 的概要文件目标可能会起作用,但不特别受支持。存在安全隐患。应适当限制对信息服务器的访问。
对 Apache HBase 进行故障排除和调试
114.一般准则
始终从主日志开始(TODO:哪几行?)。通常,它只是一遍又一遍地打印相同的行。如果没有,那就有问题了。 Google 或search-hadoop.com应该会针对您看到的那些异常返回一些匹配。
在 Apache HBase 中,很少有错误会单独出现,通常是当发生问题时,可能会出现来自各地的数百个异常和堆栈跟踪信息。解决此类问题的最佳方法是将日志记录到所有内容的开始处,例如,RegionServers 的一个窍门是它们在中止时将打印一些 Metrics,因此对* Dump *的 grepping 应该使您绕开了起点。问题。
RegionServer 的自杀是“正常的”,因为这是出问题时的自杀行为。例如,如果未更改 ulimit 和 max 传输线程(两个最重要的初始设置,请参见[ulimit]和dfs.datanode.max.transfer.threads),则在某些时候,DataNodes 将无法创建新的线程(从 HBase 的角度来看)好像 HDFS 消失了。想一想,如果您的 MySQL 数据库突然无法访问本地文件系统上的文件,将会发生什么事情,HBase 和 HDFS 也是一样。看到 RegionServer 提交 seppuku 的另一个非常常见的原因是,当它们进入长时间的垃圾回收暂停时,其暂停时间比默认的 ZooKeeper 会话超时长。有关 GC 暂停的更多信息,请参见上文 Todd Lipcon 的3 部分博客文章和GC 长时间停顿。
115. Logs
关键进程日志如下...(用启动服务的用户替换 ,将计算机名替换为 )
NameNode:* $ HADOOP_HOME/logs/hadoop-<user> -namenode-<hostname> .log *
数据节点:* $ HADOOP_HOME/logs/hadoop-<user> -datanode-<hostname> .log *
JobTracker:* $ HADOOP_HOME/logs/hadoop-<user> -jobtracker-<hostname> .log *
TaskTracker:* $ HADOOP_HOME/logs/hadoop-<user> -tasktracker-<hostname> .log *
HMaster:* $ HBASE_HOME/logs/hbase-<user> -master-<hostname> .log *
RegionServer:* $ HBASE_HOME/logs/hbase-<user> -regionserver-<hostname> .log *
ZooKeeper:* TODO *
115.1. 日志位置
对于独立部署,日志显然将存储在单台计算机上,但这仅是开发配置。生产部署需要在集群上运行。
115.1.1. NameNode
NameNode 日志位于 NameNode 服务器上。 HBase Master 通常在 NameNode 服务器以及 ZooKeeper 上运行。
对于较小的群集,JobTracker/ResourceManager 通常也可以在 NameNode 服务器上运行。
115.1.2. DataNode
每个 DataNode 服务器将具有 HDFS 的 DataNode 日志以及 HBase 的 RegionServer 日志。
此外,每个 DataNode 服务器还将具有一个 TaskTracker/NodeManager 日志,用于执行 MapReduce 任务。
115.2. 日志级别
115.2.1. 启用 RPC 级别的日志记录
在 RegionServer 上启用 RPC 级别的日志记录通常可以深入了解服务器的时序。启用后,喷出的日志量将非常庞大。不建议您将此登录保持不超过一小段时间。要启用 RPC 级别的日志记录,请浏览到 RegionServer UI 并单击* Log Level *。将软件包org.apache.hadoop.ipc的日志级别设置为DEBUG(对hadoop.ipc,不是,hbase.ipc来说是正确的)。然后尾随 RegionServers 日志。分析。
要禁用此功能,请将日志记录级别设置回INFO级别。
115.3. JVM 垃圾收集日志
Note
本节中的所有示例垃圾收集日志均基于 Java 8 输出。 Java 9 及更高版本中的统一日志的引入将导致外观迥然不同的日志。
HBase 占用大量内存,使用默认 GC,您可以在所有线程中看到长时间的停顿,包括* Juliet Pause *(也称为“死亡 GC”)。为了帮助调试或确认正在发生这种情况,可以在 Java 虚拟机中打开 GC 日志记录。
要启用此功能,请在* hbase-env.sh *中取消 Comments 以下行之一:
# This enables basic gc logging to the .out file.
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M"
# If <FILE-PATH> is not replaced, the log file(.gc) would be generated in the HBASE_LOG_DIR.
此时,您应该看到如下日志:
64898.952: [GC [1 CMS-initial-mark: 2811538K(3055704K)] 2812179K(3061272K), 0.0007360 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
64898.953: [CMS-concurrent-mark-start]
64898.971: [GC 64898.971: [ParNew: 5567K->576K(5568K), 0.0101110 secs] 2817105K->2812715K(3061272K), 0.0102200 secs] [Times: user=0.07 sys=0.00, real=0.01 secs]
在此部分中,第一行表示 CMS 初始标记为 0.0007360 秒的暂停。这将暂停整个 VM,该时间段内的所有线程。
第三行表示“次要 GC”,它将 VM 暂停 0.0101110 秒(也就是 10 毫秒)。它已将“ ParNew”从大约 5.5m 减少到 576k。在本周期的后面,我们看到:
64901.445: [CMS-concurrent-mark: 1.542/2.492 secs] [Times: user=10.49 sys=0.33, real=2.49 secs]
64901.445: [CMS-concurrent-preclean-start]
64901.453: [GC 64901.453: [ParNew: 5505K->573K(5568K), 0.0062440 secs] 2868746K->2864292K(3061272K), 0.0063360 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
64901.476: [GC 64901.476: [ParNew: 5563K->575K(5568K), 0.0072510 secs] 2869283K->2864837K(3061272K), 0.0073320 secs] [Times: user=0.05 sys=0.01, real=0.01 secs]
64901.500: [GC 64901.500: [ParNew: 5517K->573K(5568K), 0.0120390 secs] 2869780K->2865267K(3061272K), 0.0121150 secs] [Times: user=0.09 sys=0.00, real=0.01 secs]
64901.529: [GC 64901.529: [ParNew: 5507K->569K(5568K), 0.0086240 secs] 2870200K->2865742K(3061272K), 0.0087180 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
64901.554: [GC 64901.555: [ParNew: 5516K->575K(5568K), 0.0107130 secs] 2870689K->2866291K(3061272K), 0.0107820 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
64901.578: [CMS-concurrent-preclean: 0.070/0.133 secs] [Times: user=0.48 sys=0.01, real=0.14 secs]
64901.578: [CMS-concurrent-abortable-preclean-start]
64901.584: [GC 64901.584: [ParNew: 5504K->571K(5568K), 0.0087270 secs] 2871220K->2866830K(3061272K), 0.0088220 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
64901.609: [GC 64901.609: [ParNew: 5512K->569K(5568K), 0.0063370 secs] 2871771K->2867322K(3061272K), 0.0064230 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
64901.615: [CMS-concurrent-abortable-preclean: 0.007/0.037 secs] [Times: user=0.13 sys=0.00, real=0.03 secs]
64901.616: [GC[YG occupancy: 645 K (5568 K)]64901.616: [Rescan (parallel) , 0.0020210 secs]64901.618: [weak refs processing, 0.0027950 secs] [1 CMS-remark: 2866753K(3055704K)] 2867399K(3061272K), 0.0049380 secs] [Times: user=0.00 sys=0.01, real=0.01 secs]
64901.621: [CMS-concurrent-sweep-start]
第一行表示 CMS 并发标记(查找垃圾)已花费 2.4 秒。但这是一个并发的 2.4 秒,Java 尚未在任何时间暂停。
还有一些次要 GC,然后在最后第二行有一个暂停:
64901.616: [GC[YG occupancy: 645 K (5568 K)]64901.616: [Rescan (parallel) , 0.0020210 secs]64901.618: [weak refs processing, 0.0027950 secs] [1 CMS-remark: 2866753K(3055704K)] 2867399K(3061272K), 0.0049380 secs] [Times: user=0.00 sys=0.01, real=0.01 secs]
此处的暂停为 0.0049380 秒(即 4.9 毫秒),以“标记”堆。
此时,扫描开始,您可以看到堆大小减小了:
64901.637: [GC 64901.637: [ParNew: 5501K->569K(5568K), 0.0097350 secs] 2871958K->2867441K(3061272K), 0.0098370 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
... lines removed ...
64904.936: [GC 64904.936: [ParNew: 5532K->568K(5568K), 0.0070720 secs] 1365024K->1360689K(3061272K), 0.0071930 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
64904.953: [CMS-concurrent-sweep: 2.030/3.332 secs] [Times: user=9.57 sys=0.26, real=3.33 secs]
此时,CMS 扫描花费了 3.332 秒,并且堆从大约 2.8 GB 变为了 1.3 GB(大约)。
这里的关键点是保持所有这些低暂停。 CMS 停顿总是很低,但是如果您的 ParNew 开始增长,您会看到较小的 GC 停顿接近 100ms,超过 100ms 并达到 400ms。
这可能是由于 ParNew 的大小,该大小应该相对较小。如果在运行 HBase 一段时间后您的 ParNew 非常大,例如一个 ParNew 约为 150MB,那么您可能必须限制 ParNew 的大小(它越大,集合花费的时间就越长,但是如果它太小,则对象被提升到老一代太快)。在下面,我们将新 Generator 的尺寸限制为 64m。
在* hbase-env.sh *中添加以下行:
export SERVER_GC_OPTS="$SERVER_GC_OPTS -XX:NewSize=64m -XX:MaxNewSize=64m"
同样,要为 Client 端进程启用 GC 日志记录,请取消 Comments* hbase-env.sh *中的以下几行:
# This enables basic gc logging to the .out file.
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M"
# If <FILE-PATH> is not replaced, the log file(.gc) would be generated in the HBASE_LOG_DIR .
有关 GC 暂停的更多信息,请参见上面的3 部分博客文章和 Todd Lipcon。
116. Resources
116.1. search-hadoop.com
search-hadoop.com为所有邮件列表构建索引,非常适合历史搜索。当您遇到问题时,请先在此处搜索,因为问题可能已经困扰您。
116.2. 邮件列表
在Apache HBase 邮件列表上提问。 “ dev”邮件列表针对的是实际构建 Apache HBase 的开发人员社区以及当前正在开发的功能,而“ user”通常用于对 Apache HBase 的发行版提出疑问。在转到邮件列表之前,请先搜索邮件列表 Files,以确保您的问题尚未得到回答。对于那些喜欢用中文交流的人,他们可以使用“ user-zh”邮件列表而不是“ user”列表。使用search-hadoop.com。花一些时间来准备您的问题。参见Getting Answers以获取有关精心设计问题的想法。包含所有上下文并显示出作者试图在手册中找到答案并列在清单上的证据的质量问题更有可能得到迅速的答复。
116.3. Slack
请参阅http://apache-hbase.slack.com闲置 Channels
116.4. IRC
(您可能会在 SlackChannels 上得到更迅速的响应)
#hbase 在 irc.freenode.net 上
116.5. JIRA
JIRA在查找特定于 Hadoop/HBase 的问题时也非常有用。
117. Tools
117.1. 内建工具
117.1.1. 主网页界面
主机默认在端口 16010 上启动 Web 界面。
Master Web UI 列出了创建的表及其定义(例如 ColumnFamilies,blocksize 等)。此外,列出了群集中可用的 RegionServer 以及选定的高级 Metrics(请求,区域数,usedHeap,maxHeap)。主 Web UI 允许导航到每个 RegionServer 的 Web UI。
117.1.2. RegionServer Web 界面
默认情况下,RegionServers 在端口 16030 上启动 Web 界面。
RegionServer Web UI 列出了联机区域及其开始/结束键,以及时间点 RegionServerMetrics(请求,区域,storeFileIndexSize,compressionionSize 等)。
有关 Metrics 定义的更多信息,请参见HBase Metrics。
117.1.3. zkcli
zkcli是用于调查与 ZooKeeper 相关的问题的非常有用的工具。调用:
./hbase zkcli -server host:port <cmd> <args>
命令(和参数)为:
connect host:port
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
create [-s] [-e] path data acl
stat path [watch]
close
ls2 path [watch]
history
listquota path
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
117.1.4. 维护模式
如果集群陷入某种状态,而标准技术没有取得进展,则可以在“维护模式”下重启集群。此模式的功能和表面积大大减少,从而更易于执行低级更改,例如修复/恢复hbase:meta表。
要进入维护模式,请在启动主进程(-D…=true)时在hbase-site.xml或通过系统属性将hbase.master.maintenance_mode设置为true。进入和退出此模式需要重启服务,但是典型的用法是当 HBase Master 已经面临启动困难时。
启用维护模式后,主服务器将托管所有系统表-确保它具有足够的内存来执行此操作。不会从用户空间表中为 RegionServers 分配任何区域;实际上,在维护模式下它们将完全不使用。此外,主服务器将不会加载任何协处理器,不会运行任何规范化或合并/拆分操作,也不会强制执行配额。
117.2. 外部工具
117.2.1. tail
tail是命令行工具,可让您查看文件的末尾。添加-f选项,当有新数据可用时它将刷新。当您想知道正在发生的事情时,此功能非常有用,例如,当集群需要很长时间关闭或启动时,您只需触发一个新终端并尾随主日志(可能还有一些 RegionServers)即可。
117.2.2. top
top可能是最先尝试查看计算机上正在运行什么以及如何消耗资源的最重要工具之一。这是生产系统中的一个示例:
top - 14:46:59 up 39 days, 11:55, 1 user, load average: 3.75, 3.57, 3.84
Tasks: 309 total, 1 running, 308 sleeping, 0 stopped, 0 zombie
Cpu(s): 4.5%us, 1.6%sy, 0.0%ni, 91.7%id, 1.4%wa, 0.1%hi, 0.6%si, 0.0%st
Mem: 24414432k total, 24296956k used, 117476k free, 7196k buffers
Swap: 16008732k total, 14348k used, 15994384k free, 11106908k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15558 hadoop 18 -2 3292m 2.4g 3556 S 79 10.4 6523:52 java
13268 hadoop 18 -2 8967m 8.2g 4104 S 21 35.1 5170:30 java
8895 hadoop 18 -2 1581m 497m 3420 S 11 2.1 4002:32 java
…
在这里,我们可以看到最近五分钟的系统平均负载为 3.75,这非常粗略地意味着这五分钟中平均有 3.75 个线程在 awaitCPU 时间。通常,“完美”利用率等于内核数,在该数量下,机器的利用率不足,而在那之上,机器的利用率超过了。这是一个重要的概念,请参阅本文以进一步了解它:http://www.linuxjournal.com/article/9001。
除了负载,我们可以看到系统几乎在使用所有可用的 RAM,但大部分都用于 OS 缓存(很好)。交换中只有几个 KB,这是需要的,较高的数字表示交换活动,这是 Java 系统性能的克星。检测交换的另一种方法是平均负载何时通过屋顶(尽管这也可能是由于磁盘即将耗尽等引起的)。
默认情况下,进程列表并不是超级有用,我们所知道的是 3 个 Java 进程正在使用约 111%的 CPU。要知道是哪一个,只需键入c,每一行都会被扩展。Importing1将为您提供每个 CPU 使用情况的详细信息,而不是如此处所示的所有 CPU 的平均值。
117.2.3. jps
jps随每个 JDK 一起提供,并为当前用户提供 Java 进程 ID(如果为 root,则为所有用户提供 ID)。例:
hadoop@sv4borg12:~$ jps
1322 TaskTracker
17789 HRegionServer
27862 Child
1158 DataNode
25115 HQuorumPeer
2950 Jps
19750 ThriftServer
18776 jmx
依次看到:
Hadoop TaskTracker,Management 本地 Childs
HBase RegionServer,服务区域
子项,其 MapReduce 任务,无法确切分辨出哪种类型
Hadoop TaskTracker,Management 本地 Childs
Hadoop DataNode,服务块
HQuorumPeer,ZooKeeper 合奏成员
Jps,好吧……这是当前过程
ThriftServer,这是一种特殊的,只有在启动 Thrift 时才会运行
jmx,这是本地程序,是我们监视平台的一部分(可能命名不佳)。您可能没有。
然后,您可以执行诸如检查启动该过程的完整命令行的操作:
hadoop@sv4borg12:~$ ps aux | grep HRegionServer
hadoop 17789 155 35.2 9067824 8604364 ? S<l Mar04 9855:48 /usr/java/jdk1.6.0_14/bin/java -Xmx8000m -XX:+DoEscapeAnalysis -XX:+AggressiveOpts -XX:+UseConcMarkSweepGC -XX:NewSize=64m -XX:MaxNewSize=64m -XX:CMSInitiatingOccupancyFraction=88 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/export1/hadoop/logs/gc-hbase.log -Dcom.sun.management.jmxremote.port=10102 -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.password.file=/home/hadoop/hbase/conf/jmxremote.password -Dcom.sun.management.jmxremote -Dhbase.log.dir=/export1/hadoop/logs -Dhbase.log.file=hbase-hadoop-regionserver-sv4borg12.log -Dhbase.home.dir=/home/hadoop/hbase -Dhbase.id.str=hadoop -Dhbase.root.logger=INFO,DRFA -Djava.library.path=/home/hadoop/hbase/lib/native/Linux-amd64-64 -classpath /home/hadoop/hbase/bin/../conf:[many jars]:/home/hadoop/hadoop/conf org.apache.hadoop.hbase.regionserver.HRegionServer start
117.2.4. jstack
除了查看日志之外,jstack是尝试弄清楚 Java 进程正在执行的操作时最重要的工具之一。它必须与 jps 结合使用才能为其赋予进程 ID。它显示了一个线程列表,每个线程都有一个名称,并且按照创建 Sequences 显示(因此,最上面的是最新的线程)。以下是一些示例:
RegionServer 的主线程 await 主服务器执行操作:
"regionserver60020" prio=10 tid=0x0000000040ab4000 nid=0x45cf waiting on condition [0x00007f16b6a96000..0x00007f16b6a96a70]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00007f16cd5c2f30> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:198)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:1963)
at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:395)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:647)
at java.lang.Thread.run(Thread.java:619)
当前正在刷新到文件的 MemStore 刷新程序线程:
"regionserver60020.cacheFlusher" daemon prio=10 tid=0x0000000040f4e000 nid=0x45eb in Object.wait() [0x00007f16b5b86000..0x00007f16b5b87af0]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:485)
at org.apache.hadoop.ipc.Client.call(Client.java:803)
- locked <0x00007f16cb14b3a8> (a org.apache.hadoop.ipc.Client$Call)
at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:221)
at $Proxy1.complete(Unknown Source)
at sun.reflect.GeneratedMethodAccessor38.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:82)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:59)
at $Proxy1.complete(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.closeInternal(DFSClient.java:3390)
- locked <0x00007f16cb14b470> (a org.apache.hadoop.hdfs.DFSClient$DFSOutputStream)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.close(DFSClient.java:3304)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:61)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:86)
at org.apache.hadoop.hbase.io.hfile.HFile$Writer.close(HFile.java:650)
at org.apache.hadoop.hbase.regionserver.StoreFile$Writer.close(StoreFile.java:853)
at org.apache.hadoop.hbase.regionserver.Store.internalFlushCache(Store.java:467)
- locked <0x00007f16d00e6f08> (a java.lang.Object)
at org.apache.hadoop.hbase.regionserver.Store.flushCache(Store.java:427)
at org.apache.hadoop.hbase.regionserver.Store.access$100(Store.java:80)
at org.apache.hadoop.hbase.regionserver.Store$StoreFlusherImpl.flushCache(Store.java:1359)
at org.apache.hadoop.hbase.regionserver.HRegion.internalFlushcache(HRegion.java:907)
at org.apache.hadoop.hbase.regionserver.HRegion.internalFlushcache(HRegion.java:834)
at org.apache.hadoop.hbase.regionserver.HRegion.flushcache(HRegion.java:786)
at org.apache.hadoop.hbase.regionserver.MemStoreFlusher.flushRegion(MemStoreFlusher.java:250)
at org.apache.hadoop.hbase.regionserver.MemStoreFlusher.flushRegion(MemStoreFlusher.java:224)
at org.apache.hadoop.hbase.regionserver.MemStoreFlusher.run(MemStoreFlusher.java:146)
正在 await 操作(例如放置,删除,扫描等)的处理程序线程:
"IPC Server handler 16 on 60020" daemon prio=10 tid=0x00007f16b011d800 nid=0x4a5e waiting on condition [0x00007f16afefd000..0x00007f16afefd9f0]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00007f16cd3f8dd8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:158)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1925)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:358)
at org.apache.hadoop.hbase.ipc.HBaseServer$Handler.run(HBaseServer.java:1013)
一个正在忙着增加一个计数器的计数器(它处于试图创建扫描仪以读取最后一个值的阶段):
"IPC Server handler 66 on 60020" daemon prio=10 tid=0x00007f16b006e800 nid=0x4a90 runnable [0x00007f16acb77000..0x00007f16acb77cf0]
java.lang.Thread.State: RUNNABLE
at org.apache.hadoop.hbase.regionserver.KeyValueHeap.<init>(KeyValueHeap.java:56)
at org.apache.hadoop.hbase.regionserver.StoreScanner.<init>(StoreScanner.java:79)
at org.apache.hadoop.hbase.regionserver.Store.getScanner(Store.java:1202)
at org.apache.hadoop.hbase.regionserver.HRegion$RegionScanner.<init>(HRegion.java:2209)
at org.apache.hadoop.hbase.regionserver.HRegion.instantiateInternalScanner(HRegion.java:1063)
at org.apache.hadoop.hbase.regionserver.HRegion.getScanner(HRegion.java:1055)
at org.apache.hadoop.hbase.regionserver.HRegion.getScanner(HRegion.java:1039)
at org.apache.hadoop.hbase.regionserver.HRegion.getLastIncrement(HRegion.java:2875)
at org.apache.hadoop.hbase.regionserver.HRegion.incrementColumnValue(HRegion.java:2978)
at org.apache.hadoop.hbase.regionserver.HRegionServer.incrementColumnValue(HRegionServer.java:2433)
at sun.reflect.GeneratedMethodAccessor20.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.hbase.ipc.HBaseRPC$Server.call(HBaseRPC.java:560)
at org.apache.hadoop.hbase.ipc.HBaseServer$Handler.run(HBaseServer.java:1027)
从 HDFS 接收数据的线程:
"IPC Client (47) connection to sv4borg9/10.4.24.40:9000 from hadoop" daemon prio=10 tid=0x00007f16a02d0000 nid=0x4fa3 runnable [0x00007f16b517d000..0x00007f16b517dbf0]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:215)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:65)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:69)
- locked <0x00007f17d5b68c00> (a sun.nio.ch.Util$1)
- locked <0x00007f17d5b68be8> (a java.util.Collections$UnmodifiableSet)
- locked <0x00007f1877959b50> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:80)
at org.apache.hadoop.net.SocketIOWithTimeout$SelectorPool.select(SocketIOWithTimeout.java:332)
at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:157)
at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:155)
at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:128)
at java.io.FilterInputStream.read(FilterInputStream.java:116)
at org.apache.hadoop.ipc.Client$Connection$PingInputStream.read(Client.java:304)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:218)
at java.io.BufferedInputStream.read(BufferedInputStream.java:237)
- locked <0x00007f1808539178> (a java.io.BufferedInputStream)
at java.io.DataInputStream.readInt(DataInputStream.java:370)
at org.apache.hadoop.ipc.Client$Connection.receiveResponse(Client.java:569)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:477)
这是一个在 RegionServer 死后试图收回租约的 Management 员:
"LeaseChecker" daemon prio=10 tid=0x00000000407ef800 nid=0x76cd waiting on condition [0x00007f6d0eae2000..0x00007f6d0eae2a70]
--
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:485)
at org.apache.hadoop.ipc.Client.call(Client.java:726)
- locked <0x00007f6d1cd28f80> (a org.apache.hadoop.ipc.Client$Call)
at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:220)
at $Proxy1.recoverBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.processDatanodeError(DFSClient.java:2636)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.<init>(DFSClient.java:2832)
at org.apache.hadoop.hdfs.DFSClient.append(DFSClient.java:529)
at org.apache.hadoop.hdfs.DistributedFileSystem.append(DistributedFileSystem.java:186)
at org.apache.hadoop.fs.FileSystem.append(FileSystem.java:530)
at org.apache.hadoop.hbase.util.FSUtils.recoverFileLease(FSUtils.java:619)
at org.apache.hadoop.hbase.regionserver.wal.HLog.splitLog(HLog.java:1322)
at org.apache.hadoop.hbase.regionserver.wal.HLog.splitLog(HLog.java:1210)
at org.apache.hadoop.hbase.master.HMaster.splitLogAfterStartup(HMaster.java:648)
at org.apache.hadoop.hbase.master.HMaster.joinCluster(HMaster.java:572)
at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:503)
117.2.5. OpenTSDB
OpenTSDB是 Ganglia 的绝佳替代品,因为它使用 Apache HBase 存储所有时间序列,而不必进行降采样。监视托管 OpenTSDB 的 HBase 群集是一个不错的练习。
这是一个群集的示例,该群集几乎在同一时间几乎同时启动了数百次压缩,这严重影响了 IO 性能:(TODO:插入图表绘制 compactionQueueSize)
最好使用每台计算机和每个集群的所有重要图形来构建仪表板,以便快速查看调试问题。例如,在 StumbleUpon 上,每个集群只有一个仪表板,其中包含来自 os 和 Apache HBase 的最重要的 Metrics。然后,您可以在计算机级别查看详细信息。
117.2.6. clusterssh+top
clusterssh top,它就像一个穷人的监视系统,当您只有几台机器时,它非常有用,因为它很容易设置。启动 clusterssh 将为您提供每台计算机一个终端,并为您提供另一个终端,在该终端中,您键入的内容将在每个窗口中重新 Importing。这意味着您可以键入一次top,它将同时为所有计算机启动它,从而使您可以全面了解群集的当前状态。您还可以同时拖尾所有日志,编辑文件等。
118. Client
有关 HBaseClient 端的更多信息,请参见client。
118.1. ScannerTimeoutException 或 UnknownScannerException
如果从 Client 端到 RegionServer 的 RPC 调用之间的时间间隔超过了扫描超时,则抛出此错误。例如,如果Scan.setCaching设置为 500,则将有一个 RPC 调用来每 500 .next()个调用在 ResultScanner 上获取下一批行,因为数据是以 500 行的块的形式传输到 Client 端的。减少 setCaching 值可能是一个选项,但是将此值设置得太低会使行数处理效率低下。
See Scan Caching.
118.2. Thrift 和 Java API 的性能差异
如ScannerTimeoutException 或 UnknownScannerException所述,如果Scan.setCaching太高,则可能会导致性能下降甚至ScannerTimeoutExceptions。如果 ThriftClient 端对给定的工作负载使用了错误的缓存设置,则与 Java API 相比,性能可能会受到影响。要在 ThriftClient 端中为给定的扫描设置缓存,请使用scannerGetList(scannerId, numRows)方法,其中numRows是表示要缓存的行数的整数。在一种情况下,发现在相同查询的情况下,将 Thrift 扫描的缓存从 1000 减少到 100 可将性能提高到与 Java API 几乎相等。
另请参阅 Jesse Andersen 的blog post关于如何将 Thrift 与 Thrift 一起使用。
118.3. 调用 Scanner.next 时出现 LeaseException
在某些情况下,从 RegionServer 提取数据的 Client 端会收到 LeaseException 而不是通常的ScannerTimeoutException 或 UnknownScannerException。通常,exception 的来源是org.apache.hadoop.hbase.regionserver.Leases.removeLease(Leases.java:230)(行号可能会有所不同)。它往往发生在缓慢/冻结RegionServer#next调用的情况下。可以通过使hbase.rpc.timeout> hbase.client.scanner.timeout.period来防止它。苛刻的 J 将该问题作为邮件列表线程HBase,邮件#用户-租赁不存在异常的一部分进行了调查
118.4. Shell 或 Client 端应用程序在正常运行期间会引发许多可怕的异常
从 0.20.0 开始,org.apache.hadoop.hbase.*的默认日志级别是 DEBUG。
在您的 Client 端上,编辑* $ HBASE_HOME/conf/log4j.properties *并将其:log4j.logger.org.apache.hadoop.hbase=DEBUG更改为log4j.logger.org.apache.hadoop.hbase=INFO,甚至log4j.logger.org.apache.hadoop.hbase=WARN。
118.5. 长期 Client 因压缩而暂停
在 Apache HBase dist-list 上,这是一个相当常见的问题。场景是,Client 端通常会将大量数据插入相对未优化的 HBase 群集中。压缩可能会加剧暂停,尽管这不是问题的根源。
有关预创建区域的信息,请参见该模式上的表创建:预创建区域,并确认该表不是从单个区域开始的。
有关群集配置,请参见HBase Configurations,尤其是hbase.hstore.blockingStoreFiles,hbase.hregion.memstore.block.multiplier,MAX_FILESIZE(区域大小)和MEMSTORE_FLUSHSIZE.
关于为什么会发生暂停的稍长解释如下:有时,在刷新程序线程阻止的 MemStores 上放置了 puts,而该刷新程序线程又由于要压缩的文件太多而被阻塞,因为压缩程序被分配的小文件太多,因此无法进行压缩。必须重复压缩相同的数据。即使进行较小的压实,也会出现这种情况。使这种情况更加复杂的是,Apache HBase 不会压缩内存中的数据。因此,压缩后,驻留在 MemStore 中的 64MB 可能会变成 6MB 的文件-这会导致 StoreFile 变小。好处是,更多数据被打包到同一区域中,但是可以通过写入更大的文件来实现性能-这就是为什么 HBase 在写入新的 StoreFile 之前要等到 flushsize 的原因。较小的 StoreFiles 成为压缩的目标。如果不进行压缩,则文件会更大,不需要太多压缩,但这是以 I/O 为代价的。
有关更多信息,请参见长 Client 端因压缩而暂停上的该线程。
118.6. 安全 Client 端连接([由 GSSException 引起:未提供有效的凭据...])
您可能会遇到以下错误:
Secure Client Connect ([Caused by GSSException: No valid credentials provided
(Mechanism level: Request is a replay (34) V PROCESS_TGS)])
此问题是由 MIT Kerberos replay_cache 组件#1201和#5924中的错误引起的。这些错误导致 krb5-server 的旧版本错误地阻止了从主体发送的后续请求。这导致 krb5-server 阻止从一个 Client 端(一个 HTable 实例和每个 RegionServer 的多线程连接实例)发送的连接;诸如Request is a replay (34)之类的消息记录在 Client 端日志中,您可以忽略这些消息,因为默认情况下,HTable 将为每个失败的连接重试 5 * 10(50)次。重试后,如果与 RegionServer 的任何连接失败,则 HTable 将引发 IOException,以便 HTable 实例的用户 Client 端代码可以进一步处理它。注意:HBase 1.0 中不推荐使用HTable,而推荐使用Table。
或者,将 krb5-server 更新到解决这些问题的版本,例如 krb5-server-1.10.3. 有关更多详细信息,请参见 JIRA HBASE-10379。
118.7. ZooKeeperClient 端连接错误
这样的错误...
11/07/05 11:26:41 WARN zookeeper.ClientCnxn: Session 0x0 for server null,
unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(Unknown Source)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1078)
11/07/05 11:26:43 INFO zookeeper.ClientCnxn: Opening socket connection to
server localhost/127.0.0.1:2181
11/07/05 11:26:44 WARN zookeeper.ClientCnxn: Session 0x0 for server null,
unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(Unknown Source)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1078)
11/07/05 11:26:45 INFO zookeeper.ClientCnxn: Opening socket connection to
server localhost/127.0.0.1:2181
…是由于 ZooKeeper 关闭或由于网络问题而无法访问。
Utilzkcli可能有助于调查 ZooKeeper 问题。
118.8. 尽管堆大小似乎稳定,但 Client 端用尽了内存(但堆外/直接堆不断增长)
您可能会遇到在邮件线程HBase,邮件#用户-怀疑内存泄漏中描述和解决并在HBase,邮件#dev-FeedbackRe:怀疑内存泄漏中 continue 讨论的问题。解决方法是将-XX:MaxDirectMemorySize的合理值传递给 Client 端 JVM。默认情况下,MaxDirectMemorySize等于您的-Xmx最大堆大小设置(如果设置了-Xmx)。尝试将其设置为较小的值(例如,当一个用户的 Client 端堆为12g时,一个用户成功将其设置为1g)。如果将其设置得太小,它将产生FullGCs的效果,因此请使其稍稍沉一些。您只想在 Client 端进行此设置,尤其是在运行新的实验性服务器端堆外高速缓存时,因为此功能取决于能否使用大的直接缓冲区(您可能必须将单独的 Client 端和服务器端-侧面配置目录)。
118.9. 安全 Client 端无法连接([由 GSSException 引起:未提供有效的凭据(机制级别:无法找到任何 Kerberos tgt)])
可能有几种原因导致此症状。
首先,检查您是否具有有效的 Kerberos 票证。为了与安全的 Apache HBase 集群构建通信,需要一个。通过运行klist命令行实用工具,检查当前在凭证高速缓存中的票证(如果有)。如果未列出票证,则必须通过使用指定的密钥表运行kinit命令或通过交互 Importing 所需主体的密码来获得票证。
然后,咨询Java 安全指南疑难解答部分。通过将javax.security.auth.useSubjectCredsOnly系统属性值设置为false可以解决那里最常见的问题。
由于 MIT Kerberos 写入其凭据缓存的格式发生了变化,因此 Oracle JDK 6 Update 26 和更早版本中存在一个错误,该错误导致 Java 无法读取由 MIT Kerberos 1.8.1 版本创建的 Kerberos 凭据缓存。或更高。如果您的环境中组件的组合存在这种问题,要变通解决此问题,请首先使用kinit登录,然后立即使用kinit -R刷新凭据缓存。刷新将重写凭据缓存,而不会出现格式问题。
在 JDK 1.4 之前,JCE 是非 Binding 产品,因此,JCA 和 JCE 通常被称为独立的不同组件。由于 JCE 现在 Binding 在 JDK 7.0 中,因此区别变得不那么明显了。由于 JCE 使用与 JCA 相同的体系结构,因此应该更恰当地将 JCE 视为 JCA 的一部分。
由于 JDK 1.5 或更早版本,您可能需要安装Java 密码学扩展或 JCE。确保服务器和 Client 端系统上的 JCE jar 都在 Classpath 上。
您可能还需要下载无限强度的 JCE 策略文件。解压缩并解压缩下载的文件,然后将策略 jar 安装到*<java-home>/lib/security *中。
119. MapReduce
119.1. 您以为自己在集群上,但实际上是本地人
以下堆栈跟踪是使用ImportTsv发生的,但是类似的事情可能发生在任何配置错误的作业上。
WARN mapred.LocalJobRunner: job_local_0001
java.lang.IllegalArgumentException: Can't read partitions file
at org.apache.hadoop.hbase.mapreduce.hadoopbackport.TotalOrderPartitioner.setConf(TotalOrderPartitioner.java:111)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:62)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:117)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:560)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:639)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:210)
Caused by: java.io.FileNotFoundException: File _partition.lst does not exist.
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:383)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:251)
at org.apache.hadoop.fs.FileSystem.getLength(FileSystem.java:776)
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1424)
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1419)
at org.apache.hadoop.hbase.mapreduce.hadoopbackport.TotalOrderPartitioner.readPartitions(TotalOrderPartitioner.java:296)
…看到堆栈的关键部分?它的…
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:210)
LocalJobRunner 意味着作业正在本地运行,而不是在群集上运行。
要解决此问题,您应将HADOOP_CLASSPATH设置为包含 HBase 依赖项来运行 MR 作业。可以使用“ hbase classpath”Util 轻松完成此操作。例如(用您的 HBase 版本替换 VERSION):
HADOOP_CLASSPATH=`hbase classpath` hadoop jar $HBASE_HOME/hbase-mapreduce-VERSION.jar rowcounter usertable
有关 HBase MapReduce 作业和 Classpath 的更多信息,请参见HBase,MapReduce 和 CLASSPATH。
119.2. 启动工作,您将得到 java.lang.IllegalAccessError:com/google/protobuf/HBaseZeroCopyByteString 或 com.google.protobuf.ZeroCopyLiteralByteString 类无法访问其超类 com.google.protobuf.LiteralByteString
参见HBASE-10304 运行 hbase 作业 jar:IllegalAccessError:类 com.google.protobuf.ZeroCopyLiteralByteString 无法访问其超类 com.google.protobuf.LiteralByteString和HBASE-11118 针对“ IllegalAccessError:类 com.google.protobuf.ZeroCopyLiteralByteString 无法访问其超类 com.google.protobuf.LiteralByteString”的非环境变量解决方案。尝试运行 Spark 作业时,该问题也会出现。参见HBASE-10877 HBase 不可重试异常列表应扩展。
120. NameNode
有关 NameNode 的更多信息,请参见HDFS。
120.1. 表和区域的 HDFS 利用
要确定 HBase 在 HDFS 上使用了多少空间,请使用 NameNode 中的hadoop shell 命令。例如…
hadoop fs -dus /hbase/
…返回所有 HBase 对象的汇总磁盘利用率。
hadoop fs -dus /hbase/myTable
…返回 HBase 表“ myTable”的汇总磁盘利用率。
hadoop fs -du /hbase/myTable
…返回 HBase 表“ myTable”下的区域及其磁盘利用率的列表。
有关 HDFS Shell 命令的更多信息,请参见HDFS FileSystem Shell 文档。
120.2. 浏览 HBase 对象的 HDFS
有时有必要探索 HDFS 上存在的 HBase 对象。这些对象可以包括 WAL(预先写入日志),表,区域,StoreFiles 等。最简单的方法是使用在端口 50070 上运行的 NameNode Web 应用程序。NameNodeWeb 应用程序将提供指向所有 DataNodes 的链接。在群集中,以便可以无缝浏览它们。
群集中 HBase 表的 HDFS 目录结构为…
/hbase
/data
/<Namespace> (Namespaces in the cluster)
/<Table> (Tables in the cluster)
/<Region> (Regions for the table)
/<ColumnFamily> (ColumnFamilies for the Region for the table)
/<StoreFile> (StoreFiles for the ColumnFamily for the Regions for the table)
HBase WAL 的 HDFS 目录结构为..
/hbase
/WALs
/<RegionServer> (RegionServers)
/<WAL> (WAL files for the RegionServer)
有关其他非 Shell 诊断 Util(如fsck),请参见HDFS 用户指南。
120.2.1. 零尺寸 WAL,其中包含数据
问题:获得 RegionServer 的* WALs *目录中所有文件的列表时,一个文件的大小为 0,但其中包含数据。
答:这是 HDFS 的怪癖。当前正在写入的文件的大小似乎为 0,但关闭后将显示其真实大小
120.2.2. 用例
用于查询 HFS 对象的 HDFS 的两个常见用例是研究表的未压缩程度。如果每个 ColumnFamily 有大量的 StoreFiles,则可能表明需要进行重大压缩。另外,在进行重大压缩后,如果所得的 StoreFile 是“ small”,则可能表明需要减少该表的 ColumnFamilies。
120.3. 文件系统意外增长
如果您看到 HBase 意外使用文件系统,则两个可能的罪魁祸首是快照和 WAL。
Snapshots
- 创建快照时,HBase 会保留快照时重新创建表状态所需的所有内容。这包括已删除的单元格或过期的版本。因此,您的快照使用模式应进行合理计划,并且应修剪不再需要的快照。快照存储在
/hbase/.hbase-snapshot中,还原快照所需的存档存储在/hbase/archive/<_tablename_>/<_region_>/<_column_family_>/中。
- 创建快照时,HBase 会保留快照时重新创建表状态所需的所有内容。这包括已删除的单元格或过期的版本。因此,您的快照使用模式应进行合理计划,并且应修剪不再需要的快照。快照存储在
*Do not* manage snapshots or archives manually via HDFS. HBase provides APIs and
HBase Shell commands for managing them. For more information, see <<ops.snapshots>>.
WAL
- 预写日志(WAL)根据其状态存储在 HBase 根目录的子目录中,通常为
/hbase/。已处理的 WAL 存储在/hbase/oldWALs/中,损坏的 WAL 存储在/hbase/.corrupt/中进行检查。如果这些子目录之一的大小在增长,请检查 HBase 服务器日志以找到 WAL 未得到正确处理的根本原因。
- 预写日志(WAL)根据其状态存储在 HBase 根目录的子目录中,通常为
如果您使用复制并且/hbase/oldWALs/使用的空间超出预期,请记住,只要有对等项,禁用复制时就会保存 WAL。
请勿 通过 HDFS 手动 ManagementWAL。
121. Network
121.1. 网络尖峰
如果您看到周期性的网络高峰,则可能需要检查compactionQueues以查看是否发生了重大压缩。
有关 Management 压缩的更多信息,请参见Managed Compactions。
121.2. 回送 IP
HBase 希望回送 IP 地址为 127.0.0.1.
121.3. 网络接口
所有网络接口是否正常运行?你确定吗?请参阅Case Studies中的故障排除案例研究。
122. RegionServer
有关 RegionServer 的更多信息,请参见RegionServer。
122.1. 启动错误
122.1.1. 主机启动,但 RegionServers 不启动
主机认为 RegionServer 的 IP 为 127.0.0.1-这是 localhost,并且解析为主机自己的 localhost。
区域服务器错误地通知主服务器其 IP 地址为 127.0.0.1.
从…修改区域服务器上的*/etc/hosts *
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1 fully.qualified.regionservername regionservername localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
...到(从 localhost 中删除主节点的名称)…
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
122.1.2. 压缩链接错误
由于需要在每个群集上安装和配置 LZO 等压缩算法,因此这是启动错误的常见来源。如果您看到这样的消息...
11/02/20 01:32:15 ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library
java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1734)
at java.lang.Runtime.loadLibrary0(Runtime.java:823)
at java.lang.System.loadLibrary(System.java:1028)
...然后压缩库出现路径问题。请参阅链接:[LZO 压缩配置]上的“配置”部分。
122.1.3. 由于缺少文件系统的 hsync,RegionServer 中止
为了为写入集群提供数据持久性,HBase 依赖于将状态持久保存在预写日志中的能力。当使用支持检查所需调用的可用性的 Apache Hadoop Common 的文件系统 API 版本时,如果 HBase 发现集群无法安全运行,它将主动中止集群。
对于 RegionServer 角色,失败将显示在以下日志中:
2018-04-05 11:36:22,785 ERROR [regionserver/192.168.1.123:16020] wal.AsyncFSWALProvider: The RegionServer async write ahead log provider relies on the ability to call hflush and hsync for proper operation during component failures, but the current FileSystem does not support doing so. Please check the config value of 'hbase.wal.dir' and ensure it points to a FileSystem mount that has suitable capabilities for output streams.
2018-04-05 11:36:22,799 ERROR [regionserver/192.168.1.123:16020] regionserver.HRegionServer: ***** ABORTING region server 192.168.1.123,16020,1522946074234: Unhandled: cannot get log writer *****
java.io.IOException: cannot get log writer
at org.apache.hadoop.hbase.wal.AsyncFSWALProvider.createAsyncWriter(AsyncFSWALProvider.java:112)
at org.apache.hadoop.hbase.regionserver.wal.AsyncFSWAL.createWriterInstance(AsyncFSWAL.java:612)
at org.apache.hadoop.hbase.regionserver.wal.AsyncFSWAL.createWriterInstance(AsyncFSWAL.java:124)
at org.apache.hadoop.hbase.regionserver.wal.AbstractFSWAL.rollWriter(AbstractFSWAL.java:759)
at org.apache.hadoop.hbase.regionserver.wal.AbstractFSWAL.rollWriter(AbstractFSWAL.java:489)
at org.apache.hadoop.hbase.regionserver.wal.AsyncFSWAL.<init>(AsyncFSWAL.java:251)
at org.apache.hadoop.hbase.wal.AsyncFSWALProvider.createWAL(AsyncFSWALProvider.java:69)
at org.apache.hadoop.hbase.wal.AsyncFSWALProvider.createWAL(AsyncFSWALProvider.java:44)
at org.apache.hadoop.hbase.wal.AbstractFSWALProvider.getWAL(AbstractFSWALProvider.java:138)
at org.apache.hadoop.hbase.wal.AbstractFSWALProvider.getWAL(AbstractFSWALProvider.java:57)
at org.apache.hadoop.hbase.wal.WALFactory.getWAL(WALFactory.java:252)
at org.apache.hadoop.hbase.regionserver.HRegionServer.getWAL(HRegionServer.java:2105)
at org.apache.hadoop.hbase.regionserver.HRegionServer.buildServerLoad(HRegionServer.java:1326)
at org.apache.hadoop.hbase.regionserver.HRegionServer.tryRegionServerReport(HRegionServer.java:1191)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:1007)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.hadoop.hbase.util.CommonFSUtils$StreamLacksCapabilityException: hflush and hsync
at org.apache.hadoop.hbase.io.asyncfs.AsyncFSOutputHelper.createOutput(AsyncFSOutputHelper.java:69)
at org.apache.hadoop.hbase.regionserver.wal.AsyncProtobufLogWriter.initOutput(AsyncProtobufLogWriter.java:168)
at org.apache.hadoop.hbase.regionserver.wal.AbstractProtobufLogWriter.init(AbstractProtobufLogWriter.java:167)
at org.apache.hadoop.hbase.wal.AsyncFSWALProvider.createAsyncWriter(AsyncFSWALProvider.java:99)
... 15 more
如果您尝试在独立模式下运行并看到此错误,请返回快速入门-独立 HBase部分,并确保已 包括所有 给定的配置设置。
122.1.4. 由于无法初始化对 HDFS 的访问,RegionServer 中止
我们将尝试对 HBase-2.x 使用* AsyncFSWAL ,因为它具有更好的性能,同时消耗更少的资源。但是 AsyncFSWAL *的问题在于,它侵入了 DFSClient 实现的内部,因此即使升级了简单的补丁程序,在升级 hadoop 时也很容易将其破坏。
如果您未指定 wal 提供程序,则如果我们无法初始化* AsyncFSWAL ,我们将尝试使用旧的 FSHLog *,但是它可能并不总是有效。故障将显示在这样的日志中:
18/07/02 18:51:06 WARN concurrent.DefaultPromise: An exception was
thrown by org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$13.operationComplete()
java.lang.Error: Couldn't properly initialize access to HDFS
internals. Please update your WAL Provider to not make use of the
'asyncfs' provider. See HBASE-16110 for more information.
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputSaslHelper.<clinit>(FanOutOneBlockAsyncDFSOutputSaslHelper.java:268)
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper.initialize(FanOutOneBlockAsyncDFSOutputHelper.java:661)
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper.access$300(FanOutOneBlockAsyncDFSOutputHelper.java:118)
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$13.operationComplete(FanOutOneBlockAsyncDFSOutputHelper.java:720)
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$13.operationComplete(FanOutOneBlockAsyncDFSOutputHelper.java:715)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:507)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListeners0(DefaultPromise.java:500)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListenersNow(DefaultPromise.java:479)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:420)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultPromise.trySuccess(DefaultPromise.java:104)
at org.apache.hbase.thirdparty.io.netty.channel.DefaultChannelPromise.trySuccess(DefaultChannelPromise.java:82)
at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.fulfillConnectPromise(AbstractEpollChannel.java:638)
at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.finishConnect(AbstractEpollChannel.java:676)
at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.epollOutReady(AbstractEpollChannel.java:552)
at org.apache.hbase.thirdparty.io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:394)
at org.apache.hbase.thirdparty.io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:304)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)
at org.apache.hbase.thirdparty.io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoSuchMethodException:
org.apache.hadoop.hdfs.DFSClient.decryptEncryptedDataEncryptionKey(org.apache.hadoop.fs.FileEncryptionInfo)
at java.lang.Class.getDeclaredMethod(Class.java:2130)
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputSaslHelper.createTransparentCryptoHelper(FanOutOneBlockAsyncDFSOutputSaslHelper.java:232)
at org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputSaslHelper.<clinit>(FanOutOneBlockAsyncDFSOutputSaslHelper.java:262)
... 18 more
如果遇到此错误,请在配置文件中明确指定* FSHLog ,即 filesystem *。
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
并且不要忘记发送电子邮件到user@hbase.apache.org或dev@hbase.apache.org报告失败以及您的 hadoop 版本,我们将尝试在下一版本中尽快解决此问题。
122.2. 运行时错误
122.2.1. RegionServer 挂起
您是否正在运行旧的 JVM(<1.6.0_u21?)?当您查看线程转储时,是否看起来线程已被阻塞,但是没有人持有所有被锁定的锁?参见HBaseServer 中的 HBASE 3622 死锁(JVM 错误?)。在 conf/hbase-env.sh *中将-XX:+UseMembar添加到 HBase HBASE_OPTS可能会解决。
122.2.2. java.io.IOException…(打开的文件太多)
如果您看到这样的日志消息…
2010-09-13 01:24:17,336 WARN org.apache.hadoop.hdfs.server.datanode.DataNode:
Disk-related IOException in BlockReceiver constructor. Cause is java.io.IOException: Too many open files
at java.io.UnixFileSystem.createFileExclusively(Native Method)
at java.io.File.createNewFile(File.java:883)
...请参阅链接:[ulimit 和 nproc 配置]的“入门”部分。
122.2.3. xceiverCount 258 超过并发 xcievers 256 的限制
这通常显示在 DataNode 日志中。
请参阅 link:[xceivers 配置]上的“入门”部分。
122.2.4. 系统不稳定,并且出现“ java.lang.OutOfMemoryError:无法在异常中创建新的本机线程” HDFS DataNode 日志或任何系统守护程序的日志
请参见有关 ulimit 和 nproc 配置的“入门”部分。最近的 Linux 发行版的默认值为 1024-对于 HBase 而言太低了。
122.2.5. DFS 不稳定和/或 RegionServer 租约超时
如果您看到这样的警告消息...
2009-02-24 10:01:33,516 WARN org.apache.hadoop.hbase.util.Sleeper: We slept xxx ms, ten times longer than scheduled: 10000
2009-02-24 10:01:33,516 WARN org.apache.hadoop.hbase.util.Sleeper: We slept xxx ms, ten times longer than scheduled: 15000
2009-02-24 10:01:36,472 WARN org.apache.hadoop.hbase.regionserver.HRegionServer: unable to report to master for xxx milliseconds - retrying
...或看到完整的 GC 压缩,则您可能正在经历完整的 GC。
122.2.6. “没有活动节点包含当前块”和/或 YouAreDeadException
这些错误可能在 OS 文件句柄用尽时或在节点无法访问的严重网络问题期间发生。
请参阅有关 ulimit 和 nproc 配置的入门部分,并检查您的网络。
122.2.7. ZooKeeper SessionExpired 事件
Master 或 RegionServers 关闭,并显示类似日志中的消息:
WARN org.apache.zookeeper.ClientCnxn: Exception
closing session 0x278bd16a96000f to sun.nio.ch.SelectionKeyImpl@355811ec
java.io.IOException: TIMED OUT
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:906)
WARN org.apache.hadoop.hbase.util.Sleeper: We slept 79410ms, ten times longer than scheduled: 5000
INFO org.apache.zookeeper.ClientCnxn: Attempting connection to server hostname/IP:PORT
INFO org.apache.zookeeper.ClientCnxn: Priming connection to java.nio.channels.SocketChannel[connected local=/IP:PORT remote=hostname/IP:PORT]
INFO org.apache.zookeeper.ClientCnxn: Server connection successful
WARN org.apache.zookeeper.ClientCnxn: Exception closing session 0x278bd16a96000d to sun.nio.ch.SelectionKeyImpl@3544d65e
java.io.IOException: Session Expired
at org.apache.zookeeper.ClientCnxn$SendThread.readConnectResult(ClientCnxn.java:589)
at org.apache.zookeeper.ClientCnxn$SendThread.doIO(ClientCnxn.java:709)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:945)
ERROR org.apache.hadoop.hbase.regionserver.HRegionServer: ZooKeeper session expired
JVM 正在进行长时间运行的垃圾收集,这会暂停每个线程(也称为“停止世界”)。由于 RegionServer 的本地 ZooKeeperClient 端无法发送心跳,因此会话超时。根据设计,我们在超时后关闭了任何无法联系 ZooKeeper 集成的节点,以使其停止提供可能已经分配给其他地方的数据。
确保提供足够的 RAM(在* hbase-env.sh *中),默认值为 1GB 将无法承受长时间运行的导入。
确保不交换,JVM 在交换下永远不会表现良好。
确保您没有 CPU 耗尽 RegionServer 线程。例如,如果您在具有 4 个核心的计算机上使用 6 个 CPU 密集型任务运行 MapReduce 作业,则您可能饿死了 RegionServer 足以创建更长的垃圾收集暂停。
增加 ZooKeeper 会话超时
如果要增加会话超时,请将以下内容添加到* hbase-site.xml *中,以将超时从默认的 60 秒增加到 120 秒。
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>6000</value>
</property>
请注意,设置较高的超时时间意味着故障的 RegionServer 服务的区域将至少花费该时间量才能传输到另一个 RegionServer。对于服务实时请求的生产系统,我们建议将其设置为小于 1 分钟,并为群集提供过多的空间,以降低每台计算机上的内存负载(因此每台计算机收集的垃圾较少)。
如果在仅一次上传的上传期间发生这种情况(例如,最初将所有数据加载到 HBase 中),请考虑批量加载。
有关 ZooKeeper 故障排除的其他常规信息,请参见ZooKeeper,集群金丝雀。
122.2.8. NotServingRegionException
在 RegionServer 日志中以 DEBUG 级别找到此异常是“正常”。将此异常返回给 Client 端,然后 Client 端返回hbase:meta以查找已移动区域的新位置。
但是,如果 NotServingRegionException 记录为 ERROR,则 Client 端的重试用尽,可能是错误的。
122.2.9. 日志中充斥着“ 2011-01-10 12:40:48,407 INFO org.apache.hadoop.io.compress.CodecPool:Gotbrand-new 压缩机”消息
我们未使用压缩库的本机版本。参见HBASE-1900 发布 hadoop 0.21 时放回本机支持。从 Hoop lib 目录下的 hadoop 复制本机 lib 或将它们符号链接到位,消息应消失。
122.2.10. 60020 上的服务器处理程序 X 被捕获:java.nio.channels.ClosedChannelException
如果您看到此类型的消息,则表示该区域服务器正在尝试从 Client 端读取数据/向 Client 端发送数据,但该服务器已经消失。造成这种情况的典型原因是 Client 端被杀死(当 MapReduce 作业被杀死或失败时,您会看到大量此类消息)或 Client 端收到 SocketTimeoutException。这是无害的,但是如果您不做任何事情来触发它们,则应该考虑多挖一些。
122.3. 反向 DNS 导致的快照错误
HBase 中的一些操作(包括快照)都依赖于正确配置的反向 DNS。某些环境(例如 Amazon EC2)在使用反向 DNS 时会遇到麻烦。如果您在 RegionServers 上看到类似以下的错误,请检查反向 DNS 配置:
2013-05-01 00:04:56,356 DEBUG org.apache.hadoop.hbase.procedure.Subprocedure: Subprocedure 'backup1'
coordinator notified of 'acquire', waiting on 'reached' or 'abort' from coordinator.
通常,RegionServer 报告的主机名必须与主服务器尝试访问的主机名相同。通过在启动时在 RegionServer 的日志中查找以下类型的消息,可以看到主机名不匹配。
2013-05-01 00:03:00,614 INFO org.apache.hadoop.hbase.regionserver.HRegionServer: Master passed us hostname
to use. Was=myhost-1234, Now=ip-10-55-88-99.ec2.internal
122.4. 关机错误
123. Master
有关主服务器的更多信息,请参见master。
123.1. 启动错误
123.1.1. 师父说您需要运行 HBase 迁移脚本
运行该命令后,HBase 迁移脚本会说根目录中没有文件。
HBase 希望根目录不存在,或者已经由先前运行的 HBase 初始化过。如果使用 Hadoop DFS 为 HBase 创建新目录,则会发生此错误。确保 HBase 根目录当前不存在或已由先前的 HBase 运行初始化。确定的解决方案是仅使用 Hadoop dfs 删除 HBase 根目录,然后让 HBase 创建和初始化目录本身。
123.1.2. 数据包 len6080218 超出范围!
