LLAP
Hive 2.0 中已添加“实时长期处理(LLAP)”功能(HIVE-7926和相关任务)。 HIVE-9850链接了此增强功能的文档,功能和问题。
有关 LLAP 的配置,请参见Configuration Properties的 LLAP 部分。
Overview
由于社区近年来开发的各种功能和改进,包括Tez和Cost-based-optimization,Hive 的速度已大大提高。要使 Hive 迈上新台阶,需要以下内容:
异步主轴感知 IO
列块的预取和缓存
多线程 JIT 友好的操作员管道
LLAP 也称为 Live Long and Process,它提供了一种混合执行模型。它由一个长期存在的守护进程(该守护进程替换了与 HDFS DataNode 的直接交互)以及一个紧密集成的基于 DAG 的框架组成。
诸如缓存,预取,某些查询处理和访问控制之类的功能已移至守护程序中。此守护程序直接直接处理小/短查询,而任何繁重的工作都将在标准 YARN 容器中执行。
与 DataNode 相似,LLAP 守护程序也可以由其他应用程序使用,尤其是如果相对于以文件为中心的处理方法更喜欢数据的关系视图时。该守护进程还通过可选的 API(例如 InputFormat)打开,其他数据处理框架可将其用作构建块。
最后但并非最不重要的一点是,细粒度的列级访问控制-Hive 主流采用的一项关键要求-非常适合此模型。
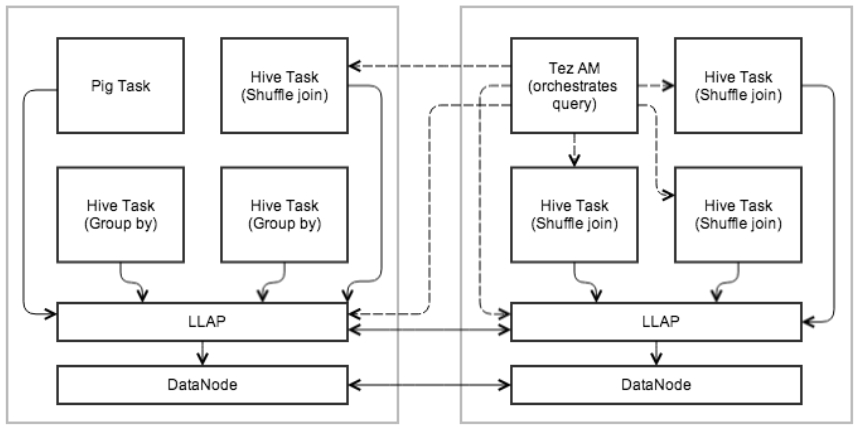
下图显示了使用 LLAP 的示例执行。 Tez AM 统筹整体执行。查询的初始阶段被推送到 LLAP 中。在还原阶段,将在单独的容器中执行大型混洗。多个查询和应用程序可以同时访问 LLAP。
Persistent Daemon
为了促进缓存和 JIT 优化并消除大多数启动成本,守护程序在群集的工作节点上运行。守护程序处理 I/O,缓存和查询片段执行。
这些节点是 Stateless 的. 对 LLAP 节点的任何请求均包含数据位置和元数据。它处理本地和远程位置;本地性是呼叫者的责任(YARN)。
恢复/弹性. 故障和恢复得以简化,因为任何数据节点仍可用于处理 Importing 数据的任何片段。因此,Tez AM 可以简单地在群集上重新运行失败的片段。
节点之间的通信. LLAP 节点能够共享数据(例如,获取分区,Broadcast 片段)。这可以通过与 Tez 中使用的相同机制来实现。
Execution Engine
LLAP 在现有的基于流程的 Hive 执行中工作,以保持 Hive 的可伸缩性和多功能性。它不会替代现有的执行模型,而是对其进行了增强。
守护程序是可选的. Hive 可以在没有它们的情况下工作,并且即使已部署并运行它们也可以绕过它们。保持与语言 Feature 有关的 Feature 奇偶性。
外部编排和执行引擎. LLAP 不是执行引擎(例如 MapReduce 或 Tez)。整个执行由现有的 Hive 执行引擎(例如 Tez)在 LLAP 节点以及常规容器上透明地调度和监视。显然,LLAP 的支持级别取决于每个单独的执行引擎(从 Tez 开始)。不计划支持 MapReduce,但以后可能会添加其他引擎。 Pig 等其他框架也可以选择使用 LLAP 守护程序。
部分执行. LLAP 守护程序执行的工作结果可以构成 Hive 查询结果的一部分,也可以根据查询传递给外部 Hive 任务。
资源 Management. YARN 仍然负责资源的 Management 和分配。 YARN 容器委派模型用于允许将分配的资源传输到 LLAP。为了避免 JVM 内存设置的限制,高速缓存的数据以及用于处理的大缓冲区(例如,分组依据,联接)将保持堆外状态。这样,守护程序可以使用少量内存,并且将根据工作负载分配其他资源(即 CPU 和内存)。
查询片段执行
对于如上所述的部分执行,LLAP 节点执行“查询片段”,例如过滤器,投影,数据转换,部分聚合,排序,存储,哈希联接/半联接等。LLAP 仅接受 Hive 代码和受祝福的 UDF。没有代码可以本地化并即时执行。出于稳定性和安全性原因进行此操作。
并行执行. LLAP 节点允许并行执行来自不同查询和会话的多个查询片段。
接口. 用户可以直接通过 Client 端 API 访问 LLAP 节点。他们能够指定关系转换并通过面向记录的流读取数据。
I/O
守护程序将 I/O 和从压缩格式的转换卸载到单独的线程。数据准备就绪后将传递给执行,因此可以在准备下一批时处理前一批。数据以简单的 RLE 编码列格式传递给执行,可以进行矢量化处理。这也是一种缓存格式,旨在最大程度地减少 I/O,缓存和执行之间的复制。
多种文件格式. I/O 和缓存取决于对基础文件格式的一些了解(尤其是要高效地进行处理时)。因此,类似于矢量化工作,通过每种格式专用的插件将支持不同的文件格式(从 ORC 开始)。此外,可能会添加通用,效率较低的插件,以支持任何 HiveImporting 格式。插件必须维护元数据并将原始数据转换为列块。
谓词和 Bloom 过滤器. 如果支持,则 SARG 和 Bloom 过滤器会向下推送到存储层。
Caching
守护程序将缓存 Importing 文件的元数据以及数据。甚至可以为当前未缓存的数据缓存元数据和索引信息。元数据在过程中存储在 Java 对象中;缓存的数据以I/O section中描述的格式存储,并保留在堆外(请参见Resource management)。
逐出策略. 逐出策略针对具有频繁(部分)表格扫描的分析工作负载进行了调整。最初,使用了像 LRFU 这样的简单策略。该策略是可插入的。
缓存粒度. 列块是缓存中数据的单位。这实现了低开销处理和存储效率之间的折衷。块的粒度取决于特定的文件格式和执行引擎(矢量化行批处理大小,ORC 条带等)。
布隆过滤器会自动创建以提供动态运行时过滤。
Workload Management
YARN 用于获取用于不同工作负载的资源。一旦从 YARN 获得了特定工作负载的资源(CPU,内存等),执行引擎就可以选择将这些资源委派给 LLAP,或在单独的进程中启动 Hive 执行程序。通过 YARN 强制执行资源具有确保节点不会因 LLAP 或其他容器而过载的优势。守护程序本身在 YARN 的控制之下。
ACID Support
LLAP 知道 Transaction。在将数据放入缓存之前,将进行增量文件合并以生成表的特定状态。