如果您的群集上有很多区域,并且在日志的此部分标题中看到了类似上面报告的错误,请参阅具有太多区域的 HBASE-4246 群集无法承受某些主故障转移方案。
123.1.3. 由于缺少文件系统的 hsync,Master 无法激活
HBase 的集群操作内部框架要求能够将状态持久保存在预写日志中。当使用支持检查所需调用的可用性的 Apache Hadoop Common 的文件系统 API 版本时,如果 HBase 发现集群无法安全运行,它将主动中止集群。
对于主角色,失败将显示在以下日志中:
2018-04-05 11:18:44,653 ERROR [Thread-21] master.HMaster: Failed to become active master
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
at org.apache.hadoop.hbase.procedure2.store.wal.WALProcedureStore.rollWriter(WALProcedureStore.java:1034)
at org.apache.hadoop.hbase.procedure2.store.wal.WALProcedureStore.recoverLease(WALProcedureStore.java:374)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.start(ProcedureExecutor.java:530)
at org.apache.hadoop.hbase.master.HMaster.startProcedureExecutor(HMaster.java:1267)
at org.apache.hadoop.hbase.master.HMaster.startServiceThreads(HMaster.java:1173)
at org.apache.hadoop.hbase.master.HMaster.finishActiveMasterInitialization(HMaster.java:881)
at org.apache.hadoop.hbase.master.HMaster.startActiveMasterManager(HMaster.java:2048)
at org.apache.hadoop.hbase.master.HMaster.lambda$run$0(HMaster.java:568)
at java.lang.Thread.run(Thread.java:745)
如果您尝试在独立模式下运行并看到此错误,请返回快速入门-独立 HBase部分,并确保已 包括所有 给定的配置设置。
123.2. 关机错误
124. ZooKeeper
124.1. 启动错误
124.1.1. 在 ZooKeeper 仲裁服务器列表中找不到我的地址:xyz
ZooKeeper 服务器无法启动,引发该错误。 xyz 是您的服务器的名称。
这是一个名称查找问题。 HBase 尝试在某台计算机上启动 ZooKeeper 服务器,但是该计算机无法在hbase.zookeeper.quorum配置中找到自己。
使用错误消息中显示的主机名代替您使用的值。如果您有 DNS 服务器,则可以在* hbase-site.xml *中设置hbase.zookeeper.dns.interface和hbase.zookeeper.dns.nameserver,以确保其解析为正确的 FQDN。
124.2. ZooKeeper,集群金丝雀
ZooKeeper 是集群的“矿井中的金丝雀”。它将是第一个注意到问题的人,以确保它很高兴成为嗡嗡作响的集群的捷径。
参见ZooKeeper 操作环境故障排除页。它具有用于检查磁盘和网络性能的建议和工具;即 ZooKeeper 和 HBase 运行所在的操作环境。
此外,Utilzkcli可能有助于调查 ZooKeeper 问题。
125. Amazon EC2
125.1. ZooKeeper 在 Amazon EC2 上似乎不起作用
部署为 Amazon EC2 实例时,HBase 无法启动。 Master 和/或 RegionServer 日志中会出现类似以下的异常:
2009-10-19 11:52:27,030 INFO org.apache.zookeeper.ClientCnxn: Attempting
connection to server ec2-174-129-15-236.compute-1.amazonaws.com/10.244.9.171:2181
2009-10-19 11:52:27,032 WARN org.apache.zookeeper.ClientCnxn: Exception
closing session 0x0 to sun.nio.ch.SelectionKeyImpl@656dc861
java.net.ConnectException: Connection refused
安全组策略阻止了公用地址上的 ZooKeeper 端口。配置 ZooKeeper 仲裁对等列表时,请使用内部 EC2 主机名。
125.2. Amazon EC2 上的不稳定
有关 HBase 和 Amazon EC2 的问题经常出现在 HBase 分发列表中。使用Search Hadoop搜索旧主题
125.3. 到 EC2 群集的远程 Java 连接不起作用
在用户列表中的远程 JavaClient 端连接到 EC2 实例上查看 Andrew 的回答。
126. HBase 和 Hadoop 版本问题
126.1. …无法与 Client 端版本进行通信…
如果您在日志中看到以下内容... 2012-09-24 10:20:52,168 致命 org.apache.hadoop.hbase.master.HMaster:未处理的异常。开始关机。 org.apache.hadoop.ipc.RemoteException:服务器 IPC 版本 7 无法与 Client 端版本 4 通信...…您是否正在尝试从具有 Hadoop 1.0.xClient 端的 HBase 与 Hadoop 2.0.x 进行通信?使用针对 Hadoop 2.0 构建的 HBase,或通过将-Dhadoop.profile = 2.0 属性传递给 Maven 来重建 HBase(有关更多信息,请参见针对各种 Hadoop 版本进行构建。)。
127. HBase 和 HDFS
Apache HDFS 的常规配置指南超出了本指南的范围。有关配置 HDFS 的详细信息,请参阅https://hadoop.apache.org/上的文档。本节从 HBase 角度处理 HDFS。
在大多数情况下,HBase 会将其数据存储在 Apache HDFS 中。这包括包含数据的 HFile,以及在将数据写入 HFile 之前存储数据并防止 RegionServer 崩溃的预写日志(WAL)。 HDFS 为 HBase 中的数据提供了可靠性和保护,因为它是分布式的。为了以最高效率运行,HBase 需要本地可用的数据。因此,在每个 RegionServer 上运行 HDFS DataNode 是一个好习惯。
HBase 和 HDFS 的重要信息和准则
HBase 是 HDFS 的 Client 端。
- HBase 是使用 HDFS
DFSClient类的 HDFSClient 端,并且对该类的引用与其他 HDFSClient 端日志消息一起出现在 HBase 日志中。
- HBase 是使用 HDFS
必须在多个位置进行配置。
- 与 HBase 相关的某些 HDFS 配置需要在 HDFS(服务器)端进行。其他必须在 HBase(在 Client 端)上完成。服务器和 Client 端都需要设置其他设置。
影响 HBase 的写入错误可能会记录在 HDFS 日志中,而不是 HBase 日志中。
- 写入时,HDFS 通过管道将通信从一个 DataNode 流向另一个。 HBase 使用 HDFSClient 端类与 HDFS NameNode 和 DataNode 进行通信。数据节点之间的通信问题记录在 HDFS 日志中,而不是 HBase 日志中。
HBase 使用两个不同的端口与 HDFS 通信。
- HBase 使用
ipc.Client接口和DataNode类与 DataNodes 通信。对它们的引用将出现在 HBase 日志中。这些通信通道均使用不同的端口(默认情况下为 50010 和 50020)。通过dfs.datanode.address和dfs.datanode.ipc.address参数在 HDFS 配置中配置了端口。
- HBase 使用
错误可能会记录在 HBase 和/或 HDFS 中。
- 对 HBase 中的 HDFS 问题进行故障排除时,请在两个地方检查日志中是否有错误。
HDFS 需要一段时间才能将节点标记为已死。您可以配置 HDFS 以避免使用陈旧的 DataNode。
- 默认情况下,HDFS 不会在 630 秒内无法访问节点之前将其标记为死节点。在 Hadoop 1.1 和 Hadoop 2.x 中,可以通过启用对过时的 DataNode 的检查来缓解此问题,尽管默认情况下会禁用此检查。您可以通过
dfs.namenode.avoid.read.stale.datanode和dfs.namenode.avoid.write.stale.datanode settings分别启用读写检查。过时的 DataNode 是dfs.namenode.stale.datanode.interval之前无法访问的 DataNode(默认为 30 秒)。避免使用过时的数据节点,并将其标记为读取或写入操作的最后一个可能的目标。有关配置的详细信息,请参阅 HDFS 文档。
- 默认情况下,HDFS 不会在 630 秒内无法访问节点之前将其标记为死节点。在 Hadoop 1.1 和 Hadoop 2.x 中,可以通过启用对过时的 DataNode 的检查来缓解此问题,尽管默认情况下会禁用此检查。您可以通过
HDFS 重试和超时的设置对于 HBase 非常重要。
- 您可以配置各种重试和超时设置。请始终参考 HDFS 文档以获取最新建议和默认值。这里列出了一些对 HBase 重要的设置。从 Hadoop 2.3 开始,默认值是最新的。查看 Hadoop 文档以获取最新值和建议。
HBase Balancer 和 HDFS Balancer 不兼容
- HDFS 平衡器尝试在数据节点之间平均分配 HDFS 块。 HBase 依靠压缩来在区域分裂或发生故障后恢复局部性。这两种类型的平衡不能很好地协同工作。
过去,普遍接受的建议是关闭 HDFS 负载平衡器并依靠 HBase 平衡器,因为 HDFS 平衡器会降低本地性。如果您的 HDFS 版本低于 2.7.1,则此建议仍然有效。
HDFS-6133通过在 HDFS 服务配置中将dfs.datanode.block-pinning.enabled属性设置为true,可以从 HDFS 负载平衡器中排除首选节点(固定)块。
通过将 HBase 平衡器类(conf:hbase.master.loadbalancer.class)切换为org.apache.hadoop.hbase.favored.FavoredNodeLoadBalancer(已记录here),可以使 HBase 使用 HDFS 首选节点功能。
Note
HDFS-6133 在 HDFS 2.7.0 和更高版本中可用,但是 HBase 不支持在 HDFS 2.7.0 上运行,因此必须将 HDFS 2.7.1 或更高版本与 HBase 一起使用。
Connection Timeouts
连接超时发生在 Client 端(HBASE)和 HDFS DataNode 之间。它们可能在构建连接,尝试读取或尝试写入时发生。以下两个设置结合使用,会影响 DFSClient 和 DataNode 之间的连接,ipc.cClient 和 DataNode 之间的连接以及两个 DataNode 之间的通信。
dfs.client.socket-timeout(默认值:60000)- 构建连接或读取时 Client 端连接超时之前的时间。该值以毫秒表示,因此默认值为 60 秒。
dfs.datanode.socket.write.timeout(默认值:480000)- 写操作超时之前的时间。默认值为 8 分钟,以毫秒为单位。
典型错误日志
在日志中经常会看到以下类型的错误。
INFO HDFS.DFSClient: Failed to connect to /xxx50010, add to deadNodes and continue java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=/region-server-1:50010] ::块的所有 DataNode 均已失效,无法恢复。这是导致此错误的事件 Sequences:
INFO org.apache.hadoop.HDFS.DFSClient: Exception in createBlockOutputStream java.net.SocketTimeoutException: 69000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=/ xxx:50010] ::这种错误表示写问题。在这种情况下,主服务器要拆分日志。它没有本地 DataNodes,因此它尝试连接到远程 DataNode,但是该 DataNode 已死。
128.运行单元测试或集成测试
128.1. 运行测试时 MiniDFSCluster 的运行时异常
如果您看到类似以下的内容
...
java.lang.NullPointerException: null
at org.apache.hadoop.hdfs.MiniDFSCluster.startDataNodes
at org.apache.hadoop.hdfs.MiniDFSCluster.<init>
at org.apache.hadoop.hbase.MiniHBaseCluster.<init>
at org.apache.hadoop.hbase.HBaseTestingUtility.startMiniDFSCluster
at org.apache.hadoop.hbase.HBaseTestingUtility.startMiniCluster
...
or
...
java.io.IOException: Shutting down
at org.apache.hadoop.hbase.MiniHBaseCluster.init
at org.apache.hadoop.hbase.MiniHBaseCluster.<init>
at org.apache.hadoop.hbase.MiniHBaseCluster.<init>
at org.apache.hadoop.hbase.HBaseTestingUtility.startMiniHBaseCluster
at org.apache.hadoop.hbase.HBaseTestingUtility.startMiniCluster
...
...然后在启动测试之前尝试发出命令 umask 022.这是HDFS-2556的解决方法
129.个案研究
有关性能和故障排除案例研究,请参阅Apache HBase 案例研究。
130.密码功能
130.1. sun.security.pkcs11.wrapper.PKCS11Exception:CKR_ARGUMENTS_BAD
此问题表现为最终由以下原因引起的异常:
Caused by: sun.security.pkcs11.wrapper.PKCS11Exception: CKR_ARGUMENTS_BAD
at sun.security.pkcs11.wrapper.PKCS11.C_DecryptUpdate(Native Method)
at sun.security.pkcs11.P11Cipher.implDoFinal(P11Cipher.java:795)
此问题似乎影响某些 Linux 供应商提供的某些版本的 OpenJDK 7. NSS 被配置为默认提供程序。如果主机具有 x86_64 体系结构,则取决于供应商软件包是否包含缺陷,NSS 提供程序将无法正常运行。
要解决此问题,请找到 JRE 主目录并编辑文件* lib/security/java.security *。编辑文件以 Comments 掉该行:
security.provider.1=sun.security.pkcs11.SunPKCS11 ${java.home}/lib/security/nss.cfg
然后相应地重新编号其余的提供程序。
131.特定于 os 的问题
131.1. 页面分配失败
Note
已知此问题会影响 CentOS 6.2 以及可能的 CentOS 6.5. https://bugzilla.redhat.com/show_bug.cgi?id=770545表示,它可能还会影响某些版本的 Red Hat Enterprise Linux。
一些用户报告看到以下错误:
kernel: java: page allocation failure. order:4, mode:0x20
据报道,提高min_free_kbytes的值可解决此问题。此参数设置为系统上 RAM 量的百分比,并在http://www.centos.org/docs/5/html/5.1/Deployment_Guide/s3-proc-sys-vm.html处进行了详细说明。
要查找系统上的当前值,请运行以下命令:
[user@host]# cat /proc/sys/vm/min_free_kbytes
接下来,提高价值。尝试将值翻倍,然后翻两番。请注意,将该值设置得太低或太高可能会对您的系统产生不利影响。有关具体建议,请咨询您的 os 供应商。
使用以下命令修改min_free_kbytes的值,用您的预期值替换*<value> *:
[user@host]# echo <value> > /proc/sys/vm/min_free_kbytes
132. JDK 问题
132.1. NoSuchMethodError:java.util.concurrent.ConcurrentHashMap.keySet
如果您在日志中看到此信息:
Caused by: java.lang.NoSuchMethodError: java.util.concurrent.ConcurrentHashMap.keySet()Ljava/util/concurrent/ConcurrentHashMap$KeySetView;
at org.apache.hadoop.hbase.master.ServerManager.findServerWithSameHostnamePortWithLock(ServerManager.java:393)
at org.apache.hadoop.hbase.master.ServerManager.checkAndRecordNewServer(ServerManager.java:307)
at org.apache.hadoop.hbase.master.ServerManager.regionServerStartup(ServerManager.java:244)
at org.apache.hadoop.hbase.master.MasterRpcServices.regionServerStartup(MasterRpcServices.java:304)
at org.apache.hadoop.hbase.protobuf.generated.RegionServerStatusProtos$RegionServerStatusService$2.callBlockingMethod(RegionServerStatusProtos.java:7910)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2020)
... 4 more
然后检查是否使用 jdk8 编译并尝试在 jdk7 上运行它。如果是这样,这将行不通。在 jdk8 上运行或与 jdk7 重新编译。参见如果在 JRE 7 上运行,则涉及 ConcurrentHashMap.keySet 的 HBASE-10607 JDK8 NoSuchMethodError。
Apache HBase 案例研究
133. Overview
本章将描述各种性能和故障排除案例研究,这些案例研究可为诊断 Apache HBase 群集问题提供有用的蓝图。
有关性能和故障排除的更多信息,请参阅Apache HBase 性能调优和故障排除和调试 Apache HBase。
134.架构设计
在此处查看架构设计案例研究:模式设计案例研究
135. Performance/Troubleshooting
135.1. 案例研究 1(单个节点上的性能问题)
135.1.1. Scenario
在计划的重新引导后,一个数据节点开始表现出异常行为。常规 MapReduce 作业针对 HBase 表运行,而 HBase 表通常在五六分钟内完成,开始需要 30 或 40 分钟才能完成。始终发现这些作业正在 awaitMap,从而减少了分配给有问题的数据节点的任务(例如,慢速 Map 任务都具有相同的 Importing 分割)。在分布式副本期间,当延迟节点严重拖延副本时,情况到了极点。
135.1.2. Hardware
Datanodes:
两个 12 核处理器
六个企业 SATA 磁盘
24 GB 的 RAM
两个绑定的千兆网卡
Network:
10 千兆架顶式交换机
20 机架之间的千兆绑定互连。
135.1.3. Hypotheses
HBase“热点”区域
我们假设我们正在经历一个熟悉的痛点:HBase 表中的“热点”区域,其中不均匀的键空间分布可以将大量请求集中到单个 HBase 区域,从而轰炸 RegionServer 进程并导致响应缓慢时间。检查 HBase 主站状态页面后,发现发往故障节点的 HBase 请求数量几乎为零。此外,对 HBase 日志的检查显示没有正在进行的区域划分,压实或其他区域转换。这有效地排除了“热点”作为观察到的缓慢的根本原因。
具有 nonlocal 数据的 HBase 区域
我们的下一个假设是,MapReduce 任务之一是从 HBase 请求非 DataNode 本地的数据,从而迫使 HDFS 通过网络从其他服务器请求数据块。对 DataNode 日志的检查表明,通过网络请求的块很少,这表明已正确分配了 HBase 区域,并且大多数必要数据位于该节点上。这排除了 nonlocal 数据导致速度降低的可能性。
由于交换或硬盘过度工作或出现故障,导致 I/Oawait 过多
在确定 Hadoop 和 HBase 不太可能成为罪魁祸首之后,我们着手对 DataNode 的硬件进行故障排除。根据设计,Java 将定期扫描其整个内存空间以进行垃圾回收。如果系统内存使用过多,则 Linux 内核可能会进入恶性循环,用尽所有资源,在 Java 尝试运行垃圾回收时将 Java 堆从磁盘来回交换到 RAM。此外,发生故障的硬盘通常会在放弃并返回错误之前重试多次读取和/或写入。当正在运行的进程 await 读取和写入完成时,这可能表现为高 iowait。最后,接近其性能范围上限的磁盘将开始引起 iowait,因为它通知内核它不能再接受任何数据,并且内核将传入的数据排队到内存中的脏写池中。但是,使用vmstat(1)和free(1),我们可以看到没有使用任何交换,并且磁盘 IO 的数量仅为每秒几千字节。
由于处理器使用率较高而导致速度变慢
接下来,我们检查以查看系统是否仅由于非常高的计算负荷而运行缓慢。 top(1)表示系统负载高于正常水平,但是vmstat(1)和mpstat(1)表示用于实际计算的处理器数量较低。
网络饱和度(获胜者)
由于磁盘和处理器均未得到充分利用,因此我们 continue 介绍网络接口的性能。 DataNode 具有两个千兆位以太网适配器,它们被绑定以形成一个主备接口。 ifconfig(8)显示了一些异常异常,即接口错误,超限,成帧错误。尽管并非闻所未闻,但这些错误在现代硬件上却极为罕见,它应该按以下方式运行:
$ /sbin/ifconfig bond0
bond0 Link encap:Ethernet HWaddr 00:00:00:00:00:00
inet addr:10.x.x.x Bcast:10.x.x.255 Mask:255.255.255.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:2990700159 errors:12 dropped:0 overruns:1 frame:6 <--- Look Here! Errors!
TX packets:3443518196 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2416328868676 (2.4 TB) TX bytes:3464991094001 (3.4 TB)
这些错误立即使我们怀疑一个或多个以太网接口可能协商了错误的线速。通过从外部主机运行 ICMP ping 并观察到往返时间超过 700ms,以及在绑定接口的成员上运行ethtool(8)并发现活动接口以全双工 100Mbs /的速度运行,可以确认这一点。 。
$ sudo ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Link partner advertised link modes: Not reported
Link partner advertised pause frame use: No
Link partner advertised auto-negotiation: No
Speed: 100Mb/s <--- Look Here! Should say 1000Mb/s!
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: Unknown
Supports Wake-on: umbg
Wake-on: g
Current message level: 0x00000003 (3)
Link detected: yes
在正常操作中,ICMP ping 往返时间应为 20ms 左右,并且接口速度和双工应分别为“ 1000MB/s”和“ Full”。
135.1.4. Resolution
确定活动的以太网适配器的速度不正确后,我们使用ifenslave(8)命令将备用接口设置为活动接口,从而立即提高了 MapReduce 性能,并使网络吞吐量提高了 10 倍:
在下次访问数据中心时,我们确定线速问题最终是由不良的网络电缆引起的,已将其更换。
135.2. 案例研究 2(2012 年性能研究)
自我描述的“我们不确定是什么问题,但似乎很慢”问题的调查结果。 http://gbif.blogspot.com/2012/03/hbase-performance-evaluation-continued.html
135.3. 案例研究 3(2010 年性能研究)
从 2010 年开始的总体集群性能调查结果。尽管此研究基于旧版本的代码库,但在方法上,此编写仍然非常有用。 http://hstack.org/hbase-performance-testing/
135.4. 案例研究 4(最大传输线程配置)
配置max.transfer.threads(以前称为xcievers)并从配置错误中诊断错误的案例研究。 http://www.larsgeorge.com/2012/03/hadoop-hbase-and-xceivers.html
另请参见dfs.datanode.max.transfer.threads。
Apache HBase 操作 Management
本章将介绍正在运行的 Apache HBase 集群所需的操作工具和实践。操作的主题与故障排除和调试 Apache HBase,Apache HBase 性能调优和Apache HBase 配置的主题相关,但其本身是一个独特的主题。
136. HBase 工具和 Util
HBase 提供了几种用于 Management,分析和调试群集的工具。尽管* dev-support/目录中提供了一些工具,但是大多数这些工具的入口点都是 bin/hbase *命令。
要查看* bin/hbase *命令的用法说明,请在不使用参数或使用-h参数的情况下运行它。这些是 HBase 0.98.x 的使用说明。某些命令(例如version,pe,ltt,clean)在以前的版本中不可用。
$ bin/hbase
Usage: hbase [<options>] <command> [<args>]
Options:
--config DIR Configuration direction to use. Default: ./conf
--hosts HOSTS Override the list in 'regionservers' file
--auth-as-server Authenticate to ZooKeeper using servers configuration
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the HBase 'fsck' tool. Defaults read-only hbck1.
Pass '-j /path/to/HBCK2.jar' to run hbase-2.x HBCK2.
snapshot Tool for managing snapshots
wal Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a ZooKeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
canary Run the Canary tool
version Print the version
backup Backup tables for recovery
restore Restore tables from existing backup image
regionsplitter Run RegionSplitter tool
rowcounter Run RowCounter tool
cellcounter Run CellCounter tool
CLASSNAME Run the class named CLASSNAME
下面的一些工具和 Util 是 Java 类,它们直接传递给* bin/hbase *命令,如使用说明的最后一行所述。其他字符,例如hbase shell(Apache HBase Shell),hbase upgrade(Upgrading)和hbase thrift(节俭 API 和过滤器语言),在本指南的其他地方介绍。
136.1. Canary
Canary 工具可以帮助用户“ canary 测试” HBase 群集状态。默认的“区域模式”从每个区域的每个列族中获取一行。在“区域服务器模式”下,Canary 工具将从集群的每个区域服务器上的随机区域中获取一行。在“动物园 Management 员模式”下,金丝雀会读取动物园 Management 员合奏中每个成员的根 znode。
要查看用法,请传递-help参数(如果不传递任何参数,Canary 工具将在默认区域“模式”下开始执行,并从集群中的每个区域获取一行)。
2018-10-16 13:11:27,037 INFO [main] tool.Canary: Execution thread count=16
Usage: canary [OPTIONS] [<TABLE1> [<TABLE2]...] | [<REGIONSERVER1> [<REGIONSERVER2]..]
Where [OPTIONS] are:
-h,-help show this help and exit.
-regionserver set 'regionserver mode'; gets row from random region on server
-allRegions get from ALL regions when 'regionserver mode', not just random one.
-zookeeper set 'zookeeper mode'; grab zookeeper.znode.parent on each ensemble member
-daemon continuous check at defined intervals.
-interval <N> interval between checks in seconds
-e consider table/regionserver argument as regular expression
-f <B> exit on first error; default=true
-failureAsError treat read/write failure as error
-t <N> timeout for canary-test run; default=600000ms
-writeSniffing enable write sniffing
-writeTable the table used for write sniffing; default=hbase:canary
-writeTableTimeout <N> timeout for writeTable; default=600000ms
-readTableTimeouts <tableName>=<read timeout>,<tableName>=<read timeout>,...
comma-separated list of table read timeouts (no spaces);
logs 'ERROR' if takes longer. default=600000ms
-permittedZookeeperFailures <N> Ignore first N failures attempting to
connect to individual zookeeper nodes in ensemble
-D<configProperty>=<value> to assign or override configuration params
-Dhbase.canary.read.raw.enabled=<true/false> Set to enable/disable raw scan; default=false
Canary runs in one of three modes: region (default), regionserver, or zookeeper.
To sniff/probe all regions, pass no arguments.
To sniff/probe all regions of a table, pass tablename.
To sniff/probe regionservers, pass -regionserver, etc.
See http://hbase.apache.org/book.html#_canary for Canary documentation.
Note
Sink类是使用hbase.canary.sink.class配置属性实例化的。
该工具将向用户返回非零错误代码,以便与其他监视工具(例如 Nagios)协作。错误代码定义为:
private static final int USAGE_EXIT_CODE = 1;
private static final int INIT_ERROR_EXIT_CODE = 2;
private static final int TIMEOUT_ERROR_EXIT_CODE = 3;
private static final int ERROR_EXIT_CODE = 4;
private static final int FAILURE_EXIT_CODE = 5;
这是基于以下给定情况的一些示例:给定两个名为 test-01 和 test-02 的 Table 对象,每个对象分别具有两个列家族 cf1 和 cf2,部署在 3 个 RegionServers 上。请参阅下表。
| RegionServer | test-01 | test-02 |
|---|---|---|
| rs1 | r1 | r2 |
| rs2 | r2 | |
| rs3 | r2 | r1 |
以下是基于先前给定情况的一些示例输出。
136.1.1. 对每个表的每个区域的每个列族(存储)进行金丝雀测试
$ ${HBASE_HOME}/bin/hbase canary
3/12/09 03:26:32 INFO tool.Canary: read from region test-01,,1386230156732.0e3c7d77ffb6361ea1b996ac1042ca9a. column family cf1 in 2ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-01,,1386230156732.0e3c7d77ffb6361ea1b996ac1042ca9a. column family cf2 in 2ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-01,0004883,1386230156732.87b55e03dfeade00f441125159f8ca87. column family cf1 in 4ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-01,0004883,1386230156732.87b55e03dfeade00f441125159f8ca87. column family cf2 in 1ms
...
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,,1386559511167.aa2951a86289281beee480f107bb36ee. column family cf1 in 5ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,,1386559511167.aa2951a86289281beee480f107bb36ee. column family cf2 in 3ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,0004883,1386559511167.cbda32d5e2e276520712d84eaaa29d84. column family cf1 in 31ms
13/12/09 03:26:32 INFO tool.Canary: read from region test-02,0004883,1386559511167.cbda32d5e2e276520712d84eaaa29d84. column family cf2 in 8ms
因此,您可以看到,表 test-01 具有两个区域和两个列族,因此处于默认“区域模式”的 Canary 工具将从 4 个(2 个区域* 2 个存储)不同的存储中选择 4 个小数据。这是默认行为。
136.1.2. 对特定表中每个区域的每个列族(存储)进行 Canary 测试
您还可以通过传递表名称来测试一个或多个特定表。
$ ${HBASE_HOME}/bin/hbase canary test-01 test-02
136.1.3. 具有 RegionServer 粒度的 Canary 测试
在“ regionserver 模式”下,Canary 工具将从每个 RegionServer 中选取一小段数据(在“ regionserver 模式”下,您也可以将一个或多个 RegionServer 名称作为参数传递给 canary 测试)。
$ ${HBASE_HOME}/bin/hbase canary -regionserver
13/12/09 06:05:17 INFO tool.Canary: Read from table:test-01 on region server:rs2 in 72ms
13/12/09 06:05:17 INFO tool.Canary: Read from table:test-02 on region server:rs3 in 34ms
13/12/09 06:05:17 INFO tool.Canary: Read from table:test-01 on region server:rs1 in 56ms
136.1.4. 具有正则表达式模式的 Canary 测试
在“区域模式”下,可以为表名传递正则表达式;在“区域服务器模式”下,可以为服务器名传递正则表达式。下面将测试表 test-01 和 test-02.
$ ${HBASE_HOME}/bin/hbase canary -e test-0[1-2]
136.1.5. 以“守护程序”运行金丝雀测试
以通过选项-interval定义的间隔重复运行(默认值为 60 秒)。如果发生任何错误,该守护程序将自行停止并返回非零错误代码。要使守护程序始终在错误中运行,请传递-f 标志并将其值设置为 false(请参见上面的用法)。
$ ${HBASE_HOME}/bin/hbase canary -daemon
要以 5 秒的间隔重复运行并且不因错误而停止,请执行以下操作。
$ ${HBASE_HOME}/bin/hbase canary -daemon -interval 5 -f false
136.1.6. 如果金丝雀测试卡住,则强制超时
在某些情况下,请求被卡住,并且没有响应发送回 Client 端。主机尚未注意到的 RegionServer 出现故障可能会发生这种情况。因此,我们提供了一个超时选项来终止 Canary 测试并返回非零错误代码。下面将超时值设置为 60 秒(默认值为 600 秒)。
$ ${HBASE_HOME}/bin/hbase canary -t 60000
136.1.7. 在金丝雀中启用写嗅探
默认情况下,canary 工具仅检查读取操作。要启用写嗅探,可以将-writeSniffing选项设置为运行 canary。启用写嗅探后,canary 工具将创建一个 hbase 表,并确保该表的区域已分发到所有区域服务器。在每个嗅探周期中,金丝雀都会尝试将数据放入这些区域,以检查每个区域服务器的写入可用性。
$ ${HBASE_HOME}/bin/hbase canary -writeSniffing
默认的写表是hbase:canary,可以用选项-writeTable指定。
$ ${HBASE_HOME}/bin/hbase canary -writeSniffing -writeTable ns:canary
每个 put 的默认值大小为 10 个字节。您可以通过配置键hbase.canary.write.value.size进行设置。
136.1.8. 将读取/写入失败视为错误
默认情况下,canary 工具仅记录读取失败信息,例如由于 RetriesExhaustedException 等。并且-将返回“正常”退出代码。要将读取/写入失败视为错误,可以使用-treatFailureAsError选项运行 canary。启用后,读/写失败将导致错误退出代码。
$ ${HBASE_HOME}/bin/hbase canary -treatFailureAsError
136.1.9. 在启用 Kerberos 的群集中运行 Canary
要在启用 Kerberos 的群集中运行 Canary,请在* hbase-site.xml *中配置以下两个属性:
hbase.client.keytab.filehbase.client.kerberos.principal
当 Canary 在守护程序模式下运行时,Kerberos 凭据每 30 秒刷新一次。
要为 Client 端配置 DNS 接口,请在* hbase-site.xml *中配置以下可选属性。
hbase.client.dns.interfacehbase.client.dns.nameserver
例子 36.启用 Kerberos 的集群中的金丝雀
本示例显示具有有效值的每个属性。
<property>
<name>hbase.client.kerberos.principal</name>
<value>hbase/_HOST@YOUR-REALM.COM</value>
</property>
<property>
<name>hbase.client.keytab.file</name>
<value>/etc/hbase/conf/keytab.krb5</value>
</property>
<!-- optional params -->
<property>
<name>hbase.client.dns.interface</name>
<value>default</value>
</property>
<property>
<name>hbase.client.dns.nameserver</name>
<value>default</value>
</property>
136.2. RegionSplitter
usage: bin/hbase regionsplitter <TABLE> <SPLITALGORITHM>
SPLITALGORITHM is the java class name of a class implementing
SplitAlgorithm, or one of the special strings
HexStringSplit or DecimalStringSplit or
UniformSplit, which are built-in split algorithms.
HexStringSplit treats keys as hexadecimal ASCII, and
DecimalStringSplit treats keys as decimal ASCII, and
UniformSplit treats keys as arbitrary bytes.
-c <region count> Create a new table with a pre-split number of
regions
-D <property=value> Override HBase Configuration Settings
-f <family:family:...> Column Families to create with new table.
Required with -c
--firstrow <arg> First Row in Table for Split Algorithm
-h Print this usage help
--lastrow <arg> Last Row in Table for Split Algorithm
-o <count> Max outstanding splits that have unfinished
major compactions
-r Perform a rolling split of an existing region
--risky Skip verification steps to complete
quickly. STRONGLY DISCOURAGED for production
systems.
有关更多详细信息,请参见手动区域分割。
136.3. 健康检查
您可以将 HBase 配置为定期运行脚本,如果脚本失败 N 次(可配置),请退出服务器。有关配置和详细信息,请参见* HBASE-7351 定期运行状况检查脚本*。
136.4. Driver
几个常用的 Util 作为Driver类提供,并由* bin/hbase 命令执行。这些 Util 代表在群集上运行的 MapReduce 作业。它们以以下方式运行,将 UtilityName *替换为您要运行的 Util。该命令假定您已将环境变量HBASE_HOME设置为服务器上 HBase 的解压缩目录。
${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.mapreduce.UtilityName
可以使用以下 Util:
LoadIncrementalHFiles- 完成批量数据加载。
CopyTable- 将表从本地群集导出到对等群集。
Export- 将表数据写入 HDFS。
Import- 导入先前的
Export操作写入的数据。
- 导入先前的
ImportTsv- 以 TSV 格式导入数据。
RowCounter- 计算 HBase 表中的行。
CellCounter- 对 HBase 表中的单元格进行计数。
replication.VerifyReplication- 比较来自两个不同群集中表的数据。警告:自从更改时间戳以来,它不适用于增量列值的单元格。请注意,此命令与其他命令位于不同的软件包中。
RowCounter和CellCounter除外的每个命令都接受一个--help参数来打印使用说明。
136.5. HBase 的 hbck
hbase-1.x 附带的hbck工具已在 hbase-2.x 中设为只读。由于 hbase 内部结构已更改,因此无法修复 hbase-2.x 群集。由于它不了解 hbase-2.x 操作,因此也不应该信任其在只读模式下的评估。
下一节介绍的新工具HBase HBCK2代替了hbck。
136.6. HBase 的 HBCK2
HBCK2是 hbase-1.x 修复工具(A.K.A hbck1)HBase hbck的后继产品。用它代替hbck1对 hbase-2.x 安装进行修复。
HBCK2不作为 hbase 的一部分提供。可以在Apache HBase HBCK2 工具处找到伴随hbase-operator-tools存储库的子项目。 HBCK2已从 hbase 中移出,因此它可以以与 hbase 核心不同的节奏进行演变。
有关HBCK2与hbck1的不同之处以及如何构建和使用它的信息,请参见\ [https://github.com/apache/hbase-operator-tools/tree/master/hbase-hbck2](HBCK2)主页。
构建完成后,您可以按以下方式运行HBCK2:
$ hbase hbck -j /path/to/HBCK2.jar
这将生成HBCK2用法,描述命令和选项。
136.7. HFile 工具
See HFile Tool.
136.8. WAL 工具
136.8.1. FSHLog 工具
FSHLog上的主要方法提供了手动拆分和转储功能。将 WAL 或拆分的乘积(* recovered.edits *的内容)传递给它。目录。
通过执行以下操作,可以获取 WAL 文件内容的文本转储:
$ ./bin/hbase org.apache.hadoop.hbase.regionserver.wal.FSHLog --dump hdfs://example.org:8020/hbase/WALs/example.org,60020,1283516293161/10.10.21.10%3A60020.1283973724012
如果文件有任何问题,返回码将为非零值,因此您可以通过将STDOUT重定向到/dev/null并测试程序返回值来测试文件的完整性。
同样,您可以执行以下操作来强制拆分日志文件目录:
$ ./bin/hbase org.apache.hadoop.hbase.regionserver.wal.FSHLog --split hdfs://example.org:8020/hbase/WALs/example.org,60020,1283516293161/
WALPrettyPrinter
WALPrettyPrinter是具有可配置选项的工具,用于打印 WAL 的内容。您可以使用“ wal”命令通过 HBase cli 调用它。
$ ./bin/hbase wal hdfs://example.org:8020/hbase/WALs/example.org,60020,1283516293161/10.10.21.10%3A60020.1283973724012
WAL Printing in older versions of HBase
在 2.0 版之前,WALPrettyPrinter被称为HLogPrettyPrinter,以 HBase 的预写日志的内部名称命名。在那些版本中,您可以使用与上述相同的配置来打印 WAL 的内容,但使用'hlog'命令。
$ ./bin/hbase hlog hdfs://example.org:8020/hbase/.logs/example.org,60020,1283516293161/10.10.21.10%3A60020.1283973724012
136.9. 压缩工具
See compression.test.
136.10. CopyTable
CopyTable 是一种 Util,可以将表的部分或全部复制到同一群集或另一个群集中。目标表必须首先存在。用法如下:
$ ./bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
/bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename>
Options:
rs.class hbase.regionserver.class of the peer cluster,
specify if different from current cluster
rs.impl hbase.regionserver.impl of the peer cluster,
startrow the start row
stoprow the stop row
starttime beginning of the time range (unixtime in millis)
without endtime means from starttime to forever
endtime end of the time range. Ignored if no starttime specified.
versions number of cell versions to copy
new.name new table's name
peer.adr Address of the peer cluster given in the format
hbase.zookeeer.quorum:hbase.zookeeper.client.port:zookeeper.znode.parent
families comma-separated list of families to copy
To copy from cf1 to cf2, give sourceCfName:destCfName.
To keep the same name, just give "cfName"
all.cells also copy delete markers and deleted cells
Args:
tablename Name of the table to copy
Examples:
To copy 'TestTable' to a cluster that uses replication for a 1 hour window:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1265875194289 --endtime=1265878794289 --peer.adr=server1,server2,server3:2181:/hbase --families=myOldCf:myNewCf,cf2,cf3 TestTable
For performance consider the following general options:
It is recommended that you set the following to >=100. A higher value uses more memory but
decreases the round trip time to the server and may increase performance.
-Dhbase.client.scanner.caching=100
The following should always be set to false, to prevent writing data twice, which may produce
inaccurate results.
-Dmapred.map.tasks.speculative.execution=false
Scanner Caching
通过作业配置中的hbase.client.scanner.caching配置 Importing 扫描的缓存。
Versions
默认情况下,除非在命令中明确指定--versions=n,否则 CopyTableUtil 仅复制行单元格的最新版本。
有关CopyTable的更多信息,请参见 Jonathan Hsieh 的使用 CopyTable 的在线 HBase 备份博客文章。
136.11. Export
导出是一种 Util,它将表的内容转储到序列文件中的 HDFS 中。可以通过协处理器端点或 MapReduce 运行导出。通过以下方式调用:
mapreduce-based Export
$ bin/hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
endpoint-based Export
Note
通过将org.apache.hadoop.hbase.coprocessor.Export添加到hbase.coprocessor.region.classes确保启用了导出协处理器。
$ bin/hbase org.apache.hadoop.hbase.coprocessor.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
outputdir 是 HDFS 目录,在导出之前不存在。完成后,调用 Export 命令的用户将拥有导出的文件。
基于端点的导出和基于 Mapreduce 的导出的比较
| Endpoint-based Export | Mapreduce-based Export | |
|---|---|---|
| HBase 版本要求 | 2.0+ | 0.2.1+ |
| Maven dependency | hbase-endpoint | hbase-mapreduce(2.0),hbase-server(2.0 之前的版本) |
| 转储前的要求 | 挂载端点,导出到目标表 | 部署 MapReduce 框架 |
| Read latency | 低,直接从区域读取数据 | 常规的传统 RPC 扫描 |
| Read Scalability | 取决于地区数量 | 取决于 Map 器的数量(请参阅 TableInputFormatBase#getSplits) |
| Timeout | 操作超时。由 hbase.client.operation.timeout 配置 | 扫描超时。由 hbase.client.scanner.timeout.period 配置 |
| Permission requirement | READ, EXECUTE | READ |
| Fault tolerance | no | 取决于 MapReduce |
Note
要查看用法说明,请运行不带任何选项的命令。可用选项包括指定列系列和在导出过程中应用过滤器。
默认情况下,Export工具仅导出给定单元格的最新版本,而不管存储的版本数如何。要导出多个版本,请用所需数量的版本替换 ***** *。
注意:Importing 扫描的缓存是通过作业配置中的hbase.client.scanner.caching配置的。
136.12. Import
导入是一个 Util,它将加载已导出回 HBase 的数据。通过以下方式调用:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
Note
要查看用法说明,请运行不带任何选项的命令。
要在 0.96 或更高版本的群集中导入 0.94 导出的文件,需要在运行以下导入命令时设置系统属性“ hbase.import.version”:
$ bin/hbase -Dhbase.import.version=0.94 org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
136.13. ImportTsv
ImportTsv 是一个 Util,可以将 TSV 格式的数据加载到 HBase 中。它有两种不同的用法:通过 Puts 将 HDFS 中的 TSV 格式的数据从 Put 加载到 HBase,以及准备要通过completebulkload加载的 StoreFiles。
通过看跌期权加载数据(即非批量加载):
$ bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns=a,b,c <tablename> <hdfs-inputdir>
要生成用于批量加载的 StoreFiles:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns=a,b,c -Dimporttsv.bulk.output=hdfs://storefile-outputdir <tablename> <hdfs-data-inputdir>
这些生成的 StoreFile 可以通过completebulkload加载到 HBase 中。
136.13.1. ImportTsv 选项
在不带参数的情况下运行ImportTsv将显示简要的用法信息:
Usage: importtsv -Dimporttsv.columns=a,b,c <tablename> <inputdir>
Imports the given input directory of TSV data into the specified table.
The column names of the TSV data must be specified using the -Dimporttsv.columns
option. This option takes the form of comma-separated column names, where each
column name is either a simple column family, or a columnfamily:qualifier. The special
column name HBASE_ROW_KEY is used to designate that this column should be used
as the row key for each imported record. You must specify exactly one column
to be the row key, and you must specify a column name for every column that exists in the
input data.
By default importtsv will load data directly into HBase. To instead generate
HFiles of data to prepare for a bulk data load, pass the option:
-Dimporttsv.bulk.output=/path/for/output
Note: the target table will be created with default column family descriptors if it does not already exist.
Other options that may be specified with -D include:
-Dimporttsv.skip.bad.lines=false - fail if encountering an invalid line
'-Dimporttsv.separator=|' - eg separate on pipes instead of tabs
-Dimporttsv.timestamp=currentTimeAsLong - use the specified timestamp for the import
-Dimporttsv.mapper.class=my.Mapper - A user-defined Mapper to use instead of org.apache.hadoop.hbase.mapreduce.TsvImporterMapper
136.13.2. ImportTsv 示例
例如,假设我们正在将数据加载到名为“ datatsv”的表中,该表的列族名为“ d”,其中包含两列“ c1”和“ c2”。
假设存在一个 Importing 文件,如下所示:
row1 c1 c2
row2 c1 c2
row3 c1 c2
row4 c1 c2
row5 c1 c2
row6 c1 c2
row7 c1 c2
row8 c1 c2
row9 c1 c2
row10 c1 c2
为了使 ImportTsv 使用此 Importing 文件,命令行需要如下所示:
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,d:c1,d:c2 -Dimporttsv.bulk.output=hdfs://storefileoutput datatsv hdfs://inputfile
...,在此示例中,第一列是行键,这就是使用 HBASE_ROW_KEY 的原因。文件中的第二和第三列将分别导入为“ d:c1”和“ d:c2”。
136.13.3. ImportTsv 警告
如果您准备了很多数据以进行批量加载,请确保已适当地预先分割了目标 HBase 表。
136.13.4. 也可以看看
有关将 HFile 批量加载到 HBase 中的更多信息,请参见arch.bulk.load。
136.14. CompleteBulkLoad
completebulkloadUtil 会将生成的 StoreFiles 移动到 HBase 表中。该 Util 通常与importtsv的输出结合使用。
有两种方法可以使用显式类名和通过驱动程序来调用此 Util:
Explicit Classname
$ bin/hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles <hdfs://storefileoutput> <tablename>
Driver
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar completebulkload <hdfs://storefileoutput> <tablename>
136.14.1. CompleteBulkLoad 警告
通过 MapReduce 生成的数据通常是使用与正在运行的 HBase 进程不兼容的文件权限创建的。假设您在启用了权限的情况下运行 HDFS,则在运行 CompleteBulkLoad 之前需要更新这些权限。
有关将 HFile 批量加载到 HBase 中的更多信息,请参见arch.bulk.load。
136.15. WALPlayer
WALPlayer 是将 WAL 文件重播到 HBase 中的 Util。
可以为一组表或所有表重放 WAL,并且可以提供一个时间范围(以毫秒为单位)。 WAL 被过滤到这组表。可以选择将输出 Map 到另一组表。
WALPlayer 还可以生成 HFile,以供以后批量导入,在这种情况下,只能指定一个表,而不能指定 Map。
Invoke via:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.WALPlayer [options] <wal inputdir> <tables> [<tableMappings>]>
For example:
$ bin/hbase org.apache.hadoop.hbase.mapreduce.WALPlayer /backuplogdir oldTable1,oldTable2 newTable1,newTable2
默认情况下,WALPlayer 作为 mapreduce 作业运行。要不在群集上将 WALPlayer 作为 mapreduce 作业运行,请通过在命令行上添加标志-Dmapreduce.jobtracker.address=local强制 WALPlayer 在本地进程中全部运行。
136.15.1. WALPlayer 选项
在不带参数的情况下运行WALPlayer将显示简要的用法信息:
Usage: WALPlayer [options] <wal inputdir> <tables> [<tableMappings>]
Replay all WAL files into HBase.
<tables> is a comma separated list of tables.
If no tables ("") are specified, all tables are imported.
(Be careful, hbase:meta entries will be imported in this case.)
WAL entries can be mapped to new set of tables via <tableMappings>.
<tableMappings> is a comma separated list of target tables.
If specified, each table in <tables> must have a mapping.
By default WALPlayer will load data directly into HBase.
To generate HFiles for a bulk data load instead, pass the following option:
-Dwal.bulk.output=/path/for/output
(Only one table can be specified, and no mapping is allowed!)
Time range options:
-Dwal.start.time=[date|ms]
-Dwal.end.time=[date|ms]
(The start and the end date of timerange. The dates can be expressed
in milliseconds since epoch or in yyyy-MM-dd'T'HH:mm:ss.SS format.
E.g. 1234567890120 or 2009-02-13T23:32:30.12)
Other options:
-Dmapreduce.job.name=jobName
Use the specified mapreduce job name for the wal player
For performance also consider the following options:
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
136.16. RowCounter
RowCounter是对表的所有行进行计数的 mapreduce 作业。这是一个很好的 Util,可以用作完整性检查,以确保在担心元数据不一致时,HBase 可以读取表的所有块。它会在一个进程中全部运行 mapreduce,但是如果您有一个 MapReduce 集群可供利用,它将运行得更快。通过使用--starttime=[starttime]和--endtime=[endtime]标志可以限制要扫描的数据的时间范围。可以使用--range=[startKey],[endKey][;[startKey],[endKey]…]选项基于密钥来限制扫描的数据。
$ bin/hbase rowcounter [options] <tablename> [--starttime=<start> --endtime=<end>] [--range=[startKey],[endKey][;[startKey],[endKey]...]] [<column1> <column2>...]
RowCounter 每个单元格仅计数一个版本。
为了提高性能,请考虑使用-Dhbase.client.scanner.caching=100和-Dmapreduce.map.speculative=false选项。
136.17. CellCounter
HBase 提供了另一个名为CellCounter的诊断 mapreduce 作业。像 RowCounter 一样,它收集有关表的更多细粒度统计信息。 CellCounter 收集的统计数据更细粒度,包括:
表中的总行数。
所有行中 CF 的总数。
所有行的总限定词。
每个 CF 的总数。
每个预选赛的总数。
每个限定符的版本总数。
该程序允许您限制运行范围。提供行正则表达式或前缀以限制要分析的行。使用--starttime=<starttime>和--endtime=<endtime>标志指定扫描表的时间范围。
使用hbase.mapreduce.scan.column.family指定扫描单个列族。
$ bin/hbase cellcounter <tablename> <outputDir> [reportSeparator] [regex or prefix] [--starttime=<starttime> --endtime=<endtime>]
注意:就像 RowCounter 一样,Importing 扫描的缓存是通过作业配置中的hbase.client.scanner.caching配置的。
136.18. mlockall
可以选择将服务器固定在物理内存中,通过使服务器在启动时调用mlockall,从而使它们不太可能在超额 Order 的环境中换出。有关如何构建可选库并使其在启动时运行的信息,请参见HBASE-4391 添加了以 root 身份启动 RS 并调用 mlockall 的功能。
136.19. 离线压缩工具
请参阅CompactionTool的用法。像这样运行:
$ ./bin/hbase org.apache.hadoop.hbase.regionserver.CompactionTool
136.20. HBase 清洁
hbase clean命令从 ZooKeeper 和/或 HDFS 中清除 HBase 数据。适合用于测试。在没有使用说明选项的情况下运行它。 HBase 0.98 中引入了hbase clean命令。
$ bin/hbase clean
Usage: hbase clean (--cleanZk|--cleanHdfs|--cleanAll)
Options:
--cleanZk cleans hbase related data from zookeeper.
--cleanHdfs cleans hbase related data from hdfs.
--cleanAll cleans hbase related data from both zookeeper and hdfs.
136.21. HBase PE
hbase pe命令运行 PerformanceEvaluation 工具,该工具用于测试。
PerformanceEvaluation 工具接受许多不同的选项和命令。有关用法说明,请运行不带任何选项的命令。
PerformanceEvaluation 工具在最新的 HBase 版本中已获得许多更新,包括对名称空间的支持,对标签的支持,单元级别的 ACL 和可见性标签,对 RPC 调用的多 get 支持,增加的采样大小,在测试过程中可以随机休眠的选项以及在测试开始之前“预热”群集。
136.22. 基础库
hbase ltt命令运行用于测试的 LoadTestToolUtil。
您必须指定-init_only或-write,-update或-read中的至少一个。有关常规用法说明,请传递-h选项。
LoadTestTool 在最近的 HBase 版本中已获得许多更新,包括对名称空间的支持,对标签的支持,单元级别的 ACLS 和可见性标签,测试与安全性相关的功能,指定每个服务器的区域数的能力,对多获取 RPC 的测试呼叫以及与复制有关的测试。
136.23. 升级前验证器
从 HBase 1 升级到 HBase 2 之前,可以使用预升级验证程序工具检查群集中的已知不兼容性。
$ bin/hbase pre-upgrade command ...
136.23.1. 协处理器验证
HBase 长期支持协处理器,但是可以在主要版本之间更改协处理器 API。协处理器验证器尝试确定旧的协处理器是否仍与实际的 HBase 版本兼容。
$ bin/hbase pre-upgrade validate-cp [-jar ...] [-class ... | -table ... | -config]
Options:
-e Treat warnings as errors.
-jar <arg> Jar file/directory of the coprocessor.
-table <arg> Table coprocessor(s) to check.
-class <arg> Coprocessor class(es) to check.
-config Scan jar for observers.
协处理器类可以通过-class选项显式声明,也可以通过-config选项从 HBase 配置中获取。表级协处理器也可以通过-table选项进行检查。该工具在其 Classpath 上搜索协处理器,但是可以通过-jar选项对其进行扩展。可以使用多个-class测试多个类,使用多个-table选项测试多个表,以及使用多个-jar选项将多个 jar 添加到 Classpath。
该工具可以报告错误和警告。错误表示 HBase 无法加载协处理器,因为它与当前版本的 HBase 不兼容。警告表示可以加载协处理器,但是它们将无法按预期工作。如果提供了-e选项,则该工具也将因警告而失败。
请注意,此工具无法验证 jar 文件的各个方面,而只是进行一些静态检查。
For example:
$ bin/hbase pre-upgrade validate-cp -jar my-coprocessor.jar -class MyMasterObserver -class MyRegionObserver
它验证位于my-coprocessor.jar中的MyMasterObserver和MyRegionObserver类。
$ bin/hbase pre-upgrade validate-cp -table .*
它验证表名与.*正则表达式匹配的每个表级协处理器。
136.23.2. DataBlockEncoding 验证
HBase 2.0 从列族中删除了PREFIX_TREE数据块编码。有关更多信息,请检查前缀树编码已删除。要验证群集中没有任何列族使用不兼容的数据块编码,请运行以下命令。
$ bin/hbase pre-upgrade validate-dbe
此检查将验证所有列族并打印出所有不兼容的内容。例如:
2018-07-13 09:58:32,028 WARN [main] tool.DataBlockEncodingValidator: Incompatible DataBlockEncoding for table: t, cf: f, encoding: PREFIX_TREE
这意味着表t,列族f的数据块编码不兼容。要解决此问题,请在 HBase shell 中使用alter命令:
alter 't', { NAME => 'f', DATA_BLOCK_ENCODING => 'FAST_DIFF' }
还请验证 HFiles,这将在下一部分中进行描述。
136.23.3. HFile 内容验证
即使将数据块编码从PREFIX_TREE更改了,仍然可以使 HFile 包含以这种方式编码的数据。要验证 HFile 2 可以读取 HFile,请使用* HFile 内容验证器*。
$ bin/hbase pre-upgrade validate-hfile
该工具将记录损坏的 HFile 和有关根本原因的详细信息。如果问题与 PREFIX_TREE 编码有关,则必须在升级到 HBase 2 之前更改编码。
以下日志消息显示了不正确的 HFile 的示例。
2018-06-05 16:20:46,976 WARN [hfilevalidator-pool1-t3] hbck.HFileCorruptionChecker: Found corrupt HFile hdfs://example.com:8020/hbase/data/default/t/72ea7f7d625ee30f959897d1a3e2c350/prefix/7e6b3d73263c4851bf2b8590a9b3791e
org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file hdfs://example.com:8020/hbase/data/default/t/72ea7f7d625ee30f959897d1a3e2c350/prefix/7e6b3d73263c4851bf2b8590a9b3791e
...
Caused by: java.io.IOException: Invalid data block encoding type in file info: PREFIX_TREE
...
Caused by: java.lang.IllegalArgumentException: No enum constant org.apache.hadoop.hbase.io.encoding.DataBlockEncoding.PREFIX_TREE
...
2018-06-05 16:20:47,322 INFO [main] tool.HFileContentValidator: Corrupted file: hdfs://example.com:8020/hbase/data/default/t/72ea7f7d625ee30f959897d1a3e2c350/prefix/7e6b3d73263c4851bf2b8590a9b3791e
2018-06-05 16:20:47,383 INFO [main] tool.HFileContentValidator: Corrupted file: hdfs://example.com:8020/hbase/archive/data/default/t/56be41796340b757eb7fff1eb5e2a905/f/29c641ae91c34fc3bee881f45436b6d1
修复 PREFIX_TREE 错误
将数据块编码更改为受支持的编码后,可能会出现PREFIX_TREE错误。之所以会发生这种情况,是因为有些 HFile 仍使用PREFIX_TREE编码,或者仍然有一些快照。
要修复 HFile,请在表上进行重大压缩(根据日志消息,它为default:t):
major_compact 't'
HFiles 也可以从快照中引用。 HFile 位于archive/data下的情况就是这样。第一步是确定哪些快照引用了 HFile(根据日志,文件名是29c641ae91c34fc3bee881f45436b6d1):
for snapshot in $(hbase snapshotinfo -list-snapshots 2> /dev/null | tail -n -1 | cut -f 1 -d \|);
do
echo "checking snapshot named '${snapshot}'";
hbase snapshotinfo -snapshot "${snapshot}" -files 2> /dev/null | grep 29c641ae91c34fc3bee881f45436b6d1;
done
该 shell 脚本的输出为:
checking snapshot named 't_snap'
1.0 K t/56be41796340b757eb7fff1eb5e2a905/f/29c641ae91c34fc3bee881f45436b6d1 (archive)
这意味着t_snap快照引用了不兼容的 HFile。如果仍然需要快照,则必须使用 HBase shell 重新创建快照:
# creating a new namespace for the cleanup process
create_namespace 'pre_upgrade_cleanup'
# creating a new snapshot
clone_snapshot 't_snap', 'pre_upgrade_cleanup:t'
alter 'pre_upgrade_cleanup:t', { NAME => 'f', DATA_BLOCK_ENCODING => 'FAST_DIFF' }
major_compact 'pre_upgrade_cleanup:t'
# removing the invalid snapshot
delete_snapshot 't_snap'
# creating a new snapshot
snapshot 'pre_upgrade_cleanup:t', 't_snap'
# removing temporary table
disable 'pre_upgrade_cleanup:t'
drop 'pre_upgrade_cleanup:t'
drop_namespace 'pre_upgrade_cleanup'
有关更多信息,请参阅HBASE-20649。
136.24. 数据块编码工具
使用不同的数据块编码器测试各种压缩算法,以对现有 HFile 进行密钥压缩。对于测试,调试和基准测试很有用。
您必须指定-f,它是 HFile 的完整路径。
结果显示了压缩/解压缩和编码/解码的性能(MB/s),以及 HFile 上的数据节省。
$ bin/hbase org.apache.hadoop.hbase.regionserver.DataBlockEncodingTool
Usages: hbase org.apache.hadoop.hbase.regionserver.DataBlockEncodingTool
Options:
-f HFile to analyse (REQUIRED)
-n Maximum number of key/value pairs to process in a single benchmark run.
-b Whether to run a benchmark to measure read throughput.
-c If this is specified, no correctness testing will be done.
-a What kind of compression algorithm use for test. Default value: GZ.
-t Number of times to run each benchmark. Default value: 12.
-omit Number of first runs of every benchmark to omit from statistics. Default value: 2.
137.区域 Management
137.1. 大压实
可以通过 HBase shell 或Admin.majorCompact请求大压缩。
注意:大型压缩不进行区域合并。有关压缩的更多信息,请参见compaction。
137.2. Merge
合并是一种 Util,可以合并同一表中的相邻区域(请参见 org.apache.hadoop.hbase.util.Merge)。
$ bin/hbase org.apache.hadoop.hbase.util.Merge <tablename> <region1> <region2>
如果您觉得您有太多的地区并想要合并它们,Merge 是您需要的 Util。群集关闭时必须运行合并。有关用法的示例,请参见奥莱利 HBase 书。
您将需要将 3 个参数传递给此应用程序。第一个是表名。第二个是要合并的第一个区域的完全限定名称,例如“ table_name,\ x0A,1342956111995.7cef47f192318ba7ccc75b1bbf27a82b”。第三个是要合并的第二个区域的完全限定名称。
此外,在HBASE-1621上附加了一个 Ruby 脚本,用于区域合并。
138.节点 Management
138.1. 节点停用
您可以通过在特定节点上的 HBase 目录中运行以下脚本来停止单个 RegionServer:
$ ./bin/hbase-daemon.sh stop regionserver
RegionServer 将首先关闭所有区域,然后关闭自身。关闭时,ZooKeeper 中的 RegionServer 的临时节点将过期。主服务器会注意到 RegionServer 消失了,并将其视为“崩溃的”服务器;它将重新分配 RegionServer 承载的节点。
Disable the Load Balancer before Decommissioning a node
如果负载均衡器在节点关闭时运行,则负载均衡器与主服务器刚刚停用的 RegionServer 的恢复之间可能存在争用。通过首先禁用平衡器来避免任何问题。请参阅下面的lb。
Kill Node Tool
在 hbase-2.0 中,在 bin 目录中,我们添加了一个名为* considerAsDead.sh *的脚本,该脚本可用于终止区域服务器。在 Zookeeper 超时到期之前,专用的监视工具可以检测到硬件问题。 * considerAsDead.sh *是将 RegionServer 标记为无效的简单函数。它将删除服务器的所有 znode,开始恢复过程。将脚本插入监视/故障检测工具,以启动更快的故障转移。请谨慎使用此破坏性工具。如果需要在 hbase-2.0 之前的 hbase 版本中使用脚本,请复制该脚本。
RegionServer 的上述停止方式的一个缺点是,区域可能长时间处于脱机状态。区域按 Sequences 关闭。如果服务器上有很多区域,则要关闭的第一个区域可能要等到所有区域都关闭并且在主服务器通知 RegionServer 的 znode 消失后才能恢复联机。在 Apache HBase 0.90.2 中,我们添加了使节点逐渐减轻负载然后关闭自身的功能。 Apache HBase 0.90.2 添加了* graceful_stop.sh *脚本。这是它的用法:
$ ./bin/graceful_stop.sh
Usage: graceful_stop.sh [--config &conf-dir>] [--restart] [--reload] [--thrift] [--rest] &hostname>
thrift If we should stop/start thrift before/after the hbase stop/start
rest If we should stop/start rest before/after the hbase stop/start
restart If we should restart after graceful stop
reload Move offloaded regions back on to the stopped server
debug Move offloaded regions back on to the stopped server
hostname Hostname of server we are to stop
要停用已加载的 RegionServer,请运行以下命令:$ ./bin/graceful_stop.sh HOSTNAME 其中HOSTNAME是承载要停用的 RegionServer 的主机。
On HOSTNAME
传递给* graceful_stop.sh 的HOSTNAME必须与 hbase 用来标识 RegionServer 的主机名匹配。检查主 UI 中的 RegionServers 列表,了解 HBase 如何引用服务器。它通常是主机名,但也可以是 FQDN。无论 HBase 使用什么,这都应该传递 graceful_stop.sh *停用脚本。如果您通过 IP,则该脚本还不够智能,无法为其创建主机名(或 FQDN),因此在检查服务器当前是否正在运行时它将失败。区域的正常卸载将无法进行。
- graceful_stop.sh 脚本将一次将区域移出已停用的 RegionServer,以最大程度地减少区域搅动。在移动下一个区域之前,它将验证部署在新位置的区域,依此类推,直到停用的服务器承载零个区域。此时, graceful_stop.sh *告诉 RegionServer
stop。此时,主服务器将通知 RegionServer 消失,但是所有区域都将被重新部署,并且由于 RegionServer 干净地关闭,因此不会拆分 WAL 日志。
Load Balancer
假定在graceful_stop脚本运行时禁用了区域负载平衡器(否则,平衡器和停用脚本最终将为区域部署而战)。使用 Shell 禁用平衡器:
hbase(main):001:0> balance_switch false
true
0 row(s) in 0.3590 seconds
这将关闭平衡器。要重新启用,请执行以下操作:
hbase(main):001:0> balance_switch true
false
0 row(s) in 0.3590 seconds
graceful_stop将检查平衡器,如果启用了平衡器,它将在工作之前将其关闭。如果由于错误而过早退出,则不会重置平衡器。因此,最好在 Management 完均衡器后再使用graceful_stop重新启用平衡器,而不用进行 counce_stop。
138.1.1. 同时停用多个 Regions 服务器
如果您有一个大型群集,则可能希望通过同时停止多个 RegionServer 一次停用一台以上的计算机。要同时优雅地耗尽多个 Regionserver,可以将 RegionServer 置于“ draining”状态。通过在 Zookeeper 中的* hbase_root/draining * znode 下创建一个条目,将 RegionServer 标记为排水节点来完成此操作。该 znode 的格式为name,port,startcode,就像* hbase_root/rs * znode 下的 regionserver 条目一样。
如果没有此功能,则停用多个节点可能不是最佳选择,因为从一个区域服务器中耗尽的区域可能会移动到其他也在耗尽中的区域服务器。将 RegionServers 标记为耗尽状态可以防止这种情况的发生。有关更多详细信息,请参见此blog post。
138.1.2. 磁盘损坏或故障
如果在磁盘普通磁盘消失的情况下,每台计算机上有足够数量的磁盘,最好设置dfs.datanode.failed.volumes.tolerated。但是通常磁盘会像“约翰·韦恩”(John Wayne)那样工作,即花一些时间解决* dmesg *里的错误,或者由于某种原因,其运行速度比同伴慢得多。在这种情况下,您要停用磁盘。您有两个选择。您可以停用 datanode或破坏性较小,因为只有坏磁盘数据将被复制,可以停止 datanode,卸载坏卷(您不能在 datanode 使用卷的同时卸载该卷),然后重新启动 datanode(假定您已将 dfs.datanode.failed.volumes.tolerated 设置为> 0)。区域服务器会在重新校准从何处获取数据的位置时会在日志中引发一些错误(可能也会滚动其 WAL 日志),但是一般而言,但对于某些延迟尖峰,它应 continue 进行调整。
Short Circuit Reads
如果要进行短路读取,则必须在停止数据节点之前将区域移出区域服务器。当进行短路读取时,尽管通过 chmod 进行了修改,因此 regionserver 无法访问,因为它已经打开了文件,即使 datanode 处于关闭状态,它也可以 continue 从坏磁盘读取文件块。重新启动数据节点后,将区域移回。
138.2. 滚动重启
某些群集配置更改要求重新启动整个群集或 RegionServer,以获取更改。此外,还支持滚动重启以升级到次要版本或维护版本,并尽可能升级到主要版本。请参阅要升级到的发行版的发行说明,以了解执行滚动升级功能的限制。
有多种方法可以重新启动群集节点,具体取决于您的情况。这些方法将在下面详细介绍。
138.2.1. 使用 rolling-restart.sh 脚本
HBase 附带了一个脚本* bin/rolling-restart.sh *,该脚本使您可以在整个集群(仅限主服务器或仅 RegionServer)上执行滚动重启。该脚本是作为您自己的脚本的模板提供的,未经明确测试。它要求配置无密码的 SSH 登录,并假定您已使用 tarball 进行部署。该脚本要求您在运行之前设置一些环境变量。检查脚本并对其进行修改以适合您的需求。
- rolling-restart.sh *常规用法
$ ./bin/rolling-restart.sh --help
Usage: rolling-restart.sh [--config <hbase-confdir>] [--rs-only] [--master-only] [--graceful] [--maxthreads xx]
仅在 RegionServers 上滚动重启
- 要仅在 RegionServer 上执行滚动重启,请使用
--rs-only选项。如果需要重新引导单个 RegionServer 或进行仅影响 RegionServer 而不影响其他 HBase 进程的配置更改,则可能有必要。
- 要仅在 RegionServer 上执行滚动重启,请使用
仅在主机上滚动重启
- 要在活动主 Master 和备份 Master 上执行滚动重启,请使用
--master-only选项。如果您知道您的配置更改仅影响主服务器而不影响 RegionServer,或者需要在运行活动主服务器的服务器上重新启动服务器,则可以使用此功能。
- 要在活动主 Master 和备份 Master 上执行滚动重启,请使用
Graceful Restart
- 如果指定
--graceful选项,则使用* bin/graceful_stop.sh *脚本重新启动 RegionServer,该脚本会将区域移出 RegionServer,然后再重新启动。这样比较安全,但是会延迟重新启动。
- 如果指定
限制线程数
- 要将滚动重启限制为仅使用特定数量的线程,请使用
--maxthreads选项。
- 要将滚动重启限制为仅使用特定数量的线程,请使用
138.2.2. 手动滚动重启
为了保持对过程的更多控制,您可能希望手动在整个群集中进行滚动重启。这使用graceful-stop.sh命令decommission。使用此方法,您可以分别重新启动每个 RegionServer,然后将其旧区域移回原位,并保持局部性。如果还需要重新启动主服务器,则需要单独执行此操作,并在使用此方法重新启动 RegionServer 之前先重新启动主服务器。以下是这种命令的示例。您可能需要根据环境进行调整。此脚本仅滚动重启 RegionServers。在移动区域之前,它将禁用负载均衡器。
$ for i in `cat conf/regionservers|sort`; do ./bin/graceful_stop.sh --restart --reload --debug $i; done &> /tmp/log.txt &;
监视*/tmp/log.txt *文件的输出,以跟踪脚本的进度。
138.2.3. 编写自己的滚动重启脚本的逻辑
如果要创建自己的滚动重启脚本,请使用以下准则。
提取新版本,验证其配置,然后使用
rsync,scp或其他安全同步机制将其同步到群集的所有节点。首先重新启动主机。如果新的 HBase 目录不同于旧的 HBase 目录(例如,用于升级),则可能需要修改这些命令。
$ ./bin/hbase-daemon.sh stop master; ./bin/hbase-daemon.sh start master
- 使用以下脚本从主服务器正常重启每个 RegionServer。
$ for i in `cat conf/regionservers|sort`; do ./bin/graceful_stop.sh --restart --reload --debug $i; done &> /tmp/log.txt &
如果您正在运行 Thrift 或 REST 服务器,请传递--thrift 或--rest 选项。有关其他可用选项,请运行bin/graceful-stop.sh --help命令。
重新启动多个 RegionServer 时,缓慢耗尽 HBase 区域非常重要。否则,多个区域将同时脱机,必须将其重新分配给其他节点,这些节点也可能很快会脱机。这会对性能产生负面影响。例如,您可以通过添加诸如sleep之类的 Shell 命令将延迟添加到上面的脚本中。要在每次 RegionServer 重新启动之间 await5 分钟,请将上面的脚本修改为以下内容:
$ for i in `cat conf/regionservers|sort`; do ./bin/graceful_stop.sh --restart --reload --debug $i & sleep 5m; done &> /tmp/log.txt &
- 再次重新启动主服务器,以清除失效的服务器列表并重新启用负载均衡器。
138.3. 添加一个新节点
在 HBase 中添加新的 Regionserver 本质上是免费的,您只需像这样启动它:$ ./bin/hbase-daemon.sh start regionserver,它将向主服务器注册。理想情况下,您还要在同一台计算机上启动一个 DataNode,以便 RS 最终可以开始具有本地文件。如果您依靠 ssh 启动守护程序,请不要忘记在主服务器的* conf/regionservers *中添加新的主机名。
此时,区域服务器不提供数据,因为还没有区域移到该服务器。如果启用了平衡器,它将开始将区域移动到新的 RS。在中小型群集上,这可能会对延迟产生非常不利的影响,因为许多区域会同时处于离线状态。因此,建议以与停用节点时相同的方式来禁用平衡器,并手动移动区域(或者甚至更好的是,使用将它们一一移动的脚本)。
移动的区域都将具有 0%的局部性,并且在缓存中将没有任何块,因此区域服务器将必须使用网络来处理请求。除了导致更高的延迟外,它还可以使用您所有网卡的容量。出于实际目的,请考虑标准的 1GigE NIC 读取的内容不能超过* 100MB/s *。在这种情况下,或者如果您在 OLAP 环境中并且需要具有局部性,则建议对压缩的区域进行较大的压缩。
139. HBaseMetrics
HBase 发出符合Hadoop Metrics API 的 Metrics。从 HBase 0.95[5]开始,HBase 被配置为发出默认度量标准集,默认采样周期为每 10 秒。您可以将 HBaseMetrics 与 Ganglia 结合使用。您还可以过滤发出哪些度量,并扩展度量框架以捕获适合您的环境的自定义度量。
139.1. Metrics 设置
对于 HBase 0.95 及更高版本,HBase 附带了默认的 Metrics 配置或* sink 。这包括各种单独的 Metrics,默认情况下每 10 秒发出一次。要为给定的区域服务器配置 Metrics,请编辑 conf/hadoop-metrics2-hbase.properties *文件。重新启动区域服务器,以使更改生效。
要更改默认接收器的采样率,请编辑以*.period开头的行。要过滤发出哪些 Metrics 或扩展 Metrics 框架,请参阅https://hadoop.apache.org/docs/current/api/org/apache/hadoop/metrics2/package-summary.html
HBase Metrics and Ganglia
默认情况下,HBase 每台区域服务器发出大量 Metrics。Ganglia 可能难以处理所有这些 Metrics。考虑增加 Ganglia 服务器的容量或减少 HBase 发出的度量标准数量。参见Metrics Filtering。
139.2. 禁用 Metrics
要禁用区域服务器的 Metrics,请编辑* conf/hadoop-metrics2-hbase.properties *文件并 Comments 掉所有未 Comments 的行。重新启动区域服务器,以使更改生效。
139.3. 发现可用 Metrics
您无需列出 HBase 默认发出的每个 Metrics,而是可以通过 JSON 输出或通过 JMX 浏览可用的 Metrics。针对主进程和每个区域服务器进程公开了不同的 Metrics。
过程:访问可用度量的 JSON 输出
启动 HBase 后,默认情况下访问区域服务器的 Web UI,位于 http:// REGIONSERVER_HOSTNAME:60030(或 HBase 1.0 中的端口 16030)。
单击顶部附近的“度量标准转储”链接。区域服务器的度量标准以 JSON 格式的 JMX bean 的转储形式提供。这将转储所有度量标准名称及其值。要在列表中包括 Metrics 描述-这在您探索可用内容时会很有用-添加查询字符串
?description=true以便您的 URL 变为 http:// REGIONSERVER_HOSTNAME:60030/jmx?description = true。并非所有的 bean 和属性都有描述。要查看主服务器的 Metrics,请改为连接到主服务器的 Web UI(默认为 http:// localhost:60010 或 HBase 1.0 中的端口 16010),然后单击其“Metrics 转储”链接。要在列表中包括 Metrics 描述-这在您探索可用内容时会很有用-添加查询字符串
?description=true以便您的 URL 变为 http:// REGIONSERVER_HOSTNAME:60010/jmx?description = true。并非所有的 bean 和属性都有描述。
您可以使用许多不同的工具通过浏览 MBean 来查看 JMX 内容。此过程使用jvisualvm,这是 JDK 中通常可用的应用程序。
过程:浏览可用度量的 JMX 输出
启动 HBase(如果尚未运行)。
在带有 GUI 显示的主机上运行命令
jvisualvm命令。您可以从命令行或适用于您的 os 的其他方法启动它。确保已安装 VisualVM-MBeans 插件。浏览至 工具→插件 。单击“已安装”,然后检查是否列出了插件。如果不是,请单击“可用插件”,选择它,然后单击“安装”。完成后,点击 关闭 。
要查看给定 HBase 进程的详细信息,请在左侧面板的 Local 子树中双击该进程。在右侧面板中将打开一个详细视图。单击“ MBeans”选项卡,该选项卡显示在右侧面板顶部。
要访问 HBaseMetrics,请导航至相应的子 bean:.* Master:.* RegionServer:
每个度量标准的名称及其当前值显示在“属性”选项卡中。对于包含更多详细信息(包括每个属性的描述)的视图,请单击“元数据”选项卡。
139.4. 度量单位
适当时,以不同的单位表示不同的 Metrics。通常,度量单位是名称(如度量标准shippedKBs)。否则,请遵循以下准则。如有疑问,您可能需要检查给定 Metrics 的来源。
引用时间点的 Metrics 通常表示为时间戳。
引用年龄的 Metrics(例如
ageOfLastShippedOp)通常以毫秒为单位。引用内存大小的 Metrics 以字节为单位。
队列的大小(例如
sizeOfLogQueue)表示为队列中的项目数。通过乘以块大小来确定大小(HDFS 中默认为 64 MB)。引用诸如给定类型的操作(例如
logEditsRead)的数量之类的度量标准表示为整数。
139.5. 最重要的主 Metrics
注意:计数通常在上一个 Metrics 报告间隔内。
hbase.master.numRegionServers
- 实时区域服务器数量
hbase.master.numDeadRegionServers
- 死区服务器数量
hbase.master.ritCount
- 转换中的区域数
hbase.master.ritCountOverThreshold
- 过渡时间超过阈值时间的区域数(默认值:60 秒)
hbase.master.ritOldestAge
- 转换中最长区域的年龄(以毫秒为单位)
139.6. 最重要的 RegionServerMetrics
注意:计数通常在上一个 Metrics 报告间隔内。
hbase.regionserver.regionCount
- 区域服务器托管的区域数
hbase.regionserver.storeFileCount
- 区域服务器当前 Management 的磁盘上的存储文件数
hbase.regionserver.storeFileSize
- 磁盘上存储文件的总大小
hbase.regionserver.hlogFileCount
- 尚未归档的预写日志数
hbase.regionserver.totalRequestCount
- 收到的请求总数
hbase.regionserver.readRequestCount
- 收到的读取请求数
hbase.regionserver.writeRequestCount
- 收到的写请求数
hbase.regionserver.numOpenConnections
- RPC 层上打开的连接数
hbase.regionserver.numActiveHandler
- 主动处理请求的 RPC 处理程序的数量
hbase.regionserver.numCallsInGeneralQueue
- 当前排队的用户请求数
hbase.regionserver.numCallsInReplicationQueue
- 从复制接收到的当前排队的操作数
hbase.regionserver.numCallsInPriorityQueue
- 当前排队的优先级(内部整理)请求数
hbase.regionserver.flushQueueLength
- memstore 刷新队列的当前深度。如果增加的话,我们在将内存存储清除到 HDFS 方面就落后了。
hbase.regionserver.updatesBlockedTime
- 毫秒更新数已被阻止,因此可以刷新内存存储
hbase.regionserver.compactionQueueLength
- 压缩请求队列的当前深度。如果增加的话,我们将在存储文件压缩方面落伍。
hbase.regionserver.blockCacheHitCount
- 块缓存命中数
hbase.regionserver.blockCacheMissCount
- 块高速缓存未命中数
hbase.regionserver.blockCacheExpressHitPercent
- 启用缓存的请求所占的时间百分比达到缓存
hbase.regionserver.percentFilesLocal
- 可以从本地 DataNode 读取的存储文件数据的百分比,0-100
hbase.regionserver.<op>_<measure>
- 操作延迟,其中\ 是追加,删除,突变,获取,重放,递增之一;其中\ 是最小值,最大值,平均值,中位数,75th_percentile,95th_percentile,99th_percentile 之一
hbase.regionserver.slow<op>Count
- 我们认为操作的速度很慢,其中\ 是上面的列表之一
hbase.regionserver.GcTimeMillis
- 垃圾收集所花费的时间(以毫秒为单位)
hbase.regionserver.GcTimeMillisParNew
- 花费在年轻一代垃圾收集上的时间(毫秒)
hbase.regionserver.GcTimeMillisConcurrentMarkSweep
- 上一代垃圾回收所花费的时间(毫秒)
hbase.regionserver.authenticationSuccesses
- 身份验证成功的 Client 端连接数
hbase.regionserver.authenticationFailures
- Client 端连接身份验证失败的次数
hbase.regionserver.mutationsWithoutWALCount
- 提交的带有标志的写计数,该标志指示它们应绕过预写日志
139.7. 元表负载 Metrics
HBase 1.4 中提供了 HBase 元表 Metrics 收集功能,但默认情况下已禁用该功能,因为它会影响群集的性能。启用它后,它将通过收集以下统计信息来帮助监视 Client 端访问模式:
hbase:meta表上的获取,放置和删除操作的数量前 N 个 Client 端进行的获取,放置和删除操作的数量
与每个表相关的操作数
与前 N 个区域相关的操作数
何时使用功能
- 此功能可以通过显示修改元信息(例如,通过创建,删除,拆分或移动表)或最常检索元数据的区域或表来帮助标识元表中的热点。它还可以通过显示哪个 Client 端最频繁地使用元表来帮助发现异常的 Client 端应用程序,例如,这可能表明缺少元表缓冲或在 Client 端应用程序中没有重复使用开放的 Client 端连接。
Possible side-effects of enabling this feature
群集中具有大量 Client 端和区域会导致注册和跟踪大量 Metrics,这可能会增加处理hbase:meta表的 HBase 区域服务器的内存和 CPU 占用空间。它还可能导致 JMX 转储大小的显着增加,这可能会影响您在 HBase 旁边使用的监视或日志聚合系统。建议仅在调试期间打开此功能。
在 JMX 哪里找到 Metrics
- 每个度量标准属性名称都将以“ MetaTable_”前缀开头。对于所有度量标准,您将看到五个不同的 JMX 属性:计数,平均速率,1 分钟速率,5 分钟速率和 15 分钟速率。您可以在 JMX 的以下 MBean 下找到这些 Metrics:
Hadoop → HBase → RegionServer → Coprocessor.Region.CP_org.apache.hadoop.hbase.coprocessor.MetaTableMetrics。
- 每个度量标准属性名称都将以“ MetaTable_”前缀开头。对于所有度量标准,您将看到五个不同的 JMX 属性:计数,平均速率,1 分钟速率,5 分钟速率和 15 分钟速率。您可以在 JMX 的以下 MBean 下找到这些 Metrics:
示例:您可以在 JMX 转储中看到的一些元表 Metrics
{
"MetaTable_get_request_count": 77309,
"MetaTable_put_request_mean_rate": 0.06339092997186495,
"MetaTable_table_MyTestTable_request_15min_rate": 1.1020599841623246,
"MetaTable_client_/172.30.65.42_lossy_request_count": 1786
"MetaTable_client_/172.30.65.45_put_request_5min_rate": 0.6189810954855728,
"MetaTable_region_1561131112259.c66e4308d492936179352c80432ccfe0._lossy_request_count": 38342,
"MetaTable_region_1561131043640.5bdffe4b9e7e334172065c853cf0caa6._lossy_request_1min_rate": 0.04925099917433935,
}
Configuration
- 要启用此功能,您必须通过将以下部分添加到 hbase-site.xml 来启用自定义协处理器。该协处理器将在所有 HBase RegionServer 上运行,但仅在
hbase:meta表所在的服务器上处于活动状态(即消耗内存/ CPU)。它将生成 JMX 度量,可以从给定 RegionServer 的 Web UI 或通过简单的 REST 调用下载 JMX 度量。这些度量将不会出现在其他 RegionServer 的 JMX 转储中。
- 要启用此功能,您必须通过将以下部分添加到 hbase-site.xml 来启用自定义协处理器。该协处理器将在所有 HBase RegionServer 上运行,但仅在
启用元表 Metrics 功能
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.MetaTableMetrics</value>
</property>
How the top-N metrics are calculated?
Metrics 的“前 N 个”类型将使用有损计数算法(如Motwani,R; Manku,G.S(2002 年)。 “数据流上的近似频率计数”定义)进行计数,该算法旨在识别频率计数超过用户给定阈值的数据流中的元素。用这种算法计算出的频率并不总是准确的,但是有一个误差阈值,用户可以将其指定为配置参数。该算法所需的运行时间空间与指定的错误阈值成反比,因此,错误参数越大,占位面积越小且度量精度越低。
您可以将算法的错误率指定为 0 到 1(不包括)之间的浮点值,默认值为 0.02. 将错误率设置为E并以N作为元表操作的总数,则将最多保留7 / E米(假设低频元素的活动均匀分布),并且每个保留的元素的频率都将高于E * N。
一个示例:假设我们对访问元表最活跃的 HBaseClient 端感兴趣。到目前为止,当元表上有 1,000,000 次操作且错误率参数设置为 0.02 时,我们可以假设 JMX 中最多只能存在 350 个与 Client 端 IP 地址相关的计数器,并且这些 Client 端中的每一个都在以下位置访问元表至少 20,000 次。
<property>
<name>hbase.util.default.lossycounting.errorrate</name>
<value>0.02</value>
</property>
140. HBase 监视
140.1. Overview
最好使用OpenTSDB之类的系统来监视每个 RegionServer 的“宏监视”,以下 Metrics 可能是最重要的。如果您的集群存在性能问题,那么您可能会在该组中看到一些不寻常的情况。
HBase
-
- See rs metrics
-
OS
-
- IO Wait
-
User CPU
Java
-
- GC
-
有关 HBaseMetrics 的更多信息,请参见hbase metrics。
140.2. 慢查询日志
HBase 慢查询日志由可解析的 JSON 结构组成,这些 JSON 结构描述了这些 Client 端操作(获取,放置,删除等)的属性,这些 Client 端操作花费的时间太长,或者产生的输出过多。如下所述,“运行时间太长”和“输出太多”的阈值是可配置的。输出是在主区域服务器日志中内联生成的,因此很容易从上下文和其他已记录事件中发现更多详细信息。如果用户只希望查看慢速查询,还可以在其前面加上标识标签(responseTooSlow),(responseTooLarge),(operationTooSlow)和(operationTooLarge),以便使用 grep 轻松进行过滤。
140.2.1. Configuration
有两个配置旋钮可用于调整记录查询时的阈值。
hbase.ipc.warn.response.time可以运行查询而不被记录的最大毫秒数。默认为 10000,即 10 秒。可以设置为-1 以禁用按时间记录。hbase.ipc.warn.response.size查询可以不记录而返回的最大响应字节大小。默认为 100 兆字节。可以设置为-1 以禁用按大小记录。
140.2.2. Metrics
慢查询日志向 JMX 公开 Metrics。
hadoop.regionserver_rpc_slowResponse一个全局 Metrics,反映触发日志记录的所有响应的持续时间。hadoop.regionserver_rpc_methodName.aboveOneSec反映持续超过一秒的所有响应的持续时间的 Metrics。
140.2.3. Output
输出标记有操作,例如(operationTooSlow)(如果呼叫是 Client 端操作,例如 Put,Get 或 Delete),我们将为其提供详细的指纹信息。如果不是,则将其标记为(responseTooSlow)并仍会生成可解析的 JSON 输出,但仅在 RPC 本身中有关其持续时间和大小的详细信息就较少。如果响应大小触发了日志记录,则TooLarge替换为TooSlow,即使大小和持续时间都触发了日志记录,也会出现TooLarge。
140.2.4. Example
2011-09-08 10:01:25,824 WARN org.apache.hadoop.ipc.HBaseServer: (operationTooSlow): {"tables":{"riley2":{"puts":[{"totalColumns":11,"families":{"actions":[{"timestamp":1315501284459,"qualifier":"0","vlen":9667580},{"timestamp":1315501284459,"qualifier":"1","vlen":10122412},{"timestamp":1315501284459,"qualifier":"2","vlen":11104617},{"timestamp":1315501284459,"qualifier":"3","vlen":13430635}]},"row":"cfcd208495d565ef66e7dff9f98764da:0"}],"families":["actions"]}},"processingtimems":956,"client":"10.47.34.63:33623","starttimems":1315501284456,"queuetimems":0,"totalPuts":1,"class":"HRegionServer","responsesize":0,"method":"multiPut"}
请注意,“表”结构中的所有内容都是由 MultiPut 的指纹生成的,而其余信息则是特定于 RPC 的,例如处理时间和 Client 端 IP /端口。其他 Client 端操作遵循相同的模式和相同的一般结构,但由于各个操作的性质而存在必要的差异。在呼叫不是 Client 操作的情况下,将完全缺少详细的指纹信息。
例如,此特定示例将表明,导致速度缓慢的可能原因仅仅是一个非常大的(大约 100MB)多 Importing,正如我们可以通过“ vlen”(即值长度)来判断 multiPut 中每个 Importing 的字段所表明的那样。
140.3. 块缓存监控
从 HBase 0.98 开始,HBase Web UI 可以监视和报告块缓存的性能。要查看块缓存报告,请单击。以下是报告功能的一些示例。
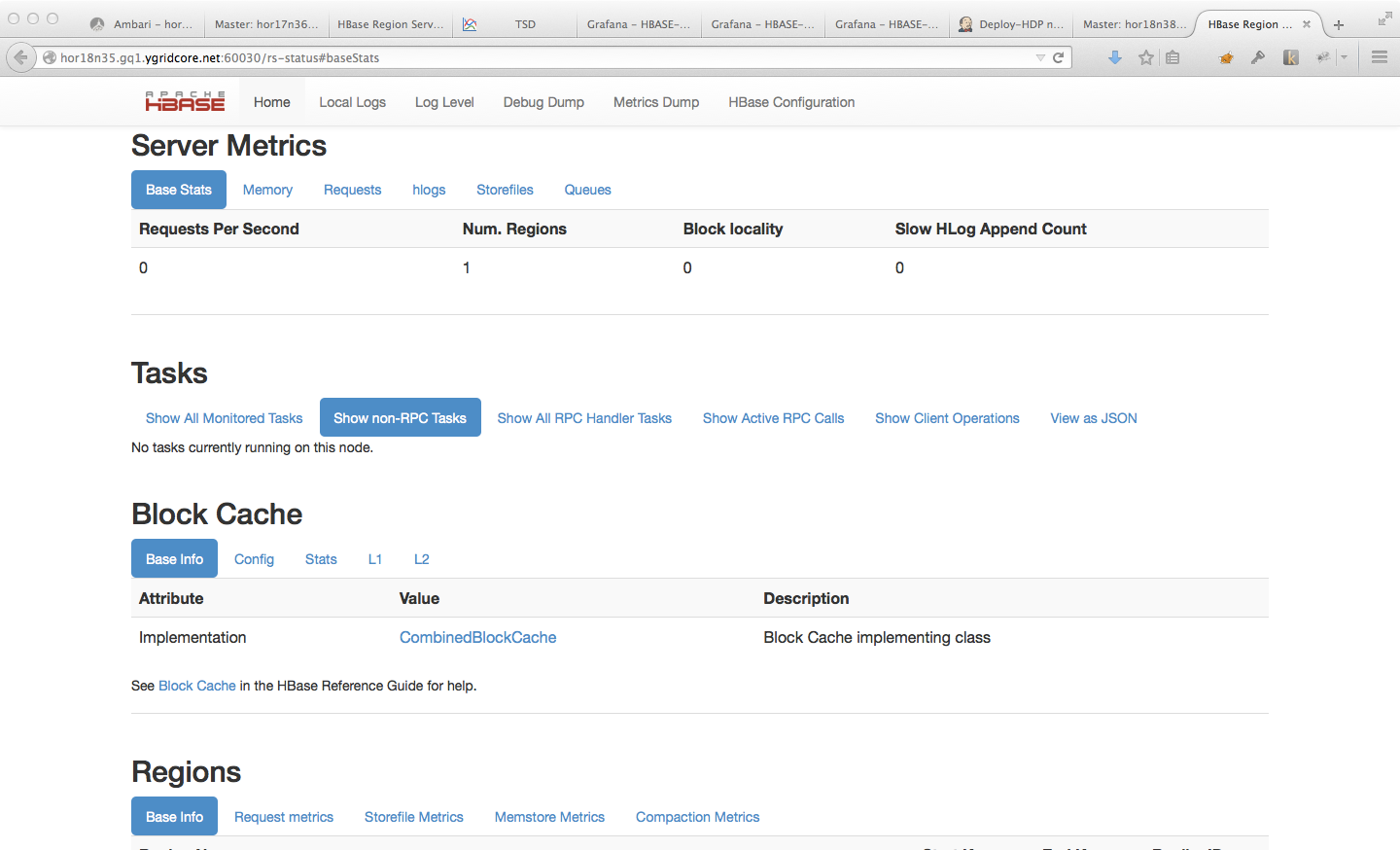
图 4.基本信息
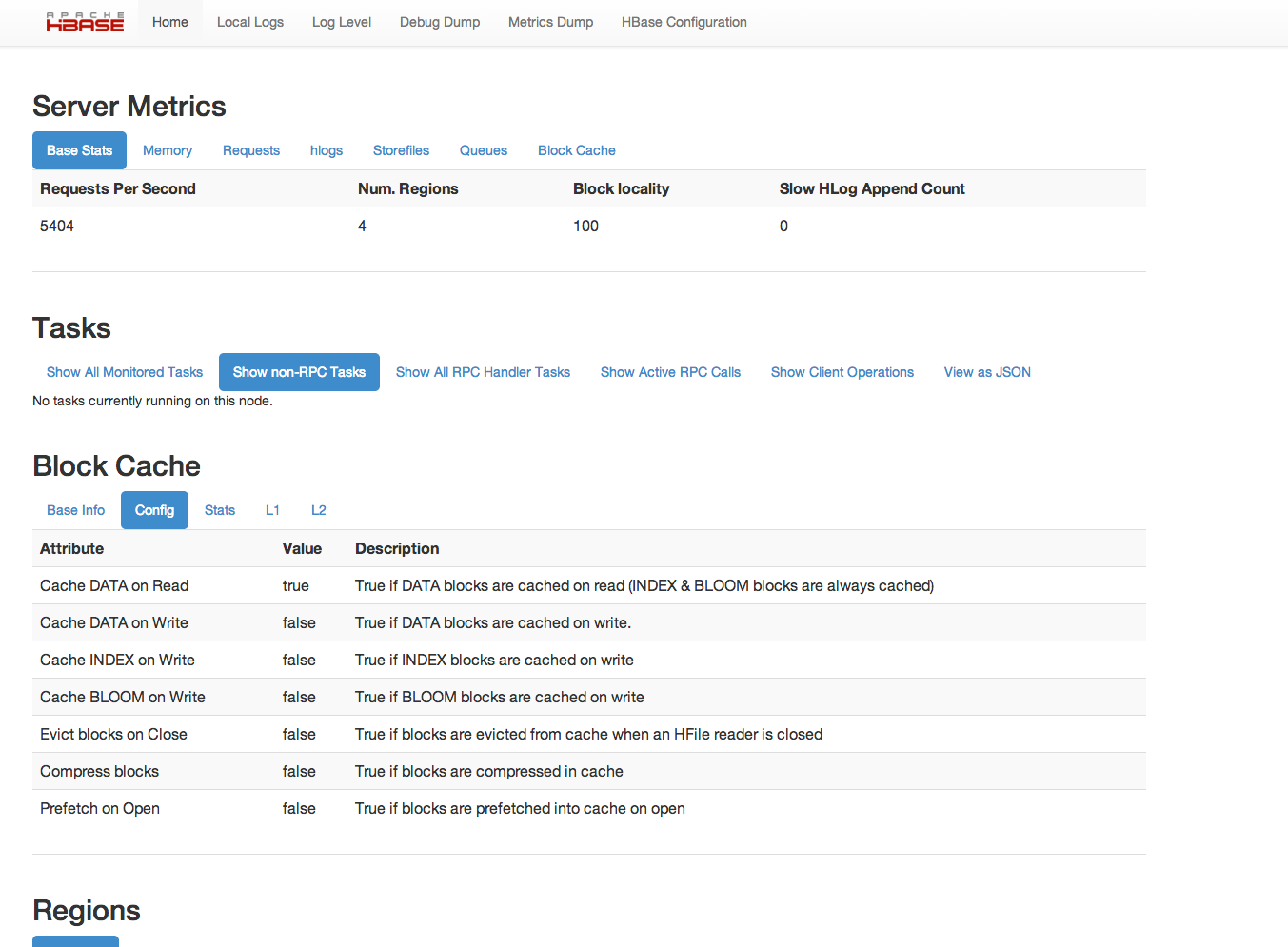
图 5.配置
图 6.统计
图 7. L1 和 L2
这不是所有可用屏幕和报告的详尽列表。在 Web UI 中查看。
141.群集复制
Note
该信息以前在Cluster Replication处可用。
HBase 提供了一种群集复制机制,通过使用源群集的预写日志(WAL)传播更改,可以使一个群集的状态与另一个群集的状态保持同步。群集复制的一些用例包括:
备份与灾难恢复
Data aggregation
地理数据分布
在线数据提取与离线数据分析相结合
Note
复制以列系列的粒度启用。在为列系列启用复制之前,请在目标群集上创建表和所有要复制的列系列。
Note
复制是异步的,因为我们在后台将 WAL 发送到另一个群集,这意味着当您要通过复制进行恢复时,可能会丢失一些数据。为了解决此问题,我们引入了一项称为同步复制的新功能。由于机制有些不同,因此我们使用一个单独的部分对其进行描述。请参阅Synchronous Replication。
141.1. 复制概述
群集复制使用源推送方法。 HBase 群集可以是源(也称为主群集或活动群集,这意味着它是新数据的始发者),目的地(也称为从属群集或被动数据库,这意味着它通过复制接收数据),或者可以同时履行两个角色。复制是异步的,复制的目标是最终的一致性。当源接收到对启用了复制的列系列的编辑时,该编辑将使用 WAL 传播到所有目标群集,该 WAL 用于 Management 相关区域的 RegionServer 上该列系列的 WAL。
当数据从一个群集复制到另一个群集时,数据的原始来源将通过作为元数据一部分的群集 ID 进行跟踪。在 HBase 0.96 和更高版本(HBASE-7709)中,还将跟踪所有已使用数据的群集。这样可以防止复制循环。
只要需要将每个区域服务器的 WAL 复制到任何从属群集,它们就必须保留在 HDFS 中。每个区域服务器都从需要复制的最旧日志中读取信息,并跟踪其在 ZooKeeper 内部处理 WAL 的进度,以简化故障恢复。指示从属群集的进度以及要处理的 WAL 队列的位置标记对于每个从属群集可能会有所不同。
参与复制的群集可以具有不同的大小。主群集依靠随机化来尝试平衡从群集上的复制流。期望从群集具有存储容量来保存复制的数据以及负责提取的任何数据。如果从属群集的空间不足,或由于其他原因无法访问,则将引发错误,而主群集将保留 WAL 并每隔一段时间重试复制。
Consistency Across Replicated Clusters
复制过程中,如何在 HBase API 之上构建应用程序至关重要。 HBase 的复制系统可将已启用列系列的 Client 端编辑至少一次交付给每个已配置的目标群集。如果无法到达给定的目的地,则复制系统将以可能重复给定消息的方式重试发送编辑。 HBase 提供了两种复制方式,一种是原始复制,另一种是串行复制。在以前的复制方式中,无法保证 Client 端编辑的交付 Sequences。在 RegionServer 发生故障的情况下,复制队列的恢复独立于服务器以前处理的单个区域的恢复而发生。这意味着,尚未复制的编辑有可能由 RegionServer 提供服务,该 RegionServer 当前的复制速度比处理失败后的编辑要慢。
这两个属性的组合(至少一次发送和缺少消息排序)意味着,如果您的应用程序使用了非幂等的操作,例如某些目标群集可能最终以不同的状态结束。增量。
为了解决该问题,HBase 现在支持串行复制,该复制将编辑操作作为来自 Client 端的请求 Sequences 发送到目标群集。参见Serial Replication。
Terminology Changes
以前,诸如* master-master , master-slave 和 cyclical *等术语用于描述 HBase 中的复制关系。这些术语增加了混乱,已被抛弃以支持有关适用于不同场景的群集拓扑的讨论。
Cluster Topologies
中央源群集可能会将更改传播到多个目标群集,以进行故障转移或由于地理分布。
源群集可能会将更改推送到目标群集,也可能会将其自己的更改推送回原始群集。
许多不同的低延迟群集可能会将更改推送到一个集中式群集,以进行备份或资源密集型数据分析作业。然后,可以将处理后的数据复制回低延迟群集。
可以将多个复制级别链接在一起,以满足组织的需求。下图显示了一个假设的场景。使用箭头跟随数据路径。
图 8.复杂集群复制配置示例
HBase 复制借鉴了 MySQL 使用的基于语句的复制设计中的许多概念。为了维护原子性,将复制整个 WALEdit(由来自 Client 端上的 Put 和 Delete 操作的多个单元格插入组成),而不是 SQL 语句。
141.2. Management 和配置群集复制
群集配置概述
配置并启动源集群和目标集群。在源集群和目标集群上创建具有相同名称和列族的表,以便目标集群知道将接收数据的存储位置。
源群集和目标群集中的所有主机应相互可达。
如果两个群集使用相同的 ZooKeeper 群集,则必须使用不同的
zookeeper.znode.parent,因为它们不能在同一文件夹中写入。在源群集的 HBase Shell 中,使用
add_peer命令将目标群集添加为对等节点。在源群集的 HBase Shell 中,使用
enable_table_replication命令启用表复制。检查日志以查看是否正在复制。如果是这样,您将看到来自 ReplicationSource 的以下消息。
LOG.info("Replicating "+clusterId + " -> " + peerClusterId);
串行复制配置
集群 Management 命令
add_peer<ID><CLUSTER_KEY>
- 在两个群集之间添加复制关系。
ID-唯一字符串,不得包含连字符。
CLUSTER_KEY:使用以下模板组成,带有适当的占位符:
hbase.zookeeper.quorum:hbase.zookeeper.property.clientPort:zookeeper.znode.parent。可以在“主 UI”信息页面上找到此值。STATE(可选):ENABLED 或 DISABLED,默认值为 ENABLED
list_peers
- 列出此群集已知的所有复制关系
enable_peer <ID>
- 启用先前禁用的复制关系
disable_peer <ID>
- 禁用复制关系。 HBase 不再将编辑发送到该对等群集,但是如果重新启用了 HBase,则它仍会跟踪需要复制的所有新 WAL。只要存在同级,就可以在启用或禁用复制时保留 WAL。
remove_peer <ID>
- 禁用并删除复制关系。 HBase 将不再将编辑发送到该对等群集或跟踪 WAL。
enable_table_replication <TABLE_NAME>
- 为所有列系列启用表复制开关。如果在目标群集中找不到该表,则它将创建一个具有相同名称和列族的表。
disable_table_replication <TABLE_NAME>
- 对所有列族禁用表复制开关。
141.3. 串行复制
注意:此功能是 HBase 2.1 中引入的
串行复制功能
串行复制支持以与日志到达源群集相同的 Sequences 将日志推送到目标群集。
为什么需要串行复制?
在 HBase 的复制中,我们通过读取每个区域服务器中的 WAL 将突变推送到目标群集。我们有 WAL 文件的队列,因此我们可以按创建时间 Sequences 读取它们。但是,当在源群集中发生区域移动或 RS 故障时,在区域移动或 RS 故障之前未推送的 hlog 条目将由原始 RS(用于区域移动)或另一个接管剩余的 hlog 的 RS 推送。失效的 RS(用于 RS 失败),并且相同区域的新条目将由现在服务于该区域的 RS 推送,但它们会同时推送同一区域的 hlog 条目而无需协调。
这种处理可能会导致源群集和目标群集之间的数据不一致:
有放置,然后删除写入源集群。
由于区域移动/ RS 故障,它们被不同的复制源线程推送到对等群集。
如果在放置之前将 delete 删除操作推入对等群集,并且在将 put 放置到对等群集之前在同等群集中发生了 flush 和 major-compact,则将收集删除并将该放置在对等群集中,但是在源群集中,该放置操作将被屏蔽删除,因此源群集和目标群集之间的数据不一致。
串行复制配置
将复制对等方的串行标志设置为 true。并且默认的串行标志为 false。
- 添加一个序列号为 true 的新复制对等体
hbase> add_peer '1', CLUSTER_KEY => "server1.cie.com:2181:/hbase", SERIAL => true
- 将复制对等方的序列标志设置为 false
hbase> set_peer_serial '1', false
- 将复制对等方的序列标志设置为 true
hbase> set_peer_serial '1', true
串行复制功能首先在HBASE-9465中完成,然后在HBASE-20046中恢复并重做。您可以在这些问题中找到更多详细信息。
141.4. 验证复制的数据
HBase 中包含的VerifyReplication MapReduce 作业对两个不同群集之间的复制数据进行了系统的比较。在主群集上运行 VerifyReplication 作业,并为其提供对等 ID 和表名称以用于验证。您可以通过指定时间范围或特定系列进一步限制验证。作业的简称为verifyrep。要运行作业,请使用如下命令:
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` "${HADOOP_HOME}/bin/hadoop" jar "${HBASE_HOME}/hbase-mapreduce-VERSION.jar" verifyrep --starttime=<timestamp> --endtime=<timestamp> --families=<myFam> <ID> <tableName>
VerifyReplication命令打印出GOODROWS和BADROWS计数器,以指示已正确复制和未正确复制的行。
141.5. 有关群集复制的详细信息
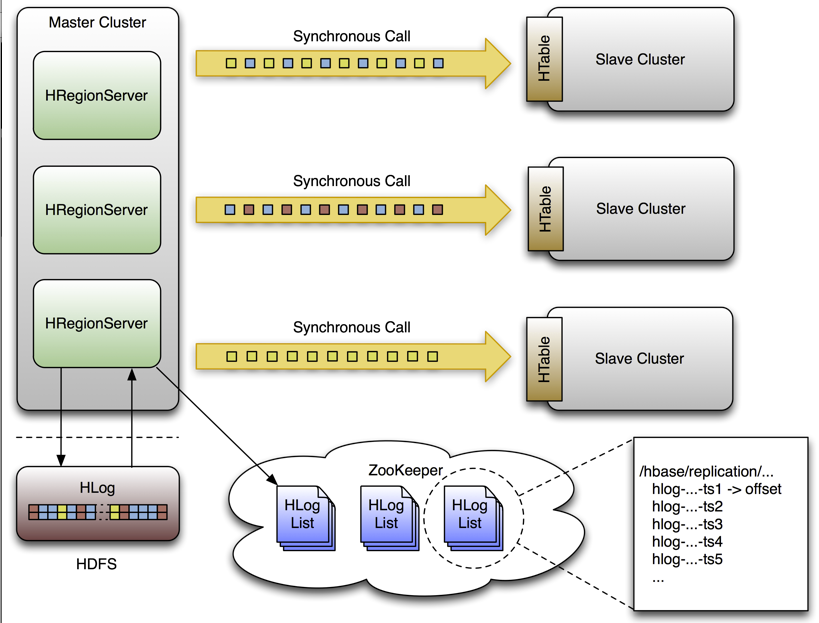
图 9.复制体系结构概述
141.5.1. WAL 的生活
一次 WAL 编辑要经历几个步骤,才能复制到从属群集。
HBaseClient 端使用“放置”或“删除”操作来操纵 HBase 中的数据。
区域服务器以某种方式将请求写入 WAL(如果未成功写入,则允许重播该请求)。
如果更改的单元格对应于要复制的列族,则将编辑添加到复制队列中。
在单独的线程中,作为批处理的一部分,从日志中读取编辑内容。仅保留符合复制条件的键值。可复制键值是其列范围为 GLOBAL 的列族的一部分,不属于诸如
hbase:meta之类的目录,不是源自目标从属群集,并且尚未被目标从属群集使用。该编辑带有主服务器的 UUID 标记,并添加到缓冲区中。当缓冲区已满或读取器到达文件末尾时,缓冲区将发送到从属群集上的随机区域服务器。
区域服务器 Sequences 读取编辑内容,并将其分成缓冲区,每个表一个缓冲区。读取所有编辑后,将使用 HBase 的普通 Client 端Table刷新每个缓冲区。已经使用了数据的主服务器的 UUID 和从服务器的 UUID 保留在应用它们的编辑中,以防止复制循环。
在主服务器中,当前正在复制的 WAL 的偏移量已在 ZooKeeper 中注册。
插入编辑的前三个步骤是相同的。
同样,在单独的线程中,区域服务器以与上述相同的方式读取,过滤和编辑日志编辑。从属区域服务器不应答 RPC 调用。
主机休眠,然后重试可配置的次数。
如果从属区域服务器仍然不可用,则主服务器选择要复制到的新区域服务器子集,然后再次尝试发送编辑缓冲区。
同时,WAL 被滚动并存储在 ZooKeeper 中的队列中。由其区域服务器“归档”的日志,通过将它们从区域服务器的日志目录移动到中央日志目录,将更新其在复制线程的内存队列中的路径。
当从属群集最终可用时,将以与正常处理期间相同的方式应用缓冲区。然后,主区域服务器将复制停机期间积压的日志积压。
传播队列故障转移负载
复制处于活动状态时,源集群中的区域服务器的子集负责将编辑内容传送到接收器。像其他所有区域服务器功能一样,如果进程或节点崩溃,则必须对此职责进行故障转移。建议使用以下配置设置,以在源群集中其余活动服务器上保持复制活动的均匀分布:
将
replication.source.maxretriesmultiplier设置为300。将
replication.source.sleepforretries设置为1(1 秒)。该值与replication.source.maxretriesmultiplier的值相结合,导致重试周期持续约 5 分钟。在源群集站点配置中将
replication.sleep.before.failover设置为30000(30 秒)。
复制期间保留标签
141.5.2. 复制内部
ZooKeeper 中的复制状态
- HBase 复制在 ZooKeeper 中保持其状态。默认情况下,状态包含在基本节点*/hbase/replication *中。该节点包含两个子节点,即
Peersznode 和RSznode。
- HBase 复制在 ZooKeeper 中保持其状态。默认情况下,状态包含在基本节点*/hbase/replication *中。该节点包含两个子节点,即
PeersZnode- 默认情况下,
peersznode 存储在*/hbase/replication/peers *中。它由所有对等复制群集的列表以及每个群集的状态组成。每个对等方的值是其群集密钥,该密钥在 HBase Shell 中提供。群集密钥包含群集仲裁中的 ZooKeeper 节点列表,ZooKeeper 仲裁的 Client 端端口以及该群集上 HDFS 中 HBase 的基本 znode。
- 默认情况下,
RSZnodersznode 包含需要复制的 WAL 日志列表。此列表按区域服务器和区域服务器要将日志传送到的对等群集划分为一组队列。 rs znode 对于群集中的每个区域服务器都有一个子 znode。子 znode 名称是区域服务器的主机名,Client 端端口和起始代码。此列表包括活动区域服务器和死区服务器。
141.5.3. 选择要复制到的区域服务器
当主群集区域服务器启动到从属群集的复制源时,它首先使用提供的群集密钥连接到从属服务器的 ZooKeeper 集成。然后,它扫描* rs/*目录以发现所有可用的接收器(接受复制的 Importing 编辑流的区域服务器),并使用默认值为 10%的配置比率随机选择它们的子集。例如,如果从属群集有 150 台计算机,则将选择 15 个作为该主群集区域服务器发送的编辑的潜在收件人。由于此选择是由每个主区域服务器执行的,因此使用所有从属区域服务器的可能性非常高,并且此方法适用于任何大小的群集。例如,将 10 台计算机的主群集复制到 5 台计算机的从属群集,并以 10%的比率进行复制,这将导致主群集区域服务器随机选择一台计算机。
每个主集群的区域服务器将一个 ZooKeeper 监视程序放置在从集群的* ${zookeeper.znode.parent}/rs *节点上。该手表用于监视从属群集的组成变化。当从从群集中删除节点时,或者如果节点发生故障或重新启动,则主群集的区域服务器将通过选择要复制到的新的从属区域服务器池来做出响应。
141.5.4. 记录日志
每个主群集区域服务器在复制 znodes 层次结构中都有自己的 znode。每个对等群集包含一个 znode(如果创建了 5 个从属群集,则将创建 5 个 znode),并且每个群集都包含要处理的 WAL 队列。这些队列中的每个队列都将跟踪由该区域服务器创建的 WAL,但是它们的大小可以不同。例如,如果一个从集群在一段时间内不可用,则不应删除 WAL,因此在处理其他从集群时它们需要留在队列中。有关示例,请参见rs.failover.details。
实例化源时,它包含区域服务器正在写入的当前 WAL。在日志滚动期间,新文件将在可用之前将其添加到每个从属群集的 znode 的队列中。这样可以确保所有消息源在区域服务器能够向其添加编辑之前都知道一个新日志,但是此操作现在更加昂贵。当复制线程无法从文件中读取更多条目(因为它到达最后一个块的末尾)并且队列中还有其他文件时,将丢弃队列项。这意味着,如果源是最新的并且从区域服务器写入的日志中复制,则读取当前文件的“结尾”将不会删除队列中的项目。
如果不再使用日志,或者日志数超过hbase.regionserver.maxlogs,则可以将其归档,因为插入速率比刷新区域快。归档日志后,将通知源线程该日志的路径已更改。如果特定的源已经完成了存档日志,它将仅忽略该消息。如果日志在队列中,则路径将在内存中更新。如果当前正在复制日志,则将自动进行更改,以使读取器在已移动时不会尝试打开文件。因为移动文件是 NameNode 操作,所以如果读取器当前正在读取日志,则不会生成任何异常。
141.5.5. 读取,过滤和发送编辑
默认情况下,源尝试从 WAL 中读取并将日志条目尽快发送到接收器。速度受日志条目筛选的限制,只有保留范围为 GLOBAL 且不属于目录表的键值将被保留。速度还受每个从属要复制的编辑列表的总大小限制,默认情况下,限制为 64 MB。使用此配置,具有三个从属的主群集区域服务器最多将使用 192 MB 来存储要复制的数据。这不考虑已过滤但未收集垃圾的数据。
一旦最大编辑量被缓冲或读取器到达 WAL 的末尾,源线程将停止读取并随机选择一个接收器复制到(从仅保留从属区域服务器的子集而生成的列表中) 。它直接向选定的区域服务器发出 RPC,并 await 方法返回。如果 RPC 成功,则源将确定当前文件是否已清空,或者它包含更多需要读取的数据。如果文件已清空,则源将删除队列中的 znode。否则,它将在日志的 znode 中注册新的偏移量。如果 RPC 引发异常,则源将重试 10 次,然后再尝试查找其他接收器。
141.5.6. 清洁日志
如果未启用复制,则主服务器的日志清理线程将使用配置的 TTL 删除旧日志。这种基于 TTL 的方法不适用于复制,因为超出其 TTL 的已存档日志可能仍在队列中。默认行为得到增强,因此,如果日志超出其 TTL,则清理线程将查找每个队列,直到找到日志为止,同时将已找到的队列缓存。如果在任何队列中都找不到该日志,则将删除该日志。下次清理过程需要查找日志时,它将使用其缓存列表开始。
Note
只要存在同级,就可以在启用或禁用复制时保存 WAL。
141.5.7. 区域服务器故障转移
当没有区域服务器发生故障时,跟踪 ZooKeeper 中的日志不会增加任何价值。不幸的是,区域服务器确实发生了故障,并且由于 ZooKeeper 的可用性很高,因此在发生故障时 Management 队列的传输非常有用。
每个主群集区域服务器都会在每个其他区域服务器上保留一个监视程序,以便在一个服务器死亡时得到通知(就像主服务器一样)。当发生故障时,他们都竞相在包含其队列的死区服务器的 znode 内创建一个名为lock的 znode。成功创建它的区域服务器然后将所有队列转移到自己的 znode,一次一次,因为 ZooKeeper 不支持重命名队列。队列全部传输后,将从旧位置删除队列。恢复的 znode 将使用从属群集的 ID 重命名,并附加死服务器的名称。
接下来,主群集区域服务器为每个复制的队列创建一个新的源线程,并且每个源线程都遵循读取/过滤器/发送模式。主要区别在于这些队列将永远不会接收新数据,因为它们不属于新的区域服务器。当阅读器到达最后一个日志的末尾时,队列的 znode 被删除,主群集区域服务器关闭该复制源。
给定具有 3 个区域服务器的主群集复制到 ID 为2的单个从属服务器,以下层次结构表示 znodes 布局在某个时间点可能是什么。区域服务器的 znode 都包含一个peers znode,其中包含一个队列。队列中的 znode 名称以address,port.timestamp的形式表示 HDFS 上的实际文件名。
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020, 123456630/
2/
1.1.1.3,60020.1280 (Contains a position)
假定 1.1.1.2 丢失了其 ZooKeeper 会话。幸存者将争分夺秒地 Creating 锁,并以 1.1.1.3 获胜。然后,它将通过附加死服务器的名称来开始将所有队列传输到其本地对等节点 znode。在 1.1.1.3 能够清理旧的 znode 之前,布局将如下所示:
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
lock
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020,123456630/
2/
1.1.1.3,60020.1280 (Contains a position)
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
一段时间后,但在 1.1.1.3 能够完成从 1.1.1.2 复制最后一个 WAL 之前,它也死了。在普通队列中还创建了一些新日志。然后,最后一个区域服务器将尝试锁定 1.1.1.3 的 znode 并将开始传输所有队列。新的布局将是:
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1378 (Contains a position)
2-1.1.1.3,60020,123456630/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790-1.1.1.3,60020,123456630/
1.1.1.2,60020.1312 (Contains a position)
1.1.1.3,60020,123456630/
lock
2/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1312 (Contains a position)
141.6. 复制 Metrics
以下度量标准在全局区域服务器级别和对等级别公开:
source.sizeOfLogQueue- 复制源处要处理的 WAL 数量(不包括正在处理的 WAL)
source.shippedOps- 运送的突变数量
source.logEditsRead- 在复制源处从 WAL 读取的突变数
source.ageOfLastShippedOp- 复制源出厂的最后一批的使用期限
source.completedLogs- 已完成向与该源关联的对等方的已确认发送的预写日志文件的数量。该 Metrics 的增加是 HBase 复制正常操作的一部分。
source.completedRecoverQueues- 此源已完成发送到关联对等方的恢复队列数。面对失败的区域服务器,此 Metrics 的增加是 HBase 复制正常恢复的一部分。
source.uncleanlyClosedLogs- 面对未完全关闭的文件,在达到可读条目的末尾之后,复制系统认为已完成的预写日志文件的数量。
source.ignoredUncleanlyClosedLogContentsInBytes- 如果未完全关闭预写日志文件,则可能会有一些条目已部分序列化。该度量标准包含 HBase 复制系统认为在面对未完全关闭的文件而跳过的文件末尾保留的此类条目的字节数。这些字节应该在不同的文件中,或者表示未确认的 Client 端写入。
source.restartedLogReading- HBase 复制系统检测到未能正确解析干净关闭的预写日志文件的次数。在这种情况下,系统从头开始重播整个日志,以确保相关对等方不会确认任何编辑失败。该 Metrics 的增加表示 HBase 复制系统难以正确处理基础分布式存储系统中的故障。不会发生数据丢失,但是您应该检查 Region Server 日志文件以了解失败的详细信息。
source.repeatedLogFileBytes- 当 HBase 复制系统确定需要重播给定的预写日志文件时,该 Metrics 将增加复制系统认为在重新开始之前关联对等方已确认的字节数。
source.closedLogsWithUnknownFileLength- 当 HBase 复制系统认为它位于预写日志文件的末尾但无法确定基础分布式存储系统中该文件的长度时,此值增加。由于复制系统无法确定可读条目的末尾是否与文件的预期末尾对齐,因此可能表示数据丢失。您应该检查 Region Server 日志文件以获取失败的详细信息。
141.7. 复制配置选项
| Option | Description | Default |
|---|---|---|
| zookeeper.znode.parent | 用于 HBase 的基本 ZooKeeper znode 的名称 | /hbase |
| zookeeper.znode.replication | 用于复制的基本 znode 的名称 | replication |
| zookeeper.znode.replication.peers | 对等 znode 的名称 | peers |
| zookeeper.znode.replication.peers.state | 对等状态 znode 的名称 | peer-state |
| zookeeper.znode.replication.rs | rs znode 的名称 | rs |
| replication.sleep.before.failover | 在尝试复制死区服务器的 WAL 队列之前,工作人员应休眠多少毫秒。 | |
| replication.executor.workers | 给定的区域服务器应尝试同时进行故障转移的区域服务器的数量。 | 1 |
141.8. 监视复制状态
您可以使用 HBase Shell 命令status 'replication'监视群集上的复制状态。该命令具有三种变体:* status 'replication'-按主机名排序打印每个源及其接收器的状态。 * status 'replication', 'source'-打印每个复制源的状态,按主机名排序。 * status 'replication', 'sink'-打印每个复制接收器的状态,按主机名排序。
142.在单个群集上运行多个工作负载
HBase 提供以下机制来 Management 处理多个工作负载的集群的性能: Quotas。 Request Queues。 Multiple-Typed Queues
142.1. Quotas
HBASE-11598 引入了 RPC 配额,使您可以基于以下限制来限制请求:
可以对指定的用户,表或名称空间强制执行这些限制。
Enabling Quotas
默认情况下禁用配额。要启用此功能,请为所有群集节点在* hbase-site.xml *文件中将hbase.quota.enabled属性设置为true。
一般配额语法
THROTTLE_TYPE 可以表示为 READ,WRITE 或默认类型(读写)。
时间范围可以用以下单位表示:
sec,min,hour,day请求大小可以用以下单位表示:
B(字节),K(千字节),M(兆字节),G(千兆字节),T(兆字节),P(千兆字节)请求数以整数形式表示,后跟字符串
req与时间有关的限制表示为要求/时间或大小/时间。例如
10req/day或100P/hour。表或区域的数量表示为整数。
设置请求配额
您可以提前设置配额规则,也可以在运行时更改油门。配额刷新期限到期后,更改将传播。该有效期默认为 5 分钟。要更改它,请修改hbase-site.xml中的hbase.quota.refresh.period属性。此属性以毫秒表示,默认为300000。
# Limit user u1 to 10 requests per second
hbase> set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => '10req/sec'
# Limit user u1 to 10 read requests per second
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => READ, USER => 'u1', LIMIT => '10req/sec'
# Limit user u1 to 10 M per day everywhere
hbase> set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => '10M/day'
# Limit user u1 to 10 M write size per sec
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => WRITE, USER => 'u1', LIMIT => '10M/sec'
# Limit user u1 to 5k per minute on table t2
hbase> set_quota TYPE => THROTTLE, USER => 'u1', TABLE => 't2', LIMIT => '5K/min'
# Limit user u1 to 10 read requests per sec on table t2
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => READ, USER => 'u1', TABLE => 't2', LIMIT => '10req/sec'
# Remove an existing limit from user u1 on namespace ns2
hbase> set_quota TYPE => THROTTLE, USER => 'u1', NAMESPACE => 'ns2', LIMIT => NONE
# Limit all users to 10 requests per hour on namespace ns1
hbase> set_quota TYPE => THROTTLE, NAMESPACE => 'ns1', LIMIT => '10req/hour'
# Limit all users to 10 T per hour on table t1
hbase> set_quota TYPE => THROTTLE, TABLE => 't1', LIMIT => '10T/hour'
# Remove all existing limits from user u1
hbase> set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => NONE
# List all quotas for user u1 in namespace ns2
hbase> list_quotas USER => 'u1, NAMESPACE => 'ns2'
# List all quotas for namespace ns2
hbase> list_quotas NAMESPACE => 'ns2'
# List all quotas for table t1
hbase> list_quotas TABLE => 't1'
# list all quotas
hbase> list_quotas
您还可以设置全局限制,并通过应用GLOBAL_BYPASS属性将用户或表排除在限制之外。
hbase> set_quota NAMESPACE => 'ns1', LIMIT => '100req/min' # a per-namespace request limit
hbase> set_quota USER => 'u1', GLOBAL_BYPASS => true # user u1 is not affected by the limit
设置命名空间配额
您可以在创建名称空间时或通过更改名称空间中的hbase.namespace.quota.maxtables property来指定给定名称空间中允许的最大表或区域数。
每个命名空间的限制表
# Create a namespace with a max of 5 tables
hbase> create_namespace 'ns1', {'hbase.namespace.quota.maxtables'=>'5'}
# Alter an existing namespace to have a max of 8 tables
hbase> alter_namespace 'ns2', {METHOD => 'set', 'hbase.namespace.quota.maxtables'=>'8'}
# Show quota information for a namespace
hbase> describe_namespace 'ns2'
# Alter an existing namespace to remove a quota
hbase> alter_namespace 'ns2', {METHOD => 'unset', NAME=>'hbase.namespace.quota.maxtables'}
每个命名空间的限制区域
# Create a namespace with a max of 10 regions
hbase> create_namespace 'ns1', {'hbase.namespace.quota.maxregions'=>'10'
# Show quota information for a namespace
hbase> describe_namespace 'ns1'
# Alter an existing namespace to have a max of 20 tables
hbase> alter_namespace 'ns2', {METHOD => 'set', 'hbase.namespace.quota.maxregions'=>'20'}
# Alter an existing namespace to remove a quota
hbase> alter_namespace 'ns2', {METHOD => 'unset', NAME=> 'hbase.namespace.quota.maxregions'}
142.2. 请求队列
如果未配置任何限制策略,则 RegionServer 收到多个请求后,它们现在将放入队列中,await 一个空闲的执行插槽(HBASE-6721)。最简单的队列是 FIFO 队列,其中每个请求都在运行之前 await 队列中的所有先前请求完成。快速或交互式查询可能会滞留在大型请求之后。
如果您能够猜测一个请求将花费多长时间,则可以通过将长请求推送到队列的末尾并允许短请求抢占它们来重新排序请求。最终,您仍然必须执行大型请求,并优先处理大型请求。短请求将是较新的,因此结果并不可怕,但与允许将大请求拆分为多个较小请求的机制相比,它仍然不是最佳选择。
HBASE-10993 引入了这样的系统,用于对长时间运行的扫描仪进行优先级排序。有两种类型的队列fifo和deadline。要配置使用的队列类型,请在hbase-site.xml中配置hbase.ipc.server.callqueue.type属性。无法估算每个请求可能花费的时间,因此取消优先级仅影响扫描,并且基于扫描请求发出的“下一个”调用的数量。假设进行全表扫描时,您的工作不太可能是交互式的,因此,如果存在并发请求,则可以通过设置hbase.ipc.server.queue.max.call.delay属性将长时间运行的扫描延迟到可调整的限制。延迟的斜率由(numNextCall * weight)的简单平方根计算得出,其中权重可通过设置hbase.ipc.server.scan.vtime.weight属性来配置。
142.3. 多类型队列
您还可以通过配置指定数量的专用处理程序和队列来对不同类型的请求进行优先级排序或取消优先级排序。您可以使用单个处理程序将扫描请求隔离在一个队列中,其他所有可用队列都可以处理短Get请求。
您可以使用工作负载类型使用静态调整选项来调整 IPC 队列和处理程序。此方法是过渡的第一步,最终将允许您在运行时更改设置,并根据负载动态调整值。
Multiple Queues
为避免争用并分离不同类型的请求,请配置hbase.ipc.server.callqueue.handler.factor属性,该属性允许您增加队列数并控制有多少处理程序可以共享同一队列。允许 Management 员增加队列数并确定有多少处理程序共享相同的队列。
在将任务添加到队列或从队列中选择任务时,使用更多队列可减少争用。您甚至可以为每个处理程序配置一个队列。权衡是,如果某些队列包含长时间运行的任务,则处理程序可能需要 await 从该队列执行,而不是从另一个具有 await 任务的队列中窃取。
读写队列
现在,有了多个队列,您就可以划分读写请求,为一种或另一种类型赋予更多的优先级(更多的队列)。使用hbase.ipc.server.callqueue.read.ratio属性可以选择提供更多读取或更多写入。
获取和扫描队列
与读/写拆分类似,您可以通过调整hbase.ipc.server.callqueue.scan.ratio属性来拆分获取和扫描,以使获取或扫描具有更高的优先级。扫描率0.1将为传入的获取提供更多的队列/处理程序,这意味着可以同时处理更多的获取,并且可以同时执行更少的扫描。值0.9将为扫描提供更多的队列/处理程序,因此执行的扫描数将增加而 gets 的数目将减少。
142.4. 空间配额
HBASE-16961为 HBase 引入了一种新的配额类型:文件系统配额。这些“空间”配额限制了 HBase 名称空间和表可以使用的文件系统上的空间量。如果恶意或无知的用户有足够的时间将数据写入 HBase 的能力,那么该用户可以通过消耗所有可用空间来有效地使 HBase 崩溃(或更糟糕的 HDFS)。当没有可用的文件系统空间时,HBase 崩溃,因为它不再可以将数据创建/同步到预写日志。
此功能允许对表或名称空间的大小设置限制。在名称空间上设置空间配额后,该配额的限制适用于该名称空间中所有表的使用总和。当具有配额的表存在于具有配额的名称空间中时,表配额的优先级高于名称空间配额。这允许在表集合上设置较大的限制,但该集合中的单个表可以设置细粒度的限制。
现有的set_quota和list_quota HBase Shell 命令可用于与空间配额进行交互。空间配额是TYPE到SPACE且具有LIMIT和POLICY属性的配额。 LIMIT是一个字符串,它表示配额主题(例如表或名称空间)可能消耗的文件系统上的空间量。例如,LIMIT的有效值为'10G','2T'或'256M'。 POLICY表示当配额使用者的使用量超过LIMIT时 HBase 将执行的操作。以下是有效的POLICY值。
NO_INSERTS-不得写入新数据(例如Put,Increment,Append)。NO_WRITES-与NO_INSERTS相同,但也不允许Deletes。NO_WRITES_COMPACTIONS-与NO_WRITES相同,但也不允许压缩。此策略仅阻止用户提交的压缩。系统仍然可以运行压缩。
DISABLE-禁用了该表,从而阻止了所有读/写访问。
设置简单的空间配额
# Sets a quota on the table 't1' with a limit of 1GB, disallowing Puts/Increments/Appends when the table exceeds 1GB
hbase> set_quota TYPE => SPACE, TABLE => 't1', LIMIT => '1G', POLICY => NO_INSERTS
# Sets a quota on the namespace 'ns1' with a limit of 50TB, disallowing Puts/Increments/Appends/Deletes
hbase> set_quota TYPE => SPACE, NAMESPACE => 'ns1', LIMIT => '50T', POLICY => NO_WRITES