可能有多个版本,并且请求指定要使用哪个版本。这样的好处是异步进行合并,并且对缓存的数据仅进行一次合并,从而避免了对操作员管道的冲击。
Security
LLAP 服务器很自然地可以在比“每个文件”更细粒度的级别上执行访问控制。由于守护程序知道要处理哪些列和记录,因此可以强制执行有关这些对象的策略。这并不是要取代当前的机制,而是要增强它们并向其他应用程序开放。
Monitoring
LLAP 监视的配置存储在 resources.json,appConfig.json 和 metainfo.xml 中,它们嵌入到 Slider 使用的templates.py中。
LLAP Monitor 守护程序在 YARN 容器上运行,类似于 LLAP 守护程序,并且在同一端口上侦听。
LLAP 度量标准收集服务器定期从所有 LLAP 守护程序收集 JMX 度量标准。
LLAP 守护程序列表是从群集中启动的 Zookeeper 服务器中提取的。
Web Services
HIVE-9814引入了以下 Web 服务:
JSON JMX 数据-/ jmx
所有线程的 JVM 堆栈跟踪-/ stacks
来自 llap-daemon-site 的 XML 配置-/ conf
HIVE-13398引入了以下 Web 服务:
LLAP 状态-/状态
LLAP 对等-/ peers
/status example
curl localhost:15002/status
{
"status" : "STARTED",
"uptime" : 139093,
"build" : "2.1.0-SNAPSHOT from 77474581df4016e3899a986e079513087a945674 by gopal source checksum a9caa5faad5906d5139c33619f1368bb"
}
/peers example
curl localhost:15002/peers
{
"dynamic" : true,
"identity" : "718264f1-722e-40f1-8265-ac25587bf336",
"peers" : [
{
"identity" : "940d6838-4dd7-4e85-95cc-5a6a2c537c04",
"host" : "sandbox121.hortonworks.com",
"management-port" : 15004,
"rpc-port" : 15001,
"shuffle-port" : 15551,
"resource" : {
"vcores" : 24,
"memory" : 128000
},
"host" : "sandbox121.hortonworks.com"
},
]
}
SLIDER 部署 YARN
可以通过Slider部署 LLAP,它绕过了节点安装和相关复杂性(HIVE-9883)。
LLAP Status
AMBARI-16149介绍了 HiveServer2 提供的 LLAP 应用程序状态。
Example usage.
/current/hive-server2-hive2/bin/hive --service llapstatus --name {llap_app_name} [-f] [-w] [-i] [-t]
-f,--findAppTimeout <findAppTimeout> Amount of time(s) that the tool will sleep to wait for the YARN application to start. negative values=wait
forever, 0=Do not wait. default=20s
-H,--help Print help information
--hiveconf <property=value> Use value for given property. Overridden by explicit parameters
-i,--refreshInterval <refreshInterval> Amount of time in seconds to wait until subsequent status checks in watch mode. Valid only for watch mode.
(Default 1s)
-n,--name <name> LLAP cluster name
-o,--outputFile <outputFile> File to which output should be written (Default stdout)
-r,--runningNodesThreshold <runningNodesThreshold> When watch mode is enabled (-w), wait until the specified threshold of nodes are running (Default 1.0
which means 100% nodes are running)
-t,--watchTimeout <watchTimeout> Exit watch mode if the desired state is not attained until the specified timeout. (Default 300s)
-w,--watch Watch mode waits until all LLAP daemons are running or subset of the nodes are running (threshold can be
specified via -r option) (Default wait until all nodes are running)
Version information
在版本 2.1.0 中使用HIVE-13643:-f或-- findAppTimeout添加了 findAppTimeout 选项。
监视和运行节点选项在版本 2.2.0 中添加了HIVE-15217和HIVE-15651:-w或--watch,-i或--refreshInterval,-t或--watchTimeout以及-r或--runningNodesThreshold。