# Sets a quota on the table 't3' with a limit of 2TB, disallowing any writes and compactions when the table exceeds 2TB.
hbase> set_quota TYPE => SPACE, TABLE => 't3', LIMIT => '2T', POLICY => NO_WRITES_COMPACTIONS
# Sets a quota on the table 't2' with a limit of 50GB, disabling the table when it exceeds 50GB
hbase> set_quota TYPE => SPACE, TABLE => 't2', LIMIT => '50G', POLICY => DISABLE
考虑以下情形以在名称空间上设置配额,覆盖该名称空间中的表上的配额
表和命名空间的空间配额
hbase> create_namespace 'ns1'
hbase> create 'ns1:t1'
hbase> create 'ns1:t2'
hbase> create 'ns1:t3'
hbase> set_quota TYPE => SPACE, NAMESPACE => 'ns1', LIMIT => '100T', POLICY => NO_INSERTS
hbase> set_quota TYPE => SPACE, TABLE => 'ns1:t2', LIMIT => '200G', POLICY => NO_WRITES
hbase> set_quota TYPE => SPACE, TABLE => 'ns1:t3', LIMIT => '20T', POLICY => NO_WRITES
在上述情况下,名称空间ns1中的表彼此之间不得占用超过 100TB 的空间。表'ns1:t2'的大小仅允许为 200GB,当使用量超过此限制时,将禁止所有写操作。表'ns1:t3'的大小可以增加到 20TB,并且如果使用量超出此限制,也将禁止所有写操作。由于“ ns1:t1”上没有表配额,因此该表可以增长到 100TB,但前提是“ ns1:t2”和“ ns1:t3”的使用量为零字节。实际上,它的限制是'ns1:t2'和'ns1:t3'的当前使用量减少 100TB。
142.5. 禁用自动删除空间配额
默认情况下,如果删除具有空间配额的表或名称空间,配额本身也将被删除。在某些情况下,可能希望不自动删除空间配额。在这些情况下,用户可以将系统配置为不通过 hbase-site.xml 自动删除任何空间配额。
<property>
<name>hbase.quota.remove.on.table.delete</name>
<value>false</value>
</property>
默认情况下,该值设置为true。
142.6. 具有空间配额的 HBase 快照
HBase 意外使用文件系统的一个常见领域是通过 HBase 快照。由于快照存在于 HBase 表 Management 之外,因此 Management 员突然意识到 HBase 快照正在使用数百 GB 或 TB 的空间,这些快照被遗忘且从未删除过,这并不少见。
HBASE-17748是总括式 JIRA 问题,它扩展了原始空间配额功能,还包括 HBase 快照。尽管这是一个令人困惑的主题,但是实现尝试以尽可能合理和简单的方式为 Management 员提供这种支持。仅在内部计算表/命名空间使用情况时,此功能不会对 Management 员与空间配额的交互进行任何更改。表和名称空间的使用将根据以下定义的规则自动合并快照占用的大小。
作为回顾,让我们介绍一下快照的生命周期:快照是指向文件系统上 HFile 列表的元数据。这就是为什么创建快照是非常便宜的操作的原因。实际上没有复制 HBase 表数据来执行快照。出于相同的原因,将快照克隆到新表中或还原表是一种廉价的操作;新表引用了文件系统上已经存在的文件,没有副本。为了将快照包括在空间配额中,我们需要定义快照引用文件时哪个表“拥有”文件(“拥有”是指包含该文件的文件系统使用情况)。
考虑针对表制作的快照。当快照引用文件时,表不再引用该文件时,“原始”表“拥有”该文件。当多个快照引用同一文件,而没有表引用该文件时,将选择排序 Sequences 最低的快照(按字典 Sequences),并从“拥有”该文件创建该快照的表。一个表中的 HFile 不是“重复计数”的,一个或多个快照引用该 HFile。
当“重新实现”表(通过clone_snapshot或restore_snapshot)时,会出现类似的文件所有权问题。在这种情况下,虽然重新实现的表引用了快照也引用的文件,但该表并不“拥有”该文件。从中创建快照的表仍然“拥有”该文件。当压缩重新实现的表或删除快照时,重新实现的表将唯一地引用一个新文件,并“拥有”该文件的用法。同样,当通过快照和restore_snapshot复制表时,新表将不会消耗任何配额大小,直到原始表停止引用文件为止,这可能是由于原始表的压缩,新表的压缩或原始表被删除。
添加了一个新的 HBase shell 命令,以检查 HBase 实例中每个快照的计算大小。
hbase> list_snapshot_sizes
SNAPSHOT SIZE
t1.s1 1159108
143. HBase 备份
执行 HBase 备份有两种主要策略:在完全关闭集群的情况下进行备份,以及在活动集群上进行备份。每种方法都有优点和缺点。
有关更多信息,请参见 Sematext 博客上的HBase 备份选项。
143.1. 完全关机备份
某些环境可以忍受其 HBase 群集的定期完全关闭,例如,如果正在使用它的后端分析功能并且不为前端网页提供服务。这样做的好处是 NameNode/Master 区域服务器处于关闭状态,因此不会丢失对 StoreFiles 或元数据的任何运行中更改。明显的缺点是群集已关闭。这些步骤包括:
143.1.1. 停止 HBase
143.1.2. Distcp
Distcp 可用于将 HDFS 中 HBase 目录的内容复制到另一个目录中的同一群集,或复制到另一个群集。
注意:Distcp 在这种情况下可以工作,因为群集已关闭并且对文件没有进行中的编辑。通常不建议在活动群集上对 HBase 目录中的文件进行分区。
143.1.3. 恢复(如果需要)
HDFS 中 hbase 目录的备份将通过 distcp 复制到“真实” hbase 目录中。复制这些文件的操作将创建新的 HDFS 元数据,这就是为什么这种还原不需要从 HBase 备份时还原 NameNode 编辑的原因,因为它是特定 HDFS 目录的还原(通过 distcp) (即 HBase 部分)而不是整个 HDFS 文件系统。
143.2. 实时群集备份-复制
该方法假定存在第二个群集。有关更多信息,请参见replication的 HBase 页面。
143.3. 实时群集备份-CopyTable
copytableUtil 既可以用于将数据从同一集群中的一个表复制到另一个表,也可以用于将数据复制到另一集群中的另一个表。
由于群集已启动,因此存在复制过程中可能会丢失编辑内容的风险。
143.4. 实时群集备份-导出
export方法将表的内容转储到同一群集上的 HDFS。要恢复数据,将使用importUtil。
由于群集已启动,因此存在导出过程中可能会丢失编辑内容的风险。
144. HBase 快照
HBase 快照使您可以复制表(内容和元数据),而对性能的影响很小。快照是表元数据和构成快照时构成表的 HFile 列表的不可变集合。快照的“克隆”从该快照创建一个新表,快照的“还原”将表的内容返回到创建快照时的表内容。 “克隆”和“还原”操作不需要复制任何数据,因为基础 HFile(包含 HBase 表数据的文件)不会通过任何一种操作进行修改。同样,将快照导出到另一个群集对本地群集的 RegionServer 几乎没有影响。
在 0.94.6 版之前,备份或克隆表的唯一方法是使用 CopyTable/ExportTable,或者在禁用表后复制 HDFS 中的所有 hfile。这些方法的缺点是,可能会降低区域服务器的性能(“复制/导出表”),或者需要禁用该表,这意味着无法进行读取或写入。这通常是不可接受的。
144.1. Configuration
要打开快照支持,只需将hbase.snapshot.enabled属性设置为 true。 (快照默认在 0.95 中启用,默认情况下在 0.94.6 中禁用)
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
144.2. 拍摄快照
您可以对表进行快照,无论该表是启用还是禁用的。快照操作不涉及任何数据复制。
$ ./bin/hbase shell
hbase> snapshot 'myTable', 'myTableSnapshot-122112'
拍摄快照而不冲洗
默认行为是在拍摄快照之前执行内存中数据的刷新。这意味着快照中包括内存中的数据。在大多数情况下,这是所需的行为。但是,如果您的设置可以忍受快照中排除的内存中的数据,则可以在拍摄快照时使用snapshot命令的SKIP_FLUSH选项禁用和刷新。
hbase> snapshot 'mytable', 'snapshot123', {SKIP_FLUSH => true}
Warning
无论启用还是禁用刷新,都无法确定或预测给定快照中是否将包含并发的插入或更新。快照只是一个时间段内表的表示。快照操作到达每个区域服务器所需的时间可能从几秒钟到一分钟不等,具体取决于资源负载和硬件或网络的速度以及其他因素。也没有办法知道给定的插入或更新是在内存中还是已刷新。
144.3. 列出快照
列出所有拍摄的快照(通过打印名称和相关信息)。
$ ./bin/hbase shell
hbase> list_snapshots
144.4. 删除快照
您可以删除快照,并且不再需要保留为该快照保留的文件。
$ ./bin/hbase shell
hbase> delete_snapshot 'myTableSnapshot-122112'
144.5. 从快照克隆表
从快照中,您可以创建一个新表(克隆操作),该表具有与拍摄快照时相同的数据。克隆操作不涉及数据副本,并且对克隆表的更改不会影响快照或原始表。
$ ./bin/hbase shell
hbase> clone_snapshot 'myTableSnapshot-122112', 'myNewTestTable'
144.6. 恢复快照
恢复操作需要禁用该表,并且该表将恢复到拍摄快照时的状态,并根据需要更改数据和架构。
$ ./bin/hbase shell
hbase> disable 'myTable'
hbase> restore_snapshot 'myTableSnapshot-122112'
Note
由于复制工作在日志级别,快照工作在文件系统级别,因此还原后,副本将与主副本处于不同状态。如果要使用还原,则需要停止复制并重做引导程序。
如果由于 Client 端行为不当导致部分数据丢失,则可以从快照克隆表并使用 Map-Reduce 作业从快照中复制所需的数据,而不是需要禁用表的完全还原。克隆到主要的。
144.7. 快照操作和 ACL
如果您将安全性与 AccessController 协处理器一起使用(请参阅hbase.accesscontrol.configuration),则只有全局 Management 员才能创建,克隆或还原快照,并且这些操作不会捕获 ACL 权限。这意味着还原表会保留现有表的 ACL 权限,而克隆表会创建一个新表,该表在 Management 员添加它们之前不会具有 ACL 权限。
144.8. 导出到另一个集群
ExportSnapshot 工具会将与快照有关的所有数据(hfile,日志,快照元数据)复制到另一个群集。该工具执行类似于 distcp 的 Map-Reduce 作业,以在两个群集之间复制文件,并且由于它在文件系统级别工作,因此 hbase 群集不必处于联机状态。
使用 16 个 Map 器将名为 MySnapshot 的快照复制到 HBase 群集 srv2(hdfs:/// srv2:8082/hbase):
$ bin/hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase -mappers 16
限制带宽消耗
您可以通过指定-bandwidth参数来限制导出快照时的带宽消耗,该参数应为代表每秒兆字节的整数。下面的示例将上面的示例限制为 200 MB /秒。
$ bin/hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase -mappers 16 -bandwidth 200
144.9. 在 Amazon S3 存储桶中存储快照
您可以使用以下过程从 Amazon S3 存储和检索快照。
Note
您还可以将快照存储在 Microsoft Azure Blob 存储中。参见在 Microsoft Azure Blob 存储中存储快照。
Prerequisites
您必须使用 HBase 1.0 或更高版本以及 Hadoop 2.6.1 或更高版本,这是使用 Amazon AWS 开发工具包的第一个配置。
您必须使用
s3a://协议连接到 Amazon S3.较旧的s3n://和s3://协议具有各种限制,并且不使用 Amazon AWS 开发工具包。s3a://URI 必须在运行命令以导出和还原快照的服务器上配置并可用。
满足前提条件后,照常进行快照。之后,您可以像下面的命令一样使用org.apache.hadoop.hbase.snapshot.ExportSnapshot命令将其导出,在copy-from或copy-to指令中替换您自己的s3a://路径,并根据需要替换或修改其他选项:
$ hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot \
-copy-from hdfs://srv2:8082/hbase \
-copy-to s3a://<bucket>/<namespace>/hbase \
-chuser MyUser \
-chgroup MyGroup \
-chmod 700 \
-mappers 16
$ hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot MySnapshot
-copy-from s3a://<bucket>/<namespace>/hbase \
-copy-to hdfs://srv2:8082/hbase \
-chuser MyUser \
-chgroup MyGroup \
-chmod 700 \
-mappers 16
您还可以通过包含-remote-dir选项将org.apache.hadoop.hbase.snapshot.SnapshotInfoUtil 与s3a://路径一起使用。
$ hbase org.apache.hadoop.hbase.snapshot.SnapshotInfo \
-remote-dir s3a://<bucket>/<namespace>/hbase \
-list-snapshots
145.在 Microsoft Azure Blob 存储中存储快照
您可以使用与在 Amazon S3 存储桶中存储快照相同的技术将快照存储在 Microsoft Azure 博客存储中。
Prerequisites
您必须将 HBase 1.2 或更高版本与 Hadoop 2.7.1 或更高版本配合使用。没有 HBase 版本支持 Hadoop 2.7.0.
必须将主机配置为了解 Azure blob 存储文件系统。参见https://hadoop.apache.org/docs/r2.7.1/hadoop-azure/index.html。
满足先决条件后,请按照在 Amazon S3 存储桶中存储快照中的说明进行操作,用wasb://或wasbs://代替协议说明符。
146.容量规划和区域大小
在规划 HBase 群集的容量并执行初始配置时,有一些注意事项。首先要对 HBase 如何在内部处理数据有扎实的了解。
146.1. 节点数和硬件/ VM 配置
146.1.1. 物理数据大小
磁盘上的物理数据大小与数据的逻辑大小不同,并且受以下因素影响:
HBase 开销增加
KeyValue 实例聚合到块中,并对其构建索引。索引也必须存储。块大小可以在每个 ColumnFamily 的基础上进行配置。参见regions.arch。
减少compression和数据块编码,具体取决于数据。另请参见this thread。您可能需要测试哪种压缩和编码(如果有)对您的数据有意义。
通过区域服务器wal的大小增加(通常是固定且可忽略的-每个 RS 小于 RS 内存大小的一半)。
通过 HDFS 复制增加-通常为 x3.
除了存储数据所需的磁盘空间外,由于区域计数和大小的某些实际限制,一个 RS 可能无法提供任意数量的数据(请参见ops.capacity.regions)。
146.1.2. 读/写吞吐量
节点的数量也可以由读取和/或写入所需的吞吐量来驱动。每个节点可获得的吞吐量在很大程度上取决于数据(尤其是键/值的大小)和请求模式,以及节点和系统配置。如果峰值负载可能是增加节点数的主要驱动力,则应该对峰值负载进行规划。 PerformanceEvaluation 和ycsb工具可用于测试单个节点或测试集群。
对于写入,由于每个区域服务器只有一个活动的 WAL,通常每个 RS 可以期望 5-15Mb/s。没有很好的读取估计,因为它很大程度上取决于数据,请求和缓存命中率。 perf.casestudy可能会有所帮助。
146.1.3. JVM GC 限制
由于 GC 的成本,RS 当前无法利用非常大的堆。除了在每台计算机上运行多个 VM 之外,也没有一种很好的方式在每个服务器上运行多个 RS-es。因此,建议为一个 RS 专用~20-24Gb 或更少的内存。大堆大小需要 GC 调整。参见gcpause,trouble.log.gc和其他地方(待办事项:在哪里?)
146.2. 确定区域数和大小
通常,较少的区域可以使集群运行更加顺畅(您可以随时稍后手动分割较大的区域(如有必要),以在集群上分散数据或请求负载);每个 RS 20-200 个区域是一个合理的范围。无法直接配置区域数量(除非您完全使用disable.splitting);调整区域大小以达到给定表大小的目标区域大小。
为多个表配置区域时,请注意,大多数区域设置都可以通过HTableDescriptor以及 shell 命令在每个表的基础上进行设置。这些设置将覆盖hbase-site.xml中的设置。如果您的表具有不同的工作负载/用例,这将很有用。
另请注意,在此处讨论区域大小时,(并且不应考虑) HDFS 复制因子,而应考虑其他因素ops.capacity.nodes.datasize.*因此,如果您的数据通过 HDFS 压缩和复制 3 种方式,“ 9 Gb 区域”表示 9 Gb 压缩数据。 HDFS 复制因子仅影响您的磁盘使用情况,对于大多数 HBase 代码是不可见的。
146.2.1. 查看当前区域数
您可以使用 HMaster UI 查看给定表的当前区域数。在“表”部分中,“在线区域”列中列出了每个表的在线区域数。此总数仅包括内存中状态,不包括禁用或脱机区域。
146.2.2. 每个 RS 的区域数-上限
在生产环境中,如果您有大量数据,通常会担心每个服务器可以拥有的最大区域数。 太多地区对此主题进行了技术讨论。基本上,最大区域数主要由内存存储使用情况决定。每个地区都有自己的 Memory 库;它们长到可配置的大小;通常在 128-256 MB 范围内,请参见hbase.hregion.memstore.flush.size。每个列族存在一个内存存储(因此,如果表中有一个 CF,则每个区域只有一个)。 RS 将总内存的一部分分配给它的内存(请参见hbase.regionserver.global.memstore.size)。如果超出了此内存(内存存储使用过多),则可能导致不良后果,例如服务器无响应或压缩风暴。每个 RS 的区域数(假设一张表)的一个很好的起点是:
((RS memory) * (total memstore fraction)) / ((memstore size)*(# column families))
此公式是伪代码。这是两个使用实际可调参数的公式,第一个用于 HBase 0.98,第二个用于 HBase0.94.x。
- HBase 0.98.x
((RS Xmx) * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * (# column families))
- HBase 0.94.x
((RS Xmx) * hbase.regionserver.global.memstore.upperLimit) / (hbase.hregion.memstore.flush.size * (# column families))+
如果给定的 RegionServer 具有 16 GB 的 RAM(使用默认设置),则该公式计算出每个 RS 的起点为 16384 * 0.4/128~51 个区域。该公式可以扩展到多个表。如果它们都具有相同的配置,则仅使用家族总数。
这个数字可以调整;上面的公式假定您所有区域的填充率大致相同。如果只有一部分区域要被主动写入,则可以将结果除以该部分来获得更大的区域数。然后,即使所有区域都被写入,所有区域的内存存储也不会被均匀填充,并且即使它们被覆盖,最终也会出现抖动(由于并发刷新的数量有限)。因此,一个区域可能比起点多出 2-3 倍;但是,数量增加会带来更大的风险。
对于繁重的写工作负载,可以在配置中增加内存存储部分,但以块缓存为代价;这也将使人们拥有更多的区域。
146.2.3. 每个 RS 的区域数-下限
HBase 通过在许多服务器上具有区域来扩展。因此,如果您有 2 个区域可存储 16GB 数据,则在 20 节点计算机上,您的数据将仅集中在少数计算机上-几乎整个群集都将处于空闲状态。实际上,这还不够强调,因为一个常见的问题是将 200MB 数据加载到 HBase 中,然后想知道为什么您的 10 节点超棒集群无法执行任何操作。
另一方面,如果您有大量数据,则可能还需要使用更多区域,以避免区域过大。
146.2.4. 最大区域大小
对于生产方案中的大型表,最大区域大小主要受压缩限制-特别是非常大的压缩。严重,会降低群集性能。当前,建议的最大区域大小是 10-20Gb,最佳是 5-10Gb。对于较旧的 0.90.x 代码库,regionsize 的上限约为 4Gb,默认值为 256Mb。
通常通过hbase.hregion.max.filesize配置将区域分为两部分的大小;有关详细信息,请参见arch.region.splits。
如果您无法很好地估计表的大小,那么在开始时,最好保持默认的区域大小,对于热表可能要更小(或手动拆分热区域以将负载分散到群集中),或者如果您的像元大小倾向于较大(100k 及以上),则可以使用更大的区域。
在 HBase 0.98 中,添加了实验性条带压缩功能,该功能将允许更大的区域,尤其是日志数据。参见ops.stripe。
146.2.5. 每个区域服务器的总数据大小
根据上述区域大小和每个区域服务器的区域数量的数字,乐观地估计,每个 RS 10 GB x 100 个区域将为每个区域服务器提供多达 1TB 的服务,这与某些已报告的多 PB 用例相符。但是,重要的是要考虑 RS 级别的数据与缓存大小之比。每台服务器 1TB 的数据和 10GB 的块缓存,将仅缓存 1%的数据,这几乎不能覆盖所有块索引。
146.3. 初始配置和调整
首先,请参见important configurations。请注意,某些配置要比其他配置更多,这取决于特定的方案。要特别注意:
hbase.regionserver.handler.count-请求处理程序线程数,对于高吞吐量工作负载至关重要。
config.wals-WAL 文件的阻止数量取决于您的内存存储配置,并且应进行相应设置,以防止在进行大量写操作时潜在的阻止。
然后,在设置集群和表时有一些注意事项。
146.3.1. Compactions
根据读/写量和 await 时间要求,最佳压缩设置可能会有所不同。有关详细信息,请参见compaction。
但是,在配置大数据量时,请记住紧缩会影响写入吞吐量。因此,对于写密集型工作负载,您可以选择较少的压缩频率和每个区域更多的存储文件。压缩的最小文件数(hbase.hstore.compaction.min)可以设置为更高的值; hbase.hstore.blockingStoreFiles也应增加,因为在这种情况下可能会累积更多文件。您也可以考虑手动 Management 压缩:managed.compactions
146.3.2. 预分桌
根据每个 RS 的目标区域数(请参阅ops.capacity.regions.count)和 RS 的数目,可以在创建时预分割表格。这样既可以避免在表开始填满时进行某些昂贵的拆分,又可以确保表开始时已经分布在许多服务器上。
如果期望该表足够大以证明这一点,则应为每个 RS 创建至少一个区域。不建议立即划分为全部目标区域数(例如 50 * RSes 数),但是可以选择较低的中间值。对于多张桌子,建议在进行预分割时保持保守(例如,每个 RS 最多预分割 1 个区域),尤其是在您不知道每张桌子将增长多少的情况下。如果拆分过多,可能会导致区域过多,而某些表的区域过多。
有关预拆分方法的信息,请参见手动区域分割决策和precreate.regions。
147.表重命名
在 hbase 及更低版本的 0.90.x 中,我们有一个简单的脚本,该脚本将重命名 hdfs 表目录,然后对 hbase:meta 表进行编辑,用新表名替换所有旧表名。该脚本称为./bin/rename_table.rb。不推荐使用该脚本并将其删除,主要是因为该脚本无法维护,并且该脚本执行的操作很残酷。
从 hbase 0.94.x 开始,您可以使用快照功能重命名表。使用 hbase shell 的方法如下:
hbase shell> disable 'tableName'
hbase shell> snapshot 'tableName', 'tableSnapshot'
hbase shell> clone_snapshot 'tableSnapshot', 'newTableName'
hbase shell> delete_snapshot 'tableSnapshot'
hbase shell> drop 'tableName'
或在代码中如下所示:
void rename(Admin admin, String oldTableName, TableName newTableName) {
String snapshotName = randomName();
admin.disableTable(oldTableName);
admin.snapshot(snapshotName, oldTableName);
admin.cloneSnapshot(snapshotName, newTableName);
admin.deleteSnapshot(snapshotName);
admin.deleteTable(oldTableName);
}
148. RegionServer 分组
RegionServer Grouping(A.K.A rsgroup)是一项高级功能,用于将 Regionserver 划分为不同的组以进行严格隔离。仅应由足够精通理解全部含义并具有足够的背景知识来 ManagementHBase 群集的用户使用。它是由 Yahoo!开发的。他们在大型网格集群上大规模运行它。参见Yahoo 的 HBase!规模。
RSGroup 是使用 Shell 命令定义和 Management 的。Shell 程序驱动一个协处理器端点,鉴于这是一个不断 Developing 的功能,该端点的 API 被标记为私有。协处理器 API 不供公众使用。可以将服务器添加到具有主机名和端口对的组中,并且可以将表移至该组,以便只有同一 rsgroup 中的 regionservers 可以托管表的区域。 RegionServers 和表一次只能属于一个 rsgroup。默认情况下,所有表和区域服务器都属于default rsgroup。也可以使用常规 API 将系统表放入 rsgroup 中。定制平衡器实现跟踪每个 rsgroup 中的分配,并确保将区域移动到该 rsgroup 中的相关区域服务器。 rsgroup 信息存储在常规 HBase 表中,并且在集群引导时使用基于 Zookeeper 的只读缓存。
要启用,请将以下内容添加到您的 hbase-site.xml 并重新启动您的 Master:
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.rsgroup.RSGroupAdminEndpoint</value>
</property>
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.hadoop.hbase.rsgroup.RSGroupBasedLoadBalancer</value>
</property>
然后使用 shell * rsgroup *命令创建和操作 RegionServer 组:添加 rsgroup,然后向其中添加服务器。要查看 hbase shell 中可用的 rsgroup 命令列表,请执行以下操作:
hbase(main):008:0> help 'rsgroup'
Took 0.5610 seconds
在较高级别,您可以使用* add_rsgroup 命令创建一个与default组不同的 rsgroup。然后,使用 move_servers_rsgroup 和 move_tables_rsgroup 命令将服务器和表添加到该组。如有必要,如果使用 balance_rsgroup *命令将表迁移到组专用服务器时速度很慢(通常不需要),请为该组运行余额。要监视命令的效果,请参阅主 UI 主页末尾的Tables标签。如果单击表,则可以查看该表在哪些服务器上部署。您应该在这里看到用 shell 命令完成的分组的反映。如果有问题,请查看主日志。
这是使用一些 rsgroup 命令的示例。要添加组,请执行以下操作:
hbase(main):008:0> add_rsgroup 'my_group'
Took 0.5610 seconds
RegionServer Groups must be Enabled
如果尚未在主服务器中启用 rsgroup 协处理器端点,并且运行了任何 rsgroup shell 命令,则将看到类似以下的错误消息:
ERROR: org.apache.hadoop.hbase.exceptions.UnknownProtocolException: No registered master coprocessor service found for name RSGroupAdminService
at org.apache.hadoop.hbase.master.MasterRpcServices.execMasterService(MasterRpcServices.java:604)
at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:1140)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:277)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:257)
使用* move_servers_rsgroup *命令将服务器(由主机名端口指定)添加到刚刚创建的组中,如下所示:
hbase(main):010:0> move_servers_rsgroup 'my_group',['k.att.net:51129']
Hostname and Port vs ServerName
rsgroup 功能仅指集群中具有主机名和端口的服务器。它不使用标识 RegionServers 的 HBase ServerName 类型。即主机名端口开始时间以区分 RegionServer 实例。 rsgroup 功能可在 RegionServer 重新启动之间保持工作状态,因此 ServerName 的启动时间(,因此 ServerName 类型的启动时间)不合适。行政
服务器在群集的整个生命周期中来来往往。当前,您必须手动将 rsgroups 中引用的服务器与正在运行的集群中节点的实际状态对齐。我们的意思是,如果停用服务器,则必须在服务器停用过程中更新 rsgroup,以删除引用。
但是,您没有说_remove_offline_servers_rsgroup_command!
删除服务器的方法是将其移动到default组。 default组很特殊。除了default rsgroup 外,所有 rsgroup 都是静态的,因为通过 shell 命令进行的编辑将持久保存到系统hbase:rsgroup表中。如果它们引用已停用的服务器,则需要对其进行更新以撤消引用。
default组与其他 rsgroup 不同,它是动态的。它的服务器列表反映了集群的当前状态。也就是说,如果您关闭了属于default rsgroup 的服务器,然后执行* get_rsgroup * default在 Shell 中列出其内容,则该服务器将不再列出。对于非default组,尽管某个模式可能处于脱机状态,但它将保留在非default组的服务器列表中。但是,如果将脱机服务器从非默认 rsgroup 移到默认服务器,它将不会显示在default列表中。它将被删除。
148.1. 最佳实践
rsgroup 功能的作者 Yahoo! HBase 工程团队已经在网格上运行了很长一段时间,并根据他们的经验提出了一些最佳实践。
148.1.1. 隔离系统表
要么有一个系统 rsgroup,其中所有系统表都在其中,要么只是将系统表保留在default rsgroup 中,并将所有用户空间表都放在非default rsgroup 中。
148.1.2. 死节点
雅虎!发现在规模上保持死节点或可疑节点的特殊 rsgroup 很有用;这是使它们一直运行直到修复的一种方法。
小心替换 rsgroup 中的死节点。开始移出死角之前,请确保有足够的活动节点。如有必要,请先移动良好的活动节点。
148.2. Troubleshooting
查看主日志将使您深入了解 rsgroup 的操作。
如果它似乎卡住了,请重新启动主进程。
148.3. 删除 RegionServer 分组
从启用了该功能的群集中删除 RegionServer Grouping 功能除了从hbase-site.xml中删除相关属性外,还涉及更多步骤。这是为了清理 RegionServer 分组相关的元数据,以便如果将来重新启用该功能,则旧的元数据将不会影响群集的功能。
- 将非默认 rsgroup 中的所有表移动到
defaultregionserver 组
#Reassigning table t1 from non default group - hbase shell
hbase(main):005:0> move_tables_rsgroup 'default',['t1']
- 将非默认 rsgroup 中的所有区域服务器移到
defaultregionserver 组
#Reassigning all the servers in the non-default rsgroup to default - hbase shell
hbase(main):008:0> move_servers_rsgroup 'default',['rs1.xxx.com:16206','rs2.xxx.com:16202','rs3.xxx.com:16204']
- 删除所有非默认的 rsgroup。
default隐式创建的 rsgroup 不必删除
#removing non default rsgroup - hbase shell
hbase(main):009:0> remove_rsgroup 'group2'
删除在
hbase-site.xml中所做的更改,然后重新启动集群从
hbase删除表hbase:rsgroup
#Through hbase shell drop table hbase:rsgroup
hbase(main):001:0> disable 'hbase:rsgroup'
0 row(s) in 2.6270 seconds
hbase(main):002:0> drop 'hbase:rsgroup'
0 row(s) in 1.2730 seconds
- 使用 zkCli.sh 从集群 ZooKeeper 中删除 znode
rsgroup
#From ZK remove the node /hbase/rsgroup through zkCli.sh
rmr /hbase/rsgroup
148.4. ACL
要启用 ACL,请将以下内容添加到 hbase-site.xml 中,然后重新启动 Master:
<property>
<name>hbase.security.authorization</name>
<value>true</value>
<property>
149.区域标准化器
区域规范化器试图使表中所有区域的大小大致相同。它通过找到一个粗略的平均值来做到这一点。大于此大小两倍的任何区域都会被分割。任何较小的区域都将合并到相邻区域中。在集群运行了一段时间之后,或者说是在诸如大型删除之类的活动爆发之后,偶尔需要在停机时间运行 Normalizer 很好。
(以下大部分细节是 Romil Choksi 在HBase 区域规范化器处从博客中批发复制的)
自 HBase-1.2 起,区域规范器已可用。它运行一组预先计算的合并/拆分操作,以调整与给定表的平均区域大小相比过大或过小的区域的大小。调用时,Region Normalizer 将为 HBase 中的所有表计算归一化“计划”。在计算计划时,系统表(例如 hbase:meta,hbase:namespace,Phoenix 系统表等)和禁用了标准化的用户表将被忽略。对于启用归一化的表,跨多个表并行执行归一化计划。
可以使用 HBase Shell 中的“ normalizer_switch”命令为整个集群全局启用或禁用 Normalizer。规范化还可以在每个表的基础上进行控制,默认情况下在创建表时将其禁用。通过将 NORMALIZATION_ENABLED 表属性设置为 true 或 false,可以启用或禁用表的规范化。
检查规范化器状态并启用/禁用规范化器
hbase(main):001:0> normalizer_enabled
true
0 row(s) in 0.4870 seconds
hbase(main):002:0> normalizer_switch false
true
0 row(s) in 0.0640 seconds
hbase(main):003:0> normalizer_enabled
false
0 row(s) in 0.0120 seconds
hbase(main):004:0> normalizer_switch true
false
0 row(s) in 0.0200 seconds
hbase(main):005:0> normalizer_enabled
true
0 row(s) in 0.0090 seconds
启用后,每 5 分钟(默认情况下)会在后台调用 Normalizer,默认情况下,可以使用hbase-site.xml中的hbase.normalization.period对其进行配置。还可以使用 HBase shell 的normalize命令随意/以编程方式调用 Normalizer。 HBase 默认情况下使用SimpleRegionNormalizer,但是用户可以设计自己的规范化器,只要他们实现 RegionNormalizer 接口即可。有关SimpleRegionNormalizer用于计算其规范化计划的逻辑的详细信息,请参见here。
下面的示例显示针对用户表计算的规范化计划,并采取合并操作作为由 SimpleRegionNormalizer 计算的规范化计划的结果。
考虑一个用户表,其中的一些预分割区域具有 3 个相等的大区域(约 10 万行)和 1 个相对较小的区域(约 25K 行)。以下是 hbase 元表扫描的片段,其中显示了用户表的每个预分割区域。
table_p8ddpd6q5z,,1469494305548.68b9892220865cb6048 column=info:regioninfo, timestamp=1469494306375, value={ENCODED => 68b9892220865cb604809c950d1adf48, NAME => 'table_p8ddpd6q5z,,1469494305548.68b989222 09c950d1adf48. 0865cb604809c950d1adf48.', STARTKEY => '', ENDKEY => '1'}
....
table_p8ddpd6q5z,1,1469494317178.867b77333bdc75a028 column=info:regioninfo, timestamp=1469494317848, value={ENCODED => 867b77333bdc75a028bb4c5e4b235f48, NAME => 'table_p8ddpd6q5z,1,1469494317178.867b7733 bb4c5e4b235f48. 3bdc75a028bb4c5e4b235f48.', STARTKEY => '1', ENDKEY => '3'}
....
table_p8ddpd6q5z,3,1469494328323.98f019a753425e7977 column=info:regioninfo, timestamp=1469494328486, value={ENCODED => 98f019a753425e7977ab8636e32deeeb, NAME => 'table_p8ddpd6q5z,3,1469494328323.98f019a7 ab8636e32deeeb. 53425e7977ab8636e32deeeb.', STARTKEY => '3', ENDKEY => '7'}
....
table_p8ddpd6q5z,7,1469494339662.94c64e748979ecbb16 column=info:regioninfo, timestamp=1469494339859, value={ENCODED => 94c64e748979ecbb166f6cc6550e25c6, NAME => 'table_p8ddpd6q5z,7,1469494339662.94c64e74 6f6cc6550e25c6. 8979ecbb166f6cc6550e25c6.', STARTKEY => '7', ENDKEY => '8'}
....
table_p8ddpd6q5z,8,1469494339662.6d2b3f5fd1595ab8e7 column=info:regioninfo, timestamp=1469494339859, value={ENCODED => 6d2b3f5fd1595ab8e7c031876057b1ee, NAME => 'table_p8ddpd6q5z,8,1469494339662.6d2b3f5f c031876057b1ee. d1595ab8e7c031876057b1ee.', STARTKEY => '8', ENDKEY => ''}
使用 HBase shell 中的'normalize'调用规范化器,HMaster 日志中的以下日志片段显示了根据为 SimpleRegionNormalizer 定义的逻辑计算出的规范化计划。由于表中相邻最小区域的总区域大小(以 MB 为单位)小于平均区域大小,因此规范化器会计算合并这两个区域的计划。
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: hbase:namespace, as it's either system table or doesn't have auto
normalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: hbase:backup, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: hbase:meta, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] master.HMaster: Skipping normalization for table: table_h2osxu3wat, as it's either system table or doesn't have autonormalization turned on
2016-07-26 07:08:26,928 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Computing normalization plan for table: table_p8ddpd6q5z, number of regions: 5
2016-07-26 07:08:26,929 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, total aggregated regions size: 12
2016-07-26 07:08:26,929 DEBUG [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, average region size: 2.4
2016-07-26 07:08:26,929 INFO [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, small region size: 0 plus its neighbor size: 0, less thanthe avg size 2.4, merging them
2016-07-26 07:08:26,971 INFO [B.fifo.QRpcServer.handler=20,queue=2,port=20000] normalizer.MergeNormalizationPlan: Executing merging normalization plan: MergeNormalizationPlan{firstRegion={ENCODED=> d51df2c58e9b525206b1325fd925a971, NAME => 'table_p8ddpd6q5z,,1469514755237.d51df2c58e9b525206b1325fd925a971.', STARTKEY => '', ENDKEY => '1'}, secondRegion={ENCODED => e69c6b25c7b9562d078d9ad3994f5330, NAME => 'table_p8ddpd6q5z,1,1469514767669.e69c6b25c7b9562d078d9ad3994f5330.',
STARTKEY => '1', ENDKEY => '3'}}
按照其计算计划的区域规范化器,将开始键为'',结束键为'1'的区域与另一个开始键为'1'和结束键为'3'的区域合并。现在,这些区域已合并,我们看到一个新的区域,其开始键为“'',结束键为“ 3”
table_p8ddpd6q5z,,1469516907210.e06c9b83c4a252b130e column=info:mergeA, timestamp=1469516907431,
value=PBUF\x08\xA5\xD9\x9E\xAF\xE2*\x12\x1B\x0A\x07default\x12\x10table_p8ddpd6q5z\x1A\x00"\x011(\x000\x00 ea74d246741ba. 8\x00
table_p8ddpd6q5z,,1469516907210.e06c9b83c4a252b130e column=info:mergeB, timestamp=1469516907431,
value=PBUF\x08\xB5\xBA\x9F\xAF\xE2*\x12\x1B\x0A\x07default\x12\x10table_p8ddpd6q5z\x1A\x011"\x013(\x000\x0 ea74d246741ba. 08\x00
table_p8ddpd6q5z,,1469516907210.e06c9b83c4a252b130e column=info:regioninfo, timestamp=1469516907431, value={ENCODED => e06c9b83c4a252b130eea74d246741ba, NAME => 'table_p8ddpd6q5z,,1469516907210.e06c9b83c ea74d246741ba. 4a252b130eea74d246741ba.', STARTKEY => '', ENDKEY => '3'}
....
table_p8ddpd6q5z,3,1469514778736.bf024670a847c0adff column=info:regioninfo, timestamp=1469514779417, value={ENCODED => bf024670a847c0adffb74b2e13408b32, NAME => 'table_p8ddpd6q5z,3,1469514778736.bf024670 b74b2e13408b32. a847c0adffb74b2e13408b32.' STARTKEY => '3', ENDKEY => '7'}
....
table_p8ddpd6q5z,7,1469514790152.7c5a67bc755e649db2 column=info:regioninfo, timestamp=1469514790312, value={ENCODED => 7c5a67bc755e649db22f49af6270f1e1, NAME => 'table_p8ddpd6q5z,7,1469514790152.7c5a67bc 2f49af6270f1e1. 755e649db22f49af6270f1e1.', STARTKEY => '7', ENDKEY => '8'}
....
table_p8ddpd6q5z,8,1469514790152.58e7503cda69f98f47 column=info:regioninfo, timestamp=1469514790312, value={ENCODED => 58e7503cda69f98f4755178e74288c3a, NAME => 'table_p8ddpd6q5z,8,1469514790152.58e7503c 55178e74288c3a. da69f98f4755178e74288c3a.', STARTKEY => '8', ENDKEY => ''}
对于具有 3 个较小区域和 1 个相对较大区域的用户表,可以看到类似的示例。对于此示例,我们有一个用户表,其中有 1 个大区域包含 10 万行,而有 3 个相对较小的区域,每个约有 33K 行。从规范化计划中可以看出,由于较大的区域是平均区域大小的两倍以上,因此将其分为两个区域,一个区域的开始键为“ 1”,结束键为“ 154717”,另一个区域的起始键为'154717',结束键为'3'
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] master.HMaster: Skipping normalization for table: hbase:backup, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Computing normalization plan for table: table_p8ddpd6q5z, number of regions: 4
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, total aggregated regions size: 12
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_p8ddpd6q5z, average region size: 3.0
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: No normalization needed, regions look good for table: table_p8ddpd6q5z
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Computing normalization plan for table: table_h2osxu3wat, number of regions: 5
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_h2osxu3wat, total aggregated regions size: 7
2016-07-26 07:39:45,636 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_h2osxu3wat, average region size: 1.4
2016-07-26 07:39:45,636 INFO [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SimpleRegionNormalizer: Table table_h2osxu3wat, large region table_h2osxu3wat,1,1469515926544.27f2fdbb2b6612ea163eb6b40753c3db. has size 4, more than twice avg size, splitting
2016-07-26 07:39:45,640 INFO [B.fifo.QRpcServer.handler=7,queue=1,port=20000] normalizer.SplitNormalizationPlan: Executing splitting normalization plan: SplitNormalizationPlan{regionInfo={ENCODED => 27f2fdbb2b6612ea163eb6b40753c3db, NAME => 'table_h2osxu3wat,1,1469515926544.27f2fdbb2b6612ea163eb6b40753c3db.', STARTKEY => '1', ENDKEY => '3'}, splitPoint=null}
2016-07-26 07:39:45,656 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] master.HMaster: Skipping normalization for table: hbase:namespace, as it's either system table or doesn't have auto normalization turned on
2016-07-26 07:39:45,656 DEBUG [B.fifo.QRpcServer.handler=7,queue=1,port=20000] master.HMaster: Skipping normalization for table: hbase:meta, as it's either system table or doesn't
have auto normalization turned on …..…..….
2016-07-26 07:39:46,246 DEBUG [AM.ZK.Worker-pool2-t278] master.RegionStates: Onlined 54de97dae764b864504704c1c8d3674a on hbase-test-rc-5.openstacklocal,16020,1469419333913 {ENCODED => 54de97dae764b864504704c1c8d3674a, NAME => 'table_h2osxu3wat,1,1469518785661.54de97dae764b864504704c1c8d3674a.', STARTKEY => '1', ENDKEY => '154717'}
2016-07-26 07:39:46,246 INFO [AM.ZK.Worker-pool2-t278] master.RegionStates: Transition {d6b5625df331cfec84dce4f1122c567f state=SPLITTING_NEW, ts=1469518786246, server=hbase-test-rc-5.openstacklocal,16020,1469419333913} to {d6b5625df331cfec84dce4f1122c567f state=OPEN, ts=1469518786246,
server=hbase-test-rc-5.openstacklocal,16020,1469419333913}
2016-07-26 07:39:46,246 DEBUG [AM.ZK.Worker-pool2-t278] master.RegionStates: Onlined d6b5625df331cfec84dce4f1122c567f on hbase-test-rc-5.openstacklocal,16020,1469419333913 {ENCODED => d6b5625df331cfec84dce4f1122c567f, NAME => 'table_h2osxu3wat,154717,1469518785661.d6b5625df331cfec84dce4f1122c567f.', STARTKEY => '154717', ENDKEY => '3'}
构建和开发 Apache HBase
本章包含有关构建和发布 HBase 代码和文档的信息和准则。熟悉这些准则将有助于 HBase 提交者更轻松地使用您的贡献。
150.参与其中
只有人们做出贡献,Apache HBase 才能变得更好!如果您想为 Apache HBase 做贡献,请寻找JIRA 中带有标签“Starters”的问题。这些是 HBase 贡献者认为值得但并非紧迫的问题,也是提升 HBase 内部结构的好方法。请参阅开发邮件列表中的对于新的贡献者来说,什么样的标签才适合解决问题?以获取背景信息。
在开始向 HBase 提交代码之前,请参考developing。
由于 Apache HBase 是 Apache Software Foundation 项目,请参见asf以获取有关 ASF 的功能的更多信息。
150.1. 邮件列表
注册开发人员列表和用户列表。参见mailing lists页。鼓励提出问题,并帮助回答其他人的问题!两种清单上的经验水平各不相同,因此鼓励耐心和礼貌(请留意 Topic)。
150.2. Slack
Apache HBase 项目具有自己的链接:Slack Channel用于实时问题和讨论。邮寄dev@hbase.apache.org以请求邀请。
150.3. 互联网中继聊天(IRC)
(注意:我们的 IRCChannels 似乎已不推荐使用上述 SlackChannels)
有关实时问题和讨论,请使用FreeNode IRC 网络上的#hbase IRCChannels。 FreeNode 提供了一个基于 Web 的 Client 端,但是大多数人更喜欢本机 Client 端,并且每个 os 都可以使用多个 Client 端。
150.4. Jira
检查Jira中是否存在问题。如果是新功能请求,增强功能或错误,请提交票证。
我们在 JIRA 中跟踪多种类型的工作:
错误:HBase 本身发生了问题。
测试:需要测试,或者测试被破坏。
新功能:您对新功能有所了解。通常最好先在邮件列表中列出这些内容,然后编写您添加到功能请求 JIRA 中的设计规范。
改进:存在一个功能,但可以对其进行调整或增强。通常最好先在邮件列表中列出这些内容并进行讨论,然后在其他人似乎对改进感兴趣的情况下总结或链接到讨论。
希望:这就像一个新功能,但是对于某些事情,您可能没有充实自己的背景。
错误和测试具有最高优先级,应该可以执行。
150.4.1. 报告有效问题的准则
- 搜索重复项 :您的问题可能已经被举报。看一下,发现其他人的措词可能有所不同。
另外,搜索邮件列表,其中可能包含有关您的问题以及如何解决此问题的信息。除非您强烈不同意决议 ,并且 愿意帮助解决该问题,否则不要针对邮件列表中已经讨论并解决的问题提出问题。
公开讨论 :使用邮件列表来讨论您发现的内容,并查看是否错过了某些内容。避免使用反向 Channel,以使您从整个项目的经验和专业知识中受益。
不要代表其他人归档 :您可能没有所有的上下文,并且没有像实际遇到此错误的人那样有足够的动力来查看它。从长远来看,鼓励其他人提出自己的问题会更有帮助。向他们指出此材料,并在一两次提供帮助。
写出良好的摘要 :良好的摘要包括有关问题,对用户或开发人员的影响以及代码区域的信息。
好:
Address new license dependencies from hadoop3-alpha4- 改进空间:
Canary is broken
- 改进空间:
如果您写了不好的标题,其他人会替您重写。这是他们本可以花时间解决此问题的时间。
在描述中提供上下文 :最好将其分为多个部分:
发生或不发生什么?
对您有何影响?
别人怎么能复制它?
“固定”会是什么样?
您不需要知道所有这些答案,而是可以提供尽可能多的信息。如果您可以提供技术信息,例如您认为可能导致问题的 Git commit SHA 或认为问题首先出现的 builds.apache.org 上的构建失败,请共享该信息。
填写所有相关字段 :这些字段可帮助我们过滤,分类和查找内容。
一个错误,一个问题,一个补丁 :为了帮助进行反向移植,请不要在多个错误之间分配问题或修复。
如果可以的话,增加价值 :即使您不知道如何解决问题,归档问题也很棒。但是,提供尽可能多的信息,愿意进行分类和回答问题以及愿意测试潜在的修补程序甚至更好!我们希望尽快解决您的问题。
如果不解决,请不要沮丧 :时间和资源是有限的。在某些情况下,我们可能无法(或可能选择不解决),尤其是在边缘情况或有解决方法的情况下。即使未解决,JIRA 也是它的公开记录,并且如果将来遇到其他类似问题,它将帮助他人。
150.4.2. 处理问题
要检查可以作为 Starters 解决的现有问题,请搜索JIRA 中带有标签“Starters”的问题。
JIRA Priorites
阻塞器 :仅当问题将可靠地导致数据丢失或群集不稳定时,才应使用。
严重 :所描述的问题在某些情况下可能导致数据丢失或群集不稳定。
重大 :重要但不是悲剧性的问题,例如对 Client 端 API 的更新将添加许多急需的功能或需要修复但不会导致数据丢失的重大错误。
次要 :有用的增强功能和烦人但不破坏性的错误。
创新 :有用的增强功能,但通常是美观的。
例子 37.吉拉 Comments 中的代码块
Jira 中常用的宏是\ {}。标记中的所有内容均已预先格式化,如本例所示。
{code}
code snippet
{code}
151. Apache HBase 存储库
Apache HBase 由多个存储库组成,这些存储库托管在Apache GitBox上。这些是以下内容:
hbase-Apache HBase 主存储库
hbase-connectors-Apache Kafka 和 Apache Spark 的连接器
hbase-operator-tools-可操作性和可支持性工具,例如HBase HBCK2
hbase-site-hbase.apache.org 网站
hbase-thirdparty-流行的第三方库的重新定位版本
152. IDEs
152.1. Eclipse
152.1.1. 代码格式化
在* dev-support/文件夹下,您将找到 hbase_eclipse_formatter.xml *。我们鼓励您在编辑 HBase 代码时在 Eclipse 中使用此格式化程序。
转到Preferences→Java→Code Style→Formatter→Import加载 xml 文件。转到Preferences→Java→Editor→Save Actions,并确保已选择“设置源代码格式”和“设置已编辑行的格式”。
除了自动格式化外,请确保遵循common.patch.feedback中说明的样式准则。
152.1.2. Eclipse Git 插件
如果通过 git 克隆了项目,请下载并安装 Git 插件(EGit)。附加到本地 git repo(通过 Git Repositories 窗口),您将能够查看文件修订历史记录,生成补丁等。
152.1.3. 使用 m2eclipse 在 Eclipse 中进行 HBase 项目设置
最简单的方法是将 m2eclipse 插件用于 Eclipse。 Eclipse Indigo 或更高版本包含 m2eclipse,或者您可以从http://www.eclipse.org/m2e/下载。它提供了针对 Eclipse 的 Maven 集成,甚至允许您使用 Eclipse 中的直接 Maven 命令来编译和测试您的项目。
要导入项目,请单击并选择 HBase 根目录。 m2eclipse为您找到所有的 hbase 模块。
如果您在工作空间中安装了 m2eclipse 并导入了 HBase,请执行以下操作来修复 Eclipse 的构建路径。
删除* target *文件夹
添加目标/生成 jamon 和目标/生成源/ java 文件夹。
从构建路径中删除* src/main/resources 和 src/test/resources *上的排除项,以避免控制台中出现错误消息,例如:
Failed to execute goal
org.apache.maven.plugins:maven-antrun-plugin:1.6:run (default) on project hbase:
'An Ant BuildException has occurred: Replace: source file .../target/classes/hbase-default.xml
doesn't exist
这还将减少 Eclipse 构建周期,并在开发时让您的生活更轻松。
152.1.4. 使用命令行在 Eclipse 中进行 HBase 项目设置
您可以从命令行生成 Eclipse 文件,而不必使用m2eclipse。
- 首先,运行以下命令,该命令将构建 HBase。您只需要执行一次。
mvn clean install -DskipTests
- 关闭 Eclipse,然后从终端在本地 HBase 项目目录中执行以下命令,以生成新的* .project 和 .classpath *文件。
mvn eclipse:eclipse
- 重新打开 Eclipse 并将 HBase 目录中的* .project *文件导入工作区。
152.1.5. MavenClasspath 变量
需要为项目设置$M2_REPO classpath 变量。这需要设置为本地 Maven 存储库,通常为*~/ .m2/repository *
如果未配置此 classpath 变量,您将在 Eclipse 中看到如下编译错误:
Description Resource Path Location Type
The project cannot be built until build path errors are resolved hbase Unknown Java Problem
Unbound classpath variable: 'M2_REPO/asm/asm/3.1/asm-3.1.jar' in project 'hbase' hbase Build path Build Path Problem
Unbound classpath variable: 'M2_REPO/com/google/guava/guava/r09/guava-r09.jar' in project 'hbase' hbase Build path Build Path Problem
Unbound classpath variable: 'M2_REPO/com/google/protobuf/protobuf-java/2.3.0/protobuf-java-2.3.0.jar' in project 'hbase' hbase Build path Build Path Problem Unbound classpath variable:
152.1.6. Eclipse 已知问题
Eclipse 当前将抱怨* Bytes.java *。无法关闭这些错误。
Description Resource Path Location Type
Access restriction: The method arrayBaseOffset(Class) from the type Unsafe is not accessible due to restriction on required library /System/Library/Java/JavaVirtualMachines/1.6.0.jdk/Contents/Classes/classes.jar Bytes.java /hbase/src/main/java/org/apache/hadoop/hbase/util line 1061 Java Problem
Access restriction: The method arrayIndexScale(Class) from the type Unsafe is not accessible due to restriction on required library /System/Library/Java/JavaVirtualMachines/1.6.0.jdk/Contents/Classes/classes.jar Bytes.java /hbase/src/main/java/org/apache/hadoop/hbase/util line 1064 Java Problem
Access restriction: The method getLong(Object, long) from the type Unsafe is not accessible due to restriction on required library /System/Library/Java/JavaVirtualMachines/1.6.0.jdk/Contents/Classes/classes.jar Bytes.java /hbase/src/main/java/org/apache/hadoop/hbase/util line 1111 Java Problem
152.1.7. Eclipse-更多信息
有关在 Windows 上为 HBase 开发设置 Eclipse 的更多信息,请参阅主题上的迈克尔·莫雷洛(Michael Morello)的博客。
152.2. IntelliJ IDEA
您可以将 IntelliJ IDEA 设置为具有与 Eclipse 类似的功能。跟着这些步骤。
Select
您不需要选择配置文件。确保已选择所需的 Maven 项目,然后单击 下一步 。
选择 JDK 的位置。
在 IntelliJ IDEA 中使用 HBase 格式化程序
使用 IntelliJ IDEA 的 Eclipse 代码格式化程序插件,可以导入eclipse.code.formatting中描述的 HBase 代码格式化程序。
152.3. 其他 IDE
镜像其他 IDE 的eclipse设置说明将很有用。如果您想提供帮助,请查看HBASE-11704。
153.构建 Apache HBase
153.1. 基本编译
HBase 是使用 Maven 编译的。您必须至少使用 Maven 3.0.4. 要检查您的 Maven 版本,请运行命令 mvn -version。
JDK Version Requirements
从 HBase 1.0 开始,必须使用 Java 7 或更高版本才能从源代码进行构建。有关受支持的 JDK 版本的更多完整信息,请参见java。
153.1.1. Maven 构建命令
所有命令均从本地 HBase 项目目录执行。
Package
从其 Java 源代码编译 HBase 的最简单命令是使用package目标,该目标将使用已编译的文件构建 JAR。
mvn package -DskipTests
或者,在编译之前进行清理:
mvn clean package -DskipTests
按照上面eclipse中所述设置 Eclipse 后,您还可以在 Eclipse 中使用 Build 命令。要创建完全可安装的 HBase 软件包,需要花费更多的工作,因此请 continue 阅读。
Compile
compile目标不会使用编译的文件创建 JAR。
mvn compile
mvn clean compile
Install
要将 JAR 安装在您的*~/ .m2/*目录中,请使用install目标。
mvn install
mvn clean install
mvn clean install -DskipTests
153.1.2. 运行所有或单个单元测试
请参阅hbase.unittests中的hbase.unittests.cmds部分
153.1.3. 针对各种 Hadoop 版本进行构建。
HBase 支持针对 Apache Hadoop 版本 2.y 和 3.y(早期发行工件)进行构建。默认情况下,我们针对 Hadoop 2.x 构建。
要针对 Hadoop 2.y 系列的特定版本进行构建,请设置例如-Dhadoop-two.version=2.6.3。
mvn -Dhadoop-two.version=2.6.3 ...
要更改我们构建的 Hadoop 的主要发行版,请在调用 mvn 时添加 hadoop.profile 属性:
mvn -Dhadoop.profile=3.0 ...
上面的代码将基于我们在* pom.xml *中作为“ 3.0”版本的任何显式 hadoop 3.y 版本构建。测试可能不会全部通过,因此除非您倾向于修复失败的测试,否则您可能需要通过-DskipTests。
要选择特定的 Hadoop 3.y 版本,您需要设置 hadoop-three.version 属性,例如-Dhadoop-three.version=3.0.0。
153.1.4. 构建 Protobuf
您可能需要更改* hbase-protocol *模块或其他模块中的 protobuf 定义。
在 hbase-2.0.0 之前,protobuf 定义文件散布在所有 hbase 模块中,但现在与 protobuf 有关的所有文件都必须驻留在 hbase-protocol 模块中。我们正试图限制 protobuf 的使用,因此我们可以自由更改版本,而不会影响任何对 protobuf 的下游项目的使用。
protobuf 文件位于* hbase-protocol/src/main/protobuf *中。为了使更改生效,您将需要重新生成类。
mvn package -pl hbase-protocol -am
同样,内部使用的 protobuf 定义位于* hbase-protocol-shaded *模块中。
mvn package -pl hbase-protocol-shaded -am
通常,protobuf 代码的生成是使用本地protoc二进制文件完成的。在我们的构建中,为了方便起见,我们使用了一个 maven 插件。但是,该插件可能无法为所有平台检索适当的二进制文件。如果您发现协议失败的平台,则必须从源代码编译协议,并独立于我们的 Maven 构建运行它。您可以通过在 maven 参数中指定-Dprotoc.skip来禁用内联代码生成,从而使构建进一步进行。
Note
如果您需要手动生成 protobuf 文件,则不应在后续的 maven 调用中使用clean,因为这将删除新生成的文件。
阅读* hbase-protocol/README.txt *了解更多详细信息
153.1.5. 构建节俭
您可能需要更改驻留在* hbase-thrift *模块或其他模块中的节俭定义。
Thrift 文件位于* hbase-thrift/src/main/resources *中。为了使更改生效,您将需要重新生成类。您可以使用 MavenProfilecompile-thrift来执行此操作。
mvn compile -Pcompile-thrift
您可能还想使用以下命令为节俭二进制文件定义thrift.path:
mvn compile -Pcompile-thrift -Dthrift.path=/opt/local/bin/thrift
153.1.6. 构建一个 tarball
您可以通过运行以下命令来构建 tarball,而无需执行releasing中描述的发布过程:
mvn -DskipTests clean install && mvn -DskipTests package assembly:single
发行版 tarball 内置在* hbase-assembly/target/hbase-<version> -bin.tar.gz *中。
您可以通过在 maven 命令中进行安装或部署之前具有 assembly:single 目标来安装或部署 tarball:
mvn -DskipTests package assembly:single install
mvn -DskipTests package assembly:single deploy
153.1.7. 构建陷阱
Maven 网站故障
如果看到Unable to find resource 'VM_global_library.vm',请忽略它。这不是错误。不过是officially ugly。
154.发布 Apache HBase
Building against HBase 1.x
HBase 1.x 需要 Java 7 才能构建。有关每个 HBase 版本的 Java 要求,请参阅java。
例子 38.例子*~/ .m2/settings.xml *文件
发布到 Maven 要求您签署要上传的工件。为了使构建为您签名,请在本地存储库中的* .m2 下正确配置 settings.xml *,如下所示。
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<servers>
<!- To publish a snapshot of some part of Maven -->
<server>
<id>apache.snapshots.https</id>
<username>YOUR_APACHE_ID
</username>
<password>YOUR_APACHE_PASSWORD
</password>
</server>
<!-- To publish a website using Maven -->
<!-- To stage a release of some part of Maven -->
<server>
<id>apache.releases.https</id>
<username>YOUR_APACHE_ID
</username>
<password>YOUR_APACHE_PASSWORD
</password>
</server>
</servers>
<profiles>
<profile>
<id>apache-release</id>
<properties>
<gpg.keyname>YOUR_KEYNAME</gpg.keyname>
<!--Keyname is something like this ... 00A5F21E... do gpg --list-keys to find it-->
<gpg.passphrase>YOUR_KEY_PASSWORD
</gpg.passphrase>
</properties>
</profile>
</profiles>
</settings>
154.1. 制作发布候选
只有提交者才能发布 hbase 构件。
在你开始之前
确保您的环境已正确设置。 Maven 和 Git 是下面使用的主要工具。您需要在本地*~/ .m2 * Maven 存储库中正确配置的* settings.xml *文件,并使用 apache 仓库登录名(请参阅示例~/ .m2/settings.xml 文件)。您还需要具有已发布的签名密钥。浏览有关如何发布的 Hadoop 如何释放 Wiki 页面。它是以下大多数说明的模型。它通常具有特定步骤的更多详细信息,例如,将代码签名密钥添加到 Apache 中的项目 KEYS 文件中,或者有关如何为发布准备更新 JIRA 的详细信息。
在使候选版本成为可能之前,请通过部署 SNAPSHOT 进行练习。检查以确保要从其发布版本的分支的最新版本传递过来。您还应该尝试在负载下的群集上尝试使用最新的分支技巧,也许是通过运行hbase-it集成测试套件几个小时来“消耗”接近候选的位。
Specifying the Heap Space for Maven
您可能会遇到 OutOfMemoryErrors 构建,特别是构建站点和文档。通过设置MAVEN_OPTS变量来增加 Maven 的堆。您可以在 Maven 命令前添加变量,如以下示例所示:
MAVEN_OPTS="-Xmx4g -XX:MaxPermSize=256m" mvn package
您也可以在环境变量或 shell 别名中进行设置。
Note
脚本* dev-support/make_rc.sh 可自动执行以下许多步骤。它将签出标签,清理签出,构建 src 和 bin tarball,然后将构建的 jar 部署到 repository.apache.org。它不会对发行版的 CHANGES.txt *进行修改,也不会对产生的工件进行检查以确保它们是“良好”的。提取生成的 tarball,验证它们看起来正确,然后启动 HBase 并检查一切是否正常运行-或将 tarball 签名并推送到people.apache.org。看一看。视需要修改/改善。
程序:释放程序
- 更新* CHANGES.txt *文件和 POM 文件。
使用上次发布以来的更改更新* CHANGES.txt *。确保指向 JIRA 的 URL 指向列出该版本修复程序的正确位置。适当调整所有 POM 文件中的版本。如果要发布候选版本,则必须从所有 pom.xml 文件的所有版本中删除-SNAPSHOT标签。如果运行此记录以发布快照,则必须将-SNAPSHOT后缀保留在 hbase 版本上。 Maven 插件版本可以在这里使用。要在 hbase 多模块项目的所有项目中设置版本,请使用如下命令:
$ mvn clean org.codehaus.mojo:versions-maven-plugin:2.5:set -DnewVersion=2.1.0-SNAPSHOT
确保 poms 中的所有版本均已更改!签入* CHANGES.txt *,并且所有 Maven 版本都会更改。
- 更新文档。
更新* src/main/asciidoc *下的文档。这通常涉及从 master 分支复制最新版本,并进行特定于版本的调整以适合此发行候选版本。
- 清理结帐目录
$ mvn clean
$ git clean -f -x -d
- 运行 Apache-Rat Check 许可证很好
$ mvn apache-rat
如果以上操作均失败,请检查大鼠日志。
$ grep 'Rat check' patchprocess/mvn_apache_rat.log
- 创建一个发布标签。假设您已经进行了基本测试,大鼠检查,通过并且一切都看起来不错,那么现在是时候标记释放候选者了(如果需要重做,请始终删除标记)。要进行标记,请执行以下操作来替换适合您的版本的版本。所有标签应为签名标签;即传递* -s *选项(有关如何设置 git 环境进行签名的信息,请参见签署工作)。
$ git tag -s 2.0.0-alpha4-RC0 -m "Tagging the 2.0.0-alpha4 first Releae Candidate (Candidates start at zero)"
或者,如果要发布版本,标签应带有* rel/*前缀,以确保将其保存在 Apache 存储库中,如下所示:
+$ git tag -s rel/2.0.0-alpha4 -m "Tagging the 2.0.0-alpha4 Release"
推动(特定)标签(仅),以便其他人可以访问。
$ git push origin 2.0.0-alpha4-RC0
- 有关如何删除标签的信息,请参见如何删除标签。涵盖删除尚未推送到远程 Apache 存储库的标签,以及删除推送到 Apache 的标签。
- 生成源压缩包。
现在,构建源 tarball。假设我们正在将标签* 2.0.0-alpha4-RC0 的源 tarball 构建到/tmp/hbase-2.0.0-alpha4-RC0/*中(此步骤要求上述的 mvn 和 git clean 步骤具有刚刚完成)。
$ git archive --format=tar.gz --output="/tmp/hbase-2.0.0-alpha4-RC0/hbase-2.0.0-alpha4-src.tar.gz" --prefix="hbase-2.0.0-alpha4/" $git_tag
在上方,我们将 hbase-2.0.0-alpha4-src.tar.gz 压缩包生成到*/tmp/hbase-2.0.0-alpha4-RC0 构建输出目录(我们不希望名称中的 RC0 这些位目前是候选版本,但是如果 VOTE 通过,它们将成为版本,因此我们不会用 RCX *污染工件名称。
- 构建二进制压缩包。接下来,构建二进制压缩包。构建时加入
-PreleaseProfile。它运行许可证 apache-rat 检查以及其他有助于确保一切健康的规则。分两步完成。
首先安装到本地存储库
$ mvn clean install -DskipTests -Prelease
接下来,生成文档并组装压缩包。请注意,此下一步可能需要花费一些时间,而这会花费几个小时来生成站点文档。
$ mvn install -DskipTests site assembly:single -Prelease
否则,当您尝试一步完成所有工作时,尤其是在新的存储库上,构建会抱怨 hbase 模块不在 maven 存储库中。在这两个步骤中似乎都需要安装目标。
提取生成的 tarball-您可以在* hbase-assembly/target *下找到它并检出。查看文档,查看其是否运行等。如果良好,请在构建输出目录中的源 tarball 旁边复制 tarball。
- 部署到 Maven 存储库。
接下来,将 HBase 部署到 Apache Maven 存储库。运行mvn deploy命令时,添加 apache-release`配置文件。此配置文件来自我们 pom 文件引用的 Apache 父 pom。只要正确设置了* settings.xml *,它就会对发布到 Maven 的工件进行签名,如示例~/ .m2/settings.xml 文件中所述。此步骤取决于本地存储库是否已由之前的 bin tarball 构建填充。
$ mvn deploy -DskipTests -Papache-release -Prelease
此命令将所有工件复制到处于“打开”状态的临时登台 Apache mvn 存储库。为了使这些 Maven 工件普遍可用,需要做更多的工作。
我们不会将 HBase tarball 发布到 Apache Maven 存储库。为避免部署 tarball,请勿在mvn deploy命令中包含assembly:single目标。如下一节所述,检查已部署的工件。
make_rc.sh
如果您运行* dev-support/make_rc.sh *脚本,这将尽您所能。要完成发行,请从现在开始使用脚本。
- 使发布候选可用。
这些工件位于处于“打开”状态的登台区域中的 Maven 存储库中。在这种“开放”状态下,您可以查看发布的内容以确保一切都很好。为此,请使用您的 Apache ID 登录到repository.apache.org的 Apache Nexus。在登台存储库中找到您的工件。单击“登台存储库”,然后找到状态为“打开”的以“ hbase”结尾的新存储库,然后选择它。使用树视图展开存储库内容的列表,并检查是否存在您期望的工件。检查 POM。只要临时仓库是打开的,如果缺少某些东西或构建不正确,您可以重新上传。
如果出现严重错误,并且您想撤消上载,则可以使用“拖放”按钮删除和删除登台存储库。有时上传会在中间失败。这是您可能必须从分段存储库中“拖放”上载的另一个原因。
如果签出,请使用“关闭”按钮关闭存储库。必须先关闭该存储库,然后才能使用它的公共 URL。关闭存储库可能需要几分钟。完成后,您将在 Nexus UI 中看到存储库的公共 URL。您可能还会收到带有 URL 的电子邮件。在宣布发布候选版本的电子邮件中,提供指向临时登台存储库的 URL。 (伙计们需要将此 repoURL 添加到本地 pom 或本地* settings.xml *文件中,以拉出已发布的发行候选工件.)
当发布投票成功结束时,返回此处并单击“发布”按钮以将工件释放到中央。发布过程将自动删除和删除登台存储库。
hbase-downstreamer
请参见hbase-downstreamer测试,以获取 HBase 下游项目的简单示例(取决于该项目)。对其进行检查并运行其简单测试,以确保将 Maven 工件正确部署到 Maven 存储库。确保编辑 pom 以指向正确的登台存储库。通过传递-U标志或删除本地存储库内容,确保在运行测试时从存储库中提取资源,并且未从本地存储库中获取资源,并检查 maven 是否已从远程存储库中提取。
有关此 Maven 登台过程的一些指针,请参见发布 Maven 工件。
如果 HBase 版本以
-SNAPSHOT结尾,则工件将移至其他位置。它们直接放入 Apache 快照存储库中,并且立即可用。制作 SNAPSHOT 版本,这就是您想要发生的事情。在此阶段,您的“构建输出目录”中有两个 zipfile,并且在 Maven 存储库的暂存区域中处于“关闭”状态的一组工件。接下来,签名,指纹,然后通过将目录提交到开发发行目录(通过查看HBASE-10554 请从镜像系统中删除旧版本上的 Comments,但本质上是对dev/hbase的 svn 签出-发行版位于release/hbase),通过 svnpubsub“暂存”您的发布候选版本的输出目录。在* version 目录*中,运行以下命令:
$ for i in *.tar.gz; do echo $i; gpg --print-md MD5 $i > $i.md5 ; done
$ for i in *.tar.gz; do echo $i; gpg --print-md SHA512 $i > $i.sha ; done
$ for i in *.tar.gz; do echo $i; gpg --armor --output $i.asc --detach-sig $i ; done
$ cd ..
# Presuming our 'build output directory' is named 0.96.0RC0, copy it to the svn checkout of the dist dev dir
# in this case named hbase.dist.dev.svn
$ cd /Users/stack/checkouts/hbase.dist.dev.svn
$ svn info
Path: .
Working Copy Root Path: /Users/stack/checkouts/hbase.dist.dev.svn
URL: https://dist.apache.org/repos/dist/dev/hbase
Repository Root: https://dist.apache.org/repos/dist
Repository UUID: 0d268c88-bc11-4956-87df-91683dc98e59
Revision: 15087
Node Kind: directory
Schedule: normal
Last Changed Author: ndimiduk
Last Changed Rev: 15045
Last Changed Date: 2016-08-28 11:13:36 -0700 (Sun, 28 Aug 2016)
$ mv 0.96.0RC0 /Users/stack/checkouts/hbase.dist.dev.svn
$ svn add 0.96.0RC0
$ svn commit ...
- 通过检查https://dist.apache.org/repos/dist/dev/hbase/来确保它实际上已发布。
在邮件列表中宣布候选发布者并进行投票。
154.2. 发布 SNAPSHOT 到 Maven
确保您的* settings.xml *设置正确(请参阅示例~/ .m2/settings.xml 文件)。确保 hbase 版本包含-SNAPSHOT作为后缀。以下是发布其 poms 中 hbase 版本为 0.96.0 的发行版的 SNAPSHOTS 的示例。
$ mvn clean install -DskipTests javadoc:aggregate site assembly:single -Prelease
$ mvn -DskipTests deploy -Papache-release
上面提到的* make_rc.sh *脚本(请参阅maven.release)可以帮助您发布SNAPSHOTS。在运行脚本之前,请确保hbase.version后缀为-SNAPSHOT。它将为您创建快照到 apache 快照存储库中。
155.对发行候选者进行投票
鼓励大家尝试对 HBase 发行候选版本进行投票。仅 PMC 成员的投票具有约束力。 PMC 成员,请阅读此 WIP 文档,其中包含针对候选发布版本Release Policy的 Policy 投票。
Note
在进行 1 项有约束力的投票之前,个人需要将签名的源代码包下载到自己的硬件上,按提供的方式进行编译,并在自己的平台上测试生成的可执行文件,同时还要验证密码签名并验证该包是否符合要求关于发布的 ASFPolicy。
关于后者,请运行mvn apache-rat:check以验证所有文件均已获得适当许可。有关我们如何完成此过程的信息,请参见HBase,邮件#dev-在最近的讨论中阐明了 ASF 发行 Policy。
156.宣布发布
一旦 RC 成功通过并且分发了所需的工件以进行发布,您将需要让所有人知道我们的闪亮新版本。这不是必需的,但是为了使发布 Management 者更轻松,我们提供了一个模板。确保将_version 和其他标记替换为相关的版本号。发送之前,您应该手动验证所有链接。
The HBase team is happy to announce the immediate availability of HBase _version_.
Apache HBase™ is an open-source, distributed, versioned, non-relational database.
Apache HBase gives you low latency random access to billions of rows with
millions of columns atop non-specialized hardware. To learn more about HBase,
see https://hbase.apache.org/.
HBase _version_ is the _nth_ minor release in the HBase _major_.x line, which aims to
improve the stability and reliability of HBase. This release includes roughly
XXX resolved issues not covered by previous _major_.x releases.
Notable new features include:
- List text descriptions of features that fit on one line
- Including if JDK or Hadoop support versions changes
- If the "stable" pointer changes, call that out
- For those with obvious JIRA IDs, include them (HBASE-YYYYY)
The full list of issues can be found in the included CHANGES.md and RELEASENOTES.md,
or via our issue tracker:
https://s.apache.org/hbase-_version_-jira
To download please follow the links and instructions on our website:
https://hbase.apache.org/downloads.html
Question, comments, and problems are always welcome at: dev@hbase.apache.org.
Thanks to all who contributed and made this release possible.
Cheers,
The HBase Dev Team
您应该将此消息发送到以下列表:dev@hbase.apache.org,user@hbase.apache.org,announce@apache.org。如果您想在发送前进行抽查,请随时通过 jira 或开发人员列表进行询问。
157.生成 HBase 参考指南
该手册使用 Asciidoc 进行了标记。然后,我们使用Asciidoctor Maven 插件将标记转换为 html。当您指定站点目标时(如运行 mvn site 时),将运行此插件。有关构建文档的更多信息,请参见有助于文件编制的附录。
158.更新 hbase.apache.org
158.1. 贡献给 hbase.apache.org
有关对文档或网站进行贡献的更多信息,请参见有助于文件编制的附录。
158.2. 发布 hbase.apache.org
有关发布网站和文档的说明,请参见发布 HBase 网站和文档。
159. Tests
开发人员至少应熟悉单元测试的详细信息; HBase 中的单元测试具有其他项目通常不具备的 Feature。
该信息是关于 HBase 本身的单元测试的。有关为 HBase 应用程序开发单元测试的信息,请参见unit.tests。
159.1. Apache HBase 模块
从 0.96 开始,Apache HBase 被分为多个模块。这为如何以及在何处编写测试创建了“有趣的”规则。如果您要为hbase-server编写代码,请参见hbase.unittests以了解如何编写测试。这些测试可以启动一个小型集群,需要对其进行分类。对于任何其他模块,例如hbase-common,测试必须是严格的单元测试,并且仅测试被测类-不允许使用 HBaseTestingUtility 或 minicluster(甚至在给定依赖树的情况下也不能使用)。
159.1.1. 测试 HBase Shell
HBase shell 及其测试主要用 jruby 编写。
为了使这些测试作为标准构建的一部分运行,有一些 JUnit 测试类负责加载 jruby 实现的测试并运行它们。将测试分为单独的类,以适应类级别的超时(有关详细信息,请参见Unit Tests)。您可以使用以下命令从顶层运行所有这些测试:
mvn clean test -Dtest=Test*Shell
如果您以前做过mvn install,则可以通过以下命令指示 maven 仅运行 hbase-shell 模块中的测试:
mvn clean test -pl hbase-shell
或者,您可以限制使用系统变量shell.test运行的 Shell 测试。此值应按名称指定与特定测试用例等效的红宝石 Literals。例如,测试用例AdminAlterTableTest中包含涵盖用于更改表的 shell 命令的测试,您可以使用以下命令运行它们:
mvn clean test -pl hbase-shell -Dshell.test=/AdminAlterTableTest/
您也可以使用Ruby 正则表达式 Literals(以/pattern/样式)来选择一组测试用例。您可以使用以下命令运行所有与 HBase admin 相关的测试,包括常规 Management 和安全性 Management:
mvn clean test -pl hbase-shell -Dshell.test=/.*Admin.*Test/
如果测试失败,您可以通过查看 surefire 报告结果的 XML 版本来查看详细信息
vim hbase-shell/target/surefire-reports/TEST-org.apache.hadoop.hbase.client.TestShell.xml
159.1.2. 在其他模块中运行测试
如果您正在开发的模块对其他 HBase 模块没有其他依赖关系,则可以将其插入 cd 并运行:
mvn test
它将仅在该模块中运行测试。如果对其他模块还有其他依赖性,那么您将已经从 ROOT HBASE DIRECTORY 运行了该命令。除非您指定跳过该模块中的测试,否则它将在其他模块中运行测试。例如,要跳过 hbase-server 模块中的测试,可以运行:
mvn clean test -PskipServerTests
从顶层目录运行除 hbase-server 以外的模块中的所有测试。请注意,您可以指定跳过多个模块以及单个模块的测试。例如,要跳过hbase-server和hbase-common中的测试,可以运行:
mvn clean test -PskipServerTests -PskipCommonTests
另外,请记住,如果您正在hbase-server模块中运行测试,则需要应用hbase.unittests.cmds中讨论的 Maven 配置文件才能使测试正常运行。
159.2. 单元测试
Apache HBase 单元测试必须带有类别 Comments,并且自hbase-2.0.0起,必须带有 HBase ClassRule标记。这是一个包含类别和 ClassRule 的测试类的示例:
...
@Category(SmallTests.class)
public class TestHRegionInfo {
@ClassRule
public static final HBaseClassTestRule CLASS_RULE =
HBaseClassTestRule.forClass(TestHRegionInfo.class);
@Test
public void testCreateHRegionInfoName() throws Exception {
// ...
}
}
这里的测试类是TestHRegionInfo。 CLASS_RULE在每个测试类中具有相同的形式,只有您通过的.class是本地测试的形式;也就是说,在 TestTimeout 测试类中,您需要将TestTimeout.class传递给CLASS_RULE而不是上面的TestHRegionInfo.class。 CLASS_RULE是我们将强制执行超时(当前将所有测试 780 秒设置为 13 分钟的硬限制)和其他跨单元测试工具的位置。测试在SmallTest类别中。
类别可以是任意的,可以作为列表提供,但是每个测试都必须携带以下大小列表中的一个:small,medium,large和integration。使用 JUnit categories来指定测试大小:SmallTests,MediumTests,LargeTests,IntegrationTests。 JUnit 类别使用 JavaComments 表示(特殊的单元测试会在所有单元测试中查找@CategoryComments 的存在,如果发现缺少大小调整标记的测试套件,它将失败。
前三个类别small,medium和large用于 Importing$ mvn test时运行的测试用例。换句话说,这三种分类适用于 HBase 单元测试。 integration类别不是用于单元测试,而是用于集成测试。这些通常在您调用$ mvn verify时运行。集成测试在integration.tests中描述。
continue 阅读以找出要用于新 HBase 测试用例的集合small,medium和large的 Comments。
Categorizing Tests
Small Tests
- 小测试用例在共享的 JVM 中执行,每个测试套件/测试类应在 15 秒或更短的时间内运行;即junit 测试治具(由测试方法组成的 Java 对象)应该在 15 秒内完成,无论它具有多少测试方法。这些测试用例不应使用小型集群。
Medium Tests
- 中等测试用例是在单独的 JVM 和单个测试套件或测试类中执行的,或者以 junit 的说法test fixture可以在 50 秒或更短的时间内运行。这些测试用例可以使用小型集群。
Large Tests
- 大型测试用例是其他所有内容。它们通常是大规模测试,针对特定错误的回归测试,超时测试或性能测试。大型测试套件所花费的时间不会超过十分钟。超时将杀死它。如果需要运行更长的时间,请将您的测试转换为集成测试。
Integration Tests
- 集成测试是系统级测试。有关更多信息,请参见integration.tests。如果您在集成测试中调用
$ mvn test,则该测试没有超时。
- 集成测试是系统级测试。有关更多信息,请参见integration.tests。如果您在集成测试中调用
159.3. 运行测试
159.3.1. 默认值:中小型类别测试
运行mvn test将在单个 JVM(无分叉)中执行所有小型测试,然后对每个测试实例在单独的 JVM 中执行中型测试。如果小测试中有错误,则不执行中测试。不执行大型测试。
159.3.2. 运行所有测试
运行mvn test -P runAllTests将在单个 JVM 中执行小型测试,然后针对每个测试在单独的 JVM 中执行中型和大型测试。如果小型测试中有错误,则不执行中型和大型测试。
159.3.3. 在包中运行单个测试或所有测试
要运行单个测试,例如MyTest,朗姆mvn test -Dtest=MyTest您还可以通过多个单独的测试作为逗号分隔列表:
mvn test -Dtest=MyTest1,MyTest2,MyTest3
您还可以通过一个软件包,该软件包将在该软件包下运行所有测试:
mvn test '-Dtest=org.apache.hadoop.hbase.client.*'
指定-Dtest后,将使用localTestsProfile。每个 junit 测试在单独的 JVM 中执行(每个测试类一个 fork)。在这种模式下运行测试时,没有并行化。您将在-report 的末尾看到一条新消息:"[INFO] Tests are skipped"。这是无害的。但是,您需要确保测试报告的Results:部分中的Tests run:的总和与您指定的测试数量相匹配,因为当指定了不存在的测试用例时,不会报告任何错误。
159.3.4. 其他测试调用排列
运行mvn test -P runSmallTests将仅使用单个 JVM 执行“小型”测试。
运行mvn test -P runMediumTests将仅执行“中等”测试,为每个测试类启动一个新的 JVM。
运行mvn test -P runLargeTests将仅执行“大型”测试,并为每个测试类启动一个新的 JVM。
为了方便起见,您可以使用单个 JVM 运行mvn test -P runDevTests来执行中小型测试。
159.3.5. 更快地运行测试
默认情况下,$ mvn test -P runAllTests并行运行 5 个测试。可以在开发人员的机器上增加它。允许每个内核并行进行 2 个测试,并且每个测试大约需要 2GB 的内存(在极端情况下),如果您拥有 8 个内核,24GB 的盒子,则可以并行进行 16 个测试。但可用内存将其限制为 12(24/2),要并行运行 12 个测试的所有测试,请执行以下操作:mvn test -P runAllTests -Dsurefire.secondPartForkCount = 12.如果使用的版本早于 2.0,请执行:mvn test -P runAllTests -Dsurefire.secondPartThreadCount = 12.要提高速度,您还可以使用虚拟磁盘。您将需要 2GB 的内存才能运行所有测试。您还需要在两次测试运行之间删除文件。在 Linux 上配置虚拟磁盘的典型方法是:
$ sudo mkdir /ram2G
sudo mount -t tmpfs -o size=2048M tmpfs /ram2G
然后,您可以使用它使用以下命令在 2.0 上运行所有 HBase 测试:
mvn test
-P runAllTests -Dsurefire.secondPartForkCount=12
-Dtest.build.data.basedirectory=/ram2G
在早期版本上,使用:
mvn test
-P runAllTests -Dsurefire.secondPartThreadCount=12
-Dtest.build.data.basedirectory=/ram2G
159.3.6. hbasetests.sh
也可以使用脚本 hbasetests.sh。该脚本与两个 maven 实例并行运行中型和大型测试,并提供一个报告。该脚本未使用 surefire 的 hbase 版本,因此除了脚本设置的两个 maven 实 exception,没有进行并行化。它必须从包含* pom.xml *的目录中执行。
例如,运行./dev-support/hbasetests.sh 将执行中小型测试。运行./dev-support/hbasetests.sh runAllTests 将执行所有测试。运行./dev-support/hbasetests.sh replayFailed 将在单独的 jvm 中且没有并行化的情况下第二次重新运行失败的测试。
159.3.7. 测试超时
未严格执行 HBase 单元测试大小分类超时。
任何运行时间超过十分钟的测试都将被超时/终止。
从 hbase-2.0.0 开始,我们已清除所有按测试方法的超时:
...
@Test(timeout=30000)
public void testCreateHRegionInfoName() throws Exception {
// ...
}
鉴于我们是整个测试治具/类/套件需要花费多长时间以及测试方法需要花费多长时间的差异很大程度上取决于上下文(加载的 Apache 基础架构与开发人员机器),因此我们不建议这样做,也没有太大的意义。没有其他任何内容)。
159.3.8. 测试资源检查器
定制的 Maven SureFire 插件侦听器在每个 HBase 单元测试运行之前和之后检查大量资源,并将其发现记录在测试输出文件的末尾,这些文件可在每个 Maven 模块的* target/surefire-reports 中找到(测试写测试)以测试类命名的报告进入此目录。请检查*-out.txt 文件)。计数的资源是线程数,文件 Descriptors 数等。如果数量增加,它将在日志中添加 LEAK?*Comments。由于您可以在后台运行 HBase 实例,因此可以删除/创建一些线程,而无需在测试中进行任何特定操作。但是,如果测试无法按预期方式运行,或者测试不应影响这些资源,则值得检查以下日志行... hbase.ResourceChecker(157):...之前和... hbase.ResourceChecker(157) ):之后...。例如:
2012-09-26 09:22:15,315 INFO [pool-1-thread-1]
hbase.ResourceChecker(157): after:
regionserver.TestColumnSeeking#testReseeking Thread=65 (was 65),
OpenFileDescriptor=107 (was 107), MaxFileDescriptor=10240 (was 10240),
ConnectionCount=1 (was 1)
159.4. 写作测试
159.4.1. 一般规则
测试应尽可能写为小测试类别。
必须编写所有测试以支持在同一台计算机上并行执行,因此,不应将共享资源用作固定端口或固定文件名。
测试不应覆盖。每秒超过 100 行的速度使日志读取和使用 I/O 变得很复杂,因此无法用于其他测试。
可以使用
HBaseTestingUtility编写测试。此类提供了帮助程序功能,用于创建临时目录并进行清理或启动集群。
159.4.2. 类别和执行时间
所有测试都必须分类,否则可以跳过。
所有测试应尽可能快地编写。
有关测试用例的类别和相应的超时,请参见hbase.unittests。这应该确保使用它的人员具有良好的并行性,并在测试失败时简化分析。
159.4.3. 在测试中睡觉
只要有可能,测试就不应使用 Thread.sleep,而应 await 它们所需的真实事件。对于 Reader 而言,这更快,更清晰。如果不测试结束条件,则测试不应执行 Thread.sleep。这样可以了解测试正在 await 什么。此外,无论机器性能如何,该测试都可以进行。睡眠应尽量少,以尽可能快。await 变量应在 40 毫秒的睡眠循环中完成。await 套接字操作应在 200 ms 的睡眠循环中完成。
159.4.4. 使用集群进行测试
使用 HRegion 进行的测试不必启动群集:区域可以使用本地文件系统。启动/停止集群大约需要 10 秒钟。它们不应按测试方法启动,而应按测试类启动。必须使用 HBaseTestingUtility#shutdownMiniCluster 关闭启动的群集,该操作会清理目录。测试应尽可能使用群集的默认设置。如果没有,则应记录下来。这将允许以后共享群集。
159.4.5. 测试骨架代码
这是一个测试框架代码,具有分类和基于类别的超时规则,可以复制和粘贴并用作测试贡献的基础。
/**
* Describe what this testcase tests. Talk about resources initialized in @BeforeClass (before
* any test is run) and before each test is run, etc.
*/
// Specify the category as explained in <<hbase.unittests,hbase.unittests>>.
@Category(SmallTests.class)
public class TestExample {
// Replace the TestExample.class in the below with the name of your test fixture class.
private static final Log LOG = LogFactory.getLog(TestExample.class);
// Handy test rule that allows you subsequently get the name of the current method. See
// down in 'testExampleFoo()' where we use it to log current test's name.
@Rule public TestName testName = new TestName();
// The below rule does two things. It decides the timeout based on the category
// (small/medium/large) of the testcase. This @Rule requires that the full testcase runs
// within this timeout irrespective of individual test methods' times. The second
// feature is we'll dump in the log when the test is done a count of threads still
// running.
@Rule public static TestRule timeout = CategoryBasedTimeout.builder().
withTimeout(this.getClass()).withLookingForStuckThread(true).build();
@Before
public void setUp() throws Exception {
}
@After
public void tearDown() throws Exception {
}
@Test
public void testExampleFoo() {
LOG.info("Running test " + testName.getMethodName());
}
}
159.5. 整合测试
HBase 集成/系统测试是超出 HBase 单元测试的测试。它们通常是持久的,可调整大小的(可以要求测试 1M 行或 1B 行),可以确定目标的(它们可以进行配置,将它们指向要运行的现成集群;集成测试不包括集群起始/停止代码),并验证成功,集成测试仅依赖于公共 API;他们不尝试检查 assert 成功/失败的服务器内部。当您需要进行单元候选者无法完成的更详尽的版本候选证明时,将执行集成测试。它们通常不在 Apache Continuous Integration 构建服务器上运行,但是,某些站点选择将集成测试作为其在实际集群上进行的连续测试的一部分。
集成测试当前位于 hbase-it 子模块的* src/test *目录下,并将与正则表达式匹配: **** /IntegrationTest ** .java *。所有集成测试也都带有@Category(IntegrationTests.class)Comments。
集成测试可以两种模式运行:使用小型集群或针对实际的分布式集群。 Maven 故障安全用于使用小型集群运行测试。 IntegrationTestsDriver 类用于对分布式集群执行测试。集成测试不应假定它们针对小型集群运行,并且不应使用私有 API 来访问集群状态。为了统一地与分布式集群或小型集群交互,可以使用IntegrationTestingUtility和HBaseCluster类以及公共 Client 端 API。
在分布式集群上,使用 ChaosMonkey 或通过集群 Management 器(例如重新启动区域服务器)操纵服务的集成测试使用 SSH 来实现。要运行这些,测试过程应该能够在远程端运行命令,因此应该相应地配置 ssh(例如,如果 HBase 在群集中的 hbase 用户下运行,则可以为该用户设置无密码的 ssh 并运行测试在它下面)。为此,可以使用hbase.it.clustermanager.ssh.user,hbase.it.clustermanager.ssh.opts和hbase.it.clustermanager.ssh.cmd配置设置。 “用户”是群集 Management 器用来执行 ssh 命令的远程用户。 “选项”包含传递给 SSH 的其他选项(例如,“-i/tmp/my-key”)。最后,如果您有一些自定义环境设置,则“ cmd”是整个 tunnel(ssh)命令的替代格式。默认字符串为\ { /usr/bin/ssh %1$s %2$s%3$s%4$s "%5$s" },这是一个很好的起点。这是带有 5 个参数的标准 Java 格式字符串,用于执行远程命令。参数 1(%1 $ s)是 SSH 选项,可通过 via opts 设置或 via 环境变量来设置,2 是 SSH 用户名,3 是“ @”(如果设置了用户名)或“”,否则,4 是目标主机名,以及 5 是要执行的逻辑命令(可能包含单引号,因此请不要使用它们)。例如,如果您在非 hbase 用户下运行测试,并希望以该用户 ssh 身份并更改为远程计算机上的 hbase,则可以使用:
/usr/bin/ssh %1$s %2$s%3$s%4$s "su hbase - -c \"%5$s\""
这样,可以终止 RS(例如)集成测试:
{/usr/bin/ssh some-hostname "su hbase - -c \"ps aux | ... | kill ...\""}
该命令记录在测试日志中,因此您可以验证它是否适合您的环境。
要禁用集成测试的运行,请在命令行-PskipIntegrationTests上传递以下配置文件。例如,
$ mvn clean install test -Dtest=TestZooKeeper -PskipIntegrationTests
159.5.1. 针对小型集群运行集成测试
HBase 0.92 添加了verify maven 目标。例如,通过执行mvn verify来调用它,将通过 maven failsafe plugin运行所有阶段,包括验证阶段,并运行上述所有 HBase 单元测试以及 HBase 集成测试组中的测试。完成 mvn install -DskipTests 之后,您可以通过调用以下命令来仅运行集成测试:
cd hbase-it
mvn verify
如果只想在顶层运行集成测试,则需要运行两个命令。首先:mvn failsafe:integration-test 实际上运行所有集成测试。
Note
即使有测试失败,此命令也将始终输出BUILD SUCCESS。
此时,您可以手工 grep 输出以查找失败的测试。但是,maven 会为我们做到这一点;只需使用:mvn failsafe:verify 上面的命令基本上查看所有测试结果(因此请不要删除“ target”目录)以查找测试失败并报告结果。
运行一部分集成测试
这与指定运行一部分单元测试的方法非常相似(请参见上文),但是使用属性it.test而不是test。要只运行IntegrationTestClassXYZ.java,请使用:mvn failsafe:integration-test -Dit.test = IntegrationTestClassXYZ 接下来,您可能想做的是运行集成测试组,说所有名为 IntegrationTestClassX * .java 的集成测试:mvn failsafe:integration -test -Dit.test = * ClassX *这将运行与 ClassX 相匹配的集成测试。这表示匹配的任何内容:“ */IntegrationTest * ClassX ”。您还可以使用逗号分隔的列表运行多组集成测试(类似于单元测试)。使用匹配列表仍然支持每个组的完整正则表达式匹配。看起来像这样:mvn failsafe:integration-test -Dit.test = * ClassX , ClassY
159.5.2. 针对分布式集群运行集成测试
如果您已经设置了 HBase 集群,则可以通过调用IntegrationTestsDriver类来启动集成测试。您可能必须先运行测试编译。配置将由 bin/hbase 脚本选择。
mvn test-compile
然后使用以下命令启动测试:
bin/hbase [--config config_dir] org.apache.hadoop.hbase.IntegrationTestsDriver
传递-h以使用此精美工具。在不带任何参数的情况下运行 IntegrationTestsDriver 将启动在hbase-it/src/test下找到的测试,该测试具有@Category(IntegrationTests.class)注解,并且名称以IntegrationTests开头。通过传递-h 来查看用法,以了解如何过滤测试类。您可以传递一个正则表达式,该正则表达式将根据完整的类名进行检查;因此,可以使用部分类名。 IntegrationTestsDriver 使用 Junit 运行测试。当前不支持使用 maven 对分布式集群运行集成测试(请参见HBASE-6201)。
这些测试通过使用DistributedHBaseCluster(实现HBaseCluster)类中的方法与分布式集群进行交互,该类又使用可插拔的ClusterManager。具体的实现提供了用于执行特定于部署和与环境有关的任务(SSH 等)的实际功能。默认的ClusterManager是HBaseClusterManager,它使用 SSH 远程执行启动/停止/ kill/signal 命令,并采用一些 posix 命令(例如 ps 等)。还假设运行测试的用户具有足够的“能力”来启动/停止远程计算机上的服务器。默认情况下,它从环境中拾取HBASE_SSH_OPTS,HBASE_HOME,HBASE_CONF_DIR,并使用bin/hbase-daemon.sh来执行操作。当前支持 tarball 部署,使用* hbase-daemons.sh *的部署和Apache Ambari部署。 */etc/init.d/*脚本目前不受支持,但可以轻松添加。对于其他部署选项,可以实施并插入 ClusterManager。
159.5.3. 破坏性集成/系统测试(ChaosMonkey)
HBase 0.96 引入了一个以Netflix 的 Chaos Monkey 工具的同名工具建模的名为ChaosMonkey的工具。 ChaosMonkey 通过杀死或断开随机服务器或将其他故障注入环境来模拟正在运行的群集中的实际故障。您可以将 ChaosMonkey 用作独立工具,以在其他测试运行时运行策略。在某些环境中,ChaosMonkey 始终处于运行状态,以便不断检查高可用性和容错功能是否按预期工作。
ChaosMonkey 定义 Actions 和 Policies 。
Actions
- 动作是事件的 sched 义序列,例如:
重新启动活动主服务器(睡眠 5 秒)
重新启动随机区域服务器(睡眠 5 秒)
重新启动随机区域服务器(睡眠 60 秒)
重新启动 META 区域服务器(睡眠 5 秒)
重新启动 ROOT 区域服务器(休眠 5 秒)
批量重启 50%的区域服务器(休眠 5 秒)
滚动重启 100%的区域服务器(休眠 5 秒)
Policies
- 策略是用于执行一个或多个动作的策略。默认策略根据 sched 义的操作权重每分钟执行一次随机操作。给定的策略将一直执行到 ChaosMonkey 被中断为止。
大多数 ChaosMonkey 操作均配置为具有合理的默认值,因此您可以对现有群集运行 ChaosMonkey,而无需任何其他配置。以下示例使用默认配置运行 ChaosMonkey:
$ bin/hbase org.apache.hadoop.hbase.util.ChaosMonkey
12/11/19 23:21:57 INFO util.ChaosMonkey: Using ChaosMonkey Policy: class org.apache.hadoop.hbase.util.ChaosMonkey$PeriodicRandomActionPolicy, period:60000
12/11/19 23:21:57 INFO util.ChaosMonkey: Sleeping for 26953 to add jitter
12/11/19 23:22:24 INFO util.ChaosMonkey: Performing action: Restart active master
12/11/19 23:22:24 INFO util.ChaosMonkey: Killing master:master.example.com,60000,1353367210440
12/11/19 23:22:24 INFO hbase.HBaseCluster: Aborting Master: master.example.com,60000,1353367210440
12/11/19 23:22:24 INFO hbase.ClusterManager: Executing remote command: ps aux | grep master | grep -v grep | tr -s ' ' | cut -d ' ' -f2 | xargs kill -s SIGKILL , hostname:master.example.com
12/11/19 23:22:25 INFO hbase.ClusterManager: Executed remote command, exit code:0 , output:
12/11/19 23:22:25 INFO hbase.HBaseCluster: Waiting service:master to stop: master.example.com,60000,1353367210440
12/11/19 23:22:25 INFO hbase.ClusterManager: Executing remote command: ps aux | grep master | grep -v grep | tr -s ' ' | cut -d ' ' -f2 , hostname:master.example.com
12/11/19 23:22:25 INFO hbase.ClusterManager: Executed remote command, exit code:0 , output:
12/11/19 23:22:25 INFO util.ChaosMonkey: Killed master server:master.example.com,60000,1353367210440
12/11/19 23:22:25 INFO util.ChaosMonkey: Sleeping for:5000
12/11/19 23:22:30 INFO util.ChaosMonkey: Starting master:master.example.com
12/11/19 23:22:30 INFO hbase.HBaseCluster: Starting Master on: master.example.com
12/11/19 23:22:30 INFO hbase.ClusterManager: Executing remote command: /homes/enis/code/hbase-0.94/bin/../bin/hbase-daemon.sh --config /homes/enis/code/hbase-0.94/bin/../conf start master , hostname:master.example.com
12/11/19 23:22:31 INFO hbase.ClusterManager: Executed remote command, exit code:0 , output:starting master, logging to /homes/enis/code/hbase-0.94/bin/../logs/hbase-enis-master-master.example.com.out
....
12/11/19 23:22:33 INFO util.ChaosMonkey: Started master: master.example.com,60000,1353367210440
12/11/19 23:22:33 INFO util.ChaosMonkey: Sleeping for:51321
12/11/19 23:23:24 INFO util.ChaosMonkey: Performing action: Restart random region server
12/11/19 23:23:24 INFO util.ChaosMonkey: Killing region server:rs3.example.com,60020,1353367027826
12/11/19 23:23:24 INFO hbase.HBaseCluster: Aborting RS: rs3.example.com,60020,1353367027826
12/11/19 23:23:24 INFO hbase.ClusterManager: Executing remote command: ps aux | grep regionserver | grep -v grep | tr -s ' ' | cut -d ' ' -f2 | xargs kill -s SIGKILL , hostname:rs3.example.com
12/11/19 23:23:25 INFO hbase.ClusterManager: Executed remote command, exit code:0 , output:
12/11/19 23:23:25 INFO hbase.HBaseCluster: Waiting service:regionserver to stop: rs3.example.com,60020,1353367027826
12/11/19 23:23:25 INFO hbase.ClusterManager: Executing remote command: ps aux | grep regionserver | grep -v grep | tr -s ' ' | cut -d ' ' -f2 , hostname:rs3.example.com
12/11/19 23:23:25 INFO hbase.ClusterManager: Executed remote command, exit code:0 , output:
12/11/19 23:23:25 INFO util.ChaosMonkey: Killed region server:rs3.example.com,60020,1353367027826. Reported num of rs:6
12/11/19 23:23:25 INFO util.ChaosMonkey: Sleeping for:60000
12/11/19 23:24:25 INFO util.ChaosMonkey: Starting region server:rs3.example.com
12/11/19 23:24:25 INFO hbase.HBaseCluster: Starting RS on: rs3.example.com
12/11/19 23:24:25 INFO hbase.ClusterManager: Executing remote command: /homes/enis/code/hbase-0.94/bin/../bin/hbase-daemon.sh --config /homes/enis/code/hbase-0.94/bin/../conf start regionserver , hostname:rs3.example.com
12/11/19 23:24:26 INFO hbase.ClusterManager: Executed remote command, exit code:0 , output:starting regionserver, logging to /homes/enis/code/hbase-0.94/bin/../logs/hbase-enis-regionserver-rs3.example.com.out
12/11/19 23:24:27 INFO util.ChaosMonkey: Started region server:rs3.example.com,60020,1353367027826. Reported num of rs:6
输出表明 ChaosMonkey 启动了默认的PeriodicRandomActionPolicy策略,该策略已配置了所有可用操作。它选择运行RestartActiveMaster和RestartRandomRs操作。
159.5.4. 可用 Policy
HBase 附带了多个 ChaosMonkey 策略,可在hbase/hbase-it/src/test/java/org/apache/hadoop/hbase/chaos/policies/目录中使用。
159.5.5. 配置单个 ChaosMonkey 操作
可以在每个测试运行中配置 ChaosMonkey 集成测试。在 HBase CLASSPATH 中创建 Java 属性文件,然后使用-monkeyProps配置标志将其传递给 ChaosMonkey。 org.apache.hadoop.hbase.chaos.factories.MonkeyConstants类中列出了可配置的属性及其默认值(如果适用)。对于具有默认值的属性,可以通过将其包含在属性文件中来覆盖它们。
以下示例使用名为monkey.properties的属性文件。
$ bin/hbase org.apache.hadoop.hbase.IntegrationTestIngest -m slowDeterministic -monkeyProps monkey.properties
上面的命令将启动集成测试和混乱猴子。它将在 HBase CLASSPATH 上查找属性文件* monkey.properties *。例如在 HBASE * conf *目录中。
这是一个混乱的猴子文件示例:
示例 ChaosMonkey 属性文件
sdm.action1.period=120000
sdm.action2.period=40000
move.regions.sleep.time=80000
move.regions.max.time=1000000
move.regions.sleep.time=80000
batch.restart.rs.ratio=0.4f
周期/时间以毫秒表示。
HBase 1.0.2 和更高版本增加了重新启动 HBase 的基础 ZooKeeper 仲裁或 HDFS 节点的功能。要使用这些操作,您需要在 ChaosMonkey 属性文件(可能是hbase-site.xml或其他属性文件)中配置一些新属性,这些新属性没有合理的默认值,因为它们是特定于部署的。
<property>
<name>hbase.it.clustermanager.hadoop.home</name>
<value>$HADOOP_HOME</value>
</property>
<property>
<name>hbase.it.clustermanager.zookeeper.home</name>
<value>$ZOOKEEPER_HOME</value>
</property>
<property>
<name>hbase.it.clustermanager.hbase.user</name>
<value>hbase</value>
</property>
<property>
<name>hbase.it.clustermanager.hadoop.hdfs.user</name>
<value>hdfs</value>
</property>
<property>
<name>hbase.it.clustermanager.zookeeper.user</name>
<value>zookeeper</value>
</property>
160.开发人员指南
160.1. Branches
我们使用 Git 进行源代码 Management,并且最新开发发生在master分支上。过去的主要/次要/维护版本都有分支,重要的功能和错误修复通常会向后移植到它们。
160.2. JIRA 中修订版本的 Policy
为了仅从发行版号确定给定修订是否在给定发行版中,定义了以下规则:
修复 X.Y.Z 的版本⇒在所有发行版 X.Y.Z'中均已修复(其中 Z'= Z)。
修复 X.Y.0 的版本⇒在所有发行版 X.Y'.中均已修复(其中 Y'= Y)。
修复 X.0.0 的版本⇒在所有发行版 X'..*中均已修复(其中 X'= X)。
根据此策略,1.3.0 的修订版本暗含 1.4.0,但 1.3.2 并不暗含 1.4.0,因为我们不能完全从数字上先得出哪个。
160.3. 规范标准
160.3.1. 接口分类
接口按受众和稳定性级别进行分类。这些标签显示在类的开头。 HBase 遵循的约定由其父项目 Hadoop 继承。
通常使用以下接口分类:
InterfaceAudience
@InterfaceAudience.Public- 用户和 HBase 应用程序的 API。这些 API 将通过主要版本的 HBase 弃用。
@InterfaceAudience.Private- 适用于 HBase 内部人员开发人员的 API。不保证将来版本的兼容性或可用性。专用接口不需要
@InterfaceStability分类。
- 适用于 HBase 内部人员开发人员的 API。不保证将来版本的兼容性或可用性。专用接口不需要
@InterfaceAudience.LimitedPrivate(HBaseInterfaceAudience.COPROC)- 适用于 HBase 协处理器编写器的 API。
否
@InterfaceAudience分类- 没有
@InterfaceAudience标签的软件包被视为私有软件包。如果可以公开访问,请标记您的新软件包。
- 没有
Excluding Non-Public Interfaces from API Documentation
API 文档(Javadoc)中应仅包括分类为@InterfaceAudience.Public的接口。对于不包含公共类的新软件包,提交者必须添加新的软件包,但* pom.xml *的ExcludePackageNames部分除外。
@InterfaceStability
@InterfaceStability对于标记为@InterfaceAudience.Public的软件包很重要。
@InterfaceStability.Stable- 没有弃用路径或非常充分的理由,不能更改标记为稳定的公共软件包。
@InterfaceStability.Unstable- 标记为不稳定的公共软件包可以更改,而无需使用弃用路径。
@InterfaceStability.Evolving- 标记为不断 Developing 的公共软件包可能会更改,但不鼓励这样做。
没有
@InterfaceStability标签- 不鼓励使用不带有
@InterfaceStability标签的公共类,应将其视为隐式不稳定。
- 不鼓励使用不带有
如果不清楚如何标记软件包,请在开发列表中询问。
160.3.2. 代码格式约定
请遵守以下准则,以便可以更快地查看您的补丁。这些准则是根据新贡献者对补丁的普遍反馈而制定的。
有关 Java 编码约定的更多信息,请参见Java 编程语言的代码约定。请参见eclipse.code.formatting以设置 Eclipse 以自动检查其中的一些准则。
Space Invaders
不要在括号周围使用多余的空格。使用第二种样式,而不是第一种。
if ( foo.equals( bar ) ) { // don't do this
if (foo.equals(bar)) {
foo = barArray[ i ]; // don't do this
foo = barArray[i];
自动生成的代码
Eclipse 中自动生成的代码通常使用错误的变量名,例如arg0。使用更多有用的变量名。在这里使用类似于第二个示例的代码。
public void readFields(DataInput arg0) throws IOException { // don't do this
foo = arg0.readUTF(); // don't do this
public void readFields(DataInput di) throws IOException {
foo = di.readUTF();
Long Lines
行数不得超过 100 个字符。您可以将 IDE 配置为自动执行此操作。
Bar bar = foo.veryLongMethodWithManyArguments(argument1, argument2, argument3, argument4, argument5, argument6, argument7, argument8, argument9); // don't do this
Bar bar = foo.veryLongMethodWithManyArguments(
argument1, argument2, argument3,argument4, argument5, argument6, argument7, argument8, argument9);
Trailing Spaces
确保在代码末尾有换行符,并避免只有空格的行。这使得差异更加有意义。您可以配置 IDE 来帮助您。
Bar bar = foo.getBar(); <--- imagine there is an extra space(s) after the semicolon.
API 文档(Javadoc)
不要忘记 Javadoc!
在预提交期间检查 Javadoc 警告。如果预提交工具给您一个“ -1”,请解决 javadoc 问题。如果添加了此类警告,则不会提交您的补丁。
另外,没有@author标签-这是规则。
Findbugs
Findbugs用于检测常见的错误模式。在预提交构建过程中将对其进行检查。如果发现错误,请修复它们。您可以使用mvn findbugs:findbugs在本地运行 findbugs,这将在本地生成findbugs文件。有时,您可能不得不编写比findbugs更智能的代码。您可以使用以下 Comments 为您的类添加 Comments,以告诉findbugs您知道自己在做什么。
@edu.umd.cs.findbugs.annotations.SuppressWarnings(
value="HE_EQUALS_USE_HASHCODE",
justification="I know what I'm doing")
使用注解的 Apache 许可版本很重要。通常,这意味着在edu.umd.cs.findbugs.annotations包中使用注解,以便我们可以依靠净室重新实现,而不是在javax.annotations包中使用注解。
Javadoc-无效的默认值
不要仅仅以 IDE 生成 Javadoc 标记的方式保留它们,也不要在其中填充冗余信息。
/**
* @param table <---- don't leave them empty!
* @param region An HRegion object. <---- don't fill redundant information!
* @return Foo Object foo just created. <---- Not useful information
* @throws SomeException <---- Not useful. Function declarations already tell that!
* @throws BarException when something went wrong <---- really?
*/
public Foo createFoo(Bar bar);
在标签中添加描述性的内容,或将其删除。首选是添加一些描述性和有用的内容。
一次只能做一件事情
如果您为某件事提交了补丁程序,请不要在完全不同的代码区域上进行自动重新格式化或不相关的重新格式化代码。
同样,请勿在 Jira 的范围之外添加无关的清理或重构。
模棱两可的单元测试
确保您清楚单元测试中要测试的内容以及原因。
160.3.3. 垃圾收集保存准则
从http://engineering.linkedin.com/performance/linkedin-feed-faster-less-jvm-garbage借鉴了以下准则。请记住它们,以尽量减少可预防的垃圾收集。请参阅博客文章,了解一些如何根据这些准则重构代码的出色示例。
小心迭代器
初始化时估计集合的大小
推迟表达评估
预先编译正则表达式模式
可以缓存
弦实习生很有用,但很危险
160.4. Invariants
我们没有很多,但下面列出了我们拥有的。当然,所有人都面临挑战,但在此之前,请遵守道路规则。
160.4.1. ZooKeeper 中没有永久状态
ZooKeeper 状态应该是瞬态的(像 Memory 一样进行处理)。如果删除 ZooKeeper 状态,则 hbase 应该能够恢复并且基本上处于相同状态。
.Exceptions:目前,我们需要解决一些 exceptions,这些 exceptions 是有关表是启用还是禁用的。
复制数据当前仅存储在 ZooKeeper 中。删除与复制相关的 ZooKeeper 数据可能会导致复制被禁用。不要删除复制树*/hbase/replication/*。
Warning
如果您从 ZooKeeper 删除复制树(/hbase/replication/),复制可能会中断,并且可能会发生数据丢失。在HBASE-10295跟踪此问题的进度。
160.5. 原位运行
如果您正在开发 Apache HBase,则经常在比单元测试中更真实的集群上测试更改很有用。在这种情况下,可以直接在本地模式下从源运行 HBase。您需要做的就是运行:
${HBASE_HOME}/bin/start-hbase.sh
这将启动完整的本地集群,就像打包 HBase 并将其安装在计算机上一样。
请记住,您需要将 HBase 安装到本地 maven 存储库中才能使原位群集正常工作。也就是说,您将需要运行:
mvn clean install -DskipTests
确保 maven 可以找到正确的 Classpath 和依赖项。通常,如果 maven 行为异常,则上面的命令只是尝试首先运行是一件好事。
160.6. 添加 Metrics
添加新功能后,开发人员可能想要添加 Metrics。 HBase 使用 Hadoop Metrics 2 系统公开 Metrics,因此添加新 Metrics 涉及将该 Metrics 公开给 hadoop 系统。不幸的是,metrics2 的 API 从 hadoop 1 更改为 hadoop2.为了解决这个问题,必须在运行时加载一组接口和实现。要深入了解这些类的原因和结构,可以阅读位于here的博客文章。要将度量添加到现有 MBean,请遵循以下简短指南:
160.6.1. 将 Metrics 名称和功能添加到 Hadoop Compat 接口。
在源接口内部,对应于度量的生成位置(例如,来自 HMaster 的 MetricsMasterSource)为度量名称和描述创建新的静态字符串。然后添加一个新方法,该方法将被调用以添加新的读数。
160.6.2. 将实现添加到 Hadoop 1 和 Hadoop 2 Compat 模块中。
在源实现的内部(例如,上面示例中的 MetricsMasterSourceImpl)在 init 方法中创建新的直方图,计数器,量表或 stat。然后,在添加到接口的方法中,将传入直方图的参数连接起来。
现在添加测试,以确保将数据正确导出到 metrics 2 系统。为此,提供了 MetricsAssertHelper。
160.7. Git 最佳实践
避免 git 合并。
- 使用
git pull --rebase或git fetch,然后使用git rebase。
- 使用
不要使用
git push --force。- 如果推送不起作用,请解决问题或寻求帮助。
如果您想到其他 Git 最佳实践,请为该文档做出贡献。
160.7.1. rebase_all_git_branches.sh
提供了* dev-support/rebase_all_git_branches.sh 脚本以帮助保持 Git 存储库的干净。使用-h参数获取使用说明。该脚本会自动刷新您的跟踪分支,尝试针对每个本地分支对其远程分支进行自动变基,并为您提供删除代表关闭的HBASE- JIRA 的任何分支的选项。该脚本具有一个可选的配置选项,即 Git 目录的位置。您可以通过编辑脚本来设置默认值。否则,您可以使用-d参数手动传递 git 目录,后跟一个绝对或相对目录名称,甚至是'。当前工作目录。该脚本在 continue 之前检查目录中是否存在名为 .git/*的子目录。
160.8. 提交补丁
如果您不熟悉向开源提交补丁程序,或者不熟悉向 Apache 提交补丁程序,请先从Apache Commons 项目阅读关于贡献补丁页面。它提供了一个很好的概述,该概述同样适用于 Apache HBase 项目。
160.8.1. 创建补丁
确保您检查common.patch.feedback的代码样式。如果您的补丁生成不正确,或者您的代码不符合代码格式准则,则可能会要求您重做一些工作。
使用 submit-patch.py(推荐)
$ dev-support/submit-patch.py -jid HBASE-xxxxx
使用此脚本可以创建补丁,上传到 jira 并有选择地在 Review Board 上创建/更新 Comment。补丁名称将自动格式化为*(JIRA)。(分支名称)。(补丁编号).patch *,以遵循 Yetus 的命名规则。使用-h标志可了解详细的使用信息。最有用的选项是:
-b BRANCH, --branch BRANCH:指定用于生成差异的基本分支。如果未指定,则使用跟踪分支。如果没有跟踪分支,将引发错误。-jid JIRA_ID, --jira-id JIRA_ID:如果使用,则从 jira 的附件中推断出下一补丁版本,并上传新补丁。脚本将要求 Importingjira 用户名/密码进行身份验证。如果未设置,则修补程序名为\ .patch。
默认情况下,它还将创建/更新审查委员会。要跳过该操作,请使用-srb选项。它使用 jira 中的“问题链接”确定是否已存在审阅请求。如果没有审阅请求,则创建一个新的审阅请求,并使用 jira 摘要,补丁说明等填充所有必填字段。还将此审阅的链接添加到 jira。
保存身份验证凭据(可选)
- 由于在 JIRA 上附加补丁并在 ReviewBoard 上创建/更改审阅请求需要有效的用户身份验证,因此脚本将提示您 Importing 用户名和密码。为避免每次麻烦,请设置具有登录详细信息的
~/.apache-creds,并按照脚本帮助消息页脚中的步骤对其进行加密。
- 由于在 JIRA 上附加补丁并在 ReviewBoard 上创建/更改审阅请求需要有效的用户身份验证,因此脚本将提示您 Importing 用户名和密码。为避免每次麻烦,请设置具有登录详细信息的
Python dependencies
- 要安装必需的 python 依赖项,请从 master 分支执行
pip install -r dev-support/python-requirements.txt。
- 要安装必需的 python 依赖项,请从 master 分支执行
Manually
首先使用
git rebase -i,将较小的提交合并(压缩)为一个较大的提交。使用 IDE 或 Git 命令创建补丁。首选
git format-patch是因为它保留修补程序作者的姓名和提交消息。同样,它默认处理二进制文件,而git diff会忽略它们,除非您使用--binary选项。补丁名称应如下以遵守 Yetus 的命名约定:
(JIRA).(branch name).(patch number).patch
例如。 HBASE-11625.master.001.patch,HBASE-XXXXX.branch-1.2.0005.patch 等使用
More→Attach Files将补丁附加到 JIRA,然后单击“提交补丁”按钮,这将触发 Hudson 作业来检查补丁的有效性。如果您的补丁程序比单个屏幕长,请在“审查委员会”上创建审查,并将链接添加到 JIRA。参见reviewboard。
通用准则很少
即使您要在另一个分支中进行修补,也请始终先对 master 分支进行修补。 HBase 提交者始终始终首先将修补程序应用于 master 分支,并在必要时向后移植。
提交一个修补程序。如有必要,请压缩本地提交以首先将本地提交合并为一个。有关压缩提交的更多信息,请参见堆栈溢出问题。
请理解,并非每个补丁都可以提交,并且补丁上可能会提供反馈。
如果您需要修改补丁,请将先前的补丁文件保留在 JIRA 上,然后上传补丁号递增的新补丁文件。
单击“取消补丁”,然后单击“提交补丁”以触发预提交运行。
160.8.2. 单元测试
进行更改时,请始终添加和/或更新相关的单元测试。在提交补丁之前,请确保新的/更改的单元测试在本地通过,因为它比 await 运行完整测试套件的预提交结果要快。这样可以节省您的时间和精力。使用mockito进行模拟,通过注入适当的故障对测试故障方案非常有用。
如果要创建新的单元测试类,请注意其他单元测试类在类名称之前如何分类/调整大小,以及用于设置/拆卸测试环境的静态方法。确保在任何新的单元测试文件中包含 Comments。有关测试的更多信息,请参见hbase.tests。
160.8.3. 整合测试
除单元测试外,重要的新功能还应提供集成测试,以适合在其配置空间的不同位置使用新功能。
160.8.4. ReviewBoard
大于一个屏幕的修补程序或将难以审核的修补程序应通过ReviewBoard进行检查。
过程:使用 ReviewBoard
如果您还没有帐号,请注册。它不使用来自issues.apache.org的凭据。登录。
单击新建审阅请求。
选择
hbase-git存储库。单击选择文件以选择差异和父差异(可选)。点击 创建审阅请求 。根据需要填写字段。至少填写摘要,然后选择
hbase作为审阅组。如果填写“错误”字段,则评审委员会将链接回相关的 JIRA。您填写的字段越多越好。点击 发布 以公开您的 Comment 请求。将会向hbase组中的每个人发送电子邮件,以查看补丁。返回 JIRA 中,单击,然后粘贴 ReviewBoard 请求的 URL。这会将 ReviewBoard 附加到 JIRA,以便于访问。
要取消请求,请单击。
有关如何使用 ReviewBoard 的更多信息,请参见ReviewBoard 文档。
160.8.5. HBase 提交者指南
成为提交者
提交者负责审查和集成代码更改,对候选发布者进行测试和投票,权衡设计讨论以及其他类型的项目贡献。 PMC 根据对项目贡献的评估,投票决定将参与者设为提交者。期望提交者展现出对项目和社区参与的高质量贡献的持续历史。
可以通过多种方式做出贡献。成为提交者没有单一的途径,也没有任何预期的时间表。提交功能,改进和错误修复是最常见的途径,但是其他方法也得到了认可和鼓励(对于作为项目和社区的 HBase 健康而言,这可能甚至更为重要)。潜在贡献的非详尽列表(无特定 Sequences):
更新文档获取新更改,最佳做法,食谱和其他改进。
保持网站最新。
执行测试并报告结果。例如,始终应进行规模测试和测试非标准配置。
维护共享的 Jenkins 测试环境和其他测试基础结构。
验证后投票释放候选人1,即使没有约束力。不具约束力的表决是非提交人的表决。
为mailing lists(主题行中通常有
[DISCUSS])上的讨论线程提供 Importing。在用户或开发人员邮件列表以及 Slack 上回答问题。
确保 HBase 社区是一个受欢迎的社区,并且我们遵守行为守则。如有疑问,请通知 PMC。
审查他人的工作(包括代码和非代码),并提供公众反馈。
报告发现的错误,或提出新的功能请求。
对问题进行分类,并使 JIRA 井井有条。这包括解决陈旧的问题,标记新问题,更新元数据以及根据需要执行的其他任务。
指导各种新的贡献者。
进行演讲并撰写有关 HBase 的博客。将它们添加到网站的News部分。
提供有关 HBase,Web UI,CLI,API 和网站的 UX 反馈。
编写演示应用程序和脚本。
帮助吸引和保留多元化的社区。
与其他项目进行交互,使 HBase 和其他项目受益。
并非每个人都能完成此列表中的所有(或什至任何)项目。如果您想其他方式做出贡献,那就去做(并将它们添加到列表中)。要使 HBase 项目产生积极影响,您需要有令人愉悦的举止和贡献的意愿。邀请成为提交人是长期与社区进行持续互动的结果,可以构建信任和认可。
New committers
鼓励新的提交者首先阅读 Apache 的通用提交者文档:
Review
HBase 提交者应尽可能多地尝试检查其他人提交的补丁。理想情况下,每个提交的补丁将在几天内由提交者进行审查。如果提交者审阅了他们尚未编写的补丁,并认为其质量足够,则他们可以提交补丁。否则,应取消补丁程序,并清楚说明拒绝该补丁程序的原因。
提交的修补程序列表位于HBase 审查队列中,该列表按上次修改时间排序。提交者应从上至下扫描列表,寻找他们认为有资格审查并可能提交的补丁。如果您发现某个补丁程序,认为您认为其他人更有资格审核,则可以在 JIRA 中按用户名提及它们。
对于不重要的更改,要求另一个提交者在提交之前检查补丁。 不允许自行提交非重要补丁. 像其他贡献者一样,使用 JIRA 中的“提交补丁”按钮,然后 await 其他提交者的+1响应后再提交。
Reject
不符合HowToContribute和代码审查清单准则的补丁应予以拒绝。提交者应始终对贡献者彬彬有礼,并尝试指导和鼓励他们做出更好的贡献。如果提交者希望改进不可接受的补丁,则应首先拒绝该补丁,提交者应附加一个新补丁以进行进一步检查。
Commit
提交者将补丁提交到 Apache HBase GIT 存储库。
Before you commit!!!!
确保您的本地配置正确,尤其是您的身份和电子邮件。检查$ git config --list 命令的输出,并确保它是正确的。如果需要指针,请参见设置 Git。
提交补丁时:
在提交消息中包括 Jira 问题 ID 以及对更改的简短描述。尝试添加不仅仅是 Jira 标题的内容,这样一来查看
git log输出的人就不必去 Jira 来了解更改的含义。确保正确获取问题 ID,因为这会使 Jira 链接到 Git 中的更改(使用问题的“全部”标签查看这些自动链接)。将修补程序提交到基于
master的新分支或其他预期分支。在此分支的名称中包含 JIRA ID 是一个好主意。通过执行 git pull --rebase 或其他类似的命令,检查要提交的相关目标分支,并确保本地分支具有所有远程更改。接下来,将更改樱桃选择到每个相关分支(例如 master),然后使用诸如 git push<remote-server><remote-branch>之类的命令将更改推送到远程分支。
Warning
如果您没有所有远程更改,则推送将失败。如果由于任何原因推送失败,请解决问题或寻求帮助。不要做 git push --force。
在提交补丁之前,您需要确定补丁的创建方式。有关创建补丁的方式的说明和首选项已更改,并且会有过渡期。
确定如何创建补丁
如果补丁的前几行看起来像是电子邮件的标题,带有“发件人”,“日期”和“主题”,则它是使用 git format-patch 创建的。这是首选方法,因为您可以重用提交者的提交消息。如果提交消息不合适,您仍然可以使用提交,然后运行
git commit --amend并根据需要重新编写单词。如果补丁的第一行与下面的相似,则使用不带
--no-prefix的 git diff 创建。这也是可以接受的。请注意文件名前面的a和b。这表明补丁不是使用--no-prefix创建的。
diff --git a/src/main/asciidoc/_chapters/developer.adoc b/src/main/asciidoc/_chapters/developer.adoc
- 如果补丁的第一行与下面的相似(没有
a和b),则该补丁是使用 git diff --no-prefix 创建的,您需要在下面的 git apply 命令中添加-p0。
diff --git src/main/asciidoc/_chapters/developer.adoc src/main/asciidoc/_chapters/developer.adoc
例子 39.提交补丁的例子
这些示例中您会注意到的一件事是,有很多 git pull 命令。实际将任何内容写入远程存储库的唯一命令是 git push,并且需要绝对确保所有内容的版本正确并且在推送之前没有任何冲突。多余的 git pull 命令通常是多余的,但比遗憾更好。
第一个示例显示了如何应用 git format-patch 生成的补丁并将其应用到master和branch-1分支。
使用 git format-patch 而不是 git diff 而不使用--no-prefix的指令是一个新指令。请参阅第二个示例,以了解如何应用 git diff 创建的补丁,以及如何教育创建补丁的人员。
$ git checkout -b HBASE-XXXX
$ git am ~/Downloads/HBASE-XXXX-v2.patch --signoff # If you are committing someone else's patch.
$ git checkout master
$ git pull --rebase
$ git cherry-pick <sha-from-commit>
# Resolve conflicts if necessary or ask the submitter to do it
$ git pull --rebase # Better safe than sorry
$ git push origin master
# Backport to branch-1
$ git checkout branch-1
$ git pull --rebase
$ git cherry-pick <sha-from-commit>
# Resolve conflicts if necessary
$ git pull --rebase # Better safe than sorry
$ git push origin branch-1
$ git branch -D HBASE-XXXX
这个例子展示了如何提交使用 git diff 而没有--no-prefix创建的补丁。如果补丁是使用--no-prefix创建的,则将-p0添加到 git apply 命令中。
$ git apply ~/Downloads/HBASE-XXXX-v2.patch
$ git commit -m "HBASE-XXXX Really Good Code Fix (Joe Schmo)" --author=<contributor> -a # This and next command is needed for patches created with 'git diff'
$ git commit --amend --signoff
$ git checkout master
$ git pull --rebase
$ git cherry-pick <sha-from-commit>
# Resolve conflicts if necessary or ask the submitter to do it
$ git pull --rebase # Better safe than sorry
$ git push origin master
# Backport to branch-1
$ git checkout branch-1
$ git pull --rebase
$ git cherry-pick <sha-from-commit>
# Resolve conflicts if necessary or ask the submitter to do it
$ git pull --rebase # Better safe than sorry
$ git push origin branch-1
$ git branch -D HBASE-XXXX
- 固定解决此问题,感谢贡献者。始终在此时设置“修复版本”,但仅对提交更改的每个分支设置单个修订版本,这是该更改将在其中出现的最早版本。
提交消息格式
提交消息应包含 JIRA ID 和补丁程序的描述。首选的提交消息格式为:
<jira-id> <jira-title> (<contributor-name-if-not-commit-author>)
HBASE-12345 Fix All The Things (jane@example.com)
如果贡献者使用 git format-patch 生成补丁,那么他们的提交消息就在他们的补丁中,您可以使用它,但是请确保 JIRA ID 位于提交消息的最前面,即使贡献者将其遗漏了也是如此。
发生冲突的问题后向后移植时添加“修改作者”
我们已经构建了以下做法:承诺掌握,然后在可能的情况下尽量选择分支机构,除非
它破坏了兼容性:在这种情况下,如果它可以在次要版本中使用,请反向移植到 branch-1 和 branch-2.
这是一项新功能:否针对维护版本,对于次要版本,请进行讨论并达成共识。
如果有较小的冲突,我们可以解决它,然后 continue 进行提交。最终提交保留原始作者。如果要修改的作者与原始提交者不同,请在提交消息的末尾添加对此的通知,例如:Amending-Author: Author <committer&apache>参见[HBase,邮件#dev-讨论上的讨论。
关闭相关的 GitHub PR
作为一个项目,我们努力确保每个变更都与 JIRA 相关联,但我们不强制要求任何特定工具用于审查。由于托管 git 存储库与 GitHub 之间 ASF 集成的实施细节,PMC 无法直接关闭 GitHub 存储库上的 PR。如果贡献者在 GitHub 上发出“拉取请求”,要么是因为贡献者发现它比将补丁附加到 JIRA 上要容易,要么是因为审阅者更喜欢使用 UI 来检查更改,因此在提交的提交中记下 PR 是很重要的到主分支,以便 PR 保持最新状态。
要详细了解有关哪种类型的提交消息将与 GitHub“通过提交中的关键字关闭”机制一起工作的详细信息,请参见GitHub 文档“使用关键字解决问题”。总之,您应该在行中添加短语“ closes #XXX”,其中 XXX 是请求请求 ID。拉取请求 ID 通常在主题标题末尾的 GitHub UI 中以灰色给出。
提交者负责确保提交不会破坏构建或测试
如果提交者提交了补丁,则确保其通过测试套件是他们的责任。如果提供者注意他们的补丁程序不会破坏 hbase 的构建和/或测试,这将很有帮助,但是最终,不能期望提供者知道像 HBase 这样的项目中发生的所有特定变化和互连。提交者应该。
Patching Etiquette
在线程HBase,邮件#dev-公告:正在进行 Git 迁移(WAS⇒Re:Git 迁移)中,就以下补丁流程达成了一致
首先针对 master 开发并提交补丁。
如果可能的话,尝试在移植时选择修补程序。
如果这不起作用,请手动将补丁提交到分支。
Merge Commits
避免合并提交,因为它们会在 git 历史 Logging 造成问题。
Committing Documentation
See 有助于文件编制的附录.
160.8.6. Dialog
提交者应该在 irc.freenode.net 的#hbase 会议室中闲逛,以进行实时讨论。但是,应在 Jira 或开发人员列表中再次重申任何实质性讨论(以及与项目外的项目相关的讨论)。
160.8.7. 不要编辑 JIRAComment
拼写错误和/或语法错误比 JIRAComment 编辑引起的干扰更可取:请参阅回复:(HBASE-451)从 HRegionInfo 删除 HTableDescriptor上的讨论
160.9. HBase-第三方依赖关系和 shade/重定位
为发布 hbase-2.0.0 创建了一个新项目。它被称为hbase-thirdparty。该项目的存在仅是为了为主要的 hbase 项目提供重新定位的或流行的第三方库(例如 guava,netty 和 protobuf)的版本。 HBase 主线项目依赖于从 hbase-thirdparty 获得的这些库的重定位版本,而不是在通常位置找到这些类。我们这样做是为了指定所需的版本。如果不迁移,则必须协调版本以匹配 hadoop,spark 和其他项目使用的版本。
对于开发人员,这意味着您需要小心地引用 netty,guava,protobuf,gson 等中的类(有关提供的内容,请参见 hbase-thirdparty pom.xml)。开发人员必须引用 hbase-thirdparty 提供的类。实际上,这通常不是问题(尽管可能会有些痛苦)。您将必须寻找特定类的搬迁版本。您可以在通用重定位前缀org.apache.hbase.thirdparty.之前添加它。例如,如果您正在寻找com.google.protobuf.Message,则可以在org.apache.hbase.thirdparty.com.google.protobuf.Message处找到 HBase 内部使用的重定位版本。
对于诸如 protobuf(请参阅本书中的 protobuf 章节)的一些第三方库,您的 IDE 可能会同时给您提供两种选择-com.google.protobuf. 和org.apache.hbase.thirdparty.com.google.protobuf. -因为这两个类都在 CLASSPATH 上。除非您正在做协处理器端点开发中所需的特殊处理(再次参见上面引用的 protobuf 一章),否则您将始终要使用 shade 版本。
hbase-thirdparty项目的组 ID 为org.apache.hbase.thirdparty。在撰写本文时,它提供了三个 jar。一个用于伪造品为hbase-thirdparty-netty的 netty,一个用于hbase-thirdparty-protobuf的 protobuf,然后是hbase-thirdpaty-miscellaneous的所有其他商品的罐子-gson,Guava-。
hbase-第三方构件是由 Apache HBase 项目在 HBase 项目 Management 委员会的主持下生产的产品。发布是通过 hbase dev 邮件列表上的常规投票项目完成的。如果 hbase-thirdparty 中存在问题,请使用 hbase JIRA 和邮件列表发布通知。
160.10. 与 HBase 相关的 Maven 原型的开发
与 HBase 相关的 Maven 原型的开发始于HBASE-14876。有关 hbase 原型基础结构的概述以及有关开发与 HBase 相关的新 Maven 原型的说明,请参阅hbase/hbase-archetypes/README.md。
HBase 应用程序的单元测试
本章讨论使用 JUnit,Mockito,MRUnit 和 HBaseTestingUtility 对 HBase 应用程序进行单元测试。许多信息来自关于测试 HBase 应用程序的社区博客文章。有关 HBase 本身的单元测试的信息,请参见hbase.tests。
161. JUnit
HBase 使用JUnit进行单元测试
本示例将单元测试添加到以下示例类:
public class MyHBaseDAO {
public static void insertRecord(Table.getTable(table), HBaseTestObj obj)
throws Exception {
Put put = createPut(obj);
table.put(put);
}
private static Put createPut(HBaseTestObj obj) {
Put put = new Put(Bytes.toBytes(obj.getRowKey()));
put.add(Bytes.toBytes("CF"), Bytes.toBytes("CQ-1"),
Bytes.toBytes(obj.getData1()));
put.add(Bytes.toBytes("CF"), Bytes.toBytes("CQ-2"),
Bytes.toBytes(obj.getData2()));
return put;
}
}
第一步是将 JUnit 依赖项添加到您的 Maven POM 文件中:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
接下来,将一些单元测试添加到您的代码中。测试用@TestComments。在这里,单元测试以粗体显示。
public class TestMyHbaseDAOData {
@Test
public void testCreatePut() throws Exception {
HBaseTestObj obj = new HBaseTestObj();
obj.setRowKey("ROWKEY-1");
obj.setData1("DATA-1");
obj.setData2("DATA-2");
Put put = MyHBaseDAO.createPut(obj);
assertEquals(obj.getRowKey(), Bytes.toString(put.getRow()));
assertEquals(obj.getData1(), Bytes.toString(put.get(Bytes.toBytes("CF"), Bytes.toBytes("CQ-1")).get(0).getValue()));
assertEquals(obj.getData2(), Bytes.toString(put.get(Bytes.toBytes("CF"), Bytes.toBytes("CQ-2")).get(0).getValue()));
}
}
这些测试确保您的createPut方法创建,填充并返回具有期望值的Put对象。当然,JUnit 可以做的还不止这些。有关 JUnit 的介绍,请参见https://github.com/junit-team/junit/wiki/Getting-started。
162. Mockito
Mockito 是一个模拟框架。它比 JUnit 更进一步,它允许您测试对象之间的交互,而不必复制整个环境。您可以在其项目站点https://code.google.com/p/mockito/上了解有关 Mockito 的更多信息。
您可以使用 Mockito 在较小的单元上进行单元测试。例如,您可以模拟org.apache.hadoop.hbase.Server实例或org.apache.hadoop.hbase.master.MasterServices接口引用,而不是完整的org.apache.hadoop.hbase.master.HMaster。
本示例以unit.tests中的示例代码为基础,以测试insertRecord方法。
首先,将 Mockito 的依赖项添加到您的 Maven POM 文件中。
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>2.1.0</version>
<scope>test</scope>
</dependency>
接下来,在测试类中添加@RunWith注解,以指导它使用 Mockito。
@RunWith(MockitoJUnitRunner.class)
public class TestMyHBaseDAO{
@Mock
Configuration config = HBaseConfiguration.create();
@Mock
Connection connection = ConnectionFactory.createConnection(config);
@Mock
private Table table;
@Captor
private ArgumentCaptor putCaptor;
@Test
public void testInsertRecord() throws Exception {
//return mock table when getTable is called
when(connection.getTable(TableName.valueOf("tablename")).thenReturn(table);
//create test object and make a call to the DAO that needs testing
HBaseTestObj obj = new HBaseTestObj();
obj.setRowKey("ROWKEY-1");
obj.setData1("DATA-1");
obj.setData2("DATA-2");
MyHBaseDAO.insertRecord(table, obj);
verify(table).put(putCaptor.capture());
Put put = putCaptor.getValue();
assertEquals(Bytes.toString(put.getRow()), obj.getRowKey());
assert(put.has(Bytes.toBytes("CF"), Bytes.toBytes("CQ-1")));
assert(put.has(Bytes.toBytes("CF"), Bytes.toBytes("CQ-2")));
assertEquals(Bytes.toString(put.get(Bytes.toBytes("CF"),Bytes.toBytes("CQ-1")).get(0).getValue()), "DATA-1");
assertEquals(Bytes.toString(put.get(Bytes.toBytes("CF"),Bytes.toBytes("CQ-2")).get(0).getValue()), "DATA-2");
}
}
该代码使用ROWKEY-1'', DATA-1'',``DATA-2''作为值填充HBaseTestObj。然后将记录插入到模拟表中。将捕获 DAO 可能插入的 Put 值,并测试值以验证它们是否符合您的期望。
此处的关键是在 DAO 外部 ManagementConnection 和 Table 实例的创建。这样您就可以干净地模拟它们并测试 Puts,如上所示。同样,您现在可以扩展到其他操作,例如“获取”,“扫描”或“删除”。
163. MRUnit
Apache MRUnit是一个库,可用于对 MapReduce 作业进行单元测试。您可以使用它以与其他 MapReduce 作业相同的方式测试 HBase 作业。
给定一个 MapReduce 作业可写入名为MyTest的 HBase 表,该表具有一个称为CF的列族,该作业的约简操作可能如下所示:
public class MyReducer extends TableReducer<Text, Text, ImmutableBytesWritable> {
public static final byte[] CF = "CF".getBytes();
public static final byte[] QUALIFIER = "CQ-1".getBytes();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//bunch of processing to extract data to be inserted, in our case, let's say we are simply
//appending all the records we receive from the mapper for this particular
//key and insert one record into HBase
StringBuffer data = new StringBuffer();
Put put = new Put(Bytes.toBytes(key.toString()));
for (Text val : values) {
data = data.append(val);
}
put.add(CF, QUALIFIER, Bytes.toBytes(data.toString()));
//write to HBase
context.write(new ImmutableBytesWritable(Bytes.toBytes(key.toString())), put);
}
}
要测试此代码,第一步是将 MRUnit 依赖项添加到 Maven POM 文件中。
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.0.0 </version>
<scope>test</scope>
</dependency>
接下来,在您的 Reducer 作业中使用 MRUnit 提供的 ReducerDriver。
public class MyReducerTest {
ReduceDriver<Text, Text, ImmutableBytesWritable, Writable> reduceDriver;
byte[] CF = "CF".getBytes();
byte[] QUALIFIER = "CQ-1".getBytes();
@Before
public void setUp() {
MyReducer reducer = new MyReducer();
reduceDriver = ReduceDriver.newReduceDriver(reducer);
}
@Test
public void testHBaseInsert() throws IOException {
String strKey = "RowKey-1", strValue = "DATA", strValue1 = "DATA1",
strValue2 = "DATA2";
List<Text> list = new ArrayList<Text>();
list.add(new Text(strValue));
list.add(new Text(strValue1));
list.add(new Text(strValue2));
//since in our case all that the reducer is doing is appending the records that the mapper
//sends it, we should get the following back
String expectedOutput = strValue + strValue1 + strValue2;
//Setup Input, mimic what mapper would have passed
//to the reducer and run test
reduceDriver.withInput(new Text(strKey), list);
//run the reducer and get its output
List<Pair<ImmutableBytesWritable, Writable>> result = reduceDriver.run();
//extract key from result and verify
assertEquals(Bytes.toString(result.get(0).getFirst().get()), strKey);
//extract value for CF/QUALIFIER and verify
Put a = (Put)result.get(0).getSecond();
String c = Bytes.toString(a.get(CF, QUALIFIER).get(0).getValue());
assertEquals(expectedOutput,c );
}
}
您的 MRUnit 测试将验证输出是否符合预期,插入 HBase 的 Put 值正确,并且 ColumnFamily 和 ColumnQualifier 值正确。
MRUnit 包含一个 MapperDriver 来测试 Map 作业,您可以使用 MRUnit 来测试其他操作,包括从 HBase 读取,处理数据或写入 HDFS,
164.使用 HBase Mini-Cluster 进行集成测试
HBase 附带了 HBaseTestingUtility,这使使用* mini-cluster *编写集成测试变得容易。第一步是向您的 Maven POM 文件添加一些依赖项。检查版本以确保它们合适。
<properties>
<hbase.version>2.0.0-SNAPSHOT</hbase.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-testing-util</artifactId>
<version>${hbase.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
此代码表示对unit.tests中显示的 MyDAO 插件的集成测试。
public class MyHBaseIntegrationTest {
private static HBaseTestingUtility utility;
byte[] CF = "CF".getBytes();
byte[] CQ1 = "CQ-1".getBytes();
byte[] CQ2 = "CQ-2".getBytes();
@Before
public void setup() throws Exception {
utility = new HBaseTestingUtility();
utility.startMiniCluster();
}
@Test
public void testInsert() throws Exception {
Table table = utility.createTable(Bytes.toBytes("MyTest"), CF);
HBaseTestObj obj = new HBaseTestObj();
obj.setRowKey("ROWKEY-1");
obj.setData1("DATA-1");
obj.setData2("DATA-2");
MyHBaseDAO.insertRecord(table, obj);
Get get1 = new Get(Bytes.toBytes(obj.getRowKey()));
get1.addColumn(CF, CQ1);
Result result1 = table.get(get1);
assertEquals(Bytes.toString(result1.getRow()), obj.getRowKey());
assertEquals(Bytes.toString(result1.value()), obj.getData1());
Get get2 = new Get(Bytes.toBytes(obj.getRowKey()));
get2.addColumn(CF, CQ2);
Result result2 = table.get(get2);
assertEquals(Bytes.toString(result2.getRow()), obj.getRowKey());
assertEquals(Bytes.toString(result2.value()), obj.getData2());
}
}
此代码创建一个 HBase 迷你集群并启动它。接下来,它创建一个名为MyTest的表,其中包含一个列族CF。插入一条记录,从同一张表执行 Get 操作,并验证插入。
Note
启动迷你集群大约需要 20 到 30 秒,但这应该适合集成测试。
有关 HBaseTestingUtility 的更多信息,请参见HBase 案例研究:使用 HBaseTestingUtility 进行本地测试和开发(2010)上的论文。
HBase 中的 Protobuf
165. Protobuf
当 HBase 保留元数据时,HBase 使用 Google 的protobufs。 HBase 使用 protobufs 描述我们向 Client 端公开的 RPC 接口(服务),例如 RegionServer 字段的Admin和Client接口,或指定开发人员通过Coprocessor Endpoint机制添加的任意扩展。
在本章中,我们将为寻求更好地了解所有工作原理的开发人员提供详细信息。本章对那些会修改或扩展 HBase 功能的人员特别有用。
使用 protobuf,您可以在.protos文件中描述序列化和服务。然后,您将这些 Descriptors 提供给 protobuf 工具protoc二进制文件,以生成可以封送和拆组所描述的序列化并 Importing 指定服务的类。
有关如何在每个模块上运行类生成的详细信息,请参见 HBase 子模块中的README.txt。例如有关如何在 hbase-protocol 模块中生成 protobuf 类的信息,请参见hbase-protocol/README.txt。
在 HBase 中,.proto个文件位于hbase-protocol模块中;一个专用于托管通用协议文件和协议生成的类的模块,HBase 在内部使用这些序列化元数据。对于需要自己的 Descriptors 的 hbase 扩展(例如 REST 或协处理器端点);它们的原型位于函数的托管模块内部:例如hbase-rest是 REST 原型文件的所在地,hbase-rsgroup表分组协处理器端点具有与表分组有关的所有原型。
Proto 由使用它们的模块托管。虽然这使得 protobuf 类的生成是分布式的,每个模块都完成了,但我们这样做是为了使模块封装所有与它们带给 hbase 的功能有关的功能。
REST 或协处理器端点的扩展将利用在 hbase-protocol 模块中找到的核心 HBase 原型。作为提供 CPEP 服务的一部分,当他们要序列化 Cell 或 Put 或通过 ServerName 等引用特定节点时,将使用这些核心原型。展望 Future,在发布 hbase-2.0.0 之后,这种做法还需要进一步探讨。我们将在后面的hbase-2.0.0部分中解释原因。
165.1. hbase-2.0.0 和 protobuf 的 shade(HBASE-15638)
从 hbase-2.0.0 开始,我们对 protobuf 的使用更加复杂。 HBase 核心 protobuf 引用是偏移的,以便引用私有的 Bindingprotobuf。 Core 停止在 com.google.protobuf.*上引用 protobuf 类,而在 HBase 特定的偏移量 org.apache.hadoop.hbase.shaded.com.google.protobuf.*上引用 protobuf。我们这样做是间接的,因此 hbase 核心可以独立于我们的依赖项依赖而 Developing 其 protobuf 版本。例如,HDFS 使用 protobuf 进行序列化。 HDFS 在我们的 CLASSPATH 上。如果没有上述间接说明,我们的 protobuf 版本将必须对齐。 HBase 将停留在 HDFS protobuf 版本上,直到 HDFS 决定升级。 HBase 和 HDFS 版本将绑定在一起。
我们必须从 protobuf-2.5.0continue 前进,因为我们需要在 protobuf-3.1.0 中添加设施。特别是能够保存副本,并避免将 probubufs 带到堆上进行序列化/反序列化。
在 hbase-2.0.0 中,我们引入了一个新模块hbase-protocol-shaded,其中包含与 protobuf 及其后续重定位/着色有关的所有内容。该模块实质上是许多旧hbase-protocol的副本,但带有额外的着色/重定位步骤。核心已移至此新模块。
也就是说,在协处理器端点(CPEP)周围会出现复杂情况。 CPEP 依赖于公开的 HBase API,这些 API 明确引用com.google.protobuf.*处的 protobuf 类。例如,在我们的表接口中,我们使用以下方法作为获取 CPEP 服务的依据:
...
<T extends com.google.protobuf.Service,R> Map<byte[],R> coprocessorService(
Class<T> service, byte[] startKey, byte[] endKey,
org.apache.hadoop.hbase.client.coprocessor.Batch.Call<T,R> callable)
throws com.google.protobuf.ServiceException, Throwable
现有的 CPEP 将引用核心 HBase 协议来指定 ServerNames 或携带 Mutations。为了在升级到 hbase-2.0.0 及更高版本时 continue 为 CPEP 及其对com.google.protobuf. 的引用提供服务,HBase 需要能够处理com.google.protobuf. 引用及其内部偏移org.apache.hadoop.hbase.shaded.com.google.protobuf.* protobuf。
hbase-protocol-shaded模块托管 HBase 核心使用的所有协议缓冲区。
但是,对于残留的 CPEP 引用hbase-protocol的(非 shade)内容,我们将 continue 处理该模块的大部分内容,以便 CPEP 可以使用它。保留hbase-protocol的大部分内容会导致重叠的“重复”原型实例,其中有些实例在其旧模块位置中以非 shade/非重定位的形式存在,在新模块中也以hbase-protocol-shadedshade 显示。换句话说,在 hbase-protocol 中有一个生成的 protobuf 类org.apache.hadoop.hbase.protobuf.generated.ServerName的实例,另一个生成的实例在所有方面都相同,除了它的 protobuf 引用是在org.apache.hadoop.hbase.shaded.protobuf.generated.ServerName处的内部 shade 版本(请注意,包名称的中间)。
如果您在hbase-protocol-shaded中扩展一个原型供内部使用,请考虑也在hbase-protocol中扩展它(并重新生成)。
展望 Future,我们将为 CPEP 提供一个通用类型的新模块,与我们的公共 API 一样,它们具有相同的防止更改的保证。去做。
过程框架(Pv2):HBASE-12439
*程序 v2…旨在提供一种统一的方式来构建…多步骤程序,以在发生故障的情况下具有回滚/前滚功能(例如,创建/删除表)。— — Pv2 的作者 Matteo Bertozzi。
借助 Pv2,您可以构建和运行状态机。它是由 Matteo 构建的,以在面对过程故障时使 HBase 中的分布式状态转换具 Elastic。在 Pv2 之前,状态转换处理在代码库中进行了扩展,其实现因转换类型和上下文而异。 Pv2 的灵感来自 Apache Accumulo 的FATE。
早期的 Pv2 方面已经在 HBase 中交付了很长一段时间,但是随着涉及更多的场景,它一直在不断 Developing。我们现在拥有的功能强大,但操作复杂且不完整,需要清理和强化。在本文档中,我们对系统进行了概述,以便您可以使用它(并帮助其完善)。
这个系统的名称很笨拙,因为 HBase 已经在快照中使用了过程的概念(请参阅 hbase-server * org.apache.hadoop.hbase.procedure *,而不是 hbase-procedure * org.apache.hadoop.hbase..procedure2 *)。 Pv2 取代并将替换 Procedure。
166. Procedures
过程是对 HBase 实体进行的转换。 HBase 实体的示例为 Regions 和 Tables。
过程由 ProcedureExecutor 实例运行。过程当前状态保存在 ProcedureStore 中。
ProcedureExecutor 对于过程内部发生的事情只有一个原始的看法。从其 PoV 提交过程,然后 ProcedureExecutorcontinue 调用*#execute(Object),直到过程完成。如果执行失败或重新启动,则可能会多次调用 Execute,因此过程代码必须是幂等的,每次运行时都必须产生相同的结果。过程代码还可以实现 rollback ,因此,如果失败,则可以撤消步骤。调用 execute()*可能导致以下可能性之一:
-
- execute()*返回
-
- null *:表示已完成。
-
- this :指示还有更多操作,请保留当前过程状态并重新 execute()*。
subprocess 的数组*:表示需要执行才能完成的一组过程(之后,我们希望框架再次调用执行)。
-
- execute()*引发异常
-
- suspend *:表示过程的执行已暂停,由于某些外部事件,可以恢复执行。过程状态保持不变。
-
- yield *:将过程添加回调度程序。过程状态不持久。
-
- interrupted :当前与 yield *相同。
上面未列出的任何* exception :过程 state 更改为 FAILED *(在此之后,我们希望框架将尝试回滚)。
ProcedureExecutor 将过程状态的框架概念标记在过程本身中;例如它在提交时将过程标记为 INITIALIZING。当执行时,它将状态移动到 RUNNABLE。完成后,过程将被标记为失败或成功。这是撰写本文时所有状态的列表:
*** INITIALIZING** *施工中的程序,尚未添加到 Actuator 中
*可运行 *程序已添加到执行程序,并准备执行。
*await 中 *该程序正在 awaitchild(subprocess)完成
*** WAITING_TIMEOUT** *该过程正在 await 超时或外部事件
*** ROLLEDBACK** *该过程失败并被回滚。
*成功 *过程执行成功完成。
*失败 *过程执行失败,可能需要回滚。
每次执行后,过程状态将持久保存到 ProcedureStore。钩子在过程上被调用,因此它们可以保留自定义状态。发生故障后,ProcedureExecutor 通过重播 ProcedureStore 的内容来重新补充其崩溃前的状态。这使过程框架可以抵抗过程故障。
166.1. Implementation
在实现过程中,过程倾向于将转换划分为更细粒度的任务,而其中一些工作项已移交给 subprocess,而大部分则作为过程中的步骤进行处理;执行的每次调用都用于执行一个步骤,然后过程放弃并返回到框架。该过程对其在处理中的位置进行自己的跟踪。
子任务或执行中的“步骤”由程序作者决定,但通常这是一小部分工作,无法进一步分解,并将处理移至其最终状态。使过程由许多小步骤而不是几个大步骤组成,使 Procedure 框架可以洞悉我们在处理中的位置。它还使框架在执行过程中更加公平。如上所述,每个步骤可能被多次调用(失败/重新启动),因此步骤必须是幂等的。
容易混淆程序本身与框架本身保持一致的状态。尝试使其与众不同。
166.2. Rollback
当该过程或 subprocess 之一失败时,将调用回滚。回滚步骤应该清除在 execute()步骤中创建的资源。万一发生故障并重新启动,rollback()可能会被多次调用,因此代码必须是幂等的。
166.3. Metrics
有一些钩子可用于在提交过程和完成过程时收集 Metrics。
updateMetricsOnSubmit()
updateMetricsOnFinish()
各个过程可以覆盖这些方法以收集过程特定的度量。这些方法的默认实现尝试获取实现接口 ProcedureMetrics 的对象,该对象封装了以下一组通用 Metrics:
SubmittedCount(计数器):一种类型的过程实例总数。
时间(直方图):过程实例的运行时直方图。
FailedCount(计数器):失败的过程实例总数。
各个过程可以实现此对象并定义这些通用的度量标准集。
166.4. Baggage
程序可以随身携带 Baggage。一个例子是最后执行的步骤(请参见上一节)。过程会保留标记当前位置的枚举。其他示例可能是过程当前正在工作的地区或服务器名称。在每次执行调用之后,都会调用 Procedure#serializeStateData。程序可以坚持下去。
166.5. 结果/状态和查询
(摘自 Matteo 的ProcedureV2 和通知总线文档)
在异步操作的情况下,必须保留结果,直到 Client 端要求为止。收到结果的“获取”后,我们可以安排删除记录。对于某些操作,结果可能是“不必要的”,尤其是在失败的情况下(例如,如果创建表失败,我们可以查询操作结果,或者可以只创建一个列表表来查看它是否被创建),因此在某些情况下,我们可以在超时后安排删除。在 Client 端,该操作将返回“过程 ID”,该 ID 可用于 await 过程完成并获取结果/异常。
Admin.doOperation() { longprocId=master.doOperation(); master.waitCompletion(procId); } +
如果主服务器在执行操作时发生故障,备用主服务器将接管进行中的一半操作并完成操作。Client 端不会注意到失败。
167. Subprocedures
subprocess 是由过程实例(父过程)的*#execute(Object)方法创建并返回的 Procedure 实例。由于 subprocess 的类型为* Procedure *,因此它们可以实例化自己的 subprocess。由于它是递归的,因此程序框架由框架维护。该框架确保在成功完成过程堆栈中的所有 subprocess 及其 subprocess 之前,父过程不会 continue 进行。
168. ProcedureExecutor
- ProcedureExecutor 使用 ProcedureStore 和 ProcedureScheduler *并执行提交给它的过程。支持的一些基本操作包括:
-
- abort(procId)*:如果未完成,则中止指定过程
-
- submit(Procedure)*:提交执行程序
获取:获取过程实例和结果的 get 方法列表
注册/取消注册侦听器:用于侦听与过程相关的通知
当* ProcedureExecutor 启动时,它将加载先前运行中持久保存在 ProcedureStore *中的过程实例。所有未完成的过程将从上次存储的状态恢复。
169. Nonces
您可以将 RPC 附带的随机数传递给过程,然后在执行者处提交。然后,该随机数将与“过程 continue”一起进行序列化。如果在重新加载时发生崩溃,则当 Client 端尝试第二次运行相同过程时,该随机数将重新放回 pid 的随机数 Map 中(它将被拒绝)。请参阅基本过程以及随机数如何成为基本数据成员。
170. Wait/Wake/Suspend/Yield
“挂起”表示停止处理程序,因为在条件发生变化之前我们无法取得更多进展;也就是说,我们发送了 RPC,需要 await 响应。它的工作方式是,过程作为 GOTO 当前处理的最后一步,从过程中抛出异常挂起的异常。挂起还将过程重新放到调度程序上。有问题的是,即使暂停,我们也要在出路时进行一些核算,这样就需要花费一些时间(我们必须更新 WAL 中的状态)。
收到来自 RS 的报告后,将调用 RegionTransitionProcedure#reportTransition。对于“分配”和“取消分配”,来自我们发送 RPC 的服务器的此事件响应将唤醒挂起的“分配/取消分配”。
171. Locking
过程锁与并发无关!它们是关于为过程提供对 HBase 实体(如表或区域)的读/写访问权限,以便有可能阻止其他过程在当前过程运行时对 HBase Entity 状态进行修改。
锁定是可选的,直到过程实现者为止,但是如果某个实体正在由过程进行操作,则所有转换都需要使用相同的锁定方案通过过程来进行,否则会造成破坏。
实际上,两个 ProcedureExecutor Worker 线程可以最终都处理同一个 Procedure 实例。如果发生这种情况,则线程将运行同一过程的不同部分,这些变化不会相互叠加(这在过程框架“挂起”的概念中很尴尬.有关此内容的更多信息,请参见下文)。
可以选择在整个过程的生命周期内保持锁定。例如,如果移动区域,则您可能希望对 HBase 区域具有独占访问权限,直到该区域完成(或失败)为止。与\ {@link #holdLock(Object)}结合使用。如果\ {@link #holdLock(Object)}返回 true,则该过程执行程序将调用一次 acquireLock(),然后在该过程完成之前才调用\ {@link #releaseLock(Object)}(通常,它将在 {@link #execute(Object)}的每次调用周围调用 release/acquire。
锁还可以维持程序的生命。即,一旦分配过程开始,我们就不希望另一个过程干预分配区域。在该过程的整个生命周期内都持有该锁的过程将 Procedure#holdLock 设置为 true。 AssignProcedure 和“分割并移动”一样执行此操作(如果在“区域”移动的中间,则不希望它“分割”)。
锁定可以终身保留。
有些锁具有层次结构。例如,采用区域锁还需要对其包含的表和名称空间进行(读取)锁定,以防止另一个过程在托管表(或名称空间)上获得排他锁。
172.过程类型
172.1. StateMachineProcedure
可以将对*#execute(Object)方法的每次调用视为在状态机中从一种状态转换为另一种状态。抽象类 StateMachineProcedure 是基础 Procedure 类的包装器,该类为将状态机实现为 Procedure 提供了构造。在每个状态转换之后,当前状态都将保留下来,以便在发生崩溃/重新启动的情况下,可以从崩溃/重新启动之前的过程的先前状态恢复状态转换。各个过程需要定义初始状态和 endpoints 状态,并为状态转换提供了钩子 executeFromState()和 setNextState()*。
172.2. RemoteProcedureDispatcher
一个新的 RemoteProcedureDispatcher(子类 RSProcedureDispatcher)Primitives 负责运行基于过程的分配“远程”组件。该调度员了解“服务器”。它按时间/次数按时间汇总分配,因此可以成批发送过程,而不是每个 RPC 发送过程。过程状态返回到 RegionServer 心跳报告在线/离线区域的背面(不再通过 ZK 发出通知)。响应被传递到 AMv2 进行“处理”。它将检查内存状态。如果存在不匹配,则假定 RS 端出了问题,它会将 RegionServer 拒之门外。超时触发重试(尚未实现!)。 Procedure 机器使用实体* locking *并确保智能地知道什么是串行的以及可以同时运行的内容,一次仅对任何一个 Region/Table 进行一次操作(锁定基于 zk,-您将 znode 放在 zk 中用于表,但现在已作为该项目的一部分转换为基于过程的表)。
173. References
Matteo 演示了过程框架的外观以及最初解决的问题附加到 Pv2 问题。
Matteo 的好医生关于问题以及 Pv2 如何通过 Route 图解决问题(来自 Pv2 JIRA)。我们应该回到 Route 图来进行通知总线,将日志拆分转换为 Pv2 等。
开发的 AMv2 说明
HBase Master 中的 AssignmentManager(AM)ManagementRegionServers 群集上的 Regions 分配。
AMv2 项目是分配的重做,旨在解决 Producing 许多运营问题的根本原因,即缓慢的分配和有问题的会计处理,从而使区域错放到臭名昭著的* Region-In-Transition(RIT) *边缘状态。
以下是按 Sequences 排列的 AMv2 关键方面的开发人员注意事项。
174. Background
HBase 1.x 中的分配在操作中存在问题。不难看出为什么。区域状态保存在 ZooKeeper 中 RPC 的另一端(终端状态-即 OPEN 或 CLOSED 已发布到* hbase:meta 表)。在 HBase-1.x.x 中,状态有多个编写者,其中的 Master 和 RegionServers 都可以同时进行状态编辑(在 hbase:meta *表中,在 ZooKeeper 上)。如果时钟出现偏差或错过了观察者,则状态更改可以跳过或覆盖。 HBase 实体(表,区域)的锁定并不全面,因此表操作(禁用/启用)可能会与区域级操作冲突;拆分或合并。区域状态是分布式的,难以推理和测试。分配操作很慢,因为每个分配都涉及通过过渡移动远程 znode。集群的大小往往达到数十万个区域。除此之外,群集启动/停止需要几个小时,并且容易损坏。
AMv2(AssignmentManager 版本 2)是 hbase-1.x AssignmentManager 的重构(HBASE-14350),以ProcedureV2 (HBASE-12439)为基础。 ProcedureV2(Pv2)*,*是一个笨拙的系统,它允许描述和运行多步状态机。它是高性能的,并且将所有状态持久保存到可在崩溃后恢复的存储。请参阅程序框架(Pv2): HBASE-12439上的配套章节,以了解有关 ProcedureV2 系统的更多信息。
在 AMv2 中,所有分配,崩溃处理,拆分和合并都将重铸为 Procedures(v2)。 ZooKeeper 已从混合中清除。与之前一样,最终的分配状态将发布到* hbase:meta *,供非 Master 参与者读取(所有 Client 端),并将中间状态保留在基于 Pv2 WAL 的本地“Store”中,但仅保留活动 Master(单个)Writer,Developing 状态。主服务器在内存中的群集映像是权限,如果有分歧,则将 RegionServers 强制遵从。 Pv2 添加了对所有核心 HBase 实体(名称空间,表和区域)的共享/独占锁定,以确保一次访问一个参与者,并防止操作争用资源(移动/拆分,禁用/分配等)。
AM 在目标专用的性能状态机上进行的 AM 重做,所有操作都由一个状态编写器采用通用的 Procedure 形式进行,这只会将 AM 提升到新的弹性和规模。
175.新系统
现在,每个为区域分配或取消分配的区域都是一个过程。移动(区域)过程是过程的组合;它是先执行取消分配过程再执行分配过程。移动过程按 Sequences 生成“分配”和“取消分配”,然后 await 其完成。
等等。 ServerCrashProcedure 生成 WAL 拆分任务,然后重新分配崩溃的服务器上托管的所有区域作为 subprocess。
AMv2 过程由主服务器在 ProcedureExecutor 实例中运行。所有过程都使用 Pv2 框架提供的 Util。
例如,过程将每个状态转换持久化到框架的过程存储。默认实现是通过保留在 HDFS 上的 WAL 完成的。崩溃时,我们重新打开存储并重新运行过程转换的所有 WAL,以使分配状态机恢复到崩溃前的状态。然后,我们 continue 执行过程。
在新系统中,主人是所有工作分配的 Authority。以前我们是模棱两可的;例如 RegionServer 负责 Split 操作。 Master 保留区域状态和服务器的内存映像。如果意见分歧,则以师父为准;在极端情况下,它将杀死不一致的 RegionServer。
一个新的 RegionStateStore 类负责将终端的 Region 状态(无论是 OPEN 还是 CLOSED)发布到_hbase:meta _table .
现在,RegionServers 在 Connection 上报告其运行版本。此版本在 AM 内部可用,可用于运行迁移滚动重启。
176.程序详细信息
176.1. Assign/Unassign
分配和取消分配子类具有共同的 RegionTransitionProcedure。由于 RTP 实例会对该区域进行锁定,因此每个区域一次只能运行一个 RegionTransitionProcedure。 RTP 基本过程包含三个步骤;存储过程步骤(REGION_TRANSITION_QUEUE);调度过程打开或关闭,然后挂起 await 远程区域服务器报告成功打开或失败(REGION_TRANSITION_DISPATCH)或通知请求该服务器的服务器崩溃的通知;最后在 hbase:meta(REGION_TRANSITION_FINISH)中注册成功的打开/关闭。
这是在日志中查找区域 56f985a727afe80a184dac75fbf6860c 的分配的方式。服务器崩溃引发了分配(进程 ID 1176 或 pid = 1176,当它是过程的父代时,标识为 ppid = 1176)。分配为 pid = 1179,两者的第二个区域由此服务器崩溃分配。
2017-05-23 12:04:24,175 INFO [ProcExecWrkr-30] procedure2.ProcedureExecutor: Initialized subprocedures=[{pid=1178, ppid=1176, state=RUNNABLE:REGION_TRANSITION_QUEUE; AssignProcedure table=IntegrationTestBigLinkedList, region=bfd57f0b72fd3ca77e9d3c5e3ae48d76, target=ve0540.halxg.example.org,16020,1495525111232}, {pid=1179, ppid=1176, state=RUNNABLE:REGION_TRANSITION_QUEUE; AssignProcedure table=IntegrationTestBigLinkedList, region=56f985a727afe80a184dac75fbf6860c, target=ve0540.halxg.example.org,16020,1495525111232}]
接下来,我们通过将过程与框架排队(“注册”)来开始分配。
2017-05-23 12:04:24,241 INFO [ProcExecWrkr-30] assignment.AssignProcedure: Start pid=1179, ppid=1176, state=RUNNABLE:REGION_TRANSITION_QUEUE; AssignProcedure table=IntegrationTestBigLinkedList, region=56f985a727afe80a184dac75fbf6860c, target=ve0540.halxg.example.org,16020,1495525111232; rit=OFFLINE, location=ve0540.halxg.example.org,16020,1495525111232; forceNewPlan=false, retain=false
通过跟踪进程的进程 ID 来跟踪日志中进程的运行,此处 pid = 1179.
接下来,进入分配阶段,在此阶段更新 hbase:meta 表,将区域状态在服务器 ve540 上设置为 OPENING。然后,我们将 rpc 分配给 ve540,要求其打开该区域。此后,我们暂停分配,直到从 ve540 返回有关其是否已成功打开区域的消息。
2017-05-23 12:04:24,494 INFO [ProcExecWrkr-38] assignment.RegionStateStore: pid=1179 updating hbase:meta row=IntegrationTestBigLinkedList,H\xE3@\x8D\x964\x9D\xDF\x8F@9\x0F\xC8\xCC\xC2,1495566261066.56f985a727afe80a184dac75fbf6860c., regionState=OPENING, regionLocation=ve0540.halxg.example.org,16020,1495525111232
2017-05-23 12:04:24,498 INFO [ProcExecWrkr-38] assignment.RegionTransitionProcedure: Dispatch pid=1179, ppid=1176, state=RUNNABLE:REGION_TRANSITION_DISPATCH; AssignProcedure table=IntegrationTestBigLinkedList, region=56f985a727afe80a184dac75fbf6860c, target=ve0540.halxg.example.org,16020,1495525111232; rit=OPENING, location=ve0540.halxg.example.org,16020,1495525111232
在下面,我们记录该区域在 ve540 上成功打开的传入报告。该过程被唤醒(您可以通过线程的名称(ProcedureExecutor 线程 ProcExecWrkr-9)告诉它该过程正在运行)。唤醒的过程将更新 hbase:meta 中的状态,以表示该区域在 ve0540 上处于打开状态。然后报告完成并退出。
2017-05-23 12:04:26,643 DEBUG [RpcServer.default.FPBQ.Fifo.handler=46,queue=1,port=16000] assignment.RegionTransitionProcedure: Received report OPENED seqId=11984985, pid=1179, ppid=1176, state=RUNNABLE:REGION_TRANSITION_DISPATCH; AssignProcedure table=IntegrationTestBigLinkedList, region=56f985a727afe80a184dac75fbf6860c, target=ve0540.halxg.example.org,16020,1495525111232; rit=OPENING, location=ve0540.halxg.example.org,16020,1495525111232 2017-05-23 12:04:26,643 INFO [ProcExecWrkr-9] assignment.RegionStateStore: pid=1179 updating hbase:meta row=IntegrationTestBigLinkedList,H\xE3@\x8D\x964\x9D\xDF\x8F@9\x0F\xC8\xCC\xC2,1495566261066.56f985a727afe80a184dac75fbf6860c., regionState=OPEN, openSeqNum=11984985, regionLocation=ve0540.halxg.example.org,16020,1495525111232
2017-05-23 12:04:26,836 INFO [ProcExecWrkr-9] procedure2.ProcedureExecutor: Finish suprocedure pid=1179, ppid=1176, state=SUCCESS; AssignProcedure table=IntegrationTestBigLinkedList, region=56f985a727afe80a184dac75fbf6860c, target=ve0540.halxg.example.org,16020,1495525111232
鉴于基于基础 RegionTransitionProcedure 的情况,取消分配看起来很相似。它具有相同的状态转换,并且基本上执行相同的步骤,但具有不同的状态名称(CLOSING,CLOSED)。
大多数其他过程是 Pv2 StateMachine 实现的子类。我们有针对表和区域的 StateMachines 类型。
177. UI
现在,可以在主服务器上的顶部栏中找到“程序和锁定”标签,该标签将您带到一个难看但有用的页面。它转储当前正在运行的过程和框架锁。当您无法确定卡住了什么时,请看一下。它将至少识别出有问题的程序(获取 pid 和 grep 日志…)。查找已运行很长时间的 ROLLEDBACK 或 pid。
178. Logging
过程在任何地方都将其进程 ID 记录为 pid =,并将其父 ID(ppid =)记录下来。工作已经完成,因此您可以 grep pid 并查看过程操作的历史记录。
179.实施说明
在本节中,我们会记录一些操作上的特质,以节省您的时间。
179.1. 区域转换 RPC 和 RS 心跳可以在主服务器上的大约同一时间到达
现在,在 RegionServer 上报告区域转换是一种与 RS 心跳不同的 RPC(“ RegionServerServices”服务)。心跳和状态更新可以大约同时到达主机。主服务器将更新其区域的内部状态,但在心跳处理时将检查此相同状态。我们可能会发现意外的情况;即刚刚报告为“已关闭”的区域,因此心跳很惊讶地在 RS 报告的背面发现“已打开”区域。在新系统中,所有从属都必须屈服于主人对集群状态的理解。主人会杀死/关闭任何未对准的实体。
为了解决上述问题,我们为内存主状态添加了一个 lastUpdate。让某个区域 State 在开始采取行动之前先过一会儿(目前为一秒钟)。
179.2. 掌握作为 RegionServer 或仅做系统表的 RegionServer
AMv2 仅强制实施 HMaster 承载系统表的当前 master 分支默认值;即 HBase 群集中的主服务器也充当 RegionServer,只是它是诸如* hbase:meta , hbase:namespace *等表,核心系统表的排他性主机。尽管不应该这样做,但这会导致几次测试失败,因为 AMv1 允许将 hbase:meta 从 Master 移出,而 AMv2 却不允许。
180.新配置
这些配置在更改时都需要文档。
180.1. hbase.procedure.remote.dispatcher.threadpool.size
Defaults 128
180.2. hbase.procedure.remote.dispatcher.delay.msec
Default 150ms
180.3. hbase.procedure.remote.dispatcher.max.queue.size
Default 32
180.4. hbase.regionserver.rpc.startup.waittime
默认值 60 秒。
181. Tools
HBASE-15592 打印步骤 WAL 内容
修补HBASE-18152 [AMv2]损坏的程序 WAL 文件;程序数据无序存储https://issues.apache.org/jira/secure/attachment/12871066/reading_bad_wal.patch
181.1. MasterProcedureSchedulerPerformanceEvaluation
与其他框架组件无关的工具,用于在过程调度程序中测试锁和队列的性能。在 proc 系统中进行任何重大更改后,请运行此命令。打印漂亮的输出:
******************************************
Time - addBack : 5.0600sec
Ops/sec - addBack : 1.9M
Time - poll : 19.4590sec
Ops/sec - poll : 501.9K
Num Operations : 10000000
Completed : 10000006
Yield : 22025876
Num Tables : 5
Regions per table : 10
Operations type : both
Threads : 10
******************************************
Raw format for scripts
RESULT [num_ops=10000000, ops_type=both, num_table=5, regions_per_table=10, threads=10, num_yield=22025876, time_addback_ms=5060, time_poll_ms=19459]
ZooKeeper
分布式 Apache HBase 安装取决于正在运行的 ZooKeeper 集群。所有参与的节点和 Client 端都必须能够访问正在运行的 ZooKeeper 集合。默认情况下,Apache HBase 为您 ManagementZooKeeper“集群”。作为 HBase 启动/停止过程的一部分,它将启动和停止 ZooKeeper 合奏。您还可以独立于 HBaseManagementZooKeeper 集成,只需将 HBase 指向它应使用的群集即可。要切换 ZooKeeper 的 HBaseManagement,请使用* conf/hbase-env.sh *中的HBASE_MANAGES_ZK变量。此变量的默认值为true,它指示 HBase 作为 HBase 启动/停止的一部分来启动/停止 ZooKeeper 集成服务器。
当 HBaseManagementZooKeeper 集合时,您可以直接在* conf/hbase-site.xml 中指定 ZooKeeper 配置。可以通过在 ZooKeeper 选项名称前加上hbase.zookeeper.property来将 ZooKeeper 配置选项设置为 HBase * hbase-site.xml * XML 配置文件中的属性。例如,可以通过设置hbase.zookeeper.property.clientPort属性来更改 ZooKeeper 中的clientPort设置。有关 HBase 使用的所有默认值(包括 ZooKeeper 配置),请参见hbase 默认配置。查找hbase.zookeeper.property前缀。有关 ZooKeeper 配置的完整列表,请参见 ZooKeeper 的 zoo.cfg 。 HBase 没有随附 zoo.cfg ,因此您需要在适当的 ZooKeeper 下载中浏览 conf *目录。
您必须至少使用hbase.zookeeper.quorum属性在* hbase-site.xml *中列出集成服务器。此属性默认为位于localhost的单个集合成员,不适用于完全分布式的 HBase。 (它仅绑定到本地计算机,远程 Client 端将无法连接)。
How many ZooKeepers should I run?
您可以运行仅包含 1 个节点的 ZooKeeper 集成,但在 Producing,建议您运行 3、5 或 7 台计算机的 ZooKeeper 集成;合奏拥有的成员越多,则合奏对主机故障的容忍度就越高。另外,运行奇数台计算机。在 ZooKeeper 中,支持偶数个对等体,但是通常不使用它,因为偶数大小的集合成比例地需要比奇数大小的集合更多的对等方。例如,一个具有 4 个对等体的合奏需要 3 个成员以形成仲裁,而具有 5 个对等体的合奏也需要 3 个形成仲裁。因此,集合 5 允许 2 个对等方发生故障,因此比 4 集合的容错性更高,后者仅允许 1 个 Down Peer。
给每个 ZooKeeper 服务器大约 1GB 的 RAM,并为其分配专用磁盘(最好使用专用磁盘来确保 ZooKeeper 性能良好)。对于负载非常重的群集,请在与 RegionServers(DataNode 和 TaskTrackers)不同的机器上运行 ZooKeeper 服务器。
例如,要让 HBase 在节点* rs{1,2,3,4,5} .example.com *上 ManagementZooKeeper 仲裁,绑定到端口 2222(默认值为 2181),请确保在 conf/hbase-env.sh 中将HBASE_MANAGE_ZKComments 掉或设置为true。 ,然后编辑 conf/hbase-site.xml 并设置hbase.zookeeper.property.clientPort和hbase.zookeeper.quorum。您还应该将hbase.zookeeper.property.dataDir设置为默认值以外的值,因为默认值使 ZooKeeper 将数据持久保存在/tmp 下,该值通常在系统重启时清除。在下面的示例中,我们让 ZooKeeper 坚持到/user/local/zookeeper *。
<configuration>
...
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
<description>Property from ZooKeeper's config zoo.cfg.
The port at which the clients will connect.
</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>rs1.example.com,rs2.example.com,rs3.example.com,rs4.example.com,rs5.example.com</value>
<description>Comma separated list of servers in the ZooKeeper Quorum.
For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost for local and pseudo-distributed modes
of operation. For a fully-distributed setup, this should be set to a full
list of ZooKeeper quorum servers. If HBASE_MANAGES_ZK is set in hbase-env.sh
this is the list of servers which we will start/stop ZooKeeper on.
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
<description>Property from ZooKeeper's config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
...
</configuration>
What version of ZooKeeper should I use?
版本越新越好。从 HBase 1.0.0 开始需要 ZooKeeper 3.4.x
ZooKeeper Maintenance
确保设置ZooKeeper Maintenance中描述的数据目录清除程序,否则几个月后您可能会遇到“有趣”的问题;也就是说,如果动物园 Management 员必须遍历成千上万条日志的目录,而这在领导者连任时是不会执行的,则它可以开始丢弃会话。
182.使用现有的 ZooKeeper 集成
要将 HBase 指向不由 HBaseManagement 的现有 ZooKeeper 群集,请将* conf/hbase-env.sh *中的HBASE_MANAGES_ZK设置为 false
...
# Tell HBase whether it should manage its own instance of ZooKeeper or not.
export HBASE_MANAGES_ZK=false
接下来,在* hbase-site.xml *中设置集合位置和 Client 端端口(如果非标准)。
当 HBaseManagementZooKeeper 时,它将作为常规启动/停止脚本的一部分来启动/停止 ZooKeeper 服务器。如果您希望独立于 HBase 启动/停止运行 ZooKeeper,则可以执行以下操作
${HBASE_HOME}/bin/hbase-daemons.sh {start,stop} zookeeper
请注意,您可以通过这种方式使用 HBase 来启动与 HBase 无关的 ZooKeeper 集群。如果您希望它在整个 HBase 重新启动期间保持正常运行,只需确保将HBASE_MANAGES_ZK设置为false,以便在 HBase 关闭时不会导致 ZooKeeper 崩溃。
有关运行不同的 ZooKeeper 群集的更多信息,请参见 ZooKeeper 入门指南。另外,请参阅ZooKeeper Wiki或ZooKeeper documentation以获取有关 ZooKeeper 大小调整的更多信息。
183.使用 ZooKeeper 进行 SASL 身份验证
较新版本的 Apache HBase(> = 0.92)将支持连接到支持 SASL 身份验证的 ZooKeeper Quorum(在 ZooKeeper 3.4.0 或更高版本中可用)。
这描述了如何设置 HBase 与 ZooKeeper Quorum 相互认证。 ZooKeeper/HBase 相互认证(HBASE-2418)是完整安全 HBase 配置(HBASE-3025)的一部分。为了简化说明,本节将忽略所需的其他配置(安全 HDFS 和协处理器配置)。为了便于学习,建议从 HBaseManagement 的 ZooKeeper 配置(而不是独立的 ZooKeeper 仲裁)开始。
183.1. os 先决条件
您需要具有有效的 Kerberos KDC 设置。对于将要运行 ZooKeeper 服务器的每个$HOST,您应该有一个原则zookeeper/$HOST。对于每个这样的主机,为zookeeper/$HOST添加服务密钥(使用kadmin或kadmin.local工具的ktadd命令),然后将此文件复制到$HOST,并使其仅对将在$HOST上运行 zookeeper 的用户可读。请注意此文件的位置,我们将在下面使用它作为* $ PATH_TO_ZOOKEEPER_KEYTAB *。
同样,对于每个将运行 HBase 服务器(主服务器或区域服务器)的$HOST,您都应具有一个原则:hbase/$HOST。对于每个主机,添加一个名为* hbase.keytab 的密钥表文件,其中包含hbase/$HOST的服务密钥,将此文件复制到$HOST,并且仅对将在$HOST上运行 HBase 服务的用户可读。注意该文件的位置,我们将在下面使用它作为 $ PATH_TO_HBASE_KEYTAB *。
每个将成为 HBaseClient 端的用户也应被赋予 Kerberos 主体。通常,此主体必须为其分配一个只有该用户知道的密码(与 HBase 服务器相反,该密钥表是密钥表文件)。应当设置 Client 端的委托人的maxrenewlife,以便可以对其进行足够的更新,以便用户可以完成其 HBaseClient 端进程。例如,如果用户运行了一个耗时最多 3 天的长时间运行的 HBaseClient 端进程,我们可以在kadmin内使用addprinc -maxrenewlife 3days创建该用户的主体。 ZooKeeperClient 端和服务器库通过运行定期唤醒以进行刷新的线程来 Management 自己的故障单刷新。
在将运行 HBaseClient 端的每个主机(例如hbase shell)上,将以下文件添加到 HBase 主目录的* conf *目录中:
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=false
useTicketCache=true;
};
我们将在下面将此 JAAS 配置文件称为* $ CLIENT_CONF *。
183.2. HBaseManagement 的 ZooKeeper 配置
在将要运行 Zookeeper,主服务器或区域服务器的每个节点上,在该节点的* HBASE_HOME *目录的 conf 目录中创建一个JAAS配置文件,如下所示:
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="$PATH_TO_ZOOKEEPER_KEYTAB"
storeKey=true
useTicketCache=false
principal="zookeeper/$HOST";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
useTicketCache=false
keyTab="$PATH_TO_HBASE_KEYTAB"
principal="hbase/$HOST";
};
其中* $ PATH_TO_HBASE_KEYTAB 和 $ PATH_TO_ZOOKEEPER_KEYTAB *文件是您在上面创建的文件,而$HOST是该节点的主机名。
ZooKeeper 仲裁服务器将使用Server部分,而 HBase 主服务器和区域服务器将使用Client部分。该文件的路径应替换下面* hbase-env.sh 中的文本 $ HBASE_SERVER_CONF *。
此文件的路径应替换下面* hbase-env.sh 中的文本 $ CLIENT_CONF *。
修改您的* hbase-env.sh *以包括以下内容:
export HBASE_OPTS="-Djava.security.auth.login.config=$CLIENT_CONF"
export HBASE_MANAGES_ZK=true
export HBASE_ZOOKEEPER_OPTS="-Djava.security.auth.login.config=$HBASE_SERVER_CONF"
export HBASE_MASTER_OPTS="-Djava.security.auth.login.config=$HBASE_SERVER_CONF"
export HBASE_REGIONSERVER_OPTS="-Djava.security.auth.login.config=$HBASE_SERVER_CONF"
其中* $ HBASE_SERVER_CONF 和 $ CLIENT_CONF *是上面创建的 JAAS 配置文件的完整路径。
在将运行 zookeeper,master 或 regionserver 的每个节点上修改您的* hbase-site.xml *以包含:
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>$ZK_NODES</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.authProvider.1</name>
<value>org.apache.zookeeper.server.auth.SASLAuthenticationProvider</value>
</property>
<property>
<name>hbase.zookeeper.property.kerberos.removeHostFromPrincipal</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.kerberos.removeRealmFromPrincipal</name>
<value>true</value>
</property>
</configuration>
其中$ZK_NODES是 ZooKeeper Quorum 主机的主机名的逗号分隔列表。
通过在适当的主机上运行以下一个或多个命令集来启动 hbase 集群:
bin/hbase zookeeper start
bin/hbase master start
bin/hbase regionserver start
183.3. 外部 ZooKeeper 配置
添加一个如下的 JAAS 配置文件:
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
useTicketCache=false
keyTab="$PATH_TO_HBASE_KEYTAB"
principal="hbase/$HOST";
};
其中* $ PATH_TO_HBASE_KEYTAB 是上面创建的用于在该主机上运行的 HBase 服务的密钥表,而$HOST是该节点的主机名。将其放在 HBase 主目录的配置目录中。我们在下面将文件的完整路径名称为 $ HBASE_SERVER_CONF *。
修改您的 hbase-env.sh 以包括以下内容:
export HBASE_OPTS="-Djava.security.auth.login.config=$CLIENT_CONF"
export HBASE_MANAGES_ZK=false
export HBASE_MASTER_OPTS="-Djava.security.auth.login.config=$HBASE_SERVER_CONF"
export HBASE_REGIONSERVER_OPTS="-Djava.security.auth.login.config=$HBASE_SERVER_CONF"
在将运行主服务器或区域服务器的每个节点上修改您的* hbase-site.xml *以包含:
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>$ZK_NODES</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.authProvider.1</name>
<value>org.apache.zookeeper.server.auth.SASLAuthenticationProvider</value>
</property>
<property>
<name>hbase.zookeeper.property.kerberos.removeHostFromPrincipal</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.kerberos.removeRealmFromPrincipal</name>
<value>true</value>
</property>
</configuration>
其中$ZK_NODES是 ZooKeeper Quorum 主机的主机名的逗号分隔列表。
还要在每个这些主机上,创建一个 JAAS 配置文件,其中包含:
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="$PATH_TO_ZOOKEEPER_KEYTAB"
storeKey=true
useTicketCache=false
principal="zookeeper/$HOST";
};
其中$HOST是每个 Quorum 主机的主机名。我们将在下面将这个文件的完整路径名称为* $ ZK_SERVER_CONF *。
在每个 ZooKeeper Quorum 主机上启动您的 ZooKeepers:
SERVER_JVMFLAGS="-Djava.security.auth.login.config=$ZK_SERVER_CONF" bin/zkServer start
通过在适当的节点上运行以下一个或多个命令集来启动 HBase 集群:
bin/hbase master start
bin/hbase regionserver start
183.4. ZooKeeper 服务器身份验证日志输出
如果上面的配置成功,您应该在 ZooKeeper 服务器日志中看到类似于以下内容:
11/12/05 22:43:39 INFO zookeeper.Login: successfully logged in.
11/12/05 22:43:39 INFO server.NIOServerCnxnFactory: binding to port 0.0.0.0/0.0.0.0:2181
11/12/05 22:43:39 INFO zookeeper.Login: TGT refresh thread started.
11/12/05 22:43:39 INFO zookeeper.Login: TGT valid starting at: Mon Dec 05 22:43:39 UTC 2011
11/12/05 22:43:39 INFO zookeeper.Login: TGT expires: Tue Dec 06 22:43:39 UTC 2011
11/12/05 22:43:39 INFO zookeeper.Login: TGT refresh sleeping until: Tue Dec 06 18:36:42 UTC 2011
..
11/12/05 22:43:59 INFO auth.SaslServerCallbackHandler:
Successfully authenticated client: authenticationID=hbase/ip-10-166-175-249.us-west-1.compute.internal@HADOOP.LOCALDOMAIN;
authorizationID=hbase/ip-10-166-175-249.us-west-1.compute.internal@HADOOP.LOCALDOMAIN.
11/12/05 22:43:59 INFO auth.SaslServerCallbackHandler: Setting authorizedID: hbase
11/12/05 22:43:59 INFO server.ZooKeeperServer: adding SASL authorization for authorizationID: hbase
183.5. ZooKeeperClient 端身份验证日志输出
在 ZooKeeperClient 端(HBase 主服务器或区域服务器)上,应该看到类似于以下内容:
11/12/05 22:43:59 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=ip-10-166-175-249.us-west-1.compute.internal:2181 sessionTimeout=180000 watcher=master:60000
11/12/05 22:43:59 INFO zookeeper.ClientCnxn: Opening socket connection to server /10.166.175.249:2181
11/12/05 22:43:59 INFO zookeeper.RecoverableZooKeeper: The identifier of this process is 14851@ip-10-166-175-249
11/12/05 22:43:59 INFO zookeeper.Login: successfully logged in.
11/12/05 22:43:59 INFO client.ZooKeeperSaslClient: Client will use GSSAPI as SASL mechanism.
11/12/05 22:43:59 INFO zookeeper.Login: TGT refresh thread started.
11/12/05 22:43:59 INFO zookeeper.ClientCnxn: Socket connection established to ip-10-166-175-249.us-west-1.compute.internal/10.166.175.249:2181, initiating session
11/12/05 22:43:59 INFO zookeeper.Login: TGT valid starting at: Mon Dec 05 22:43:59 UTC 2011
11/12/05 22:43:59 INFO zookeeper.Login: TGT expires: Tue Dec 06 22:43:59 UTC 2011
11/12/05 22:43:59 INFO zookeeper.Login: TGT refresh sleeping until: Tue Dec 06 18:30:37 UTC 2011
11/12/05 22:43:59 INFO zookeeper.ClientCnxn: Session establishment complete on server ip-10-166-175-249.us-west-1.compute.internal/10.166.175.249:2181, sessionid = 0x134106594320000, negotiated timeout = 180000
183.6. 从头开始配置
已在当前标准的 Amazon Linux AMI 上进行了测试。如上所述,首先设置 KDC 和主体。下一个结帐代码并运行健全性检查。
git clone https://gitbox.apache.org/repos/asf/hbase.git
cd hbase
mvn clean test -Dtest=TestZooKeeperACL
然后如上所述配置 HBase。手动编辑 target/cached_classpath.txt(请参见下文):
bin/hbase zookeeper &
bin/hbase master &
bin/hbase regionserver &
183.7. Future 的改进
183.7.1. 修复 target/cached_classpath.txt
您必须使用包含 HADOOP-7070 修复程序的版本覆盖target/cached_classpath.txt文件中的标准 hadoop-core jar 文件。您可以使用以下脚本来执行此操作:
echo `find ~/.m2 -name "*hadoop-core*7070*SNAPSHOT.jar"` ':' `cat target/cached_classpath.txt` | sed 's/ //g' > target/tmp.txt
mv target/tmp.txt target/cached_classpath.txt
183.7.2. 以编程方式设置 JAAS 配置
这样可以避免需要单独的 Hadoop jar 来修复HADOOP-7070。
183.7.3. 消除 kerberos.removeHostFromPrincipal 和``
Community
184. Decisions
Feature Branches
功能分支很容易制作。您不必成为一个提交者。只需在开发人员的邮件列表中将您的分支名称添加到 JIRA 中,然后提交者就会为您添加它。之后,您可以针对 Apache HBase JIRA 中的功能分支提出问题。您保存在其他地方的代码-应该公开,以便可以观察到 can―,并且可以根据进度更新开发邮件列表。当功能准备好提交时,来自提交者的 3 1 将合并您的功能。见HBase,邮件#dev-有关大型功能 dev 分支的想法
如何在 JIRA 中设置解决问题的修订版本
解决问题时,这是we agreed在 JIRA 中设置版本的方法。如果 master 将是 2.0.0,而 branch-1 是 1.4.0,则:
只提交给主用户:标记为 2.0.0
提交给 branch-1 和 master:标记为 2.0.0 和 1.4.0
提交到 branch-1.3,branch-1 和 master:标记为 2.0.0、1.4.0 和 1.3.x
提交网站修复:无版本
关于何时将已解决的 JIRA 设置为已关闭的 Policy
我们agreed对于在“固定版本/秒”字段中列出多个发行版的问题,请关闭列出的任何版本发行中的问题;随后的问题更改必须在新的 JIRA 中进行。
ZooKeeper 中只有瞬态!
您应该能够杀死 zookeeper 中的数据,并且 hbase 应该越过它重新创建 zk 内容。这是围绕这些部分的古老谚语。我们现在已经记下了。目前,我们还违反了这一基本原则-复制至少会使 zk 保持永久状态-但是我们正在努力消除 break 黄金法则的情况。
185.社区角色
185.1. 发布 Manager
每个维护的发行分支都有一个发行 Manager,他自愿协调新功能,并将错误修复程序反向移植到该发行版。发布 Manager 是committers。如果您希望将功能或错误修复程序包含在给定的版本中,请与该版本 Management 器进行通信。如果此列表已过期或您无法与列出的人联系,请与列表中的其他人联系。
Note
寿命终止版本不包括在此列表中。
表 20.版本 Management 器
| Release | Release Manager |
|---|---|
| 1.2 | Sean Busbey |
| 1.3 | Mikhail Antonov |
| 1.4 | Andrew Purtell |
| 2.0 | Michael Stack |
| 2.1 | Duo Zhang |
186.提交消息格式
我们agreed遵循以下 Git 提交消息格式:
HBASE-xxxxx <title>. (<contributor>)
如果进行提交的人是贡献者,则忽略'( )'元素。
Appendix
附录 A:对文档的贡献
Apache HBase 项目欢迎您对该项目的各个方面做出贡献,包括文档。
在 HBase 中,文档包括以下领域,可能还包括其他一些领域:
HBase 参考指南(本书)
The HBase website
API documentation
命令行 Util 输出和帮助文本
Web UI 字符串,显式帮助文本,上下文相关的字符串等
Log messages
源文件,配置文件和其他文件中的 Comments
将以上任何一种语言本地化为英语以外的目标语言
无论您要在哪个领域提供帮助,第一步几乎总是要下载(通常是通过克隆 Git 存储库)并熟悉 HBase 源代码。有关下载和构建源的信息,请参见developer。
A.1.贡献文档或其他字符串
如果您在 UI,Util,脚本,日志消息或其他地方的字符串中发现错误,或者您认为某些事情可以变得更清晰,或者您认为文本需要添加到当前不存在的地方,则第一个步骤是提交 JIRA。确保将组件设置为Documentation。大多数组件具有一个或多个默认所有者,这些默认所有者监视那些队列中出现的新问题。不管您是否有能力修复该错误,都应该在发现错误的位置进行归档。
如果您想尝试修复新提交的错误,请将其分配给自己。您将需要将 HBase Git 存储库克隆到本地系统,并在那里解决问题。开发出潜在的修补程序后,将其提交以供审核。如果它解决了该问题并被视为一种改进,则一个 HBase 提交者将酌情将其提交到一个或多个分支。
过程:提交补丁的建议工作流程
该过程比 Git 专业人员需要的过程更为详细,但该过程包含在本附录中,以便不熟悉 Git 的人在学习时可以自信地为 HBase 做出贡献。
如果尚未这样做,请在本地克隆 Git 存储库。您只需要执行一次。
通常,在检出跟踪分支的同时,使用
git pull命令将远程更改拉入本地存储库。对于您处理的每个问题,请创建一个新分支。命名分支最有效的一种约定是给定分支的名称与它涉及的 JIRA 相同:
$ git checkout -b HBASE-123456
在分支上进行建议的更改,并经常将更改提交到本地存储库。如果您需要切换到其他问题,请记住签出相应的分支。
准备好提交补丁程序时,首先请确保 HBase 可以干净构建并在修改后的分支中按预期方式运行。
如果您对文档进行了更改,请通过运行
mvn clean site确保文档和网站的构建。如果您花费几天或几周的时间来实施您的修复程序,或者您知道所使用的代码区域最近进行了很多更改,请确保将分支基于远程主服务器进行更改,并避免任何冲突。提交补丁之前。
$ git checkout HBASE-123456
$ git rebase origin/master
- 针对远程主服务器生成补丁。从 git 存储库的顶层(通常称为
hbase)运行以下命令:
$ git format-patch --stdout origin/master > HBASE-123456.patch
修补程序的名称应包含 JIRA ID。
查看补丁文件,以确保您没有意外更改任何其他文件,并且没有其他意外。
如果满意,请将补丁程序附加到 JIRA 上,然后单击“可用补丁程序”按钮。审阅者将审阅您的补丁。
如果您需要提交新版本的补丁,请将旧版本保留在 JIRA 上,并在新补丁的名称中添加一个版本号。
提交更改后,无需保留本地分支机构。
A.2.编辑 HBase 网站
HBase 网站的源位于 HBase 源中的* src/site/目录中。在此目录中,各个页面的源位于 xdocs/目录中,而这些页面中引用的图像位于 resources/images/*目录中。此目录还存储《 HBase 参考指南》中使用的映像。
该网站的页面以类似于 HTML 的 XML 语言 xdoc 编写,称为 xdoc,其参考指南位于https://maven.apache.org/archives/maven-1.x/plugins/xdoc/reference/xdocs.html。您可以在纯文本编辑器,IDE 或 XML 编辑器(例如 XML Mind XML Editor(XXE)或 Oxygen XML Author)中编辑这些文件。
要预览您的更改,请使用mvn clean site -DskipTests命令构建网站。 HTML 输出位于* target/site/*目录中。如果您对更改感到满意,请按照提交文件补丁程序中的步骤提交补丁。
A.3.发布 HBase 网站和文档
HBase 使用 ASF 的gitpubsub机制。 Jenkins 作业运行dev-support/jenkins-scripts/generate-hbase-website.sh脚本,该脚本针对hbase存储库的master分支运行mvn clean site site:stage并将生成的工件提交到hbase-site存储库的asf-site分支。推送提交后,将自动重新部署网站。如果脚本遇到错误,则会将电子邮件发送到开发人员邮件列表。您可以手动运行脚本或检查脚本以查看其中涉及的步骤。
A.4.检查 HBase 网站的链接断开
Jenkins 作业会定期运行,以使用dev-support/jenkins-scripts/check-website-links.sh脚本检查 HBase 网站的链接是否损坏。该脚本使用名为linklint的工具来检查不良链接并创建报告。如果找到断开的链接,则会将电子邮件发送到开发人员邮件列表。您可以手动运行脚本或检查脚本以查看其中涉及的步骤。
A.5. HBase 参考指南样式指南和备忘单
《 HBase 参考指南》使用 Asciidoc 编写,并使用AsciiDoctor构建。随附以下备忘单供您参考。 http://asciidoctor.org/docs/user-manual/提供了更多细致而全面的文档。
表 21. AsciiDoc 备忘单
| 元素类型 | 所需的渲染 | 如何做 | |
|---|---|---|---|
| 一个段落 | 一个段落 | 只需键入一些文本,该文本的顶部和底部都用空行。 | |
| 在段落内添加换行符,但不添加空行 | 手动换行符 | 这将在加号处中断。或在整个段落前加上包含[[%hardbreaks]' | |
| 给任何标题 | 彩色斜体粗体不同大小的文本 | ||
| 内联代码或命令 | 等宽 | `` | |
| 内联 Literals 内容(要完全按所示键入的内容) | 大胆的 mono | *`` * | |
| 内嵌可替换内容(用您自己的值替换的内容) | 粗斜体 mono | * typesomething * | |
| 带有突出显示的代码块 | 等高线,突出显示,保留空间 | [5950] ---- |
|
myAwesomeCode() ---- |
|||
| 包含在单独文件中的代码块 | 就好像是主文件的一部分一样 | [5952] ---- |
|
include::path/to/app.rb[] ---- |
|||
| 仅包含单独文件的一部分 | 类似于 Javadoc | 参见http://asciidoctor.org/docs/user-manual/#by-tagged-regions | |
| 文件名,目录名,新术语 | 斜体 | hbase-default.xml | |
| 外部裸 URL | 以 URL 作为链接文本的链接 | link:http://www.google.com |
|
| 带有文本的外部 URL | 带有任意链接文本的链接 | link:http://www.google.com[Google] |
|
| 创建一个内部锚以进行交叉引用 | 未渲染 | [[anchor_name]] |
|
| 使用其默认标题交叉引用现有锚点 | 使用元素标题(如果可用)使用内部超链接,否则使用锚点名称 | <<anchor_name>> |
|
| 使用自定义文本交叉引用现有锚点 | 使用任意文本使用内部超链接 | <<anchor_name,Anchor Text>> |
|
| 块图像 | 带有替代文本的图像 | image::sunset.jpg[Alt Text](将图像放入 src/site/resources/images 目录) |
|
| 内嵌图像 | 包含替代文本的图像,作为文本流的一部分 | image:sunset.jpg [Alt Text](仅一个冒号) |
|
| 链接到远程图像 | 显示托管在其他位置的图像 | image::http://inkscape.org/doc/examples/tux.svg[Tux,250,350](或 image:) |
|
| 在替代文本后的括号内 | 在图像中添加尺寸或 URL | 取决于 | ,指定宽度,高度和/或 link =“ http://my_link.com” |
| 脚注 | 下标链接,将您带到脚注 | Some text.footnote:[The footnote text.] |
|
| 没有标题的 Comments 或警告 | 警告图像后跟警告 | NOTE:My note hereWARNING:My warning here |
|
| 复杂 Comments | Comments 具有标题和/或多个段落和/或代码块或列表等 | 。 [NOTE] ==== |
|
这是 Comments 文本。直到第二组四个等号之前的所有内容均为音符的一部分。
----
一些源代码
----
====|
|项目符号列表|项目符号列表| * list item 1
(see http://asciidoctor.org/docs/user-manual/#unordered-lists)|
|编号列表|编号列表| . list item 2
(see http://asciidoctor.org/docs/user-manual/#ordered-lists)|
|清单|选中或未选中的框|选中:- [*]
Unchecked:- [ ]|
|多级列表|项目符号,编号或组合|。在顶层编号为(1)
* 项目符号(2),嵌套在 1 以下
* 项目符号(3),嵌套在 1 以下
。在顶层编号为(4)
* 子弹(5),嵌套在 4 以下
**项目符号(6),嵌套在 5 岁以下
-
[5977]在顶层检查(7)|
|标签列表/变量列表|列表项标题或摘要,后跟内容|标题::内容
Title::
content|
|侧边栏,引号或其他文本块|与默认格式不同的文本块|使用不同的定界符定界,请参见http://asciidoctor.org/docs/user-manual/#built-in-blocks-summary。上面的一些示例使用定界符,例如....,----,====。
[example]
====
这是一个示例块。
====
[source]
这是一个源块。
----
[note]
====
这是一个音符块。
====
[quote]
这是一个引号块。
如果要插入不断被解释的原义 Asciidoc 内容,则如有疑问,请在顶部和底部使用八个点作为分隔符。
|嵌套部分|章,节,子节等| =书籍(或章(如果该章可以单独构建,请参见下面的 leveloffset 信息))
==章节(如果章节是独立的,则为章节)
===节(或小节等)
==== Subsection
等等,最多 6 个级别(仔细考虑要比 4 个级别更深,也许您可以只为段落或列表加上标题)。请注意,您可以在包含之前直接添加:leveloffset:+1宏指令,并在之后直接将其重置为 0,从而将一本书包含在另一本书中。有关示例,请参见* book.adoc 源,因为这是本指南处理各章的方式。 请勿在序言,词汇表,附录或其他特殊类型的章节中使用. |
|包含另一个文件|包含内容就好像是内联| include::[/path/to/file.adoc]
有关大量示例。请参阅 book.adoc *。
|一张桌子|一张桌子|请参见http://asciidoctor.org/docs/user-manual/#tables。通常,行由换行符分隔,列由管道|
|Comments 出单行|在渲染过程中跳过了一行| // This line won't show up |
|Comments 一个块|在渲染过程中跳过文件的一部分| ////
斜线之间不会显示任何内容。
////|
|突出显示的待审核文本|文本显示为黄色背景| Test between #hash marks# is highlighted yellow. |
A.6.自动生成的内容
《 HBase 参考指南》的某些部分(尤其是config.files)是自动生成的,因此文档的此区域与代码保持同步。这是通过 XSLT 转换完成的,您可以在* src/main/xslt/configuration_to_asciidoc_chapter.xsl 的源代码中进行检查。这会将 hbase-common/src/main/resources/hbase-default.xml *文件转换为 Asciidoc 输出,可将其包含在《参考指南》中。
有时,有必要添加配置参数或修改其描述。对源文件进行修改,它们将在重建时包含在《参考指南》中。
将来,将来可能还会从 HBase 源文件中自动生成其他类型的内容。
A.7. 《 HBase 参考指南》中的图像
您可以在《 HBase 参考指南》中包含图像。重要的是,如果可能的话,要包括图像标题,并始终显示替代文本。这使屏幕阅读器可以导航到图像,还可以为图像提供替代文本。以下是带有标题和替代文本的图像示例。注意双冒号。
.My Image Title
image::sunset.jpg[Alt Text]
这是带有备用文本的嵌入式图像的示例。注意单个冒号。嵌入式图像不能有标题。它们通常是小图像,例如 GUI 按钮。
image:sunset.jpg[Alt Text]
进行本地构建时,将映像保存到* src/site/resources/images/*目录。链接到图像时,请勿包括路径的目录部分。在构建输出期间,图像将被复制到适当的目标位置。
当您提交包含将映像添加到《 HBase 参考指南》的补丁时,请将映像附加到 JIRA。如果提交者询问将图像提交到何处,则应进入上述目录。
A.8.在《 HBase 参考指南》中添加新的章节
如果要将新章节添加到《 HBase 参考指南》中,最简单的方法是复制现有章节文件,对其进行重命名,然后更改 ID(在方括号中)和标题。章节位于* src/main/asciidoc/_chapters/*目录中。
删除现有内容并创建新内容。然后打开* src/main/asciidoc/book.adoc *文件(这是《 HBase 参考指南》的主要文件),然后复制现有的include元素以在适当的位置添加新章节。在创建补丁之前,请确保将新文件添加到 Git 存储库。
如有疑问,请检查如何包含其他文件。
A.9.常见文件问题
以下文档问题经常出现。其中一些是首选项,但另一些则可能会产生神秘的构建错误或其他问题。
- 隔离更改以便轻松进行审核.
即使整个格式的格式随时间降低,也请小心打印或重新格式化整个 XML 文件。如果需要重新格式化文件,请在不更改任何内容的单独 JIRA 中进行。请注意,因为某些 XML 编辑器在打开新文件时会进行批量重新格式化,尤其是在编辑器中使用 GUI 模式时。
- Syntax Highlighting
《 HBase 参考指南》使用coderay突出显示语法。要为给定的代码清单启用语法突出显示,请使用以下类型的语法:
[source,xml]
----
<name>My Name</name>
----
支持几种语法类型。 《 HBase 参考指南》中最有趣的是java,xml,sql和bash。
附录 B:常见问题解答
B.1. General
什么时候应该使用 HBase?
- 请参阅“体系结构”一章中的Overview。
还有其他 HBase 常见问题解答吗?
- 请参阅 Wiki HBase Wiki 常见问题上的常见问题解答。
HBase 是否支持 SQL?
- 并不是的。正在通过Hive对 HBase 进行 SQL-ish 支持,但是 Hive 基于 MapReduce,通常不适合低延迟请求。有关 HBaseClient 端的示例,请参见Data Model部分。
如何找到 NoSQL/HBase 的示例?
- 请参阅有关 HBase 的其他信息中 BigTable 论文的链接以及其他论文。
HBase 的历史是什么?
- See hbase.history.
为什么不建议将 10MB 以上的单元用于 HBase?
- 大型单元格不适用于 HBase 的缓冲数据方法。首先,大型单元在写入时会绕过 MemStoreLAB。然后,在读取操作期间无法将它们缓存在 L2 块缓存中。相反,HBase 必须每次为其分配堆上内存。这可能会对 RegionServer 进程中的垃圾收集器产生重大影响。
B.2. Upgrading
如何将 MavenManagement 的项目从 HBase 0.94 升级到 HBase 0.96?
- 在 HBase 0.96 中,项目移至模块化结构。调整项目的依赖关系以依赖于
hbase-client模块或其他合适的模块,而不是单个 JAR。您可以根据以下 HBase 的目标版本,对 Maven 依赖项进行以下建模之一。有关更多信息,请参见第 3.5 节“从 0.94.x 升级到 0.96.x”或第 3.3 节“从 0.96.x 升级到 0.98.x”。
- 在 HBase 0.96 中,项目移至模块化结构。调整项目的依赖关系以依赖于
HBase 0.98 的 Maven 依赖关系
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.5-hadoop2</version>
</dependency>
HBase 0.96 的 Maven 依赖关系
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.96.2-hadoop2</version>
</dependency>
HBase 0.94 的 Maven 依赖关系
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>0.94.3</version>
</dependency>
B.3. Architecture
HBase 如何处理 Region-RegionServer 的分配和位置?
- See Regions.
B.4. Configuration
如何开始我的第一个集群?
- See 快速入门-独立 HBase.
在哪里可以了解其余的配置选项?
- See Apache HBase 配置.
B.5.模式设计/数据访问
我应该如何在 HBase 中设计架构?
如何在 HBase 中存储(填空)?
- See Supported Datatypes.
如何在 HBase 中处理二级索引?
- See 二级索引和备用查询路径.
我可以更改表的行键吗?
- 这是一个非常普遍的问题。你不能参见行键的不变性。
HBase 支持哪些 API?
B.6. MapReduce
如何在 HBase 中使用 MapReduce?
- See HBase 和 MapReduce.
B.7.性能与故障排除
如何提高 HBase 集群性能?
- See Apache HBase 性能调优.
如何对 HBase 群集进行故障排除?
- See 故障排除和调试 Apache HBase.
B.8.亚马逊 EC2
我在 Amazon EC2 上运行 HBase,并且…
- EC2 问题是一个特例。参见Amazon EC2和Amazon EC2。
B.9. Operations
如何 Management 我的 HBase 集群?
如何备份我的 HBase 群集?
- See HBase Backup.
B.10.行动中的 HBase
在哪里可以找到有关 HBase 的有趣视频和演示文稿?
- See 有关 HBase 的其他信息.
附录 C:访问控制矩阵
以下矩阵显示了在 HBase 中执行操作所需的权限集。在使用表格之前,请通读有关如何解释表格的信息。
解释 ACL 矩阵表
ACL 矩阵表中使用以下约定:
C.1. Scopes
权限的评估从最广泛的范围开始,一直到最窄的范围。
范围对应于数据模型的级别。从最宽到最窄,范围如下:
Scopes
Global
Namespace (NS)
Table
列族(CF)
列限定词(CQ)
Cell
例如,在表级别授予的权限将主导在列族,列限定符或单元级别进行的所有授予。用户可以在表中的任何位置执行授予所隐含的操作。在全局范围内授予的权限控制着所有人:始终允许用户在任何地方执行该操作。
C.2. Permissions
可能的权限包括:
Permissions
超级用户-属于“超级组”组且具有无限访问权限的特殊用户
Admin (A)
Create (C)
Write (W)
Read (R)
Execute (X)
在大多数情况下,权限会以预期的方式工作,但需注意以下几点:
拥有写入权限并不意味着具有读取权限。
- 用户有可能并且有时希望能够写入同一用户无法读取的数据。这样的示例之一是日志写入过程。
每个用户均可读取 hbase:meta 表,而不考虑用户的其他授予或限制。
- 这是 HBase 正常运行的要求。
如果用户同时没有“写”和“读”权限,则
CheckAndPut和CheckAndDelete操作将失败。Increment和Append操作不需要读取权限。顾名思义,
superuser有权执行所有可能的操作。对于标有*的操作,检查是在挂接后完成的,只有满足访问检查结果的子集才返回给用户。
- 下表按提供每个操作的接口排序。万一表过期,可以在* hbase-server/src/test/java/org/apache/hadoop/hbase/security/access/TestAccessController.java 中找到检查权限准确性的单元测试。访问控制本身可以在 hbase-server/src/main/java/org/apache/hadoop/hbase/security/access/AccessController.java *中进行检查。
表 22. ACL 矩阵
| Interface | Operation | Permissions | ||||
|---|---|---|---|---|---|---|
| Master | createTable | superuser|global(C)|NS(C) | ||||
| modifyTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| deleteTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| truncateTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| addColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| modifyColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C)|column(A)|column(C) | |||||
| deleteColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C)|column(A)|column(C) | |||||
| enableTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| disableTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| disableAclTable | Not allowed | |||||
| move | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| assign | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| unassign | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| regionOffline | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| balance | superuser|global(A) | |||||
| balanceSwitch | superuser|global(A) | |||||
| shutdown | superuser|global(A) | |||||
| stopMaster | superuser|global(A) | |||||
| snapshot | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| listSnapshot | superuser|global(A)|SnapshotOwner | |||||
| cloneSnapshot | 超级用户 | 全局(A) | (SnapshotOwner 和 TableName 匹配) | |||
| restoreSnapshot | 超级用户 | 全局(A) | SnapshotOwner 和(NS(A) | TableOwner | 表(A)) | |
| deleteSnapshot | superuser|global(A)|SnapshotOwner | |||||
| createNamespace | superuser|global(A) | |||||
| deleteNamespace | superuser|global(A) | |||||
| modifyNamespace | superuser|global(A) | |||||
| getNamespaceDescriptor | superuser|global(A)|NS(A) | |||||
| listNamespaceDescriptors* | superuser|global(A)|NS(A) | |||||
| flushTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| getTableDescriptors* | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) | |||||
| getTableNames* | 超级用户 | TableOwner | 任何全局或表权限 | |||
| setUserQuota(global level) | superuser|global(A) | |||||
| setUserQuota(namespace level) | superuser|global(A) | |||||
| setUserQuota(Table level) | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| setTableQuota | superuser|global(A)|NS(A)|TableOwner|table(A) | |||||
| setNamespaceQuota | superuser|global(A) | |||||
| addReplicationPeer | superuser|global(A) | |||||
| removeReplicationPeer | superuser|global(A) | |||||
| enableReplicationPeer | superuser|global(A) | |||||
| disableReplicationPeer | superuser|global(A) | |||||
| getReplicationPeerConfig | superuser|global(A) | |||||
| updateReplicationPeerConfig | superuser|global(A) | |||||
| listReplicationPeers | superuser|global(A) | |||||
| getClusterStatus | any user | |||||
| Region | openRegion | superuser|global(A) | ||||
| closeRegion | superuser|global(A) | |||||
| flush | superuser|global(A)|global(C)|TableOwner|table(A)|table(C) | |||||
| split | superuser|global(A)|TableOwner|TableOwner|table(A) | |||||
| compact | superuser|global(A)|global(C)|TableOwner|table(A)|table(C) | |||||
| getClosestRowBefore | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| getOp | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| exists | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| put | superuser|global(W)|NS(W)|table(W)|TableOwner|CF(W)|CQ(W) | |||||
| delete | superuser|global(W)|NS(W)|table(W)|TableOwner|CF(W)|CQ(W) | |||||
| batchMutate | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) | |||||
| checkAndPut | superuser|global(RW)|NS(RW)|TableOwner|table(RW)|CF(RW)|CQ(RW) | |||||
| checkAndPutAfterRowLock | superuser|global(R)|NS(R)|TableOwner|Table(R)|CF(R)|CQ(R) | |||||
| checkAndDelete | superuser|global(RW)|NS(RW)|TableOwner|table(RW)|CF(RW)|CQ(RW) | |||||
| checkAndDeleteAfterRowLock | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| incrementColumnValue | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) | |||||
| append | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) | |||||
| appendAfterRowLock | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) | |||||
| increment | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) | |||||
| incrementAfterRowLock | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) | |||||
| scannerOpen | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| scannerNext | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| scannerClose | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) | |||||
| bulkLoadHFile | superuser|global(C)|TableOwner|table(C)|CF(C) | |||||
| prepareBulkLoad | superuser|global(C)|TableOwner|table(C)|CF(C) | |||||
| cleanupBulkLoad | superuser|global(C)|TableOwner|table(C)|CF(C) | |||||
| Endpoint | invoke | superuser|global(X)|NS(X)|TableOwner|table(X) | ||||
| AccessController | grant(global level) | global(A) | ||||
| grant(namespace level) | global(A)|NS(A) | |||||
| grant(table level) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) | |||||
| revoke(global level) | global(A) | |||||
| revoke(namespace level) | global(A)|NS(A) | |||||
| revoke(table level) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) | |||||
| getUserPermissions(global level) | global(A) | |||||
| getUserPermissions(namespace level) | global(A)|NS(A) | |||||
| getUserPermissions(table level) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) | |||||
| hasPermission(table level) | global(A)|SelfUserCheck | |||||
| RegionServer | stopRegionServer | superuser|global(A) | ||||
| mergeRegions | superuser|global(A) | |||||
| rollWALWriterRequest | superuser|global(A) | |||||
| replicateLogEntries | superuser|global(W) | |||||
| RSGroup | addRSGroup | superuser|global(A) | ||||
| balanceRSGroup | superuser|global(A) | |||||
| getRSGroupInfo | superuser|global(A) | |||||
| getRSGroupInfoOfTable | superuser|global(A) | |||||
| getRSGroupOfServer | superuser|global(A) | |||||
| listRSGroups | superuser|global(A) | |||||
| moveServers | superuser|global(A) | |||||
| moveServersAndTables | superuser|global(A) | |||||
| moveTables | superuser|global(A) | |||||
| removeRSGroup | superuser|global(A) | |||||
| removeServers | superuser|global(A) |
附录 D:HBase 中的压缩和数据块编码
Note
本节中提到的编解码器用于编码和解码数据块或行键。有关复制编解码器的信息,请参见cluster.replication.preserving.tags。
本节中的某些信息是从 HBase Development 邮件列表上的discussion中提取的。
HBase 支持可以在 ColumnFamily 上启用的几种不同的压缩算法。数据块编码试图利用 HBase 的一些基本设计和模式来限制键中信息的重复,例如排序的行键和给定表的架构。压缩器可减少单元中较大的不透明字节数组的大小,并可显着减少存储未压缩数据所需的存储空间。
压缩器和数据块编码可以在同一 ColumnFamily 上一起使用。
更改在压实后生效
如果更改 ColumnFamily 的压缩或编码,则更改将在压缩期间生效。
一些编解码器利用了 Java 内置的功能,例如 GZip 压缩。其他依赖本地库。本地库可能作为 Hadoop 的一部分提供,例如 LZ4.在这种情况下,HBase 仅需要访问适当的共享库。
首先需要安装其他编解码器,例如 Google Snappy。某些编解码器的许可方式与 HBase 的许可有冲突,因此不能作为 HBase 的一部分提供。
本节讨论与 HBase 一起使用和测试的常见编解码器。无论使用哪种编解码器,请务必测试它是否已正确安装并且在群集中的所有节点上都可用。为了确保编解码器在新部署的节点上可用,可能需要执行额外的操作步骤。您可以使用compression.testUtil 来检查是否正确安装了给定的编解码器。
要将 HBase 配置为使用压缩器,请参见compressor.install。要为 ColumnFamily 启用压缩程序,请参见changing.compression。要为 ColumnFamily 启用数据块编码,请参见data.block.encoding.enable。
Block Compressors
none
Snappy
LZO
LZ4
GZ
数据块编码类型
Prefix
- 通常,键非常相似。具体而言,密钥通常共享一个公共前缀,并且仅在末尾有所不同。例如,一个键可能是
RowKey:Family:Qualifier0,下一个键可能是RowKey:Family:Qualifier1。
在 Prefix 编码中,添加了一个额外的列,用于保存当前密钥和上一个密钥之间共享的前缀长度。假设此处的第一个键与之前的键完全不同,则其前缀长度为 0.
- 通常,键非常相似。具体而言,密钥通常共享一个公共前缀,并且仅在末尾有所不同。例如,一个键可能是
第二个键的前缀长度为23,因为它们具有前 23 个共同的字符。
显然,如果密钥之间没有共同之处,那么前缀将不会带来太多好处。
下图显示了没有数据块编码的假设 ColumnFamily。

图 10.没有编码的 ColumnFamily
这是带有前缀数据编码的相同数据。

图 11.具有前缀编码的 ColumnFamily
Diff
- 差异编码在前缀编码的基础上扩展。代替 Sequences 地将密钥视为一个整体的字节序列,可以拆分每个密钥字段,以便可以更有效地压缩密钥的每个部分。
添加了两个新字段:时间戳记和类型。
如果 ColumnFamily 与上一行相同,则将其从当前行中省略。
如果键的长度,值的长度或类型与上一行相同,则省略该字段。
此外,为了提高压缩率,时间戳记将存储为前一行时间戳记的 Diff,而不是全部存储。给定 Prefix 示例中的两个行键,并且给定时间戳和相同类型的完全匹配,则第二行的值长度或类型都不需要存储,第二行的时间戳值仅为 0,而不是完整的时间戳记。
默认情况下,差异编码是禁用的,因为写入和扫描速度较慢,但会缓存更多数据。
该图像使用 Diff 编码显示了与先前图像相同的 ColumnFamily。

图 12.带有差异编码的 ColumnFamily
Fast Diff
- Fast Diff 与 Diff 相似,但是使用了更快的实现。它还添加了另一个字段,该字段存储一个位以跟踪数据本身是否与上一行相同。如果是这样,则不会再次存储数据。
如果您有长键或多列,建议使用 Fast Diff 编解码器。
数据格式几乎与 Diff 编码相同,因此没有图像可以说明。
Prefix Tree
- 前缀树编码是 HBase 0.96 中的一项实验功能。它提供了与前缀,差异和快速差异编码器类似的内存节省,但以较低的编码速度为代价提供了更快的随机访问。在 hbase-2.0.0 中将其删除。这是一个好主意,但吸收很少。如果有兴趣恢复这项工作,请编写 hbase 开发人员列表。
D.1.使用哪种压缩器或数据块编码器
使用的压缩或编解码器类型取决于数据的 Feature。选择错误的类型可能会导致数据占用更多空间而不是更少空间,并且可能会影响性能。
通常,您需要在较小的尺寸和更快的压缩/解压缩之间权衡选择。以下是一些通用准则,这些准则是从压缩和编解码器文档指南的讨论中扩展而来的。
如果您有较长的键(与值相比)或许多列,请使用前缀编码器。建议使用 FAST_DIFF。
如果值较大(并且未进行预压缩,例如图像),请使用数据块压缩器。
将 GZIP 用于冷数据,这是很少访问的。 GZIP 压缩比 Snappy 或 LZO 占用更多的 CPU 资源,但提供更高的压缩率。
对频繁访问的* hot data *使用 Snappy 或 LZO。 Snappy 和 LZO 比 GZIP 使用更少的 CPU 资源,但压缩率却不高。
在大多数情况下,默认情况下启用 Snappy 或 LZO 是一个不错的选择,因为它们的性能开销较低并且可以节省空间。
在 Snappy 于 2011 年由 Google 推出之前,LZO 是默认设置。 Snappy 具有与 LZO 相似的质量,但表现得更好。
D.2.在 HBase 中利用 Hadoop 本机库
Hadoop 共享库有很多功能,包括压缩库和快速 crc'ing(如果芯片组支持,则是硬件 crc'ing)。要使此功能可用于 HBase,请执行以下操作。如果 HBase/Hadoop 无法找到本机库版本,HBase/Hadoop 将退回到使用替代方案;否则,如果您要求使用显式压缩器且没有替代方案,则 HBase/Hadoop 将彻底失败。
首先确保您的 Hadoop。如果看到它正在启动 Hadoop 进程,请修复此消息:
16/02/09 22:40:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
这意味着未正确指向其本机库或为其他平台编译的本机库。首先解决此问题。
然后,如果您在 HBase 日志中看到以下内容,则说明 HBase 无法找到 Hadoop 本机库:
2014-08-07 09:26:20,139 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
如果库成功加载,则不会显示 WARN 消息。通常,这意味着您很好,但请 continue 阅读。
让我们假设您的 Hadoop 附带了一个本机库,该库适合您在其上运行 HBase 的平台。要检查 Hadoop 本机库是否可用于 HBase,请运行以下工具(在 Hadoop 2.1 及更高版本中可用):
$ ./bin/hbase --config ~/conf_hbase org.apache.hadoop.util.NativeLibraryChecker
2014-08-26 13:15:38,717 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
snappy: false
lz4: false
bzip2: false
2014-08-26 13:15:38,863 INFO [main] util.ExitUtil: Exiting with status 1
上面显示了本地 hadoop 库在 HBase 上下文中不可用。
上面的 NativeLibraryChecker 工具可能会再次提示所有信息都是“笨拙的”(例如,所有库都显示为“ true”,表示它们可用)。但是无论如何,请遵循以下前提以确保本机库在 HBase 上下文中可用(当要使用它们时) 。
为了解决上述问题,如果 Hadoop 和 HBase 停顿在文件系统中相邻,请在本地复制 Hadoop 本地库或将符号链接复制到它们。您还可以通过在 hbase-env.sh 中设置LD_LIBRARY_PATH环境变量来指向它们的位置。
JVM 查找本地库的位置是“取决于系统的”(请参见java.lang.System#loadLibrary(name))。在 Linux 上,默认情况下将在* lib/native/PLATFORM *中查找,其中PLATFORM是用于安装 HBase 的平台的标签。在本地 linux 机器上,似乎是 Java 属性os.name和os.arch的后接,后面是 32 位还是 64 位。启动时 HBase 会打印出所有 Java 系统属性,因此请在日志中找到 os.name 和 os.arch。例如:
...
2014-08-06 15:27:22,853 INFO [main] zookeeper.ZooKeeper: Client environment:os.name=Linux
2014-08-06 15:27:22,853 INFO [main] zookeeper.ZooKeeper: Client environment:os.arch=amd64
...
因此,在这种情况下,PLATFORM 字符串为Linux-amd64-64。复制 Hadoop 本机库或在* lib/native/Linux-amd64-64 *处进行符号链接将确保找到它们。进行此更改后,滚动重新启动。
这是如何设置符号链接的示例。让 hadoop 和 hbase 安装在您的主目录中。假设您的 hadoop 本机库位于~/ hadoop/lib/native。假设您使用的是 Linux-amd64-64 平台。在这种情况下,您将执行以下操作来链接 hadoop 本机 lib,以便 hbase 可以找到它们。
...
$ mkdir -p ~/hbaseLinux-amd64-64 -> /home/stack/hadoop/lib/native/lib/native/
$ cd ~/hbase/lib/native/
$ ln -s ~/hadoop/lib/native Linux-amd64-64
$ ls -la
# Linux-amd64-64 -> /home/USER/hadoop/lib/native
...
如果在堆栈跟踪中看到 PureJavaCrc32C,或者在性能跟踪中看到类似以下的内容,则本机无法正常运行;您正在使用 Java CRC 函数而不是本地函数:
5.02% perf-53601.map [.] Lorg/apache/hadoop/util/PureJavaCrc32C;.update
有关本机校验和支持的更多信息,请参见HBASE-11927 将本地 Hadoop 库用于 HFile 校验和(并将默认值从 CRC32 翻转到 CRC32C)。请特别参阅发行说明,以了解如何检查硬件以查看处理器是否支持硬件 CRC。或查看 Apache HBase 中的校验和博客文章。
这是如何使用LD_LIBRARY_PATH环境变量指向 Hadoop 库的示例:
$ LD_LIBRARY_PATH=~/hadoop-2.5.0-SNAPSHOT/lib/native ./bin/hbase --config ~/conf_hbase org.apache.hadoop.util.NativeLibraryChecker
2014-08-26 13:42:49,332 INFO [main] bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
2014-08-26 13:42:49,337 INFO [main] zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /home/stack/hadoop-2.5.0-SNAPSHOT/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
snappy: true /usr/lib64/libsnappy.so.1
lz4: true revision:99
bzip2: true /lib64/libbz2.so.1
启动 HBase 时,在* hbase-env.sh *中设置 LD_LIBRARY_PATH 环境变量。
D.3.压缩机的配置,安装和使用
D.3.1. 为压缩器配置 HBase
在 HBase 可以使用给定的压缩器之前,它的库必须可用。由于许可问题,在默认安装中,仅 GZ 压缩可用于 HBase(通过本机 Java 库)。其他压缩库可通过与 hadoopBinding 在一起的共享库获得。在 HBase 启动时,hadoop 本机库需要可找到。看到
主站上的压缩机支持
HBase 0.95 中引入了新的配置设置,以检查主服务器以确定在其上安装和配置了哪些数据块编码器,并假定整个集群都配置相同。 hbase.master.check.compression这个选项默认为true。这样可以防止HBASE-6370中描述的情况,在该情况下创建或修改表以支持区域服务器不支持的编解码器,从而导致故障花费很长时间并且难以调试。
如果启用了hbase.master.check.compression,则即使主服务器未运行区域服务器,也需要在主服务器上安装并配置所有所需压缩器的库。
通过本地库安装 GZ 支持
除非 CLASSPATH 上有本地 Hadoop 库,否则 HBase 使用 Java 的内置 GZip 支持。建议将库添加到 CLASSPATH 中的方法是为运行 HBase 的用户设置环境变量HBASE_LIBRARY_PATH。如果本机库不可用,并且使用 Java 的 GZIP,则Got brand-new compressor报告将出现在日志中。参见brand.new.compressor)。
安装 LZO 支持
HBase 无法与 LZO 一起使用,因为使用 Apache 软件许可证(ASL)的 HBase 和使用 GPL 许可证的 LZO 之间不兼容。有关为 HBase 配置 LZO 支持的信息,请参见Twitter 上的 Hadoop-LZO。
如果您依赖 LZO 压缩,请考虑将您的 RegionServer 配置为在 LZO 不可用时无法启动。参见hbase.regionserver.codecs。
配置 LZ4 支持
LZ4 支持与 HadoopBinding 在一起。启动 HBase 时,请确保可访问 hadoop 共享库(libhadoop.so)。配置平台后(请参见hadoop.native.lib),可以从 HBase 到本地 Hadoop 库构建符号链接。假定两个软件安装在同一位置。例如,如果我的“平台”是 Linux-amd64-64:
$ cd $HBASE_HOME
$ mkdir lib/native
$ ln -s $HADOOP_HOME/lib/native lib/native/Linux-amd64-64
使用压缩工具检查是否在所有节点上都安装了 LZ4.启动(或重新启动)HBase。之后,您可以创建和更改表以将 LZ4 用作压缩编解码器。
hbase(main):003:0> alter 'TestTable', {NAME => 'info', COMPRESSION => 'LZ4'}
安装 Snappy 支持
由于许可问题,HBase 不附带 Snappy 支持。您可以安装 Snappy 二进制文件(例如,通过在 CentOS 上使用 yum install snappy)或从源代码构建 Snappy。安装 Snappy 之后,搜索共享库,该库将称为* libsnappy.so.X ,其中 X 是数字。如果是从源代码构建的,请将共享库复制到系统上的已知位置,例如/opt/snappy/lib/*。
除了 Snappy 库之外,HBase 还需要访问 Hadoop 共享库,该库将称为* libhadoop.so.X.Y *,其中 X 和 Y 都是数字。记下 Hadoop 库的位置,或将其复制到与 Snappy 库相同的位置。
Note
Snappy 和 Hadoop 库需要在群集的每个节点上都可用。请参见compression.test,以了解如何测试这种情况。
请参阅hbase.regionserver.codecs,以配置您的 RegionServers 在给定的压缩器不可用时无法启动。
对于运行 HBase 的 os 用户,每个库位置都需要添加到环境变量HBASE_LIBRARY_PATH中。您需要重新启动 RegionServer 才能使更改生效。
CompressionTest
您可以使用 CompressionTest 工具来验证您的压缩器可用于 HBase:
$ hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://host/path/to/hbase snappy
在 RegionServer 上实施压缩设置
通过将选项 hbase.regionserver.codecs 添加到* hbase-site.xml *并将其值设置为以逗号分隔的编解码器列表,您可以配置 RegionServer 以便如果压缩配置不正确将无法重启。需要可用。例如,如果将此属性设置为lzo,gz,则如果两个压缩器都不可用,则 RegionServer 将无法启动。这将防止在未正确配置编解码器的情况下将新服务器添加到群集。
D.3.2. 在 ColumnFamily 上启用压缩
要为 ColumnFamily 启用压缩,请使用alter命令。您不需要重新创建表或复制数据。如果要更改编解码器,请确保在所有旧的 StoreFiles 被压缩之前,旧的编解码器仍然可用。
使用 HBaseShell 对现有表的 ColumnFamily 启用压缩
hbase> disable 'test'
hbase> alter 'test', {NAME => 'cf', COMPRESSION => 'GZ'}
hbase> enable 'test'
在 ColumnFamily 上创建带有压缩的新表
hbase> create 'test2', { NAME => 'cf2', COMPRESSION => 'SNAPPY' }
验证 ColumnFamily 的压缩设置
hbase> describe 'test'
DESCRIPTION ENABLED
'test', {NAME => 'cf', DATA_BLOCK_ENCODING => 'NONE false
', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0',
VERSIONS => '1', COMPRESSION => 'GZ', MIN_VERSIONS
=> '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'fa
lse', BLOCKSIZE => '65536', IN_MEMORY => 'false', B
LOCKCACHE => 'true'}
1 row(s) in 0.1070 seconds
D.3.3. 测试压缩性能
HBase 包含一个名为 LoadTestTool 的工具,该工具提供了测试压缩性能的机制。您必须指定-write或-update-read作为您的第一个参数,如果未指定其他参数,则会为每个选项打印使用建议。
LoadTestTool Usage
$ bin/hbase org.apache.hadoop.hbase.util.LoadTestTool -h
usage: bin/hbase org.apache.hadoop.hbase.util.LoadTestTool <options>
Options:
-batchupdate Whether to use batch as opposed to separate
updates for every column in a row
-bloom <arg> Bloom filter type, one of [NONE, ROW, ROWCOL]
-compression <arg> Compression type, one of [LZO, GZ, NONE, SNAPPY,
LZ4]
-data_block_encoding <arg> Encoding algorithm (e.g. prefix compression) to
use for data blocks in the test column family, one
of [NONE, PREFIX, DIFF, FAST_DIFF, ROW_INDEX_V1].
-encryption <arg> Enables transparent encryption on the test table,
one of [AES]
-generator <arg> The class which generates load for the tool. Any
args for this class can be passed as colon
separated after class name
-h,--help Show usage
-in_memory Tries to keep the HFiles of the CF inmemory as far
as possible. Not guaranteed that reads are always
served from inmemory
-init_only Initialize the test table only, don't do any
loading
-key_window <arg> The 'key window' to maintain between reads and
writes for concurrent write/read workload. The
default is 0.
-max_read_errors <arg> The maximum number of read errors to tolerate
before terminating all reader threads. The default
is 10.
-multiput Whether to use multi-puts as opposed to separate
puts for every column in a row
-num_keys <arg> The number of keys to read/write
-num_tables <arg> A positive integer number. When a number n is
speicfied, load test tool will load n table
parallely. -tn parameter value becomes table name
prefix. Each table name is in format
<tn>_1...<tn>_n
-read <arg> <verify_percent>[:<#threads=20>]
-regions_per_server <arg> A positive integer number. When a number n is
specified, load test tool will create the test
table with n regions per server
-skip_init Skip the initialization; assume test table already
exists
-start_key <arg> The first key to read/write (a 0-based index). The
default value is 0.
-tn <arg> The name of the table to read or write
-update <arg> <update_percent>[:<#threads=20>][:<#whether to
ignore nonce collisions=0>]
-write <arg> <avg_cols_per_key>:<avg_data_size>[:<#threads=20>]
-zk <arg> ZK quorum as comma-separated host names without
port numbers
-zk_root <arg> name of parent znode in zookeeper
LoadTestTool 的用法示例
$ hbase org.apache.hadoop.hbase.util.LoadTestTool -write 1:10:100 -num_keys 1000000
-read 100:30 -num_tables 1 -data_block_encoding NONE -tn load_test_tool_NONE
D.4.启用数据块编码
编解码器内置在 HBase 中,因此不需要额外的配置。通过设置DATA_BLOCK_ENCODING属性在表上启用编解码器。更改其 DATA_BLOCK_ENCODING 设置之前,请禁用该表。以下是使用 HBase Shell 的示例:
在表上启用数据块编码
hbase> disable 'test'
hbase> alter 'test', { NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF' }
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2820 seconds
hbase> enable 'test'
0 row(s) in 0.1580 seconds
验证 ColumnFamily 的数据块编码
hbase> describe 'test'
DESCRIPTION ENABLED
'test', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST true
_DIFF', BLOOMFILTER => 'ROW', REPLICATION_SCOPE =>
'0', VERSIONS => '1', COMPRESSION => 'GZ', MIN_VERS
IONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS =
> 'false', BLOCKSIZE => '65536', IN_MEMORY => 'fals
e', BLOCKCACHE => 'true'}
1 row(s) in 0.0650 seconds
附录 E:基于 HBase 的 SQL
以下项目为基于 HBase 的 SQL 提供了一些支持。
E.1.Apache 凤凰
E.2. Trafodion
附录 F:YCSB
YCSB:Yahoo!云服务基准和 HBase
待办事项:描述 YCSB 在构建适当的群集负载方面的表现如何。
TODO:描述用于 HBase 的 YCSB 的设置。特别是,在开始运行之前,请预先分割表格。有关原因,请参见HBASE-4163 为 YCSB 基准创建拆分策略;有关操作方法,请参见一些 shell 命令。
泰德·邓宁(Ted Dunning)重做了 YCSB,因此对它进行了修饰和增加了用于验证工作负载的功能。参见泰德·邓宁(Ted Dunning)的 YCSB。
附录 G:HFile 格式
本附录描述了 HFile 格式的演变。
G.1. HBase 文件格式(版本 1)
当我们将讨论对 HFile 格式的更改时,简要概述原始(HFile 版本 1)格式非常有用。
G.1.1. 版本 1 概述
版本 1 格式的 HFile 的结构如下:
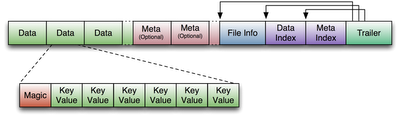
图 13. HFile V1 格式
G.1.2. 版本 1 中的块索引格式
版本 1 中的块索引非常简单。对于每个条目,它包含:
Offset (long)
未压缩大小(整数)
密钥(使用 Bytes.writeByteArray 编写的序列化字节数组)
密钥长度为可变长度整数(VInt)
- Key bytes
块索引中的条目数存储在固定文件尾部中,并且必须传递给读取块索引的方法。版本 1 中块索引的局限性之一是它不提供块的压缩大小,这对于解压缩是必需的。因此,HFile 阅读器必须根据块之间的偏移量来推断此压缩大小。我们在版本 2 中修复了此限制,在该版本中,我们存储磁盘上的块大小而不是未压缩大小,并从块头获取未压缩大小。
G.2.具有内联块的 HBase 文件格式(版本 2)
注意:此功能是 HBase 0.92 中引入的
G.2.1. Motivation
我们发现有必要在由于区域服务器中的大型 Bloom 筛选器和块索引导致内存使用率高且启动时间慢之后,修改 HFile 格式。每个 HFile,Bloom 筛选器的大小可以达到 100 MB,如果在 20 个区域中聚合,则总计为 2 GB。在同一组区域上,块索引的总大小可以增长到 6 GB。直到所有区域的块索引数据都加载完毕,该区域才被视为已打开。大型 Bloom 过滤器会产生不同的性能问题:需要进行 Bloom 过滤器查找的第一个 get 请求将导致加载整个 Bloom 过滤器位阵列的延迟。
为了加快区域服务器的启动速度,我们将 Bloom 过滤器和块索引分成多个块,并在块填满后将其写出,这也减少了 HFile writer 的内存占用。在布隆过滤器的情况下,“填满一个块”意味着积累足够的键以有效地利用固定大小的位数组,而在块索引的情况下,我们积累一个所需大小的“索引块”。 Bloom 过滤器块和索引块(我们称为“内联块”)散布在数据块中,并且副作用是,我们不再像版本 1 中那样依靠块偏移之间的差异来确定数据块的长度。 。
HFile 在设计上是一种低级文件格式,它不应处理特定于应用程序的详细信息,例如在 StoreFile 级别处理的 Bloom 过滤器。因此,我们将 HFile 中的 Bloom 过滤器块称为“内联”块。我们还为 HFile 提供了编写这些内联块的接口。
旨在减少区域服务器启动时间的另一种格式修改是使用连续的“打开时加载”部分,该部分必须在打开 HFile 时加载到内存中。当前,当 HFile 打开时,有单独的查找操作来读取预告片,数据/元索引和文件信息。要读取布隆过滤器,还有两个针对其“数据”和“元”部分的查找操作。在版本 2 中,我们寻求一次读取预告片,然后再次寻求读取从连续块中打开文件所需的所有其他内容。
G.2.2. 版本 2 概述
引入了上述功能的 HBase 版本同时读取版本 1 和 2 HFile,但仅写入版本 2 HFile。版本 2 HFile 的结构如下:
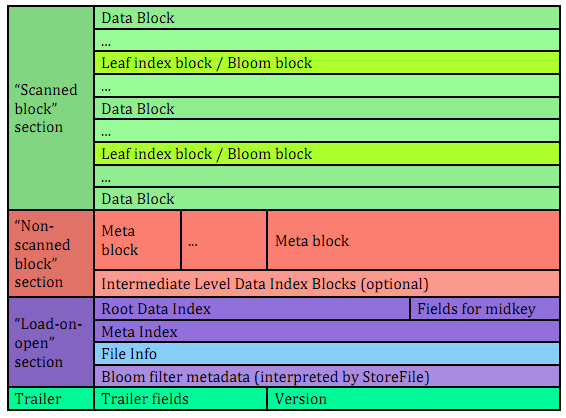
图 14. HFile 版本 2 结构
G.2.3. 统一版本 2 块格式
在版本 2 中,数据部分中的每个块都包含以下字段:
8 个字节:块类型,等同于版本 1 的“魔术记录”的字节序列。支持的块类型为:
DATA –数据块
LEAF_INDEX –多级块索引中的叶级索引块
BLOOM_CHUNK –布隆过滤块
META –元块(不再用于版本 2 中的 Bloom 过滤器)
INTERMEDIATE_INDEX –多级块索引中的中级索引块
ROOT_INDEX –多级块索引中的根级索引块
FILE_INFO –“文件信息”块,一个小键>元数据值 Map
BLOOM_META –加载>打开>打开部分中的布隆过滤器元数据块
挂车–固定尺寸的文件挂车。与上述相反,这不是 HFile v2 块,而是固定大小(对于每个 HFile 版本)的数据结构
INDEX_V1 –此块类型仅用于旧版 HFile v1 块
块数据的压缩大小,不包括标题(int)。
可用于在扫描 HFile 数据时跳过当前数据块。
- 块数据的未压缩大小,不包括标题(int)
如果压缩算法为 NONE,则等于压缩后的大小
- 相同类型的前一个块的文件偏移量(长)
可用于查找上一个数据/索引块
- 压缩数据(如果压缩算法为 NONE,则为未压缩数据)。
以下 HFile 节中使用了以上块的格式:
扫描块部分
- 该部分的名称之所以如此,是因为它包含 Sequences 扫描 HFile 时需要读取的所有数据块。还包含叶子块索引和 Bloom 块块。
非扫描区
- 本节仍然包含统一格式的 v2 块,但是在进行 Sequences 扫描时不必读取它。本节包含“元”块和中间级索引块。
我们在版本 2 中支持“元”块的方式与版本 1 中所支持的方式相同,即使我们不再在这些块中存储 Bloom 过滤器数据也是如此。
G.2.4. 版本 2 中的块索引
HFile 版本 2 中存在三种类型的块索引,以两种不同的格式(根和非根)存储:
数据索引-版本 2 多级块索引,包括:
版本 2 根索引,存储在文件的数据块索引部分
可选地,版本 2 中间级别以非%root 格式存储在文件的数据索引部分中。如果存在叶级块,则只能存在中间级
(可选)版本 2 叶子级别,以非%root 格式存储在数据块中
元索引-仅限于版本 2 根索引格式,存储在文件的元索引部分中
Bloom 索引-仅限于版本 2 根索引格式,作为 Bloom 过滤器元数据的一部分存储在“打开时加载”部分中。
G.2.5. 版本 2 中的根块索引格式
此格式适用于:
版本 2 数据索引的根级别
版本 2 中的整个 meta 和 Bloom 索引始终是单级的。
版本 2 根索引块是具有以下格式的条目序列,类似于版本 1 块索引的条目,但存储磁盘大小而不是未压缩大小。
- Offset (long)
该偏移量可能指向数据块或更深层次的索引块。
磁盘大小(整数)
密钥(使用 Bytes.writeByteArray 存储的序列化字节数组)
Key (VInt)
Key bytes
单级版本 2 块索引仅包含一个根索引块。要读取版本 2 的根索引块,需要知道条目数。对于数据索引和元索引,条目数存储在预告片中,对于 Bloom 索引,其条目存储在复合 Bloom 过滤器元数据中。
对于多级块索引,除了上述数据结构之外,我们还将以下字段存储在 HFile 的“打开时加载”部分的根索引块中:
中叶索引块偏移
中间叶子块在磁盘上的大小(意味着叶子索引块包含对文件“中间”数据块的引用)
中间叶级块中的中间键(在下面定义)的索引。
这些附加字段用于有效地检索 HFile 拆分中使用的 HFile 的中键,我们将其定义为块的第一个键,如果索引总数为(n – 1)/ 2,则从零开始。 HFile 中的块为 n。此定义与 HFile 版本 1 中确定中间键的方式一致,并且通常是合理的,因为块的平均大小可能相同,但是我们对单个键/值对的大小没有任何估计。
编写版本 2 HFile 时,将跟踪每个叶级索引块指向的数据块总数。当我们完成写操作并确定了叶级块的总数时,很明显哪个叶级块包含中键,并且上面列出的字段已计算出来。当读取 HFile 并请求中间键时,我们检索中间叶子索引块(可能从块缓存中获取),并从该叶子块内的适当位置获取中间键值。
G.2.6. 版本 2 中的非根块索引格式
此格式适用于版本 2 多级数据块索引的中间级和叶索引块。每个非根索引块的结构如下。
numEntries:条目数(整数)。
entryOffsets:块中条目的偏移量的“第二索引”,以便于在键(
numEntries + 1int 值)上进行快速的二进制搜索。最后一个值是此索引块中所有条目的总长度。例如,在条目大小为 60、80、50 的非根索引块中,“辅助索引”将包含以下 int 数组:{0, 60, 140, 190}。条目。每个条目包含:
文件中此条目引用的块的偏移量(长)
On>所引用块的磁盘大小(整数)
键。可以从 entryOffsets 计算长度。
G.2.7. 版本 2 中的 Bloom 过滤器
与版本 1 相反,在版本 2 中,HFile Bloom 筛选器元数据存储在 HFile 的“打开时加载”部分中,以便快速启动。
复合布隆过滤器。
布隆过滤器版本= 3(int)。过去曾经有一个 DynamicByteBloomFilter 类,该类的 Bloom 过滤器版本号为 2
所有复合 Bloom 过滤器块的总字节大小(长)
哈希函数数(整数
哈希函数的类型(整数)
插入到布隆过滤器中的总键数(长)
布隆过滤器中的最大键总数(长)
块数(整数)
用于 Bloom 筛选器键的比较器类,使用 Bytes.writeByteArray 存储的 UTF> 8 编码字符串
版本 2 根块索引格式的 Bloom 块索引
G.2.8. 版本 1 和 2 中的文件信息格式
文件信息块是从字节数组到字节数组的序列化 Map,带有以下键以及其他内容。 StoreFile 级别的逻辑为此添加了更多密钥。
| hfile.LASTKEY | 文件的最后一个键(字节数组) |
| hfile.AVG_KEY_LEN | 文件中的平均密钥长度(整数) |
| hfile.AVG_VALUE_LEN | 文件中的平均值长度(整数) |
在版本 2 中,我们没有更改文件格式,但是我们将文件信息移到了文件的最后部分,当打开 HFile 时可以将其作为一个块加载。
另外,我们不再将比较器存储在版本 2 文件信息中。相反,我们将其存储在固定文件预告片中。这是因为在解析 HFile 的“打开时加载”部分时,我们需要了解比较器。
G.2.9. 版本 1 和版本 2 之间的固定文件尾随格式差异
下表显示了版本 1 和 2 中固定文件预告片之间的公共字段和不同字段。请注意,预告片的大小因版本而异,因此仅在一个版本中被``固定''。但是,版本始终存储为文件中的最后四个字节的整数。
表 23. HFile 版本 1 和 2 之间的区别
| Version 1 | Version 2 |
| 文件信息偏移量(长) | |
| 数据索引偏移量(长) | loadOnOpenOffset(long)/打开文件时需要加载的节的偏移量。 |
| 数据索引条目数(整数) | |
| metaIndexOffset(long)/版本 1 的阅读器未使用此字段,因此我们从版本 2 中将其删除。/ | uncompressedDataIndexSize(long)/整个数据块索引的总未压缩大小,包括根级别,中间级别和叶级别的块。 |
| 元索引条目数(整数) | |
| 未压缩的字节总数(长) | |
| numEntries (int) | numEntries (long) |
| 压缩编解码器:0 = LZO,1 = GZ,2 = NONE(int) | 压缩编解码器:0 = LZO,1 = GZ,2 = NONE(int) |
| 数据块索引中的级别数(整数) | |
| firstDataBlockOffset(长整数)/第一个数据块的偏移量。扫描时使用。/ | |
| lastDataBlockEnd(long)/最后一个键/值数据块之后的第一个字节的偏移量。扫描时,我们不需要超出此偏移量。 | |
| 版本:1(int) | 版本:2(int) |
G.2.10. getShortMidpointKey(数据索引块的优化)
注意:此优化是在 HBase 0.95 中引入的
HFiles 包含许多块,这些块包含一系列已排序的单元格。每个单元都有一个密钥。为了节省读取 Cell 时的 IO,HFile 还具有一个索引,该索引将 Cell 的开始键 Map 到特定块开始的偏移量。在此优化之前,HBase 将使用每个数据块中第一个单元格的密钥作为索引密钥。
在 HBASE-7845 中,我们生成一个新的密钥,该密钥在字典上大于上一个块的最后一个密钥,而在字典上等于或小于当前块的开始密钥。尽管实际密钥可能很长,但此“伪密钥”或“虚拟密钥”可能要短得多。例如,如果前一个块的停止键是“ the quick brown fox”,当前块的开始键是“ the who”,则可以在我们的 hfile 索引中使用“ r”作为虚拟键。
这有两个好处:
拥有较短的键可以减少 hfile 索引的大小,(从而使我们可以在内存中保留更多的索引),并且
当目标密钥位于“虚拟密钥”和目标块中第一个元素的密钥之间时,使用更接近上一个块的结束密钥的内容可以避免潜在的额外 IO。
这种优化(由 getShortMidpointKey 方法实现)受到 LevelDB 的 ByteWiseComparatorImpl :: FindShortestSeparator()和 FindShortSuccessor()的启发。
G.3.具有安全性增强功能的 HBase 文件格式(版本 3)
注意:此功能是在 HBase 0.98 中引入的
G.3.1. Motivation
HFile 的版本 3 进行了一些更改,以简化静态加密和单元级元数据的 Management(反过来,单元级 ACL 和单元级可见性标签也需要更改)。有关更多信息,请参见hbase.encryption.server,hbase.tags,hbase.accesscontrol.configuration和hbase.visibility.labels。
G.3.2. Overview
引入了上述功能的 HBase 版本读取版本 1、2 和 3 中的 HFile,但仅写入版本 3 HFiles。版本 3 HFile 的结构与版本 2 HFile 相同。有关更多信息,请参见hfilev2.overview。
G.3.3. 版本 3 中的文件信息块
版本 3 向文件信息块中的保留键添加了另外两个信息。
| hfile.MAX_TAGS_LEN | 在此 hfile 中为任何单个单元格存储序列化标签所需的最大字节数(int) |
| hfile.TAGS_COMPRESSED | 此 hfile 的块编码器是否压缩标签? (布尔值)。仅当还存在 hfile.MAX_TAGS_LEN 时才应存在。 |
读取版本 3 HFile 时,使用MAX_TAGS_LEN来确定如何反序列化数据块中的单元。因此,使用者必须先读取文件的信息块,然后再读取任何数据块。
编写第 3 版 HFile 时,将内存存储刷新到基础文件系统时,HBase 将始终包含MAX_TAGS_LEN。
压缩现存文件时,如果所有选择的文件本身都不包含带有标签的单元格,则默认编写器将省略MAX_TAGS_LEN。
有关 zipfile 选择算法的详细信息,请参见compaction。
G.3.4. 版本 3 中的数据块
在 HFile 中,HBase 单元作为键值序列存储在数据块中(请参见hfilev1.overview或Lars George 对 HBase 存储的出色介绍)。在版本 3 中,这些 KeyValue 可选地将包含一组 0 个或更多标记:
| 没有 MAX_TAGS_LEN 的版本 1 和 2,版本 3 | 第 3 版,带有 MAX_TAGS_LEN |
| 密钥长度(4 个字节) | |
| 值长度(4 个字节) | |
| 关键字节(可变) | |
| 值字节(可变) | |
| 标签长度(2 个字节) | |
| 标签字节(可变) |
如果给定 HFile 的信息块包含MAX_TAGS_LEN的条目,则每个单元格将包含该单元格标签的长度,即使该长度为零。实际标签按标签长度(2 个字节),标签类型(1 个字节),标签字节(可变)的 Sequences 存储。单个标签字节的格式取决于标签类型。
请注意,对信息块内容的依赖意味着在读取任何数据块之前,您必须首先处理文件的信息块。这也意味着在写入数据块之前,您必须知道文件的信息块是否包含MAX_TAGS_LEN。
G.3.5. 版本 3 中的固定文件预告片
用 HFile 版本 3 编写的固定文件预告片始终使用协议缓冲区进行序列化。此外,它向版本 2 的协议缓冲区(称为加密密钥)添加了一个可选字段。如果将 HBase 配置为加密 HFile,则此字段将存储此特定 HFile 的数据加密密钥,并使用 AES 使用当前群集主密钥进行加密。有关更多信息,请参见hbase.encryption.server。
附录 H:有关 HBase 的其他信息
H.1. HBase 视频
HBase 简介
HBase 简介,作者是 Todd Lipcon(2011 年芝加哥数据峰会)。
使用 HBase 在 Facebook 上构建实时服务,作者:乔纳森·格雷(2011 年柏林流行语)
吉恩·丹尼尔·克莱恩斯(Jean-Daniel Cryans)的HBase 的多种用途(柏林流行语 2011)。
H.2. HBase 演示文稿(幻灯片)
先进的 HBase 架构设计,作者:Lars George(Hadoop World,2011 年)。
HBase 简介,作者是 Todd Lipcon(2011 年芝加哥数据峰会)。
从 HBase 安装中获得最大收益,作者 Ryan Rawson,乔纳森·格雷(Jonathan Gray,Hadoop 世界,2009 年)。
H.3. HBase 论文
Google BigTable(2006)。
HBase 和 HDFS 位置,作者:拉斯·乔治(Lars George),2010 年。
Ian Varley 的没有关系:非关系数据库的混合祝福(2009)。
H.4. HBase 站点
Cloudera 的 HBase 博客有许多指向有用的 HBase 信息的链接。
CAP Confusion是有关分布式存储系统的背景信息的相关条目。
HBase RefCard来自 DZone。
H.5. HBase 书
HBase:Authority 指南由拉斯·乔治(Lars George)提供。
H.6. Hadoop 书籍
Hadoop:Authority 指南,汤姆·怀特(Tom White)。
附录 I:HBase 历史记录
2006:BigTable由 Google 发表的论文。
2006 (年底):HBase 开发开始。
2008:HBase 成为 Hadoop 子项目。
2010:HBase 成为 Apache 顶级项目。
附录 J:HBase 和 Apache 软件基金会
HBase 是 Apache Software Foundation 中的一个项目,因此 ASF 有责任确保项目正常运行。
J.1. ASF 开发流程
有关 ASF 的结构(例如 PMC,提交者,贡献者)的各种信息,有关贡献和参与的技巧以及 ASF 开源的工作方式,请参见Apache 开发流程页面。
J.2. ASF 董事会报告
每季度一次,ASF 产品组合中的每个项目都会向 ASF 董事会提交报告。这是由 HBase 项目负责人和提交者完成的。有关更多信息,请参见ASF 董事会报告。
附录 K:Apache HBase Orca

图 15. Apache HBase Orca,HBase 颜色和字体
Orca 是 Apache HBase 的吉祥物。请参阅 NOTICES.txt。我们在这里获得的 Orca 徽标:http://www.vectorfree.com/jumping-orca它已获得知识共享署名 3.0 的许可。请参见https://creativecommons.org/licenses/by/3.0/us/我们通过剥离彩色背景,将其反转然后旋转一些来更改徽标。
HBase 的“官方”颜色是“国际橙(工程)”,这是旧金山金门大 bridge的颜色,用于 NASA 使用的宇航服。
我们的“字体”是Bitsumishi。
附录 L:在 HBase 中启用类似 Dapper 的跟踪
HBase 包括使用开源跟踪库Apache HTrace跟踪请求的工具。设置跟踪非常简单,但是目前需要对 Client 端代码进行一些非常小的更改(将来可能会删除此要求)。
在HBASE-6449中添加了在 HBase 中使用 HTrace 3 对该功能的支持。从 HBase 2.0 开始,通过HBASE-18601对 HTrace 4 进行了不兼容的更新。本节提供的示例将使用 HTrace 4 软件包名称,语法和约定。有关较旧的示例,请查阅本指南的早期版本。
L.1. SpanReceivers
跟踪系统通过在称为“Span”的结构中收集信息来工作。您可以通过实现SpanReceiver接口来选择接收此信息的方式,该接口定义了一种方法:
public void receiveSpan(Span span);
每当 Span 完成时,此方法就用作回调。 HTrace 允许您使用任意数量的 SpanReceiver,因此您可以轻松地将跟踪信息发送到多个目的地。
通过在* hbase-site.xml *属性:hbase.trace.spanreceiver.classes中放置实现SpanReceiver的类的标准类名的逗号分隔列表,配置所需的 SpanReceivers。
HTrace 包含一个LocalFileSpanReceiver,该LocalFileSpanReceiver以基于 JSON 的格式将所有 span 信息写入本地文件。 LocalFileSpanReceiver在* hbase-site.xml *中查找hbase.local-file-span-receiver.path属性,该属性的值描述节点应将其 Span 信息写入到的文件的名称。
<property>
<name>hbase.trace.spanreceiver.classes</name>
<value>org.apache.htrace.core.LocalFileSpanReceiver</value>
</property>
<property>
<name>hbase.htrace.local-file-span-receiver.path</name>
<value>/var/log/hbase/htrace.out</value>
</property>
HTrace 还提供ZipkinSpanReceiver,它将 Span 转换为ZipkinSpan 格式并将其发送到 Zipkin 服务器。为了使用此 span 接收器,您需要在群集中所有节点上将 htrace-zipkin 的 jar 安装到 HBase 的 Classpath 中。
- htrace-zipkin *已发布到Maven 中央存储库。您可以从那里获得最新版本,也可以只在本地构建(有关此操作的信息,请参见HTrace主页),然后将其复制到所有节点。
ZipkinSpanReceiver用于* hbase-site.xml *中名为hbase.htrace.zipkin.collector-hostname和hbase.htrace.zipkin.collector-port的属性,其值描述了将 Span 信息发送到的 Zipkin 收集器服务器。
<property>
<name>hbase.trace.spanreceiver.classes</name>
<value>org.apache.htrace.core.ZipkinSpanReceiver</value>
</property>
<property>
<name>hbase.htrace.zipkin.collector-hostname</name>
<value>localhost</value>
</property>
<property>
<name>hbase.htrace.zipkin.collector-port</name>
<value>9410</value>
</property>
如果您不想使用随附的 Span 接收器,建议您编写自己的接收器(以LocalFileSpanReceiver为例)。如果您认为其他人将从您的接收器中受益,请向 HTrace 项目提交 JIRA。
187.Client 端修改
为了打开您的 Client 端代码中的跟踪,您必须在每个 Client 端进程中初始化一次将模块的发送范围发送给接收方。
private SpanReceiverHost spanReceiverHost;
...
Configuration conf = HBaseConfiguration.create();
SpanReceiverHost spanReceiverHost = SpanReceiverHost.getInstance(conf);
然后,您可以简单地在您认为有趣的请求之前开始跟踪范围,并在完成请求后将其关闭。例如,如果要跟踪所有的 get 操作,则可以更改此操作:
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("t1"));
Get get = new Get(Bytes.toBytes("r1"));
Result res = table.get(get);
into:
TraceScope ts = Trace.startSpan("Gets", Sampler.ALWAYS);
try {
Table table = connection.getTable(TableName.valueOf("t1"));
Get get = new Get(Bytes.toBytes("r1"));
Result res = table.get(get);
} finally {
ts.close();
}
如果要跟踪一半的“获取”操作,则可以传入:
new ProbabilitySampler(0.5)
代替Sampler.ALWAYS到Trace.startSpan()。有关采样器的更多信息,请参见 HTrace * README *。
188.从 HBase Shell 进行跟踪
您可以使用trace命令来跟踪来自 HBase Shell 的请求。 trace 'start'命令打开跟踪,而trace 'stop'命令关闭跟踪。
hbase(main):001:0> trace 'start'
hbase(main):002:0> put 'test', 'row1', 'f:', 'val1' # traced commands
hbase(main):003:0> trace 'stop'
trace 'start'和trace 'stop'总是返回布尔值,表示是否正在进行跟踪。结果,trace 'stop'成功返回 false。 trace 'status'仅返回是否打开跟踪。
hbase(main):001:0> trace 'start'
=> true
hbase(main):002:0> trace 'status'
=> true
hbase(main):003:0> trace 'stop'
=> false
hbase(main):004:0> trace 'status'
=> false
附录 M:0.95 RPC 规范
在 0.95 中,所有 Client 端/服务器通信都是通过protobuf'ed消息而不是Hadoop Writables完成的。因此,我们的 RPC 连线格式会更改。本文档描述了 Client 端/服务器请求/响应协议以及我们新的 RPC 有线格式。
有关 0.94 及更高版本中 RPC 的内容,请参见 Benoît/ Tsuna 的非官方的 Hadoop/HBase RPC 协议文档。有关我们如何达到此规格的更多背景信息,请参见HBase RPC:在制品
M.1. Goals
我们可以 Developing 的线格式
一种不需要我们重写服务器核心或从根本上更改其当前体系结构的格式(供以后使用)。
M.2. TODO
当前指定格式的问题列表,以及我们希望在版本 2 中使用的格式,等等。例如,如果要移动服务器异步或支持流传输/分块,我们必须更改什么?
原理图
简要描述线格式的语法。目前,我们已经有了这些单词和 rpc protobuf idl 的内容,但是来回的语法将有助于 rpc 的 Developing。同样,在 Client 端/服务器交互上的一些状态机将有助于理解(并确保正确的实现)。
M.3. RPC
Client 端将发送有关连接构建的设置信息。此后,Client 端针对远程服务器调用发送 protobuf 消息并接收 protobuf 消息的方法。通信是同步的。所有来回前后都带有一个整数,该整数具有请求/响应的总长度。 (可选)可以将 Cells(KeyValues)传递到后续 Cell 块中的 probubuf 之外(因为我们无法对 MB 的 KeyValue 进行 protobuf或 Cells)。这些 CellBlock 被编码并可以选择压缩。
有关所涉及的 protobuf 的更多详细信息,请参阅 master 中的RPC.proto文件。
M.3.1. 连接设置
Client 端启动连接。
Client
在构建连接时,Client 端发送一个前导,后跟一个连接头。
<preamble>
<MAGIC 4 byte integer> <1 byte RPC Format Version> <1 byte auth type>
我们需要 auth 方法规范。如果启用了身份验证,则在此处对连接头进行编码。
例如:HBas0x000x50-4 个字节的 MAGIC-`HBas'-加上一个字节的版本(在这种情况下为 0)和一个字节的 0x50(简单)。身份验证类型。
\
具有用户信息和``协议'',以及 Client 端将使用发送 CellBlocks 的编码器和压缩。 CellBlock 编码器和压缩机在连接寿命内。 CellBlock 编码器实现 org.apache.hadoop.hbase.codec.Codec。然后,也可以压缩 CellBlocks。压缩器实现 org.apache.hadoop.io.compress.CompressionCodec。这个 protobuf 是使用 writeDelimited 编写的,因此以序列化长度的 pb varint 开头
Server
Client 端发送前导码和连接头后,如果成功构建连接,服务器将不响应。没有响应表示服务器已准备就绪,可以接受请求并发出响应。如果序言中的版本或身份验证不一致,或者服务器在解析序言时遇到问题,它将抛出 org.apache.hadoop.hbase.ipc.FatalConnectionException 解释错误,然后断开连接。如果 Client 端在连接 Headers 中(即连接序言后的 protobuf 消息)向服务器请求不支持的服务,或者服务器不提供编解码器,则再次抛出 FatalConnectionException 及其解释。
M.3.2. Request
构建连接后,Client 端发出请求。服务器响应。
一个请求由一个 protobuf RequestHeader 和一个 protobuf Message 参数组成。Headers 包含方法名称以及(可选)可能跟随的可选 CellBlock 上的元数据。参数类型适合所调用的方法:即,如果我们正在执行 getRegionInfo 请求,则 protobuf 消息参数将是 GetRegionInfoRequest 的实例。响应将是 GetRegionInfoResponse。可以选择使用 CellBlock 传递大量 RPC 数据:即 Cells/KeyValues。
Request Parts
<Total Length>
该请求以一个 int 开头,该 int 保持其后的总长度。
\
接下来是 Cell 块 IFF 上的 call.id,trace.id 和方法名称等,包括可选的元数据。数据在此 pb 消息中进行了内联协议存储,或者可选地包含在以下 CellBlock 中
\
如果调用的方法是 getRegionInfo,则如果研究 Client 端到 Regionserver 协议的服务 Descriptors,则会发现请求在此位置发送了 GetRegionInfoRequest protobuf Message 参数。
<CellBlock>
编码并可选压缩的 Cell 块。
M.3.3. Response
与请求相同,它是一个 protobuf ResponseHeader,后跟一个 protobuf 消息响应,其中消息响应类型适合所调用的方法。大量数据可能来自随后的 CellBlock。
Response Parts
<Total Length>
该响应以一个 int 开头,该 int 保持其后的总长度。
\
将具有 call.id 等。如果处理失败,则将包含异常。可选地,在可选的 IFF 上包括元数据,随后是一个 CellBlock。
\
返回或如果异常则为空。如果正在调用的方法是 getRegionInfo,则如果研究 Client 端到区域服务器协议的服务 Descriptors,则会发现该响应在此位置发送了 GetRegionInfoResponse protobuf Message 参数。
<CellBlock>
编码并可选压缩的 Cell 块。
M.3.4. Exceptions
有两种不同的类型。有一个失败的请求,该请求封装在响应的响应头中。连接保持打开状态以接收新请求。第二种类型 FatalConnectionException 终止连接。
异常可以携带额外的信息。请参阅 ExceptionResponse protobuf 类型。它具有一个标志,指示不要重试以及其他各种有效负载,以帮助提高 Client 端的响应能力。
M.3.5. CellBlocks
这些未版本化。服务器可以执行编解码器,或者不能执行编解码器。如果说新版本的编解码器具有更严格的编码,请给它一个新的类名。编解码器将一直存在于服务器上,以便旧 Client 端可以连接。
M.4. Notes
Constraints
在某种程度上,当前的有线格式 wire 即所有以长度为前缀的请求和响应 responses 均由当前的服务器非异步体系结构决定。
一个胖的 PB 请求或 Headers 参数
我们先用 pbHeaders,然后是 pb param 发出请求,然后是 pbHeaders,然后是 pb 响应。执行 Headers 参数,而不是包含 Headers 和参数内容的单个 protobuf 消息:
更接近我们目前拥有的
拥有一个单一的脂肪铅需要额外的复制,以将已经铅的参数放入脂肪请求铅的主体中(并获得相同的结果)
阅读参数之前,我们可以决定是否接受请求。例如,请求的优先级可能较低。照原样,由于当前已实现服务器,因此一口气读取了 Headers 参数,因此这是一个 TODO。
优点是次要的。如果以后,发请求有明显的优势,以后可以推出 v2.
M.4.1. RPC 配置
CellBlock Codecs
若要启用除默认KeyValueCodec以外的其他编解码器,请将hbase.client.rpc.codec设置为要使用的编解码器类的名称。编解码器必须实现 hbase 的Codec接口。构建连接后,所有通过的单元格块都将与此编解码器一起发送。只要编解码器位于服务器的 CLASSPATH 上,服务器就会使用相同的编解码器返回单元块(否则您将获得UnsupportedCellCodecException)。
要更改默认编解码器,请设置hbase.client.default.rpc.codec。
要完全禁用单元块并使用纯 protobuf,请将默认设置为空字符串,并且不要在配置中指定编解码器。因此,将hbase.client.default.rpc.codec设置为空字符串,而不设置hbase.client.rpc.codec。这将导致 Client 端在未指定编解码器的情况下连接到服务器。如果服务器看不到编解码器,它将以纯 protobuf 返回所有响应。始终运行纯 protobuf 会比使用 cellblock 慢。
Compression
使用 hadoop 的压缩编解码器。要启用对传递的 CellBlocks 的压缩,请将hbase.client.rpc.compressor设置为要使用的 Compressor 的名称。 Compressor 必须实现 Hadoop 的 CompressionCodec 接口。构建连接后,所有通过的单元块将被压缩发送。只要压缩程序位于其 CLASSPATH 上,服务器将返回使用同一压缩程序压缩的单元块(否则您将获得UnsupportedCompressionCodecException)。
附录 N:HBase 版本之间的已知不兼容性
189. HBase 2.0 不兼容的更改
本附录描述了从 HBase 的早期版本到 HBase 2.0 的不兼容更改。此列表并不意味着完全包含所有可能的不兼容性。而是,此内容旨在深入了解大多数用户将面对的来自 HBase 1.x 版本的一些不兼容问题。
189.1. HBase 2.0 的主要更改列表
HBASE-1912- HBCK 是用于捕获不一致情况的 HBase 数据库检查工具。作为 HBaseManagement 员,您不应使用 HBase 1.0 版 hbck 工具来检查 HBase 2.0 数据库。这样做将破坏数据库并引发异常错误。
HBASE-16189 和 HBASE-18945-您无法通过 HBase 1.0 版本打开 HBase 2.0 hfile。如果您是使用 HBase 1.x 版的 Management 员或 HBase 用户,则必须首先将其滚动升级到最新版本的 HBase 1.x,然后再升级到 HBase 2.0.
HBASE-18240-更改了 ReplicationEndpoint 接口。它还引入了新的 hbase-third-party 1.0,它将所有第三方 Util 打包在一起,这些 Util 有望在 hbase 群集中运行。
189.2. 协处理器 API 更改
HBASE-16769-MasterObserver 和 RegionServerObserver 中已弃用的 PB 引用。
HBASE-17312-[JDK8]对观察者协处理器使用默认方法。 BaseMasterAndRegionObserver,BaseMasterObserver,BaseRegionObserver,BaseRegionServerObserver 和 BaseWALObserver 的接口类使用 JDK8 的'default'关键字提供空操作和无操作实现。
接口 HTableInterface HBase 2.0 对以下列出的方法进行了以下更改:
189.2.1. [-]接口 CoprocessorEnvironment 更改(2)
| Change | Result |
| 抽象方法 getTable(TableName)已被移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getTable(TableName,ExecutorService)已被移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
- Public Audience
下表描述了协处理器的更改。
[-]类 CoprocessorRpcChannel(1)
| Change | Result |
| 此类已成为接口。 | 根据此类的用途,Client 端程序可能会被 IncompatibleClassChangeError 或 InstantiationError 异常中断。 |
Class CoprocessorHost<E>
属于“受众专用”但已删除的类。
| Change | Result |
| 字段协处理器的类型已从 java.util.SortedSet<E>更改为 org.apache.hadoop.hbase.util.SortedList<E>。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
189.2.2. MasterObserver
HBase 2.0 对 MasterObserver 接口进行了以下更改。
[-]界面 MasterObserver(14)
| Change | Result |
| 已从该接口中删除了抽象方法 voidpostCloneSnapshot(ObserverContext,HBaseProtos.SnapshotDescription,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 此接口中已删除了抽象方法 voidpostCreateTable(ObserverContext,HTableDescriptor,HRegionInfo [])。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从此接口中删除了抽象方法 voidpostDeleteSnapshot(ObserverContext,HBaseProtos.SnapshotDescription)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 抽象方法 voidpostGetTableDescriptors(ObserverContext,List)已从此接口中移除。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从此接口中删除抽象方法 voidpostModifyTable(ObserverContext,TableName,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从该接口中删除了抽象方法 voidpostRestoreSnapshot(ObserverContext,HBaseProtos.SnapshotDescription,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从该接口中删除了抽象方法 voidpostSnapshot(ObserverContext,HBaseProtos.SnapshotDescription,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从该接口中删除了抽象方法 voidpreCloneSnapshot(ObserverContext,HBaseProtos.SnapshotDescription,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从该接口中删除了抽象方法 voidpreCreateTable(ObserverContext,HTableDescriptor,HRegionInfo [])。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 抽象方法 voidpreDeleteSnapshot(ObserverContext,HBaseProtos.SnapshotDescription)已从此接口中移除。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 抽象方法 voidpreGetTableDescriptors(ObserverContext,List,List)已从此接口中删除。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 此接口中已删除了抽象方法 voidpreModifyTable(ObserverContext,TableName,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从该接口中删除了抽象方法 voidpreRestoreSnapshot(ObserverContext,HBaseProtos.SnapshotDescription,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
| 已从该接口中删除了抽象方法 voidpreSnapshot(ObserverContext,HBaseProtos.SnapshotDescription,HTableDescriptor)。 | Client 端程序可能会被 NoSuchMethodErrorexception 中断。 |
189.2.3. RegionObserver
HBase 2.0 对 RegionObserver 接口进行了以下更改。
[-]界面 RegionObserver(13)
| Change | Result |
| 已从该接口中删除了抽象方法 voidpostCloseRegionOperation(ObserverContext,HRegion.Operation)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除了抽象方法 voidpostCompactSelection(ObserverContext,Store,ImmutableList)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从此接口中删除了抽象方法 voidpostCompactSelection(ObserverContext,Store,ImmutableList,CompactionRequest)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 voidpostGetClosestRowBefore(ObserverContext,byte [],byte [],Result)已从该接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 DeleteTrackerpostInstantiateDeleteTracker(ObserverContext,DeleteTracker)已从此接口中删除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 voidpostSplit(ObserverContext,HRegion,HRegion)已从此接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除抽象方法 voidpostStartRegionOperation(ObserverContext,HRegion.Operation)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除了抽象方法 StoreFile.ReaderpostStoreFileReaderOpen(ObserverContext,FileSystem,Path,FSDataInputStreamWrapper,long,CacheConfig,Reference,StoreFile.Reader)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除了抽象方法 voidpostWALRestore(ObserverContext,HRegionInfo,HLogKey,WALEdit)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从此接口中删除了抽象方法 InternalScannerpreFlushScannerOpen(ObserverContext,Store,KeyValueScanner,InternalScanner)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 voidpreGetClosestRowBefore(ObserverContext,byte [],byte [],Result)已从该接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除了抽象方法 StoreFile.ReaderpreStoreFileReaderOpen(ObserverContext,FileSystem,Path,FSDataInputStreamWrapper,long,CacheConfig,Reference,StoreFile.Reader)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除了抽象方法 voidpreWALRestore(ObserverContext,HRegionInfo,HLogKey,WALEdit)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.4. WALObserver
HBase 2.0 对 WALObserver 界面进行了以下更改。
[-]界面 WALObserver
| Change | Result |
| 已从该接口中删除了抽象方法 voidpostWALWrite(ObserverContext,HRegionInfo,HLogKey,WALEdit)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除了抽象方法 booleanpreWALWrite(ObserverContext,HRegionInfo,HLogKey,WALEdit)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.5. Miscellaneous
HBase 2.0 对以下类进行了更改:
hbase-server-1.0.0.jar,OnlineRegions.class 包 org.apache.hadoop.hbase.regionserver
[-] OnlineRegions.getFromOnlineRegions(字符串 p1)[摘要]:HRegion
org/apache/hadoop/hbase/regionserver/OnlineRegions.getFromOnlineRegions:(Ljava/lang/String;)Lorg/apache/hadoop/hbase/regionserver/HRegion;
| Change | Result |
| 返回值类型已从“区域”更改为“区域”。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
hbase-server-1.0.0.jar,RegionCoprocessorEnvironment.class 包 org.apache.hadoop.hbase.coprocessor
[-] RegionCoprocessorEnvironment.getRegion()[摘要]:HRegion
org/apache/hadoop/hbase/coprocessor/RegionCoprocessorEnvironment.getRegion:()Lorg/apache/hadoop/hbase/regionserver/HRegion;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.regionserver.HRegion 更改为 org.apache.hadoop.hbase.regionserver.Region。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
hbase-server-1.0.0.jar,RegionCoprocessorHost.class 包 org.apache.hadoop.hbase.regionserver
[-] RegionCoprocessorHost.postAppend(追加追加,结果结果):无效
org/apache/hadoop/hbase/regionserver/RegionCoprocessorHost.postAppend:(Lorg/apache/hadoop/hbase/client/Append;Lorg/apache/hadoop/hbase/client/Result;)V
| Change | Result |
| 返回值类型已从 void 更改为 org.apache.hadoop.hbase.client.Result。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] RegionCoprocessorHost.preStoreFileReaderOpen(FileSystem fs,Path p,FSDataInputStreamWrapper in,long size,CacheConfig cacheConf,Reference r):StoreFile.Reader
org/apache/hadoop/hbase/regionserver/RegionCoprocessorHost.preStoreFileReaderOpen:(Lorg/apache/hadoop/fs/FileSystem;Lorg/apache/hadoop/fs/Path;Lorg/apache/hadoop/hbase/io/FSDataInputStreamWrapper;JLorg/apache/hadoop/hbase/io/hfile/CacheConfig;Lorg/apache/hadoop/hbase/io/Reference;)Lorg/apache/hadoop/hbase/regionserver/StoreFile$Reader;
| Change | Result |
| 返回值类型已从 StoreFile.Reader 更改为 StoreFileReader。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.6. IPC
189.2.7. 计划程序更改:
- 以下方法变得抽象:
package org.apache.hadoop.hbase.ipc
[-] RpcScheduler 类(1)
| Change | Result |
| 抽象方法 void dispatch(CallRunner)已从此类移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
hbase-server-1.0.0.jar,RpcScheduler.class 包 org.apache.hadoop.hbase.ipc
[-] RpcScheduler.dispatch(CallRunner p1)[摘要]:无效 1
org/apache/hadoop/hbase/ipc/RpcScheduler.dispatch:(Lorg/apache/hadoop/hbase/ipc/CallRunner;)V
| Change | Result |
| 返回值类型已从 void 更改为 boolean。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
- 以下抽象方法已删除:
[-]界面 PriorityFunction(2)
| Change | Result |
| 抽象方法 longgetDeadline(RPCProtos.RequestHeader,Message)已从此接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 此接口中已删除了抽象方法 int getPriority(RPCProtos.RequestHeader,Message)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.8. 服务器 API 更改:
[-]类 RpcServer(12)
| Change | Result |
| 字段类型 CurCall 已从 java.lang.ThreadLocal<RpcServer.Call>更改为 java.lang.ThreadLocal<RpcCall>。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 这节课变得抽象了。 | Client 端程序可能会被 InstantiationError 异常中断。 |
| 抽象方法 int getNumOpenConnections()已添加到此类。 | 此类变得抽象,并且 Client 端程序可能会因 InstantiationError 异常而中断。 |
| 此类中已删除类型为 org.apache.hadoop.hbase.util.Counter 的字段 callQueueSize。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 此类中已删除类型为 java.util.List<RpcServer.Connection>的字段 connectionList。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| int 类型的 maxIdleTime 字段已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 类型为 int 的 numConnections 字段已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 类型为 int 的 site 端口已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 类型为 long 的字段 purgeTimeout 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| RpcServer.Responder 类型的字段响应器已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 类型为 int 的 socketSendBufferSize 字段已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| int 类型的 field thresholdIdleConnections 字段已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
以下抽象方法已删除:
| Change | Result |
| 从此接口中删除了抽象方法 Pair<Message,CellScanner>调用(BlockingService,Descriptors.MethodDescriptor,Message,CellScanner,long,MonitoredRPCHandler)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.9. 复制和 WAL 更改:
HBASE-18733:WALKey 已在 HBase 2.0 中完全清除。以下是对 WALKey 的更改:
[-] classWALKey(8)
| Change | Result |
| 字段 clusterIds 的访问级别已从“保护”更改为“私有”。 | Client 端程序可能会被 IllegalAccessError 异常中断。 |
| 字段 compressionContext 的访问级别已从受保护更改为私有。 | Client 端程序可能会被 IllegalAccessError 异常中断。 |
| 字段 encodingRegionName 的访问级别已从保护更改为私有。 | Client 端程序可能会被 IllegalAccessError 异常中断。 |
| 字段表名的访问级别已从保护更改为私有。 | Client 端程序可能会被 IllegalAccessError 异常中断。 |
| 字段 writeTime 的访问级别已从保护更改为私有。 | Client 端程序可能会被 IllegalAccessError 异常中断。 |
以下字段已删除:
| Change | Result |
| org.apache.commons.logging.Log 类型的字段 LOG 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| WALKey.Version 类型的字段 VERSION 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| long 类型的字段 logSeqNum 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
以下是对 WALEdit.class 的更改:hbase-server-1.0.0.jar,WALEdit.class 包 org.apache.hadoop.hbase.regionserver.wal
WALEdit.getCompaction(Cell kv)[静态]:WALProtos.CompactionDescriptor(1)
org/apache/hadoop/hbase/regionserver/wal/WALEdit.getCompaction:(Lorg/apache/hadoop/hbase/Cell;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$CompactionDescriptor;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generate.WALProtos.CompactionDescriptor 更改为 org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.CompactionDescriptor。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
WALEdit.getFlushDescriptor(Cell cell)[静态]:WALProtos.FlushDescriptor(1)
org/apache/hadoop/hbase/regionserver/wal/WALEdit.getFlushDescriptor:(Lorg/apache/hadoop/hbase/Cell;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$FlushDescriptor;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generate.WALProtos.FlushDescriptor 更改为 org.apache.hadoop.hbase.shaded.protobuf.generation.WALProtos.FlushDescriptor。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
WALEdit.getRegionEventDescriptor(Cell cell)[静态]:WALProtos.RegionEventDescriptor(1)
org/apache/hadoop/hbase/regionserver/wal/WALEdit.getRegionEventDescriptor:(Lorg/apache/hadoop/hbase/Cell;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$RegionEventDescriptor;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generate.WALProtos.RegionEventDescriptor 更改为 org.apache.hadoop.hbase.shaded.protobuf.Generated.WALProtos.RegionEventDescriptor。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
以下是对 WALKey.class 的更改:包 org.apache.hadoop.hbase.wal
WALKey.getBuilder(WALCellCodec.ByteStringCompressor 压缩器):WALProtos.WALKey.Builder 1
org/apache/hadoop/hbase/wal/WALKey.getBuilder:(Lorg/apache/hadoop/hbase/regionserver/wal/WALCellCodec$ByteStringCompressor;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$WALKey$Builder;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generate.WALProtos.WALKey.Builder 更改为 org.apache.hadoop.hbase.shaded.protobuf.generation.WALProtos.WALKey.Builder。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.10. 不推荐使用的 API 或协处理器:
HBASE-16769-已删除来自 MasterObserver 和 RegionServerObserver 的 PB 引用。
189.2.11. Management 界面 API 的更改:
您不能使用包含 RelicationAdmin,ACC,Thrift 和 REST 的 Admin ops 的 HBase 1.0Client 端来 ManagementHBase 2.0 群集。返回 protobuf 的方法已更改为返回 POJO。 API 中不再使用 pb。对于异步方法,返回值已从 void 更改为 Future。 HBASE-18106-Admin.listProcedures 和 Admin.listLocks 被重命名为 getProcedures 和 getLocks。 MapReduce 利用 Admin 来执行 admin.getClusterStatus()来计算拆分。
Admin API 的节俭用法:compact(ByteBuffer)createTable(ByteBuffer,List)deleteTable(ByteBuffer)disableTable(ByteBuffer)enableTable(ByteBuffer)getTableNames()majorCompact(ByteBuffer)
REST 对 Admin API 的使用:hbase-rest org.apache.hadoop.hbase.rest RootResource getTableList()TableName [] tableNames = servlet.getAdmin()。listTableNames(); SchemaResource delete(UriInfo)Management 员 admin = servlet.getAdmin(); update(TableSchemaModel,boolean,UriInfo)Management 员 admin = servlet.getAdmin(); StorageClusterStatusResource get(UriInfo)ClusterStatus status = servlet.getAdmin()。getClusterStatus(); StorageClusterVersionResource get(UriInfo)model.setVersion(servlet.getAdmin()。getClusterStatus()。getHBaseVersion()); TableResource exist()返回 servlet.getAdmin()。tableExists(TableName.valueOf(table));
以下是对 Management 界面的更改:
[-]界面 Admin(9)
| Change | Result |
| 此接口中已删除了抽象方法 createTableAsync(HTableDescriptor,byte [] [])。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 disableTableAsync(TableName)已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 enableTableAsync(TableName)已从该接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getCompactionState(TableName)已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getCompactionStateForRegion(byte [])已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除抽象方法 isSnapshotFinished(HBaseProtos.SnapshotDescription)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法快照(String,TableName,HBaseProtos.SnapshotDescription.Type)已从此接口中删除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法快照(HBaseProtos.SnapshotDescription)已从此接口中删除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 已从该接口中删除抽象方法 takeSnapshotAsync(HBaseProtos.SnapshotDescription)。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
以下是对 Admin.class 的更改:hbase-client-1.0.0.jar,Admin.class 包 org.apache.hadoop.hbase.client
[-] Admin.createTableAsync(HTableDescriptor p1,byte [] [] p2)[摘要]:无效 1
org/apache/hadoop/hbase/client/Admin.createTableAsync:(Lorg/apache/hadoop/hbase/HTableDescriptor;[[B)V
| Change | Result |
| 返回值类型已从 void 更改为 java.util.concurrent.Future<java.lang.Void>。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] Admin.disableTableAsync(TableName p1)[摘要]:无效 1
org/apache/hadoop/hbase/client/Admin.disableTableAsync:(Lorg/apache/hadoop/hbase/TableName;)V
| Change | Result |
| 返回值类型已从 void 更改为 java.util.concurrent.Future<java.lang.Void>。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
Admin.enableTableAsync(TableName p1)[摘要]:无效 1
org/apache/hadoop/hbase/client/Admin.enableTableAsync:(Lorg/apache/hadoop/hbase/TableName;)V
| Change | Result |
| 返回值类型已从 void 更改为 java.util.concurrent.Future<java.lang.Void>。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] Admin.getCompactionState(TableName p1)[摘要]:AdminProtos.GetRegionInfoResponse.CompactionState 1
org/apache/hadoop/hbase/client/Admin.getCompactionState:(Lorg/apache/hadoop/hbase/TableName;)Lorg/apache/hadoop/hbase/protobuf/generated/AdminProtos$GetRegionInfoResponse$CompactionState;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generation.AdminProtos.GetRegionInfoResponse.CompactionState 更改为 CompactionState。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] Admin.getCompactionStateForRegion(byte [] p1)[摘要]:AdminProtos.GetRegionInfoResponse.CompactionState 1
org/apache/hadoop/hbase/client/Admin.getCompactionStateForRegion:([B)Lorg/apache/hadoop/hbase/protobuf/generated/AdminProtos$GetRegionInfoResponse$CompactionState;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generation.AdminProtos.GetRegionInfoResponse.CompactionState 更改为 CompactionState。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.12. HTableDescriptor 和 HColumnDescriptor 的更改
HTableDescriptor 和 HColumnDescriptor 已成为接口,您可以通过 Builders 创建它。 HCD 已成为 CFD。它不再实现可写接口。软件包 org.apache.hadoop.hbase
[-]类 HColumnDescriptor(1)
| Change | Result |
| 删除了超级接口 org.apache.hadoop.io.WritableComparable<HColumnDescriptor>。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
1.0.0 中的 HColumnDescriptor{code} @ InterfaceAudience.Public @InterfaceStability。不断 Developing 的公共类 HColumnDescriptor 实现 WritableComparable<HColumnDescriptor>{ {}
HColumnDescriptor 在 2.0{code} @ InterfaceAudience.Public @Deprecated //在 3.0 公共类中将其删除 HColumnDescriptor 实现 ColumnFamilyDescriptor,Comparable<HColumnDescriptor>{ {}
对于 META_TABLEDESC,在 1.0.0 中的 HTD 中已不建议使用 maker 方法。 OWNER_KEY 仍在 HTD 中。
HTableDescriptor 类(3)
| Change | Result |
| 删除了超级接口 org.apache.hadoop.io.WritableComparable<HTableDescriptor>。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| HTableDescriptor 类型的字段 META_TABLEDESC 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
hbase-client-1.0.0.jar,HTableDescriptor.class 包 org.apache.hadoop.hbase
[-] HTableDescriptor.getColumnFamilies():HColumnDescriptor
org/apache/hadoop/hbase/HTableDescriptor.getColumnFamilies:()[Lorg/apache/hadoop/hbase/HColumnDescriptor;
[-]类 HColumnDescriptor(1)
| Change | Result |
| 返回值类型已从 HColumnDescriptor []更改为 client.ColumnFamilyDescriptor []。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] HTableDescriptor.getCoprocessors():列表\ (1)
org/apache/hadoop/hbase/HTableDescriptor.getCoprocessors:()Ljava/util/List;
| Change | Result |
| 返回值类型已从 java.util.List<java.lang.String>更改为 java.util.Collection。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
- HBASE-12990 MetaScanner 被删除,并由 MetaTableAccessor 代替。
HTableWrapper changes:
hbase-server-1.0.0.jar,HTableWrapper.class 包 org.apache.hadoop.hbase.client
[-] HTableWrapper.createWrapper(List openTables,TableName tableName,CoprocessorHost.Environment env,ExecutorService pool)[静态]:HTableInterface 1
org/apache/hadoop/hbase/client/HTableWrapper.createWrapper:(Ljava/util/List;Lorg/apache/hadoop/hbase/TableName;Lorg/apache/hadoop/hbase/coprocessor/CoprocessorHost$Environment;Ljava/util/concurrent/ExecutorService;)Lorg/apache/hadoop/hbase/client/HTableInterface;
| Change | Result |
| 返回值类型已从 HTableInterface 更改为 Table。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
HBASE-12586:删除所有公共 HTable 构造函数并删除 ConnectionManager#\ {delete,get} Connection。
HBASE-9117:删除 HTablePool 和所有与 HConnection 池相关的 API。
HBASE-13214:从 HTable 类中删除不推荐使用和未使用的方法以下是对 Table 接口的更改:
[-]界面表(4)
| Change | Result |
| 抽象方法批处理(List<?>)已从该接口中删除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 batchCallback(List<?>,Batch.Callback)已从该接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getWriteBufferSize()已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 setWriteBufferSize(long)已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.13. 表(在 1.0.1 中)弃用的缓冲方法,在 2.0.0 中已删除
HBASE-13298-澄清 Table。\ {set|get} WriteBufferSize()是否已弃用。
LockTimeoutException 和 OperationConflictException 类已被删除。
189.2.14. class OperationConflictException(1)
| Change | Result |
| 此类已被删除。 | Client 端程序可能会被 NoClassDefFoundErrorexception 中断。 |
189.2.15. 类 class LockTimeoutException(1)
| Change | Result |
| 此类已被删除。 | Client 端程序可能会被 NoClassDefFoundErrorexception 中断。 |
189.2.16. 过滤器 API 更改:
删除了以下方法:软件包 org.apache.hadoop.hbase.filter
[-]类过滤器(2)
| Change | Result |
| 抽象方法 getNextKeyHint(KeyValue)已从此类移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法转换(KeyValue)已从此类移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
HBASE-12296 过滤器应与 ByteBufferedCell 一起使用。
HConnection 在 HBase 2.0 中已删除。
RegionLoad 和 ServerLoad 在内部移至带 shade 的 PB。
[-]类 RegionLoad(1)
| Change | Result |
| 字段类型的区域 LoadPB 已从 protobuf.generation.ClusterStatusProtos.RegionLoad 更改为 shaded.protobuf.generation.ClusterStatusProtos.RegionLoad。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
- HBASE-15783:AccessControlConstants#OP_ATTRIBUTE_ACL_STRATEGY_CELL_FIRST 不再使用。软件包 org.apache.hadoop.hbase.security.access
[-]界面 AccessControlConstants(3)
| Change | Result |
| 从此接口中删除了类型为 java.lang.String 的字段 OP_ATTRIBUTE_ACL_STRATEGY。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 字节[]类型的字段 OP_ATTRIBUTE_ACL_STRATEGY_CELL_FIRST 已从该接口中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 字节[]类型的字段 OP_ATTRIBUTE_ACL_STRATEGY_DEFAULT 已从该接口中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
ServerLoad 返回 long 而不是 int 1
hbase-client-1.0.0.jar,ServerLoad.class 包 org.apache.hadoop.hbase
[-] ServerLoad.getNumberOfRequests():整数 1
org/apache/hadoop/hbase/ServerLoad.getNumberOfRequests:()I
| Change | Result |
| 返回值类型已从 int 更改为 long。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] ServerLoad.getReadRequestsCount():整数 1
org/apache/hadoop/hbase/ServerLoad.getReadRequestsCount:()I
| Change | Result |
| 返回值类型已从 int 更改为 long。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] ServerLoad.getTotalNumberOfRequests():整数 1
org/apache/hadoop/hbase/ServerLoad.getTotalNumberOfRequests:()I
| Change | Result |
| 返回值类型已从 int 更改为 long。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
[-] ServerLoad.getWriteRequestsCount():整数 1
org/apache/hadoop/hbase/ServerLoad.getWriteRequestsCount:()I
| Change | Result |
| 返回值类型已从 int 更改为 long。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
HBASE-13636 删除对 HBASE-4072 的弃用(读取 zoo.cfg)
H 常量被删除。 HBASE-16040 删除配置“ hbase.replication”
[-]级 HConstants(6)
| Change | Result |
| 布尔类型的字段 DEFAULT_HBASE_CONFIG_READ_ZOOKEEPER_CONFIG 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 从此类中删除了类型为 java.lang.String 的字段 HBASE_CONFIG_READ_ZOOKEEPER_CONFIG。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 布尔类型的字段 REPLICATION_ENABLE_DEFAULT 已从此类中删除。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 从此类中删除了类型为 java.lang.String 的字段 REPLICATION_ENABLE_KEY。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 此类中已删除类型为 java.lang.String 的字段 ZOOKEEPER_CONFIG_NAME。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
| 此类中已删除类型为 java.lang.String 的字段 ZOOKEEPER_USEMULTI。 | Client 端程序可能会被 NoSuchFieldError 异常中断。 |
- HBASE-18732:[compat 1-2] HBASE-14047 删除了没有弃用周期的 Cell 方法。
[-]界面单元 5
| Change | Result |
| 抽象方法 getFamily()已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getMvccVersion()已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getQualifier()已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getRow()已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
| 抽象方法 getValue()已从该接口移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
- HBASE-18795:仅对测试暴露 KeyValue.getBuffer()。仅在先前不建议使用的测试中允许 KV#getBuffer。
189.2.17. 区域扫描仪更改:
[-]界面 RegionScanner(1)
| Change | Result |
| 抽象方法 boolean nextRaw(List,int)已从该接口中移除。 | Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.18. StoreFile 更改:
[-]类 StoreFile(1)
| Change | Result |
| 此类成为接口。 | 取决于此类的用法,Client 端程序可能会被 IncompatibleClassChangeError 或 InstantiationError 异常中断。 |
189.2.19. Mapreduce 更改:
HFile * Format 已在 HBase 2.0 中删除。
189.2.20. ClusterStatus 更改:
HBASE-15843:使用 Set hbase-client-1.0.0.jar,ClusterStatus.class 包 org.apache.hadoop.hbase 替换 RegionState.getRegionInTransition()Map。
[-] ClusterStatus.getRegionsInTransition():Map\ <String,RegionState> 1
org/apache/hadoop/hbase/ClusterStatus.getRegionsInTransition:()Ljava/util/Map;
| Change | Result |
| 返回值类型已从 java.util.Map<java.lang.String,master.RegionState>更改为 java.util.List<master.RegionState>。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
ClusterStatus 中的其他更改包括删除从 API 清除 PB 之后不再需要的转换方法。
189.2.21. 从 API 清除 PB
PB 在 HBase 2.0 中的 API 中已弃用。
[-] HBaseSnapshotException.getSnapshotDescription():HBaseProtos.SnapshotDescription 1
org/apache/hadoop/hbase/snapshot/HBaseSnapshotException.getSnapshotDescription:()Lorg/apache/hadoop/hbase/protobuf/generated/HBaseProtos$SnapshotDescription;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generation.HBaseProtos.SnapshotDescription 更改为 org.apache.hadoop.hbase.client.SnapshotDescription。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
- HBASE-15609:从 Result,DoubleColumnInterpreter 和任何此类面向公众的 2.0 类中删除 PB 引用。 hbase-client-1.0.0.jar,Result.class 包 org.apache.hadoop.hbase.client
[-] Result.getStats():ClientProtos.RegionLoadStats 1
org/apache/hadoop/hbase/client/Result.getStats:()Lorg/apache/hadoop/hbase/protobuf/generated/ClientProtos$RegionLoadStats;
| Change | Result |
| 返回值类型已从 org.apache.hadoop.hbase.protobuf.generation.ClientProtos.RegionLoadStats 更改为 RegionLoadStats。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.22. REST 更改:
hbase-rest-1.0.0.jar,Client.class 包 org.apache.hadoop.hbase.rest.client
[-] Client.getHttpClient():HttpClient 1
org/apache/hadoop/hbase/rest/client/Client.getHttpClient:()Lorg/apache/commons/httpclient/HttpClient
| Change | Result |
| 返回值类型已从 org.apache.commons.httpclient.HttpClient 更改为 org.apache.http.client.HttpClient。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
hbase-rest-1.0.0.jar,Response.class 包 org.apache.hadoop.hbase.rest.client
[-] Response.getHeaders():标题[] 1
org/apache/hadoop/hbase/rest/client/Response.getHeaders:()[Lorg/apache/commons/httpclient/Header;
| Change | Result |
| 返回值类型已从 org.apache.commons.httpclient.Header []更改为 org.apache.http.Header []。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.23. PrettyPrinter 的更改:
hbase-server-1.0.0.jar,HFilePrettyPrinter.class 包 org.apache.hadoop.hbase.io.hfile
[-] HFilePrettyPrinter.processFile(路径文件):无效 1
org/apache/hadoop/hbase/io/hfile/HFilePrettyPrinter.processFile:(Lorg/apache/hadoop/fs/Path;)V
| Change | Result |
| 返回值类型已从 void 更改为 int。 | 此方法已删除,因为返回类型是方法签名的一部分。Client 端程序可能会被 NoSuchMethodError 异常中断。 |
189.2.24. AccessControlClient 的更改:
HBASE-13171 更改 AccessControlClient 方法以接受连接对象以减少设置时间。通过以下方法更改了参数:
hbase-client-1.2.7-SNAPSHOT.jar,AccessControlClient.class 包 org.apache.hadoop.hbase.security.access AccessControlClient.getUserPermissions(配置 conf,字符串 tableRegex)[静态]:列表\ 已弃用 org /apache/hadoop/hbase/security/access/AccessControlClient.getUserPermissions:(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;)Ljava/util/List;
AccessControlClient.grant(Configuration conf,String namespace,String userName,Permission.Action…actions)[静态]:void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.grant:(Lorg/apache/hadoop/conf/Configuration; Ljava/lang/String; Ljava/lang/String; [Lorg/apache/hadoop/hbase/security/access/Permission $ Action;)V
AccessControlClient.grant(配置 conf,字符串 userName,Permission.Action…操作)[静态]:无效 已弃用 org/apache/hadoop/hbase/security/access/AccessControlClient.grant:(Lorg/apache/hadoop/conf/Configuration; Ljava/lang/String; [Lorg/apache/hadoop/hbase/security/access/Permission $ Action;)V
AccessControlClient.grant(配置 conf,TableName tableName,字符串 userName,byte []系列,byte [] qual,Permission.Action…操作)[静态]:无效 已弃用 org/apache/hadoop/hbase/security/access /AccessControlClient.grant:(Lorg/apache/hadoop/conf/Configuration;Lorg/apache/hadoop/hbase/TableName;Ljava/lang/String;[B[B[L[Lorg/apache/hadoop/hbase/security/access/Permission $动作;)V
AccessControlClient.isAccessControllerRunning(Configuration conf)[静态]:布尔值 DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.isAccessControllerRunning:(Lorg/apache/hadoop/conf/Configuration;)Z
AccessControlClient.revoke(配置 conf,字符串名称空间,字符串 userName,Permission.Action…操作)[静态]:无效 已弃用 org/apache/hadoop/hbase/security/access/AccessControlClient.revoke:(Lorg/apache/hadoop/conf/Configuration; Ljava/lang/String; Ljava/lang/String; [Lorg/apache/hadoop/hbase/security/access/Permission $ Action;)V
AccessControlClient.revoke(配置 conf,字符串 userName,Permission.Action…操作)[静态]:无效 已弃用 org/apache/hadoop/hbase/security/access/AccessControlClient.revoke:(Lorg/apache/hadoop/conf/Configuration; Ljava/lang/String; [Lorg/apache/hadoop/hbase/security/access/Permission $ Action;)V
AccessControlClient.revoke(配置 conf,TableName tableName,字符串用户名,byte []系列,byte []限定符,Permission.Action…操作)[静态]:void 已弃用 org/apache/hadoop/hbase/security/access /AccessControlClient.revoke:(Lorg/apache/hadoop/conf/Configuration;Lorg/apache/hadoop/hbase/TableName;Ljava/lang/String;[B[B[L[Lorg/apache/hadoop/hbase/security/access/Permission $动作;)V
HBASE-18731:[compat 1-2]将与 Protobuf 内部相关的 QuotaSettings 的受保护方法标记为 IA。私有
- 1。参见“源兼容性” https://blogs.oracle.com/darcy/entry/kinds_of_compatibility
- 2。参见http://docs.oracle.com/javase/specs/jls/se7/html/jls-13.html。
- 3。请注意,这表示可能会损坏的东西,而不是会损坏的东西。我们将/应该在发行说明中添加细节。
- 4。 comp_matrix_offline_upgrade_note,可能需要运行不降级的脱机升级工具。通常,我们仅支持将数据从主要版本 X 迁移到主要版本 X 1.
- 5。在 HBase 0.96 中重做了 Metrics 系统。有关详细信息,请参见 Elliot Clark 的“迁移到新度量标准热点-度量标准 2”